Difussion Researches
- Related Project: Private
- Category: Paper Review
- Date: 2024-07-19
Difussion Researches
Difusion 관련 연구 동향 및 활용 사례 등
Contents
[1] Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
- url: https://arxiv.org/abs/2407.03300
- pdf: https://arxiv.org/pdf/2407.03300
- html: https://arxiv.org/html/2407.03300v1
- blog: https://boyuan.space/diffusion-forcing/
- abstract: In this work, we introduce ChatQA 2, a Llama3-based model designed to bridge the gap between open-access LLMs and leading proprietary models (e.g., GPT-4-Turbo) in long-context understanding and retrieval-augmented generation (RAG) capabilities. These two capabilities are essential for LLMs to process large volumes of information that cannot fit into a single prompt and are complementary to each other, depending on the downstream tasks and computational budgets. We present a detailed continued training recipe to extend the context window of Llama3-70B-base from 8K to 128K tokens, along with a three-stage instruction tuning process to enhance the model’s instruction-following, RAG performance, and long-context understanding capabilities. Our results demonstrate that the Llama3-ChatQA-2-70B model achieves accuracy comparable to GPT-4-Turbo-2024-0409 on many long-context understanding tasks and surpasses it on the RAG benchmark. Interestingly, we find that the state-of-the-art long-context retriever can alleviate the top-k context fragmentation issue in RAG, further improving RAG-based results for long-context understanding tasks. We also provide extensive comparisons between RAG and long-context solutions using state-of-the-art long-context LLMs.
TL;DR
- Diffusion Forcing은 다음 토큰 예측 모델과 전체 시퀀스 확산 모델의 강점을 결합합니다.
- 독립적인 토큰 노이즈 레벨을 통해 시퀀스 생성 모델링을 훈련합니다.
- 다양한 응용 분야에서 유연한 샘플링과 안정적인 시퀀스 생성을 가능하게 합니다.
1. Diffusion Forcing의 개념과 수학적 기초
Diffusion Forcing은 “teacher 강제(Teacher Forcing)”와 “확산 모델(Diffusion Models)”의 개념에서 영감을 받아, 다음 토큰 예측 모델의 유연한 생성 능력과 전체 시퀀스 확산 모델의 시퀀스 수준 유도 능력을 결합하여 훈련하는 패러다임입니다.
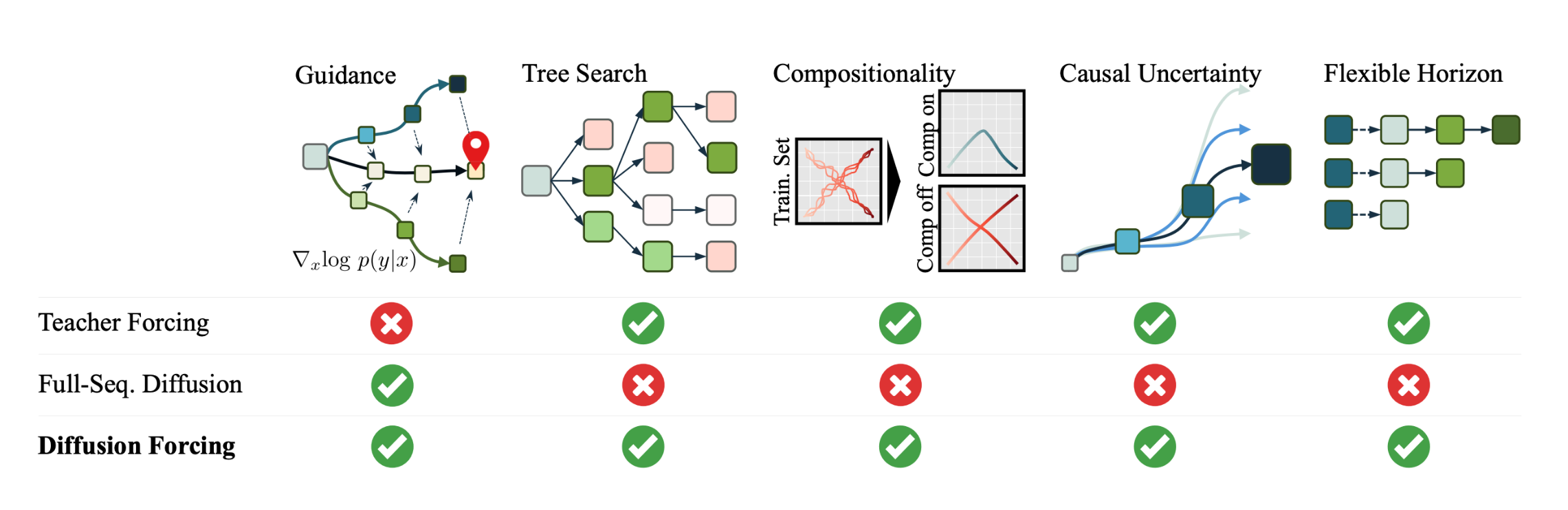
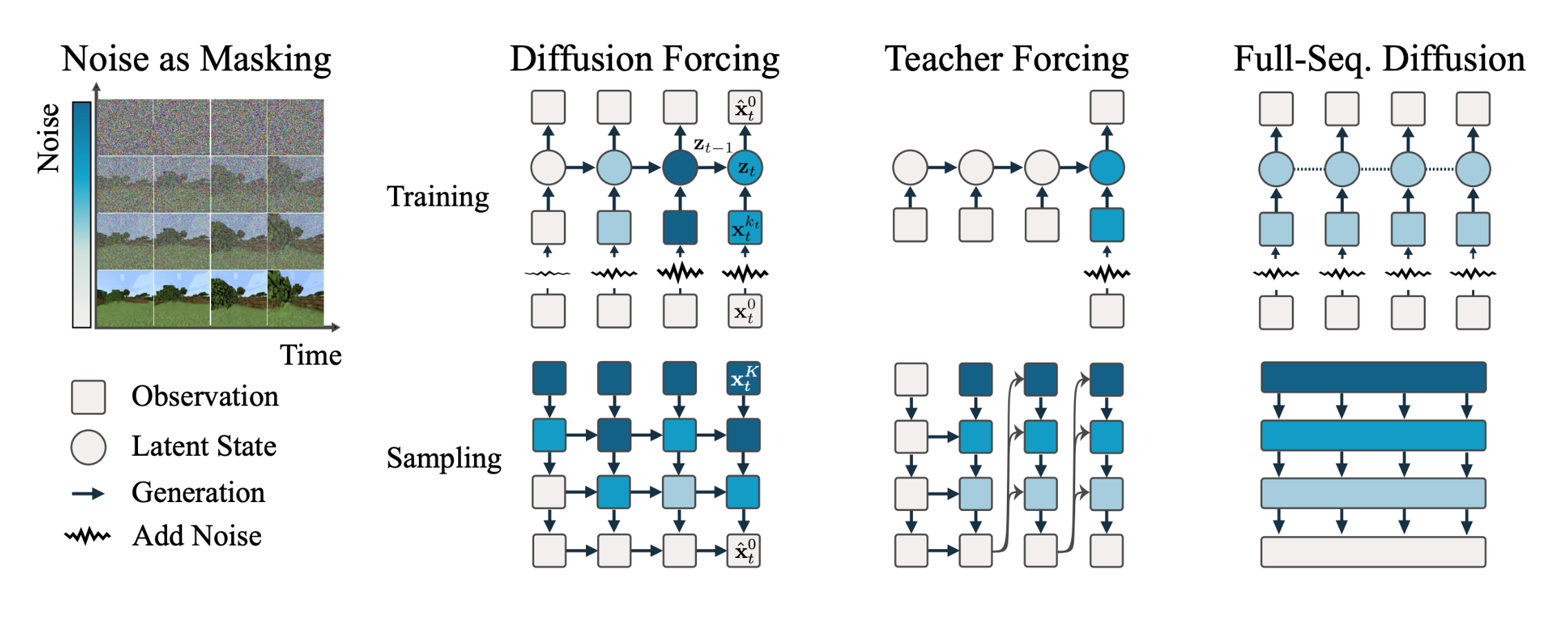
이 방법은 토큰마다 독립적인 노이즈 레벨을 적용하여 각 토큰을 디노이징하는 확산 모델을 훈련합니다. Denoiser 네트워크 $\mathcal{D}_{\theta}$는 확산 시간 $t$와 이산 잠재 변수 $\mathbf{z}$에 따라 노이즈를 제거한 이미지를 예측하는 역할을 하며, 다음과 같이 정의됩니다.
\[p(\mathbf{x}_{t-1}\\|\mathbf{x}_t) = \frac{p(\mathbf{x}_t\\|\mathbf{x}_{t-1})p(\mathbf{x}_{t-1})}{p(\mathbf{x}_t)}\]$\mathbf{x}_t$는 노이즈가 추가된 시퀀스 상태를 나타내며, \(p(\mathbf{x}_t\\|\mathbf{x}_{t-1})\)는 이전 상태에서 다음 상태로의 전이 확률을 나타내고, 이 방식은 각 토큰의 노이즈 수준을 조절함으로써, 샘플링 시간에 따라 모델의 행동을 유연하게 제어할 수 있게 합니다.
The denoiser neural network
\[\mathcal{D}_{\theta}: \mathbb{R}^d \times \mathbb{R} \times \mathbb{N}^m \rightarrow \mathbb{R}^d\], corresponding to DisCo-Diff’s DM, which predicts denoised images conditioned on diffusion time $t$ and discrete latent $\mathbf{z}$
We propose Discrete-Continuous Latent Variable Diffusion Models (DisCo-Diff), DMs augmented with additional discrete latent variables that encode additional high-level information about the data and can be used by the main DM to simplify its denoising task (Fig. 1). These discrete latents are inferred through an encoder network and learnt end-to-end together with the DM. Thereby, the discrete latents directly learn to encode information that is beneficial for reducing the DM’s score matching objective and making the DM’s hard task of mapping simple noise to complex data easier.
2. Diffusion Forcing의 방법
Diffusion Forcing은 각 토큰에 대해 다른 노이즈 레벨을 사용하여 시퀀스를 확산시키는 방법을 채택하는데, 이는 모델이 시퀀스를 생성하는 동안 노이즈의 양을 독립적으로 조정하여, 다양한 시나리오에 맞는 생성을 가능하게 합니다. 이런 접근 방식은 다음과 같은 수식으로 나타낼 수 있습니다.
\[\mathbf{x}_t = \sqrt{1-\beta_t}\mathbf{x}_{t-1} + \sqrt{\beta_t}\epsilon, \quad \epsilon \sim \mathcal{N}(0, I)\]$\beta_t$는 시간 $t$에서의 노이즈 비율을 결정하며, $\epsilon$은 표준 정규 분포에서 추출된 노이즈로, 이런 독립적 노이즈 레벨 구성은 모델이 더 정확하게 미래 토큰을 예측하고, 장기적으로 안정적인 생성을 유도하는 데 도움을 줄 수 있습니다.
3. 실험 및 결과 분석
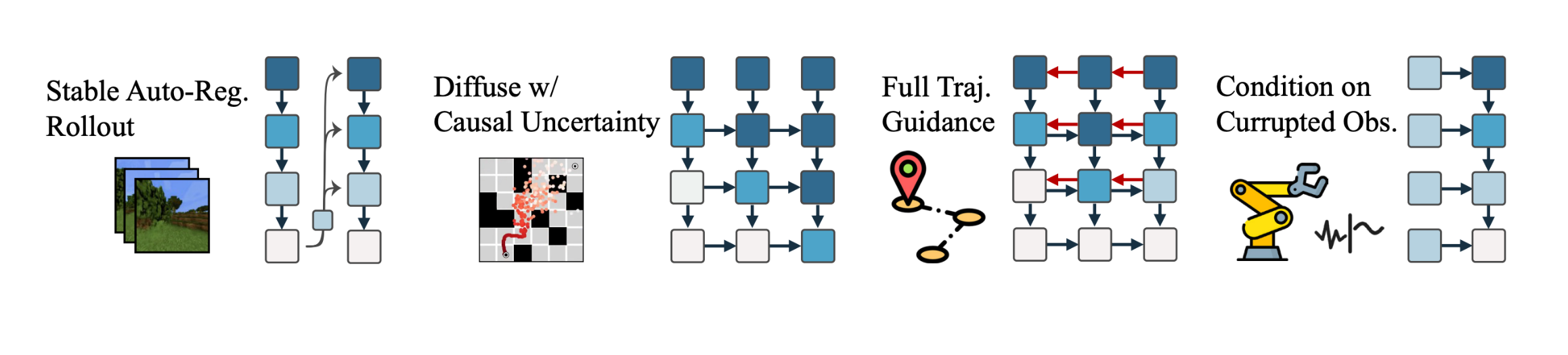
Diffusion Forcing은 DMLab 및 Minecraft 데이터셋에서 비디오 예측 작업을 수행하고, 다음과 같은 실험 설정을 통해 그 성능을 검증합니다.
- DMLab 데이터셋: 모델은 36 프레임에 대해 훈련되었으며, 2000 프레임 이상을 안정적으로 생성할 수 있습니다. 이는 모델이 훈련 범위를 넘어서는 시퀀스를 안정적으로 생성할 수 있음을 보여줍니다.
- Minecraft 데이터셋: 72 프레임에 대해 훈련된 모델은 2000 프레임 이상을 생성할 수 있으며, 데이터셋의 구조적 문제에도 불구하고 안정적인 생성이 가능했습니다.
위와 같이 Diffusion Forcing이 기존의 teacher 강제 방식이나 순차적 확산 모델의 한계를 극복하고, 더욱 안정적이고 일관된 시퀀스 생성을 가능하게 하는 새로운 방법임을 보입니다.
[2] DisCo-Diff
- url: https://arxiv.org/abs/2407.03300
- pdf: https://arxiv.org/pdf/2407.03300
- html: https://arxiv.org/html/2407.03300v1
- abstract: Diffusion models (DMs) have revolutionized generative learning. They utilize a diffusion process to encode data into a simple Gaussian distribution. However, encoding a complex, potentially multimodal data distribution into a single continuous Gaussian distribution arguably represents an unnecessarily challenging learning problem. We propose Discrete-Continuous Latent Variable Diffusion Models (DisCo-Diff) to simplify this task by introducing complementary discrete latent variables. We augment DMs with learnable discrete latents, inferred with an encoder, and train DM and encoder end-to-end. DisCo-Diff does not rely on pre-trained networks, making the framework universally applicable. The discrete latents significantly simplify learning the DM’s complex noise-to-data mapping by reducing the curvature of the DM’s generative ODE. An additional autoregressive transformer models the distribution of the discrete latents, a simple step because DisCo-Diff requires only few discrete variables with small codebooks. We validate DisCo-Diff on toy data, several image synthesis tasks as well as molecular docking, and find that introducing discrete latents consistently improves model performance. For example, DisCo-Diff achieves state-of-the-art FID scores on class-conditioned ImageNet-64/128 datasets with ODE sampler.
TL;DR
- DisCo-Diff는 복잡한 데이터 분포를 단순화하여 효율적인 생성 모델 학습을 가능하게 하는 이산 및 연속 잠재 변수를 결합합니다.
- (이산 잠재 변수의 중요성) 이산 잠재 변수는 모델의 학습 과정을 단순화하고, 데이터의 다양한 모드를 효과적으로 캡처합니다.
- (범용성과 성능 개선) DisCo-Diff는 다양한 데이터셋과 작업에서 범용적으로 적용되며, 향상된 성능을 제공합니다.
1. 서론
디퓨전 모델(DMs)은 고해상도 이미지, 분자 구조 생성 등 다양한 분야에서 혁신적인 성과를 보였습니다. 기존의 DMs는 단순한 가우시안 분포로 데이터를 인코딩하는 과정에서 복잡성과 멀티모달성을 갖는 데이터 분포를 학습하는 데 한계가 있었습니다. 본 연구에서는 이런 문제를 해결하기 위해 Discrete-Continuous Latent Variable Diffusion Models(DisCo-Diff)를 제안합니다. DisCo-Diff는 이산 잠재 변수를 도입하여 데이터의 복잡한 특성을 간소화하고, 모델의 성능을 향상시키는 방법을 개발했습니다.
2. 배경
DisCo-Diff는 연속 시간 디퓨전 모델을 기반으로 하며, EDM(Extended Diffusion Models) 프레임워크를 따릅니다. 기존 DMs는 $\sigma^2(t)$-분산의 가우시안 노이즈를 사용하여 데이터 $\mathbf{y} \sim p_{\text{data}}(\mathbf{x})$를 변형시키고, 이 과정을 통해 데이터 분포를 모델링합니다. DMs는 이런 노이즈 데이터를 점차 정제하면서 원본 데이터를 복원하는 과정을 거칩니다. 이 과정은 다음과 같은 확률적 또는 결정론적 차분 방정식을 통해 모델링됩니다.
\[d\mathbf{x} = -\dot{\sigma}(t) \sigma(t) \nabla_x \log p(\mathbf{x}; \sigma(t)) \, dt + \sqrt{2\beta(t)} \sigma(t) \, d\omega_t\]이 식에서 $\nabla_x \log p(\mathbf{x}; \sigma(t))$는 확산된 분포의 스코어 함수를 나타냅니다. DMs의 훈련은 이 스코어 함수를 근사하는 모델을 학습하는 것을 목표로 하며, 이는 다음과 같은 디노이징(denoising) 스코어 매칭 목적함수를 최소화함으로써 이루어집니다. ($\mathbf{n} \sim \mathcal{N}(0, \sigma^2(t) \mathbf{I})$는 가우시안 노이즈 )
\[\mathbb{E}_{\mathbf{y} \sim p_{\text{data}}(\mathbf{y})} \mathbb{E}_{t, \mathbf{n}} \left[ \lambda(t) \| \mathbf{D}_{\theta}(\mathbf{y} + \mathbf{n}, \sigma(t)) - \mathbf{y} \|_2^2 \right]\]3. DisCo-Diff 모델
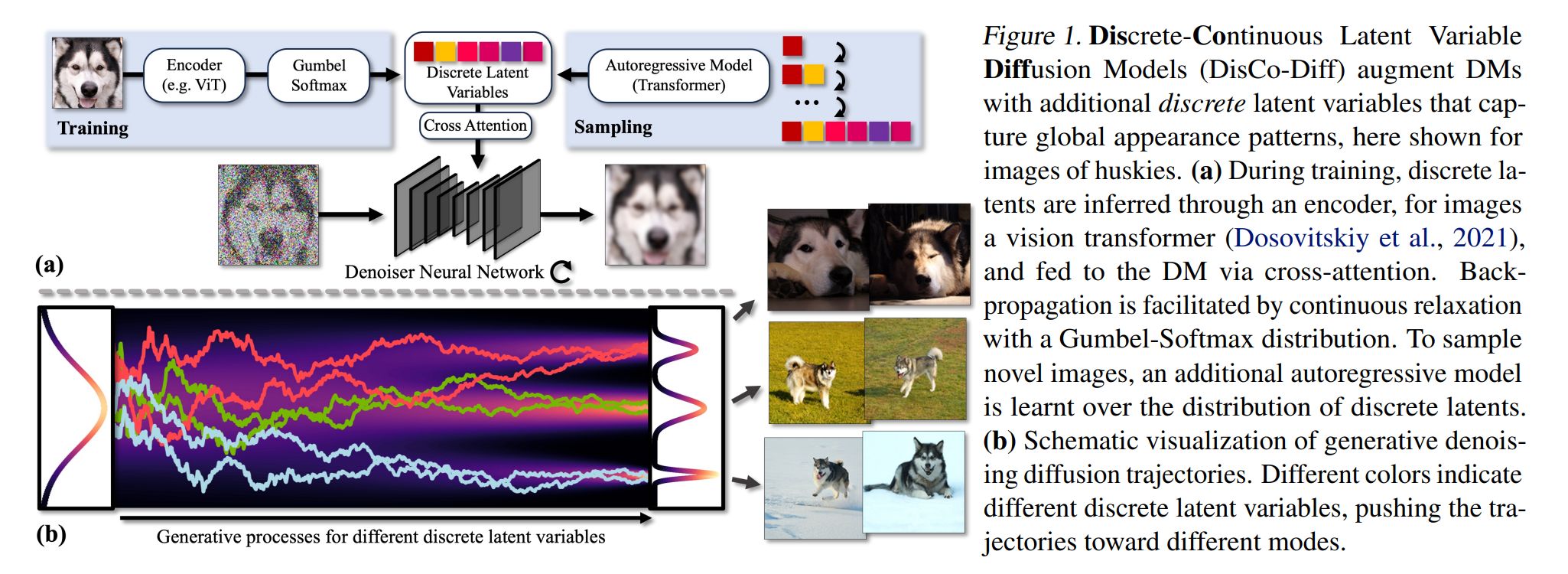
3.1 생성 모델 및 훈련 목표
DisCo-Diff는 디퓨전 모델의 학습 과정에 이산 잠재 변수 $\mathbf{z} \in \mathbb{N}^m$을 도입하여, 각 변수가 크기 $\mathbf{k}$의 범주형 분포에서 무작위로 선택됩니다. 모델은 세 가지 주요 구성 요소로 이루어져 있습니다. 데노이저 신경망 \(\mathbf{D}_{\theta}\), 이산 잠재 변수를 인퍼런스하는 인코더 \(\mathbf{E}_{\phi}\), 그리고 이산 잠재 변수의 분포를 모델링하는 자기회귀 모델 \(\mathbf{A}_{\psi}\)입니다. 이산 잠재 변수를 포함하는 확장된 디노이징(denoising) 스코어 매칭 목적함수는 다음과 같습니다.
\[\mathbb{E}_{\mathbf{y}} \mathbb{E}_{\mathbf{z} \sim \mathbf{E}_{\phi}(\mathbf{y})} \mathbb{E}_{t, \mathbf{n}} \left[ \lambda(t) \| \mathbf{D}_{\theta}(\mathbf{y} + \mathbf{n}, \sigma(t), \mathbf{z}) - \mathbf{y} \|_2^2 \right]\]3.2 동기 및 관련 작업
이산 잠재 변수는 DM의 복잡한 노이즈-투-데이터 매핑을 단순화하고, 학습 과정을 향상시킵니다. 본 연구에서는 이산 및 연속 잠재 변수의 조합이 데이터의 글로벌 멀티모달 구조와 로컬 연속 변이를 모두 효과적으로 캡처할 수 있는 이상적인 생성 모델을 제공한다고 언급합니다.
3.3 아키텍처
DisCo-Diff는 이미지 합성을 위해 U-Net과 같은 구조를 사용하며, 이산 잠재 변수를 크로스 어텐션 메커니즘을 통해 통합합니다. 이 구조는 이산 잠재 변수가 전체 이미지 특성에 글로벌한 영향을 미치도록 설계되었습니다.
4. 실험 및 결과
DisCo-Diff는 여러 데이터셋과 벤치마크에서 우수한 성능을 보였으며, 특히 ImageNet에서의 이미지 생성 작업에서 SOTA 성능을 달성했습니다. 모델은 2D 장난감 데이터 및 분자 도킹 작업에도 적용되어, 이산 잠재 변수가 모델 성능을 개선하는 데 어떻게 기여하는지 보여줍니다.
[3] Context-Guided Diffusion for Out-of-Distribution Molecular and Protein Design
- url: https://arxiv.org/abs/2407.11942
- pdf: https://arxiv.org/pdf/2407.11942
- html: https://arxiv.org/html/2407.11942v1
- abstract: Generative models have the potential to accelerate key steps in the discovery of novel molecular therapeutics and materials. Diffusion models have recently emerged as a powerful approach, excelling at unconditional sample generation and, with data-driven guidance, conditional generation within their training domain. Reliably sampling from high-value regions beyond the training data, however, remains an open challenge – with current methods predominantly focusing on modifying the diffusion process itself. In this paper, we develop context-guided diffusion (CGD), a simple plug-and-play method that leverages unlabeled data and smoothness constraints to improve the out-of-distribution generalization of guided diffusion models. We demonstrate that this approach leads to substantial performance gains across various settings, including continuous, discrete, and graph-structured diffusion processes with applications across drug discovery, materials science, and protein design.
[Discovery of novel molecular therapeutics and materials using difussion]
TL;DR
- 노이즈 주입을 통해 데이터 분포에서 샘플을 생성하는 확산 모델에 관한 설명 (확산 모델을 통한 분자 발견 가속화)
- 조건부 샘플링 기법과 이를 위한 분류기 지도 방식의 소개 및 분석 (데이터 기반 지도와 컨텍스트 지도를 활용한 조건부 샘플링)
- 레이블 없는 데이터와 평활성 제약을 이용한 분포 외 일반화 개선
- 컨텍스트 인식 지도 모델을 통한 신뢰도 높은 예측 및 외부 분포 샘플 생성 방법 제안
1. 서론
분자 발견의 중심 목표는 바람직한 기능적 특성을 가진 새로운 화합물을 식별하는 것입니다. 약물과 같은 소분자의 경우 탐색 공간의 크기가 \(10^{60}\)에 이르고, \(N\) 길이의 단백질 서열에 대해서는 \(20^N\)의 크기로 나타납니다. 이런 방대한 탐색 공간을 효과적으로 탐색하는 것은 결합 최적화 문제로서 큰 도전이며, 후보 화합물을 합성하고 실험적으로 검증하는 데 드는 비용을 고려할 때, 이런 공간에서 고가치 하위 집합을 찾는 방법은 현대 분자 설계의 핵심 문제입니다.
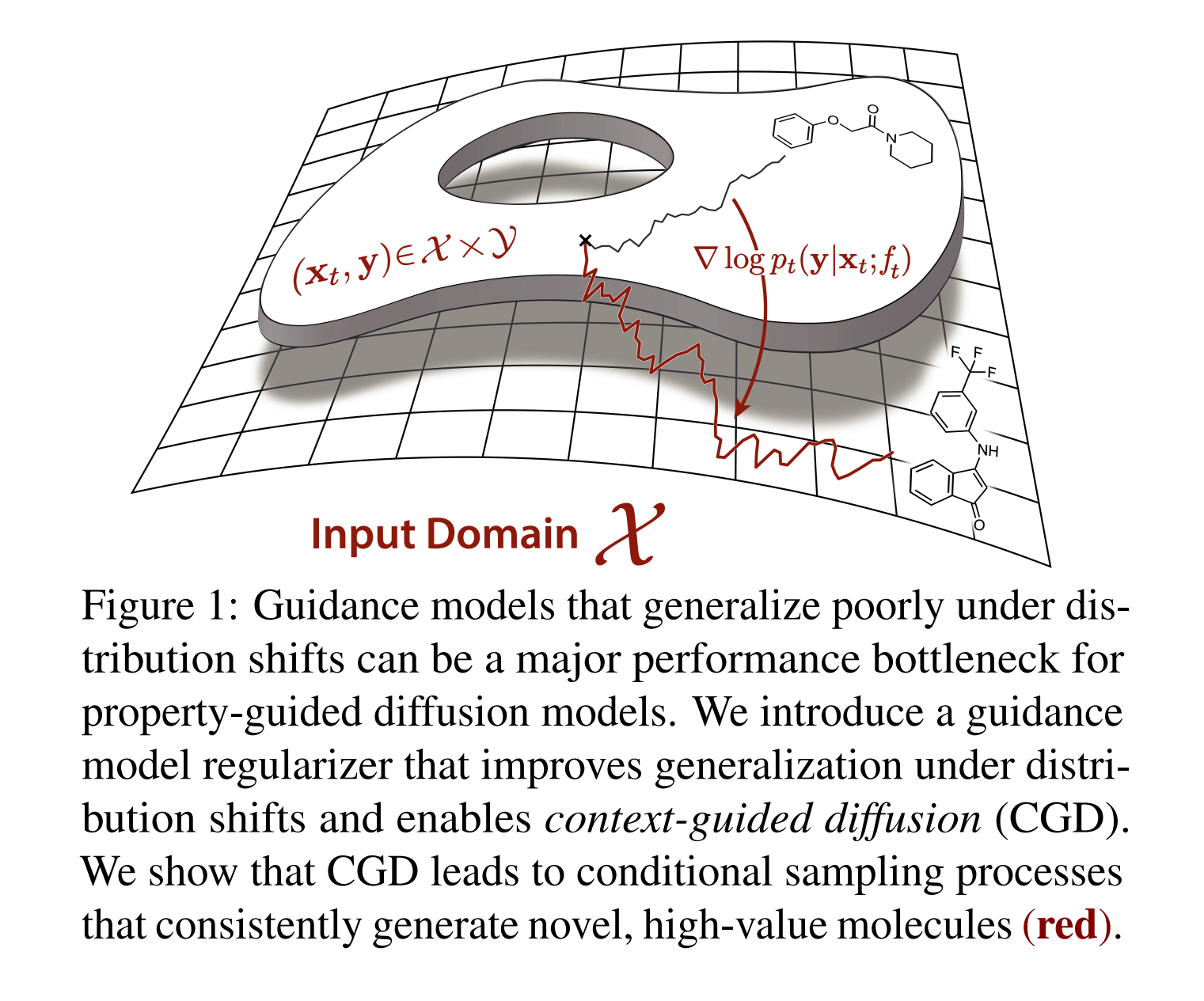
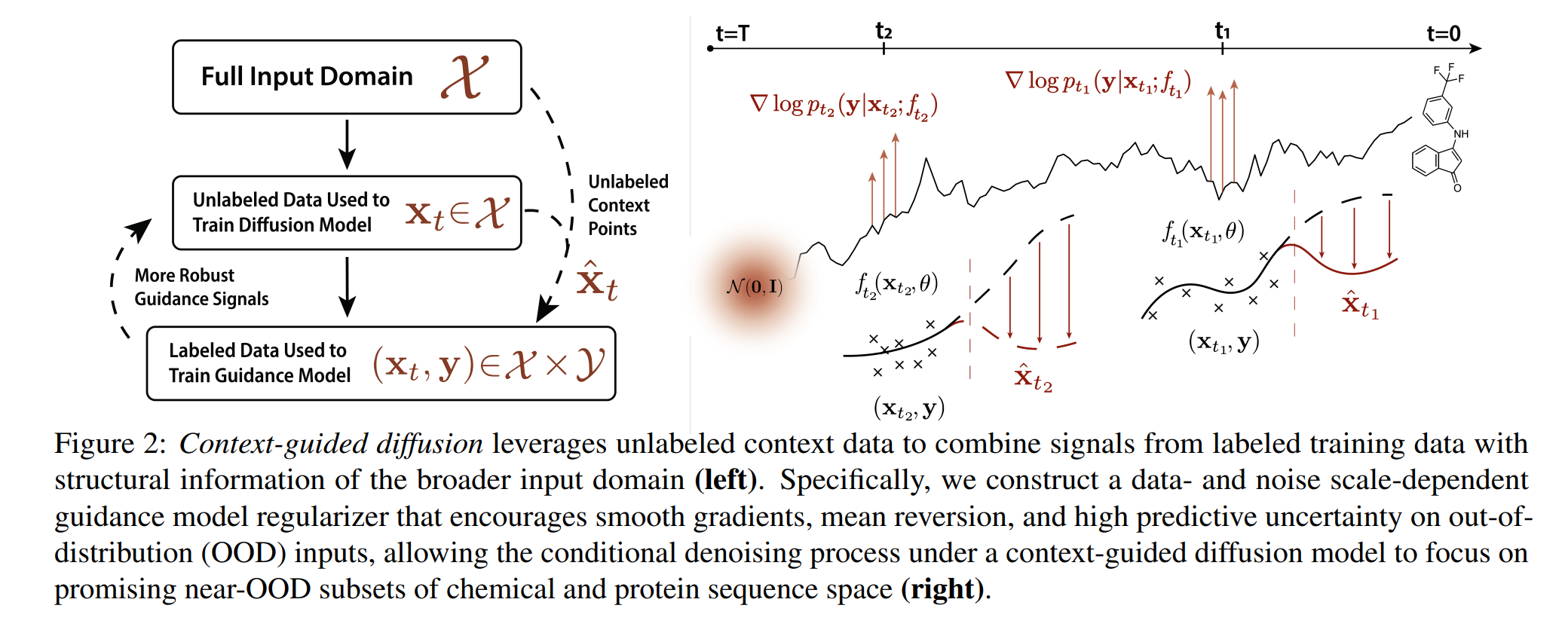
2. Guided Diffusion Models
2.1 Unconditional Diffusion Models
무조건적 확산 모델은 데이터 분포 \(p_0\)로부터 샘플을 시작하여 이를 점차적으로 노이즈를 더해 추적 가능한 기준 분포 \(p_T\)에 근접하도록 합니다. 이 과정은 확률 미분 방정식(SDE)으로 정의되며, 수식은 다음과 같습니다.
\[dX_t = f(X_t, t) + g(t) \, dB_t,\]\(X_0 \sim p_0\)는 데이터 분포에서 샘플링되며, \(B_t\)는 \(d\)-차원 브라운 운동을 나타냅니다. 노이즈 규모 \(\beta_t > 0\)는 시간이 지남에 따라 점차 증가하며, 이는 \(X_t \sim p_t\)를 \(p_T = \mathcal{N}(0, I)\)에 수렴하게 만듭니다.
새로운 샘플을 생성하기 위해, 이런 전진 노이즈 과정은 시간을 역전하는 방식으로 사용되며, 역시간 SDE는 다음과 같이 주어집니다.
\[dX_t = -\beta_t \left(\frac{1}{2} X_t + \nabla \log p_t(X_t)\right) dt + \beta_t \, dB_t,\]이때, \(X_T \sim p_T\)는 기준 분포에서 샘플링되며 점차적으로 더 맑은 상태로 복원됩니다. 이 과정에서 \(\nabla \log p_t(X_t)\)는 시간에 따라 변하는 스코어 네트워크 \(s_\psi(x_t, t)\)를 통해 추정됩니다.
2.2 Guided Diffusion Models
가이드 확산 모델은 특정 속성 \(y\), 예를 들어 특정 클래스의 이미지나 바람직한 약리 효과를 가진 분자 등을 갖는 샘플을 생성하기 위해 조건부 생성 과정을 도입합니다. 조건부 역시간 SDE는 다음과 같이 표현됩니다.
\[dX_t = -\beta_t \left(\frac{1}{2} X_t + \nabla \log p_t(X_t \\| y)\right) dt + \beta_t \, dB_t,\]\(\nabla \log p_t(X_t \\| y)\)는 조건부 점수 함수로, 레이블 데이터셋에서 훈련된 시간 종속적인 판별 지도 모델 \(f_t(x_t; \theta)\)를 통해 계산되며, 이 모델은 조건부 스코어를 계산하여, 예측된 레이블 \(y\)의 확률이 높은 샘플을 생성하는 역할을 합니다.
3. Context-Guided Diffusion Models
3.1 Standard Guidance Model Training
표준 지도 모델 훈련은 주어진 시간 단계에서 독립 동일 분포(i.i.d) 데이터 실현 \(\mathcal{D}_t = \{(x_t(n), \overline{y}(n))\}_n=1^N\)을 이용하여 슈퍼바이즈드 학습을 적용합니다. 음의 로그 가능도 목표는 다음과 같이 정의됩니다.
\[\mathcal{L}(\theta, \mathcal{D}_\mathcal{T}, \mathcal{T}) = -\sum_{n=1}^N \log p_\mathcal{T}(y(n) | x_\mathcal{T}(n); f_\mathcal{T}(x_\mathcal{T}(n); \theta))\]\(\mathcal{T} \sim p_\mathcal{T}(t)\)는 무작위로 샘플링된 시간 단계로, 위 목표는 \(L2\)-constrained 목적함수를 최소화하여 최적화됩니다.
3.2 Context-Aware Guidance Models
컨텍스트 인식 지도 모델은 입력 도메인의 일부분에 대해서만 레이블 데이터가 존재할 때의 문제를 해결하기 위해 설계되었습니다. 이는 분포 이동 시 일반적으로 적용 가능한 모델 행동을 코딩하는 정규화항을 도입하여 해결합니다. 이 정규화항은 입력 도메인의 레이블이 없는 부분에서 높은 불확실성을 가지도록 만들어 줍니다.
3.3 Generation via Context-Guided Diffusion
훈련된 컨텍스트 인식 지도 모델을 사용하여 원하는 속성을 지닌 샘플을 생성합니다. 이 과정은 기존의 가이드 확산 모델 프레임워크에 통합될 수 있으며, 샘플링 시 표준 가이드 함수를 컨텍스트 인식 가이드 함수로 교체함으로써 이루어지며, 모듈식 접근 방식이므로 구현에 있어 최소한의 추가 작업만을 요구합니다.