Training Language Models on the Knowledge Graph
- Related Project: Private
- Category: Paper Review
- Date: 2024-08-14
Training Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
- url: https://arxiv.org/abs/2408.07852
- pdf: https://arxiv.org/pdf/2408.07852
- html: https://arxiv.org/html/2408.07852v1
- abstract: While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on ≤5% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM’s outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.
- 지식 그래프(KG) 기반 언어 모델 훈련을 통해 환각(hallucination) 현상을 체계적으로 분석합니다.
- 환각을 줄이기 위한 다양한 모델 크기 및 데이터셋 크기 변화에 따른 수학적 접근과 실험 결과를 제시합니다.
- 환각 감지 및 수정 방법을 논리적으로 설명하며, 수학적 수식을 통해 결론을 도출합니다.
환각을 줄이기 위한 주요 발견
- 더 큰 모델과 더 긴 훈련 시간을 통해 환각률을 줄일 수 있지만, 데이터셋 크기가 증가할수록 환각률이 다시 상승할 수 있기 때문에, 모델의 크기와 훈련 데이터 크기 간의 균형을 잘 맞추는 것이 중요하다. → 특정 도메인 스페서픽한 LLM들은 언제나 큰 코퍼스의 데이터 분포가 중요하다. 이를 자동화하기 위한 시도들(이전 블로그에 이진 최적화 등)이 있지만, 결국엔 다시 조정해줘야한다.
- 최소한 20회 이상의 에포크를 통해 훈련할 경우, 환각률이 크게 감소하지만, 에포크 수가 너무 많으면 모델이 훈련 중 보지 못한 데이터에 대해 일반화 능력이 감소할 수 있으므로, 적절한 에포크 수를 설정하는 것이 필요하다. → 에포크를 늘리면 환각은 줄지만, perplexity나 퍼포먼스도 같이 떨어진다. 즉, SFT 데이터셋에 너무 과하게 오버피팅될 수 있음. 그렇다면 굳이 LLM을 학습할 필요가 없을 수 있다.
- 템퍼리처를 낮추면 모델의 예측이 더 확실해지면서 환각률이 감소하지만, 동시에 모델의 예측 다양성(Recall)도 감소하므로 높은 Precision(Precision)를 원할 경우 템퍼리처를 낮추고, 예측 다양성을 중시할 경우 템퍼리처를 높이는 방법을 사용할 수 있다. → 템퍼리처를 낮추면 역시 트레이닝 셋을 그대로 등장시킬 확률이 올라가므로… 이것 역시 이렇게 사용할 것이라면 굳이 LLM을 사용할 필요가 없을 수 있다.
- 환각률을 최소화하기 위해서는 최적화된 모델 크기보다 훨씬 큰 모델과 더 많은 계산 자원이 필요하며, 효율성을 높이기 위해서는 Retrieval-Augmentation과 같은 대안적인 방법을 고려할 수 있습니다. → 큰 모델과 더 많은 학습을 하면 그에 따라 조정해줘야할 것이 많으므로, 당연히 파라미터가 증가하니까 레이어의 중복(Anthropic 토이 모델 참고)을 줄일 수 있으므로 환각에는 적절할 수 있지만, 그것 역시 더 많은 영역이 학습되면 비슷하게 환각을 보일 것 같습니다. LLaMA-4 405B가 얼마나 모든 도메인에서 좋은 성능을 보이느냐에 따라서 환각 및 RAG에 대한 사용 방향도 달라지지 않을까 싶습니다.
- 환각 탐지기를 통해 모델의 환각을 사전에 감지하고 수정할 수 있었고, 토큰 단위 탐지기가 문장 단위 탐지기보다 일반적으로 더 높은 정확도를 보였다. 그러나, 모델 크기가 커질수록 환각 감지의 어려움이 증가할 수 있다. → 환각은 토큰 레벨로 체크해서 보는 것이 좋다. 넥스트 토큰으로 리턴 된 토큰의 로짓이 낮음에도 불구하고 나와서 그 뒤에 계속 붙으면 환각일 수 있으므로…최근 많은 주제로 나오는 경로(trajectory)와 관련된 인사이트가 될 수 있을 것 같습니다.
1. 서론 (Introduction)
대규모 언어모델(Large Language Models, LMs)의 생성 및 예측 능력은 급격히 발전하고 있지만, 여전히 중요한 문제 중 하나는 환각(hallucination) 현상입니다. 환각이란 모델이 존재하지 않는 정보를 생성하는 현상으로, 이는 데이터셋의 모호성이나 훈련 과정의 불확실성으로 인해 발생할 수 있습니다. 본 연구에서는 지식 그래프(Knowledge Graph, KG)를 사용하여 이런 환각을 정의하고, 정량화하며, 환각이 모델의 크기와 데이터셋의 크기와 어떻게 상관되는지를 연구합니다.
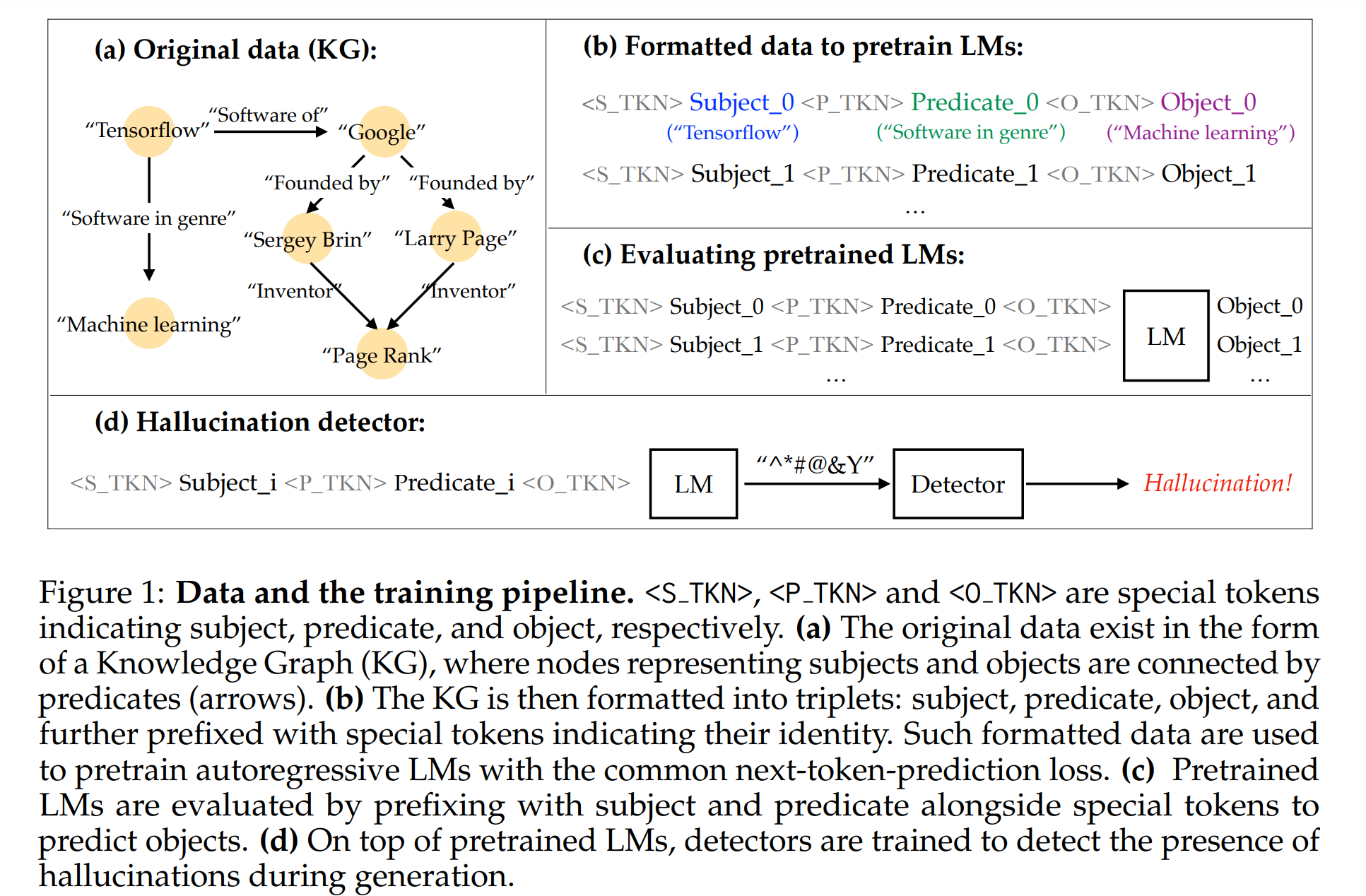
지식 그래프는 주체(Subject), 술어(Predicate), 객체(Object)로 구성된 삼중항(triplet)을 포함하고 있으며, 이런 구조화된 데이터를 통해 모델이 훈련 중에 보았던 정보를 명확하게 통제할 수 있습니다. 이는 자연어 기반 데이터와는 달리, 모델이 학습한 정보와 그렇지 않은 정보를 정확히 구분할 수 있는 이점을 제공합니다.
2. 언어 모델의 지식 통제 (Controlling What an LM Knows)
2.1 지식 그래프 데이터셋 (The Knowledge Graph dataset)
지식 그래프(KG)는 정보의 일관성을 보장하고, 현실 세계의 정보 구조를 반영합니다. 본 연구에서는 Google이 제공한 지식 그래프를 사용하여 언어 모델을 훈련합니다. 지식 그래프는 주체, 술어, 객체로 구성된 삼중항을 포함하며, 이들 각각 앞에 특수 토큰을 추가하여 모델이 이를 쉽게 인식할 수 있도록 합니다. 이런 데이터셋을 사용함으로써, 모델이 학습한 정보를 쉽게 검증할 수 있으며, 모델이 예측하는 정보의 정확도를 체계적으로 평가할 수 있습니다.
데이터셋은 세 가지 가시성 수준으로 나뉩니다.
- 완전 가시 데이터셋(fully visible set, FVS): 모델과 탐지기 모두가 훈련에 사용되는 데이터셋
- 부분 가시 데이터셋(partially visible set, PVS): 모델만 훈련에 사용되고, 탐지기는 훈련에 사용되지 않음.
- 비가시 데이터셋(invisible set, IVS): 모델과 탐지기 모두 훈련에 사용되지 않는 테스트용 데이터셋
이런 데이터셋을 구성하기 위해, 주체 수준에서 독립적인 분할을 수행합니다. 주체-술어 쌍이 다수의 객체와 연결된 경우, 모든 객체가 동일한 집합에 속하도록 하여 정확한 평가가 가능하도록 합니다. 또한, 일부 주체-술어 쌍은 수백 개의 객체와 연결되어 있으며, 이런 경우 극단적인 길이를 가지는 항목을 제거하여 의미 있는 분석이 가능하도록 했습니다.
2.2 지식 그래프를 활용한 언어 모델 훈련 (Training LMs on the Knowledge Graph)
언어 모델의 훈련은 Transformer 기반의 디코더 전용 모델을 사용하여 진행됩니다. 모델의 크기와 데이터셋의 크기를 다양하게 조절하여 실험을 수행하였으며, 훈련 데이터셋은 1%에서 100%에 이르는 다양한 크기로 구성되었습니다. 훈련 과정에서는 삼중항을 기반으로 자동회귀(Auto-regressive) 방식의 손실 함수, 즉 cross-entropy loss를 최소화하는 방식으로 최적화가 이루어졌습니다.
주목할만한 점은 모델 크기와 훈련 데이터의 크기에 따라 모델의 성능 및 환각 빈도가 어떻게 변화하는지를 분석했다는 것입니다.
\[\mathcal{L}(\theta) = -\frac{1}{N} \sum_{i=1}^{N} \log P_\theta(y_i | x_i)\]\(\mathcal{L}(\theta)\)는 손실 함수, \(N\)은 훈련 샘플의 수, \(y_i\)는 실제 객체, \(x_i\)는 주체와 술어, 그리고 \(P_\theta(y_i \\| x_i)\)는 주어진 주체와 술어에 대해 객체를 예측할 확률
모델의 학습은 Adam 옵티마이저를 사용하여 수행되었으며, 학습률은 선형 웜업(linear warmup)과 코사인 감쇠(cosine decay)를 통해 최적화되었습니다. 모델의 크기 및 학습 반복 횟수에 따라 학습률을 조정하였으며, 이로 인해 다양한 모델 크기와 데이터셋 크기에서 환각 빈도의 변화를 체계적으로 분석할 수 있었습니다.
3. 환각율과 스케일의 관계 (Hallucination Rate and How It Scales)
- 모델 크기와 데이터셋 크기에 따른 환각률의 변화를 수학적 분석과 실험적 데이터를 통해 체계적으로 분석하고,
- 환각률 감소를 위한 최적의 훈련 방법을 제시하며, 훈련 에포크 수와 데이터셋 크기 간의 상호작용을 상세히 설명합니다.
- 모델 스케일이 환각 감지 성능에 미치는 영향을 탐구하며, 이를 수학적 수식과 실험 결과로 뒷받침합니다.
스케일링 법칙(Scaling Laws)은 모델 크기와 훈련 데이터셋 크기에 따라 언어 모델(LM)의 교차 엔트로피 손실(Cross-Entropy Loss)이 특정 패턴에 따라 감소하는 경험적 현상입니다 (Kaplan et al., 2020; Hoffmann et al., 2022). 교차 엔트로피 손실이 모델 예측의 정확도와 관련이 있는 만큼, 환각률이 유사한 경향을 따를 것이라고 생각할 수 있습니다. 하지만, 본 연구에서 얻은 결과(Figure 2)에 따르면 환각률은 이런 패턴을 따르지 않습니다.
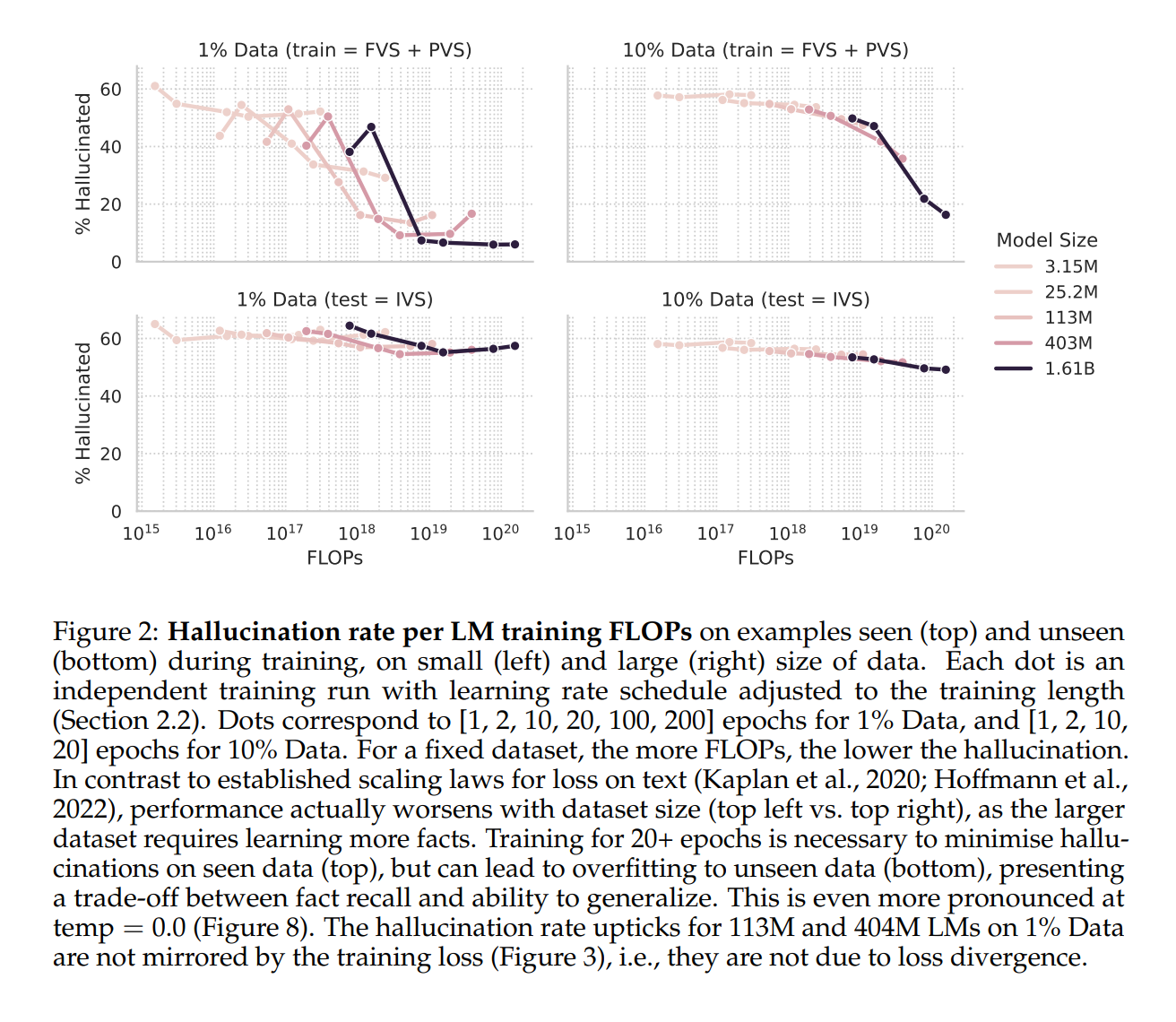
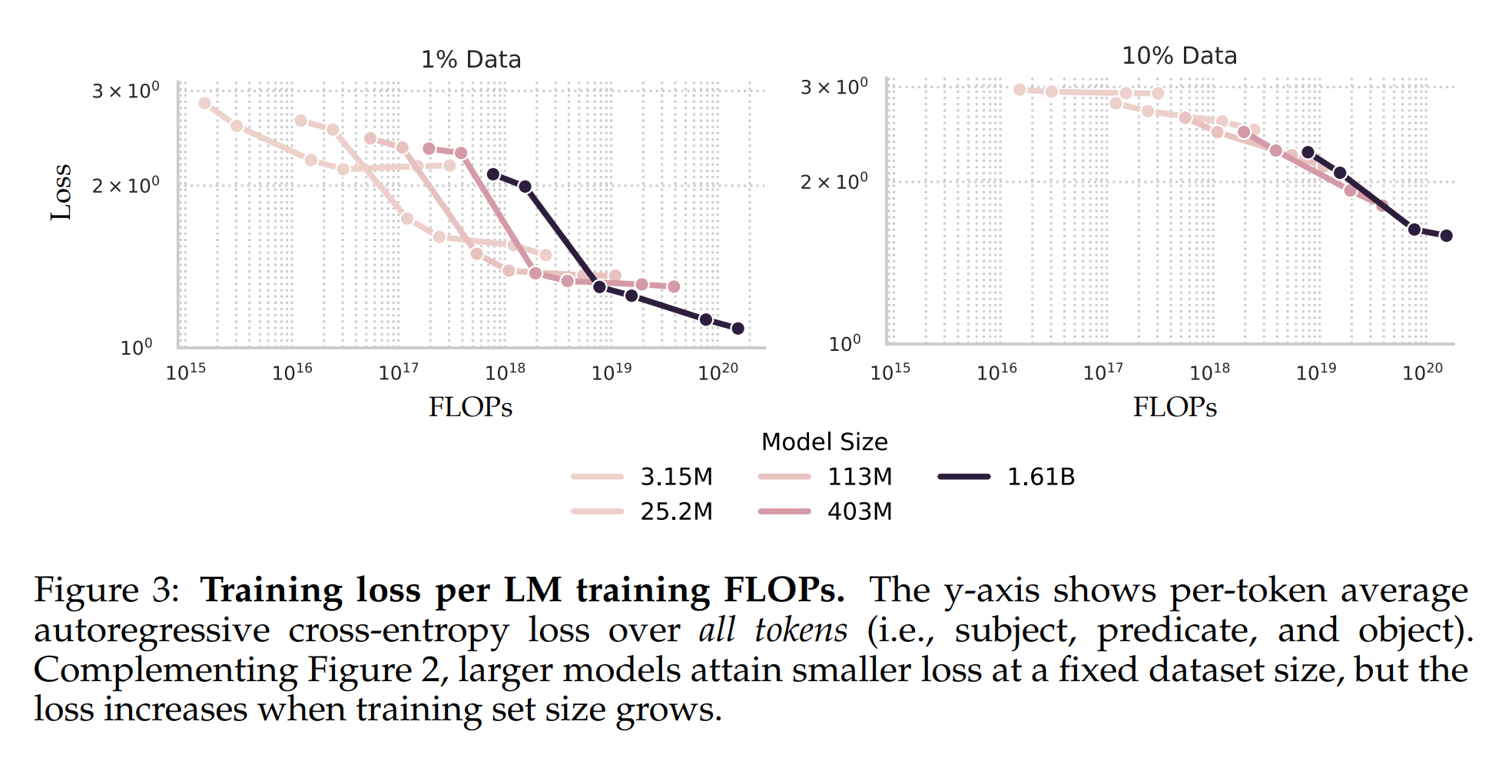
3.1 데이터셋 크기 증가와 환각률의 상관관계
고정된 데이터셋 크기에서, 더 큰 모델이나 훈련을 더 오래 진행한 모델은 일반적으로 환각률이 낮아집니다. 그러나 데이터셋 크기를 증가시키면, 오히려 환각률이 높아지는 현상이 나타납니다. 이는 다음 두 가지 요인 때문입니다.
- 기억이 필요한 삼중항: 많은 지식 그래프(KG) 삼중항은 다른 데이터 포인트에서 인퍼런스할 수 없기 때문에 기억해야만 한다.
- 삼중항의 단일 출현: 각 삼중항은 훈련 세트에서 한 번만 등장하므로 반복 학습이 어렵다.
이런 요인은 특히 훈련 시 보지 못한 데이터에서 50% 이상의 환각률을 보이며, 이는 기억의 필요성을 잘 보여줍니다. 기억이 필요한 예시로는 앨범의 트랙 이름이나 출생 날짜 등이 있습니다.
환각률의 수학적 모델링은 다음과 같은 관계식으로 설명될 수 있습니다.
\[\text{Hallucination Rate} \propto \frac{1}{\text{Model Size}} \times \log(\text{Data Size})\]이 수식은 모델의 크기와 훈련 데이터셋의 크기에 따라 환각률이 어떻게 변할 수 있는지를 보여주며 모델 크기가 커질수록 환각률은 감소하지만, 데이터셋 크기가 증가하면 기억해야 할 정보량이 증가하여 환각률이 다시 상승할 수 있다고 언급합니다.
3.2 훈련 에포크 수와 환각률의 관계
또 다른 중요한 발견은, 20회 이상의 에포크 훈련이 특정 모델 크기에 대해 최소한의 환각률을 달성하기 위해 필요하다는 점입니다. 이는 현재의 일반적인 훈련 방법(e.g., 1~2회 에포크 훈련)과는 크게 대조됩니다 (Chowdhery et al., 2023; Hoffmann et al., 2022; Touvron et al., 2023).
하지만 20회 이상의 에포크 훈련은 훈련 중 보지 못한 데이터에 대한 일반화 능력을 감소시키는 부작용을 초래할 수 있습니다. 이는 Figure 2의 하단 그래프에서 나타나듯, 일정 에포크 이후 환각률이 다시 상승하는 경향에서 확인할 수 있습니다. 이런 현상은 특히 템퍼리처 파라미터 \(temp = 0.0\)에서 더욱 두드러지며, 환각률과 모델의 다른 성능 지표 간의 절충(trade-off)을 나타냅니다.
3.3 템퍼리처와 환각률의 상관관계
템퍼리처(temperature)는 모델의 예측 다양성을 제어하는 중요한 파라미터로, 템퍼리처가 낮을수록 모델의 예측이 더 확실해지지만, 이는 곧 환각률을 낮추는 반면 모델의 예측 다양성(Recall)을 감소시킵니다. 예를 들어, 템퍼리처를 1.0에서 0.0으로 낮추면, 가장 큰 모델에서도 훈련 데이터에서 본 데이터에 대한 환각률이 약 5%에서 1.5%로 줄어듭니다.
이를 수식으로 표현하면,
\[\text{Precision} \propto \frac{1}{\text{Hallucination Rate}}, \quad \text{Recall} \propto \text{Temperature}\]이 수식은 템퍼리처가 낮을수록 Precision(Precision)가 증가하지만, 재현율(Recall)은 감소한다는 것을 의미합니다. Figure 4에서, 템퍼리처 변화에 따른 Precision와 재현율의 변화를 시각화하여 이런 관계를 더욱 명확하게 확인할 수 있습니다.
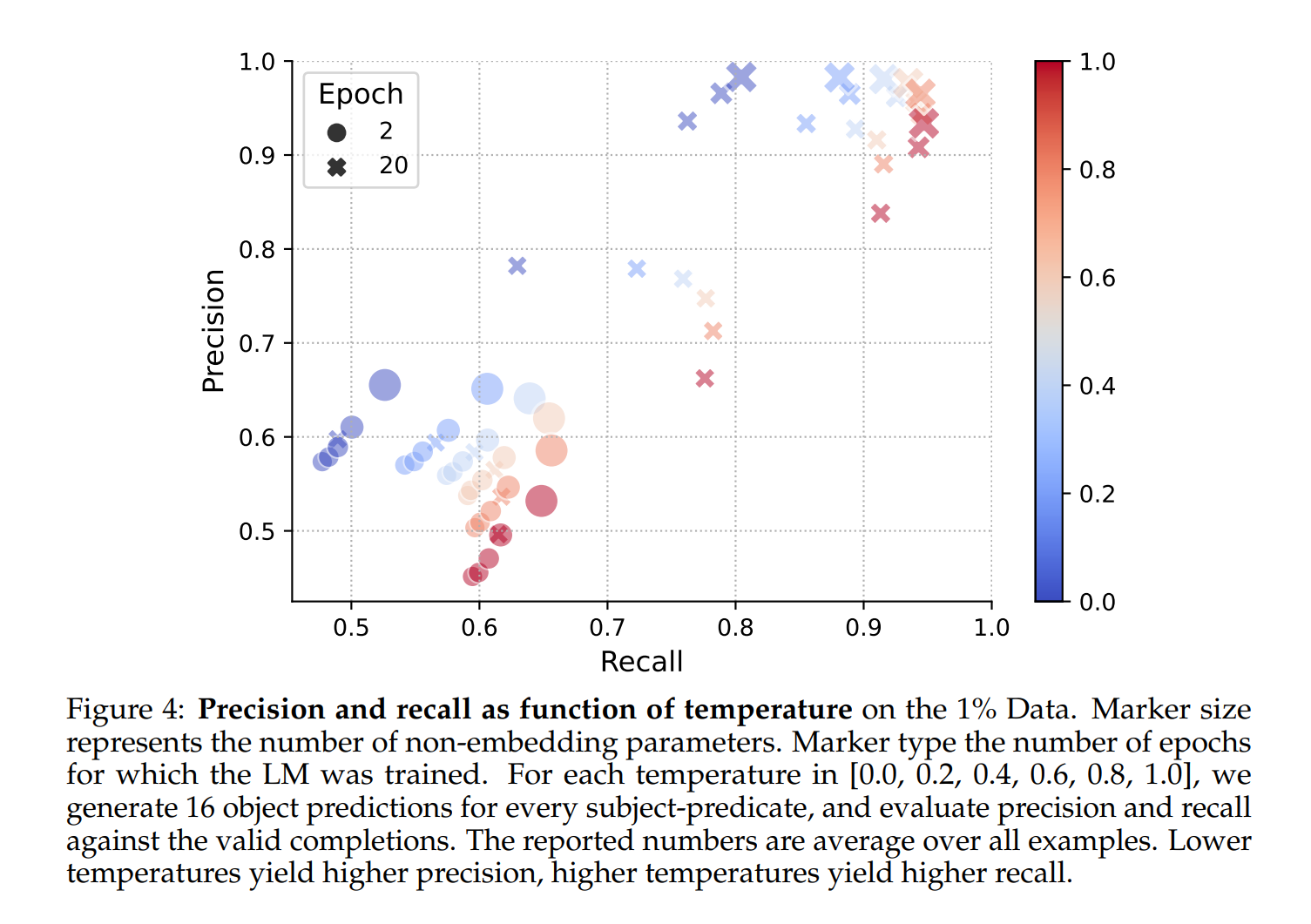
3.4 모델 크기와 최적화의 상관관계
현재 일반적으로 사용되는 최적의 모델 크기보다 훨씬 큰 모델이 훈련 데이터에서 본 데이터에 대한 환각률을 최소화하기 위해 필요합니다. 이는 현재의 최적화 전략과는 상반되는 결과로, 더 큰 모델이 더 나은 성능을 보이기 위해서는 현재보다 훨씬 더 큰 계산 자원이 필요하다는 것을 시사합니다. 이를 해결하기 위한 대안으로는 Retrieval-Augmentation(Lewis et al., 2020; Borgeaud et al., 2022)이나 모델의 불확실성 표현 방법(Dhuliawala et al., 2023; OpenAI, 2023; Li et al., 2023) 등이 제안될 수 있습니다.
4. 환각 감지 성능과 스케일의 관계 (Hallucination Detectability and How It Scales)
4.1 실험 설정 (Setup)
앞서 살펴본 바와 같이, 환각률은 모델 크기와 훈련 길이에 따라 감소하는 경향이 있습니다. 그러나, 주어진 훈련 데이터셋 크기에 비해 훨씬 큰 모델들도 여전히 약 5%의 환각률을 보이며, 훈련 중 보지 못한 데이터에서는 약 50%의 환각률을 유지합니다(Figure 2). 따라서 다른 방법을 통해 환각률을 추가적으로 줄일 수 있는지에 대한 이해가 필요합니다.
환각 탐지기의 성능은 크게 두 가지로 나뉩니다.
- 문장 단위 탐지기(sentence): 주어진 주체-술어-객체 삼중항을 분석하여 객체가 환각인지 여부를 판단합니다.
- 토큰 단위 탐지기(token): 훈련된 언어 모델의 특정 레이어에서 토큰 임베딩을 받아 이를 분석하여 해당 토큰이 환각인지 여부를 판단합니다.
각 탐지기의 성능은 다음과 같은 수학적 수식으로 평가할 수 있습니다.
\[\text{AUC-PR} \propto \frac{1}{\text{Hallucination Rate}}\]이 수식은 모델의 환각률이 낮을수록 환각 탐지기의 AUC-PR이 감소할 수 있음을 나타냅니다.
즉, 더 큰 모델일수록 환각률은 낮아지지만, 이로 인해 환각을 감지하는 것이 더 어려워질 수 있다는 것을 의미합니다.
4.2 실험 결과
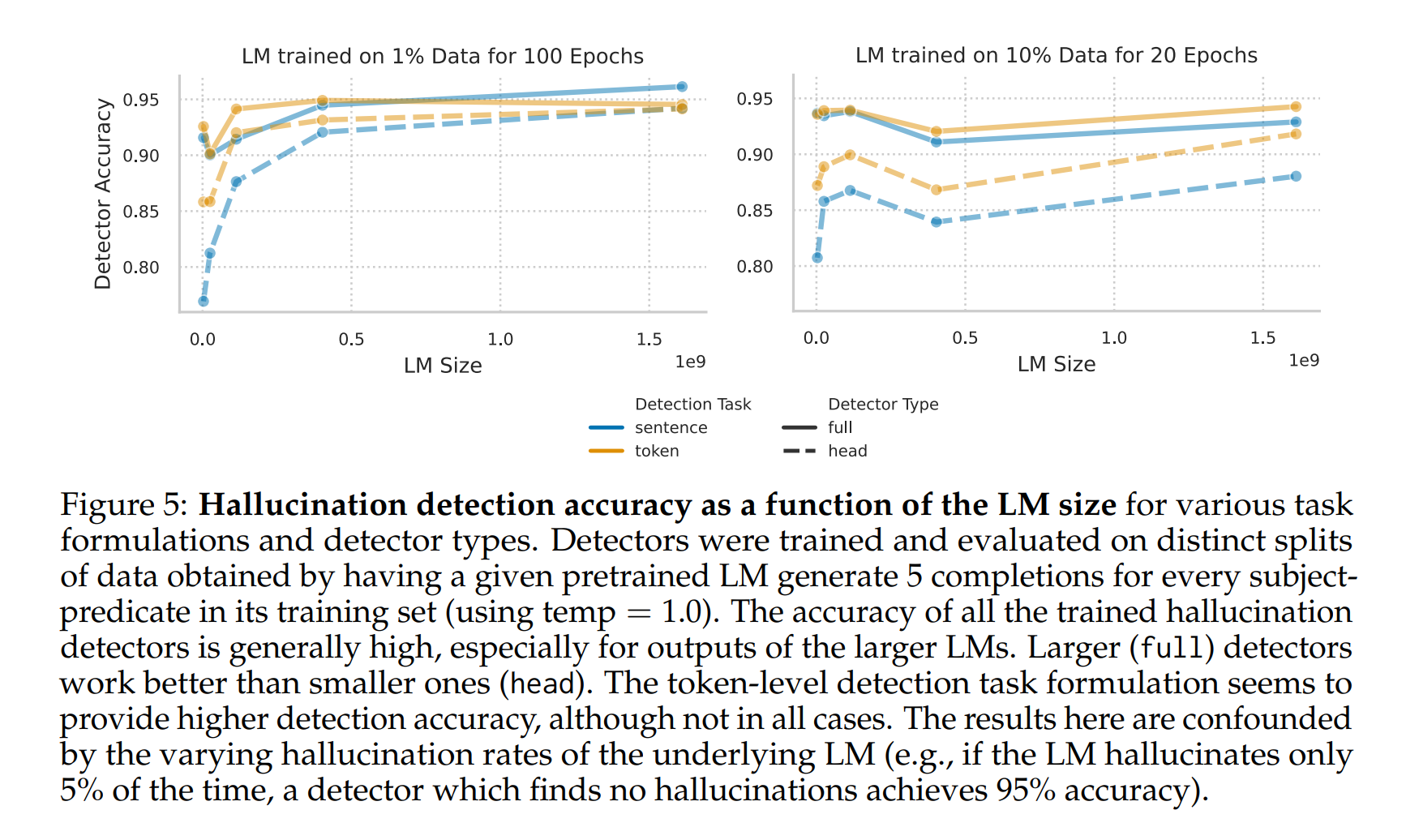
Figure 5에서, 사전 훈련된 언어 모델 크기가 전체 감지 정확도에 미치는 영향을 보여줍니다. 예상대로, 풀(Full) 탐지기가 헤드(Head) 탐지기보다 더 나은 성능을 보입니다. 이는 풀 탐지기가 더 유연하기 때문이며, 다른 메트릭에서도 유사한 결과를 보입니다. 토큰 단위 탐지기가 문장 단위 탐지기보다 일반적으로 더 높은 정확도를 제공합니다.
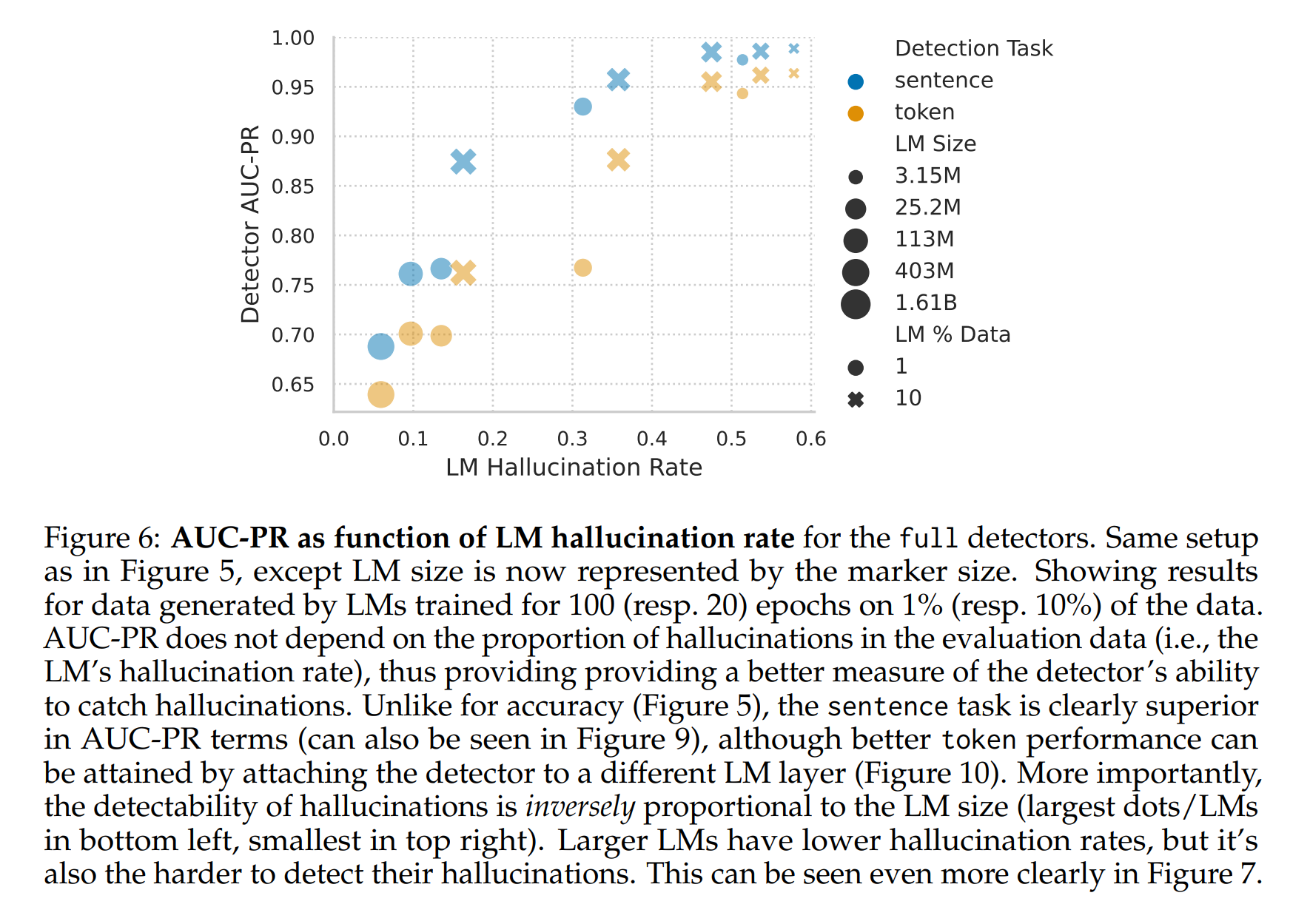
하지만, 이런 결과는 기본 언어 모델의 환각률에 대한 민감성에 의해 혼란스러울 수 있습니다. 예를 들어, 환각률이 5%에 불과한 경우, 모든 환각을 잡는 단순한 탐지기도 95%의 정확도를 달성할 수 있습니다.
5. 한계점
본 연구의 결과는 SOTA(SOTA) 언어 모델의 동작과 일치하지 않을 수 있습니다. 첫째, 지식 그래프는 일반적으로 언어 모델 훈련에 사용되는 데이터와 다릅니다. 둘째, 본 연구에서 훈련된 모델은 SOTA 모델보다 훨씬 작으며, 이에 따라 비례적으로 작은 데이터셋을 사용했습니다. 셋째, 본 연구는 훈련 데이터에 문자 그대로 등장한 정보를 기억하지 못하는 환각만을 연구했습니다. 이런 이유로, 일부 결론은 다른 유형의 환각에 적용되지 않을 수 있습니다.
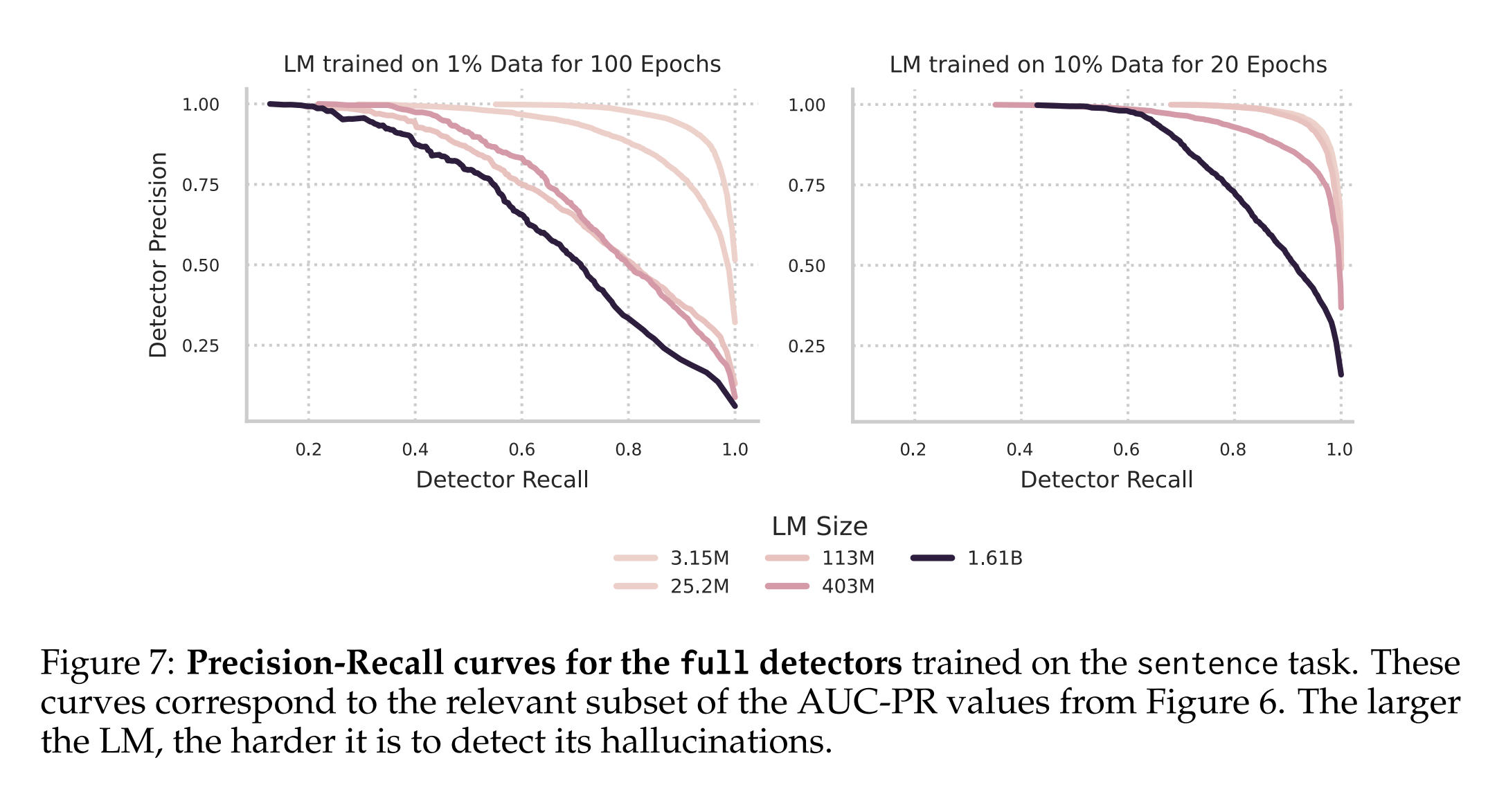
탐지기 성능 평가에서도 일반적인 경향성에 집중했으며, 특정 방법이 더 나은 결과를 제공할 수 있는 가능성을 배제하지 않았습니다. 그러나 탐지기 성능이 모델 크기에 따라 달라진다는 결과의 일관성은 이런 경향이 일반적인 특성임을 시사합니다. 마지막으로, 데이터셋의 불균형은 환각 탐지기의 성능에 강한 영향을 미쳤으며, 이런 불균형을 조정하기 위한 방법을 실험하지 않았습니다.
이와 같이 본 연구는 언어 모델의 환각률과 그 감지 성능을 모델 크기와 훈련 길이 측면에서 체계적으로 분석하며, 이에 대한 수학적 모델링과 실험적 결과를 제시합니다.