Reasoning | Strategic CoT
- Related Project: Private
- Category: Paper Review
- Date: 2024-09-05
Strategic Chain-of-Thought: Guiding Accurate Reasoning in LLMs through Strategy Elicitation
- url: https://arxiv.org/abs/2409.03271
- pdf: https://arxiv.org/pdf/2409.03271
- html: https://arxiv.org/html/2409.03271v1
- abstract: The Chain-of-Thought (CoT) paradigm has emerged as a critical approach for enhancing the reasoning capabilities of large language models (LLMs). However, despite their widespread adoption and success, CoT methods often exhibit instability due to their inability to consistently ensure the quality of generated reasoning paths, leading to sub-optimal reasoning performance. To address this challenge, we propose the $\textbf{Strategic Chain-of-Thought}$ (SCoT), a novel methodology designed to refine LLM performance by integrating strategic knowledge prior to generating intermediate reasoning steps. SCoT employs a two-stage approach within a single prompt: first eliciting an effective problem-solving strategy, which is then used to guide the generation of high-quality CoT paths and final answers. Our experiments across eight challenging reasoning datasets demonstrate significant improvements, including a 21.05% increase on the GSM8K dataset and 24.13% on the Tracking_Objects dataset, respectively, using the Llama3-8b model. Additionally, we extend the SCoT framework to develop a few-shot method with automatically matched demonstrations, yielding even stronger results. These findings underscore the efficacy of SCoT, highlighting its potential to substantially enhance LLM performance in complex reasoning tasks.
TL;DR
- 대규모 언어모델(LLMs)의 인퍼런스 능력 향상을 위한 전략적 사고 연쇄(SCoT) 방법 제안, 문제 해결을 위한 전략을 선택해 그것에 기반해 답변하도록 유도
- 전략적 지식 활용을 통한 고품질 인퍼런스 경로 생성 및 정확도 향상
- 8개 인퍼런스 데이터셋에서 성능 개선 입증 및 few-shot 방법으로 확장
SCoT 방법 개요
SCoT(Strategic Chain-of-Thought)는 먼저 문제 해결을 위한 전략을 탐색해 결정하고, 그 뒤에 답변하도록 유도하는 것을 의미하며 일반화할 수 있는 전략 탐색을 통해 약간의 인퍼런스 비용의 손실을 감수하고 추가적인 외부 데이터 등 없이 더 나은 답변을 할 수 있다고 주장
| SCoT 장점 | SCoT 단점 |
|---|---|
| 다양한 도메인 적용 가능성 | 모델 크기 의존성 |
| Few-shot 학습 확장성 | 복잡한 프롬프트 구조 |
| 프롬프트 자동 생성 잠재력 | 도메인별 전략 조정 필요성 |
| 외부 지식 불필요 | 전략 유효성 검증 필요성 |
문제 정의
선행 연구인 CoT(Chain of Thought)는 인퍼런스 경로와 프롬프트 퀄리티에 최종 결과가 크게 좌우되는 문제가 있었던 문제를 전략적 프롬프팅으로 해결할 수 있다고 언급합니다. (중간 인퍼런스 경로가 잘못된 경우 연쇄적으로 잘못된 결론에 도달한다는 후속 연구들이 보고되어 인퍼런스 경로에 대한 다양한 방식들의 조합이 제시되어 왔음. 본 블로그에 trajectory 혹은 reasoning path와 관련된 내용 참조)
선행연구(Chain of Thought, CoT)와의 비교
- CoT는 단순히 단계별 해결을 요청하는 반면, SCoT는 문제 분석, 전략 수립, 전략 적용의 세 단계로 구조화되어 있습니다. (CoT 대비 세분화된 구조 사용, 그러나 비용 추가)
- SCoT는 명시적으로 전략 개발을 요구하며, 이를 통해 더 체계적인 문제 해결을 유도할 수 있다고 언급합니다. (전략적 접근)
- SCoT는 모델에 “전문적인 문제 해결사” 역할을 부여하여 더 전문적인 접근을 유도할 수 있다고 언급합니다. (역할 설정)
- SCoT는 각 단계에 대해 더 구체적인 지침을 제공하여 모델의 응답을 더 정교하게 유도할 수 있다고 언급합니다. (상세 지침 추가)
SCoT vs. CoT
| 항목 | SCoT | CoT |
|---|---|---|
| 성능 | 대부분 과제에서 우수 | 베이스 라인 |
| 안정성 | 높음 (전략적 지식 활용) | 변동성 있음 |
| 효율성 | 단일 쿼리 방식 가능 | 다중 쿼리 방식 |
| 출력 길이 | 상대적으로 긴 편 | 베이스 라인 |
| 복잡성 | 높음 (전략 생성 단계 포함) | 상대적으로 낮음 |
Zero-shot vs. Few-shot
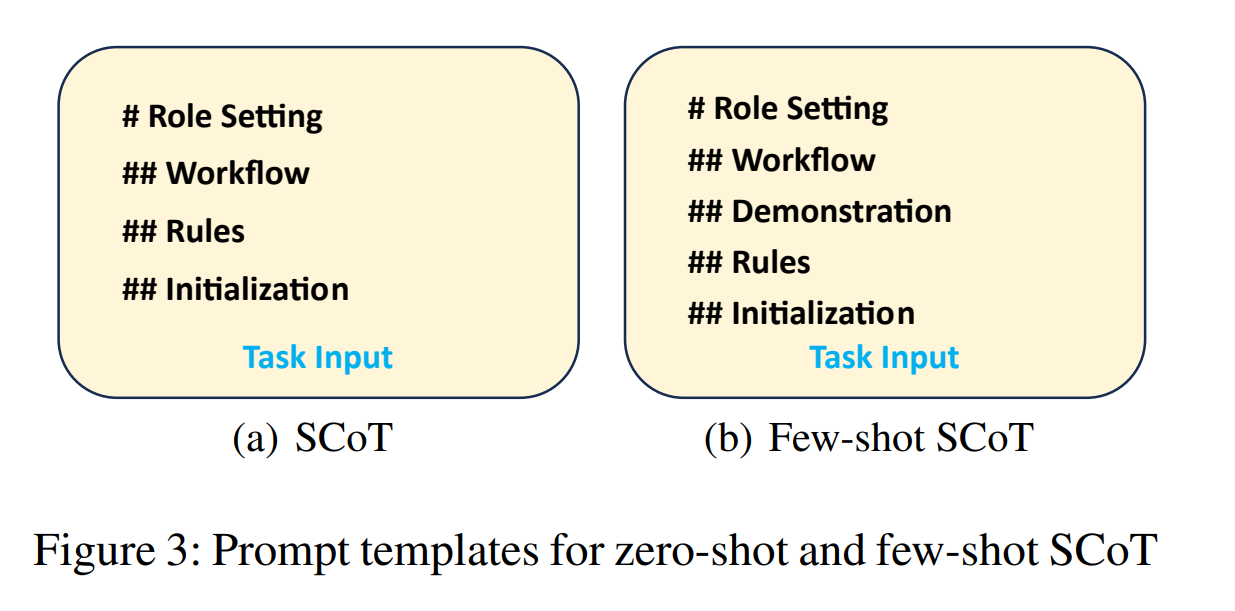
Zero-shot SCoT
- 다음 원칙에 따라 전략적 지식 구성
- 모델이 인퍼런스 단계를 주의 깊게 따를 때 정확한 답변을 생성할 수 있는 체계적인 접근 방식을 제공해야 한다.
- 각 단계는 정확성을 보장하고 모호성을 유발할 수 있는 지나치게 간단한 출력을 방지하기 위해 충분히 상세해야 하지만, 전체 방법의 단계는 과도하게 복잡해서는 안된다.
- 모델(LLM)은 문제 해결을 위한 가장 효과적이고 효율적인 방법 중 하나를 식별하고 결정 (두 가지 방법 중 일반화 가능한 전략 및 지식을 결정)
- 모델(LLM)은 이후 식별된 전략적 지식을 적용하여 문제를 해결하고 최종 답변을 도출
Few-shot SCoT
- 훈련 세트의 각 질문에 대해 zero-shot SCoT 방법을 적용하여 해당 SCoT 답변을 생성 (데모코퍼스)
- 상기 1의 데모코퍼스의 생성된 답변을 실제 답과 비교해 정확한 질문-SCoT 답변 쌍만 유지 (수동으로)
- 이후 두 번의 쿼리 프로세스에서 다음 세 단계를 포함
- LLM이 문제와 관련된 전략적 지식을 생성 (초안)
- 생성된 전략적 지식을 사용하여 1단계에서 생성한 데모 코퍼스를 검색하고, 데모코퍼스와 가장 유사한 페어 매칭
- 선택된 데모를 입력 프롬프트에 few-shot 예시로 통합해서 프롬프트 수정 (최종 예측을 생성)
SCoT와 CoT 0-shot 프롬프트 예시
논문에 구체적으로 제시되어 있는 예시는 아님, Figure 3이 공식적인 템플릿 예시
Chain-of-Thought (CoT) 0-shot 프롬프트(예시)
질문: {질문 내용}
단계별로 문제를 해결해 주세요. 각 단계에서 당신의 인퍼런스를 설명하고, 가장 나은 전략을 선정하세요. 중간에 선택한 전략을 선택해 최종 답변을 제시해 주세요.
답변:
Strategic Chain-of-Thought (SCoT) 0-shot 프롬프트
# Role Setting
## Workflow
## Rules (핵심)
## Initialization
당신은 전문적인 문제 해결사입니다. 주어진 문제를 해결하기 위해 다음 단계를 따라주세요.
1. 문제 분석: 주어진 문제를 주의 깊게 읽고 핵심 요소를 파악하세요.
2. 전략 수립: 문제를 효과적으로 해결할 수 있는 전략을 개발하세요. 이 전략은 문제의 핵심을 다루고, 체계적이며 효율적인 접근 방식이어야 합니다.
3. 전략 적용 및 문제 해결: 개발한 전략을 단계별로 적용하여 문제를 해결하세요. 각 단계에서 당신의 인퍼런스를 설명하고, 최종 답변을 제시해 주세요.
질문: {질문 내용}
답변:
1. Introduction
대규모 언어모델(LLMs)은 다양한 인퍼런스 작업에서 놀라운 효과를 보여주고 있습니다. 특히 Chain-of-Thought(CoT) 패러다임은 LLMs의 인퍼런스 능력을 향상시켰습니다. CoT는 중간 인퍼런스 단계를 생성하여 복잡한 문제를 해결하는 방식으로, 현대 자연어 처리 분야에서 널리 채택되고 있습니다.
그러나 CoT 방법은 생성된 인퍼런스 경로의 품질이 일관되지 않아 불안정성을 보이는 문제가 있습니다. 이는 인지과학의 관점에서 볼 때, Sweller의 인지 부하 이론과 유사한 현상입니다. 서로 다른 문제 해결 전략은 각기 다른 수준의 인지 부하를 유발하며, 이는 오류 발생 확률에 영향을 미칩니다.
이런 문제를 해결하기 위해 다양한 방법들이 제안되었습니다.
- (1) 투표 기반 접근 방식: Wang et al. (2022)과 Zhang et al. (2023)은 다양한 인퍼런스 경로를 생성하고 가장 신뢰할 수 있는 답변에 투표하는 방식을 제안했습니다.
- (2) RAG(Retrieval-Augmented Generation) 기반 접근 방식: Lewis et al. (2021), Yang et al. (2024b), Zheng et al. (2023) 등은 외부 지식을 활용하여 다단계 프롬프트 전략을 사용하는 방법을 개발했습니다.
- (3) 프롬프트 향상 알고리즘: Suzgun and Kalai (2024)는 다양한 프롬프트 향상 알고리즘을 통합하여 실제 작동 중에 최적의 알고리즘을 동적으로 선택하는 방법을 제안했습니다.
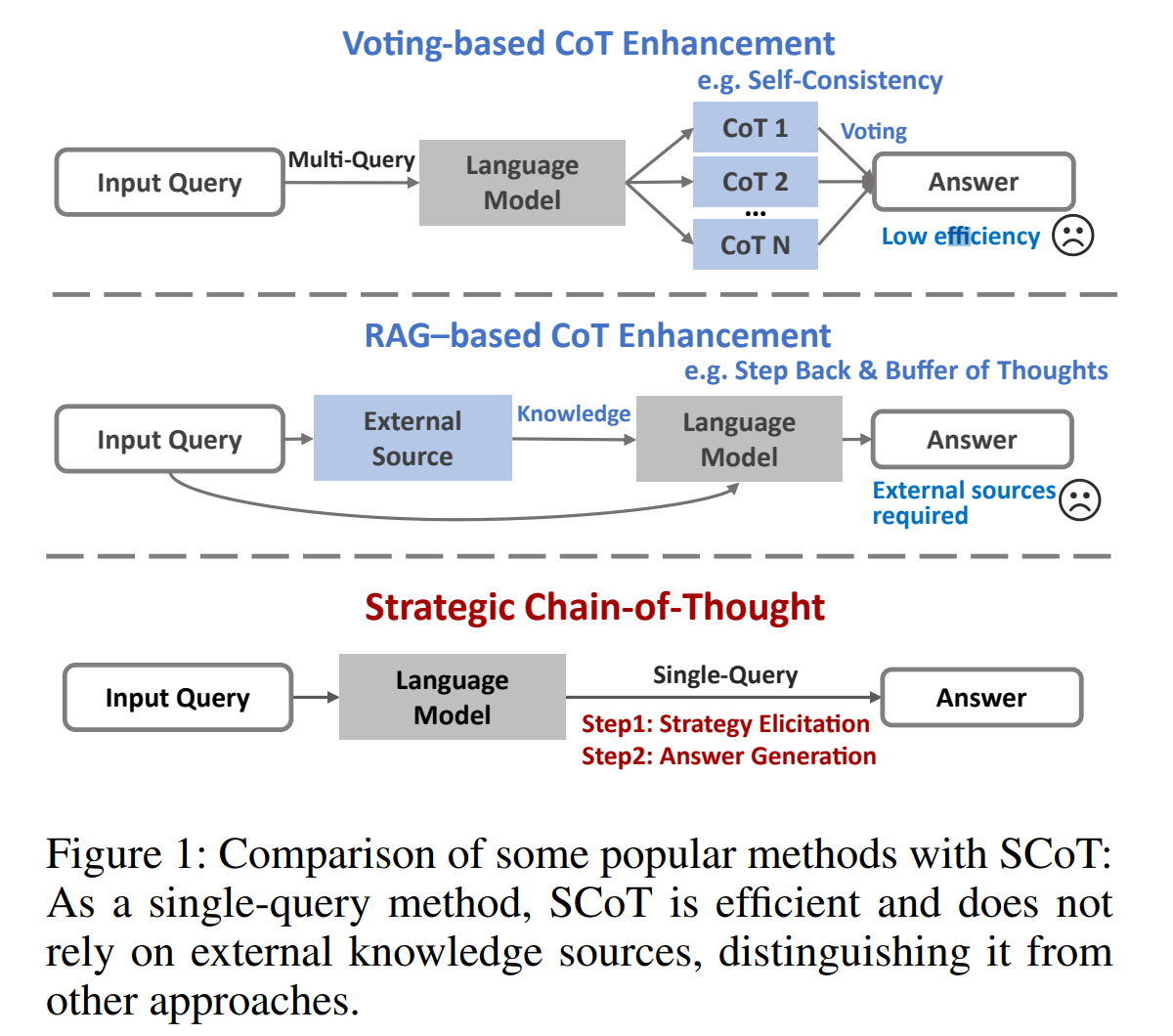
이런 방법들은 경로 품질의 변동성을 줄이는 데 도움이 되지만, 상당한 자원을 요구하는 단점이 있습니다. 예를 들어, Self-Consistency 방법은 최대 40회의 쿼리를 필요로 하며, BoT 기법은 다단계 쿼리를 포함하고, 일부 접근 방식은 최적의 성능을 위해 외부 지식 소스의 통합이 필요합니다. (RAG)
이런 배경에서, 본 논문은 Strategic Chain-of-Thought(SCoT)라는 새로운 접근 방식을 제안합니다. SCoT는 전략적 지식을 통합하여 CoT 경로 생성의 품질을 향상시키는 것을 목표로 합니다.
SCoT 방법은 단일 프롬프트 내에서 두 단계로 진행됩니다.
- 문제 해결을 위한 가장 효과적인 전략을 탐색하고 식별 (전략적 지식 유도)
- 식별된 전략적 지식을 사용하여 고품질 CoT 경로를 생성하고 정확한 최종 답변을 도출 (전략적 지식 적용)
SCoT의 주요 장점은 멀티 쿼리 접근 방식이나 추가 지식 소스 없이 모델의 인퍼런스 능력을 향상시켜 계산 오버헤드와 운영 비용을 줄일 수 있다고 언급합니다.
2. Related Work
2.1 문제 해결에서의 전략적 다양성
문제 해결 분야에서는 하나의 보편적인 접근 방식이 존재하지 않습니다. 각 문제의 복잡성에 따라 효과적인 해결책을 찾기 위해 다양한 전략이 필요합니다. 교육학과 인지과학 분야에서는 문제 해결을 위해 여러 접근 방식을 사용하는 현상이 일반적입니다(Sweller 1988; Rusczyk 2003).
유사하게, 연구자들은 LLMs가 하나의 질문에 대해 다양한 해결 경로를 생성할 수 있음을 발견했습니다(Wang and Zhou 2024; Wang et al. 2022). 이런 방법들의 문제 해결 전략과 답변은 상당히 다를 수 있습니다.
2.2 CoT 경로 개선
현재 모델이 생성한 내용의 품질을 향상시키기 위한 방법은 다양하고 정교합니다.
-
투표 기반 메커니즘 Wang et al. (2022)은 Self-Consistency 방법을 소개했습니다. 이 방법은 20개 이상의 CoT 경로를 생성한 후, 가장 일관된 답변에 투표하여 인퍼런스 정확도를 향상시킵니다.
- 외부 소스 활용
- Zheng et al. (2023)은 Step Back 방법을 제안했습니다. 이 방법은 모델에게 질문의 추상을 생성하도록 프롬프트를 주어 더 깊은 논리 구조를 파악하고, 이를 통해 RAG 능력을 향상시킵니다.
- Yang et al. (2024b)은 Buffer of Thoughts라는 또 다른 RAG 기반 방법을 개발했습니다. 이 방법은 외부 소스에서 추출한 지식과 각 작업에 대해 미리 정의된 지식 카테고리를 사용합니다.
-
외부 도구 활용 Gao et al. (2023)은 PAL을 제안했습니다. 이 방법은 대규모 언어모델을 활용하여 문제를 파싱하고 중간 인퍼런스 단계로 프로그램을 생성한 후, Python 인터프리터와 같은 런타임 환경에 해결을 위임합니다.
- 메타 프롬프팅 Suzgun and Kalai (2024)는 기존의 프롬프트 기반 프레임워크를 통합하여 가장 효과적인 인퍼런스 전략을 동적으로 선택할 수 있게 하는 메타 프롬프팅을 소개했습니다.
이런 방법들은 본질적으로 복잡하며, 일부는 작업에 민감하고 다른 일부는 멀티 턴 프롬프팅을 포함합니다. 그러나 이들은 LLMs의 인퍼런스 능력을 향상시키는 데 상당한 효과를 보여주었으며, 이를 통해 머신러닝에서 CoT 생성의 경계를 확장하고 있습니다.
3. 방법
3.1 전략적 지식
LLMs는 동일한 문제에 대해 다양한 CoT 경로를 생성하는 경향이 있습니다. 그러나 이런 CoT 경로의 품질은 상당히 다를 수 있습니다(Wang and Zhou 2024; Wang et al. 2022).
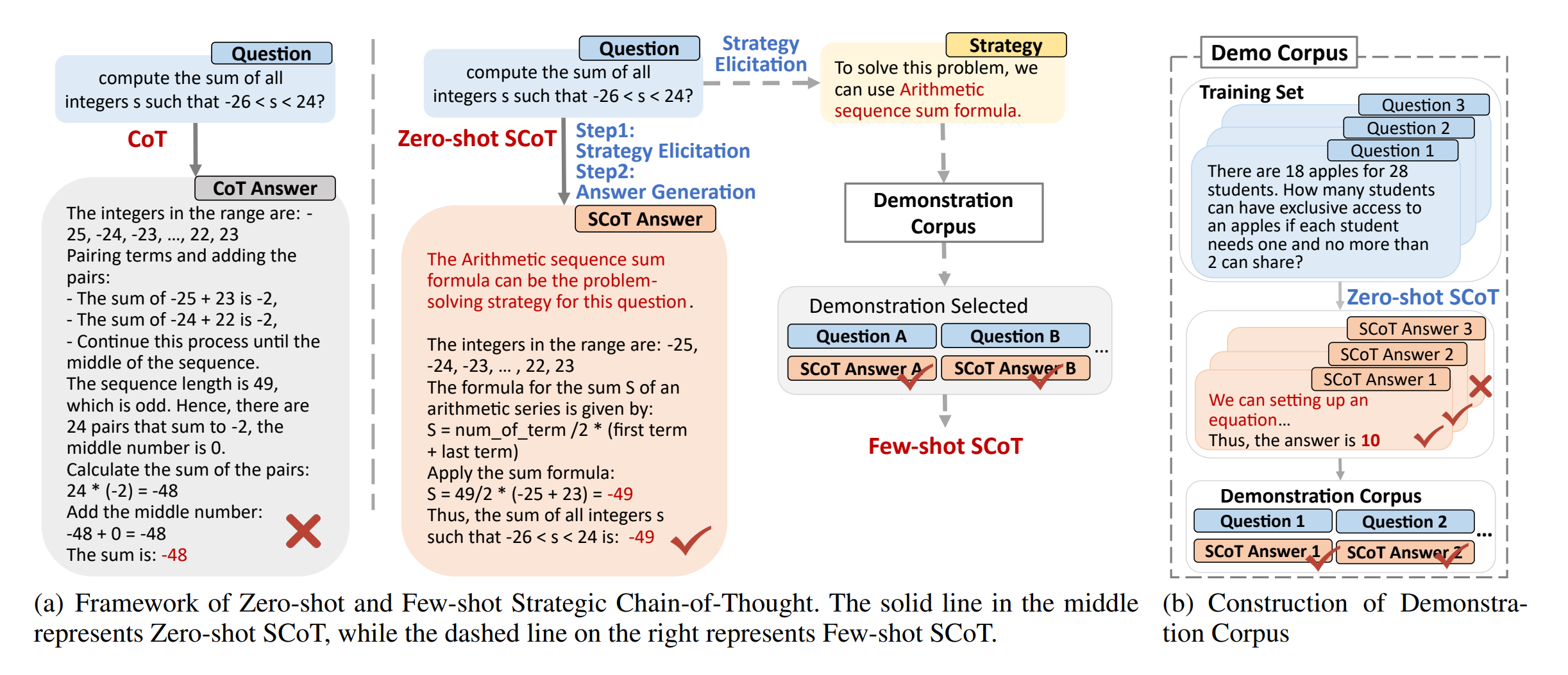
예를 들어, “모든 정수 s에 대해 $-26 < s < 24$를 만족하는 s의 합을 계산하라”는 수학 문제를 해결하기 위해 고려할 수 있는 두 가지 접근 방식이 있습니다.
-
항 쌍 방식 이 방법은 대칭성을 이용하여 양 끝의 항들을 짝지어 더합니다.
\[\begin{align*} \text{Sum} &= (-25 + 23) + (-24 + 22) + \cdots + (-1 + 1) + 0 \\ &= (-2) + (-2) + \cdots + (-2) + 0 \\ &= -2 \times 24 + 0 \\ &= -48 + 0 = -48 \end{align*}\]$-2$의 쌍이 24개 있고, 중앙값 0이 한 번 나타납니다.
-
등차수열의 합 공식 사용
\[\text{Sum} = \frac{n(a_1 + a_n)}{2}\] \[\begin{align*} \text{Sum} &= \frac{49(-25 + 23)}{2} \\ &= \frac{49(-2)}{2} \\ &= -49 \end{align*}\]
두 방법 모두 올바른 결과를 리턴하지만, 등차수열의 합 공식을 사용하는 두 번째 방법이 계산 과정이 더 간단하고 오류 가능성이 낮아 더 효율적입니다. (SCoT가 선호하는 전략적 접근 방식의 예)
두 방법 모두 문제 해결에 유효하지만, 첫 번째 접근 방식은 중간 단계의 복잡성으로 인해 일반적으로 덜 안정적인 출력을 생성합니다. 반면, 등차수열 공식을 적용하는 두 번째 접근 방식은 일반적으로 더 높은 품질과 안정적인 모델 출력을 생성합니다. 이 경우, 등차수열 공식이 전략적 지식으로 간주됩니다.
전략적 지식(Strategy)은 정확하고 안정적인 해결책으로 인퍼런스를 이끄는 잘 정의된 방법 또는 원칙을 의미합니다. 이는 원하는 결과로 논리적으로 이어지는 구조화된 프로세스를 사용하여 CoT 생성의 안정성을 향상시키고 전반적인 결과의 품질을 개선합니다.
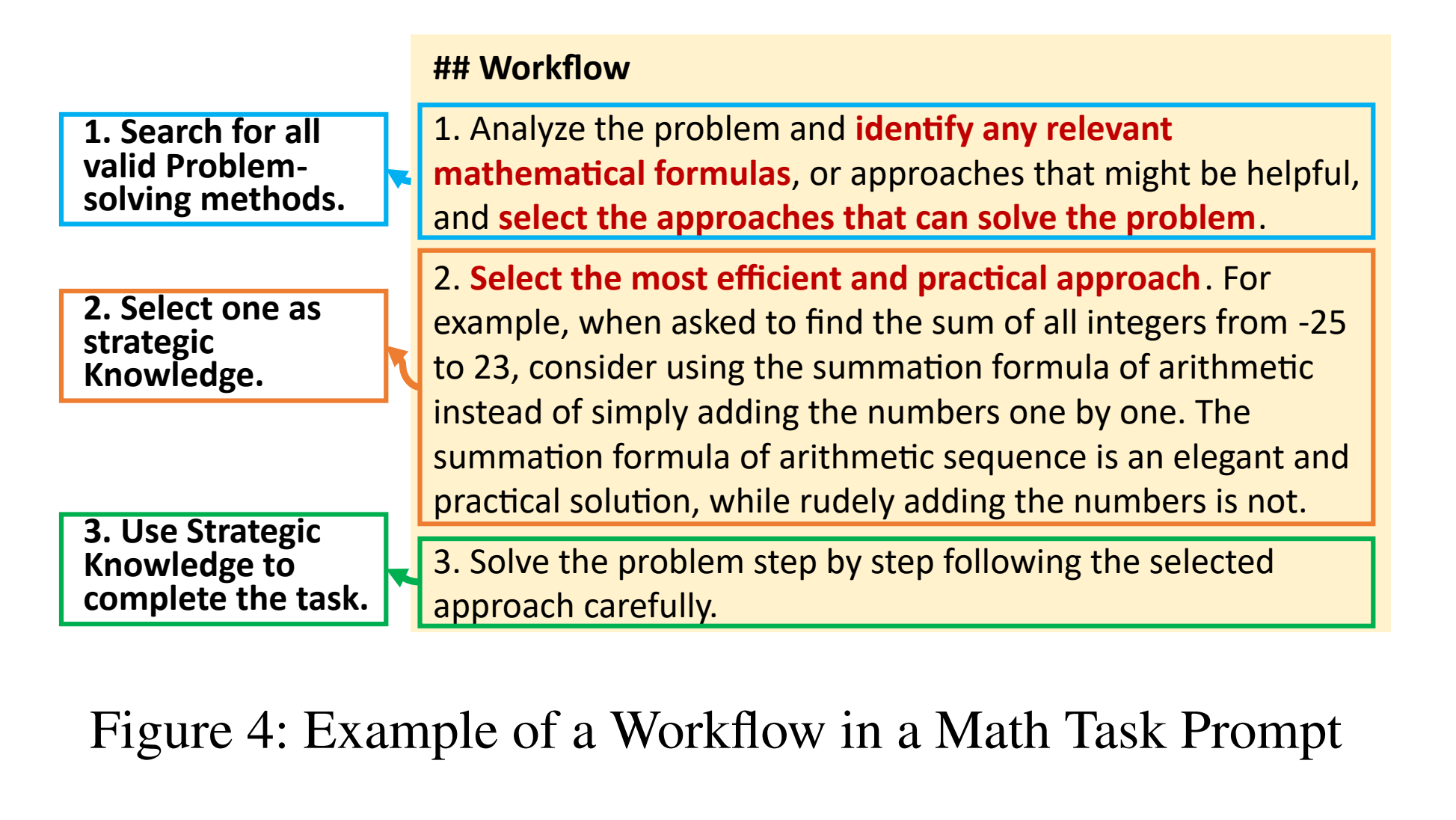
구체적으로, 전략적 지식은 다음 원칙을 따라야 합니다.
- 모델이 인퍼런스 단계를 주의 깊게 따를 때 정확한 답변을 생성할 수 있는 체계적인 접근 방식을 제공해야 한다.
- 각 단계는 정확성을 보장하고 모호성을 유발할 수 있는 지나치게 간단한 출력을 방지하기 위해 충분히 상세해야 하지만, 전체 방법의 단계는 과도하게 복잡해서는 안된다.
3.2 전략적 사고 연쇄(SCoT)
전략적 지식의 개념을 바탕으로, LLMs의 인퍼런스 품질을 향상시키기 위한 프롬프트 기반 방법인 Strategic Chain-of-Thought(SCoT)를 제안합니다.
SCoT 방법은 모델이 직접 답변을 생성하는 대신, 먼저 전략적 지식을 유도한 후 답변을 생성하도록 합니다. 구체적으로, 단일 쿼리 설정에서 SCoT는 두 가지 주요 단계를 포함합니다.
전략적 지식을 유도한 후 답변을 생성
- 모델은 문제 해결을 위한 가장 효과적이고 효율적인 방법 중 하나를 식별하고 결정해 해당 작업의 전략적 지식으로 삼습니다. (전략적 지식 유도)
- 모델은 이후 상기 1에서 정의한 식별된 전략적 지식을 적용하여 문제를 해결하고 최종 답변을 도출합니다. (전략적 지식 적용)
SCoT 프롬프트는 다음 다섯 가지 구성 요소로 이루어집니다.
- mathematical reasoning
- commonsense reasoning
- physical reasoning
- spatial reasoning
- multi-hop reasoning.
프롬프트는 단일 프롬프트 내에 통합된 세 단계로 구성된 구조화된 워크플로우를 포함하며 처음 두 단계는 문제 해결을 위한 전략적 지식을 식별하고 유도하도록 설계되었으며, 세 번째 단계는 전략을 적용하여 답변을 생성하는 데 중점을 둡니다.
전략적 지식 식별을 위한 규칙은 도메인에 따라 다릅니다.
- 수학: 우아하고 효율적인 해결책 생성 선호 (e.g., 수열의 합을 구하기 위한 등차수열 공식 사용)
- 물리학: 가장 관련성 높고 간단한 공식 또는 프로세스 선택 (e.g., 힘 계산을 위한 $F = ma$ 적용)
- 멀티 홉 인퍼런스: 문제 분해의 적절한 세분화 수준 결정 및 관련 정보 회상
- 기타 도메인: 알고리즘과 휴리스틱을 통해 복잡한 시스템을 최적화하는 등의 방법 개발
3.3 Few-shot SCoT
SCoT 방법을 확장하여 few-shot 버전을 개발했습니다. 이 접근 방식은 전략을 사용하여 데모를 선택하는 방식으로 구성되며, 다음과 같이 두 단계로 구조화됩니다. (인퍼런스 비용은 늘지만, 성능은 소폭 개선)
1단계: 전략적 지식 기반 데모 코퍼스 구축
- SCoT 답변 생성
- 훈련 세트의 각 질문에 대해 zero-shot SCoT 방법을 적용하여 해당 SCoT 답변을 생성합니다.
- 데모 코퍼스 구축
- 생성된 답변을 실제 답과 비교하여, 정확한 질문-SCoT 답변 쌍만 유지합니다.
- 이 단계는 이런 문제들에 사용된 전략적 지식이 정확하고 관련성이 있다고 가정하고,
- 검증된 질문-SCoT 답변 쌍들을 전략적 지식을 기반으로 데모 코퍼스로 컴파일합니다. (데모 코퍼스 축적)
데모 코퍼스의 수동 검증 및 구축으로 SFT & DPO로의 alignment를 배제할 수 없으므로 결과를 조금 더 신중히 해석해야할 필요가 있을 것으로 생각됩니다.
2단계: 모델 인퍼런스
이 단계는 두 번의 쿼리 프로세스에서 다음 세 단계를 포함합니다.
- 전략적 지식 생성
- LLM이 문제와 관련된 전략적 지식을 생성
- 이 단계는 최종 답변 생성보다는 문제 이해에 초점을 맞춥니다.
- 데모 매칭
- 생성된 전략적 지식을 사용하여 1단계에서 생성한 데모 코퍼스를 검색
- 가장 유사한 예시들의 SCoT 답변과 가장 관련성 높은 데모를 식별하고 매칭
- Few-shot 인퍼런스
- 선택된 데모를 입력 프롬프트에 few-shot 예시로 통합
- 이 통합은 모델이 제공된 예시를 기반으로 최종 예측을 생성하도록 유도
실험 및 결과
SCoT의 효과를 검증하기 위해 8개의 인퍼런스 데이터셋에서 실험을 진행했습니다. 이 데이터셋들은 다음과 같은 5개의 서로 다른 도메인을 포함합니다.
- 수학적 인퍼런스
- 상식 인퍼런스
- 물리적 인퍼런스
- 공간 인퍼런스
- 멀티 홉 인퍼런스
실험 결과, 다양한 모델에서 상당한 성능 향상을 보였습니다. 특히 주목할 만한 결과는 다음과 같습니다.
- GSM8K 데이터셋: Llama3-8b 모델에서 21.05% 정확도 향상
- Tracking_Objects 데이터셋: Llama3-8b 모델에서 24.13% 정확도 향상
이런 결과는 SCoT 접근 방식의 효과성을 입증하며, 다양한 인퍼런스 작업에서 LLM의 성능을 크게 개선할 수 있음을 보여줍니다.
예시로 이해하기
SCoT 방법의 수학적 인퍼런스 과정을 자세히 살펴보겠습니다. “모든 정수 s에 대해 $-26 < s < 24$를 만족하는 s의 합을 계산하라”는 예제를 사용하여 단계별로 분석하겠습니다.
1단계: 전략적 지식 유도
LLM은 이 문제에 대해 두 가지 가능한 접근 방식을 고려합니다.
-
항 쌍 방식 \(\text{Sum} = (-25 + 23) + (-24 + 22) + ... + (-1 + 1) + 0\)
-
등차수열의 합 공식 사용 \(\text{Sum} = \frac{n(a_1 + a_n)}{2}\)
2단계: 전략적 지식 선택
LLM은 등차수열의 합 공식이 더 안정적이고 효율적인 방법이라고 판단합니다. 이유는 다음과 같습니다.
- 등차수열 공식은 단 한 번의 계산으로 결과를 얻을 수 있습니다. (계산의 단순성)
- 항 쌍 방식은 많은 중간 계산 단계를 포함하므로 오류 가능성이 높습니다. (오류 가능성 감소)
- 등차수열 공식은 항의 개수에 상관없이 적용 가능합니다. (일반화 가능성)
3단계: 선택된 전략 적용
등차수열의 합 공식을 사용하여 문제를 해결합니다.
- 범위 확인: $-25 \leq s \leq 23$ (정수 s에 대해)
- 값 계산
- 첫 항 $a_1 = -25$
- 마지막 항 $a_n = 23$
- 항의 개수 $n = 23 - (-25) + 1 = 49$
- 합 계산 \(\begin{align*} \text{Sum} &= \frac{n(a_1 + a_n)}{2} \\ &= \frac{49(-25 + 23)}{2} \\ &= \frac{49(-2)}{2} \\ &= -49 \end{align*}\)
이 과정을 통해 SCoT는 보다 안정적이고 정확한 인퍼런스 경로를 생성할 수 있습니다. 전략적 지식(등차수열의 합 공식)을 먼저 식별하고 적용함으로써, 복잡한 중간 단계를 거치지 않고 직접적으로 해답에 도달할 수 있습니다. 이는 오류 가능성을 줄이고 인퍼런스의 질을 향상시키는 SCoT 방법의 장점을 잘 보여줍니다.
4. Experimental Setup
- Strategic Chain-of-Thought (SCoT) 방법의 실험 설정 및 결과 분석
- 다양한 데이터셋과 모델에서 SCoT의 성능 향상 입증
- SCoT의 구성 요소 분석 및 효율성 평가
4.1 데이터셋 및 작업
SCoT 방법의 효과를 검증하기 위해 다양한 인퍼런스 관련 데이터셋을 사용했습니다.
- 수학 및 물리 인퍼런스: MathQA, AQuA, GSM8K, MMLU-high-school-math, ARC_Challenge
- 상식 및 멀티 홉 인퍼런스: CommonsenseQA (CSQA), StrategyQA (SQA)
- 공간 인퍼런스: Tracking_Object (Object)
Few-shot SCoT 버전에서는 충분히 큰 훈련 세트가 필요한 MathQA, AQuA, GSM8K, ARC 데이터셋만 사용했습니다.
4.2 모델
다음 LLM들을 사용하여 SCoT 방법의 효과를 검증했습니다.
- Llama3 시리즈 (Llama3-8B, Llama3-70B, Llama3.1-8B, Llama3.1-70B)
- Llama2 시리즈 (Llama2-7B, Llama2-13B, Llama2-70B)
- Mistral-7B
- Qwen2 시리즈 (Qwen2-7B, Qwen2-72B)
- ChatGLM4-9B
4.3 베이스라인
Zero-shot 프롬프트, Self-Consistency, Step Back을 베이스라인으로 사용했습니다.
5. Experimental Results
5.1 모든 데이터셋에 대한 결과
- Llama3-8B 모델은 평균 6.92% 성능 향상
- Mistral-7B 모델은 평균 3.81% 성능 향상
- GSM8K 데이터셋에서 52.11%에서 73.16%로 큰 성능 향상
- Tracking_Object 데이터셋에서 24.13% 성능 향상
- Few-shot SCoT는 대부분의 데이터셋에서 가장 좋은 성능을 보임
5.2 모든 모델에 대한 결과
- 대부분의 모델에서 SCoT는 성능을 향상시킴
- 정확도 향상 범위: 1.11% ~ 24.13%
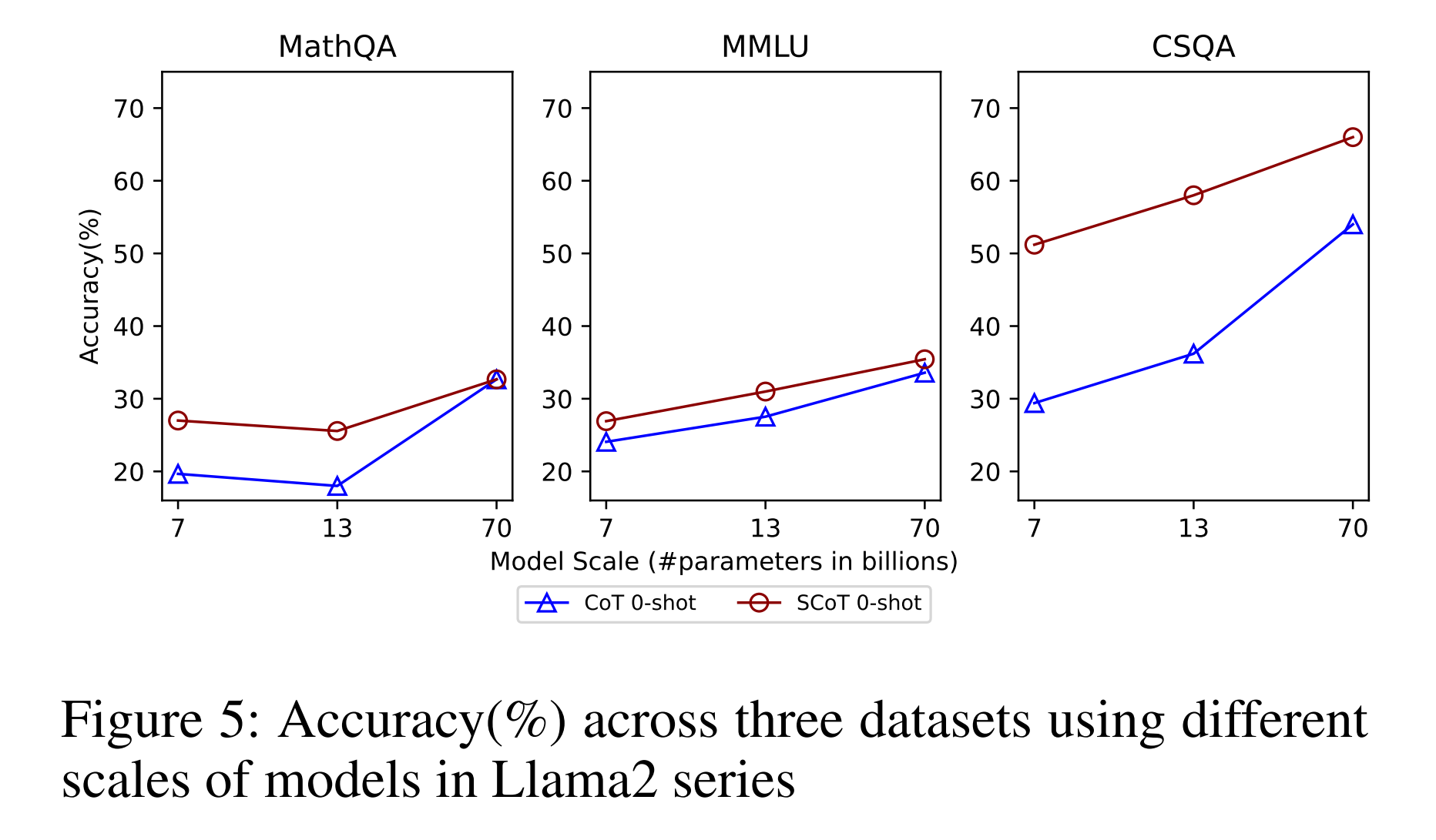
5.3 모델 규모의 영향
- Llama2 모델 시리즈 실험 결과, 모든 크기의 모델에서 SCoT가 성능 향상을 보임
- 모델 크기가 커질수록 성능 향상 폭이 약간 감소하는 경향
6. Ablation Study
SCoT 프롬프트의 다양한 구성 요소가 모델의 정확도에 미치는 영향을 조사하기 위해 광범위한 실험을 수행했습니다. 주요 구성 요소로는 역할(Role), 워크플로우(Workflow), 구조(Structure), 그리고 데모의 수량 등이 포함됩니다. Table 3은 이런 실험 결과를 보여줍니다.
| Method | AQuA | ARC |
|---|---|---|
| Mistral-7B* | 29.13% | 67.20% |
| Mistral-7B + Role* | 27.95% | 69.80% |
| Mistral-7B + Role | 32.28% | 71.20% |
| Mistral-7B + WorkFlow* | 33.07% | 70.40% |
| Mistral-7B + WorkFlow | 31.89% | 70.40% |
| SCoT 0-shot (Ours) | 33.60% | 72.20% |
| SCoT 1-shot (Ours) | 35.04% | 73.20% |
| SCoT 3-shot (Ours) | 35.43% | 73.20% |
Table 3: SCoT 프롬프트 구성 요소에 대한 Ablation 연구. *는 마크다운 형식이 아닌 것을 나타내며, *가 없는 것은 마크다운 형식을 나타냅니다.
실험 결과를 분석해보면 다음과 같은 결과를 관찰합니다.
- 역할(Role) 추가
- 마크다운 형식을 사용하지 않았을 때, AQuA 데이터셋에서는 성능이 약간 감소했지만 ARC 데이터셋에서는 향상되었습니다.
- 마크다운 형식을 사용했을 때, 두 데이터셋 모두에서 성능이 향상되었습니다.
- 워크플로우(Workflow) 통합
- 마크다운 형식의 사용 여부와 관계없이 두 데이터셋 모두에서 성능이 향상되었습니다.
- SCoT 0-shot
- 역할과 워크플로우를 모두 포함한 SCoT 0-shot 방법은 두 데이터셋에서 가장 높은 성능을 보였습니다.
- Few-shot SCoT
- 데모의 수를 증가시키면서 few-shot SCoT의 성능을 평가했습니다.
- 1-shot에서 3-shot으로 데모 수를 늘렸을 때, 성능이 약간 향상되거나 유지되는 것을 확인했습니다.
이런 결과는 SCoT 프롬프트의 각 구성 요소가 모델의 성능 향상에 기여함을 보여줍니다. 특히, 역할과 워크플로우의 추가, 그리고 마크다운 형식의 사용이 점진적으로 정확도를 향상시키는 것을 확인할 수 있습니다. 또한, few-shot 설정에서 데모의 수를 늘리는 것이 일정 수준까지는 성능 향상에 도움이 되지만, 그 이상에서는 큰 변화가 없음을 알 수 있습니다.
이런 ablation study의 결과는 SCoT 방법의 각 구성 요소가 모델의 인퍼런스 능력 향상에 어떻게 기여하는지 이해하는 데 도움을 주고, 향후 SCoT 방법을 더욱 최적화하고 개선할 수 있는 방향을 제시합니다.
7. Case Study
SCoT 방법의 효과를 더 깊이 이해하기 위해 상세한 사례 연구를 수행했습니다. 이 연구는 모델에서 도출된 전략적 지식의 타당성에 초점을 맞추었으며, 여러 전형적인 사례를 분석했습니다.

7.1 수학 영역
수학 문제에서 SCoT 출력은 문제를 직접 분석하여 답을 얻는 대신 부등식을 사용하여 문제를 해결하는 경향을 보였습니다. 예를 들어, 개구리 점프 계산 문제에서:
- CoT 접근: 최종 점프의 영향을 잘못 계산할 수 있는 위험이 있습니다.
- SCoT 접근: 모든 제약 조건을 고려하고 문제를 체계적으로 해결함으로써 정확한 계산을 보장합니다.
7.2 물리학 영역
물리학 문제에서는 다음과 같은 차이점이 관찰되었습니다.
- CoT 출력: 작업 입력의 특정 문구(e.g., “커패시터”)에 오도되어 잘못된 공식을 선택할 수 있습니다.
- SCoT 접근: 올바른 공식을 성공적으로 도출했습니다.
7.3 멀티 홉 인퍼런스 작업
복잡한 인퍼런스이 필요한 멀티 홉 인퍼런스 작업에서도 차이가 나타났습니다.
- CoT 출력: 세부사항에 집중하여 후속 논리적 인퍼런스이 불완전할 수 있습니다.
- SCoT 접근: 전체적인 맥락을 고려하여 답변을 생성합니다.
이런 사례 연구는 SCoT 방법이 다양한 도메인에서 더 체계적이고 정확한 문제 해결 방식을 제공함을 보여줍니다.
8. 효율성 분석
SCoT의 효율성을 평가하기 위해 출력 토큰 길이를 측정했습니다. Table 4는 AQuA, GSM8K, Tracking_Object 데이터셋에 대한 CoT 0-shot과 SCoT 0-shot 방법의 토큰 길이를 비교합니다.
| Dataset | Method | Llama3-8B | Mistral-7B |
|---|---|---|---|
| AQuA | CoT 0-shot | 361.384 | 270.260 |
| SCoT 0-shot | 370.378 | 458.413 | |
| GSM8K | CoT 0-shot | 130.532 | 858.507 |
| SCoT 0-shot | 206.278 | 611.848 | |
| Object | CoT 0-shot | 121.460 | 89.654 |
| SCoT 0-shot | 174.888 | 162.822 |
Table 4: SCoT와 CoT 0-shot 방법의 토큰 길이 비교
-
GSM8K 데이터셋에서 Mistral-7B 모델의 출력 토큰 길이가 SCoT 방법으로 감소했습니다. 이는 CoT 0-shot에서 모델이 특정 답변 범위를 반복적으로 생성하는 경향 때문일 수 있습니다.
-
SCoT의 길이는 CoT의 1.03배에서 1.8배 사이로 변동하며, 평균적으로 약 1.5배입니다.
이 결과는 SCoT가 CoT보다 약간 느리지만 여전히 관리 가능한 수준의 효율성을 유지함을 보여주며, 멀티 쿼리 방법에 비해 SCoT가 더 효율적임을 강조할 수 있습니다.
전략적 선택이라고 부르는 한 단계 문제 해결이 추가되기 때문
9. Discussion: Auto SCoT
SCoT 개념의 유효성을 입증하기 위해, SCoT 프롬프트 템플릿의 자동 생성 가능성을 평가하는 예비 실험을 수행했습니다. Qwen2-72B 모델에 SCoT 개념을 제공하여 해당 프롬프트 템플릿을 생성하고, 이를 AQuA 데이터셋에서 테스트했습니다. 결과는 Table 5와 같습니다.
| Method | Accuracy |
|---|---|
| CoT 0-shot | 29.13 |
| SCoT 0-shot | 33.60 |
| Auto SCoT | 31.89 |
Table 5: SCoT 개념을 기반으로 LLM이 자동 생성한 프롬프트의 정확도(%)
이 결과는 자동 생성된 SCoT 기반 프롬프트의 정확도가 수동으로 작성된 SCoT 프롬프트보다는 낮지만, 0-shot CoT 성능보다는 우수함을 보여줍니다. 이는 SCoT 기반 프롬프트 템플릿의 자동 생성이 실현 가능함을 시사합니다.
10. Conclusion
SCoT는 전략적 지식을 유도하고 적용하는 구조화된 워크플로우를 통합하여 모델의 고품질 출력 생성 능력을 향상시키고, 사전 정의된 전략적 지식 기반 코퍼스에서 전략적 지식을 통해 데모를 매칭하는 few-shot 버전으로 SCoT를 확장했습니다.
실험 결과는 0-shot SCoT와 few-shot SCoT 모두의 효과를 입증했습니다. 전반적으로 SCoT는 LLM의 인퍼런스 경로 품질을 개선하는 유망한 프레임워크를 제공하고, 향후 연구에서는 더 복잡한 문제에 대한 SCoT의 효과를 평가하고 추가 응용 분야를 탐구할 예정이라고 합니다.