Reasoning | Constrained CoT
- Related Project: Private
- Category: Paper Review
- Date: 2024-08-01
Concise Thoughts: Impact of Output Length on LLM Reasoning and Cost
- url: https://arxiv.org/abs/2407.19825
- pdf: https://arxiv.org/pdf/2407.19825
- html: https://arxiv.org/html/2407.19825v1
- abstract: Today’s large language models (LLMs) can solve challenging question-answering tasks, and prompt engineering techniques, such as chain-of-thought (CoT), have gained attention for enhancing the explanation and correctness of outputs. Nevertheless, models require significant time to generate answers augmented with lengthy reasoning details. To address this issue, this paper analyzes the impact of output lengths on LLM inference pipelines and proposes novel metrics to evaluate them in terms of \textit{correct conciseness}. It also examines the impact of controlling output length through a refined prompt engineering strategy, Constrained-CoT (CCoT), which encourages the model to limit output length. Experiments on pre-trained LLMs demonstrated the benefit of the proposed metrics and the effectiveness of CCoT across different models. For instance, constraining the reasoning of LLaMA2-70b to 100 words improves the accuracy from 36.01% (CoT) to 41.07% (CCoT) on the GSM8K dataset, while reducing the average output length by 28 words.
SKIP Paper, 답변의 길이를 30단어로 제한하라와 같은 추가적인 제약 프롬프트로 구체화하는 방식 정도로 넘기면 됨.
TL;DR
“답변의 길이를 30단어로 제한하라” 같은 지시 제약을 프롬프트에 추가해 출력을 제한 → Constrained(??) + 정확도 뿐만 아니라 간결성을 평가할 수 있는 벤치마크 공개
- 대규모 언어모델(Large Language Models, LLMs)의 인퍼런스 시간 단축과 출력의 정확성 개선을 위해 제안된 새로운 메트릭과 제한된 사고 과정(Constrained Chain-of-Thought, CCoT) 접근 방식을 소개합니다.
- CCoT는 출력의 길이를 제어함으로써 모델의 시간 예측 가능성을 향상시키는 것을 목표로 합니다.
- 제한된 사고 체인(CCoT) 프롬프트는 출력 길이 제한을 통해 인퍼런스 시간과 정확성 사이의 균형을 개선합니다.
- CoT 프롬프트와 CCoT 프롬프트 사이의 주요 차이점은 출력 길이에 대한 명시적 제약을 포함한다는 점입니다.
- CCoT는 특히 0-shot 학습 설정에서 CoT 대비 효율성과 정확성을 증진시키는 데 유용합니다.
MMLU의 하네스와 허깅 페이스 구현체에 대한 논쟁과 비슷
제한된 사고 체인(CCoT) 프롬프트의 도입 배경과 목적
제한된 사고 체인(CCoT) 프롬프트는 인퍼런스 과정에서의 출력 길이와 시간 효율성을 중시합니다. 기존의 사고 체인(CoT) 방식에서 발전하여, CCoT는 출력 길이에 명시적 제약을 두어 더욱 집약적이고 정확한 답변을 유도하며, 특히 대규모 언어모델(LLM)이 다양한 데이터셋과 벤치마크, 예를 들어 GSM8K 데이터셋에서 질문에 대해 효율적으로 답변할 수 있도록 설계되었습니다.
CoT와 CCoT의 구조 비교
CoT 프롬프트는 다음과 같이 정의됩니다.
\[x = \text{concat}(x_{us}, x_{p})\]\(x_{us}\)는 사용자의 질문을, \(x_{p}\)는 사고 과정을 단계별로 설명하는 명시적 요청을 내는 반면, CCoT는 추가적인 제약을 포함하는 구조를 갖고 있습니다.
\[x = \text{concat}(x_{us}, x_{p}, x_{l})\]\(x_{l}\)은 출력 길이에 대한 제약을 명시하는 문장으로 “답변의 길이를 30단어로 제한하라”와 같은 지시를 포함합니다.
이 구조에서 \(x_{l}\)의 도입은 출력의 최대 길이를 제한함으로써 모델이 인퍼런스 과정을 더욱 집약적으로 수행하도록 하며, 특히 시간이 중요한 응용에서 모델의 성능을 크게 향상시킬 수 있으며, 출력 길이의 제한은 다음과 같이 모델의 인퍼런스 효율성에 직접적인 영향을 미칩니다.
- 인퍼런스 시간 단축: 출력 길이가 줄어들면 모델이 처리해야 하는 정보량이 감소하여 처리 속도가 빨라지며,
- 정확도 개선: 불필요한 정보의 제거는 오류 가능성을 줄이고 필수적인 정보에 집중하게 만들 수 있다고 언급합니다.
1. 서론
최근 대규모 언어모델(LLMs)은 복잡한 질문 응답 작업에서 향상된 능력을 보여주었습니다. 이런 모델의 성능 향상에는 아키텍처와 훈련 방법의 지속적인 발전이 크게 기여했습니다. 특히, 사고 과정(Chain-of-Thought, CoT) 프롬프팅 기술이 주목받으며 모델의 출력 설명과 정확성 향상에 도움을 주었습니다.
그러나 이런 접근 방식은 출력의 길이를 늘리고, 따라서 모델이 응답을 생성하는 데 필요한 시간도 증가시킬 수 있습니다.
LLMs의 정확도를 높이기 위한 연구가 주로 진행되어 왔으며, 모델이 더 긴 출력을 생성하게 하여 사용자가 관련 정보를 효율적으로 추출하는 것을 어렵게 만드는 문제가 있었습니다. 이를 해결하기 위해, 입력 데이터에 특정 패턴을 추가하는 프롬프트 기반 접근 방식이 제안되었지만, 이는 출력의 길이를 증가시키는 결과를 낳았습니다.
이 연구에서는 출력의 길이와 인퍼런스 시간의 관계를 보여주는 실험을 바탕으로, 출력의 간결성과 정확성을 동시에 평가할 수 있는 새로운 메트릭을 제안합니다.
세 가지 새로운 메트릭 제시
제안된 세 가지 새로운 메트릭은 모델의 정확성을 출력 길이가 인퍼런스 시간에 미치는 영향을 고려하여 재평가하는 것을 목표로 합니다.
CCoT 접근방식
제한된 사고 과정(Constrained Chain-of-Thought, CCoT)을 통해 모델이 출력의 길이를 제어하도록 유도하는 새로운 프롬프트 공학 전략을 소개합니다. 이 접근 방식은 모델이 제공하는 출력의 길이를 특정한 경계 이하로 유지하도록 요청함으로써, 간결한 인퍼런스를 생성하도록 합니다.
다양한 사전 훈련된 LLMs에서 CCoT 방법을 사용한 결과, 출력의 길이가 줄어들고 정확성이 향상되는 것을 확인할 수 있었습니다. 특히, Llama2-70b 모델에서는 CCoT-100을 적용하여 평균 출력 길이가 71 단어로 감소하고 정확도가 41.07%로 증가했습니다.
LLMs는 주로 자동 회귀 트랜스포머 구조를 기반으로 하며, 각 단어를 순차적으로 디코딩하는 방식으로 텍스트를 생성합니다. 출력의 길이가 길어질수록 모델은 더 많은 인퍼런스 패스를 수행해야 하며, 이는 인퍼런스 시간을 증가시킵니다.
\[\text{Inference Time} \propto \text{Number of Words in Output}\]CCoT 접근 방식은 이런 문제를 해결하기 위해 출력 길이를 제한하는 것을 목표로 하며, 출력 길이 제한을 통해 모델은 불필요한 정보를 줄이고 핵심적인 내용만을 포함시킬 수 있습니다.
\[\text{Constrained Output Length} \leq \text{Specified Bound}\]이런 접근 방식은 모델이 효율적으로 정보를 처리하고 사용자와의 상호작용에서 더욱 신속하게 응답할 수 있게 합니다. CCoT를 통해 간결하고 정확한 출력을 생성하는 것이 목표입니다.

2. 관련 연구
최근 대규모 언어모델(LLM)에 대한 연구는 주로 모델의 정확성 향상에 중점을 두고 있습니다(Jiang et al., 2020; Kaplan et al., 2020; Zhu et al., 2023). 그러나 모델의 규모가 커짐에 따라 더욱 광범위하고 세부적인 응답을 생성하는 경향이 있으며, 이로 인해 현실과 괴리된 정보(홀루시네이션)를 제공하거나(Kadavath et al., 2022), 불필요하게 긴 설명을 동반할 수 있습니다(Qiu et al., 2024; Azaria and Mitchell, 2023). 이는 중요한 정보가 가려져 사용자가 관련 내용을 효과적으로 파악하기 어렵게 만듭니다(Khashabi et al., 2021; Wang et al., 2024).
이런 문제를 해결하기 위해, Li et al.(2021)은 멀티홉 처리 기술을 제안했습니다. 이 기술은 인코더에서 질문에 대한 가장 관련성 높은 텍스트를 추출하여 답변의 근거를 제공합니다. 또한, LLM의 정확성을 더욱 향상시키기 위한 여러 프롬프트 엔지니어링 방법들이 소개되었습니다(Qin and Eisner, 2021). 프롬프트 엔지니어링은 모델이 더 정확하고 관련성 높은 응답을 생성하도록 입력 패턴을 전략적으로 설계하는 것을 말합니다(Reynolds and McDonell, 2021; Marvin et al., 2023). 그러나 이런 접근 방식은 대부분 출력 길이를 증가시키며, 이는 사실적이고 간결한 답변 제공을 어렵게 만듭니다(Shi et al., 2023).
특히, 사고 과정(Chain-of-Thought, CoT) 프롬프팅(Wei et al., 2022)은 QA 작업에서 유의미한 이점을 보여주었습니다. 이 방법은 모델에게 최종 응답과 함께 단계별 설명을 요구함으로써 응답의 정확성을 높입니다. 그러나 섹션 3에서 강조된 바와 같이, CoT로 생성된 답변은 길이가 길어지므로 생성 시간이 증가합니다(Liu et al., 2018; Takase and Okazaki, 2019).
대부분의 채택된 메트릭(Lin, 2004; Stallings and Gillmore, 1971)과 벤치마크(Clark et al., 2018; Lin et al., 2021)는 응답의 정확성만을 다루고, 간결성이나 응답 시간은 크게 고려하지 않습니다(Bhargava et al., 2023). 그러나 이런 속성들은 사용자와의 대화형 상호작용을 필요로 하는 애플리케이션에서 바람직합니다.
이 연구에서는 응답의 간결성과 정확성을 모두 고려하는 새로운 메트릭을 제안합니다. 또한, LLM이 출력에서 인퍼런스 길이를 제어할 수 있는 능력을 이해하기 위해, 사고 과정의 제한된 버전인 제한된 사고 과정(Constrained Chain-of-Thought, CCoT)을 제안합니다. 이 방법은 모델에게 인퍼런스의 길이를 명시적으로 제어하도록 요청합니다. 이 새로운 메트릭을 평가하고 제안된 프롬프트 접근 방식을 테스트함으로써, 그것이 답변의 질과 특히 LLM의 응답 시간에 어떤 영향을 미치는지를 분석합니다.
3. 동기 및 배경
TL;DR
- 대규모 언어모델의 응답 시간은 출력 길이에 강하게 의존하며,
- 사고 과정 기법은 응답의 정확성을 향상시키지만, 응답 시간도 지연시킨다.
- 따라서, 본 연구에서는 출력의 길이를 제어하여 응답 시간을 단축하는 방법을 제안합니다.
대규모 언어모델(LLM)의 응답 생성 시간은 모델의 구조, 전처리 및 후처리 단계, 답변 디코딩 과정 및 질문의 특성에 따라 달라집니다. 특히, 프롬프트 엔지니어링 기법을 사용할 때 응답 시간에 미치는 영향은 복잡합니다. 이런 상황을 수식으로 표현하면 다음과 같습니다.
\[\hat{y} = f(x)\]\(f\)는 모델을 나타내며, \(x\)는 N(x) 토큰을 포함하는 입력 프롬프트, \(\hat{y}\)는 출력입니다. \(N\)은 길이 연산자로, 토큰의 수를 계산합니다.
모델이 사용하는 인코더-디코더 구조에서, 인코더 \(f_e\)와 디코더 \(f_d\) 함수는 다음과 같이 정의됩니다.
\[a(i) = f_d(f_e(x), [a(0), \ldots, a(i-1)]), \quad i > 0\]이 식에서 \(a(i)\)는 이전에 생성된 토큰과 인코더의 임베딩 표현을 기반으로 계산되며, 출력 토큰의 집합이 클수록 모델이 답변을 생성하는 데 필요한 시간이 늘어나는데, 이는 디코더가 더 자주 호출되기 때문입니다.
데이터셋과 벤치마크 분석
Falcon-40b와 같은 다양한 모델을 사용하여 여러 데이터셋(CNN/dailynews, squad combination, FELM, AG)에서 요약, QA, 문맥-질문, 주제 모델링 등의 하위 작업을 수행한 결과를 분석했습니다. 이런 데이터셋을 사용하여 응답 시간과 출력 길이의 관계를 조사했습니다. (Figure 1 참조)
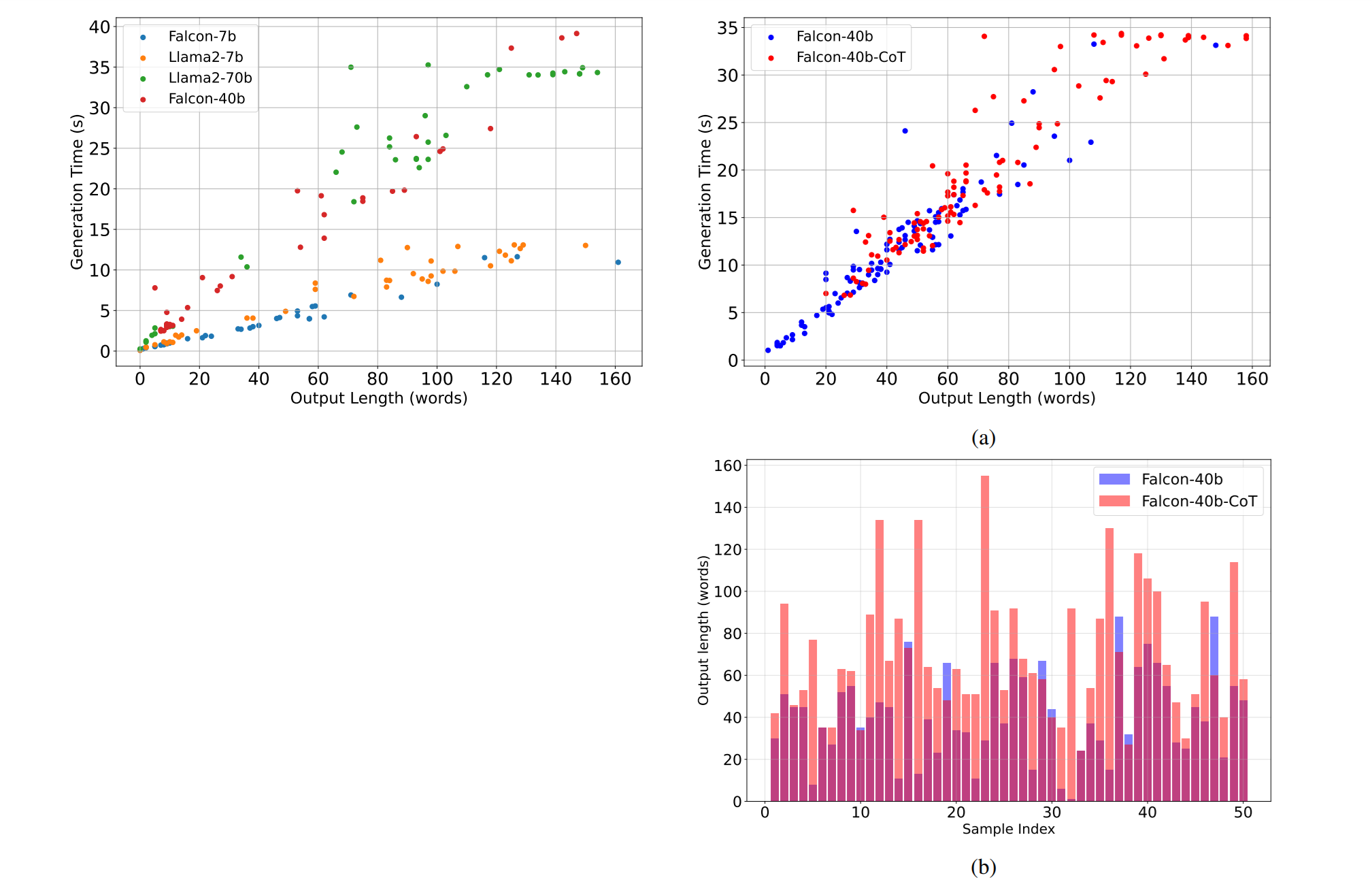
사고 과정의 영향
CoT 기법을 사용하면 응답의 정확성은 향상되지만, 출력 길이와 생성 시간도 함께 증가한다는 점이 확인되었습니다. GSM8K 데이터셋에서 수행된 실험(Figure 2a, 2b 참조)에서 CoT가 사용되었을 때와 사용되지 않았을 때의 출력 길이와 응답 시간을 비교 분석했습니다. CoT를 사용할 때 출력 길이와 응답 시간이 눈에 띄게 증가하는 것을 볼 수 있습니다.
4. 간결성과 정확성을 위한 메트릭
이 섹션에서는 대규모 언어모델(LLM)이 정확하면서도 간결한 응답을 제공할 수 있는 능력을 평가하기 위해 세 가지 새로운 메트릭을 제시합니다. 기존의 정확성 메트릭을 재정의하여 LLM 출력의 정확성에 간결성 측면을 통합하는 것이 주된 아이디어입니다.
응답 \(\hat{y}\)가 주어진 ground truth \(y\)와 일치할 때 정확하다고 간주됩니다. 이를 통해 LLM의 정확성은 다음과 같이 계산됩니다.
\[A = \frac{1}{N} \sum_{i=1}^N 1(\Gamma(\hat{y_i}), y_i)\]\(N\)은 테스트 샘플의 수이고, \(1(u, v)\)는 지시 함수(indicator function)로, \(u = v\)일 때 1을, 그렇지 않을 때 0을 반환합니다. \(\Gamma\)는 사용자가 정의한 함수로, 정규 표현식을 사용하여 문장에서 특정 패턴을 추출하거나(pseudo-judge 접근 방식을 사용하여) 이차 대규모 모델을 판단자로 사용할 수 있습니다.
출력 \(\hat{y_i}\)의 간결성은 그 정확성과 함께 다음과 같이 통합될 수 있습니다. 긴 출력에 대한 패널티 항 \(p(\hat{y_i})\)를 곱하여
\[\frac{1}{N} \sum_{i=1}^N [1(\Gamma(\hat{y_i}), y_i) \cdot p(\hat{y_i})]\]특정 메트릭 정의
-
Hard-$k$ Concise Accuracy (HCA($k$))
정확한 출력이 사용자가 지정한 길이 \(k\)를 초과하지 않는 비율을 측정합니다.
\[HCA(k) = \frac{1}{N} \sum_{i=1}^N [1(\Gamma(\hat{y_i}), y_i) \cdot \text{phard}(\hat{y_i}, k)]\]상기 식에서,
\[\text{phard}(\hat{y_i}, k) = \begin{cases} 1 & \text{if } N(\hat{y_i}) \leq k \\ 0 & \text{otherwise} \end{cases}\] -
Soft-$k$ Concise Accuracy (SCA($k$, $\alpha$))
최대 길이 \(k\)를 초과하는 정확한 답변에 대해 지수적으로 감소하는 패널티 항을 적용하여 일반화된 메트릭입니다.
\[SCA(k, \alpha) = \frac{1}{N} \sum_{i=1}^N [1(\Gamma(\hat{y_i}), y_i) \cdot \text{psoft}(\hat{y_i}, k, \alpha)]\]상기 식에서,
\[\text{psoft}(\hat{y_i}, k, \alpha) = \min \left(1, e^{\frac{k-N(\hat{y_i})}{\alpha}}\right)\] -
Consistent Concise Accuracy (CCA($k$, $\alpha$, $\beta$))
출력 길이의 변동을 고려하여 이전 메트릭을 더욱 일반화합니다.
\[CCA(k, \alpha, \beta) = SCA(k, \alpha) \cdot \text{pvar}(\sigma, \beta)\]상기 식에서,
\[\text{pvar}(\sigma, \beta) = \min \left(1, e^{\frac{\beta-\sigma}{\beta}}\right)\]- HCA($k$) 메트릭은 특정 최대 길이를 넘지 않는 응답만을 고려하여 간결성을 강조합니다.
- SCA($k$, $\alpha$)는 길이 \(k\)를 초과하는 답변에 대해 어느 정도 관용을 허용하면서 간결성을 측정합니다.
- CCA($k$, $\alpha$, $\beta$)는 응답 길이의 일관성까지 고려하여 모델이 균일한 길이의 응답을 생성하는지를 평가합니다. 높은 \(\sigma\) 값은 모델의 응답 길이가 다양함을 나타내며, 이는 응답 시간 예측을 어렵게 만듭니다.
MMLU의 하네스와 허깅페이스 구현체에서의 논쟁과 CCA와 유사
이 메트릭들은 LLM의 출력이 얼마나 정확하고 간결한지를 종합적으로 평가하며, 특히 실시간 시스템이나 계산 자원이 제한된 환경에서의 사용하기 적합하다고 언급합니다.
5. CCoT 프롬프팅의 이해와 활용
목적과 개요
제한된 사고 체인(CCoT)은 인퍼런스 시간과 출력 길이 사이의 관계에 대한 더 깊은 이해를 바탕으로, 기존 사고 체인(CoT)의 이점을 유지하면서 사용 효율성을 향상시키기 위한 방법으로 이 섹션에서는 CoT의 사용을 개선하여 인퍼런스 과정에서의 효율성과 정확성 사이에 더 나은 균형을 달성하는 것을 목표로 합니다.
CoT 대 CCoT의 구현
-
CoT 프롬프트 \(x = \text{concat}(x_{us}, x_{p})\) \(x_{us}\)는 사용자 입력을, \(x_{p}\)는 단계별 인퍼런스를 요청하는 문장을 의미합니다.
-
CCoT 프롬프트 \(x = \text{concat}(x_{us}, x_{p}, x_{l})\) \(x_{l}\)은 출력 길이에 대한 제약을 지정하는 문장으로, 예를 들어 “답변 길이를 30단어로 제한하라”와 같은 지시가 포함됩니다.
예시 및 분석
0-shot 설정에서 GSM8K 데이터셋으로부터 추출된 질문에 대해 CCoT를 적용한 사례를 통해 CoT와 CCoT의 차이를 분석합니다. CoT를 사용한 경우 답변은 67단어로 길게 나타나는 반면, CCoT 프롬프트는 45단어 제한으로 34단어의 정확한 답변을 생성했으며, 이런 결과는 출력 길이를 제한함으로써 모델이 더 간결하고 정확한 답변을 생산할 수 있음을 시사합니다.
6. 실험
실험은 다음과 같은 연구 질문을 조사합니다.
- RQ1. CCoT 접근 방식이 효율성과 정확성 측면에서 유익한가?
- RQ2. CCoT에 비해 고전적인 CoT와 비교했을 때 어떤 모델이 혜택을 받는가?
- RQ3. LLM이 명시적인 프롬프트 요청에 기반하여 출력 길이를 제어할 수 있는 능력은 어느 정도인가?
- RQ4. 제안된 메트릭이 효율성과 정확성의 측면을 모두 해결하는데 도움이 되는가? CCoT의 영향이 제안된 메트릭에 반영되는가?
6.1 실험 설정
실험은 NVIDIA A100 GPU 8개를 사용하여 Text Generation Inference (TGI) 플랫폼에서 수행되었습니다. Hugging Face에서 제공하는 다양한 사전 훈련된 LLMs가 평가되었습니다. 이들 모델은 GSM8k 테스트 세트에서 평가되었으며, 이 데이터셋는 모델이 수학적 인퍼런스를 얼마나 잘 처리하는지 평가하는 데 일반적으로 사용됩니다.
6.2 CCoT의 비용 및 성능 평가
CCoT의 계산 시간 및 정확도에 미치는 영향을 평가하기 위해 실험이 수행되었습니다. 결과는 다양한 LLM 아키텍처에 대한 CCoT의 적합성에 대한 통찰을 제공합니다. 각 선택된 LLM은 GSM8K 테스트 데이터셋를 사용하여 평가되었으며, 평문 프롬프트(기본), CoT, 그리고 다양한 길이 제한을 가진 CCoT가 사용되었습니다.
\[\text{예: } \text{Base, CoT, CCoT-15, CCoT-30, CCoT-45, CCoT-60, CCoT-100}\]6.3 출력 길이 제어 능력
CCoT 프롬프팅이 평균적으로 정확도와 생성 시간에 어떻게 영향을 미치는지 살펴본 이전 실험에 이어, CCoT 프롬프팅이 각 테스트 샘플의 출력 길이를 효과적으로 제한할 수 있는지를 평가했습니다. 다양한 길이 제약을 가진 CCoT 프롬프트를 테스트하여 출력 길이에 대한 통계를 분석했습니다.
\[\text{예: } \text{CCoT-15, CCoT-30, CCoT-45, CCoT-60, CCoT-100}\]6.4 정확한 간결성 평가
제안된 메트릭은 모델이 출력 길이를 줄이면서 일정 수준의 정확성을 유지하는 능력을 새로운 관점에서 평가하기 위해 적용되었습니다. Hard-k concise accuracy(HCA)와 Soft Conciseness Accuracy(SCA)는 출력 길이가 지정된 값 k 미만인 정확한 답변만을 고려하여 정확도를 평가합니다.
\[\text{HCA}(k) = \text{SCA}(k, \alpha), \text{ if } \sigma \leq \beta, \text{ otherwise CCA decreases exponentially for } \sigma > \beta\]7. 논의 및 결론
이 연구에서는 LLM이 텍스트-텍스트 생성 작업에서 제공하는 답변의 간결성을 다루는 것의 중요성을 논의하고, 적절한 프롬프트 엔지니어링 접근 방식인 Constrained Chain-of-Thought(CCoT)를 통해 출력 길이를 제어할 수 있는 가능성을 조사하였습니다. 이어서, 평문 프롬프팅 및 CoT와 비교하여 CCoT의 생성 시간 및 응답의 정확성에 미치는 영향을 평가하였습니다. 이를 위해, 사용자 지정 파라미터에 따른 출력의 간결성 및 정확성을 고려한 세 가지 새로운 메트릭이 제안되었습니다.
실험 결과를 통해 도출된 첫 번째 관찰 결과는 모든 모델이 출력 길이를 제어할 수 있는 것은 아니라는 점입니다(RQ2). 특히 작은 모델들인 Falcon-7b, LLama2-7b, Vicuna-13b는 CCoT 프롬프트에서 주어진 길이 제약을 준수하는 데 더 많은 어려움을 겪는 반면, Falcon-40b와 Llama2-70b와 같은 큰 모델들은 더 큰 제어 능력을 보였습니다(섹션 6.2). 작은 LLM의 이런 어려움은 훈련 중 사용된 데이터셋과 모델 파라미터의 수와 같은 다양한 요인에 의해 영향을 받을 수 있습니다. 이 문제들을 이해하고 제안된 메트릭을 파인튜닝 과정에 통합하는 것을 평가하는 것은 더 깊은 조사가 필요하며, 이는 향후 작업의 일부입니다.
반면 Falcon-40b와 Llama2-70b와 같은 큰 모델들에 대해서는, CCoT는 평문 프롬프트와 CoT에 비해 LLM의 정확성과 효율성을 향상시킬 수 있었습니다(RQ1). 특정 모델들(Llama2-70b와 Vicuna-13b)의 정확성 향상은 이 연구의 범위를 벗어나지만, 간결성의 효과를 분석하는 향후 연구로 이어질 수 있는 흥미로운 주제를 제시합니다. 추가적으로, LLM의 정확한 간결성을 평가하기 위해 최신 평가 기술을 사용하는 판단 모델을 포함시키는 것을 목표로 하는 또 다른 흥미로운 미래 방향이 있을 수 있습니다(Zheng et al., 2024; Huang et al., 2024).
결론적으로, 제안된 작업은 LLM의 간결성에 더 많은 주의를 기울일 필요성을 강조하며, 출력의 길이에 대한 정확성을 평가할 수 있는 새로운 성능 지표를 제안합니다.