Flash Attention-2
- Related Project: Private
- Category: Paper Review
- Date: 2023-09-01
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
- url: https://arxiv.org/abs/2307.08691
- pdf: https://arxiv.org/pdf/2307.08691
- related-TextGenerationLLM-project: https://github.com/jzhang38/TinyLlama
- abstract: Scaling Transformers to longer sequence lengths has been a major problem in the last several years, promising to improve performance in language modeling and high-resolution image understanding, as well as to unlock new applications in code, audio, and video generation. The attention layer is the main bottleneck in scaling to longer sequences, as its runtime and memory increase quadratically in the sequence length. FlashAttention exploits the asymmetric GPU memory hierarchy to bring significant memory saving (linear instead of quadratic) and runtime speedup (2-4× compared to optimized baselines), with no approximation. However, FlashAttention is still not nearly as fast as optimized matrix-multiply (GEMM) operations, reaching only 25-40\% of the theoretical maximum FLOPs/s. We observe that the inefficiency is due to suboptimal work partitioning between different thread blocks and warps on the GPU, causing either low-occupancy or unnecessary shared memory reads/writes. We propose FlashAttention-2, with better work partitioning to address these issues. In particular, we (1) tweak the algorithm to reduce the number of non-matmul FLOPs (2) parallelize the attention computation, even for a single head, across different thread blocks to increase occupancy, and (3) within each thread block, distribute the work between warps to reduce communication through shared memory. These yield around 2× speedup compared to FlashAttention, reaching 50-73\% of the theoretical maximum FLOPs/s on A100 and getting close to the efficiency of GEMM operations. We empirically validate that when used end-to-end to train GPT-style models, FlashAttention-2 reaches training speed of up to 225 TFLOPs/s per A100 GPU (72\% model FLOPs utilization).
Contents
TL;DR
- 트랜스포머의 컨텍스트 길이 확장 연구
- FlashAttention과 FlashAttention-2 알고리즘 도입 및 개선
- 계산 효율성 증대와 GPU 자원 최적화 실현
1. 서론
트랜스포머 모델에서 컨텍스트 길이를 확장하는 것은 계산 비용과 메모리 요구 사항이 입력 시퀀스 길이에 따라 제곱으로 증가하기 때문에 큰 도전이 됩니다. 이런 문제를 해결하기 위해 Dao 등은 FlashAttention 알고리즘을 제안하여 표준 attention의 계산과 메모리 사용을 줄이는 방법을 모색하였습니다. 본 논문에서는 FlashAttention의 개선 버전인 FlashAttention-2를 소개하고, 효율성을 더욱 향상시키기 위한 방법을 제안합니다.
2. 배경
2.1 하드웨어 특성
GPU는 높은 병렬 처리 능력을 가지고 있으며, 특히 행렬 곱셈을 위한 텐서 코어 같은 전용 유닛이 탑재되어 있습니다. 이런 특성은 행렬 곱셈 작업을 빠르게 수행할 수 있게 해 주며, FlashAttention과 같은 최적화된 알고리즘에서 중요한 역할을 합니다.
2.2 표준 Attention 구현
기본적인 Attention 메커니즘은 입력 시퀀스 \(Q\), \(K\), \(V\)에 대해 다음과 같은 수식을 계산합니다.
\(S = QK^T\) \(P = \text{softmax}(S)\) \(O = PV\)
이 과정은 메모리와 계산량이 많이 필요한 작업으로, 특히 \(S\)와 \(P\)를 메모리에 저장하는 것이 큰 부담이 됩니다.
3. FlashAttention-2: 알고리즘, 병렬 처리 및 작업 분할
FlashAttention-2는 기존 FlashAttention의 비행렬 곱셈 연산(FLOPs)을 줄이는 것을 목표로 합니다. 이는 GPU에서 행렬 곱셈이 훨씬 빠르게 수행될 수 있도록 하기 위함입니다.
3.1 알고리즘 개선
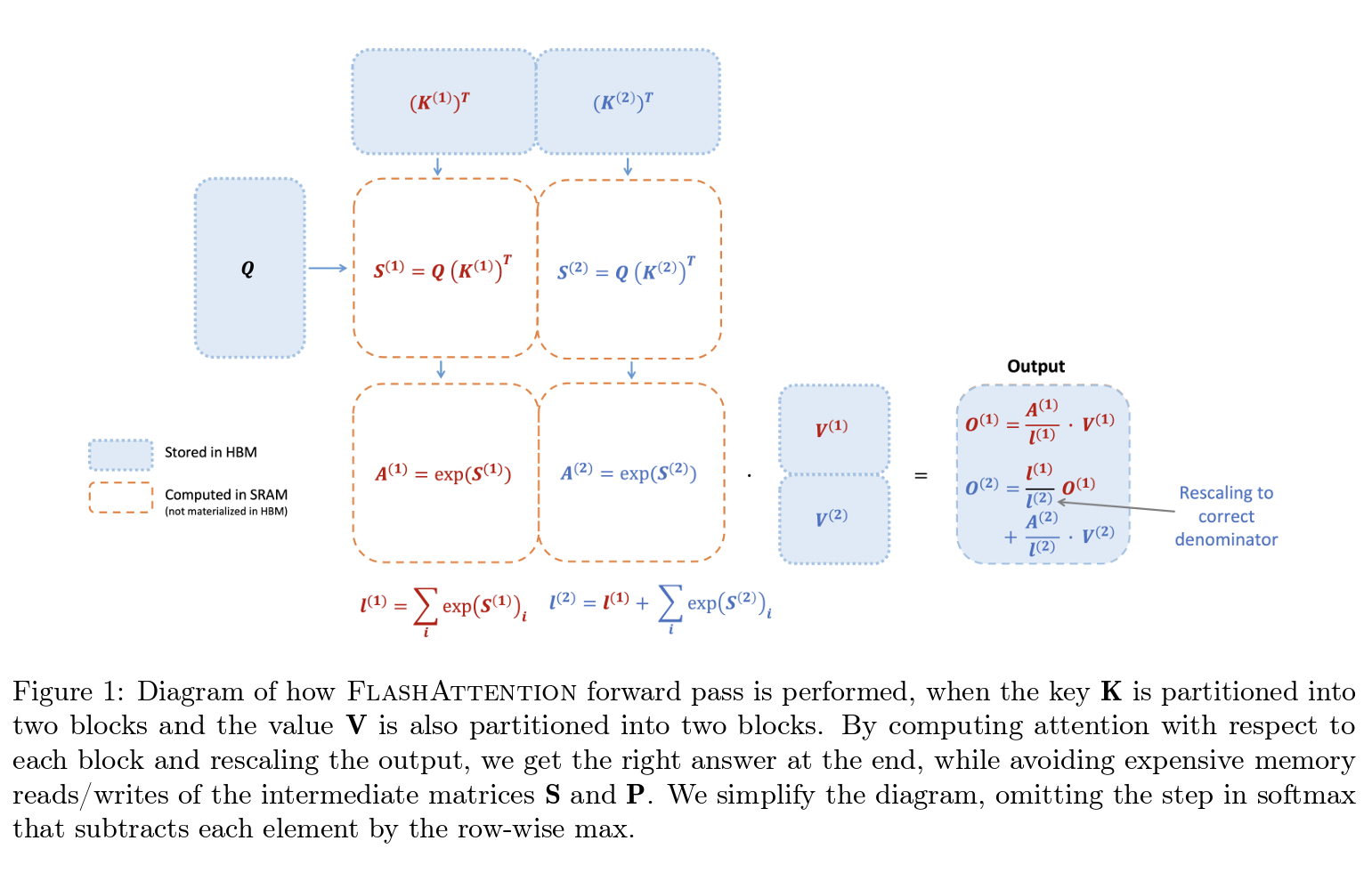
FlashAttention-2는 online softmax 기법을 사용하여 불필요한 메모리 접근을 최소화합니다. 이를 통해 각 블록의 softmax를 계산하고 최종 결과를 조정하여 정확한 출력을 도출할 수 있습니다. 예를 들어, 다음과 같이 계산을 수행합니다.
\[\begin{align*} &\text{For each block } i: \\ &m_i = \max(S_i) \\ &\ell_i = \sum \exp(S_i - m_i) \\ &P_i = \frac{\exp(S_i - m_i)}{\ell_i} \\ &O_i = P_i V \\ \end{align*}\]3.2 병렬 처리 및 작업 분할
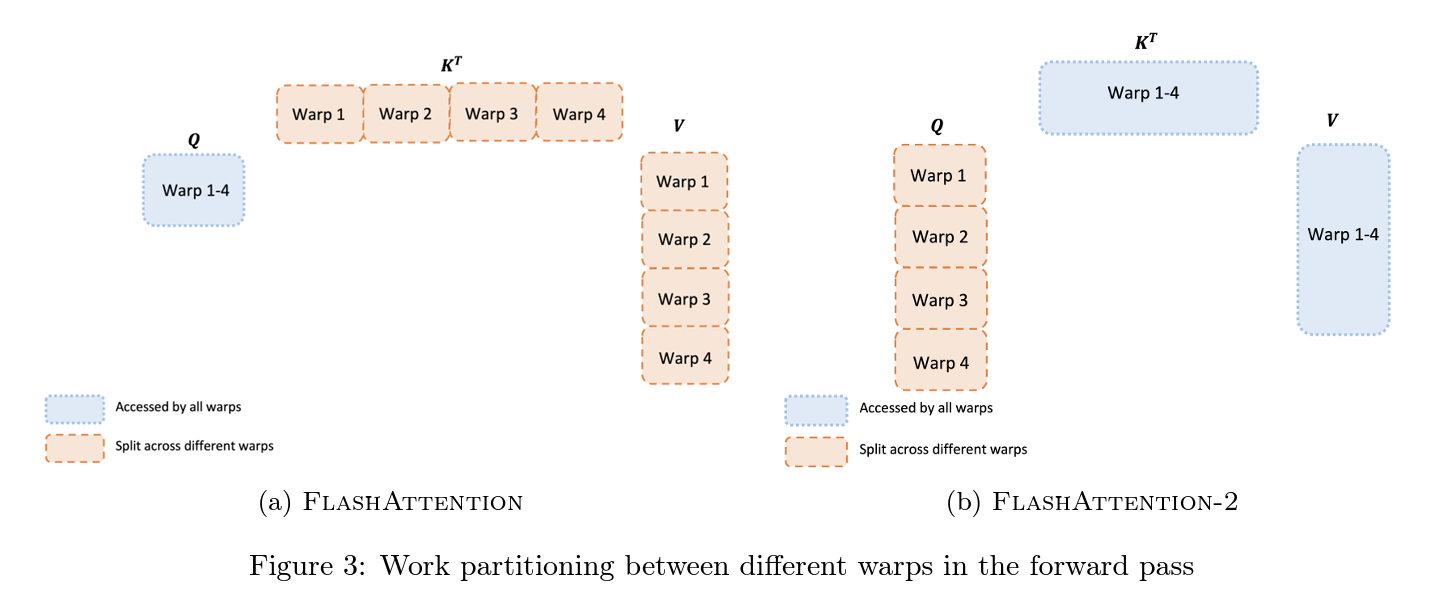
FlashAttention-2는 시퀀스 길이 차원뿐만 아니라 배치 및 헤드 수 차원에서도 계산을 병렬화하여 GPU 자원의 활용도를 높이며, 특히 긴 시퀀스를 처리할 때 효과적입니다.
또, 각 스레드 블록 내에서 다른 워프들 사이의 작업을 분할하여 통신과 공유 메모리 접근을 최소화해서 전반적인 속도를 높입니다.
3.3 FlashAttention-2의 포워드 및 백워드 패스
FlashAttention-2는 기존의 FlashAttention 알고리즘을 개선하여 비행렬 곱셈 연산을 줄이고, GPU의 병렬 처리 능력을 극대화하기 위한 방법을 도입했습니다.
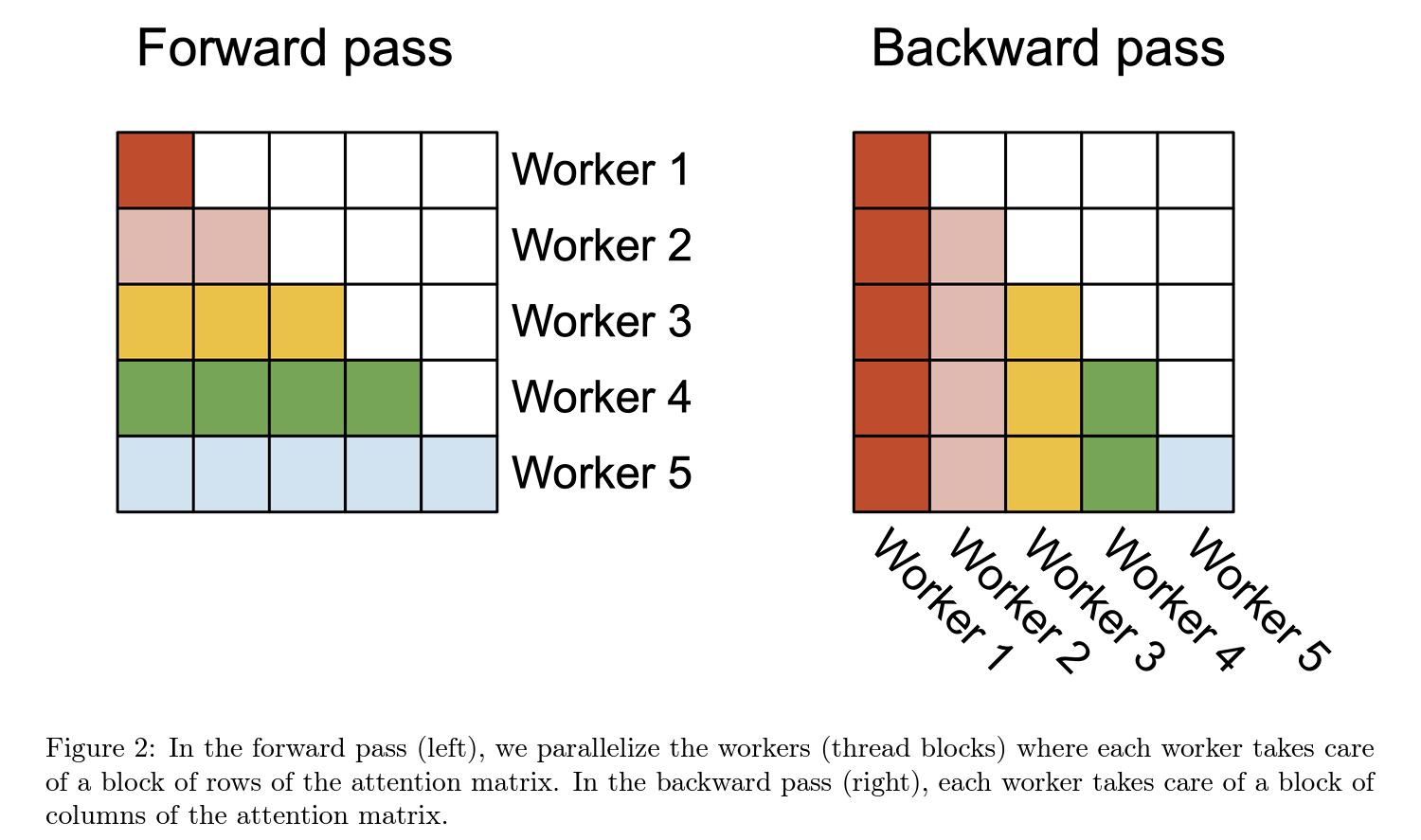
3.3.1 포워드 패스
FlashAttention-2의 포워드 패스는 입력 시퀀스 \(Q\), \(K\), \(V\)를 처리하여 출력 \(O\)를 계산합니다. 주요 개선 사항은 메모리 접근을 최소화하고, 계산 효율성을 극대화하는 것입니다.
- 블록 분할 및 로드: 입력 시퀀스는 블록 단위로 나누어져 각 블록이 GPU의 SRAM에 로드됩니다. 이는 메모리 대역폭 사용을 최적화하고, 필요한 데이터만 빠르게 접근할 수 있게 합니다.
- 로컬 소프트맥스 및 스케일링: 각 블록에 대해 로컬 소프트맥스 계산이 수행되며, 이 결과는 나중에 전체 소프트맥스의 정확한 결과를 재조정하는 데 사용됩니다. 이 접근 방식은 각 블록의 계산을 독립적으로 수행할 수 있게 하여 병렬 처리 효율을 증가시킵니다.
- 병렬 실행: 블록 단위의 계산은 GPU의 다수의 스레드 블록에 의해 동시에 수행됩니다. 각 스레드 블록은 서로 독립적으로 작동하므로, GPU 리소스의 사용률을 극대화합니다.
3.3.2 백워드 패스
백워드 패스는 학습 과정에서 그래디언트를 계산하여 모델의 가중치를 업데이트하는 데 사용됩니다. FlashAttention-2는 백워드 패스를 최적화하여 메모리 사용량을 줄이고 계산 속도를 향상시킵니다.
- 그래디언트 계산: 출력 \(O\)의 그래디언트 \(dO\)를 기반으로, 입력 \(Q\), \(K\), \(V\)에 대한 그래디언트 \(dQ\), \(dK\), \(dV\)를 계산합니다. 이 계산은 각 입력 블록에 대해 독립적으로 수행됩니다.
- 효율적 메모리 관리: FlashAttention-2는 중간 계산 결과를 메모리에 저장하지 않고, 필요할 때마다 다시 계산함으로써 메모리 요구량을 줄이며, 특히 큰 모델과 긴 시퀀스를 처리할 때 메모리 부족 문제를 완화시킵니다.
- 워프 간 작업 분할: 백워드 패스에서도 포워드 패스와 유사하게 GPU 내의 워프(warp) 간에 작업을 분할하여 실행합니다. 각 워프는 독립적으로 특정 부분의 그래디언트를 계산하고, 필요한 경우 다른 워프와의 동기화를 통해 전체 그래디언트를 완성합니다.
4. 실증적 검증
FlashAttention-2는 다양한 설정에서 기존 FlashAttention 대비 약 2배의 속도 향상을 보였습니다. 특히, 이런 개선은 GPT 스타일 모델의 학습 속도를 증가시켜, 최대 225 TFLOPs/s의 성능을 A100 GPU에서 달성하였습니다.
Related Model
TinyLlama-1.1B
The TinyLlama project aims to pretrain a 1.1B Llama model on 3 trillion tokens. With some proper optimization, we can achieve this within a span of “just” 90 days using 16 A100-40G GPUs. The training has started on 2023-09-01.
We adopted exactly the same architecture and tokenizer as Llama 2. This means TinyLlama can be plugged and played in many open-source projects built upon Llama. Besides, TinyLlama is compact with only 1.1B parameters. This compactness allows it to cater to a multitude of applications demanding a restricted computation and memory footprint.
Releases Schedule
We will be rolling out intermediate checkpoints following the below schedule. We also include some baseline models for comparison.
| Date | HF Checkpoint | Tokens | Step | HellaSwag Acc_norm |
|---|---|---|---|---|
| Baseline | StableLM-Alpha-3B | 800B | – | 38.31 |
| Baseline | Pythia-1B-intermediate-step-50k-105b | 105B | 50k | 42.04 |
| Baseline | Pythia-1B | 300B | 143k | 47.16 |
| 2023-09-04 | TinyLlama-1.1B-intermediate-step-50k-105b | 105B | 50k | 43.50 |
Meanwhile, you can track the live cross entropy loss here.
Potential Usecase
Tiny but strong language models are useful for many applications. Here are some potential usecases:
- Assisting speculative decoding of larger models. (See this tutorial by Andrej Karpathy)
- Deployment on edge devices with restricted memory and computational capacities, for functionalities like real-time machine translation without an internet connection (the 4bit-quantized TinyLlama-1.1B’s weight only takes up 550MB RAM).
- Enabling real-time dialogue generation in video games.
Moreover, our code can be a reference for enthusiasts keen on pretraining language models under 5 billion parameters without diving too early into Megatron-LM.
Training Details
Below are some details of our training setup:
| Setting | Description |
|---|---|
| Parameters | 1.1B |
| Attention Variant | Grouped Query Attention |
| Model Size | Layers: 22, Heads: 32, Query Groups: 4, Embedding Size: 2048, Intermediate Size (Swiglu): 5632 |
| Sequence Length | 2048 |
| Batch Size | 2 million tokens (2048 * 1024) |
| Learning Rate | 4e-4 |
| Learning Rate Schedule | Cosine with 2000 warmup steps |
| Training Data | Slimpajama & Starcoderdata |
| Data Preprocessing | Excluded GitHub subset of Slimpajama; Sampled all code from Starcoderdata |
| Combined Dataset Size | Around 950B tokens |
| Total Tokens During Training | 3 trillion (slightly more than 3 epochs/1430k steps) |
| Natural Language to Code Ratio | 7:3 |
| Hardware | 16 A100-40G GPUs |
Blazingly Fast
Our codebase supports the following features:
- multi-gpu and multi-node distributed training with FSDP.
- flash attention 2.
- fused layernorm.
- fused swiglu.
- fused cross entropy loss .
- fused rotary positional embedding.
Thanks to those optimizations, we achieve a throughput of 24k tokens per second per A100-40G GPU, which translates to 56% model flops utilization without activation checkpointing (We expect the MFU to be even higher on A100-80G). It means you can train a chinchilla-optimal TinyLlama (1.1B param, 22B tokens) in 32 hours with 8 A100. Those optimizations also greatly reduce the memory footprint, allowing us to stuff our 1.1B model into 40GB GPU RAM and train with a per-gpu batch size of 16k tokens. You can also pretrain TinyLlama on 3090/4090 GPUs with a smaller per-gpu batch size. Below is a comparison of the training speed of our codebase with that of Pythia and MPT.
| Model | A100 GPU hours taken on 300B tokens |
|---|---|
| TinyLlama-1.1B | 3456 |
| Pythia-1.0B | 4830 |
| MPT-1.3B | 7920 |
The Pythia number comes from their paper. The MPT number comes from here, in which they say MPT-1.3B “ was trained on 440 A100-40GBs for about half a day” on 200B tokens.
The fact that TinyLlama is a relatively small model with grouped query attention means it is also fast during inference. Below are some throughputs that we measure:
| Framework | Device | Settings | Throughput (tokens/sec) |
|---|---|---|---|
| Llama.cpp | Mac M2 16GB RAM | batch_size=1; 4-bit inference | 71.8 |
| vLLM | A40 GPU | batch_size=100, n=10 | 7094.5 |