Survey | LLM Recommendation
- Related Project: Private
- Category: Paper Review
- Date: 2024-09-12
A Survey on Large Language Models for Recommendation
- url: https://arxiv.org/abs/2305.19860
- pdf: https://arxiv.org/pdf/2305.19860
- html: https://arxiv.org/html/2305.19860v5
- abstract: Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, this https URL.
TL;DR
- 대규모 언어모델(LLM)을 추천 시스템에 적용하는 두 가지 주요 패러다임: 판별적 LLM(DLLM4Rec)과 생성적 LLM(GLLM4Rec)
- DLLM4Rec은 주로 BERT 계열 모델을 사용하여 텍스트 특징 추출 및 임베딩에 활용, 파인튜닝과 프롬프트 튜닝이 주요 적용 방식
- LLM 기반 추천 시스템은 텍스트 특징의 고품질 representation과 외부 지식을 활용하여 아이템-사용자 상관관계를 수립하고 추천 품질을 향상
1. 서론
대규모 언어모델(Large Language Models, LLMs)은 자연어 처리(NLP) 분야에서 혁신적인 도구로 부상했으며, 최근 추천 시스템(Recommendation Systems, RS) 분야에서도 큰 주목을 받고 있습니다. 이런 LLM의 특징과 장점은 다음과 같습니다.
- 방대한 양의 데이터를 활용한 자기지도 학습
- 보편적 representation 학습에서의 향상된 성과
- 파인튜닝, 프롬프트 튜닝 등 다양한 전이 학습 기술을 통한 추천 시스템 성능 향상
LLM을 추천 시스템에 효과적으로 활용하는 핵심 전략은 다음과 같습니다.
- 텍스트 특징의 고품질 representation 활용 → LLM의 깊은 언어 이해를 통해 아이템과 사용자 정보를 풍부하게 representation
- 외부 지식의 광범위한 coverage 활용 → LLM에 내재된 방대한 지식을 통해 아이템과 사용자 간 복잡한 상관관계 수립
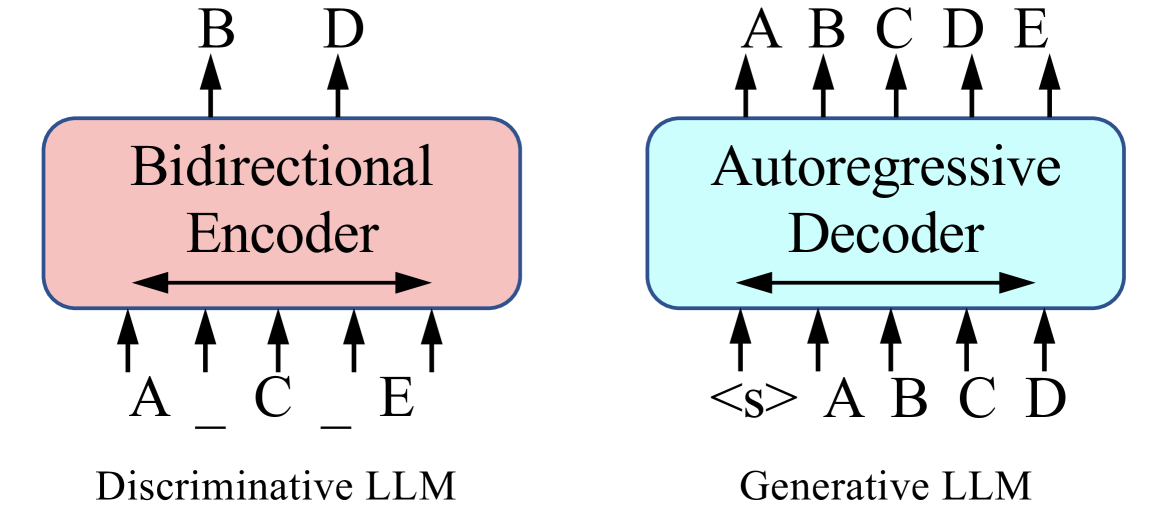 Figure 1:Two major training paradigms of large language models: Discriminative LLM (e.g. BERT) and Generative LLM (e.g. GPT).
Figure 1:Two major training paradigms of large language models: Discriminative LLM (e.g. BERT) and Generative LLM (e.g. GPT).
이 survey에서는 LLM 기반 추천 시스템을 두 가지 주요 패러다임으로 체계적으로 분류하고 분석합니다.
- Discriminative LLM for Recommendation (DLLM4Rec) → 주로 BERT 계열 모델을 활용한 판별적 접근
- Generative LLM for Recommendation (GLLM4Rec) → GPT 등의 생성 모델을 활용한 접근, 본 survey에서 처음으로 체계적 정리 시도
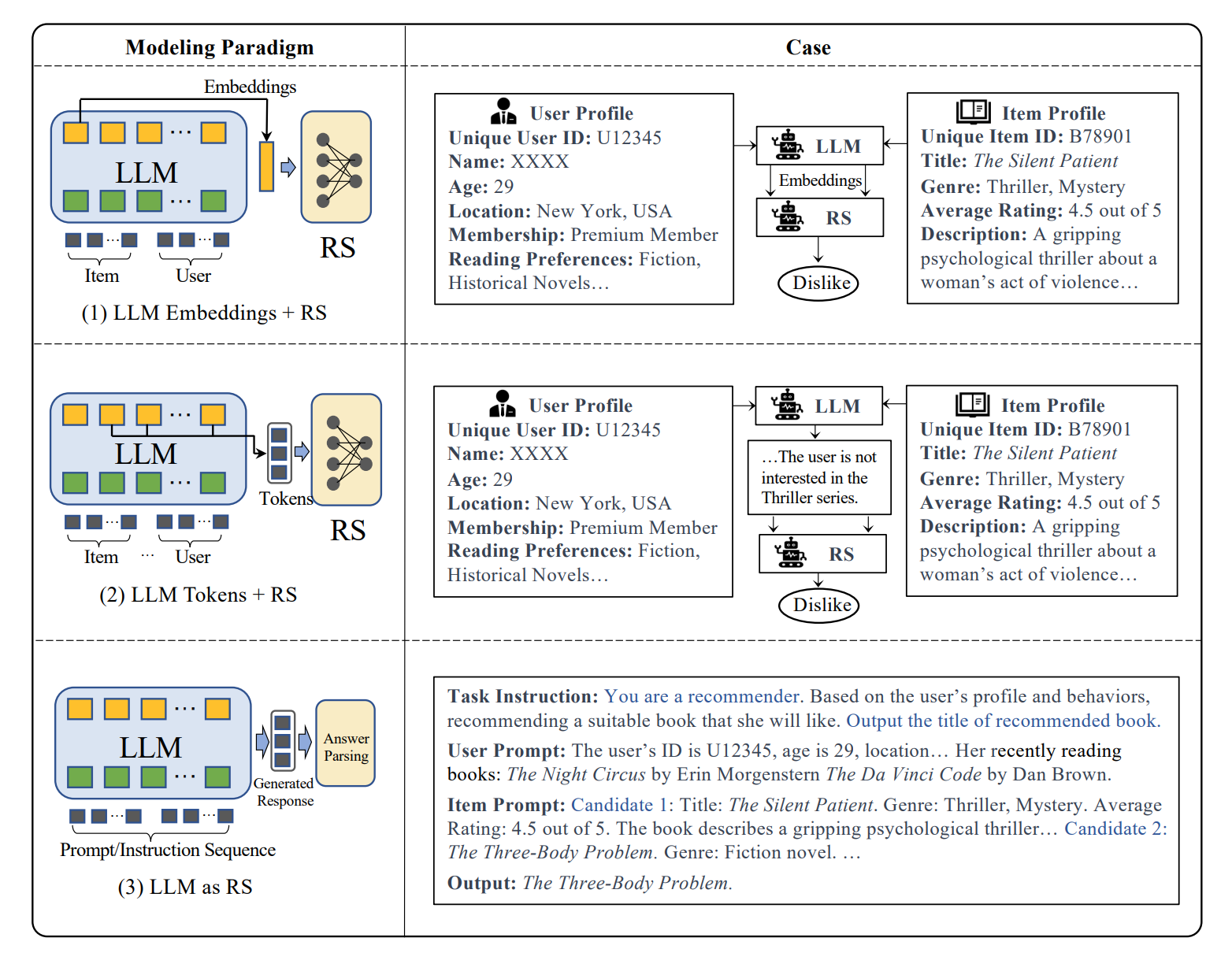 Figure 2:Three representative modeling paradigms of the research for large language models on recommendation systems.
Figure 2:Three representative modeling paradigms of the research for large language models on recommendation systems.
2. 모델링 패러다임과 분류
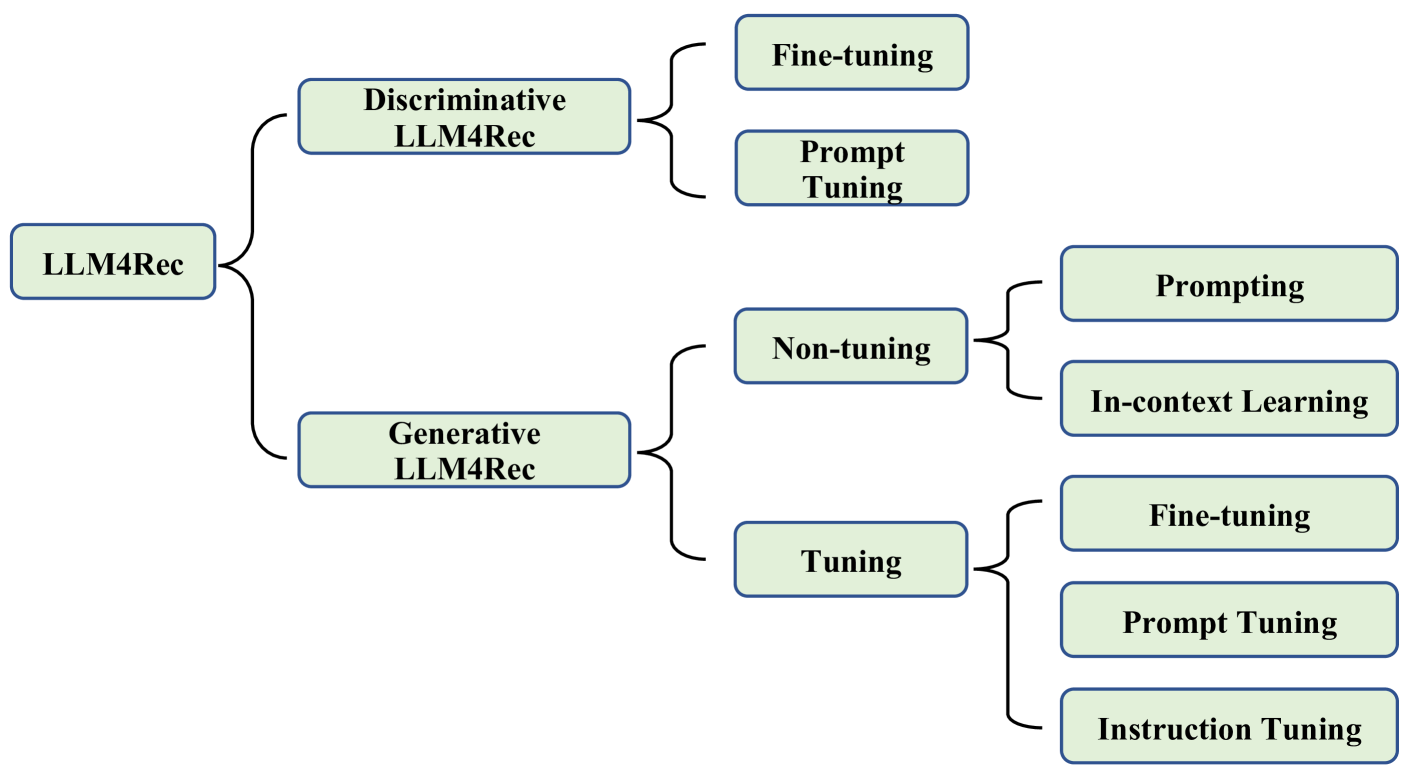 Figure 3:A taxonomy of the research for large language models on recommendation systems.
Figure 3:A taxonomy of the research for large language models on recommendation systems.
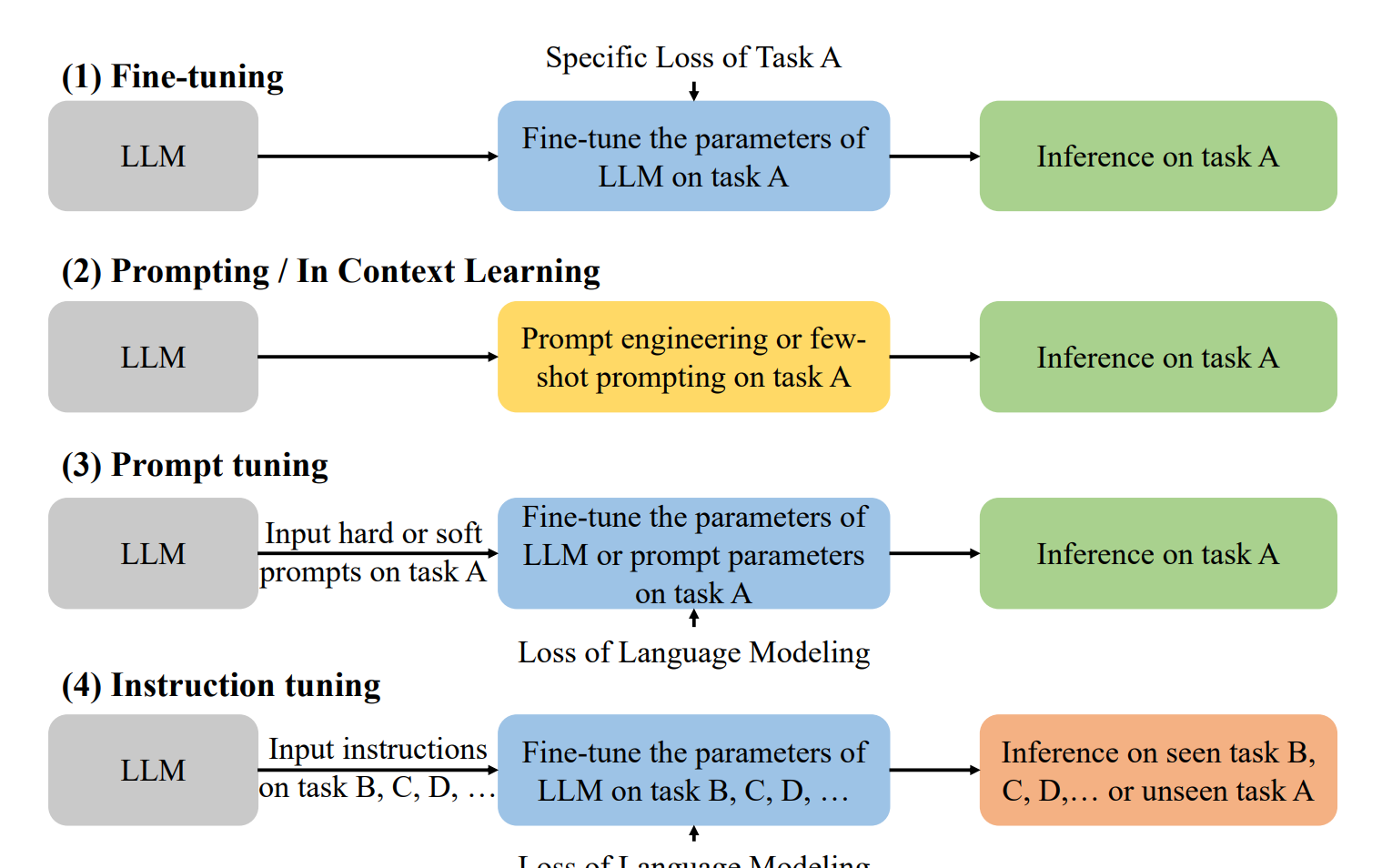 Figure 4:Detailed explanation of five different training (domain adaption) manners for LLM-based recommendations.
Figure 4:Detailed explanation of five different training (domain adaption) manners for LLM-based recommendations.
LLM 기반 추천 시스템의 모델링 패러다임은 크게 세 가지로 구분됩니다.
- LLM Embeddings + RS
- LLM을 특징 추출기로 활용
- 아이템과 사용자 특징을 LLM에 입력하여 고차원 임베딩 생성
- 생성된 지식 기반 임베딩을 전통적인 RS 모델의 입력으로 활용
- 장점: 풍부한 의미 정보 포착, 데이터 희소성 문제 완화
- LLM Tokens + RS
- 아이템과 사용자 특징을 기반으로 의미 있는 토큰 시퀀스 생성
- 생성된 토큰은 의미론적 마이닝을 통해 잠재적 선호도와 관계 포착
- 이를 추천 시스템의 의사결정 과정에 통합하여 정확도 향상
- 장점: 명시적인 특징 엔지니어링 감소, 자연어 형태의 유연한 입력 처리
- LLM as RS
- 사전 학습된 LLM을 직접 강력한 추천 시스템으로 전환
- 입력 시퀀스: 사용자 프로필 설명, 과거 행동 프롬프트, 추천 작업 지시 등으로 구성
- 출력 시퀀스: 자연어 형태의 합리적이고 설명 가능한 추천 결과 제공
- 장점: 높은 유연성, 0-shot/퓨샷 학습 가능, 설명 가능한 추천
이런 패러다임은 사용된 LLM의 특성에 따라 크게 두 가지 카테고리로 나눌 수 있습니다.
- Discriminative LLMs for Recommendation (DLLM4Rec)
- BERT 계열 모델 주로 활용
- 텍스트 이해와 특징 추출에 강점
- Generative LLMs for Recommendation (GLLM4Rec)
- GPT 계열 모델 주로 활용
- 텍스트 생성과 유연한 태스크 수행에 강점
각 카테고리는 학습 방식에 따라 더 세분화되며, 주요 학습 방식으로는 파인튜닝(fine-tuning), 프롬프트 튜닝(prompt tuning), 어댑터 튜닝(adapter tuning) 등이 있습니다.
3. Discriminative LLMs for Recommendation (DLLM4Rec)
DLLM4Rec은 주로 BERT 계열 모델을 활용하며, 텍스트 이해와 특징 추출에 강점을 가집니다. 주요 적용 방식은 다음과 같습니다.
3.1 파인튜닝 (Fine-tuning)
파인튜닝은 사전 학습된 언어 모델을 특정 추천 작업이나 도메인에 적응시키는 기술입니다.
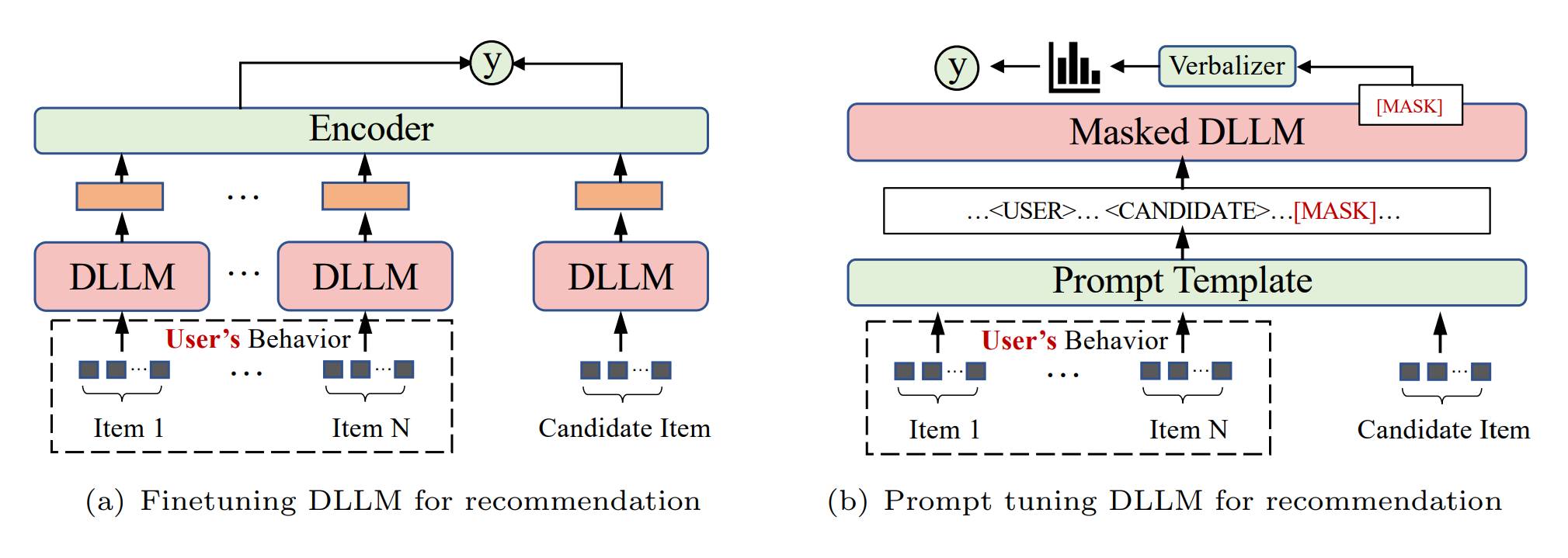 Figure 5:Discriminative LLMs for recommendation.
Figure 5:Discriminative LLMs for recommendation.
과정
- 사전 학습된 LLM의 파라미터로 초기화
- 추천 특화 데이터셋(e.g., 사용자-아이템 상호작용, 아이템 설명 등)으로 추가 학습
- 작업 특화 데이터를 기반으로 모델 파라미터 점진적 업데이트
주요 연구 및 방법
- U-BERT [14]
- 사용자 representation 학습을 위한 새로운 사전 학습 및 파인튜닝 접근 방식
- 콘텐츠가 풍부한 도메인의 정보를 활용하여 행동 데이터가 부족한 사용자의 특징 보완
- 리뷰 co-matching 레이어를 통해 사용자와 아이템 리뷰 간 암묵적 의미 상호작용 포착
- UserBERT [15]
- 자기 지도 학습 작업을 통한 사용자 모델링 강화
- 중간 난이도의 대조 학습, 마스크된 행동 예측, 행동 시퀀스 매칭 등의 기법 활용
- 사용자의 내재적 관심사와 연관성을 포착하여 정확한 사용자 representation 학습
- BECR [16]
- 깊은 문맥적 토큰 상호작용과 전통적 어휘 용어 매칭 특징을 결합한 경량 재순위 체계
- 복합 토큰 인코딩을 통해 쿼리 representation을 유니그램 및 스킵-n-그램 기반의 사전 계산 가능한 토큰 임베딩으로 근사
- ad-hoc 랭킹의 관련성과 효율성 사이의 합리적인 트레이드오프 달성
이외에도 다양한 특수 상황에 대한 연구가 진행되었습니다.
- 그룹 추천 [19]
- 검색/매칭 [20]
- CTR 예측 [21]
- 순차적/세션 기반 추천 (BERT4Rec [22], RESETBERT4Rec [23])
3.2 프롬프트 튜닝 (Prompt Tuning)
프롬프트 튜닝은 하드/소프트 프롬프트와 레이블 단어 verbalizer를 사용하여 추천 튜닝의 목표를 사전 학습된 손실과 정렬시키는 방법입니다.
주요 특징
- DLLM의 마스크 기반 학습을 활용
- Verbalizer를 통해 DLLM의 [MASK] 위치 예측 단어와 실제 레이블 간 매핑 설정
- 언어 모델과 추천 작업 간의 연결 확립
주요 연구 및 방법
- [35]
- BERT의 Masked Language Modeling (MLM) 헤드를 활용한 아이템 장르 이해
- cloze-style 프롬프트를 통해 BERT의 아이템 장르 이해도 파악
- BERT의 Next Sentence Prediction (NSP) 헤드와 representation 유사도(SIM)를 활용하여 관련/비관련 검색 및 추천 쿼리-문서 입력 비교
- 파인튜닝 없이도 BERT가 랭킹 과정에서 관련 아이템 우선순위 지정 가능성 확인
- [36]
- 프롬프트를 활용한 대화형 추천 시스템 개발
- BERT 기반 아이템 인코더를 통해 각 아이템의 메타데이터를 직접 임베딩으로 매핑
- Prompt4NR [38]
- 뉴스 추천을 위한 프롬프트 학습 패러다임 적용
- 후보 뉴스에 대한 사용자 클릭 예측 목표를 cloze-style 마스크 예측 작업으로 재정의
- 다중 프롬프트 앙상블링을 통한 성능 향상 확인
- 이산 및 연속 템플릿에서 단일 프롬프트 대비 우수한 결과 달성
결론적으로, DLLM4Rec은 강력한 외부 지식과 개인화된 사용자 선호도를 효과적으로 융합하여 다음과 같은 이점을 제공합니다.
- 추천 정확도 향상 → 풍부한 텍스트 representation과 깊은 언어 이해를 통해 아이템-사용자 관계를 더 정확히 포착
- 콜드 스타트 문제 완화 → 제한된 역사적 데이터를 가진 새로운 아이템에 대해서도 텍스트 정보를 활용한 추천 가능
- 설명 가능성 증대 → 언어 모델의 특성을 활용하여 추천 결과에 대한 자연어 설명 생성 가능
4. Generative LLMs for Recommendation
생성형 대규모 언어모델(Generative Large Language Models, GLLMs)은 판별형 모델에 비해 자연어 생성 능력이 뛰어납니다. 이런 특성으로 인해 GLLM 기반 접근 방식은 추천 작업을 자연어 작업으로 변환하여 직접 추천 결과를 생성하는 방식을 취합니다. 주요 적용 기법으로는 문맥 내 학습(in-context learning), 프롬프트 튜닝(prompt tuning), 명령어 튜닝(instruction tuning) 등이 있습니다.
GLLM 기반 접근 방식은 크게 두 가지 패러다임으로 나눌 수 있습니다.
- 비튜닝 패러다임 (Non-tuning Paradigm)
- 튜닝 패러다임 (Tuning Paradigm)
4.1 비튜닝 패러다임
이 패러다임은 LLM이 이미 추천 능력을 갖추고 있다고 가정하고, 특정 프롬프트를 통해 이 능력을 끌어내는 방식입니다. 주로 두 가지 접근 방식이 있습니다.
4.1.1 프롬프팅 (Prompting)
프롬프팅은 LLM이 추천 작업을 더 잘 이해하고 해결할 수 있도록 적절한 지시와 프롬프트를 설계하는 방법입니다.
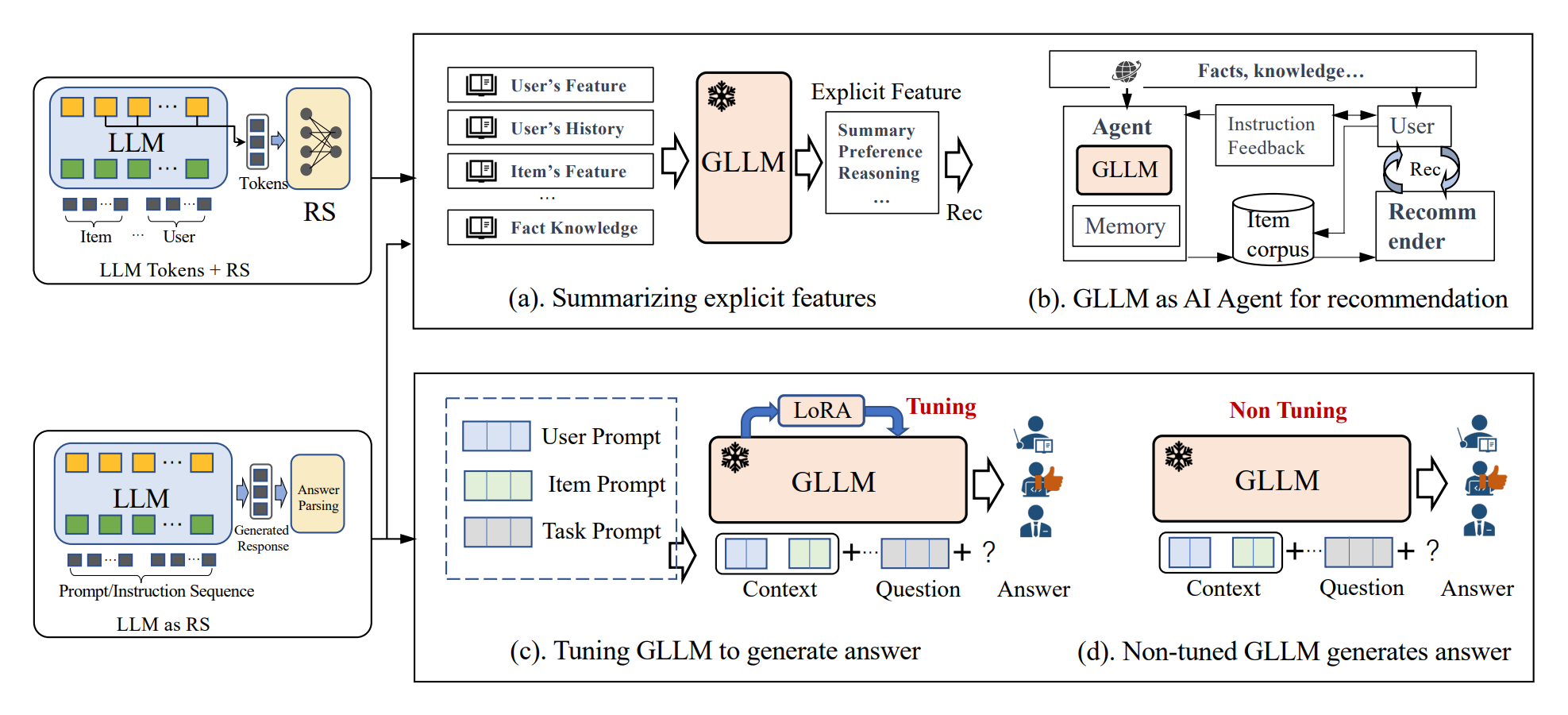 Figure 6:Generative LLMs for recommendation.
Figure 6:Generative LLMs for recommendation.
주요 연구
- [41] : 5가지 일반적인 추천 작업에 대한 ChatGPT의 성능을 평가하고, 일반적인 추천 프롬프트 구성 프레임워크를 제안
- [42] : ChatGPT의 추천 능력을 3가지 일반적인 정보 검색 작업에 대해 경험적으로 분석
- [44] : 다양한 프롬프트 입력의 효과를 평가하기 위해 세 가지 프롬프트 템플릿을 설계
- MINT [45] : 사용자의 상호작용 데이터를 기반으로 의도를 요약하는 프롬프트를 사용
- KAR [46] : 분해 프롬프팅(factorization prompting)을 도입하여 사용자 선호도와 사실적 지식에 대한 정확한 인퍼런스를 유도
4.1.2 문맥 내 학습 (In-context Learning)
문맥 내 학습은 프롬프트에 데모 예제를 추가하여 LLM이 추천 작업을 더 잘 이해하도록 하는 기법입니다.
주요 연구
- [47] : 입력 상호작용 시퀀스 자체를 증강하여 데모 예제를 도입
- [74] : 지시 형식, 작업 일관성, 데모 선택, 데모 수의 영향을 조사
- [41], [42] : 다양한 추천 작업에 대한 데모 예제 템플릿을 설계
4.2 튜닝 패러다임
이 패러다임은 LLM의 추천 능력을 더욱 향상시키기 위해 추가적인 파인튜닝이나 프롬프트 학습을 수행합니다. 크게 세 가지 유형으로 나눌 수 있습니다.
4.2.1 파인튜닝 (Fine-tuning)
LLM을 사용자나 아이템의 representation을 추출하는 인코더로 활용하고, downstream 추천 작업의 특정 손실 함수로 파라미터를 파인튜닝합니다.
주요 연구
- GPTRec [77] : GPT-2 기반의 생성적 순차 추천 모델
- [78] : 사용자 히스토리를 프롬프트로 포맷하고 평점 예측 작업을 다중 분류와 회귀로 공식화
- [32] : GPT-3와 같은 대규모 LLM의 텍스트 기반 협업 필터링에 대한 영향 연구
4.2.2 프롬프트 튜닝 (Prompt Tuning)
LLM이 사용자/아이템 정보를 입력으로 받아 사용자 선호도나 관심 아이템을 출력하도록 합니다.
주요 연구
- TALLRec [79] : 자기 지시 데이터로 사전 파인튜닝 후 추천 튜닝 수행
- GenRec [81] : 생성형 LLM의 생성 능력을 활용해 직접 추천할 대상 아이템 생성
- [82] : LLM을 활용한 다단계 접근 방식 제안 (사용자 선호도 요약 → 검색 모듈 → 최종 추천)
- PBNR [87] : 사용자 행동과 뉴스를 텍스트로 설명하는 개인화된 프롬프트 설계
- UniCRS [90] : 지식 강화 프롬프트 학습 기반의 통합 대화형 추천 시스템
4.2.3 명령어 튜닝 (Instruction Tuning)
다양한 유형의 지시를 사용하여 여러 작업에 대해 LLM을 파인튜닝합니다. 이를 통해 휴먼의 의도와 더 잘 정렬되고 더 나은 0-shot 능력을 얻을 수 있습니다.
주요 연구
- [2] : T5 모델을 5가지 다른 유형의 지시에 대해 파인튜닝
- [103] : M6 모델을 3가지 유형의 작업에 대해 파인튜닝
- [104] : 일반적인 지시 형식을 설계하고 39개의 지시 템플릿을 수동으로 설계
- [105] : Meituan 데이터셋에서 이질적 지식을 추출하고 프롬프트 엔지니어링을 통해 행동 텍스트 구성
- [106] : 특정 작업에 대한 이산 프롬프트를 연속적인 프롬프트 벡터 세트로 증류하여 ID와 단어 연결
결론적으로, 생성형 LLM을 활용한 추천 시스템은 자연어 생성 능력과 0-shot/퓨샷 학습 능력을 활용하여 더욱 유연하고 개인화된 추천을 제공할 수 있습니다. 비튜닝 패러다임은 비용 효율적이고 실용적인 접근 방식을 제공하는 반면, 튜닝 패러다임은 더 높은 성능과 작업 특화된 능력을 얻을 수 있습니다. 향후 연구에서는 더 효과적인 프롬프트 설계, 다중 작업 학습, 그리고 LLM과 전통적인 추천 모델의 결합 등이 주요 과제가 될 것으로 예상됩니다.
| Adaption | Paper | Base Model | Recommendation Task | Modeling Paradigm |
|---|---|---|---|---|
| Discriminative LLMs for Recommendation | ||||
| Fine-tuning | [28] | BERT/UniLM | News Recommendation | LLM Embeddings + RS |
| [14] | BERT | User Representation | LLM Embeddings + RS | |
| [19] | BERT | Group Recommendation | LLM as RS | |
| [20] | BERT | Search/Matching | LLM Embeddings + RS | |
| [21] | BERT | CTR Prediction | LLM Embeddings + RS | |
| [108] | BERT/RoBERTa | Conversational RS | LLM Embeddings + RS | |
| Prompt Tuning | [38] | BERT | Sequential Recommendation | LLM as RS |
| [36] | DistilBERT/GPT-2 | Conversational RS | LLM as RS | |
| [37] | BERT | Conversational RS | LLM Embeddings + RS | |
| [35] | BERT | Conversational RS | LLM as RS | |
| Generative LLMs for Recommendation | ||||
| Non-tuning | [58] | ChatGPT | News Recommendation | LLM Tokens + RS |
| [90] | DialoGPT/RoBERTa | Converational RS | LLM Tokens + RS / LLM as RS | |
| [4] | GPT-2 | Sequential Recommendation | LLM as RS | |
| [56] | GPT-3.5 | Sequential Recommendation | LLM Tokens + RS / LLM as RS | |
| [6] | ChatGPT/GPT-3.5 | Sequential Recommendation | LLM as RS | |
| [68] | ChatGPT | Generative Recommendation | LLM as RS | |
| [47] | ChatGPT | Sequential Recommendation | LLM as RS | |
| [48] | ChatGPT/GPT-3.5 | Passage Reranking | LLM as RS | |
| [109] | T5/GPT-3.5/GPT-4 | Passage Reranking | LLM as RS | |
| [41] | ChatGPT | Five Tasks | LLM as RS | |
| [42] | ChatGPT/GPT-3.5 | Sequential Recommendation | LLM as RS | |
| [46] | ChatGLM | CTR Prediction | LLM Tokens + RS | |
| [70] | ChatGPT | Recommendation Agent | LLM Tokens + RS | |
| [71] | ChatGPT | Recommendation Agent | LLM Tokens + RS | |
| Tuning | [104] | FLAN-T5 | Three Tasks | LLM as RS |
| [78] | FLAN-T5/ChatGPT | Rating Prediction | LLM as RS | |
| [79] | LLaMA-7B | Movie/Book RS | LLM as RS | |
| [7] | GPT-2 | Explainable RS | LLM as RS | |
| [2] | T5 | Five Tasks | LLM as RS | |
| [103] | M6 | Five Tasks | LLM as RS | |
| [91] | BART/LLaMA | Text-based/Sequential Recommendation | LLM as RS | |
| [101] | BELLE | Job Recommendation | LLM as RS | |
| [100] | BELLE | Generative Recommendation | LLM Tokens +RS | |
| [110] | UniTRecAU | Text-based Recommendation | LLM as RS | |
| [92] | LLaMA-7B | Movie/Game RS | LLM as RS | |
| [32] | OPT | Text-based Recommendation | LLM Embeddings +RS | |
| [106] | T5-small | Three Tasks | LLM as RS | |
| [111] | RoBERTa/GLM | CTR Prediction | LLM Embeddings +RS |
| 적응 방식 | 논문 | 기본 모델 | 추천 작업 | 모델링 패러다임 |
|---|---|---|---|---|
| 판별적 LLM (Discriminative LLMs) | ||||
| 파인튜닝 | [28] | BERT/UniLM | 뉴스 추천 | LLM Embeddings + RS |
| [14] | BERT | 사용자 표현 | LLM Embeddings + RS | |
| [19] | BERT | 그룹 추천 | LLM as RS | |
| [20] | BERT | 검색/매칭 | LLM Embeddings + RS | |
| [21] | BERT | CTR 예측 | LLM Embeddings + RS | |
| [108] | BERT/RoBERTa | 대화형 RS | LLM Embeddings + RS | |
| 프롬프트 튜닝 | [38] | BERT | 순차 추천 | LLM as RS |
| [36] | DistilBERT/GPT-2 | 대화형 RS | LLM as RS | |
| [37] | BERT | 대화형 RS | LLM Embeddings + RS | |
| [35] | BERT | 대화형 RS | LLM as RS | |
| 생성적 LLM (Generative LLMs) | ||||
| 비튜닝 | [58] | ChatGPT | 뉴스 추천 | LLM Tokens + RS |
| [90] | DialoGPT/RoBERTa | 대화형 RS | LLM Tokens + RS / LLM as RS | |
| [4] | GPT-2 | 순차 추천 | LLM as RS | |
| [56] | GPT-3.5 | 순차 추천 | LLM Tokens + RS / LLM as RS | |
| [6] | ChatGPT/GPT-3.5 | 순차 추천 | LLM as RS | |
| [68] | ChatGPT | 생성적 추천 | LLM as RS | |
| [47] | ChatGPT | 순차 추천 | LLM as RS | |
| [48] | ChatGPT/GPT-3.5 | 문단 재순위화 | LLM as RS | |
| [109] | T5/GPT-3.5/GPT-4 | 문단 재순위화 | LLM as RS | |
| [41] | ChatGPT | 5가지 작업 | LLM as RS | |
| [42] | ChatGPT/GPT-3.5 | 순차 추천 | LLM as RS | |
| [46] | ChatGLM | CTR 예측 | LLM Tokens + RS | |
| [70] | ChatGPT | 추천 에이전트 | LLM Tokens + RS | |
| [71] | ChatGPT | 추천 에이전트 | LLM Tokens + RS | |
| 튜닝 | [104] | FLAN-T5 | 3가지 작업 | LLM as RS |
| [78] | FLAN-T5/ChatGPT | 평점 예측 | LLM as RS | |
| [79] | LLaMA-7B | 영화/책 RS | LLM as RS | |
| [7] | GPT-2 | 설명 가능한 RS | LLM as RS | |
| [2] | T5 | 5가지 작업 | LLM as RS | |
| [103] | M6 | 5가지 작업 | LLM as RS | |
| [91] | BART/LLaMA | 텍스트 기반/순차 추천 | LLM as RS | |
| [101] | BELLE | 직업 추천 | LLM as RS | |
| [100] | BELLE | 생성적 추천 | LLM Tokens + RS | |
| [110] | UniTRecAU | 텍스트 기반 추천 | LLM as RS | |
| [92] | LLaMA-7B | 영화/게임 RS | LLM as RS | |
| [32] | OPT | 텍스트 기반 추천 | LLM Embeddings + RS | |
| [106] | T5-small | 3가지 작업 | LLM as RS | |
| [111] | RoBERTa/GLM | CTR 예측 | LLM Embeddings + RS |
5. 주요 발견 사항
이 조사에서는 대규모 언어모델, 특히 생성형 언어 모델의 추천 시스템 적용 패러다임과 적응 전략을 체계적으로 검토하고, 특정 작업에서 전통적인 추천 모델의 성능을 향상시킬 수 있는 잠재력을 확인했습니다. 그러나 이 분야의 전반적인 탐구는 아직 초기 단계에 있음을 주목해야 합니다. 연구자들은 가장 가치 있는 문제점과 해결해야 할 과제를 결정하는 데 어려움을 겪을 수 있으며 이를 해결하기 위해, 대규모 모델 추천에 관한 수많은 연구에서 제시된 공통적인 발견 사항을 요약했습니다.
Figure 7에서 볼 수 있듯이, 이런 발견은 특정 기술적 과제를 강조하고 이 분야의 추가 발전을 위한 잠재적 기회를 제시합니다.
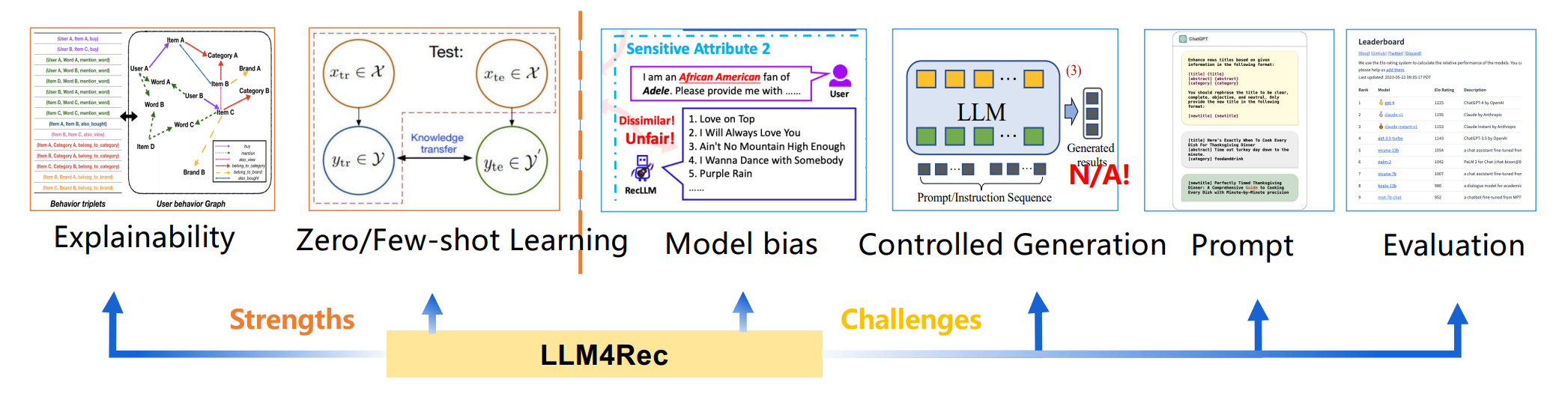 Fig 7: The major strengths and technical challenges of LLM4Rec.
Fig 7: The major strengths and technical challenges of LLM4Rec.
| Name | Scene | Tasks | Information | URL |
|---|---|---|---|---|
| Amazon Review [112] | Commerce | Seq Rec / CF Rec | 8283만 평점, 2098만 사용자, 935만 아이템 (1996년 5월 - 2014년 7월) | 링크 |
| Amazon-M2 [85] | Commerce | Seq Rec / CF Rec | 360만 학습 세션, 36만 테스트 세션, 141만 제품 | 링크 |
| Amazon Review 2023 [113] | Commerce | Seq Rec / CF Rec | 5.7억 리뷰, 4800만 아이템, 33개 카테고리 | 링크 |
| Steam [114] | Game | Seq Rec / CF Rec | 779만 리뷰, 257만 사용자, 1.5만 아이템 | 링크 |
| MovieLens | Movie | General | 영화 평점 및 태깅 활동 | 링크 |
| Yelp | Commerce | General | 699만 리뷰, 15만 비즈니스, 20만 사진 | 링크 |
| Douban [115] | Movie, Music, Book | Seq Rec / CF Rec | 영화, 음악, 책 도메인의 평점, 리뷰, 아이템 정보 등 | 링크 |
| MIND [116] | News | General | 16만 영어 뉴스 기사, 1500만 임프레션 로그 | 링크 |
| U-NEED [117] | Commerce | Conversation Rec | 7,698 주석 처리된 대화, 33만 사용자 행동, 33만 제품 지식 | 링크 |
| KuaiSAR [118] | Video | Search and Rec | 2.6만 사용자, 689만 아이템, 45만 쿼리, 1966만 액션 | 링크 |
| Tenrec [119] | Video, Article | General | 500만 사용자, 1.4억 상호작용 | 링크 |
| PixelRec [120] | Video | Seq Rec / CF Rec | 2억 사용자-이미지 상호작용, 3000만 사용자, 40만 커버 이미지 | 링크 |
5.1 모델 편향
위치 편향, 인기도 편향, 공정성 편향, 개인화 편향 등 다양한 유형의 편향이 LLM 기반 추천 시스템에 존재합니다. 이런 편향들은 추천 결과의 품질과 다양성에 영향을 미치며, 이를 해결하기 위한 추가 연구가 필요합니다.
5.2 추천 프롬프트 설계
사용자/아이템 representation, 제한된 컨텍스트 길이 등의 문제가 LLM 기반 추천 시스템의 성능에 영향을 미칩니다. 이런 문제들을 해결하기 위한 다양한 기법들이 제안되고 있지만, 여전히 개선의 여지가 있습니다.
5.3 유망한 능력
제로/퓨샷 추천 능력과 설명 가능한 능력은 LLM의 주목할 만한 특성입니다. 이런 능력들은 콜드 스타트 문제 해결과 투명한 추천 시스템 구축에 큰 잠재력을 보여줍니다.
5.4 평가 문제
생성 제어, 평가 기준, 데이터셋 등의 문제는 LLM 기반 추천 시스템의 평가와 관련된 주요 과제입니다. 특히 생성형 추천 작업에 대한 적절한 평가 방법과 벤치마크 개발이 필요합니다.
6. 결론
이 논문에서는 추천 시스템을 위한 대규모 언어모델(LLMs)의 연구 분야를 검토했습니다. 기존 연구를 판별 모델과 생성 모델로 분류하고, 도메인 적응 방식에 따라 자세히 설명했습니다. 개념적 혼란을 방지하기 위해 LLM 기반 추천에서의 파인튜닝, 프롬프팅, 프롬프트 튜닝, 명령어 튜닝의 정의와 구별을 제공했습니다. 아는 한, 이 조사는 추천 시스템을 위한 생성형 LLM에 특화된 최초의 체계적이고 최신 리뷰로, 수많은 관련 연구에서 제시된 공통적인 발견과 과제를 요약했습니다.
미래를 전망해보면, 컴퓨팅 능력이 계속 발전하고 인공지능 영역이 확장됨에 따라 추천 시스템에서 LLM의 더욱 정교한 응용이 예상됩니다. 이런 모델의 적응성과 정확성이 더 다양한 영역에서 활용되어, 멀티모달 입력을 고려한 실시간 개인화 추천으로 이어질 수 있는 유망한 지평이 열릴 것입니다. 또한 윤리적 고려사항이 중요해짐에 따라, 미래의 LLM 기반 추천 시스템은 공정성, 책임성, 투명성을 더욱 본질적으로 통합할 수 있을 것입니다.
결론적으로, 추천 시스템에서 LLM을 이해하고 구현하는 데 상당한 진전을 이루었지만, 앞으로의 여정은 혁신과 개선의 기회로 가득 차 있습니다. 조사가 이 역동적이고 끊임없이 진화하는 분야에서 다음 발견의 물결을 위한 기초적인 디딤돌 역할을 하기를 바랍니다.
주요 포인트
- LLM 기반 추천 시스템의 연구를 판별 모델과 생성 모델로 분류하여 체계적으로 검토
- 파인튜닝, 프롬프팅, 프롬프트 튜닝, 명령어 튜닝 등 주요 기법의 정의와 구별 제공
- 생성형 LLM을 위한 최초의 체계적이고 최신 리뷰 제공
- 공통적인 발견과 과제 요약
- 미래 전망: 더 정교한 LLM 응용, 멀티모달 입력 고려, 윤리적 고려사항 통합
- 혁신과 개선의 기회가 풍부한 분야로 인식