Chunking Methods
- Related Project: Private
- Category: Paper Review
- Date: 2024-08-27
Chunking in Long-Context Embedding Models
- url: https://jina.ai/news/late-chunking-in-long-context-embedding-models/
- abstract: About a year ago, in October 2023, we released the world’s first open-source embedding model with an 8K context length,
jina-embeddings-v2-base-en. Since then, there has been quite some debate about the usefulness of long-context in embedding models. For many applications, encoding a document thousands of words long into a single embedding representation is not ideal. Many use cases require retrieving smaller portions of the text, and dense vector-based retrieval systems often perform better with smaller text segments, as the semantics are less likely to be “over-compressed” in the embedding vectors.
임베딩과 토크나이저 쪽으로 잘하고 있는 Jina.AI 모델 관련 글 Chunking에 대해서는 DCA(Dual Chunk Attention), Qwen, ChatQA2, RAG(Medical Graph, TransformerSSM) 등 다양한 분야에서 활용.
RAG, LLM의 인퍼런스 또는 학습시 토큰 레벨, 청킹 레벨 그리고 논리적 사고를 이어주는 것 등에 많이 응용되는 편인 것 같습니다. 현재 자연어 임베딩은 대부분 SBERT의 경량화된 임베딩 모델을 사용하는 편인데, Jina.AI 의 방향성도 굉장히 유망하다고 생각하고 있습니다.
- 문맥 정보의 유지를 위한 Late Chunking 기법 도입
- 긴 문맥 임베딩 모델을 사용해, 청킹 이후 풀링을 통한 문맥 정보 보존하는 세부적인 청킹 방법 설명 및 모델 소개
- BeIR 벤치마크를 통한 Late Chunking의 성능 평가
| 구분 | 설명 |
|---|---|
| 모델명 | jina-embeddings-v2-base-en |
| 모델 아키텍처 | BERT 기반, ALiBi (Attention with Linear Biases)를 통한 대칭 양방향 지원 |
| 지원 시퀀스 길이 | 최대 8192 토큰 |
| training dataset | C4 데이터셋에서 사전 훈련 후, Jina AI가 수집한 4억 개 이상의 문장 쌍과 하드 네거티브 사용 |
| 주요 활용 사례 | 긴 문서 검색, 의미적 텍스트 유사성, 텍스트 리랭킹, 추천 시스템, RAG, LLM 기반 생성 검색 등 |
| 파라미터 수 | 137백만 파라미터 |
| 추가 모델 버전 | jina-embeddings-v2-small-en (33백만 파라미터), 다양한 언어 지원 버전 등 포함 |
| 훈련 세부사항 | 512 시퀀스 길이로 학습하고, ALiBi를 사용해 긴 시퀀스 길이로 확장 가능 |
1. 도입
긴 문서를 처리하면서 문맥 정보를 유지하는 새로운 방법인 ‘Late Chunking’는 기존의 청킹 방법이 문맥 정보를 상실하는 문제점을 해결하기 위해 고안되었습니다. 8192 토큰 길이를 지원하는 jina-embeddings-v2-base-en 모델을 활용해 긴 문맥 정보를 효과적으로 임베딩할 수 있는 청킹 방식을 제안하며, 특히 문맥 의존성이 높은 긴 문서에서의 정보 손실을 최소화할 수 있다고 보고합니다.
2. 문제 정의 및 배경 지식
긴 문서를 처리할 때 일반적으로 사용되는 청킹 방법은 문서를 임의의 길이로 나누어 각 청크를 독립적으로 임베딩하는 과정을 포함합니다. 이 과정에서 문맥적 연관성이 무시되어 중요한 정보가 손실될 수 있으며, 특히 문맥이 길어지는 경우 문제가 두드러지게 됩니다. (일반적으로 알려진 청킹 방법들의 한계)

\(\text{Embedding}(X) = \text{MeanPooling}(\text{Transformer}(X_i))\) ($X_i$는 입력 텍스트의 $i$번째 청크)
위와 같이 기존의 청킹 방법들은 각 청크를 독립적으로 임베딩하어 문맥 정보를 상실하는 문제가 발생합니다.
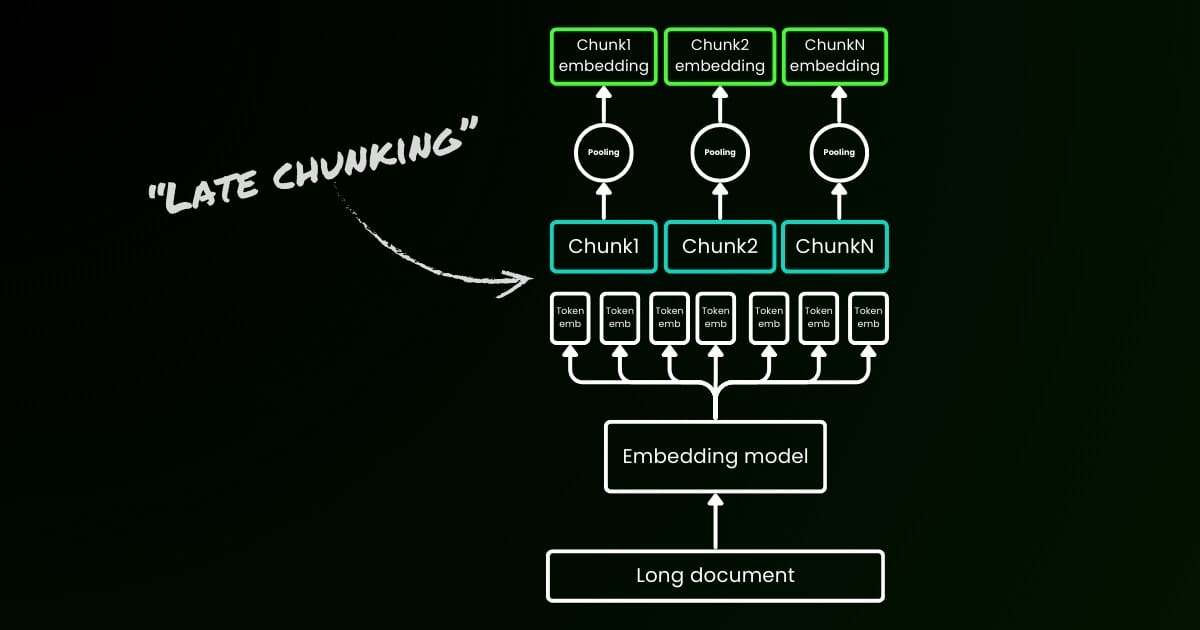
3. Late Chunking 방법
‘Late Chunking’ 방법은 전체 문서나 긴 부분을 한 번에 트랜스포머 모델에 통과시키고, 그 결과로 나온 토큰 벡터들을 청킹 후에 평균 풀링(mean pooling)을 적용하는 방식입니다. 이 방법은 각 청크가 전체 문맥 정보를 반영하도록 하여 문맥 의존성을 유지합니다.
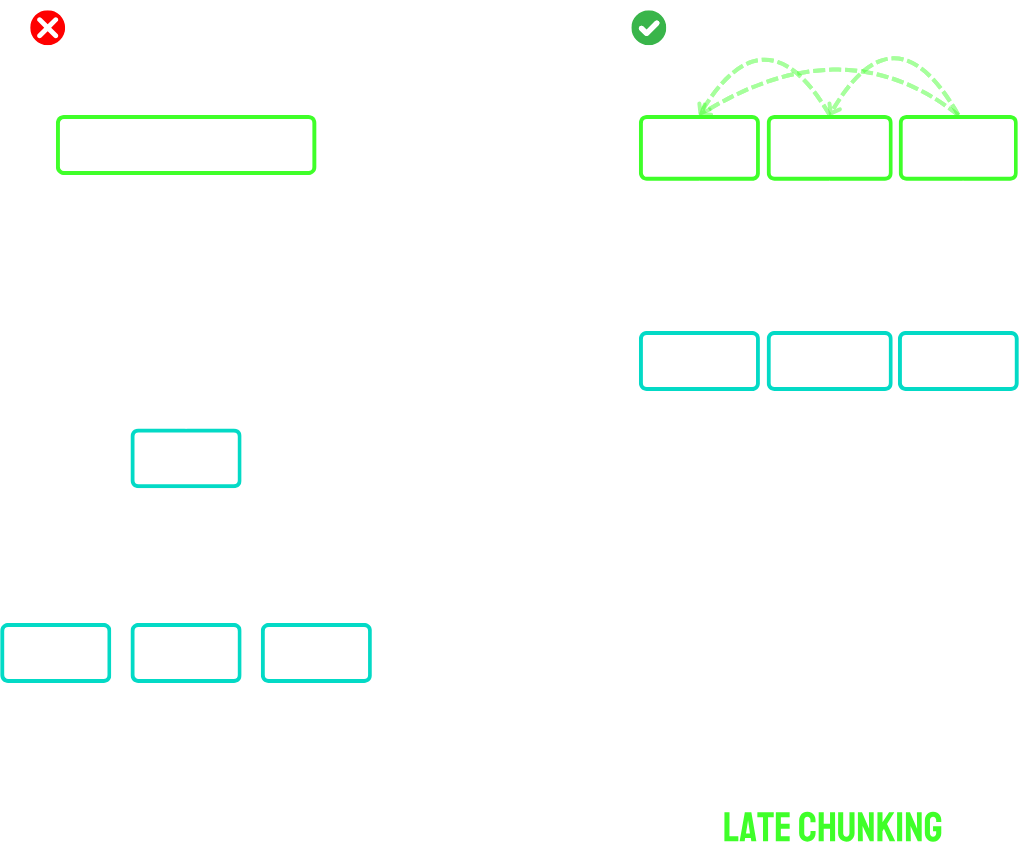
이 수식에서 $\text{Transformer}(X)_{\text{chunk}}$는 전체 문서의 트랜스포머에 의해 생성된 토큰 벡터를 청크로 나눈 후 적용되는 평균 풀링을 나타냅니다. 이는 각 청크가 이전 청크의 정보를 ‘조건부로’ 포함하게 되므로 더 풍부한 문맥 정보를 임베딩할 수 있습니다.
4. 실험 및 평가
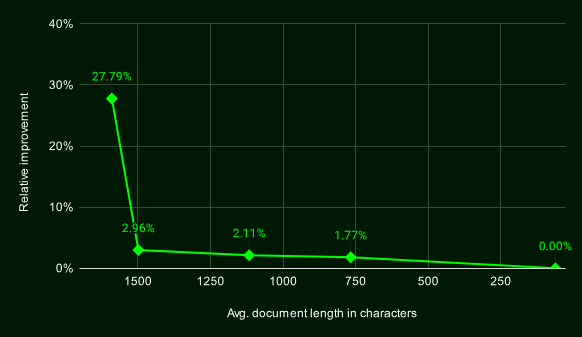
Late Chunking의 효과를 검증하기 위해, BeIR 벤치마크 데이터셋을 사용하여 여러 청킹 방식의 성능을 비교 분석했습니다. 각 청크는 벡터 인덱스에 저장되며, 질의에 가장 유사한 청크를 k-최근접 이웃 방법(kNN)을 통해 검색합니다. 이 방법은 각 청크가 독립적으로 임베딩되는 나이브 방식에 비해 높은 성능을 보여주었습니다. ($\text{rel}_i$는 $i$번째 청크의 관련성 점수이며, $Z$는 정규화 상수)
다음 공식은 검색된 문서의 순위와 관련성을 평가하는 데 사용됩니다.
\[\text{nDCG@10} = \frac{1}{Z} \sum_{i=1}^{10} \frac{2^{\text{rel}_i} - 1}{\log_2(i+1)}\]5. 결론
Late Chunking은 긴 문맥 임베딩 모델을 활용하여 각 청크가 문맥 정보를 더욱 효과적으로 반영할 수 있도록 합니다. 문서의 길이가 길수록 그 효과가 더욱 두드러지며(일반적인 청킹의 한계를 극복하기 위해 후단에서 mean pooling을 하기 때문), 긴 문맥 정보를 요구하는 다양한 응용 분야에서 응용할 수 있습니다.
[참고자료 1] 모델 카드 jinaai/jina-embeddings-v2-base-en
jina-embeddings-v2-base-en은 8192 시퀀스 길이를 지원하는 영어 단일 언어 임베딩 모델로, 더 긴 시퀀스 길이를 지원하기 위해 대칭 양방향 ALiBi를 지원하는 BERT 아키텍처(JinaBERT)를 기반으로 합니다. 이 모델은 C4 데이터셋에서 사전 훈련되었으며, Jina AI가 수집한 4억 개 이상의 문장 쌍과 하드 네거티브를 사용해 추가 훈련되었습니다. 이 문장 쌍은 다양한 도메인에서 얻어졌으며 철저한 정제 과정을 거쳐 선별되었습니다.
이 임베딩 모델은 512 시퀀스 길이로 훈련되었지만, ALiBi 덕분에 8k 시퀀스 길이(또는 그 이상)로 확장할 수 있습니다. 이로 인해 모델은 긴 문서 처리가 필요한 다양하게 사용할 수 있습니다. (긴 문서 검색, 의미적 텍스트 유사성, 텍스트 리랭킹, 추천, RAG 및 LLM 기반 생성 검색 등)
모델은 1억 3700만 개의 파라미터를 가지며, 단일 GPU 사용이 권장됩니다.
jina-embeddings-v2-small-en: 3300만 파라미터.jina-embeddings-v2-base-en: 1억 3700만 파라미터 (현재 위치).jina-embeddings-v2-base-zh: 중-영 이중 언어 임베딩.jina-embeddings-v2-base-de: 독-영 이중 언어 임베딩.jina-embeddings-v2-base-es: 스페인-영 이중 언어 임베딩.
데이터 및 파라미터
모델을 통합할 때 평균 풀링(mean pooling)을 적용해야 하며, transformers 패키지에서 직접 Jina 임베딩 모델을 사용할 수 있습니다.
!pip install transformers
from transformers import AutoModel
from numpy.linalg import norm
cos_sim = lambda a, b: (a @ b.T) / (norm(a) * norm(b))
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
embeddings = model.encode(['How is the weather today?', 'What is the current weather like today?'])
print(cos_sim(embeddings[0], embeddings[1]))
짧은 시퀀스를 처리하려면, encode 함수에 max_length 파라미터 사용
embeddings = model.encode(
['Very long ... document'],
max_length=2048
)
최신 릴리스(v2.3.0)의 sentence-transformers도 Jina 임베딩을 지원합니다.
!pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
"jinaai/jina-embeddings-v2-base-en",
trust_remote_code=True
)
model.max_seq_length = 1024
embeddings = model.encode([
'How is the weather today?',
'What is the current weather like today?'
])
print(cos_sim(embeddings[0], embeddings[1]))
RAG용 Jina 임베딩 사용
LLamaIndex의 최신 블로그 포스트에 따르면, OpenAI 또는 JinaAI-Base 임베딩과 CohereRerank/bge-reranker-large reranker의 조합이 히트율과 MRR에서 최고 성능을 달성한다고 합니다.
추후 개발 계획
- 이중 언어 임베딩 모델 지원 확대: 스페인어, 프랑스어, 이탈리아어, 일본어 포함
- 멀티모달 RAG 애플리케이션을 가능하게 하는 멀티모달 임베딩 모델
- 고성능 리랭커
Jina Embeddings V2 기술 보고서 참조