RAG, WebSearch | MindSearch
- Related Project: Private
- Category: Paper Review
- Date: 2024-08-01
MindSearch: Mimicking Human Minds Elicits Deep AI Searcher
- url: https://arxiv.org/abs/2407.20183
- pdf: https://arxiv.org/pdf/2407.20183
- html: https://arxiv.org/html/2407.20183v1
- abstract: Information seeking and integration is a complex cognitive task that consumes enormous time and effort. Inspired by the remarkable progress of Large Language Models, recent works attempt to solve this task by combining LLMs and search engines. However, these methods still obtain unsatisfying performance due to three challenges: (1) complex requests often cannot be accurately and completely retrieved by the search engine once (2) corresponding information to be integrated is spread over multiple web pages along with massive noise, and (3) a large number of web pages with long contents may quickly exceed the maximum context length of LLMs. Inspired by the cognitive process when humans solve these problems, we introduce MindSearch to mimic the human minds in web information seeking and integration, which can be instantiated by a simple yet effective LLM-based multi-agent framework. The WebPlanner models the human mind of multi-step information seeking as a dynamic graph construction process: it decomposes the user query into atomic sub-questions as nodes in the graph and progressively extends the graph based on the search result from WebSearcher. Tasked with each sub-question, WebSearcher performs hierarchical information retrieval with search engines and collects valuable information for WebPlanner. The multi-agent design of MindSearch enables the whole framework to seek and integrate information parallelly from larger-scale (e.g., more than 300) web pages in 3 minutes, which is worth 3 hours of human effort. MindSearch demonstrates significant improvement in the response quality in terms of depth and breadth, on both close-set and open-set QA problems. Besides, responses from MindSearch based on InternLM2.5-7B are preferable by humans to ChatGPT-Web and this http URL applications, which implies that MindSearch can already deliver a competitive solution to the proprietary AI search engine.
Contents
TL;DR
사용자의 쿼리(프롬프트)에 필요한 세부 문제를 나누어서 DAG로 정리하고, 이를 기반으로 웹 서치한 뒤 결과를 요약해서 정보를 제공하는 방식으로 Web Search를 기반으로 문제를 해결할 수 있으며, 효용을 보임.
- 검색 엔진과 LLM을 결합하여, 복잡한 웹 기반 정보 검색 및 문제 해결을 도모 + 파이썬 인터프리팅으로 검증(코드)
- WebPlanner와 WebSearcher로 크게 나눌 수 있음.
- (1) WebPlanner는 전체적으로 복잡한 사용자 질문을 분해하고 위상학적 관계를 파악하여 조율하고, 더 효율적인 문제 해결 경로를 제시 (사용자 질문 \(Q\)의 해결 경로는 Directed Acyclic Graph, DAG \(G(Q) = \langle V, E \rangle\)로 모델링)
- (2) WebSearcher는 다양한 검색 엔진의 API를 사용하는 RAG 에이전트로, 초기 질문에서 파생된 여러 쿼리를 생성하여 웹에서 정보를 검색하고 요약하여 계층적 검색을 수행하고, 문제 해결을 위한 정보를 제공
- 상기 방식으로 다중 에이전트의 협업(SDK나 API 등)하여 웹의 정보를 활용하여 더 긴 컨텍스트(웹 리턴을 다 요약해서 LLM의 인풋으로 전달하므로)에 대한 문제를 효과적으로 처리할 수 있음을 주장
Self-Reasoning RAG와 접근방식은 비슷하지만, 웹 서치가 포함됨. 웹 서치 기반 연구나 RAG에서 흔하게 사용되는 방식이지만 2,000개의 샘플로 효과적임을 실험적으로 보임.
1 서론
휴먼의 일상에서 정보 탐색과 통합은 필수적인 인지 과정으로, 막대한 시간과 노력을 요구합니다. 검색 엔진의 출현은 정보 탐색 과정을 혁신적으로 간소화시켰지만, 복잡한 휴먼의 의도에 기반한 웹 정보의 통합에는 여전히 어려움이 있습니다. 최근 LLMs는 다양한 영역에서 인퍼런스 및 언어 이해, 정보 통합에 있어 눈에 띄는 진전을 보였지만, 정확한 지식 전달에는 한계가 있습니다. 이에 LLMs와 검색 엔진의 결합이 새로운 해결책을 제시하고 있으며, 이를 통해 웹 정보 탐색 및 통합 문제를 혁신적으로 해결할 수 있는 기회를 제공합니다. 기존 연구들은 정보 탐색과 통합 작업을 단순히 RAG(Retrieve-Augment-Generate) 작업으로 취급했으나, 이런 접근은 웹 기반 정보 검색의 Depth와 복잡성에 대한 표면적인 참여로 인해 서브옵티멀한 성능을 초래했습니다. 이를 극복하기 위해, MindSearch, 즉 고차원적인 계획과 다중 에이전트 프레임워크를 제안합니다.
2 MindSearch
MindSearch는 언어 모델(Large Language Models, LLMs)과 검색 엔진을 결합하여 복잡한 웹 기반 정보 검색 및 통합 문제를 해결합니다. 이 시스템은 WebPlanner와 WebSearcher로 구성되어 있으며, 각각은 명확한 역할을 수행하여 정보 탐색 및 처리 과정을 최적화합니다.
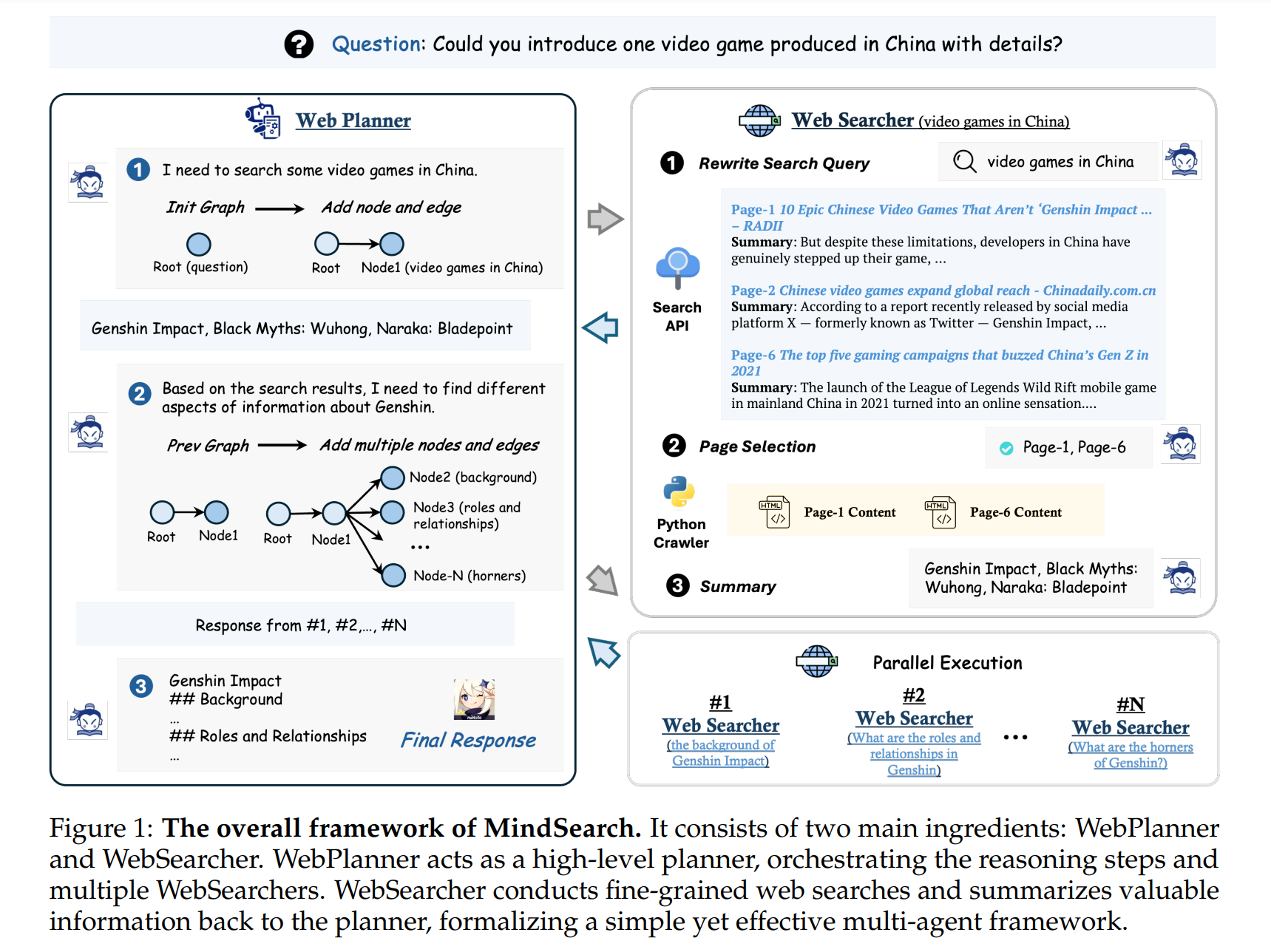
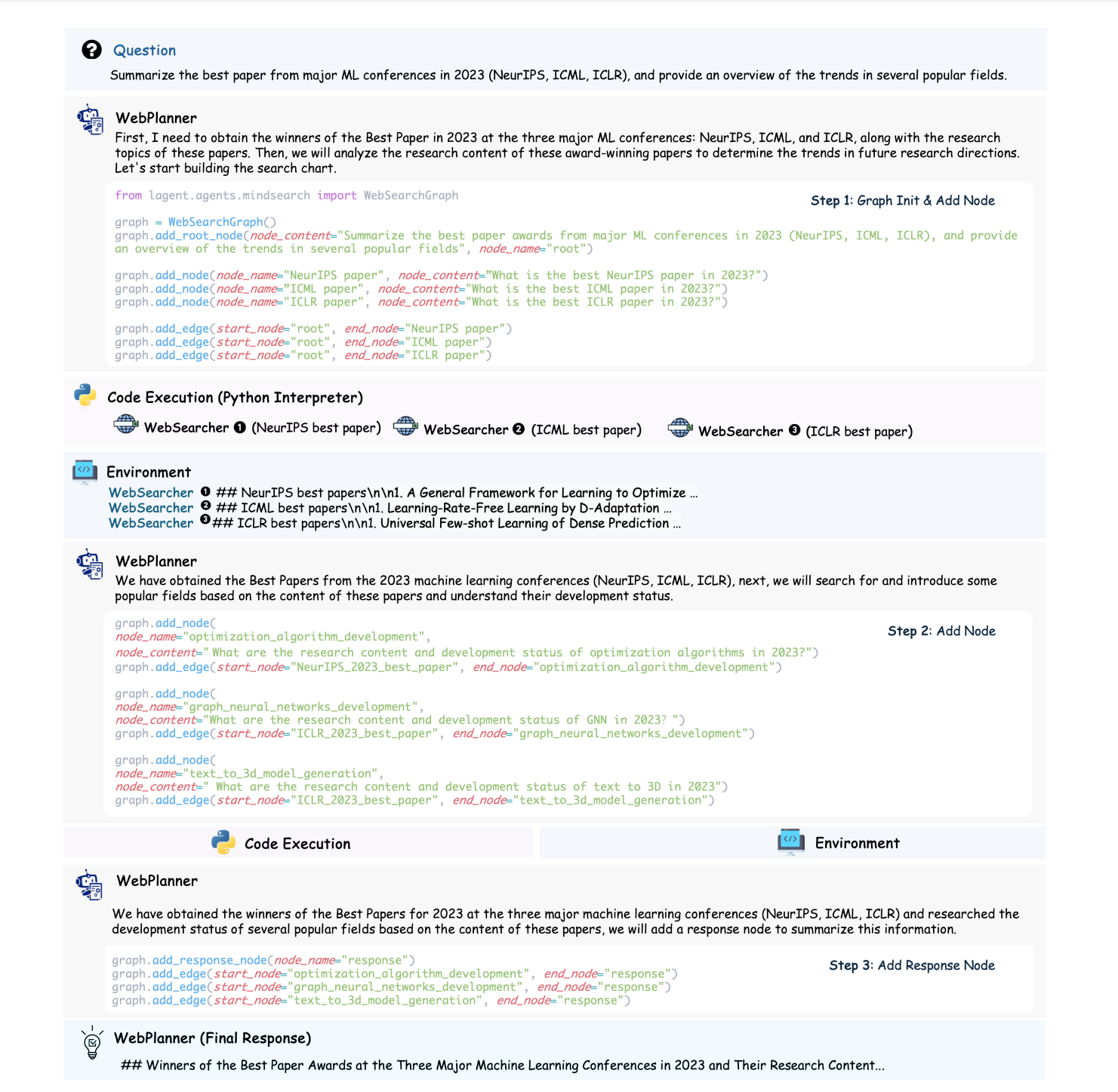
2.1 WebPlanner: 그래프 구성을 통한 계획
WebPlanner는 고차원 계획자로서, 복잡한 사용자 질문을 분해하고 위상학적 관계를 파악하여 조율하는 역할을 수행합니다. 이 과정은 LLMs가 직면한 한계를 극복하고, 더 효율적인 문제 해결 경로(trajectory)를 제시합니다.
[DAG 구성]
사용자 질문 \(Q\)의 해결 경로는 유향 비순환 그래프(Directed Acyclic Graph, DAG) \(G(Q) = \langle V, E \rangle\)로 모델링됩니다. \(V\)는 독립적 웹 검색 작업을 나타내는 노드 집합이며, \(E\)는 노드 간의 인퍼런스적 위상 관계를 나타내는 방향성 간선입니다. 이 DAG는 최적의 실행 경로를 도출하는 복잡성을 포착하여 LLM에게 보다 형식적이고 직관적인 작업 표현을 제공합니다.
[코드 상호작용]
LLM은 코드 작성을 통해 직접적으로 그래프와 상호 작용합니다. 노드 추가나 간선 추가와 같은 원자적 기능을 통해 인퍼런스 그래프를 동적으로 수정하며, Python 인터프리터를 통해 실행되는 새 코드를 출력합니다. 이 과정을 통해 모든 정보가 수집되면, 계획자는 최종 응답을 생성합니다. WebPlanner는 고차원 계획자로서, 인퍼런스 단계를 조율하고 다른 에이전트들을 조정합니다. 복잡한 질문을 분해하고 이들의 위상학적 관계를 이해하는 데 어려움을 겪는 현 LLMs의 한계를 극복하기 위해, 문제 해결 과정을 유향 비순환 그래프(Directed Acyclic Graph, DAG)로 모델링합니다. 사용자 질문 \(Q\)의 해결 경로는 \(G(Q) = \langle V, E \rangle\)로 표현되며, \(V\)는 독립적 웹 검색을 나타내는 노드 집합이고, \(E\)는 노드 간의 인퍼런스 위상 관계를 나타내는 방향성 간선입니다. 이런 DAG 형식은 최적 실행 경로를 찾는 복잡성을 포착하며, LLMs에 보다 형식적이고 직관적인 표현을 제공합니다. 코드 작성을 통해 그래프와 상호 작용하도록 LLM을 명시적으로 요청하여, 노드 추가나 간선 추가와 같은 원자적 코드 기능을 미리 정의합니다. 각 턴에서, LLM은 대화 전체를 읽은 후, 인퍼런스 그래프에 대한 생각과 새 코드를 출력하고, 이는 Python 인터프리터로 실행됩니다. 모든 정보가 수집되면, 계획자는 최종 응답을 생성합니다.
2.2 WebSearcher: 계층적 검색을 통한 웹 탐색
WebSearcher는 인터넷 접근 권한을 갖춘 RAG 에이전트로, 초기 질문에서 파생된 여러 쿼리를 생성하여 웹에서 정보를 검색하고 요약합니다. 이는 Google, Bing, DuckDuckGo 등의 검색 API를 사용하여 수행됩니다.
선택된 웹 페이지의 핵심 내용은 LLM의 입력으로 추가되며, 이를 통해 원래 질문에 대한 응답이 생성됩니다. 이 계층적 접근 방식은 웹 페이지 탐색의 어려움을 줄이고 심층적인 정보를 효과적으로 추출할 수 있도록 합니다.
WebSearcher는 인터넷 접근 권한을 가진 정교한 RAG 에이전트로서, 검색 결과를 기반으로 가치 있는 응답을 요약합니다. 초기에 LLM은 WebPlanner로부터 할당받은 질문을 기반으로 여러 유사한 쿼리를 생성하여 검색 내용을 확장하고 관련 정보의 회수를 향상시킵니다. 이 쿼리들은 Google, Bing, DuckDuckGo와 같은 검색 API를 통해 실행되며, 웹 URL, 제목, 요약을 포함한 핵심 내용을 반환합니다. 선택된 웹 페이지의 전체 내용이 LLM의 입력에 추가된 후, 이 결과를 읽고 원래 질문에 대한 응답을 생성합니다. 이 계층적 검색 접근 방식은 방대한 웹 페이지 탐색의 어려움을 크게 줄이며, 심층적인 세부 정보를 효율적으로 추출할 수 있게 합니다.
2.3 LLM 컨텍스트 관리 in MindSearch
다중 에이전트 협업
MindSearch는 다중 에이전트 프레임워크를 통해 복잡한 정보 탐색 및 통합을 단순화합니다. WebPlanner는 검색 작업을 별도의 검색 에이전트에게 할당하고, WebSearcher는 각 서브 쿼리에 대한 정보만을 처리합니다.
효율적인 컨텍스트 관리
명확한 역할 분배 덕분에 MindSearch는 전체 프로세스 중 컨텍스트 계산을 줄이면서 긴 컨텍스트 작업에 대한 효율적인 관리 솔루션을 제공합니다. 이 프레임워크는 또한 단일 LLM을 훈련시키는 직관적이고 간단한 방법을 제공하여 3분 이내에 300페이지 이상의 관련 정보를 수집 및 통합할 수 있는 능력을 보여줍니다.
MindSearch는 복잡한 정보 탐색 및 통합을 위해 간단한 다중 에이전트 솔루션을 제공합니다. 이 패러다임은 다른 에이전트 간의 긴 컨텍스트 관리를 자연스럽게 가능하게 하며, 특히 모델이 많은 웹 페이지를 빠르게 읽어야 할 상황에서 전체 프레임워크의 효율성을 향상시킵니다. WebPlanner는 검색 작업을 별도의 검색 에이전트로 분배하고, WebSearcher는 각각의 서브 쿼리에 대한 내용만 검색합니다. 명확한 역할 분배 덕분에 MindSearch는 전체 프로세스 중 컨텍스트 계산을 크게 줄이면서, 긴 컨텍스트 작업에 대한 효율적인 컨텍스트 관리 솔루션을 제공합니다. 이 다중 에이전트 프레임워크는 또한 단일 LLM을 훈련시키기 위한 직관적이고 간단한 긴 컨텍스트 작업 구축 파이프라인을 제공합니다. 최종적으로, MindSearch는 3분 이내에 300페이지 이상의 관련 정보를 수집 및 통합할 수 있으며, 이는 유사한 인지 작업을 수행하는 데 3시간이 걸릴 수 있는 휴먼 전문가에 비해 현저한 효율성을 보여줍니다.
3 실험
3.1 Open-set QA
3.1.1 실행 세부사항
실제 세계의 100개의 휴먼 질의를 엄선하여 MindSearch, Perplexity.ai의 Pro 버전, 그리고 ChatGPT의 검색 플러그인을 통해 응답을 수집하였습니다. 이를 평가하기 위해 5명의 휴먼 전문가가 ‘Depth’, ‘Breadth’, ‘Accuracy’의 세 가지 측면에서 선호하는 응답을 수동으로 선택하였습니다. 이 평가는 평가자가 응답과 그 방법의 연관성을 인지하지 못하도록 하여 공정성을 보장하였습니다.
3.1.2 결과 및 분석
MindSearch는 기존 모델들에 비해 ‘Depth’와 ‘Breadth’에서 눈에 띄게 개선된 응답을 제공함으로써 제안된 WebPlanner의 우수성을 입증하였습니다.
DAG 구축 단계에서 코드 통합을 통해 LLM은 복잡한 문제를 실행 가능한 쿼리로 점진적으로 분해할 수 있으며, 검색 공간의 탐색과 시간 효율성 사이의 균형을 맞추는 데 성공하였습니다.
그러나 'Accuracy' 측면에서는 MindSearch가 기대만큼의 성능을 보이지 못했으며, 이는 보다 상세한 검색 결과가 모델이 초기 문제에 집중하는 것을 방해할 수 있기 때문일 것으로 추정됩니다.
3.2 Closed-set QA
3.2.1 실행 세부사항
다양한 Closed-set QA 작업에 대해 광범위하게 평가를 수행하며, 특히 Bamboogle, Musique, HotpotQA 등의 벤치마크를 사용하여 일반화 능력을 검증합니다.
실험 설정에서는 GPT-4o(비오픈소스 LLM) 및 InternLM2.5-7b-chat(오픈소스 LLM)을 백엔드로 선택하였습니다.
3.2.2 결과 및 분석
MindSearch는 기본 베이스라인 모델들, 즉 검색 엔진 없이 직접 처리하는 LLM과 단순히 검색 엔진을 외부 도구로 사용하는 ReAct 스타일 상호작용을 큰 차이로 능가하였습니다. 이는 제안된 방법의 효과를 입증하며, 특히 비오픈소스 LLM에서 오픈소스 LLM으로 전환할 때 이점이 더욱 확대됩니다. 이는 MindSearch가 약한 LLM을 보다 넓은 지식으로 강화하고 환각 문제를 완화하는 간단한 접근 방식을 제공한다는 것을 입증합니다.
MindSearch의 실험 결과는 이 시스템이 Closed-set 및 Open-set QA 작업 모두에서 기존 방법보다 우수한 성능을 보인다는 것을 보여줍니다. 특히, 정보의 ‘Depth’와 ‘Breadth’을 향상시키는 것은 LLM의 문제 해결 능력을 강화하는 중요한 요소로 작용합니다.
하지만, ‘Accuracy’ 문제는 향후 개선이 필요한 영역으로 남아 있으며, 이는 웹 탐색 과정에서의 환각 문제를 완화하는 것을 자연스러운 후속 작업으로 제시합니다. 이런 결과들은 MindSearch가 효과적으로 웹 정보를 검색하고 통합하는 데 있어 LLM과 검색 엔진의 융합을 통한 새로운 접근 방식의 유효성을 강조합니다.
4 관련 연구
4.1 LLM과 도구 활용
LLM을 다양한 도구와 원활하게 통합하는 ‘도구 학습 프레임워크’는 복잡한 문제에 대한 동적인 해결책을 제공합니다. 이 통합은 LLM의 해석 가능성과 신뢰성을 향상시키는 데 도움이 되며, 환각 감소, 코드 생성, 질문 응답 등 다양한 작업에서의 강건성과 적응성을 개선합니다. 최근 연구에서는 검색 엔진, 데이터베이스, API 등을 포함하여 LLM이 특정 작업에 가장 적합한 도구에 접근할 수 있도록 검색 메커니즘을 개선하는 데 집중하고 있습니다.
4.2 RAG와 LLM
RAG(Retrieve-and-Generate)는 특히 오픈 도메인 시나리오에서 지식 집약적 문제에 대응하는 데 유의미한 장점을 보입니다. RAG는 LLM이 리트리버와 통합되어 적시에 정보를 제공하고 효과적인 해결책을 제공합니다. RAG는 환각 감소, 코드 생성, 질문 응답 등 다양한 작업에 적용되며, 최근 연구는 RAG 시스템의 검색 구성 요소를 강화하고 언어 모델의 독해 능력을 최적화하는 데 초점을 맞추고 있습니다.
4.3 웹 에이전트
웹 자동화 에이전트는 질문 응답 도구에서 복잡한 웹 상호작용을 수행할 수 있는 정교한 시스템으로 진화하였습니다. 초기 모델인 WebGPT와 WebGLM은 주로 QA 작업을 다루었지만, 최근에는 더 동적인 작업으로 전환되었습니다. MindAct와 WebAgent와 같은 최신 모델은 향상된 웹 탐색 능력을 보여줍니다. AutoWebGLM은 강화 학습과 행동 복제 기술을 통합하여 실제 응용 프로그램에 적합한 확장 가능하고 다재다능한 솔루션을 제공합니다. 본 논문은 주로 검색 엔진을 사용한 웹 정보 탐색 및 통합 작업에 중점을 두고, 이를 위해 다중 에이전트 프레임워크로 주요 챌린지를 해결합니다.
5. Conclusion
본 연구에서는 LLM과 다양한 도구의 통합을 통해 LLM의 기능을 확장하고 강화하는 것을 목표로 합니다. 특히, RAG의 구조를 사용하여 LLM이 실시간으로 적절한 정보를 검색하고 통합할 수 있도록 하여, 질문에 대한 응답의 정확도와 효율성을 크게 향상시키고 있습니다. 이런 접근 방식은 LLM이 더욱 정교하고 신뢰성 있는 정보에 기반한 응답을 생성하도록 지원하며, 다양한 도메인에서의 적응성을 증가시킵니다.
실험적으로 본 연구는 LLM이 도구를 효과적으로 활용하여 복잡한 문제를 해결하고, 특히 웹 검색과 정보 통합의 맥락에서 더욱 정확하고 심층적인 정보를 제공하는 데 중점을 두고 있습니다.