Mutual Reasoning
- Related Project: Private
- Category: Paper Review
- Date: 2024-08-15
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers
- url: https://arxiv.org/abs/2408.06195
- pdf: https://arxiv.org/pdf/2408.06195
- html: https://arxiv.org/html/2408.06195v1
- abstract: This paper introduces rStar, a self-play mutual reasoning approach that significantly improves reasoning capabilities of small language models (SLMs) without fine-tuning or superior models. rStar decouples reasoning into a self-play mutual generation-discrimination process. First, a target SLM augments the Monte Carlo Tree Search (MCTS) with a rich set of human-like reasoning actions to construct higher quality reasoning trajectories. Next, another SLM, with capabilities similar to the target SLM, acts as a discriminator to verify each trajectory generated by the target SLM. The mutually agreed reasoning trajectories are considered mutual consistent, thus are more likely to be correct. Extensive experiments across five SLMs demonstrate rStar can effectively solve diverse reasoning problems, including GSM8K, GSM-Hard, MATH, SVAMP, and StrategyQA. Remarkably, rStar boosts GSM8K accuracy from 12.51% to 63.91% for LLaMA2-7B, from 36.46% to 81.88% for Mistral-7B, from 74.53% to 91.13% for LLaMA3-8B-Instruct. Code will be available at this https URL.
MicroSoft Research
- 작은 언어 모델(SLM)의 인퍼런스 능력을 향상시키기 위한 새로운 방법인 rStar를 소개합니다.
- Monte Carlo Tree Search(MCTS)와 상호 일관성을 기반으로 한 자가 생성-판별 과정으로 SLM의 성능을 극대화합니다.
- 다양한 인퍼런스 과제를 통해 rStar의 우수성을 입증하며, 기존 방법과의 비교 실험 결과를 제시합니다.
(사견이자 잡설이므로 무시)결국 ML, DL은 휴먼이 할 수 있는 내용을 정교하게 정리하고, 수치화한 통계모델이다. 휴먼이 할 수 있는 것, 휴먼이 인퍼런스하는 과정을 모방하는 것을 수식화해야하는데, 고민하다보면 문제는 휴먼 스스로도 현재 어떻게 언어와 사고가 발생하는지 정확히 정립하지 못 한 것 같다는 생각이 자주 든다. 비전도 그렇지만 LM의 경우, 휴먼 스스로도 어떤 회로로 말이나 생각이 떠오르거나 창조되는 지 알기 어렵다. 비전의 경우는 대략적으로 레퍼런스를 보고, 기존에 본 실물을 상기하는 과정을 이식할 수 있다. 그러나 언어나 생각의 경우 어떤 사람이 당장 떠오르는 단어나 대화에 필요한 대화 내용을 상기하는 것(인퍼런스 패스)을 제대로 상상하기 어렵다. 따라서 현재는 최대한 많은 데이터들을 정제해서 부어보는 것, 인퍼런스 시에 비어있는 정보를 최소한의 공수로 채워주는 것, 오류나 정보들을 정렬해주는 것, 그리고 인퍼런스 결과들을 확인하고 그것에 대해 다시 임페리컬하게 평가해보는 것 등에 대한 다양한 시도들이 있는 것 같다. 결국 언어나 심리학자분들과 누가 얼마나 잘 협업해서 이식하는 게 중요하지 않을까… 그런 면에서 클로드가 처음부터 레이어와 모델을 심층적으로 분석한 게 현재 Sornet-3.5 버전 퍼포먼스의 비법이 아닐까…
환각을 줄이기 위해 본 논문은
-
모델이 다양한 인퍼런스 경로를 생성하고 탐색할 수 있도록 Monte Carlo Tree Search (MCTS)를 활용하여, 한 가지 행동 유형에만 의존하지 않고 여러가지 휴먼과 유사한 행동을 포함하도록 해야해 복잡한 문제를 더 효과적으로 해결할 수 있다고 언급합니다. (적극 동의)
액션 액션 이름 설명 A1 단일 생각을 제안 주어진 질문에 대해 다음 단일 생각을 생성하도록 LLM을 프롬프트합니다. 이는 CoT 방법보다 간단하며 더 나은 의사 결정을 도와줍니다. A2 나머지 생각 단계를 제안 현재 생성된 인퍼런스 단계에 기반하여 나머지 단계를 직접 생성하도록 합니다. 이는 빠른 문제 해결을 가능하게 합니다. A3 다음 하위 질문과 답변을 제안 복잡한 문제를 간단한 하위 질문으로 분해하여 순차적으로 해결하는 방식으로, RAP의 구현을 따릅니다. A4 하위 질문에 대한 답변을 다시 제안 하위 질문이 A3에 의해 올바르게 답변되지 않았을 경우, 이 액션을 사용하여 다시 답변하도록 합니다. 이를 통해 정확도를 향상시킬 수 있습니다. A5 질문/하위 질문을 다시 표현 질문을 잘못 이해한 경우, 이 액션을 사용하여 질문을 더 명확하게 다시 표현하도록 합니다. - 모델이 생성한 인퍼런스 경로의 정확성을 높이기 위해, 두 번째 SLM(Small Language Model)을 판별기로 사용하여 상호 일관성을 확인합니다. 이 과정을 통해 서로 일치하는 경로를 선택함으로써 모델의 정확도를 높일 수 있습니다.
- 중간 단계에서의 신뢰할 수 없는 자기 평가를 피하고, 각 행동의 가치를 평가할 수 있는 보상 함수를 설계하여 인퍼런스 경로의 확장을 효율적으로 유도합니다. 이 보상 함수를 통해 자주 올바른 답을 이끌어내는 행동에 더 높은 보상을 부여하여 모델의 학습을 개선합니다.
- 더 많은 롤아웃을 통해 더 다양한 후보 해결책을 생성하되, 그에 따른 인퍼런스 비용도 고려해야 합니다. 적절한 롤아웃 수를 통해 효율적인 탐색이 가능하며, 성능을 크게 향상시킬 수 있습니다.
- 다양한 크기의 언어 모델(SLM 등)을 판별기로 활용하여, 모델 선택이 전체 성능에 미치는 영향을 분석하고, 특정 모델에 의존하지 않는 견고한 인퍼런스 방식을 개발합니다.
1. Monte Carlo Tree Search(MCTS) 기반의 인퍼런스 경로 생성
rStar는 먼저 MCTS를 사용하여 다양한 인퍼런스 경로를 생성합니다. MCTS는 일반적으로 체스나 바둑과 같은 게임에서 사용되는 탐색 알고리즘으로, 가능한 경로를 시뮬레이션하고 가장 유망한 경로를 선택합니다. 이를 수학적으로 표현하면, 다음과 같습니다.
\[U(s, a) = Q(s, a) + c \times \sqrt{\frac{\log N(s)}{N(s, a)}}\]\(U(s, a)\)는 상태 \(s\)에서 행동 \(a\)의 선택 우선순위(priority)를 의미하며, \(Q(s, a)\)는 상태 \(s\)에서 행동 \(a\)를 선택했을 때의 예상 가치(value)를 나타냅니다. 또한, \(c\)는 탐색 상수, \(N(s)\)는 상태 \(s\)에서의 전체 방문 횟수, \(N(s, a)\)는 상태 \(s\)에서 행동 \(a\)의 방문 횟수를 의미합니다. 이 알고리즘은 탐색과 활용(exploitation) 간의 균형을 맞추며, 최적의 인퍼런스 경로를 찾기 위해 사용됩니다.
2. 상호 일관성 기반 판별 과정
생성된 인퍼런스 경로의 품질을 판단하기 위해 rStar는 두 번째 SLM을 판별자로 활용합니다. 이 판별자는 생성된 경로의 일부를 힌트로 받아 나머지 인퍼런스 단계를 완성하도록 요구받습니다. 이 과정에서 상호 일관성(mutual consistency)을 통해 경로의 품질을 평가합니다.
상호 일관성의 수학적 모델링은 다음과 같이 표현될 수 있습니다.
\[\text{MC}(T_1, T_2) = \frac{\sum_{i=1}^{n} \mathbf{1}(T_1[i] = T_2[i])}{n}\]\(T_1\)과 \(T_2\)는 두 SLM이 생성한 인퍼런스 경로를 나타내며, \(\mathbf{1}\)은 두 경로가 일치하는지를 나타내는 지표 함수입니다. \(MC(T_1, T_2)\)는 두 경로 간의 일관성을 정량화하며, 일관성이 높은 경로를 더 높은 품질로 간주합니다.
3. 최종 인퍼런스 경로 결정
rStar는 위의 과정을 통해 생성된 다양한 경로 중 가장 높은 품질의 경로를 선택하여 최종 답변으로 결정합니다. 이 선택 과정은 각 경로에 대한 상호 일관성 평가를 기반으로 하며, 가장 일관성이 높은 경로가 최종적으로 선택됩니다.
1. 서론
대규모 언어모델(LLMs)은 많은 성공을 거두었지만, 복잡한 인퍼런스 작업에서는 여전히 상당한 어려움을 겪고 있습니다(Valmeekam et al., 2022; Weng et al., 2023). 예를 들어, 최신 모델인 Mistral-7B(Jiang et al., 2023)는 GSM8K 데이터셋에서 체인 오브 띠어(Chain-of-Thought, CoT) 기법을 사용해도 36.5%의 정확도에 그칩니다(Wei et al., 2022). 이런 한계를 극복하기 위해서는 파인튜닝이 효과적인 방법으로 알려져 있지만, 대부분의 언어 모델은 GPT-4와 같은 우수한 모델에 의해 증류(distilled)되거나 합성된 데이터를 사용하여 파인튜닝에 의존합니다(Wang et al., 2024a; Gou et al., 2023). 그러나, 최근 커뮤니티에서는 우수한 teacher 모델 없이 인퍼런스 능력을 향상시키는 도전적인 방법에 대해 활발히 연구하고 있습니다.
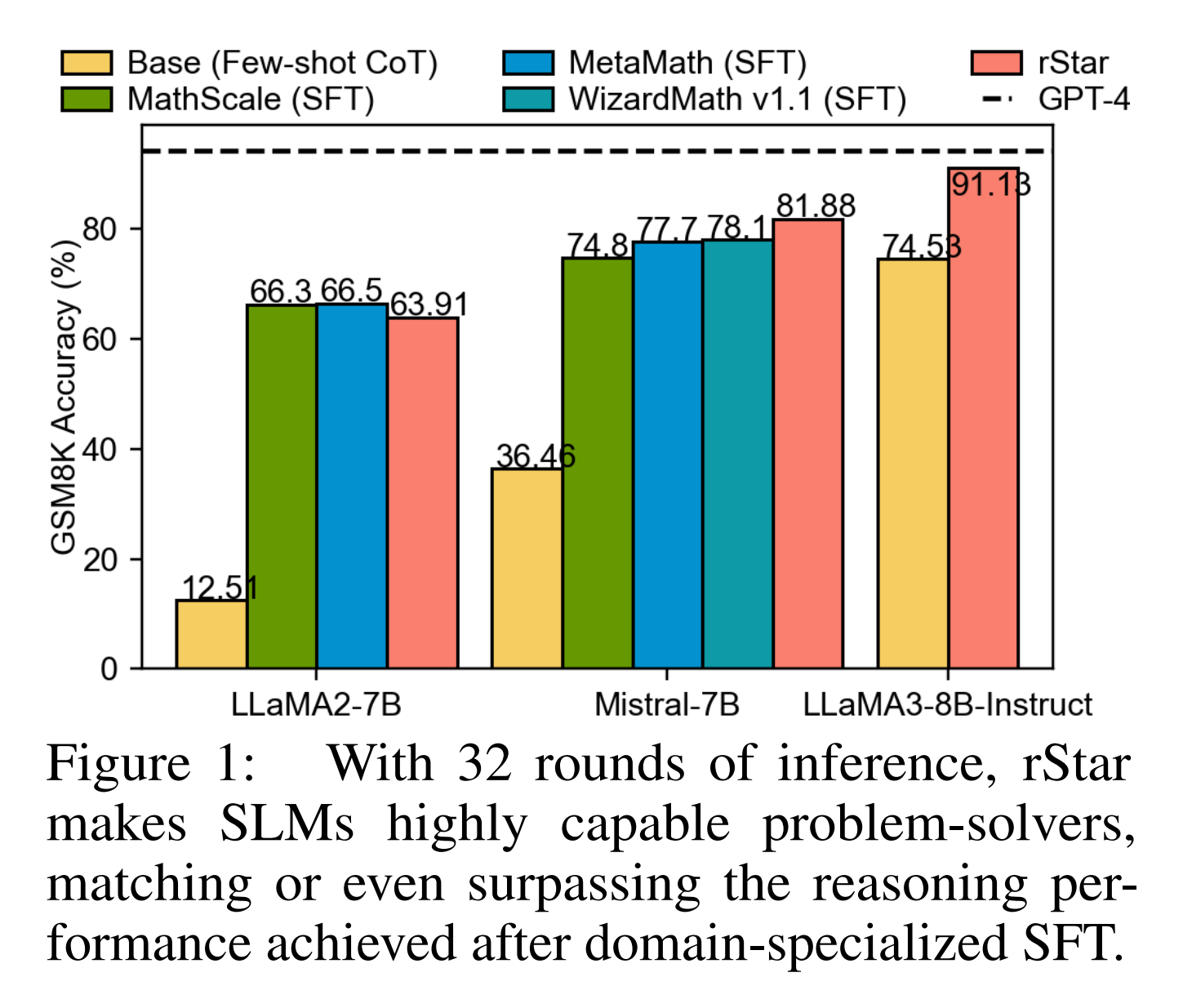
rStar는 이런 접근 방식을 해결하기 위해 설계된 새로운 방법입니다. rStar는 SLM이 자기 자신을 활용해 인퍼런스 능력을 향상시키는 자가 생성-판별(self-play mutual generation-discrimination) 과정을 도입합니다. 이 과정은 모델이 문제 해결에 있어 상호 협력적 인퍼런스(mutual reasoning)을 할 수 있도록 유도하며, SLM이 인퍼런스를 수행하는 동안 정확도를 높이도록 합니다.
1.1 문제 정의 및 접근 방식
rStar는 다음과 같은 두 가지 주요 문제를 해결하기 위해 설계되었습니다.
- 인퍼런스 공간 탐색의 어려움: LLM은 많은 시도 후에도 여전히 낮은 품질의 인퍼런스 경로에 갇히는 경우가 많습니다.
- 인퍼런스 경로의 품질 판단의 어려움: LLM이 고품질의 인퍼런스 경로를 찾아내더라도, 그 품질을 판단하거나 올바른 최종 답변을 결정하기가 어렵습니다.
rStar는 이런 문제를 해결하기 위해 Monte Carlo Tree Search(MCTS)를 사용하여 다양한 인퍼런스 경로를 생성하며, 상호 일관성을 기반으로 한 판별 과정을 통해 최종 인퍼런스 경로를 결정합니다. 이 과정에서 두 번째 SLM이 판별자(discriminator)로 작용하여 생성된 각 인퍼런스 경로의 품질을 평가합니다. 이 평가 과정에서는 부분적인 힌트를 제공하여 더 정확한 피드백을 얻도록 합니다.
2. 관련 연구
인퍼런스를 촉진하기 위해 LLM을 프롬프트하는 방법, LLM의 자가 개선(self-improvement), 인퍼런스 경로 샘플링 및 답변 검증 등의 다양한 연구가 존재합니다. 특히, CoT와 같은 프롬프트 기반 방법(Wei et al., 2022)은 단일 라운드 인퍼런스 성능을 향상시키기 위해 설계된 방법입니다. 그러나 SLM에서는 이런 방법들이 충분한 성과를 내지 못하는 경우가 많습니다.
3. 방법
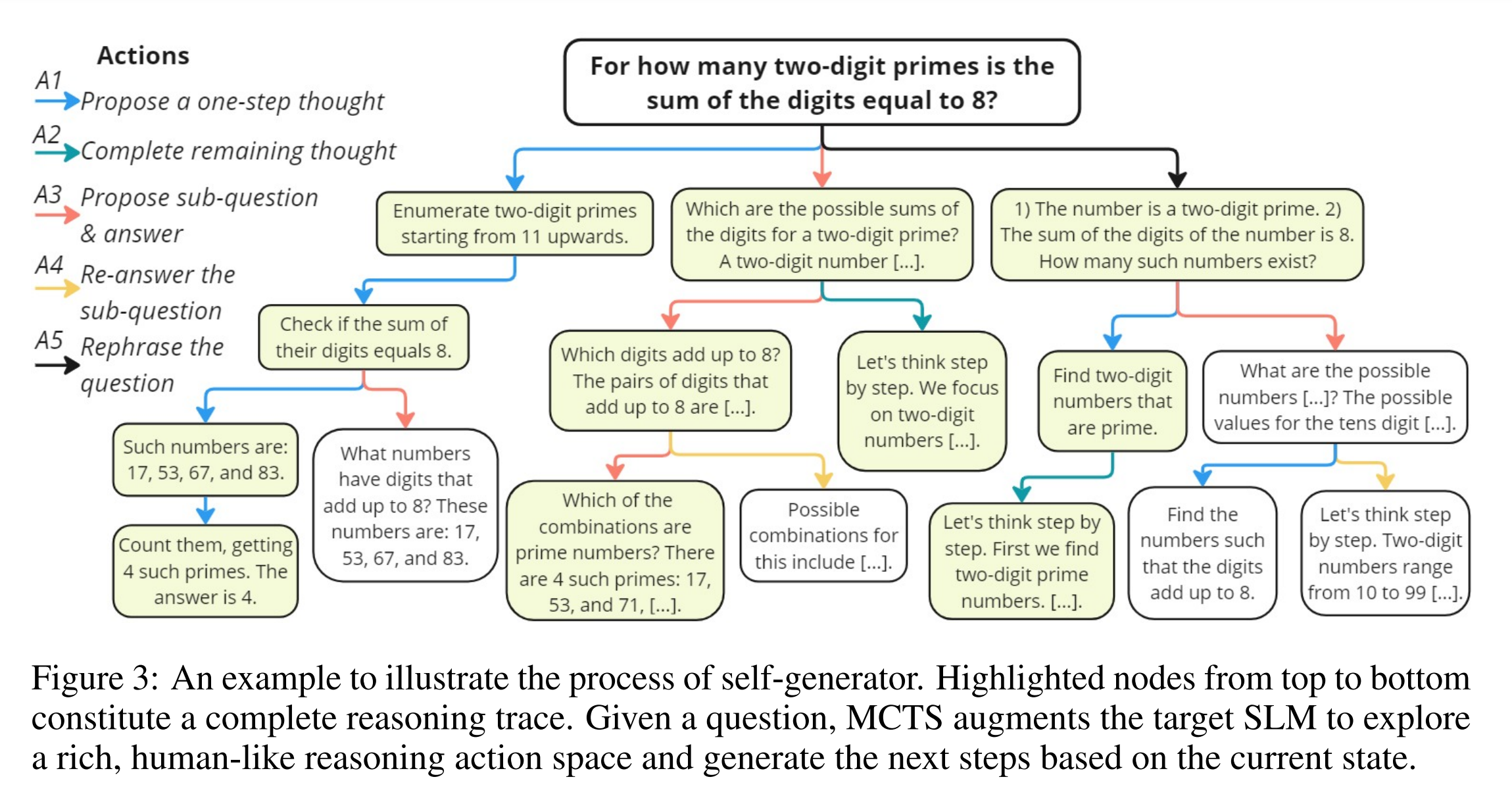
3.1 개요
문제 정의
SLM(Small Language Models)의 인퍼런스 문제를 해결하기 위해, 이 문제를 다단계 인퍼런스 생성 작업으로 정의합니다. 문제를 단순한 하위 작업으로 나누는 것이 SLM이 전체 인퍼런스 단계를 한 번에 완성하는 것보다 더 효과적입니다. 이를 위해, Monte Carlo Tree Search(MCTS) 알고리즘(Kocsis & Szepesvári, 2006)을 사용하여 목표 SLM을 확장하고 다단계 인퍼런스 솔루션을 자가 생성하도록 합니다.
챌린지
MCTS는 SLM이 여러 가능한 솔루션을 탐색하고 평가할 수 있도록 도와줍니다. 그러나 SLM의 제한된 능력으로 인해 기존의 MCTS는 최소한의 개선만을 가져옵니다. 첫째, 방대한 솔루션 공간은 SLM이 효과적인 솔루션을 생성하는 데 어려움을 겪게 만듭니다. 기존의 MCTS 기반 방법(Hao et al., 2023; Kang et al., 2024)은 단일 액션을 사용하여 다양성을 제한하고 작업 간 일반화에 어려움을 겪습니다. 둘째, 각 액션에 정확한 보상을 제공하는 것은 어렵습니다. 정확한 중간 단계의 보상을 제공할 수 없으면, 최종 답변의 정확성을 판단하기가 어렵습니다. 따라서, rStar는 이 문제를 해결하기 위해 휴먼과 유사한 다양한 인퍼런스 액션을 도입하고, 신뢰성 있는 보상 함수와 상호 일관성을 기반으로 한 검증 과정을 추가합니다.
3.2 MCTS Rollout을 통한 자가 인퍼런스 경로 생성 (Self-generating Reasoning Trajectory with MCTS Rollout)
휴먼과 유사한 다양한 인퍼런스 액션
MCTS 생성의 핵심은 액션 공간입니다. 대부분의 MCTS 기반 방법은 단일 액션 유형을 사용하여 트리를 구축합니다. 예를 들어, RAP에서는 다음 하위 질문을 제안하는 액션을 사용하고, AlphaMath(Chen et al., 2024a)와 MindStar(Kang et al., 2024)에서는 다음 인퍼런스 단계를 생성하는 액션을 사용합니다. 그러나 단일 액션 유형에 의존하면 비효율적인 공간 탐색으로 이어질 수 있습니다.
이에 대응하기 위해, 사람들이 문제를 해결하는 방식을 다시 검토했습니다. 사람들은 다양한 액션을 사용하여 문제를 해결합니다. 이를 기반으로, 5가지의 다양한 액션을 도입하여 SLM의 잠재력을 최대한 활용합니다.
- A1: 단일 생각을 제안
이 액션은 주어진 질문에 대해 다음 단일 생각을 생성하도록 LLM을 프롬프트합니다. 이는 기존의 CoT(Chain-of-Thought) 방법보다 간단하며, 더 나은 의사 결정을 할 수 있도록 도와줄 수 있다고 언급합니다. - A2: 나머지 생각 단계를 제안
이 액션은 현재 생성된 인퍼런스 단계에 기반하여 나머지 단계를 직접 생성하도록 해 빠른 문제 해결을 가능하게 할 수 있다고 분석합니다. - A3: 다음 하위 질문과 답변을 제안
복잡한 문제를 일련의 더 간단한 하위 질문으로 분해하여 순차적으로 해결하는 방식으로, RAP의 구현을 따릅니다. - A4: 하위 질문에 대한 답변을 다시 제안
하위 질문이 A3에 의해 올바르게 답변되지 않았을 경우, 이 액션을 사용하여 다시 답변하도록 합니다. 이를 통해 정확도를 향상시킬 수 있었다고 언급합니다. - A5: 질문/하위 질문을 다시 표현
질문을 잘못 이해한 경우, 이 액션을 사용하여 질문을 더 명확하게 다시 표현하도록 합니다.
위의 5가지 액션을 다양한 액션 공간을 정의하며, 각 단계에서 MCTS는 이 공간에서 액션을 선택하여 다음 인퍼런스 단계를 생성합니다. 특정 액션은 순서가 필연적일 수 있는데 예를 들어, A4는 A3 이후에만 발생할 수 있으며, A5는 루트 질문 이후에만 발생할 수 있습니다.
보상 함수 (Reward Function)
MCTS의 또 다른 중요한 요소는 각 액션의 가치를 평가하고 트리 확장을 지시하는 보상 함수입니다. SLM에 대해 간단하지만 효과적인 보상 함수를 설계했습니다. 첫째, SLM의 제한된 능력으로 인해 중간 노드에 대해 자기 보상 기술을 배제했습니다. 둘째, 다양한 인퍼런스 작업 간의 일반화를 보장하기 위해 외부 감독을 도입하지 않았습니다. 대신, AlphaGo(Silver et al., 2017)에서 영감을 받아 각 중간 노드를 최종 올바른 답변에 대한 기여도를 기반으로 평가합니다.
$Q(s, a)$는 액션 \(a\)에 의해 생성된 노드 \(s\)의 보상 값을 나타냅니다. 모든 탐색되지 않은 노드는 초기값으로 \(Q(s_i, a_i) = 0\)을 할당받아, 초기에는 무작위로 트리가 확장됩니다. 첫 번째 터미널 노드에 도달하면, 최종 답변의 정확성에 따라 보상 점수를 계산합니다. 이 점수는 해당 경로의 모든 중간 노드로 전파되어 업데이트됩니다.
3.3 상호 일관성을 통한 인퍼런스 경로 선택 (Reasoning Trajectory Selection with Mutual Consistency)
상호 일관성
기존 MCTS에서는 일반적으로 특정 메트릭을 기반으로 하나의 경로가 최종 솔루션으로 선택됩니다. 그러나 다양한 방법을 시도한 후, 단일 메트릭으로 올바른 답을 포함하는 경로를 선택하기 어렵다는 것을 발견했습니다. 따라서 모든 경로를 수집하고, 상호 일관성을 사용하여 답을 선택하는 방식을 제안합니다.
상호 일관성을 적용하기 위해, 두 번째 SLM을 판별자(discriminator)로 도입하여 각 후보 경로에 대해 외부 비지도 피드백을 제공합니다. 예를 들어, 경로 \(t = x \oplus s_1 \oplus s_2 \oplus ... \oplus s_d\)의 일부 단계부터 마스크하여 판별자에게 초기 경로를 프롬프트로 제공하고 나머지 단계를 완성하도록 합니다. 초기 경로가 힌트로 제공되므로 판별자가 올바른 답을 제공할 가능성이 높아집니다. 상호 일관성을 통해 경로가 일치하는지 비교하여, 일치하는 경로를 최종 선택에 고려합니다.
최종 경로 선택
상호 일관성을 적용한 후, 목표 SLM으로 돌아와 검증된 경로 중 최종 경로를 선택합니다. 각 경로의 최종 점수는 보상과 터미널 노드의 신뢰도 점수를 곱하여 계산됩니다. 가장 높은 최종 점수를 가진 경로가 솔루션으로 선택됩니다.
rStar 방법은 SLM이 제한된 능력에도 불구하고, MCTS와 상호 일관성을 사용하여 더 높은 정확도의 인퍼런스를 수행할 수 있도록 돕습니다. 이를 통해 다양한 인퍼런스 작업에서 SLM의 성능을 극대화할 수 있습니다.
4. 실험
4.1 실험 설정 (Setup)
모델과 데이터셋
rStar는 다양한 LLM과 인퍼런스 작업에 적용 가능한 일반적인 접근 방식입니다. 5가지 SLM(Phi3-mini (3.8B), LLaMA2-7B, Mistral-7B, LLaMA3-8B, LLaMA3-8B-Instruct)을 평가했습니다. 또한, 4개의 수학적 작업(GSM8K, GSM-Hard, MATH, SVAMP)과 1개의 상식 인퍼런스 작업(StrategyQA)을 포함한 5가지 인퍼런스 작업에서 테스트를 진행했습니다.
구현 세부사항
자가 인퍼런스 경로 생성 단계에서, 각 목표 SLM에 대해 MCTS를 사용하여 32번의 롤아웃을 수행했습니다. MATH 작업의 경우, 깊이 \(d\)를 8로 설정했고, 다른 작업에서는 \(d = 5\)로 설정했습니다. 액션 \(A_1\)과 \(A_3\)는 깊이당 최대 5개의 노드를 가지며, 다른 액션은 기본적으로 1개의 노드를 가집니다. 경로 판별 단계에서는 Phi3-mini-4k(3.8B 파라미터)를 판별기로 사용하여 효율적인 인퍼런스를 수행했습니다. Phi3가 목표 SLM일 때는 자기 판별을 수행하도록 설정했습니다. 각 경로에 대해, 경로의 20%에서 80% 사이의 단계를 무작위로 분할하여, 처음 절반의 단계를 판별기 SLM에 입력으로 제공하고 나머지 단계를 완성하도록 했습니다.
4.2 주요 결과
베이스 라인 비교
rStar를 세 가지 강력한 베이스 라인과 비교했습니다. (i) 단일 라운드 CoT 프롬프트, (ii) 다중 라운드 CoT 프롬프트, (iii) 다중 라운드 자기 개선 접근 방식. 이를 통해 rStar의 성능을 평가했습니다.
다양한 인퍼런스 벤치마크에서의 결과
rStar가 다양한 인퍼런스 벤치마크에서 효과적임을 확인했습니다. 예를 들어, LLaMA2-7B는 원래 GSM8K에서 12.51%의 정확도를 보였으나, rStar를 적용한 후 63.91%로 향상되었습니다. 이는 파인튜닝 후의 성능과 거의 일치하는 결과입니다. Mistral 모델은 rStar를 통해 파인튜닝된 MetaMath보다 +4.18% 더 높은 성능을 보였습니다.
또한, rStar는 다양한 작업에서 평가된 여러 SLM의 인퍼런스 정확도를 일관되게 향상시켰으며, 이는 기존의 방법들이 모든 벤치마크에서 일관된 성능을 보이지 못하는 것과 대조적입니다. 예를 들어, SC는 세 가지 수학적 작업에서 향상된 성능을 보였지만, StrategyQA와 같은 논리적 인퍼런스 작업에서는 덜 효과적이었습니다.
어려운 수학적 데이터셋에서의 결과
rStar는 더 어려운 수학적 데이터셋(GSM-Hard, MATH)에서도 향상된 성능을 보였습니다. 특히, MATH-500 데이터셋에서 rStar는 SOTA 베이스 라인보다 최대 +12.9% 및 +9.14%의 성능 향상을 보였습니다.
4.3 소거 연구 (Ablation Study)
MCTS 생성기의 효과
rStar의 MCTS 생성기를 세 가지 베이스 라인과 비교했습니다. (i) RAP에서 사용된 MCTS 생성기, (ii) SC의 128번 무작위 샘플링 솔루션, (iii) 자기 평가(Self-evaluation)를 사용하는 생성기. 결과적으로, 생성기가 다양한 답변 검증 방법에서도 베이스 라인 생성기보다 일관되게 우수한 성능을 보였습니다.
판별기의 효과
두 가지 실험을 통해 판별기의 효과를 평가했습니다. 첫째, 판별 접근 방식을 다수결 투표 및 자기 검증(Self-verification)과 비교했습니다. 두 번째로, 다양한 LLM을 사용하여 판별 모델 선택이 성능에 미치는 영향을 연구했습니다. 그 결과, 더 강력한 GPT-4를 판별기로 사용했을 때 성능이 약간 향상되었지만, 상호 인퍼런스 일관성 방법이 SLM을 사용하여 답변을 효과적으로 검증할 수 있음을 보여주었습니다.
5. 결론
이 연구에서 SLM의 인퍼런스 능력을 크게 향상시키는 rStar 방법을 제시했습니다. rStar는 MCTS와 상호 일관성 기반의 자가 생성-판별 과정을 통해 인퍼런스 정확도를 향상시킵니다. 다양한 SLM과 인퍼런스 작업에서 rStar의 우수성이 입증되었으며, 이는 기존의 다중 라운드 프롬프트 및 자기 개선 방법보다 향상된 성능을 제공할 수 있다고 언급합니다.