Model | Open AI - Sora
- Related Project: Private
- Category: Paper Review
- Date: 2024-02-26
Video generation models as world simulators
- url: https://openai.com/research/video-generation-models-as-world-simulators
- pdf: Technical report not published yet.
- abstract: We explore large-scale training of generative models on video data. Specifically, we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios. We leverage a transformer architecture that operates on spacetime patches of video and image latent codes. Our largest model, Sora, is capable of generating a minute of high fidelity video. Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.
- related_paper:
- VAE: Auto-Encoding Variational Bayes
- Vivit: A video vision transformer
- Scalable Diffusion Models with Transformers
- Genie: Generative Interactive Environments
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
- Efficient High-Resolution Deep Learning: A Survey
- Neural Network Diffusion
Contents
TL;DR
- 방법: 다양한 시각 데이터를 통합된 표현으로 변환하여 생성 모델의 대규모 학습을 가능하게 함.
- 정성적 평가: Sora의 기능과 한계를 논의하며, 모델과 구현의 세부 사항을 제외함.
- 혁신적 접근: 패치 기반 표현과 스케일링 가능한 트랜스포머 모델을 통해 영상 데이터의 효율적 처리와 생성.
1. 서론
문제 정의 및 목표
시각 데이터의 통합 표현을 통해 대규모 생성 모델 학습을 최적화하고자 한다. 본 논문에서는 다음 두 가지 주요 영역을 다룬다.
- 방법: 시각 데이터의 모든 유형을 통합된 표현으로 변환하는 방법을 설명
- 정성적 평가: Sora의 능력과 한계를 논의하되, 모델 및 구현의 구체적인 사항은 제외
선행 연구 및 비교
이전의 연구들은 비디오 데이터 생성 모델링을 위해 다양한 접근 방식을 사용해 왔다.
- 순환 신경망 (Recurrent Networks)
- 생성적 적대 신경망 (Generative Adversarial Networks, GANs)
- 자기회귀 트랜스포머 (Autoregressive Transformers)
- 확산 모델 (Diffusion Models)
이런 방법들은 주로 특정 범주의 시각 데이터를 대상으로 하며, 짧은 비디오나 고정된 크기의 비디오에 중점을 두었다.
2. Turning Visual Data into Patches
대규모 언어모델의 성공은 인터넷 규모의 데이터를 훈련하여 일반적인 역량을 얻는 데서 비롯되었으며, 이는 다양한 텍스트 모달리티를 통합하는 토큰 사용을 통해 가능해졌다. 본 연구에서는 이런 이점을 시각 데이터 생성 모델이 어떻게 계승할 수 있는지 탐구한다. 언어 모델은 텍스트 토큰을 사용하지만, Sora는 시각 패치를 사용한다. 패치는 시각 데이터 모델의 효과적인 표현으로 입증되었다.
3. Implementation of Patches
3.1 비디오를 패치로 변환하는 과정
비디오를 낮은 차원의 잠재 공간으로 압축한 후, 이 표현을 시공간 패치로 분해한다. 이는 고해상도의 데이터를 보다 효율적으로 처리할 수 있게 한다.
3.2 비디오 압축 네트워크 (Video Compression Network)
비디오의 차원을 축소하는 네트워크를 훈련시킨다. 이 네트워크는 원시 비디오를 입력으로 받아 시간적 및 공간적으로 압축된 잠재 표현을 출력한다. Sora는 이 압축된 잠재 공간에서 훈련되고, 생성된 잠재 표현을 다시 픽셀 공간으로 매핑하는 디코더 모델을 사용한다.
3.3 시공간 잠재 패치 (Spacetime Latent Patches)
압축된 입력 비디오에서 시공간 패치 시퀀스를 추출하여 트랜스포머 토큰으로 사용한다. 이 방법은 이미지에도 적용할 수 있으며, 이미지를 단일 프레임 비디오로 간주한다. 패치 기반 표현은 다양한 해상도, 기간 및 화면 비율의 비디오와 이미지를 훈련할 수 있게 한다.
\[\text{Given a compressed video, } V_{compressed}, \text{ we extract spacetime patches: } \{P_i\}_{i=1}^n.\]각 패치 $P_i$는 $V_{compressed}$의 부분 공간을 나타내며, 이 패치는 트랜스포머 토큰으로 사용된다. 이 접근 방식은 이미지에도 적용 가능하며, 이미지를 단일 프레임 비디오로 간주하여 처리한다.
4. 트랜스포머의 스케일링 (Scaling Transformers for Video Generation)
4.1 확산 모델 (Diffusion Model)
Sora는 입력 노이즈 패치와 텍스트 프롬프트와 같은 조건 정보를 기반으로 원래의 “깨끗한” 패치를 예측하도록 훈련된 확산 모델을 사용한다. 중요한 점은 Sora가 확산 트랜스포머라는 점이다.
Let \(x_0\) be the original patch and \(x_t\) be the noisy patch at timestep \(t\). The diffusion process is defined as:
\[q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{\alpha_t} x_{t-1}, (1 - \alpha_t) I)\]트랜스포머는 다양한 도메인에서 향상된 확장성을 보여주었으며, 시각 데이터 생성에도 유효하다. 본 연구에서는 확산 트랜스포머가 비디오 모델로서 효과적으로 확장됨을 발견했다.
5. 실험 설정 및 결과 (Experimental Setup and Results)
5.1 기본 컴퓨팅 (Base Compute)
4배, 32배의 컴퓨팅 자원을 사용하여 다양한 기간, 해상도, 화면 비율의 비디오를 훈련한다. 기존 접근 방식은 비디오를 표준 크기로 조정, 자르기 또는 트림하는 반면, 본 연구는 데이터의 원본 크기에서 훈련하는 것이 여러 이점을 제공함을 발견했다.
5.2 샘플링 유연성 (Sampling Flexibility)
Sora는 1920 x 1080p의 와이드스크린 비디오, 1080 x 1920의 세로 비디오 등 다양한 비디오를 생성할 수 있다. 이는 Sora가 다양한 기기의 원본 화면 비율로 콘텐츠를 생성할 수 있게 하며, 낮은 해상도로 빠르게 프로토타이핑한 후 전체 해상도로 생성할 수 있게 한다.
5.3 향상된 프레이밍 및 구성 (Improved Framing and Composition)
원본 화면 비율에서 훈련하면 구성과 프레이밍이 개선됨을 실험적으로 발견했다. 정사각형 크롭으로 훈련된 모델은 피사체가 부분적으로만 보이는 비디오를 생성할 수 있는 반면, Sora는 개선된 프레이밍을 제공한다.
Let \(V_{\text{native}}\) be a video at its native aspect ratio, and \(V_{\text{square}}\) be the same video cropped to a square.
\[\text{Framing Quality}(V_{native}) > \text{Framing Quality}(V_{square})\]5.4 언어 이해 (Language Understanding)
텍스트-비디오 생성 시스템을 훈련하려면 많은 비디오와 해당 텍스트 캡션이 필요하다. DALL·E 3에서 도입된 리캡셔닝 기술을 비디오에 적용하여 훈련 세트의 모든 비디오에 대한 텍스트 캡션을 생성한다. 이를 통해 텍스트 충실도와 비디오 전반의 품질이 향상된다.
6. 결론 (Conclusion)
Sora의 방법은 샘플링 유연성, 프레이밍 및 구성 개선, 텍스트-비디오 생성의 언어 이해 향상에서 상당한 발전을 이룬다. 이 포괄적인 접근 방식은 사용자의 프롬프트를 정확하게 따르는 고품질 비디오를 생성할 수 있게 하여, 다양한 콘텐츠 유형과 형식에 대한 모델의 적응력을 보여준다.
\[\text{Overall Quality}(Sora) > \text{Overall Quality}(Previous Methods)\]Sora는 시각 데이터 생성 모델링 분야에서 중요한 진전을 나타내며, 다양한 고품질 시각 콘텐츠를 생성하는 유연하고 강력한 도구를 제공한다.
Technical Report: Sora’s Unified Representation for Visual Data
Overview
This report delves into two primary areas:
- Methodology: Describes how visual data of all types is transformed into a unified representation to facilitate the large-scale training of generative models.
- Qualitative Evaluation: Discusses the capabilities and limitations of Sora, excluding model and implementation specifics.
-
Background and Comparison
Prior studies on generative modeling of video data have employed various approaches, such as:
- Recurrent Networks ([1], [2], [3])
- Generative Adversarial Networks (GANs) ([4], [5], [6], [7])
- Autoregressive Transformers ([8], [9])
- Diffusion Models ([10], [11], [12])
These methods typically target a specific category of visual data, focusing on shorter videos or videos of a fixed size.
-
Turning visual data into patches
We take inspiration from large language models which acquire generalist capabilities by training on internet-scale data. [13], [14] The success of the LLM paradigm is enabled in part by the use of tokens that elegantly unify diverse modalities of text—code, math and various natural languages. In this work, we consider how generative models of visual data can inherit such benefits. Whereas LLMs have text tokens, Sora has visual patches. Patches have previously been shown to be an effective representation for models of visual data.[15], [16], [17],[18]
We find that patches are a highly-scalable and effective representation for training generative models on diverse types of videos and images.
-
Figure Patches
At a high level, we turn videos into patches by first compressing videos into a lower-dimensional latent space,19 and subsequently decomposing the representation into spacetime patches.
-
Video compression network
We train a network that reduces the dimensionality of visual data. [20] This network takes raw video as input and outputs a latent representation that is compressed both temporally and spatially. Sora is trained on and subsequently generates videos within this compressed latent space. We also train a corresponding decoder model that maps generated latents back to pixel space.
-
Spacetime latent patches
Given a compressed input video, we extract a sequence of spacetime patches which act as transformer tokens. This scheme works for images too since images are just videos with a single frame. Our patch-based representation enables Sora to train on videos and images of variable resolutions, durations and aspect ratios. At inference time, we can control the size of generated videos by arranging randomly-initialized patches in an appropriately-sized grid.
-
Scaling transformers for video generation
Sora is a diffusion model [21], [22], [23], [24], [25]; given input noisy patches (and conditioning information like text prompts), it’s trained to predict the original “clean” patches. Importantly, Sora is a diffusion transformer.26 Transformers have demonstrated remarkable scaling properties across a variety of domains, including language modeling,[13], [14] computer vision, [15], [16], [17], [18] and image generation. [27], [28], [29]
-
Figure Diffusion
In this work, we find that diffusion transformers scale effectively as video models as well. Below, we show a comparison of video samples with fixed seeds and inputs as training progresses. Sample quality improves markedly as training compute increases.
-
Base compute
4x compute, 32x compute, variable durations, resolutions, aspect ratios Past approaches to image and video generation typically resize, crop or trim videos to a standard size—e.g., 4 second videos at 256x256 resolution. We find that instead training on data at its native size provides several benefits.
-
Sampling flexibility
Sora can sample widescreen 1920 x 1080p videos, vertical 1080x1920 videos and everything inbetween. This lets Sora create content for different devices directly at their native aspect ratios. It also lets us quickly prototype content at lower sizes before generating at full resolution—all with the same model.
-
Improved framing and composition
We empirically find that training on videos at their native aspect ratios improves composition and framing. We compare Sora against a version of our model that crops all training videos to be square, which is common practice when training generative models. The model trained on square crops (left) sometimes generates videos where the subject is only partially in view. In comparison, videos from Sora (right) have improved framing.
-
Language understanding
Training text-to-video generation systems requires a large amount of videos with corresponding text captions. We apply the re-captioning technique introduced in DALL·E 330 to videos. We first train a highly descriptive captioner model and then use it to produce text captions for all videos in our training set. We find that training on highly descriptive video captions improves text fidelity as well as the overall quality of videos. Similar to DALL·E 3, we also leverage GPT to turn short user prompts into longer detailed captions that are sent to the video model. This enables Sora to generate high quality videos that accurately follow user prompts.
-
Approach
Sora stands out as a generalist model for visual data, offering several key advantages:
- Versatility: Capable of generating videos and images across a wide range of durations, aspect ratios, and resolutions.
- High Definition: Supports the generation of up to a full minute of high-definition video, surpassing the limitations of prior work.
-
Turning Visual Data into Patches
Inspired by the success of large language models (LLMs) that train on diverse internet-scale data to acquire general capabilities across various domains including code, mathematics, and multiple natural languages, this work explores the adaptation of a similar approach to generative models of visual data. The core idea revolves around the concept of “patches,” akin to the text tokens in LLMs, but designed for the visual domain.
-
Implementation of Patches
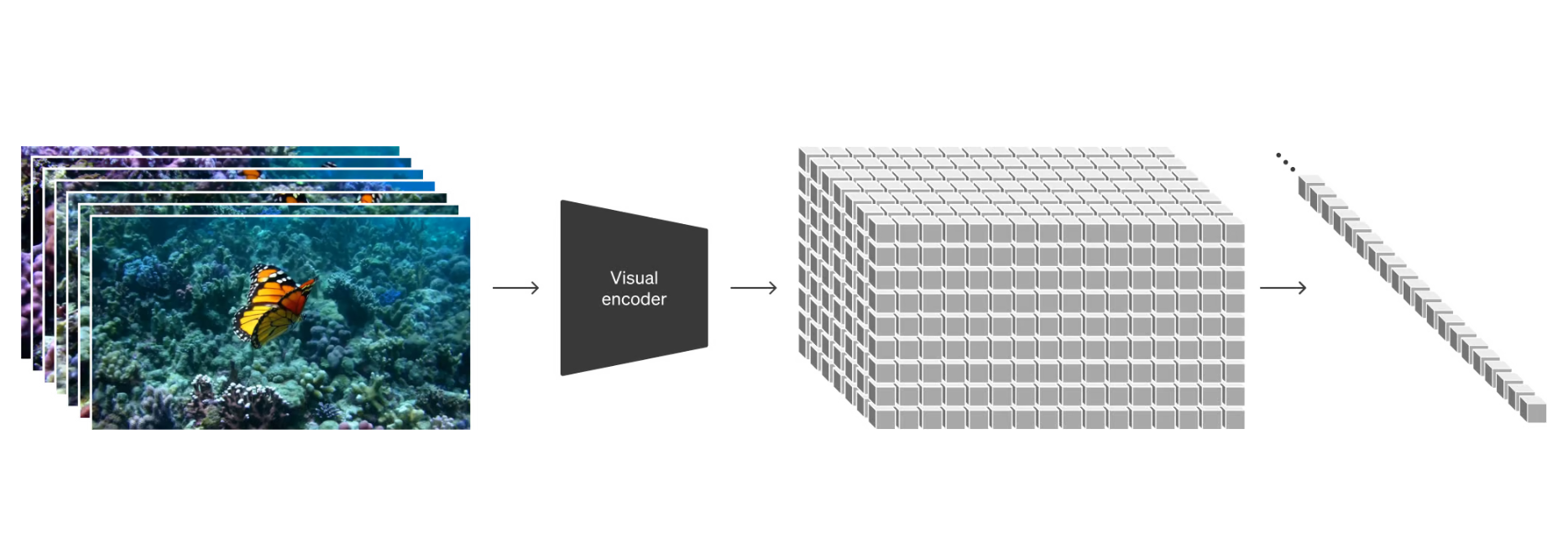
- Inspiration from LLMs: The paradigm shift towards utilizing tokens in LLMs, which enables them to handle diverse modalities of text, serves as the inspiration for employing patches in the visual domain.
- Visual Patches: Analogous to text tokens in LLMs, Sora utilizes “visual patches” as a foundational building block. This method has been previously validated as an efficient representation for visual data models.
- Scalability and Effectiveness: Patches are identified as a scalable and effective representation for training generative models on a wide array of videos and images, promoting the development of more versatile and capable generative models.
- Video Compression: The process begins by compressing videos into a lower-dimensional latent space, setting the stage for further decomposition.
- Spacetime Patches: Following compression, the representation is broken down into spacetime patches, facilitating a comprehensive and efficient means to model and generate visual data.
This approach underscores the potential of borrowing conceptual frameworks from the realm of language processing and applying them to the visual domain, paving the way for more advanced and capable generative models.
-
Video Compression Network

- To reduce the dimensionality of visual data through a network that takes raw video as input and produces a compressed latent representation, both temporally and spatially.
- Sora is trained within this compressed latent space and uses a decoder model to map generated latents back to pixel space, facilitating the generation of videos from these compressed representations.
-
Spacetime Latent Patches
- Mechanism: For a given compressed input video, a sequence of spacetime patches is extracted, serving as transformer tokens. This approach applies to images as well, treating them as single-frame videos.
- Flexibility: Enables training on videos and images of variable resolutions, durations, and aspect ratios. At inference, video size can be controlled by arranging randomly-initialized patches on a grid.
-
Scaling Transformers for Video Generation
- Model Type: Sora utilizes a diffusion model, trained to predict original “clean” patches from noisy inputs, functioning as a diffusion transformer.
- Scalability: Demonstrates effective scaling for video models, improving sample quality with increased training compute.
-
Key Features and Innovations
- Variable Sizes: Trains on native-sized data, allowing for generation of content in various aspect ratios and resolutions without resizing, cropping, or trimming.
- Sampling Flexibility: Capable of generating content for different devices in their native aspect ratios, and allows for prototyping at lower sizes before full-resolution generation.
- Improved Framing: Training on native aspect ratios leads to better composition and framing compared to models trained on square crops.
- Language Understanding: Uses a re-captioning technique for text-to-video systems, improving text fidelity and video quality. Leverages GPT for enhancing user prompts into detailed captions for video generation.
-
Conclusion
- Sora’s method offers significant improvements in sampling flexibility, framing, and composition, alongside enhanced language understanding for text-to-video generation. This comprehensive approach allows for the creation of high-quality videos that closely follow user prompts, showcasing the model’s adaptability to different content types and formats.
- Sora represents a significant advancement in the field of generative modeling for visual data, providing a flexible and powerful tool for creating diverse and high-quality visual content.
References
[1] Srivastava, Nitish, Elman Mansimov, and Ruslan Salakhudinov. “Unsupervised learning of video representations using lstms.” International conference on machine learning. PMLR, 2015.
[2] Chiappa, Silvia, et al. “Recurrent environment simulators.” arXiv preprint arXiv:1704.02254 (2017).
[3] Ha, David, and Jürgen Schmidhuber. “World models.” arXiv preprint arXiv:1803.10122 (2018).
[4] Vondrick, Carl, Hamed Pirsiavash, and Antonio Torralba. “Generating videos with scene dynamics.” Advances in neural information processing systems 29 (2016).
[5] Tulyakov, Sergey, et al. “Mocogan: Decomposing motion and content for video generation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[6] Clark, Aidan, Jeff Donahue, and Karen Simonyan. “Adversarial video generation on complex datasets.” arXiv preprint arXiv:1907.06571 (2019).
[7] Brooks, Tim, et al. “Generating long videos of dynamic scenes.” Advances in Neural Information Processing Systems 35 (2022): 31769-31781.
[8] Yan, Wilson, et al. “Videogpt: Video generation using vq-vae and transformers.” arXiv preprint arXiv:2104.10157 (2021).
[9] Wu, Chenfei, et al. “Nüwa: Visual synthesis pre-training for neural visual world creation.” European conference on computer vision. Cham: Springer Nature Switzerland, 2022.
[10] Ho, Jonathan, et al. “Imagen video: High definition video generation with diffusion models.” arXiv preprint arXiv:2210.02303 (2022).
[11] Blattmann, Andreas, et al. “Align your latents: High-resolution video synthesis with latent diffusion models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
[12] Gupta, Agrim, et al. “Photorealistic video generation with diffusion models.” arXiv preprint arXiv:2312.06662 (2023).
[13] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[14] Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.
[15] Dosovitskiy, Alexey, et al. “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[16] Arnab, Anurag, et al. “Vivit: A video vision transformer.” Proceedings of the IEEE/CVF international conference on computer vision. 2021.
[17] He, Kaiming, et al. “Masked autoencoders are scalable vision learners.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
[18] Dehghani, Mostafa, et al. “Patch n’Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution.” arXiv preprint arXiv:2307.06304 (2023).
[19] Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
[20] Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013).
[21] Sohl-Dickstein, Jascha, et al. “Deep unsupervised learning using nonequilibrium thermodynamics.” International conference on machine learning. PMLR, 2015.
[22] Ho, Jonathan, Ajay Jain, and Pieter Abbeel. “Denoising diffusion probabilistic models.” Advances in neural information processing systems 33 (2020): 6840-6851.
[23] Nichol, Alexander Quinn, and Prafulla Dhariwal. “Improved denoising diffusion probabilistic models.” International Conference on Machine Learning. PMLR, 2021.
[24] Dhariwal, Prafulla, and Alexander Quinn Nichol. “Diffusion Models Beat GANs on Image Synthesis.” Advances in Neural Information Processing Systems. 2021.
[25] Karras, Tero, et al. “Elucidating the design space of diffusion-based generative models.” Advances in Neural Information Processing Systems 35 (2022): 26565-26577.
[26] Peebles, William, and Saining Xie. “Scalable diffusion models with transformers.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[27] Chen, Mark, et al. “Generative pretraining from pixels.” International conference on machine learning. PMLR, 2020.
[28] Ramesh, Aditya, et al. “Zero-shot text-to-image generation.” International Conference on Machine Learning. PMLR, 2021.
[29] Yu, Jiahui, et al. “Scaling autoregressive models for content-rich text-to-image generation.” arXiv preprint arXiv:2206.10789 2.3 (2022): 5.
[30] Betker, James, et al. “Improving image generation with better captions.” Computer Science. https://cdn.openai.com/papers/dall-e-3.pdf 2.3 (2023): 8
[31] Ramesh, Aditya, et al. “Hierarchical text-conditional image generation with clip latents.” arXiv preprint arXiv:2204.06125 1.2 (2022): 3.
[32] Meng, Chenlin, et al. “Sdedit: Guided image synthesis and editing with stochastic differential equations.” arXiv preprint
Architecture Overview
After reading the papers below, the architecture here should start to make sense. The technical report is a 10,000 foot view and my hope is that each paper will zoom into different aspects and paint the full picture. There is a nice literature review called “Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models” that gives a high level diagram of a reverse engineered architecture.
The team at OpenAI states that Sora is a “Diffusion Transformer” which combines many of the concepts listed in the papers above, but applied applied to latent spacetime patches generated from video.
This is a combination of the style of patches used in the Vision Transformer (ViT) paper, with latent spaces similar to the Latent Diffusion Paper, but combined in the style of the Diffusion Transformer. They not only have patches in width and height of the image but extend it to the time dimension of video.
It’s hard to say how exactly they collected the training data for all of this, but it seems like a combination of the techniques in the Dalle-3 paper as well as using GPT-4 to elaborate on textual descriptions of images, that they then turn into videos. Training data is likely the main secret sauce here, hence has the least level of detail in the technical report.
-
Use Cases There are many interesting use cases and applications for video generation technologies like Sora. Whether it be movies, education, gaming, healthcare or robotics, there is no doubt generating realistic videos from natural language prompts is going to shake up multiple industries. The note at the bottom of this diagram rings true for us at Oxen.ai. If you are not familiar with Oxen.ai we are building open source tools to help you collaborate on and evaluate data the comes in and out of machine learning models. We believe that many people need visibility into this data, and that it should be a collaborative effort. AI is touching many different fields and industries and the more eyes on the data that trains and evaluates these models, the better.
Check us out here: Oxen.ai
Paper Reading List
Background Papers
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- Applied widely across various domains, notably in diffusion models such as Stable Diffusion for noise mitigation learning. Essential for understanding past advancements.
- Attention Is All You Need
- A seminal work in machine translation that established the foundation for Transformer architectures, now fundamental in applications like ChatGPT.
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- Demonstrated the application of Transformers to image recognition, surpassing traditional Convolutional Neural Networks when trained on extensive datasets.
- High-Resolution Image Synthesis with Latent Diffusion Models
- Introduced techniques behind image generation innovations like Stable Diffusion, using latent representations and U-Net architectures.
- Learning Transferable Visual Models From Natural Language Supervision (CLIP)
- Developed methods for embedding both text and image data in a unified latent space, enhancing synergy in language-image generative models.
- Vector Quantised Variational Auto Encoder (VQ-VAE)
- Used for reducing the dimensionality of raw video data, serving as a powerful method for unsupervised pre-training to capture latent representations.
Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
- Diffusion Transformer (DiT)
- Integrates various prior concepts with a transformer operating on latent patches, improving efficiency and data processing for high-quality image generation.
Video Generation Papers
- ViViT: A Video Vision Transformer
- Explores video tokenization for tasks such as classification and generation, focusing on the necessary “spatio-temporal tokens.”
- Imagen Video: High Definition Video Generation with Diffusion Models
- A text-conditional video generation system utilizing a series of video diffusion models for producing high-quality videos.
- Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
- Introduces a temporal dimension to latent diffusion models, applying innovative techniques to enhance temporal consistency.
- Photorealistic Video Generation with Diffusion Models
- Describes W.A.L.T, a transformer-based diffusion model approach for generating photorealistic videos, closely paralleling the techniques used in Sora.
Vision-Language Understanding
- DALL-E 3: Data-Driven Image Generation with Generative Pre-trained Transformers
- Shows how to generate images from textual descriptions, focusing on the placement and context of objects within images.
- CLIP-guided Text-to-Image Generation
- Extends the capabilities of DALL-E by utilizing CLIP embeddings to guide the image generation process from text descriptions.