VL | Qwen2-VL
- Related Project: Private
- Category: Paper Review
- Date: 2024-09-03
Qwen2-VL: To See the World More Clearly
- url: https://qwenlm.github.io/blog/qwen2-vl/
- github: https://github.com/QwenLM/Qwen2-VL
- abstract: After a year’s relentless efforts, today we are thrilled to release Qwen2-VL! Qwen2-VL is the latest version of the vision language models in the Qwen model families. (1) SoTA understanding of images of various resolution & ratio: Qwen2-VL achieves state-of-the-art performance on visual understanding benchmarks, including MathVista, DocVQA, RealWorldQA, MTVQA, etc. (2) Understanding videos of 20min+: with the online streaming capabilities, Qwen2-VL can understand videos over 20 minutes by high-quality video-based question answering, dialog, content creation, etc. (3) Agent that can operate your mobiles, robots, etc.: with the abilities of complex reasoning and decision making, Qwen2-VL can be integrated with devices like mobile phones, robots, etc., for automatic operation based on visual environment and text instructions. (4) Multilingual Support: to serve global users, besides English and Chinese, Qwen2-VL now supports the understanding of texts in different languages inside images, including most European languages, Japanese, Korean, Arabic, Vietnamese, etc.
TL;DR
- Qwen2-VL은 이미지, 비디오, 다국어 텍스트를 포함한 다양한 시각적 입력을 처리할 수 있는 최신 비전-언어 모델입니다.
- 모델은 Naive Dynamic Resolution과 Multimodal Rotary Position Embedding (M-ROPE)을 도입하여 임의 해상도의 이미지 처리와 1D 텍스트, 2D 이미지, 3D 비디오 정보의 통합을 가능하게 했습니다.
- Qwen2-VL은 복잡한 문제 해결, 수학적 능력, 문서 이해, 다국어 지원 등 다양한 분야에서 최고 수준의 성능을 보여주며, 오픈소스 및 API를 통해 접근 가능합니다.
1. 소개
Qwen2-VL은 Qwen 모델 계열의 최신 비전-언어 모델로, 2024년 8월 29일에 발표되었습니다. 이 모델은 이전 버전인 Qwen-VL에 비해 상당한 개선을 이루었으며, 다양한 해상도와 비율의 이미지 이해, 20분 이상의 비디오 이해, 모바일 기기나 로봇 등의 조작을 위한 에이전트 기능, 그리고 다국어 지원 등의 새로운 기능을 갖추고 있습니다.
2. 모델 성능
Qwen2-VL은 복잡한 대학 수준의 문제 해결, 수학적 능력, 문서 및 표 이해, 다국어 텍스트-이미지 이해, 일반 시나리오 질문 답변, 비디오 이해, 그리고 에이전트 기반 상호작용 등 6가지 주요 차원에서 평가되었습니다.
2.1 72B 모델 성능
72B 모델은 대부분의 지표에서 최고 수준의 성능을 보여주며, GPT-4나 Claude 3.5-Sonnet와 같은 비공개 모델을 능가하는 경우도 있습니다. 특히 문서 이해 분야에서 두각을 나타냅니다.
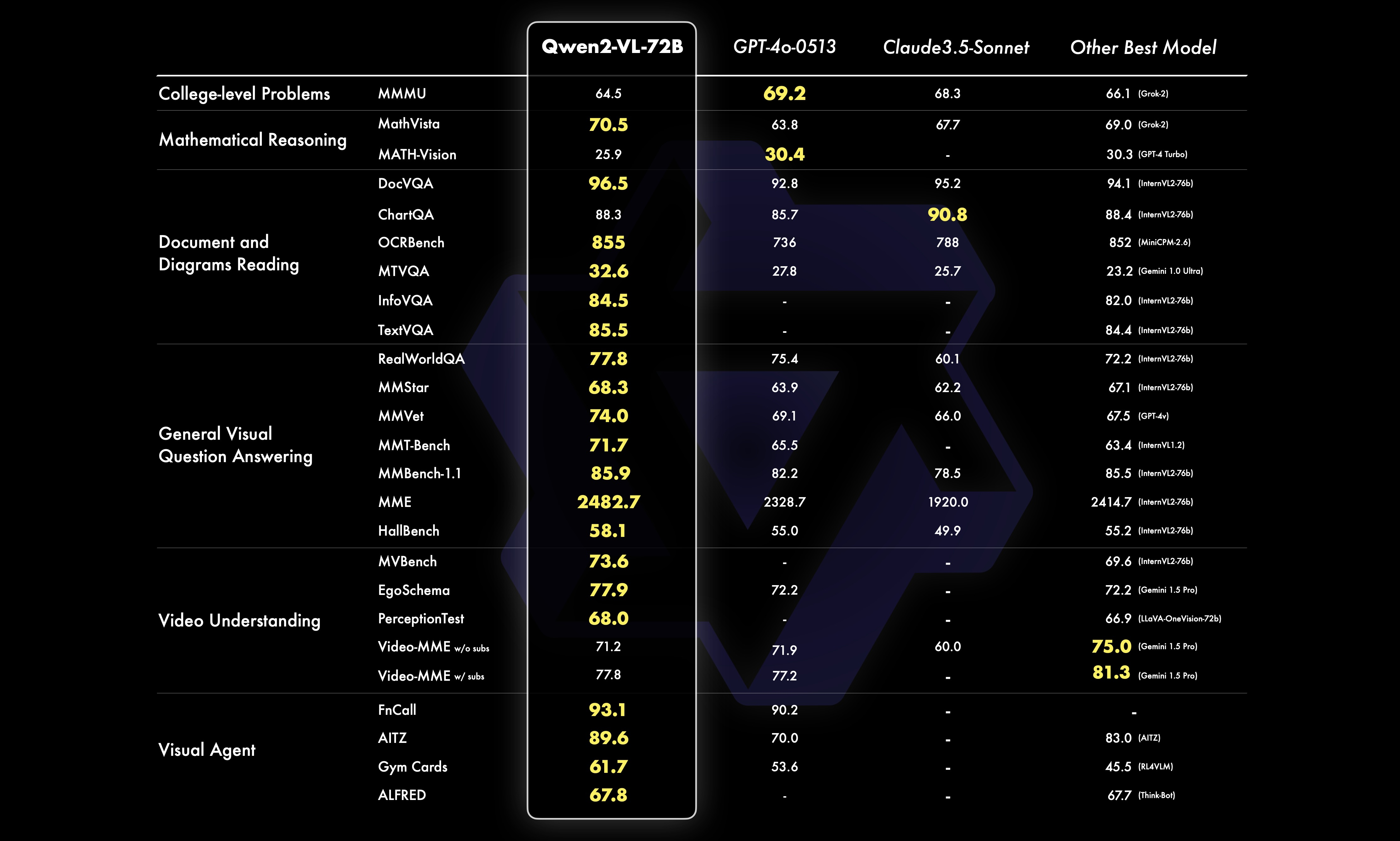
2.2 7B 모델 성능
7B 규모의 모델은 이미지, 다중 이미지, 비디오 입력을 지원하면서도 비용 효율적인 모델 크기에서 경쟁력 있는 성능을 제공합니다. 특히 DocVQA와 같은 문서 이해 작업과 MTVQA로 평가된 이미지의 다국어 텍스트 이해에서 최고 수준의 성능을 보여줍니다.
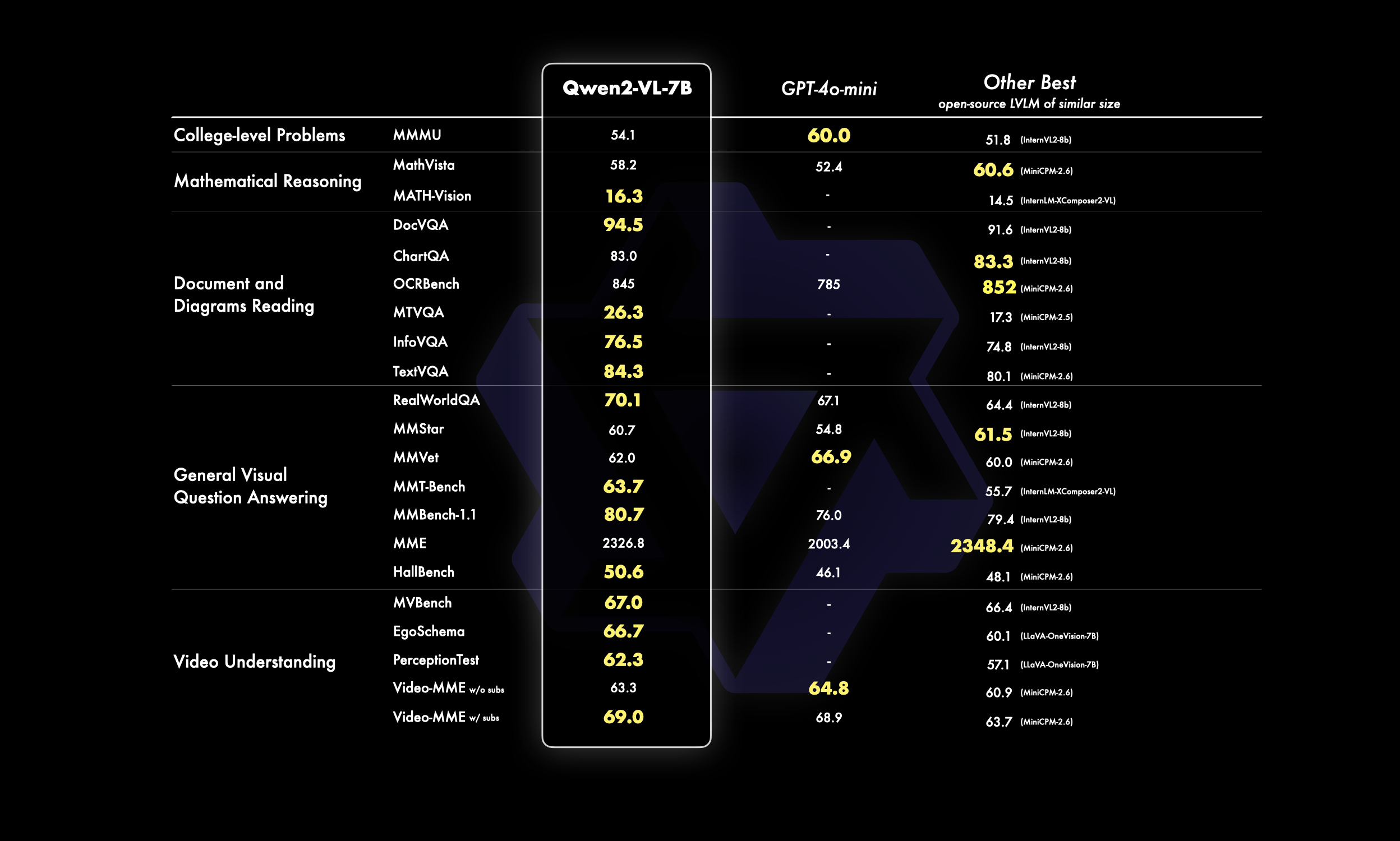
2.3 2B 모델 성능
새롭게 소개된 2B 모델은 모바일 배포를 위해 최적화되었으며, 작은 크기에도 불구하고 이미지, 비디오, 다국어 이해에서 강력한 성능을 보여줍니다. 특히 비디오 관련 작업, 문서 이해, 일반 시나리오 질문 답변에서 유사한 규모의 다른 모델들과 비교했을 때 우수한 성능을 보입니다.
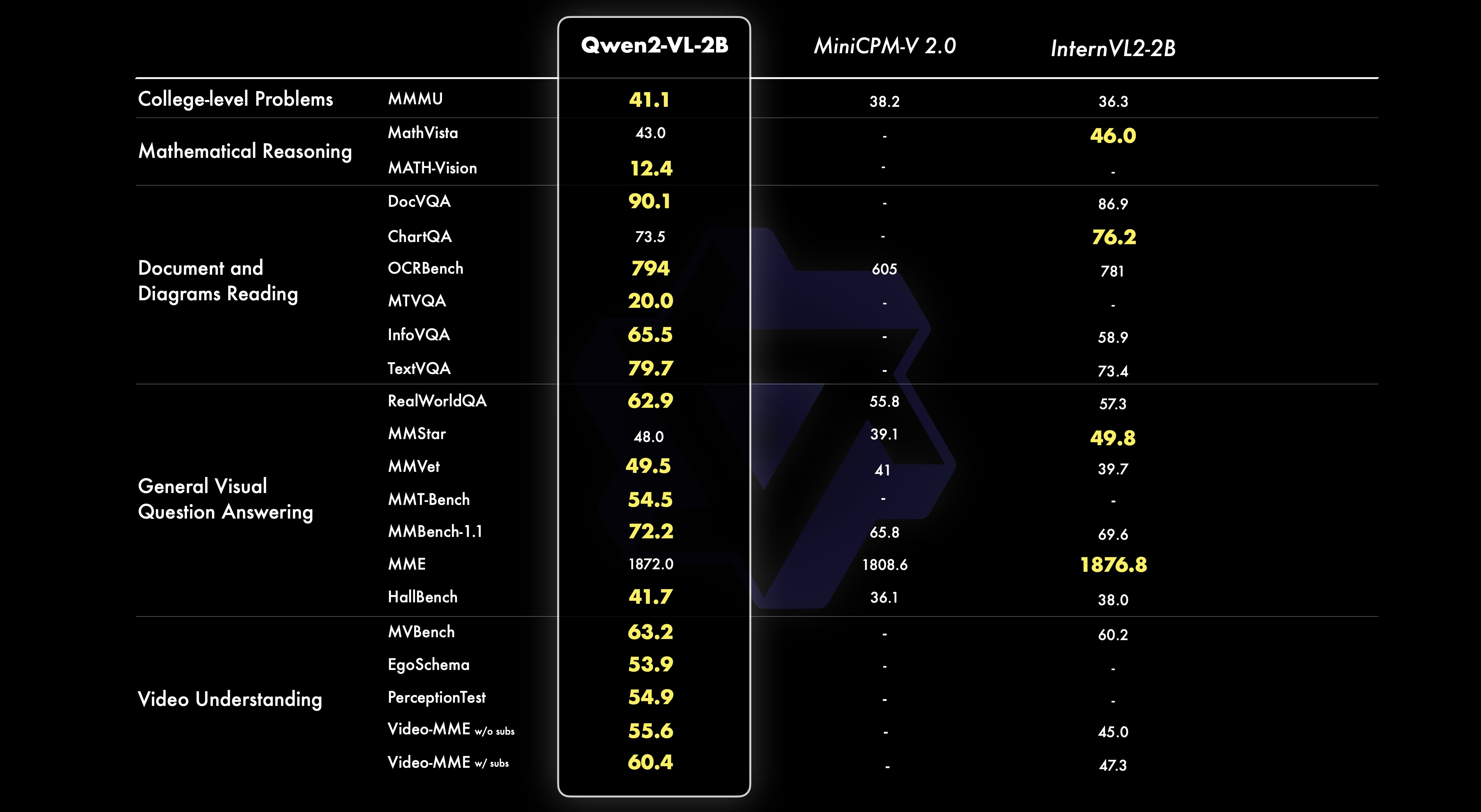
3. 모델 기능
3.1 향상된 인식 능력
Qwen2-VL은 객체 인식 능력이 향상되어 식물과 랜드마크를 넘어 장면 내 여러 객체 간의 복잡한 관계를 이해할 수 있게 되었습니다. 또한 손글씨 텍스트와 이미지 내 다양한 언어 인식 능력이 크게 향상되어 전 세계 사용자들에게 더 접근성 있는 모델이 되었습니다.
3.2 시각적 인퍼런스: 실제 문제 해결
이번 iteration에서 Qwen2-VL의 수학 및 코딩 능력이 크게 향상되었습니다. 모델은 이미지 분석을 통한 문제 해결뿐만 아니라 차트 분석을 통한 복잡한 수학 문제의 해석 및 해결도 가능합니다. 극단적인 종횡비로 왜곡된 이미지도 정확하게 해석할 수 있습니다. 또한 실제 이미지와 차트에서 정보를 추출하는 능력과 instruction following 능력이 강화되었습니다. 이런 시각적 인식과 논리적 인퍼런스의 융합은 모델이 실제적인 문제를 해결할 수 있게 하며, 추상적 개념과 구체적 솔루션 사이의 간극을 좁힙니다.
3.3 비디오 이해 및 실시간 채팅
Qwen2-VL은 정적 이미지를 넘어 비디오 콘텐츠 분석에도 능숙합니다. 비디오 내용을 요약하고, 관련 질문에 답변하며, 실시간으로 지속적인 대화를 유지할 수 있습니다. 이 기능을 통해 개인 비서 역할을 수행하며, 비디오 콘텐츠에서 직접 정보와 통찰력을 제공할 수 있습니다.
3.4 시각적 에이전트 능력: 함수 호출 및 시각적 상호작용
Qwen2-VL은 시각적 에이전트로서 강력한 잠재력을 보여주며, 휴먼의 세계 인식과 유사한 상호작용을 가능하게 합니다.
- 함수 호출: 모델은 시각적 단서를 해석하여 외부 도구를 활용해 실시간 데이터(e.g., 항공편 상태, 날씨 예보, 패키지 추적 등)를 검색할 수 있습니다. 이런 시각적 해석과 기능적 실행의 통합은 정보 관리와 의사 결정을 위한 강력한 도구로 모델의 유용성을 높입니다.
- 시각적 상호작용: 이는 휴먼의 인식을 모방하는 중요한 진전을 나타냅니다. 모델이 휴먼의 감각과 유사하게 시각적 자극과 상호작용할 수 있게 함으로써, AI의 환경 인식 및 반응 능력의 경계를 넓히고 있습니다. 이 기능은 Qwen2-VL이 단순한 관찰자가 아닌 시각적 경험의 적극적인 참여자로 작용할 수 있는 보다 직관적이고 몰입도 높은 상호작용의 길을 열어줍니다.
4. 모델 아키텍처
Qwen2-VL은 Qwen-VL 아키텍처를 기반으로 하며, Vision Transformer (ViT) 모델과 Qwen2 언어 모델을 활용합니다. 모든 변형에서 약 600M 파라미터를 가진 ViT를 사용하여 이미지와 비디오 입력을 원활하게 처리할 수 있도록 설계되었습니다. 비디오의 시각 정보를 효과적으로 인식하고 이해하는 모델의 능력을 더욱 향상시키기 위해 몇 가지 주요 업그레이드를 도입했습니다.
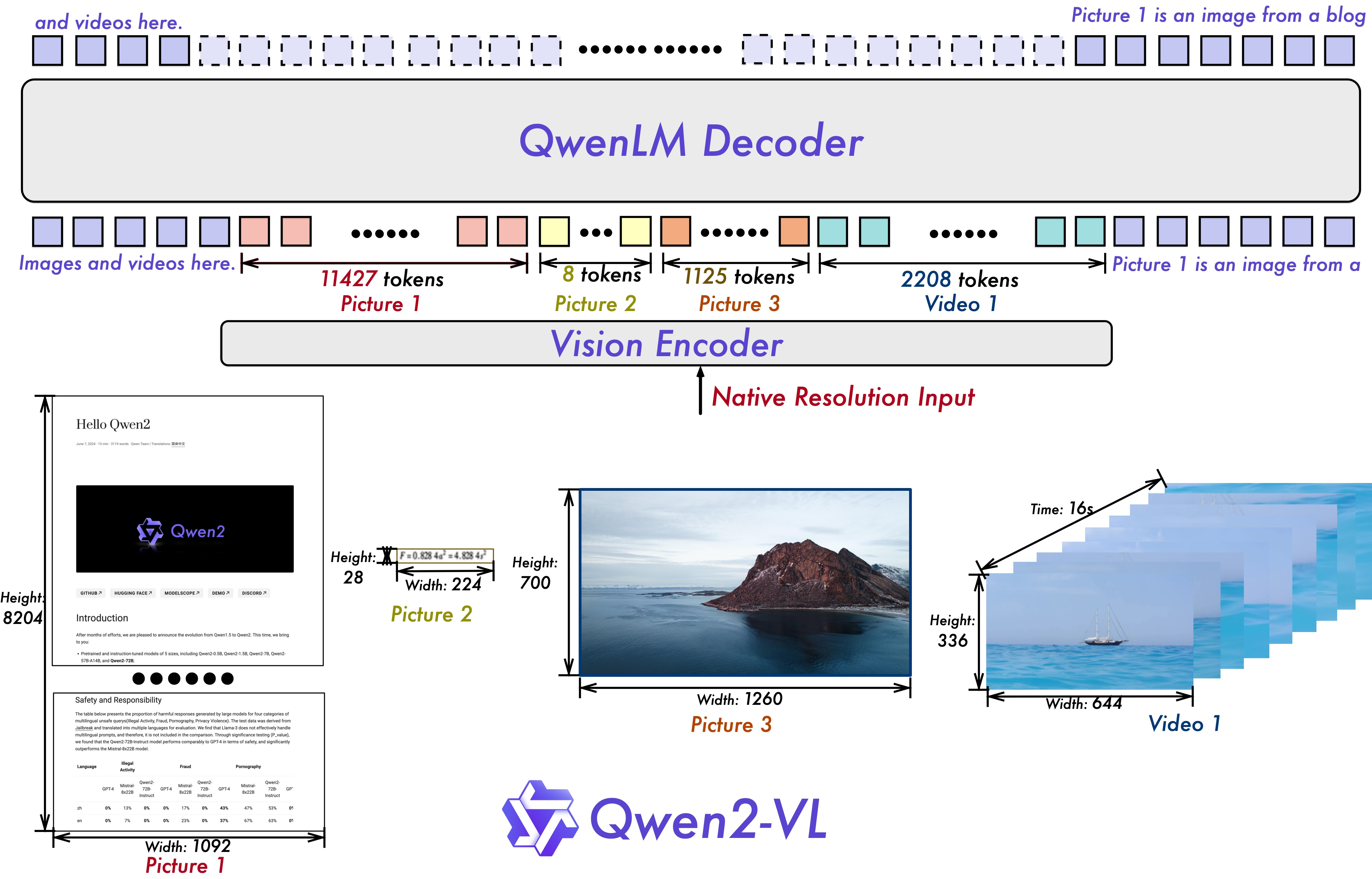
4.1 Naive Dynamic Resolution 지원
Qwen2-VL의 주요 아키텍처 개선 사항 중 하나는 Naive Dynamic Resolution 지원의 구현입니다. 이전 버전과 달리 Qwen2-VL은 임의의 이미지 해상도를 처리할 수 있으며, 이를 동적인 수의 시각적 토큰으로 매핑하여 모델 입력과 이미지의 내재적 정보 간의 일관성을 보장합니다. 이 접근 방식은 휴먼의 시각적 인식과 더 유사하며, 모델이 명확도나 크기에 관계없이 모든 이미지를 처리할 수 있게 합니다.
4.2 Multimodal Rotary Position Embedding (M-ROPE)
또 다른 주요 아키텍처 개선 사항은 Multimodal Rotary Position Embedding (M-ROPE)의 혁신입니다. 원래의 rotary embedding을 시간적 정보와 공간적(높이와 너비) 정보를 나타내는 세 부분으로 분해함으로써, M-ROPE는 LLM이 1D 텍스트, 2D 시각, 3D 비디오 위치 정보를 동시에 포착하고 통합할 수 있게 합니다.

RoPE가 각 토큰의 시퀀스의 위치를 임베딩했다면, M-ROPE는 말 그대로 시간 축을 시퀀스로 사용합니다. 즉, 기존의 VL 모델들이 Cross-modality의 피쳐를 정렬하는 과정이였다면, 해당 M-ROPE의 경우 비디오의 시퀀스와 싱크를 맞춘 리얼 서비스를 고려한 아키텍처로 이번 Qwen2-VL의 경우 비디오 모달과 STT&TTS와의 활용에 대한 서비스를 고려한 것으로 생각할 수도 있을 것 같습니다.
이런 아키텍처 개선은 Qwen2-VL의 성능을 향상시켰습니다. Naive Dynamic Resolution 지원을 통해 모델은 다양한 해상도의 이미지를 더 효과적으로 처리할 수 있게 되었고, M-ROPE의 도입으로 텍스트, 이미지, 비디오 데이터의 복잡한 상호 관계를 더 잘 이해할 수 있게 되었습니다.
1. Naive Dynamic Resolution
이 방법은 입력 이미지의 해상도에 따라 동적으로 토큰 수를 조정합니다.
\[N_{tokens} = \left\lfloor \frac{H \times W}{P^2} \right\rfloor\]$H$와 $W$는 각각 이미지의 높이와 너비이고, $P$는 패치 크기입니다. 이를 통해 모델은 다양한 해상도의 이미지를 일관되게 처리할 수 있습니다.
2. Multimodal Rotary Position Embedding (M-ROPE)
M-ROPE는 기존의 RoPE(Rotary Position Embedding)를 확장한 것으로, 시간과 공간 차원을 모두 고려합니다.
\[PE(t, h, w) = [R_t(\theta_t) \otimes R_h(\theta_h) \otimes R_w(\theta_w)] \times x\]$R_t$, $R_h$, $R_w$는 각각 시간, 높이, 너비에 대한 회전 행렬이고, $\theta_t$, $\theta_h$, $\theta_w$는 해당 차원의 각도입니다. $x$는 입력 벡터입니다.
5. Qwen2-VL 개발하기
Qwen2-VL-72B 모델은 공식 API를 통해 접근할 수 있으며, Qwen2-VL-2B와 Qwen2-VL-7B 모델은 오픈 소스로 제공되어 Hugging Face와 ModelScope에서 사용할 수 있습니다.
Qwen2-VL-72B 모델을 사용하기 위한 코드 예시
from openai import OpenAI
import os
import base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# Path to your image
image_path = "dog_and_girl.jpeg"
# Getting the base64 string
base64_image = encode_image(image_path)
def get_response():
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-vl-max-0809",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What is this?"},
{
"type": "image_url",
"image_url": {
"url": "https://dashscope.oss-cn-beijing.aliyuncs.com/images/dog_and_girl.jpeg"
},
},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{base64_image}"},
},
],
}
],
top_p=0.8,
stream=True,
stream_options={"include_usage": True},
)
for chunk in completion:
print(chunk.model_dump_json())
if __name__ == "__main__":
get_response()
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2-VL-7B-Instruct", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2-VL-7B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
# The default range for the number of visual tokens per image in the model is 4-16384. You can set min_pixels and max_pixels according to your needs, such as a token count range of 256-1280, to balance speed and memory usage.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)