Speculative Diffusion Decoding
- Related Project: Private
- Category: Paper Review
- Date: 2024-08-10
Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion
- url: https://arxiv.org/abs/2408.05636
- pdf: https://arxiv.org/pdf/2408.05636
- html: https://arxiv.org/html/2408.05636v1
- abstract: Speculative decoding has emerged as a widely adopted method to accelerate large language model inference without sacrificing the quality of the model outputs. While this technique has facilitated notable speed improvements by enabling parallel sequence verification, its efficiency remains inherently limited by the reliance on incremental token generation in existing draft models. To overcome this limitation, this paper proposes an adaptation of speculative decoding which uses discrete diffusion models to generate draft sequences. This allows parallelization of both the drafting and verification steps, providing significant speed-ups to the inference process. Our proposed approach, $\textit{Speculative Diffusion Decoding (SpecDiff)}$, is validated on standard language generation benchmarks and empirically demonstrated to provide a $\textbf{up to 8.7x speed-up over standard generation processes and up to 2.5x speed-up over existing speculative decoding approaches.}$
TL;DR
- 본 연구에서는 언어 생성 작업을 위해 스페큘러티브 디코딩 방법을 사용하며, 이는 두 개의 언어 모델 \(M_p\)와 \(M_q\)를 병렬적으로 활용하여 토큰 생성 속도를 향상시킨다.
- 기존의 연속적 토큰 샘플링 대신 전체 시퀀스를 병렬로 생성하는 디퓨전 언어 모델을 사용하여 인퍼런스 시간을 크게 단축시킨다.
- 디퓨전 기반 모델 \(M_q\)는 고효율의 토큰 생성을 가능하게 하며, \(M_p\)는 이를 검증하여 최종 토큰을 선택하는 SpecDiff 디코딩 프로세스를 개발
구현 참고 GitHub https://github.com/lucidrains/speculative-decoding
트랜스포머의 인퍼런스 비효율성을 해결하기위해 Mamba와 비슷하게 더 유망하게 검토되어야 할 아키텍처이지 않을까… 결국 새로운 트랜스포머는 Diffusion 모델과의 결합이 유력하지 않을까…라고 상상을 해보며…
핵심 아이디어: 자기 회귀 모델보다 훨씬 빠른 디퓨전 모델을 통한 초안 생성
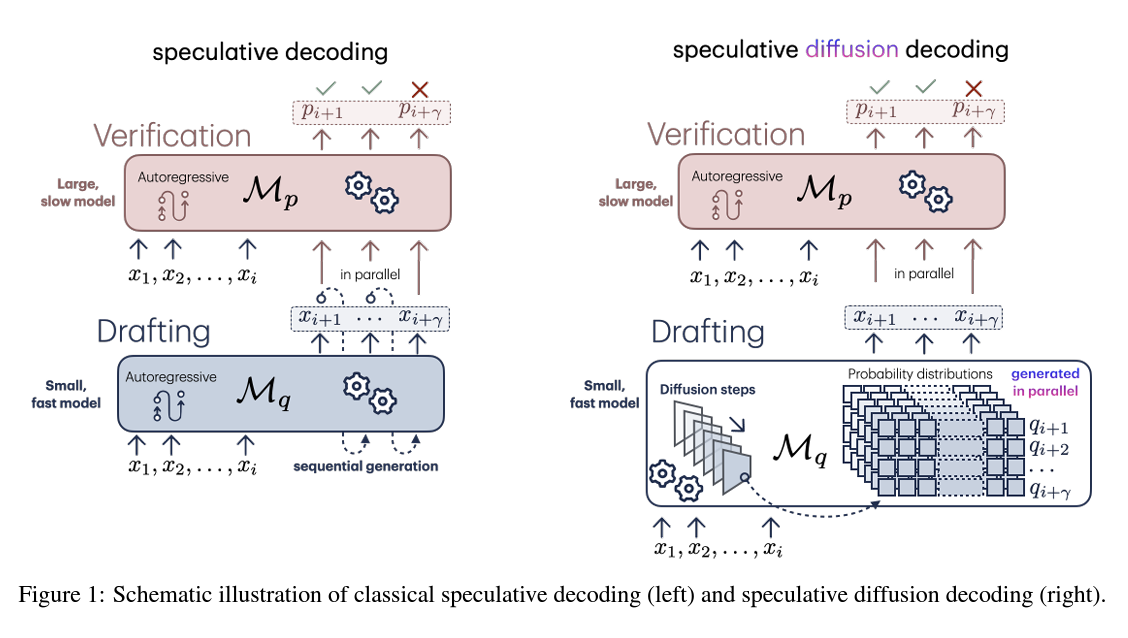
Speculative Decoding은 간단히 말해 “초안 후 검증(draft-then-verify)” 접근 방식으로, 우선 \(M_q\)로 후보 토큰 시퀀스를 생성한 뒤 \(M_p\)는 이를 병렬로 검증해 토큰 생성의 순차적 의존성을 완화하고, 병렬 처리를 통해 속도를 향상시키기 위한 아키텍처입니다.
- \(M_p\): 원래의 목표 모델로, 생성하고자 하는 최종 토큰의 분포 \(p(x)\)를 계산
- \(M_q\): 보다 작은 드래프터(drafter) 모델로, 목표 모델의 분포를 근사하여 \(q(x)\)를 계산
드래프터 모델 \(M_q\)에 의해 병렬로 빠르게 초안 생성 → 목표 모델 \(M_p\)에 의한 검증 → 토큰 검증 후 폐기 or 수용
최근 중요하게 연구되고 있는 인퍼런스 패스에서 토큰 레벨의 오류 발생 시 퀄리티가 크게 달라지는만큼 드래프터 모델 혹은 검증 모델이 퀄리티 컨트롤을 하게 하면서 동시에 레이턴시에서 손실을 최소화할 수 있는 방안에서의 연구
- 초안 생성: Diffusion Model \(M_q\)는 T 단계에 걸쳐 노이즈를 제거하며 토큰 시퀀스 \(\{x_{i+1}, ..., x_{i+γ}\}\)를 생성 \(\{q_{i+1}, ..., q_{i+γ}\}^T \sim \mathcal{N}(0, \sigma_T I)\) 이후 각 단계에서 시퀀스는 점차 정제되며 최종적으로 확률 분포 \(q_0\)에 수렴
- 병렬 검증: 목표 모델 \(M_p\)는 병렬로 해당 시퀀스를 검증하며 \(p(x)\)를 계산하고,
- 토큰 승인: 앞서 설명한 방식대로, 토큰 승인 여부를 결정
- 토큰 조정: 필요에 따라 목표 모델의 분포 \(p(x)\)를 조정하여 최종 토큰을 선택
본 포스트 맨 밑에 참고자료 확인
1. 서론
트랜스포머 기반 언어 모델이 확장됨에 따라 성능이 향상되고 새로운 기능이 등장하고 있습니다. 이런 대규모 언어모델(LLM)은 코드 생성, 질문 응답, 요약 등 다양한 용도로 널리 사용되고 있습니다. 하지만 이런 모델을 대규모로 운영하는 것은 상당한 전기, 시간 및 금전적 비용을 수반합니다. 여러 절감 방법이 있지만, 이들은 종종 모델 성능 저하와 같은 새로운 문제를 일으킵니다. 이와 달리, 추측 디코딩(speculative decoding) 방법은 모델의 출력 품질을 저하시키지 않으면서도 효율을 2-3배 향상시킬 수 있는 방법으로, 이 방법은 작고 효율적인 드래프트 모델을 사용하여 여러 토큰을 순차적으로 생성한 후, 타겟 LLM이 동시에 모든 드래프트된 토큰을 평가하여 일관성을 검사합니다.
2. 관련 연구
자기 회귀 언어 모델은 언어 생성 작업에서 최고의 성능을 제공하지만, 증분 디코딩은 인퍼런스 시간에 상당한 오버헤드를 발생시킵니다. 이는 토큰 생성 과정이 순차적이기 때문에 병렬 처리가 어렵습니다. 최근 연구에서는 토큰 생성을 병렬화하는 디코딩 구현과 전체 시퀀스를 동시에 생성할 수 있는 비자기 회귀 언어 모델에 대해 탐구하고 있습니다. 추측 디코딩은 작은 자기 회귀 모델을 사용하여 원본 모델이 검증할 후보 시퀀스를 예측하는 방법으로, 이를 통해 메모리 관련 제약을 극복하고 여러 병렬화 기술을 도입하여 드래프팅 과정을 개선하고 있습니다.
비자기 회귀 언어 모델은 전체 시퀀스를 동시에 생성하여 생성 속도를 높일 수 있습니다. 최근에는 확산 언어 모델이 등장하여 토큰 시퀀스를 동시에 생성하는 효율성을 더욱 향상시키고 있습니다. 이런 모델은 언어 생성을 임베딩 공간 또는 생성된 토큰의 확률 분포를 통해 확산 과정으로 재구성합니다.
본 논문의 기여는 다음과 같습니다.
- 새로운 통합 제안: 생성적 확산 언어 모델을 추측 디코딩과 통합하는 새로운 방법을 제안합니다. 이는 드래프트 모델이 타겟 모델에 의해 자주 수용될 때 효율적이며, 확산 모델은 여러 토큰을 동시에 생성할 수 있기 때문에 효율적입니다.
- 실증적 증명: 이 혼합 모델이 인퍼런스 시간을 크게 단축시키면서도 원본 대규모 언어모델의 높은 품질 출력을 유지할 수 있음을 실증적으로 보여줍니다.
- 출력 일치 보장: 확산 언어 모델이 생성하는 모든 생성물이 더 크고 계산 요구가 높은 모델이 생성하는 출력과 일치하도록 합니다.
- 새로운 벤치마크 설정: CNN/DM 및 OpenWebText 데이터셋에서 언어 완성 작업에 대한 속도에 대한 새로운 벤치마크를 설정합니다.
이런 기여를 통해 이 연구는 확산 모델이 인퍼런스 시간을 대폭 단축시키면서도 자기 회귀 모델과 비교하여 표준 언어 메트릭에서 눈에 띄게 높은 복잡도를 보이지 않을 때, 이 모델들의 속도를 활용할 수 있는 방법을 처음으로 보여줍니다.
3. 기초 설정과 목표
본 연구는 토큰 생성을 위한 조건부 분포 \(p(x_{i+1} \mid x_1, ..., x_i)\)를 이용하여 주어진 토큰 시퀀스 \(x_1, x_2, ..., x_i\)로부터 다음 \(n\)개의 토큰 \(x_{i+1}, ..., x_{i+n}\)을 생성하는 작업에 집중합니다. 이 과정에서, 스페큘러티브 디코딩은 두 개의 언어 모델 \(M_p\)와 \(M_q\)를 활용하여 토큰 생성을 병렬화합니다. \(M_q\)는 더 작고 효율적인 모델로, \(M_p\)의 분포를 근사하며, 이렇게 생성된 토큰 시퀀스는 \(M_p\)에 의해 검증됩니다.
4. 스페큘러티브 디퓨전 모델
스페큘러티브 디코딩은 언어 생성의 인퍼런스 시간을 개선하였으나, 하이퍼파라미터의 파인튜닝이 필요합니다. 특히, \(\gamma\)의 길이는 속도 향상과 성능을 극대화하기 위해 적절히 조정되어야 합니다. 디퓨전 언어 모델은 토큰 시퀀스를 연속적으로 샘플링하는 대신 전체 시퀀스를 병렬로 생성함으로써 유사한 크기의 자기회귀 모델보다 훨씬 빠른 속도를 제공합니다.
4.1 SpecDiff: 수식적 접근
디퓨전 모델을 사용한 언어 모델링에서는, 이산적인 디퓨전 과정을 통해 조합적 출력 공간에 맞는 시퀀스를 생성합니다. 이 과정에서 Lou 등은 점수 엔트로피 손실 \(\text{Score Entropy Loss}\)을 사용하여 디퓨전 모델을 학습합니다.
\[\mathbb{E}_{x \sim p} \left[ \sum_{y \neq x} w_{xy} \left( s_\theta(x)_y - \frac{p(y)}{p(x)} \log s_\theta(x)_y + K\left(\frac{p(y)}{p(x)}\right) \right) \right]\]\(s_\theta(x)_y\)는 디퓨전 모델, \(w\)는 비음수 가중치 행렬, \(K(a) = a(\log a - 1)\)는 정규화 함수로 이 손실은 사전 학습 및 파인튜닝에 직접 사용됩니다. 출력 행렬은 가능한 토큰들의 조합을 greedy decoding으로 생성하며, 이는 최종적으로 각 draft 토큰이 수락될지 여부를 결정하는 데 사용됩니다.
이와 같은 방법을 통해 SpecDiff는 기존의 스페큘러티브 디코딩 접근 방식과는 다르게 더 높은 값을 \(\gamma\)로 확장할 수 있으며, 이는 전체적인 성능과 효율성을 높이는 데 기여합니다.
5. 실험
SpecDiff의 효율성을 검증하기 위해 텍스트 요약 및 일반 텍스트 생성을 포함한 벤치마크를 사용하여 실험을 진행하였습니다. 이 연구에서는 NVIDIA A100 시리즈 GPU(80GB)를 활용하고 CUDA 11.8을 이용하여 모든 평가가 이루어졌으며, FlashAttention을 사용하여 실험 성능을 최적화하였습니다.
5.1 실험 설정
설정
두 가지 표준 자연어 처리 작업인 텍스트 요약(CNN/DM 데이터셋 사용)과 텍스트 생성(OpenWebText 데이터셋에서 파인튜닝)에 대해 모델을 평가했습니다. 각 실험 설정에서 모델은 1024 토큰을 요청하는 확률적 디코딩 방식(temperature = 1)을 사용했습니다. 타겟 모델로는 GPT-2 XL(1.5B) 및 GPT-NEO(2.7B)를 사용하고, 드래프터 모델로는 SEDD-Absorbing Small(90M)을 파인튜닝하여 사용했습니다. 이 드래프터 모델은 기존 베이스라인 드래프터인 GPT-2(86M)와 비교 가능한 크기입니다.
평가 지표
Walltime speed-up 및 초안당 수용된 토큰 수(accepted tokens per draft)로 성능을 평가했습니다. \(\alpha\)는 수용된 토큰의 비율, \(\gamma\)는 생성된 토큰 시퀀스의 길이를 나타냅니다. 이 지표들은 SpecDiff가 사용하는 디퓨전 기반 드래프터를 사용할 때 \(\gamma\)의 연장에 따른 부담이 거의 없음을 실증적으로 보여주기 때문에 중요하며, 이 결과들은 Leviathan 등의 표준 자기회귀 디코딩 및 기존 스페큘러티브 디코딩 방법과 비교되었습니다.
5.2 결과 및 토론
성능 개선
SpecDiff를 사용하는 디퓨전 기반 드래프터 모델은 기존의 자기회귀 드래프터 모델과 비교하여, 테스트된 설정과 타겟 모델 아키텍처에서 표준 스페큘러티브 디코딩 방법을 크게 뛰어넘는 성능을 보여주었습니다. SpecDiff는 최대 8.7배까지 속도 향상을 달성했으며, 스페큘러티브 디코딩의 효율성을 2.5배 이상 증가시켰습니다.
구조적 차이점
기존의 스페큘러티브 디코딩 구현은 드래프터와 타겟 모델 간에 공통 아키텍처를 사용했지만, SpecDiff는 시퀀스 드래프팅을 위해 전혀 다른 아키텍처를 사용하는 데에도 강건함을 보였습니다. \(\gamma\)가 증가함에 따라 \(\alpha\)가 감소하였지만, 드래프트 시퀀스당 수용된 토큰 수는 여전히 크게 증가하였습니다. SpecDiff에서 사용된 \(\gamma\)의 큰 값은 디퓨전 언어 모델이 전체 시퀀스를 병렬로 생성하고, 자기회귀 모델과는 달리, 드래프터 기반의 시퀀스 길이를 증가시키는 데 부담이 거의 없다는 점을 강조합니다.
6. 향후 작업 및 제한사항
이 연구는 스페큘러티브 디코딩 문헌에 중요한 진전을 제시하지만, SpecDiff는 디퓨전 언어 모델과 자기회귀 모델의 통합을 기초로 더 많은 작업을 유도합니다. 현재 SpecDiff의 구현은 GPT-2 토크나이저를 사용하는 모델에 제한되어 있으며, 이를 더 큰 모델에 적용하면 표준 스페큘러티브 디코딩보다 더 큰 속도 향상을 달성할 수 있을 것입니다. 또한, 부분적으로 생성된 정보를 사용하는 것이 다양한 모달리티의 디퓨전 모델을 사용할 때 이미 효과적임을 보여주었지만, 이 연구는 거부된 토큰의 로짓으로 드래프터 모델을 핫-스타트하는 개선을 완벽하게 실현하지는 못했습니다.
7. 결론
이 논문은 현재 대규모 언어모델의 비용이 많이 드는 인퍼런스 시간에 동기를 부여하여, 이산 디퓨전 모델과 자기회귀 언어 모델의 새로운 통합을 제안합니다. 제안된 방법인 Speculative Diffusion Decoding은 기존의 스페큘러티브 디코딩 스킴을 수정하여 비자기회귀 디퓨전 모델을 드래프트 모델로 통합합니다. 이 실증적 평가는 제안된 방법이 언어 생성의 표준 벤치마크에서 기존의 작업보다 8배 이상 빠르고 2.5배 이상 효율적임을 보여줍니다.
[참고자료 1] Speculative Decoding을 활용한 새로운 트랜스포머 모델의 변환 알고리즘 상세 설명
Speculative Diffusion Model에 대해 기존의 자기 회귀 모델(autoregressive model)과 비교하여 새로운 방법이 어떻게 효율성을 높이는지, 그리고 그 내부 알고리즘이 어떻게 동작하는지를 단계별로 살펴봅니다.
전체적으로 사용되는 모델의 종류 및 역할은 다음과 같습니다.
- 목표 모델 \(M_p\)는 트랜스포머 기반의 큰 언어 모델로, 최종 결과물의 정확한 확률 분포를 계산
- 드래프터 모델 \(M_q\)는 보다 작은 Diffusion Model로, 목표 모델을 대신해 효율적으로 텍스트 초안을 생성
- Diffusion Model은 트랜스포머 아키텍처를 활용하며, 노이즈를 추가하고 제거하는 과정을 통해 데이터를 생성
1. 자기 회귀 모델(트랜스포머)의 일반적인 개념 및 한계
우선, 자기 회귀 모델(Autoregressive Model, AR Model)에 대해 간단히 짚고 넘어가겠습니다. 자기 회귀 모델은 다음 토큰을 생성하기 위해 이전 토큰들을 순차적으로 활용하는 모델로 예를 들어, 주어진 토큰 시퀀스 \(\{x_1, x_2, ..., x_i\}\)가 있을 때, 이 시퀀스를 기반으로 다음 \(n\)개의 토큰 \(\{x_{i+1}, ..., x_{i+n}\}\)을 생성하는 것을 목표로 합니다.
이 과정에서 각 토큰 \(x_{i+k}\)는 이전의 모든 토큰 \(\{x_1, ..., x_{i+k-1}\}\)에 의존하여 생성되므로 토큰 생성 과정이 순차적이며, 속도가 느려질 수 있는 단점이 있습니다.
2. Speculative Decoding의 도입
Speculative Decoding은 이런 자기 회귀 모델의 효율성을 높이기 위해 제안된 기법입니다. 이 기법은 두 가지 모델을 활용합니다.
- \(M_p\): 원래의 목표 모델로, 생성하고자 하는 최종 토큰의 분포 \(p(x)\)를 계산
- \(M_q\): 보다 작은 드래프터(drafter) 모델로, 목표 모델의 분포를 근사하여 \(q(x)\)를 계산
Speculative Decoding은 간단히 말해 “초안 후 검증(draft-then-verify)” 접근 방식입니다. 우선 \(M_q\)로 후보 토큰 시퀀스를 생성한 뒤, \(M_p\)는 이를 병렬로 검증해 토큰 생성의 순차적 의존성을 완화하고, 병렬 처리를 통해 속도를 향상시킬 수 있습니다.
이처럼 SpecDiff는 Diffusion Model의 고유한 속성을 활용하여 효율적이고 빠른 텍스트 생성을 가능하게 합니다. 이 기술은 특히 대규모 언어모델에서의 병렬 처리 능력을 크게 향상시킬 수 있습니다.
3. Speculative Decoding의 동작 원리
3.1 토큰 생성 및 검증 과정
- 드래프터 모델 \(M_q\)에 의한 초안 생성
- \(M_q\)는 \(γ\)개의 토큰을 생성합니다. 이 토큰들은 \(x_{i+1}, ..., x_{i+γ}\)로 불리며, 이들의 분포는 \(q(x)\)로 나타낼 수 있습니다.
- 목표 모델 \(M_p\)에 의한 검증
- \(M_p\)는 생성된 토큰들을 기반으로 해당 토큰들의 정확한 분포 \(p(x)\)를 계산합니다.
- \(M_p\)는 \(p(x)\)가 \(q(x)\)보다 큰 경우, 해당 토큰을 승인합니다. 반대로, \(p(x)\)가 \(q(x)\)보다 작은 경우, 토큰을 거부할 수 있습니다.
- 토큰 승인 기준
- 각 토큰에 대해 \(q(x) \leq p(x)\)이면 토큰이 승인되며, \(q(x) > p(x)\)이면 \(1 - \frac{p(x)}{q(x)}\)의 확률로 거부됩니다.
- 만약 한 토큰이 거부되면, 해당 토큰 이후의 모든 토큰도 함께 폐기됩니다.
3.2 Speculative Decoding의 수학적 표현
토큰의 승인 확률 \(\alpha\)는 다음과 같이 계산됩니다. (\(D_{KL}\)은 두 분포 \(p\)와 \(q\) 사이의 Kullback-Leibler 다이버전스)
\[\alpha = 1 - \mathbb{E}(D_{KL}(p || q))\]이 수식은 목표 모델과 드래프터 모델의 분포가 얼마나 일치하는지를 나타내며, 분포의 불일치가 작을수록 높은 승인이 이루어집니다.
4. Speculative Diffusion Model의 도입
Speculative Diffusion Model (SpecDiff)은 기존의 Speculative Decoding을 확장하여 도입된 새로운 기법으로 이 모델은 드래프터 모델로서 Diffusion Model을 사용합니다.
4.1 Diffusion Model의 특징
Diffusion Model은 연속적인 방식으로 토큰 시퀀스를 생성하는 대신, 전체 시퀀스를 병렬로 생성할 수 있습니다. 이로 인해 긴 시퀀스를 생성할 때 더 높은 속도 이점을 가질 수 있습니다.
Diffusion Model은 또한 노이즈가 추가된 상태에서 토큰 시퀀스를 점차 정제(refine)하는 방식으로 동작합니다. 이는 토큰 시퀀스를 한 번에 생성하는 대신, 여러 단계에 걸쳐 정교화하는 방식으로 이루어집니다.
[Speculative Diffusion Model에서 사용되는 모델들의 설명]
\[\alpha = 1 - \mathbb{E}(D_{KL}(p || q))\]- \(\alpha\): 토큰의 승인 확률
- \(D_{KL}(p \\|\\| q)\): 두 분포 $p$와 \(q\) 사이의 Kullback-Leibler 다이버전스
- \(M_p\): 목표 모델
- \(M_q\): 드래프터 모델
4.1.1 목표 모델 \(M_p\)와 드래프터 모델 \(M_q\)
SpecDiff에서 두 가지 주요 모델이 사용됩니다.
- 목표 모델 \(M_p\)
- 최종적으로 생성될 텍스트의 정확한 확률 분포를 계산하며,
- 대개 크고 복잡한 트랜스포머 기반의 언어 모델로, 높은 정확도를 보이는 모델을 의미합니다. 예를 들어, GPT-3와 같은 일반적인 LLM 모델로 생각할 수 있습니다.
- 드래프터 모델 \(M_q\)
- 목표 모델 \(M_p\)를 대신해 빠르고 효율적으로 초안(candidate sequence)을 생성하는 모델로,
- 더 작은 크기이거나 더 효율적인 구조를 가지도록 설계해 목표 모델의 분포를 근사하는 방식으로 동작합니다.
4.1.2 Diffusion Model의 배경
Diffusion Model은 주로 이미지 생성에서 성공적으로 활용된 모델로, 텍스트 생성에도 적용될 수 있습니다. 이 모델의 주요 개념은 ‘노이즈 제거’를 통해 점차적으로 데이터를 정제(refine)하는 것입니다.
Diffusion Process (확산 과정)
- 노이즈 추가: 초기 데이터(e.g., 텍스트 시퀀스)에 점진적으로 노이즈를 추가합니다. 이 과정은 데이터가 점점 무작위화되는 방향으로 진행됩니다.
- 노이즈 제거: 이후, 이 노이즈를 단계적으로 제거하며, 원래의 데이터에 가까운 상태로 되돌립니다. 이 과정에서 새로운 데이터(e.g., 새로운 텍스트 시퀀스)가 생성됩니다.
Diffusion Model의 학습
- training dataset: Diffusion Model은 대규모 텍스트 데이터셋을 사용해 학습됩니다. 이는 일반적인 언어 모델과 유사하게, 텍스트의 확률 분포를 학습하는 과정입니다.
- 손실 함수: 모델은 특정 손실 함수(e.g., 스코어 엔트로피 손실, Score Entropy Loss)를 사용해 학습됩니다. 이 손실 함수는 모델이 노이즈가 섞인 상태의 데이터를 원래 상태로 되돌리는 데 얼마나 잘 수행하는지를 측정합니다.
4.2.3 Diffusion Model의 아키텍처
Diffusion Model은 일반적으로 트랜스포머(Transformer) 아키텍처를 기반으로 합니다. 트랜스포머는 자연어 처리(NLP)에서 높은 성능을 자랑하는 구조로, 특히 다음과 같은 구성 요소를 포함합니다.
- Self-Attention 메커니즘: 입력 데이터의 각 요소(토큰)가 다른 모든 요소와 상호작용할 수 있도록 하여, 문맥 정보를 잘 반영할 수 있습니다.
- Feed-Forward 네트워크: 각 토큰의 특징을 강화하고, 최종 출력값을 계산합니다.
Diffusion Model은 이 트랜스포머 구조를 활용하여, 입력 텍스트 시퀀스에 노이즈를 추가하고 제거하는 과정을 수행합니다. 이 과정에서 모델은 점차 텍스트를 정제하여 최종 출력을 생성합니다.
SpecDiff에서는 Diffusion Model이 드래프터 모델 \(M_q\)로 사용됩니다. 즉, 이 모델이 목표 모델 \(M_p\) 대신 텍스트 시퀀스의 초안을 생성합니다. Diffusion Model의 특성상, 병렬적으로 많은 토큰을 한 번에 생성할 수 있어, 긴 텍스트 생성 시 더 빠르고 효율적으로 처리할 수 있는 것을 특징으로 합니다.
5. SpecDiff의 알고리즘
마지막으로 SpecDiff의 전체적인 동작 과정을 살펴보겠습니다.
- 초안 생성: Diffusion Model \(M_q\)는 T 단계에 걸쳐 노이즈를 제거하며 토큰 시퀀스 \(\{x_{i+1}, ..., x_{i+γ}\}\)를 생성합니다. \(\{q_{i+1}, ..., q_{i+γ}\}^T \sim \mathcal{N}(0, \sigma_T I)\) 이후 각 단계에서 시퀀스는 점차 정제되며 최종적으로 확률 분포 \(q_0\)에 수렴합니다.
- 병렬 검증: 목표 모델 \(M_p\)는 병렬로 해당 시퀀스를 검증하며 \(p(x)\)를 계산하고,
- 토큰 승인: 앞서 설명한 방식대로, 토큰 승인 여부를 결정합니다.
- 토큰 조정: 필요에 따라 목표 모델의 분포 \(p(x)\)를 조정하여 최종 토큰을 선택합니다.