To Code, or Not To Code
- Related Project: Private
- Category: Paper Review
- Date: 2024-08-20
To Code, or Not To Code? Exploring Impact of Code in Pre-training
- url: https://arxiv.org/abs/2408.10914
- pdf: https://arxiv.org/pdf/2408.10914
- html: https://arxiv.org/html/2408.10914v1
- abstract: Including code in the pre-training data mixture, even for models not specifically designed for code, has become a common practice in LLMs pre-training. While there has been anecdotal consensus among practitioners that code data plays a vital role in general LLMs’ performance, there is only limited work analyzing the precise impact of code on non-code tasks. In this work, we systematically investigate the impact of code data on general performance. We ask “what is the impact of code data used in pre-training on a large variety of downstream tasks beyond code generation”. We conduct extensive ablations and evaluate across a broad range of natural language reasoning tasks, world knowledge tasks, code benchmarks, and LLM-as-a-judge win-rates for models with sizes ranging from 470M to 2.8B parameters. Across settings, we find a consistent results that code is a critical building block for generalization far beyond coding tasks and improvements to code quality have an outsized impact across all tasks. In particular, compared to text-only pre-training, the addition of code results in up to relative increase of 8.2% in natural language (NL) reasoning, 4.2% in world knowledge, 6.6% improvement in generative win-rates, and a 12x boost in code performance respectively. Our work suggests investments in code quality and preserving code during pre-training have positive impacts.
TL;DR
- 코드 데이터의 프리트레이닝 통합은 자연어 처리와 월드 지식의 성능을 현저하게 향상시킨다고 보고하고,
- 자연어 인퍼런스, 월드 지식, 코드 성능 등 다양한 벤치마크를 사용하여 모델 성능 평가를 수행합니다.
- 코드 데이터의 비율, 질, 초기화, 모델 크기 및 트레이닝 단계의 조정을 통해 성능 향상을 모색합니다.
코드 데이터가 대규모 언어모델(LLMs)의 사전 훈련에서 중요한 역할을 하며, 코드 생성을 넘어 다양한 작업에 걸쳐 성능을 향상시키는 데 기여한다는 것을 주장
-
코드 데이터를 사전 훈련에 포함시키는 것이 자연어 인퍼런스, World Knowledge, 그리고 생성 작업의 승률 등 다양한 비코드 작업에서 성능을 향상시키는 데 중요했으며, 특히 코드 데이터의 비율을 적절히 조정하면서 다양한 훈련 단계에서 코드의 질을 개선하는 것이 성능에 큰 영향을 미쳤다고 보고합니다.
-
코드 데이터의 비율이 증가함에 따라 코드 관련 작업의 성능은 선형적으로 향상되지만, 자연어 인퍼런스과 World Knowledge과 같은 비코드 작업에서는 일정 비율 이상에서 성능이 급격히 저하되므로, 코드의 비율과 질이 모델의 일반화 성능에 중요한 변수임을 시사합니다.
-
사전 훈련의 쿨다운 단계에서 고품질 데이터 소스를 강조하여 코드 데이터를 포함시킬 때, 자연어 인퍼런스, World Knowledge, 코드 작업 성능이 상대적으로 크게 향상되었는데, 이를 통해 코드 데이터가 쿨다운 단계에서도 중요한 역할을 할 수 있음을 시사합니다.
-
종합하면 코드와 텍스트 데이터를 균형 있게 혼합하여 사전 훈련하는 것이 자연어 작업에서 가장 좋은 성능을 보였다고 언급하고, 이런 구성이 World Knowledge과 자연어 인퍼런스 뿐만 아니라 생성 작업에서도 성능 개선을 보여 일반적인 downstream 성능에 가장 적합한 모델 변형일 수 있다고 언급합니다.
즉, 코드 데이터는 단순한 코드 생성을 넘어서 LLMs의 성능을 향상시키는데 중요한 요소로 작용하며, 이를 통해 모델의 일반화 능력과 다양한 NLP 작업에서의 성능을 개선할 수 있으므로 비록 코드 모델이 아닐지라도 (1) 사전 훈련 과정 전반에 걸쳐 코드 데이터를 효과적으로 활용하는 것을 추천하며, 특히 (2) 고품질의 코드 데이터를 사용하는 것이 중요할 수 있다고 언급합니다. (최근 Your Context Is Not an Array 논문에서처럼 코드에 대한 토크나이저 뿐만 아니라 연산기 호 역시 제대로 토크나이저에 포함시키는 게 중요하지 않을까요…코드의 경우 Lean Github, DeepSeek-Prover 외 작업들을 보면 포맷도…그리고 LLM Format의 임팩트를 조사한 논문을 보면, 프롬프트 엔지니어링 혹은 SFT, DPO 시에도 몇 개의 포맷으로 테스트하는 것도 필요할 것 같습니다.)
1. 소개
최신의 모델들은 다양한 데이터 소스의 중요성을 강조하며, 특히 코드 데이터의 비율 증가가 LLM의 성능에 중요한 영향을 미친다는 것을 보여줍니다. Llama 3 모델의 경우 Llama 2에 비해 코드 데이터 비율을 크게 늘렸습니다(17% 대 4.5%). 이 논문은 이런 데이터 분포 변화가 downstream 작업에 어떤 영향을 미치는지 분석하는 것을 목표로 합니다.
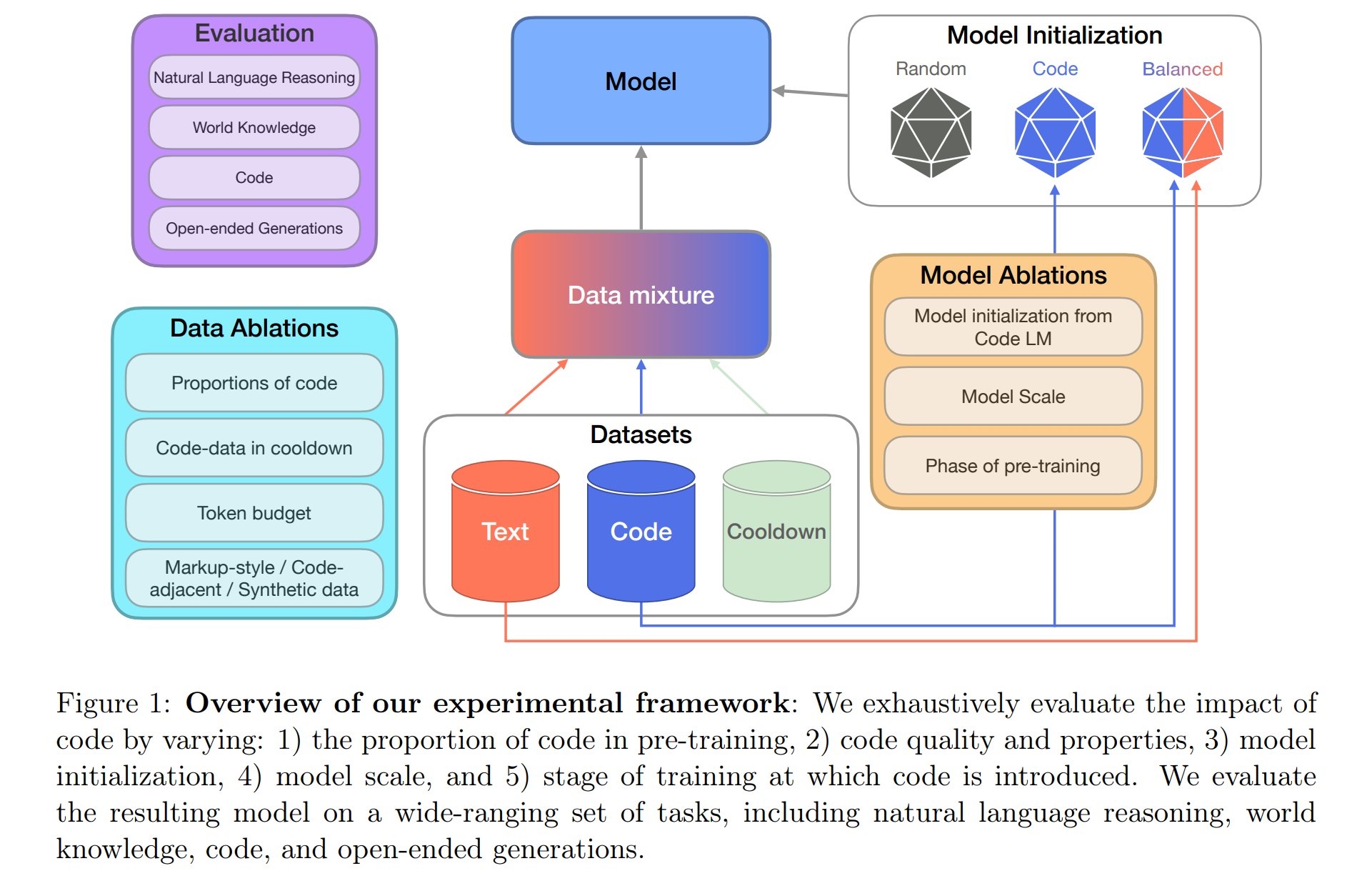
2. 방법
2.1 프리트레이닝 데이터
- 텍스트 데이터셋: SlimPajama는 다양한 출처(e.g., CommonCrawl, C4, Wikipedia 등)에서 수집된 데이터로, 코드 및 코드 인접 데이터를 제외한 순수 텍스트 데이터입로 총 503B 토큰으로 구성
- 코드 데이터셋: 여러 소스(e.g., GitHub, StackExchange)에서 수집한 코드 데이터 및 마크업 스타일 데이터(e.g., HTML, CSS)를 사용합니다. 품질이 보증된 합성 코드 데이터도 실험에 포함시켜 데이터의 질적 향상을 모색합니다.
- 프리트레이닝 쿨다운: 훈련의 마지막 단계에서 고품질 데이터셋의 비중을 높이고 학습률을 낮추는 쿨다운 조정이 모델의 성능을 크게 향상시키는 것으로 나타났다고 보고
2.2 평가
자연어 인퍼런스, 월드 지식, 코드 성능을 평가하는 다양한 벤치마크를 사용해 코드 데이터가 모델 성능에 미치는 영향을 광범위하게 분석하며 LLM-as-a-judge 평가를 통해 생성 작업의 승률도 측정합니다.
2.3 결과
코드 데이터의 프리트레이닝 통합이 다양한 비코드 작업에서 모델의 성능을 향상시키는 중요한 요소임을 확인했습니다. 특히, 코드 데이터를 추가한 경우 자연어 인퍼런스에서 8.2%, 월드 지식에서 4.2%, 생성 승률에서 6.6%의 향상을 보였으며, 코드 성능은 12배 향상되었습니다. 쿨다운 단계에서도 코드 데이터를 추가함으로써 성능이 추가적으로 향상되었습니다.
-
성능 증가율 계산 수식
\[\text{Performance Increase Rate} (\%) = \frac{\text{Performance After Code Addition} - \text{Performance Before Code Addition}}{\text{Performance Before Code Addition}} \times 100\]예를 들어, 자연어 인퍼런스에서의 성능 향상은 다음과 같이 계산했다고 합니다.
\[\Delta \text{NL Performance} = \frac{58.2 - 50.2}{50.2} \times 100 = 15.94\%\]
3. 결과 및 토론
이 섹션에서는 각 실험 변형의 설명과 전체 결과를 보고합니다. 체계적으로 다음을 조사합니다. (3.1) 코드 사전 훈련 모델로 LLM 초기화, (3.2) 모델 규모의 영향 (3.2절), (3.3) 사전 훈련 데이터에서 코드의 비율 변화, (3.4) 코드 데이터의 품질과 특성, (3.5) 사전 훈련 쿨다운에서의 코드 데이터, (3.6) 최종 사전 훈련 레시피를 비교합니다.
다음과 같이 정의하여 각 모델들의 레시피 및 성능을 비교합니다.
| 모델 명칭 | 초기화 방식 | 데이터 비율 | 토큰 수 (Billion) |
|---|---|---|---|
| 텍스트 LM (Text LM) | Glorot-normal 초기화 [Glorot et al., 2011] | 텍스트 데이터만 (Text-only) | 400B |
| 균형 LM (Balanced LM) | Glorot-normal 초기화 [Glorot et al., 2011] | 코드 50%, 텍스트 50% (50% Code, 50% Text) | 400B |
| 균형 초기화 텍스트 LM (Balanced → Text) | 균형 LM (50% 코드, 50% 텍스트)으로 초기화 | 텍스트 데이터만으로 지속적 사전 훈련 (Text-only) | 200B |
| 코드 초기화 텍스트 LM (Code → Text) | 코드-LM (80% 코드 데이터, 20% 마크업 스타일 코드 데이터)으로 초기화 | 코드 데이터 사전 훈련 후 텍스트 데이터로 지속적 사전 훈련 | 200B + 200B |
3.1 LLM을 코드 사전 훈련 모델로 초기화
자연어 작업에서는 100% 및 50% 코드 모델을 통해 각각 8.8%, 8.2%의 성능 향상을 보이며, 50% 코드 + 50% 텍스트로 균형 잡힌 사전 훈련을 할 경우 코드 생성 성능이 가장 우수했으나 자연어 작업에서는 다소 뒤처짐을 확인.
- 자연어 작업 성능 향상: 코드 사전 훈련 모델로 초기화하면 자연어 작업에서 성능이 향상됩니다. 100% 및 50% 코드 모델을 기반으로 지속적인 텍스트 사전 훈련은 각각 8.8%, 8.2%의 상대적 이득을 나타냅니다.
- 지식 작업에서의 성능: 100% 코드로 초기화했을 때 텍스트 전용 베이스라인과 동일한 성능을 보이지만, 50% 코드는 4.2%의 상대적 개선을 달성합니다.
- 균형 잡힌 사전 훈련: 50% 코드, 50% 텍스트로 균형 잡힌 사전 훈련을 할 경우 코드 생성 성능이 가장 우수합니다. 그러나 이 모델은 자연어 작업에서 코드 및 균형 초기화된 텍스트 모델보다 뒤처집니다.
3.2 모델 규모의 영향
모델 규모가 470M에서 2.8B로 확장될 때 자연어 인퍼런스와 지식 작업에서 성능이 각각 평균 30%, 31.7%, 33.1% 향상됨을 확인
- 규모 증가에 따른 성능 개선: 470M에서 2.8B로 모델 규모를 확장하면 자연어 인퍼런스과 지식 작업에서 평균 성능이 각각 30%, 31.7%, 33.1% 향상됩니다. 특히 2.8B 모델은 월드 지식에서 470M 모델의 결과를 거의 세 배로 늘립니다.
- 코드 생성과 자연어 작업 간의 트레이드오프: 더 큰 규모의 모델에서는 자연어 작업과 코드 생성 사이의 트레이드오프가 증가합니다.
3.3 사전 훈련에서의 코드 데이터 비율
월드 지식과 자연어 인퍼런스 벤치마크에서 최고의 성능을 위해서는 코드 비율이 25%가 최적임을 확인하고, 코드를 포함하지 않을 경우 자연어 인퍼런스 성능이 3.4% 감소함을 확인
- 최적의 코드 비율: 월드 지식과 자연어 인퍼런스 벤치마크에서 최고의 평균 성능을 위해서는 코드 비율이 25%가 최적입니다. 코드 비율이 75% 이상일 때 성능이 급격히 저하됩니다.
- 코드 데이터의 중요성: 코드를 포함하지 않은 경우, 25% 코드로 사전 훈련할 때보다 자연어 인퍼런스 성능이 3.4% 감소합니다.
3.4 코드 데이터의 품질과 특성이 일반 성능에 미치는 영향
고품질 합성 코드 데이터는 자연어 인퍼런스에서 9%, 코드 벤치마크에서 44.9%의 상대적 성능 향상을 보임.
- 고품질 합성 코드 데이터의 영향: 소량이라도 고품질 합성 코드 데이터는 자연어 인퍼런스에서 9%, 코드 벤치마크에서 44.9%의 상대적 성능 향상을 가져옵니다.
- 지속적인 사전 훈련에서의 데이터 전송: 합성 코드 데이터를 포함한 최고의 변형은 지속적인 사전 훈련에서도 더 나은 성능을 보여줍니다.
사전 훈련 데이터에서 코드의 비율을 변화시키는 실험에서는 코드 비율의 증가가 코드 작업 성능을 거의 선형적으로 향상시키는 것을 관찰할 수 있습니다. 예를 들어, 코드 성능이 다음과 같이 계산됩니다.
\[\text{Performance Increase} = \left(\frac{\text{Code Performance at 100\% Code} - \text{Code Performance at 25\% Code}}{\text{Code Performance at 25\% Code}}\right) \times 100\%\]이는 코드 비율이 25%에서 100%로 증가할 때 코드 성능이 2.6배 증가한다는 것을 수학적으로 보여줍니다.
이런 수식적 접근은 각 실험 설정에서 코드 데이터의 비율이 어떻게 일반 성능에 영향을 미치는지를 정량적으로 평가하는 데 도움을 줍니다.
3.5 프리트레이닝 쿨다운 단계에서 코드의 영향
쿨다운 단계에서 코드 데이터 포함은 NL 인퍼런스, World Knowledge, 코드 성능에서 각각 3.6%, 10.1%, 20%의 상대적 개선을 보임.
- [전제] 고품질 데이터의 가중치 증가와 코드 데이터 포함
- [주장] 이런 변경은 NL 인퍼런스과 코드 작업에서 모델의 이해 및 실행 능력을 향상
이 섹션에서는 프리트레이닝의 마지막 단계에서 코드를 도입하는 것의 영향을 평가합니다. 여기서는 고품질의 텍스트, 수학, 코드, 지시 스타일 데이터셋의 가중치를 높이는 쿨다운을 고려합니다. 일정한 learning rate을 코사인 기반에서 최종 학습률이 \(1e^{-6}\)인 선형 감쇠로 변경합니다. 쿨다운 단계에서 코드를 포함하는 것의 영향을 평가하기 위해 세 가지 모델을 비교합니다. 쿨다운 전의 프리트레이닝 모델, 코드 데이터 없는 쿨다운, 그리고 코드 데이터 20%를 포함한 쿨다운. 사용된 모델은 균형 잡힌 사전 훈련 → 텍스트 모델로, 프리트레이닝에서 가장 우수한 변형입니다. 변형 간에는 동일한 토큰 예산(40B 토큰, 프리트레인된 모델의 10% 토큰 예산)을 유지합니다.
- 프리트레이닝 쿨다운에 코드 데이터 포함: 코드 데이터가 NL 인퍼런스, World Knowledge, 코드 성능에서 각각 3.6%, 10.1%, 20%의 상대적 개선을 보임.
- 수학적 논리와 설명: 쿨다운 단계에서의 데이터 품질 가중치 조정과 학습률 선형 감소는 코드 데이터의 효과를 극대화하는 것으로 분석됨.
- 코드 없는 쿨다운과 비교했을 때, 코드 포함 쿨다운이 NL 인퍼런스과 코드 벤치마크에서 성능을 크게 향상시킴.
쿨다운 단계에서 다음과 같이 학습률 감소 함수를 사용합니다. (\(\text{Initial LR}\)은 초기 학습률, \(\text{Final LR}\)은 최종 학습률, \(k\)는 감소 상수, \(t\)는 학습 시간, \(t_0\)는 중간점)
\[\text{Learning Rate}(t) = \frac{\text{Initial LR} - \text{Final LR}}{1 + \exp(-k \cdot (t - t_0))} + \text{Final LR}\]학습률 감소 함수는 초기에 빠르게 감소하다가 점차 완만해지는 형태로, 데이터의 품질을 점진적으로 강조하는 효과를 내며, 특히 고품질 코드 데이터의 영향을 극대화하기 위해 사용했다고 합니다.
결론적으로 코드 데이터를 포함할 경우 NL 인퍼런스, World Knowledge, 코드 벤치마크에서 각각 3.6%, 10.1%, 20%의 개선을 보여주었습니다.
즉, 코드 데이터를 포함한 쿨다운은 모델 성능을 크게 향상시킬 수 있다고 보고합니다.
3.6 프리트레이닝 레시피 비교
균형잡힌 모델 → 텍스트 모델은 NL 인퍼런스에서 8.2%의 상대적 증가, World Knowledge에서 4.2%의 개선, 코드 성능에서 12배 향상을 보임.
이 섹션에서는 다양한 프리트레이닝 레시피의 효과를 비교하고, 최적의 레시피를 제안합니다.
텍스트 전용 프리트레이닝과 비교했을 때, 최고 변형인 균형 잡힌 사전 훈련 → 텍스트 모델은 NL 인퍼런스에서 8.2%의 상대적 증가, World Knowledge에서 4.2%, 생성 승률에서 6.6%의 개선, 그리고 코드 성능에서 12배 향상을 보였습니다. 또한 코드와 함께 쿨다운을 수행하면 균형 잡힌 사전 훈련 → 텍스트 결과가 NL 인퍼런스에서 3.6%, World Knowledge에서 10.1%, 코드에서 20% 개선되었으며, 생성 승률은 52.3%에 도달했습니다.
코드 데이터를 포함하는 것은 NL 인퍼런스, World Knowledge 및 생성 품질에 중요한 개선을 제공하는 것을 확인했으며, 프리트레이닝 초기부터 코드 데이터를 포함하는 균형잡힌 혼합을 사용하고, 지속적인 프리트레이닝에서는 코드 비율을 상대적으로 낮추며, 쿨다운 혼합에 코드 데이터를 포함하는 것을 권장합니다.
코드 및 텍스트 데이터의 혼합 및 학습 레시피 권장 색인마킹
4. 관련 연구
선행 연구 개요
다양한 연구들이 사전 훈련 데이터의 연령, 품질, 독성, 도메인의 효과를 조사해왔습니다. 데이터 필터링, 중복 제거, 데이터 가지치기 등 다양한 데이터 처리 방법이 성능에 미치는 영향에 대해서도 연구되었습니다. 또한, 합성 데이터의 역할을 고려한 연구들이 성능 향상을 위해 수행되었으며, 이는 오픈 웨이트와 독점 모델 간의 성능 격차를 줄이는 데 도움을 주었습니다. 이런 연구들은 훈련 데이터의 특성에 초점을 맞춘 광범위한 처리를 다루지만, 본 연구는 코드의 역할을 명확히 이해하는 데 중점을 둡니다.
코드의 역할 이해
LLM 사전 훈련에서 코드를 데이터 혼합에 포함시키는 것은 일반적인 관행입니다. 이는 코드 완성과 생성뿐만 아니라 엔티티 링킹, 상식 인퍼런스, 수학적 인퍼런스 등 다양한 NLP 작업에서 LLM의 성능을 향상시키는 것으로 나타났습니다. 특히, 코드 데이터가 사전 훈련 성능을 향상시킬 수 있다는 것이 연구를 통해 입증되었습니다.
관련 연구에 대한 심층 분석
사전 훈련 데이터의 성분은 최근 연구에서 핵심적인 관심사로 떠올랐습니다. 특히, 데이터의 연령, 품질, 독성, 그리고 도메인이 모델의 성능에 미치는 영향에 대한 연구가 활발히 이루어지고 있습니다. 이 글에서는 해당 연구 동향을 구체적으로 살펴보고, 이런 요소들이 어떻게 머신러닝 모델, 특히 대규모 언어모델(Large Language Models, LLM)의 사전 훈련에 영향을 미치는지 탐구해보겠습니다.
1. 데이터 필터링과 정제의 중요성
필터링과 데이터의 중복 제거는 모델 학습에 있어 중요한 단계입니다. Raffel et al. (2020)과 Rae et al. (2022b)는 필터링 기법이 어떻게 데이터셋의 품질을 향상시키고, 결국 모델의 성능을 개선하는지에 대해 보고했습니다. 특히, 이들 연구는 비효율적인 데이터를 제거함으로써 학습 과정에서의 노이즈을 줄이고, 모델이 더 관련성 높고 유의미한 패턴을 학습할 수 있게 돕는다고 강조합니다.
2. 데이터 가지치기와 성능 최적화
Lozhkov et al. (2024) 및 Marion et al. (2023)은 데이터 가지치기가 어떻게 전체 학습 과정을 최적화하는지에 대한 연구를 진행했습니다. 이 방법은 특히 대규모 데이터셋을 다룰 때 중요하며, 불필요하거나 오해의 소지가 있는 정보를 사전에 제거함으로써 학습 효율을 향상시킵니다.
3. 합성 데이터의 활용
최근 연구에서는 합성 데이터가 실제 데이터에서 발생할 수 있는 격차를 메우는 데 유용하다는 점이 밝혀졌습니다. Shimabucoro et al. (2024)과 Dang et al. (2024)은 합성 데이터가 특히 데이터 부족 문제를 겪고 있는 도메인에서 모델의 성능을 향상시킬 수 있음을 입증했습니다. 예를 들어, 특정 언어나 전문 분야 지식이 부족한 경우, 합성 데이터를 통해 이런 부족분을 보완할 수 있습니다.
4. 코드 데이터의 구체적 역할
코드를 포함하는 사전 훈련 데이터 믹스의 효과는 특히 LLM에서 두드러집니다. 코드 데이터의 포함은 단순히 코드 생성과 완성을 넘어서, 모델의 상식 인퍼런스, 수학적 인퍼런스 능력을 향상시키는데 기여하는 것으로 알려져있습니다 (Muennighoff et al., 2023a; Fu & Khot, 2022). 이는 코드가 복잡한 논리 구조와 패턴을 포함하고 있기 때문에, 모델이 더 추상적이고 복잡한 인퍼런스를 수행하는데 필요한 능력을 개발할 수 있도록할 수 있습니다.
선행 연구 및 본 논문에서 탐구한 바와 같이 사전 훈련 데이터의 성분은 모델의 학습 능력과 최종 성능에 지대한 영향을 미칠 수 있음을 언급합니다. 각 연구는 데이터의 특정 측면을 조명하며, 이런 다양한 접근 방식은 결국 보다 정교하고 효율적인 모델 학습을 가능하게 하므로 데이터 관리와 최적화는 LLM 개발에서도 필수적이라는 점을 언급합니다. (매우 동의)
5. 결론
본 연구는 사전 훈련에 사용된 코드 데이터가 코드 생성을 넘어서 다양한 downstream 작업에 미치는 영향을 시스템적으로 조사한 첫 사례입니다. 코드 성능뿐만 아니라 자연어 성능과 생성 품질에 초점을 맞추어, 사전 훈련에서의 코드 역할을 다각도로 분석했습니다. 결과적으로, 코드는 비코드 작업의 성능을 크게 향상시키는 데 필수적인 요소로 나타났으며, 코드 데이터의 소량 추가만으로도 자연어 인퍼런스과 코드 성능에 큰 영향을 미칠 수 있습니다.
본 연구에서는 다음과 같이 코드 데이터의 효과를 정량화하였습니다.
\[\text{Relative Increase} = \left(\frac{\text{Performance with Code} - \text{Performance without Code}}{\text{Performance without Code}}\right) \times 100\%\]이 수식을 통해 코드의 추가가 자연어 인퍼런스, World Knowledge, 생성 승률에서 각각 8.2%, 4.2%, 6.6%의 상대적 증가를 가져왔다고 보고합니다. 또한, 고품질 합성 데이터의 추가는 자연어 인퍼런스과 코드 성능을 각각 9%, 44.9% 올리는 데 기여했다고 보고합니다.
6. 제한 사항
본 연구는 코드 데이터가 자연어 작업에 미치는 영향을 체계적으로 조사했지만, 안전성에 대한 영향은 다루지 않았습니다.
대규모 모델 사이즈에서의 연구는 계산 비용의 제약으로 인해 한정적이므로 충분히 검토하지는 못 했지만, 470M부터 2.8B까지의 모델에서 일관된 결과를 얻었기 때문에 더 큰 모델 크기와 토큰 예산에서도 유사한 결과가 나타날 것으로 예상한다고 언급합니다.