Model | LLaVA
- Related Project: Private
- Category: Paper Review
- Date: 2023-10-24
[1] Improved Baselines with Visual Instruction Tuning
- url: https://arxiv.org/abs/2310.03744
- pdf: https://arxiv.org/pdf/2310.03744
- abstract: Large multimodal models (LMM) have recently shown encouraging progress with visual instruction tuning. In this note, we show that the fully-connected vision-language cross-modal connector in LLaVA is surprisingly powerful and data-efficient. With simple modifications to LLaVA, namely, using CLIP-ViT-L-336px with an MLP projection and adding academic-task-oriented VQA data with simple response formatting prompts, we establish stronger baselines that achieve state-of-the-art across 11 benchmarks. Our final 13B checkpoint uses merely 1.2M publicly available data, and finishes full training in ~1 day on a single 8-A100 node. We hope this can make state-of-the-art LMM research more accessible. Code and model will be publicly available.
- github: https://github.com/haotian-liu/LLaVA
Contents
TL;DR
- LLaVA 모델과 간단한 개선 사항 도입으로 벤치마크 성능 향상
- 수학적 연결 및 수식적 논리를 통한 교차 모달 연결의 최적화
- 공개 데이터셋 활용 및 단일 하드웨어에서의 효율적인 훈련
1 서론
대규모 멀티모달 모델(Large Multimodal Models, LMMs)은 일반 목적의 비서를 구현하기 위한 중요한 구성 요소로서, 최근 다양한 연구에서 주목받고 있습니다. 이런 LMMs의 핵심 개념으로 ‘시각적 지시 튜닝(Visual Instruction Tuning)’이 부상하고 있으며, 이는 LLaVA와 MiniGPT-4 같은 모델들이 자연스러운 지시 이해와 시각적 인퍼런스 능력에서 향상된 성과를 보여주었기 때문입니다. 특히, LLaVA는 기존의 복잡한 시각 리샘플러 대신 간단한 MLP 교차 모달 연결기를 사용하여, 600K의 이미지-텍스트 쌍만을 이용해 훈련되었다는 점에서 주목할 만합니다. 이는 효율적인 벤치마크 성능을 달성하면서도 공개적으로 이용 가능한 데이터만을 사용한다는 점에서 큰 의의가 있습니다.
시각적 지시 튜닝에 있어, LLaVA의 MLP 교차 모달 연결은 다음과 같은 수학적 표현으로 설명될 수 있습니다.
\[y = f(x) = Wx + b\]\(x\)는 입력 이미지에서 추출된 특징 벡터, \(W\)는 학습 가능한 가중치 행렬, \(b\)는 편향 벡터로 이 식은 입력 이미지의 특징과 언어 모델의 언어적 특징을 연결하는 역할을 합니다. 이런 접근 방식으로 모델이 training dataset와 벤치마크 데이터 사이에서 언어와 시각 정보를 효율적으로 통합할 수 있게 해줍니다.
2 배경
LLaVA의 주요 구성 요소로는 pre-trained 시각적 인코더, 대규모 언어모델, 그리고 시각-언어 교차 모달 연결이 있습니다. 특히, LLaVA는 그 구조의 단순성에도 불구하고 다양한 벤치마크에서 인상적인 성과를 보여줍니다. 초기 단계에서는 이미지와 텍스트 쌍을 이용해 시각적 특징과 언어 모델의 단어 임베딩 공간을 맞추는 작업이 이루어지고, 시각적 지시 튜닝 단계에서는 모델을 시각적 지시에 맞춰 파인튜닝합니다.
수학적 연결 시각적 인코더 출력 \(Z_v\)와 언어 모델 출력을 연결하는 과정은 수학적으로 다음과 같이 표현될 수 있습니다.
\[H_v = W \cdot Z_v\]\(H_v\)는 언어 모델의 단어 임베딩 공간에 매핑된 시각적 토큰 시퀀스로 이 연결 과정은 멀티모달 데이터에서 효과적인 학습을 가능하게 하는 핵심 요소입니다.
3 LLaVA의 개선된 베이스 라인
- 시각적 지시 사항에 따른 튜닝 모델 LLaVA와 InstructBLIP의 비교 연구
- LLaVA가 단일응답 포맷을 정제하여 학술적 과제에 대한 성능 개선을 시도
- 멀티레이어 퍼셉트론(MLP)을 사용하여 데이터와 모델의 스케일 업을 통한 성능 향상 연구
LLaVA 모델의 개선된 베이스 라인은 시각적 지시 튜닝의 초기 작업에서 발견되었으며, 이 모델은 비교적 적은 계산량과 training dataset를 사용하면서도 다양한 벤치마크에서 좋은 성능을 달성합니다. LLaVA는 기존 모델들과 비교하여 데이터 효율성과 시각적 이해 능력에서 우수하다는 것이 입증되었습니다.
LLaVA 훈련에 있어서, 두 단계의 지시 튜닝 절차가 고려됩니다.
- 특징 정렬 사전 훈련: 가중치 행렬 \(W\)만이 학습 가능한 파라미터로 고려됩니다.
- 종단 간 파인튜닝: 가중치 행렬과 LLM의 파라미터 모두 업데이트됩니다.
3.1. 사전 준비
LLaVA 모델은 단일 선형 계층을 사용하여 시각적 특성을 언어 공간으로 투영하며, 전체 LLM을 시각적 지시 사항 튜닝에 최적화합니다. 그러나 LLaVA는 단답형 답변을 요구하는 학술적 벤치마크에서는 성능이 떨어집니다. 이는 훈련 데이터 분포에 이런 유형의 데이터가 부족하기 때문입니다. 반면, InstructBLIP 모델은 VQA-v2와 같은 학술 과제 지향 데이터셋를 포함하여 VQA 벤치마크에서의 성능을 향상시키기 위해 노력합니다. 이 모델은 129M 개의 이미지-텍스트 쌍에 대한 사전 훈련을 거쳐 지시 사항 인식 Qformer를 최적화합니다.
3.2. 응답 형식 프롬프팅
InstructBLIP의 짧은 형식과 긴 형식의 VQA 간 균형을 맞추는 데 실패한 주된 이유는 다음과 같습니다. 첫째, 응답 형식에 대한 모호한 프롬프트는 LLM을 자연스러운 시각적 대화에도 불구하고 단답형 응답으로 행동하게 만듭니다. 둘째, LLM의 파인튜닝이 이루어지지 않았습니다. 따라서 단답형 답변을 더 잘 처리하기 위해 VQA 질문의 끝에 명확한 출력 형식을 지시하는 단일 응답 형식 프롬프트를 사용할 것을 제안합니다.
\[\text{예시: Q: \{질문\} A: \{답변\}}\]3.3. 데이터 및 모델 스케일링
MLP를 통한 성능 향상을 위해, 두 계층 MLP를 사용하여 LLaVA의 멀티모달 능력을 향상시키고자 합니다. 추가적으로 학술 과제 지향 VQA 데이터셋를 포함시켜 모델의 능력을 다양한 방면에서 증진시키고자 합니다.
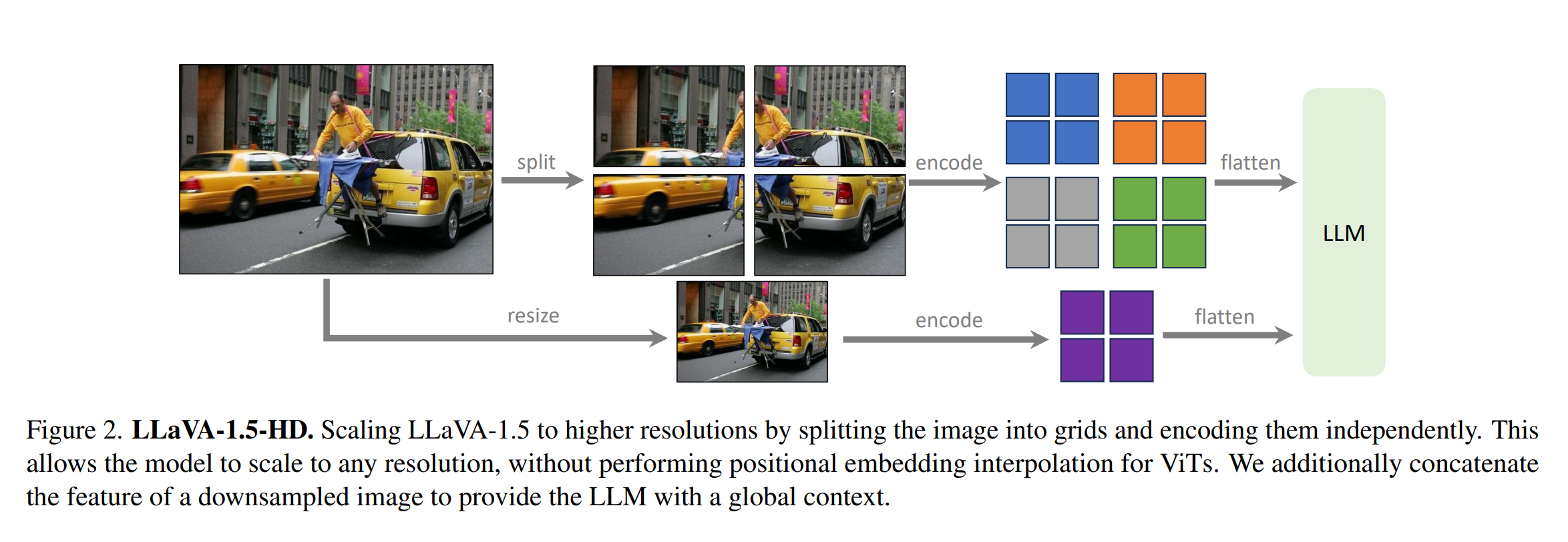
\[\text{MLP 구성: } \text{입력층} \rightarrow \text{은닉층} \rightarrow \text{출력층}\]LLaVA-1.5-HD는 이미지를 그리드로 분할하고 독립적으로 인코딩하여 모델이 어떠한 해상도에서도 확장 가능하도록 합니다. 그 후, 다운샘플된 이미지의 특성을 추가하여 LLM에 전역 컨텍스트를 제공합니다. 이런 방식은 LLaVA-1.5의 데이터 효율성을 유지하면서 입력 이미지의 해상도를 자유롭게 조정할 수 있게 해 줍니다.
\[\text{LLaVA-1.5-HD의 구조: } \begin{align*} \text{이미지 분할} &\rightarrow \text{독립 인코딩} \\ &\rightarrow \text{특성 맵 결합} \\ &\rightarrow \text{LLM 입력} \end{align*}\]이런 접근 방식으로 LLaVA가 InstructBLIP에 비해 세 가지 태스크에서 더 나은 성능을 나타내는 것을 확인합니다.
[참고자료 1] LLaVA의 교차 모달 연결
LLaVA 모델의 중요한 수학적 구성요소 중 하나는 시각적 데이터와 언어 데이터를 효율적으로 결합하는 교차 모달 연결입니다.
1. 교차 모달 연결의 수학적 기초
교차 모달 연결기의 핵심은 시각적 특징과 언어 모델의 임베딩을 하나의 공통된 특징 공간으로 선형 변환(linear transformation)을 사용해 매핑하는 것입니다.
선형 변환의 정의
선형 변환은 다음과 같은 수식으로 표현됩니다.
\[\mathbf{y} = \mathbf{Wx} + \mathbf{b}\]- \(\mathbf{x}\)는 입력 벡터(시각적 특징),
- \(\mathbf{W}\)는 변환을 위한 가중치 행렬,
- \(\mathbf{b}\)는 편향 벡터,
- \(\mathbf{y}\)는 변환된 벡터(언어 모델의 임베딩 공간으로 매핑된 시각적 특징)
이 과정은 입력된 시각적 데이터 \(\mathbf{x}\)를 언어 모델이 처리할 수 있는 형태로 변환하여, 시각 정보와 언어 정보가 결합된 상태에서 의미 있는 출력을 생성할 수 있게 합니다.
2. 손실 함수와 최적화
LLaVA 모델의 학습은 손실 함수(loss function)를 최소화함으로써 이루어집니다. 이 손실 함수는 모델의 예측이 실제 데이터와 얼마나 잘 일치하는지를 측정합니다.
로그 가능도 함수
LLaVA는 로그 가능도(log likelihood) 함수를 사용하여 training dataset에 대한 모델의 성능을 평가합니다. 로그 가능도 함수는 다음과 같이 표현됩니다.
\[\mathcal{L}( ext) = \log P_\theta (\mathbf{X}_{\text{text}} \\| \mathbf{X}_{\text{image}})\]- \(\mathcal{L}( ext)\)는 로그 가능도,
- \(\theta\)는 모델의 파라미터,
- \(\mathbf{X}_{\text{text}}\)는 목표 텍스트 데이터,
- \(\mathbf{X}_{\text{image}}\)는 입력 이미지 데이터입니다.
이 함수를 최대화해서 입력 이미지에 대한 정확한 텍스트 설명을 생성하는 모델의 능력을 향상시킵니다.
3. 수학적 최적화
모델 훈련에서 중요한 과정은 파라미터 \(\theta\)를 조정하여 로그 가능도를 최대화하는 것입니다. 이를 위해 경사 하강법(Gradient Descent)과 같은 최적화 알고리즘이 사용됩니다. 경사 하강법은 파라미터를 조금씩 조정하면서 전체 데이터셋에 대한 손실 함수의 값을 점차 줄여 나가는 방식으로 작동합니다.
\[\theta_{\text{new}} = \theta_{\text{old}} - \eta \nabla_\theta \mathcal{L}( ext)\]- \(\theta_{\text{old}}\)와 \(\theta_{\text{new}}\)는 각각 업데이트 전후의 파라미터,
- \(\eta\)는 학습률(learning rate),
- \(\nabla_\theta \mathcal{L}( ext)\)는 손실 함수의 파라미터에 대한 기울기입니다.
이 최적화를 통해 LLaVA는 주어진 지시에 따라 시각적 내용을 이해하고 자연스럽게 반응할 수 있는 능력을 개발합니다.
1 Introduction
Large multimodal models (LMMs) have become increasingly popular in the research community, as they are the key building blocks towards general-purpose assistants [1, 22, 35]. Recent studies on LMMs are converging on a central concept known as visual instruction tuning [28]. The results are promising, e.g. LLaVA [28] and MiniGPT-4 [49] demonstrate impressive results on natural instruction-following and visual reasoning capabilities. To better understand the capability of LMMs, multiple benchmarks [11, 20, 26, 29, 43] have been proposed. Recent works further demonstrate improved performance by scaling up the pretraining data [2, 9], instruction-following data [9, 21, 45, 46], visual encoders [2], or language models [31], respectively. The LLaVA architecture is also leveraged in different downstream tasks and domains, including region-level [6, 44] and pixel-level [19] understanding, biomedical assistants [23], image generation [3], adversarial studies [4, 47].
This note establishes stronger and more feasible baselines built upon the LLaVA framework. We report that two simple improvements, namely, an MLP cross-modal connector and incorporating academic task related data such as VQA, are orthogonal to the framework of LLaVA, and when used with LLaVA, lead to better multimodal understanding capabilities. In contrast to InstructBLIP [9] or Qwen-VL [2], which trains specially designed visual resamplers on hundreds of millions or even billions of image-text paired data, LLaVA uses the simplest architecture design for LMMs and requires only training a simple fully-connected projection layer on merely 600K image-text pairs. Our final model can finish training in ∼1 day on a single 8-A100 machine and achieves state-of-the-art results on a wide range of benchmarks. Moreover, unlike Qwen-VL [2] that includes in-house data in training, LLaVA utilizes only publicly available data. We hope these improved and easily-reproducible baselines will provide a reference for future research in open-source LMM.
2 Background
Instruction-following LMM. Common architectures include a pre-trained visual backbone to encode visual features, a pre-trained large language model (LLM) to comprehend the user instructions and produce responses, and a vision-language cross-modal connector to align the vision encoder outputs to the language models. As shown in Fig. 1, LLaVA [28] is perhaps the simplest architecture for LMMs. Optionally, visual resamplers (e.g. Qformer [24]) are used to reduce the number of visual patches [2, 9, 49]. Training an instruction-following LMM usually follows a two-stage protocol. First, the vision-language alignment pretraining stage leverages image-text pairs to align the visual features with the language model’s word embedding space. Earlier works utilize relatively few image-text pairs (e.g. ∼600K [28] or ∼6M [49]), while some recent works pretrain the vision-language connector for a specific language model on a large amount of image-text pairs (e.g. 129M [9] and 1.4B [2]), to maximize the LMM’s performance. Second, the visual instruction tuning stage tunes the model on visual instructions, to enable the model to follow users’ diverse requests on instructions that involve the visual contents.
Multimodal instruction-following data. In NLP, studies show that the quality of instruction-following data largely affects the capability of the resulting instruction-following models [48]. For visual instruction tuning, LLaVA [28] is the pioneer to leverage text-only GPT-4 to expand the existing COCO [27] bounding box and caption dataset to a multi-modal instruction-following dataset that contains three types of instruction-following data: conversational-style QA, detailed description, and complex reasoning. LLaVA’s pipeline has been employed to expand to textual understanding [45], million-scales [46], and region-level conversations [6]. InstructBLIP [9] incorporates academic-task-oriented VQA datasets to further enhance the model’s visual capabilities. Conversely, [5] identifies that such naive data merging can result in the models that tend to overfit to VQA datasets and thus are inability to participate in natural conversations. The authors further propose to leverage the LLaVA pipeline to convert VQA datasets to a conversational style. While this proves effective for training, it introduces added complexities in data scaling.
3 Improved Baselines of LLaVA
Overview. As the initial work of visual instruction tuning, LLaVA has showcased commendable proficiency in visual reasoning capabilities, surpassing even more recent models on diverse benchmarks for real-life visual instruction-following tasks, while only falling short on academic benchmarks that typically require short-form answers (e.g. single-word). The latter was attributed to the fact that LLaVA has not been pretrained on large-scale data, as other approaches do. In this note, we first study the scaling effect of data, models, and input image resolution on a selection of three datasets in Table 1, and then compare the final model against existing LMMs on a diverse set of 12 benchmarks in Table 2. We show that the LLaVA’s architecture is powerful and data-efficient for visual instruction tuning and achieves the best performance using significantly less compute and training data than all other methods.
Response formatting prompts. We find that the inability [5] to balance between short- and long-form VQA for approaches like InstructBLIP [9] is mainly due to the following reasons. First, ambiguous prompts on the response format. For example, Q: {Question} A: {Answer}. Such prompts do not clearly indicate the desirable output format and can overfit an LLM behaviorally to short-form answers even for natural visual conversations. Second, not fine-tuning the LLM. The first issue is worsened by InstructBLIP only fine-tuning the Qformer for instruction-tuning. It requires the Qformer’s visual output tokens to control the length of the LLM’s output to be either long-form or short-form, as in prefix tuning [25], but Qformer may lack the capability of properly doing so, due to its limited capacity compared with LLMs like LLaMA. See Table 6 for a qualitative example.
To address this, we propose to use a single response formatting prompt that clearly indicates the output format, to be appended at the end of VQA questions when promoting short answers: Answer the question using a single word or phrase. We empirically show that when LLM is fine-tuned with such prompts, LLaVA is able to properly adjust the output format according to the user’s instructions, and does not require additional processing of the VQA data us-
[2] Visual Instruction Tuning
- url: https://arxiv.org/abs/2304.08485
- pdf: https://arxiv.org/pdf/2304.08485
- abstract: Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, we introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
1 Introduction
Humans interact with the world through many channels such as vision and language, as each individual channel has a unique advantage in representing and communicating certain world concepts, and thus facilitates a better understanding of the world. One of the core aspirations in artificial intelligence is to develop a general-purpose assistant that can effectively follow multi-modal vision-and-language instructions, aligned with human intent to complete various real-world tasks in the wild [4, 24].
To this end, the community has witnessed an emergent interest in developing language-augmented foundation vision models [24, 14], with strong capabilities in open-world visual understanding such as classification [36, 18, 53, 50, 35], detection [26, 58, 29], segmentation [23, 59, 54], and captioning [46, 25], as well as visual generation and editing [38, 39, 52, 13, 40, 27]. We refer readers to the Computer Vision in the Wild reading list for a more up-to-date literature compilation [11]. In this line of work, each task is solved independently by one single large vision model, with the task instruction implicitly considered in the model design. Further, language is only utilized to describe the image content. While this allows language to play an important role in mapping visual signals to language semantics—a common channel for human communication, it leads to models that usually have a fixed interface with limited interactivity and adaptability to the user’s instructions.
Large language models (LLM), on the other hand, have shown that language can play a wider role: a universal interface for a general-purpose assistant, where various task instructions can be explicitly represented in language and guide the end-to-end trained neural assistant to switch to the task of interest to solve it. For example, the recent success of ChatGPT [31] and GPT-4 [32] have demonstrated the power of aligned LLMs in following human instructions and have stimulated tremendous interest in developing open-source LLMs. Among them, LLaMA [44] is an open-source LLM that matches the performance of GPT-3. Alpaca [43], Vicuna [45], GPT-4-LLM [34]
2 Related Work
-
Multimodal Instruction-following Agents. In computer vision, existing works that build instruction-following agents can be broadly categorized into two classes: (i) End-to-end trained models, which are separately explored in each specific research topic. For example, the vision-language navigation task [3, 16] and Habitat [42] require the embodied AI agent to follow natural language instructions and take a sequence of actions to complete goals in visual environments. In the image editing domain, given an input image and a written instruction that tells the agent what to do, InstructPix2Pix [6] edits images by following the human instructions. (ii) A system that coordinates various models via LangChain [1] / LLMs [31], such as Visual ChatGPT [49], X-GPT [59], MM-REACT [51]. While sharing the same north star in building instruction-following agents, we focus on developing an end-to-end trained multimodal model for multiple tasks.
-
Instruction Tuning. In the natural language processing (NLP) community, to enable LLMs such as GPT-3 [7], T5 [37], PaLM [9], and OPT [56] to follow natural language instructions and complete real-world tasks, researchers have explored methods for LLM instruction-tuning [33, 48, 47], leading to instruction-tuned counterparts such as InstructGPT [33]/ChatGPT [31], FLAN-T5 [10], FLAN-PaLM [10], and OPT-IML [19], respectively. It turns out this simple approach can effectively improve the zero- and few-shot generalization abilities of LLMs. It is thus natural to borrow the idea from NLP to computer vision. Flamingo [2] can be viewed as the GPT-3 moment in the multimodal domain, due to its strong performance on zero-shot task transfer and in-context-learning. Other LMMs trained on image-text pairs include BLIP-2 [25], FROMAGe [22], and KOSMOS-1 [17]. PaLM-E [12] is an LMM for embodied AI. Based on the recent “best” open-source LLM LLaMA, OpenFlamingo [5] and LLaMA-Adapter [55] are open-source efforts that enable LLaMA to use image inputs, paving a way to build open-source multimodal LLMs. While promising task transfer generalization performance is presented, these models are not explicitly instruction-tuned with vision-language instruction data. In this paper, we aim to fill this gap and study its effectiveness. To clarify, visual instruction tuning is different from visual prompt tuning [20]: the former aims to improve the model’s instruction-following abilities, while the latter aims to improve the parameter-efficiency in model adaptation.
-
GPT-assisted Visual Instruction Data Generation The community has witnessed a surge in the amount of public multimodal data such as image-text pairs, ranging from CC [8] to LAION [41]. However, when it comes to multimodal instruction-following data, the available amount is limited, partially because the process is time-consuming and less well-defined when human crowd-sourcing is considered. Inspired by the success of recent GPT models in text-annotation tasks [15], we propose to leverage ChatGPT/GPT-4 for multimodal instruction-following data collection, based on the widely existing image-pair data.
For an image $Xv$ and its associated caption $Xc$, it is natural to create a set of questions $Xq$ with the intent to instruct the assistant to describe the image content. We prompt GPT-4 and curate such a questions list in Table 8 in the Appendix. Therefore, a simple way to expand an image-text pair to its instruction-following version is:
Human : Xq Xv<STOP> Assistant : Xc<STOP>Though cheap to construct, this simple expanded version lacks diversity and in-depth reasoning in both the instructions and responses.
To mitigate this issue, we leverage language-only GPT-4 or ChatGPT as the strong teacher (both accept only text as input), to create instruction-following data involving visual content. Specifically, in order to encode an image into its visual features to prompt a text-only GPT, we use two types of symbolic representations: - Captions: Captions typically describe the visual scene from various perspectives. - Bounding Boxes: Bounding boxes usually localize the objects in the scene, and each box encodes the object concept and its spatial location.
One example is shown in the top block of Table 1.
This symbolic representation allows us to encode the image as an LLM-recognizable sequence. We use COCO images [28] and generate three types of instruction-following data. One example per type is shown in the bottom block of Table 1. For each type, we first manually design a few examples. They are the only human annotations we have during data collection and are used as seed examples in in-context-learning to query GPT-4. - Conversation: We design a conversation between the assistant and a person asking questions about the photo. - Detailed Description: To include a rich and comprehensive description for an image. - Complex Reasoning: The above two types focus on the visual content itself, based on which we further create in-depth reasoning questions.
We collect 158K unique language-image instruction-following samples in total, including 58K in conversations, 23K in detailed descriptions, and 77K in complex reasoning, respectively. We ablated the use of ChatGPT and GPT-4 in our early experiments and found that GPT-4 can consistently provide higher-quality instruction-following data, such as spatial reasoning.
3 Visual Instruction Tuning
3.1 Architecture
The primary goal is to effectively leverage the capabilities of both the pre-trained LLM and visual model. The network architecture is illustrated in Figure 1. We choose LLaMA as our LLM $f_{\phi}(\cdot)$ parameterized by $\phi$, as its effectiveness has been demonstrated in several open-source language-only instruction-tuning works [43, 45, 34].
For an input image $X_v$, we consider the pre-trained CLIP visual encoder ViT-L/14 [36], which provides the visual feature $Z_v = g(X_v)$. The grid features before and after the last Transformer layer are considered in our experiments. We consider a simple linear layer to connect image features into the word embedding space. Specifically, we apply a trainable projection matrix $W$ to convert $Z_v$ into language embedding tokens $H_v$, which have the same dimensionality of the word embedding space in the language model.
\[H_v = W \cdot Z_v, \text{ with } Z_v = g(X_v)\]Thus we have a sequence of visual tokens $H_v$. Note that our simple projection scheme is lightweight and cost-effective, which allows us to iterate data-centric experiments quickly. More sophisticated (but expensive) schemes to connect the image and language representations can also be considered, such as gated cross-attention in Flamingo [2] and Q-former in BLIP-2 [25], or other vision encoders such as SAM [21] that provide object-level features. We leave exploring possibly more effective and sophisticated architecture designs for LLaVA as future work.
3.2 Training
For each image $Xv$, we generate multi-turn conversation data ($X1$ to $T$), where $T$ is the total number of turns. We organize them as a sequence, by treating all answers as the assistant’s response, and the instruction $Xt_instruct$ at the t-th turn as:
\[$Xt_instruct$ = Xt_q, Xt_v\]This leads to the unified format for the multimodal instruction-following sequence illustrated in Table 2. We perform instruction-tuning of the LLM on the prediction tokens, using its original auto-regressive training objective.
Specifically, for a sequence of length L, we compute the probability of generating target answers $Xa$ by:
\[p(Xa\\|Xv, Xinstruct) = Π i=1 to L pθ(xi\\|Xv, Xinstruct,<i, Xa,<i)\]where θ is the trainable parameters, \(Xinstruct<i\) and \(Xa<i\) are the instruction and answer tokens in all turns before the current prediction token xi, respectively.
For LLaVA model training, we consider a two-stage instruction-tuning procedure.
- Stage 1: Pre-training for Feature Alignment. To strike a balance between concept coverage and training efficiency, we filter CC3M to 595K image-text pairs. These pairs are converted to the instruction-following data using the naive expansion method described in Section 3. Each sample can be treated as a single-turn conversation. In training, we keep both the visual encoder and LLM weights frozen and maximize the likelihood of
with trainable parameters $\theta = W$ (the projection matrix) only. This stage can be understood as training a compatible visual tokenizer for the frozen LLM.
- Stage 2: Fine-tuning End-to-End. We only keep the visual encoder weights frozen and continue to update both the pre-trained weights of the projection layer and LLM in LLaVA; i.e., the trainable parameters are $\theta = {W, \phi}$ in
We consider two specific use case scenarios:
- Multimodal Chatbot: We develop a Chatbot by fine-tuning on the 158K unique language-image instruction-following data collected in Section 3. Among the three types of responses, conversation is multi-turn while the other two are single-turn. They are uniformly sampled in training.
- Science QA: We study our method on the ScienceQA benchmark [30], the first large-scale multimodal science question dataset that annotates the answers with detailed lectures and explanations. Each question is provided a context in the form of natural language or an image. The assistant provides the reasoning process in natural language and selects the answer from multiple choices. For training in we organize the data as a single-turn conversation, the question & context as $X_{\text{instruct}}$, and reasoning & answer as $X_a$.
4 Experiments
4.1 Multimodal Chatbot
We have developed a Chatbot demo to showcase LLaVA’s image understanding and conversation capabilities. To further investigate LLaVA’s ability to process visual input and follow instructions, we first use examples from the original GPT-4 paper [32], as shown in Table 4 and Table 5. The prompts require in-depth image understanding. For comparison, we quote the prompts and responses of the multimodal GPT-4 from their paper and query BLIP-2 and OpenFlamingo model checkpoints to get their responses.
Surprisingly, despite LLaVA being trained with a relatively small multimodal instruction-following dataset (approximately 80K unique images), it demonstrates quite similar reasoning results to multimodal GPT-4 on these two examples. Note that both images are out-of-domain for LLaVA, yet it comprehends the scenes and follows the question instructions to respond. In contrast, BLIP-2 and OpenFlamingo focus on describing the image rather than following the user’s instruction to answer appropriately. More examples are shown in Figure 3, Figure 4, and Figure 5. We recommend readers to interact with LLaVA to study its performance.
5 Quantitative Evaluation
To systematically assess LLaVA’s performance in instruction-following, we employ a quantitative metric inspired by [45]. We leverage GPT-4 to evaluate the quality of our model’s generated responses. Specifically, we randomly select 30 images from the COCO validation split and generate three types of questions (conversation, detailed description, complex reasoning) using the proposed data generation pipeline. LLaVA predicts the answers based on the question and the visual input image. GPT-4 makes a reference prediction based on the question, ground-truth bounding boxes, and captions, setting an upper bound for the teacher model. After obtaining the responses from both models, we provide the question, visual information (in the format of captions and bounding boxes), and the generated responses from both assistants to GPT-4. GPT-4 evaluates the helpfulness, relevance, accuracy, and level of detail in the responses from the assistants, providing an overall score on a scale of 1 to 10, where a higher score indicates better overall performance. GPT-4 also provides a comprehensive explanation of the evaluation to help us better understand the models.
We vary the training datasets to study the effectiveness of different types of instruction-following data, and the results are shown in Table 3. With instruction tuning, the model’s capability to follow user instructions improves significantly by over 50 points. Additionally, adding a small amount of detailed description and complex reasoning questions contributes to a considerable improvement in the model’s overall capability by 7 points. Furthermore, it improves the model’s performance on conversational questions, suggesting that the overall enhancement in reasoning capability is complementary to its conversational capabilities. Finally, having all three types of data yields the best performance at 85.1%. We hope this evaluation protocol serves as a starting point for a comprehensive assessment of the capabilities of large multimodal models.
ScienceQA
- ScienceQA [30] comprises 21k multimodal multiple-choice questions with rich domain diversity across 3 subjects, 26 topics, 127 categories, and 379 skills. The benchmark dataset is split into training, validation, and test sets with 12,726, 4,241, and 4,241 examples, respectively. We consider two representative methods, including the GPT-3.5 model (text-davinci-002) with and without chain-of-thoughts (CoT), LLaMA-Adapter [55], as well as multimodal chain-of-thoughts (MM-CoT) [57], the current state-of-the-art method on this dataset. For more baseline numbers, please see [30].
- The results are reported in Table 6. For LLaVA, we use the visual features before the last layer, ask the model to predict reasons first and then the answer, and train it for 12 epochs. It achieves an accuracy of 90.92%, which is close to the state-of-the-art’s 91.68%. To explore the limits of LLMs, we also prompt GPT-4 using 2-shot in-context-learning and achieve an accuracy of 82.69%, a 7.52% absolute gain compared with GPT-3.5’s 75.17%. For a substantial number of questions, GPT-4 fails simply because it reports insufficient context, such as images or plots. We combine the outcomes from our model and GPT-4 using two schemes: (i) GPT-4 complement, where GPT-4’s prediction is used whenever it fails to provide answers, yielding an accuracy of 90.97%, almost the same as applying our method alone. (ii) GPT-4 as the judge, where GPT-4 provides a final answer based on the question and both outcomes, leading to a new state-of-the-art accuracy of 92.53%. To our knowledge, this is the first time that GPT-4 is used for model ensembling. We hope this finding can encourage future research to explore more effective methods to leverage LLMs for model ensembling.
[3] LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day
- url: https://arxiv.org/abs/2306.00890
- pdf: https://arxiv.org/pdf/2306.00890
- abstract: Conversational generative AI has demonstrated remarkable promise for empowering biomedical practitioners, but current investigations focus on unimodal text. Multimodal conversational AI has seen rapid progress by leveraging billions of image-text pairs from the public web, but such general-domain vision-language models still lack sophistication in understanding and conversing about biomedical images. In this paper, we propose a cost-efficient approach for training a vision-language conversational assistant that can answer open-ended research questions of biomedical images. The key idea is to leverage a large-scale, broad-coverage biomedical figure-caption dataset extracted from PubMed Central, use GPT-4 to self-instruct open-ended instruction-following data from the captions, and then fine-tune a large general-domain vision-language model using a novel curriculum learning method. Specifically, the model first learns to align biomedical vocabulary using the figure-caption pairs as is, then learns to master open-ended conversational semantics using GPT-4 generated instruction-following data, broadly mimicking how a layperson gradually acquires biomedical knowledge. This enables us to train a Large Language and Vision Assistant for BioMedicine (LLaVA-Med) in less than 15 hours (with eight A100s). LLaVA-Med exhibits excellent multimodal conversational capability and can follow open-ended instruction to assist with inquiries about a biomedical image. On three standard biomedical visual question answering datasets, LLaVA-Med outperforms previous supervised state-of-the-art on certain metrics. To facilitate biomedical multimodal research, we will release our instruction-following data and the LLaVA-Med model.