Post | RAG
- Related Project: Private
- Category: Paper Review
- Date: 2025-02-17
RAG
- url: https://arxiv.org/abs/2406.09827
- pdf: https://arxiv.org/pdf/2406.09827
- html: https://arxiv.org/html/2406.09827v1
- ralated: https://www.linkedin.com/feed/update/urn:li:groupPost:961087-7295846111309676545?utm_source=social_share_send&utm_medium=member_desktop_web&rcm=ACoAADACrAAB7zXxxkMv0ZdrxZDIvP430BSLjjw
- abstract: In modern large language models (LLMs), increasing the context length is crucial for improving comprehension and coherence in long-context, multi-modal, and retrieval-augmented language generation. While many recent transformer models attempt to extend their context length over a million tokens, they remain impractical due to the quadratic time and space complexities. Although recent works on linear and sparse attention mechanisms can achieve this goal, their real-world applicability is often limited by the need to re-train from scratch and significantly worse performance. In response, we propose a novel approach, Hierarchically Pruned Attention (HiP), which reduces the time complexity of the attention mechanism to O(TlogT) and the space complexity to O(T), where T is the sequence length. We notice a pattern in the attention scores of pretrained LLMs where tokens close together tend to have similar scores, which we call ``attention locality’’. Based on this observation, we utilize a novel tree-search-like algorithm that estimates the top-k key tokens for a given query on the fly, which is mathematically guaranteed to have better performance than random attention pruning. In addition to improving the time complexity of the attention mechanism, we further optimize GPU memory usage by implementing KV cache offloading, which stores only O(logT) tokens on the GPU while maintaining similar decoding throughput. Experiments on benchmarks show that HiP, with its training-free nature, significantly reduces both prefill and decoding latencies, as well as memory usage, while maintaining high-quality generation with minimal degradation. HiP enables pretrained LLMs to scale up to millions of tokens on commodity GPUs, potentially unlocking long-context LLM applications previously deemed infeasible.
해당 포스트는 다음 내용을 포함하고 있습니다.
- 기초 모델의 dense 벡터 임베딩을 사용한 의미 검색
- 검색 증강 생성(RAG)
- 검색과 대규모 언어모델(LLM)을 결합한 질의 응답 및 요약
- Transformer 기반 LLM 파인튜닝
- 사용자 신호 및 벡터 임베딩을 기반으로 한 개인화된 검색
- 사용자 행동 신호 수집 및 신호 강화 모델 구축
- 도메인별 학습을 위한 의미 지식 그래프
- 멀티모달 검색(텍스트, 이미지 및 기타 유형에 대한 하이브리드 쿼리)
- 일반화 가능한 머신러닝 순위 모델 구현(순위 매기기 학습)
- 머신러닝 순위를 자동화하기 위한 클릭 모델 구축
- ANN 검색, 양자화, 표현 학습, 바이 인코더 대 크로스 인코더와 같은 vector search 최적화 기술
- 생성 검색, 하이브리드 검색 및 검색 프런티어
Part 1: Modern Search Relevance
1. AI 기반 검색 소개
1.1 AI 기반 검색의 필요성
- 현대의 검색 인터페이스 대부분의 현대 애플리케이션에서 데이터와 상호작용하는 기본 사용자 인터페이스로 자리잡았으며, 검색은 모든 디지털 상호작용에서 언제나 사용 가능한 도구로 자리잡고 있음.
- 예시: 구글, 바이두, 빙과 같은 웹사이트를 생각할 때 가장 먼저 떠오르는 것이 검색 엔진으로
- 높아진 기대치 과거에는 “10개의 파란색 티셔츠의 링크”를 제공하는 것이 전부였으나, 현재는 검색 기술의 지능 수준에 대한 기대가 급격하게 상승하였음.
1.2 AI 기반 검색의 작동 방식
- 도메인 인식 특정 사용 사례와 문서의 코퍼스에 대한 엔티티, 용어, 카테고리, 속성을 이해해야
- 맥락적 & 개인화 사용자, 쿼리, 도메인 맥락을 고려하여 사용자 의도를 더 잘 이해
- 대화형 자연어로 상호작용하며 다단계 검색 과정을 안내하고, 새로운 정보를 학습하고 기억
- 멀티모달 텍스트, 음성, 이미지 및 비디오 검색 등을 모두 처리할 수 있음.
- 지능형 예측 입력, 철자 교정, 의도 분류 등을 통해 적시에 적절한 답변을 제공
- 보조적 링크 제공을 넘어 직접적인 답변과 실행 가능한 액션 제공
1.3 AI 기반 검색을 위한 핵심 기술
- 자동화 학습 기술 활용 기본 텍스트 검색에서 출발하여 자동화된 학습 기술을 통해 검색 최적화를 수행
TL;DR AI 기반 검색은 현대 애플리케이션에서 사용자 경험을 개선하기 위한 필수 요소로 자리잡고 있으며, 도메인 인식, 개인화, 멀티모달 처리, 지능형 검색 등을 통해 사용자 의도를 보다 정확하게 파악 자동화된 학습 기술을 활용하여 검색 최적화를 구현하고자 하는 모든 조직에 필수적인 가이드로 작용
이미지 및 예시
AI 기반 검색 시스템의 작동 방식 및 흐름을 시각적으로 표현한 다이어그램
- 예시: 패션 상품 검색에서 이미지와 상품 메타 정보를 활용하여 사용자에게 개인화된 추천 제공.
- 인풋 사용자가 업로드한 패션 상품 이미지 및 관련 메타 정보
- 아웃풋 유사한 패션 상품의 목록과 사용자에게 추천되는 관련 상품
- AI 기반 검색을 제공하기 위해서는 사용자 의도를 해석하고 그에 맞는 콘텐츠를 반환하는 과정에서 관련된 다양한 차원을 일관되게 이해하는 것이 중요하며, 정보 검색 분야에서는 검색 엔진과 추천 엔진이 가장 많이 사용되는 기술로, 사용자의 정보 필요를 충족시키기 위해 콘텐츠를 제공
- 많은 조직이 검색 엔진과 추천 엔진을 별도의 기술로 보고, 서로 다른 사용 사례를 해결한다고 생각하지만, 실제로 종종 동일한 조직 내에서 서로 다른 기술 세트를 가진 팀들이 독립적으로 검색 엔진과 추천 엔진을 개발
-
이 섹션에서는 검색과 추천을 별도의 기능 및 팀으로 분리할 때 발생할 수 있는 비효율적인 결과에 대해 설명
- 검색 엔진
- 명시적으로 쿼리를 입력하고, 응답을 받기 위한 기술로 인식됨
- 일반적으로 텍스트 박스를 통해 사용자가 키워드나 자연어 질문을 입력할 수 있도록 제공
- 결과는 보통 리스트 형태로 반환되며, 초기 쿼리를 더 세분화할 수 있는 필터링 옵션이 제공됨
- 사용자가 검색 세션을 마치면, 새로운 쿼리를 입력하고 이전 검색의 맥락을 지우고 새롭게 시작할 수 있음
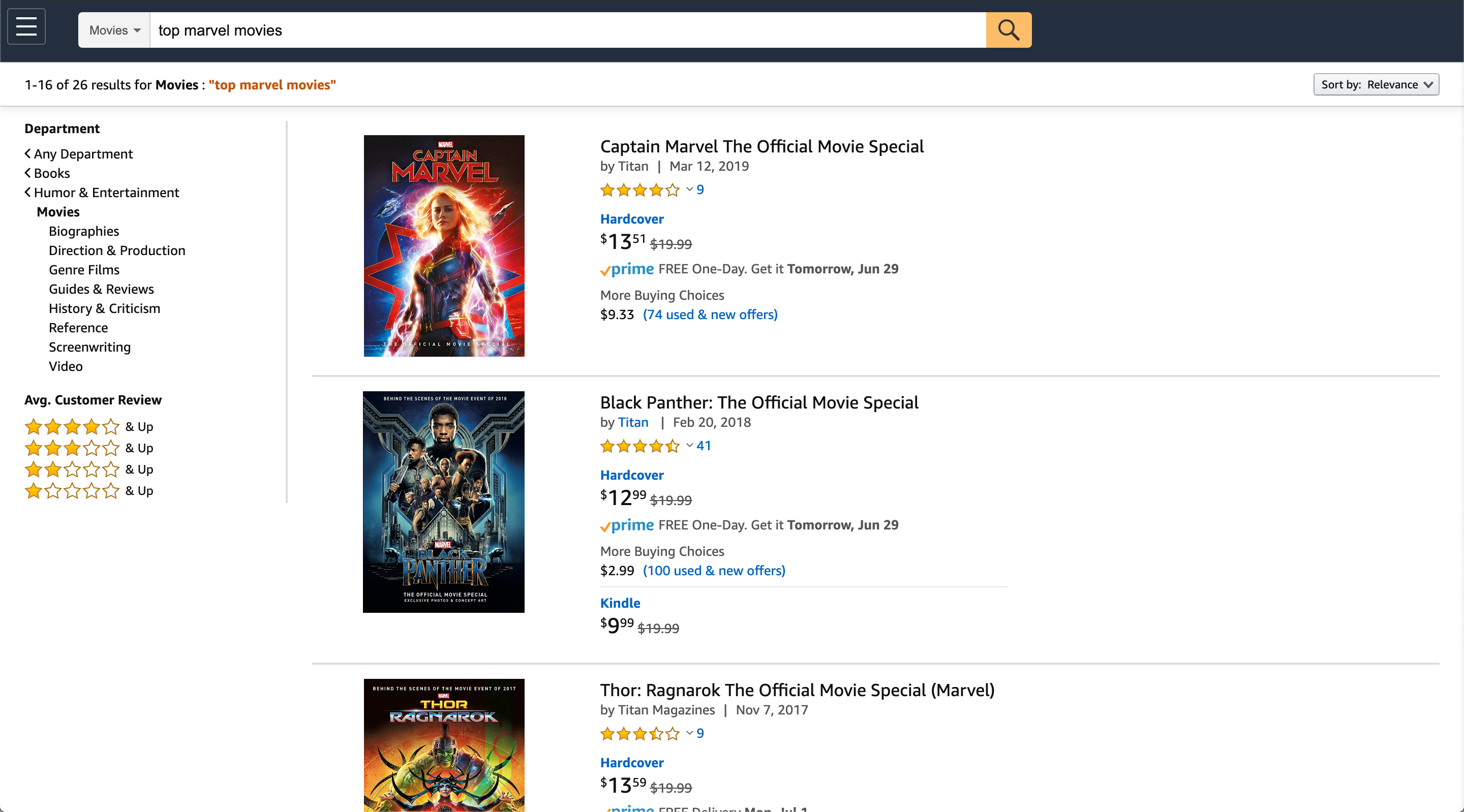
Figure 1.1 일반적인 검색 경험을 보여주는 이미지로, 사용자가 쿼리를 입력하고 필터링 옵션을 통해 검색 결과를 세분화할 수 있는 모습
1.1 사용자 의도 검색
1.1.1 검색 엔진
- 크로스 기능적 시스템으로, 수백만, 수십억, 경우에 따라 수조 개의 문서를 다루며, 동시 쿼리를 처리하고, 수백 밀리초 내에 검색 결과를 제공함
- 실시간 처리 및 신규 데이터에 대한 거의 실시간 검색도 필요하며, 이를 위해 다수의 서버에 걸쳐 병렬 처리 가능해야 함
- 분산 시스템, 동시성, 데이터 구조, 운영 체제, 고성능 컴퓨팅에 대한 깊은 이해가 필요
기술적인 요구 사항이 높기 때문에, 검색 엔진 개발은 여러 전문가와 협업이 필요 검색 엔진은 사용자 의도를 완전히 해석하기 위해 콘텐츠, 사용자, 도메인에 대한 철저한 이해가 필요 이는 추천 엔진 관련 주제를 논의한 후 다시 다룰 것임.
p9
검색 엔진은 대규모 확장성을 염두에 두고 설계되며, 분산 시스템과 동시성, 데이터 구조, 운영 체제, 고성능 컴퓨팅에 대한 깊은 이해를 요구 검색 엔진은 인버티드 인덱스와 같은 검색 전용 데이터 구조를 구축하고, 선형 대수학과 벡터 유사도 점수, 텍스트 분석 및 자연어 처리에 대한 경험이 필요
- 검색 엔진의 주요 요소
- 인버티드 인덱스: 문서의 각 단어를 인덱스하여 빠른 검색을 가능하게 하는 데이터 구조
- 벡터 유사도 점수: 검색 쿼리와 문서 간의 유사도를 측정하여 검색 결과의 정확성을 높이는 방법
- 텍스트 분석 및 자연어 처리: 사용자 쿼리를 보다 정확하게 해석하고 이해하는 데 도움을 줌
검색 엔진의 성능과 관련성 향상을 위해, 검색 팀은 랭킹 모델, A/B 테스트, 클릭 모델, 피처 엔지니어링, 쿼리 해석 및 의도 발견과 같은 도구를 사용 검색 품질을 평가하고 개선하기 위해 데이터 분석가, DevOps 엔지니어, 제품 관리자 등 다양한 전문가의 협력이 필요
p10
추천 엔진은 일반적으로 사용자가 직접 입력하지 않고, 사용자에 대해 알고 있는 정보를 바탕으로 콘텐츠를 제공하는 시스템으로 인식됨. 하지만 이는 과도한 단순화이며, 실제로는 사용자의 브라우징 및 구매 이력을 기반으로 개인화된 콘텐츠를 제공
- 추천 엔진의 주요 유형
- 콘텐츠 기반 추천: 사용자와 항목 간의 속성을 기반으로 유사한 콘텐츠를 추천
- 행동 기반 추천: 사용자의 행동 패턴을 분석하여 관련 콘텐츠를 추천
- 멀티모달 추천: 여러 종류의 데이터를 결합하여 보다 정교한 추천을 제공
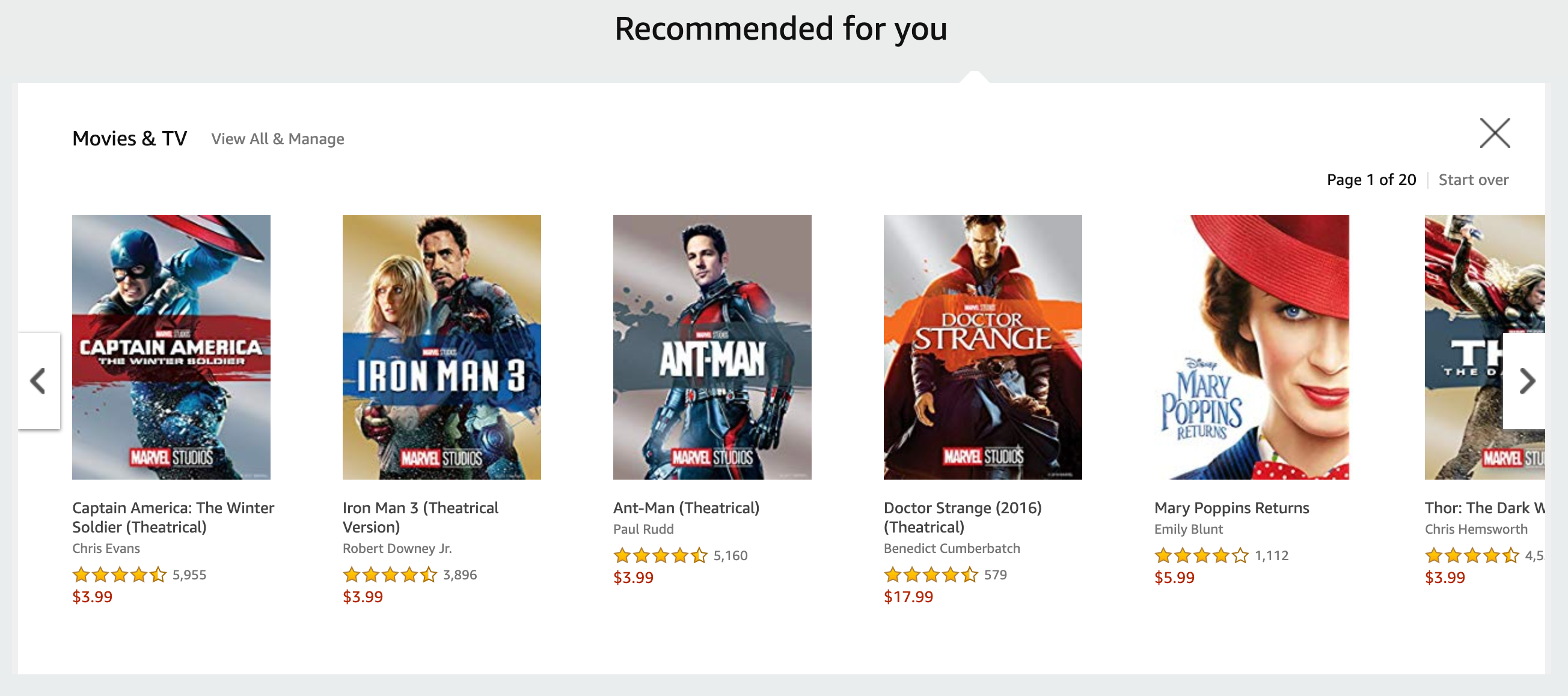
Figure 1.2 사용자의 구매 패턴에 기반하여 유사한 항목을 추천하는 모습
p11
추천 알고리즘은 보통 사용자와 항목 간의 속성을 공유함으로써 새로운 콘텐츠를 추천 예를 들어, 구직 웹사이트에서 사용자는 “직업명”, “산업”, “연봉 범위”, “경력”, “기술”과 같은 속성을 가질 수 있음. 콘텐츠 기반 추천 알고리즘은 이런 속성을 분석하여 사용자가 원하는 속성과 가장 잘 맞는 작업을 추천 이를 사용자-항목 추천이라고
- 콘텐츠 기반 추천 시스템의 예시
- 특정 직무를 좋아하는 사용자가 있으면, 그 직무와 유사한 속성을 가진 다른 직무를 추천함
- 제품 상세 페이지에서 사용자가 이미 관심을 갖고 있는 항목과 관련된 추가 항목을 탐색하도록 도움
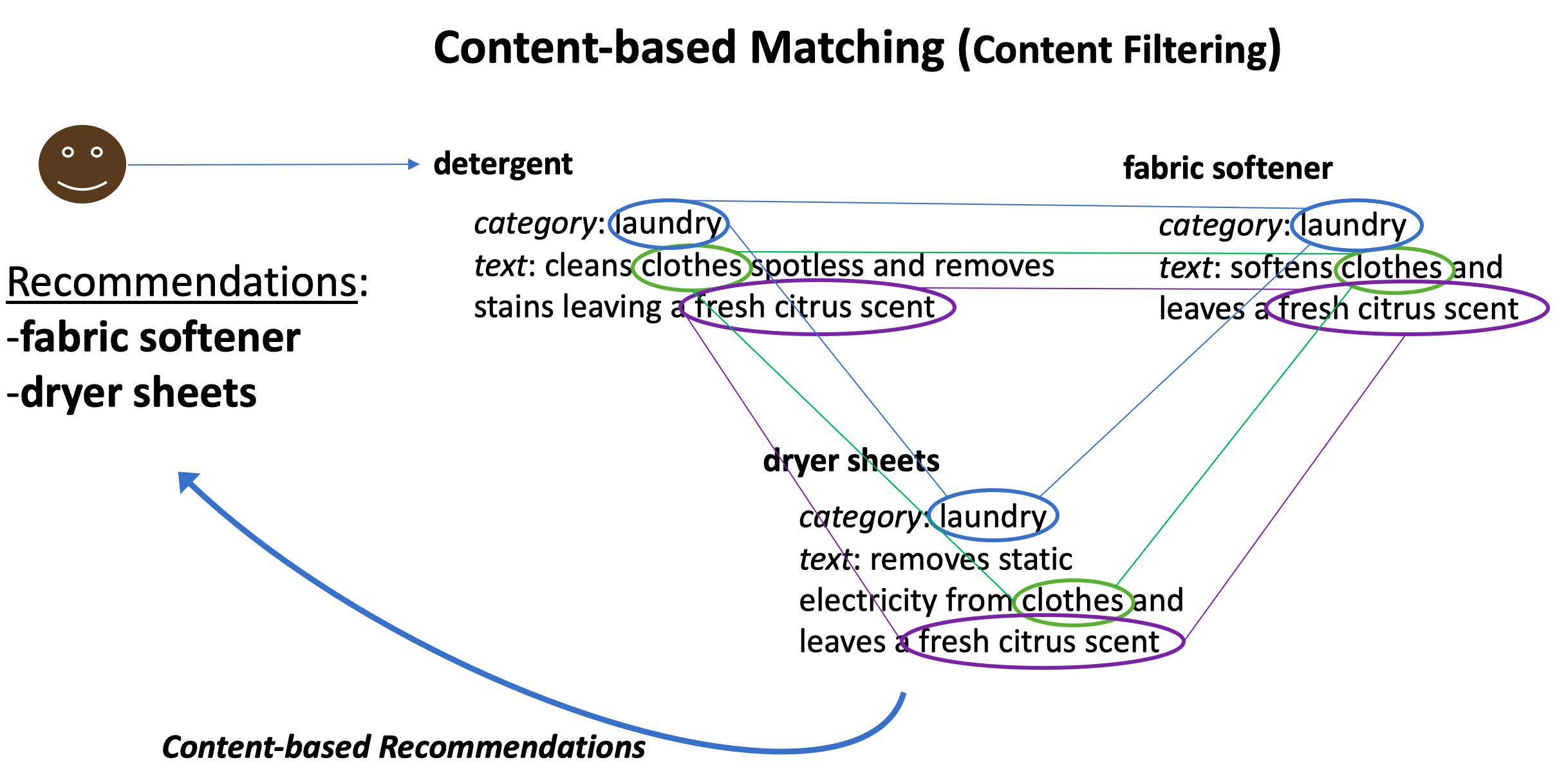
Figure 1.3 사용자가 관심을 가진 항목의 속성을 기반으로 유사한 항목을 추천하는 콘텐츠 기반 추천 시스템의 예
TL;DR
- 검색 엔진과 추천 엔진은 사용자 정보를 기반으로 콘텐츠를 제공하는 두 가지 주요 기술임.
- 검색 엔진은 명시적인 쿼리를 기반으로 하고, 추천 엔진은 사용자의 행동 데이터와 속성을 기반으로
- 효과적인 검색 및 추천 시스템은 다양한 전문가의 협력이 필요하며, 사용자 의도를 정확히 파악하는 것이 중요
#
ai-powered-search/
- 추천 시스템 알고리즘에 대한 추가 정보: Recommendation Systems
패션 상품 검색 예시
패션 상품 검색에 AI 기반의 검색 및 추천 시스템을 적용하면, 사용자의 구매 및 브라우징 이력, 선호 스타일 등의 데이터를 기반으로 개인화된 상품을 추천할 수 있음. 예를 들어, 사용자가 특정 스타일의 옷을 검색하면, 유사한 스타일이나 색상, 브랜드의 다른 상품을 추천하여 구매 경험을 향상시킬 수 있음. 이런 시스템은 이미지 메타정보를 활용하여 비슷한 패턴이나 색상의 상품을 자동으로 탐색하고 추천함으로써 사용자 만족도를 높일 수 있음.
콘텐츠 기반 추천 시스템의 맥락에서의 아이템-아이템 추천
아이템-아이템 추천의 개념은 콘텐츠 기반 추천 시스템에서 모든 추천을 설명할 수 있는 중요한 개념임. 각 아이템은 추천받는 다른 엔티티들과 속성을 공유하는 임의의 엔티티로 간주됨.
- 알고리즘 사용자와 아이템(e.g., 문서) 간의 상호작용을 활용하여 아이템 그룹 간의 유사한 관심 패턴을 발견하는 방식
- 협업 필터링 여러 사용자가 참여하는 투표 과정을 통해 가장 높은 유사성을 나타내는 매치를 필터링
- 유사한 사용자(즉, 유사한 선호도를 가진 사용자)는 같은 아이템에 상호작용할 가능성이 높음
- 사용자가 여러 아이템과 상호작용할 때, 비관련 아이템보다 유사한 아이템을 찾고 상호작용할 가능성이 높음
- 협업 필터링 여러 사용자가 참여하는 투표 과정을 통해 가장 높은 유사성을 나타내는 매치를 필터링
협업 필터링의 피쳐
- 크라우드 소싱 방식: 아이템 자체의 피쳐(이름, 브랜드, 색상, 텍스트 등)이 아닌 사용자와 아이템의 상호작용 정보만 필요
- 사용자와 상호작용 수가 많을수록 알고리즘이 똑똑해짐 → 사용자 행동 신호가 많아질수록 더 나은 성과를 보임
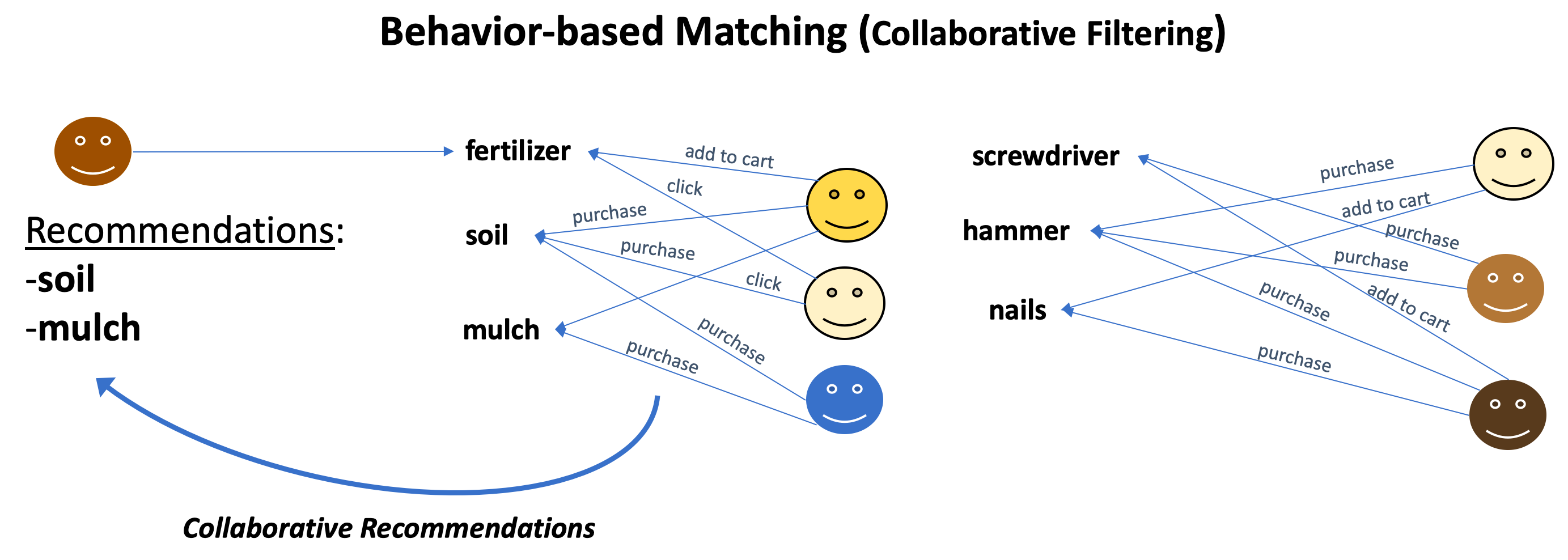
Figure 1.4 여러 사용자 간의 행동 신호의 겹침을 활용한 협업 필터링 기반 추천 예시
콜드 스타트 문제와 다중 모드 추천 시스템
- 콜드 스타트 문제 사용자 행동 신호에 의존하다 보니 새로운 아이템에 대한 추천이 어려움
- 다중 모드 추천 시스템 콘텐츠 기반과 행동 기반 추천의 Pros(+)을 결합하여 콜드 스타트 문제를 해결
- 행동 신호가 많을 경우: 협업 필터링 우선
- 행동 신호가 적을 경우: 콘텐츠 기반 매처 활용
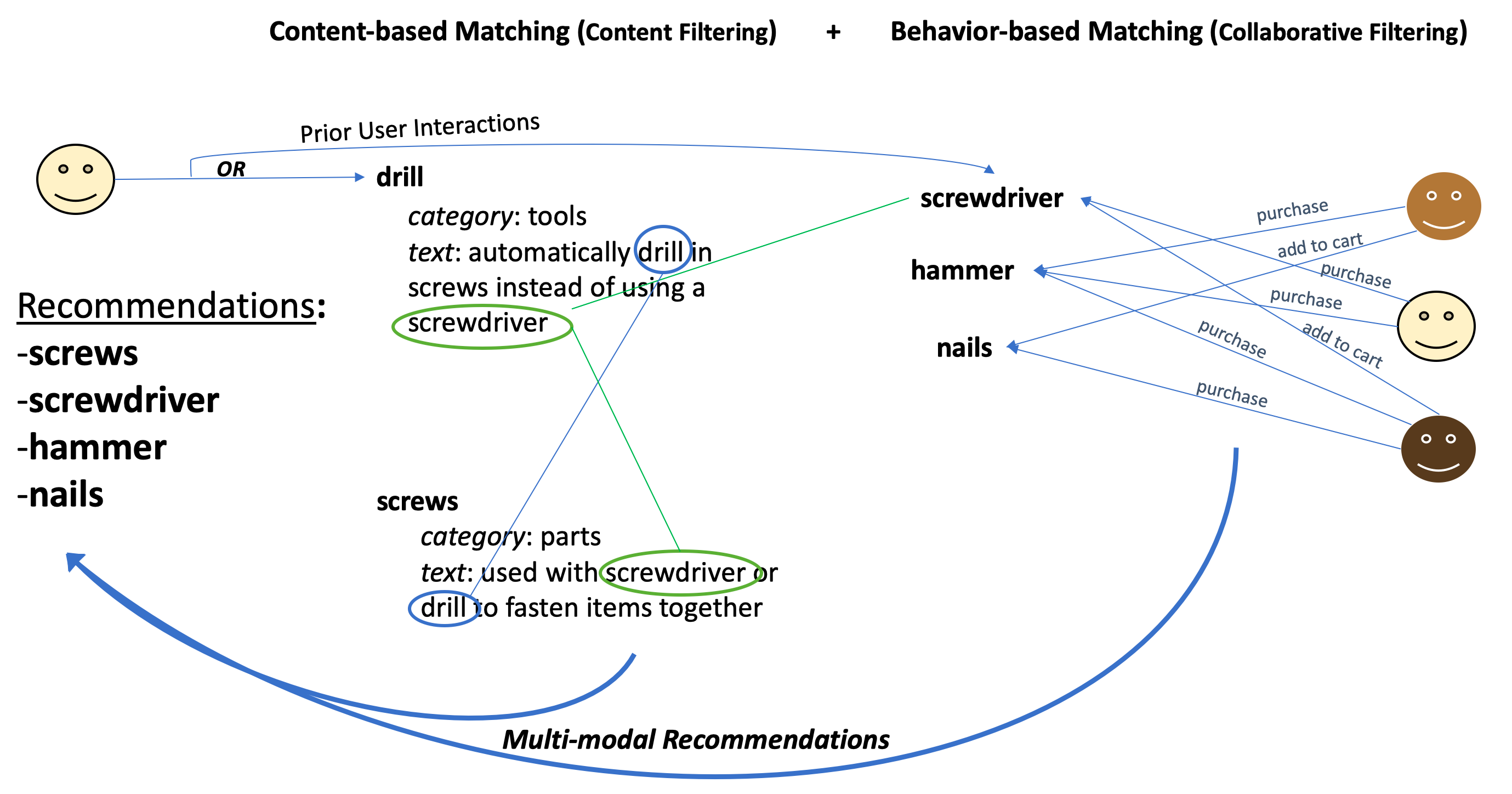
Figure 1.5 콘텐츠 기반 매칭과 협업 필터링을 결합한 다중 모드 추천 알고리즘의 작동 방식
핵심 콘텐츠 기반 추천에서 아이템 간 유사성을 활용하여 추천하는 방법을 설명하고, 협업 필터링을 통해 사용자 행동 데이터를 기반으로 더 나은 추천을 제공할 수 있음을 보임. 다만, 콜드 스타트 문제를 해결하기 위해 다중 모드 추천 시스템을 도입하여 콘텐츠 기반과 행동 기반 추천의 Pros(+)을 결합
검색 엔진과 추천 엔진의 비교
- 검색 엔진 사용자의 명시적 쿼리에 의해 작동
- 추천 엔진 명시적 사용자 입력 없이 기존에 알고 있거나 인퍼런스된 지식에 기반하여 사용자가 원하는 내용을 추천
사례
- 사용자가 뉴욕에서 “steamed bagels”를 검색했을 때 다른 지역의 결과가 나오는 문제
- 공항에서 “driver”를 검색했을 때 골프 클럽이나 드라이버 관련 결과가 나오는 문제
정보 검색 연속체와 개인화된 검색
- 개인화된 검색 사용자 입력과 사용자의 특정 의도 및 선호도를 결합하여 사용자 맞춤 결과 제공
- 사용자 프로필을 활용하여 검색 및 추천 개선 가능
- 사용자의 선호도를 기반으로 추천 엔진의 정확도를 높일 수 있음
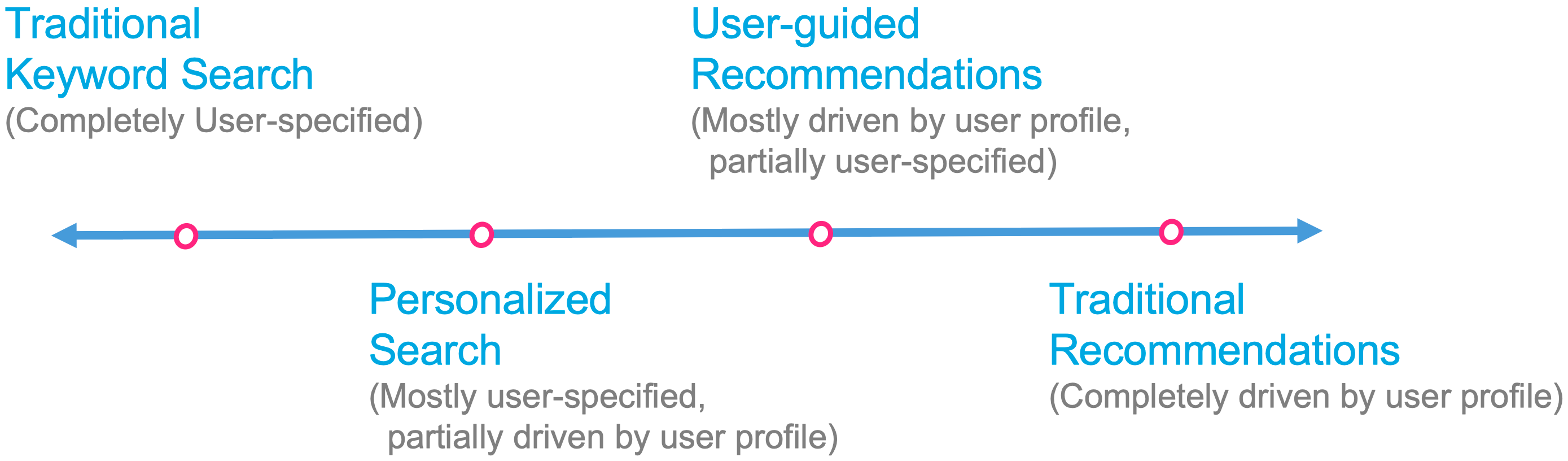
Figure 1.6 개인화 스펙트럼, 전통적 키워드 검색과 전통적 추천의 연속체
핵심 검색 엔진과 추천 엔진은 사용자 요청을 처리하는 방식에서 차이가 있으며, 개인화된 접근을 통해 사용자 프로필을 활용하여 더 나은 결과를 제공할 수 있음. 개인화 스펙트럼을 통해 다양한 정보 검색 방법을 설명
통합 접근 방식을 통한 검색 및 추천 최적화
1.1 검색과 추천의 통합 문제
검색과 추천 시스템은 종종 별개의 문제로 인식되며 이는 DataScience Team과 Engineering Team 간의 분리된 개발로 이어지고, 각 팀은 서로 다른 목표를 가지고 시스템을 구축하게 되는 문제가 발생
- DataScience Team: 개인화 및 세분화 모델 구축
- Pros(+): 특정 콘텐츠 추천에 강점
- Cons(-): 검색 기능 부족
- Engineering Team: 대규모 키워드 매칭 엔진 구축
- Pros(+): 대량의 데이터를 빠르게 처리
- Cons(-): 개인화 모델 활용 어려움
Conway’s Law: 조직은 자신의 커뮤니케이션 구조를 반영한 시스템을 설계 이는 검색과 추천 간의 분리를 심화시킴 → 결과적으로 통합된 개인화 스펙트럼을 최적화하기 어려움.
TL;DR
- 검색과 추천을 별개로 인식하면 통합적 성능 저하 발생.
- Conway’s Law에 따라 조직 구조가 시스템 설계에 영향을 미침.
- 통합적 접근 필요.
1.1.4 의미론적 검색과 지식 그래프
의미론적 검색은 도메인에 대한 깊은 이해를 요구하며, 지식 그래프를 활용하여 쿼리의 의미를 파악
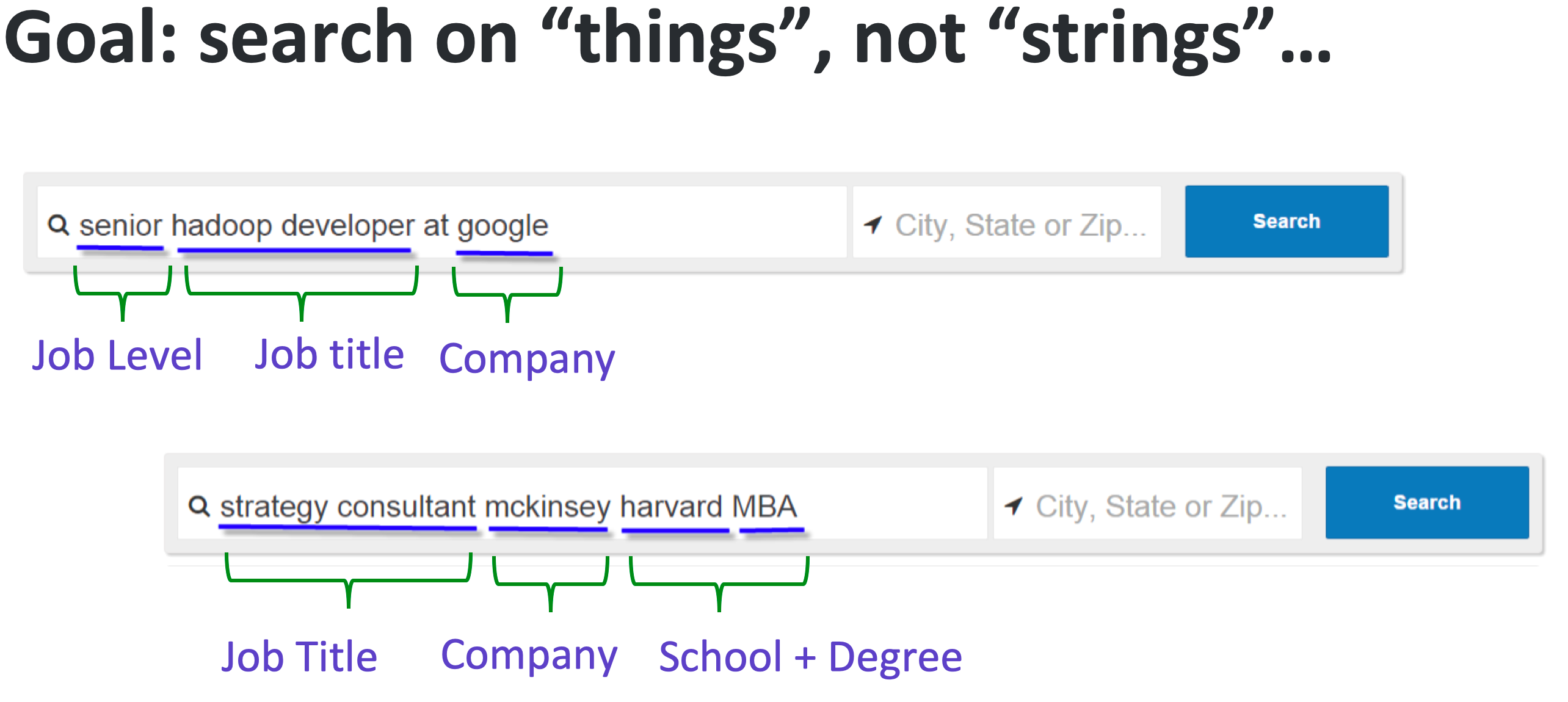 쿼리 내의 엔티티를 이해하여 ‘문자열’이 아닌 ‘사물’을 검색하는 과정을 시각화한 이미지
쿼리 내의 엔티티를 이해하여 ‘문자열’이 아닌 ‘사물’을 검색하는 과정을 시각화한 이미지
대기업들은 엔티티 관계를 이해하기 위해 사전과 지식 그래프를 수작업으로 구축해 왔으나, AI 기반 검색 엔진은 이런 정보를 자동으로 학습하게 되고, 이는 확장 가능한 솔루션을 제공할 수 있음을 의미
- AI 기반 검색 엔진: 지속적인 학습을 통해 도메인 지식 획득
- Pros(+): 자동화된 의미론적 이해, 확장성
TL;DR
- 의미론적 검색은 도메인 지식 필요.
- AI 기반 검색 엔진은 자동화된 학습으로 도메인 지식 획득.
- 지식 그래프는 쿼리의 의미를 효과적으로 파악하는 데 기여.
1.1.5 사용자 의도 이해의 차원
사용자 의도를 이해하기 위해서는 세 가지 요소가 필요함: 콘텐츠 이해, 사용자 이해, 도메인 이해.
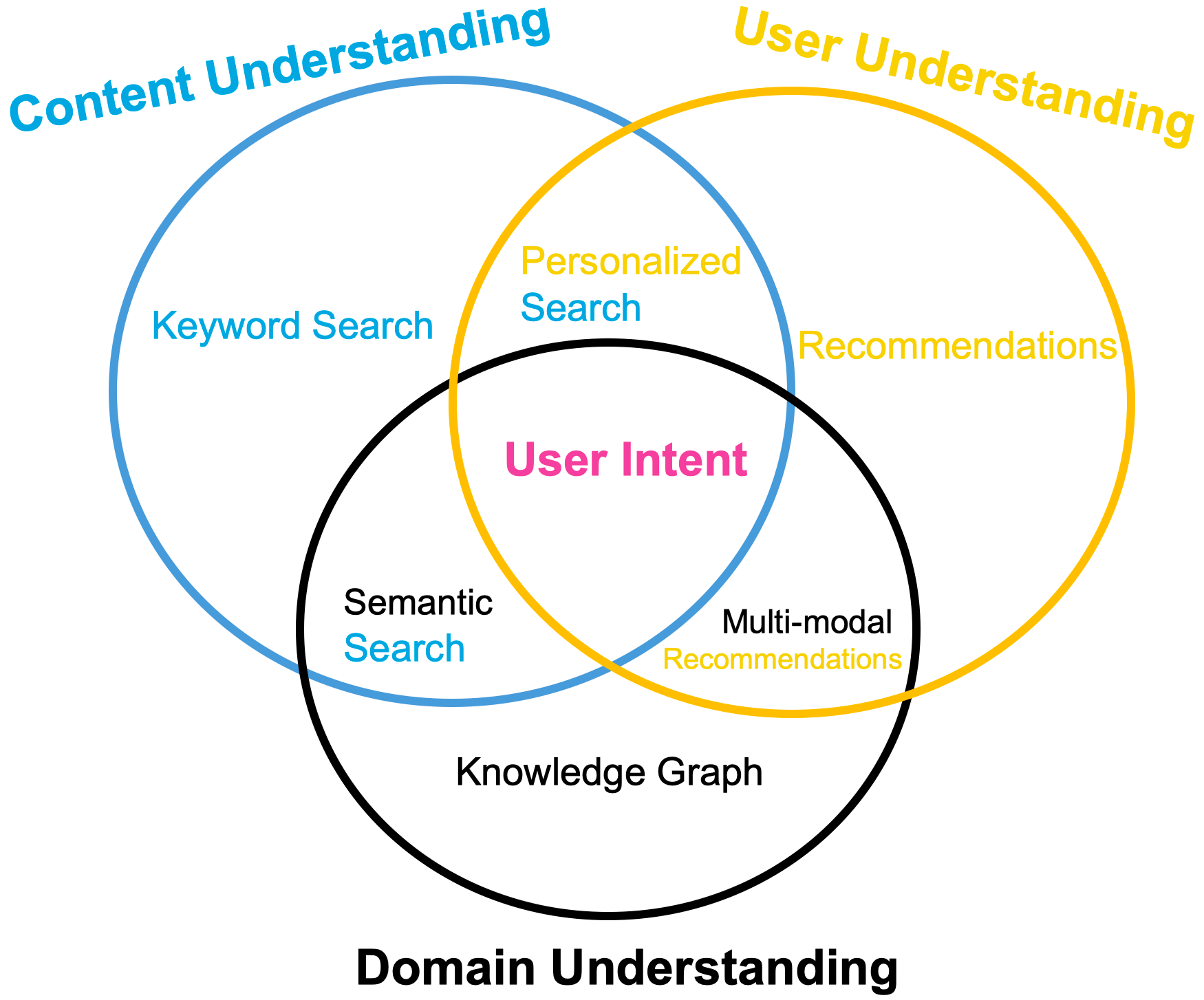
사용자 의도를 이해하기 위한 세 가지 요소 간의 상호작용
- 콘텐츠 이해: 키워드 매칭
- 사용자 이해: 개인화된 결과 제공
- 도메인 이해: 도메인 내에서의 의미 파악
이 요소들이 통합되면, AI 기반 검색은 모든 사용자 쿼리에 대해 전문가 수준의 이해와 매칭을 수행 가능
TL;DR
- 사용자 의도 이해에 필요한 세 가지 요소: 콘텐츠, 사용자, 도메인 이해.
- 이들 요소의 통합은 AI 기반 검색의 성능을 극대화
- 전문가 수준의 이해와 매칭 가능.
1.2 AI 기반 검색을 위한 핵심 기술
AI 기반 검색 시스템을 구축하기 위한 주요 기술
- 프로그래밍 언어: Python
- 데이터 처리 프레임워크: Spark (PySpark)
- 배포 메커니즘: Docker Containers
- 코드 설정 및 워크스루: Jupyter Notebooks
- 검색 엔진: Apache Solr
추가적으로 고려할 수 있는 검색 엔진
- Lucene, Elasticsearch, Open Search, Lucidworks Fusion, Milvus, Vespa
TL;DR
- AI 기반 검색을 위한 주요 기술: Python, Spark, Docker 등
- 다양한 검색 엔진 옵션 제공
- 책의 예제는 이런 기술을 기반으로 설명
기술적 선택과 구현
1.2.1 프로그래밍 언어: Python
- Python 선택 이유
- 데이터 과학자와 소프트웨어 엔지니어 모두에게 유명한 언어
- 데이터 과학 분야에서 가장 많이 사용됨
- 소프트웨어 엔지니어링 분야에서 C와 Java 다음으로 많이 사용됨
- 데이터 과학 프레임워크 대부분이 Python으로 작성되었거나 Python 바인딩을 제공
- 초심자에게도 읽기 쉽고 접근성이 높음
- 데이터 과학자와 소프트웨어 엔지니어 모두에게 유명한 언어
1.2.2 데이터 처리 프레임워크: Spark (PySpark)
- Apache Spark의 Pros(+)
- 대규모 데이터 처리에 적합
- 단일 서버에서도 실행 가능하지만, 대규모 클러스터로 확장 가능
- 데이터 프레임을 사용하여 다양한 데이터 소스에서 데이터를 처리하고 저장 가능
- Apache Solr와 Elasticsearch와 같은 검색 플랫폼과 통합하여 데이터 처리 및 검색 데이터 강화 가능
1.2.3 전달 메커니즘: Docker 컨테이너
- Docker 활용 이유
- 수백 개의 라이브러리와 종속성을 포함한 환경 설정을 간소화
- 운영 체제 간의 버전 충돌 없이 코드 실행 가능
- Jupyter 노트북과 결합하여 코드 예제를 쉽게 실행하고 실험 가능
1.2.4 코드 설정 및 워크스루: Jupyter 노트북
- Jupyter 노트북의 Pros(+)
- 코드 예제를 튜토리얼 형태로 제공
- 코드 변경 및 실행이 웹 브라우저에서 간편히 가능
- 시스템 명령어 없이도 코드 실행 가능하게 설계
1.2.5 검색 엔진 기술 선택
- Apache Solr 선택 이유
- 오픈 소스이면서 Lucene 기반의 검색 엔진
- Solr의 고유 기능 (e.g., 텍스트 태거, 시맨틱 지식 그래프 등) 활용 가능
- Elasticsearch와 달리 2021년 이후 오픈 소스 유지
- Lucene 기반의 다른 엔진 사용자에게도 개념 전이 용이
TL;DR
- Python은 데이터 과학과 소프트웨어 엔지니어링 모두에서 널리 사용되며, Spark는 대규모 데이터 처리에 적합.
- Docker와 Jupyter 노트북을 활용하여 코드 배포와 실행을 간소화하고, Solr를 기반으로 한 예제를 통해 검색 엔진 기술을 설명.
- Lucene 기반의 Solr는 오픈 소스로, AI 기반 검색에 필요한 다양한 기능을 제공하며, 다른 Lucene 기반 엔진 사용자에게도 유용.
추가 자료
패션 상품 검색 적용 예시
- 적용 시나리오
- 이미지와 상품 메타 정보를 기반으로 유사한 패션 상품을 검색
- 모델 예시 Convolutional Neural Network (CNN)
- Input 패션 이미지 데이터셋
- Output 이미지 피쳐 벡터
- Spark를 활용하여 대량의 이미지 데이터를 병렬 처리
- Solr를 사용하여 인덱싱된 데이터에서 빠른 검색 수행
해당 기법을 통해 대규모 패션 상품 데이터베이스에서 사용자에게 적합한 상품을 빠르게 추천할 수 있음.
기술적 분석과 구현 전략
1. OpenSearch 프로젝트의 배경
- OpenSearch: Elasticsearch의 오픈 소스 포크 → Amazon이 2021년 4월에 출시
- 배경: Elastic이 2021년 1월에 오픈 소스 라이선스를 포기함
- 목표: Elasticsearch와 Solr의 오픈 소스 대안 제공
- 전망: Amazon의 관리 하에 프로젝트의 발전 방향이 결정될 것임
TL;DR
- OpenSearch는 Amazon에 의해 개발된 Elasticsearch의 오픈 소스 포크
- Lucidworks Fusion은 AI 기반 검색 기능을 즉시 제공하는 상업 솔루션
- Milvus와 Vespa는 벡터 및 텍스트 검색 기능을 결합한 차세대 검색 엔진
2. AI-Powered 검색의 진화
2.1 자연어 모델의 발전
- 자연어 모델의 발전: 쿼리와 문서를 dense 벡터 공간에 맵핑하는 새로운 검색 및 랭킹 메커니즘 생성
- 신경망 검색: dense vector search 방법에 기반
- Milvus: 오픈 소스 벡터 데이터베이스, 효율적인 벡터 인덱싱 및 근사 최근접 이웃 검색 제공
- Vespa: 전통적인 키워드 검색 엔진 + 벡터 및 텐서 지원 → 다차원 데이터 검색 가능
2.2 Jina 프레임워크
- Jina: 신경망 검색 시스템을 구축하기 위한 오픈 소스 프레임워크
- 기능: 문서 및 쿼리 처리 파이프라인 개발 지원
- 초점: 차세대 검색 기능 통합, 예를 들어 시맨틱 검색, 질문 답변, 멀티모달 검색 등
3. AI-Powered 검색의 대상 독자와 요구 사항
3.1 대상 기술 세트와 직업
- 대상 독자: 검색 엔지니어, 소프트웨어 엔지니어, 데이터 과학자
- 요구 기술: Solr 또는 Elasticsearch와 같은 검색 기술에 대한 기본 이해
3.2 시스템 요구 사항
- 하드웨어: 최소 8GB RAM, 25GB 디스크 공간
- 소프트웨어: Java 8+, Docker, Mac/Linux/Windows 환경
4. AI-Powered 검색의 구현 단계
4.1 설치와 기본 설정
- Elasticsearch/OpenSearch, Solr, Vespa 설치 → 문서 인덱싱
- 기본 키워드 매칭 필요 시: 복잡한 AI 기능 도입 전 신중한 접근 필요
4.2 검색 지능의 발전
- 검색 지능의 발전: 기본 키워드 검색에서 시작해, 검색 관련성 개선을 위한 수작업 튜닝 → AI 기반 검색 기능 도입
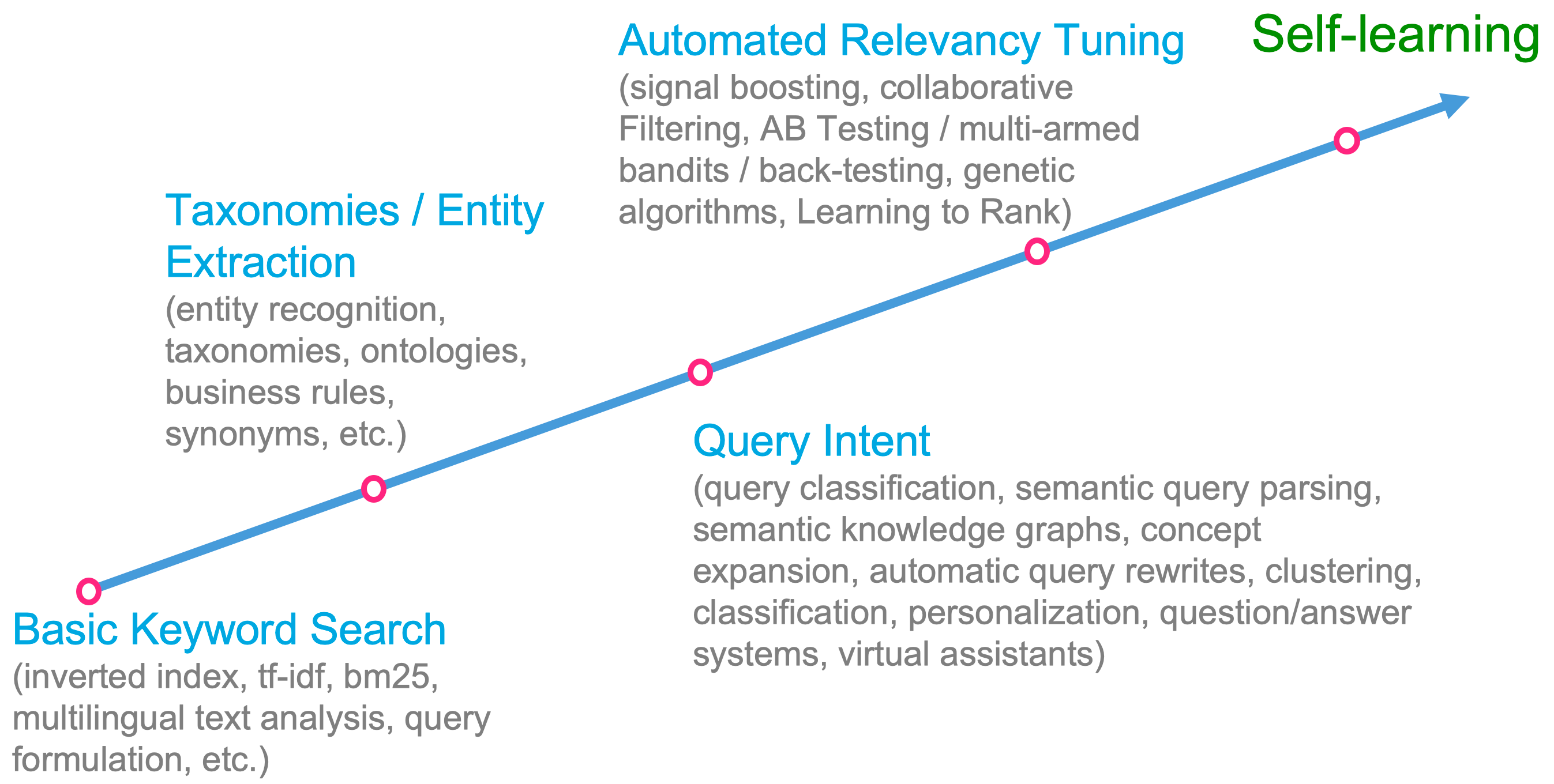 검색 지능의 전형적인 발전 과정, 기본 키워드 검색에서 시작해 자가 학습 검색 플랫폼으로 발전
검색 지능의 전형적인 발전 과정, 기본 키워드 검색에서 시작해 자가 학습 검색 플랫폼으로 발전
소결
- AI 기반 검색: 검색 관련성을 크게 향상시키는 복잡한 기능을 제공함
- 각 기술의 강점을 이해하고 적절히 활용할 필요성 강조
- AI-powered 검색의 구현은 복잡성과 리소스를 고려하여 신중히 접근해야 함
이 책은 AI 기반 검색의 다양한 기술을 다루며, 독자가 이런 기술을 효과적으로 활용할 수 있도록 돕는 것을 목표로
AI 기반 검색 엔진의 도입과 발전
1. 검색 기능의 도메인 이해 및 개선
- 시작: 검색 기능에 도메인 이해를 주입하는 필요성 인식
- 조직: 동의어 목록, 분류 체계, 알려진 엔티티 목록, 도메인 전용 비즈니스 규칙 등에 투자
- 목표: 사용자 쿼리를 성공적으로 해석하고 사용자 의도를 이해하는 것
- 해결책: 쿼리 분류, 의미론적 쿼리 파싱, 지식 그래프, 개인화 등의 기술에 투자
- 성공: 사용자 신호 및 테스트를 통해 자동화된 프로세스로 발전
- 방법: A/B 테스트, 멀티암드 밴딧, 오프라인 관련성 시뮬레이션 등
- 목표: 검색 인텔리전스의 모든 단계를 자동화하고 엔진의 자가 학습 가능하게 함
2. 전통적 키워드 검색과 관련성 엔지니어링
- 시작: 전통적 키워드 검색 구축이 첫 단계
- 관련성 엔지니어링: 검색 관련성 최대화를 위한 콘텐츠 이해, 부스트 조정, 쿼리 파라미터 조정
- 발전: 사용자 이해 및 추천 영역으로 확장하며 도메인 이해 및 의미론적 검색으로 진화
- AI 기반 검색 엔진과 전통적 검색 엔진의 차이
- 전통적 엔진: 최적화된 검색 경험 제공
- AI 기반 엔진: Reflected Intelligence를 통해 지속적으로 학습하고 개선
TL;DR 검색 기능의 개선은 도메인 이해 주입에서 시작하며, 사용자 쿼리 해석 및 의도 이해가 중요 전통적 키워드 검색이 기초를 제공하며, AI 기반 검색 엔진은 Reflected Intelligence를 통해 지속적인 학습과 개선을 가능하게
3. Reflected Intelligence와 피드백 루프
- 개념: 사용자 입력, 콘텐츠 업데이트, 사용자 상호작용을 활용하여 검색 품질 지속 개선
- 피드백 루프: 교육에 비유하여, 상호작용 없이는 학습이 어려움
- 검색 엔진: 피드백 루프를 통해 상호작용 학습 시스템에 적합
- 피드백 루프의 흐름
- 사용자 쿼리 발행 → 검색 수행 → 결과 반환
- 사용자의 행동: 클릭, 장바구니 추가, 구매 등
- 행동 분석: 검색 결과의 관련성에 대한 단서 제공
- 피드백 루프의 적용
- 예시: 특정 쿼리에서 결과 3번에 대한 클릭이 많으면 결과 정렬 자동 조정
- 목표: 지속적인 검색 경험 개선
4. 사용자 신호와 콘텐츠의 역할
- 신호: 사용자 상호작용의 데이터 포인트
- 예시: 검색, 클릭, 구매 등의 모든 상호작용 기록
- 머신러닝 알고리즘 활용: 사용자, 콘텐츠, 도메인 이해 모델 생성
- 콘텐츠의 역할
- 도메인 모델: 문서의 키워드, 카테고리, 엔티티를 통해 도메인 이해
- 의미론적 그래프: 도메인 데이터의 강력한 의미론적 검색 지원
TL;DR 피드백 루프는 검색 품질을 지속적으로 개선하며, 사용자 신호와 콘텐츠는 AI 기반 검색 엔진의 지능 엔진을 구동하는 두 가지 주요 요소임. 신호는 사용자의 상호작용을 기록하고, 콘텐츠는 도메인을 이해하는 데 중요한 역할을
5. 패션 상품 검색에 대한 적용 예시
- 이미지와 상품 메타 데이터 기반 검색
- 사용 모델: CNN(Convolutional Neural Network), RNN(Recurrent Neural Network)
- 인풋: 상품 이미지, 텍스트 설명
- 아웃풋: 관련 상품 리스트, 추천 상품
- 적용 방법
- 이미지 인식: CNN을 통해 상품 이미지의 피쳐 추출
- 메타 데이터 분석: RNN을 통해 텍스트 설명의 의미론적 이해
- 사용자 피드백: 클릭, 구매 등의 행동을 신호로 활용하여 검색 결과 최적화
이런 방식으로, 패션 상품 검색에 AI 기반 검색 엔진을 적용하면 사용자의 실제 클릭 및 구매 데이터를 활용해 추천 결과를 지속적으로 개선할 수 있음
AI 기반 검색 엔진의 설계와 구현 방법
p32
- Deep Learning의 복잡성
- 현대의 많은 AI 기법들이 인공 신경망 기반의 딥러닝에 의존
- 딥러닝 모델의 내부 복잡성으로 인해 특정 예측이나 출력에 기여하는 요소를 휴먼이 이해하기 어려움 → “Black Box AI” 문제 발생
- 잘못된 판단을 내릴 때 디버깅 및 수정이 어려움.
- 따라서, Explainable AI 또는 Interpretable AI와 같은 분야가 등장하여 이런 모델을 이해, 관리 및 신뢰할 수 있도록
- AI-보조 휴먼 큐레이션
- 이 책에서는 AI를 사용하여 검색 지능을 자동화하되, 휴먼이 개입하여 자신의 전문 지식을 투입할 수 있도록
- 휴먼이 표현할 수 있는 형태로 지능을 만들고, 이를 휴먼 지능으로 수정 및 보강하는 것을 목표로
- AI-보조 검색 엔진의 아키텍처는 여러 빌딩 블록을 조합해 스마트한 엔드 투 엔드 시스템을 구축해야
- 구성 요소
- 코어 검색 엔진: Solr, Elasticsearch/OpenSearch, Vespa 등
- 검색 가능 콘텐츠를 엔진에 피드하여 유용하게 변환 → 문서 분류, 필드 값 정규화, 텍스트에서 엔티티 추출, 감정 분석, 콘텐츠 클러스터링, 구문 탐지 및 주석, 추가 데이터 통합 등
- 이후, 쿼리 파이프라인을 통해 들어오는 쿼리를 구문 분석하고, 구문 및 엔티티 식별, 관련 용어/동의어 및 개념 확장, 철자 오류 수정 등을 수행하여 코어 엔진이 가장 관련성 높은 결과를 찾을 수 있도록 쿼리를 재구성
p33
- 도메인 지식의 중요성
- 쿼리 지능에는 도메인에 대한 강력한 이해가 필요
- 사용자 신호와 콘텐츠에 대한 배치 작업 실행 → 패턴 학습 및 도메인 특화 지능 도출
- 예: 사용자 오타 및 교정 선택(6장), 인기 문서 부스팅(8장), 미지의 쿼리에서 최적의 랭킹(10장)
- 실시간 쿼리 처리
- 쿼리는 실시간으로 처리되어야 하며, 밀리초 단위로 반환이 기대됨.
- Spark 등 작업 처리 프레임워크 및 워크플로우 스케줄링 메커니즘 필요.
- 사용자 신호의 지속적인 수집 및 저장 메커니즘도 필요
- 신호 모델 생성: 인기 쿼리 항목 부스팅, 전체 쿼리 적용 학습 랭킹 모델, 사용자별 추천 및 개인화 선호도 생성
- 지속적인 학습 및 개선
- 시스템은 지속적인 문서 변경 및 사용자 신호 스트림을 수신하고, 이를 통해 모델을 학습 및 개선하며, 지속적으로 검색 결과를 조정하고 변화의 영향을 측정하여 보다 지능적인 결과 제공.
p34
- 고도화된 검색 기대
- 도메인 인식, 컨텍스트 인식, 개인화, 대화형, 다중 모드(텍스트, 음성, 이미지 등) 검색 기대
- 정보 검색 내에서 검색과 추천은 개인화 스펙트럼의 양 극단
- 사용자 의도 해석: 콘텐츠, 사용자 및 플랫폼의 도메인 지식 동시 이해 필요
- 최적 검색 관련성: 개인화 검색, 시맨틱 검색, 다중 모드 추천의 교차점
- 이 책의 기술은 대부분의 검색 플랫폼에 적용 가능하며, 주로 Apache Solr와 Apache Spark 활용
- AI-기반 검색은 콘텐츠와 사용자 신호라는 두 가지 연료로 작동
- Reflected Intelligence를 통해 지속적으로 신호 수집, 결과 조정 및 개선 측정을 수행하여 학습 및 향상
p35
- 자연어 처리의 복잡성
- 지능형 검색 구현을 위해 자연어의 복잡성과 뉘앙스를 다루어야
- 키워드, 엔티티, 개념, 오타, 동의어, 약어, 모호한 용어, 개념 간 명시적 및 암묵적 관계, 분류 체계 내 계층적 관계, 온톨로지 내 상위 관계, 지식 그래프 내 엔티티 관계의 구체적 인스턴스를 처리해야
- 핵심
- AI 기반 검색 엔진은 심층 학습 모델의 복잡성을 해결하기 위해 Explainable AI와 같은 기술이 필요
- 도메인 지식과 실시간 쿼리 처리가 필요하며, Spark와 같은 도구를 통해 지속적으로 학습하고 개선해야
- 자연어의 복잡성을 이해하고 다루면서 검색 관련성을 최적화하는 것이 필요
-
추가 자료 및 예시
- 패션 상품 검색 예시: 이미지와 상품 메타 정보를 활용한 검색 방식으로, 사용자는 특정 스타일이나 브랜드의 이미지를 업로드하고, 검색 엔진은 해당 이미지를 바탕으로 유사한 패션 아이템을 추천 이미지 인풋은 딥러닝 기반의 이미지 분석 모델을 사용하여 주요 피쳐을 추출하고, 메타 정보와 결합하여 유사 아이템을 검색 검색 결과는 유사도 점수에 따라 랭크되어 사용자에게 제공됨.
p36
- 자연어 이해 및 검색 문제 해결을 위한 철학적 기초 구축
- 철학적 기초는 AI 기반 검색 시스템에서 모든 구성 요소가 통합되고 일관되게 작동하도록
- 자연어 이해 문제를 해결하고 검색 애플리케이션을 더 지능적으로 만들기 위한 솔루션 적용.
- 자유 텍스트 및 비정형 데이터 소스의 본질에 대한 일반적인 오해 논의.
- 비정형 데이터의 정의 및 오해
- 비정형 데이터는 사전 정의된 스키마에 맞지 않는 텍스트 데이터로 설명됨.
- “비정형”이라는 용어는 텍스트의 의미를 충분히 설명하지 못 텍스트는 문법적 규칙 등을 통해 구조화됨.
- 예시: 라디오에서 재생되는 노래도 고유한 특성을 가지지만 일반적인 속성을 따르며 의미 전달 가능.
- 예시 이미지 및 설명
- Figure 2.1: 일반적인 검색 엔진에서 발견할 수 있는 비정형 데이터 텍스트 예시.
p37

- 비정형 데이터의 다른 유형
- 텍스트 외에도 이미지, 오디오, 비디오 등이 비정형 데이터의 특성을 공유
- Figure 2.2: 텍스트 외 다양한 비정형 데이터 유형 예시(오디오, 이미지, 비디오 포함).
- 오디오 및 이미지의 특성
- 오디오는 감정, 목소리 톤 등의 뉴앙스를 효과적으로 인코딩할 수 있음.
- 이미지는 색상의 그리드를 통해 아이디어를 표현하며, 비디오 역시 여러 이미지와 오디오의 조합임.
p38
- 반정형 데이터: 비정형 데이터가 구조화된 데이터와 혼합된 형태
- 로그 데이터는 이벤트 날짜, 유형, 설명이 포함된 반정형 데이터의 예시.
- 비정형 데이터와 구조화된 데이터 비교
- SQL 데이터베이스의 레코드는 컬럼으로 분할되며, 이 중 일부는 이산적(discrete) 값과 연속적(continuous) 값을 가짐.
- 이산적 값은 열거형 목록에서 유래된 값이며, 연속적 값은 범위 내의 값을 나타냄.
p39
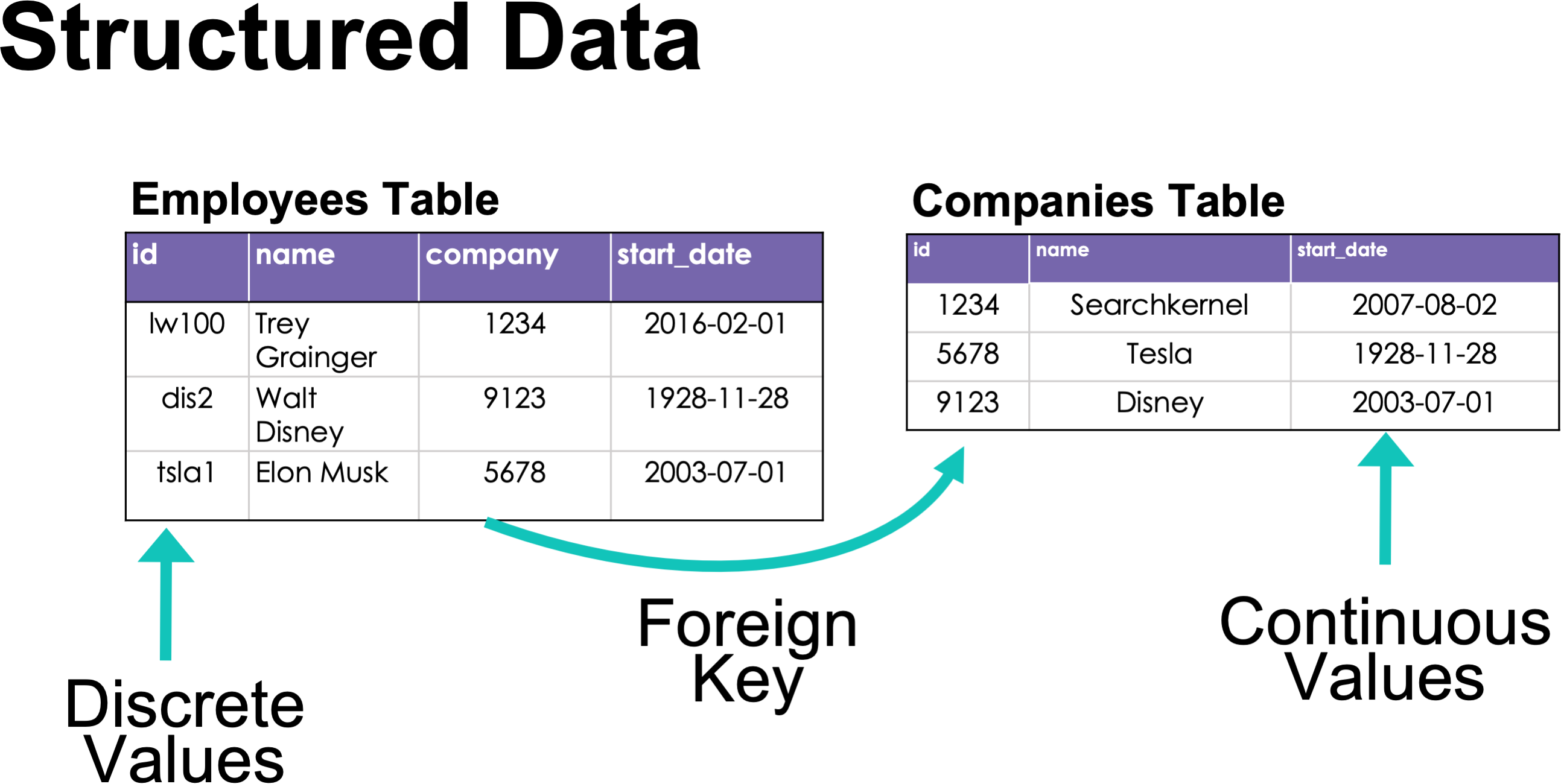
- 구조화된 데이터에서의 관계 및 조인(join)
- 외부 키(foreign key)를 사용하여 서로 다른 테이블의 레코드를 연결
- Figure 2.3: 데이터베이스에서 이산적, 연속적 값 및 외부 키를 사용하는 예
- 비정형 데이터에서도 유사한 조인 기법 적용 가능
- 비정형 데이터에는 명시적으로 모델링된 테이블만큼 명확한 구조가 없지만, 유연한 구조 내에 많은 정보가 포함됨
- 비정형 데이터에서 외부 키와 유사한 개념을 사용하여 문서 간 관계를 찾고 조인 가능
TL;DR
- 비정형 데이터는 텍스트의 의미를 충분히 설명하지 못하며, 구조화된 데이터와 유사한 규칙과 구조를 따름
- 다양한 비정형 데이터 유형은 텍스트뿐 아니라 이미지, 오디오, 비디오를 포함하여 검색 엔진에서 처리됨
- 구조화된 데이터와 비정형 데이터 간의 유사한 조인 기법을 통해 관계 발견 가능
- 패션 상품 검색 예시
- 이미지와 상품 메타 정보를 기반으로 패션 상품 검색 시, 이미지의 색상 및 패턴을 텍스트와 연결하여 유사한 제품 추천 가능
- 머신러닝 모델을 활용하여 이미지의 주요 피쳐을 추출하고, 텍스트 메타데이터와 함께 검색 엔진에 통합하여 검색 정확도 향상
이와 같이, 비정형 데이터는 본래 구조가 없다고 여겨지지만 실제로는 다양한 규칙과 구조를 포함하고 있으며, 이를 통해 검색 및 데이터 처리에 적용할 수 있는 다양한 방법이 존재
Unstructured Data and Fuzzy Foreign Keys
p40
Unstructured Data in Search Engines
- 개념 설명
- “Activate”라는 용어는 기술 컨퍼런스를 가리킴.
- 동일한 단어가 두 개의 다른 텍스트 섹션에서 사용됨.
- 각 정보 조각(텍스트 블록, 이미지, 비디오, 오디오 클립)은 검색 엔진의 별도 문서로 표현됨.
- 데이터베이스의 두 행이 같은 “Activate” 값을 포함하는 것과 유사하게, 두 문서가 “Activate”라는 외래 키로 연결됨.
- 이미지 설명
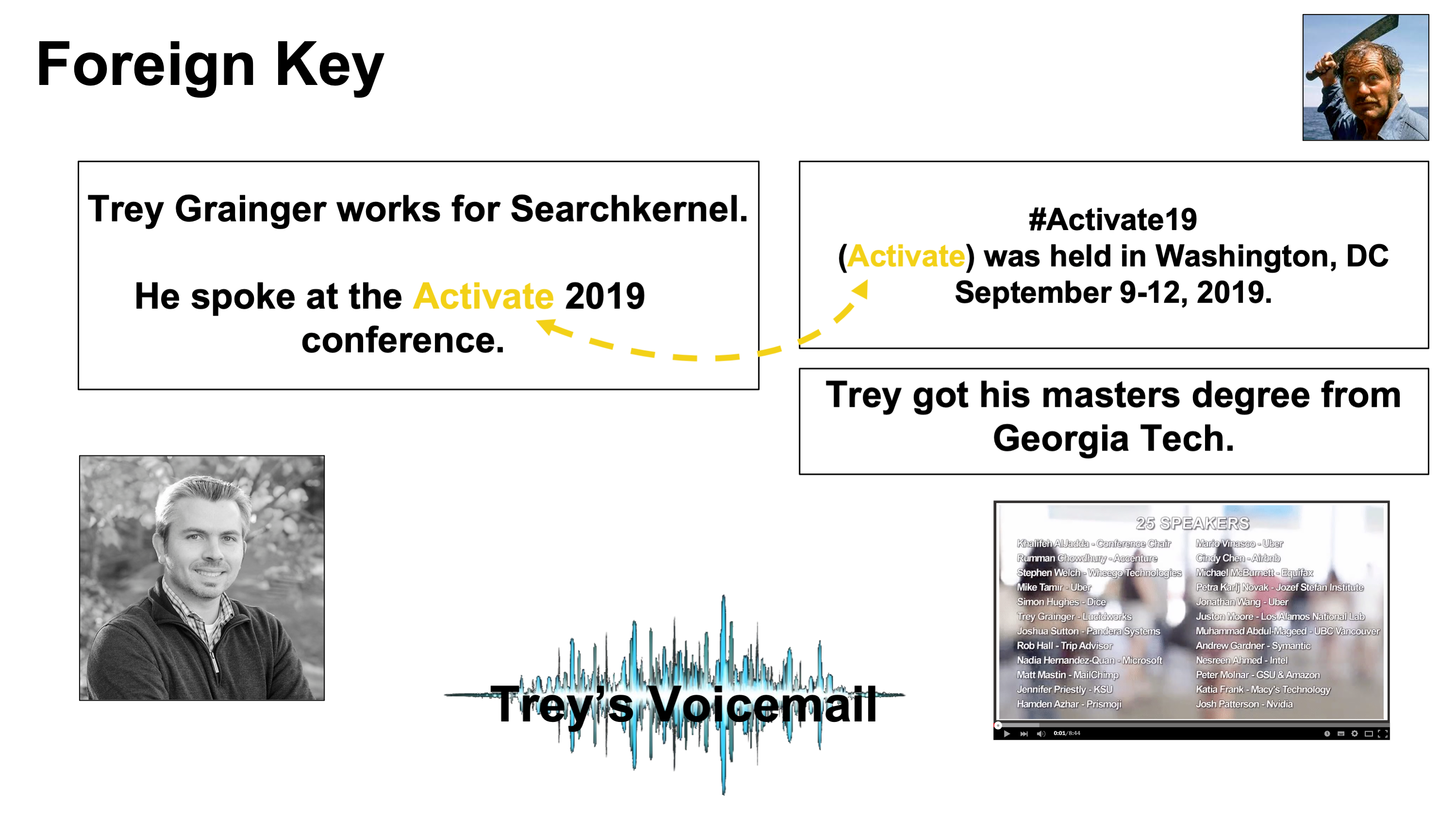
- Figure 2.4: 비구조적 데이터에서의 외래 키. 두 관련 텍스트 문서를 연결하는 동일한 용어 사용 예
- 비구조적 데이터의 Pros(+)
- 전통적 구조 데이터 모델링보다 강력
- 예시: 두 문서가 “Trey Grainger”와 “Trey”라는 이름으로 연결
TL;DR
- 동일한 용어가 여러 문서에서 사용되며, 이는 비구조적 데이터의 외래 키로 작용
- 비구조적 데이터는 전통적 데이터베이스보다 더 유연
- 데이터는 강력한 문맥적 관계를 통해 연결될 수 있음.
p41
Fuzzy Foreign Keys
- 개념 설명
- 두 문서가 서로 다른 용어로 동일한 엔티티를 참조하지만 동일한 의미로 해석됨.
- “Fuzzy Foreign Key” 개념 도입: 동일한 엔티티로 해결하기 위해 자연어 처리(NLP) 및 엔티티 해결 기술 필요
- 이미지 설명
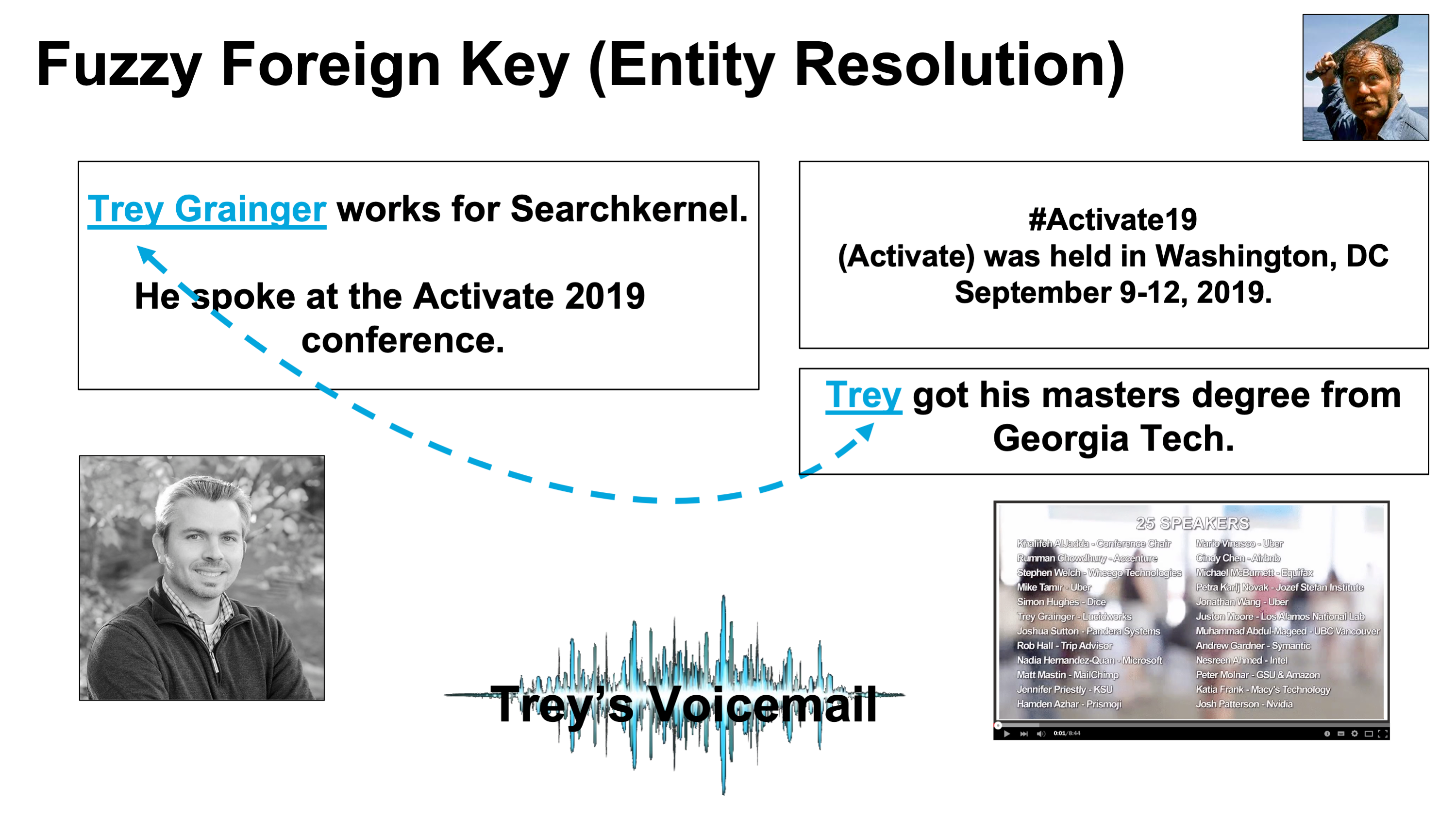
- Figure 2.5: 다른 용어 시퀀스를 사용하여 동일한 엔티티를 참조하는 예시.
- 엔티티 해결
- “Trey”와 “Trey Grainger”가 동일 엔티티를 나타냄.
- “he”와 “his”도 동일 엔티티로 해석 가능
TL;DR
- Fuzzy Foreign Key는 유연한 엔티티 결합을 가능하게
- 자연어 처리 기술이 필요
- 동일한 엔티티를 여러 방식으로 해석하여 문서 간 결합 가능.
p42
Fuzzier Foreign Keys
- 개념 설명
- 고유명사, 대명사, 이미지, 비디오 참조가 동일 엔티티로 해결됨.
- 비구조적 정보의 숨겨진 구조를 활용하여 문서 결합 및 엔티티 학습
- 이미지 설명
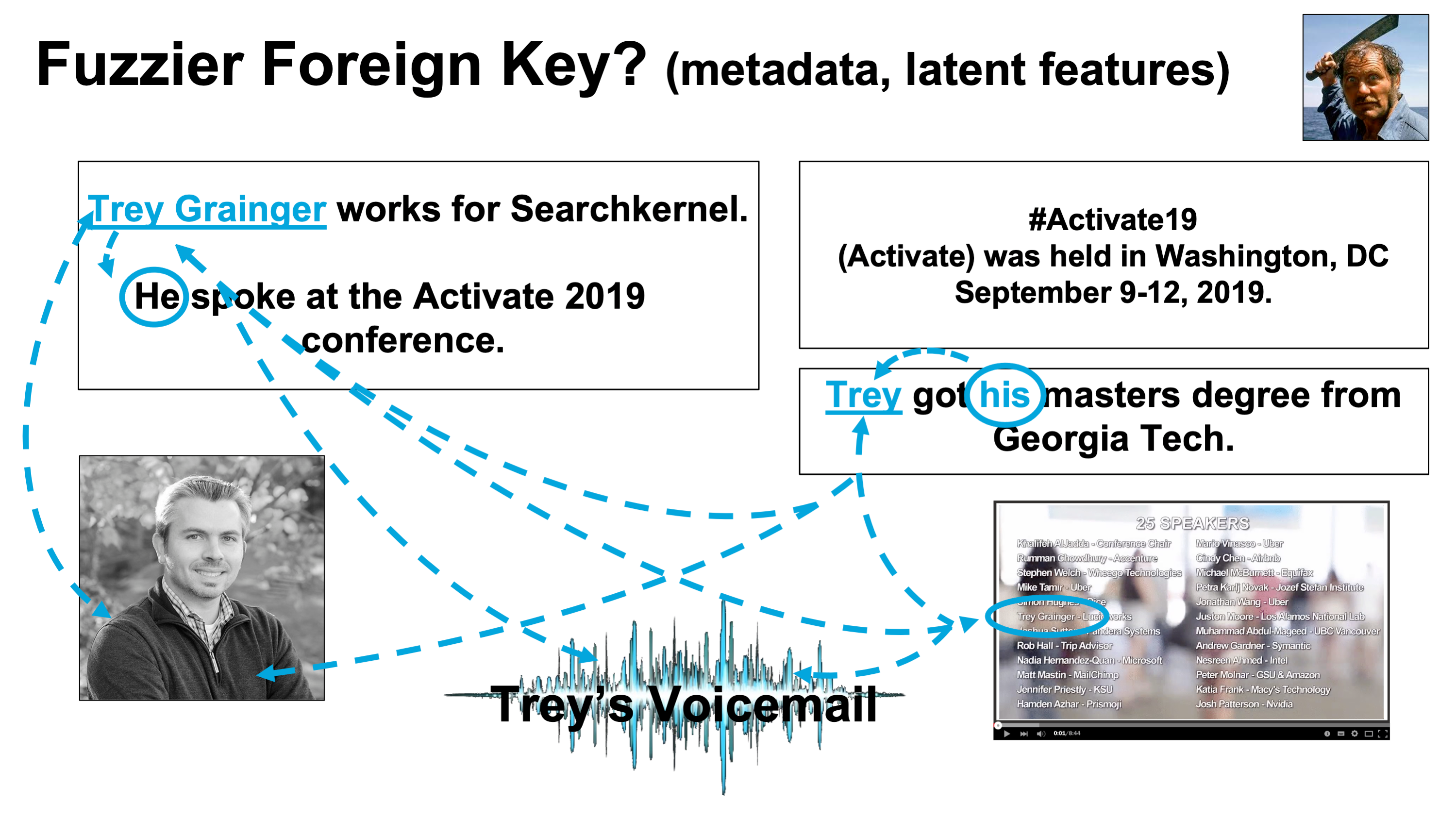
- Figure 2.6: 다양한 참조를 동일 엔티티로 해결 예
- 문제점 및 해결
- 다의어(polysemy) 문제: 동일 철자 단어가 여러 의미 가질 수 있으며,
- AI 기반 검색 엔진은 문맥을 활용하여 이런 차이를 구별해야 함.
TL;DR
- 이미지와 비디오 참조도 동일 엔티티로 해결 가능
- 다의어 문제는 검색 응용에서 큰 문제로 작용
- 문맥 기반의 차이 구별이 필요
p43
Dealing with Ambiguous Terms
- 개념 설명
- “Trey Grainger” 검색 시 다양한 이미지 결과 반환
- 검색어의 다의성 문제 강조: 동일 철자지만 다른 의미 가질 수 있음
- AI 기반 검색 엔진은 문맥을 활용하여 의미 구별 필요
- 이미지 설명
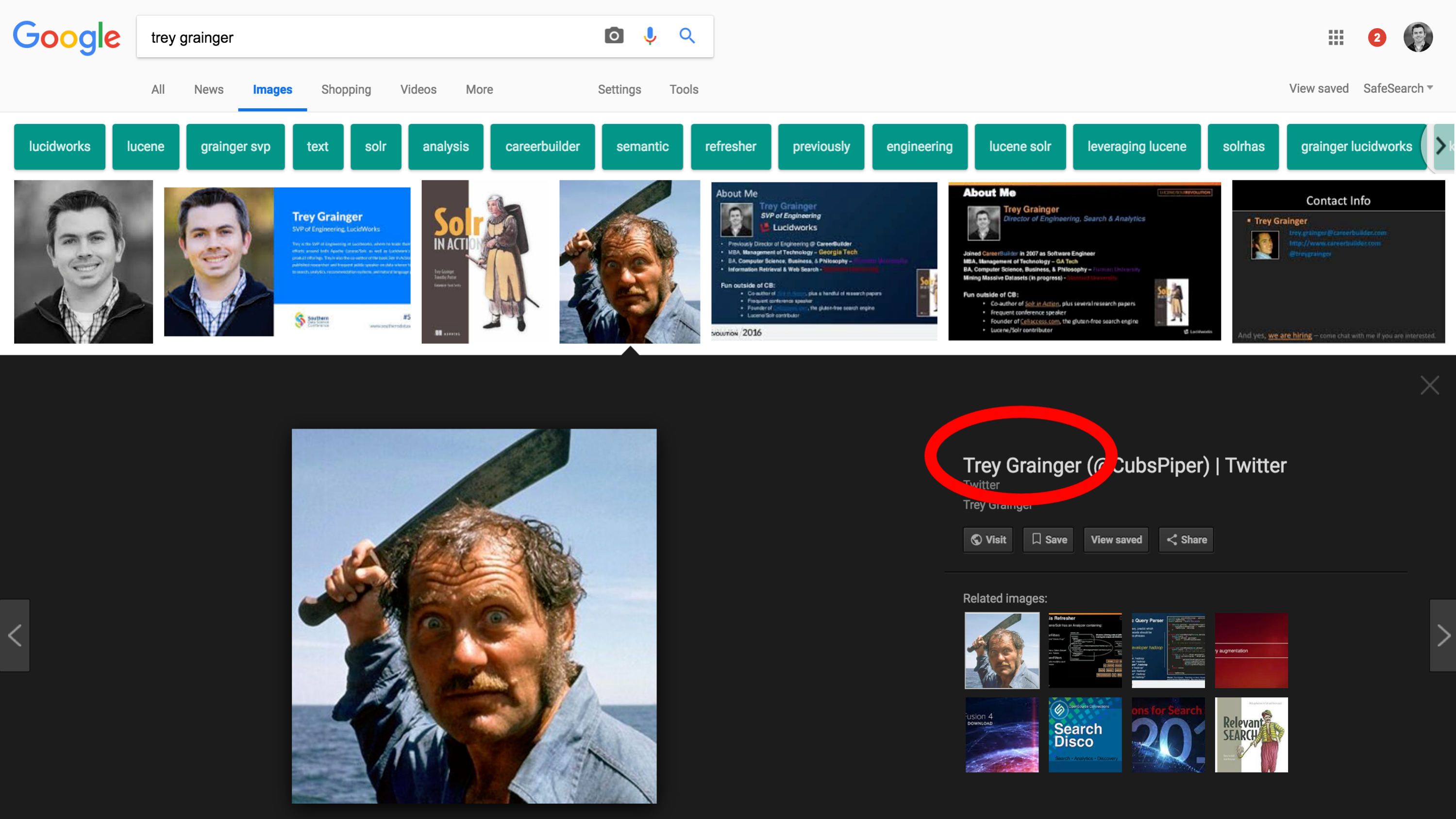 Figure 2.7: “Trey Grainger” 검색 결과 이미지.
Figure 2.7: “Trey Grainger” 검색 결과 이미지.
- 유의점
- 검색 시 다의어 문제 인식 필요
- AI 엔진은 문맥 이해 및 차이 구별을 통해 정확한 정보 제공해야 함.
TL;DR
- 다의어 문제는 검색 정확도에 큰 영향을 미치며,
- AI는 문맥을 통해 의미 구별을 수행해야 함
- 비구조적 데이터는 많은 관계를 포함한 그래프로 이해 가능
관계 그래프와 자연어의 구조
1. Giant Graph of Relationships
1.1 관계 그래프의 이해
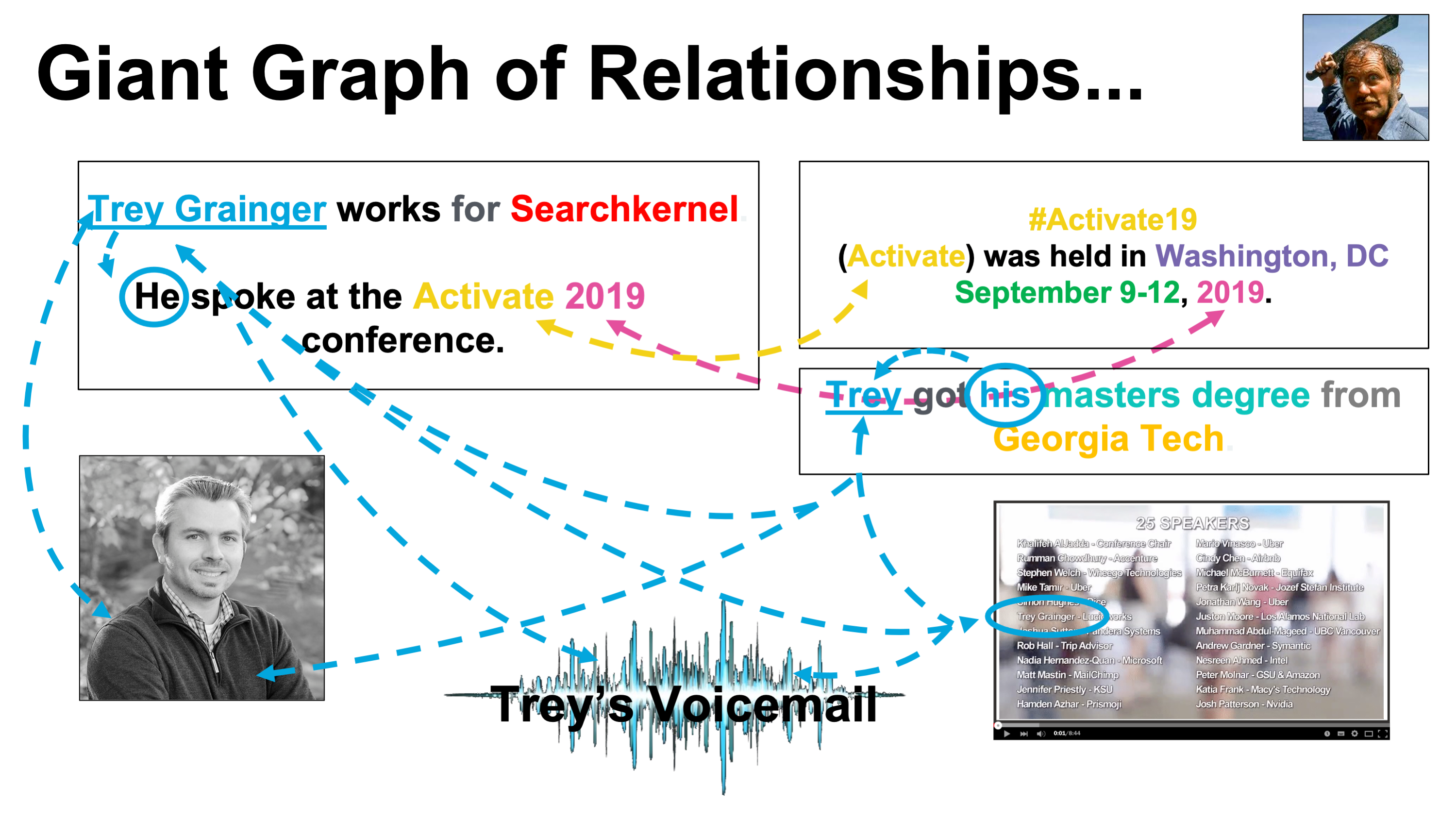
Figure 2.8: 관계의 대규모 그래프
- 관계 그래프는 문서 간의 연결성에서 파생됨
- 이름, 날짜, 사건, 장소, 인물, 기업 등 다양한 엔티티 존재
- 문서 간 엔티티의 조인을 통해 관계 인퍼런스 가능
- 이미지의 올바른 비모호화 수행 → “마체테 남자”가 그래프에서 분리됨
1.2 대규모 문서에서의 학습
- 소수의 문서에서 이런 정보를 학습 가능 → 수천, 수백만, 수십억 문서에서 학습할 수 있는 가능성
- AI 기반 검색 플랫폼의 일부로 데이터에서 통찰력 학습 수행
- 이런 방대한 관계 그래프를 활용하여 지능 구현 필요
- 역방향 인덱스의 구조 활용 → 추가적인 데이터 모델링 없이 그래프 탐색 용이
- 5장에서 데이터에 숨겨진 의미적 지식 그래프 활용 방법 심층 탐구 예정
TL;DR
- 문서 간의 엔티티 연결을 통해 대규모 관계 그래프 형성.
- AI 기반 검색 플랫폼에서 이런 그래프를 활용하여 지능적 통찰력 학습.
- 역방향 인덱스를 통해 추가적 모델링 없이 그래프 탐색 가능.
2. 자연어의 구조
2.1 자연어의 계층적 구조

Figure 2.9: 자연어의 의미적 데이터 인코딩
- 문자 → 문자 시퀀스 → 용어 → 용어 시퀀스 → 필드 → 문서 → 코퍼스의 계층적 구조
- 문자: 개별 문자, 숫자, 기호
- 문자 시퀀스: “e”, “en”, “eng”, “engineer” 등
- 용어: “engineer”, “engineering” 등의 단어
- 용어 시퀀스: “software engineer”, “senior software engineer” 등
2.2 용어 시퀀스와 구의 차이
- 구(Phrase) 모든 용어가 순차적으로 나타나는 용어 시퀀스
- 예: “chief executive officer”는 구이면서 용어 시퀀스
- “chief officer”~2은 비순차적 용어 시퀀스에 해당
2.3 텍스트 분석의 중요성
- 텍스트 필드는 텍스트 분석기를 통해 다양한 방식으로 분석 가능
- 공백 및 구두점 분할, 소문자화, 노이즈 제거, 스테밍 또는 표제화, 악센트 제거 등 포함
- Solr in Action 6장에서 텍스트 분석 과정 상세 참조 가능
TL;DR
- 자연어는 문자부터 코퍼스까지의 계층적 구조로 구성.
- 용어 시퀀스는 순차적 용어의 조합이며, 구는 그 특별한 형태.
- 텍스트 분석을 통해 문서의 의미를 더 명확히 이해 가능.
3. 분포 의미론과 단어 임베딩
3.1 분포 의미론의 개념
- 분포 가설: 비슷한 맥락에서 등장하는 단어는 유사한 의미 공유
- 대표적 인용: “You shall know a word by the company it keeps.” - John Rupert Firth
3.2 검색 엔진에서의 활용
- 검색 엔진은 분포 의미론을 활용하여 문서의 맥락 파악 용이
- 예시 쿼리: “C-level executives”를 찾기 위한 문자 시퀀스 쿼리
c?o: “CEO”, “CMO”, “CFO” 등 매칭"VP Engineering"~2: “VP Engineering”, “VP of Engineering” 등 매칭
- 역방향 인덱스는 복잡한 boolean 쿼리 지원
- 예:
(Microsoft OR MS) AND Word
- 예:
TL;DR
- 분포 의미론: 비슷한 맥락의 단어는 유사한 의미를 가짐.
- 검색 엔진에서 분포 의미론 활용하여 문서의 맥락 이해 가능.
- 역방향 인덱스를 통한 복잡한 쿼리 지원으로 다양한 검색 가능.
벡터의 소개
p48
- 벡터의 개념
- 벡터: 항목의 속성을 설명하는 값의 목록
- 예: 집의 속성 → 가격, 크기, 침실 수
- 벡터 표현: 예를 들어, $100,000의 가격, 1000 평방 피트, 2개의 침실로 구성된 집은 \([100000, 1000, 2]\)로 표현됨
- 속성: 벡터의 각 요소는 ‘차원’으로 불림
- 벡터 공간: 특정 차원 집합으로 구성된 공간
- 다른 항목(e.g., 아파트, 주택 등)도 동일한 벡터 공간 내에서 표현 가능
- 예: \([1000000, 9850, 12]\) 및 \([120000, 1400, 3]\)과 같은 벡터는 동일한 벡터 공간 내에서 비교 가능
- 벡터 연산: 수학적 연산을 통해 트렌드 학습 및 벡터 비교 가능
- 예: “침실 수가 증가함에 따라 집의 가격이 증가하는 경향” 확인 가능
- 유사성 계산: 예를 들어, \([120000, 1400, 3]\) 집이 \([100000, 1000, 2]\) 집과 더 유사하다고 판단 가능
- 벡터: 항목의 속성을 설명하는 값의 목록
- 단어 임베딩의 활용
- 분포 가설: 용어 및 용어 시퀀스의 의미 이해를 위한 방법
- 단어 임베딩: 주어진 용어 시퀀스의 의미를 나타내는 수치 벡터
- 예: 단어 또는 구문이 축소된 차원 벡터로 인코딩됨
- 해당 벡터를 활용하여 의미적으로 가장 관련 있는 문서 탐색 가능
TL;DR
- 벡터는 항목의 속성을 설명하는 값의 목록으로, 다양한 항목을 동일한 벡터 공간 내에서 표현 가능
- 단어 임베딩은 용어의 의미를 수치 벡터로 표현하여 의미적으로 관련 있는 문서를 찾는 데 사용됨.
- 유사성 계산을 통해 벡터 간의 관계를 평가하고, 관련 항목을 효과적으로 탐색 가능
p49
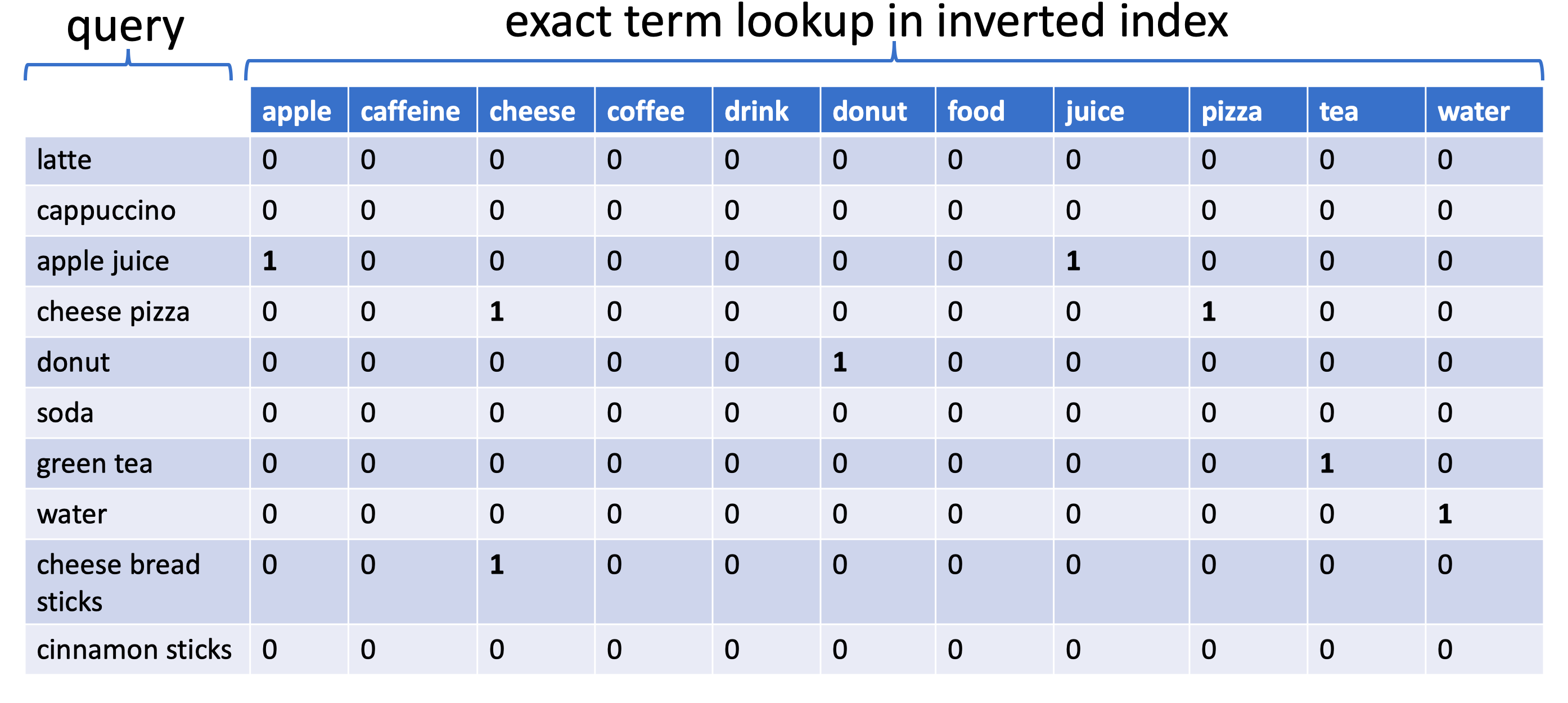
- 벡터 매핑 및 유사성 평가
- 검색 엔진의 기본 동작 방식: 쿼리가 인덱스 내 각 용어에 대한 벡터로 매핑됨
- 쿼리 내 존재하는 용어의 차원 값은 “1”, 존재하지 않는 경우 “0”
- 문서 유사성 계산: 쿼리 벡터와 문서 벡터 간의 유사성 점수를 계산하여 관련 문서 식별
- 한계: 정확한 키워드 일치에는 적합하나, 관련 항목 탐색에는 한계 존재
- 예: “soda”는 쿼리에 있지만 인덱스에 없으면 0 결과 반환
- “caffeine” 존재하더라도 “latte”, “cappuccino”와 연관성 평가 불가
- 검색 엔진의 기본 동작 방식: 쿼리가 인덱스 내 각 용어에 대한 벡터로 매핑됨
p50
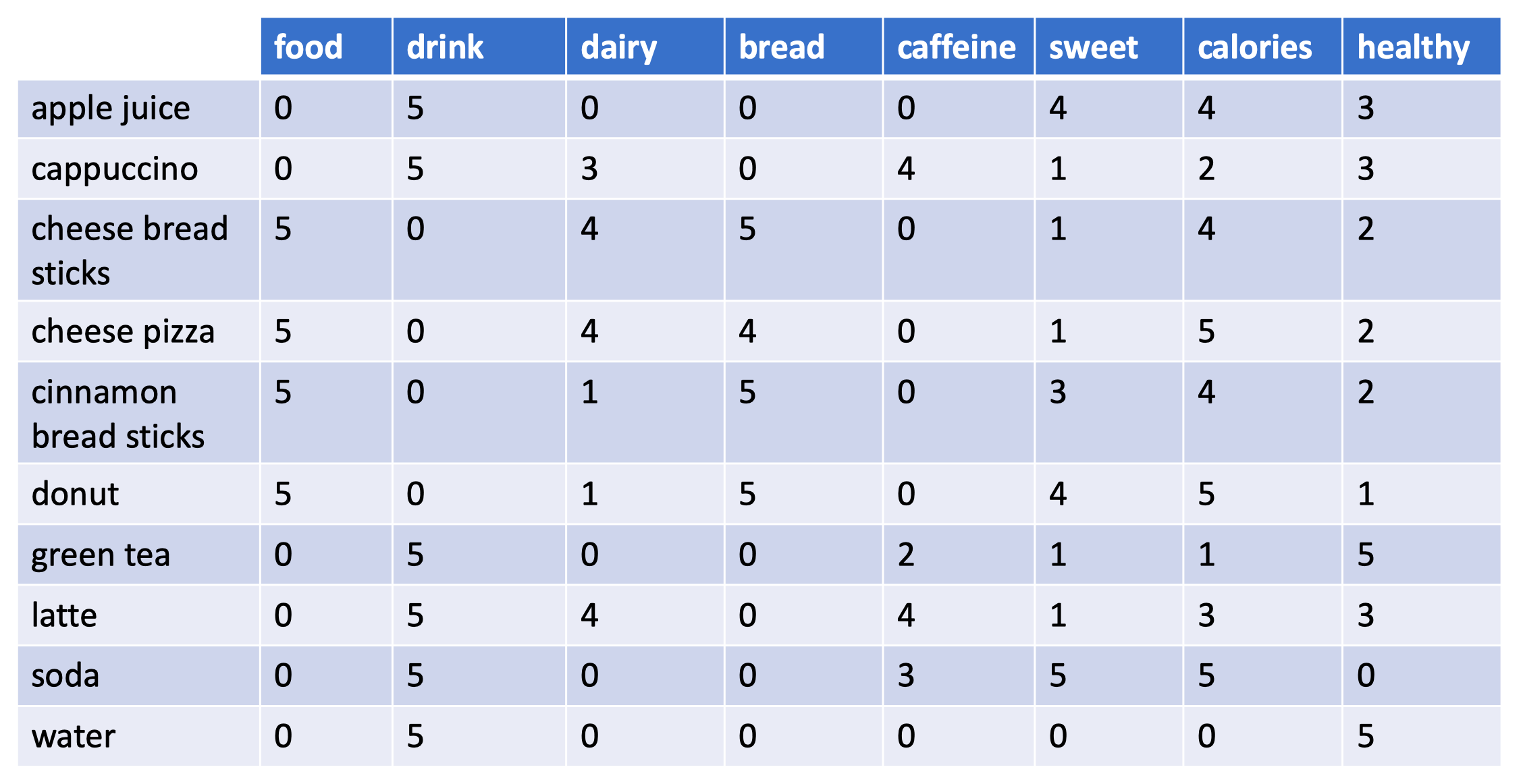
- 차원 축소 및 단어 임베딩
- 차원 축소: 용어가 고차원 벡터로 매핑됨
- 예: “healthy”, “caffeine”, “food”와 같은 속성 평가
- 유사성 계산: 코사인 유사도 또는 거리 측정을 통해 벡터 간의 관계 평가
- 점곱 및 벡터 크기로 스케일링하여 유사성 계산
- 차원 축소: 용어가 고차원 벡터로 매핑됨
p51
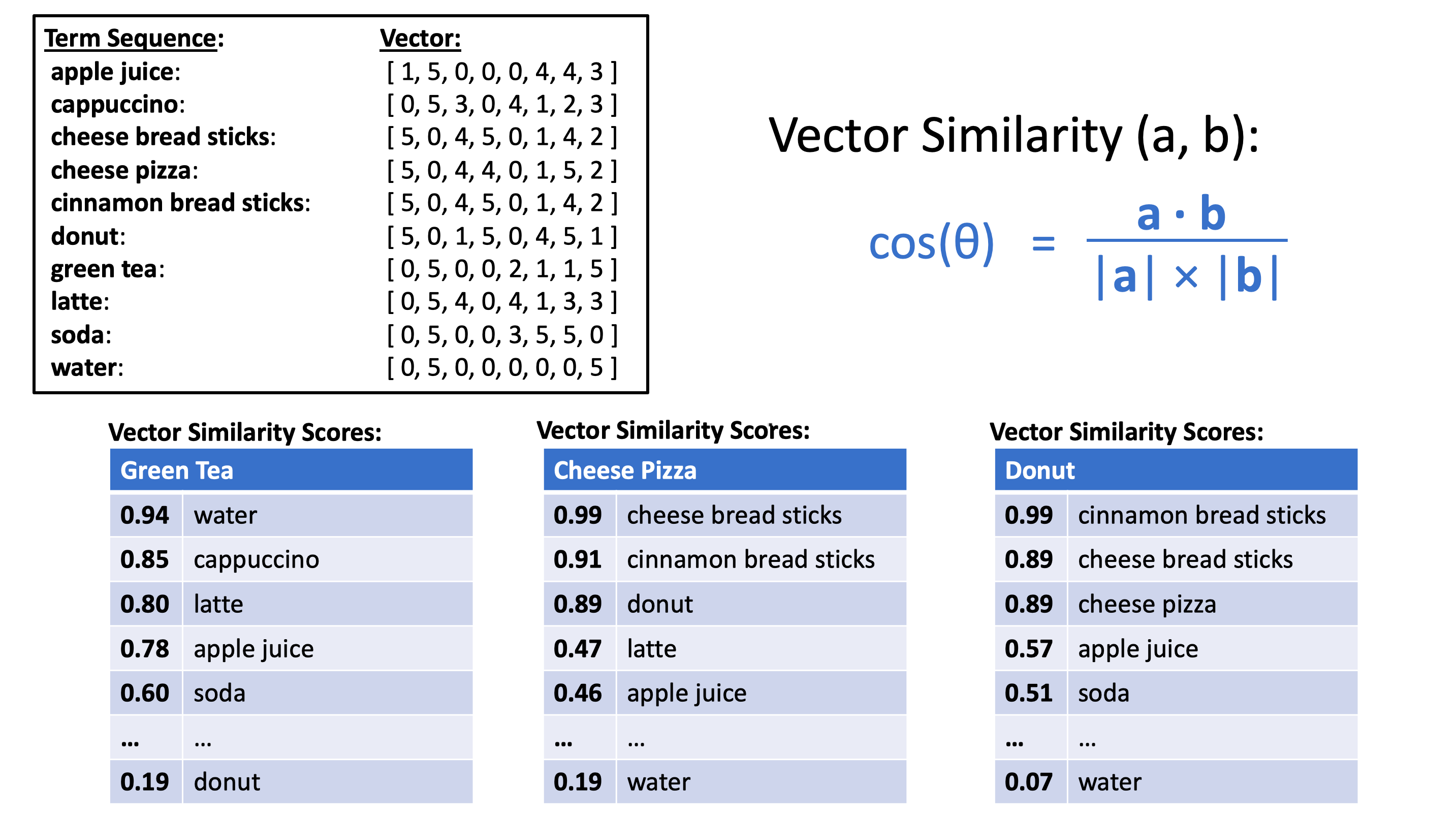
- 유사성 평가 예시
- 예: “green tea”와 다른 용어 시퀀스 간의 유사성 평가
- “water”, “cappuccino”, “latte”, “apple juice”, “soda”가 가장 관련 있음
- “donut”는 가장 관련 없다고 평가됨
- 검색 엔진 내 벡터 스코어링: 두 단계 프로세스
- 첫 번째 단계: 키워드 검색
- 두 번째 단계: 결과 문서 스코어링
- 벡터 기반 검색 구현에 대한 추가 논의는 13장에서 다룰 예정
- 예: “green tea”와 다른 용어 시퀀스 간의 유사성 평가
TL;DR
- 쿼리와 문서 간의 유사성은 벡터 스코어링으로 평가되며, 정확한 키워드 일치에는 한계가 있음.
- 차원 축소된 단어 임베딩을 통해 의미적으로 관련 있는 항목을 효과적으로 탐색 가능.
- 벡터 스코어링은 검색 엔진에서 관련 문서를 식별하는 데 중요한 역할을 수행
관련 문서 및 예시
- 패션 상품 검색 예시:
- 이미지 및 상품 메타 정보를 기반으로 유사성 평가
- 이미지 벡터와 메타 정보 벡터의 유사성을 통해 관련 상품 탐색
위 내용을 바탕으로 벡터 및 단어 임베딩의 중요성과 활용 방법에 대해 이해할 수 있음. 더욱 심도 있는 내용은 이후 장에서 다룰 예정임.
도메인 특화 지식 모델링
속성 벡터와 임베딩
- 속성 벡터의 역할 쿼리 내 다른 용어 시퀀스를 나타내거나, 문서 내 용어 시퀀스를 나타내거나, 전체 문서를 나타내는 데 사용됨.
- 용어 및 용어 시퀀스는 워드 임베딩으로 인코딩됨
- 문장 임베딩 전체 문장 인코딩
- 단락 임베딩 전체 단락 인코딩
- 문서 임베딩 전체 문서 인코딩
- 추상적 차원 딥러닝 모델이 문서 내 문자 시퀀스와 클러스터링에서 불명확한 특성을 추출
- 차원을 쉽게 레이블링할 수 없으나, 모델의 예측력을 향상시킨다면 큰 문제는 아님
- 결론 분산 의미론과 워드 임베딩의 힘을 결합한 여러 모델을 사용하는 것이 최선의 결과를 만듦.
지식 모델링 기법
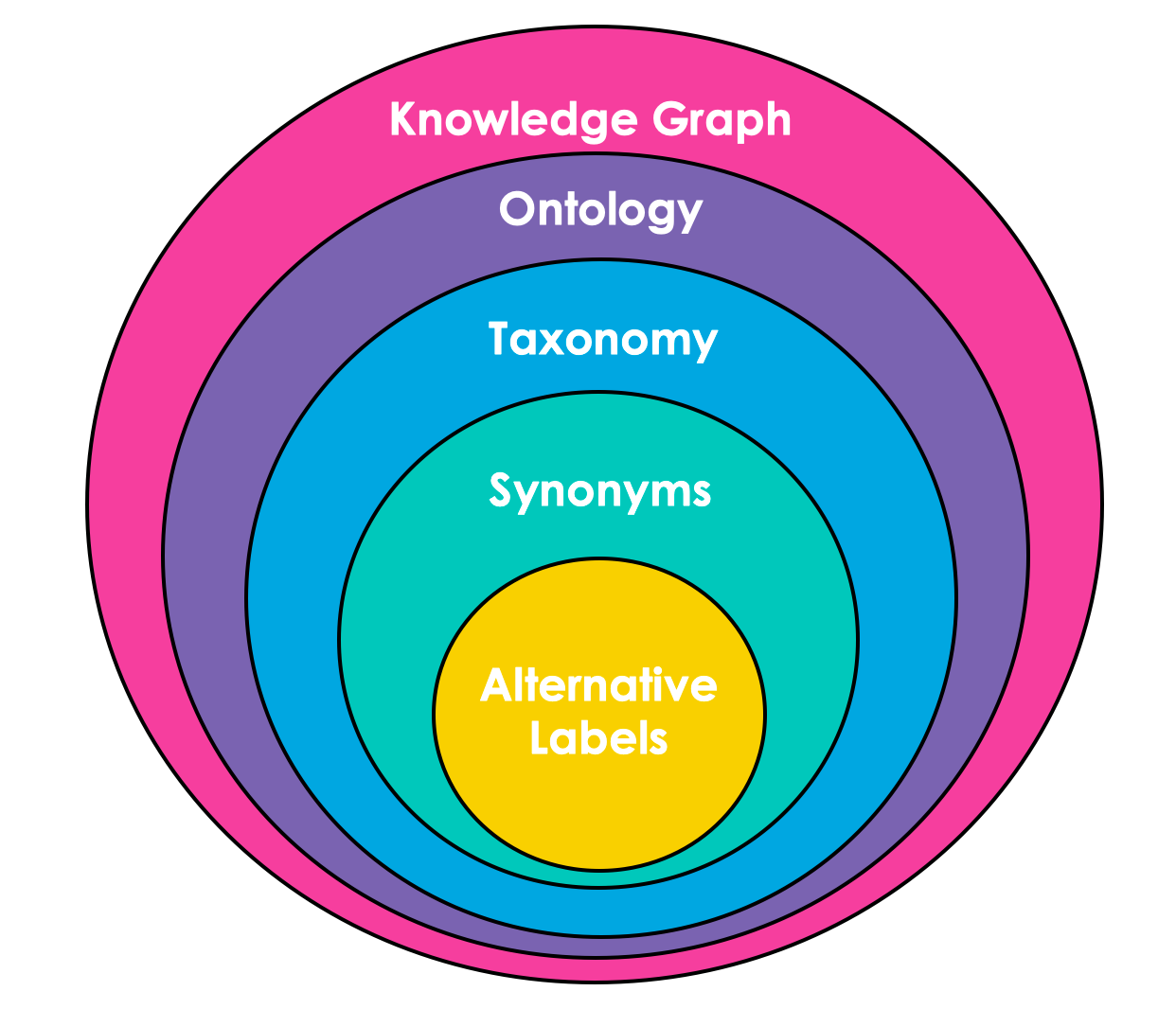
- 대체 레이블(Alternative Labels) 동일한 의미를 가진 용어 시퀀스.
- 예: CTO => Chief Technology Officer
- 동의어(Synonyms) 같은 의미 또는 유사한 의미를 나타낼 수 있는 용어 시퀀스.
- 예: human => homo sapiens, mankind
- 분류학(Taxonomy) 사물을 카테고리로 분류.
- 예: human is mammal
- 온톨로지(Ontology) 사물 간 관계의 매핑.
- 지식 그래프(Knowledge Graph) 온톨로지의 구현체로, 관련된 사물도 포함
지식 모델링의 정의와 적용
- 대체 레이블 약어나 철자 오류 등을 포함한 용어 교체.
- 동의어 검색 엔진에서 자주 사용, 용어 확장의 역할.
- 분류학 콘텐츠를 계층 구조로 분류, 웹사이트 네비게이션에 사용됨.
- 온톨로지 도메인 내 사물 간 추상적 관계 정의.
- 지식 그래프 온톨로지를 기반으로 구체적인 엔티티와 관계 포
TL;DR
- 속성 벡터는 문서의 단어 시퀀스를 표현하며, 딥러닝으로 추상적 특성을 추출
- 대체 레이블, 동의어, 분류학, 온톨로지, 지식 그래프 등의 지식 모델링 기법이 존재.
- 지식 그래프는 온톨로지의 상세한 구현으로, 관계와 엔티티를 포함
자연어 이해의 챌린지
- 다의어 문제 단어의 다양한 의미로 인해 발생하는 모호성 문제.
- 예: “driver”는 차량 운전자, 골프채, 소프트웨어 드라이버 등 여러 의미로 사용됨.
지식 모델링과 자연어 이해는 검색 시스템의 정확성을 높이는 데 필수적임. 다양한 모델과 기법을 조합하여 더 나은 검색 결과를 제공할 수 있음.
위 내용은 지식 모델링과 자연어 이해의 다양한 기법과 챌린지를 논리적으로 설명하였음. 각 기법의 정의와 활용 방안을 통해 검색 시스템의 성능 향상을 도모
2.5.2 The Challenge of Understanding Context
컨텍스트 기반 의미 해석의 중요성
- 컨텍스트의 다양성
- ‘vehicle driver’라는 카테고리 내에서도 다양한 세부 의미가 존재함
- 예: 택시 기사, Uber 기사, CDL을 보유한 트럭 기사, 버스 기사 등
- 버스 기사 내에서도 학교 버스 기사, 공공 시내 버스 기사, 관광 버스 기사 등으로 세분화 가능함
- 같은 용어라도 사용되는 문맥에 따라 의미가 달라짐
- 고정된 동의어 목록을 생성하는 것만으로는 부족함
- ‘vehicle driver’라는 카테고리 내에서도 다양한 세부 의미가 존재함
- 문맥에 의존한 의미 클러스터
- 모든 단어와 구문은 “문맥에 의존하는 의미의 클러스터”임
- 즉, 특정 문맥에 따라 다양하게 해석될 수 있음
- 고정된 동의어 목록은 비효율적임
- 모든 단어와 구문은 “문맥에 의존하는 의미의 클러스터”임
- 검색어의 문맥 해석 필요성
- 사용자가 입력하는 구문에 대한 정확하고 미세한 해석 필요
- 다양한 문맥에서의 의미를 학습하기 위한 방법 필요
2.5.3 The Challenge of Personalization
- 개인화의 복잡성
- 사용자의 브랜드 선호도가 검색 결과에 영향을 미침
- 예: Apple 제품을 자주 검색하는 사용자가 다른 카테고리에서도 Apple 제품을 선호한다고 가정할 수 없음
- 개인화는 사용자 의도를 잘못 해석할 가능성이 높음
- 사용자 의도와 브랜드 선호도의 균형 잡기
- 사용자의 브랜드 선호도가 검색 결과에 영향을 미침
- 개인화의 어려움
- 개인화는 AI 기반 검색 애플리케이션에서 가장 어려운 부분 중 하나임
- 추천 엔진을 제외하고는 잘 구현되지 않음
2.5.4 Challenges Interpreting Queries vs. Documents
- 문서와 검색어의 차이
- 문서는 긴 텍스트 블록으로 더 많은 문맥 제공
- 검색어는 짧고 다중 아이디어를 포함하는 경우가 많음
- 검색어 해석을 위한 외부 문맥 활용
- 자연어 처리 기법 대신 문서 코퍼스를 활용한 해석 필요
- 사용자 행동 신호를 분석하여 실제 의도 파악
2.5.5 Challenges Interpreting Query Intent
- 검색어 의도의 다양성
- 검색어는 단순한 키워드 매칭을 넘어선 고유의 의도를 가지고 있음
- 예: “who is the CEO?”는 사실 확인, “support”는 웹사이트의 지원 섹션 탐색
- 검색어의 구체성과 일반성
- 구체적인 검색어는 구매 의도 표현 가능성 높음
- 예: “verizon silver iphone 8 plus 64GB”는 특정 제품에 대한 구매 의도
2.6 The Fuel Powering AI-powered Search
- Reflected Intelligence와 피드백 루프
- 콘텐츠와 사용자 상호작용에서 지속적인 학습
- 문서와 사용자 행동 신호 모두에 적용 가능
- 문서 및 사용자 행동 신호에서 의미 파생
- 예: “machine learning”이 “data scientist”, “software engineer”와 자주 나타남
- 사용자 행동 패턴도 유사하여, 검색 로그에서 연관 용어 및 시퀀스 학습 가능
TL;DR
- 검색어는 문맥에 의존하여 다양한 의미를 가질 수 있으며, 고정된 동의어 목록으로는 한계가 있음.
- 개인화된 검색 경험을 제공하는 것은 사용자의 브랜드 선호도와 관련하여 복잡한 문제를 야기할 수 있음.
- 검색어는 짧고 문맥이 부족하므로, 외부 문맥을 활용한 해석이 필요하며, AI 기반의 검색을 통해 사용자 의도를 파악하는 것이 중요
링크 및 이미지 설명
- 이미지: AI-Powered Search의 시각적 설명 자료
- AI 기반 검색 엔진의 작동 방식과 사용자의 검색 의도를 이해하는 데 도움을 줌
패션 상품 검색 예시
- 문제 이미지 및 상품 메타 정보를 기반으로 패션 상품 검색
- 해결 딥러닝 기반 모델을 활용하여 이미지 및 메타 데이터를 분석, 유사한 패션 상품 추천
- 모델 인풋 사용자 제공 이미지, 텍스트 메타 데이터
- 모델 아웃풋 유사한 패션 상품 목록
- 적용 모델 예시 ResNet, VGGNet 등의 이미지 인식 모델
- ResNet 잔차 학습(residual learning)을 통해 깊은 신경망 학습 가능
- VGGNet 깊은 고정 크기 필터를 사용하여 이미지 피쳐 추출
이런 방식으로 AI 기반의 검색은 사용자에게 보다 개인화되고 정확한 검색 결과를 제공할 수 있음.
Content and User Signals in Search Applications
1. Introduction
-
Content and User Signals
→ 콘텐츠와 사용자 신호를 효과적으로 활용하는 것은 AI 기반 검색 애플리케이션의 성능을 크게 향상시킴 → 콘텐츠가 풍부하거나 사용자 신호가 많거나, 최적의 경우 둘 다 풍부하면 더욱 스마트한 검색 애플리케이션 구현 가능 -
Unstructured Data as Hyper-structured Data
→ 비구조적 데이터는 사실상 도메인 특정 지식을 나타내는 거대한 그래프와 같음 → 검색 엔진은 분포 의미론을 활용하여 텍스트의 의미 관계를 해석하고, 이를 통해 의미를 해석할 수 있음

2. Search Engines and Relevance
-
Search Engine Functions
→ 콘텐츠를 수집하고, 쿼리와 일치하는 콘텐츠를 반환하며, 그 콘텐츠를 쿼리와의 일치 정도에 따라 정렬함 → 일치 정도는 일반적으로 쿼리 키워드의 문서 내 일치도를 기반으로 한 점수로 측정됨 -
Controlling Relevance
→ 관련성 계산은 유연하게 구성 가능하며, 쿼리별로 조정 가능함 → 도메인별 및 사용자별 관련성 랭킹 기능을 구현할 수 있음
3. Vector Space Model and Cosine Similarity
-
Mapping Text to Vectors
→ 쿼리와 문서를 벡터로 변환하여 유사성을 측정함 → 각 단어는 벡터의 다양한 차원을 나타내며, 쿼리의 경우 관련 단어에만 1의 값을 부여하고 나머지는 0으로 설정 -
Cosine Similarity Calculation
→ 두 벡터 간의 코사인 각도를 계산하여 유사성을 측정함 → 예를 들어, “apple juice”라는 쿼리는 관련 단어의 위치에 1을 부여하는 벡터로 표현됨
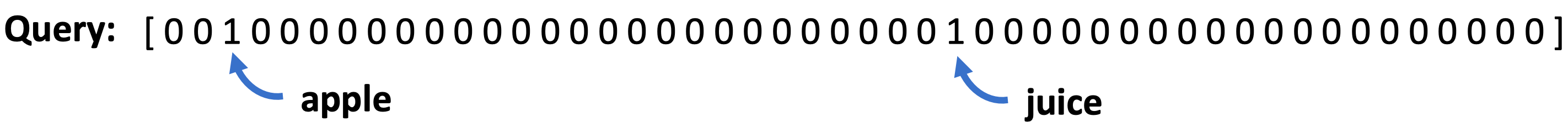
4. Application: Fashion Product Search
-
Example Implementation
→ 이미지 및 메타 데이터를 기반으로 패션 상품 검색을 수행할 수 있음 → 예를 들어, 특정 패션 아이템의 이미지가 주어지면, 유사한 아이템을 찾기 위해 해당 이미지의 피쳐을 벡터로 변환하여 검색함 -
Utilized Models
→ Convolutional Neural Networks (CNNs) 등 최신 이미지 분석 모델을 활용하여 이미지 피쳐 추출 → 추출된 벡터를 통해 유사성을 계산하고, 관련 상품을 추천함
5. Summary
- 콘텐츠와 사용자 신호는 AI 기반 검색 애플리케이션의 핵심 연료로 작용
- 벡터 공간 모델과 코사인 유사성은 텍스트 기반 검색의 핵심 기술임.
- 최신 이미지 분석 모델을 활용하여 패션 상품 검색에 적용 가능
참고 문서 및 링크
본 블로그 포스트는 검색 엔진의 핵심 기술과 이를 패션 상품 검색에 적용할 수 있는 방법을 논리적으로 정리하였음. 이미지와 메타 데이터를 기반으로 한 검색 기술은 다양한 분야에서의 활용 가능성을 보여줌.
p64
문서를 순위화하기 위해, 문서와 쿼리 간의 코사인 유사도를 계산하는 과정을 사용 이 코사인 값이 각 문서의 관련성 점수가 되며, 이 점수를 기준으로 문서들을 정렬할 수 있음.
Listing 3.1 코드는 쿼리와 문서 벡터를 어떻게 표현하고, 각각의 문서와 쿼리 간의 코사인 유사도를 계산하는지를 보여줌.
Listing 3.1: 쿼리와 문서 벡터 사이의 코사인 유사도 계산
결과: 흥미로운 점은 두 문서가 전혀 다른 내용을 가지고 있음에도 불구하고 동일한 관련성 점수를 받았다는 것임. 이는 즉각적으로 이해하기 어려울 수 있으므로, 의미 있는 피쳐들만을 집중하여 계산을 단순화해 보겠음.
3.1.2 dense 벡터 표현 간의 유사도 계산
query_vector = np.array([0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
doc1_vector = np.array([0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0])
doc2_vector = np.array([1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1])
def cos_sim(vector1, vector2): return dot(vector1, vector2) / (norm(vector1) * norm(vector2))
doc1_score = cos_sim(query_vector, doc1_vector) doc2_score = cos_sim(query_vector, doc2_vector)
print(“Relevance Scores:\n doc1: “ + num2str(doc1_score) + “\n doc2: “ + num2str(doc2_score))
결과
doc1: 0.2828
doc2: 0.2828
TL;DR
- 문서와 쿼리 벡터 간의 코사인 유사도를 통해 문서의 관련성 점수를 계산
- dense 벡터는 모든 가능한 차원에 대한 값을 포함하므로 계산에 비효율적일 수 있음.
- 의미 있는 피쳐만을 포함하는 희소 벡터를 사용하여 계산을 단순화할 수 있음.
p65
이전 섹션의 계산을 이해하기 위해서는 쿼리와 문서 모두에 공통적으로 나타나는 피쳐만이 중요하다는 점을 이해해야 다른 피쳐들(쿼리에 없는 단어들)은 문서의 순위에 영향을 주지 않음. 결과적으로, 의미 없는 항목을 벡터에서 제거하여 희소 벡터 표현으로 변환 가능
희소 벡터 표현은 계산에 필요한 값만 포함하며, 불필요한 0 값을 제거 이는 검색 엔진의 스코어링 작업에서 효율적임.
Listing 3.2는 의미 있는 항목만 포함한 희소 벡터를 사용하여 쿼리와 문서 벡터 간의 코사인 유사도를 계산하는 방법을 보여줌.
Listing 3.2: 희소 쿼리와 문서 벡터 간의 코사인 유사도 계산
3.1.3 희소 벡터 표현 간의 유사도 계산
sparse_query_vector = [1, 1] #[apple, juice]
sparse_doc1_vector = [1, 1]
sparse_doc2_vector = [1, 1]
doc1_score = cos_sim(sparse_query_vector, sparse_doc1_vector)
doc2_score = cos_sim(sparse_query_vector, sparse_doc2_vector)
print("Relevance Scores:\n doc1: " + num2str(doc1_score) + "\n doc2: " +
num2str(doc2_score))
p66
희소 벡터 계산은 두 문서가 동일한 상대적 점수를 얻지만, 실제 점수는 1.0임. 이는 코사인 계산에서 벡터가 완벽하게 일치함을 의미
흥미로운 점
- 희소 벡터 계산은 여전히 두 문서가 동일한 관련성 점수를 반환
- 절대 점수는 다르지만, 두 벡터 타입 내에서 상대적 점수는 동일
- 쿼리와 각 문서 간의 피쳐 가중치가 동일하여 코사인 점수가 1.0임.
Sidebar: 벡터 vs. 벡터 표현
- dense 벡터: 대부분의 값이 0이 아닌 벡터
- 희소 벡터: 대부분의 값이 0인 벡터
- 벡터 표현: 실제 데이터 구조를 다룸. 희소 벡터 표현을 사용하여 0이 아닌 값만 처리
검색 엔진은 벡터의 각 피쳐을 1(존재) 또는 0(비존재)로 고려하지 않고, 각 피쳐이 얼마나 잘 일치하는지를 기반으로 점수를 제공
결과
doc1: 1.0
doc2: 1.0
TL;DR
- 희소 벡터 표현은 계산 효율성을 높이고 관련성 점수를 쉽게 비교할 수 있게
- 코사인 유사도를 사용할 때 쿼리와 문서 간의 피쳐 가중치가 중요
- 검색 엔진은 단순한 존재 여부가 아닌 일치도를 기반으로 점수를 조정
p67
이전 섹션의 문제는 용어 벡터의 피쳐이 단순히 단어의 존재 여부만을 나타낸다는 것임. 이는 두 문서(doc1, doc2)가 항상 동일한 코사인 유사도 점수를 가지게 만듦.
용어 빈도(term frequency)를 사용하여 문서가 단어를 얼마나 잘 대표하는지를 측정 가능 특정 문서에서 용어가 더 자주 나타날수록, 해당 문서가 쿼리와 더 관련이 있을 가능성이 높음.
Listing 3.3은 용어 빈도 기반의 벡터로 코사인 유사도를 계산하는 방법을 보여줌.
Listing 3.3: Raw term counts 기반의 용어 빈도 벡터의 코사인 유사도
3.1.4 용어 빈도(TF): 문서가 용어와 얼마나 잘 일치하는지 측정
doc1_tf_vector = [1, 1] #[apple:1, juice:1]
doc2_tf_vector = [3, 4] #[apple:3, juice:4]
query_vector = [1, 1] #[apple:1, juice:1]
doc1_score = num2str(cos_sim(query_vector, doc1_tf_vector))
doc2_score = num2str(cos_sim(query_vector, doc2_tf_vector))
print("Relevance Scores:\n doc1: " + str(doc1_score) + "\n doc2: " +
str(doc2_score))
결과:
doc1: 1.0
doc2: 0.9899
TL;DR
- 용어 빈도는 문서가 쿼리와 얼마나 잘 일치하는지를 나타내는 중요한 지표로
- 용어 빈도를 사용하여 코사인 유사도 점수를 조정하면 문서의 관련성을 더 정확하게 측정할 수 있음.
- 다른 스코어링 함수로 전환하여 피쳐 가중치의 증가에 따라 점수가 증가하도록 조정할 수 있음.
텍스트 유사도 평가 및 개선 방법
1. 서론
1.1. 문제 인식
- 텍스트 유사도 평가에서 단순히 단어 빈도만을 활용하는 방식의 제한
- 예: ‘apple’과 ‘juice’가 독립적인 용어로 처리됨
- 개선 필요: 문장 혹은 구문을 하나의 단위로 인식하여 더 높은 유사도 점수 부여 필요
1.2. 해결 방법
- 벡터 기반 유사도 평가 및 텍스트 기반 키워드 점수 조정
- 최적의 매칭을 위한 쿼리 벡터 조정
2. 코사인 유사도와 벡터 연산
2.1. 코사인 유사도 정의
- 벡터 간의 유사도를 측정하는 방법
- 수식: \(\text{cosine similarity} = \frac\)
- \(A\)와 \(B\)는 각각의 텍스트 벡터임
2.2. 텍스트 벡터 생성
- 예
- 문서 1: “In light of the big reveal in the interview, …”
- 문서 2: “My favorite book is the cat in the hat, …”
- 문서 3: “My careless neighbors apparently let a stray cat stay in their garage …”
- 단어 ‘the’, ‘cat’, ‘in’, ‘the’, ‘hat’에 대한 빈도 벡터 생성
- 문서별 단어 빈도 벡터 계산 및 출력
3. TF 계산의 문제 및 개선
3.1. 기존 TF의 문제점
- 단순 빈도로 인해 긴 문서가 과대 평가됨
- 예: 문서 내 단어 반복이 많아질수록 점수가 높아짐
3.2. 개선된 TF 계산 방법
- TF를 각 단어 출현 수의 제곱근으로 계산
- 수식: \(\text{TF} = \frac{\sqrt{\text{term count}}}{\text{vector length}}\)
- 문서 길이에 따른 정규화 포함
4. 개선 후 결과
4.1. 결과 비교
- 개선된 TF를 사용하여 코사인 유사도 계산
- 이전보다 직관적인 결과 도출
- 예: ‘The Cat in the Hat’ 관련 문서가 더 높은 점수 획득
4.2. 핵심
- 텍스트 유사도 계산에서 단순 TF 대신 제곱근 및 정규화를 통해 개선된 결과 도출
- 벡터 기반의 코사인 유사도를 통한 문서 간 유사성 평가
- 일관된 TF 계산으로 긴 문서와 짧은 문서 간의 비교 가능
5. 응용 사례: 패션 상품 검색
5.1. 이미지 및 텍스트 기반 검색
- 이미지 및 메타 데이터를 활용한 패션 상품 검색
- 예: 이미지에서 패턴, 색상 등을 벡터화하여 유사한 패션 상품 추천
- 메타 데이터에서 키워드 추출 및 TF 계산을 통해 검색 결과 개선
5.2. 기술 구현
- 이미지 벡터화: CNN(Convolutional Neural Network) 활용
- 텍스트 분석: TF-IDF 및 개선된 TF로 키워드 추출
6. 결론
6.1. 최종 정리
- 개선된 TF 계산 방식과 코사인 유사도의 결합으로 텍스트 유사도 평가의 정확성 향상
- 다양한 응용 분야에서의 활용 가능성 증대
6.2. 향후 연구 방향
- 더 복잡한 구문 인식 및 다양한 언어 지원을 위한 추가 연구 필요

Figure 3.3 Term Frequency Calculation.
- \(t\)는 용어, \(d\)는 문서를 나타냄
- TF는 현재 문서에서 용어가 나타나는 횟수의 제곱근을, 문서 내 전체 용어 수로 나눈 값
- 제곱근을 통한 빈도 감쇠 및 문서 길이에 따른 정규화로 긴 문서와 짧은 문서 간 비교 가능
p72
정규화된 TF(Term Frequency) 도입으로 인해 doc2가 가장 높은 순위를 기록, 이는 예상된 결과임. 이는 doc1이 특정 단어를 너무 많이 포함하여 발생하는 가중치 감소 효과 때문임. 그러나 doc1이 여전히 두 번째로 높은 순위를 차지, 개선된 TF 함수가 doc3를 상위로 끌어올리기에 부족했음.
- 문제점: 특정 단어의 중요성이 반영되지 않음
- 예시: “the”와 “in”보다 “cat”과 “hat”이 더 중요
- 해결책: 각 단어의 중요성을 고려한 새로운 변수 도입 필요.
단어 빈도(TF)는 문서와 쿼리의 일치도를 측정하는 데 유용하지만, 각 단어의 중요성을 구별하는 데 한계가 있음. 이 섹션에서는 특정 키워드의 중요성을 문서 빈도(DF)를 통해 평가하는 방법을 설명
- 문서 빈도(DF): 특정 단어가 포함된 문서 수를 나타냄.
- 직관: 일반적인 단어보다 드문 단어가 더 중요
- 수식: DF는 특정 단어를 포함한 문서 수로 계산됨. 숫자가 낮을수록 쿼리에서 중요성이 큼.
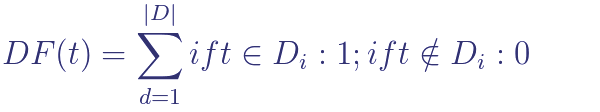
문서 빈도 계산을 나타냄. 모든 문서 집합 D와 입력 단어 t가 주어지며, DF는 입력 단어를 포함하는 문서의 수를 나타냄. 숫자가 낮을수록 쿼리에서 중요성이 더 크다는 것을 의미
labels: [the, cat, in, the, hat]
doc1_vector: [0.0942, 0.0, 0.0769, 0.0942, 0.0]
doc2_vector: [0.0456, 0.0456, 0.0456, 0.0456, 0.0456]
doc3_vector: [0.0, 0.0385, 0.0544, 0.0, 0.0385]
query_vector: [0.0942, 0.0456, 0.0769, 0.0942, 0.0456]
Relevance Scores:
doc2: 0.9222
doc1: 0.9559
doc3: 0.5995
3.1.5 역문서 빈도(IDF): 쿼리에서 단어의 중요성 측정
p73
- IDF 도입 이유: 더 중요한 단어가 높은 점수를 받도록 하기 위
- IDF 정의: 문서 빈도의 역수를 취
-
수식: $$ \text{IDF}(t) = 1 + \log\left(\frac{ D }{\text{DF}(t) + 1}\right) $$ - 의미: DF가 낮을수록 단어의 중요성이 커짐.
-
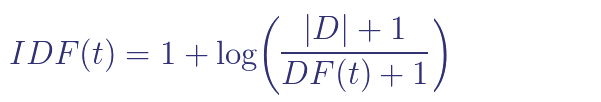
| 역문서 빈도 계산을 나타냄. | D | 는 전체 문서 수, t는 단어, DF(t)는 해당 단어를 포함하는 문서 수임. 숫자가 낮을수록 단어의 중요성이 적음을 의미하며, 숫자가 높을수록 쿼리의 관련성 점수에 더 큰 영향을 미침. |
df_map = {"the": 9500, "cat": 100, "in":9000, "hat":50}
totalDocs = 10000
def idf(term):
return 1 + np.log(totalDocs / (df_map[term] + 1))
idf_vector = np.array([idf("the"), idf("cat"), idf("in"), idf("the"), idf("hat")])
print ("labels: [the, cat, in, the, hat]\nidf_vector: " + vec2str(idf_vector))
labels: [the, cat, in, the, hat]
idf_vector: [1.0512, 5.5952, 1.1052, 1.0512, 6.2785]
- 결과: 단어의 상대적 중요도가 반영되어 “hat”과 “cat”이 가장 높은 중요도를 가짐.
p74
TF와 IDF의 결합으로 균형 잡힌 관련성 점수인 TF-IDF를 생성할 수 있음.
- TF: 문서가 단어를 얼마나 잘 설명하는지를 측정.
- IDF: 각 단어의 중요성을 측정.
TF-IDF는 문서와 쿼리의 텍스트 유사성을 평가하는 데 널리 사용됨. 이는 두 요소를 결합하여 텍스트 기반 관련성 점수를 계산
- 수식: \(\text{TF-IDF} = \text{TF} \times \text{IDF}^2\)
p75
코드 예제: 쿼리 “the cat in the hat”에 대한 TF-IDF 순위 계산
def tf_idf(tf, idf):
return tf * idf**2
query = "the cat in the hat"
print ("labels: [the, cat, in, the, hat]")
doc1_tfidf = [
tf_idf(tf(doc1, "the"), idf("the")),
tf_idf(tf(doc1, "cat"), idf("cat")),
tf_idf(tf(doc1, "in"), idf("in")),
tf_idf(tf(doc1, "the"), idf("the")),
tf_idf(tf(doc1, "hat"), idf("hat"))
]
print("doc1_tfidf: " + vec2str(doc1_tfidf))
doc2_tfidf = [
tf_idf(tf(doc2, "the"), idf("the")),
tf_idf(tf(doc2, "cat"), idf("cat")),
tf_idf(tf(doc2, "in"), idf("in")),
tf_idf(tf(doc2, "the"), idf("the")),
tf_idf(tf(doc2, "hat"), idf("hat"))
]
print("doc2_tfidf: " + vec2str(doc2_tfidf))
doc3_tfidf = [
tf_idf(tf(doc3, "the"), idf("the")),
tf_idf(tf(doc3, "cat"), idf("cat")),
tf_idf(tf(doc3, "in"), idf("in")),
tf_idf(tf(doc3, "the"), idf("the")),
tf_idf(tf(doc3, "hat"), idf("hat"))
]
print("doc3_tfidf: " + vec2str(doc3_tfidf))
query_tfidf = np.maximum.reduce([doc1_tfidf, doc2_tfidf, doc3_tfidf])
doc1_relevance = cos_sim(query_tfidf,doc1_tfidf)
doc2_relevance = cos_sim(query_tfidf,doc2_tfidf)
doc3_relevance = cos_sim(query_tfidf,doc3_tfidf)
print("\nRelevance Scores:\n doc2: " + num2str(doc2_relevance)
+ "\n doc3: " + num2str(doc3_relevance)
+ "\n doc1: " + num2str(doc1_relevance))
- 결과: doc2가 가장 높은 점수를 얻으며, 중요한 단어를 가장 잘 일치시킴. doc3는 적은 횟수로 모든 단어를 포함하며 두 번째로 높은 점수를 얻음. doc1는 중요하지 않은 단어만 풍부하게 포함하여 가장 낮은 점수를 얻음.
labels: [the, cat, in, the, hat]
doc1_tfidf: [0.1041, 0.0, 0.094, 0.1041, 0.0]
doc2_tfidf: [0.0504, 1.4282, 0.0557, 0.0504, 1.7983]
doc3_tfidf: [0.0, 1.2041, 0.0664, 0.0, 1.5161]
Relevance Scores:
doc2: 0.9993
doc3: 0.9979
doc1: 0.0758
TL;DR
- 정규화된 TF는 문서의 단어 일치도를 개선하지만, 단어 중요성을 반영하지 못하게 되며,
- IDF를 통해 드문 단어의 중요성을 반영하여 단어의 상대적 중요성을 평가.
- TF-IDF는 문서와 쿼리의 유사성을 균형 있게 평가하는 데 사용되며, 중요한 단어가 더 많은 가중치를 얻음.
적용 예시: 패션 상품 검색
패션 상품을 검색할 때도 TF-IDF를 활용할 수 있음. 예를 들어, 사용자가 “red dress with floral pattern”이라는 쿼리를 입력했을 때, 각 패션 아이템의 텍스트 설명을 분석하여 쿼리와의 관련성을 평가
- 인풋: 각 상품의 텍스트 설명
- 아웃풋: 쿼리와의 유사성 점수
TF-IDF는 “red”, “dress”, “floral”, “pattern”과 같은 단어의 출현 빈도와 중요성을 고려하여 검색 결과를 순위화 이 방법은 이미지 검색에서도 메타 데이터를 활용하여 유사성을 평가할 수 있음.
- 인풋 예시: 상품 설명 텍스트
- 아웃풋 예시: 관련성 점수 기반 순위화된 상품 리스트
이런 접근 방식은 검색 결과의 정확성을 높이고, 사용자에게 더 만족스러운 검색 경험을 제공할 수 있음.
기술 블로그: 검색 엔진에서의 유사도 계산 및 BM25
개요
검색 엔진에서 문서의 관련성을 평가하기 위한 다양한 방법이 존재 대표적으로 사용되는 기법은 Cosine Similarity와 TF-IDF이며, 최근에는 BM25가 이런 방법을 보다 개선한 형태로 주목받고 있음. 본 포스트에서는 각 기법의 수학적 배경과 실제 활용 사례를 중심으로 설명
1. Cosine Similarity vs. TF-IDF 매칭 점수
- Cosine Similarity 두 벡터 사이의 각도를 기반으로 유사도를 계산 벡터의 크기를 무시하고, 두 벡터가 이루는 각도에 집중 따라서, 쿼리 벡터 내의 각 단어의 최대 점수를 사용하여 유사도를 계산
- 예: 쿼리 벡터가
[1, 1]일 때, 문서 벡터[2, 2],[3, 3],[N, N]은 모두 코사인 값1.0을 가짐. 이는 모든 문서가 쿼리와 동일한 비율로 키워드를 포함하고 있음을 의미
- 예: 쿼리 벡터가
- TF-IDF (Term Frequency-Inverse Document Frequency) 단어의 발생 빈도(TF)와 문서 내에서의 중요도(IDF)를 반영하여 각 단어의 가중치를 설정
- TF는 특정 단어가 문서 내에서 얼마나 자주 등장하는지를 측정하고, IDF는 전체 문서 집합에서 해당 단어의 중요성을 나타냄.
- 검색 엔진에서 TF-IDF는 문서의 관련성을 평가하는 데 있어 중요한 역할을
TL;DR
- Cosine Similarity는 벡터의 각도를 기반으로 유사도를 계산하며, 벡터 크기를 무시
- TF-IDF는 단어의 빈도와 중요도를 고려하여 문서의 관련성을 평가
- BM25는 TF-IDF와 유사하지만, 문서 길이 정규화 및 빈도 포화점 조절 기능을 추가하여 보다 정교한 유사도 계산을 가능하게
2. BM25: Lucene의 기본 텍스트-유사도 알고리즘
- BM25 (Okapi “Best Matching” version 25) Apache Lucene, Solr, Elasticsearch 등에서 기본적으로 사용되는 유사도 알고리즘. 1994년에 처음 발표되었으며, 기존 TF-IDF 코사인 유사도 순위를 개선
- TF 및 IDF 활용 기본적으로 TF-IDF를 기반으로 하며, 추가적인 파라미터를 통해 단어 빈도 포화점 및 문서 길이 정규화를 용이하게 제어
- 수식 설명
\(\text{Score}(D, Q) = \sum_{t \in Q} \text{IDF}(t) \cdot \frac{\text{TF}(t, D) \cdot (k_1 + 1)}{\text{TF}(t, D) + k_1 \cdot (1 - b + b \cdot \frac{|D|}{\text{avgdl}})}\)
- \(\text{IDF}(t)\): 단어 \(t\)의 중요도
- \(\text{TF}(t, D)\): 문서 \(D\) 내 단어 \(t\)의 빈도
- \(k_1\), \(b\): 조정 가능한 파라미터
-
$$ D $$: 문서의 길이 - \(\text{avgdl}\): 전체 문서 집합의 평균 문서 길이
3. BM25 적용 예제
- Solr에서의 BM25 활용 Solr를 통해 BM25 계산을 시뮬레이션하고, 문서 컬렉션을 생성하여 검색 쿼리를 실행
- 컬렉션 생성 및 문서 추가
collection = "cat_in_the_hat" create_collection(collection) upsert_text_field(collection, "title") upsert_text_field(collection, "description") docs = [ {"id": "doc1", "title": "Worst", "description": "The interesting thing..."}, {"id": "doc2", "title": "Best", "description": "My favorite book..."}, {"id": "doc3", "title": "Okay", "description": "My neighbors let..."} ] response = requests.POST(solr_url + collection + "/update?commit=true", json=docs).json()
- 컬렉션 생성 및 문서 추가
-
검색 및 결과 확인 생성된 컬렉션에 대해 쿼리를 실행하여 BM25 점수를 확인
- Apache Solr Documentation

Figure 3.6 BM25 Scoring Function BM25의 수식 구조를 시각적으로 설명하며, 각 단어의 추가 발생이 점수에 얼마나 기여하는지를 조절하는 \(k\) 파라미터와, 문서 길이에 따른 정규화를 수행하는 \(b\) 파라미터를 설명
이와 같은 방식으로 BM25를 활용하여 패션 상품을 검색할 때, 이미지 및 텍스트 메타 정보를 활용하여 보다 정확한 검색 결과를 제공할 수 있음. 예를 들어, 특정 색상이나 스타일의 이미지를 입력하여 유사한 패션 아이템을 추천받을 수 있으며, 텍스트 설명과 결합하여 보다 풍부한 검색 경험을 제공
p80
Listing 3.12: BM25 유사도 점수를 통한 순위 매기기 및 점검
-
목표 주어진 쿼리와 문서에 대해 BM25 알고리즘을 사용하여 문서의 유사도 점수를 계산하고, 순위 매김 과정을 점검
- 쿼리 설정
query = "the cat in the hat"설정- 요청 형식:
request = { "query": query, "fields": ["id", "title", "description", "score", "[explain style=html]"], "params": { "qf": "description", "defType": "edismax", "indent": "true" } } - IPython을 사용하여 쿼리 및 순위가 매겨진 문서 결과를 HTML 형식으로 표시
- 응답 처리
- Solr 서버에 요청을 보내 응답을 JSON 형식으로 변환 후, HTML 형식으로 변환하여 시각적으로 표시
response = str(requests.POST(solr_url + collection + "/select",
json=request).json()["response"]["docs"]).replace('\\n', '').replace(", '", ",<br/>'")
display(HTML(response))
- 쿼리:
the cat in the hat - 순위 매겨진 문서
- doc2
- 제목:
Best - 설명:
My favorite book is the cat in the hat, which is about a crazy cat who breaks into a house and creates a crazy afternoon for two kids. - 점수:
0.6823196 - 설명:
- BM25 점수 계산 과정 설명
0.6823196 = sum of: [...]
- BM25 점수 계산 과정 설명
- 제목:
p81
-
계산 과정
- TF (Term Frequency) 계산:
\(\text{tf} = \frac{\text{freq}}{\text{freq} + k1 \times (1 - b + b \times \frac{\text{dl}}{\text{avgdl}})}\)
freq: 문서 내에서의 용어 출현 횟수k1: 용어 포화 파라미터 (대부분 1.2 사용)b: 길이 정규화 파라미터 (주로 0.75 사용)dl: 필드의 길이avgdl: 필드의 평균 길이
- IDF (Inverse Document Frequency) 계산:
\(\text{idf} = \log\left(1 + \frac{N - n + 0.5}{n + 0.5}\right)\)
n: 용어를 포함한 문서 수N: 필드에 존재하는 전체 문서 수
- TF (Term Frequency) 계산:
\(\text{tf} = \frac{\text{freq}}{\text{freq} + k1 \times (1 - b + b \times \frac{\text{dl}}{\text{avgdl}})}\)
p82
- 구체적 예시
- doc3
- 제목:
Okay - 설명:
My neighbors let the stray cat stay in their garage, which resulted in my favorite hat that I let them borrow being ruined. - 점수:
0.62850046 - 설명:
- BM25 점수 계산 과정 설명
- 각 용어별 TF, IDF 계산 및 결과 합산
- 제목:
- doc3
p83
- BM25 vs TF-IDF
- BM25는 TF-IDF를 기반으로 복잡한 계산을 수행하나, 기본적으로 TF-IDF를 중심으로 동작
- 쿼리를 벡터로 생각하는 대신, 수학적 함수로 구성된 것으로 간주 가능
- Solr의 쿼리 문법을 사용하여 BM25 점수 계산
TL;DR
- BM25 알고리즘은 TF와 IDF를 결합하여 문서의 유사도를 계산
- 각 용어별로 개별 계산된 점수들이 합산되어 최종 BM25 점수가 도출됨.
- Solr 쿼리를 통해 BM25 점수를 함수로 표현하여 동일한 결과를 얻을 수 있음.
- 적용 예시
- 패션 상품 검색: 이미지 및 상품 메타정보를 사용하여 BM25를 통해 유사한 스타일의 상품을 검색 가능
- 이미지의 색상, 패턴, 텍스트 설명을 BM25의 필드로 활용하여 유사도 기반 검색 구현 가능
텍스트 유사성 및 관련성 강화 기법
1. 텍스트 유사성 계산 및 쿼리 함수 활용
1.1. 텍스트 유사성 및 쿼리 함수 설명
- Query Function 검색 엔진의 쿼리 내 각 용어는 실제로는 구성 가능한 스코어링 함수로 작동함
- 예) BM25 유사도 알고리즘: 기본적으로 텍스트 기반 유사도를 계산하는 함수로 많이 사용됨
query = ‘{!func}query(“the”) {!func}query(“cat”) {!func}query(“in”) {!func}query(“the”) {!func}query(“hat”)’
- Request 구성 쿼리를 구성하여 검색 요청을 생성함
fields: 검색 결과에 포함될 필드 지정params: 쿼리의 다양한 파라미터 설정 예시
request = {
"query": query,
"fields": ["id", "title", "score"],
"params": {
"qf": "description",
"defType": "edismax",
"indent": "true"
}
}
- output 쿼리 결과를 HTML 형식으로 출력하여 가독성 향상
response = str(requests.POST(solr_url + collection + "/select",
json=request).json()["response"]["docs"]).replace('\\n', '').replace(", ", ",<br/>'")
TL;DR
- 쿼리 내 각 용어는 스코어링 함수로 구성 가능하며, BM25 유사도 알고리즘이 기본으로 사용됨.
- 쿼리 요청은
fields와params를 통해 구성되고, 결과는 HTML로 출력됨. - 다양한 함수와 파라미터를 사용하여 복합적인 검색 결과를 조정 가능
2. 관련성 강화 기법
2.1. 관련성 강화 기법 목록
- 지리적 부스트(Geospatial Boosting) 사용자 위치 근처의 문서에 가중치 부여
- 날짜 부스트(Date Boosting) 최신 문서에 가중치 부여
- 인기 부스트(Popularity Boosting) 유명한 문서에 가중치 부여
- 필드 부스트(Field Boosting) 특정 필드에 일치하는 용어에 가중치 부여
- 카테고리 부스트(Category Boosting) 쿼리 용어와 관련된 카테고리에 속한 문서에 가중치 부여
- 구문 부스트(Phrase Boosting) 여러 용어로 이루어진 구문에 일치하는 문서에 가중치 부여
- 의미 확장(Semantic Expansion) 쿼리 키워드와 관련된 다른 단어 또는 개념을 포함하는 문서에 가중치 부여
2.2. 필드 부스트 예시
- edismax 쿼리 파서 활용 필드 부스트를 통해 특정 필드에 가중치 조정 가능
q={!type=edismax}the cat in the hat
qf="title^10 description^2.5"
- 구문 부스트 특정 구문에 대해 필드 내에서 가중치를 부여하는 방식
Boost docs containing the exact phrase “the cat in the hat” in the title field
TL;DR
- 관련성 강화 기법은 지리적, 날짜, 인기, 필드, 카테고리, 구문, 의미 확장 등 다양한 기법으로 구성됨.
edismax쿼리 파서를 통해 특정 필드에 대한 가중치를 조정 가능- 구문 부스트는 특정 구문에 대해 필드 내에서 가중치를 부여하여 검색 결과에 반영
3. 복합적인 정렬 및 가중치 조정
3.1. 복합 정렬 및 가중치 조정
-
기능 쿼리 활용 다양한 기능을 통해 복합적인 정렬 및 가중치 조정 가능
q={!func}scale(query($keywords),0,25) {!func}recip(geodist($lat_long_field,$user_latitude,$user_longitude), 1,25,1) {!func}recip(ms(NOW/HOUR,modify_date),3.16e-11,25,1) {!func}scale(popularity,0,25) -
가중치 조정 각 기능의 상대적 기여도를 설정하여 최종 관련성 계산에 반영
3.2. 학습 기반 랭킹 모델
- 학습 기반 랭킹 챕터 10에서 학습 기반 랭킹 모델을 통해 자동으로 의사 결정을 내리는 방법 제시
TL;DR
- 복합적인 기능 쿼리를 활용하여 다양한 요소를 반영한 정렬 및 가중치 조정 가능
- 각 기능의 상대적 가중치를 조정하여 최종 관련성 계산에 반영
- 학습 기반 랭킹 모델을 통해 의사 결정을 자동화할 수 있으며, 이는 챕터 10에서 다룸.
4. 추가 참고 자료
- Solr in Action Trey Grainger와 Timothy Potter의 “Solr in Action”의 챕터 15에서 복잡한 쿼리 연산에 대한 상세 설명 제공
- Solr Reference Guide Solr의 기능 쿼리에 대한 문서는 Solr Reference Guide의 function query 섹션에서 확인 가능
TL;DR
- Trey Grainger와 Timothy Potter의 “Solr in Action” 챕터 15에서 복잡한 쿼리 연산에 대한 심도 있는 설명 제공.
- Solr Reference Guide의 function query 섹션에서 기능 쿼리에 대한 추가적인 정보 확인 가능.
- 추가 자료를 통해 기능 쿼리에 대한 이해를 심화할 수 있음.
검색 엔진에서의 부스팅과 필터링
3.2.4 부스팅과 필터링의 차이
검색 엔진에서 문서의 관련성을 평가하고 순위를 매기는 방법은 중요 이 과정에서 주로 사용되는 두 가지 부스팅 기법은 덧셈 부스팅 (Additive Boosting)과 곱셈 부스팅 (Multiplicative Boosting)임.
- 덧셈 부스팅 (Additive Boosting)
- 각 피처가 전체 관련성 함수에 기여하는 정도를 명확히 제한함으로써 부스팅 효과를 얻음.
- 예: 각 피처의 최소 및 최대 값을 명시적으로 제한하여, 각 피처가 전체 검색 점수에 기여하는 바가 명확해짐.
- Pros(+): 여러 피처의 기여도를 명확히 조정할 수 있음.
- Cons(-): 피처의 수가 증가할수록 복잡도가 높아짐.
- 곱셈 부스팅 (Multiplicative Boosting)
- 각 부스팅이 문서의 전체 관련성 점수에 곱해지므로 부스팅 효과가 누적됨.
- 예: 문서의 관련성 점수를 인기도 필드의 값에 10을 곱하여 부스팅.
- Pros(+): 다양한 관련성 피처를 쉽게 조합할 수 있음.
- Cons(-): 특정 피처의 부스팅 값이 너무 높아지면 다른 피처를 압도할 수 있음.
코드 예제
곱셈 부스팅의 예를 들자면, Solr에서 다음과 같이 사용할 수 있음
q=the cat in the hat&
defType=edismax&
boost=mul(popularity,10)
또는
q=the cat in the hat
{!boost b=mul(popularity,10)}
TL;DR
- 덧셈 부스팅은 각 피처의 기여도를 명확히 조정할 수 있지만 복잡도가 높아질 수 있음.
- 곱셈 부스팅은 다양한 피처를 조합할 수 있는 유연성을 제공하지만, 특정 피처가 다른 피처를 압도할 위험이 있음.
- 두 가지 부스팅 방식은 상황에 따라 유용하게 사용될 수 있으며, 실험을 통해 최적의 결과를 찾아야
3.2.5 논리적 매칭: 쿼리 내 용어 간의 관계 가중치
검색 엔진에서의 매칭은 크게 두 가지 단계로 나눌 수 있음
- 매칭 (Filtering): 쿼리에 적합한 문서 집합을 필터링.
- 랭킹 (Ranking): 필터링된 문서들을 관련성에 따라 정렬.
특히, 필터링은 성능 최적화에 기여하며, 논리적으로 일치하는 문서 집합을 줄임으로써 검색 엔진의 응답 시간을 단축할 수 있음. 필터링을 통해 검색 결과의 총 문서 수를 줄이고, 사용자가 결과 집합을 탐색하고 세분화할 수 있도록 도움.
논리적 매칭의 예
- “statue of liberty”라는 쿼리에 대해, 논리적 매칭은 다음과 같이 다르게 적용될 수 있음:
- “statue of liberty”: 문서가 정확한 구문을 포함할 때만 매칭.
- “statue AND of AND liberty”: 모든 용어를 포함하는 문서와 매칭.
- “statue OR of OR liberty”: 하나 이상의 용어를 포함하는 문서와 매칭.
최소 매칭 (Minimum Match) 파라미터
Solr의 mm 파라미터는 최소 매칭 임계값을 설정하여 각 쿼리의 논리적 구조를 쉽게 제어할 수 있음. 예를 들어, 다음과 같이 사용할 수 있음:
mm=100% ## 모든 쿼리 용어가 일치해야 함
mm=0% ## 적어도 한 개의 쿼리 용어가 일치해야 함
mm=2 ## 적어도 두 개의 쿼리 용어가 일치해야 함
3.2.6 필터링과 스코어링의 분리
Solr에서는 필터링과 스코어링을 제어하는 두 가지 주요 방법이 있음:
- 쿼리 (Query) 파라미터 (
q): 검색 쿼리 자체를 정의. - 필터 (Filter) 파라미터 (
fq): 필터링을 통해 결과 집합을 좁힘.
예를 들어, 다음과 같은 쿼리를 통해 특정 카테고리 및 관객을 대상으로 필터링할 수 있음:
q=the cat in the hat&
fq=category:books&
fq=audience:kid&
defType=edismax&
mm=100%&
qf=description
관련 문서 및 기술
- Solr Reference Guide를 통해 Solr의 필터링 및 부스팅 기능에 대한 자세한 정보를 확인할 수 있음.
- 검색 엔진 최적화 및 부스팅 기법의 이해는 사용자 경험을 크게 향상시킬 수 있으며, 패션 상품 검색과 같은 실생활 응용에 유용하게 사용될 수 있음.
p92
필터링과 관련 파라미터의 역할
q(query) 파라미터- 필터와 관련성 랭킹을 위한 피처 벡터 역할 수행
- 필터링과 스코어링을 동시에 수행 → 쿼리에서는 비효율적일 수 있음
fq(filter query) 파라미터- 오직 필터링 목적
- 관련성 랭킹에는 관여하지 않음
bq(boost query) 파라미터- 오직 관련성에 기반한 부스트 기능
- 필터링은 수행하지 않음
논리적 차이점
q는 필터링과 관련성 랭킹을 동시에 수행fq는 필터링 전용bq는 관련성 부스트 전용
#> 예시 쿼리
q={!func}query("{!type=edismax qf=description mm=100% v=$query}")&
fq={!cache=false v=$query}&
query=the cat in the hat
q=*:*
&bq={!type=edismax qf=description mm=100% v=$query}&
fq={!cache=false v=$query}&
query=the cat in the hat
cache=false: 필터 캐시 비활성화- 사용자 입력 쿼리의 다양성 때문에 캐시 비활성화가 필요
TL;DR
q,fq,bq파라미터는 각각 다른 역할을 수행하며,q는 두 가지 역할을 하며,- 필터 캐시는 사용자 입력 쿼리의 다양성 때문에 비활성화가 필요할 수 있음.
- 필터링과 관련성 랭킹의 분리는 복잡한 랭킹 함수를 구축할 때 유리
p93
도메인 특화 관련성 랭킹
- 도메인 특화 요소 예시
- 레스토랑 검색에서는 지리적 근접성, 사용자 맞춤식 요구 사항 등이 중요
- 뉴스 검색에서는 최신성, 인기, 지리적 영역이 중요
- 전자상거래에서는 전환 가능성 등이 중요
관련성 엔지니어링
- 관련성 엔지니어링
- 검색 엔진의 관련성을 조정하는 전문 분야
- “Relevant Search” 서적 추천
TL;DR
- 도메인 특화 관련성 랭킹은 사용자 경험을 향상시킴.
- 관련성 엔지니어링은 검색 엔진의 성능 향상에 필수적임.
- 관련성 랭킹은 자동화된 학습 기법을 통해 최적화될 수 있음.
p94
AI 기반 검색 엔진 구축
- AI를 활용한 검색 엔진
- 머신 러닝을 통해 최적의 관련성 알고리즘 자동 생성 및 가중치 설정
- 사용자의 행동을 기반으로 학습하여 관련성을 향상
관련성 최적화 방법
- TF-IDF 및 BM25: 텍스트 유사성 평가에 사용
- 텍스트 유사성 스코어링 외에도 사용자 특화 피처 활용 필요
TL;DR
- AI 기반 검색 엔진은 사용자 행동을 기반으로 관련성을 자동으로 학습
- 텍스트 유사성 스코어링 외에도 다양한 피처를 활용하여 관련성을 최적화할 수 있음.
- 머신 러닝을 통해 도메인 특화 및 사용자 특화 관련성을 구현할 수 있음.
p95
크라우드소싱을 통한 관련성 향상
- 사용자 행동 신호 수집 및 활용
- Reflected Intelligence를 통한 모델 자동 조정
- 크라우드소싱을 통해 콘텐츠 기반 신호 학습
크라우드소싱의 중요성
- 사용자 행동 기반의 암묵적 학습
- 사용자의 집단적 통찰을 활용하여 검색 플랫폼의 관련성을 개선
TL;DR
- 크라우드소싱은 사용자 행동을 통해 검색 관련성을 향상시키는 데 유용하며,
- 사용자의 집단적 통찰을 통해 자동화된 모델 조정 가능.
- 검색 플랫폼의 관련성 향상을 위한 다양한 신호 수집 및 활용 필요.
이 문서는 다양한 검색 관련성 최적화 기법을 설명하며, 각 파라미터의 역할과 이들의 조합을 통해 검색 결과를 어떻게 최적화할 수 있는지를 다루고 있음. 특히, AI 및 머신 러닝을 활용한 자동화된 관련성 최적화 방법에 초점을 맞추고 있음.
사용자 신호와 콘텐츠의 조화로운 활용
4.1 사용자 신호 작업
4.1.1 신호와 콘텐츠
-
사용자 신호의 정의 사용자가 검색 쿼리를 발행하고, 결과를 클릭하거나, 제품을 구매하는 등의 행동을 통해 사용자의 의도를 인퍼런스할 수 있는 신호 생성 → 이런 신호는 사용자의 의도를 이해하는 데 중요한 역할을
- 콘텐츠의 정의 검색 엔진에서 다루는 콘텐츠는 주로 문서 형태로 존재하며, 웹 페이지, 제품 목록, 이미지, 데이터 등이 포함됨 → 콘텐츠는 사용자가 검색하는 정보 자체를 포함하고 있음.
- 신호와 콘텐츠의 관계 콘텐츠는 검색의 대상, 신호는 사용자의 상호작용을 반영 → 두 가지 정보 소스를 통해 검색 정확성을 향상시킬 수 있음.
- 예시 “driver”라는 단어의 동의어를 찾는 과정에서 콘텐츠 기반 접근은 “taxi”, “car” 등의 단어를 우선적으로 찾음. 반면, 신호 기반 접근은 “screwdriver”, “printer” 등의 단어를 강조함 → 콘텐츠는 문서 내 의미를, 신호는 사용자가 찾고자 하는 의미를 반영
핵심 사용자 신호는 사용자의 의도를 인퍼런스하는 데 중요하며, 콘텐츠는 검색의 대상이 됨. 두 가지 접근을 통합하여 더 정확한 검색 시스템 구축 가능. 콘텐츠와 신호의 조화로운 활용이 중요
4.1.2 제품 및 신호 데이터셋 설정 (RetroTech)
-
RetroTech 사례 소개 전자상거래 검색은 다양한 AI 기반 검색 기법을 탐구할 수 있는 좋은 기회 제공. RetroTech는 빈티지 하드웨어, 소프트웨어, 멀티미디어 제품을 제공하는 이커머스 플랫폼임.
-
데이터셋 설정 RetroTech 웹사이트의 약 50,000개 제품을 검색 엔진에 로드하여 검색 가능하도록 설정 → 제품 카탈로그와 사용자 신호 데이터를 포함한 CSV 파일을 통해 데이터셋 구성.
-
코드 실행 및 결과
- 제품 컬렉션 생성:
create_collection(products_collection) - 스키마 수정: 특정 필드를 키워드로 검색 가능하도록 설정.
- CSV 파일 로드 및 제품 문서 인덱싱: Spark를 활용하여 CSV 파일을 읽고 Solr로 저장.
- 제품 컬렉션 생성:
## Create Products Collection
products_collection = "products"
create_collection(products_collection)
## Modify Schema to make some fields explicitly searchable by keyword
upsert_text_field(products_collection, "upc")
upsert_text_field(products_collection, "name")
upsert_text_field(products_collection, "longDescription")
upsert_text_field(products_collection, "manufacturer")
print("Loading Products...")
csvFile = "../data/retrotech/products.csv"
product_update_opts = {"zkhost": "aips-zk", "collection": products_collection,
"gen_uniq_key": "true", "commit_within": "5000"}
csvDF = spark.read.format("com.databricks.spark.csv").option(
"header", "true").option("inferSchema", "true").load(csvFile)
csvDF.write.format("solr").options(**product_update_opts).mode(
"overwrite").save()
print("Products Schema: ")
csvDF.printSchema()
print("Status: Success")
핵심 RetroTech의 사례를 통해 전자상거래의 AI 기반 검색 기법을 탐구하고, 제품 및 사용자 신호 데이터셋 설정을 통해 검색 엔진에 데이터를 로드하여 검색 가능하도록 Spark를 활용하여 CSV 파일을 Solr로 저장하여 데이터 인덱싱.
이미지 및 상품 메타 정보를 활용한 패션 상품 검색
-
이미지 및 메타 정보 활용 패션 상품 검색에서 이미지는 중요한 역할을 하며, 메타 정보(e.g., 색상, 크기, 브랜드 등)와 결합하여 검색 정확도를 높임.
- 모델 활용 예시
- 인풋 패션 이미지 및 메타 정보
- 모델 CNN(Convolutional Neural Networks) 기반의 이미지 인식 모델
- 아웃풋 유사한 패션 아이템 추천
- 적용 방법 이미지 기반 검색에서는 CNN을 활용하여 이미지의 피쳐을 추출하고, 메타 정보와 결합하여 사용자의 검색 의도에 부합하는 결과를 제공.
핵심 패션 상품 검색에서 이미지는 중요한 요소로, 메타 정보와 결합하여 검색 정확도를 향상시킴. CNN 모델을 활용하여 이미지 피쳐을 추출하고, 사용자에게 적합한 패션 아이템을 추천 가능.
p.100: Indexing and Searching Product Catalog
- Indexing Process
- ‘products’ 컬렉션 초기화 → 성공
- ‘upc’, ‘name’, ‘longDescription’, ‘manufacturer’ 필드 추가 → 성공
- 제품 데이터 로딩 → 성공
- 제품 스키마
root |-- upc: long (nullable = true) |-- name: string (nullable = true) |-- manufacturer: string (nullable = true) |-- shortDescription: string (nullable = true) |-- longDescription: string (nullable = true)
- 검색 예시: ipod
- request
{ "query": "ipod", "fields": ["upc", "name", "manufacturer", "score"], "limit": 5, "params": { "qf": "name manufacturer longDescription", "defType": "edismax", "sort": "score desc, upc asc" } } - 결과: 검색은 성공적으로 수행되었으나, 결과의 연관성은 낮음
- request
- 핵심
제품 컬렉션이 성공적으로 색인되어 기본적인 키워드 검색이 가능해짐. 그러나 검색 결과의 품질은 아직 개선이 필요 이를 기반으로 AI 기반 검색 기능을 추가할 예정임.
p.101: 제품 검색 결과
-
Figure 4.1 설명

‘ipod’를 검색한 결과가 화면에 나타남. 제품 카탈로그가 색인되어 있으며, 검색 쿼리에 대한 결과를 반환 -
향후 계획
- AI 기반 검색 기능 도입 예정
- 신호 데이터 활용 시작
p.102: 신호 데이터 로딩 및 구조
- 신호 데이터 로딩 절차
- 신호 컬렉션 생성 및 초기화 → 성공
- CSV 파일에서 데이터 로드 및 Solr 저장 → 성공
- 신호 스키마
root |-- query_id: string (nullable = true) |-- user: string (nullable = true) |-- type: string (nullable = true) |-- target: string (nullable = true) |-- signal_time: timestamp (nullable = true)
- 핵심
실사용자 데이터가 없는 환경에서 생성한 신호 데이터셋 활용 가능. 신호 데이터를 실시간 검색 시나리오와 외부 처리에 활용할 수 있도록 구조화. 다양한 신호의 속성을 기록하여 분석에 활용할 예정.
p.103: 신호 데이터의 예시와 구조
- 신호 데이터의 구조
- ‘query_id’: 쿼리 신호의 고유 ID
- ‘user’: 특정 사용자를 나타내는 식별자
- ‘type’: 신호의 유형 (query, click, purchase 등)
- ‘target’: 신호가 적용된 콘텐츠
- ‘signal_time’: 신호 발생 일시
- 사용자 행동 시퀀스와 신호 예시
- ‘ipad’ 검색 → ‘doc1’, ‘doc2’, ‘doc3’ 반환
- ‘doc1’ 클릭 후 ‘doc3’ 클릭
- ‘doc3’ 장바구니에 추가
- ‘ipad cover’ 검색 → ‘doc4’, ‘doc5’ 반환
- ‘doc4’ 클릭 및 장바구니 추가
- ‘doc3’, ‘doc4’ 구매
- 핵심
다양한 사용자 행동이 신호 데이터로 기록되며, 이는 검색 결과의 개선에 활용되며, 신호 데이터는 유연하게 구조화되어 있어 다양한 분석에 적용 가능.
응용 예시: 패션 상품 검색
- 이미지 및 상품 메타 정보를 기반으로 한 검색에는 신호 데이터를 활용하여 사용자 선호도를 반영한 추천 시스템 구축 가능.
- 예를 들어, 사용자가 특정 브랜드의 제품을 자주 클릭하는 경우 해당 브랜드의 신상품을 우선적으로 노출하는 방식으로 활용 가능.
사용자 신호와 Reflected Intelligence: AI 기반 검색 엔진의 고도화
사용자 신호의 구조와 수집
- 신호 유형 분류:
query,results신호는 각각 별도의 신호로 분리 구성- → 쿼리와 결과가 동시에 발생하지만, 테이블 구조 일관성을 유지하기 위함
- → “next page” 링크 클릭 시 추가 신호를 시간별로 추가 가능
- 신호 구조:
query_id는 사용자 쿼리의 특정 시간 인스턴스를 식별- → 동일 쿼리 키워드라도 결과가 시간에 따라 다르므로 사용자의 반응 분석 가능
- 결과 신호의 정렬:
results신호는 문서의 순서를 유지하는 정렬된 리스트- → 검색 결과의 순서가 일부 알고리즘에서 관련성을 측정하는 데 중요
- 구매 신호 분리: 각 항목별로 별도의
purchase신호 생성- → 서로 다른 쿼리에서 유래한 구매 항목을 추적하기 위한 목적
TL;DR
- 사용자 신호는 쿼리의 결과와 사용자의 상호작용을 상세히 추적할 수 있도록 구조화됨.
query_id와 신호의 순서를 통해 사용자의 쿼리 반응 분석 및 결과 정렬 가능.- 신호를 기반으로 사용자 상호작용 패턴을 학습하고, 검색 결과의 관련성을 개선 가능한 구조 제공.
사용자, 세션, 요청 모델링
- 사용자 식별 계층: 사용자 식별 정보의 중요도에 따른 계층적 구조
- →
User ID,Device ID,Browser ID,Session ID,Request ID - → 가능한 가장 높은 수준의 식별자에 사용자를 연결하는 것이 목표
- →
- 식별자 간의 관계:
Browser ID→ 여러Session ID포함 가능Session ID→ 여러Request ID포함 가능
- 쿠키의 역할: 브라우저 쿠키를 통해 신호를 식별하고 세션 및 요청 간의 연결 유지
TL;DR
- 사용자 식별 계층을 통해 다양한 수준의 사용자 데이터 추적 가능
- 식별자의 지속성을 유지하여 사용자 상호작용 패턴을 학습하고 분석
- 브라우저 쿠키는 식별자 간의 지속적 연결을 위한 핵심 매개체 역할
Reflected Intelligence의 도입
- Reflected Intelligence 개념: 사용자 상호작용 신호를 통한 피드백 루프 생성
- → 지속적 학습과 개선을 통해 검색 엔진의 관련성 향상
- 신호 처리 및 학습: 사용자 쿼리 및 상호작용 신호를 학습하여 관련성 모델 생성
- → 유명한 결과 부스트, 사용자 맞춤형 결과 제공
- → 일반 문서 속성 학습 및 순위 알고리즘 조정
- 자동화된 학습 시스템: 새로운 사용자 상호작용으로 개선된 검색 결과를 생성
- → 사용자의 관심사 및 컨텐츠 변화에 따른 자동 조정
TL;DR
- Reflected Intelligence는 사용자 상호작용을 통한 지속적 학습과 검색 결과 개선을 목표로
- 학습된 관련성 모델은 사용자 쿼리에 대한 더 나은 검색 결과 제공 가능.
- 지속적 피드백 루프를 통해 검색 시스템은 시간이 지남에 따라 자동으로 스마트해짐.
예시: 패션 상품 검색에의 응용
- 이미지 및 상품 메타 정보를 통한 검색: 이미지에서 색상, 스타일, 패턴 등의 속성을 추출하여 검색
- → 인풋: 사용자 업로드 이미지 또는 선택한 스타일 속성
- → 아웃풋: 유사한 스타일의 패션 상품 리스트
- 모델 활용: CNN(Convolutional Neural Network) 등을 통해 이미지 피쳐 추출
- → 사용자 선호도를 기반으로 결과를 개인화하고 관련성 높은 상품 추천
이미지 설명
- Figure 4.2 Reflected Intelligence Process:
- 사용자 쿼리 입력 → 결과 확인 및 상호작용 → 신호 처리 및 학습 모델 생성 → 향후 검색 결과 개선
이와 같은 방법의 적용은 AI 기반 검색 엔진의 효율성을 극대화하고, 사용자 경험의 향상에 기여 Reflected Intelligence는 검색 시스템의 지속적인 최적화를 가능케
4.2.2 Signals Boosting을 통한 인기 관련성 향상
Signals Boosting 모델 개요
- Signals Boosting 가장 간단하면서도 검색 쿼리의 관련성을 향상시키는 데 효과적인 방법.
- 유명한 쿼리는 더 많은 신호를 생성함
- 이런 신호를 활용해 관련성을 개선하는 모델 학습 가능
Signals Boosting 작동 방식
- 쿼리 입력 사용자가 검색 엔진에 쿼리를 입력.
- 예시: “ipad”라는 쿼리를 검색 엔진에 입력
- 관련 이미지:

- 설명: 여러 번 언급된 키워드가 높은 순위로 반환됨. 그러나 사용자가 의도한 주요 제품보다는 키워드가 자주 언급된 액세서리가 더 높은 순위로 나타날 수 있음.
- Aggregate User Behavior 유명한 쿼리에서 사용자 행동을 집계하여 최적의 제품을 자동으로 학습하고 반환.
- 피드백 루프: 사용자 상호작용 정보를 수집하여 신호 부스팅 모델 업데이트
- 관련 이미지:
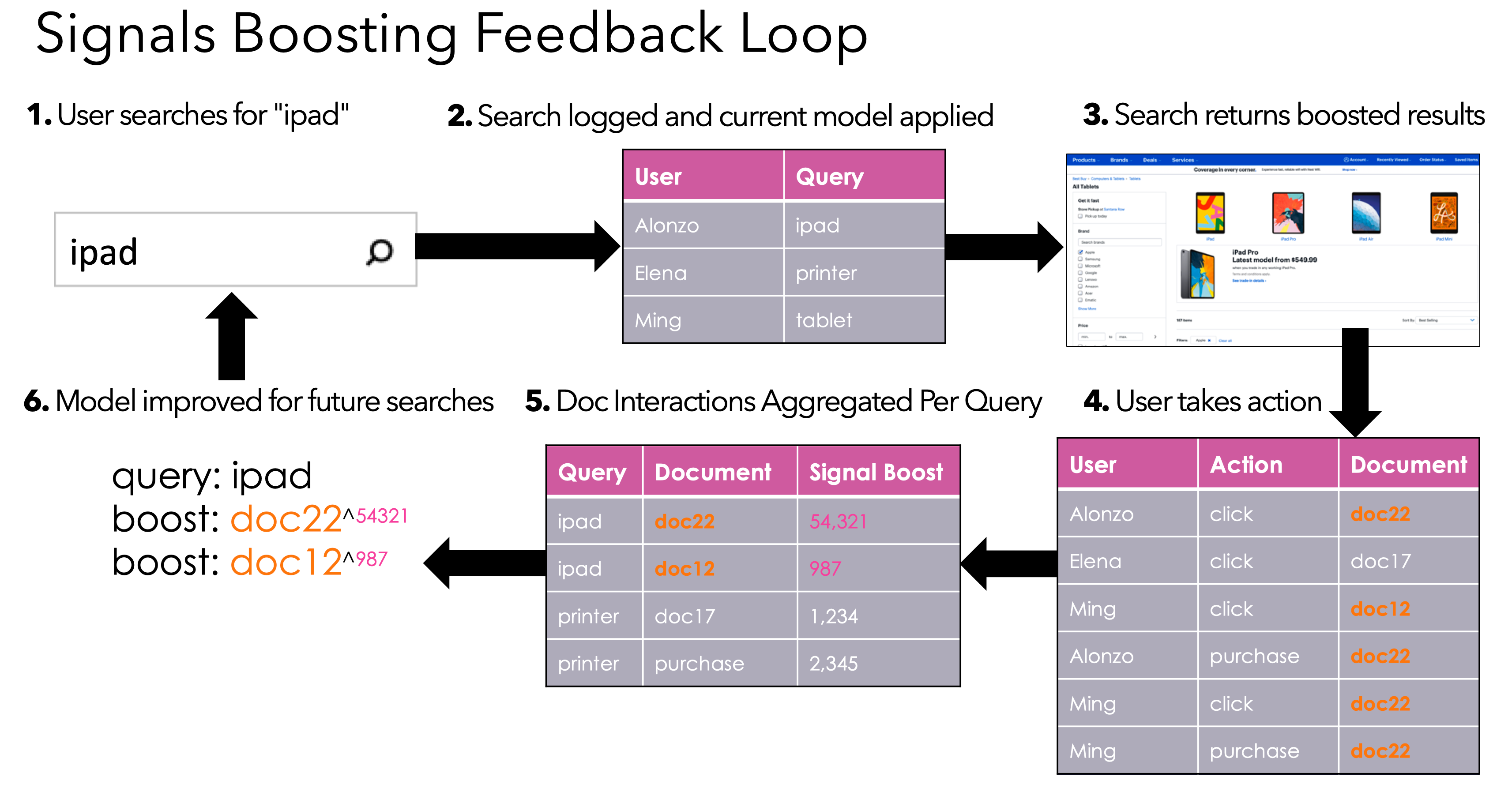
- 설명: 사용자의 검색이 기록되고, 신호 부스팅 모델이 적용되어 부스팅된 결과 반환. 사용자 상호작용 후 신호를 집계하여 신호 부스팅 모델 업데이트.
Signals Boosting 모델 구현
- 신호 집계
- 신호를 집계하여 쿼리 또는 문서에 부스트 추가
- Sidecar Collection 활용: 기본 컬렉션과 함께 유용한 데이터 저장
select q.target as query, c.target as doc, count(c.target) as boost
from signals c left join signals q on c.query_id = q.query_id
where c.type = 'click' AND q.type = 'query'
group by query, doc
order by boost desc
- 신호 부스팅 모델 생성
TL;DR
- Signals Boosting은 인기 쿼리에서 생성된 사용자 신호를 활용하여 검색 관련성을 향상시킴.
- 피드백 루프를 통해 사용자 상호작용을 지속적으로 반영하여 모델을 업데이트
- Sidecar Collection을 사용하여 신호를 집계하고 부스트를 추가하여 검색 결과를 최적화
패션 상품 검색에의 적용 예시
- 이미지 및 상품 메타 정보 기반 검색 이미지와 메타 데이터를 활용해 신호를 수집하고 부스팅 모델에 적용
- 인풋: 이미지 데이터, 상품 설명, 사용자 검색 쿼리
- 아웃풋: 관련성 높은 패션 아이템 추천
- 모델 활용 Fashion-MNIST 데이터셋을 이용한 CNN 모델 적용
- 인풋: 패션 아이템 이미지
- 아웃풋: 유사한 패션 아이템 추천
p112
Listing 4.7: Signals Boosting Query 생성하기
- Boost Documents
- 주요 작업: 문서의 검색 순위를 개선하기 위해 Signals Boosting Query를 생성
- 예시: 특정 쿼리 “ipad”에 대해 Signals Boosting을 적용하여 더 관련성 높은 검색 결과를 얻음.
- Boost Query
query = "ipad" signals_boosts_query = { "query": query, "fields": ["doc", "boost"], "limit": 10, "params": { "defType": "edismax", "qf": "query", "sort": "boost desc" } } signals_boosts = requests.POST(solr_url + signals_boosting_collection + "/select", json=signals_boosts_query).json()["response"]["docs"] print("Boost Documents: \n") print(signals_boosts)- 과정 설명
query변수에 “ipad”를 설정- Solr 쿼리 파라미터를 설정하여 Signals Boosting을 사용할 문서 리스트를 가져옴.
- 부스트 값에 따라 정렬된 결과를 반환
- 과정 설명
- Boost Query 생성
product_boosts = "" for entry in signals_boosts: if len(product_boosts) > 0product_boosts += " " product_boosts += '"' + entry['doc'] + '"^' + str(entry['boost']) print("\nBoost Query: \n" + product_boosts)- 과정 설명
signals_boosts리스트에서 각 문서에 대해 부스트 쿼리를 생성.- 문서 ID와 부스트 값을 결합하여 새로운 쿼리를 생성
- 과정 설명
- 최종 검색 요청
collection = "products" request = { "query": query, "fields": ["upc", "name", "manufacturer", "score"], "limit": 5, "params": { "qf": "name manufacturer longDescription", "defType": "edismax", "indent": "true", "sort": "score desc, upc asc", "boost": "sum(1,query({! df=upc v=$signals_boosting}))", "signals_boosting": product_boosts } } search_results = requests.POST(solr_url + collection + "/select", json=request) .json()["response"]["docs"] display(HTML(render_search_results(query, search_results)))- 과정 설명
- 최종적으로 생성된 부스트 쿼리를 검색 요청에 포함하여 Solr에 전달
- 검색 결과를 렌더링하여 사용자에게 표시
- 과정 설명
- 예시 결과
- 부스트 값이 높은 순서대로 문서 리스트가 반환됨.
[{'doc': '885909457588', 'boost': 966}, {'doc': '885909457595', 'boost': 205}, {'doc': '885909471812', 'boost': 202}, {'doc': '886111287055', 'boost': 109}, {'doc': '843404073153', 'boost': 73}, {'doc': '635753493559', 'boost': 62}, {'doc': '885909457601', 'boost': 62}, {'doc': '885909472376', 'boost': 61}, {'doc': '610839379408', 'boost': 29}, {'doc': '884962753071', 'boost': 28}]
- 부스트 값이 높은 순서대로 문서 리스트가 반환됨.
p113
- Signals Boosting Query의 주요 기능
- 문서 정렬 부스트 값에 따라 정렬된 문서를 조회하여 검색 엔진에 전달
- 검색 엔진 전달 부스트 쿼리를 검색 엔진에 전달하여 관련성을 개선
- Boosting 파라미터
"boost": "sum(1,query({! df=upc v=$signals_boosting}))"- 설명: UPC 필드를 기준으로 부스트 쿼리를 적용하여 검색 결과의 관련성을 높임.
"signals_boosting": product_boosts- 설명:
product_boosts는 부스트 쿼리를 생성한 리스트로, 검색 엔진에 전달됨.
- 설명:
- 결과 분석
- 초기의 키워드 검색이 iPad 액세서리에 집중되었으나, Signals Boosting 적용 후 실제 iPad 기기가 검색됨.
- Figure 4.5는 Signals Boosting이 적용된 새로운 결과를 보여줌.
p114
- Figure 4.5 설명
- Signals Boosting이 활성화된 검색 결과를 시각화
- 사용자들이 실제로 상호작용한 문서를 기반으로 크라우드소싱된 결과를 보여줌.
- 결과 개선 효과
- Signals Boosting 적용 후, 사용자 의도에 맞춘 검색 결과 제공.
- 대중적인 쿼리에 대해 높은 신뢰성을 바탕으로 한 크라우드소싱 접근 방식을 적용
- 그러나 유명한 제품에서 멀어질수록 Signals Boosting의 효과는 감소할 수 있음.
p115
- 목표 Signals Boosting을 통한 초기 구현 사례를 기반으로 한 end-to-end Reflected Intelligence 모델 설명.
- 고려사항
- 쿼리 시간 또는 문서 기반 부스트 선택하고,
- 새로운 신호의 가중치를 높이는 방법임
- 악의적인 사용자의 잘못된 신호 방지하고
- 다양한 출처의 신호 결합할 수 있는 방법임
- 다른 모델 소개
- Collaborative Filtering
- “개인화된 관련성”을 목표로
- 기존 사용자의 선호도를 기반으로 다른 사용자의 선호도를 예측
- 추천 엔진에서 널리 사용되는 알고리즘으로, “이 아이템을 좋아한 사용자는 다른 아이템도 좋아했습니다”와 같은 추천 리스트 생성.
- Figure 4.6은 Signals Boosting 모델에서 보았던 Reflected Intelligence 피드백 루프와 유사
- Collaborative Filtering
- 핵심
- Signals Boosting은 문서와 쿼리의 관련성을 높이기 위한 기법으로,
- 부스트 쿼리는 검색 엔진의 결과 정렬을 개선
- Collaborative Filtering은 사용자 개인화에 초점을 맞춤
이 가이드를 통해 Signals Boosting 및 Collaborative Filtering을 활용하여 검색 관련성을 어떻게 개선할 수 있는지 이해할 수 있음. 이런 기법들은 검색 엔진의 성능을 높이는 데 중요한 역할을 하며, 사용자 경험을 크게 개선 다음 장에서는 이런 기법들의 심화된 내용을 다룰 예정임.
1. Collaborative Filtering 개요
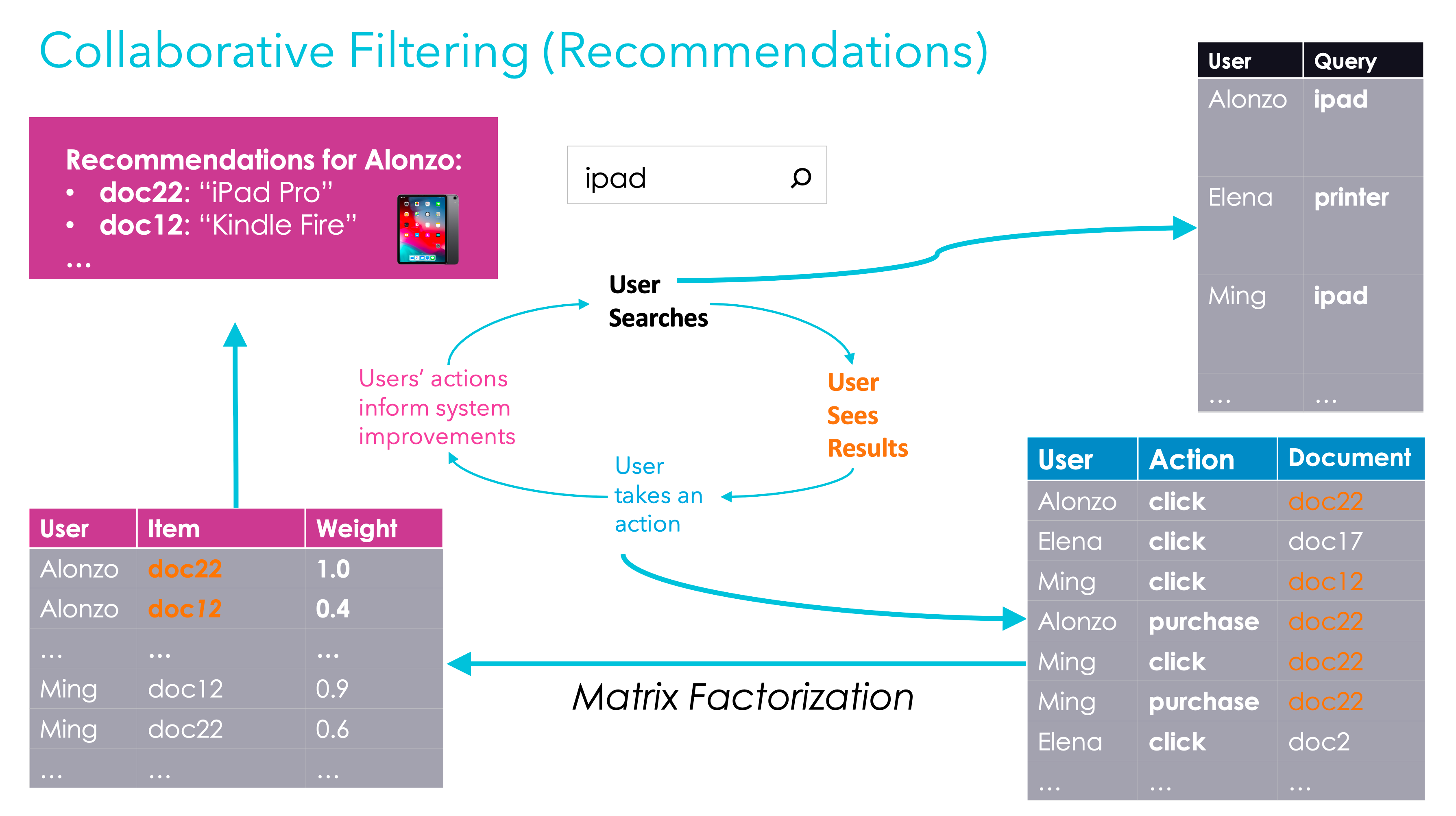
Figure 4.6 사용자-아이템 추천을 위한 Collaborative Filtering. 사용자는 과거 행동을 기반으로 다른 사용자가 좋아했던 아이템을 추천받음. 이때, 다른 사용자들도 동일한 아이템과 상호작용
- Collaborative Filtering 신호 수집 → 모델 구축 → 관련 매치 생성 → 결과 로그 기록의 반복적 피드백 루프 사용
- 사용자와 아이템 간의 상호작용을 신호로 기록
- 사용자-아이템 상호작용 행렬 생성
- 각 사용자와 아이템 간의 관계 강도는 긍정적 상호작용(클릭, 구매, 평점 등)에 기초함
1.1 행렬 요인의 활용
- 행렬 팩토라이제이션(Matrix Factorization) 사용자-아이템 상호작용 행렬을 두 개의 행렬로 분해
- 사용자와 잠재 “요인” 간의 매핑
- 잠재 요인과 아이템 간의 매핑
- 차원 축소를 통한 의미 매칭 가능
- 잠재 요인(Latent Factors) 문서의 공유 관심사를 나타내는 속성
- 유사 문서 매칭: 사용자 관심사를 군중 소싱으로 탐색
1.2 Collaborative Filtering의 한계
- Cold Start Problem 새로운 문서가 신호를 생성하지 못해 표시되지 않는 문제
- 유명한 문서만 더욱 부각되어 다양성 감소
2. Learning to Rank 개요
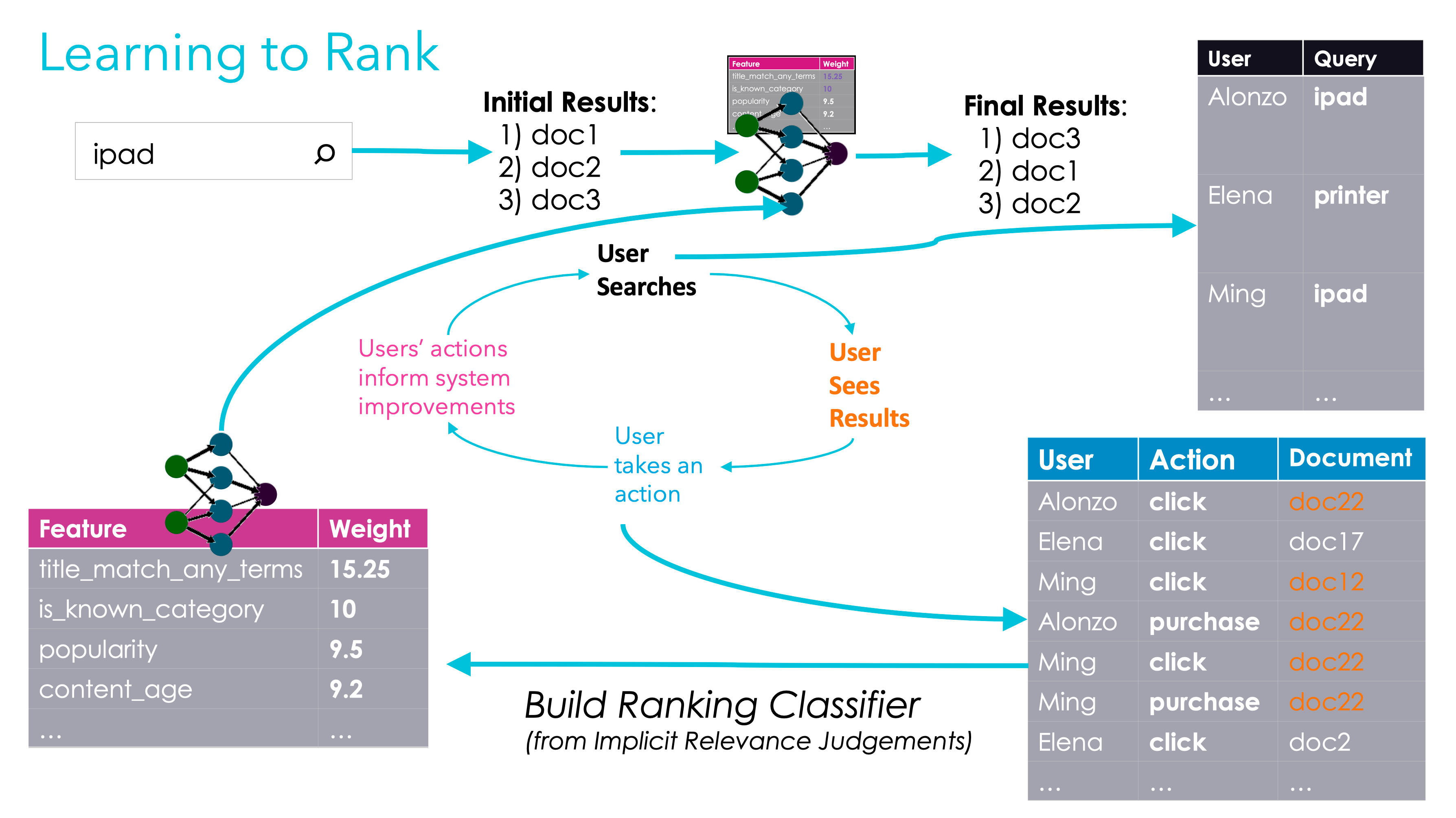
Figure 4.7 Learning to Rank의 일반화된 흐름. 사용자 판단을 기반으로 랭킹 분류기를 구축하여 검색 결과 재정렬.
- Learning to Rank 문서와 쿼리의 매칭 점수를 부여하는 랭킹 분류기 생성
- 수동 조정 없이 중요 피처 학습
- 다양한 쿼리에 일반적으로 적용 가능한 모델 구축
2.1 Learning to Rank의 프로세스
- 랭킹 분류기의 구축 사용자 판단 목록을 기반으로 모델 학습
- 모델의 피처 예시: 제목 일치, 카테고리 인식, 인기도, 문서 나이 등
- 검색 엔진에 배포하여 결과 향상
- 실시간 유저 플로우 초기 검색 결과 → 랭킹 분류기 적용 → 최종 결과 재정렬
- 초기 빠른 랭킹 함수(BM25 등)로 상위 문서 선택 후, 랭킹 분류기로 재정렬
2.2 Learning to Rank의 Pros(+)
- 명시적/암시적 판단 활용 가능 전문가의 명시적 판단 또는 사용자 신호에서 추출된 암시적 판단
- 다양한 방식으로 training dataset 생성 가능
3. 핵심
- Collaborative Filtering은 사용자 행동 데이터를 기반으로 추천 시스템을 구축하며, cold start 문제를 가짐.
- Learning to Rank는 문서와 쿼리의 중요 피처를 학습하여 검색 결과를 최적화하는 모델을 구축
- 두 방법 모두 사용자의 상호작용 데이터를 활용하여 문서의 관련성을 평가하고, 검색 경험을 향상시킴.
4. 패션 상품 검색 예시
- 이미지와 상품 메타 정보를 활용한 추천 시스템 Collaborative Filtering과 Learning to Rank를 결합하여 구현 가능
- 인풋: 사용자 행동 데이터(클릭, 구매), 이미지 데이터
- 아웃풋: 사용자 취향에 맞는 패션 상품 추천
- 모델 적용 이미지 피쳐 추출 후, Collaborative Filtering으로 유사 사용자 기반 추천 및 Learning to Rank로 최적화된 검색 순위 제공
Collaborative Filtering과 Learning to Rank의 이론적 배경과 활용 방법을 상세히 설명하며, 패션 상품 검색에의 적용 가능성을 제시
Reflected Intelligence and Knowledge Graphs
p.120
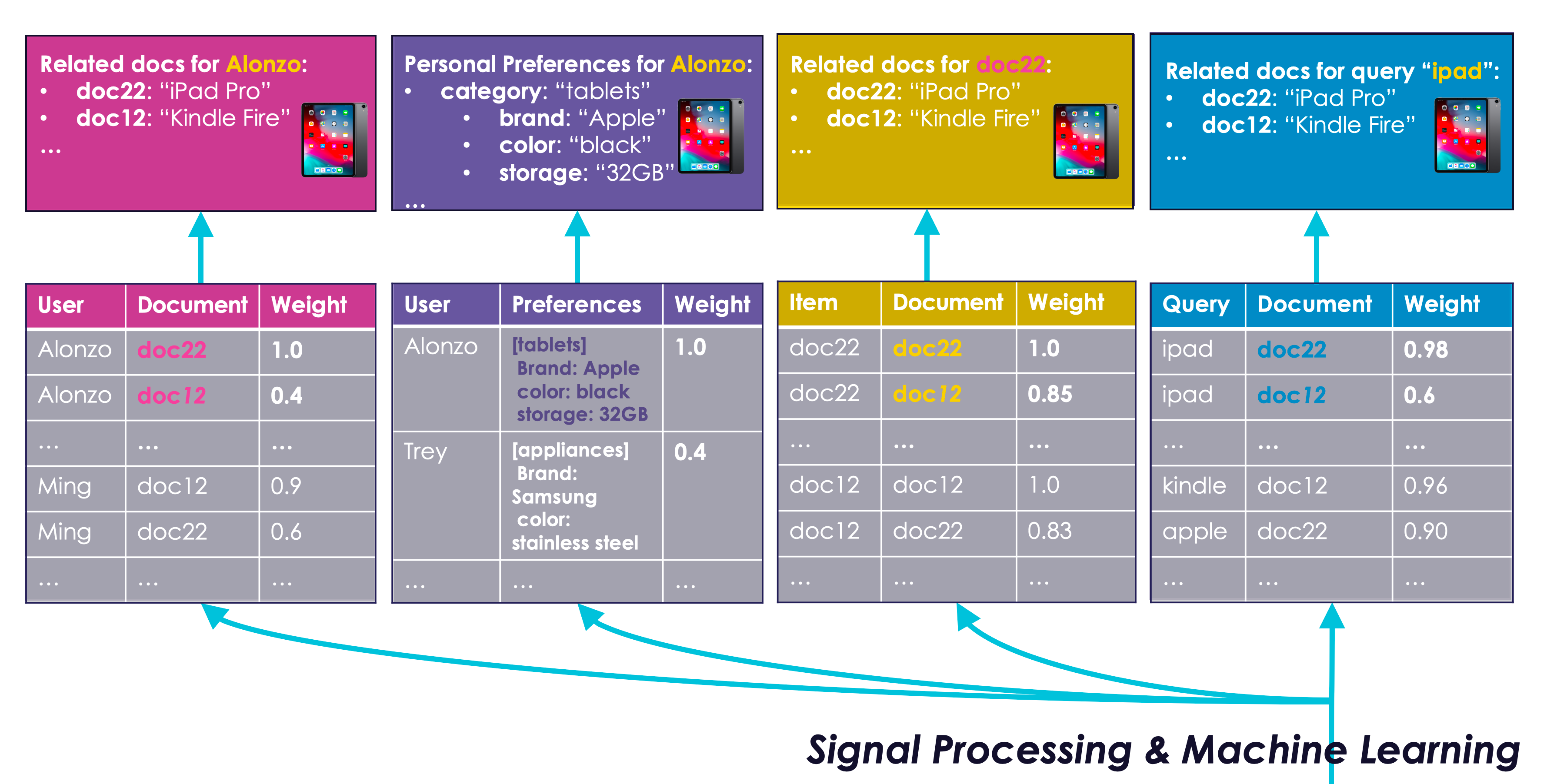
Figure 4.8: 다양한 Reflected Intelligence 모델
- 첫 번째 박스 사용자와 아이템 간 유사성을 추천을 위해 학습
- 두 번째 박스 사용자 프로필을 위한 특정 속성 기반 선호도 학습
- 세 번째 박스 아이템 간 유사성을 추천을 위해 학습
- 네 번째 박스 쿼리-아이템 추천을 위한 학습
Reflected Intelligence의 개념
- Reflected Intelligence 사용자로부터 학습하고 그 학습된 내용을 반영하는 과정
- 신호 부스팅, 협업 필터링, Learning to Rank 기술에 국한되지 않음
- 콘텐츠 기반의 Reflected Intelligence 도출 가능
Crowdsourcing의 역할
- 내재적 피드백 사용자 신호를 통해 군중 지성 도출 가능
- 컨텐츠 기반 Crowdsourcing AI 기반 검색 플랫폼에서 활용
예시
- 문서 품질 평가 고객 리뷰 활용
- 감정 분석 알고리즘 긍정, 중립, 부정적 감정을 파악
- 문서 부스팅/패널티 감정 분석 결과에 따라 문서의 중요도 조정
p.121
알고리즘과 신호의 중요성
- Page Rank 알고리즘 구글의 성공 요인 중 하나
- 텍스트 외의 웹 페이지 크리에이터 행동 분석
- 링크 측정 고품질 웹사이트로의 링크를 통해 ‘품질’ 측정
정보 활용의 중요성
- 외부 콘텐츠와의 관계 직접 사용자 상호작용, 포럼의 댓글과 피드백, 웹사이트 간 링크 활용
- 지식 그래프 링크 간의 관계 학습을 통해 도메인 이해 자동화
p.122
AI-기반 검색 엔진의 연료
- 신호와 콘텐츠 AI 검색 엔진을 구동하는 주요 요소
- 신호 부스팅 대중성 있는 관련성 제공
- 협업 필터링 개인화된 관련성 제공
- Learning to Rank 일반화된 관련성 제공
- 기타 Reflected Intelligence 콘텐츠 활용 기법 포함
TL;DR
- Reflected Intelligence는 사용자 상호작용을 학습하여 검색 결과의 관련성을 자동으로 증가시킴.
- 신호 부스팅, 협업 필터링, Learning to Rank가 주요 기법이며, 콘텐츠 기반 기법도 존재
- 지식 그래프를 활용하여 문서 간의 관계를 이해하고, 검색 쿼리 확장을 통해 검색 정확도를 향상시킬 수 있음.
p.123
지식 그래프의 활용
- 도메인 특정 용어 해석 콘텐츠 내의 관계를 활용하여 도메인 이해
- 전통적 지식 그래프: 도메인 내 명시적 관계 모델링
- 의미적 지식 그래프: 도메인 내 의미적 관계 실시간 인퍼런스
다양한 데이터셋 활용
- 지식 그래프 구축 및 적용을 통한 쿼리 이해 개선
- 오픈 정보 추출 텍스트로부터 지식 그래프 생성
- 의미적 지식 그래프 활용 쿼리 확장, 문서 추천
결론
- 콘텐츠와 사용자 신호를 활용하여 AI 기반의 높은 관련성 검색 엔진 구축 가능
- 지식 그래프와 의미적 연결을 통해 자동화된 도메인 이해 가능
예시: 패션 상품 검색
- 이미지와 상품 메타 정보 활용 패션 아이템 검색
- 모델 CNN 기반 이미지 인식, NLP 기반 메타 정보 분석
- 인풋 사용자 이미지, 메타 데이터
- 아웃풋 유사 아이템 추천, 사용자 선호도 기반 맞춤 추천
이와 같은 방식으로 Reflected Intelligence와 지식 그래프를 활용하여 다양한 도메인에서의 검색 관련성을 높일 수 있음.
지식 그래프 구축 및 활용에 대한 기술적 접근
1.4 지식 그래프의 기초
-
지식 그래프 개념 도입
→ 지식 그래프는 노드와 엣지를 통해 표현됨
→ 노드는 엔티티(e.g., 용어, 사람, 장소, 개념 등)
→ 엣지는 두 노드 간의 관계를 나타냄
→ Figure 5.1 참고 -
지식 그래프 예시 설명
→ 저자, 연구 논문, 학술 대회, 도시, 국가, 날짜 등의 노드
→ 엣지를 따라 탐색하여 정보 인퍼런스 가능
→ 예: 저자가 2016년 10월 캐나다 몬트리올에 있었음을 인퍼런스
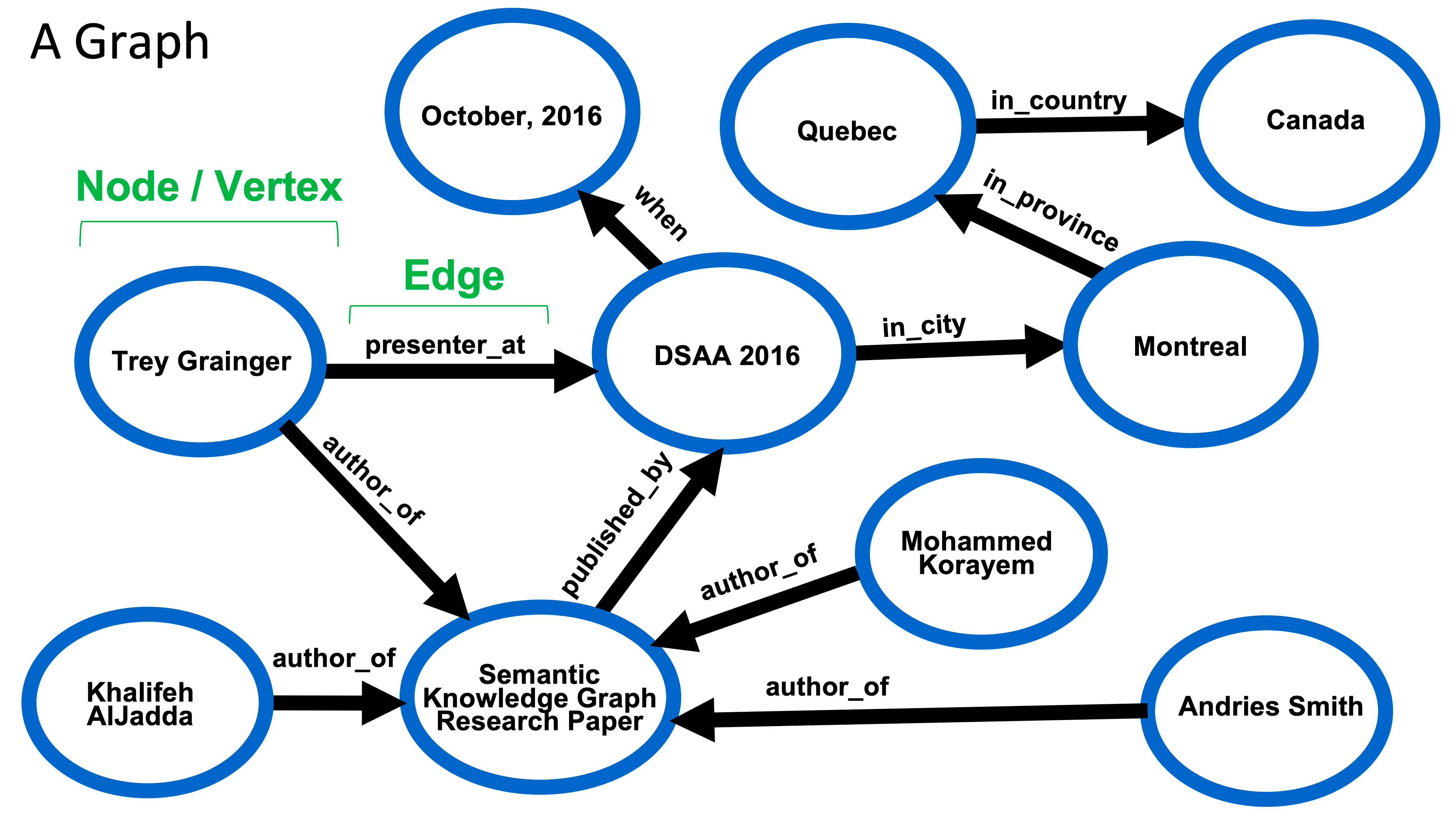{kind=link}
TL;DR
- 지식 그래프는 노드와 엣지로 구성되어 다양한 엔티티와 관계를 표현
- 노드와 엣지를 따라 탐색하여 새로운 정보를 인퍼런스 가능
- 지식 그래프는 사실적 지식을 표현하며, 이를 통해 다양한 분석과 인퍼런스이 가능
5.1 지식 그래프 활용 방법
- 지식 그래프 구축 방법
- 그래프 데이터베이스로 직접 구축 (Neo4j, ArangoDB 등)
- 기존 지식 그래프 활용 (ConceptNet, DBPedia 등)
- 데이터로부터 자동 생성하여 지식 추출
- 방법의 장Cons(-)
→ 일반 지식 검색 엔진: 기존 지식 그래프 활용
→ 도메인 특화 검색 엔진: 도메인 특화 엔티티 포함 필요
→ 자동 생성 접근 방식에 중점, 수동 생성 및 기존 그래프 활용은 외부 자료 참고
5.2 명시적 지식 그래프 구축
-
Apache Solr의 활용
→ 명시적 그래프 탐색 기능 내장
→ 외부 시스템 필요 없이 지식 그래프 구현 가능 -
외부 그래프 데이터베이스 사용의 복잡성
→ 요청 조율, 데이터 동기화, 인프라 관리 복잡
→ 검색 엔진에서 일부 그래프 작업의 효율적 수행 가능 -
통합 플랫폼으로서의 검색 엔진
→ 검색 기능과 지식 그래프 기능의 결합으로 시너지 효과 제공
TL;DR
- 명시적 그래프 탐색 기능이 포함된 Apache Solr을 통해 지식 그래프를 효과적으로 구현 가능.
- 외부 그래프 데이터베이스 사용 시 복잡성 증가, 검색 엔진 내 구현이 효율적.
- 검색 엔진을 통합 플랫폼으로 활용하여 검색 및 지식 그래프 기능 결합.
5.3 콘텐츠로부터의 자동 지식 그래프 추출
-
Open Information Extraction의 역할
→ 자연어 처리(NLP)를 통한 텍스트에서의 사실 추출
→ 의존성 그래프 사용: 문장의 구문적 구조 분석 -
임의 관계와 하위 관계 추출
→ 명사와 동사 분석을 통한 RDF 트리플 형성
→ 예: “Colin attends Riverside High School” → (“Colin”, “attends”, “Riverside High School”) -
SpaCy 라이브러리를 통한 예시
→ 자연어 처리 라이브러리로 텍스트 구문 분석 및 관계 추출
→ Listing 5.1에서 Python 코드를 통해 관계 생성
{kind=link}
TL;DR
- 자연어 처리를 통해 텍스트에서 관계를 추출하고, RDF 트리플로 표현.
- SpaCy와 같은 NLP 라이브러리로 자동 팩트 추출 가능.
- 명사, 동사 분석을 통해 지식 그래프의 노드와 엣지를 형성하여 관계 파악.
예시: 패션 상품 검색의 적용
-
이미지와 메타정보 기반 검색
→ 이미지 처리 모델을 통해 상품의 특성 추출
→ 메타정보와 결합하여 지식 그래프의 노드 및 엣지 생성
→ 예: 이미지에서 색상, 스타일, 브랜드 정보 추출 → RDF 트리플 형성 -
모델 활용
→ CNN(Convolutional Neural Network)를 통한 이미지 피쳐 추출
→ NLP 모델로 제품 설명 텍스트 처리 및 관계 분석 -
검색 엔진 통합
→ Apache Solr와 같은 플랫폼에 지식 그래프 통합
→ 사용자가 입력한 키워드와 이미지 정보를 기반으로 검색 결과 제공
이와 같이, 지식 그래프를 다양한 방법으로 구축하고 활용함으로써, 정확한 정보 추출 및 검색 서비스를 제공할 수 있음. SpaCy와 같은 NLP 도구를 사용하여 텍스트로부터 직접 정보를 추출하고, 이를 지식 그래프로 통합하여 복합적인 정보 검색이 가능하도록
지식 그래프 구축 및 하이퍼님 관계 추출
1. 지식 그래프 구축
- 관계 추출 및 지식 그래프 저장
- 주어/관계/목적어 튜플 저장 → 지식 그래프로 변환 및 탐색 가능
- Figure 5.2 추출된 지식 그래프 시각화
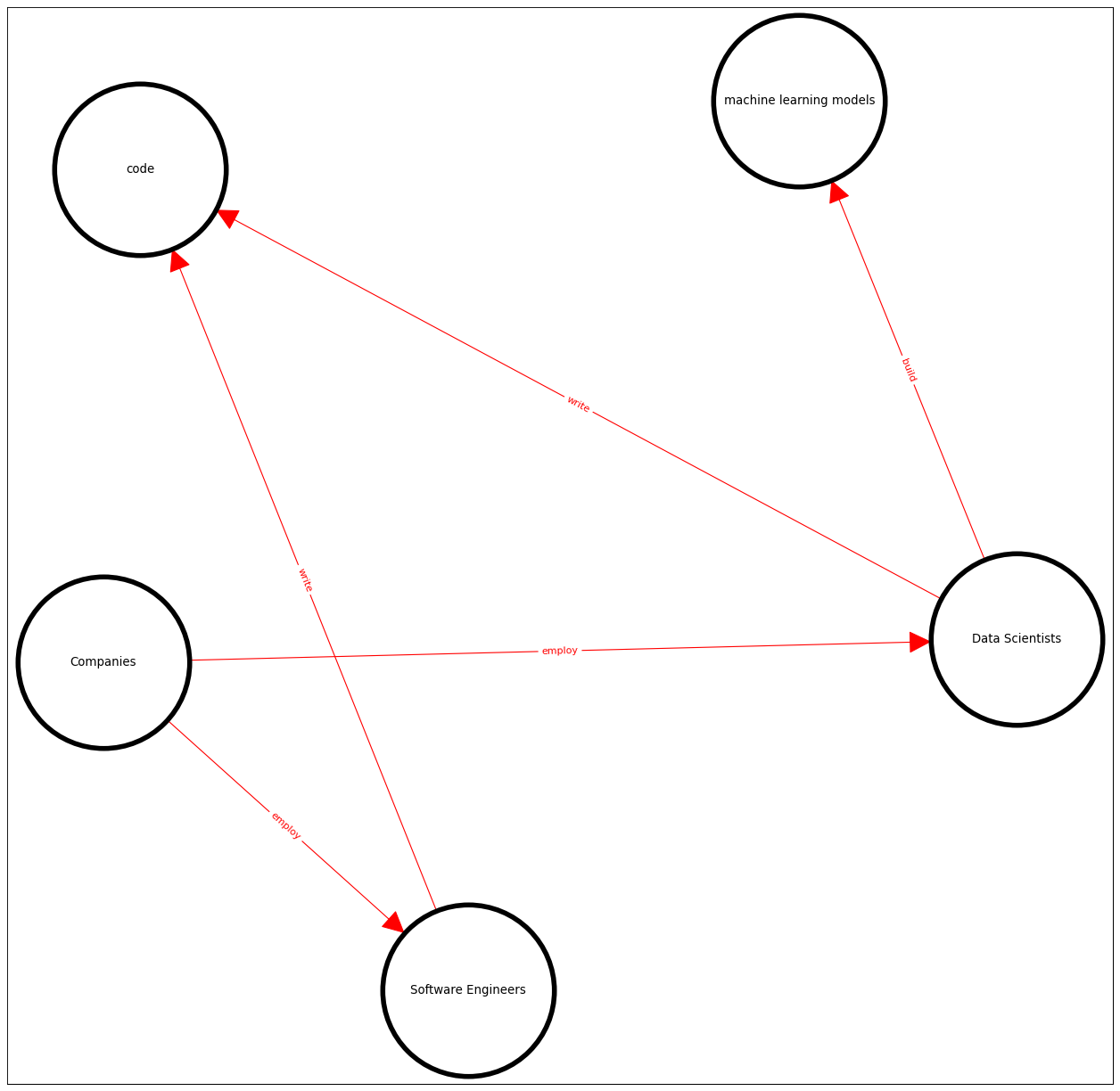
- 설명: 이 그래프의 노드와 엣지는 텍스트 내용에서 품사 패턴에 기반하여 자동 추출됨.
- 추출 메커니즘
- SpaCy 라이브러리 활용: 딥러닝 기반 신경망 언어 모델 사용 → 품사, 구문, 의존성 및 상호참조 탐지
- 파싱 메커니즘: 영어의 알려진 의미 패턴을 따르는 규칙 기반 방법 사용
- 문제점 및 해결책
- 임의의 동사를 관계로 파싱 시 노이즈 발생 가능성
- 동사의 변형, 동의어 및 의미 중첩 → 관계 리스트 정리 필요
2. 하이퍼님 및 하이포님 추출
- 관계 정의
- 하이포님 “is a” 또는 “is instance of” 관계를 유지하는 엔티티
- 하이퍼님 하이포님의 일반화된 형태
- 예시: 필립스 헤드 스크류드라이버(하이포님) → 스크류드라이버(하이퍼님) → 도구(하이퍼님)
- Hearst 패턴 활용
- 하이퍼님/하이포님 관계 추출에 효과적임
- Listing 5.2 Hearst 패턴 예시
simple_hearst_patterns = [ ('(NP_\\w+ (, )?such as (NP_\\w+ ?(, )?(and |or )?)+)', 'first'), ('(such NP_\\w+ (, )?as (NP_\\w+ ?(, )?(and |or )?)+)', 'first'), ('((NP_\\w+ ?(, )?)+(and |or )?other NP_\\w+)', 'last'), ('(NP_\\w+ (, )?include (NP_\\w+ ?(, )?(and |or )?)+)', 'first'), ('(NP_\\w+ (, )?especially (NP_\\w+ ?(, )?(and |or )?)+)', 'first'), ]
3. 하이퍼님 관계 추출 예시
- 패턴 매칭 및 결과
- 문자열 내 패턴 매칭 → 명사구(NP_) 발견 → 하이퍼님/하이포님 관계 추출
- Listing 5.3 Hearst 패턴을 이용한 관계 추출 예시
text_content = """ Many data scientists have skills such as machine learning, python, deep learning, apache spark, or collaborative filtering, among others ... """ h = HearstPatterns() extracted_relationships = h.find_hyponyms(text_content) facts = list() for pair in extracted_relationships: facts.append([pair[0], "is_a", pair[1]]) print(*facts, sep="\n")
- [‘machine learning’, ‘is_a’, ‘skill’]
- [‘python’, ‘is_a’, ‘skill’]
- [‘Google’, ‘is_a’, ‘tech company’]
- [‘San Francisco’, ‘is_a’, ‘big city’]
4. 결과 분석
- 지식 그래프 시각화
- Figure 5.3 Hearst 패턴을 통해 생성된 지식 그래프
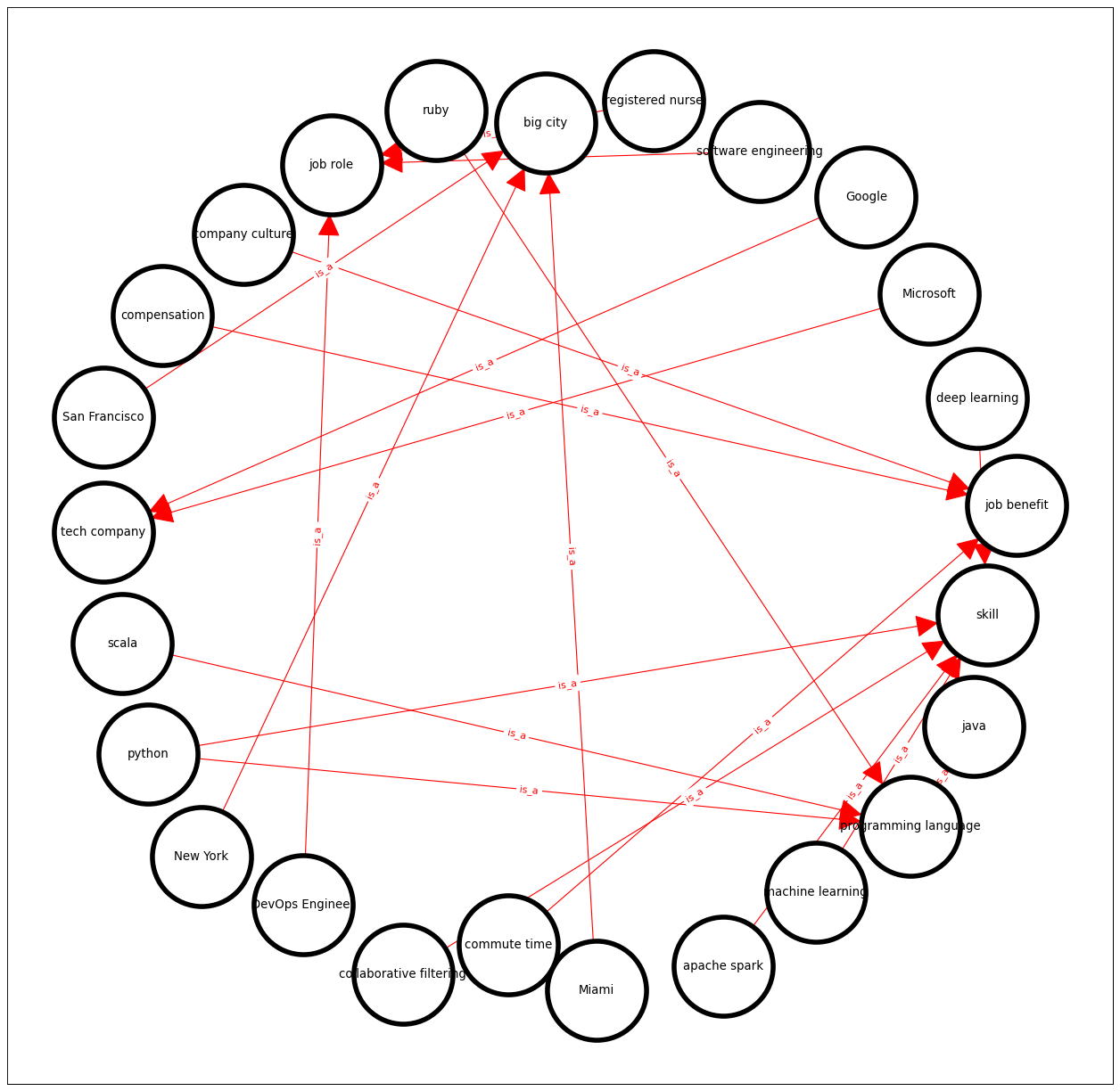
- 설명: 모든 노드가 “is_a” 엣지를 통해 연결됨.
- Figure 5.3 Hearst 패턴을 통해 생성된 지식 그래프
- 노이즈 감소
- 임의의 관계 추출에서 발생한 불일치 및 노이즈 제거
- 유의어, 철자 오류 등의 모호성 해결 가능
핵심
- 주어/관계/목적어 튜플을 이용한 지식 그래프 구축 및 SpaCy 라이브러리를 통한 품사 패턴 탐지.
- Hearst 패턴을 활용한 하이퍼님/하이포님 관계 추출로 노이즈 감소.
- 추출된 관계와 지식 그래프의 시각화를 통해 명확한 관계 구조 제시.
참고 문서 및 링크
- SpaCy 라이브러리 공식 문서
- Hearst 패턴 관련 논문 및 자료
이와 같은 방법은 이미지와 상품 메타 정보를 기반으로 패션 상품을 검색하는 데에도 적용 가능 예를 들어, “셔츠”라는 하이퍼님에 대해 “드레스 셔츠”, “티셔츠” 등의 하이포님을 추출하여 보다 정확한 검색 결과 제공 가능.
Section 5.4: Learning Intent by Traversing Semantic Knowledge Graphs
5.4.1 What is a Semantic Knowledge Graph?
- Semantic Knowledge Graph 정의
- “Semantic Knowledge Graph” = 실시간으로 도메인 내의 관계를 탐색하고 순위를 매길 수 있는 자동 생성 모델
- 기존 검색 엔진 = 쿼리에 대한 문서 검색 및 순위 매김
- Semantic Knowledge Graph = 쿼리에 가장 적합한 용어를 검색하고 순위 매김
- 예시
- 건강 관련 문서를 색인하고 ‘advil’을 검색
- 전통적인 검색 엔진 = ‘advil’이 포함된 문서 반환
- Semantic Knowledge Graph = 관련 용어 반환 (e.g., advil, motrin, aleve, ibuprofen, alleve)
- “Dynamic Synonyms” 개념
- 용어가 동일한 의미를 지닌 것이 아니라 개념적으로 관련된 용어로 확장 가능
TL;DR
- Semantic Knowledge Graph는 실시간 관계 탐색 및 순위를 지원하는 자동 생성된 모델임.
- 전통적인 검색 엔진과 달리 쿼리에 적합한 용어를 검색하고 순위를 매김.
- 동적 동의어를 통해 쿼리 확장 및 관련 문서 검색을 개선
5.4.2 Indexing the Datasets
- 데이터셋 선택
- 직업 게시판 (job board POSTings) 데이터셋
- StackExchange 데이터 덤프 (health, scifi, devops, outdoors, travel, cooking)
- 색인화 과정
- Semantic Knowledge Graph 사용 전, 데이터셋을 색인화해야 함
- Inverted Index와 Forward Index 활용
- Figure 5.4 설명
- Inverted Index = 문서의 각 필드를 용어 목록으로 매핑
- Forward Index = 용어를 문서 목록으로 매핑
- 이중 방향 매핑 = 그래프 탐색 및 관계 발견에 중요
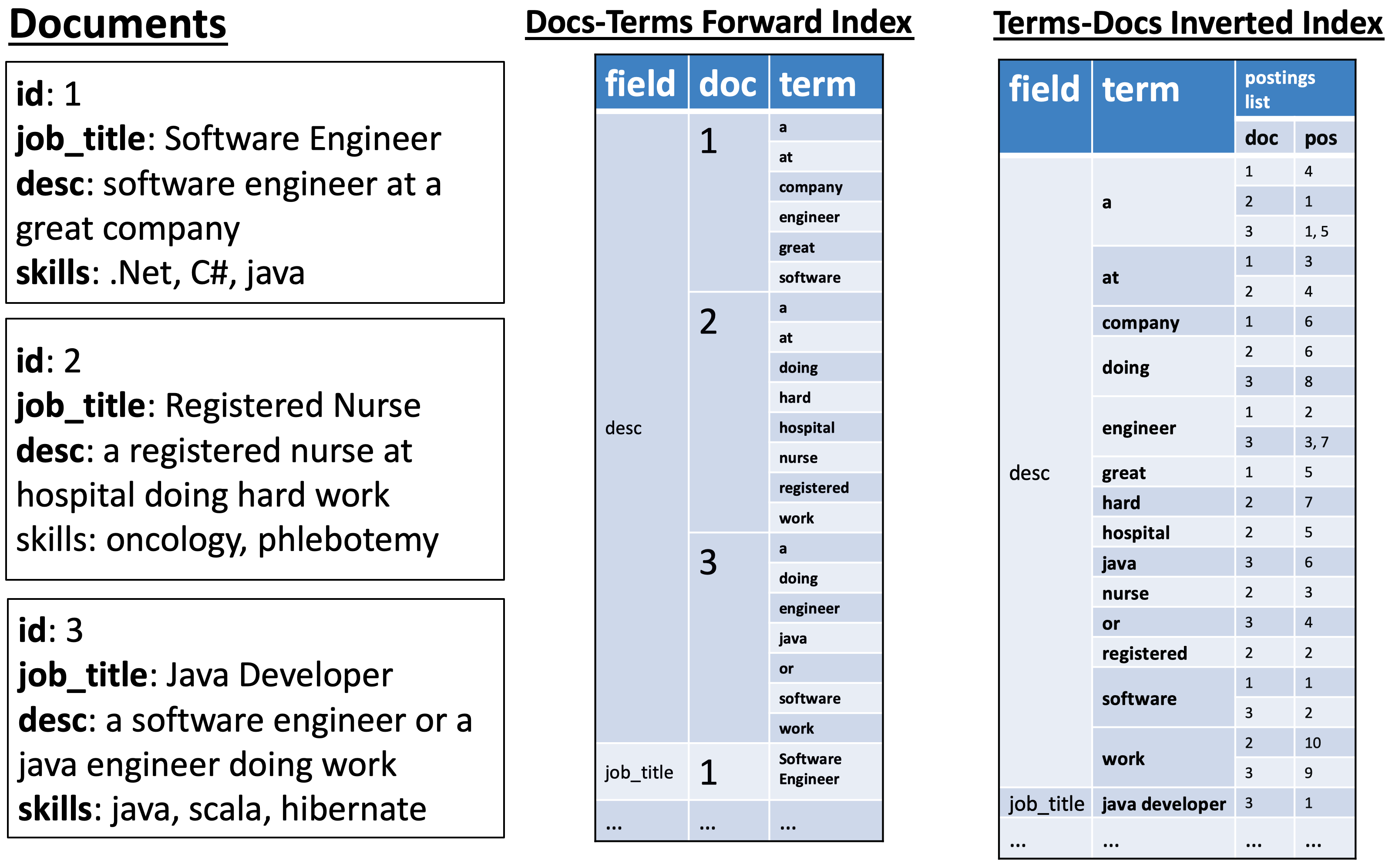
- 이미지 설명
- Inverted Index와 Forward Index의 관계를 보여주는 Figure
- 문서가 어떻게 Inverted Index와 Forward Index로 매핑되는지 시각화
- 각 문서의 ‘job_title’, ‘desc’, ‘skills’ 필드가 용어와 문서로 매핑됨
5.4.3 Structure of a Semantic Knowledge Graph
- 구조 이해
- Inverted Index = 용어를 문서 집합에 매핑
- Forward Index = 문서를 용어 목록에 매핑
- 두 인덱스를 통해 문서-용어-문서 간의 관계 탐색 가능
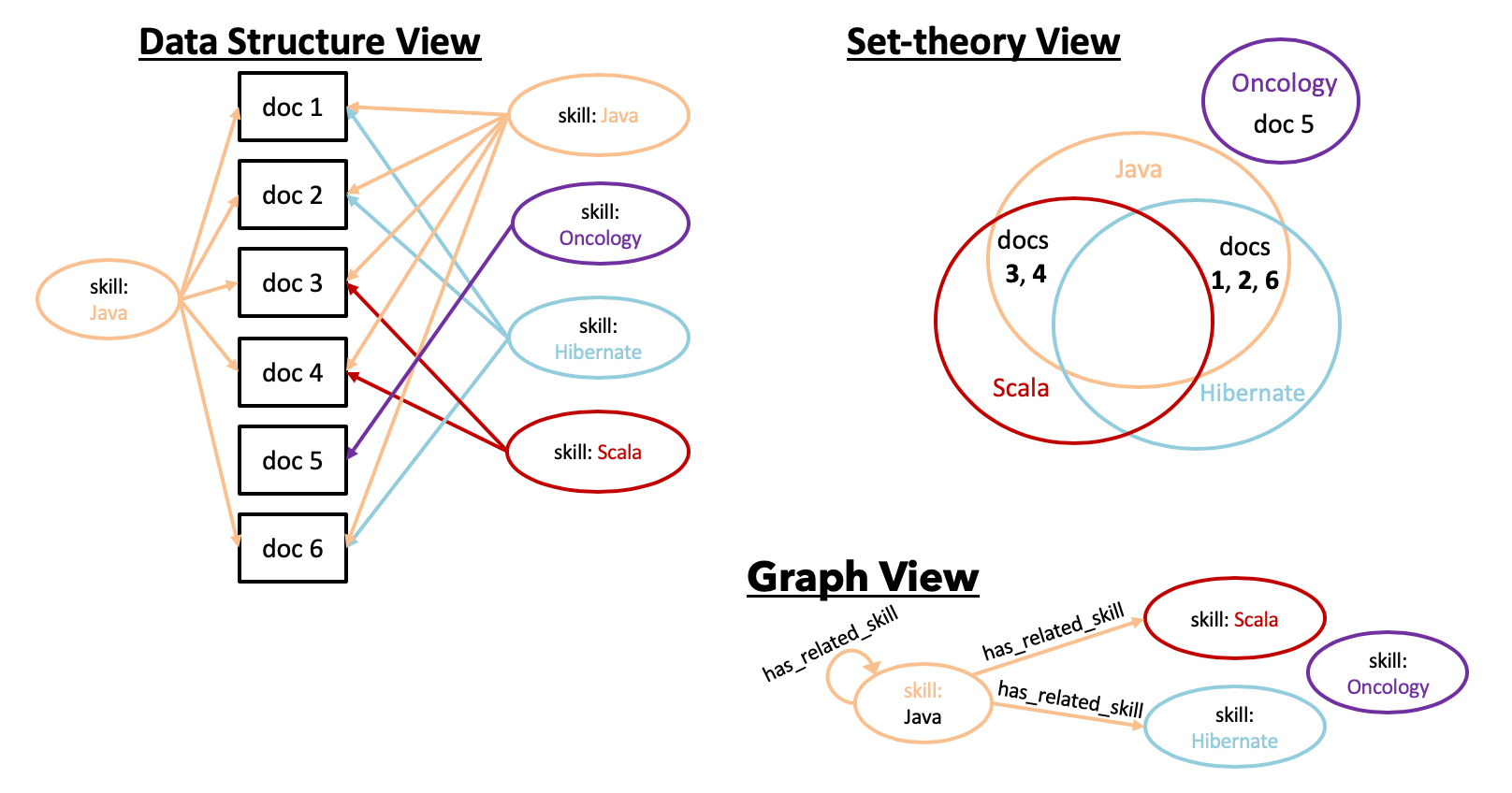
- 이미지 설명
- Semantic Knowledge Graph의 세 가지 표현: 데이터 구조, 집합 이론, 그래프
- 데이터 구조: 용어와 문서 관계
- 집합 이론: 문서 집합의 교차점이 관계 형성
- 그래프: 노드와 엣지로 구성된 시각적 표현
패션 상품 검색 적용 예시
- 이미지 및 메타 정보 활용
- 이미지 속성 및 텍스트 메타 정보를 Semantic Knowledge Graph로 모델링
- 예: ‘청바지’ 검색 시 관련 이미지 및 텍스트 정보 자동 반환
- 모델 활용
- 인풋: 이미지 속성, 텍스트 메타 정보
- 아웃풋: 관련 패션 아이템 추천 및 검색 결과 확장
- 기술 적용
- 패션 웹사이트에서 사용자 경험 개선을 위해 Semantic Knowledge Graph 적용
- 관련 아이템 및 스타일 제안 기능 강화
위와 같은 방식으로 Semantic Knowledge Graph는 다양한 도메인에서의 쿼리 확장 및 관련 데이터 탐색에 강력한 도구로 활용될 수 있음.
Semantic Knowledge Graphs and Their Application in Search Engines
1. Introduction to Semantic Knowledge Graphs
Semantic knowledge graphs represent an advanced abstraction layer built on top of existing inverted indexes. These graphs enhance traditional search engines by not only matching and ranking documents but also focusing on the semantic relationships between terms. This allows for more nuanced and context-aware search results.
- Primary Function Discover and score the strength of semantic relationships between nodes (terms or queries).
- Semantic Similarity Critical for understanding the relationship between nodes.
2. Graph Traversal and Semantic Relationships
2.1 Multi-level Graph Traversal
- Inverted Index Maps terms to documents.
- Forward Index Maps documents back to terms.
- Traversal Nodes (terms/queries) can traverse through these indexes to form multi-level graphs.
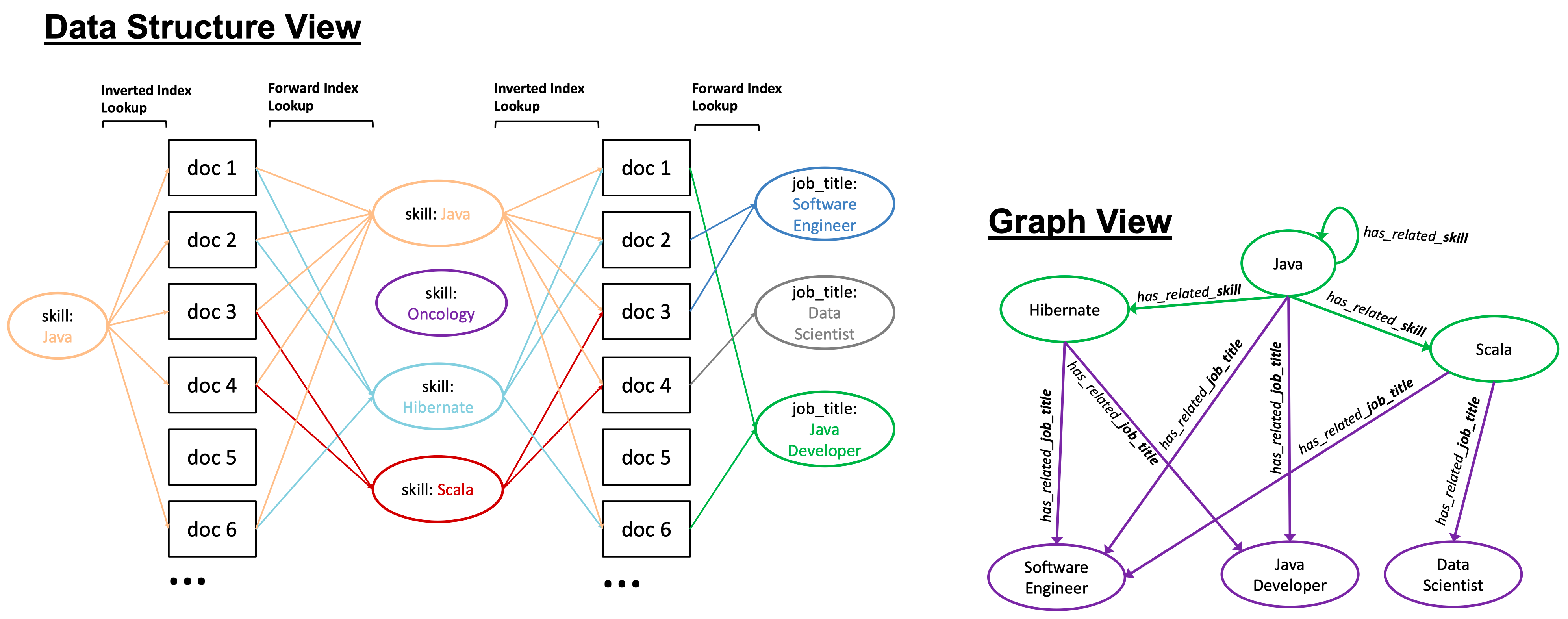
- Figure 5.6 Explanation Demonstrates a multi-level traversal from skills (e.g., Java) to job titles (e.g., Software Engineer). Not all nodes are connected (e.g., Oncology) due to lack of document overlap.
2.2 Scoring Semantic Relationships
- Importance Prioritizes edges during graph traversal.
- Calculation Based on semantic similarity and relatedness.
3. Calculating Semantic Similarity and Relatedness
3.1 Distributional Hypothesis
- Concept Words appearing in similar contexts tend to have similar meanings.
- Example “Pain” co-occurs with “Advil” more frequently than with random terms.
Key Insight Semantic similarity is not just about co-occurrence but the statistical significance of this co-occurrence.
3.2 Relatedness Calculation
- Formula
\(z = \frac{\text{countFg}(x) - \text{totalDocsFG} \cdot \text{probBG}(x)}{\sqrt{\text{totalDocsFG} \cdot \text{probBG}(x) \cdot (1 - \text{probBG}(x))}}\)
- Foreground Set Documents matching a specific query (e.g., “pain”).
- Background Set All documents.
- z-score Measures how much more often a term occurs in the foreground set compared to the background.
Summary High relatedness scores indicate strong semantic relationships.
4. Application in Real-World Search Engines
4.1 Apache Solr Integration
- Faceting API Built-in capabilities for semantic knowledge graphs.
- Example Discovering related terms to “Advil” in a health forum dataset.
{
"params": {
"qf": "title body",
"fore": "{!type=$defType qf=$qf v=$q}",
"back": "*:*",
...
},
"query": "advil",
...
}
4.2 Query Expansion Using Semantic Knowledge Graphs
- Purpose Enhance search results by including related terms.
- Example Expanding “advil” to include terms like “motrin”, “aleve”, etc., with respective relatedness scores.
Expanded Query Example
advil OR motrin^0.59897 OR aleve^0.4662 OR ibuprofen^0.3824
5. Conclusion
Semantic knowledge graphs significantly enhance search engine capabilities by understanding and utilizing the semantic relationships between terms. This allows for more accurate and contextually relevant search results, improving user satisfaction and search engine performance.
In summary, semantic knowledge graphs build on existing search engine indexes to uncover and leverage semantic relationships between terms, offering an advanced layer for query expansion and relevance ranking, ultimately leading to more precise search results.
p.140
Listing 5.5: Discovering Context for Unknown Terms
- Query Example obscure term “vibranium”
- Contextual Expansion Provides useful context for unfamiliar terms
- Related Terms Derived from semantic relationships
- “Wakanda”: Fictional country in Marvel
- “Adamantium”: Another fictional metal
- “Panther”, “Klaue”, “Klaw”: Associated with vibranium
Query Parameters:
- query “vibranium”
- collection “stackexchange”
- params
"qf": “title body”"fore":{!type=$defType qf=$qf v=$q}"back": “:”"defType": “edismax”"rows": 0"echoParams": “none”"omitHeader": “true”
Facet Configuration:
- Facet “body”
- Type “terms”
- Field “body”
- Sort { “relatedness”: “desc”}
- mincount 2
- limit 8
- Sub-facet
- relatedness
- Type “func”
- Function
relatedness($fore,$back)
- relatedness
Code Execution:
search_results = requests.POST(solr_url + collection + “/select”, json=request).json()
for bucket in search_results[“facets”][“body”][“buckets”]: print(str(bucket[“val”]) + “ “ + str(bucket[“relatedness”][“relatedness”]))
Output:
vibranium 0.92227
wakandan 0.75429
wakanda 0.75295
adamantium 0.7447
panther's 0.69835
klaue 0.68083
klaw 0.65195
panther 0.65169
Summary Semantic knowledge graphs help discover context for unknown terms by expanding queries with related concepts, improving both recall and precision of search results.
p.141
Query Expansion and Semantic Knowledge Graphs
- Significance Auto-generated knowledge graphs enhance query recall and precision
- Query Expansion Example
- Algorithm Boolean OR search with semantic weighting
- Boosting Original term boosted by 5x
- Semantic Similarity Weights based on similarity scores
Expanded Query Generation:
query_expansion = “”
terms = search_results[“facets”][“body”][“buckets”] for bucket in search_results[“facets”][“body”][“buckets”]: term = bucket[“val”] boost = bucket[“relatedness”][“relatedness”] if len(query_expansion) > 0: query_expansion += “ “ query_expansion += “ “ + term + “^” + str(boost)
expanded_query = query + “^5” + query_expansion
print(“Expanded Query:\n” + expanded_query)
Example Output
Expanded Query:
vibranium^5 vibranium^0.92228 wakandan^0.75429 wakanda^0.75295 adamantium^0.7447 panther's^0.69835 klaue^0.68083 klaw^0.65195 panther^0.65169
Summary Query expansion uses semantic graphs to include related terms, boosting recall by enhancing context, while the original query term maintains higher relevance.
p.142
Query Augmentation Strategies
- Purpose Adjust precision and recall in search results
- Methods
- Simple Expansion Includes all semantically related terms
- Precision Increase Minimum match (mm) thresholds
Query 예시```
- Simple Expansion
q={!edismax qf="title body" mm="0%"}vibranium vibranium^0.92227 wakandan^0.75429 wakanda^0.75295 adamantium^0.7447 panther's^0.69835 klaue^0.68083 klaw^0.65195 panther^0.65169 - Increased Precision
q={!edismax qf="title body" mm="30%"}vibranium vibranium^0.92227 wakandan^0.75429 wakanda^0.75295 adamantium^0.7447 panther's^0.69835 klaue^0.68083 klaw^0.65195 panther^0.65169
Summary Different strategies for query augmentation balance between increasing precision and recall by setting minimum match criteria or boosting specific terms.
p.143
Advanced Query Techniques
- Precision and Recall Balance
- Two-term Requirement Ensures documents match additional terms
- Conceptual Similarity Allows recall of conceptually related documents
Advanced Query 예시:
- Same Results, Improved Ranking
q={!edismax qf="title body" mm="2"}vibranium &boost=query($expanded_query) &expanded_query=vibranium^5 vibranium^0.92227 wakandan^0.75429 wakanda^0.75295 adamantium^0.7447 panther's^0.69835 klaue^0.68083 klaw^0.65195 panther^0.65169
Summary By utilizing semantic knowledge graphs, queries can be rewritten to enhance recall and precision, adapt to user needs, and provide better domain-specific search results.
Conclusion
- Semantic Knowledge Graphs Enhance search by expanding queries with related terms
- Trade-offs Adjust query strategies for desired balance of precision and recall
- Practical Application Enables content-based recommendations and improved search accuracy
Semantic Knowledge Graph를 활용한 문서 쿼리 생성 과정
p144
- Semantic Knowledge Graph 활용
- 노드: 임의의 쿼리를 표현할 수 있는 기능
- 문서 내 용어, 구문, 값 등을 임의의 노드로 모델링
- 문서의 주제와 관련하여 용어들을 스코어링
- 문서의 미묘한 맥락을 가장 잘 표현하는 쿼리 생성
p145
- 예시: “Star Wars” 문서의 용어 변환 및 스코어링
- 문서: “luke”, “magneto”, “cyclops”, “darth vader” 등 포함
- Semantic Knowledge Graph로 각 용어의 관련성 스코어링
- 주요 코드: Python을 사용한 용어 스코어링 및 쿼리 생성
import collections from mergedeep import merge
Solr URL과 컬렉션 설정
solr_url = "http://example-solr-url.com"
collection = "stackexchange"
classification = "star wars"
문서 내용 정의
document = """this doc contains the words luke, magneto, cyclops, darth vader,
princess leia, wolverine, apple, banana, galaxy, force, blaster,
and chloe."""
키워드 추출을 위한 엔티티 추출기 실행
parsed_document = ["this", "doc", "contains", "the", "words", "luke", \
"magneto", "cyclops", "darth vader", "princess leia", \
"wolverine", "apple", "banana", "galaxy", "force", \
"blaster", "and", "chloe"]
쿼리 생성
request = {"query": classification, "params": {}, "facet": {}}
용어별 쿼리와 스코어링 설정
i = 0
for term in parsed_document:
i += 1
key = "t" + str(i)
key2 = "${" + key + "}"
request["params"][key] = term
request["facet"][key2] = {
"type": "query",
"q": "{!edismax qf=${qf} v=" + key2 + "}",
"facet": {"stats": "${relatedness_func}"}
}
print(json.dumps(request, indent=" "))
요청 병합 및 검색 결과 획득
full_request = merge(request_template, request)
search_results = requests.POST(solr_url + collection + "/select",
json=full_request).json()
스코어 파싱 함수 정의
def parse_scores(search_results):
results = collections.OrderedDict()
for key in search_results["facets"]:
if key != "count" and key != "" and "stats" in search_results["facets"][key]:
relatedness = search_results["facets"][key]["stats"]["relatedness"]
results[key] = relatedness
return list(reversed(sorted(results.items(), key=lambda kv: kv[1])))
스코어링된 용어 출력
scored_terms = parse_scores(search_results)
for scored_term in scored_terms:
print(scored_term)
p146
- 스코어링된 노드
- “Star Wars” 주제와의 관련성에 따라 정렬된 용어 목록
- 0.25 이상의 양수 관련성만 필터링하여 유의미한 용어 추출
{ “query”: “star wars”, “params”: { “t1”: “this”, “t2”: “doc”, “t3”: “contains”, “t4”: “the”, “t5”: “words”, “t6”: “luke”, “t7”: “magneto”, “t8”: “cyclops”, “t9”: “darth vader”, “t10”: “princess leia”, “t11”: “wolverine”, “t12”: “apple”, “t13”: “banana”, “t14”: “galaxy”, “t15”: “force”, “t16”: “blaster”, “t17”: “and”, “t18”: “chloe” }, “facet”: { “${t1}”: { “type”: “query”, “q”: “{!edismax qf=${qf} v=${t1}}”, “facet”: { “stats”: “${relatedness_func}” } }, … “${t18}”: { “type”: “query”, “q”: “{!edismax qf=${qf} v=${t18}}”, “facet”: { “stats”: “${relatedness_func}” } } } }
- 관련성 스코어 예시
- ‘luke’, 0.66366
- ‘darth vader’, 0.6311
- ‘force’, 0.59269
- ‘galaxy’, 0.45858
- ‘blaster’, 0.39121
- ‘princess leia’, 0.25119
p147
- 확장된 쿼리 생성
- Listing 5.9: 스코어링된 구문을 기반으로 쿼리 생성
- 낮은 관련성 점수 필터링 후 깔끔한 용어 목록 생성
- 쿼리 실행 및 결과
- Listing 5.10: 상위 랭킹 문서 반환을 위한 검색 실행
- 스코어링된 용어를 쿼리로 전달하여 콘텐츠 기반 추천 수행
rec_query = ""
for scored_term in scored_terms:
term = scored_term[0]
boost = scored_term[1]
if len(rec_query) > 0:
rec_query += " "
if boost > 0.25:
rec_query += term + "^" + str(boost)
print("Expanded Query:\n" + rec_query)
쿼리 예시
luke^0.66366 "darth vader"^0.6311 force^0.59269 galaxy^0.45858 blaster^0.39121 "princess leia"^0.25119
import collections
## 검색 요청 설정
collection = "stackexchange"
request = {
"params": {
"qf": "title body",
"defType": "edismax",
"rows": 5,
"echoParams": "none",
"omitHeader": "true",
"mm": "0",
"fl": "title",
"fq": "title:[* TO *]" ## 제목이 있는 문서만 표시
},
"query": rec_query
}
## 검색 실행 및 output
search_results = requests.POST(solr_url + collection + "/select",
json=request).json()
print(json.dumps(search_results, indent=" "))
TL;DR
- Semantic Knowledge Graph를 통해 문서의 용어를 주제와 관련한 스코어로 변환하여 관련 쿼리를 생성.
- Python 코드로 스코어링된 용어를 기반으로 쿼리를 확장하고, 0.25 이상의 관련성만 필터링하여 유의미한 결과 도출.
- 생성된 쿼리를 사용하여 콘텐츠 기반 추천을 실행하고, 상위 랭킹 문서를 반환.
AI를 활용한 콘텐츠 기반 추천 알고리즘과 시맨틱 지식 그래프
콘텐츠 기반 추천 알고리즘
- 사용자 행동 신호(검색, 클릭 등)를 활용한 추천(협업 필터링)을 4장에서 다룸.
- 사용자 신호가 부족할 때 신호 기반 접근 방식에만 의존하기 어려움.
- 문서의 내용을 바탕으로 유사한 문서를 찾는 콘텐츠 기반 접근 방식 → 사용자 신호에 의존하지 않고도 맥락 및 도메인 인식 추천 제공 가능.
시맨틱 지식 그래프와 콘텐츠 기반 추천
- 시작 문서의 실제 용어를 기반으로 콘텐츠 기반 추천 쿼리 생성.
- 시맨틱 지식 그래프는 전달된 용어에 한정되지 않음.
- 시작 문서 용어와 의미적으로 관련된 추가 용어 탐색 가능.
- 제한된 주제의 경우, 추천 쿼리에 맞는 문서가 충분하지 않을 때 유용.
시맨틱 지식 그래프의 활용
- 기본 개념
- 노드: 쿼리를 통해 문서 집합으로 구성됨.
- 엣지: 두 노드가 공유하는 문서 집합.
- 노드와 엣지 모두 문서 집합으로 표현됨.
- 예시: “Jean Grey”와의 관계 탐색
- 시작 노드: “Jean Grey”
- 관계 노드: “in love with”
- 종료 노드: “Jean Grey”와 “in love with”의 문맥적 관련 용어 탐색.
- 구현 코드
- 쿼리 실행을 통한 문서 검색 및 관련 용어 추출.
- “Jean Grey”와 가장 관련 있는 용어를 통계적으로 결정.
- 결과 해석
- 관련 용어: Jean Grey, Cyclops, Wolverine 등.
- 노이즈 존재: X-Men, mutant 등과 같은 의미적으로 덜 관련된 용어도 포
- 시맨틱 지식 그래프의 한계와 개선
- 통계적 상관관계에 의존 → 노이즈 발생 가능.
- 명시적 엔티티 모델링 없이도 상당히 우수한 결과 제공.
- 결과 개선을 위해 추가적인 정제 및 필터링 필요.
요약
- 콘텐츠 기반 추천은 사용자 신호가 부족할 때 유용한 방법.
- 시맨틱 지식 그래프는 의미적으로 관련된 용어 탐색에 활용 가능.
- Jean Grey와의 관계 탐색을 통해 시맨틱 지식 그래프의 가능성과 한계를 확인
시맨틱 지식 그래프의 패션 상품 검색 적용
- 이미지와 메타 정보를 활용한 검색
- 시작 노드: 특정 패션 아이템(e.g., “레드 드레스”)
- 관계 노드: “유사한 스타일”, “같은 브랜드”
- 종료 노드: 관련 패션 아이템 탐색
- 모델 활용
- 인풋: 패션 아이템 이미지 및 텍스트 메타 정보
- 아웃풋: 유사 스타일의 다른 패션 아이템 추천
- 적용 예시
- 사용자가 특정 드레스를 검색하면, 시맨틱 지식 그래프를 통해 유사한 스타일 또는 같은 브랜드의 다른 아이템 추천.
- 다양한 패션 스타일과 트렌드를 반영한 추천 가능.
이와 같은 방식으로 시맨틱 지식 그래프는 다양한 도메인에 적용 가능하며, 특히 사용자 신호가 부족한 상황에서 효율적인 도구로 활용될 수 있음.
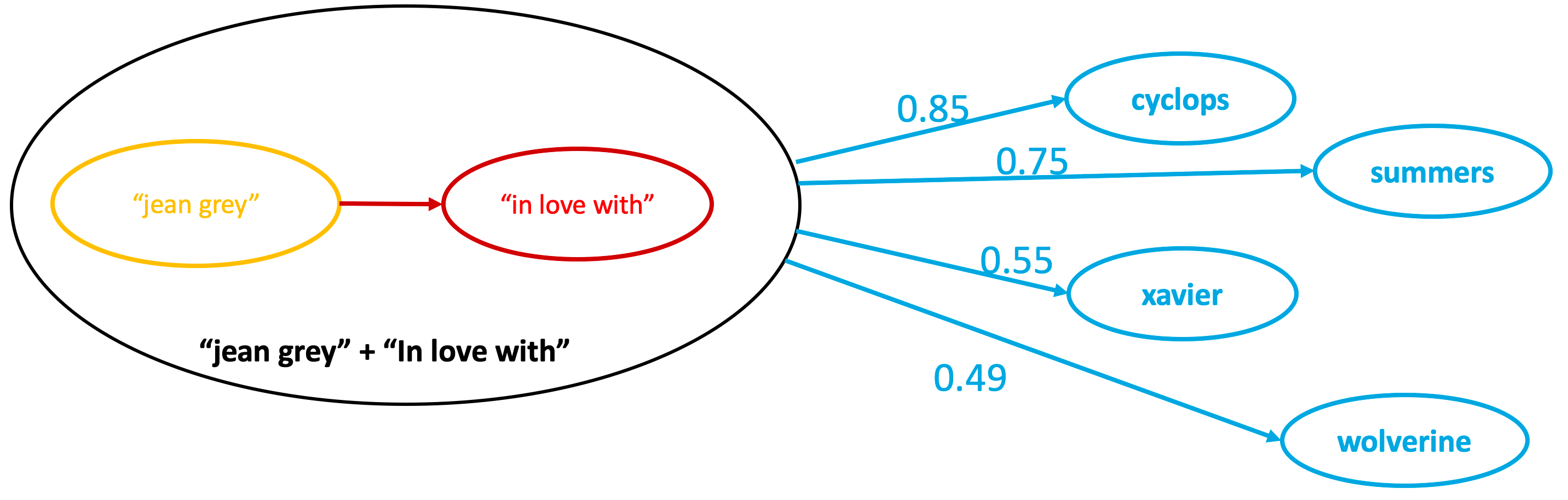
기술 블로그: 지식 그래프와 의미 검색의 융합
1. 개요
지식 그래프는 도메인 내 엔티티들 간의 관계를 모델링하는 기술이며, 명시적인 관계를 통해 구축하거나 콘텐츠로부터 동적으로 추출 가능 이 과정에서 Open Information Extraction(OIE) 기술을 활용하여 주관, 관계, 객체의 삼중항(triples)을 추출하여 지식 그래프를 형성 이를 통해 의미 기반 검색에서 콘텐츠를 직접 활용하여 데이터 모델링 없이도 검색을 수행할 수 있음.
2. 지식 그래프의 활용
- 지식 그래프 구축 명시적 관계 구축 또는 콘텐츠로부터의 동적 추출
- OIE를 이용한 삼중항 추출: 주관, 관계, 객체의 형태로 관계 파악
- 노이즈이 많은 데이터 생성 가능성: 하이포님/하이퍼님 관계 추출을 통한 노이즈 감소
- 의미 검색에서의 사용 임의의 의미 관계를 탐색 및 랭킹
- 콘텐츠를 지식 그래프로 활용
- 사용자의 의도를 잘 이해하기 위해 도메인 및 컨텍스트에 민감한 쿼리 확장 및 재작성 수행
3. 핵심
- 지식 그래프는 도메인 내 엔티티 간 관계를 명시적으로 모델링
- OIE를 통해 주관, 관계, 객체의 삼중항을 추출하여 노이즈을 줄인 지식 그래프 구축 가능.
- 의미 검색에서는 임의의 의미 관계 탐색 및 랭킹을 통해 사용자 의도 이해와 도메인에 민감한 쿼리 확장 가능.
4. 쿼리 의도 분류 및 의미 검색
4.1 쿼리 의도 분류
- 의도 분류의 필요성 쿼리의 의도는 키워드만큼 중요 예를 들어 “driver crashed” 쿼리는 뉴스나 여행 문맥에서는 교통사고를 의미할 수 있으나, 기술 문맥에서는 드라이버 소프트웨어의 오류를 의미할 수 있음.
- K-Nearest Neighbor(KNN) 활용 데이터 포인트(쿼리나 용어)와 유사한 상위 K개의 데이터 포인트 검색
- 지식 그래프 탐색 각 레벨에서 KNN 검색 수행
- 쿼리 분류 사용자의 쿼리를 시작점으로 하여 가장 관련성 높은 카테고리 찾기
5. 의미 기반의 패션 상품 검색 예시
- 이미지와 메타 정보를 활용한 검색 패션 상품 검색에서 지식 그래프를 활용하여 이미지를 기반으로 관련 상품 추천
- 입력 사용자의 패션 아이템 이미지 및 메타 정보
- 출력 관련된 패션 아이템 목록
- 모델 활용 CNN(Convolutional Neural Networks)로 이미지 피쳐 추출, 지식 그래프로 유사 패션 아이템 검색
6. 결론
지식 그래프는 의미 검색에서 도메인 내 엔티티들 간의 관계를 모델링하여 사용자 의도 이해를 돕고, 쿼리 확장 및 재작성에 기여 이를 통해 사용자의 검색 경험을 향상시키고, 다양한 도메인에서 더욱 정교한 검색 결과 제공 가능. 다음 장에서는 이런 지식 그래프를 활용한 쿼리 파싱 및 통합 방법에 대해 심도 있게 다룰 예정임.
Semantic Knowledge Graph를 활용한 쿼리 분류와 의미 해석
1. 서론
- 배경 이전 장에서 구축한 Stackexchange 데이터셋의 시맨틱 지식 그래프 활용
- 목적 쿼리 분류와 쿼리 의미 해석
- 데이터셋 scifi, health, cooking, devops 등 다양한 Stack Exchange 카테고리
2. 쿼리 분류 과정
2.1. 알고리즘 설명
- 목표 쿼리에 대해 가장 관련성 높은 카테고리 찾기
- 방법 시맨틱 유사성을 기반으로 한 카테고리 분류
- 코드 예시 Listing 6.1에 제시된 Python 코드
def run_query_classification(query, keywords_field="body", classification_field="category", classification_limit=5, min_occurrences=5):
classification_query = {
"params": {
"qf": keywords_field,
"fore": "{!type=$defType qf=$qf v=$q}",
"back": "*:*",
"defType": "edismax",
"rows": 0,
"echoParams": "none",
"omitHeader": "true"
},
"query": query,
"facet": {
"classification": {
"type": "terms",
"field": classification_field,
"sort": {"classification_relatedness": "desc"},
"mincount": min_occurrences,
"limit": classification_limit,
"facet": {
"classification_relatedness": {
"type": "func",
"func": "relatedness($fore,$back)"
}
}
}
}
}
search_results = requests.POST(solr_url + collection + "/select", json=classification_query).json()
## output
print("Query: " + query)
print(" Classifications: ")
for classification_bucket in search_results["facets"]["classification"]["buckets"]:
print(" " + str(classification_bucket["val"]) + " " + str(classification_bucket["classification_relatedness"]["relatedness"]))
print("\n")
2.2. 쿼리 예시 및 결과
- 예시 쿼리 “docker”, “airplane”, “camping”, “alien”, “passport”, “driver”
- 결과 관련성 점수와 함께 각 쿼리에 대한 카테고리 분류
예시 output
Query: docker
Classifications:
devops 0.8376
Query: airplane
Classifications:
travel 0.20591
Query: airplane AND crash
Classifications:
scifi 0.01938
travel -0.01068
Query: camping
Classifications:
outdoors 0.40323
travel 0.10778
Query: alien
Classifications:
scifi 0.51953
Query: passport
Classifications:
travel 0.73494
Query: driver
Classifications:
travel 0.23835
devops 0.04461
Query: driver AND taxi
Classifications:
travel 0.1525
scifi -0.1301
Query: driver AND install
Classifications:
devops 0.1661
travel -0.03103
3. 논리적 전개와 수학적 배경
3.1. 시맨틱 유사성 계산
- 논리 시맨틱 지식 그래프를 통해 쿼리와 카테고리의 유사성 측정
- 수식 유사성 함수 $relatedness(fore, back)$ 사용
3.2. 삼단 논법 적용
- 전제1 쿼리와 카테고리 간 시맨틱 관계 존재
- 전제2 유사성 점수가 높은 카테고리가 더 관련 있음
- 결론 유사성 점수를 기반으로 쿼리 분류 가능
4. 쿼리 의미 해석
4.1. 다의어 처리
- 문제 쿼리에 포함된 다의어의 다중 의미
- 예시 “driver”의 여러 의미 (차량 운전사, 소프트웨어 드라이버 등)
4.2. 해결 방법
- 방법 그래프 탐색을 통해 추가적인 문맥 정보 반영
- 예시 결과 “driver AND taxi”, “driver AND install” 각각의 카테고리 분류
5. 핵심
- 시맨틱 지식 그래프를 활용한 쿼리 분류는 유사성 점수를 기반으로 하여 관련 카테고리를 식별
- 다의어 처리에는 추가적인 그래프 탐색이 필요하며, 이를 통해 쿼리의 문맥을 더 명확히 해석할 수 있음.
- 이런 방법은 복잡한 쿼리를 실시간으로 처리하는 데 유효하게 사용될 수 있음.
이 문서는 시맨틱 지식 그래프를 활용하여 쿼리를 분류하고 다의어를 해석하는 방법에 대해 설명합니다. 각 단계는 논리적 전개와 수학적 배경을 포함하여 상세히 설명되었으며, 실용적인 예시와 결과도 포함되었습니다.
다의어 검색을 위한 의미 분별 기술
1. 개요
검색 엔진이 다의어의 의미를 분별하여 각 문맥에 맞는 관련 용어 리스트를 생성하는 것이 중요 이는 사용자의 명확한 의도를 이해하고 반영하기 위함임. 다의어의 의미를 분별하지 않고 단순히 관련 용어를 한 리스트로 묶는 것은 사용자의 명확한 의도를 반영하지 못할 수 있음.
2. 의미 분별을 위한 시맨틱 그래프 활용
- 시맨틱 지식 그래프 활용
- 쿼리를 미리 정의된 카테고리 세트로 자동 분류
- 쿼리 분류 후 관련 용어 리스트를 특정 쿼리 분류에 맞게 문맥화
- 쿼리 → 분류 → 용어로의 트래버설을 통해 각 상위 분류 내에서 원 쿼리의 문맥화된 해석을 설명하는 용어 리스트 생성
3. 의미 분별 쿼리 함수 (Listing 6.2)
- 목표 쿼리의 의도를 다양한 문맥에서 분별
- 구현 방법
- 특정 문맥으로의 트래버설 후 키워드로의 트래버설 수행
- 관련 문맥을 찾고, 원 쿼리에 특정한 관련 용어를 찾음
- 문맥 필드와 키워드 필드를 이용한 이중 레벨 트래버설 수행
def run_disambiguation_query(query, keywords_field="body", context_field="category",
keywords_limit=10, context_limit=5, min_occurrences=5):
disambiguation_query = {
"params": {
"qf": keywords_field,
"fore": "{!type=$defType qf=$qf v=$q}",
"back": "*:*",
"defType": "edismax",
"rows": 0,
"echoParams": "none",
"omitHeader": "true"
},
"query": query,
"facet": {
"context": {
"type": "terms",
"field": context_field,
"sort": {"context_relatedness": "desc"},
"mincount": min_occurrences,
"limit": context_limit,
"facet": {
"context_relatedness": {
"type": "func",
"func": "relatedness($fore,$back)"
},
"keywords": {
"type": "terms",
"field": keywords_field,
"mincount": min_occurrences,
"limit": keywords_limit,
"sort": {"keywords_relatedness": "desc"},
"facet": {
"keywords_relatedness": {
"type": "func",
"func": "relatedness($fore,$back)"
}
}
}
}
}
}
}
search_results = requests.POST(solr_url + collection + "/select", json=disambiguation_query).json()
print("Query: " + query)
for context_bucket in search_results["facets"]["context"]["buckets"]:
print(" Context: " + str(context_bucket["val"]) + " " +
str(context_bucket["context_relatedness"]["relatedness"]))
print(" Keywords: ")
for keywords_bucket in context_bucket["keywords"]["buckets"]:
print(" " + str(keywords_bucket["val"]) + " " +
str(keywords_bucket["keywords_relatedness"]["relatedness"]))
print("\n")
4. 쿼리 실행 및 결과 분석
4.1 쿼리 실행 (Listing 6.3)
- 목적 여러 쿼리에 대해 의미 분별 수행
- 결과 각 쿼리에 대한 다양한 문맥에서의 의미를 분별하여 관련 용어 리스트 생성
run_disambiguation_query(query="server", context_field="category", keywords_field="body")
run_disambiguation_query(query="driver", context_field="category", keywords_field="body", context_limit=2)
run_disambiguation_query(query="chef", context_field="category", keywords_field="body", context_limit=2)
4.2 결과 분석
- Table 6.1 “server” 쿼리에 대한 문맥화된 관련 용어 리스트
- 가장 관련성 높은 카테고리:
devops(0.787) - devops 문맥에서
server는 도구 관리, 빌딩, 배포에 집중 scifi문맥에서는 일반적인 컴퓨팅 관련 의미travel문맥에서는 식당에서 일하는 사람에 대한 의미
- 가장 관련성 높은 카테고리:
- Table 6.2 “driver” 쿼리에 대한 문맥화된 관련 용어 리스트
- 가장 관련성 높은 카테고리:
travel(0.23835) - travel 문맥에서는
taxi,car,license등이 포함 - devops 문맥에서는 컴퓨터 관련 드라이버와 관련
- 가장 관련성 높은 카테고리:
5. 핵심
- 다의어를 분별하여 문맥에 맞는 관련 용어 리스트를 생성하는 것은 사용자의 명확한 의도를 반영하기 위해 필수적임.
- 시맨틱 지식 그래프를 활용하여 쿼리를 카테고리로 자동 분류하고, 문맥화된 용어 리스트를 생성
- 각 쿼리에 대한 의미 분별을 통해 사용자가 의도하는 문맥적 의미를 반영한 검색 결과 제공 가능.
6. 응용 예시 - 패션 상품 검색
- 이미지와 상품 메타 정보를 이용한 패션 상품 검색
- 이미지 기반 검색: CNN을 활용하여 이미지 피쳐 추출
- 상품 메타 정보 활용: 카테고리와 속성 정보를 포함한 시맨틱 그래프 구축
- 예시
- 입력 사용자가 업로드한 패션 아이템 이미지
- 처리 이미지 피쳐 벡터 추출 → 시맨틱 그래프 트래버설 → 카테고리별 연관성 높은 제품 추천
- 출력 문맥화된 관련 패션 아이템 리스트
이와 같은 기술을 통해 다양한 문맥에서 다의어의 의미를 분별하고 사용자의 의도에 맞는 정확한 검색 결과를 제공할 수 있음.
Semantic Query Interpretation and User Signal Analysis for Enhanced AI-Powered Search
6.3 Learning Related Phrases from Query Signals
Semantic Interpretation of Queries
- Query Disambiguation
- 예를 들어, “chef”라는 쿼리는 여러 의미를 가질 수 있음.
- Table 6.3에서 보여주는 것처럼, “chef”는 “devops”와 “cooking”이라는 두 가지 문맥에서 다르게 해석됨.
- devops Chef 소프트웨어(서버 구축 및 배포에 사용) 관련 키워드 포
- 관련 키워드:
puppet,ansible,docs.chef.io등.
- 관련 키워드:
- cooking 음식 준비하는 사람 관련.
- 관련 키워드:
recipe,taste,restaurant등.
- 관련 키워드:
- 쿼리의 의미를 명확히 하기 위해 사용자 문맥을 고려할 필요가 있음.
TL;DR
- 쿼리의 의미를 문맥에 따라 해석하여 사용자 의도를 정확히 파악할 수 있음.
- 쿼리 로그를 분석하여 사용자의 검색 패턴과 관련 키워드를 학습할 수 있음.
- AI 검색 엔진에서 이 정보를 활용하여 보다 정교하고 문맥화된 검색 결과 제공 가능.
User Query Logs as Knowledge Source
- 쿼리 로그의 사용
- 사용자가 입력한 쿼리와 시간 정보 포
- 같은 사용자가 짧은 시간 내에 입력한 여러 쿼리는 서로 관련될 가능성이 높음.
- Figure 6.2 사용자의 쿼리 로그 시퀀스를 통해 쿼리 간의 연관성을 파악할 수 있음.
- 예시: “iphond”는 “iphone”의 오타, “iphone accessories”는 “iphone accessories”의 오타 등.
Mining Query Logs for Related Queries
- 데이터 변환
- 사용자 신호를 간단한 형태로 변환하여 처리 용이성 증대.
Listing 6.4: 각 쿼리의 발생을 검색한 사용자와 매핑.
## Calculation: Mapping signals into keyword, user pairs
spark.sql("""
select lower(searches.target) as keyword, searches.user as user
from signals as searches
where searches.type='query'
""").createOrReplaceTempView('user_searches')
## Show Results:
spark.sql("""select count(*) from user_searches """).show(1)
spark.sql("""select * from user_searches """).show(3)
- 쿼리 쌍의 분석
- 같은 사용자가 입력한 쿼리 쌍을 찾아 관련성을 평가
Listing 6.5: 사용자들이 검색한 쿼리의 총 발생 수와 공동 발생 수를 계산하여 관련성 높은 쿼리 쌍 식별.
## Calculation: Total occurrences and coocurrences of queries
spark.sql('''
select k1.keyword as keyword1, k2.keyword as keyword2,
count(distinct k1.user) users_cooc
from user_searches k1 join user_searches k2 on k1.user = k2.user where
k1.keyword > k2.keyword
group by k1.keyword, k2.keyword ''').createOrReplaceTempView('keywords_users_cooc')
spark.sql('''
select keyword , count(distinct user) users_occ
from user_searches
group by keyword ''').createOrReplaceTempView('keywords_users_oc')
## Show Results:
spark.sql('''select * from keywords_users_oc order by users_occ desc''').show(10)
spark.sql('''select * from keywords_users_cooc order by users_cooc desc''').show(10)
- 사용자 쿼리 로그를 분석하여 관련 키워드를 학습하고 쿼리 확장을 통해 검색 효율을 높일 수 있음.
- 쿼리 신호를 사용하여 문맥화된 검색 결과 제공 가능.
- AI 기반 검색 엔진에서 사용자 의도에 맞춘 검색 기능 구현 가능.
관련 자료 및 적용 사례
- 패션 상품 검색 사례: 이미지와 텍스트 메타데이터를 결합하여 사용자가 원하는 스타일의 패션 아이템을 탐색할 수 있는 시스템 구현 가능. 예를 들어, 사용자가 입력한 “red dress”라는 쿼리에 대해 관련 이미지와 상품 정보를 제공하여 검색 정확도 향상.
1. Query Pair Analysis and PMI Calculation
1.1 Query Pair Analysis
-
Query Pair Cooccurrence → 사용자가 동시에 검색한 쿼리 쌍의 총 개수 분석
→ 예시:iphone 4s와iphone은 자주 함께 검색됨 -
Generalization Hierarchy → 예:
iphone>iphone 4>iphone 4s
→ 일반적인 형태에서 구체적인 형태로 발전하는 계층 구조 -
데이터 희소성 문제 → 가장 높은 cooccurrence를 보인 쿼리 쌍조차 23명의 사용자에 불과함
→ 이는 데이터 포인트가 희소하다는 것을 의미하며, 노이즈가 포함될 가능성 높음
1.2 Pointwise Mutual Information (PMI)
-
PMI 정의 → 두 이벤트 간의 연관성을 측정하는 척도
→ 자연어 처리에서 두 단어가 함께 나타날 확률과 우연히 함께 나타날 확률 비교 -
PMI 계산 공식 \(\text{PMI}(k1, k2) = \log{\frac{P(k1, k2)}{P(k1) \times P(k2)}}\)
→ $P(k1, k2)$: 두 키워드가 동시에 검색된 빈도
→ $P(k1)$, $P(k2)$: 각각의 키워드가 개별적으로 검색된 빈도 -
PMI2 변형 → $k = 2$로 설정하여 빈도에 상관없이 일관된 점수 유지
→ 스파크 SQL을 사용한 PMI2 계산 예시:spark.sql(''' select k1.keyword as k1, k2.keyword as k2, k1_k2.users_cooc, k1.users_occ as n_users1, k2.users_occ as n_users2, log(pow(k1_k2.users_cooc,2) / (k1.users_occ*k2.users_occ)) as pmi2 from keywords_users_cooc as k1_k2 join keywords_users_oc as k1 on k1_k2.keyword1= k1.keyword join keywords_users_oc as k2 on k1_k2.keyword2 = k2.keyword ''').registerTempTable('user_related_keywords_pmi')
1.3 Composite Score Calculation
-
Composite Score 정의 → cooccurrence와 PMI 점수를 결합하여 쿼리의 연관성을 측정
→ 인기와 연관성의 균형을 맞춰 점수 산출 -
Composite Score 공식 \(\text{comp_score}(q1,q2) = \frac{((r1(q1,q2) + r2(q1,q2))/(r1(q1,q2) \times r2(q1,q2)) )}2\)
→ $r1$: cooccurrence 순위
→ $r2$: PMI 순위 -
Composite Score 계산 예시
spark.sql(''' select *, (r1 + r2 /( r1 * r2))/2 as comp_score from ( select *, rank() over (partition by 1 order by users_cooc desc ) r1 , rank() over (partition by 1 order by pmi2 desc ) r2 from user_related_keywords_pmi ) a ''' ).registerTempTable('users_related_keywords_comp_score')
2. 결과 및 적용
2.1 결과 해석
-
고찰 → Composite Score는 cooccurrence와 PMI의 한계를 극복하여 합리적인 결과 제공
→ 예시:green lantern과captain america는 높은 연관성을 가짐 -
Noise 문제 → 특정 쿼리 쌍에서의 낮은 데이터 포인트로 인해 노이즈 발생 가능성 존재
→ 작은 사용자 그룹에서의 빈도는 쉽게 노이즈로 작용할 수 있음
2.2 패션 상품 검색에의 적용
-
패션 상품 검색 → 이미지와 상품 메타 정보를 기반으로 한 검색 시, PMI와 Composite Score 활용 가능
→ 예:nike와running shoes는 함께 검색될 가능성이 높음 -
모델 활용 → 인풋: 상품 이미지 및 메타 정보 (e.g., 브랜드, 색상)
→ 아웃풋: 유사 상품 추천 리스트 제공
TL;DR
- Query Pair Analysis에서는 사용자의 검색 쿼리 쌍을 PMI를 이용하여 관련성을 평가
- PMI는 두 단어의 연관성을 측정하여 우연히 함께 나타날 확률과 비교함으로써 키워드의 의미적 연관성을 파악
- Composite Score를 통해 cooccurrence와 PMI의 Pros(+)을 결합하여 보다 신뢰할 수 있는 쿼리 연관성을 제공
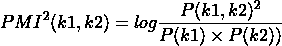
이미지 설명 쿼리 쌍의 cooccurrence와 PMI를 시각화하여 연관성을 평가하는 과정의 흐름을 나타냄. 각 쿼리 쌍의 빈도와 관련성 점수가 그래프로 표현됨.
이 자료는 사용자 검색 패턴에 따른 쿼리 쌍의 관련성을 파악하는 데 있어 PMI와 Composite Score의 활용 가능성을 보여주는 예시임. 이런 방법은 특히 패션 상품 검색과 같은 비슷한 분야에서의 응용 가능성을 확장할 수 있음.
제품 클릭 신호를 통한 관련 쿼리 찾기
1. 개요
사용자가 쿼리를 통해 상호 작용하는 제품을 분석하여 관련 쿼리를 찾는 방법에 대해 설명 많은 사용자가 겹치는 쿼리를 검색하는 사례를 통해 관련 용어를 찾는 기술은 데이터가 희소할 수 있으므로 종종 사용자 외의 기준으로 집계를 수행하는 것이 유리
1.1. 쿼리 및 클릭 신호 통합
- 쿼리 신호 사용자가 검색한 쿼리 기록
- 클릭 신호 사용자가 특정 검색 결과를 클릭한 기록
- 목표 사용자와 쿼리, 클릭된 제품을 모두 매핑하여 데이터의 관계성을 파악
spark.sql("""select lower(searches.target) as keyword,
searches.user as user, clicks.target as product
from signals as searches right join signals as clicks on searches.query_id
= clicks.query_id
where searches.type='query' and clicks.type = 'click'""").
createOrReplaceTempView('keyword_click_product')
1.2. 결과 분석
- Original signals format 원본 신호 형식
- Simplified signals format 단순화된 신호 형식
2. 관련 쿼리 찾기
2.1. 쿼리 및 제품 상호작용 분석
- 목표 독립적인 사용자들이 동일한 제품을 찾기 위해 사용한 두 쿼리 간의 관계 강도를 측정
- 논리 전개
- 각 사용자는 관련된 아이템을 검색할 가능성이 높음
- 각 제품 또한 관련된 쿼리로 검색될 가능성이 있음
- 따라서, 동일한 제품을 찾기 위해 사용된 쿼리의 집합을 분석하여 관련성을 파악
#Calculation:
spark.sql('''
select k1.keyword as k1, k2.keyword as k2, sum(p1) n_users1,sum(p2) n_users2,
sum(p1+p2) as users_cooc, count(1) n_products
from
(select keyword, product, count(1) as p1 from keyword_click_product group by
keyword, product) as k1
join
(select keyword, product, count(1) as p2 from keyword_click_product group by
keyword, product) as k2
on k1.product = k2.product
where k1.keyword > k2.keyword
group by k1.keyword, k2.keyword
''').createOrReplaceTempView('keyword_click_product_cooc')
2.2. 결과 해석
- n_users1, n_users2 각 쿼리로 인해 클릭된 제품의 수를 통해 쿼리의 인기도 파악
- users_cooc 두 쿼리의 총 사용자 수로, 두 쿼리가 얼마나 자주 함께 사용되는지를 나타냄
- n_products 두 쿼리가 동일한 제품을 찾기 위해 사용된 횟수
3. 키워드 인기도 분석
3.1. 키워드 인기도 계산
- 목표 쿼리 신호에서 최소 한 번의 제품 클릭을 발생시킨 키워드의 인기도를 계산
- 방법 각 키워드가 얼마나 많은 사용자에 의해 사용되었는지를 집계하여 인기도를 평가
#Calculation:
spark.sql('''
select keyword, count(1) as n_users from keyword_click_product group by
keyword
''').registerTempTable('keyword_click_product_oc')
3.2. 결과 해석
- 인기도가 높은 키워드 쿼리 신호에서 가장 많은 제품 클릭을 발생시킨 키워드
4. 패션 상품 검색에의 적용
4.1. 이미지 및 메타 정보를 활용한 검색
- 이미지 인풋 상품의 이미지 데이터
- 메타정보 인풋 상품의 색상, 스타일, 브랜드 등 추가 정보
- 모델 아웃풋 관련 상품 목록 및 유사도 점수
4.2. 모델 설명
- 사용 모델 CNN(Convolutional Neural Network) 기반 이미지 분석 모델
- 활용 방법 이미지와 메타 데이터를 입력하여 패션 상품의 유사성을 계산하고, 유사 상품을 추천
핵심
- 쿼리와 클릭 신호를 통합하여 사용자의 검색 패턴을 분석
- 동일한 제품을 찾기 위해 사용된 쿼리 간의 관계 강도를 측정하여 관련 쿼리를 찾음.
- 쿼리 신호를 통해 키워드의 인기도를 계산하여 패션 상품 검색에 적용 가능성을 탐색
6.4 사용자 신호로부터의 구문 탐지
6.4.1 쿼리를 엔티티로 취급하기
사용자 쿼리를 엔티티로 취급 → RetroTech 전자상거래 사이트와 같은 사례에서 효과적임
- 대부분의 쿼리가 실제 제품명, 카테고리, 브랜드명, 회사명, 혹은 인명 등을 포함
- 높은 인기 쿼리가 별도의 파싱 없이도 곧바로 사용할 수 있는 엔티티로 간주될 수 있음
핵심
- 쿼리를 엔티티로 취급하면 복잡한 파싱 과정 없이도 엔티티 목록을 구축할 수 있음.
- 높은 사용자 수의 쿼리는 높은 신뢰도로 엔티티 목록에 추가될 수 있음.
- 문서와 쿼리를 교차 참조하여 노이즈를 줄이는 방법이 효과적일 수 있음.
6.4.2 복잡한 쿼리에서 엔티티 추출하기
복잡한 쿼리는 노이즈를 포함할 수 있음 → 엔티티로 직접 사용하기 어려움
- 논리 구조, 쿼리 연산자 등 포함
- 이런 경우 5장에서 다룬 엔티티 추출 전략을 쿼리 신호에 재적용하는 것이 효과적일 수 있음
엔티티 추출 전략
- 기본적으로 검색엔진은 쿼리를 개별 키워드로 파싱하여 역색인(inverted index)에서 해당 키워드를 찾음
- 예: “new york city” 쿼리 → 기본적으로 “new AND york AND city”로 해석됨
- 이로 인해 키워드를 개별적으로 평가하며, 문구의 의미를 이해하지 못함
- 구문에서 도메인 특화 구문을 식별하고 추출하면 더 정확한 쿼리 해석 및 관련성을 높일 수 있음
- 문서에서 도메인 특화 구문을 추출한 방법을 활용하여 쿼리에서도 적용 가능
- Spacy NLP 라이브러리를 사용하여 종속 구문 분석을 통해 명사구를 추출
- 쿼리가 너무 짧아 종속 구문 분석이 어려운 경우, 발견된 구문의 품사 필터링을 통해 명사구로 제한 가능
예시: 상품 메타 정보를 기반으로 한 패션 상품 검색
- 이미지와 상품 메타 정보를 입력으로 사용
- 모델: CNN 기반 이미지 분석 모델, RNN 기반 텍스트 분석 모델 등
- 인풋: 상품 이미지, 상품 설명 텍스트, 메타데이터 등
- 아웃풋: 상품의 주요 피쳐 벡터, 유사 상품 리스트 등
- 상품 검색 모델은 사용자의 쿼리와 데이터베이스의 상품 메타 정보를 매칭하여 유사 상품을 추천
Image: 상품 이미지와 메타 정보를 통한 검색 프로세스
상품 검색 시스템의 흐름을 보여주는 이미지. 사용자는 입력된 쿼리를 통해 상품 이미지를 업로드하고, 메타 정보를 제공. 시스템은 이미지와 메타 정보를 기반으로 유사 상품을 검색하여 추천
p176-179 요약
- 쿼리와 상품 상호작용을 기반으로 한 관련 용어 계산에서 PMI와 복합 점수를 활용하여 쿼리 쌍을 평가
- 쿼리 엔티티 추출의 경우, 사용자 신호에서 직접적으로 엔티티를 추출하는 방법이 효과적임.
- 복잡한 쿼리에서 엔티티를 추출하기 위해서는 기존의 문서 기반 엔티티 추출 전략을 쿼리에 적용해야
관련 문서 및 링크
테크니컬 블로그: AI 기반 검색 시스템에서의 철자 교정 및 대체 표현 학습
1. 도메인 특정 구문과 관련 구문 추출
- 목표 검색 쿼리에서 도메인 특정 구문을 추출하여 지식 그래프에 추가.
- 쿼리 토큰화 → 구문 구문 제거(e.g., , , 등)
- 도메인 특정 구문 탐지 → 관련 구문 탐색
- 챌린지 잘못된 철자 및 대체 철자 처리 필요.
- 예시 “laptop”의 관련 구문은 “computer”, “netbook”, “tablet”일 수 있지만, 잘못된 철자는 “latop”, “laptok”, “lapptop”일 수 있음.
2. 철자 교정 구현 방법
- 일반적인 방법 문서 기반의 철자 교정 시스템 사용.
- Apache Solr: 파일, 사전, 인덱스 기반 철자 교정 제공.
- Elasticsearch, OpenSearch: 특정 컨텍스트에 맞춘 철자 교정 제공.
- 핵심
- 철자 교정은 대부분의 검색 엔진에 내장된 기능임.
- 사용자 신호를 통해 보다 정확한 철자 교정 가능.
- 잘못된 철자 및 대체 철자를 표준 형태로 정규화하여 검색 수행.
3. 철자 교정의 챌린지
3.1 문서 기반 철자 교정의 한계
- 문제 사용자 컨텍스트 부족.
- 인덱스 내에 일정 횟수 이상 등장하지 않는 키워드는 인덱스의 모든 용어를 탐색하여 가장 흔한 키워드 반환 → 부정확한 결과 초래.
{
"collection": "products",
"query": "moden",
"request": {
"params": {
"q.op": "and",
"rows": 0,
"indent": "on"
},
"query": "moden"
}
}
- 예시 결과 “moden” 쿼리에 대한 교정 제안으로 “modern”, “model”, “modem” 등 반환.
- “modem”이 가장 적합한 교정으로 판단되지만, 문서 기반 철자 교정은 이를 식별하지 못
3.2 사용자 신호 기반 철자 교정
- 목표 사용자의 쿼리 행동으로부터 철자 교정 학습.
- 방법 사용자 쿼리 신호 분석.
- 유사 철자 용어 탐색 → 올바른 철자와 잘못된 변형 구분.
- 쿼리 신호 전처리 → 대소문자 무시, 중복 쿼리 제거.
- 방법 사용자 쿼리 신호 분석.
SELECT LOWER(searches.target) AS keyword, searches.user AS user
FROM signals AS searches
WHERE searches.type='query'
GROUP BY keyword, user
- Pros(+) 사용자 신호를 통해 더 높은 정확도의 철자 교정 가능.
- 예시 특정 사용자가 지속적으로 잘못된 쿼리를 입력할 경우, 해당 사용자의 쿼리 패턴을 분석하여 더 나은 교정 제안 가능.
4. 패션 상품 검색에의 응용
- 이미지 및 상품 메타 정보 활용 패션 상품 검색 시 이미지 및 텍스트 메타 정보를 활용하여 사용자가 잘못 입력한 검색어를 자동으로 교정.
- 모델 CNN 기반 이미지 인식 모델, NLP 기반 텍스트 분석 모델 사용.
- 인풋 사용자 쿼리, 상품 이미지 및 설명.
- 아웃풋 정규화된 검색어 및 관련 상품 제안.
- 핵심
- 사용자 신호를 기반으로 한 철자 교정은 검색 정확도를 높이는 데 기여.
- 이미지 및 텍스트 분석 기술을 결합하여 패션 상품 검색의 효율성 증가.
- 사용자 경험을 향상시키기 위한 실시간 철자 교정 및 관련 상품 추천 가능.
5. 관련 문서와 링크
- Apache Solr 문서: Solr Spell Checking
- Elasticsearch 문서: Elasticsearch Suggesters
이 블로그 포스트는 AI 기반의 검색 시스템에서 철자 교정과 대체 표현을 효과적으로 처리하는 방법을 다루며, 사용자의 검색 경험을 향상시키는 기술적 접근 방식을 제시
p.184 - 토큰화 및 정제 과정
Listing 6.15: 쿼리 내 용어를 토큰화 및 필터링하여 정제된 단어 목록 생성
- 목표 쿼리 내의 단어를 정제하여 정확한 철자와 오타를 구분하는 것임.
- 과정
- 1단계 불용어(stopwords) 정의
- 불필요한 단어나 오타로 간주되지 않는 단어 설정
- 2단계 쿼리 분할
- 공백을 기준으로 쿼리를 개별 단어로 분리
- 3단계 불필요한 용어 제거
- 불용어, 너무 짧은 단어, 숫자 제거
- 4단계 각 남은 토큰의 출현 횟수 계산
- 1단계 불용어(stopwords) 정의
- 수식적 접근
- \[\text{Term Frequency (TF)} = \frac{\text{Number of times term } t \text{ appears in a document}}{\text{Total number of terms in the document}}\]
- 결과
- 정제된 토큰 리스트 생성 후, 자주 출현하는 토큰과 드물게 출현하는 토큰을 구분
- 오타는 상대적으로 드물게 발생하고, 정확한 철자는 자주 발생하므로, 이를 통해 정규 철자와 오타를 구분
- 추가 단계
- 5단계 정정 목록의 청결도 유지
- 자주 출현하는 용어와 드물게 출현하는 용어에 대한 임계값 설정
- 컬렉션의 크기에 따라 절대 숫자 대신 분위(quantiles) 사용
- 5단계 정정 목록의 청결도 유지
결과
- Python 코드 예시
stop_words = set(stopwords.words('english'))
word_list = defaultdict(int)
for row in query_signals:
query = row["keyword"]
tokenizer = RegexpTokenizer(r'\w+')
tokens = tokenizer.tokenize(query)
for token in tokens:
if token not in stop_words and len(token) > 3 and not token.isdigit():
word_list[token] += 1
quantiles_to_check = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
quantile_values = np.quantile(np.array(list(word_list.values())), quantiles_to_check)
quantiles = dict(zip(quantiles_to_check, quantile_values))
- 핵심
- 쿼리 내 단어를 정제하여 자주 출현하는 단어와 드물게 출현하는 단어를 구분
- 이를 통해 정확한 철자와 오타를 구별할 수 있음.
- 절대 숫자 대신 분위(quantiles)를 사용하여 임계값을 설정
p.185 - 분위와 오타 탐지
- 80%의 용어가 142.2회 이하로 검색됨 (상위 20%는 이보다 많이 검색됨).
- 20%의 용어가 6.0회 이하로 검색됨.
- 페레토 법칙 적용:
- 상위 20% 검색 쿼리가 중요한 용어일 가능성 높음.
- 하위 20%가 오타일 가능성 높음.
- 정확도 향상
- 오타를 0.1 분위수로, 정확 철자를 0.9 분위수로 설정 가능.
- 과정
- 용어를 “오타 후보군”과 “정정 후보군”으로 나눔.
- 사용자가 오타 및 정정 후보군을 검색할 때 고품질의 철자 교정 가능.
Python 코드 예시
misspell_candidates = []
correction_candidates = []
misspell_counts = []
correction_counts = []
misspell_length = []
correction_length = []
misspell_initial = []
correction_initial = []
for k, v in word_list.items():
if v <= quantiles[0.2]:
misspell_candidates.append(k)
misspell_counts.append(v)
misspell_length.append(len(k))
misspell_initial.append(k[0])
if v >= quantiles[0.8]:
correction_candidates.append(k)
correction_counts.append(v)
correction_length.append(len(k))
correction_initial.append(k[0])
- 핵심
- 상위 20%는 중요한 용어, 하위 20%는 오타로 간주.
- 용어를 “오타 후보군”과 “정정 후보군”으로 나눔.
- 분위수를 통해 임계값 설정.
p.186 - 후보군 데이터프레임 생성
- 데이터프레임 생성 오타 및 정정 후보군을 데이터프레임에 로드.
- 비교 효율성 데이터프레임을 사용하여 비교 효율성 증가.
데이터프레임 변환 예시
misspell_candidates_df = pd.DataFrame({
"misspell": misspell_candidates,
"misspell_counts": misspell_counts,
"misspell_length": misspell_length,
"initial": misspell_initial
})
correction_candidates_df = pd.DataFrame({
"correction": correction_candidates,
"correction_counts": correction_counts,
"correction_length": correction_length,
"initial": correction_initial
})
misspell_candidates_df.head(10)
- 결과
- 오타 후보의 샘플링 결과, “singin”, “nintendogs”, “tosheba”가 명백한 오타임.
- 용어 길이에 따라 여러 철자 오류 발생 가능성 있음.
- 핵심
- 데이터프레임을 사용하여 오타 및 정정 후보군 관리.
- 철자 오류는 용어 길이에 따라 증가할 수 있음.
- 오타 후보의 샘플링을 통해 오타 탐지 가능.
p.187 - 철자 교정을 위한 매칭
Listing 6.18: 철자 교정 계산
- edit distance 기준 철자 오류를 정정 후보와 비교할 때 고려할 거리.
- good_match 함수 용어 길이에 따른 edit distance 허용 범위 설정.
Python 코드 예시
def good_match(len1, len2, edit_dist):
match = 0
min_length = min(len1, len2)
if min_length < 8:
if edit_dist == 1: match = 1
elif min_length < 11:
if edit_dist <= 2: match = 1
else:
if edit_dist == 3: match = 1
return match
matches_candidates = pd.merge(misspell_candidates_df, correction_candidates_df, on="initial")
matches_candidates["edit_dist"] = matches_candidates.apply(lambda row: nltk.edit_distance(row.misspell, row.correction), axis=1)
matches_candidates["good_match"] = matches_candidates.apply(lambda row: good_match(row.misspell_length, row.correction_length, row.edit_dist), axis=1)
matches = matches_candidates[matches_candidates["good_match"] == 1].drop(["initial", "good_match"], axis=1)
matches_final = matches.sort_values(by=['correction_counts'], ascending=[False])[["misspell", "correction", "misspell_counts", "correction_counts", "edit_dist"]].head(20)
- 결과
- 동일한 초기 문자로 시작하는 오타와 정정 후보군 매칭.
- edit distance를 계산하여 철자 교정 수행.
- 핵심
- edit distance를 고려하여 철자 교정 리스트 생성.
- good_match 함수로 철자 오류 허용 범위 설정.
- 최종 매칭 결과를 통해 철자 오류 교정 가능.
위 내용은 철자 교정 시스템을 구현하는 과정에서 발생하는 다양한 단계와 수학적 접근을 설명 이를 통해 철자 오류를 정정하고 검색 품질을 향상시킬 수 있음.
Spelling Correction and Semantic Search Techniques
1. Introduction
Page 188부터 시작하여, 이 문서에서는 사용자 신호 기반의 철자 교정 모델과 문맥에 따라 의미를 해석하는 방법을 다루고 있음. 특히 철자 교정에 있어 문서 기반 접근 방식과 사용자 신호 기반 접근 방식의 차이를 설명하고, 이를 통해 얻은 철자 교정의 결과를 어떻게 활용할 수 있는지에 대해 서술
2. Spelling Correction from User Signals
2.1 사용자 신호 기반 철자 교정
- 기존 문서 기반 철자 교정은 단어의 발생 빈도를 기반으로
- 사용자 신호 기반 철자 교정은 사용자 검색어에서 발생한 신호를 활용
- 예: “moden”을 사용자 신호 기반 모델로 교정하면 “modern”으로 정확히 매핑됨.
2.2 다중 단어 철자 교정
- 다중 단어 철자 교정을 위해 바이어스 체인 분석(Bayesian analysis)을 사용할 수 있음.
- 쿼리를 토큰화하지 않고 전체 쿼리 문자열을 교정하는 방법도 있음.
- 예: “latop”을 “laptop”으로 교정.
Results:
misspell correction misspell_counts correction_counts edit_dist
latop laptop 5 14258 1
touxhpad touchpad 5 11578 1
...
TL;DR
- 사용자 신호를 활용한 철자 교정은 문서 기반 접근 방식보다 사용자 의도를 더 잘 반영할 수 있음.
- 다중 단어 쿼리의 교정이 가능하며, 이는 제품명 등에서 유용하게 활용될 수 있음.
- 특정 브랜드 변형 등에 대해서는 추가적인 처리 로직이 필요할 수 있음.
3. Semantic Search Techniques
3.1 의미론적 지식 그래프 활용
- 도메인 특화 언어의 문맥과 의미를 이해하기 위해 의미론적 지식 그래프 사용.
- 쿼리 분류 및 용어의 모호성 해소 가능.
3.2 사용자 신호로부터 관계 추출
- 사용자 신호는 문서보다 사용자 이해에 더 나은 문맥 제공.
- 쿼리 신호에서 구문, 철자 오류 및 대체 철자 추출 가능.
3.3 도메인 특화 구문 학습
- 문서 또는 사용자 신호로부터 도메인 특화 구문 및 관련 구문 학습 가능.
- 쿼리 의도를 해석하기 위한 중요한 도구로 활용.
TL;DR
- 의미론적 지식 그래프는 쿼리 의도를 해석하고 필터링을 개선하는 데 유용
- 사용자 신호를 통해 문서보다 더 나은 도메인 특화 용어 학습 가능.
- 철자 오류와 대체 철자를 학습하여 사용자 의도를 더 잘 반영할 수 있음.
4. Signals Boosting and Popular Queries
4.1 신호 부스팅 개요
- 신호 부스팅은 유명한 쿼리와 문서의 관련성 순위를 향상시킴.
- 신호 부스팅 모델은 강력한 인퍼런스를 활용하여 중요한 쿼리가 가장 관련성 높은 문서를 반환하도록 조정
4.2 신호 부스팅 기법
- 사용자 신호 집계하여 인기 기반 순위 모델 생성.
- 노이즈가 있는 쿼리 입력에 대해 신호 정규화.
- 신호 스팸 및 사용자 조작 방지.
- 최근 신호를 더 중요하게 다루기 위한 시간 감쇠 적용.
- 여러 신호 유형을 통합한 신호 부스팅 모델 구축.
TL;DR
- 신호 부스팅은 검색 엔진에서 인기 쿼리의 관련성을 높이는 데 필수적임.
- 사용자 신호는 유명한 검색 결과의 정확성을 높이는 강력한 도구임.
- 신호 부스팅 모델은 검색 엔진의 유연성과 성능을 향상시키는 데 기여
5. Conclusion
이 장에서는 철자 교정 및 의미론적 검색 기술을 통해 사용자 의도를 더 잘 이해하고 해석하는 방법을 탐구 이런 기술은 검색 엔진에서 쿼리 해석 능력을 향상시키는 데 중요한 역할을 하며, 다음 장에서는 이런 기술을 통합하여 최적의 의미론적 검색 시스템을 구축하는 방법을 설명할 예정임.
Signal Boosting 모델에 대한 심층 분석
1. 신호 부스팅 모델 개요
- 목표 검색 쿼리 결과의 관련성을 높이기 위한 신호 부스팅 모델 구축.
- 데이터셋 Retrotech 데이터셋 사용.
- 방법 사용자가 검색한 쿼리에 따른 문서 클릭 신호를 집계하여 관련성을 높임.
- 예: ‘ipad’ 쿼리에 대한 클릭 수를 기반으로 문서에 부스팅 적용.
2. 기본 신호 부스팅 모델
- Figure 8.1 설명
- 이미지 신호 부스팅 전후의 검색 결과 비교.
- 의미 신호 부스팅을 통해 유명한 항목이 검색 결과 상단에 배치됨.
- 기본 모델의 한계
- 데이터 편향 및 조작 가능성 존재.
- Noise 제거 기술 필요.
3. 신호 정규화 필요성
- 문제점 쿼리 변형으로 인한 신호의 노이즈 발생.
- 예: ‘iPad’, ‘ipad’, ‘Ipad’, ‘IPad’ 등.
- Listing 8.1 다양한 쿼리 변형에 따른 부스팅 목록.
- 해결책 쿼리 정규화.
- 방법 대소문자 무시 및 공백 제거.
- Listing 8.2 정규화된 쿼리 부스팅 목록.
4. 쿼리 정규화의 효과
- 결과
- 중복성 감소 및 신호 강도 증가.
- 동일 쿼리를 일관되게 처리하여 신호 부스팅 모델 강화.
5. 신호 집계 및 부스팅 적용 예시
-
신호 집계 쿼리
select lower(q.target) as query, c.target as doc, count(c.target) as boost from signals c left join signals q on c.query_id = q.query_id where c.type = ‘click’ AND q.type = ‘query’ group by query, doc order by boost desc
-
정규화된 신호 부스팅 적용
- ‘ipad’, ‘ipad 2’, ‘ipad2’ 등으로 강화된 신호 부스팅 결과.
6. 핵심
- 신호 부스팅 모델은 쿼리에 대한 클릭 신호를 활용해 검색 결과의 관련성을 높임.
- 쿼리 정규화를 통해 데이터 노이즈을 제거하고, 신호 부스팅 모델의 효과를 극대화
- 정규화된 쿼리로 신호를 집계하여 부스팅 모델의 강도를 강화
추가 적용 사례: 패션 상품 검색
- 이미지와 상품 메타 정보를 기반으로 한 적용
- 모델 CNN(Convolutional Neural Network) 사용.
- 인풋 패션 상품 이미지와 메타 데이터.
- 아웃풋 검색 결과에 대해 신호 부스팅을 통한 관련성 높은 상품 추천.
- 예시
- 상품 이미지에서 색상, 스타일, 브랜드 등의 정보를 추출하여 신호 부스팅에 활용.
- 사용자 클릭 신호를 반영한 상품 추천 시스템 구축.
이와 같은 방식으로 신호 부스팅 모델은 다양한 도메인에서 검색 결과의 관련성을 높이는 데 사용될 수 있음. 이를 통해 사용자 경험을 개선하고 검색의 정확성을 높일 수 있음.
8.3 Fighting Signal Spam
8.3.1 Using Signal Spam to Manipulate Search Results
- 사용자 신호 스팸의 문제
- 크라우드소싱된 데이터를 사용하는 경우, 사용자들이 데이터 입력을 조작하여 검색 엔진의 동작을 왜곡할 가능성에 대한 고려 필요.
- 사용자 신호, 특히 클릭 신호를 악의적으로 조작하여 검색 결과를 왜곡할 수 있음.
- 시나리오 설명
- 특정 사용자가 “Star Wars”를 검색할 때마다 물리적인 쓰레기통이 최상위에 표시되도록 의도적으로 신호 스팸을 생성.
- 이런 사용자는 검색 엔진이 유명한 항목을 상위에 표시한다는 점을 악용하여, Star Wars 테마의 쓰레기통에 대한 가짜 클릭을 반복하여 검색 결과를 조작할 수 있음.
- Figure 8.2 설명
- 기본적인 “Star Wars” 쿼리에 대한 신호 부스팅이 활성화된 상태에서의 예상 검색 결과.
- 악의적인 신호 스팸이 없는 상태에서의 정상적인 인기 제품들이 상위에 노출됨.
코드 예시 및 알고리즘 설명
- Listing 8.3: 스팸 쿼리 및 클릭 생성
- 5000개의 쿼리와 5000개의 클릭 신호를 생성하여 검색 엔진에 전달.
- 해당 신호를 인덱스에 커밋하여 신호 부스팅 모델에 포
import datetime
spam_user = "u8675309"
spam_query = "star wars"
spam_signal_boost_doc_upc = "45626176"
num = 0
while (num < 5000):
query_id = "u8675309_0_" + str(num)
next_query_signal = {
"query_id": query_id,
"user": spam_user,
"type": "query",
"target": spam_query,
"signal_time": datetime.datetime.now().strftime("%Y-%m-%dT%H:%M:%SZ"),
"id": "spam_signal_query_" + str(num)
}
next_click_signal = {
"query_id": query_id,
"user": spam_user,
"type": "click",
"target": spam_signal_boost_doc_upc,
"signal_time": datetime.datetime.now().strftime("%Y-%m-%dT%H:%M:%SZ"),
"id": "spam_signal_click_" + str(num)
}
collection = "signals"
requests.POST(solr_url + collection + "/update/json/docs", json=next_query_signal)
requests.POST(solr_url + collection + "/update/json/docs", json=next_click_signal)
num += 1
requests.POST(solr_url + collection + "/update/json/docs?commit=true")
signals_collection = "signals"
signals_aggregation_collection = "signals_boosts_with_spam"
aggregate_signals(signals_collection, signals_aggregation_collection, normalized_signals_aggregation_query)
- Listing 8.3 설명
- 사용자 “u8675309”이 “Star Wars” 쿼리에 대해 반복적으로 쿼리와 클릭 신호를 생성.
- 이런 신호를 활용하여 신호 부스팅 모델에 포함시킴.
- Listing 8.4: 조작된 신호 부스팅 모델을 사용한 검색 결과
- 스팸 신호가 포함된 신호 부스팅 모델을 로드하고, 이를 기반으로 “Star Wars” 쿼리에 대한 검색을 수행.
query = "star wars"
collection = "products"
signals_boosts = get_query_time_boosts(query, "signals_boosts_with_spam")
boosted_query = get_main_query(query, signals_boosts)
search_results = requests.POST(solr_url + collection + "/select", json=boosted_query).json()["response"]["docs"]
print(search_results)
display(HTML(render_search_results(query, search_results)))
- Listing 8.4 설명
- 조작된 신호 부스팅 모델을 기반으로 검색 결과를 생성.
- Figure 8.3에서는 조작된 검색 결과가 표시되며, Star Wars 쓰레기통이 최상위에 노출됨.
핵심
- 신호 스팸을 통해 검색 엔진의 결과를 조작할 수 있는 가능성 존재.
- 반복적인 쿼리와 클릭 신호를 생성하여 특정 제품을 상위에 노출시키는 방식 시연.
- 조작된 신호 부스팅 모델을 사용하여 검색 결과가 어떻게 달라지는지를 확인.
패션 상품 검색에의 적용
- 이미지와 상품 메타 정보를 기반으로 한 검색 시나리오
- 사용자가 이미지로 특정 패션 아이템을 검색할 때, 이미지의 메타데이터와 사용자 신호를 활용하여 검색 결과를 최적화 가능.
- 예를 들어, 특정 브랜드의 신발 이미지를 검색할 때, 해당 브랜드의 유명한 다른 제품들이 상위에 노출되도록 신호 부스팅 적용 가능.
- 적용 모델의 인풋과 아웃풋
- 인풋: 사용자 이미지, 메타데이터, 과거 클릭 신호.
- 아웃풋: 최적화된 검색 결과 리스트, 사용자 선호를 반영한 상품 추천.
위 내용은 검색 엔진 최적화를 위한 신호 처리 기법에 대한 이해를 돕고, 악의적인 데이터 조작을 방지하기 위한 전략을 제시하는 데 기여
위의 설명은 검색 엔진 최적화 과정에서 신호 스팸을 다루는 방법과 이를 방지하기 위한 전략을 제시하며, 특히 패션 상품 검색에의 적용 가능성을 탐색 검색 엔진의 신호 부스팅 모델이 어떻게 조작될 수 있는지를 설명하고, 이런 문제를 방지하기 위한 방법을 제시
p200
- Figure 8.3 사용자가 검색 엔진에 허위 신호를 반복적으로 입력하여 검색 결과 상위를 조작한 사례
- 사용자가 특정 결과를 여러 번 클릭하여 검색 결과의 상위를 변경함
- 이런 조작된 검색 결과는 이후 방문자에게도 동일하게 노출될 위험 존재 → 신호 부스팅 모델의 강건성 필요
- Crowdsourced Data 사용 시 고려사항
- 사용자 신호 기반의 순위 알고리즘 조작 방지 필수
- 간단한 대처 방법: 동일 사용자의 중복 클릭을 하나의 “투표”로 제한 → 악의적인 사용자의 중복 클릭 무력화
8.3.2 사용자 기반 필터링을 통한 신호 스팸 방지
p201
- 중복 신호 제거
- 동일 사용자의 중복 클릭 무시하여 신호 부스팅 모델에 미치는 영향을 최소화
- Listing 8.5 사용자별 신호 중복 제거 쿼리
select query, doc, count(doc) as boost from ( select lower(q.target) as query, c.target as doc, c.user as boost, max(c.signal_time) from signals c left join signals q on c.query_id = q.query_id where c.type = 'click' AND q.type = 'query' group by c.user, q.target, c.target ) as x group by query, doc order by boost desc - 결과: 모든 사용자가 쿼리/문서 쌍당 하나의 신호로 제한됨 → 악의적인 사용자의 영향력 감소
- Table 8.1 스팸 신호 제거 전후의 신호 집계 비교
- 스팸 신호 제거 전: 5000개의 신호
- 스팸 신호 제거 후: 1개의 신호
- 핵심
- 동일 사용자의 중복 신호를 하나로 통합하여 신호 모델의 왜곡 방지
- 사용자 식별자로 스팸 신호 제거 가능 (사용자 ID, 세션 ID 등)
- 신호 유형별 중요도에 따라 가중치를 부여하여 모델의 신뢰성 강화
196
p202
- 신호 스팸 방지를 위한 추가 방법
- 중요한 신호와 쉽게 조작 가능한 신호 분리
- 구매 신호는 클릭 신호보다 강력한 신호로 간주 → 사용자 인증 및 결제 정보 요구
- 신호 유형별 중요도에 따라 가중치 부여 → 구매 신호에 더 높은 가중치 부여
- Retrotech 데이터셋의 신호 유형
- 쿼리, 클릭, 장바구니 추가, 구매
- 클릭 신호는 제품에 대한 강한 관심을 나타내지 않음
8.4 여러 신호 유형 결합
197
p203
- 신호 유형별 가중치 할당
- 클릭: 1 신호, 장바구니 추가: 10 신호, 구매: 25 신호 → 구매 신호의 중요도 강조
- 노이즈 감소 및 신뢰성 높은 신호의 영향력 강화
- Listing 8.6 다양한 신호 유형을 가중치에 따라 결합
select query, doc, ( (1 * click_boost) + (10 * add_to_cart_boost) + (25 * purchase_boost) ) as boost from ( select query, doc, sum(click) as click_boost, sum(add_to_cart) as add_to_cart_boost, sum(purchase) as purchase_boost from ( select lower(q.target) as query, cap.target as doc, if(cap.type = 'click', 1, 0) as click, if(cap.type = 'add-to-cart', 1, 0) as add_to_cart, if(cap.type = 'purchase', 1, 0) as purchase from signals cap left join signals q on cap.query_id = q.query_id where (cap.type != 'query' AND q.type = 'query') ) raw_signals group by query, doc ) as per_type_boosts- 다양한 신호 유형을 결합하여 보다 신뢰성 있는 신호 부스팅 모델 구축
- 핵심
- 신호 유형별로 가중치를 부여하여 신호의 중요도에 따라 부스팅 모델 조정
- 클릭보다 장바구니 추가 및 구매 신호에 더 높은 가중치 부여
- 결합된 신호 유형을 통해 검색 엔진의 신뢰성과 정확성 향상
이런 방법을 이미지와 상품 메타 정보를 기반으로 한 패션 상품 검색에 적용하면, 사용자가 특정 패션 아이템을 검색할 때 클릭(1), 장바구니 추가(10), 구매(25)와 같은 신호를 반영하여 검색 결과의 순위를 조정할 수 있음. 이는 검색 엔진이 사용자 의도를 더 잘 파악하고 개인화된 검색 결과를 제공하는데 기여
신호 기반 랭킹 모델의 구성 및 최적화
1. 신호의 가중치 설정
여러 신호를 결합하여 전체 부스트 값을 최적화하는 과정에서 각 신호 타입은 독립적으로 합산된 후 결합됨.
- SQL 쿼리를 통해 각 쿼리/문서 쌍의 전체 부스트는 다음과 같은 방식으로 계산됨:
- 클릭 신호는 가중치 1로 계산
- 장바구니에 추가된 신호는 가중치 10으로 곱하여 계산
- 구매 신호는 가중치 25로 곱하여 계산
→ 제안된 가중치:
- 장바구니 추가: 10x
- 구매: 25x
- 이런 상대 가중치는 각 도메인에 맞게 전적으로 구성할 수 있음
이런 구성은 대부분의 전자상거래 시나리오에서 효과적일 수 있음. 예를 들어, 식료품 배달 앱의 경우 대부분의 사용자가 장바구니에 추가한 제품을 구매할 가능성이 높으며, 이런 경우 장바구니에 추가하는 것이 추가 가치를 제공하지 않을 수 있음.
2. 부정적 신호의 도입
- 부정적 신호 부스트의 개념 도입:
- 예: 장바구니에서 제거, 제품 반품, 검색 결과에서 건너뛰기 등의 부정적 신호
- 부정적 피드백을 처리하는 것은 긍정적 신호를 처리하는 것만큼 간단함: 신호에 점점 더 부정적인 가중치를 할당
TL;DR
- 신호의 상대적 가중치는 도메인에 따라 조정 가능하며, 부정적 신호도 중요하게 다룰 수 있음.
- 신호는 다양한 입력 파라미터를 받아 가중치에 따라 랭킹 점수를 반환하는 단순한 선형 함수로 처리 가능.
- 신호의 가중치를 튜닝하는 과정은 수동으로 수행하거나, Learning to Rank와 같은 머신러닝 기법을 활용할 수 있음.
3. 신호의 시간적 가치
- 신호는 항상 유용성을 유지하지 않음.
- 시나리오에 맞게 신호의 시간적 가치를 고려해야
3.1 전자상거래 검색 엔진
- 제품이 수년간 유지되며, 오랜 관심 기록이 있는 제품이 우수한 상품일 가능성이 높음.
- 신호의 시간적 가치를 동일하게 처리
3.2 구인 검색 엔진
- 문서(직업)는 몇 주 또는 몇 달 동안만 존재하며, 새로운 신호가 오래된 상호작용보다 더 중요하지 않음.
- 모든 클릭 신호는 동일한 가중치를 받아야 하며, 모든 구인 신청 신호도 동일한 가중치를 받아야
3.3 뉴스 검색 엔진
- 최신 공개 뉴스가 가장 큰 가시성을 가지며, 최신 신호가 오래된 신호보다 훨씬 더 가치가 있음.
- 감쇠 함수 사용: 예를 들어, 반감기가 30일인 감쇠 함수는 현재 신호에 100% 가중치를 부여
4. 시간 감쇠 및 단기 신호
신호의 시간 감쇠를 모델링하는 가장 쉬운 방법은 반감기 함수 사용:
\[time\_based\_signal\_weight = starting\_weight \times 0.5^{(signal\_age/half\_life)}\]starting_weight: 신호의 타입에 따라 상대적 가중치 (e.g., 클릭: 1, 장바구니 추가: 10, 구매: 25)signal_age: 신호의 연령half_life: 신호가 절반의 가치를 잃는 시간
[Figure 8.4: 감쇠 함수가 시간에 따라 신호 가중치에 미치는 영향]
결론
신호 기반 랭킹 모델은 다중 입력 파라미터를 통해 구성 가능하며, 다양한 신호의 상대적 가중치를 조정하여 모델의 강건성을 향상시킬 수 있음. 최적의 균형을 달성하기 위해 수동으로 조정하거나 Learning to Rank 기술을 활용할 수 있음. 신호의 시간적 가치를 고려한 설정은 특정 도메인에 따라 달라질 수 있으며, 특히 뉴스 검색 엔진과 같은 시나리오에서는 반감기 함수를 활용하여 최신 신호에 더 높은 가중치를 할당하는 것이 중요
8.4 시그널 감쇠 함수의 이해
Figure 8.4는 시간이 지남에 따라 다양한 반감기 값을 기반으로 시그널의 감소를 보여줌. 반감기가 증가하면 개별 시그널이 부스팅 효과를 더 오래 유지
- 하루 반감기: 급격한 감소
- 하루 안에 충분한 시그널을 수집하기 어려움
- 시그널이 그렇게 빨리 무의미해지는 경우는 적음
- 30일, 60일, 120일 반감기: 오래된 시그널을 공격적으로 할인하면서도 잔여 가치를 모델에 기여하도록 유지
- 장기 문서의 경우 시그널을 수년 동안 활용 가능
TL;DR
- 시그널의 반감기는 시그널의 유효기간을 결정하는 중요한 요소임.
- 반감기가 길수록 시그널의 부스팅 효과가 지속됨.
- 다양한 반감기를 통해 시그널의 중요성을 조정할 수 있음.
8.7 시그널 부스팅 모델에 반감기 함수 적용
Listing 8.7에서는 반감기 30일을 설정한 시그널 부스팅 모델에 시간 감쇠 함수를 적용하는 방법을 설명
- Configurable Parameters
half_life_days: 반감기 설정, 기본 30일signal_weight: 시그널 유형에 따른 가중치 (e.g., 클릭=1, 장바구니 추가=10, 구매=25 등)target_date: 시그널의 최대 가치를 얻는 날짜, 보통 현재 날짜를 사용
시그널 시간 감쇠 함수의 수학적 설명
시간 감쇠 함수는 다음과 같은 수식을 사용하여 시그널의 가중치를 계산함:
\[\text{time\_weighted\_boost} = \text{signal\_weight} \times \left(0.5^{\frac{\text{datediff}(\text{target\_date}, \text{signal\_time})}{\text{half\_life\_days}}}\right)\]signal_weight: 시그널의 종류에 따른 초기 가중치datediff(target_date, signal_time): target_date와 signal_time 간의 날짜 차이half_life_days: 반감기 설정
이 수식은 시간 경과에 따른 시그널의 가중치 감소를 설명 datediff가 클수록 시그널의 가중치는 작아짐.
TL;DR
- 시간 감쇠 함수는 반감기를 통해 시그널의 가중치를 계산.
- 반감기를 조정하여 시그널의 유효성을 조정 가능.
- 시그널의 목적과 특성에 따라 반감기와 가중치를 설정하여 최적화 가능.
8.6 인덱스 시점 vs. 쿼리 시점 부스팅: 규모와 유연성의 균형
8.6.1 쿼리 시점 부스팅의 장Cons(-)
Pros(+)
- 유연성
- 각 쿼리의 시그널을 개별적으로 업데이트 가능
- 부스팅 기능의 활성화/비활성화 용이
- 다양한 시그널 부스팅 알고리즘 간 전환 가능
Cons(-)
- 성능 문제
- 부스팅을 위한 별도 검색 필요, 추가 처리와 지연 발생
- 긴 문서 목록의 부스팅 처리 어려움
- 검색 결과 페이지네이션 지원 불가
TL;DR
- 쿼리 시점 부스팅은 유연성을 제공하지만 성능 문제를 수반.
- 각 쿼리에 대해 개별 시그널 업데이트 가능.
- 성능 문제로 인해 모든 사용 사례에 적합하지 않을 수 있음.
예시: 패션 상품 검색에서의 시그널 부스팅 적용
패션 상품 검색에서는 이미지와 상품 메타 정보를 기반으로 한 시그널 부스팅이 효과적임. 예를 들어, 특정 계절이나 이벤트에 따라 검색 빈도가 달라지는 상품에 대해 시그널 부스팅을 적용할 수 있음.
예시 시나리오
- 인풋 사용자 클릭 로그, 구매 이력, 검색 키워드
- 아웃풋 시기별 부스팅된 상품 목록
- 모델 사용 클릭 로그를 기반으로 계절 상품의 가중치를 조정하고, 구매 이력을 통해 특정 이벤트 상품의 부스팅 효과를 극대화
이를 통해 사용자 경험을 향상시키고, 검색 결과의 관련성을 높일 수 있음.
Index-time Signals Boosting: A Comprehensive Approach
1. Index-time vs Query-time Signals Boosting
- Query-time Boosting 문제점
- 문서의 수가 많을 경우, 모든 문서에 대한 Boosting 수행 어려움
- Boost 값에 의한 검색 결과의 순서가 항상 일관적이지 않음
- 사용자가 페이지를 이동할 때마다 결과가 섞여서 사용자 경험 저하
- Index-time Boosting 소개
- 유명한 쿼리를 문서에 포함하여 인덱싱 시점에 Boosting 수행
- 쿼리 시 새로운 필드를 검색하여 자동 Boost 적용
- 쿼리의 인기도를 문서에 반영해 보다 안정적이고 일관된 검색 결과 제공
2. Index-time Boosting 구현 방법
- 신호 집계 모델 사용 쿼리별로 문서와 Boost 가중치 쌍 생성
- 워크플로우 추가 단계 각 문서에 쿼리와 관련된 Boost 가중치 필드 추가
signals_boosts필드 생성- Solr의
DelimitedPayloadBoostFilter사용하여 쿼리와 Boost 함께 인덱싱
– Solr를 사용하여 ‘signals_boosts’ 필드에 쿼리와 Boost 값 저장
signals_boosts_collection="normalized_signals_boosts"
signals_boosts_opts={"zkhost": "aips-zk", "collection": signals_boosts_collection}
df = spark.read.format("solr").options(**signals_boosts_opts).load()
df.registerTempTable(signals_boosts_collection)
products_collection="products_with_signals_boosts"
products_read_boosts_opts={"zkhost": "aips-zk", "collection": products_collection}
df = spark.read.format("solr").options(**products_read_boosts_opts).load()
df.registerTempTable(products_collection)
boosts_query = """
SELECT p.*, b.signals_boosts from (
SELECT doc, concat_ws(',',collect_list(concat(query, '|', boost))) as signals_boosts
FROM """ + signals_boosts_collection + """ GROUP BY doc
) b inner join """ + products_collection + """ p on p.upc = b.doc
"""
products_write_boosts_opts={"zkhost": "aips-zk", "collection": products_collection, "gen_uniq_key": "true", "commit_within": "5000"}
spark.sql(boosts_query).write.format("solr").options(**products_write_boosts_opts).mode("overwrite").save()
3. Query 수행 시 Index-time Signals Boosting 적용
- 쿼리 수행 방법
payload()함수를 사용하여 인덱싱된 Boost 값 기반으로 점수 조정- 쿼리와
signals_boosts필드 일치 시 점수 증가
query = "ipad"
def get_query(query, signals_boosts_field):
request = {
"query": query,
"fields": ["upc", "name", "manufacturer", "score"],
"limit": 3,
"params": {
"qf": "name manufacturer longDescription",
"defType": "edismax",
"indent": "true",
"sort": "score desc, upc asc",
"qf": "name manufacturer longDescription",
"boost": "payload(" + signals_boosts_field + ", \"" + query + "\", 1, first)"
}
}
return request
collection = "products_with_signals_boosts"
boosted_query = get_query(query, signals_boosts_field)
search_results = requests.POST(solr_url + collection + "/select", json=boosted_query).json()["response"]["docs"]
4. Index-time Signals Boosting의 효과
- 검색 결과 개선
- 모든 문서에 대해 Boost 적용 가능
- 일관된 검색 결과 제공
- 사용자 경험 개선

- Figure 8.5 Index-time Boosting 결과, Query-time Boosting과 유사한 출력
5. Index-time Boosting의 Pros(+)
- Boosting 적용의 일관성 증가
- 검색 속도 및 사용자 경험 개선
- 쿼리 인기도에 기반하여 문서의 가치를 반영
TL;DR
- Index-time Boosting은 쿼리 인기도를 문서에 반영하여 보다 안정적이고 일관된 검색 결과 제공.
- 쿼리 수행 시
payload()함수를 사용하여 인덱싱된 Boost 값을 기반으로 검색 점수 조정.- 모든 문서에 Boost 적용이 가능하며, 사용자 경험과 검색 결과의 통일성을 극대화
인덱스 시간 부스팅(Index-Time Boosting) 분석
3. 인덱스 시간 부스팅의 특성
- 인덱스 시간 부스팅의 피쳐:
- 부스트 쿼리는 부스트 필드에 대한 단일 키워드 검색임.
- 쿼리와 일치하는 모든 문서가 부스트됨.
- 결과 페이지의 문제 해결: 모든 문서가 효율적으로 로드되고 쿼리에 추가됨.
→ 인덱스 시간 부스팅은 모든 쿼리가 일관되고 완전한 부스팅을 받도록 보장 → 쿼리 실행 전 추가 조회 제거로 쿼리 속도 향상 가능.
인덱스 시간 부스팅의 Cons(-)
- 부스트 값이 각 문서에 인덱싱되므로, 키워드 추가/제거 시 모든 관련 문서 재인덱싱 필요.
- 신호 부스팅 집계가 키워드별로 점진적으로 업데이트되면, 지속적인 재인덱싱 필요.
→ 이런 인덱싱 압력은 검색 엔진의 운영 복잡성을 증가시킴. → 쿼리 성능을 유지하기 위해 인덱스 서버와 검색 인덱스 서버를 분리하여 운영하는 것이 바람직
인덱스와 쿼리의 분리
- Apache Solr에서 인덱스는 “샤드”로 나누어짐: 각 샤드는 컬렉션 내 문서의 부분 집합을 포
- 샤드의 복제본은 데이터의 복사본을 가짐.
- 검색 시, Solr는 각 샤드의 복제본에 쿼리를 전송하고 결과를 병합하여 사용자에게 반환
→ 샤드를 추가하여 더 많은 문서를 더 짧은 시간에 검색 가능. → 복제본 추가로 내결함성 증가 및 더 많은 검색 가능.
신호 부스팅의 필요성과 방법
- 신호 부스팅은 쿼리에 대한 사용자 신호 집계를 통해 미래의 쿼리에 관련성 부스트로 사용.
- 쿼리 변형을 동일하게 처리해 사용자 신호의 노이즈을 줄이고, 더 견고한 신호 부스팅 모델 구축.
- 스팸 및 악의적 신호 방지로 모델의 품질 유지.
- 서로 다른 신호 유형을 가중 합산하여 단일 신호 부스팅 모델로 결합.
- 시간 감쇠 함수 도입으로 최근 신호가 더 큰 가중치를 가짐.
TL;DR
- 인덱스 시간 부스팅은 모든 쿼리에 대해 일관된 부스팅을 제공하고 쿼리 속도를 향상시킴.
- 인덱스 시간 부스팅의 Cons(-)은 키워드 변경 시 모든 문서 재인덱싱의 필요성으로 인해 운영 복잡성을 증가시킴.
- Solr와 같은 시스템에서 인덱싱과 쿼리를 분리하여 인덱스 시간 부스팅의 Cons(-)을 완화할 수 있음.
예시: 패션 상품 검색
- 이미지와 상품 메타 정보를 기반으로 패션 상품을 검색하는 방법:
- 이미지 피쳐 추출: CNN(Convolutional Neural Network) 모델 사용.
- 메타 정보 처리: NLP(Natural Language Processing) 모델로 키워드 추출.
- 인풋: 이미지 데이터, 텍스트 데이터.
- 아웃풋: 관련성 높은 패션 상품 리스트.
→ 인덱스 시간 부스팅을 적용하여 유명한 패션 아이템을 검색 결과 상위에 배치.
참고 문서
- Apache Solr 공식 문서: Apache Solr
Generalized Relevance Ranking Models with Learning to Rank (LTR)
1. Learning to Rank (LTR) Overview
- Learning to Rank (LTR):
- 목적: 검색 엔진에서 결과의 순위를 최적화하여 사용자에게 가장 관련성 높은 결과 제공
- 과정: 사용자가 지정한 관련성 요소를 통해 모델 학습
- 적용: 간단한 선형 가중치 모델부터 복잡한 딥러닝 모델까지 다양한 형태로 구현 가능
- Manual Relevance Tuning:
- 관련성 조정의 필요성: 사용자가 원하는 이상적인 순위에 최대한 가깝게 결과를 정렬
- 예시: 영화 검색 엔진에서 ‘The Social Network’라는 영화 문서 활용
- 문서 속성 예시: 제목, 개요, 태그라인, 개봉 연도
- 수식:
q=title:(${keywords})^10 overview:(${keywords})^20 {!func}release_year^0.01
2. LTR 시스템 구성 요소
- Judgment Lists:
- 역할: 모델 학습을 위한 훈련 데이터
- 설명: 클릭 데이터 등에서 관련 문서에 대한 판단 목록 생성
- Feature Logging:
- 역할: 모델 학습 시 판단 데이터와 피쳐 데이터 결합
- 과정: 검색 엔진이 피쳐을 나타내는 쿼리를 저장 및 계산하도록 요청
- Transform to Machine Learning Problem:
- 목표: 랭킹 작업을 전통적 머신러닝 문제로 변환
- 방법: 검색 쿼리를 통해 피쳐 데이터 수집
- Train and Evaluate Model:
- 과정: 모델 생성 및 일반화 가능성 검증
- 목표: 새로운 쿼리에도 잘 작동하는 모델 구축
- Store the Model:
- 역할: 검색 인프라에 모델 업로드, 검색 시 사용할 피쳐 지정
- Search Using the Model:
- 최종 목표: 모델을 사용하여 검색 실행
3. LTR 시스템 구현 및 예시
- Figure 10.1: LTR 시스템의 워크플로우
- 설명: 훈련 데이터(판단 목록)를 모델로 변환하여 관련성 순위를 일반화
- 활용: 머신러닝 기반 시스템과의 비교를 통해 차이점 탐색
- Table 10.1: Classic Machine Learning vs Learning to Rank
- 훈련 데이터:
- 전통적 머신러닝: 과거 데이터 예측
- LTR: 쿼리에 대한 관련/비관련 문서 판단 목록
- 피쳐 데이터:
- 전통적 머신러닝: 예측에 사용되는 데이터
- LTR: 관련 결과가 높은 순위로 정렬되도록 하는 검색 쿼리
- 모델:
- 전통적 머신러닝: 입력 피쳐을 예측으로 변환
- LTR: 랭킹 피쳐을 결합하여 잠재적 검색 결과에 관련성 점수 부여
- 훈련 데이터:
TL;DR
- LTR은 검색 엔진 최적화를 위해 다양한 형태의 머신러닝 모델을 활용하여 결과의 순위를 조정하는 기법임.
- LTR 시스템은 판단 목록을 통해 훈련 데이터를 수집하고, 이를 활용해 최적의 랭킹 기능을 학습
- LTR은 전통적 머신러닝과 유사하지만, 검색 쿼리와 관련성에 특화된 점이 피쳐임.
참고 링크 및 추가 자료
- TheMovieDB: 영화 데이터베이스 활용 예시
- Elasticsearch LTR Plugin: Elasticsearch용 LTR 플러그인
이 문서는 Learning to Rank의 개념과 구현 방법을 다양한 예시와 수식을 통해 설명하며, 전통적인 머신러닝과의 차이점도 명확히 비교합니다. 이는 검색 엔진의 성능을 최적화하기 위한 중요한 기법으로, LTR 모델을 통해 사용자에게 보다 관련성 높은 검색 결과를 제공할 수 있습니다.
학습을 위한 랭킹(LTR) 구현: 데이터 수집과 피처 엔지니어링
1. LTR의 개요 및 데이터 수집
1.1 LTR의 핵심: 판단 목록(Judgment List)
- Judgment List 정의 LTR 모델 훈련에 사용되는 데이터 목록. 각 문서의 쿼리에 대한 관련성을 나타내는 레이블 목록.
- 예:
0은 관련 없는 문서,1은 관련 있는 문서.
- 예:
- 데이터 생성 예시
- 쿼리 “social network”에 대해 “The Social Network”를 관련 있는 문서로 레이블링.
- 쿼리 “star wars”에 대해 “Return Of The Jedi”를 관련 있는 문서로 레이블링.
from ltr.judgments import Judgment
Judgment(grade=1, keywords='social network', doc_id=37799)
- 다양한 쿼리에 대한 레이블링
- “social network”와 “star wars” 쿼리에 대한 다양한 영화의 관련성 레이블링.
- Listing 10.3에 따라 관련성과 관련 없는 영화에 대한 예시 제공.
1.2 관련성 레이블의 출처
- 레이블 생성 방법
- 영화 전문가의 수작업 또는 사용자 클릭 기반.
- 대량의 훈련 데이터를 얻기 위해 클릭 트래픽에서 레이블을 추출.
- 클릭 모델을 사용하여 관련성 판단.
2. 피처 로깅과 엔지니어링
2.1 피처 정의와 활용
- 피처의 의미 문서, 쿼리 또는 쿼리-문서 관계의 수치적 속성.
- 예: BM25 점수, 제목 매칭 강도 등.
- 피처 엔지니어링 특정 매칭 기준을 정의하고, 이를 위해 검색 엔진을 이용해 피처를 추출.
2.2 피처 로그와 엔지니어링 과정
- 피처 로깅
- Judgment list에서 각 쿼리-문서 쌍에 대해 피처를 계산.
- Table 10.2와 같은 형태로 피처 값 계산.
q=title:(${keywords})^10 overview:(${keywords})^20 {!func}release_year^0.01
3. 피처 저장과 검색 엔진 활용
3.1 Solr를 통한 피처 저장
- Solr에서 피처 생성
- HTTP PUT 요청을 통해 피처 생성.
- 제목 필드 관련 점수(
title_bm25), 개요 필드 관련 점수(overview_bm25), 영화의 개봉 연도(release_year) 등 정의.
feature_set = [
{
"name" : "title_bm25",
"store": "movies",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"q" : "title:(${keywords})"
}
},
{
"name" : "overview_bm25",
"store": "movies",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"q" : "overview:(${keywords})"
}
},
{
"name" : "release_year",
"store": "movies",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"q" : "{!func}release_year"
}}]
- 피처 로깅
- 각 쿼리에 대해 피처를 추출하고, 이를 기반으로 LTR 모델 훈련.
TL;DR
- LTR 구현을 위해 관련성 판단 목록을 구성하고, 이를 통해 클릭 기반 알고리즘으로 훈련 데이터를 수집
- 피처는 쿼리와 문서의 수치적 특성을 나타내며, 이를 통해 랭킹 함수를 구축
- Solr를 활용하여 피처를 저장 및 관리하고, 이를 기반으로 피처 로깅을 수행하여 LTR 모델을 훈련
다음 단계에서는 학습된 모델을 활용하여 실제 검색 시스템에 적용하는 방법을 탐구하며, 이 과정에서 구체적인 사례 연구를 통해 이해를 돕고, 피처 엔지니어링의 중요성을 강조
페이셜 이미지와 메타 정보를 활용한 패션 상품 검색: 테크니컬 접근
1. 소개
AI 기술이 발전하면서 패션 산업에서도 이미지와 메타 정보를 활용한 검색 시스템이 주목받고 있음. 이런 시스템은 사용자가 입력한 사진이나 텍스트를 기반으로 관련 상품을 효과적으로 검색하여 추천 이 글에서는 Solr와 같은 검색 엔진을 활용한 머신러닝 기반의 학습-순위(Learning to Rank, LTR) 시스템을 중심으로 이미지와 메타 정보를 활용한 패션 상품 검색 기술을 자세히 설명
2. Solr를 활용한 LTR 시스템 구현
2.1 기능 로깅과 데이터 수집
- 기능 로깅 Solr의 기능 저장소를 사용하여 쿼리에 대한 관련 문서와 비관련 문서의 기능 값을 로깅
- 쿼리 예시: “소셜 네트워크”
- 관련 문서: The Social Network
- 비관련 문서: Life As We Know It 등
- 데이터 수집 Solr의 응답에서 각 문서에 대해 계산된 기능 값을 포함하여 데이터 수집.
fl파라미터를 통해 필요한 기능 데이터를 각 문서 응답에 추가.efi파라미터를 사용하여 쿼리 키워드를 전달하고 추가 쿼리 시간 정보를 사용하여 각 기능을 계산.
logging_solr_query = {
"fl": "id,title,[features store=movies efi.keywords=\"social network\"]",
'q': "id:37799 OR id:267752 OR id:38408 OR id:28303",
'rows': 10,
'wt': 'json'
}
resp = requests.POST('http://aips-solr:8983/solr/tmdb/select', data=logging_solr_query)
resp.json()
2.2 기능 로깅 결과
- 각 문서에 대해
title_bm25,overview_bm25,release_year과 같은 기능 값 로깅. - 예시:
- 문서 ID: 38408
- 제목: Life As We Know It
- 기능:
title_bm25=0.0, overview_bm25=4.353118, release_year=2010.0
2.3 요약
Solr를 이용해 기능 로깅을 수행하여 쿼리와 관련된 각 문서의 기능 값을 수집 이를 통해 관련성과 비관련성을 판단할 수 있음. 다음 단계로는 LTR을 머신러닝 문제로 변환하여 학습을 시작
3. LTR을 머신러닝 문제로 변환
3.1 training dataset 준비
- 판단 리스트 각 쿼리에 대해 관련성 여부를 판단하여 training dataset 생성.
- 예시
- 쿼리: “소셜 네트워크”
- 관련 문서: Judgment(grade=1, qid=1, keywords=social network, doc_id=37799, features=[8.243603, 3.8143613, 2010.0], weight=1)
3.2 머신러닝을 통한 순위 결정
- 목표 관련 문서를 상위로, 비관련 문서를 하위로 정렬할 수 있는 모델 구축.
- 피쳐 각각의 학습 예제는 단일로 큰 의미를 가지지 않으며, 쿼리 내에서의 상대적 순서가 중요
4. 머신러닝 모델링
4.1 모델링 개요
- 목표 각 쿼리에 대한 결과 집합을 이상적인 순서로 배치.
- 비교 LTR은 개별 관련성 점수를 예측하는 대신, 쿼리 내에서 결과의 순서를 중요시
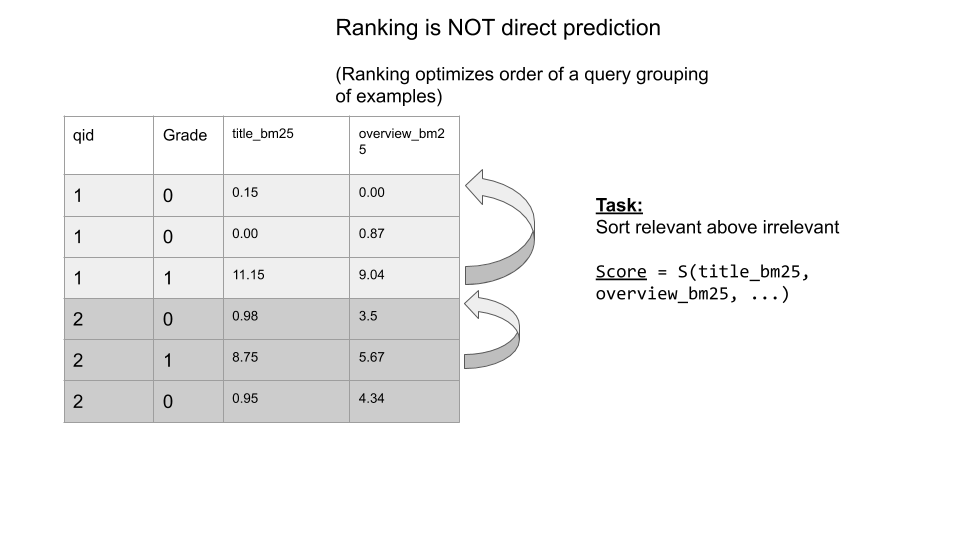
4.2 요약
LTR을 통해 각 쿼리의 결과 집합을 이상적인 순서로 배치하는 것이 목표임. 이는 개별 문서의 관련성 점수를 예측하는 것과는 다른 접근 방식으로, 쿼리 내에서 상대적 순서가 중요
5. 패션 상품 검색에의 응용
5.1 이미지와 메타 정보 기반 검색
- 시스템 설계 패션 상품의 이미지를 입력으로 받아 관련 상품 검색.
- 모델 활용 CNN 기반 이미지 피쳐 추출, 메타 정보는 Solr로 처리하여 관련성 점수 계산.
5.2 예시
- 입력 사용자가 업로드한 패션 아이템 이미지
- 출력 관련 패션 아이템 리스트
- 모델 이미지 피쳐 추출을 위한 CNN, 메타 정보 분석을 위한 LTR
6. 결론
패션 상품 검색에 이미지와 메타 정보를 활용하는 방법은 사용자 경험을 크게 향상시킬 수 있음. Solr와 같은 검색 엔진과 머신러닝 기법을 결합하여 효과적인 순위 결정과 관련성 높은 검색 결과를 제공할 수 있음. 이런 기술은 패션 산업 뿐만 아니라 다양한 분야에 적용 가능
10.3 Point-wise Machine Learning vs Learning to Rank (LTR)
p232
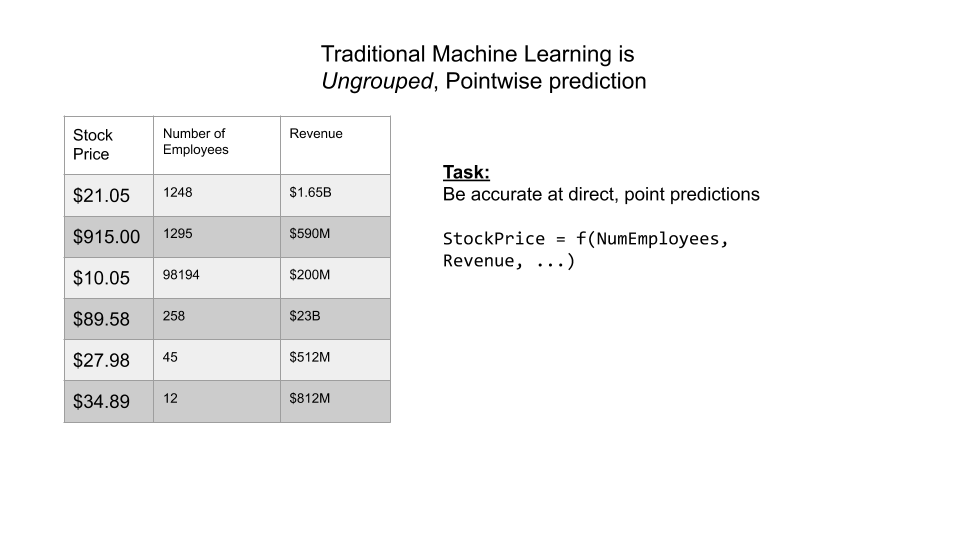
Figure 10.3 점별 머신러닝은 개별 데이터 포인트(e.g., 주가, 온도)의 예측 최적화를 시도 검색 관련성 문제는 점별 예측과 다름. 대신 검색 쿼리로 그룹화된 예제의 순위를 최적화해야
- LTR, 즉 Learning to Rank는 점별 머신러닝과 다름
- 대부분의 LTR 방법은 순위를 점별 학습 문제로 변환하여 해결
- 주식 가격 예측과 유사한 방식으로 접근
예: SVMRank 모델을 통해 랭킹 태스크 변환 방법 살펴보기
- LTR의 핵심: 모델
- 관련성과 무관성을 피쳐들과 연결짓는 알고리즘
- SVMRank 모델 탐구
- SVM의 의미 이해
- 일반화 가능한 LTR 모델 구축 방법
TL;DR
- LTR은 검색 쿼리로 그룹화된 예제의 순위를 최적화하는 문제임.
- SVMRank는 순위 문제를 이진 분류 문제로 변환하여 접근
- LTR의 핵심은 관련성과 무관성의 관계를 학습하는 모델임.
10.4 SVMRank: 랭킹을 이진 분류로 변환
p233
SVMRank의 주요 개념
- SVM: 두 클래스 간 최적의 분리 초평면(hyperplane)을 찾음
- 예: 동물이 개인지 고양이인지 구분
- 높이와 무게를 기준으로 클래스 분리 (Figure 10.4 참고)
- 예: 동물이 개인지 고양이인지 구분
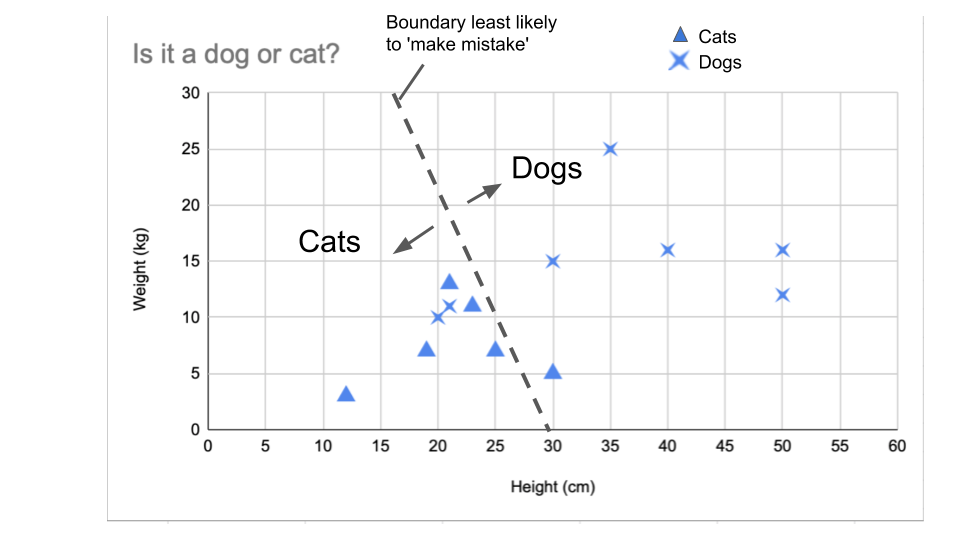
Figure 10.4 동물의 높이와 무게를 기반으로 개와 고양이를 구분하는 SVM 예제. 검색 결과를 관련성과 무관성으로 구분하는 데 유사한 방법 사용 가능.
- 최적의 분리 초평면
- 훈련 데이터에서의 오류 최소화
- 새로운 데이터에 대해 잘 일반화 가능
- SVM의 특성
- 피쳐의 범위에 민감
- 예: 높이 피쳐이 밀리미터 단위로 주어질 경우 (Figure 10.5 참고)

Figure 10.5 SVM이 피쳐의 범위에 민감하게 반응함을 보여주는 예제. 피쳐의 범위가 모델에 부당한 영향을 미치지 않도록 정규화 필요.
TL;DR
- SVM은 두 클래스 간 최적의 분리 초평면을 찾음.
- 분리 초평면은 데이터의 일반화 가능성을 높임.
- SVM은 피쳐의 범위에 민감하므로 정규화가 필요
10.4.1 SVMRank: 이진 분류로의 변환
p234
- SVM은 데이터가 정규화되었을 때 좋은 성능 발휘
- 정규화: 피쳐값을 비교 가능한 범위로 조정
- 예:
release_year의 평균이 1990년일 때 1990년의 영화는 0으로 정규화 - 표준편차를 기준으로 +1/-1로 매핑
- SVMRank의 목표
- 관련성과 무관성을 구분하는 모델 구축
- 새로운 쿼리에 대해서도 적용 가능
- LTR 태스크의 재구성
- 랭킹을 전통적인 머신러닝 태스크로 변환
- 예:
star wars,social network쿼리의 두 가지 피쳐 (title_bm25,overview_bm25) 사용
Figure 10.6 star wars와 social network 쿼리의 피쳐 점수
TL;DR
- SVM은 정규화된 데이터에서 최적의 성능을 발휘
- SVMRank는 랭킹 태스크를 이진 분류로 변환
- 두 가지 피쳐을 사용하여 쿼리의 관련성을 평가할 수 있음.
10.4.2 LTR 훈련 데이터의 이진 분류로의 변환
p235
- 각 피쳐의 정규화
- Step 2의 로그 출력값을 정규화하여
normed_judgments생성
- Step 2의 로그 출력값을 정규화하여
-
Listing 10.8: LTR 훈련 세트를 정규화된 세트로 변환
- 예:
title_bm25,overview_bm25,release_year의 원시 값과 정규화된 값 비교 title_bm25의 로그 점수 8.243603은 평균 대비 4.4829 표준편차에 해당
- 예:
-
Figure 10.7: 정규화된 피쳐 플롯, 각 축의 스케일이 다름
- 정규화 수행
- 코드를 통해 정규화된 피쳐 생성
means, std_devs, normed_judgments = normalize_features(logged_judgments) logged_judgments[360], normed_judgments[360]
- 예제:
social network쿼리의 정규화된 피쳐들
TL;DR
- 훈련 데이터의 각 피쳐은 정규화가 필요
- 정규화를 통해 피쳐을 비교 가능한 범위로 조정
- 정규화된 데이터를 통해 SVMRank의 이진 분류 모델을 구축
관련 문서 및 예시
- SVM 및 LTR 관련 참고 서적: Grokking Machine Learning by Luis Serrano
- 패션 상품 검색 예시: 이미지 및 상품 메타 데이터 기반으로 검색 결과의 관련성을 평가하는 데 SVMRank 사용 가능. 모델의 인풋은 상품 이미지와 메타 데이터이며, 아웃풋은 관련성 점수임. ai-powered-search/
1. 배경 및 이미지 설명
- Figure 10.7 이 Figure은 ‘스타워즈’와 ‘소셜 네트워크’라는 영화의 정규화된 등급을 보여줌. 그래프의 각 증가는 평균보다 표준 편차만큼 위 또는 아래의 값을 나타냄.
정규화된 데이터 사용 → 피쳐량들을 일관된 범위로 강제 조정 → SVM이 큰 범위를 가진 피쳐량에 편향되지 않음. 이제 이 작업을 이진 분류 문제로 변환할 준비가 완료됨.
2. SVMRank 알고리즘의 개요
- SVM Rank의 역할 랭킹 문제를 이진 분류 문제로 변환 → 주어진 쿼리에 대해 잘못된 순서의 쌍을 최소화하는 작업으로 변환
- Pair-wise 변환 쿼리의 각 판단을 비교하여 해당 쿼리에 대해 관련성과 비관련성의 쌍별 차이를 계산
3. Pair-wise 알고리즘의 상세 설명
- 알고리즘의 작동 방식
- 각 쿼리에 대한 판단을 비교
- 관련성 있는 문서와 비관련성 있는 문서 간의 피쳐 차이를 계산
- 첫 번째 판단이 두 번째 판단보다 더 관련성이 높다면 +1로 레이블링, 반대의 경우 -1로 레이블링.
- 새로운 훈련 세트를 구축함 → 기존의 훈련 세트에서 ‘feature_deltas’와 ‘predictor_deltas’ 생성.
4. Pseudocode 및 예시
foreach query in queries:
foreach judged_document_1 in query.judgments:
foreach judged_document_2 in query.judgments:
if judged_document_1.grade > judged_document_2.grade:
predictor_deltas.append(+1)
feature_deltas.append(judged_document_1.features - judged_document_2.features)
else if judged_document_1.grade < judged_document_2.grade:
predictor_deltas.append(-1)
feature_deltas.append(judged_document_1.features - judged_document_2.features)
5. 예시: “Network” vs “The Social Network”
- Figure 10.8 SVMRank 변환 후 ‘소셜 네트워크’와 ‘스타워즈’ 문서의 쌍별 차이를 보여줌.
- 예시 비교
- “The Social Network”의 피쳐: [4.483, 2.100]
- “Network”의 피쳐: [3.101, 1.443]
- 델타 계산: [4.483, 2.100] - [3.101, 1.443] = [1.382, 0.657]
- 이 결과는 ‘feature_deltas’에 추가되고, ‘predictor_deltas’에는 +1이 추가됨.
6. 요약
- SVMRank는 랭킹 문제를 이진 분류 문제로 변환하여 쿼리에 대한 관련성과 비관련성 판단을 비교
- 쌍별 차이를 계산하여 새로운 훈련 세트를 생성
- 예시를 통해 ‘The Social Network’와 ‘Network’의 차이를 계산하여 훈련 데이터로 전환
7. 관련 문서 및 링크
ai-powered-search/
8. 패션 상품 검색에의 응용
- 이미지 및 상품 메타 정보를 통한 검색
- 입력: 패션 상품 이미지, 설명 및 메타 정보
- 모델: 이미지에서 피쳐을 추출하여 메타 정보와 결합, SVMRank를 활용해 관련성 높은 상품을 추천
- 출력: 관련성 높은 패션 상품 목록
이런 방식으로 SVMRank의 알고리즘은 다양한 분야에 적용 가능 특히, 이미지와 메타 정보를 결합하여 사용자에게 최적화된 검색 결과를 제공할 수 있음.
p240
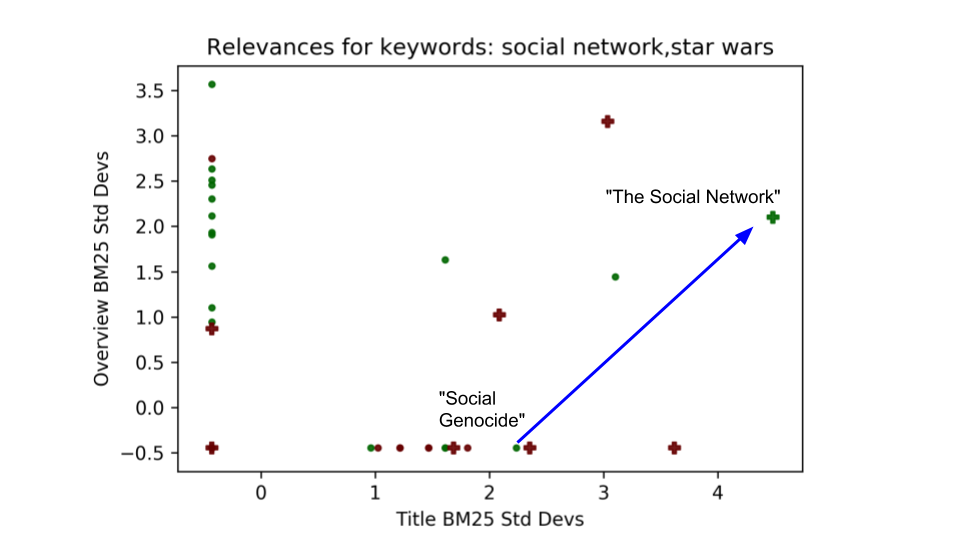
Figure 10.11 ‘Social Genocide’와 ‘The Social Network’의 비교. 쿼리 ‘social network’에 대한 문서의 관련성을 비교
- 두 문서의 관련성 비교 방법 제시
- 긍정적 값 추가: 더 관련성이 높은 문서가 먼저 나오는 경우
- 부정적 값 추가: 덜 관련성이 있는 문서가 먼저 나오는 경우
-
Listing 10.11 “Social Genocide”와 “The Social Network”를 포인트 와이즈 트레이닝 데이터에 추가
- 각 문서 쌍의 차이를 반복하여 포인트 와이즈 트레이닝 세트 생성
- 이후 다른 쿼리에 대한 차이도 기록
-
Figure 10.12 두 번째 쿼리 예시 (‘star wars’)에 대한 문서 비교
- 긍정적 예제:
predictor_deltas.append(+1) - 특성 차이 계산:
[4.483, 2.100] - [2.234, -0.444] = [2.249, 2.544] - 부정적 예제:
predictor_deltas.append(-1) - 특성 차이 계산:
[2.234, -0.444] - [4.483, 2.100] = [-2.249, -2.544]
- 긍정적 예제:
p241
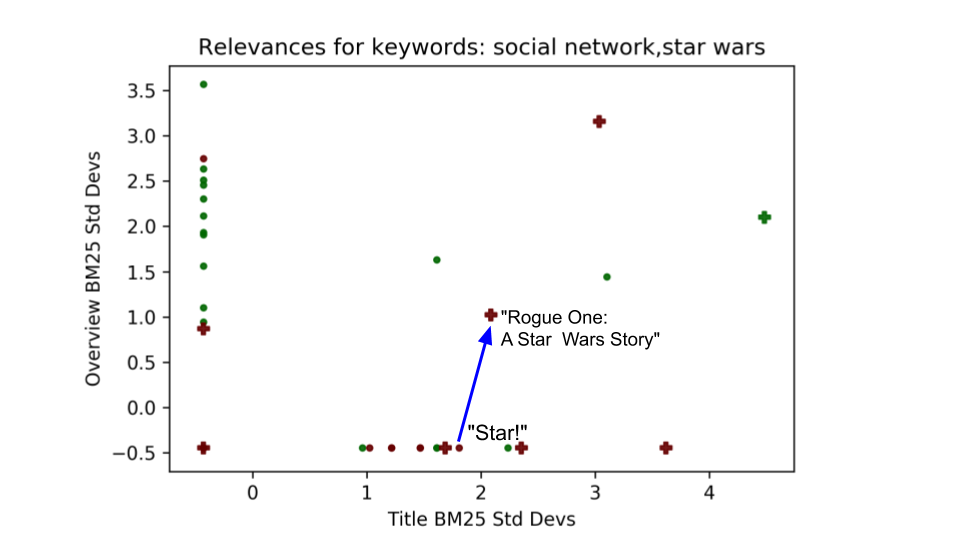
Figure 10.12 ‘Rogue One: A Star Wars Movie’와 ‘Star!’의 쿼리 ‘star wars’에 대한 비교.
- ‘social network’에서 다른 쿼리로 전환
-
문서의 관련성과 비관련성을 구별하기 위해 특성 값의 차이를 계속 계산
- 긍정적 예제:
predictor_deltas.append(+1) - 특성 차이 계산:
[2.088, 1.024] - [1.808, -0.444] - 부정적 예제:
predictor_deltas.append(-1) - 특성 차이 계산:
[1.808, -0.444] - [2.088, 1.024]
p242
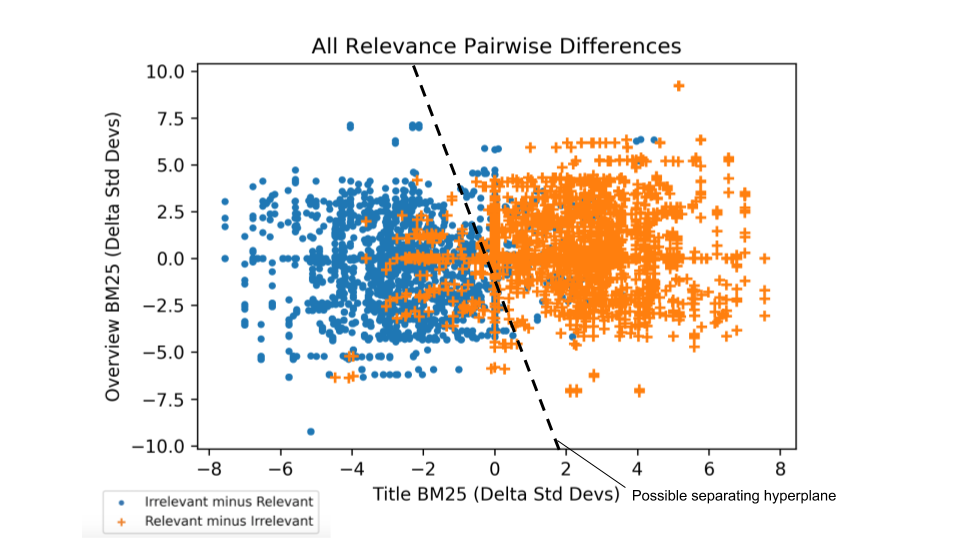
Figure 10.13 관련 문서와 비관련 문서를 구분하는 하이퍼플레인.
-
높은
title_bm25점수와overview_bm25점수가 문서의 관련성과 상관관계가 있음을 시각적으로 확인 가능 -
LTR 방법 검토 필요
- 람다MART와 같은 다른 방법은 전통적인 검색 관련성 순위 지표를 직접 최적화할 수 있음
- 충분한 데이터 준비의 중요성 강조
feature_deltas와predictor_deltas를 사용하여 클래식 머신러닝 모델 학습 준비
p243
- SVMRank의 하이퍼플레인 사용
- 하이퍼플레인 정의: 평면에 수직인 벡터
- SVM 라이브러리 사용시 각 특성의 가중치를 알 수 있음
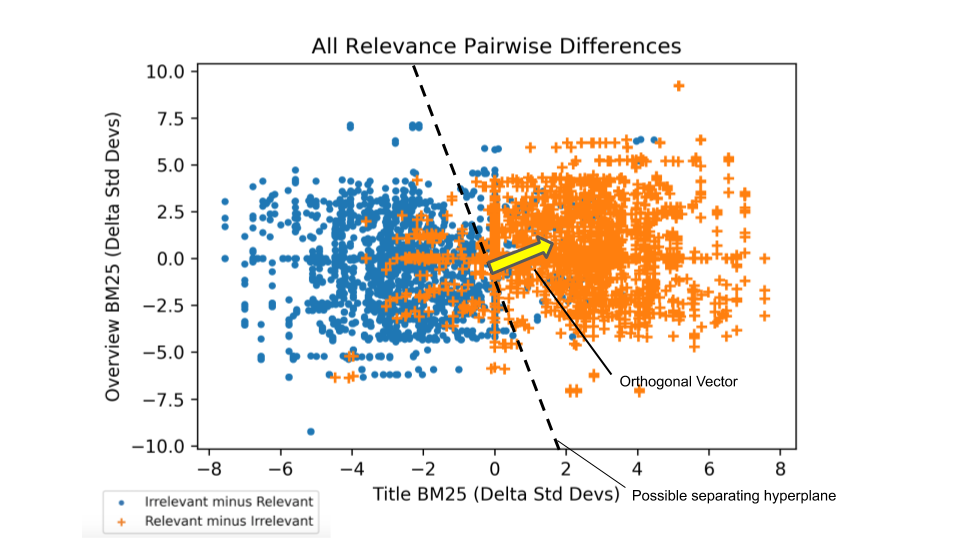
Figure 10.14 하이퍼플레인을 정의하는 수직 벡터. 관련성 방향을 가리킴.
- 수직 벡터: 방향성 제공
title_bm25가 강한 영향력,overview_bm25가 약간의 영향력
- 데이터에서 차이값(deltas)을 계산하여 SVM 학습
Listing 10.12: 하이퍼플레인을 정의하는 벡터 획득
TL;DR
- 문서 쌍의 관련성을 비교하여 포인트 와이즈 트레이닝 데이터 생성.
- SVMRank를 통해 하이퍼플레인을 정의하고, 각 특성의 가중치를 학습하여 관련 문서와 비관련 문서를 구분.
- 하이퍼플레인 벡터를 스코어링 함수로 변환하여 관련성을 예측하고, 새로운 쿼리와 문서에도 확장 가능.
관련 문서 및 추가 예시
- 배경 지식: 랭킹 학습(Learning to Rank, LTR) 및 SVMRank
- 예시: 패션 상품 검색에서 이미지와 테그 기반으로 관련 상품 추천
- 인풋: 이미지 및 상품 메타 정보
- 아웃풋: 관련성 높은 패션 아이템 추천
- 활용 모델: CNN 기반의 이미지 분석 및 SVM 기반의 랭킹 모델
머신 러닝을 활용한 검색 모델 구축: SVM을 이용한 예제
1. SVM으로 선형 모델 학습하기
1.1 Scikit-learn을 사용한 선형 SVM 생성
- 목표 Scikit-learn을 통해 선형 SVM을 학습시켜 데이터를 분리하는 초평면 정의
- training dataset
feature_deltas와predictor_deltasfeature_deltas: 일반적으로 각 데이터 포인트의 피쳐 차이를 나타냄predictor_deltas: 예측 값의 차이를 나타내며, +1 또는 -1로 구성됨
- 결과 학습된 모델은 분리 초평면에 수직인 벡터를 형성 이 벡터는 주어진 피쳐들에 따라 가중치를 부여하여 문서의 순위를 매김
from sklearn import svm model = svm.LinearSVC(max_iter=10000, verbose=1) model.fit(feature_deltas, predictor_deltas) model.coef_
- 모델의 가중치
array([[0.40512169, 0.29006365, 0.14451721]])title_bm25: 가장 큰 가중치overview_bm25: 중간 가중치release_year: 가장 작은 가중치
1.2 모델을 랭킹 함수로 사용하기
- 쿼리 사용자가
wrath of khan을 입력할 경우 - 문서 랭킹 “Star Trek II: The Wrath of Khan”이 어떻게 랭킹될 것인가?
- 피쳐 벡터를 표준화하여 가중치와 곱한 후 합산하여 점수 계산
Unnormalized feature vector example
[5.9217176, 3.401492, 1982.0]
Normalized feature vector
[3.099, 1.825, -0.568]
Relevance score calculation
(3.099 * 0.405) + (1.825 * 0.290) + (-0.568 * 0.1445) = 1.702
- 예상 결과 “Star Trek III: The Search for Spock”은 낮은 점수를 받음
2. 모델의 일반화 가능성 평가
2.1 테스트/훈련 데이터 분할
- 목적 모델의 일반화 가능성을 검증하며, 새로운 쿼리에 대해 정확히 작동하는지 확인
- 방법 쿼리 수준에서 테스트/훈련 데이터 분할
proportion_train=0.1로 설정하여 10%의 데이터를 훈련 데이터로 사용
all_qids = list(set([j.qid for j in normed_judgments]))
random.shuffle(all_qids)
test_train_split_idx = int(len(all_qids) * proportion_train)
test_qids=all_qids[:test_train_split_idx]
train_qids=all_qids[test_train_split_idx:]
train_data = []; test_data=[]
for j in normed_judgments:
if j.qid in train_qids:
train_data.append(j)
elif j.qid in test_qids:
test_data.append(j)
2.2 모델 검증
- 평가 지표 Top N (N=4) 결과 중 관련된 결과의 비율을 측정하는 단순 Precision 메트릭 사용
def eval_model(test_data, model):
tot_prec = 0
num_queries = 0
for qid, query_judgments in groupby(test_data, key=lambda j: j.qid):
query_judgments = list(query_judgments)
ranked = rank(query_judgments, model)
tot_relevant = 0
for j in ranked[:4]:
if j.grade == 1:
tot_relevant += 1
query_prec = tot_relevant/4.0
tot_prec += query_prec
num_queries += 1
return tot_prec / num_queries
- 예상 Precision 약 0.3 - 0.4
3. Solr에 모델 배포 및 검색 구현
3.1 Solr와의 통합
- 목적 Solr에 모델을 업로드하여 실제 검색 결과를 확인
- 방법
- 각 피쳐의 평균과 표준 편차를 저장하여 Solr이 값을 정규화할 수 있게 함
q="title:(${keywords})^10 overview:(${keywords})^20
release_year^0.01"
TL;DR
- Scikit-learn을 사용하여 선형 SVM을 학습시켜 데이터의 차이를 분리하는 모델 생성.
- 모델의 일반화 가능성을 테스트/훈련 데이터 분할을 통해 검증하고, Precision 메트릭을 사용하여 평가.
- Solr에 모델을 배포하여 검색 결과를 최적화하고, 결과를 확인
Learning to Rank (LTR) with Solr: A Detailed Guide
10.16 Solr에 모델 업로드하기: 정규화 및 가중치 적용
- Feature Store 모델 평가 시 필요한 피처를 저장 및 검색하는 저장소.
- → 피처 이름을 참조하여 모델 평가 시 피처 값 계산.
- 모델 평가 전 실행할 피처 특정 피처를 평가 전 실행하여 모델 효율성 증가.
- 피처 정규화 방식 모델 적용 전 피처 값의 표준화 필요.
- → 예:
StandardNormalizer사용.- 평균(Avg) 및 표준 편차(Std) 설정.
- → 예:
- 모델 내 피처의 가중치 각 피처의 중요도를 결정하는 요소.
PUT http://aips-solr:8983/solr/tmdb/schema/model-store
{
"store": "movies",
"class": "org.apache.solr.ltr.model.LinearModel",
"name": "movie_titles",
"features": [
{
"name": "title_bm25",
"norm": {
"class": "org.apache.solr.ltr.norm.StandardNormalizer",
"params": {
"avg": "1.5939970007512951",
"std": "3.689972140122766"
}
}
},
{
"name": "overview_bm25",
"norm": {
"class": "org.apache.solr.ltr.norm.StandardNormalizer",
"params": {
"avg": "1.4658440933160637",
"std": "3.2978986984657808"
}
}
},
{
"name": "release_year",
"norm": {
"class": "org.apache.solr.ltr.norm.StandardNormalizer",
"params": {
"avg": "1993.3349740932642",
"std": "19.964916628520722"
}
}
}
],
"params": {
"weights": {
"title_bm25": 0.40512169,
"overview_bm25": 0.29006365,
"release_year": 0.14451721
}
}
}
- 모델과 피처 스토어 연계 모델은 피처 스토어와 연계되어 피처 이름으로 피처 값 검색 가능.
TL;DR
- Solr의 Learning to Rank(LTR) 모델은 피처 스토어를 통해 피처를 관리
- 피처 정규화는 모델 평가 전 필수 단계이며, 가중치는 피처 중요도를 결정
- 최적의 LTR 결과를 위해 모델과 피처의 상호작용을 잘 이해해야
10.17 LTR 모델로 60,000개 문서 랭킹
- 모델 실행 60,000개의 문서에 대해 지정된 파라미터로 모델 실행.
- 결과 평가 초기 쿼리 없이 인덱스 순서대로 문서에 모델 적용.
- → 60,000개 문서 랭킹 성공.
- 효율적 랭킹 대규모 결과 집합에 대해 재랭킹 비효율적.
- → 기본 매칭 후 소규모 후보 문서에 대해 재랭킹 수행 권장.
request = {
"fields": ["title", "id", "score"],
"limit": 5,
"params": {
"q": "{!ltr reRankDocs=60000 model=movie_model efi.keywords=\"harry potter\"}"
}
}
resp = requests.POST('http://aips-solr:8983/solr/tmdb/select', json=request)
resp.json()["response"]["docs"]
TL;DR
- LTR 모델은 대규모 문서를 효율적으로 랭킹 가능
- 초기 검색 후 재랭킹으로 비용 절감 및 효율성 증가.
- Solr의 LTR 쿼리 파서를 통해 복잡한 검색 요구 충족 가능.
10.18 상위 500개 문서 재랭킹
- 첫 번째 Solr 쿼리 간단한 edismax 쿼리 사용.
- 재랭킹 초기 랭킹 결과에서 상위 500개 문서에 대해 재랭킹 수행.
- 모델 복잡성 복잡한 모델일수록 정확도 향상 가능.
- → 단순 모델은 빠르고 이해가 쉬움.
request = {
"fields": ["title", "id", "score"],
"limit": 5,
"params": {
"rq": "{!ltr reRankDocs=500 model=movie_model efi.keywords=\"harry potter\"}",
"qf": "title overview",
"defType": "edismax",
"q": "harry potter"
}
}
resp = requests.POST('http://aips-solr:8983/solr/tmdb/select', json=request)
resp.json()["response"]["docs"]
TL;DR
- 복잡한 모델은 높은 정확도를 제공하지만 계산 비용 증가.
- 상위 문서 재랭킹으로 검색 효율성 향상.
- 피처 복잡성과 수는 모델 성능에 큰 영향을 미침.
10.7 LTR 성능에 대한 고찰
- 모델 복잡성 복잡한 모델일수록 일반화 능력 증가.
- 재랭킹 깊이 깊은 재랭킹은 더 많은 문서 발견 가능.
- 피처 복잡성 및 수 복잡한 피처는 모델 성능에 기여하지만 속도 저하 위험.
10.8 요약
- LTR은 모든 검색에 적용 가능한 일반화된 랭킹 함수 생성.
- Solr LTR은 피처를 저장하고 기록하여 랭킹 모델에 적용.
- 피처는 쿼리와 문서의 여러 속성을 반영 가능.
예시: 패션 상품 검색
- 인풋 상품 이미지, 텍스트 설명.
- 아웃풋 유사 상품 리스트.
- 모델 활용 이미지 및 텍스트 기반 피처 추출 후 LTR 모델 적용.
- 모델 인풋/아웃풋 이미지 피처, 텍스트 피처 / 유사 상품 순위.
이와 같은 과정은 패션 상품 검색에서 이미지 및 텍스트 메타 정보를 활용하여 유사한 패션 아이템을 검색하는 데 적용될 수 있음. 이때, LTR 모델은 이미지 피처와 텍스트 피처를 기반으로 검색 결과의 순위를 매김으로써 사용자의 검색 의도에 맞는 결과를 반환 가능.
Chapter 11: Automating Learning to Rank (LTR) Using User Behavioral Signals
11.1 Building Learning to Rank Training Data from User Clicks
11.1.1 Generating Implicit, Probabilistic Judgments from Signals
p252
이전 장에서 Learning to Rank (LTR) 모델을 단계별로 학습하는 과정을 다루었음. 이 장에서는 LTR 학습 프로세스를 블랙 박스로 취급하여, LTR을 자율주행차처럼 최적의 목적지로 향하게 조정하는 방법을 탐구
- LTR은 정확한 training dataset에 기반하여 효과적으로 작동 training dataset는 사용자가 검색 결과가 어떻게 최적으로 정렬되기를 원하는지를 설명
- 사용자 상호작용에 기반하여 무엇이 관련성이 있는지를 아는 것은 많은 챌린지를 수반
- 이런 챌린지를 극복하고 training dataset에 대한 높은 신뢰도를 얻으면, 최신의 사용자 관련성 기대치를 포착하기 위해 LTR을 정기적으로 재학습하는 자동화 시스템을 구축할 수 있음.
TL;DR
- LTR의 효과성은 정확한 training dataset에 달려 있음.
- 사용자 행동 신호를 통해 자동으로 LTR을 재학습할 수 있음.
- training dataset의 품질을 향상시키는 것이 중요
Figure 11.1: Automated Learning to Rank 시스템이 사용자 신호로부터 자동으로 학습하고 재학습하는 방식
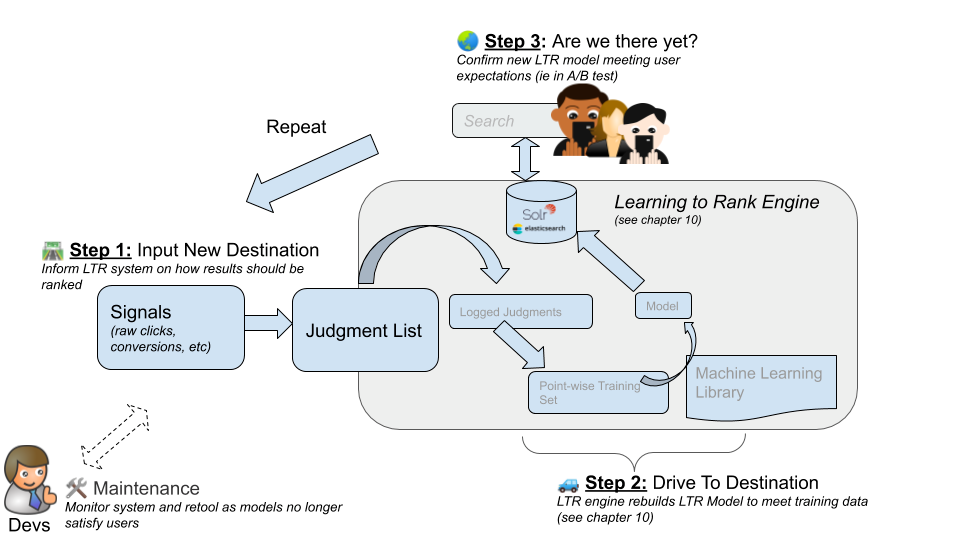{kind=link}
p253
자동화된 LTR 프로세스 단계:
- 새로운 목적지 입력 사용자 행동 신호(검색, 클릭, 전환 등)에 기반하여 이상적인 관련성을 설명하는 training dataset를 LTR 시스템에 입력
- 목적지로 이동 제공된 training dataset를 사용하여 LTR 모델을 재학습
- 도착 확인 모델이 실제로 사용자에게 도움이 되는지, 그리고 향후 모델이 다른 경로를 탐색해야 하는지를 평가
이 프로세스는 연속적으로 반복되어 관련성을 자동으로 최적화 검색 팀은 자동화된 LTR의 성능을 모니터링하고 필요 시 개입
p254
클릭을 LTR training dataset로 사용할 때의 함의:
- 클릭을 사용한 training dataset는 수동 레이블보다 더 많은 불확실성을 포함 클릭의 이유를 알기 어려움.
-
사용자 사이에 차이가 있으며, 검색 상호작용은 추가적인 불확실성을 야기
- 암시적 판단 사용자의 실제 상호작용에서 유래한 판단으로, 명시적 판단과 대비됨. 사용자가 실제로 수행하는 작업을 포착
#> 예시: 영화 쿼리의 암시적 판단 생성
Judgment객체를 사용하여 각 영화의 관련성을 확률적으로 레이블링grade는 결과가 관련성이 있을 확률을 나타냄.
mini_judg_list=[
Judgment(grade=0.99, keywords='star wars', doc_id='11'), ## Star Wars, A New Hope
Judgment(grade=0.80, keywords='star wars', doc_id='1892'), ## Return of the Jedi
Judgment(grade=0.20, keywords='star wars', doc_id='54138'), ## Star Trek Into Darkness
Judgment(grade=0.01, keywords='star wars', doc_id='85783'), ## The Star
Judgment(grade=0.20, keywords='star wars', doc_id='325553'), ## Battlestar Galactica
]
Star Wars, A New Hope는 높은 관련성 확률을 가짐.The Star는 낮은 관련성을 가짐.
p255
암시적 판단의 Pros(+):
- 최신성 최신 사용자 검색 기대치로 오늘의 LTR 모델을 자동으로 학습할 수 있음.
- 저비용 명시적 판단 캡처보다 비용 효율적임.
- 실제 사용 사례 캡처 사용자 실제 작업을 포착하여, 인위적인 실험실 환경과 대비됨.
TL;DR
- 암시적 판단은 실제 사용자 상호작용에서 유래하며, 명시적 판단에 비해 저비용임.
- 클릭 기반 데이터는 불확실성을 포함하나, 확률적 판단을 통해 이를 보완
- LTR 재학습을 통해 사용자 기대치에 맞춘 검색 결과를 제공
Click Model을 활용한 자동화된 LTR 모델 학습
1. 확률적 판단을 활용한 LTR 모델 학습
-
확률적 등급의 도입
→ 기존의 이진 판단을 넘어, 0~1 사이의 확률적 등급 도입
→ 등급을 정량화하여 학습 가능한 형식으로 변환 필요
→ 예: 0.75 이상을 관련 있음으로 지정하여 학습 -
LambdaMART와 같은 알고리즘 활용
→ 등급 범위 1~4를 활용하여 특정 임계값 설정
→ 예: 0.25 미만은 1, 0.25 이상 0.5 미만은 2로 지정 -
SVMRank 알고리즘의 확장
→ 더 관련 있는 항목의 피쳐에서 덜 관련 있는 항목의 피쳐을 뺌
→ 확률적 판단에서도 사용 가능함
→ 예: “Return of The Jedi” (grade=0.8)가 “Star Trek Into Darkness” (grade=0.2)보다 더 관련 있음으로 판단 -
코드 재활용
→ Chapter 10의 코드를 활용하여 모델 재학습
→ 클릭 모델을 통한 LTR 학습 예시 제공
TL;DR
- 확률적 판단을 도입하여 더 세밀한 LTR 모델 학습 가능.
- LambdaMART와 SVMRank 알고리즘을 확장하여 활용.
- 기존 코드를 활용한 클릭 모델 기반 LTR 학습 예시 제공.
2. 클릭-스루 비율(CTR) 모델: 첫 번째 클릭 모델
-
CTR의 정의
→ 검색 결과에 대한 클릭 수를 해당 결과가 검색에 나타난 횟수로 나눔
→ CTR=1: 항상 클릭됨, CTR=0: 전혀 클릭되지 않음 -
검색 세션 데이터 활용
→ 예시 쿼리: “transformers dark of the moon”
→ 세션 데이터를 활용하여 각 문서의 CTR 계산
QUERY='transformers dark of the moon'
query_sessions = sessions[sessions['query'] == QUERY]
click_counts = query_sessions.groupby('doc_id')['clicked'].sum()
sess_counts = query_sessions.groupby('doc_id')['sess_id'].nunique()
ctrs = click_counts / sess_counts
ctrs.sort_values(ascending=False)
- CTR 결과 분석
→ 가장 높은 CTR을 가진 문서:97360810042
→ 가장 낮은 CTR을 가진 문서:24543750949
TL;DR
- CTR은 검색 결과가 얼마나 자주 클릭되는지를 나타내는 지표.
- 세션 데이터를 통해 각 문서의 CTR 계산 가능.
- CTR을 통해 이상적인 검색 결과 순위를 시각적으로 파악 가능.
3. 클릭 모델의 이상적인 검색 결과
-
Figure 11.2 설명
→ “Transformers Dark Of The Moon”에 대한 CTR 기반 이상적 검색 결과
→ LTR 모델의 방향성을 시각적으로 보여줌 -
결과 분석
→ 가장 높은 CTR을 가진 Blu-ray의 점수가 예상보다 낮음
→ DVD는 관련 없는 항목들 뒤에 위치
TL;DR
- CTR 기반 이상적 검색 결과를 통해 LTR 모델의 방향성을 이해할 수 있음.
- Blu-ray의 CTR이 예상보다 낮고 DVD는 예상보다 뒤에 위치
- CTR은 검색 결과의 품질을 평가하는 데 유용하지만 한계가 존재
4. 결론
-
CTR의 유용성과 한계
→ CTR은 간단하지만 검색 결과의 품질 평가에 유용
→ 그러나 실제 관련성 판단에서의 한계 존재 -
향후 방향
→ 더 정교한 클릭 모델 개발 필요
→ 관련 연구 및 선행 기술 참고 -
추가 참고 자료
→ “Click Models for Web Search” by Chuklin, Markov, and de Rijke
→ 검색 클릭 신호를 처리하는데 내재된 편향 탐구
이런 방식으로 클릭 모델을 활용하여 패션 상품 검색에 적용할 수 있으며, 사용자 클릭 데이터를 분석하여 각 상품의 CTR을 계산하고, 이를 통해 보다 관련성 높은 검색 결과를 제공할 수 있음. 패션 상품의 경우, 이미지 메타 정보와 사용자 클릭 데이터를 결합하여 보다 정확한 추천 시스템 구축 가능.
p.260
인과관계 분석: 클릭 데이터의 문제점
- 문제 제기 DVD가 Blu-Ray보다 더 높은 순위를 받을 것으로 예상됨.
- 추가 예시 ‘Transformers: Dark of the Moon’ 검색 시 결과
- 결과 분석
- 상위 두 결과가 의류 건조기 → 타당함
- 다음은 의류 건조기 부품 → 의문
- ‘The Independent’라는 영화 등장 → 무작위
- 그 다음은 세탁기 액세서리 → 약간 관련
- 마지막으로 헤어드라이어 → 단어 ‘dryer’의 다른 의미로 해석 가능
- 결과 분석
- CTR의 판단력에 대한 의문
- CTR 기반의 판단이 LTR 모델의 성공적인 생산 배치로 이어질지 의문
- 판단 리스트의 유효성을 평가하는 방법의 필요성 제기
- 주관적 해석이 클릭 모델의 데이터만큼 오류가 있을 가능성
Figure 11.3: “Dryer” 검색어에 대한 클릭률 기반 이상적인 검색 결과. “The Independent” 영화는 이 쿼리에 적절하지 않음.
TL;DR
- DVD가 Blu-Ray보다 높은 순위를 받을 것으로 예상되었으나 기존 클릭 데이터는 무작위 결과를 포함
- CTR 기반의 판단이 LTR 모델의 성공적인 구현으로 이어질지 의문이며, 주관적 판단의 오류 가능성 제기.
- 판단 리스트의 유효성 평가 기준 필요성 강조.
p.261
편향과 클릭 데이터
- 편향 정의
- 클릭 모델에서 편향이란 사용자 심리, 검색 인터페이스 디자인, 노이즈 데이터에 의해 발생
- 클릭 데이터의 관련성을 판단하는 데 직접적이지 않은 요소가 있음
- 편향의 유형
- Algorithmic Biases
- Position Bias 상위 결과 클릭 증가
- Confidence Bias 데이터 신호 적은 문서가 지나치게 영향
- Presentation Bias 검색 결과 미노출 시 클릭 없음
- Non-algorithmic Biases
- Attractiveness Bias 매력적인 결과가 클릭을 유도하나 스팸 가능성
- Performance Bias 느린 검색에 사용자가 포기
- Algorithmic Biases
- AI-Powered Search의 초점 Algorithmic Biases에 초점, 하지만 Non-algorithmic Biases도 중요함
- 추가 리소스 Max Irwin의 “An Introduction to Search Quality” 추천
TL;DR
- 클릭 데이터는 사용자 심리 및 인터페이스 디자인에 의해 편향될 수 있음.
- Algorithmic Biases는 검색 결과의 순위 및 표시 방식에 영향을 미침.
- Non-algorithmic Biases는 사용자 경험과 관련된 다양한 이슈를 포함
p.262
Position Bias 극복하기
- Position Bias 정의
- 상위에 위치한 검색 결과를 사용자들이 더 신뢰하는 경향
- 요인
- Trust Bias 검색 엔진의 신뢰
- Scanning Behaviors 사용자 검색 결과 탐색 패턴
- Visibility 상위 결과의 가시성
- RetroTech 데이터에서의 Position Bias
- 평균 클릭률(CTR)을 통해 Position Bias를 측정
- Listing 11.5 각 순위에서의 클릭률 분석
TL;DR
- Position Bias는 상위 검색 결과에 대한 사용자 신뢰도에 의해 영향을 받음.
- RetroTech 데이터에서 평균 클릭률을 통해 Position Bias를 측정 가능.
- Position Bias 극복을 위한 새로운 클릭 모델 고려 필요.
p.263
Listing 11.5: 순위별 클릭률 분석
- 세션 수에 따른 클릭률 계산
rank=0의 CTR은 0.25,rank=1은 0.143 등으로 순위에 따라 CTR이 감소
- 위치 편향에 대한 추가 분석
- 평균 순위를 통해 검색어 ‘Transformers: Dark of the Moon’에 대한 문서 순위를 분석
- 결과
- 상위 순위에서의 클릭률이 높음을 확인
- 문서의 평균 순위를 통해 검색 결과의 전형적 순위를 확인 가능
num_sessions = len(sessions['sess_id'].unique())
global_ctrs = sessions.groupby('rank')['clicked'].sum() / num_sessions
global_ctrs
rank
0.0 0.249727
1.0 0.142673
2.0 0.084218
3.0 0.063073
4.0 0.056255
5.0 0.042255
6.0 0.033236
7.0 0.038000
8.0 0.020964
9.0 0.017364
10.0 0.013982
TL;DR
- RetroTech 데이터에서 순위별 클릭률은 상위에 위치한 결과일수록 높음.
- 검색어 ‘Transformers: Dark of the Moon’의 세션 분석을 통해 위치 편향을 확인.
- Position Bias 극복을 위한 클릭 모델 개선 필요.
패션 상품 검색을 위한 Click Model과 Position Bias 해결법
1. 검색 결과 페이지의 위치 편향(Position Bias) 문제
- 검색 엔진에서 특정 문서가 검색 결과 상위에 위치 → 사용자는 상위 결과를 더 많이 클릭 → 위치 편향(Position Bias) 발생
- 위치 편향: 사용자가 클릭한 결과가 실제로 관련성이 높다는 것이 아니라, 상위에 위치했기 때문에 클릭된 것임
- <Figure 11.4>에서 다양한 영화들이 검색 결과로 나타남 → “The A team”, “Fast Five” 등 관련 없는 결과가 상위에 위치 → CTR 모델이 잘못된 결과를 관련 있다고 판단
2. 클릭 모델의 필요성 및 “Examine” 개념
- 클릭 모델: 사용자의 클릭 데이터를 기반으로 검색 결과의 관련성을 평가하기 위해 개발
- Examine: 사용자가 검색 결과를 실제로 인식했는지를 나타내는 개념
- Impressions: 사용자의 화면에 렌더링된 모든 결과
- Examines: 사용자가 실제로 주목한 결과
- <Figure 11.5>에서 Impressions와 Examines의 차이를 시각적으로 설명
- 모니터에 렌더링된 모든 결과(Impressions) 중 사용자가 실제로 주목한 결과(Examines)
3. Simplified Dynamic Bayesian Network(SDBN) 클릭 모델
3.1 SDBN의 개요
- SDBN: Dynamic Bayesian Network(DBN) 모델의 단순화된 버전
- 검색 세션에서 사용자가 문서를 주목했는지를 확률적으로 판단
- 마지막 클릭된 문서의 위치를 기준으로, 그보다 위에 있는 문서들을 주목된 것으로 간주
3.2 SDBN의 알고리즘
- 각 세션에서 마지막 클릭 마크
- 마지막 클릭 위의 모든 문서를 Examined로 간주
- 문서의 총 클릭 수를 총 Examines로 나누어 관련성 평가
3.3 SDBN의 Pros(+)
- 위치 편향을 해결하기 위한 Examines 개념 도입
- 세션별로 동적인 CTR을 계산하여 문서의 관련성을 평가
4. 패션 상품 검색에서의 활용 예시
- 패션 상품 검색 상황에서 SDBN 적용
- 인풋: 사용자 검색 쿼리, 검색 결과 페이지
- 아웃풋: 사용자가 실제로 주목하고 클릭한 상품의 리스트
- 사용자가 주목한 상품을 기반으로 관련성 높은 상품 추천
- 이미지와 상품 메타 정보를 활용하여 검색 결과의 관련성을 높임
5. 핵심
- 위치 편향은 검색 결과의 정확성을 저해할 수 있으며,
- SDBN 클릭 모델은 “Examine” 개념을 통해 위치 편향을 극복하고, 검색 결과의 관련성을 정확하게 평가
- 패션 상품 검색에 SDBN을 적용하면, 사용자 경험을 개선하고 더 나은 검색 결과를 제공할 수 있음.
위 내용은 검색 엔진의 위치 편향 문제를 해결하기 위한 클릭 모델의 발전과 그 적용 사례를 설명하며, 특히 SDBN 모델이 Examines 개념을 통해 위치 편향을 극복하는 방법을 소개
SDBN 알고리즘을 통한 검색 결과 분석
p268
Session별 데이터 처리
- Session 선택
- Query가 ‘dryer’인 모든 세션 선택 → 세션 내에서의 클릭 정보를 분석.
- 마지막 클릭 위치 계산
- 각 세션에서 클릭된 마지막 순위를 계산하여 저장
- 수식 \(\text{last\_click\_per\_session} = \text{sdbn\_sessions.groupby(['clicked', 'sess\_id'])['rank'].max()[True]}\)
- 클릭된 위치 표시
- 각 세션에서 마지막 클릭보다 높은 순위의 위치를 ‘examined’로 표시
- 수식 \(\text{sdbn\_sessions['examined']} = \text{sdbn\_sessions['rank']} \leq \text{sdbn\_sessions['last\_click\_rank']}\)
- 세션 3의 예시 관찰
- sess_id=3의 경우, rank 9까지 모두 ‘examined’로 표시됨.
- 클릭 및 검토 수 집계
- 각 문서에 대해 총 클릭 수와 검토 수를 집계
- 수식 \(\text{sdbn} = \text{sdbn\_sessions[sdbn\_sessions['examined']].groupby('doc\_id')[['clicked', 'examined']].sum()}\)
TL;DR
- ‘dryer’ 쿼리에 대한 각 세션의 마지막 클릭 위치를 기반으로 검토된 위치를 표시.
- 각 문서에 대해 클릭 횟수와 검토 횟수를 집계하여 문서의 중요도를 평가.
- sess_id=3의 예시에서는 rank 9까지가 검토된 것으로 표시됨.
p269
SDBN 점수 계산
- 검토된 데이터 필터링
- 검토된 행만 필터링하여 각 문서의 총 클릭 및 검토 횟수 계산.
- 최종 SDBN 점수 계산
- 수식 \(\text{sdbn['grade']} = \frac{\text{sdbn['clicked']}}{\text{sdbn['examined']}}\)
- 결과 정렬
- SDBN 점수를 기준으로 내림차순 정렬하여 가장 관련성이 높은 문서 식별.
TL;DR
- 검토된 행만 필터링하여 문서별 클릭 횟수와 검토 횟수 집계.
- 클릭 횟수를 검토 횟수로 나누어 SDBN 점수를 계산.
- 가장 높은 SDBN 점수를 가진 문서가 가장 관련성이 높은 것으로 평가됨.
p270
- 설명 Figure 11.6은 ‘dryer’ 쿼리에 대한 이상적인 검색 결과를 SDBN 알고리즘을 통해 시각화한 것임. 세탁과 관련된 제품이 더 눈에 띄게 검색됨.
p271

- 설명 Figure 11.7은 ‘transformers dark of the moon’ 쿼리에 대한 이상적인 검색 결과를 나타냄. DVD, 블루레이 영화 및 CD 사운드트랙이 상위에 위치
주관적 분석
- ‘dryer’의 경우, 세탁기와 관련된 액세서리도 비슷한 점수를 받음.
- ‘transformers dark of the moon’에서는 블루레이 영화가 높은 점수를 기록하며, 사운드트랙 CD가 DVD보다 높은 순위를 획득
결론
- SDBN 알고리즘은 클릭 데이터를 통해 문서의 중요도를 평가하며, CTR에 비해 더 직관적인 결과를 도출
- 다음 장에서는 판정 품질을 더욱 객관적으로 평가하는 방법을 탐구할 예정임.
1. 배경 및 문제 정의
1.1 야구 타율과 데이터 신뢰성
- 야구 타율 타율은 선수의 타석에서 안타를 기록한 비율을 의미
- 예: 프로 선수의 타율이 0.3 이상일 경우 우수한 성적으로 평가됨.
- 반면, 리틀 리그에서 첫 타석에서 안타를 기록한 선수의 타율은 1.0이 됨.
- → 단순한 결과만으로 해당 선수가 우수한 선수라고 결론짓기 어려움.
- 데이터 신뢰성 문제
- 운에 의해 클릭된 경우가 많을 때 해당 데이터의 신뢰성 문제 발생.
- → 이런 데이터는 training dataset에 편향을 줄 수 있음.
1.2 SDBN 데이터셋의 신뢰성 문제
- 문제 정의
- SDBN 데이터에서 낮은 신뢰성의 데이터 포인트가 training dataset를 왜곡
- → 예: “Transformers Dark of The Moon” 사운드트랙 CD가 상위에 랭크됨.
- 데이터 분석
- SDBN 통계 재계산 필요
- → 예제 코드 Listing 11.10: SDBN 클릭, 검토, 등급 재계산
QUERY = 'transformers dark of the moon'
sdbn_sessions = sessions[sessions['query'] == QUERY].copy().set_index('sess_id')
last_click_per_session = sdbn_sessions.groupby(['clicked', 'sess_id'])['rank'].max()[True]
sdbn_sessions['last_click_rank'] = last_click_per_session
sdbn_sessions['examined'] = sdbn_sessions['rank'] <= sdbn_sessions['last_click_rank']
sdbn = sdbn_sessions[sdbn_sessions['examined']].groupby('doc_id')['clicked', 'examined'].sum()
sdbn['grade'] = sdbn['clicked'] / sdbn['examined']
sdbn = sdbn.sort_values('grade', ascending=False)
2. 저신뢰성 데이터에 대한 해결책
2.1 신뢰성 편향 문제
- 극단적 예시
- 한 명의 사용자에 의해 검토된 문서가 완벽한 1.0 등급을 받는 경우 발생.
- → 이는 불균형한 데이터로 인한 문제를 야기
- 신뢰도
- 통계적으로 유의미하지 않은 사건에 기초한 등급은 낮은 신뢰도를 가짐.
- → 다수의 검토를 거친 데이터가 더 높은 신뢰도를 제공
2.2 Beta 분포를 활용한 신뢰도 모델링
- Beta 분포
- 확률을 두 값, \(a\)와 \(b\)로 표현하여 신뢰도를 관리.
- → 성공 횟수와 실패 횟수를 기반으로 확률을 조정.
- 수식
- 평균: \(\text{mean} = \frac{a}{a+b}\)
- → 초기 확률값을 유지하면서 데이터에 따라 점진적으로 이동.
- 예시
- 야구 타율의 일반적인 평균을 초기값으로 삼고, 추가 데이터에 따라 점진적으로 조정.
3. 결론 및 요약
- 핵심
- 낮은 신뢰성 데이터는 training dataset에 편향을 초래할 수 있음.
- Beta 분포를 사용하여 데이터의 신뢰도를 확률적으로 조정 가능.
- 지역적인 확률 모델보다 일반적인 초기 확률값을 기반으로 데이터 해석 권장.
-
추가 연구 및 링크
- 패션 상품 검색 예시
- 이미지와 상품 메타 정보를 기반으로 검색 시, 낮은 클릭 데이터를 단순히 제거하기보다 Beta 분포를 활용하여 신뢰도를 조정.
- → training dataset의 편향을 줄이고, 검색 결과의 정확성을 높임.
베타 분포를 통한 클릭 모델의 업데이트
베타 분포(Beta Distribution)는 주어진 데이터에 대한 초기 신념(prior belief)을 업데이트하는 데 유용한 도구로, 특히 클릭 데이터와 같은 불확실한 정보에 대해 결론을 쉽게 내리지 않도록 도와줌. 이는 초기 신념을 설정하고, 새로운 데이터가 들어올 때마다 이를 기반으로 신념을 업데이트하는 방식으로 작동 아래에서는 이런 베타 분포의 원리를 단계별로 설명하고, 이를 SDBN(Sequential Dependent Browsing Model) 클릭 모델에 적용하는 방법을 살펴봄.
1. 초기 신념 설정과 베타 분포
- 초기 신념은 특정 데이터가 얼마나 신뢰할 수 있는지를 나타내는 값으로, 주어진 사례에 따라 다르게 설정할 수 있음.
- 예를 들어, 문서의 관련성(relevance grade)을 0.125로 설정하고, 이는 \(0.125 = \frac{a}{a+b}\)의 형태로 표현됨.
- 이때 선택할 수 있는 \(a\)와 \(b\)의 값은 다양하며, 예를 들어 \(a=2.5\), \(b=17.5\)를 선택할 수 있음. 이를 그래프로 나타내면, 대부분의 관련성 점수가 어떻게 분포되는지를 관찰할 수 있음.
 Figure 11.8: 관련성 점수가 0.125인 경우의 베타 분포. 초기의 관련성 등급에 해당하는 평균과 가능성이 높은 관련성 등급의 분포를 보여줌.
Figure 11.8: 관련성 점수가 0.125인 경우의 베타 분포. 초기의 관련성 등급에 해당하는 평균과 가능성이 높은 관련성 등급의 분포를 보여줌.
2. 데이터 관찰 후 신념 업데이트
- 새로운 클릭 데이터가 관찰되면 \(a\)의 값을 업데이트하여 새로운 신념을 형성할 수 있음. 예를 들어, 문서의 첫 번째 클릭을 관찰하여 \(a=3.5\), \(b=17.5\)로 업데이트할 수 있음.
- 이를 통해 업데이트된 분포의 평균은 \(\frac{3.5}{3.5+17.5} = 0.16666\)이 되어 초기 신념보다 약간 높아짐. 이는 클릭 횟수가 추가됨에 따라 초기 신념이 점진적으로 변화하는 것을 의미
 Figure 11.9: 클릭이 추가된 후의 관련성 점수에 대한 베타 분포. 클릭을 통한 업데이트로 초기 신념이 약간 높아짐.
Figure 11.9: 클릭이 추가된 후의 관련성 점수에 대한 베타 분포. 클릭을 통한 업데이트로 초기 신념이 약간 높아짐.
3. 베타 분포에서의 사전 분포와 사후 분포
- 초기의 \(a\)와 \(b\) 값으로 설정된 분포를 사전 분포(prior distribution)라 하며, 이는 예상하는 초기 신념을 나타냄.
- 새로운 데이터가 들어와 \(a\)와 \(b\)를 업데이트하면 사후 분포(POSTerior distribution)가 형성됨. 이는 업데이트된 신념을 나타냄.
- 초기의 \(a\)와 \(b\) 값의 크기는 초기 신념의 강도를 결정하며, 작은 값일수록 업데이트의 영향이 큼. 예를 들어, \(a=0.25\), \(b=1.75\)로 설정한 경우, 클릭 한 번으로도 평균이 크게 변
4. SDBN 모델에서의 베타 분포 적용
- SDBN 모델에서는 각 문서에 대한 클릭 수와 조회 수를 기반으로 관련성을 평가 초기 관련성 등급을 0.3으로 설정하고, \(a=30\), \(b=70\)으로 초기 사전 분포를 설정
- 클릭 데이터가 추가되면 \(a\)와 \(b\)를 업데이트하여 사후 분포를 계산 예를 들어, 클릭 수와 조회 수에 따라 각 문서의 업데이트된 관련성 점수를 계산할 수 있음.
PRIOR_GRADE = 0.3
PRIOR_WEIGHT = 100
sdbn['prior_a'] = PRIOR_GRADE * PRIOR_WEIGHT
sdbn['prior_b'] = (1 - PRIOR_GRADE) * PRIOR_WEIGHT
sdbn['POSTerior_a'] = sdbn['prior_a'] + sdbn['clicked']
sdbn['POSTerior_b'] = sdbn['prior_b'] + (sdbn['examined'] - sdbn['clicked'])
sdbn['beta_grade'] = sdbn['POSTerior_a'] / (sdbn['POSTerior_a'] + sdbn['POSTerior_b'])
sdbn.sort_values('beta_grade', ascending=False)
TL;DR
- 베타 분포를 통해 초기 신념을 설정하고, 새로운 데이터가 들어올 때마다 이를 기반으로 신념을 업데이트
- SDBN 모델에서 초기 관련성 등급을 설정하고, 클릭 및 조회 데이터를 기반으로 관련성을 업데이트하여 보다 정확한 평가를 수행
- 베타 분포의 초기값 설정은 업데이트의 민감도를 결정하며, 이를 적절히 조정하여 원하는 수준의 신뢰성을 확보할 수 있음.
p280
Figure 11.10 및 11.11 설명
- Figure 11.10 베타 조정된 SDBN 이상 결과를 보여줌.
- 피쳐 이전의 등급 0.3 주위로 더 집중됨.
- 의미 등급의 변동이 줄어들어 예측의 안정성이 증가

- Figure 11.11 베타 조정된 SDBN 이상 결과를 보여줌.
- 관찰 사운드트랙의 관련성 등급이 이전보다 낮아짐.
- 의미 사운드트랙의 관련성이 0.3의 우선값에 더 가까워짐.
SDBN 모델링에 대한 신뢰도 조정
- Figure 11.12 SDBN 판단의 신뢰도 모델링 전후 비교.
- 변화 사운드트랙 등급이 0.48에서 0.4로 감소.
- 의미 DVD 등급은 거의 변화 없음 (0.39에서 0.36으로 감소).
요약
베타 조정 SDBN 모델은 등급의 집중도를 높여 결과의 안정성을 강화 사운드트랙의 관련성 등급은 신뢰도 조정 후 우선값에 가깝게 조정됨. DVD 등급은 상대적으로 변화가 적음.
추가 자료
- 관련 논문 SDBN 모델에 대한 신뢰도 조정 연구
p281
LTR(학습-순위화) 모델의 중요성
- 소규모 데이터 문제 해결 LTR에서 낮은 신뢰도와 같은 소규모 데이터 문제를 해결해야
- 자동화된 LTR 피드백 루프 프레젠테이션 편향 극복 및 사용자 피드백 루프 개선 필요.
- LTR 모델 훈련 합리적인 훈련 데이터를 통해 LTR 모델 개발.
LTR 모델 실험
- 노트북 활용 RetroTech 데이터를 사용하여 LTR 실험.
- 주요 기능 클릭 세션 데이터를 SDBN 클릭 모델과 베타 우선값을 사용하여 판단으로 변환.
- Solr LTR 플러그인 Solr에서 LTR 기능 로딩 및 데이터 변환.
요약
LTR 모델은 소규모 데이터 문제 해결에 필수적이며, 피드백 루프를 통해 프레젠테이션 편향을 극복 RetroTech 데이터로 LTR 실험을 통해 다양한 기능을 탐색 가능.
p282

Figure 11.12: LTR 시스템 탐색 노트북
- 기능 모델 테스트 드라이브 가능.
- 튜닝 초대 클릭 모델 파라미터 조정, 새로운 기능 탐색 및 LTR 모델 최적화 방법 탐구.
모델 최적화
- 변수 탐색 주관적 가정을 데이터 기반으로 검토.
- 다양한 쿼리 테스트 예를 들어, “transformers dvd” 쿼리에서 관련 문서와 비관련 문서를 구별하는 방법 탐구.
요약
LTR 시스템 노트북을 통해 모델을 테스트하고 최적화 가능. 클릭 모델 파라미터와 새로운 기능을 탐색하여 결과 개선 가능.
p283
Figure 11.13: 훈련된 모델 순위
- 쿼리 “transformers dvd”.
- 개선 가능성 현재 순위를 개선할 방법 모색.
프레젠테이션 편향 극복
- 문제점 사용자 행동이 현재 검색 결과에 편향됨.
- 해결책 모델의 현실 사용 시 발생할 수 있는 편향 문제를 실시간으로 감시.
요약
훈련된 LTR 모델의 순위를 개선할 수 있는 방법 탐색 필요. 프레젠테이션 편향을 극복하여 모델의 실제 사용 시 문제를 최소화해야
이 내용은 LTR(학습-순위화) 모델의 구성과 최적화에 관한 것으로, SDBN 모델과 신뢰도 조정을 통해 검색의 질을 높이고, 프레젠테이션 편향을 극복하려는 다양한 방법을 제시 RetroTech 데이터를 통해 실험적으로 접근하여 결과를 개선할 수 있는 방안을 탐구
Learning to Rank (LTR) 자동화 및 실시간 사용자 피드백 활용
p284
- 사용자 클릭 데이터를 신뢰할 수 있는 관련성 판단으로 변환 → LTR 자동화 가능
- 클릭 모델 필요
- A/B 테스트 등으로 클릭 모델 평가 필요 → 자동화된 LTR 시스템의 신뢰성 보장
- 학습된 (암묵적) 관련성 판단 리스트 → 기존의 랭킹 학습 프로세스에 통합 가능
- 수동으로 생성된 판단 리스트를 대체하거나 보강
- 원시 클릭 데이터의 문제점 알고리즘의 랭킹 및 검색 결과 표시 방식의 편향 존재
- 위치 편향(position bias) 사용자들은 상위에 랭크된 결과를 선호
- 클릭 모델 사용 → 사용자가 문서나 검색 결과의 위치를 검토한 확률 추적 → 위치 편향 극복
- 대부분의 검색 애플리케이션 → 불필요한 클릭 데이터 존재
- 이런 불필요한 결과에 편향된 training dataset → 신뢰도 편향(confidence bias) 발생
- 베타 분포 사용 → 새로운 관측치와 함께 점진적 업데이트로 신뢰도 편향 극복
p285
- LTR 모델의 실세계 적용
- 이전 장에서는 사용자 클릭으로 자동 생성된 training dataset로 모델 구축
- 이번 장에서는 모델을 실세계로 이동, (시뮬레이션된) 실시간 사용자와 함께 테스트
- 자동화된 LTR 시스템의 비유: 자율주행 자동차
- 내부적으로는 엔진 역할: 과거의 판단 기준에 따라 모델 재학습
- 모델 training dataset를 자율주행 자동차의 방향과 비교: 검색 결과와의 이전 상호작용 기반으로 자동으로 판단 학습
- 실시간 사용자 피드백 활용 → 모델 성능 평가 및 피드백 루프 탈출
- A/B 테스트 실시간 사용자에게 무작위로 다른 모델 할당 → 비즈니스 결과(e.g., 매출) 평가
- 자동화된 LTR 시스템의 A/B 테스트의 중요성
p286
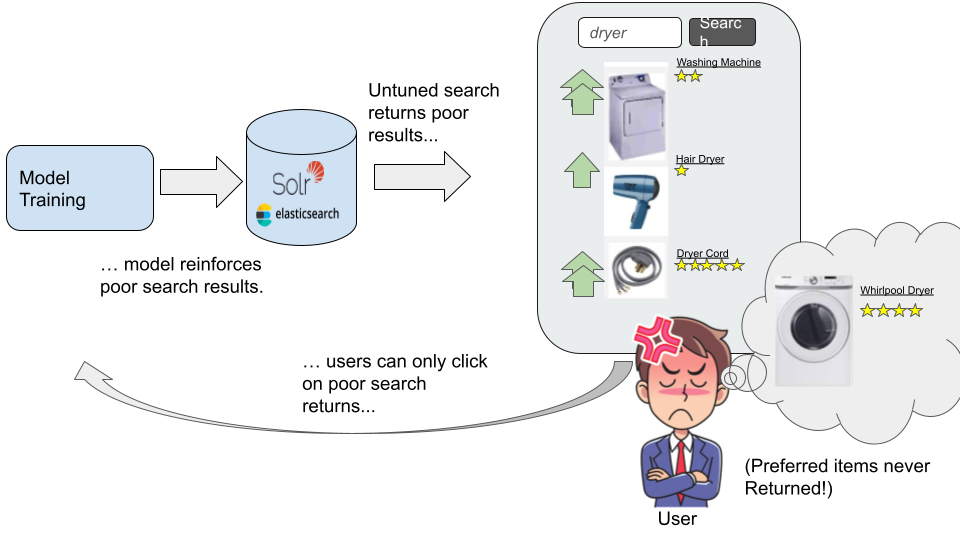
- Figure 12.1 표현 편향의 부정적 피드백 루프
- 사용자가 클릭하지 않는 검색 결과는 모델이 학습할 수 없음 → 현 모델의 지식 확장 불가
-
표현 편향 사용자가 보는 결과에 따라 모델이 학습
- A/B 테스트 탐구 후, 표현 편향 극복
- 자율주행 자동차의 비유: 하나의 비효율적 경로만 학습한 경우
- 대안적 경로 탐색 필요: 새로운 검색 결과 유형 탐색 → 사용자가 관련성을 학습
p287
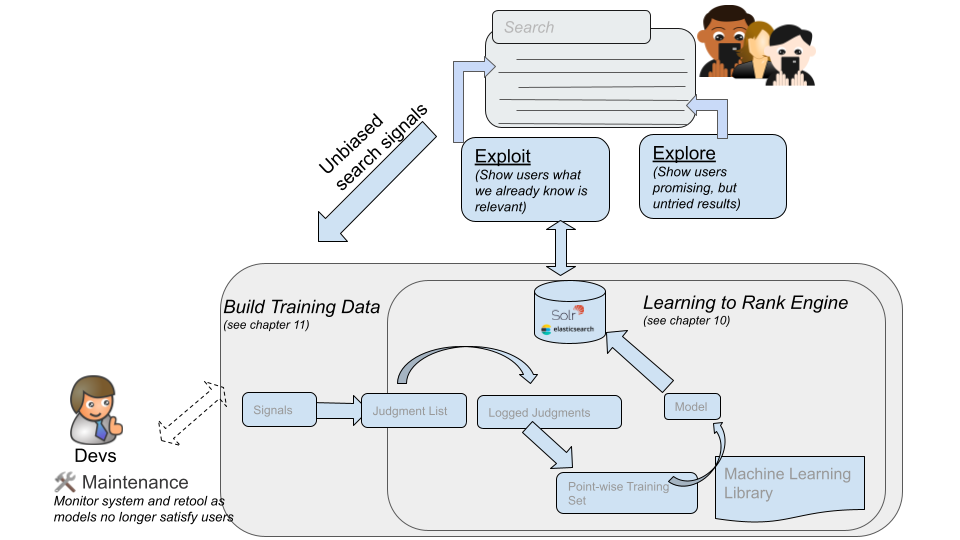
- Figure 12.2 실시간 사용자와의 자동화된 LTR 시스템
- 표현 편향 극복 → 사용자와 함께 보지 못한 결과 탐색 → training dataset 범위 확장
- A/B 테스트 시작 전, 챕터 10과 11의 지식을 코드로 통합
- Python 헬퍼 함수로 변환
- SDBN 클릭 모델 사용 → 원시 세션 클릭으로부터 training dataset 재구축
- 클릭 모델의 작동 원시 클릭을 학습 레이블로 변환
- 쿼리 문자열, 결과의 랭크, 문서, 클릭 여부 등 포함
TL;DR
- LTR 자동화를 위한 클릭 모델의 필요성 및 편향 극복 방법 논의.
- 실시간 사용자 피드백을 통한 A/B 테스트의 중요성 강조.
- 표현 편향 극복을 위한 새로운 탐색 경로의 필요성 및 적용 방법 제시.
이 문서는 클릭 데이터를 활용한 LTR의 자동화 및 실세계 적용에 대한 내용을 다루고 있음. A/B 테스트를 통해 사용자 피드백을 수집하고, 표현 편향을 극복하여 모델의 성능을 향상시키는 방법을 제시 실시간 사용자를 활용하여 모델의 성능을 검증하고, 새로운 탐색 경로를 통해 training dataset의 범위를 확장하는 전략을 설명
AI-Powered 검색: 데이터프레임과 모델 훈련
1. 데이터프레임의 구성 및 역할
1.1 데이터프레임 설명
- 데이터프레임 각 쿼리-문서 쌍에 대해 클릭된 횟수(
clicked)와 검사된 횟수(examined)를 저장하는 구조.- 클릭(
clicked) 특정 쿼리에 대해 사용자가 클릭한 총 횟수. - 검사(
examined) 사용자가 결과를 인지한 횟수.
- 클릭(
- 통계적 지표
grade: 문서의 관련성을 나타내는 기초 지표,clicked를examined로 단순 나누어 계산.beta_grade:grade보다 정보량이 많은 사례에 더 높은 가중치를 두는 수정된 지표.
1.2 클릭 모델의 중요성
- SDBN 클릭 모델 초기 구현은
grade를 사용하였으나, 정보량의 중요성을 고려하여beta_grade를 채택.- 예시 1회 클릭, 1회 검사 (1/1 = 1.0)와 100회 클릭, 100회 검사 (100/100 = 1.0)의 차이를 반영.
 이미지 설명: 데이터프레임은 쿼리와 문서 ID에 따라 클릭 및 검사를 기록하며,
이미지 설명: 데이터프레임은 쿼리와 문서 ID에 따라 클릭 및 검사를 기록하며, grade와 beta_grade를 계산하여 문서의 관련성을 평가할 수 있음.
2. 모델 훈련과 평가
2.1 모델 훈련 과정
- 훈련 데이터 생성 기존 세션 데이터를 기반으로 training dataset 생성.
- 모델 훈련 RankSVM 모델을 훈련하여 Solr에 업로드.
- 기능 설계
long_description_bm25: 긴 설명에서의 BM25 검색.short_description_constant: 짧은 설명에서의 상수 검색.
random.seed(1234)
feature_set = [
{
"name": "long_description_bm25",
"store": "test",
"class": "org.apache.solr.ltr.feature.SolrFeature",
"params": {"q": "longDescription:(${keywords})"}
},
{
"name": "short_description_constant",
"store": "test",
"class": "org.apache.solr.ltr.feature.SolrFeature",
"params": {"q": "shortDescription:(${keywords})^=1"}
}
]
train, test = test_train_split(sdbn, train=0.8)
ranksvm_ltr(train, model_name='test1', feature_set=feature_set)
2.2 모델 평가
- 평가 지표
precision사용, 10개의 상위 관련성 점수를 합산하여 평균 계산. - 기타 지표 DCG, NDCG, ERR 등 정밀한 평가를 위한 통계적 지표 존재.
3. A/B 테스트와 모델 개선
3.1 A/B 테스트
- 새로운 모델 테스트
Listing 12.3의 개선된 모델을 기존 모델과 비교. - 모델 개선 새로운 기능 세트를 사용하여 더 나은 성능을 보여줌.
feature_set_better = [
{
"name": "name_fuzzy",
"store": "test",
"class": "org.apache.solr.ltr.feature.SolrFeature",
"params": {"q": "name_ngram:(${keywords})"}
},
{
"name": "name_pf2",
"store": "test",
"class": "org.apache.solr.ltr.feature.SolrFeature",
"params": {"q": "{!edismax qf=name name pf2=name}(${keywords})"}
},
{
"name": "shortDescription_pf2",
"store": "test",
"class": "org.apache.solr.ltr.feature.SolrFeature",
"params": {"q": "{!edismax qf=shortDescription pf2=shortDescription}(${keywords})"}
},
]
train, test = test_train_split(sdbn, train=0.8)
ranksvm_ltr(train, 'test2', feature_set_better)
3.2 결과 및 개선 방향
- 실험 결과 새로운 모델이 더 높은 관련성을 보임.
- 피드백 루프 자동화된 LTR 피드백 루프를 통해 지속적인 개선 가능.
핵심
- 데이터프레임을 통해 쿼리-문서 쌍의 클릭 및 검사 횟수를 분석하여 관련성을 평가.
- RankSVM 모델을 사용하여 학습 및 평가,
precision을 비롯한 다양한 지표로 성능 측정. - A/B 테스트를 통해 새로운 기능 세트를 적용한 모델의 성능을 비교 및 개선.
12.2.2 자동화된 LTR에서의 A/B 테스트 정의
A/B 테스트는 사용자 경험을 개선하기 위한 중요한 도구로, 자동화된 LTR 시스템에서도 필수적인 역할을 수행 A/B 테스트는 두 가지 이상의 변형을 설정하고, 각 변형에 사용자를 무작위로 할당하여 결과를 비교하는 실험적 방법임.
- A/B 테스트의 설정
- 무작위 할당 사용자를 무작위로 두 개의 변형(e.g., LTR 모델) 중 하나에 할당
- 변형의 차이점 각 변형은 서로 다른 애플리케이션 기능을 포함할 수 있음. 예를 들어, 버튼의 색상 변경부터 새로운 관련성 랭킹 알고리즘까지 다양
- 비즈니스 목표 판매, 앱 사용 시간, 사용자 유지 등 비즈니스가 중요하게 여기는 결과에 따라 성능을 평가
이런 A/B 테스트는 시스템의 변화가 실제 비즈니스 목표에 어떤 영향을 미치는지 평가할 수 있는 궁극적인 도구로 작용
12.2.3 우수한 모델을 A/B 테스트로 졸업시키기
새로운 모델을 A/B 테스트에 배치하여 성능을 평가함으로써, 기존의 부진한 모델을 대체할 수 있는 가능성을 탐색
- 시뮬레이션 설정
- 사용자 할당 1000명의 사용자를 무작위로 두 모델(test1과 test2)에 할당.
- 사용자 행동 사용자가 특정 아이템을 구매하려는 의도를 가지고 검색을 시도 원하는 아이템이 검색 결과에 보이면 구매하고, 그렇지 않으면 검색을 종료
- 데이터 수집 각 모델에 대한 구매 횟수를 기록하여 성능을 비교
이런 과정을 통해 사용자 행동을 분석하고, 각 모델의 실제 성능을 평가할 수 있음.
12.2.4 ‘좋은’ 모델이 실패할 때: 실패한 A/B 테스트로부터 배울 수 있는 점
모델이 실험실에서는 훌륭하지만, A/B 테스트에서는 실패하는 경우도 발생 이는 훈련 데이터의 잘못된 사양 때문일 수 있음.
- 바이어스 문제
- 위치 바이어스(Position Bias) 사용자 클릭이 결과의 위치에 따라 영향을 받을 수 있음.
- 신뢰 바이어스(Confidence Bias) 사용자가 더 잘 알려진 브랜드나 제품을 선호하는 경향이 있음.
- 행동 신호 고려 클릭 후의 행동, 예를 들어 ‘좋아요’ 버튼 클릭, 장바구니 추가 등이 더 나은 판단을 위한 신호로 고려될 수 있음.
이와 같은 문제를 통해 모델이 실패한 원인을 파악하고, 향후 개선 방향을 모색할 수 있음.
TL;DR
- A/B 테스트는 두 가지 이상의 변형을 비교하여 시스템의 변화를 평가하는 중요한 도구로, 자동화된 LTR 시스템에서 필수적임.
- 우수한 모델을 A/B 테스트에 투입하여 실제 사용자 행동을 기반으로 성능을 평가하고, 부진한 모델을 대체할 가능성을 탐색
- 실험실에서 훌륭한 모델이라도 A/B 테스트에서 실패할 수 있으며, 이는 훈련 데이터의 잘못된 사양이나 바이어스 문제 때문일 수 있음.
#
- Machine Learning Bookcamp by Alexey Grigorov
- Tuning Up from A/B Testing to Bayesian Optimization by David Sweet
패션 상품 검색 예시
- 입력 이미지 및 상품 메타 정보
- 모델 활용 유사 이미지 검색 모델과 메타 정보 기반 필터링 알고리즘 사용
- 출력 관련성 높은 패션 상품 리스트
- 적용 방법 이미지 피쳐 추출 후, 메타 정보와 결합하여 사용자에게 개인화된 검색 결과 제공
p296
검색 시스템에서 미시적 관점(zero in to the microscopic)으로 특정 쿼리와 문서의 관계를 살펴보면, 인과관계가 복잡해짐. 단일 제품은 구매 수가 적음 → 예를 들어, $1000짜리 TV는 많은 사람들이 보지만 구매하는 사람은 적음 → 데이터가 충분하지 않으면 쿼리에 대한 특정 제품의 관련성을 알 수 없음.
- Search UX, 도메인 및 행동의 다양성 검색 영역은 계속 진화 중이며, 표준 클릭 모델(click models)이 대부분의 시나리오에서 충분
- 문제점 클릭 모델의 훈련 데이터 문제 → 사용자들은 보이지 않는 것과 상호작용하지 않음(presentation bias).
- 결과 특정 영화가 훈련 데이터에 없을 경우, 자동화된 LTR 시스템은 그 영화의 관련성을 학습할 수 없음.

Figure 12.4 Presentation Bias를 설명 → 사용자가 볼 수 없는 결과와 상호작용하지 않으므로, 클릭 데이터가 없는 결과를 탐색해야
TL;DR
- Presentation Bias 사용자가 보지 못한 결과는 클릭되지 않기 때문에 관련성을 판단할 수 없고,
- Explore vs Exploit Tradeoff 현재의 지식을 활용(exploit)하면서 새로운 지식을 탐색(explore)하는 균형을 유지해야
- Active Learning 시스템이 스스로 학습에 참여하여 훈련 데이터를 확장하는 방법 필요.
p297
Explore vs Exploit Tradeoff 모델의 현재 지식을 활용하면서 새로운 지식을 탐색하는 균형 유지 필요.
- Exploit 현재 알고 있는 최적의 성능을 활용 → 현재의 LTR 모델이 훈련 데이터에 맞춰 최적화됨.
- Explore 새로운 문서 유형에 대한 클릭 모델 커버리지 확장 → 새로운 지식 획득.
Presentation Bias 해결 훈련 데이터가 부족한 영역을 탐지하고 보완해야
- Blind Spots 훈련 데이터에 포함되지 않은 잠재적으로 관련 있는 검색 결과를 탐지 → 모델을 재훈련하여 더욱 강력한 모델 구축.
p298
Listing 12.5 새로운 feature_set 생성하여 explore
- Features
long_desc_match,short_desc_match,name_match: 기존에 학습된 기능과 일치 여부 확인.has_promotion: 마케팅 채널을 통해 홍보 중인 경우 1.0 값을 가짐.
feature_set = [
{
"name" : "long_desc_match",
"store": "explore",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"q" : "longDescription:(${keywords})^=1"
}
},
...
{
"name" : "has_promotion",
"store": "explore",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"q" : "promotion_b:true"
}
},
]
결과 분석 특정 쿼리에서 누락된 문서 유형 식별 → transformers dvd 쿼리의 예시로 blind spots 탐지.
p299
Gaussian Process 예측과 함께 해당 예측의 확률 분포를 제공하는 통계 모델.
- 목적 단순한 수작업 분석을 넘어, 체계적으로 데이터 갭을 탐지하여 자동화된 탐색 수행.
- 예시
transformers dvd의 결과와 관련된 현재 데이터의 빈틈을 체계적으로 탐색.
query grade long_desc_match short_desc_match name_match has_promotion
618 transformers dvd 0.0 1.0 0.0 1.0 0.0
...
625 transformers dvd 0.0 1.0 0.0 1.0 0.0
TL;DR
- Blind Spots 훈련 데이터의 누락된 영역을 탐지하고 보완하여 모델 훈련 개선.
- Gaussian Process 탐색 대상 지역을 선택하여 체계적인 데이터 갭 탐지.
- 자동화된 탐색 수작업 분석을 넘어 체계적이고 자동화된 데이터 탐색 방법 제안.
위의 내용은 검색 시스템에서 발생하는 presentation bias 문제를 해결하기 위한 다양한 방법을 소개하고 있으며, 특히 explore vs exploit tradeoff와 active learning의 중요성을 강조 Gaussian Process를 활용하여 체계적으로 데이터의 누락된 영역을 탐지하고 보완하는 방법을 제안
Gaussian Processes를 활용한 탐색과 활용의 균형 맞추기
1. Gaussian Processes 소개
1.1 Gaussian Processes란?
Gaussian Processes(GP)는 머신러닝에서 중요한 역할을 수행하는 비모수적 베이지안 방법임. 이는 주어진 데이터 포인트들 사이의 관계를 나타내는 함수의 분포를 정의하여, 불확실성을 포함한 예측을 가능하게
- 비모수적 접근 데이터의 구조에 대해 사전 정보 없이 작업.
- 베이지안 접근 불확실성을 정량화하여 예측 제공.
1.2 Gaussian Processes의 직관적 이해
- 강의 예시 과학자가 미지의 강을 탐험하는 시나리오를 통해 GP의 직관적 이해를 도모.
- 탐색과 활용 새로운 시기를 탐험하여 지식을 확장하고, 기존 데이터를 통해 안전한 탐험 시기를 선택.
2. Gaussian Processes의 수학적 배경
2.1 GP의 수학적 정의
- 공분산 함수 두 데이터 포인트 사이의 상관성을 정의하는 함수.
- 평균 함수 각 데이터 포인트의 기대값을 정의하는 함수.
\(m(x)\)는 평균 함수, \(k(x, x')\)는 공분산 함수
2.2 수학적 접근을 통한 예측
- 예측의 불확실성 GP는 예측값 뿐만 아니라 그 예측의 불확실성을 함께 제공.
- 연속 함수로서의 표현 대부분의 경우 GP는 특정 형태의 연속 함수를 배우고자
3. 예시: 강 탐험 시나리오
3.1 탐험 날짜 선택
- 이전 관측 데이터 활용 이전 탐험 데이터(e.g., 4월 강 깊이 2미터)를 기반으로 다음 날 예측.
- 불확실성 예측 관측 데이터에서 멀어질수록 불확실성이 증가.
3.2 Gaussian Processes의 적용
- 데이터 기반 결정 가까운 관측치 기반의 예측은 안전하지만, 지식 확장은 제한적.
- 리스크 및 보상 관리 미지의 시기에 대한 탐험은 높은 리스크를 동반하지만, 큰 지식 확장을 기대할 수 있음.
4. Gaussian Processes를 활용한 검색 최적화
4.1 검색 결과의 Relevance Ranking
- 유사성 기반의 예측 유사한 검색 결과는 유사한 관련성을 가짐.
- 예측 불확실성 관리 기존 데이터에서 멀어질수록 관련성 예측에 대한 불확실성이 증가.
4.2 GaussianProcessRegressor 모델 훈련
from sklearn.gaussian_process import GaussianProcessRegressor
y_train = transformers_dvds['grade']
x_train = transformers_dvds[['long_desc_match', 'short_desc_match', 'name_match', 'has_promotion']]
gpr = GaussianProcessRegressor()
gpr.fit(x_train, y_train)
- 훈련 데이터
transformers_dvds데이터셋의 다양한 피쳐을 활용하여 모델 훈련.
4.3 탐색 후보 생성 및 평가
- 후보 생성 각 피쳐값을 0 또는 1로 설정하여 다양한 조합 생성.
- 예측 및 평가 각 후보에 대해 예측 등급 및 표준편차를 계산하여 불확실성을 평가.
index = pd.MultiIndex.from_product([zero_or_one] * 4, names=['long_desc_match', 'short_desc_match', 'name_match', 'has_promotion'])
explore_options = pd.DataFrame(index=index).reset_index()
predictions_with_std = gpr.predict(explore_options[['long_desc_match', 'short_desc_match', 'name_match', 'has_promotion']], return_std=True)
explore_options['predicted_grade'] = predictions_with_std[0]
explore_options['prediction_stddev'] = predictions_with_std[1]
5. 결론
5.1 Gaussian Processes의 이점
- 탐색과 활용의 균형 안전한 결과와 새로운 지식의 발굴 사이에서 균형을 유지.
- 불확실성 관리 예측의 불확실성을 정량화하여 현명한 의사결정 지원.
5.2 패션 상품 검색에의 응용
- 이미지 및 메타 정보 활용 상품 이미지를 기반으로 유사한 상품을 탐색.
- 고객 선호도 반영 고객의 검색 패턴을 학습하고 개인화된 검색 결과 제공.
TL;DR
- Gaussian Processes는 함수의 불확실성을 고려하여 예측을 수행하는 강력한 머신러닝 기법임.
- 탐색과 활용의 균형을 통해 안전한 결과와 지식 확장을 동시에 달성 가능.
- 예측 불확실성을 정량화하여 패션 상품 검색 등 다양한 분야에 응용 가능
기대 개선(Expected Improvement) 알고리즘에 의한 후보 탐색
p304
- 기대 개선(Expected Improvement) 알고리즘:
- 높은 잠재적 상승 가능성을 가진 후보 선택
- 두 가지 경우:
- 높은 확실성을 가진 경우: 표준 편차 낮고 예측 등급 높음
- 높은 불확실성을 가진 경우: 예측 등급 높아 도전 가치 있음
- 수식
- 기대 개선 = 기회 * 개선 확률 + 표준 편차 * 정규분포 확률 밀도 함수
- \[\text{expected\_improvement} = \text{opportunity} \times \text{prob\_of\_improvement} + \text{prediction\_stddev} \times \text{norm.pdf} \left( \frac{\text{opportunity}}{\text{prediction\_stddev}} \right)\]
- 예시 데이터
long_desc_match,short_desc_match,name_match,has_promotion등의 속성으로 구성- 각 행의
expected_improvement값에 따라 정렬
- 핵심
- 기대 개선 알고리즘은 상위 잠재력 후보를 선택하며, 확실성과 불확실성을 모두 고려
- 두 가지 클라우스: 확실성 있는 경우와 높은 표준 편차의 불확실한 경우.
- 수식을 통해 기대 개선 값을 계산하고, 이를 기반으로 최적의 탐색 후보 결정.
p305
- 파라미터
theta조정theta값 증가 → 표준 편차 높은 후보 선호theta값 너무 높음 → 유용성 고려 없이 학습 목적의 후보 선택theta값 너무 낮음 → 기존 지식에 치우침
- 최적의
theta값 선택- 과학자와 유사한 탐험 성향 모델링
theta = 0.6선택으로 기존 LTR 시스템 보강
- Solr 검색 예시
- 프로모션 있는 제품 탐색
- Solr 쿼리 발행 및 결과 무작위 순서로 정렬
- 핵심
theta파라미터는 후보 선택 방식에 큰 영향을 미치며, 적절한 값 설정 중요.- Solr을 활용한 탐색으로 새로운 제품 정보를 사용자에게 제공.
- 최적화된 후보 선택으로 LTR 시스템 성능 향상 유도.
p306
- Solr에서 레트로테크(레트로 기술) 제품 탐색
expected_improvement기반 최적 탐색 후보 추출- Solr 쿼리로 프로모션 제품 검색 및 무작위 정렬
- 코드 설명
explore함수: 탐색 벡터 기반 쿼리 변환, 무작위 문서 선택- Solr 서버에 요청 후 응답에서 UPC 추출
- 결과
- 예시: “Transformers Dark of The Moon: Two Disc-Blu Ray DVD Combo” 선택
- 핵심
expected_improvement계산으로 Solr에서 최적 후보 탐색 가능.- 무작위 정렬을 통해 다양한 결과를 시험하고 탐색 기회 확대.
- UPC 기반으로 특정 제품 선택하여 사용자에게 제공.
p307
- 탐색 후보 디자인 결정
- UPC
97360810042를 검색 결과의 세 번째 위치에 삽입 - 새로운 세션 생성 및 클릭 여부 시뮬레이션
- UPC
- 세션 데이터 활용
- 새로운 세션을 기존 데이터에 추가하여 LTR 훈련 데이터 생성
- Automated LTR 알고리즘에 탐색 데이터 반영
- SDBN 판단 재생성
sessions_to_sdbn함수로 새로운 세션 데이터에서 SDBN 판단 생성transformers dvd쿼리에 대한 새로운 SDBN 판단 출력
- 핵심
- 탐색 후보 삽입을 통해 사용자 행동 분석 및 LTR 모델 개선.
- 새로운 세션 데이터로 LTR 훈련 데이터 재생성 및 모델 성능 향상.
- A/B 테스트를 통해 새로운 모델의 효과 검증.
이 문서는 기대 개선 알고리즘을 활용한 후보 탐색 및 Solr 검색에 대한 심층적인 설명을 제공합니다. 특히, theta 파라미터 조정과 Solr에서의 탐색 과정을 통해 후보 선택 및 사용자 행동 분석의 중요성을 강조합니다. 추가로, 새로운 LTR 모델 훈련 및 A/B 테스트를 통한 성능 검증 과정을 설명합니다.
Automated LTR System을 통한 효과적 모델 개선
1. 새로운 상품의 추가와 탐색 기능의 통합
- 새로운 상품의 등장
- UPC 코드
97368920347을 가진 새로운 상품The Transformers: The Movie - DVD추가 promotion_b플래그가true로 설정됨 → 이전 섹션의 “탐색” 후보로 선정된 상품 중 하나
- UPC 코드
- 탐색 기능을 메인 모델로 통합
has_promotion기능을 메인 모델로 이동하여 훈련 실행- 훈련 결과 및 새로운 기능의 효과 관찰 → 모델 성능 향상 기대
2. 모델 재구축과 성능 평가
- 모델 재구축
has_promotion을 LTR(Learning to Rank) 모델에 추가- 쿼리 수준에서 테스트-트레인 분할 수행
- Rank SVM 모델을 트레인 데이터로 훈련
- 테스트 데이터로 모델 평가
- 결과의 개선
- 이전 결과와 비교하여 새로운 기능 추가 후 오프라인 테스트 성능 대폭 개선
transformers dvd검색 시 Precision 상승
3. A/B 테스트와 자동 탐색 시스템
- A/B 테스트 재실행
a_or_b_model함수를 사용하여 모델 선택- 1000명의 사용자 시뮬레이션
test1과test3모델 간의 구매 비교test3모델에서 구매 증가 확인 → 새로운 모델의 성공적인 탐색 및 학습 증명
- 자동 탐색 LTR 시스템
- 최신 사용자 행동을 반영하여 자동으로 학습 및 탐색
- 사용자 상호작용을 기반으로 새로운 관련성을 탐색
4. Automated LTR 알고리즘 요약
- Exploit 기존 데이터로 LTR 모델 훈련 및 랭킹 수행
- Explore 가설적 ‘탐색’ 기능 사용하여 데이터의 맹점 제거
- Gather 배포된 모델과 훈련된
gpr모델을 통해 탐색/착취 검색 결과 표시 및 클릭 수집
핵심
has_promotion기능을 추가하여 LTR 모델 성능 개선을 확인- A/B 테스트를 통해
test3모델의 우수한 성능을 실증 - Automated LTR 시스템은 지속적인 학습과 탐색을 통해 데이터의 맹점을 극복
패션 상품 검색 예시
- 인풋 이미지 및 상품 메타 정보 (e.g., 스타일, 색상, 소재)
- 아웃풋 관련 패션 상품 리스트
- 활용 모델 딥러닝 기반 이미지 인식 모델 (e.g., CNN) 및 메타 정보 기반 추천 알고리즘
- 적용 사용자의 선호도 및 최신 트렌드를 반영한 맞춤형 상품 추천 제공
위 과정을 통해 데이터의 맹점을 식별하고, 지속적으로 모델을 개선하여 사용자 경험을 향상시킬 수 있음. 새로운 탐색 기능을 통한 LTR 모델의 개선은 AI 기반 검색 시스템의 핵심 요소로 자리잡고 있음.
기술 블로그: Fully Automated LTR 알고리즘과 Dense Vector 기반 검색
자동화된 학습을 통한 검색 순위 알고리즘
p312 - LTR 알고리즘 개요
Listing 12.13 - Fully Automated LTR Algorithm Summarized
- Training 단계 이미 알고 있는 좋은 특성과 현재의 훈련 데이터를 바탕으로 LTR(Learning to Rank) 모델을 훈련
- LTR 모델: 순위 학습에서 주로 사용되는 RankSVM과 같은 알고리즘 활용
- 입력 데이터: 사용자 세션 기반의 SDBN(Stochastic Discriminative Bayesian Network) 클릭 모델로 생성된 데이터
- 탐색 단계 새로운 특성을 가설화하여 블라인드 스팟(훈련 데이터의 결핍)을 탐색
- “Expected Improvement” 알고리즘 사용: 새로운 탐색 후보 선택
- 새로운 세션 데이터를 수집하여 훈련 데이터를 재생성
- Exploitation 새로운 특성을 실험 후, 성공적인 경우 Production에 포함
- Exploit Feature Set: 기존의 탐색된 특성을 기반으로 최적의 검색 순위를 결정
exploit_feature_set = [
{
"name" : "name_fuzzy",
"store": "exploit",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"q" : "name_ngram:(${keywords})"
}
}
...
]
- Training & Testing SDBN을 사용하여 80% 훈련 데이터와 20% 테스트 데이터로 분할
- RankSVM을 사용하여 모델 훈련 및 평가
train, test = test_train_split(sdbn, train=0.8)
ranksvm_ltr(train, model_name='exploit', feature_set=exploit_feature_set)
eval_model(test, model_name='exploit', sdbn=new_sdbn)
- Exploration 새로운 특성 실험을 위한 탐색
- Explore Feature Set: 다양한 특성을 실험하여 새로운 가능성 탐색
explore_feature_set = [
{
"name" : "manufacturer_match",
"store": "explore",
"class" : "org.apache.solr.ltr.feature.SolrFeature",
"params" : {
"q" : "manufacturer:(${keywords})^=1"
}
}
...
]
- Gathering Data 세션 데이터를 SDBN으로 변환하여 훈련 데이터 강화
sdbn = sessions_to_sdbn(sessions, prior_weight=10, prior_grade=0.2)
- 반복 탐색 및 Exploit Loop 반복
핵심 Fully Automated LTR 알고리즘은 기존의 클릭 데이터를 퇴출하고 새로운 트렌드에 맞는 특성을 선택하여 최적의 검색 순위를 도출. 모델은 블라인드 스팟을 탐색하여 사용자의 기대치를 최대화하도록 설계됨.
p313 - Presentation Bias와 Active Learning
- Offline Test 훈련 데이터를 근사화하는 특성의 성능은 오프라인 테스트에서 검증
- A/B 테스트: 훈련 데이터의 편향성 확인 및 수정 필요
- Presentation Bias: 모델이 사용자 클릭을 통해 관련성을 학습하지 못하는 경우 발생
- Active Learning Automated LTR 프로세스가 훈련 데이터의 블라인드 스팟을 능동적으로 탐색
- Gaussian Process: 탐색의 유망한 기회를 선택, 누락된 훈련 데이터를 찾아 사용자에게 표시
- Automated LTR의 개선 기존 지식을 활용한 탐색과 블라인드 스팟 탐색을 결합하여 지속적 개선
핵심 Presentation Bias를 극복하기 위해 모델이 능동적으로 블라인드 스팟을 탐색하도록 하며, Gaussian Process와 같은 방법을 사용하여 누락된 데이터를 찾아 사용자가 기대하는 검색 결과를 제공.
Dense Vector 기반 검색과 의미 표현
p314 - Dense Vector 검색의 도입
- Dense Vector의 개념 텍스트의 의미를 수치 벡터로 변환하여 비교
- 예: “Hello to you!” (영어)와 “Barev Dzes” (아르메니아어)는 같은 의미를 지님
- 유사성 측정(metric)을 사용하여 벡터 간의 유사성 평가
- Transformer 모델의 활용 텍스트 표현과 검색에 미치는 영향
- Autocomplete와 같은 기능 구현
- Approximate Nearest Neighbor (ANN) 검색을 통한 Dense Vector 검색 속도 향상
p315 - 텍스트 임베딩을 통한 의미 표현
- Embedding의 활용 자연어 처리(NLP)에서 임베딩을 사용하여 텍스트를 기계가 처리 가능한 데이터로 변환
- NLP 기법과 도구: https://nlpprogress.com/에서 다양한 문제 영역 확인 가능
- 의미의 표현 텍스트 임베딩을 통해 검색 엔진 내에서 쿼리와 문서 해석을 향상
핵심 Dense Vector는 텍스트의 의미를 벡터로 표현하여 검색의 효율성을 높임. Transformer 모델 및 NLP 기법을 활용하여 텍스트 임베딩을 통해 검색 엔진의 쿼리 및 문서 해석을 강화.
결론
Fully Automated LTR 알고리즘은 탐색과 Exploit을 통해 검색의 정확성을 높이며, Dense Vector와 NLP 기법은 검색의 효율성을 극대화 이런 기술은 패션 상품 검색과 같은 실제 응용 분야에서 이미지와 메타 정보를 기반으로 최적의 검색 결과를 제공하는 데 기여.
p316
dense 벡터를 이용한 검색의 일반 이론
- dense 벡터(dense vector)를 사용하는 검색은 희소 벡터(sparse vector)와는 근본적으로 다른 텍스트 처리 및 관계 설정 방식을 요구함
- 희소 vector search과 비교하여, dense vector search의 작동 방식을 간략히 검토함
- 가장 일반적인 희소 vector search 유사성 함수인 BM25와 비교하여, dense vector search에서 사용되는 유사성의 한 유형을 소개함
사이드바: 최근접 이웃 검색
- 최근접 이웃 검색(kNN, k-nearest-neighbor)
- 동일한 차원의 수치 벡터를 데이터 구조에 색인하고, 쿼리 벡터를 사용하여 가장 가까운 ‘k’개의 관련 벡터를 검색하는 문제 공간
- 두 벡터 간의 유사성을 계산하기 위해 코사인 유사도 사용 (1.2.2절에서 다룸)
- 희소 vector search
- 역색인(inverted index) 사용 필요
- 역색인은 교과서의 뒷부분에 있는 용어 목록처럼 소스 콘텐츠에서 위치를 참조하는 용어 목록
- 정보 구조화: 토큰을 사전으로 처리 및 정규화하여 게시물(문서 식별자 및 발생 위치)에 대한 참조를 생성
- 결과 데이터 구조(역색인)는 빠른 토큰 검색을 가능하게 함
- 검색 시, 쿼리 용어를 토큰화 및 정규화하고, 역색인을 사용해 문서 결과를 매칭하여 검색 수행
- BM25 공식을 적용해 문서를 점수화하고 유사성에 따라 순위 매김 (3.2절에서 다룸)
- 쿼리 용어 및 문서 피쳐에 대한 점수를 적용하여 빠르고 관련성 있는 검색 수행
- ‘쿼리 용어 의존성’ 모델의 Cons(-) 존재: 쿼리 용어 문자열의 존재 및 개수를 기반으로 검색 및 순위 매김
- dense 벡터 접근 방식은 쿼리 간에도 비교 가능한 전역적 관련성 제공 가능
핵심
dense vector search은 희소 vector search과 달리 텍스트의 의미를 포착하여 검색 및 순위 매김을 수행 희소 벡터는 주로 쿼리 용어의 존재와 개수에 의존하는 반면, dense 벡터는 쿼리 간에 비교 가능한 전역적 관련성을 제공 최근접 이웃 검색은 동일한 차원의 수치 벡터 색인을 통해 가장 유사한 벡터를 식별
p317
임베딩
- 임베딩은 텍스트로부터 학습된 지식의 표현을 유지하는 수치적 피쳐의 dense 벡터
- 다양한 길이의 콘텐츠에 걸쳐 확장 가능
- 단어, 문장, 단락, 심지어 전체 문서를 나타낼 수 있는 다양한 임베딩 생성 가능
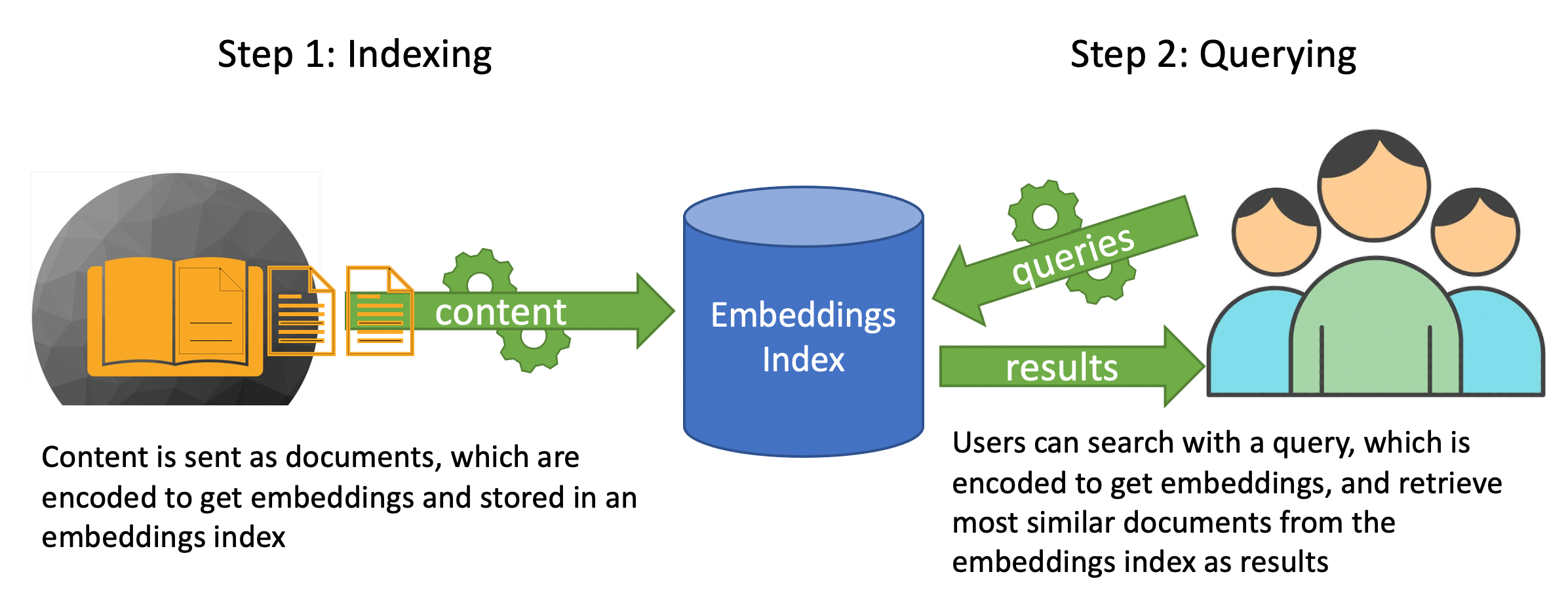
- Figure 13.1 임베딩 인덱스를 구축하고 검색하는 과정
- 왼쪽에서 콘텐츠를 처리하여 인덱스에 추가함
- 오른쪽에서 사용자가 인덱스를 쿼리하여 결과를 검색함
- 문서와 쿼리의 임베딩은 동일한 벡터 공간에 존재함
- 문서를 하나의 벡터 공간에 매핑하고 쿼리를 다른 벡터 공간에 매핑하면 비효율적임
- 효과적인 검색을 위해 동일한 공간에 있어야 함
- 임베딩이란 무엇이며, 어떻게 검색하는가?
- 임베딩은 특정 차원의 벡터
- 두 벡터 간의 유사성을 비교하기 위해 코사인 유사도 또는 유사한 거리 측정 사용
- 쿼리 벡터와 모든 문서 벡터를 비교하여 가장 유사한 문서 벡터를 최근접 이웃으로 정의
핵심: 임베딩은 텍스트의 의미를 벡터로 표현하여 동일한 벡터 공간에서 문서와 쿼리를 검색 코사인 유사도를 사용해 쿼리와 문서 벡터 간의 유사성을 측정하며, 동일한 벡터 공간에 존재해야 효과적임. 최근접 이웃은 쿼리와 가장 유사한 문서를 의미
p318
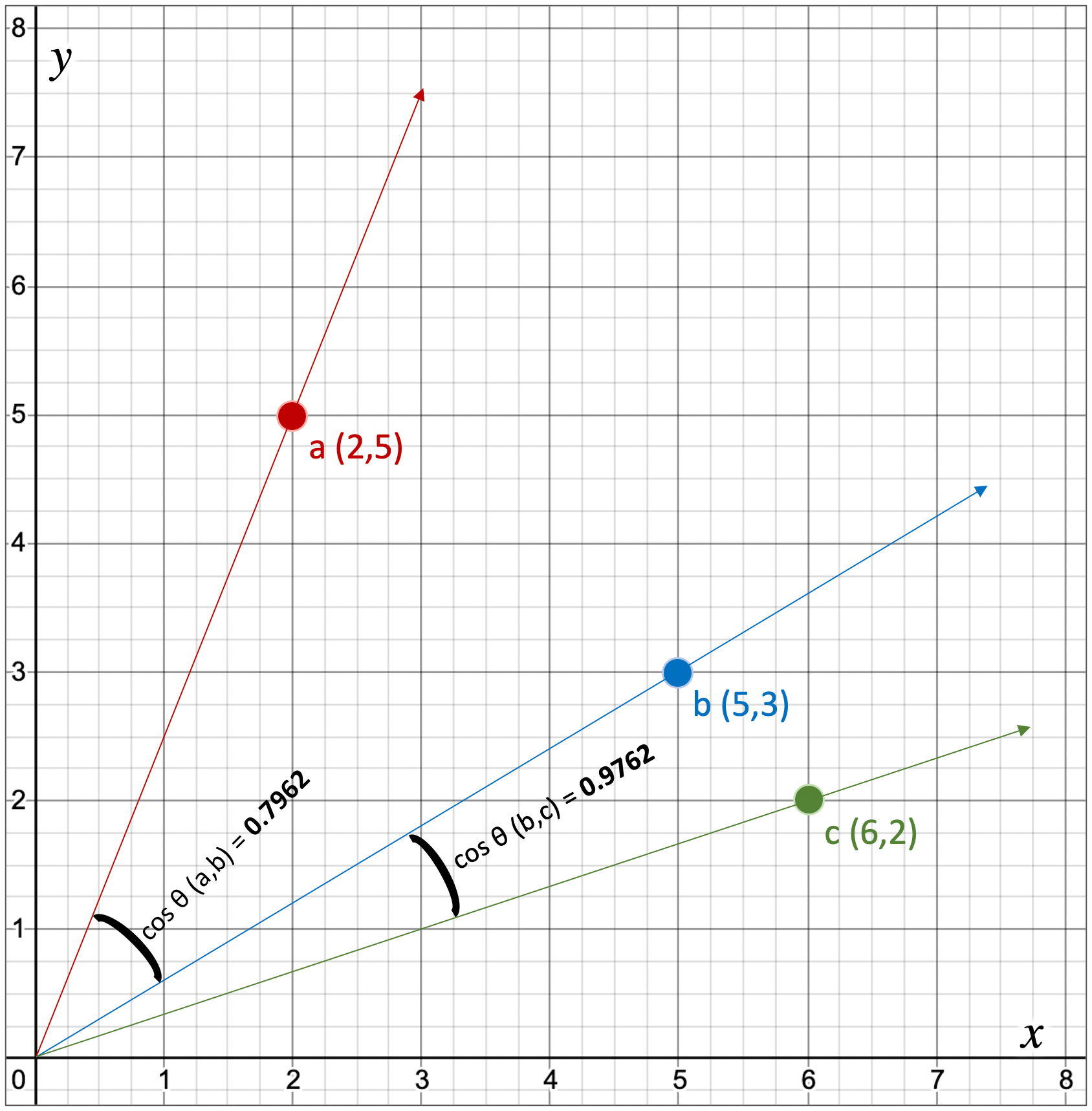
- Figure 13.2 좌표 평면에 플롯된 세 벡터 (a, b, c)
- 벡터 a와 b, b와 c의 유사성을 코사인 유사도로 설명
- 세 벡터 간 코사인 유사도, 유사성 순서에 따라 정렬
- cosine similarity (b,c) = 0.9762
- cosine similarity (a,b) = 0.7962
- cosine similarity (a,c) = 0.6459
-
b와 c가 가장 가까우며, 세 벡터 중 b와 c가 가장 유사함
- 코사인 유사도를 벡터의 길이에 상관없이 적용 가능
- 3차원 공간에서는 (x, y, z) 세 가지 피쳐을 가진 벡터 비교
- dense 벡터 임베딩 공간에서는 수백 차원의 벡터 사용
- 차원의 수와 상관없이 동일한 공식 사용
핵심: 세 벡터 간의 코사인 유사도를 계산하여 가장 유사한 벡터를 식별할 수 있음. dense 벡터 임베딩 공간에서는 수백 차원의 벡터를 사용하지만, 코사인 유사도 공식은 동일하게 적용됨. b와 c가 가장 유사한 벡터로 식별됨.
p319
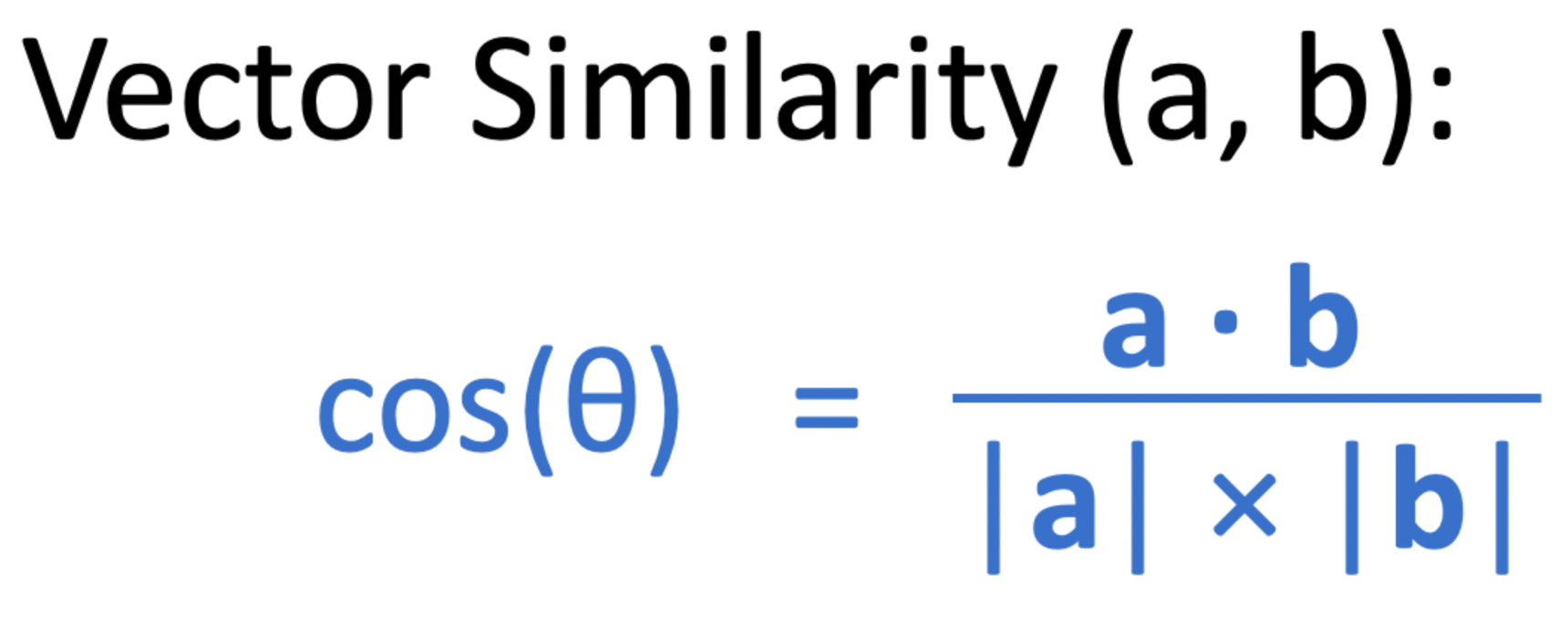
- Figure 13.3 두 벡터의 코사인 유사도를 계산하는 공식
- 벡터 간 유사성을 평가하기 위한 기본적인 수학적 도구
-
3.1절에서 이 코사인 유사도 계산을 사용해 벡터 간 유사성을 점수화하는 방법 복습
- dense vector search 및 최근접 이웃 유사성의 기본 이해를 바탕으로, 다음 단계는 임베딩을 얻는 방법을 이해하는 것
Transformer를 사용한 텍스트 임베딩 획득
- Transformer: 의미를 벡터로 인코딩하고, 그 의미를 변환된 표현으로 디코딩하는 딥 뉴럴 네트워크 아키텍처
- 용어 레이블을 문맥에 따라 dense 벡터로 표현 (인코딩)
- 출력 모델을 활용하여 벡터를 다른 텍스트 표현으로 변환 (디코딩)
- 인코딩과 디코딩의 분리된 기능은 임베딩을 의미의 표현으로 사용 가능하게 함
- Transformer Encoder의 예시: BERT
TL;DR Transformer는 텍스트의 의미를 인코딩하여 벡터로 표현하는 D/L 모델로, BERT가 그 대표적인 예tldlau, 인코딩과 디코딩 과정은 분리되어 있어 임베딩을 독립적인 의미 표현으로 활용 가능 코사인 유사도는 벡터 간의 유사성을 측정하는 기본 도구로 사용됨.
Transformer와 NLP: 깊은 이해와 응용
1. 자연어 처리와 Transformer의 역사적 배경
- 1953년, Cloze Test의 도입
- 문맥 이해를 시험하기 위해 개발된 Cloze Test, 예: “I went to the ____ and bought some vegetables.” 빈칸에 ‘store’, ‘market’ 등 다양한 답변 가능.
- 1995년, 독해력 테스트
- 긴 문단을 읽고 질문에 답하며 어텐션과 이해도를 평가하는 방식. 예: “How far away from the sea is the churchyard?”에 ‘twenty miles’로 응답.
- 대규모 언어모델의 기초 형성
- Cloze Test와 같은 이해력 테스트는 대규모 텍스트 데이터셋을 이용한 NLP 모델의 기초 이론으로 발전.
2. Transformer와 BERT의 혁신적 기법
- Transformer의 역할
- 자연어 처리에서 컴퓨팅, 언어학, 심리학의 교차점에 위치.
- 대량의 계산 능력을 사용하여 언어와 기계 간의 간극을 메우는 것을 목표로
- BERT의 도입
- 2018년 발표된 Google Research의 “Bidirectional Encoder Representations from Transformers” 논문.
- Cloze Test와 Attention 메커니즘을 사용하여 언어 이해 벤치마크에서 SOTA 성능 달성.
- 논문 링크: BERT 논문
- BERT의 학습 방법
- ‘자기지도 학습’ 방식으로 Cloze Test를 모델에 제공.
- 데이터 레이블링 없이 모델이 스스로 테스트를 생성하고 학습.
- 주요 학습 기법: Masked Language Modeling (e.g., 문장에서 15% 토큰 삭제 후 예측).
3. Transformer의 기술적 구현
- 토크나이저의 역할
- 입력 텍스트를 사전 정의된 단어 조각(word pieces)으로 분할.
- BERT 논문에서는 30,000개 단어 조각 사용.
- 예: “It’s” → ‘it’, “’”, ‘s’로 분할.
- BERT 모델과 인코딩 과정
- 토크나이징된 토큰 스트림을 BERT 모델에 전달하여 인코딩 수행.
- 인코딩된 결과는 각 토큰에 대한 벡터의 배열로 표현된 텐서 형태.
- Transformer를 활용한 검색
- 대량의 계산과 시간이 필요한 모델 학습 대신, 사전 학습된 모델을 활용하여 효율성 극대화.
- 검색을 위한 자연어 자동 완성 기능 구축: 텍스트를 Transformer로 인코딩하여 임베딩 인덱스 생성.
- 쿼리 시 임베딩을 비교하여 가장 유사한 개념 반환.
TL;DR
- Transformer와 BERT는 Cloze Test와 Attention을 결합하여 언어 이해의 새로운 기준을 제시.
- BERT는 ‘자기지도 학습’을 통해 대규모 데이터셋에서 효율적으로 학습, 토크나이제이션을 통해 세밀한 언어 표현을 다룸.
- 사전 학습된 모델을 활용하여 자연어 처리 응용 프로그램 개발의 효율성을 높임, 특히 검색 시스템에서 강력한 성능 발휘.
참고 이미지 설명
- Figure 13.4: Transformer 인코더 구조
- 텍스트를 토크나이저를 통해 단어 조각으로 분할하고, BERT 모델에 전달하여 벡터 인코딩 수행.
- Figure 13.5: Transformer를 활용한 검색 아키텍처
- Transformer 인코딩 벡터를 사용한 검색 시스템의 개념적 구조.
관련 링크 및 자료
이 글에서는 Transformer와 BERT의 역사적 배경, 기술적 구현 및 검색 시스템에서의 응용 방법을 상세히 설명하였음. 이런 지식을 활용하여 다양한 자연어 처리 응용 프로그램을 효과적으로 개발할 수 있음.
자연어 처리와 검색 시스템 구현: Outdoors 데이터셋과 SBERT 활용
1. Outdoors 데이터셋 구성 및 인덱싱
- 데이터 출처 및 인덱스 구성
- 콘텐츠 소스, 최근접 이웃 인덱스, Transformer 기반 벡터 추출, 유사도 공식을 사용하여 파이프라인 구축
- Stack Exchange의 Outdoors 데이터셋 활용
- Transformer 모델들이 Wikipedia를 기반으로 학습됨
- Wikipedia의 Outdoors 관련 섹션 활용
- Wikipedia Outdoors
- 데이터셋 스키마 정의
- Listing 13.1: Outdoors 데이터셋 컬렉션 생성 및 데이터 인덱싱
- 데이터 문서 구조: 질문과 답변으로 구성, 계층적 구조로 연결
- 각 문서는
POST_type_id필드 포함- 질문(
POST_type_id=1) - 답변(
POST_type_id=2)
- 질문(
- 데이터 필드
- 주요 필드:
url,POST_type_id,accepted_answer_id,parent_id,score,view_count,body,title,tags,answer_count,owner_user_id
- 주요 필드:
2. Outdoors 데이터셋 쿼리 및 검색
- 명사구 기반 쿼리 실행
- Listing 13.2: 명사구로 Outdoors 데이터셋 쿼리
- 질문 문서(
POST_type_id=1): 질문의 제목 요약 - 답변 문서(
POST_type_id=2): 질문에 대한 답변 제공
- 쿼리 예시
- 질문: “What is the safest way to purify water?”
- 답변: 다양한 물 정화 방법, 예시로 필터, 요오드, 끓이기 등
- 관련 문서:
id=7,POST_type_id=2
- 검색의 한계
- 기본 검색의 한계: 키워드 기반 검색의 정확도 부족
- 예시: “What is DEET?” 쿼리에 대한 비관련성 결과
- 해결 방안: Transformer 기반 자연어 검색 도입 필요
3. Transformer 모델과 SBERT 도입
- Transformer 모델의 한계
- 파인튜닝되지 않은 모델 사용의 문제점
- 특정 작업에 맞춘 파인튜닝 필요
- 파인튜닝 및 STS-Benchmark
- Semantic Text Similarity Benchmark(STS-B): 문장 간 의미적 유사성 평가
- 파인튜닝 통해 텍스트 유사성 발견 작업 수행
- SBERT 소개
- Sentence-BERT(SBERT): Transformer 기반 문장 유사성 라이브러리
- SBERT의 피쳐: BERT 모델을 파인튜닝하여 문장 유사성 최적화
- SBERT 논문: arXiv:1908.10084
4. 패션 상품 검색에의 적용
- 이미지 및 상품 메타 정보를 활용한 검색
- 이미지 및 텍스트 메타데이터를 활용하여 패션 상품 검색
- 모델 인풋: 상품 이미지, 텍스트 설명
- 모델 아웃풋: 유사 이미지 및 관련 상품 추천
- SBERT 및 Transformer 모델을 활용한 유사성 평가
핵심
- Outdoors 데이터셋을 활용하여 질문과 답변 구조의 문서를 인덱싱하고 검색 시스템 구현.
- 키워드 기반 검색의 한계를 극복하기 위해 Transformer 모델과 SBERT를 도입하여 문장 유사성 기반 검색 구현.
- 이미지 및 메타데이터를 활용하여 패션 상품 검색 시스템에 응용 가능성 모색.
이 문서는 자연어 처리와 검색 시스템 구현에 관한 내용을 다루며, Outdoors 데이터셋을 활용한 인덱싱과 Transformer 모델을 통한 검색 성능 향상을 목표로 한다. SBERT를 통해 문장 유사성을 기반으로 한 검색을 수행하며, 이런 기술을 패션 상품 검색에 적용할 수 있는 가능성을 제시한다.
SBERT를 활용한 자연어 처리와 문장 임베딩
1. RoBERTa 모델 구조와 SBERT 활용
SBERT(Sentence-BERT)는 문장 임베딩을 생성하기 위한 모델로, RoBERTa 아키텍처를 기반으로
- RoBERTa: BERT의 개선판으로, 하이퍼파라미터 최적화 및 원래 기법의 약간의 수정이 포함됨.
- 하이퍼파라미터: 학습 전에 변경 가능한 파라미터로, 학습 과정과 최종 모델 결과에 영향을 미침.
- 초기에는 적절한 값을 알 수 없으며, 반복과 측정을 통해 최적의 값 도출.
핵심: SBERT는 RoBERTa 기반의 문장 임베딩 모델로, 하이퍼파라미터 조정을 통해 성능을 최적화 NLI와 mean-tokens 기법을 사용하여 768 차원의 임베딩 벡터 생성.
2. SBERT 모델 로딩 및 문장 임베딩 생성
사전 학습된 ‘roberta-base-nli-stsb-mean-tokens’ 모델을 sentence_transformers 라이브러리를 통해 불러와 문장 임베딩 생성.
- NLI: 자연어 인퍼런스(Natural Language Inference)의 약자로, 언어 예측을 위한 NLP의 하위 분야.
- mean-tokens: 전체 문장 토큰화 후, 임베딩의 플로팅 포인트 값들의 평균을 계산하여 단일 임베딩 벡터 반환.
from sentence_transformers import SentenceTransformer
stsb = SentenceTransformer('roberta-base-nli-stsb-mean-tokens')
- 문장을 SBERT에 입력하여 임베딩을 생성하며, 결과는 768 차원의 플로팅 포인트 값으로 구성된 텐서.
- 텐서: 다차원 행렬을 포함하는 Python 객체로, Transformer 인코더에서 텍스트 인코딩 시 생성됨.
3. 문장 간 코사인 유사도 계산
문장 간 유사도 계산을 위해 PyTorch의 cosine similarity 함수를 사용하여 임베딩 간의 유사도 비교.
- 유사도 점수는 0.0(가장 유사하지 않음)에서 1.0(가장 유사함) 사이.
- ‘it’s raining hard’와 ‘it is wet outside’는 가장 유사한 문장으로 평가됨.
phrases = ["it's raining hard","it is wet outside","cars drive fast","motorcycles are loud"]
embeddings = stsb.encode(phrases, convert_to_tensor=True)
from sentence_transformers import util as STutil
similarities = STutil.pytorch_cos_sim(embeddings, embeddings)
- 유사도 행렬은 4x4 크기로, 각 문장과 자기 자신 및 다른 모든 문장과의 유사도를 포
4. 유사도 기반 정렬 및 output
유사도 점수를 기준으로 문장 쌍을 정렬하여 가장 유사한 쌍과 가장 비유사한 쌍을 식별.
- ‘it’s raining hard’와 ‘it is wet outside’는 가장 높은 유사도 점수(0.67)를 가짐.
- 코사인 유사도를 통해 문장의 의미적 유사성을 효과적으로 평가 가능.
import pandas as pd
a_phrases = []
b_phrases = []
scores = []
for a in range(len(similarities)-1):
for b in range(a+1, len(similarities)):
a_phrases.append(phrases[a])
b_phrases.append(phrases[b])
scores.append(float(similarities[a][b]))
df = pd.DataFrame({"phrase a":a_phrases,"phrase b":b_phrases, "score":scores})
df.sort_values(by=["score"], ascending=False, ignore_index=True)
5. 자연어 자동 완성 구현
임베딩 기술을 활용하여 자연어 자동 완성 기능 구현.
- SpaCy 라이브러리를 사용해 명사구와 동사구를 추출하여 사전에 저장하고 임베딩 처리.
- 근사 최근접 이웃 인덱스를 통해 실시간으로 유사한 개념을 쿼리하여 사용자에게 제공.
핵심: 유사도 기반 문장 비교는 의미적 유사성을 효과적으로 평가하며, 자연어 자동 완성에 유용하게 적용 가능. SpaCy와 SBERT를 결합하여 자연어 처리의 실제 활용 사례를 제시
6. 패션 상품 검색 적용
이미지와 상품 메타 정보를 기반으로 SBERT를 활용한 패션 상품 검색 방법 탐색.
- 이미지 피쳐과 텍스트 설명을 조합하여 통합 임베딩 벡터 생성.
- 통합 벡터를 이용해 유사한 패션 상품을 효율적으로 검색 가능.
## Example for fashion item search
fashion_phrases = ["red dress", "blue jeans", "black shoes"]
fashion_embeddings = stsb.encode(fashion_phrases, convert_to_tensor=True)
fashion_similarities = STutil.pytorch_cos_sim(fashion_embeddings, fashion_embeddings)
핵심 SBERT와 통합 임베딩을 활용한 패션 상품 검색은 이미지와 텍스트 정보를 결합하여 효율적인 검색 결과를 제공하며, 자연어 처리와 컴퓨터 비전의 융합을 통한 혁신적인 검색 방법을 제시
Advanced Natural Language Processing in Search Applications
1. Introduction to Search Applications
- 자연어 처리(NLP)의 중요성: 검색 애플리케이션 구축 시 NLP 기술의 활용이 필수적임.
- NLP 기술을 사용할 때도 예외 없이 중요
2. Concept Extraction Strategy Using SpaCy
- 기본 전략 제시 Listing 13.9는 자동완성 결과에서 노이즈를 제거하고, 적절한 품질을 가진 후보 개념을 추출하는 전략을 제공
2.1. SpaCy Matcher 활용
- 품사 태그 기반 패턴 탐색 SpaCy matcher를 활용해 명사와 동사 패턴 탐색.
- 불필요한 동사 제거 ‘to be’ 같은 빈도 높은 동사 제거로 개념 제안의 혼란을 줄임.
- 처리 성능 향상 SpaCy의 pipe 메소드 사용 → 병렬로 텍스트 처리, 처리량 증가.
phrases = []
sources = []
matcher = Matcher(nlp.vocab)
nountags = ['NN','NNP','NNS','NOUN']
verbtags = ['VB','VBD','VBG','VBN','VBP','VBZ','VERB']
matcher.add("noun_phrases", [[{"TAG":{"IN": nountags}, "IS_ALPHA": True,"OP":"+"}]])
matcher.add("verb_phrases", [[{"TAG":{"IN": verbtags}, "IS_ALPHA": True,"OP":"+", "LEMMA":{"NOT_IN":["be"]}}]])
for doc,idx in nlp.pipe(yieldTuple(df,"body",total=total), batch_size=40, n_threads=4, as_tuples=True):
text = doc.text
matches = matcher(doc)
for matchid,start,end in matches:
span = doc[start:end]
phrases.append(normalize(span))
sources.append(span.text)
concepts = {}
labels = {}
for i in range(len(phrases)):
phrase = phrases[i]
if phrase not in concepts:
concepts[phrase] = 0
labels[phrase] = sources[i]
concepts[phrase] += 1
3. Concept Frequency Analysis
- 빈도 기반 필터링 Listing 13.10에서 빈도 5 이상인 개념만 필터링하여 중요 개념만 남김.
concepts, labels = getConcepts(outdoors_dataframe, load_from_cache=True)
topcons = {k: v for (k, v) in concepts.items() if v > 5 }
print('Total number of labels:', len(labels.keys()))
print('Total number of concepts:', len(concepts.keys()))
print('Concepts with greater than 5 term frequency:', len(topcons.keys()))
print(json.dumps(topcons, indent=2))
- 결과 요약
- 총 레이블 수: 124,260
- 총 개념 수: 124,366
- 빈도 5 이상 개념 수: 12,375
4. Embedding Extraction Using SBERT/RoBERTa
- 복잡한 정규화 진행 유사한 개념을 768차원 dense 벡터 공간으로 정규화하여 검색 성능 향상.
- SBERT/RoBERTa 모델 이용 개념 임베딩 계산 후 pickle 파일로 저장하여 재사용 가능.
4.1. Embedding 계산 및 저장
def get_embeddings(concepts, minimum_frequency, load_from_cache=True):
phrases = [key for (key, tf) in concepts.items() if tf >= minimum_frequency]
if not load_from_cache:
embeddings = stsb.encode(phrases, convert_to_tensor=True)
with open('data/outdoors_embeddings.pickle', 'wb') as fd:
pickle.dump(embeddings, fd)
else:
with open('data/outdoors_embeddings.pickle', 'rb') as fd:
embeddings = pickle.load(fd)
return phrases, embeddings
minimum_frequency = 6
phrases, embeddings = get_embeddings(concepts, minimum_frequency, load_from_cache=True)
print('Number of embeddings:', len(embeddings))
print('Dimensions per embedding:', len(embeddings[0]))
- 결과 요약
- 임베딩 수: 12,375
- 임베딩 차원: 768
5. Key Takeaways
- NLP 기술을 통해 검색 애플리케이션의 성능을 극대화할 수 있음.
- SpaCy matcher와 병렬 처리를 통해 텍스트 처리 효율을 높임.
- SBERT/RoBERTa 임베딩을 활용해 개념의 의미적 유사성을 향상시킴.
6. 적용 사례: 패션 상품 검색
- 이미지 및 상품 메타 정보 기반 검색 SBERT/RoBERTa 임베딩을 활용해 유사한 패션 상품 검색 가능.
- 실제 예시
- 인풋 사용자의 패션 이미지 및 텍스트 설명.
- 모델 활용 SBERT/RoBERTa로 인코딩 후 유사도 검색.
- 아웃풋 유사한 스타일의 패션 아이템 추천.
참조 링크
이 블로그 포스트는 자연어 처리 기술을 검색 애플리케이션에 적용하는 방법을 다루고 있으며, SpaCy와 SBERT/RoBERTa를 활용한 개념 추출 및 임베딩 계산을 통해 검색 성능을 향상시키는 방법을 설명합니다. 패션 상품 검색 예시를 통해 실질적인 적용 사례도 제시합니다.
p336
Figure 13.6 벡터 공간에서 개념 임베딩의 3D 시각화
- 벡터 공간에서 개념의 유사성을 나타내기 위해 일부 개념의 유사성이 레이블로 표시됨.
- 개념 예시: “wind”와 “block” → 두 개념이 벡터 공간에서 서로 어떤 관계에 있는지 시각화.
- 768차원의 각 임베딩을 3차원(x,y,z)으로 축소. → 시각화를 용이하게 하기 위 → 차원 축소는 많은 피쳐을 가진 벡터를 적은 피쳐을 가진 벡터로 축소하는 기법. → 이 과정에서 벡터 공간 내 관계를 최대한 유지
사이드바: 차원 축소의 맥락 손실
- 차원 축소 시 많은 맥락이 손실됨.
- Figure 13.6의 시각화는 벡터 공간과 개념 유사성에 대한 직관을 제공하기 위
- 3차원으로 축소하는 것이 개념을 대표하는 이상적인 방법은 아님.
p337
임베딩을 활용한 대규모 비교
- Listing 13.11에서 임베딩을 사용해 용어 간의 유사성을 대규모로 비교.
- 코사인 유사도를 계산하여 각 임베딩 간의 관련성 평가.
- 예시 제한: 비교되는 임베딩 수를 제한. → 계산량이 많아질 경우 시스템 성능 저하 우려.
계산 예시
- 각 임베딩의 차원: 768
- 상위 500개의 임베딩 비교 → 500×500×768 = 192,000,000 부동소수점 계산.
- 전체 12,375개의 임베딩 비교 → 12,375×12,375×768 = 117,612,000,000 부동소수점 계산. → 처리 속도 저하 및 메모리 사용량 증가.
Listing 13.12 유사성 점수 분포
- 유사성이 높은 쌍 찾기
- phrase a와 phrase b의 유사성을 리스트에 추가
- 유사성이 높은 순으로 정렬
similarities = STutil.pytorch_cos_sim(embeddings[0:505], embeddings[0:505])
a_phrases = []
b_phrases = []
scores = []
for a in range(len(similarities)-1):
for b in range(a+1, len(similarities)):
a_phrases.append(phrases[a])
b_phrases.append(phrases[b])
scores.append(float(similarities[a][b]))
comparisons = pandas.DataFrame({"phrase a":a_phrases,"phrase b":b_phrases,"score":scores,"name":"similarity"})
comparisons = comparisons.sort_values(by=["score"], ascending=False, ignore_index=True)
p338
유사성 점수 분포 분석
- Listing 13.12의 비교 결과는 모든 문구의 유사성을 정렬하여 보관.
- 예시: “protect”와 “protection”의 코사인 유사도 0.928.
- Figure 13.7의 분포 시각화를 통해 유사성이 높은 개념의 비율 이해. → 대부분의 유사성 점수가 0.6 이하, 대다수는 0.4 미만.
유사성 분포 결과
- 505개의 개념 비교 → 505×505 = 255,025개의 유사성 계산.
- Listing 13.13에서 유사성 분포 시각화
candidate_synonyms = comparisons[comparisons["score"]>0.0]
{
ggplot(candidate_synonyms, aes('name','score')) +
geom_violin(color='blue')
}
p339
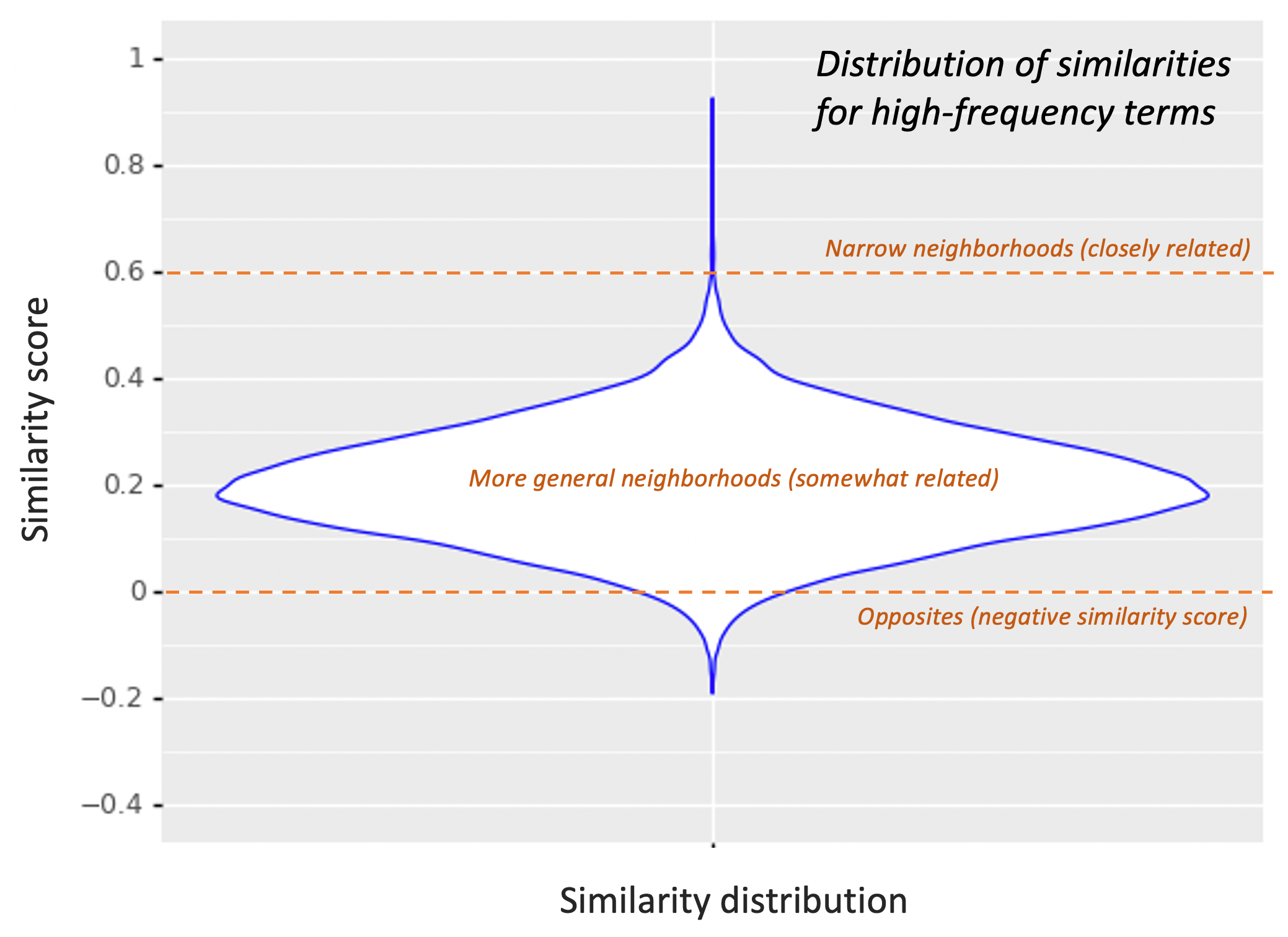
Figure 13.7 유사성 점수 분포
- 상위 505개의 개념 간 비교 시 코사인 유사도 분포.
- 대부분의 비교 결과가 0.6 이상의 점수를 넘지 않음.
- 대부분의 점수가 0.4 이하 (낮은 신뢰도).
유사성 기준점 설정
- 유사성 점수 분포를 통해 기준점 설정에 대한 직관 제공.
- 추후 구현 시, 검색 시점에 높은 유사도를 보이는 문서만 비교.
- Listing 13.15에서 활용 예정.
근사 최근접 이웃 검색
- 전체 12,375개 용어를 모두 비교하지 않기 위한 효율적 해결책 필요.
- STutil.pytorch_cos_sim 방법 사용 시의 비효율성 극복 필요.
TL;DR
- 차원 축소 기법을 활용하여 복잡한 벡터 공간을 3차원으로 시각화, 맥락이 일부 손실됨을 인지.
- 코사인 유사도를 사용하여 임베딩 간 유사성 평가, 계산량이 많아 처리 성능에 영향을 미침.
- 유사성 점수 분포를 통해 검색 시점에서의 효율적인 기준점 설정 가능, 근사 최근접 이웃 검색으로 최적화 필요.
Approximate Nearest Neighbor (ANN) Search와 Hierarchical Navigable Small World (HNSW) 알고리즘
1. ANN Search의 필요성 및 Pros(+)
- 목표 주어진 용어에 대해 가장 관련성이 높은 개념을 효율적으로 찾기 위
- 전체 사전에서 임베딩 유사성을 계산하지 않고도 관련 개념을 제공.
- 피쳐 일부 정확성을 희생함으로써 로그 수준의 계산 복잡성과 메모리 및 공간 효율성을 갖춤.
- 인덱스-타임 전략을 통해 검색 가능한 콘텐츠 벡터를 사전에 저장.
- 비유 dense vector search의 “역색인”으로 생각할 수 있음.
2. HNSW 알고리즘의 이해
- 기본 개념 계층적 네비게이블 작은 세계 그래프를 기반으로 한 K-최근접 이웃 검색
- 계층적으로 구성된 근접 그래프 집합을 점진적으로 구축.
- 유사한 벡터를 군집화하여 인덱스 생성.
- 데이터는 이웃으로 조직되고, 이웃 간의 관계를 통해 연결됨.
- Pros(+) HNSW는 Recall과 쿼리 처리량 간의 균형을 제공하고, 다양한 ANN 접근 방식 중 가장 유명한 방법 중 하나.
3. HNSW와 다른 ANN 기법 비교
- 예시 Locality Sensitive Hashing (LSH)
- 벡터 공간을 해시 버킷으로 나누고 각 dense 벡터를 해당 버킷에 해싱.
- HNSW에 비해 Recall이 낮지만, 데이터 독립적으로 생성된 이웃을 제공하여 분산 시스템의 샤딩 요구에 부합할 수 있음.
4. NMSLIB를 통한 HNSW 구현
- 라이브러리 선택 이유 빠르고 사용이 간편하며 코드가 적음.
- 사용법
- NMSLIB 초기화 및 dense 벡터 일괄 추가.
- 인덱스 생성 및 쿼리 수행.
- 실제 사례 용어 ‘bag’과 유사한 개념 검색.
- 인덱싱 후 쿼리를 통해 연관된 하이퍼님을 제안, 더 정밀한 용어를 제공.
5. 실질적인 적용 사례 - 패션 상품 검색
- 기술 적용 이미지와 상품 메타 정보를 사용하여 패션 아이템 검색.
- 모델 사용 SBERT를 통한 임베딩 생성, HNSW 인덱스를 통한 유사 제품 검색.
- 예시 사용자가 특정 가방 이미지를 입력하면, 유사한 디자인과 스타일의 가방을 추천.
6. Appendix: 코드 구현 예시 및 성능 튜닝
- 임베딩 생성 및 인덱스 커밋 SBERT로 쿼리 임베딩 생성, HNSW 인덱스에 추가.
- 유사도 기준 코사인 유사도가 0.75 이상일 때 매치로 간주.
- 코드 예시
def semantic_suggest(query, k=20): matches = [] embeddings = stsb.encode([query], convert_to_tensor=True) ids, distances = index.knnQuery(embeddings[0], k=k) for i in range(len(ids)): text = phrases[ids[i]] dist = 1.0 - distances[i] if dist > 0.75: matches.append((text, dist)) if not len(matches): matches.append((phrases[ids[1]], 1.0 - distances[1])) return matches
7. 성능 최적화 및 하드웨어 고려
- 생산 환경 CPU 병목 가능성, 스케일에 따른 처리량 측정 및 하드웨어 추가 필요.
- 추가적인 리소스 ANN 벤치마크 사이트 ann-benchmarks.com 참고
TL;DR
- ANN 검색은 정확성을 일부 희생하면서 효율성을 높이는 방법으로, HNSW 알고리즘을 통해 dense 벡터를 효과적으로 검색
- NMSLIB를 사용하여 HNSW를 구현하고, SBERT를 활용한 쿼리 임베딩으로 유사한 패션 상품을 검색할 수 있음.
- 코딩 예제와 성능 최적화 방법을 통해 실제 시스템에서의 적용 가능성을 높였음.
p344
레이블링된 데이터셋를 사용하여 정확도를 측정하는 것이 중요 실제 고객에게 솔루션을 배포하기 전에 이런 방식으로 정확도를 측정해야 14장에서 질의응답 구현 시 레이블링된 데이터를 사용하여 실제 정확도 측정을 시연할 예정임.
추가적인 자동완성 값을 직접 시도해 볼 수 있음. 어떤 값들이 잘 작동하는지, 어떤 값들이 그렇지 않은지 확인할 수 있음.
지금까지 배운 내용을 바탕으로 dense vector search을 다음 단계로 발전시킬 예정임: 검색 시점에 쿼리 임베딩을 문서 임베딩과 쿼리하여 검색을 수행
자동완성을 첫 번째 구현으로 시작한 이유는 언어 유사성의 기본을 이해하는 데 도움이 되었기 때문임. 벡터 공간에서 유사하거나 유사하지 않은 이유에 대한 직관이 있어야 언어 임베딩을 사용할 때 무한히 반복되는 Recall 문제를 피할 수 있음. 이 직관을 쌓기 위해 각각 몇 단어로 이루어진 기본 개념의 매칭과 스코어링부터 시작했음.
이제 전체 문장을 비교하는 단계로 넘어갈 것임. 이를 통해 제목에 대한 의미론적 검색을 수행할 예정임. 쿼리로 시작하여 문서 목록을 반환 Outdoors Stack Exchange 데이터셋를 검색하고 있으므로 문서 제목은 기여자가 질문한 내용을 요약한 것임. 보너스로, 이전 섹션의 동일한 구현을 사용하여 유사한 질문 제목을 검색할 수 있음.
이 섹션은 대부분 이전 섹션의 인코딩 및 유사성 방법의 반복이므로 빠르게 진행될 것임. 코드도 더욱 짧아짐, 개념을 추출할 필요가 없기 때문임.
다음 단계로 진행
- 아웃도어 데이터셋의 모든 제목에 대한 임베딩을 얻음.
- 임베딩으로 NMSLIB 인덱스를 생성
- 쿼리에 대한 임베딩을 얻음.
- NMSLIB 인덱스를 검색
- 가장 가까운 제목을 표시
NMSLIB 인덱스는 제목 임베딩으로 구성됨. 이전의 자동완성 예제와 동일한 방법을 사용하지만 이제는 개념을 변환하는 대신 아웃도어 커뮤니티가 한 모든 질문의 제목을 변환 Listing 13.16에서는 제목을 임베딩으로 인코딩하는 과정을 보여줌.
13.6 Semantic Search with large language model embeddings
13.6.1 Getting titles and their embeddings
p345
Listing 13.16 Encode the titles into embeddings
- 아웃도어 코퍼스에서 모든 질문의 제목을 가져옴.
- 제목에 대한 임베딩을 얻음 (이 과정은 시간이 걸림).
결과
- 5331개의 제목을 임베딩으로 인코딩 제목 임베딩 유사성 분포는 Figure 13.8에 표시됨.
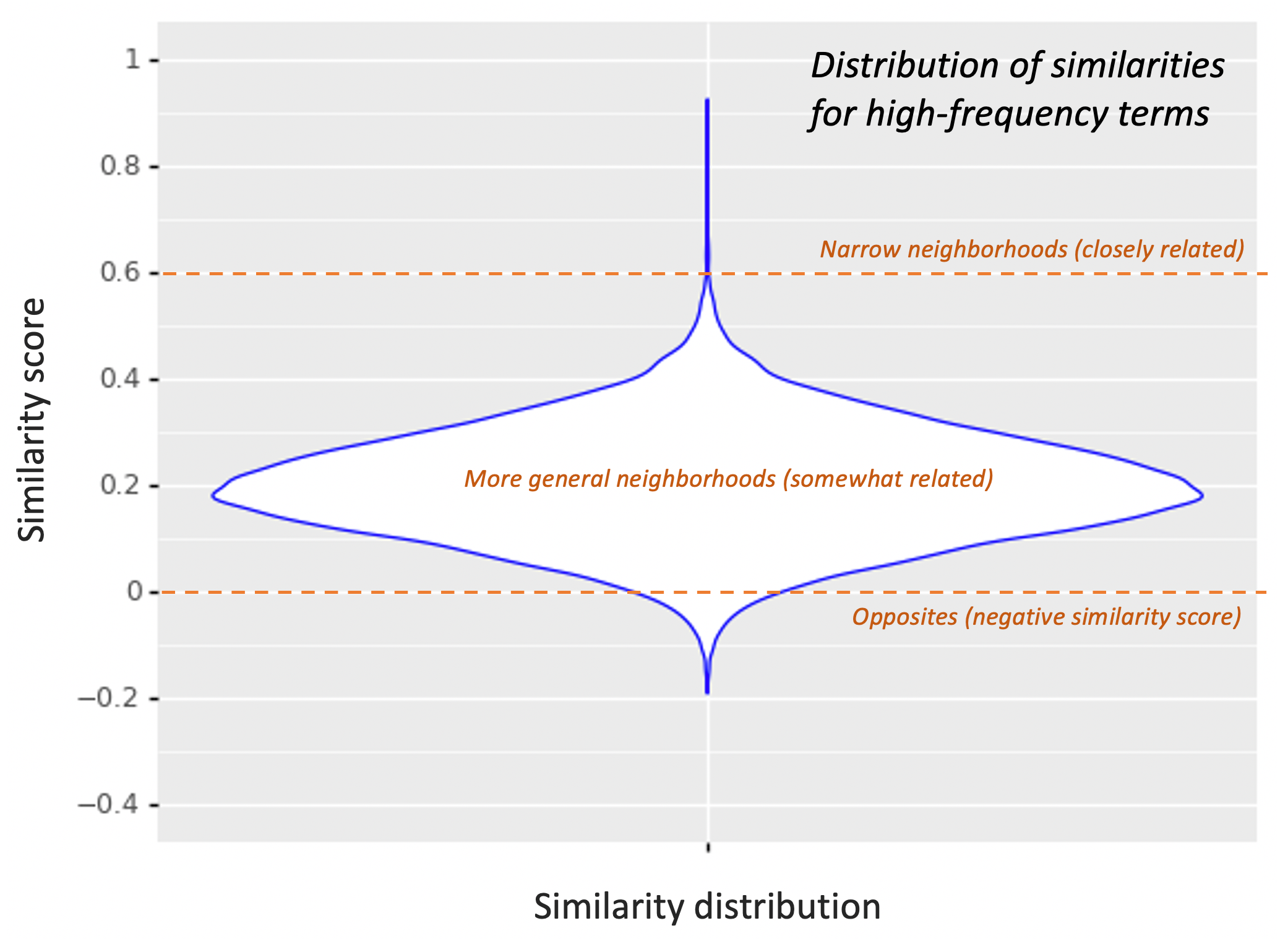
Figure 13.8 모든 제목 임베딩 간의 유사성
Figure 13.8과 Figure 13.7의 개념 유사성 분포 비교. 제목과 개념 간의 차이로 인해 약간 다른 형태와 점수 분포를 보임. Figure 13.7은 더 긴 ‘바늘’ 모양을 가짐. 이는 제목이 더 구체적이기 때문임.
titles = list(filter(None, list(outdoors_dataframe['title'])))
embeddings = get_embeddings(titles)
print('Number of embeddings:', len(embeddings))
print('Dimensions per embedding:', len(embeddings[0]))
- Number of embeddings: 5331
- Dimensions per embedding: 768
p346
-
제목이 명사 및 동사 구보다 더 구체적이므로 다르게 연관되고, 임베딩 생성 후 최근접 이웃 인덱스를 쉽게 생성할 수 있음, Listing 13.17 참조. (Listing 13.17 Create the ANN title embeddings index)
-
새로 생성된 인덱스를 통해 검색이 쉬워짐! Listing 13.18에서는 쿼리에 대한 질문 제목에 대한 ANN 검색을 구현하는 새로운 메서드를 보여줌. 이는 Listing 13.15에서 자동완성을 위해 구현한
semantic_suggest와 유사
Listing 13.18 Perform a semantic search for titles
- 쿼리를 받아들이고 기본적으로 가장 가까운 10개의 이웃을 반환
- 하이퍼파라미터 경고! 0.6이 아닌 값으로 변경하면 검색의 Recall이 변경됨.
- 제목 인덱스에 대해 ANN 검색 수행!
13.6.2 Creating and searching the nearest-neighbor index
import nmslib
index = nmslib.init(method='hnsw', space='cosinesimil')
index.addDataPointBatch(embeddings)
index.createIndex(print_progress=True)
def semantic_search(query, k=10, minimum_similarity=0.6):
matches = []
embeddings = stsb.encode([query], convert_to_tensor=True)
ids, distances = index.knnQuery(embeddings[0], k=k)
for i in range(len(ids)):
text = titles[ids[i]]
dist = 1.0 - distances[i]
if dist > minimum_similarity:
matches.append((text, dist))
if not len(matches):
matches.append((titles[ids[1]], 1.0 - distances[1]))
print_labels(query, matches)
semantic_search('mountain hike')
p347
- 성공적! 이제 결과를 잘 반영하고 있는지를 평가해보자. 모두 관련성이 있는가? 그렇다 - 모두 쿼리
mountain hike와 관련된 질문임. 그러나 가장 관련성이 높은 문서인지는 알 수 없음. 이는mountain hike가 충분한 맥락을 제공하지 않기 때문임. 따라서 제목이 쿼리와 의미론적으로 유사하지만 사용자가 원하는 문서인지 판단할 수 없음.
그럼에도 불구하고 이 임베딩 기반 검색 방법은 매칭 및 랭킹 도구 상자에 흥미로운 새로운 기능을 제공 그러나 결과가 더 나은지는 맥락에 따라 다름.
SIDEBAR: Reranking results found with dense vector similarity
-
Listing 13.17에서 기본
minimum_similarity점수 임계값을 0.6보다 크게 설정 Figure 13.8의 제목 유사성 분포를 검사하고 이 값을 0.6보다 다르게 설정할 것인지 고려할 수 있음. -
minimum_similarity를 0.6보다 낮은 값(e.g., 0.5)으로 설정하면 Recall이 증가할 수 있으며,k를 10보다 높은 값(e.g., 250)으로 변경하여 리랭크 윈도우 크기로 설정할 수 있음. 그런 다음 이 더 큰 결과 집합을 사용하여 Learning to Rank 리랭킹 단계에서 여러 기능 중 하나로 코사인 유사성을 사용하여 리랭킹을 수행할 수 있음. -
Solr는 아직 이 기능을 제공하지 않지만 Vespa.ai와 같은 다른 엔진에서는 가능 10장에서 배운 내용을 사용하여 어떻게 dense 벡터 유사성을 학습-랭크 모델에 통합할 수 있을지 생각해보라.
-
그래서 다시 자동화된 관련성 조정의 게임으로 돌아옴. 임베딩의 코사인 유사성은 성숙한 AI 기반 검색 스택에서 많은 신호나 기능 중 하나임. 이 유사성은 개인화, 학습-랭크와 함께 사용될 기능임.
Results for: mountain hike
0.725 | How is elevation gain and change measured for hiking trails?
0.706 | Hints for hiking the west highland way
0.698 | Fitness for hiking to Everest base camp
0.697 | Which altitude profile and height is optimal for Everesting by hiking?
0.678 | How to prepare on hiking routes?
0.678 | Long distance hiking trail markings in North America or parts thereof
0.675 | How far is a reasonable distance for someone to hike on their first trip?
0.668 | How to plan a day hike
0.666 | How do I Plan a Hiking Trip to Rocky Mountain National Park, CO
0.665 | Is there special etiquette for hiking the Appalachian Trail (AT) during AT Season
TL;DR
- 레이블링된 데이터셋를 사용하여 정확도를 측정하는 것이 중요하며, dense vector search을 통해 쿼리 임베딩과 문서 임베딩을 매칭하여 검색 성능을 개선할 수 있음.
- 성능 향상을 위해 최근접 이웃 인덱스를 생성하고 쿼리에 대한 임베딩을 얻어 검색을 수행하며, 임베딩 기반 검색 방법은 새로운 매칭 및 랭킹 기능을 제공
- 관련성 조정 및 리랭킹을 통해 검색 성능을 최적화할 수 있으며, 코사인 유사성은 학습-랭크 등 다양한 기능과 함께 사용할 수 있음.