RAG, Reasoning | Self-Reasoning RAG
- Related Project: Private
- Category: Paper Review
- Date: 2024-08-01
Improving Retrieval Augmented Language Model with Self-Reasoning
- url: https://arxiv.org/abs/2407.19813
- pdf: https://arxiv.org/pdf/2407.19813
- html: https://arxiv.org/html/2407.19813v1
- abstract: The Retrieval-Augmented Language Model (RALM) has shown remarkable performance on knowledge-intensive tasks by incorporating external knowledge during inference, which mitigates the factual hallucinations inherited in large language models (LLMs). Despite these advancements, challenges persist in the implementation of RALMs, particularly concerning their reliability and traceability. To be specific, the irrelevant document retrieval may result in unhelpful response generation or even deteriorate the performance of LLMs, while the lack of proper citations in generated outputs complicates efforts to verify the trustworthiness of the models. To this end, we propose a novel self-reasoning framework aimed at improving the reliability and traceability of RALMs, whose core idea is to leverage reasoning trajectories generated by the LLM itself. The framework involves constructing self-reason trajectories with three processes: a relevance-aware process, an evidence-aware selective process, and a trajectory analysis process. We have evaluated our framework across four public datasets (two short-form QA datasets, one long-form QA dataset, and one fact verification dataset) to demonstrate the superiority of our method, which can outperform existing state-of-art models and can achieve comparable performance with GPT-4, while only using 2,000 training samples.
TL;DR
- 자체 인퍼런스 프레임워크를 통한 언어 모델 개선
- 자료 검색 및 선택 과정을 통해 정보의 정확성 강화
- 효율적인 훈련 샘플 사용으로 최고 수준의 모델 성능 달성
LLM이 검색된 문서와 질문 사이의 관련성을 판단한 뒤 → 관련 문서를 선택하고, 그 문서에서 핵심 문장을 근거로 채택 → 이전 두 과정에서 생성된 인퍼런스 경로 및 근거 등을 기반으로 간단한 분석을 수행해 최종적으로 답변을 인퍼런스하는 프로세스를 사용
제한된 태스크에서 2,000개의 훈련 샘플만을 사용해 GPT-4와 비교 가능한 성능을 달성함을 보이며, 효율적인 훈련 샘플 사용의 중요성을 강조함. 즉, 필요한 고퀄리티 데이터와 근거들이 제공되는 것으로 일부 영역에서는 SOTA 모델들을 능가할 수 있음. (현실적으로 서비스 혹은 사용 전에 RAG를 사용하는 것이 SFT나 DPO와 같은 Pre-Post Training보다 효율이 좋다고 평가하는 것 같습니다.)
1. 서론
언어 모델은 인퍼런스 중 외부 지식을 통합함으로써 지식 집약적 작업에서 향상된 성능을 발휘합니다. 하지만, 이런 통합 과정에서 문제점이 발생하는데, 특히 검색된 문서의 관련성이 떨어질 경우 모델의 성능을 저하시키고, 정확한 출처 표기 없이 생성된 출력은 모델의 신뢰성 검증을 어렵게 만듭니다. 본 논문에서는 자체 인퍼런스 경로를 생성하여 RALM의 신뢰성과 추적 가능성을 향상시키는 새로운 프레임워크를 제안합니다.
이를 위해, 먼저 기존의 연구들이 어떻게 LLM을 개선하기 위해 외부 정보를 검색하여 사용하는지를 조사합니다. 예를 들어, Menick 등(2022)과 Nakano 등(2021)은 검색된 문서를 활용하여 질문에 답하는 방법을 LLM에 지시하거나 훈련시킵니다. 이는 LLM이 검색된 문서를 바탕으로 정보를 통합하고 정확한 답변을 생성하도록 돕습니다.
2. 관련 연구
2.1 정보 검색을 통한 언어 모델의 성능 향상
이전 연구들은 검색된 정보를 통해 LLM의 성능을 향상시키기 위한 다양한 접근 방식을 탐구하였습니다. 구체적으로, Guu 등(2020)과 Borgeaud 등(2022)은 언어 모델을 검색된 문단과 함께 사전 훈련시키는 방법을 제안했습니다. 이 방법들은 LLM이 관련 지식을 효과적으로 활용하여 질의 응답과 같은 지식 집약적 작업에서 더 정확한 답변을 생성할 수 있도록 돕습니다.
2.2 RALM의 견고성 향상
Yu 등(2023)은 RALM 전에 자연어 인퍼런스 모델을 사용하여 관련 없는 문서를 걸러내는 방법을 사용하고, Xu 등(2023a)은 검색된 문서를 필터링하거나 압축하는 기억 모델을 사용합니다. 이들 연구는 외부 도구에 의존하지 않고, 중요 문장을 식별하고 관련 문서를 인용하여 오류를 제거하는 종단 간 프레임워크를 통해 RALM의 정확성과 신뢰성을 향상시킵니다.
3. 예비 연구
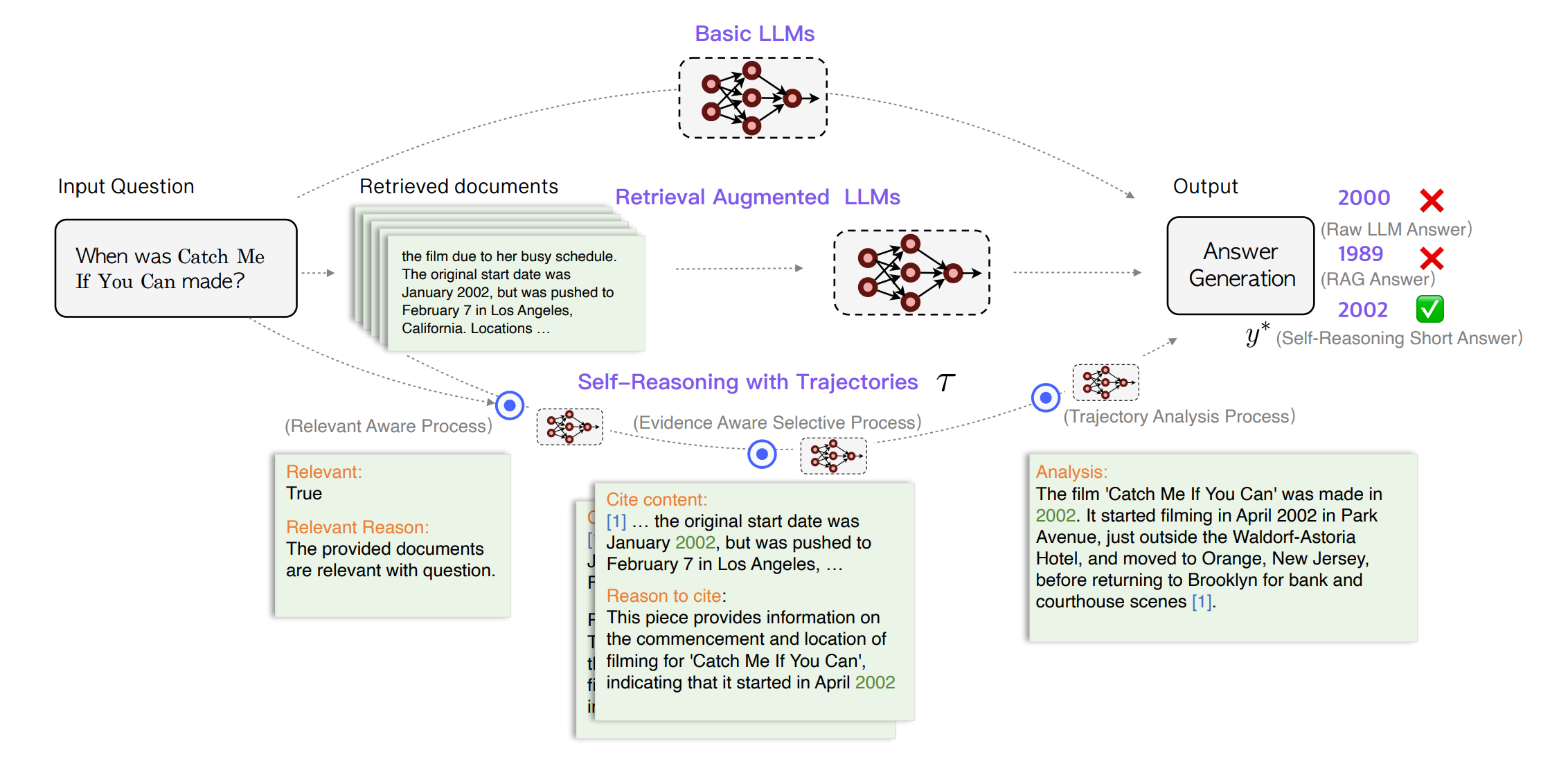
본 섹션에서는 자체 인퍼런스를 통한 검색 증강 생성 문제를 공식적으로 정의합니다. 주어진 질문 \(q\)와 문서 집합 \(D\)에 대해, LLM이 생성한 답변 \(y\)는 \(m\)개의 문장과 \(n\)개의 토큰으로 정의될 수 있으며, \(y = (s_1, s_2, \dots, s_m) = (w_1, w_2, \dots, w_n)\)로 표현됩니다. \(s_i\)는 \(i\)-번째 문장이고 \(w_j\)는 생성된 답변에서 \(j\)-번째 토큰입니다. 또한, 장문 QA 설정에서 각 문장 \(s_i\)는 문서 목록 \(C_i = \{c_i^{(1)}, c_i^{(2)}, \dots\}\)을 인용해야 하며, \(c_i^{(k)} \in D\)입니다. 본 연구에서는 LLM(e.g., LLaMA2)을 훈련하여 먼저 자체 인퍼런스를 통해 인퍼런스 궤적 \(\tau\)를 생성하고, 이를 조건으로 하여 장문 및 단문 답변 \(y^*\)을 생성하도록 합니다. 모델 출력은 \(y = \text{concat}(\tau, y^*)\)로, \(\tau\)와 \(y^*\)의 연결입니다. \(\tau\)와 \(y^*\)의 생성은 SELF-REASONING 프레임워크 내에서 단일 패스로 수행됩니다.
4. 방법
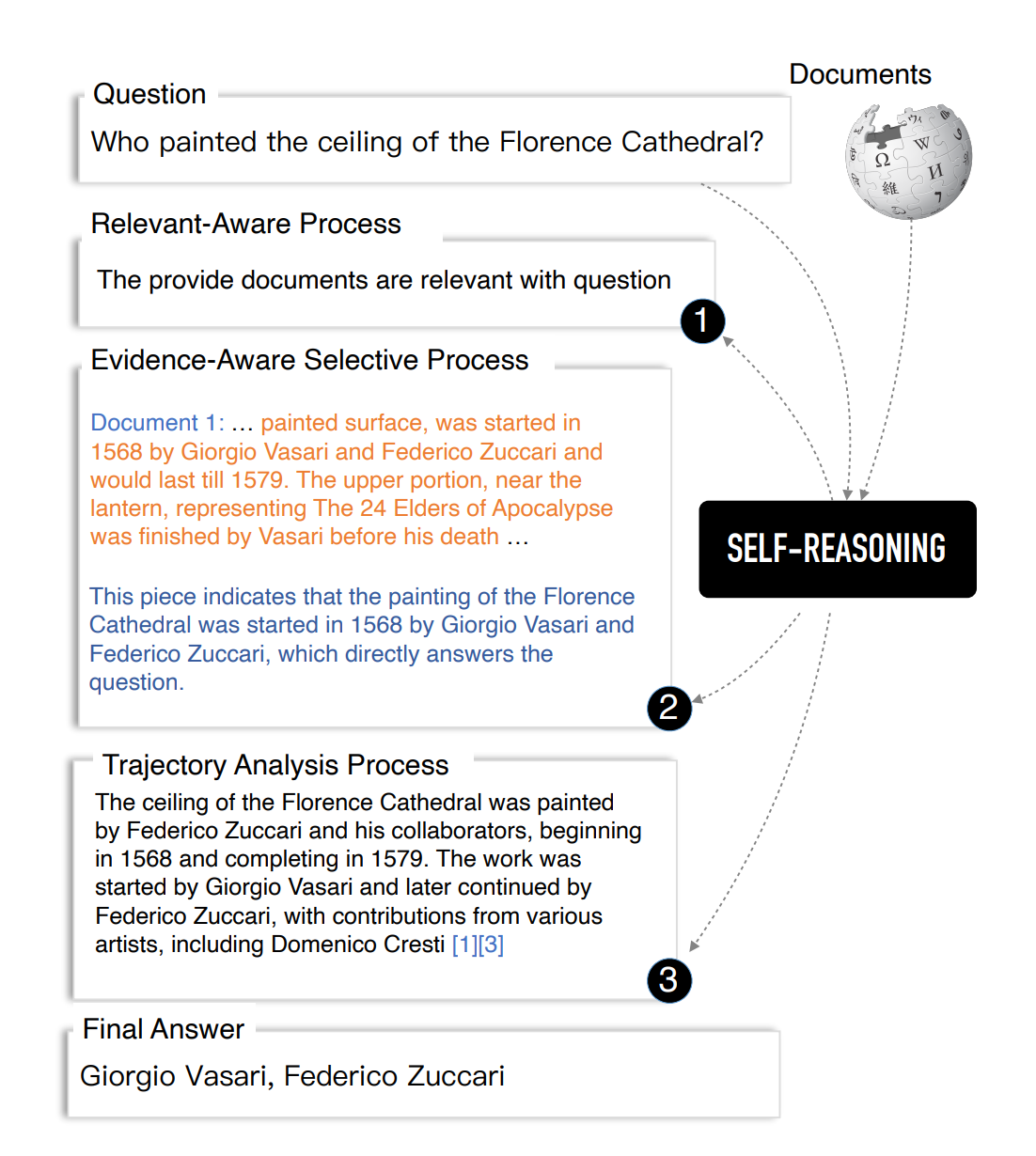
본 논문에서 제안하는 자체 인퍼런스 프레임워크는 다음 세 가지 과정으로 구성되며, 자체 인퍼런스 경로를 통해 문서의 관련성과 중요성을 판단하고, 이를 기반으로 더 정확하고 신뢰할 수 있는 답변을 생성할 수 있도록 합니다.
-
관련성 인식 과정 (Relevance-Aware Process, RAP) \(\text{Relevance} = \text{Judge}(\text{Document}, \text{Question})\) 이 과정에서는 LLM이 검색된 문서와 질문 사이의 관련성을 판단합니다.
-
증거 인식 선택 과정 (Evidence-Aware Selective Process, EAP) \(\text{Evidence} = \text{Select}(\text{Key Sentences}, \text{Cited Documents})\) LLM은 관련 문서를 선택하고, 그 문서에서 핵심 문장을 증거로 자동 선택합니다.
-
경로 분석 과정 (Trajectory Analysis Process, TAP) \(\text{Answer} = \text{Analyze}(\text{Self-Reasoning Trajectories})\) LLM은 이전 두 과정에서 생성된 자체 인퍼런스 경로를 바탕으로 간결한 분석을 수행하고 최종적으로 인퍼런스된 답변을 제공합니다.
본 연구는 네 가지 공개 데이터셋(두 개의 단답형 QA, 하나의 장문형 QA, 하나의 사실 검증 데이터셋)에서 프레임워크를 평가하여 기존의 최고 수준의 모델들을 능가하는 성능을 보여주었습니다. 이는 단지 2,000개의 훈련 샘플만을 사용하여 GPT-4와 비교 가능한 성능을 달성함으로써, 효율적인 훈련 샘플 사용의 중요성을 강조합니다.
이 실험은 프레임워크가 어떻게 각 단계에서 정보의 정확성을 검증하고, 이를 바탕으로 정확한 답변을 생성하는지를 보여줍니다. 이는 프레임워크가 실제 응용 프로그램에서 얼마나 효과적일 수 있는지를 시사합니다.
4.1 관련성 인식 과정
본 연구에서는 DPR(Karpukhin 등, 2020)과 Contriever(Izacard 등, 2021)를 기본 검색기 \(R\)로 사용하여 상위 \(k\)개의 관련 문서를 회상합니다. 주어진 질문과 문서 집합에 대해 모델이 문서 \(D\)와 주어진 질문 \(q\) 사이의 관련성을 판단하도록 지시합니다. 모델은 주어진 문서가 왜 관련이 있는지를 설명하는 이유를 명시적으로 생성하도록 요청받습니다. 출력은 관련성과 관련 이유의 두 필드를 포함해야 하며, 만약 검색된 문서가 모두 무관한 경우, 모델은 사전 훈련 단계에서 획득한 내부 지식을 바탕으로 답변을 제공해야 합니다. 관련성 인식 과정에서 생성된 자체 인퍼런스 궤적을 \(\tau_r\)로 정의합니다.
4.2 증거 인식 선택 과정
질문에 답변해야 할 때 사람들은 일반적으로 제공된 문서에서 중요한 문장을 식별한 후 이를 주요 포인트로 인용하거나 강조합니다. 이 문서 인용 과정은 독해 능력을 향상시키고 여러 단문 답변을 결합하여 다양한 측면을 다루는 기술로서 사용될 수 있습니다. LLM은 이런 선택 과정과 인용을 명시적으로 수행해야 합니다. 본 연구에서는 LLM이 선택된 문장이 질문에 답하는 데 왜 지지적이고 타당한지를 명시적으로 밝히도록 요구합니다. 선택된 문장을 증거로 정의하며, 상위 \(k\)개 문서를 검색한 후, 증거 인식 선택 과정에 대한 자체 인퍼런스 방법은 다음과 같이 수식화됩니다. 먼저, LLM이 관련 문서를 선택하고 선택된 문서에서 핵심 문장의 스니펫을 자동으로 선택하도록 지시한 다음, 선택된 스니펫이 질문에 답할 수 있는 이유를 LLM이 출력하도록 요청합니다. 중간 출력은 여러 내용을 포함하는 목록이며, 각 내용은 인용 내용과 인용 이유의 두 필드를 포함해야 합니다. 증거 인식 선택 과정에서 생성된 자체 인퍼런스 궤적을 \(\tau_e\)로 정의합니다.
4.3 경로 분석 과정
마지막으로, 이전 과정에서의 모든 자체 인퍼런스 궤적(\(\tau_r\) 및 \(\tau_e\))을 함께 결합하여 인퍼런스 스니펫의 연쇄를 형성함으로써 검색 증강 생성의 전반적인 성능을 향상시킵니다. 구체적으로, LLM에게 자체 인퍼런스 궤적을 분석하고 궁극적으로 간결한 분석과 짧은 답변을 출력하도록 요청합니다. LLM은 분석과 답변의 두 필드를 포함하는 내용을 출력하도록 지시받습니다. 경로 분석 과정에서 생성된 자체 인퍼런스 궤적을 \(\tau_a\)로 정의합니다. 본 연구에서 분석 출력은 장문 답변으로 정의되며, 답변 출력은 단문 답변으로 정의됩니다. 5.2절에서는 장문 및 단문 QA 설정의 성능을 추가적으로 탐구합니다.
5. 실험
5.1 데이터셋 및 설정
본 연구의 자체 인퍼런스 프레임워크의 효과를 입증하기 위해 두 개의 단답형 QA 데이터셋(NaturalQuestion과 PopQA), 하나의 장문형 QA 데이터셋(ASQA), 그리고 하나의 사실 검증 데이터셋(FEVER)에서 광범위한 실험적 평가를 수행합니다. 각 데이터셋의 상세 설명은 Appendix §A.3에서 확인할 수 있습니다. DPR과 Contriever-MS MARCO를 사용하여 위키피디아에서 상위 다섯 개 문서를 검색합니다.
5.2 평가 지표
- 단답형 QA 지표: 모델 예측에 정답이 포함되는지를 기반으로 정확도를 보고합니다.
- 장문형 QA 지표: 정확도 측정을 위해 EM Recall을 보고하고, 인용의 정확도를 위해 인용 Recall과 인용 Precision를 사용합니다.
- 사실 검증 지표: 세 가지 클래스 분류 정확도를 보고합니다.
5.3 Baseline Model
- 검색 없는 기본 모델: LLaMA2-7B, LLaMA2-13B 및 지시 튜닝된 채팅 버전인 LLaMA2-Chat-7B, LLaMA2-Chat-13B을 평가합니다.
- 검색이 포함된 모델: LLaMA2 및 Vicuna 시리즈 모델을 사용하여 평가하며, LLaMA2-FT를 포함하여 공정한 비교를 위해 여러 모델을 평가합니다. 또한 RECOMP, ReAct, Self-RAG와 같이 추가적인 GPT-4 생성 샘플이나 외부 도구를 사용하여 훈련된 모델들과 비교합니다.
5.4 주요 결과
다양한 방법에 대한 성능 비교는 표 1에서 확인할 수 있습니다. 단답형 QA 평가에서 검색 증강 LLM의 성능이 기본 모델보다 일관되게 더 우수함을 확인할 수 있습니다. 특히 같은 파라미터 크기를 가진 모델들 중에서 SELF-REASONING 프레임워크가 대부분의 강력한 Baseline Model을 능가합니다. SELF-REASONING 프레임워크는 단 2,000개의 자체 인퍼런스 궤적 샘플만을 사용하여 훈련된 종단 간 시스템으로, Self-RAG가 추가적인 46,000 인스턴스를 사용하여 반사 토큰을 예측하는 비평 모델을 훈련하는 것과 대조됩니다. 이런 효율성은 훈련 과정을 단순화할 뿐만 아니라 자원 소비를 줄입니다.
장문형 QA 평가에서는 EM Recall 지표가 필요하며, 다수의 문서를 이해하고 답변을 통합해야 합니다. EAP 및 TAP는 다문서 독해를 위해 특별히 설계되었으며, 이를 통해 다른 Baseline Model을 능가하는 성능을 달성합니다. 인용 평가 지표 측면에서는, SELF-REASONING 프레임워크가 GPT-4를 능가하는 결과를 달성합니다(ASQA 인용 Recall에서 72.3 대 68.5).
사실 검증 평가에서 SELF-REASONING은 모든 Baseline Model을 압도하는 우수한 성능을 보여주며, Self-RAG 모델보다 훨씬 높은 정확도를 달성합니다(83.9 대 72.1). 이 프레임워크의 RAP는 검색된 문서와 질문 사이의 관련성을 판단하도록 설계되어 있어, 이 사실 검증 작업에서 정확도를 향상시킵니다.
이런 결과들은 SELF-REASONING 프레임워크가 실제 응용 프로그램에서 어떻게 작동하는지 보여주는 사례 연구를 통해 실제 시나리오에서의 운영을 보다 깊이 있게 분석할 수 있도록 합니다(Appendix §A.6 참조).
6. 분석
6.1 Ablation Study
본 연구에서는 자체 인퍼런스 프레임워크 내 각 과정의 개별 기여도를 분석하기 위해 두 개의 단답형 QA 데이터셋과 사실 검증 데이터셋에 대한 Ablation Study를 수행합니다. 점진적 학습(GL) 방법과 데이터 생성의 품질 관리(QC)의 효과도 추가로 탐구합니다(자세한 분석은 Appendix §A.7 참조). 주요 Ablation Study 결과는 다음과 같습니다.
- 관련성 인식 과정(RAP) 제거 시: NQ, PopQA, FEVER 데이터셋 모두에서 성능 하락을 관찰하며, FEVER 데이터셋에서 가장 큰 성능 하락이 나타납니다. 이는 문서와 질문 간의 관련성 고려가 성능 향상에 중요하다는 것을 시사합니다.
- 증거 인식 선택 과정(EAP) 제거 시: 단답형 QA 데이터셋에서 평균 정확도가 60.9에서 56.3으로 감소합니다. 이는 자체 인퍼런스를 통해 생성된 문서 인용과 핵심 문장 스니펫이 정확도 향상에 중요하다는 것을 나타냅니다.
- 경로 분석 과정(TAP) 제거 시: 세 데이터셋 모두에서 성능이 감소하며, 이는 이전 두 과정에서 생성된 궤적에 기반한 자체 분석이 LLM의 성능을 향상시킬 수 있음을 보여줍니다.
6.2 검색 견고성 분석
검색기가 완벽하지 않고, 과거 연구들이 노이즈이 많은 검색이 LLM의 성능에 부정적인 영향을 줄 수 있음을 보여주었습니다. 본 섹션에서는 RALM의 견고성을 검증하기 위해 두 가지 설정을 디자인합니다. 첫 번째 설정에서는 검색된 문서의 순서가 RALM의 성능에 영향을 미치는지를 테스트하며, 두 번째 설정에서는 노이즈이 많은 문서가 LLM의 성능에 미치는 영향을 테스트합니다. 노이즈이 많은 문서를 제시할 때, 모든 모델이 성능 저하를 경험하며, 자체 인퍼런스 프레임워크는 상대적으로 최소한의 성능 저하를 보여 견고함을 입증합니다.
6.3 인용 분석
NLI 모델에 의한 자동 평가가 부분적으로 지원되는 인용을 감지할 수 없기 때문에, 본 섹션에서는 휴먼 평가를 통한 인용 분석을 논의합니다. 휴먼 평가는 두 가지 차원에서 수행됩니다. 1) 인용 Recall: 평가자는 주어진 진술과 그 진술이 참조하는 모든 문서를 제공받고, 문서가 주어진 진술을 완전히 지원하는지 판단합니다. 2) 인용 Precision: 주어진 진술과 그 인용 중 하나를 갖고 평가자는 인용이 진술을 완전히 지원하는지, 부분적으로 지원하는지, 또는 지원하지 않는지를 판단합니다. 휴먼 평가 결과는 자동 평가와 잘 일치하며, 종종 자동 평가에 비해 높은 점수를 나타냅니다.
7. 결론
RALM은 지식 집약적 작업에서 LLM의 성능을 효과적으로 향상시킬 수 있습니다. 그러나 신뢰성과 추적 가능성에 대한 우려가 지속적으로 제기됩니다. 이런 제한을 해결하기 위해, 본 연구에서는 LLM 자체가 생성한 인퍼런스 궤적을 사용하여 RALM의 성능을 향상시키는 새로운 자체 인퍼런스 프레임워크를 제안합니다. 이 프레임워크는 관련성 인식 과정, 증거 인식 선택 과정, 그리고 경로 분석 과정으로 구성됩니다. 네 개의 공개 데이터셋에서 광범위한 실험을 수행하여, 기존 최고 수준의 모델들을 능가하는 프레임워크의 우수성을 입증합니다.