Model | Falcon
- Related Project: private
- Category: Paper Review
- Date: 2023-08-11
The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only
- url: https://arxiv.org/abs/2306.01116
- pdf: https://arxiv.org/pdf/2306.01116
- huggingface-model: https://huggingface.co/tiiuae/falcon-7b
- dataset: https://huggingface.co/datasets/tiiuae/falcon-refinedweb
- abstarct: Large language models are commonly trained on a mixture of filtered web data and curated high-quality corpora, such as social media conversations, books, or technical papers. This curation process is believed to be necessary to produce performant models with broad zero-shot generalization abilities. However, as larger models requiring pretraining on trillions of tokens are considered, it is unclear how scalable is curation and whether we will run out of unique high-quality data soon. At variance with previous beliefs, we show that properly filtered and deduplicated web data alone can lead to powerful models; even significantly outperforming models from the state-of-the-art trained on The Pile. Despite extensive filtering, the high-quality data we extract from the web is still plentiful, and we are able to obtain five trillion tokens from CommonCrawl. We publicly release an extract of 600 billion tokens from our RefinedWeb dataset, and 1.3/7.5B parameters language models trained on it.
[데이터 전처리 및 프로세스 핵심색인마킹]
Contents
- The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only
TL;DR
- 데이터셋 크기와 품질 증가를 통한 LLM 훈련의 중요성
- 웹 데이터의 정제 및 중복 제거를 통한 고품질 데이터 생성
- 수학적 접근 및 알고리즘을 사용하여 데이터 처리의 효율성과 정확성 향상
1. 서론
서론에서는 대규모 언어모델(Large Language Models, LLMs)을 훈련시키는 데 필요한 대규모 데이터셋의 중요성을 강조합니다. 이는 최근 연구에서 제안된 것으로, 모델 크기 뿐만 아니라 데이터셋 크기를 동시에 확장하는 것이 중요하다고 지적합니다.
자연어 처리의 발전은 점차적으로 컴퓨팅 규모에 의존하게 되었으며, 특히 대규모 언어모델의 경우, 모델 크기와 데이터셋 크기를 함께 확대하는 것이 중요해졌습니다(Hoffmann et al., 2022). 이전의 연구들은 주로 모델 크기에 초점을 맞추었지만, 최근 연구는 데이터의 질과 양 모두를 증가시키는 것이 필수적임을 언급합니다. 이는 데이터의 질적, 법적 문제로 인해 데이터 확보가 병목 현상을 일으킬 수 있다는 문제점을 제기합니다(Villalobos et al., 2022). 예를 들어, GPT-3와 같은 모델을 최적으로 훈련하기 위해서는 최소 3,5000억 토큰이 필요한데, 이는 현재 공개된 데이터셋의 양보다 훨씬 많은 수치입니다.
LLM의 발전은 단순히 계산 규모의 증가만으로 이루어지는 것이 아니라, 품질이 높은 대규모 데이터셋를 사용함으로써 더욱 향상됩니다. 이런 데이터는 종종 웹 크롤링을 통해 얻지만, 이런 데이터의 품질은 다양하며, 때로는 저품질 데이터가 포함될 수 있습니다. 따라서, 고품질의 training dataset를 확보하는 것이 중요하며, 이는 훈련된 모델의 성능에 직접적인 영향을 미칩니다.
2. 선행 연구
선행 연구에서는 대규모 데이터셋의 필요성과 함께 데이터의 품질이 LLM의 성능에 미치는 영향을 다룹니다. 초기 LLM들은 간단한 문장 데이터를 사용했지만, 점차 문서 중심의 데이터로 이동했으며, 이는 모델이 더 긴 문맥을 이해할 수 있게 했습니다. 그러나 이런 데이터셋는 종종 큐레이션 과정을 거치지 않아 품질이 낮을 수 있으며, 이는 모델 훈련에 부정적인 영향을 미칠 수 있습니다.
대규모 언어모델 훈련을 위해 다양한 데이터 소스가 사용되었습니다. 초기 모델들은 긴 문서가 포함된 데이터셋의 중요성을 인식했고(Radford et al., 2018), 이후 웹 크롤링 데이터가 주류를 이루게 되었습니다. 그러나, 이런 웹 데이터는 종종 저품질 데이터가 많아 효과적인 모델 훈련에 한계가 있었습니다. 따라서, 고품질 데이터의 필요성이 대두되었고, 여러 연구에서는 웹 데이터와 고품질 데이터를 결합한 방식을 사용했습니다.
3. 방법
이 논문에서는 대규모 웹 데이터를 활용하여 언어 모델을 훈련하기 위한 새로운 파이프라인 MDR(MacroData Refinement)을 소개합니다. 이 파이프라인은 엄격한 중복 제거와 필터링을 통해 데이터의 질을 향상시키며, 다음과 같은 원칙을 따릅니다.
설계 원칙
- 규모 우선: 40-200B 파라미터 모델 훈련을 위해 트릴리언 토큰 규모의 데이터셋 생성을 목표로 합니다.
- 엄격한 중복 제거: 이전 연구에서 중복 제거의 중요성이 강조되었기 때문에(Lee et al., 2022), 문서 단위와 토큰 단위에서 정확한 중복 제거를 수행합니다.
- 중립적 필터링: ML 기반 필터링을 피하고 단순한 규칙과 휴리스틱을 사용하여 언어 식별 및 부적절한 콘텐츠 필터링을 진행합니다.
제안된 방법은 웹 데이터의 정제와 중복 제거 과정을 포함합니다. 이는 효율적인 데이터 사용과 고품질 데이터의 확보를 목표로 합니다.
데이터 읽기
웹에서 스크랩된 데이터는 WARC 형식으로 제공되며, 주요 내용만 추출하기 위한 여러 단계를 거칩니다.
URL 필터링
부적절하거나 사기성 사이트를 걸러내기 위한 첫 번째 필터링입니다. 이 단계는 각 URL의 점수를 기반으로 하며, 특정 키워드의 존재를 평가합니다.
텍스트 추출
주요 내용만을 추출하기 위해 ‘trafilatura’ 라이브러리를 사용합니다. 추출된 텍스트는 규칙적인 표현을 사용하여 추가적으로 포맷팅됩니다.
언어 식별
FastText 언어 분류기를 사용하여 문서의 주 언어를 식별합니다. 이 과정에서 자연어가 아닌 페이지는 제거됩니다.
3.1. 데이터 정제(필터링)
반복 제거
중복되거나 반복적인 내용을 포함하는 문서는 모델의 일반화 능력을 저하시킬 수 있으므로 제거합니다.
문서별 필터링
스팸이나 특수 문자 시퀀스 등의 저품질 콘텐츠를 걸러내기 위해 품질 필터를 적용합니다.
라인별 수정
웹 페이지의 필요 없는 부분들을 제거하기 위한 필터가 적용됩니다.
데이터 정제는 불필요하거나 오류가 있는 데이터를 제거하는 과정으로 다음과 같이 수식으로 표현할 수 있습니다.
\[P_{filtered} = \{d \in D \\| f(d) > \theta\}\]\(D\)는 원본 데이터 집합, \(d\)는 개별 문서, \(f(d)\)는 문서의 품질을 평가하는 함수, 그리고 \(\theta\)는 품질 임계값입니다. 이 수식은 데이터를 필터링하는 데 사용되는 품질 기준을 수학적으로 정의합니다.
3.2. 중복 제거
퍼지 중복 제거
MinHash 알고리즘을 사용하여 유사 문서를 제거합니다. 이 방법은 문서 간의 근사적 유사성을 평가하여 높은 중복도를 가진 문서 쌍을 제거합니다.
정확한 중복 제거
특정 문자열 시퀀스의 완전한 일치를 찾아 제거합니다. 이는 문서 내의 일부만을 변경하므로 문서 전체를 삭제하지 않습니다.
URL 중복 제거
URL의 중복을 확인하고 중복되는 URL을 제거합니다. 이는 데이터셋의 다양성을 확보하기 위해 필수적입니다.
중복 제거는 데이터셋에서 중복되는 항목을 식별하고 제거하는 과정입니다. 이 과정은 다음과 같은 수합적 접근 방식을 사용합니다.
\[D_{unique} = \bigcup_{i=1}^{n} \{d_i \in D \\| \not\exists j < i, d_j \equiv d_i\}\]\(\equiv\)는 두 문서가 동등하다는 것을 나타내며, 데이터셋에서 중복을 제거함으로써 모델이 데이터의 다양성을 더 잘 학습하도록 도울 수 있습니다.
4. 실험
여러가지 벤치마크와 상태 기반 모델을 사용하여 실험을 설정하고, RefinedWeb이 기존의 고품질 데이터셋과 비교할 때 어떤 성능을 보이는지 평가합니다.
웹 데이터의 성능 평가
여러 파라미터 모델을 사용하여 웹 데이터만으로 훈련된 모델과 고품질 데이터셋을 사용한 모델을 비교합니다. 결과는 RefinedWeb이 고품질 소스를 사용한 모델과 유사한 성능을 보임을 확인합니다.
MDR의 다른 데이터셋 적용
MDR 파이프라인의 필터링과 중복 제거 단계를 다른 데이터셋에 적용하여 그 효과를 평가합니다. 결과적으로, 엄격한 중복 제거는 일관되게 성능을 향상시키며, 필터링 휴리스틱은 데이터 소스에 따라 조정이 필요함을 보여줍니다.
5. 결론
이 연구는 웹 데이터만으로도 충분히 높은 품질의 언어 모델을 훈련할 수 있음을 보여주며, 대규모 데이터의 필터링과 중복 제거가 언어 모델의 성능에 중요한 영향을 미친다는 점을 강조하고, 대규모 언어모델 훈련에 필요한 고품질의 대규모 데이터셋를 생성하는 방법을 제안합니다.
웹 데이터의 정제 및 중복 제거 과정을 통해 데이터의 품질을 향상시키고, 이를 통해 더 나은 모델을 훈련할 수 있다고 언급합니다.
[참고자료 1] 비슷한 데이터셋 Common Crawl
Common Crawl은 캘리포니아 샌프란시스코와 로스앤젤레스에 본사를 둔 비영리 단체로, 웹 사이트를 크롤링하여 수집한 대규모 데이터를 공개적으로 제공합니다. 이 단체는 2007년에 길 엘바즈(Gil Elbaz)에 의해 설립되었으며, 조직의 고문으로는 피터 노빅(Peter Norvig)과 리치 스크렌타(Rich Skrenta), 에바 호(Eva Ho) 등이 있습니다.
Common Crawl은 공개 데이터의 접근성을 높이고, 교육적 및 연구적 목적으로 널리 활용될 수 있는 자원을 제공함으로써, 전 세계 데이터 과학자 및 연구자들에게 중요한 기여를 하고 있습니다.
주요 기능 및 활동
- 데이터 수집: Common Crawl은 매달 인터넷의 다양한 웹페이지를 크롤링하여 데이터를 수집합니다. 이렇게 수집된 데이터는 테라바이트(TB) 단위로 쌓여 있으며, 2008년부터 지속적으로 데이터가 축적되고 있습니다.
- 데이터 공개: 수집된 데이터는 누구나 자유롭게 사용할 수 있도록 공개되어 있으며, 이 데이터를 활용하여 다양한 연구나 프로젝트에 사용할 수 있습니다.
- 언어 분포: 2023년 3월 기준으로 최신 Common Crawl 데이터셋에서는 문서의 46%가 영어로 되어 있으며, 독일어, 러시아어, 일본어, 프랑스어, 스페인어, 중국어 등이 그 뒤를 이어 각각 6% 미만으로 분포하고 있습니다.
- 저작권: 크롤러는
nofollow및robots.txt지침을 준수하며, 수집된 데이터에 포함된 저작권이 있는 작업은 미국에서 공정 이용 주장 하에 배포됩니다. - 오픈 소스: Common Crawl 데이터를 처리하는 오픈 소스 코드도 공개적으로 제공되어 있어, 누구나 이를 다운로드하고 활용할 수 있습니다.
히스토리
- 2012년부터 아마존 웹 서비스(AWS)의 공공 데이터셋 프로그램을 통해 Common Crawl의 아카이브를 호스팅하기 시작
- 2013년에는
.arc파일 형식에서.warc파일 형식으로 전환하여 데이터 저장 방식을 개선 - 2020년에는 Common Crawl의 필터링된 버전이 OpenAI의 GPT-3 언어 모델 훈련에 사용됨.
Model Card
- 모델은 기술 혁신 연구소(Technology Innovation Institute)에 의해 개발
- 모델 생성 날짜: Falcon-RW 모델은 2022년 12월/2023년 1월에 훈련
- 모델 유형 및 훈련 정보: Falcon-RW는 원인 언어 모델링 목표로 훈련된 자동 회귀적 변환 모델
- GPT-3(Brown 등, 2020) 기반 아키텍처를 사용하며, ALiBi 이중 위치 인코딩(Press 등, 2021) 및 Flash Attention(Dao 등, 2022)을 사용
라이선스
- Apache 2.0 라이선스를 사용하며, 라이선스 내용은 다음을 참조 https://www.apache.org/licenses/LICENSE-2.0
사용 목적
- 주요 사용 목적: 대규모 언어모델 연구 및 충분히 필터링 및 중복 제거된 웹 데이터가 대규모 언어모델의 특성(공정성, 안전성, 제한 사항, 능력 등)에 미치는 영향을 연구하는 것
- 주요 사용자: 자연어 처리 연구자.
- 스코프 밖의 사용 사례: 위험 평가 및 완화 조치 없이 생산적인 사용 사례, 비책임적 또는 해로운 사용 사례는 스코프 밖
관련 요인 및 평가
- 관련 요인: Falcon-RW 모델은 영어 데이터만으로 훈련되며, 다른 언어에 적절하게 일반화되지 않을 것으로 예상 또한, 웹에서 일반적으로 만날 수 있는 고정관념과 편견을 가질 수 있음
- 평가 요인: 모델의 온라인 독성을 평가했으며, Perspective API의 정의에 따른 것으로 “무례하거나 무례한 콘텐츠”를 고려 그러나 사회적 편견 또는 해로운 측면에 대한 우려를 포함하지 않음
평가 데이터
- 데이터셋: 18가지 다양한 작업에서 0-shot 정확도를 평가하며, 자세한 내용은 표 3을 참조하십시오.
- 동기: 다른 모델과의 비교를 위해 작업을 선택하고 집계하여 문헌에서 모델을 구축했음
- 전처리: Gao 등(2021)의 기본 프롬프트와 설정을 사용
데이터 집합 목적 및 생성 정보
- 목적: RefinedWeb은 대규모 언어모델 사전 훈련을 위한 데이터 집합으로 생성
- 생성자 및 기관: 기술 혁신 연구소(Technology Innovation Institute)에서 생성
- 자금 조달: 개인 기부로 생성
데이터 구성과 관련된 정보
- 인스턴스: 텍스트 문서로, 단일 웹 페이지를 나타냄
- 총 인스턴스 수: 약 100억 개의 문서 또는 약 5조 개의 토큰이 포함되어 있으며, 공개 버전은 전체의 10%에 해당하는 하위 집합
- 무작위 샘플: Common Crawl 덤프를 모두 사용하여 구축되었으며, 공개 버전은 600GT의 임의 추출
- 인스턴스 데이터: 텍스트 문서 및 Common Crawl의 원산지 및 소스 페이지 URL과 관련된 메타데이터가 포함되어 있으며, 멀티모달 버전에는 이미지 링크가 포함
데이터 처리와 관련된 정보
- 오류 및 중복: 콘텐츠 필터링 및 중복 문서 제거를 통해 오류 및 중복이 일부 있을 수 있음
- 외부 리소스: 기본 버전은 자체 포함되어 있지만 멀티모달 버전에는 외부 이미지 링크가 포함
- 기밀 정보: 데이터 집합의 모든 문서는 공개적으로 사용 가능한 정보
- 노출되는 데이터: 데이터에는 노출될 경우 무례하거나 불안한 내용이 포함될 수 있음
데이터 수집과 관련된 정보
- 데이터 획득: Common Crawl 재단에서 WARC 및 WET 파일 다운로드로 데이터를 확보했음
- 수집 프로세스: Common Crawl 웹사이트의 데이터 수집 절차를 따랐음
- 데이터 수집 시간: 2008년부터 2023년 1월/2월까지 모든 Common Crawl 덤프에서 데이터를 수집했음
데이터 전처리 및 레이블링
- 전처리: 콘텐츠 필터링, 언어 식별 및 중복 제거 등의 방법을 사용하여 데이터를 전처리했음
- 소프트웨어: 전처리 및 레이블링에 사용된 소프트웨어는 공개되지 않았음
데이터 사용 및 배포
- 사용: 데이터는 대규모 언어모델 개발 및 과학 실험에 사용
- 배포: 데이터는 Hugging Face Hub를 통해 배포
- 배포 일정: 데이터는 즉시 사용 가능
- 라이센스: 공개 버전은 ODC-By1.0 라이센스에 따라 사용 가능하며, Common Crawl의 ToU를 따라야 함.
데이터 업데이트 및 확장
- 업데이트: 데이터는 업데이트되지 않을 예정
- 확장 및 기여: 데이터 집합을 확장, 보완 또는 기여하는 메커니즘에 대한 정보는 제공되지 않았음
- IP 제한 및 규정: 데이터에 대한 IP 제한 또는 규정 제한 사항은 제작자의 지식 범위 내에서는 없음
Model Developer and Details
- The models were created by the Technology Innovation Institute.
- Model Date: Falcon-RW models were trained in December 2022/January 2023.
- Model Type and Training Information: Falcon-RW is an autoregressive Transformer model trained with a causal language modeling objective. It is based on the architecture of GPT-3 (Brown et al., 2020) and incorporates ALiBi positional encodings (Press et al., 2021) and Flash Attention (Dao et al., 2022). For more details, refer to Section 4.1.
- License: The model is licensed under Apache 2.0, and the license details can be found at https://www.apache.org/licenses/LICENSE-2.0.
- Point of Contact: falconTextGenerationLLM@tii.ae
Intended Use
- Primary Intended Uses: Research on large language models and the influence of adequately filtered and deduplicated web data on the properties of large language models (fairness, safety, limitations, capabilities, etc.).
- Primary Intended Users: NLP researchers.
- Out-of-Scope Use Cases: Production use without adequate risk assessment and mitigation; any use cases that may be considered irresponsible or harmful.
Factors
- Relevant Factors: Falcon-RW models are trained on English data only and may not generalize appropriately to other languages. Additionally, as they are trained on a large-scale corporate representative of the web, they may carry the stereotypes and biases commonly encountered online.
Evaluation Factors
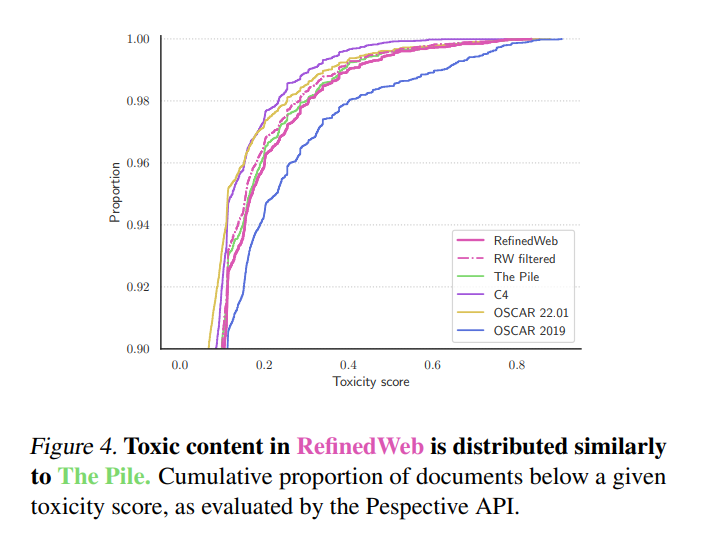
- We evaluated the toxicity of the underlying pretraining dataset and found it to be in line with common curated pretraining datasets such as The Pile (see Figure 4). Note that this evaluation only considers toxicity under the definition of Perspective API as “content that is rude or disrespectful.” Importantly, this evaluation does not address concerns about social biases or harmfulness.
Metrics
- Model Performance Measures: The evaluation focuses on measuring the zero-shot generalization capabilities of the models across a wide range of tasks, leveraging the EleutherAI language model evaluation harness (Gao et al., 2021).
- Variation Approaches: Due to the costs associated with training Falcon-RW, the models cannot be trained multiple times to measure variability across training runs.
Evaluation Data
- Datasets: Zero-shot accuracy is evaluated on 18 varied tasks, detailed in Table 3.
- Motivation: Tasks were selected and aggregated to build comparisons with other models in the literature (see Section 4.1; Appendix F.1 for details).
-
Preprocessing: Default prompts and setups from Gao et al. (2021) are used.
-
Data Refining Standard
Check Question? Description For what purpose was the dataset created? RefinedWeb was created to serve as a large-scale dataset for the pretraining of large language models. It may be used on its own or augmented with curated sources. Who created the dataset and on behalf of which entity? The dataset was created by the Technology Innovation Institute. Who funded the creation of the dataset? The creation of the dataset was privately funded by the Technology Innovation Institute. Any other comments? RefinedWeb is built on top of Common Crawl, using the Macrodata Refinement Pipeline. It adheres to specific principles, including scale, strict deduplication, and neutral filtering. What do the instances that comprise the dataset represent? Instances are text-only documents corresponding to single web pages. How many instances are there in total? RefinedWeb contains approximately 10 billion documents, or around 5 trillion tokens. The public version is a subset representing a tenth of the full version. Does the dataset contain all possible instances or is it a sample? RefinedWeb is built using all Common Crawl dumps until June 2023; it could be updated with additional dumps. The public release is a 600GT random extract from the 5,000GT full dataset. What data does each instance consist of? Each instance is a text-only document with metadata about its origin in Common Crawl and source page URL. A multimodal version also contains interlaced links to images. Is there a label or target associated with each instance? No. Is any information missing from individual instances? No. Are relationships between individual instances made explicit? No. Are there recommended data splits? No. Are there any errors, sources of noise, or redundancies in the dataset? Despite best efforts to filter content and deduplicate documents, some errors or redundancies may be present. Is the dataset self-contained or does it rely on external resources? The base version of the dataset is self-contained, but the multimodal version includes links to external images. Does the dataset contain data that might be considered confidential? All documents in RefinedWeb have been publicly available online. Does the dataset contain data that might be offensive or cause anxiety if viewed directly? Yes, the dataset may contain such content, similar to ThePile. How was the data associated with each instance acquired? The data was acquired by downloading WARC and WET files from the Common Crawl foundation. What mechanisms or procedures were used to collect the data? Common Crawl’s data collection procedures were followed; details can be found on their website. If the dataset is a sample, what was the sampling strategy? When using subsets, random sampling from the original data was employed. Who was involved in the data collection process and how were they compensated? Common Crawl performed the original data collection; authors from this paper were involved in retrieving and preparing it. Over what time frame was the data collected? Data was collected from all Common Crawl dumps from 2008 to January/February 2023. Were any ethical review processes conducted? No. Was any preprocessing, cleaning, or labeling of the data done? Yes, extensive preprocessing and cleaning were done, including content filtering, language identification, and deduplication. Was the “raw” data saved in addition to the preprocessed/cleaned/labeled data? Raw data was saved during development for some intermediary outputs, but not for the final production version due to storage constraints. Is the software used for preprocessing/cleaning/labeling the data available? No. Has the dataset been used for any tasks already? Yes, it has been used for developing large language models and scientific experiments. Is there a repository that links to any or all papers or systems that use the dataset? No. What other tasks could the dataset be used for? RefinedWeb may be suitable for various downstream uses due to its large-scale and representative nature. Is there anything about the composition or collection process that might impact future uses? The public extract draws only from the English version, limiting multilingual applications. Are there tasks for which the dataset should not be used? It should not be used for irresponsible or harmful tasks. Will the dataset be distributed to third parties outside of the entity on behalf of which it was created? A 600GT extract will be made publicly available for NLP practitioners, but not the full version. How will the dataset be distributed? The dataset will be available through the Hugging Face Hub. When will the dataset be distributed? The dataset is available immediately. Will the dataset be distributed under a copyright or other intellectual property (IP) license, and/or under applicable terms of use (ToU)? The public extract is available under an ODC-By1.0 license; Common Crawl’s ToU should also be followed. Have any third parties imposed IP-based or other restrictions on the data associated with the instances? Not to the knowledge of the creators. Do any export controls or other regulatory restrictions apply to the dataset or to individual instances? Not to the knowledge of the creators. Will the dataset be updated? No. If others want to extend/augment/build on/contribute to the dataset, is there a mechanism for them to do so? This information is not provided in the document. -
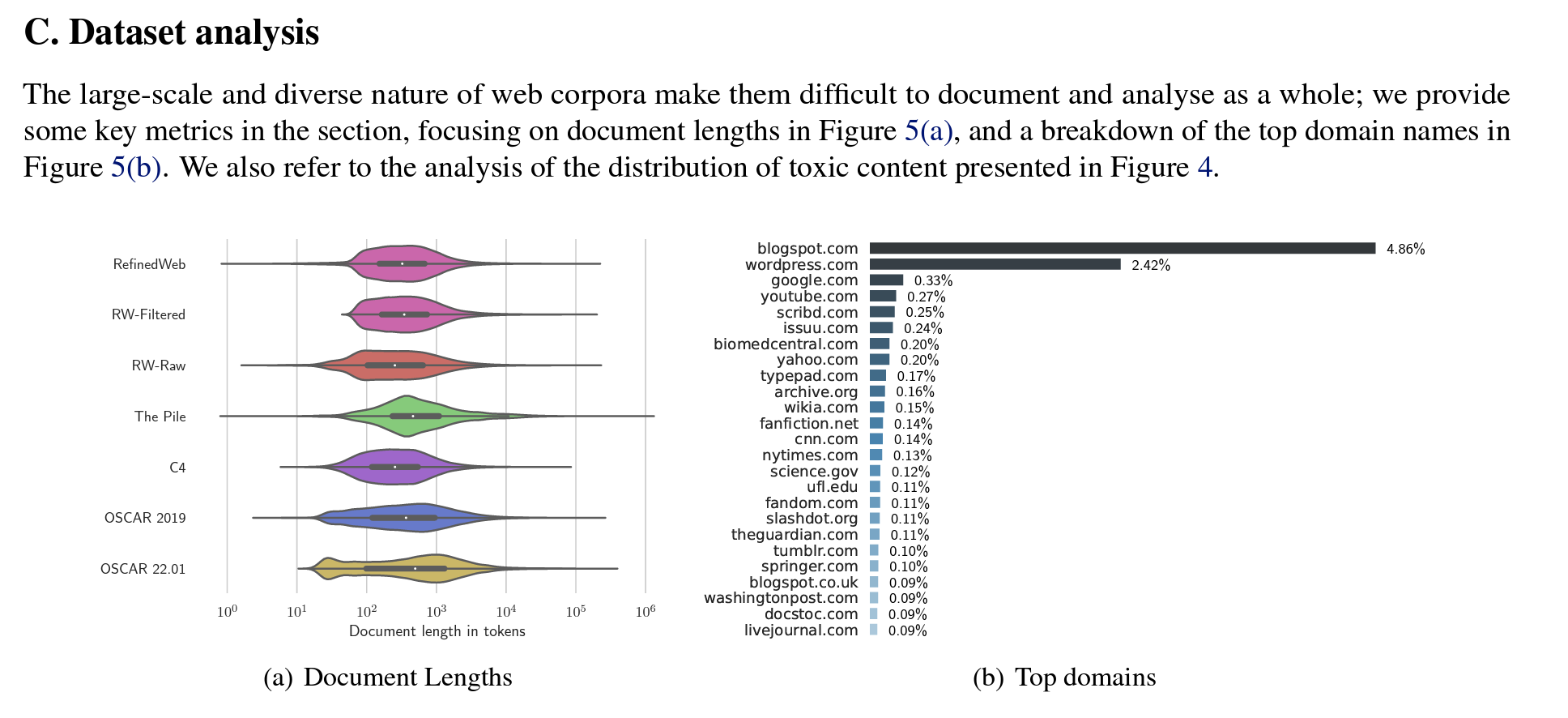
Data Analysis
1 Introduction
Progress in natural language processing is increasingly driven by sheer compute scale alone (Sevilla et al., 2022): as more compute is expended to train large language models (LLM), they gain and exhibit powerful emergent capabilities (Brown et al., 2020; Wei et al., 2022). To best benefit from scaling, recent scaling laws dictate that both model size and dataset size should jointly be increased (Hoffmann et al., 2022). This is at variance with earlier findings, which had argued that scaling should focus on model size first and foremost, with minimal data scaling (Kaplan et al., 2020). This joint scaling paradigm raises significant challenges: although plentiful, text data is not infinite, especially so when considerations on data quality and licensing are taken into account – leading some researchers to argue scaling may soon be bottlenecked by data availability (Villalobos et al., 2022). Concretely, optimally training a GPT-3 sized model (175B parameters) would require no less than 3,500 billion tokens of text according to Hoffmann et al. (2022). This is twice as much as the largest pretraining datasets ever demonstrated (Hoffmann et al., 2022; Touvron et al., 2023), and ten times more than the largest publicly available English datasets such as OSCAR (Ortiz Su´arez et al., 2019), C4 (Raffel et al., 2020), or The Pile (Gao et al., 2020). Massively scaling-up pretraining data is made even more challenging by the fact LLMs are commonly trained using a mixture of web crawls and so-called “high-quality” data (Brown et al., 2020; Gao et al., 2020). Typical high-quality corpora include curated sources of books, technical documents, human-selected webpages, or social media conversations. The increased diversity and quality brought forth by these curated corpora is believed to be a key component of performant models (Scao et al., 2022b). Unfortunately, curation is labor-intensive: typically, each source requires specialized processing, while yielding a limited amount of data. Furthermore, licensed sources raise legal challenges. Nevertheless, most pretraining data is still sourced from massive web crawls which can be scaled up to trillions of tokens with limited human intervention. However, the quality of this data has traditionally been seen as (much) inferior to that of the manually curated data sources. Even finely processed sources of web data, such as C4 (Raffel et al., 2020) or OSCAR (Ortiz Su´arez et al., 2019), are regarded as inferior to curated corpora for LLMs (Rae et al., 2021; Scao et al., 2022b), producing less performant models. To sustain the ever-increasing data needs of larger and larger LLMs, and to streamline data pipelines and reduce the need for human-intensive curation, we propose to explore how web data can be better processed to significantly improve its quality, resulting in models as capable, if not more capable, than models trained on curated corpora.
2 Related works
-
Pretraining data for large language models
Early large language models identified the importance of datasets with long, coherent documents (Radford et al., 2018; Devlin et al., 2019). Moving on from the previously used sentence-wise datasets (Chelba et al., 2013), they instead leveraged document-focused, single-domain corpora like Wikipedia or Book Corpus (Zhu et al., 2015). As models increased in scale, datasets based on massive web scrapes gained prevalence (Ortiz Su´arez et al., 2019; Raffel et al., 2020). However, further work argued that these untargeted web scrapes fell short of human-curated data (Radford et al., 2019), leading to the wide adoption of curated datasets such as The Pile (Gao et al., 2020), which combine web data with books, technical articles, and social media conversations. At scale, it has been proposed to emulate the human curation process by leveraging weak signals: for instance, by crawling the top links of a forum (Gokaslan et al., 2019). Targeted corpora can also produce domain-specific models (Beltagy et al., 2019), or broaden the expressiveness of models (e.g., for conversational modalities Adiwardana et al. (2020); Thoppilan et al. (2022)). Latest large language models (Brown et al., 2020; Rae et al., 2021; Chowdhery et al., 2022; Scao et al., 2022a) are trained on giant aggregated corpora, combining both massive web scrape and so-called “high-quality” curated single-domain sources (e.g., news, books, technical papers, social media conversations). These targeted sources are often upsampled – from one to five times is most common – to increase their representation in the final dataset. The diversity and “higher quality” brought forth by these aggregated datasets is thought to be central to model quality; web data alone is considered insufficient to train powerful large language models (Liu et al., 2019; Scao et al., 2022b).
-
Pipelines for web data
Massive web datasets are typically built upon Common Crawl, a publicly available scrape of the internet, which has now been running for 12 years and has collected petabytes of data. Working with data scraped from all over the internet presents unique challenges: notably, a significant portion is low-quality machine-generated spam or pornographic content (Trinh & Le, 2018; Kreutzer et al., 2022). Accordingly, training on unfiltered web data is undesirable, resulting in poorly performing models (Raffel et al., 2020). Modern pipelines focus on filtering out this undesirable content (Wenzek et al., 2020). Broadly speaking, these pipelines usually combine a variety of stages: (1) language identification, leveraging inexpensive n-gram models (e.g., fastText Joulin et al. (2016)); (2) filtering rules and heuristics, such as only keeping lines with valid punctuation,
-
Macrodata Refinement and Refined Web
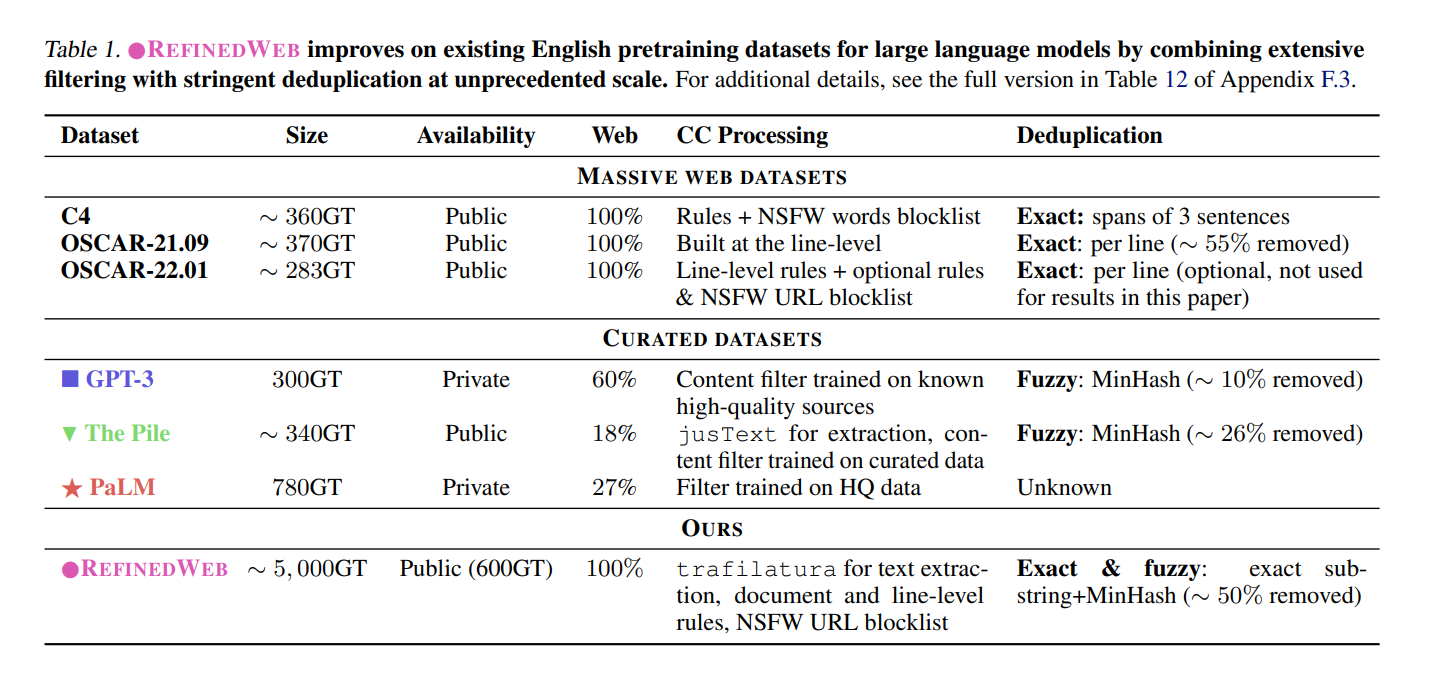
We introduce MDR (MacroData Refinement), a pipeline for filtering and deduplicating web data from Common Crawl at very large scale. Using MDR, we produce REFINEDWEB, an English pretraining dataset of five trillion tokens based on web data only. We leverage strict filtering and stringent deduplication to uplift the quality of web data, distilling it down to a corpus matching the quality of aggregated corpora used to train state-of-the-art models.
3 Design Principles
We abide by the following guidelines:
- Scale first: We intend MDR to produce datasets to be used to train 40-200B parameters models, thus requiring trillions of tokens (Hoffmann et al., 2022). For English-only Refined Web, we target a size of 3-6 trillion tokens. Specifically, we eschew any labor-intensive human curation process and focus on Common Crawl instead of disparate single-domain sources.
- Strict deduplication: Inspired by the work of Lee et al. (2022), which demonstrated the value of deduplication for large language models, we implement a rigorous deduplication pipeline. We combine both exact and fuzzy deduplication, and use strict settings leading to removal rates far higher than others have reported.
- Neutral filtering: To avoid introducing further undesirable biases into the model (Dodge et al., 2021; Welbl et al., 2021), we avoid using ML-based filtering outside of language identification. We stick to simpler rules and heuristics and use only URL filtering for adult content. Table 2 and Figure 2 outline the full MDR pipeline.
3.1 Document Preparation: Reading Data, Filtering URLs, Extracting Text, and Language Identification

-
Reading the data
Common Crawl is available in either WARC (raw HTML response) or WET files (preprocessed to only include plaintext). Individual files correspond to a page at a given URL; these constitute single documents/samples. Working with WET files would spare us from running our own HTML extraction; however, in line with previous works (Gao et al., 2020; Rae et al., 2021), we found WET files to include undesirable navigation menus, ads, and other irrelevant texts. Accordingly, our pipeline starts from raw WARC files, read with the warciolibrary.
-
URL filtering
Before undertaking any compute-heavy processing, we perform a first filtering based on the URL alone. This targets fraudulent and/or adult websites (e.g., predominantly pornographic, violent, related to gambling, etc.). We base our filtering on two rules: (1) an aggregated blocklist of 4.6M domains; (2) a URL score, based on the presence of words from a list we curated and weighed by severity. We found that commonly used blocklists include many false positives, such as popular blogging platforms or even pop culture websites. Furthermore, word-based rules (like the one used in C4, Raffel et al. (2020)) can easily result in medical and legal pages being blocked. Our final detailed rules based on this investigation are shared in Appendix G.1. Since we intend Refined Web to be used as part of an aggregated dataset along with curated corpora, we also filtered common sources of high-quality data: Wikipedia, arXiv, etc. The detailed list is available in Appendix G.1.
-
Text extraction
We want to extract only the main content of the page, ignoring menus, headers, footers, and ads among others. Lopukhin (2019) found that trafilatura (Barbaresi, 2021) was the best non-commercial library for retrieving content from blog posts and news articles. Although this is only a narrow subset of the kind of pages making up Common Crawl, we found this finding to hold more broadly. We use trafilatura for text extraction and apply extra formatting via regular expressions: we limit newlines to two consecutive ones and remove all URLs.
-
Language identification
We use the fastText language classifier of CCNet (Wenzek et al., 2020) at the document level: it uses characters n-gram and was trained on Wikipedia, supporting 176 languages. We remove documents for which the top language scores below 0.65; this usually corresponds to pages without any natural text. For this paper, we focus on English; Refined Web can also be derived for other languages, see Appendix D for details. The data we retrieve at this stage, called RW-RAW, corresponds to what we can extract with the minimal amount of filtering. At this stage, only 48% of the original documents are left, mostly filtered out by language identification.
3.2 Filtering: Document-wise and Line-wise
-
Repetition removal
Due to crawling errors and low-quality sources, many documents contain repeated sequences; this may cause pathological behavior in the final model (Holtzman et al., 2019). We could catch this content at the later deduplication stage, but it is cheaper and easier to catch it document-wise early on. We implement the heuristics of Rae et al. (2021) and remove any document with excessive line, paragraph, or n-gram repetitions.
-
Document-wise filtering
A significant fraction of pages are machine-generated spam, made predominantly of lists of keywords, boilerplate text, or sequences of special characters. Such documents are not suitable for language modeling; to filter them out, we adopt the quality filtering heuristics of Rae et al. (2021). These focus on removing outliers in terms of overall length, symbol-to-word ratio, and other criteria ensuring the document is actual natural language. We note that these filters have to be adapted on a per-language basis, as they may result in over-filtering if naively transferred from English to other languages.
-
Line-wise corrections
Despite the improvements brought forth by using trafilatura instead of relying on preprocessed files, many documents remain interlaced with undesirable lines (e.g., social media counters, navigation buttons). Accordingly, we devised a line-correction filter, targeting these undesirable items. If these corrections remove more than 5% of a document, we remove it entirely. See Appendix G.2 for details. The data we retrieve at this stage has gone through all of the filtering heuristics in the MDR pipeline. We refer to this dataset as RW-FILTERED. Only 23% of the documents of Common Crawl are left, with around 50% of the documents of RW-Raw removed by the filtering.
3.3 Deduplication: Fuzzy, Exact, and Across Dumps
After filtering, although data quality has improved, a large fraction of the content is repeated across documents. This may be due to the crawler indirectly hitting the same page multiple times, boilerplate content being repeated (e.g., licenses), or even plagiarism. These duplicates can strongly impact models, favoring memorization instead of generalization (Lee et al., 2022; Hernandez et al., 2022). Since deduplication is expensive, it has seen limited adoption in public datasets (Ortiz Su´arez et al., 2019; Raffel et al., 2020). We adopt an aggressive deduplication strategy, combining both fuzzy document matches and exact sequences removal.
Fuzzy Deduplication
We remove similar documents by applying MinHash (Broder, 1997): for each document, we compute a sketch and measure its approximate similarity with other documents, eventually removing pairs with high overlap. MinHash excels at finding templated documents: licenses with only specific entities differing, placeholder SEO text repeated across websites—see examples of the biggest clusters in Appendix H.1. We perform MinHash deduplication using 9,000 hashes per document, calculated over 5-grams and divided into 20 buckets of 450 hashes. Using less aggressive settings, such as the 10 hashes of The Pile (Gao et al., 2020), resulted in lower deduplication rates and worsened model performance. See Appendix G.3.1 for more details about our MinHash setup.
Exact Deduplication
Exact substring operates at the sequence-level instead of the document-level, finding matches between strings that are exact token-by-token matches by using a suffix array (Manber & Myers, 1993) (e.g., specific disclaimers or notices, which may not compromise the entire document as showcased in Appendix H.2). We remove any match of more than 50 consecutive tokens, using the implementation of Lee et al. (2022). We note that exact substring alters documents, by removing specific spans: we also experimented with dropping entire documents or loss-masking the duplicated strings instead of cutting them, but this didn’t result in significant changes in zero-shot performance—see Appendix G.3.2.
URL Deduplication
Because of computational constraints, it is impossible for us to perform deduplication directly on RW-Filtered. Instead, we split CommonCrawl into 100 parts, where each part contains a hundredth of each dump, and perform deduplication on individual parts. Most of the larger duplicate clusters (e.g., licences, common spams) will be shared across parts, and effectively removed. However, we found that CommonCrawl dumps had significant overlap, with URLs being revisited across dumps despite no change in content. Accordingly, we keep a list of the URLs of all samples we have kept from each part, and remove them from subsequent parts being processed.
4 Experiments

We now validate that RefinedWeb can be used to train powerful models, matching the zero-shot performance obtained with curated corpora and state-of-the-art language models.
4.1 Setting
-
Evaluation: Unlike previous works, we focus our evaluation on zero-shot generalization across many tasks rather than measuring validation loss. Our evaluation setup is inspired by the one used by the architecture and scaling group of Big Science (Scao et al., 2022b). We base our evaluation on the Eleuther AI evaluation harness (Gao et al., 2021), allowing us to evaluate across a wide range of tasks in the zero-shot setting.
- Comparisons: We distinguish three levels of comparisons:
- Internal comparisons, with models trained and evaluated within our codebase.
- Benchmark-level comparisons, with models trained with a different codebase but evaluated with the Eleuther AI harness.
- External comparisons with state-of-the-art models like Brown et al. (2020) and Chowdhery et al. (2022).
- Models: We train 1B, 3B, and 7B parameters autoregressive decoder-only models, diverging mostly on our use of ALiBi (Press et al., 2021). We use FlashAttention (Dao et al., 2022) in a custom codebase. We train internal models on both The Pile and RefinedWeb to control for deviations caused by our pretraining setup.
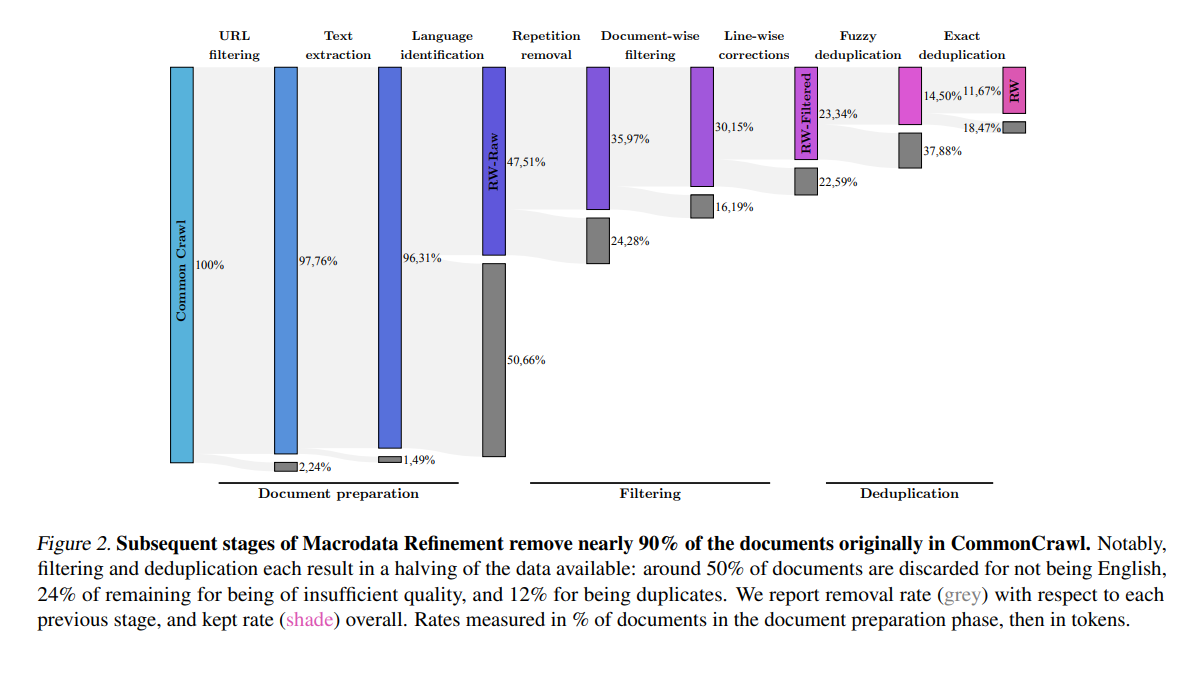
4.2 Can web data alone outperform curated corpora?
We perform a small-scale study with 1B and 3B parameters models trained to optimality on popular web and curated datasets. Then, we scale up to 1B and 7B models trained on 350GT, and compare zero-shot generalization to state-of-the-art models.
Small-Scale Study
We first consider popular public web datasets such as OSCAR-2019 (Ortiz Suarez et al., 2019), OSCAR-2022 (Abadji et al., 2021), and C4 (Raffel et al., 2020), along with The Pile (Gao et al., 2020) as the most popular publicly available curated dataset, and variations of RefinedWeb (RW-Raw, RW-Filtered, and RW as described in Section 3). All models are trained with the same architecture and internal codebase; they are evaluated within the same framework—only pretraining datasets differ.
Results averaged on the small-scale aggregate of 6 tasks are presented in Table 4. We observe relatively strong performance of all web datasets compared to The Pile, showcasing that curation is not a silver bullet for performant language models. C4 is identified as a strong pretraining dataset, aligning with the findings of Scao et al. (2022b). However, The Pile underperforms more in our benchmarks. Disappointing results on OSCAR-22.01 may be due to the main version of the dataset being distributed without deduplication. For RefinedWeb, both filtering and deduplication significantly improve performance.
Full-Scale Models
We validate these results with comparisons with state-of-the-art models by scaling our previous experiments to train 1B and 7B models on 350GT. Additionally, we train a 1B model on 350GT on The Pile as a control for the influence of our pretraining setup. We compare with several models:
- GPT-3 series (Brown et al., 2020)
- FairSeq series (Artetxe et al., 2021)
- GPT-Neo(X)/J models (Black et al., 2021; Wang & Komatsuzaki, 2021; Black et al., 2022)
- OPT series (Zhang et al., 2022)
- BigScience Architecture and Scaling Pile model (Scao et al., 2022b)
- PaLM-8B (Chowdhery et al., 2022)
- Aleph Alpha Luminous 13B (Aleph Alpha, 2023)
- Pythia series (Biderman et al., 2023)
- Cerebras-GPT series (Dey et al., 2023)
For GPT-3, we distinguish between results obtained through the API (babbage and curie) with the EleutherAI LM evaluation harness (Gao et al., 2021) (), and results reported in their paper, with a different evaluation setup (†). For PaLM and OPT, results were also obtained with a different evaluation suite (†), while for other models they were obtained with the evaluation harness as well (), allowing for more direct comparisons.
Results on main-agg are presented in Figure 1, and in Figure 3 for core-agg and ext-agg. We find that open models consistently underperform models trained on private curated corpora, such as GPT-3—even when using a similar evaluation setup. Conversely, models trained on RefinedWeb are able to match the performance of the GPT-3 series using web data alone, even though common high-quality sources used in The Pile are excluded from RefinedWeb (see Table 14 in Appendix).
Challenging existing beliefs on data quality and LLMs, models trained on adequately filtered and deduplicated web data alone can match the performance of models trained on curated data.
4.3 Do Other Corpora Benefit from MDR?
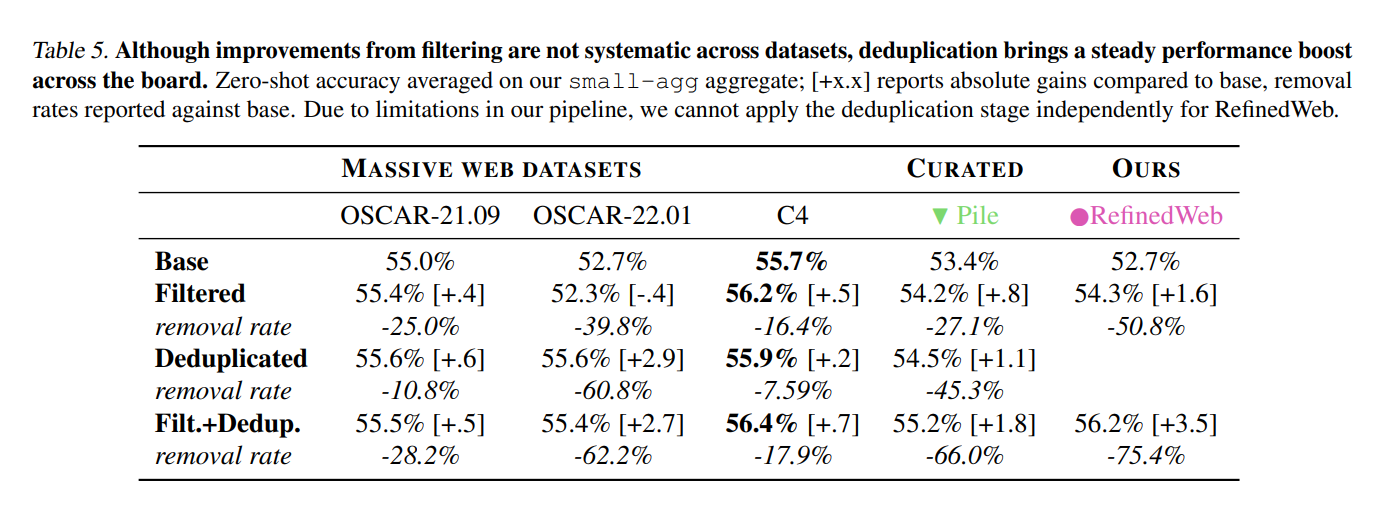
Ablating the contributions and evaluating the performance of individual components in the MDR pipeline is difficult: for most heuristics, there is no agreed-upon ground truth, and changes may be too insignificant to result in sufficient zero-shot signal after pretraining. In the first half of Section 4.2, we identified that subsequent stages of RefinedWeb (raw, filtered, final) led to improvements in performance. In this section, we propose to apply independently the filtering and deduplication stages of MDR to popular pretraining datasets, studying whether they generalize widely.
Results on the small-agg are reported in Table 5. First, we find that improvements from filtering are not systematic. On The Pile, we had to adjust our line length and characters ratio heuristics to avoid expunging books and code. Despite improvements on OSCAR-21.09, C4, and The Pile, our filters worsen performance on OSCAR-22.01; generally, removal rates from filtering do not seem strongly correlated with downstream accuracy. Conversely, deduplication delivers a steady boost across all datasets, and removal rates are better correlated with changes in performance. We find OSCAR-21.09 and C4 to be already well deduplicated, while The Pile and OSCAR-22.01 exhibit 40-60% duplicates. The base version of OSCAR-22.01 is distributed without deduplication; for The Pile, this is consistent with the findings of Zhang et al. (2022). Finally, combining filtering and deduplication results in further improvements; interestingly, although performance is now more uniform across datasets, differences remain, suggesting that flaws in the original text extraction and processing can’t be fully compensated for.
By processing C4 through MDR, we are able to obtain subsets of data which might slightly outperform RefinedWeb; this combines both the stringent filtering of C4 (e.g., strict NSFW word blocklist, 3-sentence span deduplication) with our own filters and deduplication. While such a combination results in rejection rates that would be unacceptable for our target of 3-6 trillion tokens, this represents an interesting perspective for shorter runs, which may be able to extract extremely high-quality subsets from large web datasets.
While filtering heuristics may require source-dependent tuning, stringent deduplication improves zero-shot performance across datasets consistently.
5. Conclusion
As LLMs are widely adopted, models trained past the recommendations of scaling laws are bound to become increasingly common to amortize inference costs (Touvron et al., 2023). This will further drive the need for pretraining datasets with trillions of tokens, an order of magnitude beyond publicly available corpora. We have demonstrated that stringent filtering and deduplication could result in a five trillion tokens web only dataset suitable to produce models competitive with the state-of-the-art, even outperforming LLMs trained on curated corpora. We publicly release a 600GT extract of RefinedWeb, and note that RefinedWeb has already been used to train state-of-the-art language models, such as Falcon-40B (Almazrouei et al., 2023).
Appendix
- Motivation
| Check Question? | Description |
|---|---|
| For what purpose was the dataset created? | RefinedWeb was created to serve as a large-scale dataset for the pretraining of large language models. It may be used on its own or augmented with curated sources (e.g., Wikipedia, StackOverflow). |
| Who created the dataset and on behalf of which entity? | The dataset was created by the Technology Innovation Institute. |
| Who funded the creation of the dataset? | The creation of the dataset was privately funded by the Technology Innovation Institute. |
| Any other comment? | RefinedWeb is built on top of Common Crawl, using the Macrodata Refinement Pipeline, which combines content extraction, filtering heuristics, and deduplication. In designing RefinedWeb, we abided by the following philosophy: (1) Scale first: We intend MDR to produce datasets to be used to train 40-200 billion parameters models, thus requiring trillions of tokens (Hoffmann et al., 2022). For English-only RefinedWeb, we target a size of 3-6 trillion tokens. Specifically, we eschew any labor-intensive human curation process and focus on Common Crawl instead of disparate single-domain sources. (2) Strict deduplication: Inspired by the work of Lee et al. (2022), which demonstrated the value of deduplication for large language models, we implement a rigorous deduplication pipeline. We combine both exact and fuzzy deduplication and use strict settings leading to removal rates far higher than others have reported. (3) Neutral filtering: To avoid introducing further undesirable biases into the model (Dodge et al., 2021; Welbl et al., 2021), we avoid using ML-based filtering outside of language identification. We stick to simple rules and heuristics and use only URL filtering for adult content. |
- Composition
| Check Question? | Description |
|---|---|
| What do the instances that comprise the dataset represent? | Instances are text-only documents, corresponding to single webpages. |
| How many instances are there in total? | RefinedWeb contains approximately 10 billion documents, or around 5 trillion tokens. The public version is a subset representing a tenth of the full version. |
| Does the dataset contain all possible instances, or is it a sample (not necessarily random) of instances from a larger set? | RefinedWeb is built using all Common Crawl dumps until the 2023-06 one; it could be updated with additional dumps as they are released. The public release of RefinedWeb is a 600GT random extract of the 5,000GT of the full dataset. For all experiments, we randomly sampled from the public extract or earlier development versions of it. |
| What data does each instance consist of? | Each instance is a text-only document, with metadata about its origin in Common Crawl and source page URL. We also distribute a multimodal version of RefinedWeb, containing interlaced links to images. |
| Is there a label or target associated with each instance? | No. |
| Is any information missing from individual instances? | No. |
| Are relationships between individual instances made explicit? | No. |
| Are there recommended data splits? | No. |
| Are there any errors, sources of noise, or redundancies in the dataset? | Despite our best efforts to filter content that does not qualify as natural language and to deduplicate documents, our pipeline may let through documents that may be considered as errors or redundant. |
| Is the dataset self-contained, or does it link to or otherwise rely on external resources? | The base version of the dataset is self-contained, but the multimodal version is interlaced with links to images – these are not distributed as part of the dataset and constitute an external source. |
| Does the dataset contain data that might be considered confidential? | All documents in RefinedWeb have been publicly available online. |
| Does the dataset contain data that, if viewed directly, might be offensive, insulting, threatening, or might otherwise cause anxiety? | Yes, as this type of data is prevalent on the internet, it is likely our dataset contains such content. Notably, we estimate the prevalence of toxic content in the dataset to be similar to The Pile (Figure 4). |
- Preprocessing
| Check Question? | Description |
|---|---|
| How was the data associated with each instance acquired? | We downloaded with warcio publicly available WET files from the Common Crawl Foundation. |
| What mechanisms or procedures were used to collect the data? | We refer to the Common Crawl website (commoncrawl.org) for details on how they collect data. |
| If the dataset is a sample from a larger set, what was the sampling strategy? | Whenever we use subsets, we randomly sample from the original data. |
| Who was involved in the data collection process and how were they compensated? | The original data collection was performed by Common Crawl; authors from this paper were involved in retrieving it and preparing it. |
| Over what timeframe was the data collected? | We use all Common Crawl dumps from 2008 to January/February 2023. |
| Were any ethical review processes conducted? | No. |
- Uses
| Check Question? | Description |
|---|---|
| Has the dataset been used for any tasks already? | Yes, this data has been used to develop large language models: both for scientific experiments (e.g., this paper) and production use. |
| Is there a repository that links to any or all papers or systems that use the dataset? | No. |
| What (other) tasks could the dataset be used for? | RefinedWeb was built as a large-scale corpora representative of the web, and as such, it may serve many downstream uses which are difficult to predict. |
| Is there anything about the composition of the dataset or the way it was collected and preprocessed/cleaned/labeled that might impact future uses? | For the public extract of RefinedWeb, we chose to only draw from the English version of the dataset, preventing multilingual applications. |
| Are there tasks for which the dataset should not be used? | Any tasks which may be considered irresponsible or harmful. |
- Distribution
| Check Question? | Description |
|---|---|
| Will the dataset be distributed to third parties outside of the entity on behalf of which the dataset was created? | Yes, we make a 600GT extract publicly available for NLP practitioners. We currently don’t plan to share the full version of the dataset. |
| How will the dataset be distributed? | The dataset will be made available through the Hugging Face Hub. |
| When will the dataset be distributed? | The dataset is available immediately. |
| Will the dataset be distributed under a copyright or other intellectual property (IP) license, and/or under applicable terms of use (ToU)? | The public extract is made available under an ODC-By1.0 license; users should also abide by the Common Crawl ToU: Common Crawl ToU. |
| Have any third parties imposed IP-based or other restrictions on the data associated with the instances? | Not to our knowledge. |
| Do any export controls or other regulatory restrictions apply to the dataset or to individual instances? | Not to our knowledge. |
- Maintenance
| Check Question? | Description |
|---|---|
| Who will be supporting/hosting/maintaining the dataset? | The dataset will be hosted on the Hugging Face Hub, and we have no plans to further support or maintain it once it is released. |
| How can the owner/curator/manager of the dataset be contacted? | You can contact the owner/curator/manager at falconTextGenerationLLM@tii.ae. |
| Is there an erratum? | No. |
| Will the dataset be updated? | No. |
| If others want to extend/augment/build on/contribute to the dataset, is there a mechanism for them to do so? | This information is not provided in the document. |