Model | Platypus
- Related Project: private
- Category: Paper Review
- Date: 2023-08-16
Contents
- \(1\) Platypus: Quick, Cheap, and Powerful Refinement of LLMs
- \(2\) Towards a Unified View of Parameter-Efficient Transfer Learning
[1] Platypus: Quick, Cheap, and Powerful Refinement of LLMs
- web: https://platypus-TextGenerationLLM.github.io
- url: https://arxiv.org/abs/2308.07317
- pdf: https://arxiv.org/pdf/2308.07317
- abstract: We present Platypus, a family of fine-tuned and merged Large Language Models (LLMs) that achieves the strongest performance and currently stands at first place in HuggingFace’s Open LLM Leaderboard as of the release date of this work. In this work we describe (1) our curated dataset Open-Platypus, that is a subset of other open datasets and which we release to the public (2) our process of fine-tuning and merging LoRA modules in order to conserve the strong prior of pretrained LLMs, while bringing specific domain knowledge to the surface (3) our efforts in checking for test data leaks and contamination in the training data, which can inform future research. Specifically, the Platypus family achieves strong performance in quantitative LLM metrics across model sizes, topping the global Open LLM leaderboard while using just a fraction of the fine-tuning data and overall compute that are required for other state-of-the-art fine-tuned LLMs. In particular, a 13B Platypus model can be trained on a single A100 GPU using 25k questions in 5 hours. This is a testament of the quality of our Open-Platypus dataset, and opens opportunities for more improvements in the field.
- github: https://platypus-TextGenerationLLM.github.io
TL;DR
- Open-Platypus라는 오픈 데이터셋의 선별 데이터셋 공개
- Dataset optimization: 데이터셋 크기를 줄이고 데이터 중복을 제거하는 데 사용할 수 있는 되는 유사성 배제 접근 방식을 적용하고 자세히 설명함.
- Addressing contamination: 개방형 LLM Training Set으에서 오염 문제를 심도 있게 탐구하여, 이 문제를 우회하기 위해 데이터 필터링 프로세스에 집중하였음.
- Fine-tuning and merging: 기존 방법에서 영감을 얻은 LoRA 모듈에 대한 선택, 병합 및 파인튜닝 프로세스 최적화 수행.
- 휴먼이 생성한 질문들로 최소한의 파인튜닝 시간과 비용을 사용하여 모델 성능을 개선할 수 있음을 보임. with only about 10% generated by an LLM, Open-Platypus enables robust performance with minimal fine-tuning time and cost.
Overview
This dataset is focused on improving LLM logical reasoning skills and was used to train the Platypus2 models. It is comprised of the following datasets, which were filtered using keyword search and then Sentence Transformers to remove questions with a similarity above 80%:
| Dataset Name | License Type | # Leaked Questions |
|---|---|---|
| PRM800K | MIT | 77 |
| ScienceQA | CC BY-NC-SA 4.0 | 0 |
| SciBench | MIT | 0 |
| ReClor | Non-commercial | 0 |
| TheoremQA | MIT | 0 |
| nuprl/leetcode-solutions-python-testgen-gpt4 | None listed | 0 |
| jondurbin/airoboros-gpt4-1.4.1 | other | 13 |
| TigerResearch/tigerbot-kaggle-leetcodesolutions-en-2k | apache-2.0 | 0 |
| openbookQA | apache-2.0 | 6 |
| ARB | MIT | 0 |
| timdettmers/openassistant-guanaco | apache-2.0 | 13 |
| ehartford/dolphin (first 25k rows) | apache-2.0 | 0 |
Table 1: Datasets, Licenses, and Number of Leaked Questions. *The datasets marked with asterisks were not added to Open-Platypus but we include them because we ran contamination checks when considering which models to merge.
-
Data Contamination Check
We’ve removed approximately 200 questions that appear in the Hugging Face benchmark test sets. Please see our paper and project webpage for additional information.
-
Model Info
Please see models at garage-bAInd.
-
Training and filtering code
Please see the Platypus GitHub repo.
-
Contamination
- 단순한 암기를 통해 편향된 결과를 피하기 위해 벤치마크 테스트 질문이 Training Set으로 누출을 방지하는 태스크에 우선 순위를 높게 두었음.
-
정확성을 높이기 위해 노력하지만, 질문을 제기할 수 있는 다양한 방법과 일반적인 도메인 지식의 영향을 고려할 때 질문을 중복으로 표시하는 데 있어 유연성이 필요하다는 것을 인지하고 있으므로, 잠재적인 누출을 관리하기 위해 벤치마크 질문과 80% 이상의 코사인 임베딩 유사성을 가진 Open-Platypus의 질문을 수동으로 필터링하는 휴리스틱 사용하였음.
-
Duplicate
- 거의 완벽한 중복이며, 단어의 작은 변경 또는 약간의 재배열을 의미하며,
- 표에 유출된 질문 수에 의해 정의되는 true contamination을 의미할 수 있다고 주장함.
These are near-exact replicas of test set questions, with perhaps a minor word change or slight rearrangement. This is the only category we count as “true” contamination, as defined by the number of leaked questions in the table above. Specific examples of this can be seen in:

-
Gray-area
- 정확하지는 않지만 일반적인 지식의 범주 내에 속하는 질문을 포괄하는 것을 의미일 수 있다고 함.
- 전문 지식이 필요한 것이 많으며, 지시 사항은 동일하지만 답변이 동의어인 질문들을 포함하였다고 함.
The next group, termed gray-area, encompasses questions that are not exact duplicates and fall within the realm of general knowledge. While we leave the final judgement of these questions to the open-source community, we believe they often necessitate expert knowledge. Notably, this category includes questions with identical instructions but answers that are synonymous: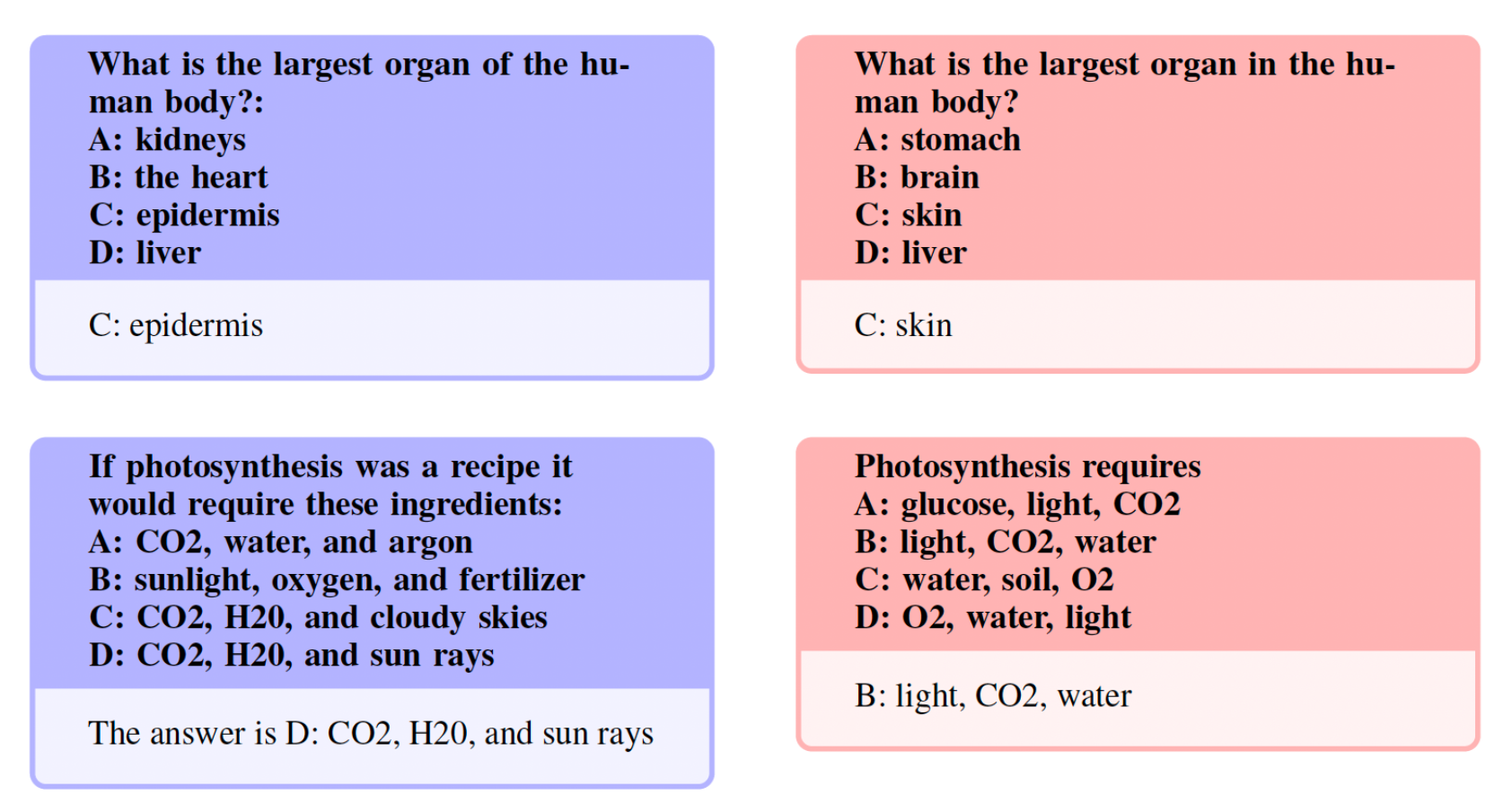
-
Similar but different
- 질문들이 높은 유사도 점수를 갖지만, 미묘한 질문의 변화로 답변이 달라질 수 있다고 함.
hese questions have high similarity scores but differ significantly in answers due to subtle question variations. Please see the paper for detailed examples.

- 질문들이 높은 유사도 점수를 갖지만, 미묘한 질문의 변화로 답변이 달라질 수 있다고 함.
hese questions have high similarity scores but differ significantly in answers due to subtle question variations. Please see the paper for detailed examples.
[질문의 변화로 인한 성능 변화 색인마킹]
-
Fine-tuning & Merging
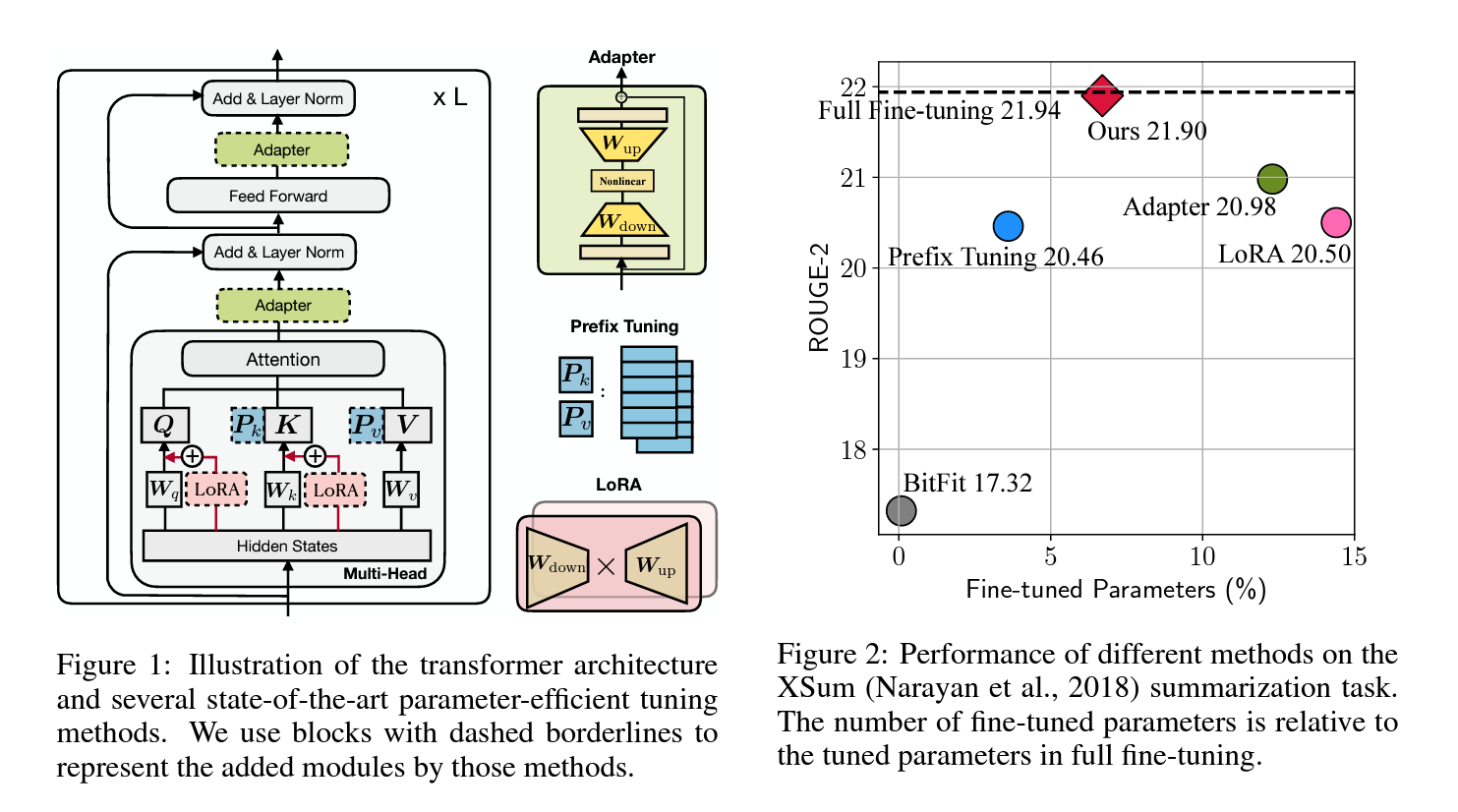
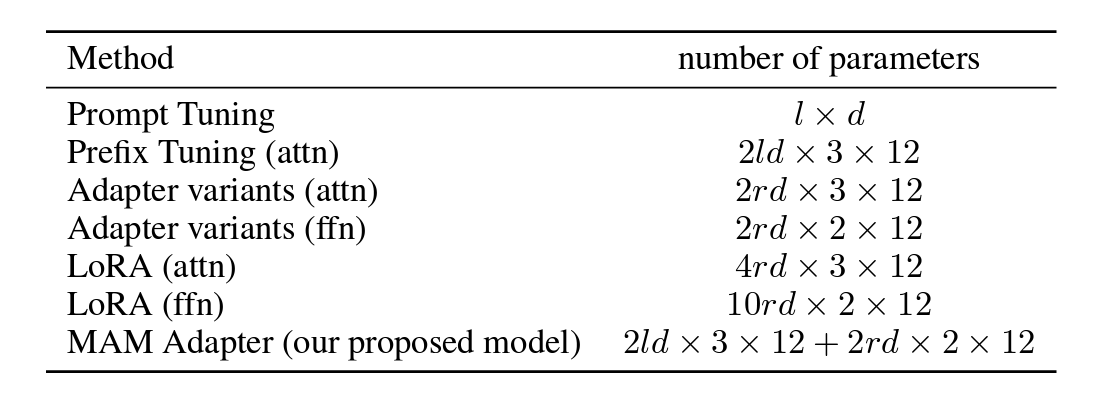
After refining our dataset, we center on two methods: Low Rank Approximation (LoRA) training and Parameter-Efficient Fine-Tuning (PEFT) library. Unlike full fine-tuning, LoRA preserves pre-trained model weights, integrating rank decomposition matrices in transformer layers. This cuts down trainable parameters, saving on training time and cost. Initially, our fine-tuning honed in on attention modules like
v_proj,q_proj,k_proj, ando_proj. Later, based on insights from He et al., we transitioned togate_proj,down_proj, andup_projmodules. These showed better results except when trainable parameters were less than 0.1% of the total. We applied this uniformly to both our 13B and 70B models, which resulted in 0.27% and 0.2% trainable parameters. The only variance was the initial learning rate between these models. For an in depth breakdown of our pipeline, pleaase refer to the paper.
- LoRA와 PEFT에 집중하였으며,
- 처음에는
v_proj,q_proj,k_proj,o_proj에 집중하다가 나중에는 He et al.에 소개된 방법대로gate_proj,down_proj,up_proj모듈로 변경했고, 더 나은 결과를 보였다고 함. - 또한 13B와 70B 모두 initial learning rate를 제외하고는 거의 비슷했으며
- 13B의 경우 0.27%
- 70B의 경우 0.2% trainable parameters를 얻었다고 함.
- 처음에는
- LoRA와 PEFT에 집중하였으며,
1 Introduction
Our work centers around improving the performance of base Large Language Models (LLMs) by fine-tuning models using parameter-efficient tuning (PEFT) on a small, yet powerful, curated dataset named Open-Platypus. This work resides in the context of recent advancements in the domain of LLMs. The rapid growth of these models was kick-started by the emergence of scaling laws [19]. Soon after, 100B+ parameter models like PaLM [6] and GPT-3 [3] were proposed. Task-specific models came next, such as Galactica for scientific tasks [39]. Chinchillia [16] was introduced along with a novel scaling law approach that shifts the emphasis from model size to the number of processed tokens.
To challenge the dominance of closed-source models like OpenAI’s GPT-3.5 and GPT-4, Meta released the original LLaMA models [40], now known for their computational efficiency during inference. Open-source initiatives such as BLOOM [34] and Falcon [2] have also been released to challenge the hegemony of their closed-source counterparts. Recently, MetaAI released LLaMA-2 models [41]. Shortly after the initial release, the 70B parameter model was fine-tuned by StabilityAI to create StableBeluga2 [26] using an Orca-styled dataset [29]. As the scale of both network architectures and training datasets have grown, the push towards employing LLMs as generalist tools able to handle a wide array of tasks has intensified. For the largest models, their abilities as generalists make them well-suited for many NLP tasks [30], with smaller models struggling to maintain the same level of versatility.
Strategies for Bridging the Divide
A number of strategies have been employed to try and bridge this divide. A prominent method known as knowledge distillation [17,15,47] aims to transfer knowledge from a large, more performant teacher model to a smaller student model, preserving performance while reducing computational overhead. Recently, the most popular method involves distilling the knowledge from a large training dataset into a small one, making it less computationally expensive than traditional approaches [49]. These methods also tend to take advantage of instruction tuning [44], which has proven an effective method for improving the general performance of LLMs. Projects like Stanford’s Alpaca [38] and WizardLM [48] provide frameworks for generating high-quality, instruction-formatted data. Fine-tuning base models on these types of datasets and applying self-instruct methodology [43] has led to marked improvements in both their quantitative and qualitative performance [7].
The Mixture of Experts approach [36,35] employs conditional computation, activating network sections based on individual examples. This technique boosts model capacity without a linear rise in computation. Sparse variants, like the SwitchTransformer [11], activate select experts per token or example, introducing network sparsity. Such models excel in scalability across domains and retention in continual learning, as seen with ExpertGate [1]. Yet, ineffective expert routing can result in under-training and uneven specialization of experts. Following the recent arrival of LoRA is Quantized-LoRA (QLoRA) [8], which has been recognized as an efficient and cost-effective methodology. The authors of [8] concurrently released Guanaco, a new model family. The best Guanaco models currently rank 7th and 12th on the HuggingFace leaderboard as of this report’s release. Notwithstanding, our initial decision to employ LoRA occurred before the release of QLoRA, and we stuck with it since it proved effective within our existing workflow—namely being compatible and successful at model merging. Since our future goals include reducing training time and cost, we would be excited to use quantized LoRA in our pipeline and compare results.
Domain-Specific Training and Specialized Models
Other approaches have centered on training LLMs in specific tasks such as coding [25], quantitative reasoning [22], and biomedical knowledge [37]. This specialized training has its own merits. By focusing on narrower domains, these models can achieve higher accuracy rates and more relevant output in their respective fields.
One large limitation of this approach, especially for domain-specific models derived from large, pre-trained ones, is that the fine-tuning process can be time-consuming and costly. Our work seeks to address these issues by focusing on refining a training recipe aimed to maintain the benefits of instruction tuning, namely generalized improvement, while also imparting specific domain knowledge. We find that domain-specific datasets increase performance on a selected category of tasks, which when combined with mergings significantly reduce training time. Our core contributions are as follows:
- Open-Platypus: A small-scale dataset that consists of a curated sub-selection of public text datasets. The dataset is focused on improving LLMs’ STEM and logic knowledge and is made up of 11 open-sourced datasets. It is comprised mainly of human-designed questions, with only 10% of questions generated by an LLM. The main advantage of Open-Platypus is that, given its size and quality, it allows for very strong performance with short and cheap fine-tuning time and cost. Specifically, one can train their own 13B model on a single A100 GPU using 25k questions in 5 hours.
- A description of our process of similarity exclusion in order to reduce the size of our dataset, as well as reduce data redundancy.
- A detailed look into the ever-present phenomenon of contamination of open LLM training sets with data contained in important LLM test sets, and a description of our training data filtering process in order to avoid this pitfall.
-
A description of our selection and merging process for our specialized fine-tuned LoRA modules.
- Open-Platypus와 함께 PEFT 및 LoRA를 사용하여 LLM을 최적화하는 데 집중하였음.
- OpenAI의 GPT-3.5 및 GPT-4와 같은 높은 모델이 표준이 되고, TII의 Falcon 및 Meta의 LLaMA와 같은 모델이 대안으로 제시되고 있지만, 모델을 효율적으로 파인튜닝하는 것에 대해서 연구하고자 함.
- 따라서 데이터셋 추출 및 instruction 튜닝의 이점을 활용하여 도메인별 지식을 강조하면서 향상된 성능을 보장하는 것을 목표로 하였음.
2 Methods
Curating Open-Platypus
Our decisions regarding data selection for fine-tuning the LLaMA-2 models were influenced by several factors:
- The Superficial Alignment Hypothesis presented by [51], which states that model knowledge is almost entirely learned during pre-training, and with minimal training data, it is possible to achieve excellent results aligning model outputs.
- The LLaMA-2 introductory paper [41], which states that the base models had not yet reached saturation.
- The work of [12], highlighting the importance of high-quality input data for training effective models.
To optimize training time and model performance, our approach to fine-tuning the LLaMA-2 models was a balanced blend of the above points. By focusing on depth in specific areas, diversity of input prompts, and keeping the size of the training set small, we aimed to maximize the precision and relevance of our models’ outputs. We curated a content-filtered, instruction-tuned dataset called Open-Platypus, which draws from a variety of open-sourced datasets.
Open-Platypus is made up of 11 open-sourced datasets, detailed in Table 1. It primarily consists of human-designed questions, with only around 10% of questions generated by an LLM. Given our focus on STEM and logic, we primarily pulled from datasets geared towards those subjects, supplementing them with keyword-filtered content from datasets with broader subject coverage, namely Openassistant-Guanaco [8] and airoboros [9]. The backbone of Open-Platypus is a modified version of MATH [14] that has been supplemented with expanded step-by-step solutions from PRM800K [23]. We employed the Alpaca instruction-tuning format, where each question is structured with an instruction, input, and output.
Removing Similar & Duplicate Questions
After collecting data from various sources, we ran it through a de-duplication process to minimize the chances of memorization. We removed word-for-word duplicate instructions and instructions that had 80% cosine similarity with the SentenceTransformers [31] embeddings of other instructions in our train set. Our motivation behind this was that longer answers likely translate to more detailed explanations and step-by-step solutions.
Contamination Check
A core component of our methodology revolves around ensuring that none of the benchmark test questions inadvertently leak into the training set. We seek to prevent memorization of test data from skewing the benchmark results. With that in mind, we developed heuristics to guide manual filtering of questions from Open-Platypus that scored >80% similarity to any benchmark questions. We categorize potential leaks into three groups: duplicate, gray-area, and similar but different.
Fine-tuning & Merging
After refining the dataset and triple-checking for contamination, our methodology centers on two main points: the effectiveness of Low-Rank Approximation (LoRA) training and the built-in model merging capabilities of the State-of-the-art Parameter-Efficient Fine-Tuning (PEFT) library. Different from full fine-tuning methods, LoRA freezes pre-trained model weights and adds rank decomposition matrices into each layer of the transformer. This reduces the number of trainable parameters for downstream tasks and, by extension, the time and cost of training. In addition to PEFT and LoRA, we fine-tuned our models using the HuggingFace transformers library.
Our initial attempts at fine-tuning the models focused on certain modules. We later moved on to other modules recommended by [13], due to their superior performance. For consistency, we adopted this strategy for both the 13B and 70B billion parameter fine-tunes. The only difference between our models is the initial learning rate.
Merging Considerations
We deliberately chose not to merge with any models trained using contaminated datasets. We performed contamination checks on datasets used to train models we merged with to the best of our abilities. Additional details regarding merging considerations are included in the next section, as this is dependent on the fine-tune benchmark results.
3 Results
In this section, we present a detailed analysis of our models’ performance, benchmarking them against other state-of-the-art models. Our primary objective was to discern the effects of merging both broad and niche models and to assess the advantages of fine-tuning on our dataset. Moving forward, “base model” refers to the model on which the LoRA adapters are merged.
According to the HuggingFace OpenLLM Leaderboard data dated 8/10/23 (Table 3), our Platypus2-70B-instruct variant has outperformed its competitors, securing the top position with an average score of 73.13. Notably, our Stable-Platypus2-13B model, as shown in Table 4, stands out as the premier 13 billion parameter model with an average score of 63.96.
The objective of our model merging strategy is to assess the synergistic effects of integrating with broad models like Instruct and Beluga, or specialized models such as Camel. An interesting observation was with the Dolphin merge, where instead of using the conventional Platypus adapters, we opted for the exported Platypus merged with the base LLaMA-2. This decision was influenced by our contamination check experiments of the Dolphin dataset. Dolphin-Platypus2-70B is the only merge that did not perform better than both the base and adapter models. Additionally, there was a smaller score discrepancy between the base Platypus and Dolphin models than the other models being discussed. This led us back to Camel, which had previously shown promising results in our initial tests using 13B.
Post-fine-tuning, both the 13B and 70B models demonstrated marked improvements over the base LLaMA-2 models, particularly in the ARC and TruthfulQA benchmarks. This prompted us to explore the potential of merging with other fine-tuned variants. While the 70B merges showed marginal variations from the baseline scores, the 13B merges, especially with StableBeluga, displayed significant enhancements. For instance, the merge with StableBeluga outperformed its constituent models by at least 0.5% across most benchmarks, with a notable 2.91% increase in TruthfulQA. Additionally, Stable-Platypus2-13B also showed an overall increase of +1.05% over the base model.
Given that TruthfulQA questions are primarily “knowledge” questions (as opposed to “reasoning” questions), the consistent improvement in TruthfulQA scores across merges suggests that merging models effectively broadens the knowledge base rather than enhancing reasoning capabilities. This observation aligns with the nature of TruthfulQA questions, which are primarily knowledge-based. The LLaMA-2 paper’s assertion that model saturation hasn’t been reached further supports the idea that merging can introduce “new” information to the model.
The results underscore the potential of model merging as a strategy to enhance performance. The choice of models for merging, whether broad or focused, plays a pivotal role in determining the outcome. Our experiments with Dolphin, for instance, underscore the importance of iterative testing and model selection. The consistent performance of models like Camel-Platypus2-70B across different benchmarks further emphasizes this point.
In the ARC-Challenge, Hellaswag, and TruthfulQA tests, the Camel-Platypus2-70B model exhibited the most significant positive change with a +4.12% improvement in ARC-challenge. This suggests that the Camel-Platypus2-70B model, when merged with the Platypus adapter, is potentially the most effective combination for tasks related to the ARC-Challenge.
For the MMLU tests, the results were more varied. The Platypus2-70B-instruct model displayed a remarkable +18.18% improvement in abstract algebra, while the Camel-Platypus2-13B model showed a decline of -15.62%. This indicates that the effectiveness of the merge varies depending on the specific domain of the test. Notably, in machine learning, the Camel-Platypus2-70B model demonstrated a significant increase of +26.32%, reinforcing the potential of this model in specific domains.
Drawing from the broader content of our paper, these results underscore the importance of selecting the appropriate model for merging with the Platypus adapter. The performance enhancements or declines are not uniform across all domains, emphasizing the need for domain-specific evaluations before finalizing a merge.
Deep Dive into the Benchmark Metric Tasks
The Appendix contains a breakdown of each MMLU task by change in percent and percent change. The rest of this discussion will be referencing percent change, but we include both for transparency. A deeper dive into the performance metrics of the base models revealed that two models with very similar scores do not necessarily merge into a superior model.
- ARC-Challenge, Hellaswag, TruthfulQA-MC: Table 5
- Most Notable Improvement: The Camel-Platypus2-70B model in the ARC-challenge test exhibited the highest positive change with a +4.12% improvement. This indicates that for tasks related to the ARC-Challenge, the Camel-Platypus2-70B model, when merged with the Platypus adapter, is potentially the most effective.
- Consistent Performer: The Stable-Platypus2-13B model showed consistent positive changes across all three tests compared to the base model, indicating its reliable performance when merged with the Platypus adapter.
- Variability in Results: The results for TruthfulQA were particularly varied, with the Stable-Platypus2-13B model showing a significant +5.87% improvement, while the Dolphin-Platypus2-70B model showed a decline of -1.37%.
| Test Name | Camel-P2-13B | Stable-P2-13B | P2-70B-ins | Dolphin-P2-70B | Camel-P2-70B |
|---|---|---|---|---|---|
| arc_challenge | -0.14 | +1.10 | +1.08 | +1.10 | +4.12 |
| hellaswag | -0.06 | +0.02 | +0.06 | -0.14 | -0.24 |
| truthfulqa_mc | +4.33 | +5.87 | +0.02 | -1.37 | +0.53 |
Table 5: Percent Change over “Base” Model - ARC-Challenge, Hellaswag, TruthfulQA-MC
-
MMLU: Table 7
- Standout Performance: 퍼포먼스는
Camel-Platypus2-70B가 +26.32% 개선, 형식 논리 테스트 결과는Stable-Platypus2-13B의 경우는 +27.27% 개선, Camel-Platypus2-13B는 -2.13% 감소하였음. In the machine learning test, the Camel-Platypus2-70B model displayed a remarkable +26.32% improvement, indicating its potential effectiveness in machine learning domains when merged with the Platypus adapter. - Diverse Results: The results for the formal logic test were diverse, with the Stable-Platypus2-13B model showing a significant +27.27% improvement, while the Camel-Platypus2-13B model showed a decline of -2.13%.
- Consistent Domains: 마케팅과 같은 도메인에서는 모든 모델의 변화가 미미하였고, 특정 도메인에 제한됨. In domains like marketing, the changes across all models were minimal, suggesting that the impact of merging with the Platypus adapter might be limited in certain domains.
- Significant Declines: 대학 물리학 테스트에서는 상당한 감소를 보였는데, 잠재적인 호환성 문제나 비효율성 문제가 나타나는 것으로 보였다고 함. The college physics test showed significant declines for the Platypus2-70B-instruct, Dolphin-Platypus2-70B, and Camel-Platypus2-70B models, with changes of -20.93%, -13.16%, and -18.42% respectively. This indicates potential compatibility issues or inefficiencies when these models are merged with the Platypus adapter for tasks related to college physics.
- Standout Performance: 퍼포먼스는
In this context, basemodel refers to the model on which the adapters are merged.
| Test Name | Camel-P2-13B | Stable-P2-13B | P2-70B-ins | Dolphin-P2-70B | Camel-P2-70B |
|---|---|---|---|---|---|
| abstract_algebra | -15.62 | -6.06 | +18.18 | -11.11 | +11.76 |
| anatomy | -6.67 | +12.90 | -9.09 | +1.16 | 0.00 |
| astronomy | -3.23 | +8.75 | -7.81 | -7.20 | -6.25 |
| business_ethics | -3.51 | +1.69 | -4.05 | +2.86 | -2.67 |
| clinical_knowledge | -2.52 | 0.00 | +2.06 | +0.53 | +1.05 |
| college_biology | +8.43 | +8.99 | +0.83 | +2.59 | -4.92 |
| college_chemistry | +2.56 | -2.70 | -6.12 | 0.00 | 0.00 |
| college_computer_science | 0.00 | -2.17 | -3.33 | -7.02 | -10.00 |
| college_mathematics | +6.67 | +8.82 | +4.76 | +2.56 | +5.13 |
| college_medicine | -5.38 | +2.15 | +4.39 | +2.70 | +0.86 |
| college_physics | +3.33 | -2.94 | -20.93 | -13.16 | -18.42 |
| computer_security | -1.43 | -12.16 | -1.30 | -3.80 | +1.32 |
| conceptual_physics | +3.13 | +4.55 | -4.82 | -3.85 | 0.00 |
| econometrics | +10.26 | +14.71 | +3.77 | +4.08 | +5.77 |
| electrical_engineering | -15.79 | -8.86 | -7.45 | -10.00 | -9.28 |
| elementary_mathematics | +6.02 | -3.10 | -3.39 | +4.22 | +0.59 |
| formal_logic | -2.13 | +27.27 | +13.56 | +12.07 | +22.41 |
| global_facts | +21.21 | +2.63 | +4.26 | -6.52 | -5.66 |
| hs_biology | -4.19 | -5.29 | +2.39 | +1.64 | -0.40 |
| hs_chemistry | -3.41 | -1.14 | -3.51 | +3.85 | +5.66 |
| hs_computer_science | -8.20 | 0.00 | -1.27 | 0.00 | -3.75 |
| hs_european_history | +1.80 | 0.00 | +4.32 | +2.17 | +0.72 |
| hs_geography | -2.70 | -0.68 | +0.58 | -5.06 | -1.74 |
| hs_government_and_politics | +8.33 | +4.40 | +1.66 | -1.67 | -1.10 |
| hs_macroeconomics | -4.37 | +1.34 | +1.81 | +2.61 | -1.42 |
| hs_mathematics | -7.69 | +15.19 | -5.81 | -10.87 | -21.51 |
| hs_microeconomics | -2.26 | -2.11 | +2.20 | +1.12 | +1.12 |
| hs_physics | -3.51 | -4.00 | +1.41 | -2.67 | -4.17 |
| hs_psychology | +1.42 | +4.59 | +0.41 | -0.82 | +0.61 |
| hs_statistics | +3.19 | +7.37 | +2.31 | +4.96 | +2.34 |
| hs_us_history | +5.23 | +8.50 | -2.12 | +0.54 | -3.21 |
| hs_world_history | +5.75 | +3.37 | +0.94 | +1.44 | +2.36 |
| human_aging | +1.40 | -4.00 | +2.26 | -1.14 | +1.15 |
| human_sexuality | -1.32 | -3.37 | -5.31 | -1.83 | -7.14 |
| international_law | +2.33 | -2.15 | +0.96 | -2.80 | +1.94 |
| jurisprudence | -5.19 | -2.47 | +1.12 | -2.20 | 0.00 |
| logical_fallacies | -4.63 | -1.74 | +2.29 | 0.00 | -5.11 |
| machine_learning | -15.38 | -14.00 | +22.81 | +16.07 | +26.32 |
| management | -2.63 | -1.27 | +2.35 | 0.00 | +3.53 |
| marketing | +1.08 | -2.58 | +0.95 | +0.94 | +0.94 |
| medical_genetics | +13.21 | -5.97 | 0.00 | -1.39 | -1.45 |
| miscellaneous | +1.86 | +0.66 | +0.15 | -0.29 | -0.59 |
| moral_disputes | +1.81 | -0.45 | -2.96 | -1.15 | -5.04 |
| moral_scenarios | +3.54 | +19.74 | +7.95 | +17.71 | +6.37 |
| nutrition | -5.43 | 0.00 | -2.98 | +2.23 | -2.54 |
| philosophy | +1.00 | +2.45 | 0.00 | +1.25 | +1.25 |
| prehistory | +1.46 | +6.83 | 0.00 | +3.01 | -1.47 |
| professional_accounting | +10.00 | +4.10 | -1.23 | +3.29 | -1.90 |
| professional_law | +8.01 | +10.05 | +6.61 | +5.31 | +5.13 |
| professional_medicine | +4.29 | +9.59 | -1.49 | -2.50 | -3.40 |
| professional_psychology | +4.69 | +3.64 | -1.07 | +0.22 | +0.22 |
| public_relations | -5.33 | +5.71 | -4.88 | -1.25 | 0.00 |
| security_studies | -2.03 | -3.16 | -5.47 | -3.08 | -0.52 |
| sociology | -5.92 | -6.16 | +1.14 | +1.14 | +0.58 |
| us_foreign_policy | -8.54 | -4.82 | -4.44 | -4.40 | -3.33 |
| virology | -5.41 | -1.28 | +1.14 | -2.20 | +4.60 |
| world_religions | +0.75 | +0.75 | -2.00 | -2.03 | -3.29 |
Table 7: Percent Change over “Base” Model - MMLU
- 병합의 효과는 도메인별로 다르며, 일반적인 해결책은 없고, 연구자와 실무자들은 자신들의 특정 관심 도메인에서의 성능 향상 또는 감소를 신중하게 평가한 후 병합을 최종 결정해야 한다고 조언함. The tables provide a comprehensive view of how different models perform when merged with the Platypus adapter across various domains. It’s evident that the effectiveness of the merge is domain-specific, and there’s no one-size-fits-all solution. Researchers and practitioners should carefully evaluate the performance enhancements or declines in their specific domain of interest before finalizing a merge.
MMLU TEST NAME
| English Name | Korean Name |
|---|---|
| abstract_algebra | 추상 대수 |
| anatomy | 해부학 |
| astronomy | 천문학 |
| business_ethics | 경영 윤리 |
| clinical_knowledge | 임상 지식 |
| college_biology | 대학 생물학 |
| college_chemistry | 대학 화학 |
| college_computer_science | 대학 컴퓨터 과학 |
| college_mathematics | 대학 수학 |
| college_medicine | 대학 의학 |
| college_physics | 대학 물리학 |
| computer_security | 컴퓨터 보안 |
| conceptual_physics | 개념 물리학 |
| econometrics | 계량 경제학 |
| electrical_engineering | 전기 공학 |
| elementary_mathematics | 초등 수학 |
| formal_logic | 형식 논리 |
| global_facts | 세계적 사실 |
| hs_biology | 고등 생물학 |
| hs_chemistry | 고등 화학 |
| hs_computer_science | 고등 컴퓨터 과학 |
| hs_european_history | 고등 유럽사 |
| hs_geography | 고등 지리 |
| hs_government_and_politics | 고등 정부와 정치 |
| hs_macroeconomics | 고등 거시경제학 |
| hs_mathematics | 고등 수학 |
| hs_microeconomics | 고등 미시경제학 |
| hs_physics | 고등 물리학 |
| hs_psychology | 고등 심리학 |
| hs_statistics | 고등 통계학 |
| hs_us_history | 고등 미국사 |
| hs_world_history | 고등 세계사 |
| human_aging | 노화 |
| human_sexuality | 휴먼 성적 삶 |
| international_law | 국제법 |
| jurisprudence | 법철학 |
| logical_fallacies | 논리 오류 |
| machine_learning | 머신러닝 |
| management | 경영 |
| marketing | 마케팅 |
| medical_genetics | 의료 유전학 |
| miscellaneous | 기타 |
| moral_disputes | 도덕적 분쟁 |
| moral_scenarios | 도덕적 시나리오 |
| nutrition | 영양 |
| philosophy | 철학 |
| prehistory | 사전 역사 |
| professional_accounting | 전문 회계 |
| professional_law | 전문 법 |
| professional_medicine | 전문 의학 |
| professional_psychology | 전문 심리학 |
| public_relations | 홍보 |
| security_studies | 보안 연구 |
| sociology | 사회학 |
| us_foreign_policy | 미국 외교 정책 |
| virology | 바이러스학 |
| world_religions | 세계 종교 |
- Broader Impacts & Future Work
- 간결한 모델의 효율성을 활용하고 개별 어댑터의 Precision를 통합하는 것은 전략적일 수 있다고 함. (위에 성능에서도 보듯이 도메인별로 다른 결과를 보여줬으므로 일반화된 솔루션이 되기는 어려울 수 있다는 점은 다시 한 번 확인함.)
- 이런 생태계에서 입력과 training dataset 간의 유사성은 사후 요인으로 사용되어 출력이 유사한 데이터에 의해 정보를 얻도록 편향되게 할 수 있다고 함.
- 전문가의 혼합 (Mixture of Experts, MoEs) 는 도메인별 훈련의 성공을 고려할 때 정확도를 더 향상시키는 유망한 방법이고, 이 관점을 기반으로 LIMA는 특정 도메인을 위해 정밀하게 선별된 작은 데이터셋을 제시함.
- 이 접근 방식의 이점은 분류 훈련 프로세스의 간소화와 어댑터의 평균 훈련 입력 간 빠른 코사인 유사도 검색과 같은 것을 통해 효율적인 학습을 제시함.
- LIMA 전략이 LoRA와 PEFT 분야에서 적용 가능한지에 대해서 추가적인 연구를 진행할 예정이라고 함.
- 특히 기준 점수가 유사한 모델의 맥락에서 모델 병합의 미묘한 측면을 더 깊이 이해하는 데 집중할 것이며, 6개 모델의 성공적인 LoRA 병합인 Lazarus와 같은 모델을 활용하는 가능성도 탐구할 수 있을 것이라고 함. Modern LLMs often require considerable computational resources, making their training and inference costs restrictive for those with limited budgets. While techniques like quantization and LoRA provide some relief, a notable observation from the HuggingFace leaderboard is the success of smaller models in specific tasks, such as role-playing and question answering. It may be strategic to harness the efficiency of these compact models and merge them with the precision of individual adapters. In that ecosystem, the similarity between inputs and training data is used as an a posteriori factor, biasing the outputs to be informed by similar data.
Mixture of Experts (MoEs) presents a promising avenue for further enhancing accuracy, given the success of domain-specific training. Future exploration could also involve integrating alpaca and orca-styled datasets, as well as examining the potential of QLoRA within our pipeline. Building on this perspective, LIMA suggests a future characterized by an array of small, meticulously curated datasets for niche domains. The advantages of this approach are evident: streamlined fine-tuning processes and rapid cosine similarity searches across average training inputs of adapters.
An intriguing inquiry is the applicability of the LIMA strategy within the LoRA and PEFT landscapes. This question warrants further investigation in subsequent studies. Future work might delve deeper into understanding the nuances of model merging, especially in the context of models with similar baseline scores. The potential of leveraging models like Lazarus, a successful LoRA merge of 6 models, could also be explored.
-
Limitations
Platypus, as a fine-tuned extension of LLaMA-2, retains many of the foundational model’s constraints and introduces specific challenges due to its targeted training. It shares LLaMA-2’s static knowledge base, which may become outdated. There’s also a risk of generating inaccurate or inappropriate content, especially with unclear prompts. Although Platypus is enhanced for STEM and logic in English, its proficiency in other languages is not assured and can be inconsistent. It may occasionally produce content that’s biased, offensive, or harmful. Efforts to mitigate these issues have been made, but challenges, especially in non-English languages, remain.
The potential misuse of Platypus for malicious activities is a concern. Developers should conduct safety testing tailored to their application before deployment. Platypus may have limitations outside its primary domain, so users should exercise caution and consider additional fine-tuning for optimal performance. Users should ensure no overlap between Platypus’s training data and other benchmark test sets. We’ve been cautious about data contamination and have avoided merging with models trained on tainted datasets. While we are confident there is no contamination in our cleaned training data, it is unlikely but not impossible that some questions slipped through the cracks. For a comprehensive understanding of these limitations, please refer to the limitations section in the paper.
[2] Towards a Unified View of Parameter-Efficient Transfer Learning
- url: https://arxiv.org/abs/2110.04366
- pdf: https://arxiv.org/pdf/2110.04366
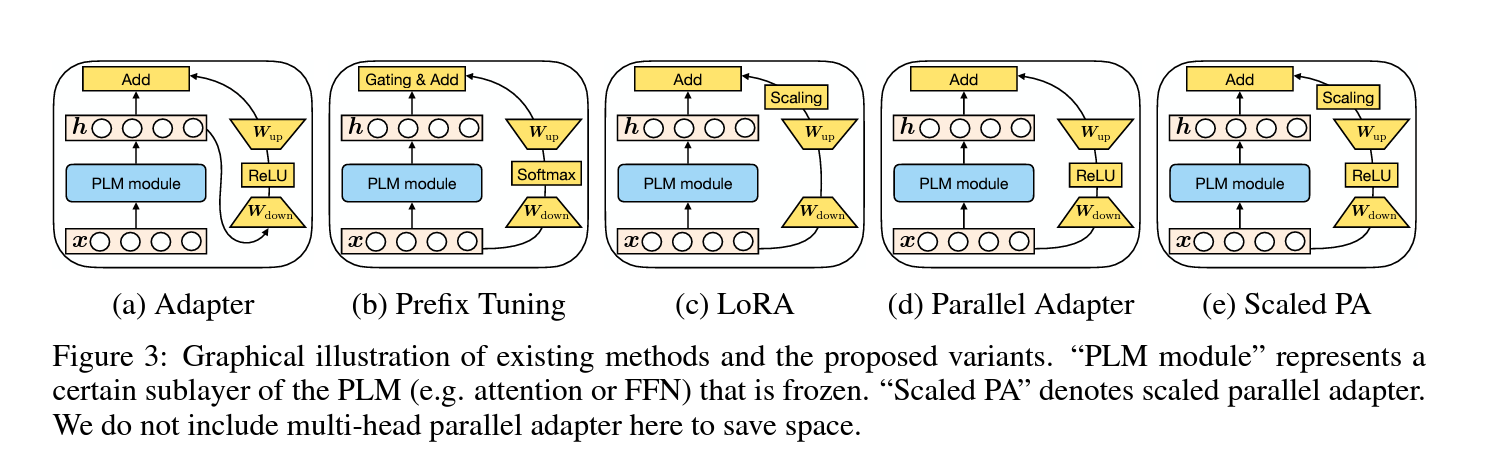
- abstract: Fine-tuning large pre-trained language models on downstream tasks has become the de-facto learning paradigm in NLP. However, conventional approaches fine-tune all the parameters of the pre-trained model, which becomes prohibitive as the model size and the number of tasks grow. Recent work has proposed a variety of parameter-efficient transfer learning methods that only fine-tune a small number of (extra) parameters to attain strong performance. While effective, the critical ingredients for success and the connections among the various methods are poorly understood. In this paper, we break down the design of state-of-the-art parameter-efficient transfer learning methods and present a unified framework that establishes connections between them. Specifically, we re-frame them as modifications to specific hidden states in pre-trained models, and define a set of design dimensions along which different methods vary, such as the function to compute the modification and the position to apply the modification. Through comprehensive empirical studies across machine translation, text summarization, language understanding, and text classification benchmarks, we utilize the unified view to identify important design choices in previous methods. Furthermore, our unified framework enables the transfer of design elements across different approaches, and as a result we are able to instantiate new parameter-efficient fine-tuning methods that tune less parameters than previous methods while being more effective, achieving comparable results to fine-tuning all parameters on all four tasks.
TL;DR
- downstream 작업에서 pre-training된 대규모 언어모델을 파인튜닝하는 것은 NLP의 사실상의 학습 패러다임이 되었으나, 기존의 접근 방식은 pre-training된 모델의 모든 파라미터를 파인튜닝하기 때문에 모델 크기와 작업 수가 증가함에 따라 엄청난 비용이 소요됨.
- 이 문제점을 해결하고자 소수의 (추가) 파라미터만 파인튜닝하여 우수한 성능을 달성하는 다양한 파라미터 효율적 전이 학습 방법이 제안되었고, 이런 방법들은 효과적이기는 하지만, 성공의 핵심 요소와 다양한 방법 간의 연관성에 대해서는 잘 알려져 있지 않음.
- 이 백서에서는 SOTA 파라미터 효율적 전이 학습 방법의 설계를 세분화하고 이들 간의 연결을 설정하는 통합 프레임워크를 제시하고, 특히, pre-training된 모델에서 특정 hidden state에 대한 수정으로 프레임을 재구성하여 수정을 계산하는 함수 및 수정을 적용하는 위치 등 다양한 방법에 따라 달라지는 일련의 차원 설계를 정의하고자 함.
- 기계 번역, 텍스트 요약, 언어 이해, 텍스트 분류 벤치마크 전반에 걸친 포괄적인 경험적 연구를 통해 통합된 뷰를 활용하여 이전 방법에서 중요한 설계 선택을 식별해보고, 통합 서로 다른 접근 방식 간에 디자인 요소를 이전할 수 있는 통합프레임워크를 제시함.
- 결과적으로 이전 방법보다 더 적은 파라미터를 조정하면서도, 더 효율적인 새로운 파라미터 파인튜닝 방법을 인스턴스화하여, 4가지 작업 모두에서 모든 파라미터를 파인튜닝하는 것과 비슷한 결과를 얻는 것을 확인하였음.