MoD | VideoLLM-MoD
- Related Project: Private
- Category: Paper Review
- Date: 2024-08-29
VideoLLM-MoD: Efficient Video-Language Streaming with Mixture-of-Depths Vision Computation
- url: https://arxiv.org/abs/2408.16730
- pdf: https://arxiv.org/pdf/2408.16730
- html: https://arxiv.org/html/2408.16730v1
- abstract: A well-known dilemma in large vision-language models (e.g., GPT-4, LLaVA) is that while increasing the number of vision tokens generally enhances visual understanding, it also significantly raises memory and computational costs, especially in long-term, dense video frame streaming scenarios. Although learnable approaches like Q-Former and Perceiver Resampler have been developed to reduce the vision token burden, they overlook the context causally modeled by LLMs (i.e., key-value cache), potentially leading to missed visual cues when addressing user queries. In this paper, we introduce a novel approach to reduce vision compute by leveraging redundant vision tokens “skipping layers” rather than decreasing the number of vision tokens. Our method, VideoLLM-MoD, is inspired by mixture-of-depths LLMs and addresses the challenge of numerous vision tokens in long-term or streaming video. Specifically, for each transformer layer, we learn to skip the computation for a high proportion (e.g., 80\%) of vision tokens, passing them directly to the next layer. This approach significantly enhances model efficiency, achieving approximately 42\% time and 30\% memory savings for the entire training. Moreover, our method reduces the computation in the context and avoid decreasing the vision tokens, thus preserving or even improving performance compared to the vanilla model. We conduct extensive experiments to demonstrate the effectiveness of VideoLLM-MoD, showing its state-of-the-art results on multiple benchmarks, including narration, forecasting, and summarization tasks in COIN, Ego4D, and Ego-Exo4D datasets.
TL;DR
- VideoLLM-MoD는 온라인 비디오 처리를 위한 효율적인 대규모 멀티모달 모델로, 비전 토큰의 “레이어 스킵” 기법을 통해 계산 비용을 줄입니다.
- LayerExpert 모듈을 도입하여 각 프레임의 중요한 비전 토큰만을 선택적으로 처리함으로써 컴퓨팅 리소스를 효율적으로 할당합니다.
- 이 접근 방식은 기존 모델 대비 약 42%의 시간과 30%의 메모리를 절약하면서도 성능을 유지하거나 개선하는 효과를 보여줍니다.
VideoLLM-MoD는 “Mixture-of-Depth” 접근 방식을 사용해 (핵심) 각 비디오 프레임에서 LayerExpert 모듈이 중요한 비전 토큰을 선택적으로 처리해 선택된 토큰만 후속 self-attention과 FFN 연산을 거치고, 나머지는 residual connection을 통해 건너뜁니다.
이 방식으로 계산 비용을 크게 줄이면서도 중요한 시각 정보를 유지할 수 있으며, 모델이 각 레이어에서 중요한 시각 정보에 집중하도록 강제하여 더 강건한 학습을 가능케한다고 언급합니다.
-
LayerExpert 모듈 도입
특정 레이어에서 어떤 비전 토큰을 처리할지 결정하는 학습 가능한 모듈을 도입
-
계산 비용 감소
Full-computation 베이스라인 대비 약 40% 적은 계산량으로 유사하거나 더 나은 성능을 달성
-
성능 향상
비전 토큰의 선택적 처리를 통해 오히려 과적합을 줄이고 더 강건한 모델을 학습할 수 있음을 발견했다고 보고 (이건 조금 더 살펴보아야…)
-
온라인 및 오프라인 시나리오 적용
제안된 방법이 실시간 비디오 처리뿐만 아니라 전통적인 오프라인 비디오 처리에도 효과적임을 입증
1. 소개 (Introduction)
최근 GPT-4와 같은 대규모 언어모델(Large Language Models, LLMs)의 발전으로 인해 JARVIS와 같은 AI 어시스턴트의 개발이 현실화되고 있습니다. 이런 어시스턴트는 스트리밍 방식으로 작동하며 항상 켜져 있고 사용자와의 상호작용을 위해 멀티모달 기능을 갖추어야 합니다.
기존의 비디오 기반 대규모 멀티모달 모델(Large Multi-modal Models, LMMs)들은 일반적인 시각 콘텐츠 이해와 인퍼런스에 있어 상당한 능력을 보여주었습니다. 하지만 멀티모달 모델들은 주로 오프라인 설정에서 작동하며, 비디오 내의 일부 샘플링된 프레임에 대해서만 이벤트 수준의 응답을 제공합니다. 이는 연속적인 비디오 프레임에 대해 즉각적이고 간결하며 프레임에 맞춘 답변이 필요한 온라인 설정에는 적합하지 않습니다.
GPT-4와 가장 유사한 모델 개념은 VideoLLM-online입니다. 이 모델은 지속적으로 비디오 프레임을 받아들이고 사용자 쿼리에 대해 시간적으로 정렬된 응답을 제공합니다. 예를 들어, “소금을 넣어야 할 때를 알려주세요”라는 쿼리에 대해, 온라인 어시스턴트는 각 들어오는 프레임을 평가하고 역사적인 시각 및 언어적 컨텍스트를 고려하여 시간에 맞춘 제안을 해야 합니다.
하지만 온라인 어시스턴트는 긴 비디오의 모든 프레임에 대해 인과적 모델링을 수행해야 하기 때문에 상당한 계산 요구사항에 직면합니다. 현재의 접근 방식은 각 프레임에 대해 CLS 토큰만을 사용하여 시각적 능력을 공간적 이해로 제한하고 있어, 세밀한 장면 이해가 필요한 시나리오에는 부적합합니다.
프레임당 더 많은 풀링된 공간 토큰을 통합하여 공간적 이해를 향상시키는 것이 직관적입니다. (Figure 1 참조) 그러나 온라인 시나리오에서 비전 해상도를 확장하는 것은 어려운 과제로 기존 LLMs의 밀집 어텐션 메커니즘과 딥 레이어 디자인으로 인해, 비전 토큰 수가 증가함에 따라 GPU 메모리와 학습 시간을 포함한 학습 비용이 이차적으로 증가합니다(e.g., 600개 프레임으로 구성된 비디오에 대해 0.6k → 6k 비전 토큰).
이 논문에서는 온라인 비디오 대규모 언어모델을 위한 효율적인 비전 해상도 확장 접근 방식인 VideoLLM-MoD를 제안합니다. Mixture-of-Experts (MoE)에서 영감을 받아, 특정 블록의 비전 토큰이 후속 셀프 어텐션 및 FFN 연산으로 라우팅되거나 잔차 연결을 통해 우회될 수 있다고 제안합니다. 이 접근 방식을 비전 토큰에 대한 Mixture-of-Depth라고 부르며, 중복되는 비전 정보를 자연스럽게 줄일 수 있습니다.
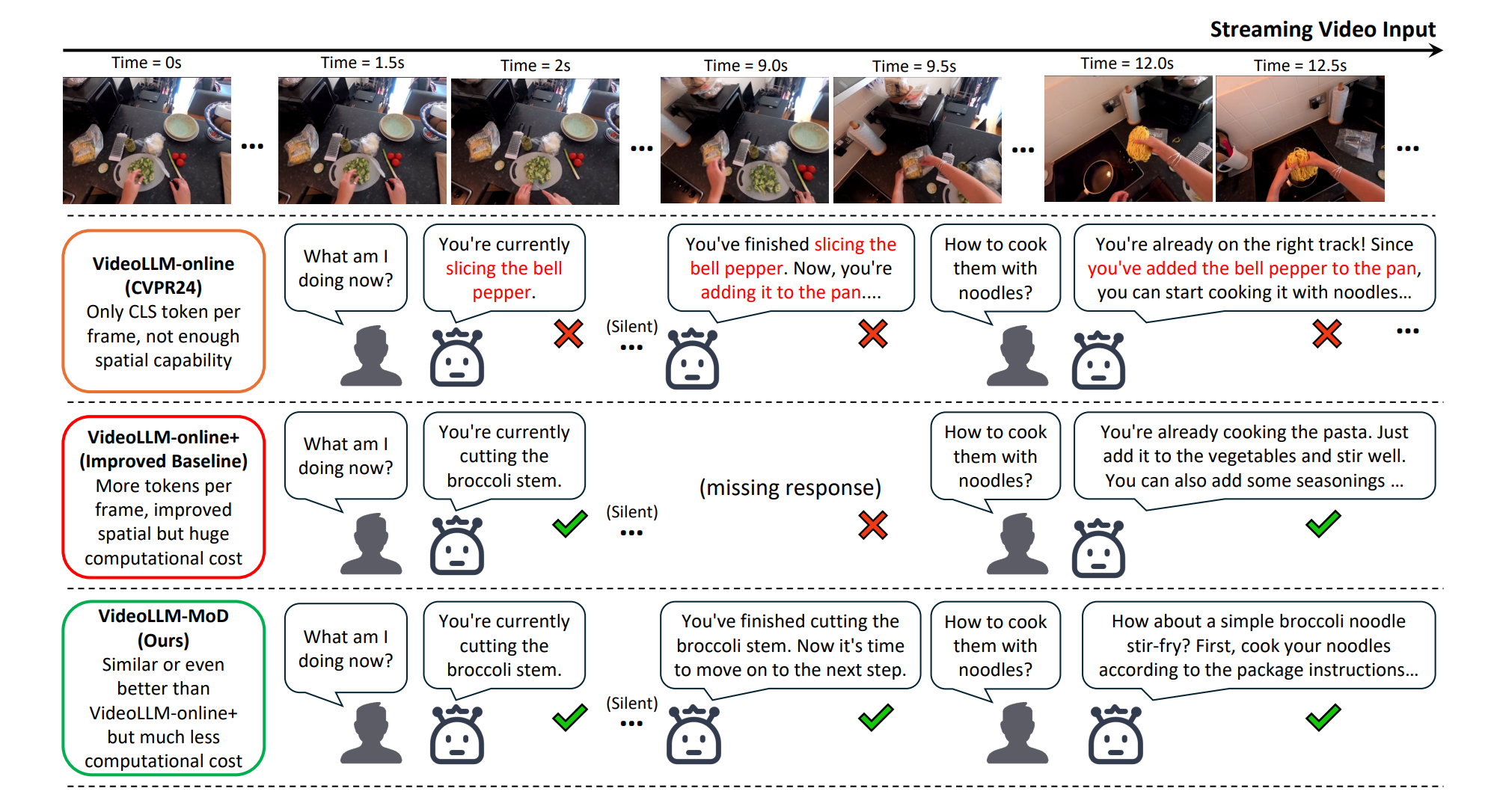
Figure 1: Cases of VIDEOLLM-MOD on Ego4D GoalStep [58] video. Using only CLS token often results in spatial understanding errors, e.g., mistaking ‘broccoli’ for ‘bell pepper.’ VIDEOLLM-MOD improves fine-grained spatial ability by integrating more spatial tokens while reducing computation
costs compared to the improved baseline. Text in red indicates incorrect response.
VideoLLM-MoD의 핵심 아이디어는 각 프레임에서 중요한 비전 토큰만을 선택적으로 처리하는 것으로 이를 위해 LayerExpert라는 학습 가능한 모듈을 도입합니다. LayerExpert는 다음과 같은 수식으로 표현될 수 있습니다.
\[P(t_i) = \text{softmax}(W \cdot f(t_i) + b)\]- $t_i$는 $i$번째 비전 토큰
- $f(t_i)$는 토큰의 특징 벡터
- $W$와 $b$는 학습 가능한 가중치와 편향
- $P(t_i)$는 해당 토큰이 처리되어야 할 확률
이 확률을 기반으로 top-k 라우팅 메커니즘을 사용하여 처리할 토큰을 선택합니다.
\[\text{selected_tokens} = \text{topk}(P(t_1), P(t_2), ..., P(t_n), k)\]선택된 토큰들만 후속 셀프 어텐션과 FFN 연산을 거치게 되며, 나머지는 잔차 연결을 통해 스킵됩니다. 이 과정은 다음과 같이 표현될 수 있습니다.
\[\text{output} = \begin{cases} \text{SelfAttention}(\text{FFN}(t_i)) & \text{if } t_i \in \text{selected_tokens} \\ t_i & \text{otherwise} \end{cases}\]이런 접근 방식은 컨텍스트의 완전성을 보존하면서도 계산량을 크게 줄일 수 있습니다.
기술적 기여는 다음과 같습니다.
- 계산 비용을 줄이면서 비슷하거나 더 나은 성능을 달성하는 온라인 VideoLLM을 위한 효율적인 비전 해상도 확장 접근 방식인 VideoLLM-MoD를 제안합니다.
- 특정 레이어에서 어떤 비전 토큰을 처리해야 하는지 결정하는 LayerExpert를 제안하여 모델이 들어오는 프레임 내의 중요한 영역에 적응적으로 계산을 할당할 수 있게 합니다.
- Ego4D, EgoExo4D, COIN 벤치마크에서의 실험을 통해 VideoLLM-MoD의 효과성과 일반화 가능성을 입증합니다.
이런 접근 방식은 온라인 비디오 처리의 효율성을 크게 향상시키면서도 모델의 성능을 유지하거나 개선할 수 있음을 보여줍니다.
2. 관련 연구 (Related Work)
2.1 Transformer 기반 모델의 효율적 모델링
Transformer 모델의 가장 큰 문제점 중 하나는 시퀀스 길이에 따른 제곱 복잡도입니다. 이는 시퀀스 길이를 확장하는 데 주요 병목 현상이 됩니다. 최근의 대규모 멀티모달 모델(LMMs)에서는 고정된 크기의 접두사 비전 토큰을 사용하여 효율성을 향상시켰습니다. 그러나 이 문제는 온라인 비디오 시나리오에서 더욱 두드러집니다.
기존의 대규모 언어모델(LLMs) 연구에서는 성능을 유지하면서 인퍼런스 시 계산 비용을 줄이기 위해 희소 계산을 사용 그러나 이런 방법들은 여전히 상당한 학습 비용을 필요로 합니다. 토큰 가지치기와 병합 기술을 통해 학습 비용을 줄이려는 노력도 있었지만, 이는 오프라인 계산을 필요로 하기 때문에 온라인 시나리오에는 적합하지 않습니다.
Mixture-of-Depth 접근 방식은 언어 토큰에 대한 모델 깊이 전반에 걸친 계산 할당을 조사하여 성능과 속도의 균형을 맞추었습니다. VideoLLM-MoD는 이 접근 방식을 온라인 비디오로 확장합니다. 모델 깊이에 따라 컨텍스트 내 비전 계산을 줄이는 것이 성능을 유지할 뿐만 아니라 비디오의 높은 중복성을 제거함으로써 성능을 향상시킬 수 있다는 것을 발견
2.2 온라인 비디오 이해를 위한 대규모 멀티모달 모델
최근의 대규모 멀티모달 모델(LMMs)은 시간적 행동 위치 파악, 비디오 대화 및 질문 답변과 같은 다양한 표준 벤치마크를 다룰 수 있습니다. 그러나 이런 모델들은 “오프라인” 설정에서 전체 비디오 프레임을 분석하여 예측을 수행하며, 증강 현실(AR) 안경이나 자율 주행 시스템과 같은 실시간 애플리케이션에 최적화되어 있지 않습니다.
이런 수요 증가에 대응하여, 현재 타임스탬프에서 이벤트를 해석하는 온라인 시나리오를 위한 벤치마크가 점점 더 중요해지고 있습니다. VideoLLM-online은 온라인 비디오 시나리오에서 LLMs를 사용하여 어시스턴트를 구축하는 첫 시도였습니다. 그러나 이 모델은 각 프레임을 표현하기 위해 단일 CLS 토큰만을 사용하여 공간적 능력이 제한적이며, 비전 규모를 확장하는 것은 계산적으로 비용이 많이 듭니다.
VideoLLM-MoD는 컨텍스트 내 비전 계산을 줄임으로써 비전 해상도를 효율적으로 확장하는 방법을 제안합니다. 이를 통해 높은 계산 비용 없이 공간적 능력을 향상시킬 수 있습니다.
2.3 대규모 멀티모달 모델을 위한 비전 해상도 확장
LMMs의 비전 해상도를 확장하는 것은 비전 능력을 향상시키는 효과적인 방법입니다. 예를 들어, LLaVA-NeXT는 LLaVA-1.5보다 5배 더 많은 비전 토큰을 사용하여 향상된 비전 이해를 달성 그러나 온라인 비디오 시나리오에서 비전 토큰을 확장하는 것은 상당한 챌린지를 제시합니다. 긴 비디오의 모든 들어오는 프레임을 처리해야 하기 때문에 학습 비용이 비전 토큰의 확장에 따라 이차적으로 증가합니다.
LLMs에서 긴 컨텍스트 비전 토큰을 처리하기 위해, CogAgent는 디코더 레이어 전반에 걸친 크로스 어텐션를 통해 고해상도 이미지 특징을 저해상도 경로에 통합합니다. LLaMA-VID는 컨텍스트 주의를 사용하여 각 프레임을 두 개의 키 토큰으로 표현합니다. 그러나 이 두 접근 방식은 오프라인 비디오에만 적용 가능하며, 추가적인 크로스 어텐션 메커니즘으로 인한 높은 지연 시간은 온라인 시나리오에서 받아들일 수 없습니다.
반면에 VideoLLM-MoD는 지속적으로 스트리밍 비디오-언어 입력을 받아들이고 추가적인 오버헤드 없이 모든 전방 패스 동안 효율적으로 계산을 줄일 수 있습니다. 이는 시간에 맞춘 응답을 가능하게 하여 실시간 애플리케이션에 적합합니다.
VideoLLM-MoD의 핵심 아이디어는 각 레이어에서 처리할 비전 토큰을 선택적으로 결정하는 것입니다. 이를 위해 LayerExpert라는 학습 가능한 모듈을 도입 LayerExpert의 작동 원리는 다음과 같습니다.
-
각 비전 토큰 $t_i$에 대해, LayerExpert는 해당 토큰이 현재 레이어에서 처리되어야 할 확률을 계산합니다.
\[P(t_i) = \sigma(W \cdot f(t_i) + b)\]$\sigma$는 시그모이드 함수, $W$와 $b$는 학습 가능한 가중치와 편향, $f(t_i)$는 토큰의 특징 벡터
-
계산된 확률을 기반으로 top-k 선택을 수행합니다.
\[\text{selected\_tokens} = \text{topk}(\{P(t_i) \| i = 1, ..., N\}, k)\]N은 총 비전 토큰의 수이고, k는 선택할 토큰의 수
-
선택된 토큰들만 현재 레이어의 셀프 어텐션과 FFN 연산을 거치게 됩니다.
\[\text{output}_i = \begin{cases} \text{FFN}(\text{SelfAttention}(t_i)) & \text{if } t_i \in \text{selected\_tokens} \\ t_i & \text{otherwise} \end{cases}\]
이런 방식으로, VideoLLM-MoD는 각 레이어에서 중요한 비전 토큰만을 선택적으로 처리함으로써 계산 효율성을 크게 향상시킵니다. 동시에 모든 토큰을 컨텍스트에 유지함으로써 정보의 손실을 최소화합니다.
이 접근 방식의 효과성은 다양한 벤치마크에서 입증되었습니다. 특히 Ego4D, EgoExo4D, COIN 데이터셋을 사용하여 실험을 수행
- Ego4D: 일상생활의 자연스러운 첫 인칭 시점 비디오를 포함하는 대규모 데이터셋
- EgoExo4D: 첫 인칭과 제3자 시점의 비디오를 동시에 포함하는 멀티뷰 데이터셋
- COIN: 다양한 일상 작업의 교육용 비디오를 포함하는 데이터셋
이런 다양한 데이터셋에서의 실험을 통해 VideoLLM-MoD가 다양한 비디오 이해 작업에서 효과적임을 보여주었습니다. 특히 서술(narration), 예측(forecasting), 요약(summarization) 작업에서 우수한 성능을 달성
결론적으로, 비전 토큰의 선택적 처리를 통해 계산 비용을 크게 줄이면서도 모델의 성능을 유지하거나 개선할 수 있음을 보여줍니다.
3. 방법
이 섹션에서는 더 큰 비전 해상도로 온라인 비디오 대규모 언어모델을 효율적으로 학습하기 위한 VideoLLM-MoD 프레임워크에 대한 방법을 소개합니다.
3.1 모델 아키텍처
전체 모델 아키텍처는 Figure 3과 같이 LLaVA와 유사한 디자인을 갖고 있습니다. 모델은 세 가지 주요 구성 요소로 이루어져 있습니다.
- 이미지 인코더
- MLP 프로젝터
- 언어 모델
각 비디오 프레임 임베딩은 $(1 + h_p \times w_p) \times c$ 형태로 표현되며, 이는 CLS 토큰과 평균 풀링된 공간 토큰을 나타냅니다. 이미지 인코더로 추출된 프레임 임베딩은 MLP 프로젝터를 통해 프레임 토큰으로 처리됩니다. 이 토큰들은 언어 토큰과 interleave되어 LLM의 입력을 형성합니다. 효율적인 튜닝을 위해 LLM의 모든 선형 레이어에 LoRA를 적용합니다. 가장 중요한 비전 토큰을 선택하기 위해 일부 레이어에는 LayerExpert 모듈이 장착되어 있습니다.
VideoLLM-online을 따라, 언어 모델링(LM) 손실 외에도 불필요한 응답 출력을 방지하기 위한 추가적인 스트리밍 손실을 사용합니다. 두 훈련 목표 모두 다음과 같은 교차 엔트로피 손실을 사용합니다.
\[\mathcal{L} = \frac{1}{N} \sum_{j=1}^N \left( -l_{j+1} \log P_j[\text{Txt}_{j+1}] \underbrace{}_{\text{LM Loss}} - \sigma s_j \log P_j[\text{EOS}] \underbrace{}_{\text{Streaming Loss}} \right)\]$l_j$와 $s_j$는 조건 지시자로
- $l_j$는 $j$번째 토큰이 언어 응답 토큰이면 1, 그렇지 않으면 0입니다.
- $s_j$는 (1) $j$번째 토큰이 프레임의 마지막 토큰이고, (2) $l_{j+1} = 0$인 경우 1입니다.
스트리밍 EOS 손실은 응답 이전 프레임들에 적용됩니다. $P_j[\text{Txt}_{j+1}]$은 $j$번째 토큰에 대한 언어 모델 헤드의 출력으로, $(j+1)$번째 텍스트 토큰과 관련된 확률을 나타냅니다. $P_j[\text{EOS}]$는 EOS 토큰에 대한 확률을 나타냅니다. 두 목표는 스트리밍 손실 가중치 $\sigma$를 사용하여 균형을 맞춥니다.
3.2 온라인 비디오를 위한 비전 해상도 확장
개발 동기 Figure 1에서 보듯이 온라인 어시스턴트의 성능은 비전 규모(즉, $(1 + h_p \times w_p)$)가 증가함에 따라 향상됩니다. 그러나 온라인 시나리오에서 비전 해상도를 향상시키는 것은 도전적인 과제입니다. 비디오 길이에 따라 비전 토큰의 수가 증가하여 계산 복잡도가 이차적으로 증가하기 때문입니다. 표 7에서 보듯이, 온라인 videoLLM은 완전한 시각 및 언어적 역사적 맥락의 무결성을 유지하기 위해 학습과 인퍼런스 모두에서 긴 비디오의 모든 프레임을 처리해야 하므로 GPU 메모리와 계산 리소스에 상당한 요구를 합니다.
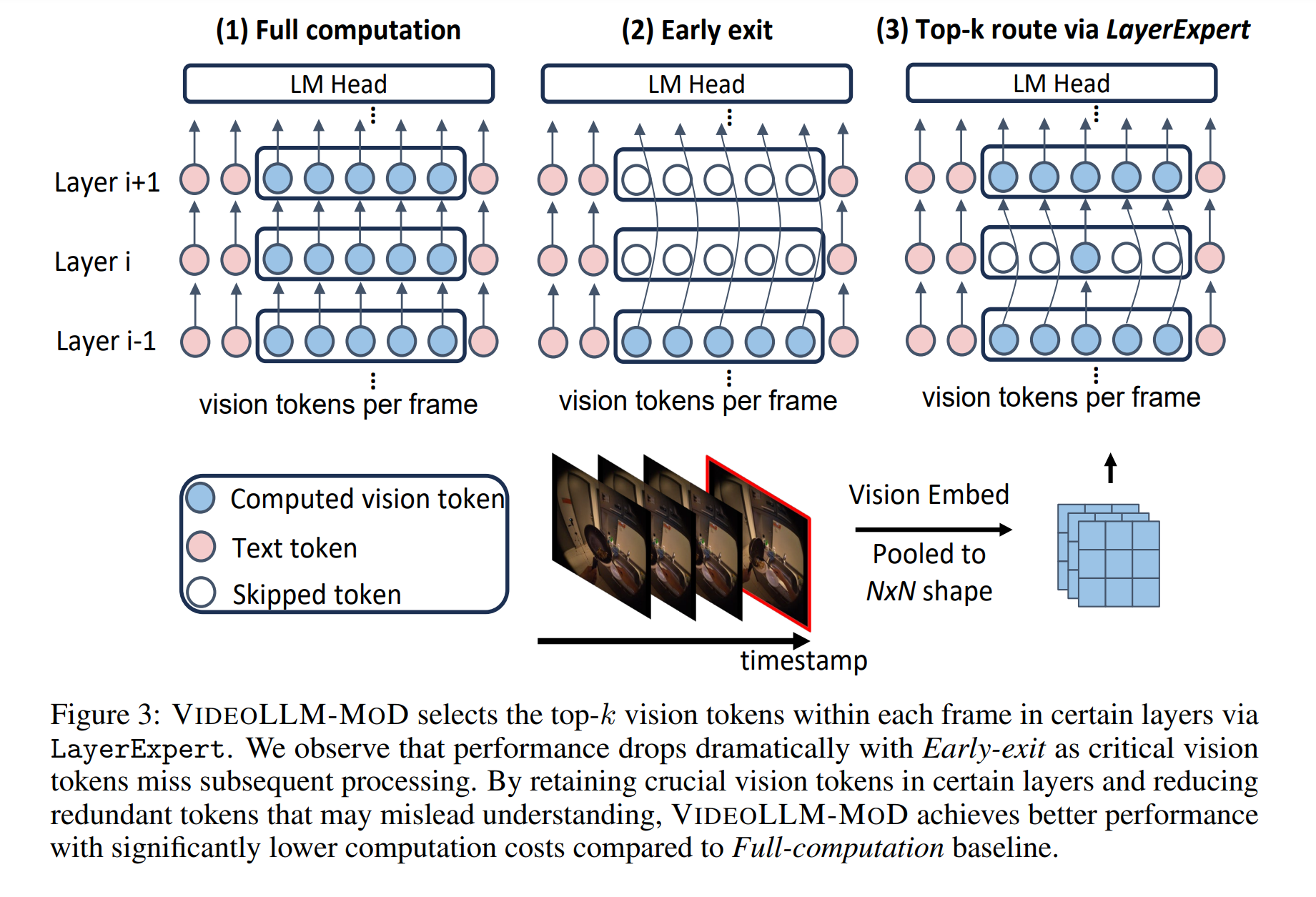
비디오가 시간적, 공간적으로 높은 중복성을 보인다고 가정합니다. 연속된 프레임들은 종종 그 내용의 많은 부분을 공유하기 때문입니다, 특히 프레임들이 빠른 연속으로 캡처된 경우에 그렇습니다. 휴먼이 주변을 지속적으로 “보지만” 항상 모든 시각적 세부사항에 “집중”하지는 않는 것처럼, 깊은 모델로 처리할 때 특정 레이어에서 일부 비전 토큰을 건너뛰는 것이 직관적입니다.
특정 블록에서 LayerExpert를 통한 비전 토큰 선택: 각 블록마다 LayerExpert 모듈을 사용하여 선택/라우팅 동작을 학습합니다. 즉, 어떤 비전 토큰이 더 많거나 적은 처리를 필요로 하는지 학습합니다. LayerExpert는 프레임 내 각 비전 토큰의 “중요도 점수”(스칼라 가중치)를 식별하고, 상위 $k$개의 비전 토큰만이 후속 연산에 의해 처리됩니다. 주목할 점은 온라인 스트리밍 시나리오에서 서로 다른 프레임의 비전 토큰들이 인과적 방식으로 처리되므로, 상위 $k$ 선택은 프레임 수준에서 수행됩니다. 즉, 각 프레임 내에서 상위 $k$개의 비전 토큰이 선택됩니다. 언어 토큰은 중복성이 훨씬 낮고 비전 토큰에 비해 수가 훨씬 적기 때문에 항상 처리됩니다.
구체적으로, $n_t$개의 언어 토큰과 $n_v$개의 비전 토큰이 interleave된 길이 $N$의 시퀀스가 있다고 가정합니다. 주어진 레이어 $l$에 대해, 시퀀스는 $X_l = {\text{Interleaved}(x_{t_i}^l, x_{v_i}^l) | 1 \leq t_i \leq n_t, 1 \leq v_i \leq n_v}$입니다. 각 프레임의 $(1 + h_p \times w_p)$ 비전 토큰 내에서, LayerExpert는 선형 투영 $\mu_{t_i}^l = w_\theta^T x_{v_i}^l$을 사용하여 주어진 비전 토큰의 중요도 점수 $\mu$를 결정합니다. 그런 다음, 비전 토큰은 비전 유지 비율 $r$에 따라 후속 처리를 위해 선택되며, $P_r^l$은 프레임 비전 토큰의 가중치 $\mu$ 중 $(1-r)$번째 백분위수입니다. 주어진 비전 토큰에 대한 블록의 출력은 다음과 같습니다.
\[x_{v_i}^{l+1} = \begin{cases} \mu_{v_i} f_i(\hat{\mathbf{X}}^l) + x_{v_i}^l, & \text{if } \mu_{v_i} > P_r^l \\ x_{v_i}^l, & \text{if } \mu_{v_i} \leq P_r^l \end{cases}\]$\hat{X}^l$은 레이어 $l$에서 모든 언어 토큰과 상위 $k$개의 비전 토큰으로 구성된 interleave된 토큰을 나타내며, $f_i$는 후속 self-attention과 FFN 연산을 나타냅니다.
3.3 VideoLLM-MoD의 효율성 분석
접근 방식의 계산 비용을 추가로 분석합니다. 디코더 레이어를 제외한 다른 모듈(LayerExpert, MLP 프로젝터, LoRA)은 특정 입력이 주어졌을 때 고정되어 있으며 언어 모델의 디코더 레이어보다 크기가 훨씬 작습니다. 따라서 이들의 FLOPs 계산을 무시하고 다중 헤드 주의(MHA)와 피드포워드 네트워크(FFN) 모듈의 계산만을 FLOPs 추정에 고려합니다.
언어 모델이 총 $L$개의 숨겨진 레이어를 가지고 있고, $d$와 $m$이 각각 숨겨진 크기 차원과 FFN의 중간 크기를 나타낸다고 가정합니다. 입력 시퀀스는 $n_v$개의 비전 토큰과 $n_t$개의 언어 토큰으로 interleave되어 있습니다. 전체 디코더 레이어 중 $K$개의 레이어에 비전 유지 비율 $r$을 가진 LayerExpert를 삽입합니다. 각 주의 헤드에 대해, LayerExpert가 있는 레이어의 이론적 FLOPs는 다음과 같습니다.
\[\text{FLOPs}_\text{LayerExpert} = 4(n_t + rn_v)d^2 + 2(n_t + rn_v)^2d + 2(n_t + rn_v)dm\]바닐라 트랜스포머 레이어에서는 $r = 1$입니다. 온라인 비디오 설정에서는 비전 토큰이 언어 토큰보다 훨씬 많으므로, 즉 $n_v \gg n_t$이므로, 전체 디코더의 FLOPs는 비전 유지 비율 $r$과 LayerExpert가 장착된 레이어 수에 비례합니다.
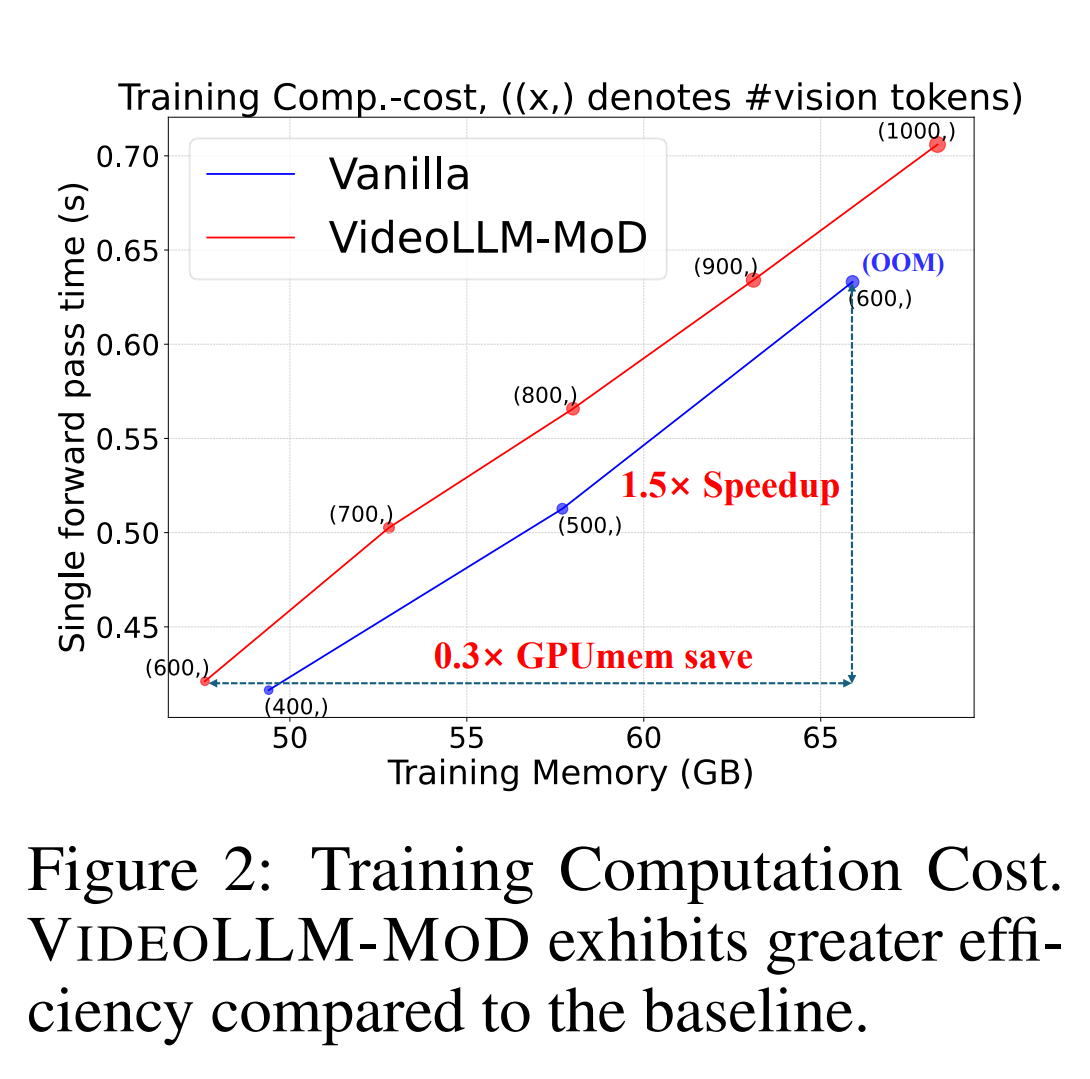
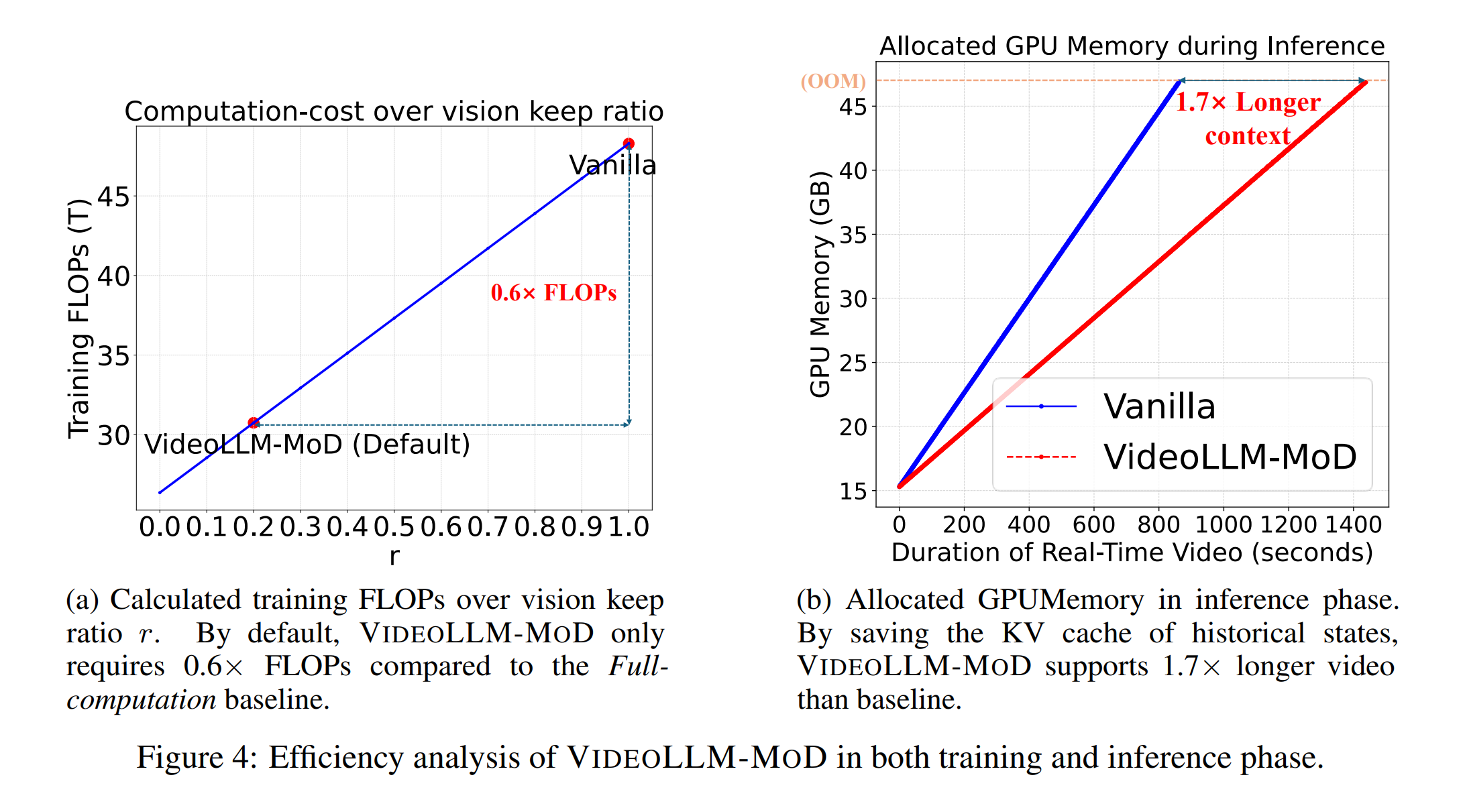
\[\text{FLOPs}_\text{decoder} = \sum_{k=K+1}^L \text{FLOPs}_\text{LayerExpert}(r) + \sum_{k=K+1}^L \text{FLOPs}_\text{vanilla}\]실제 시나리오에서 학습 단계 동안 VideoLLM-MoD와 Full-computation 베이스 라인의 총 FLOPs를 추가로 계산 Figure 4(a)에서 보듯이, VideoLLM-MoD의 실제 FLOPs는 베이스 라인의 0.6배에 불과하며, 각 프레임의 비전 규모가 더 커지면 이 값을 더욱 줄일 수 있어 본 논문의 접근 방식의 향상된 확장성을 보여줍니다.
특정 레이어에서 중복되는 비전 토큰을 건너뛰면서, VideoLLM-MoD는 학습 계산 비용을 줄일 뿐만 아니라 인퍼런스 효율성도 개선합니다. Figure 4(b)에서 보듯이, 역사적 상태의 중간 KV 캐시를 줄임으로써 베이스 라인에 비해 1.7배 더 긴 컨텍스트를 지원하고 비교 가능한 인퍼런스 속도를 달성할 수 있어 실제 응용 프로그램에 배포하기 용이합니다.
- VideoLLM-MoD는 온라인 및 오프라인 비디오 처리를 위한 효율적인 모델로, Ego4D, EgoExo4D, COIN 등 다양한 데이터셋에서 검증되었습니다.
- LayerExpert 모듈을 통해 중요한 비전 토큰을 선택적으로 처리하여 계산 비용을 줄이면서도 성능을 유지하거나 개선합니다.
- 실험 결과, VideoLLM-MoD는 Full-computation 모델과 비교하여 더 적은 계산 비용으로 유사하거나 더 나은 성능을 달성
4. 실험 (Experiments)
4.1 실험 설정 (Experimental Settings)
데이터셋
VideoLLM-MoD의 효과성을 검증하기 위해 온라인 및 오프라인 설정에서 다양한 데이터셋을 사용했습니다.
- Ego4D 내레이션 스트림 벤치마크: 시간에 맞춘 내레이션 생성을 목표로 합니다.
- Ego4D 장기 행동 예측(LTA) 벤치마크: 이전 8단계를 기반으로 다음 20개의 행동(동사 및 명사)을 예측합니다.
- EgoExo4D 세밀한 키스텝 인식 벤치마크: 절차적 1인칭 비디오에서 세밀한 키 스텝을 인식합니다.
- COIN 벤치마크: 단계 인식, 단계 예측, 작업 요약, 절차 예측, 목표가 있는 절차 예측 등 6가지 벤치마크를 포함합니다.
평가 지표 및 구현 세부사항
- 온라인 벤치마크: 언어 모델링 능력 평가를 위해 LM-PPL과 LM-Correctness를, 시간적 정렬 능력 평가를 위해 TimeDiff와 Fluency를 사용
- 모델 구성: SigLIP-L/16를 시각 인코더로, 2층 MLP를 멀티모달 프로젝터로, Meta-Llama-3-8B-Instruct를 언어 모델로 사용
- 비전 임베딩: 각 비디오 프레임에 대해 (1+3×3) 토큰을 사용했으며, 프레임 속도는 2 FPS입니다.
- 학습 설정: 8개의 NVIDIA A100 GPU를 사용했으며, LoRA를 언어 모델의 모든 선형 레이어에 적용
4.2 온라인 실험 (Online Experiments)
Table 1에서 볼 수 있듯이, VideoLLM-MoD는 다양한 베이스라인과 비교되었습니다. 주요 결과는 다음과 같습니다.
- VideoLLM-online: CLS 토큰만 사용하여 각 프레임을 임베딩하므로, 세밀한 비전에 크게 의존하지 않는 간단한 내레이션 작업에서는 약간 낮은 성능을 보였습니다.
- Full-computation: 모든 비전 토큰을 모든 레이어에서 밀집하게 처리하여 학습 비용이 크게 증가합니다.
- EarlyExit: 얕은 레이어에서만 모든 비전 토큰을 처리하고 깊은 레이어에서는 건너뜁니다. 계산량은 가장 낮지만 성능도 가장 낮습니다.
- LayerSkip: 격층으로 모든 비전 토큰을 건너뜁니다. VideoLLM-MoD와 비교하여 성능이 크게 떨어집니다.
- VideoLLM-MoD: Full-computation 베이스라인과 비교하여 성능을 유지하면서도 계산 비용을 크게 줄였습니다. 실제 사용에서는 Full-computation 베이스라인보다 더 나은 성능을 보였습니다.
이런 결과는 VideoLLM-MoD가 온라인 비디오 시나리오에서 최상의 균형을 제공함을 보여줍니다. 과도한 프레임 처리 시 계산 비용을 크게 줄이면서도 성능을 유지할 수 있습니다.
4.3 Ablation Study
LayerExpert의 삽입 전략
Table 2는 LayerExpert의 다양한 삽입 전략에 대한 결과를 보여줍니다. Interleaved 전략(격층으로 LayerExpert 삽입)이 계산 비용과 성능 사이에서 가장 좋은 균형을 보여주었습니다.
중요한 비전 토큰 선택
Table 3은 중요한 비전 토큰을 선택하는 다양한 전략의 결과를 보여줍니다. 랜덤 또는 균일 선택 전략에 비해 학습 가능한 선택 전략이 더 나은 성능을 보였습니다. 이는 어떤 비전 토큰을 처리할지 결정하는 것이 성능을 유지하면서 중복성을 줄이는 데 필수적임을 시사합니다.
4.4 오프라인 실험 (Offline Experiments)
Table 4와 5는 COIN, Ego4D LTA, EgoExo4D Fine-grained Keystep Recognition 벤치마크에서의 결과를 보여줍니다. VideoLLM-MoD는 대부분의 벤치마크에서 최고의 성능을 달성했으며, 특히 복잡한 공간적 맥락 이해가 필요한 작업에서 우수한 성능을 보였습니다.
VideoLLM-MoD의 핵심 아이디어는 LayerExpert를 사용하여 각 레이어에서 처리할 중요한 비전 토큰을 선택하는 것입니다. 이 과정은 다음과 같이 수식화될 수 있습니다.
-
각 비전 토큰 $t_i$에 대한 중요도 점수 계산
\[s_i = \sigma(W \cdot f(t_i) + b)\]$\sigma$는 시그모이드 함수, $W$와 $b$는 학습 가능한 파라미터, $f(t_i)$는 토큰의 특징 벡터입니다.
-
Top-k 선택
\[\text{selected\_tokens} = \text{topk}(\{s_i \| i = 1, ..., N\}, k)\]$N$은 총 비전 토큰 수, $k = r \cdot N$이며 $r$은 유지 비율입니다.
-
선택된 토큰 처리
\[\text{output}_i = \begin{cases} \text{LLM\_layer}(t_i) & \text{if } t_i \in \text{selected\_tokens} \\ t_i & \text{otherwise} \end{cases}\]$\text{LLM_layer}$는 언어 모델의 현재 레이어를 나타냅니다.
이런 방식으로 VideoLLM-MoD는 중요한 비전 정보를 유지하면서 계산 효율성을 크게 향상시킵니다.
4.5 VideoLLM-MoD의 시각화 (Visualization of VideoLLM-MoD)
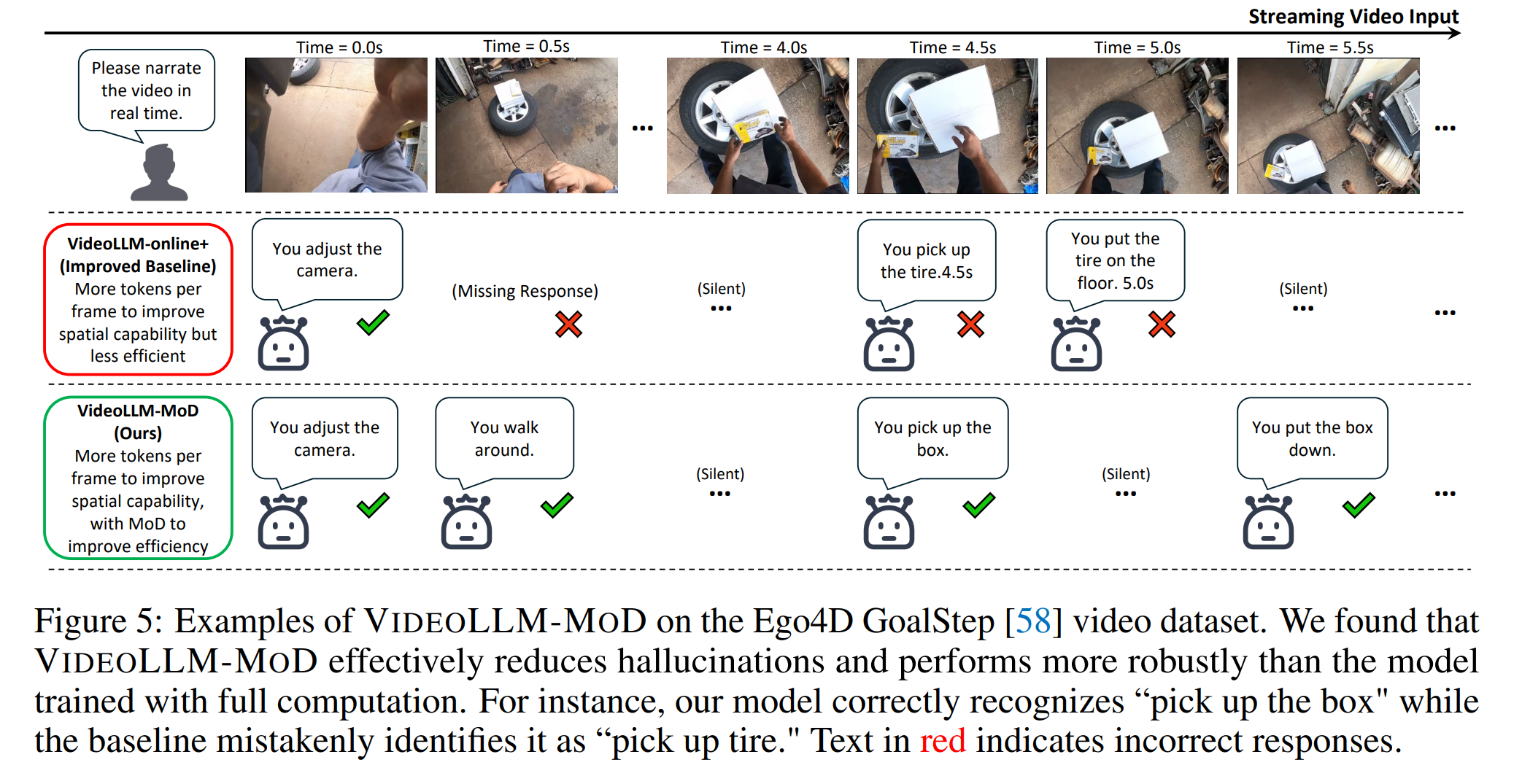
Figure 5는 VideoLLM-MoD가 Full-computation 베이스라인보다 더 강건하게 작동함을 보여줍니다. 중요한 비전 토큰을 선택함으로써 학습의 난이도가 증가하지만, 이는 각 레이어의 MoD 게이트가 현재 인과 맥락에서 중요한 비전 토큰에 집중하도록 강제합니다. 이 전략은 과적합의 위험을 줄이고 더 강건한 모델을 만들어낼 수 있습니다.
VideoLLM-MoD는 온라인 비디오 처리를 위한 효율적이고 강력한 모델임이 다양한 실험을 통해 입증되었습니다. 중요한 비전 토큰을 선택적으로 처리함으로써 계산 비용을 크게 줄이면서도 성능을 유지하거나 개선할 수 있었다고 언급합니다.