RAG | Context Embedding for RAG
- Related Project: Private
- Category: Paper Review
- Date: 2024-07-12
Context Embeddings for Efficient Answer Generation in RAG (COCOM)
- url: https://arxiv.org/abs/2407.09252
- pdf: https://arxiv.org/pdf/2407.09252
- html: https://arxiv.org/html/2407.09252v1
- abstract: Retrieval-Augmented Generation (RAG) allows overcoming the limited knowledge of LLMs by extending the input with external information. As a consequence, the contextual inputs to the model become much longer which slows down decoding time directly translating to the time a user has to wait for an answer. We address this challenge by presenting COCOM, an effective context compression method, reducing long contexts to only a handful of Context Embeddings speeding up the generation time by a large margin. Our method allows for different compression rates trading off decoding time for answer quality. Compared to earlier methods, COCOM allows for handling multiple contexts more effectively, significantly reducing decoding time for long inputs. Our method demonstrates a speed-up of up to 5.69 × while achieving higher performance compared to existing efficient context compression methods.
Contents
TL;DR
- 컨텍스트 압축 모델 COCOM 개발: 컨텍스트을 간소화하여 응답 생성 속도 향상
- 다양한 압축률 제공: 효율성과 효과성의 균형을 맞추는 다양한 압축률을 제공
- 실험을 통한 검증: 다양한 QA 작업에서의 효과성과 효율성을 실험을 통해 입증
1. 서론
대규모 언어모델(LLMs)은 엄청난 양의 텍스트 데이터를 통해 사전 학습되며, 이런 학습을 통해 언어 모델링 뿐만 아니라 지식 기반을 구축합니다. 그러나 모델이 pre-training dataset에 포함된 지식에만 제한된다는 문제가 있습니다. 이를 해결하기 위해, 본 논문에서는 외부 정보를 통해 입력을 확장하는 검색 증강 생성(Retrieval-Augmented Generation, RAG) 방법을 사용하며, 입력 컨텍스트을 압축하는 새로운 방법 COCOM을 제시하여 응답 생성 시간을 크게 단축시킵니다. 이런 접근 방식은 입력 컨텍스트의 길이 증가로 인해 발생하는 디코딩 시간의 증가를 해결합니다.
2. 관련 연구
RAG 시스템에서 컨텍스트을 압축하는 방법에는 주로 두 가지 접근 방식을 활용합니다.
- 어휘 기반 압축(lexical-based compression): 중요하지 않은 토큰을 식별하고 필터링하는 방식
- 임베딩 기반 압축(embedding-based compression): 컨텍스트을 요약 임베딩으로 변환하여 LLM 입력에 더 적은 토큰을 사용하는 방식
2.1 어휘 기반 압축
어휘 기반 압축은 쿼리와 독립적인 토큰 필터링 모듈을 사용하여 컨텍스트에서 중요한 토큰을 선택합니다. 이 방식은 온라인에서 부분적으로 압축을 처리해야 하므로 레이턴시가 증가할 수 있습니다.
2.2 임베딩 기반 압축
임베딩 기반 압축은 컨텍스트을 하나 또는 여러 요약 임베딩으로 압축하며, 이를 통해 디코더 모델이 직접 해석할 수 있도록 합니다. 이 방법은 특히 다음 토큰 예측 작업(Next Token Prediction)을 통해 요약 임베딩을 학습하며, 이는 컨텍스트 데이터의 관련 내용을 효과적으로 담을 수 있는지에 대한 의문을 제기합니다.
3. RAG 작업 및 COCOM 접근 방법
이 장에서는 RAG 작업과 효과적인 컨텍스트 압축을 위한 새로운 COCOM 접근 방법을 자세히 설명합니다.
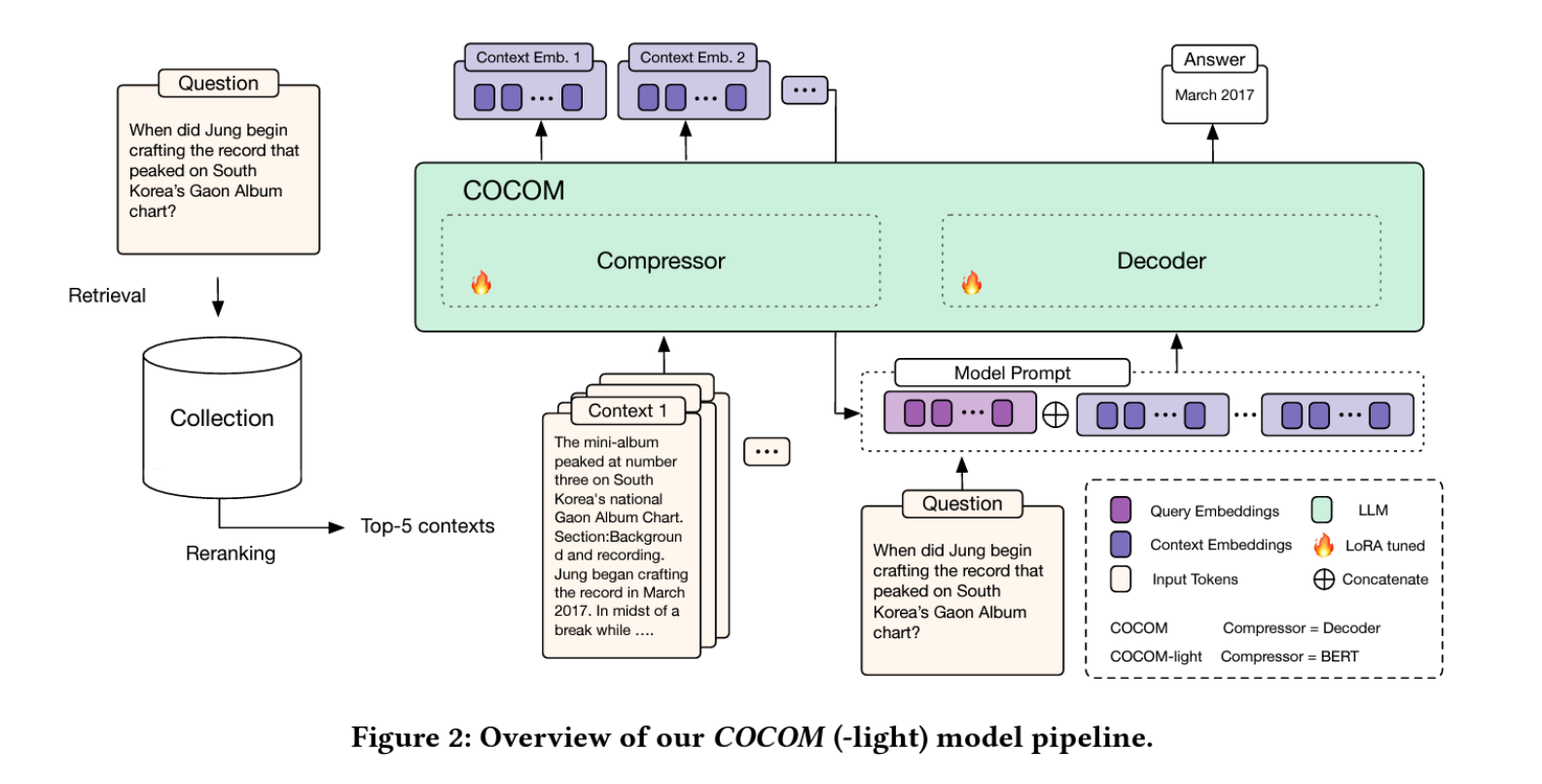
본 연구에서는 RAG 작업을 위해 컨텍스트을 압축하는 새로운 방법 COCOM을 소개합니다. 이 방법은 컨텍스트을 소수의 컨텍스트 임베딩으로 압축하여 LLM에 입력하고, 이를 통해 입력 크기를 크게 줄이며 디코딩 시간을 단축합니다. COCOM은 다양한 압축률을 제공하여 디코딩 시간과 답변 품질 간의 트레이드오프를 가능하게 합니다.
3.1. 작업 정의: RAG
RAG는 랭킹 시스템 \(\mathcal{R}\)과 파라미터화된 생성 언어 모델 \(\theta_{LLM}\)을 사용하며, 랭킹 시스템은 여러 단계로 구성될 수 있습니다. 먼저, 랭킹 시스템은 컬렉션을 기반으로 검색 인덱스 \(\mathcal{I}\)를 구축합니다. 그 후, 요청 시점에 인덱스 \(\mathcal{I}\)를 검색하여 사용자 입력 \(x\)에 관련된 컨텍스트 세그먼트 \(\mathcal{C}\)를 생성합니다. \(f_{\mathcal{I}, \mathcal{R}} : \{x\} \rightarrow \mathcal{C}\)
이어서, LLM은 컨텍스트 \(\mathcal{C}\)와 사용자 입력 \(x\)를 바탕으로 응답 \(r\)을 생성합니다. \(\theta_{LLM} : \{\mathcal{C}, x\} \rightarrow r\) RAG에서 컨텍스트은 LLM의 입력에 추가되어 입력 크기를 크게 증가시킵니다. \(|\mathcal{C}| \gg |x|\).
3.2. COCOM: 효과적인 컨텍스트 압축
COCOM의 주요 아이디어는 컨텍스트을 표면 형태의 입력 토큰에서 더 작은 컨텍스트 임베딩 집합으로 압축하여 LLM의 입력으로 사용함으로써 효율성을 향상시키는 것입니다. 구체적으로, 컨텍스트 \(\mathcal{C}\)가 토큰 시퀀스 \(\{t_1, t_2, \ldots, t_n\}\)으로 토크나이즈된 후, 압축 모델 \(\phi_{comp}\)을 사용하여 컨텍스트 \(\mathcal{C}\)를 컨텍스트 임베딩 \(\mathcal{E}\), 즉 더 작은 임베딩 집합 \(\{e_1, e_2, \ldots, e_k\}\)로 압축합니다. \(k \ll n\)이며, 각 임베딩 \(e_i \in \mathbb{R}^d\)는 LLM의 향상된 \(d\)입니다.
\[\phi_{comp} : \{t_1, t_2, \ldots, t_n\} \rightarrow \{e_1, e_2, \ldots, e_k\} \in \mathbb{R}^d\]다음으로, 압축된 컨텍스트 임베딩 \(\mathcal{E}\)와 사용자 입력 \(x\)를 바탕으로 LLM \(\theta_{LLM}\)은 응답 \(r\)을 생성합니다.
\[\theta_{LLM} : \{\mathcal{E}, x\} \rightarrow r\]\(\phi_{comp}\) 모델은 입력 토큰의 내용을 압축 형태로 포착하는 컨텍스트 임베딩을 생성하도록 훈련되며, \(\theta_{LLM}\)은 이 컨텍스트 임베딩을 디코딩하여 사용자 쿼리에 필요한 관련 정보를 추출하도록 함께 훈련됩니다.
COCOM은 컨텍스트 임베딩을 독립적으로 압축하므로 개별 컨텍스트을 한 번만 LLM에 의해 컨텍스트화할 필요가 있으며, 이를 오프라인에서 미리 계산하고 저장할 수 있어 인퍼런스 시 LLM의 계산 비용을 대폭 줄일 수 있습니다. 또한 긴 컨텍스트 대신 소수의 컨텍스트 임베딩만을 제공함으로써 입력 크기를 크게 줄이고 응답 생성 속도를 대폭 향상시킵니다.
COCOM에서는 압축과 응답 생성을 위해 동일한 모델 $ \phi_{comp} = \theta_{LLM} $을 사용합니다. 따라서 두 작업에 대해 단일 모델을 효과적으로 훈련합니다. 압축 작업을 위해 입력에 특수 토큰
실험에서 나중에 입증될 것처럼, 방법은 BERT와 같은 가벼운 인코더 전용 모델을 포함하여 어떤 임베딩 모델도 압축기로 사용할 수 있게 합니다.
3.2.1. 적응 가능한 압축률
컨텍스트 임베딩의 수 \(k = \\|\mathcal{E}\\|\)는 변화할 수 있으며, 원본 컨텍스트 \(\mathcal{C} = \{t_1, \ldots, t_n\}\)의 압축 수준을 제어할 수 있습니다. 토큰화된 입력의 길이 \(n = \\|\mathcal{C}\\|\)를 기반으로 압축률 \(\xi\)을 계산합니다.
\[\xi = \lfloor \frac{n}{\xi} \rfloor\]예를 들어, 길이 \(n = 128\)의 컨텍스트을 압축률 \(\xi = 64\)로 압축할 경우 2개의 컨텍스트 임베딩을 얻으며, 입력을 64배 줄입니다.
3.2.2. 다중 컨텍스트 처리
지식 집약적 작업에서는 여러 검색된 텍스트의 컨텍스트을 제공하는 것이 필요합니다. 전통적인 RAG에서는 여러 패시지의 컨텍스트이 연결되어 모델에 제공됩니다. COCOM에서는 각각의 컨텍스트을 독립적으로 압축한 후, 이를 LLM에 제공하여 다중 패시지를 처리합니다. 컨텍스트을 구별하기 위해 [SEP] special token을 삽입합니다.
3.3. 컨텍스트 임베딩의 사전 훈련
다음 토큰 예측 작업을 변형하여 컨텍스트을 컨텍스트 임베딩으로 압축하고 이를 LLM의 입력으로 사용하는 방법을 학습합니다.
3.3.1. 컨텍스트 임베딩을 이용한 자동 인코딩
기존의 다음 토큰 예측 작업을 수정하여 압축된 컨텍스트 임베딩 \(\mathcal{E}\)에서 원본 입력 토큰을 복구합니다. 이를 통해 압축기와 LLM을 함께 훈련하여 원래의 입력을 효과적으로 압축하고 해제하는 방법을 학습합니다.
\[\mathcal{E} = \phi_{comp}(x_1, x_2, \ldots, x_T)\] \[\mathcal{L}(\theta_{LLM}, \phi_{comp}) = -\sum_{x_t \in \mathcal{X}} \log P_{\theta_{LLM}}(x_t | \mathcal{E}, x_1, \ldots, x_{t-1})\]이 작업은 컨텍스트 임베딩을 사용하여 질문에 답하는 최종 목표로 나아가는 초기 단계로, 입력의 효과적인 압축 및 해제를 학습합니다.
3.3.2. 컨텍스트 임베딩에서의 언어 모델링
이 최종 작업은 컨텍스트 임베딩을 기반으로 질문에 답하기 위한 것입니다. 언어 모델링 작업에서는 모델이 주어진 입력에 대한 컨텍스트 임베딩에 조건을 부여받아 이어지는 입력을 생성하도록 학습합니다. 입력 \(\mathcal{X}\)를 \(\mathcal{X}_A = \{x_1, x_2, \ldots, x_j\}\)와 \(\mathcal{X}_B = \{x_{j+1}, \ldots, x_T\}\)로 나눈 뒤, \(\mathcal{X}_A\)를 \(\mathcal{E}_A\)로 압축합니다. 그리고 압축된 표현 \(\mathcal{E}_A = \phi_{comp}(\mathcal{X}_A)\)를 기반으로 \(\mathcal{X}_B\)의 이어지는 부분을 생성합니다.
\[\mathcal{L}(\theta_{LLM}, \phi_{comp}) = -\sum_{x_t \in \mathcal{X}_B} \log P_{\theta_{LLM}}(x_t | \phi_{comp}(\mathcal{X}_A), x_1, \ldots, x_{t-1})\]위 작업은 자동 인코딩 작업을 보완하며, 컨텍스트 임베딩의 내용을 효과적으로 활용하여 질문에 답하는 능력을 학습합니다.
4. 실험 설계
실험은 다섯 가지 QA 작업을 포함하여 RAG 모델을 평가합니다. 실험 결과는 COCOM이 기존의 효율적인 컨텍스트 압축 방법과 비교하여 더 높은 성능을 달성하며, 디코딩 시간을 최대 5.69배까지 단축시킵니다.
5. COCOM 결과
COCOM은 다양한 QA 작업에서의 효과성과 효율성을 입증합니다. 추가적인 압축률로 인한 효율성-효과성 트레이드오프를 연구하고, 압축에 필요한 시간과 메모리 요구 사항을 조사합니다.
6. 모델 압축 영향 분석
이 섹션에서는 압축이 모델 성능에 미치는 영향을 분석합니다. 특히, 프리트레이닝 콜렉션, 프리트레이닝, 파인튜닝 및 디코더의 고정 여부가 타겟 데이터셋에서의 성능에 어떤 영향을 미치는지에 대해 분석합니다.
7. 토론 및 결론
본 논문은 RAG 시스템에서의 컨텍스트 압축 방법으로서 COCOM의 유효성을 증명하며, 향후 연구 방향과 해당 접근 방식의 잠재적 한계를 논의합니다.