Data Composition | AutoScale
- Related Project: Private
- Category: Paper Review
- Date: 2024-07-29
AutoScale: Automatic Prediction of Compute-optimal Data Composition for Training LLMs
- url: https://arxiv.org/abs/2407.20177
- pdf: https://arxiv.org/pdf/2407.20177
- abstract: To ensure performance on a diverse set of downstream tasks, LLMs are pretrained via data mixtures over different domains. In this work, we demonstrate that the optimal data composition for a fixed compute budget varies depending on the scale of the training data, suggesting that the common practice of empirically determining an optimal composition using small-scale experiments will not yield the optimal data mixtures when scaling up to the final model. To address this challenge, we propose AutoScale, an automated tool that finds a compute-optimal data composition for training at any desired target scale. AutoScale first determines the optimal composition at a small scale using a novel bilevel optimization framework, Direct Data Optimization (DDO), and then fits a predictor to estimate the optimal composition at larger scales. The predictor’s design is inspired by our theoretical analysis of scaling laws related to data composition, which could be of independent interest. In empirical studies with pre-training 774M Decoder-only LMs (GPT-2 Large) on RedPajama dataset, AutoScale decreases validation perplexity at least 25% faster than any baseline with up to 38% speed up compared to without reweighting, achieving the best overall performance across downstream tasks. On pre-training Encoder-only LMs (BERT) with masked language modeling, DDO is shown to decrease loss on all domains while visibly improving average task performance on GLUE benchmark by 8.7% and on large-scale QA dataset (SQuAD) by 5.9% compared with without reweighting. AutoScale speeds up training by up to 28%. Our codes are open-sourced.
Contents
TL;DR
최적의 LLM 훈련 데이터셋 구성을 찾는 것을 목표로 이원 최적화, 스케일링 법칙 등을 통해 최적의 데이터 구성비를 예측하기 위한 알고리즘 및 프레임워크 개발하고, Emperical하게 탐구합니다. (그러나 데이터 퀄리티 컨트롤에 대한 언급이 거의 없음)
- 영역별 가중치 재분배를 통한 데이터 구성 최적화: AutoScale은 작은 규모에서 최적의 데이터 구성을 결정하고, 이를 기반으로 더 큰 규모에서의 최적의 데이터 구성비를 예측하기 위한 도구로 사용됩니다.
- 이중 최적화 프레임워크(Direct Data Optimization, DDO): 제안하는 DDO는 데이터 소스의 신경망 스케일링 법칙을 추정하고 최적화하여 전체적인 최적점을 단계적으로 찾아 이론적 결과를 실제적으로 검증하여 데이터를 구성합니다.
- AutoScale을 사용한 결과, Validation Perplexity가 기존 방법보다 최소 25% 빠르게 감소하며, 훈련 효율이 최대 38%까지 향상되었다고 언급합니다.
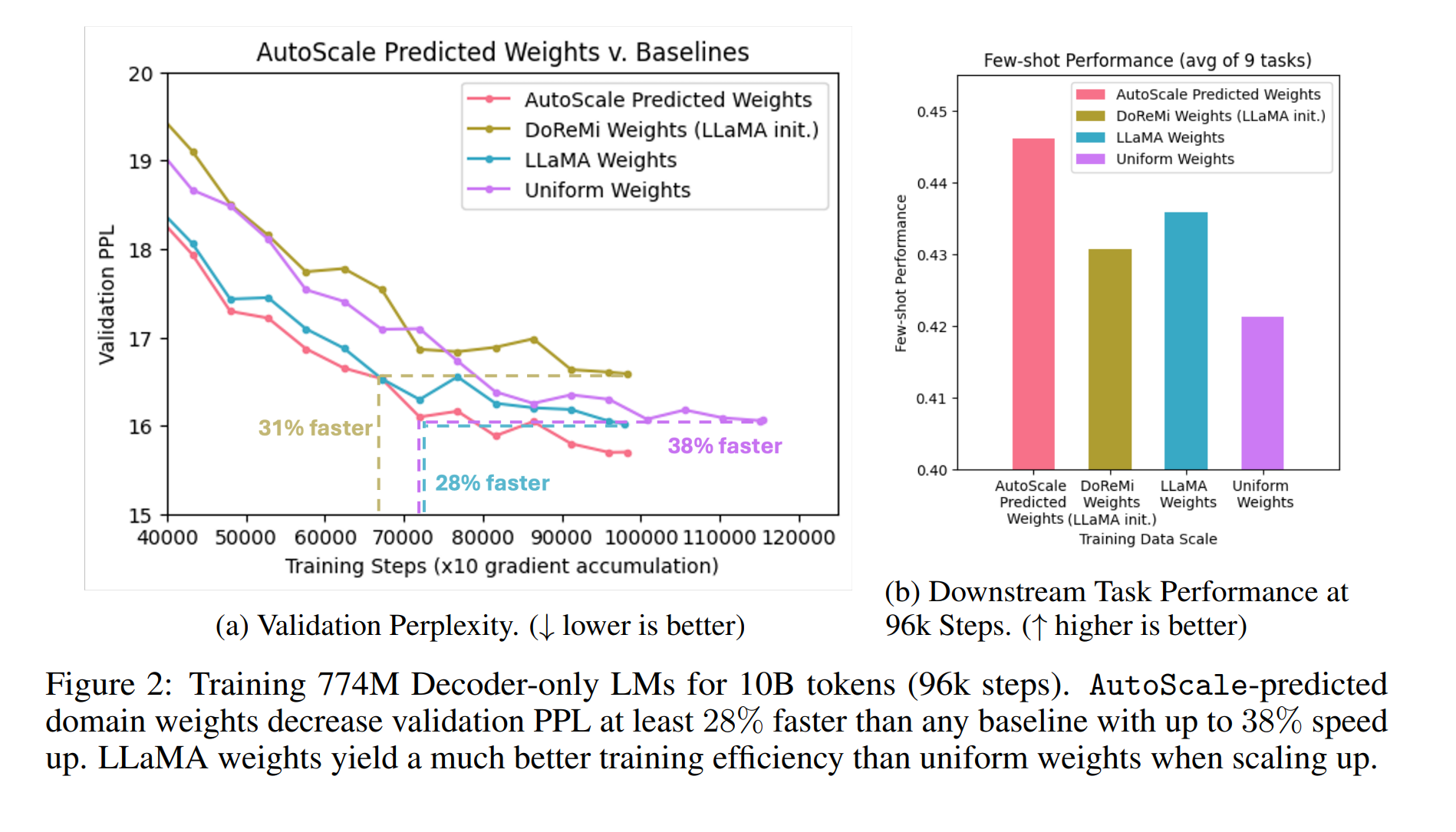
관련 Figure들은 대부분 Uniform보다 추정해서 구성한 데이터셋으로 학습한 것이 더 빠르게 수렴함을 보이기 위함.
Overview
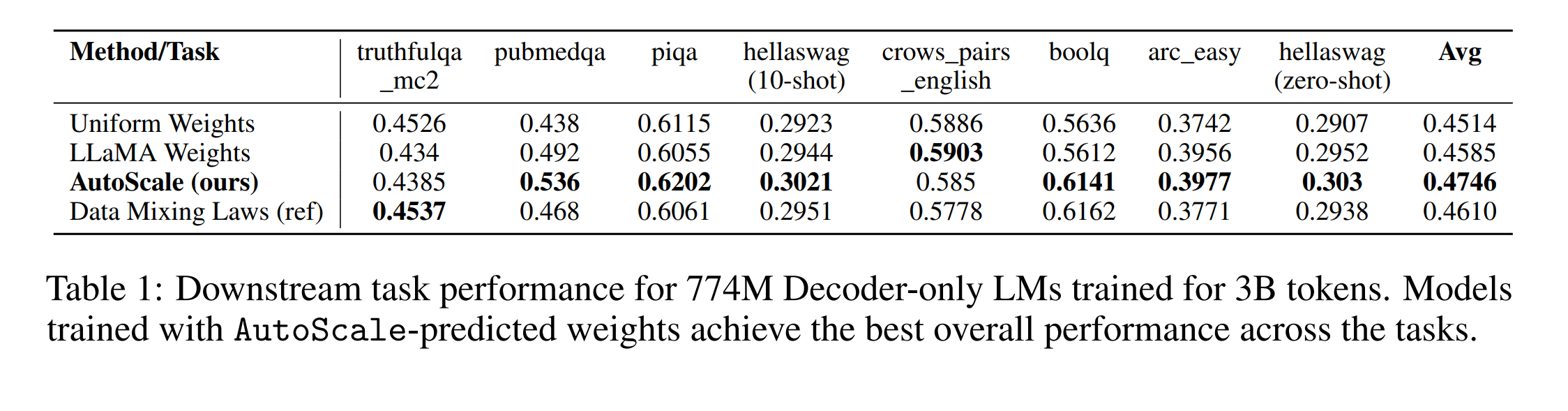
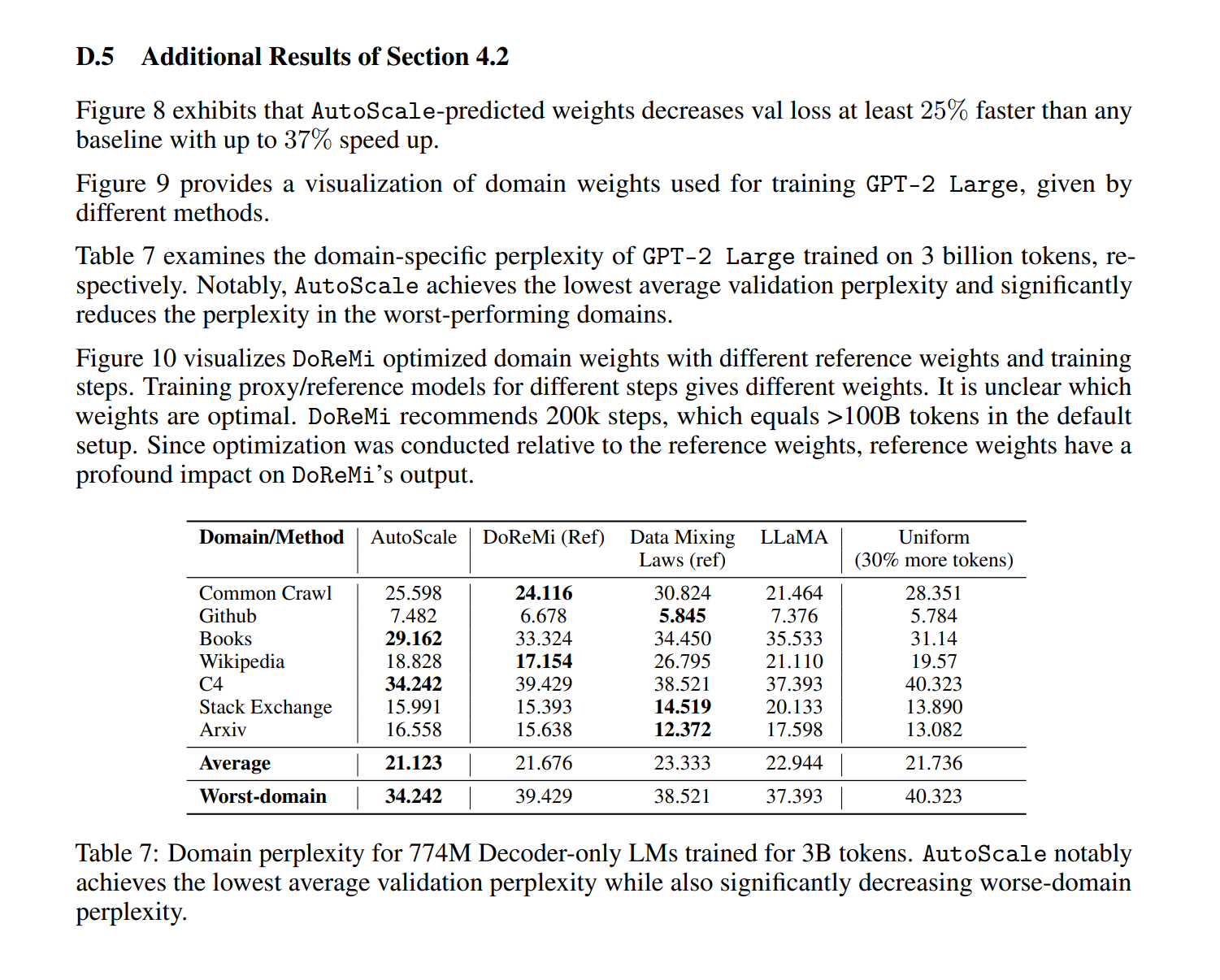
Appendix에 관련 내용이 있으나, 데이터 양에 대한 컨트롤만 되었기 때문에, 해당 내용은 Appendix나 실험 셋팅과 결과를 자세히 살펴보면 좋을 것 같습니다.
이원최적화(Bi-Level Optimization)에서의 AutoScale과 Direct Data Optimization (DDO)
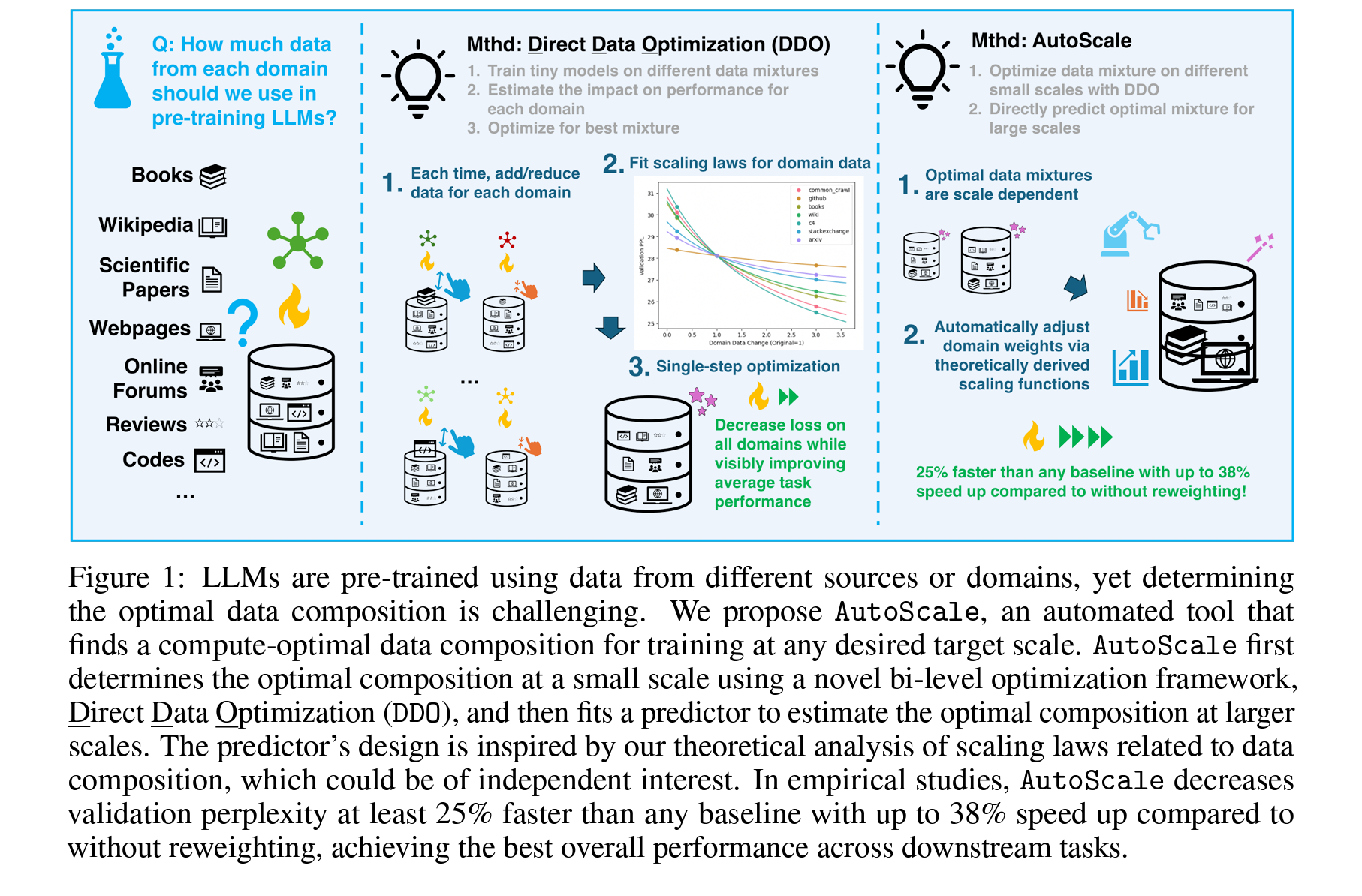
이원최적화는 주로 하위 문제의 해결 결과가 상위 문제의 결정 변수에 영향을 미치는 상황에서 사용됩니다. 이 구조는 특히 언어 모델링과 같은 분야에서 데이터 선택과 모델 성능 최적화 문제를 효과적으로 다룰 때 유용합니다. AutoScale과 DDO 모두 이런 이원최적화 구조를 내포하고 있습니다.
Algorithm 1: Direct Data Optimization (DDO)
DDO는 특정 데이터 예산 하에서 각 도메인의 가중치를 조정하여 모델의 검증 손실을 최소화하는 방식으로 최적화를 수행합니다. 이 과정은 각 도메인에 대한 가중치를 소량 조정하여(증가시키거나 감소시키거나) 그 영향을 평가하고, 최종적으로 가장 낮은 손실을 제공하는 가중치 조합을 결정합니다.
- 가중치 초기화: 모든 도메인에 대해 균등하게 \(\frac{1}{m}\)로 초기화합니다.
- 가중치 조정: 각 도메인의 가중치를 증가시키거나 감소시킨 후, 모델을 다시 훈련시켜 각 설정에서의 손실을 평가합니다.
- 손실 함수의 최소화: 가중치 조정에 따른 손실을 측정하여, 가중치 조정 전후의 손실 차이를 최소화하는 함수 \(b_j, c_j\)를 통해 최적의 가중치를 회귀 분석으로 결정합니다.
[DDO 수학적 이해]
- \(m\): 데이터 도메인의 수
- \(N_0\): 데이터 예산
- \(w_i\): 각 도메인 \(i\)의 초기 가중치
-
도메인 가중치 초기화: 모든 도메인의 가중치를 균등하게 설정
\[w_i \leftarrow \frac{1}{m}\]- \(w_i\): $i$번째 도메인의 가중치
- \(m\): 전체 도메인의 수
\(m\)개의 도메인이 있을 때, 모든 도메인에 대한 초기 가중치 \(w_i\)를 동일하게 설정합니다. \(\frac{1}{m}\)은 각 도메인이 전체에서 차지하는 비율을 균등하게 나눈 값입니다.
-
각 도메인에서 \(w_i \cdot N\) 만큼의 데이터를 샘플링하여 훈련 데이터를 구성
각 도메인 \(D_i\)에서 \(w_i \cdot N\)만큼의 데이터를 샘플링하여 훈련 데이터 \(S_i\)를 구성합니다. 이는 도메인별로 가중치에 비례하는 데이터 양을 확보함으로써 샘플링의 균형을 맞춥니다.
\(S_i \subset D_i\) where \(\\|S_i\\| = w_i \cdot N\)
- \(S_i\): $i$번째 도메인에서 샘플링된 데이터셋
- \(D_i\): $i$번째 도메인의 전체 데이터셋
- \(N\): 샘플링하고자 하는 총 데이터 수
-
가중치 조정과 손실 평가
특정 도메인의 가중치를 증가시키거나 감소시키는 실험을 통해, 해당 도메인의 중요도에 따른 모델의 손실을 평가합니다. 즉, 가중치를 조정하고, 이런 조정이 모델 손실 \(L_j^+\)과 \(L_j^-\)에 어떤 영향을 미치는지 측정합니다.
\(w_j^+ = 3 \cdot w_j\)와 \(w_j^- = \frac{1}{3} \cdot w_j\)를 통해 가중치를 조정하고, 이에 따른 모델의 손실 \(L_j^+\)와 \(L_j^-\)를 계산합니다.
-
손실 함수의 최소화
가중치 조정에 따른 손실을 최소화하는 파라미터 \(b_j\)와 \(c_j\)를 찾습니다. 이 과정은 다양한 가중치 조정 상황에서 모델의 예측 성능을 최적화하기 위한 파라미터 조정입니다.
\(b_j\)와 \(c_j\)를 조정하여, 새롭게 조정된 가중치에 대한 손실을 최소화하는 함수를 찾습니다.
\[\arg\min_{b_j, c_j} \left[L_0 - (w_i \cdot N)^{-b_j} - c_j\right]^2 + \left[L_j^+ - (3 \cdot w_i \cdot N)^{-b_j} c_j\right]^2 + \left[L_j^- - (\frac{1}{3} \cdot w_i \cdot N)^{-b_j} - c_j\right]^2\] -
검증 손실을 최소화하는 도메인 가중치 결정
마지막 결정 단계에서는 최적화 과정을 거쳐 가중치 $ w^* $를 도출해 모델의 검증 손실을 최소화하는 도메인 가중치를 결정합니다.
전체 도메인 가중치 집합 \(W_m\) 중에서, 모델의 검증 손실을 최소화하는 최적의 가중치 \(w^*\)를 찾습니다. 즉, 마지막 과정으로 전체 훈련 세트에 대해 가장 효율적인 도메인 가중치를 결정하도록 최적화합니다.
\[w^* = \arg\min_{w' \in W_m} \sum_{i=1}^m (w'_i \cdot N)^{-b_i}\]
DDO는 데이터 도메인의 가중치를 최적화함으로써, 주어진 데이터 예산 내에서 가능한 상위 모델 성능을 달성하고자 하며, 이 과정은 각 도메인의 중요성을 평가하고, 최적의 데이터 혼합을 통해 모델의 일반화 능력을 향상시키는 것을 목표로 합니다.
AutoScale과 DDO 모두 최적화 문제에서의 하위 레벨(도메인 가중치 결정) 결과가 상위 레벨(전체 모델 성능)에 어떻게 영향을 미치는지를 평가하며, 알고리즘은 모델의 학습 과정과 성능에 중요한 데이터 도메인을 동적으로 조정하여 최적화하려는 공통된 목표를 공유합니다. 본 논문에서 이원최적화 방식은 도메인 간의 최적의 균형을 찾아내는 데 사용됩니다.
Algorithm 2: AutoScale
AutoScale은 목표 데이터 규모 \(N^{(t)}\)에 대해 최적의 도메인 가중치 \(w^{(t)*}\)를 예측하는 알고리즘입니다. 주어진 두 데이터 규모 \(N^{(1)}\)과 \(N^{(2)}\)에서의 최적 가중치 \(w^{(1)*}\)과 \(w^{(2)*}\)을 바탕으로, 새로운 규모 \(N^{(x)}\)에 대한 예측을 수행합니다.
이 과정은 주어진 데이터 규모에서 얻은 가중치를 다음 규모로 확장하는 것으로, 데이터 규모가 증가함에 따라 가중치가 어떻게 변화해야 하는지를 예측하는 것입니다.
- 초기 데이터 비율: \(N^{(1)*}\)과 \(N^{(2)*}\)는 각각 \(w^{(1)*} \cdot N^{(1)}\)과 \(w^{(2)*} \cdot N^{(2)}\)로 계산되며, 이는 각 데이터 규모에 대한 최적의 데이터 분포를 나타냅니다.
- 가중치 추정: \(N^{(x)*}\)는 \(N^{(2)*}\)을 \(N^{(1)*}\)의 비율로 조정하여 다음 규모의 최적 데이터를 예측합니다. 이는 상위 문제에서 하위 문제의 결과(이전 규모의 최적 가중치)를 사용하여 새로운 규모의 가중치를 추정하는 과정입니다.
[AutoScale 수학적 이해]
AutoScale은 데이터 규모와 도메인 가중치를 기반으로 최적화된 데이터 샘플링을 추진하는 데 초점을 맞추며, 두 개의 초기 데이터 규모에서 얻은 결과를 활용하여 다음 데이터 규모에서의 최적 도메인 가중치를 인퍼런스하게 됩니다.
- \(N^{(1)}\), \(N^{(2)}\): 초기 데이터 규모
- \(w^{(1)*}\), \(w^{(2)*}\): \(N^{(1)}\)과 \(N^{(2)}\)에서의 최적 도메인 가중치
- \(N^{(t)}\): 목표 데이터 규모
-
각 데이터 규모 \(N^{(1)}\), \(N^{(2)}\)에 대한 최적화된 도메인 데이터의 양을 계산
\(N^{(1)*} = w^{(1)*} \cdot N^{(1)}\)와 \(N^{(2)*} = w^{(2)*} \cdot N^{(2)}\)
위 수식은 각 데이터 규모 \(N^{(1)}\)과 \(N^{(2)}\)에서 최적의 도메인 가중치 \(w^{(1)*}\)와 \(w^{(2)*}\)를 적용하여 최적화된 도메인 데이터의 양을 계산하여 각 도메인에서 얼마나 많은 데이터를 샘플링해야 하는지 결정합니다.
-
\(N^{(1)}\)과 \(N^{(2)}\)에서 얻은 데이터 비율을 사용하여 다음 예측 데이터 규모 \(N^{(x)*}\)를 계산해 **이전 데이터 포인트들을 기반으로 다음 단계의 최적 데이터 구성을 토의하여 결정합니다.
위 수식은 이전 두 데이터 규모에서 계산된 최적화된 도메인 데이터의 양을 통해 다음 데이터 규모의 최적화된 도메인 데이터의 양을 예측하며, \(N^{(1)*}\)와 \(N^{(2)*}\)의 비율을 사용하여 \(N^{(x)*}\)를 추정합니다.
\[N^{(x)*} = \frac{N^{(2)*}}{(N^{(1)*})^{-1} N^{(2)*}}\] -
반복
\(N^{(x)}\)가 \(N^{(t)}\)보다 작은 동안, \(N^{(x)*}\)를 업데이트하고 \(N^{(x)}\)를 계산하며, 이 과정을 목표 데이터 규모 \(N^{(t)}\)에 도달할 때까지 반복됩니다.
최종 계산된 \(N^{(x)*}\)에서 목표 데이터 규모에 대한 최적 도메인 가중치 \(w^{(t)*}\)를 도출합니다.
\[w^{(t)*} = \frac{N^{(x)*}}{N^{(x)}}\]이 최종 수식은 \(N^{(x)*}\)를 \(N^{(x)}\)로 나누어 각 도메인의 최종 가중치 \(w^{(t)*}\)를 계산하여, 최적화된 도메인 가중치를 얻기 위한 결정 단계입니다.
1. 서론
AutoScale은 여러 출처에서 데이터를 사용하여 대규모 언어모델(LLM)을 사전 훈련하는 현실적 문제를 해결하기 위한 도구입니다. 이런 모델의 훈련은 많은 계산 자원을 요구하므로, 작은 규모에서 최적의 데이터 구성을 실험적으로 찾은 뒤 이를 더 큰 규모로 확장하는 전략이 필요합니다. 이는 이중 최적화(bi-level optimization) 문제로 접근됩니다. 즉, 최적화의 첫 단계에서는 각 데이터 소스의 가중치를 조정하여 소규모 모델에서 최적의 성능을 달성하고, 두 번째 단계에서는 이 가중치를 확장하여 실제 모델의 훈련 데이터 구성을 최적화합니다.
제안하는 접근방법: Direct Data Optimization (DDO)
DDO는 데이터 소스의 영향을 정량화하고 최적화하는 알고리즘으로, 각 데이터 소스에서 기대할 수 있는 성능 개선을 예측하여 가장 효과적인 데이터 조합을 결정합니다. 수학적으로, DDO는 다음과 같은 최적화 문제를 해결합니다.
\[\min_{\mathbf{w}} L(\mathbf{w}) = \sum_{i=1}^n w_i \cdot L_i\]\(w_i\)는 데이터 소스 \(i\)의 가중치이고, \(L_i\)는 해당 데이터 소스의 손실 함수입니다. DDO는 이 최적화 문제를 통해 모델의 검증 손실을 최소화하면서 데이터 구성을 결정합니다.
실험은 GPT-2 Large 모델과 BERT 모델을 사용하여 진행되었습니다. AutoScale은 DDO 알고리즘을 사용하여 각 데이터 소스의 가중치를 최적화하고, 이를 기반으로 더 큰 규모의 데이터 구성을 예측하였습니다. 결과적으로, AutoScale은 검증 perplexity를 크게 감소시키고, GLUE 및 SQuAD 벤치마크에서 성능을 개선했습니다. 이는 다음 수식으로 설명할 수 있습니다. (\(w_i^{*}\)는 최적화된 데이터 소스의 가중치 )
\[L_{new} = \sum_{i=1}^n w_i^{*} \cdot L_i < L_{old}\]2. Compute-optimal Training Data Compositions
AutoScale과 같은 도구의 개발은 대규모 언어모델의 사전 훈련을 더 효율적으로 만들 수 있으며, 특히 다양한 데이터 소스에서 최적의 데이터 구성을 자동으로 찾는 능력이 중요합니다. 이는 더 큰 규모의 모델에서도 일관된 성능 개선을 실현할 수 있음을 보여줍니다.
2.1 문제 정의
LLM을 다양한 도메인의 데이터 구성 \(S\)로 훈련시킬 때, 각 도메인에서의 데이터 비율을 ‘도메인 가중치’ \(w = [w_1, w_2, \dots, w_m]^T\)로 정의하고, 이때 \(N = \\|S\\|\)는 트레이닝 데이터의 전체 토큰 수를 나타냅니다. 각 도메인별 가중치는 \(w_i = \frac{N_i}{N}\)로 주어지며, \(\\|S_i\\|\)는 도메인 \(i\)의 트레이닝 데이터 토큰 수를 의미합니다.
본 문제의 주요 목표는 주어진 계산 예산하에 평가 손실을 최소화하면서 정보 획득을 최대화하는 것입니다.
2.2 문제 해결 방법
이 문제를 이원 최적화 문제로 설정하고, 효율적인 해결 방법을 도입합니다.
상위 문제는 최적의 도메인 가중치를 찾는 것이며, 하위 문제는 특정 가중치로 모델을 훈련시키는 것입니다. 주로 그래디언트 강하법을 사용하여 가중치를 업데이트하며, 이때의 그래디언트는 경험적 방법(e.g, Finite Difference Method)으로 추정됩니다. 이런 과정은 반복적인 모델 재훈련을 요구하며, 효율적인 계산을 위해 프록시 모델을 사용하여 데이터 구성을 최적화한 후, 최적화된 가중치로 전체 모델을 훈련시킵니다.
훈련 데이터의 최적 구성을 찾기 위해, 다음과 같은 최소화 문제를 고려합니다.
\[w^* = \arg \min_{w \in W_m} \sum_{i=1}^m LP_i(A(N,w), D_{v_i})\]\(LP_v(A(N,w))\)는 주어진 도메인 가중치 \(w\)로 모델 \(A\)를 훈련시킬 때의 총 평가 손실을 나타내며, \(LP_i\)는 개별 도메인의 검증 데이터에 대한 모델의 손실이빈다. \(W_m\)은 확률 집합 \(\{w \\| \sum_{i=1}^m w_i = 1 \land 0 \leq w_i \leq 1 \, \forall i \in \{1, 2, \dots, m\}\}\)입니다.
이 이원 최적화 문제는 수치적으로 복잡할 수 있으므로 경험적(Emperical)인 방법을 통해 그래디언트를 추정해야 합니다.
이를 위해, 더 작은 크기나 적은 데이터로 훈련된 프록시 모델을 사용하여 성능을 예측해 전체 모델을 위한 최적의 데이터 구성을 결정해야 합니다.
상기 문제 해결 방법은 데이터의 양과 분포가 모델의 평가 손실에 미치는 영향을 수학적으로 모델링하고, 이를 최적화하는 과정에서 실제 데이터를 이용한 반복적인 테스트를 통해 이론적 결과를 실제적으로 검증하는 접근 방식을 취합니다.
3. Predicting Optimal Data Compositions for Larger Scales
목표는 다양한 데이터 소스로부터 수집한 훈련 데이터를 사용하여 언어 모델(Large Language Model, LLM)을 훈련시키는 것으로, 고려해야할 중요한 점은 각 데이터 소스(도메인)별로 어떤 비율로 데이터를 사용할지 결정하는 것, 즉 '도메인 가중치'를 최적화하는 것입니다.
이 최적화 과정은 주어진 컴퓨팅 리소스(데이터 크기) 내에서 모델의 평가 손실을 최대한 줄이는 방향으로 이루어져야 합니다. 평가 손실의 감소는 정보 이득의 측정으로 간주되며, 이는 학습 효율성을 극대화하는 데 중요합니다.
모델을 훈련시키기 위해 각 도메인에서 얼마나 많은 데이터를 사용할지 결정하는 것은 복잡한 문제입니다. 도메인 가중치 \(w = [w_1, w_2, \ldots, w_m]^T\)를 사용하여 이를 정의하며, \(w_i = \frac{N_i}{N}\)는 전체 데이터 중 도메인 \(i\)에서 가져온 데이터의 비율을 나타냅니다.
이런 설정을 바탕으로, 학습 알고리즘 A를 사용하여 모델의 파라미터 \(\theta\)를 최적화합니다. 이 과정은 아래와 같은 이원 최적화 문제로 구성됩니다.
\[\min_{w \in W_m} \left\{ \sum_{i=1}^m LP_i(A(N, w), D_{v_i}) \right\} \quad \text{s.t.} \quad A(N, w) = \arg \min_{\theta} L(\theta, S(N,w))\]\(LP_i(A(N, w), D_{v_i})\)는 도메인 \(i\)의 검증 데이터에 대해 계산된 모델의 손실을 나타냅니다. 이 최적화 문제는 각 도메인의 가중치를 조절하여 전체적인 모델 성능을 최적화하려는 시도입니다.
[스케일링 법칙을 이용한 근사적 해법]
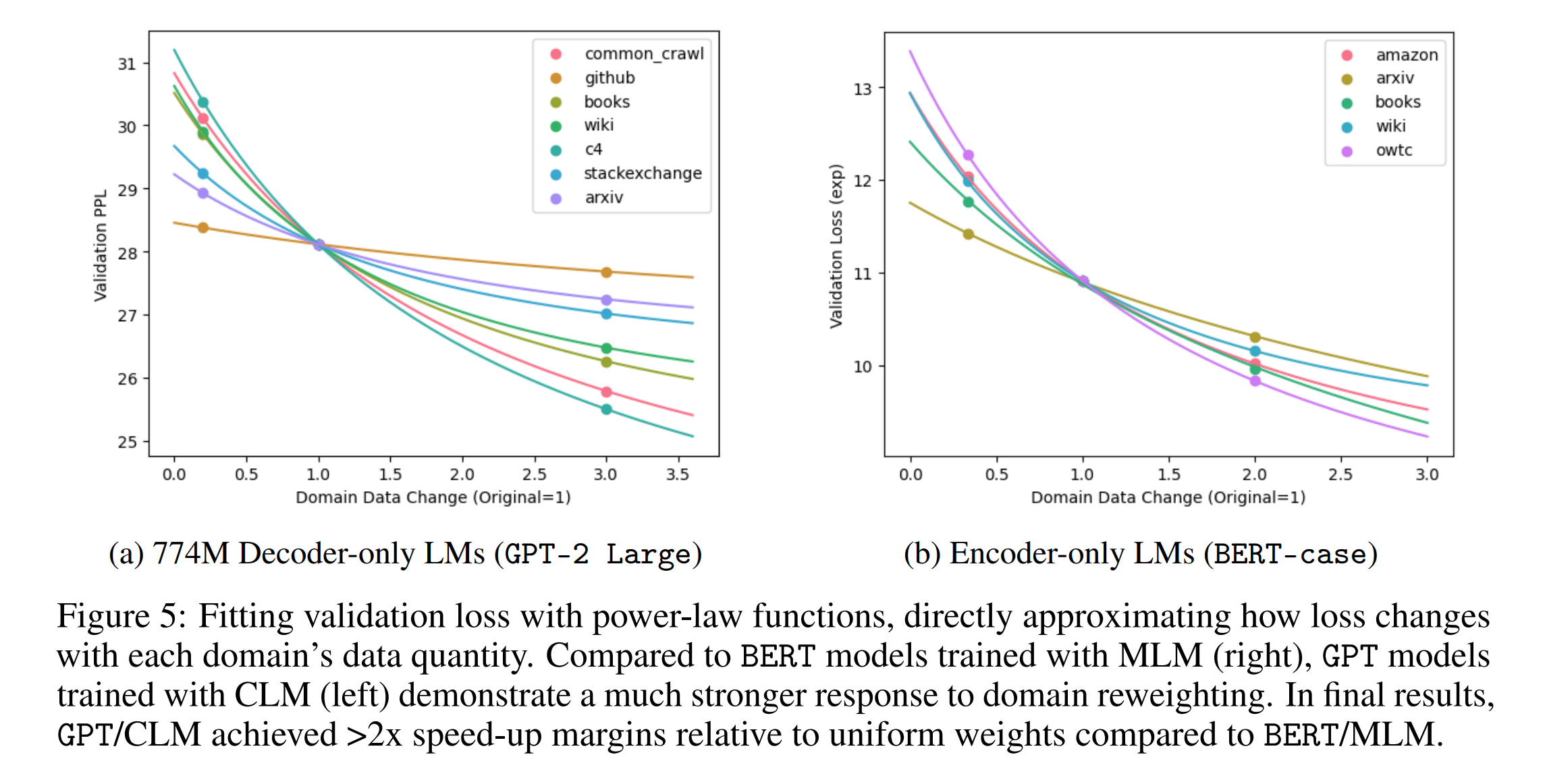
LLM을 재훈련하는 비용이 높기 때문에, 대신 프록시 모델을 사용하여 데이터 구성을 먼저 최적화한 다음 이를 전체 모델에 적용합니다. 이때 스케일링 법칙을 활용하여 모델의 평가 손실과 훈련 데이터 크기 사이의 관계를 멱법칙(Power Law) 함수로 근사화합니다.
\[LP_v(A(N, w)) = N^{-\gamma} + L_0\]\(L_0\)은 기본 손실을, \(\gamma\)는 손실 감소율을 나타내는 상수입니다. 이 근사치를 사용하여 새로운 데이터 구성에서 모델의 성능을 예측하고 최적화합니다.
[최적화 알고리즘]
\[\textbf{Algorithm 1: Direct Data Optimization (DDO)}\] \[\textbf{Require:} \\ m \text{ domains (data sources) with data } D_1, \ldots, D_m, \\ \text{data budget } N_0 (\ll \text{ data budget for full-scale training}), \\ \text{training dataset } S, \text{ model } A, \text{ validation loss function } L_v.\] \[\begin{align*} \text{Initialize weights for all domains } \forall i \in \{1,\ldots,m\}: &\quad w_i \leftarrow \frac{1}{m}; \\ \text{Initialize training data for all domains } \forall i \in \{1,\ldots,m\}: &\quad \text{sample } S_i \subset D_i \text{ where } |S_i| = w_i \cdot N; \\ \text{Train the model on data } S = \{S_1,\ldots,S_m\} &\text{ and evaluates its loss } L_0 \leftarrow L_v(A(S)); \\ \text{for } j \text{ from } 1 \text{ to } m \text{ do} \\ &\quad w_j^+ \leftarrow 3 \cdot w_j; \\ &\quad \text{Resample } S_j^+ \subset D_j \text{ where } |S_j^+| = w_j^+ \cdot N; \\ &\quad \text{Train the model on data } S = (\{S_1,\ldots,S_m\} \setminus S_j) \cup S_j^+ \\ &\quad \text{and evaluates its loss } L_j^+ \leftarrow L_v(A(S)); \\ &\quad w_j^- \leftarrow \frac{1}{3} \cdot w_j; \\ &\quad \text{Resample } S_j^- \subset D_j \text{ where } |S_j^-| = w_j^- \cdot N; \\ &\quad \text{Train the model on data } S = (\{S_1,\ldots,S_m\} \setminus S_j) \cup S_j^- \\ &\quad \text{and evaluates its loss } L_j^- \leftarrow L_v(A(S)); \\ &\quad \text{OLS fit for scaling functions } b_j, c_j = \arg\min_{b_j, c_j} \left[L_0 - (w_i \cdot N)^{-b_j} - c_j\right]^2 \\ &\quad + \left[L_j^+ - (3 \cdot w_i \cdot N)^{-b_j} - c_j\right]^2 \\ &\quad + \left[L_j^- - \left(\frac{1}{3} \cdot w_i \cdot N\right)^{-b_j} - c_j\right]^2; \\ \text{end for} \\ \text{Output optimized domain weights } w^* &= \arg\min_{w' \in W_m} \sum_{i=1}^m (w'_i \cdot N)^{-b_i}. \end{align*}\]최종적으로 다음 함수를 최소화하는 도메인 가중치 \(w'\)를 찾습니다.
\[\min_{w' \in W_m} \left\{ \sum_{i=1}^m (N_i^0 + w'_i \cdot N)^{-b_i} \right\}\]이 함수는 각 도메인에서 새롭게 조정된 데이터 양에 대한 손실을 모델링하며, 볼록 최적화(Convex Optimization) 문제로 정의되며, 도메인 가중치를 최적화함으로써 주어진 데이터와 컴퓨팅 리소스 내에서 모델의 성능을 극대화할 수 있다고 언급합니다.
상기 접근 방식은 이론적으로는 탄탄할지 몰라도, 실제 적용 시 많은 계산 리소스를 요구하므로 현실적으로 사용하기 곤란할 수 있기때문에 실제 구현 시에는 계산 효율성과 솔루션의 질 사이에 균형을 맞추어야 하는데, 이런 최적화 문제를 해결하기 위해 개발된 알고리즘들과 기법들은 다양한 데이터셋와 모델 구조에 적용 가능하게 해줄 수 있으며, 효율적인 데이터 사용을 통해 더 나은 모델 학습을 생성할 수 있다고 언급합니다.
3.1 도메인 가중치의 스케일링
신경망 스케일링 법칙은 평가 손실과 훈련 데이터 양 사이의 관계를 \(L = N^{-\gamma} + L_0\)로 정의합니다. \(L_0\)은 변하지 않는 손실을, \(\gamma\)는 상수를 나타냅니다. 복수의 독립적인 과제에 대한 평가 메트릭을 고려할 때, 각 훈련 샘플이 하나의 과제에만 기여하고 각 과제의 손실은 훈련 데이터 양에 따라 멱법칙(Power Law) 함수로 스케일링됩니다. 그 결과, \(m\) 개의 과제에 대한 종합 평가 손실은 \(L = L_0 + \sum_{i=1}^m \beta_i \cdot N_i^{-\gamma_i}\)로 표현됩니다.
[이론 및 예측 모델]
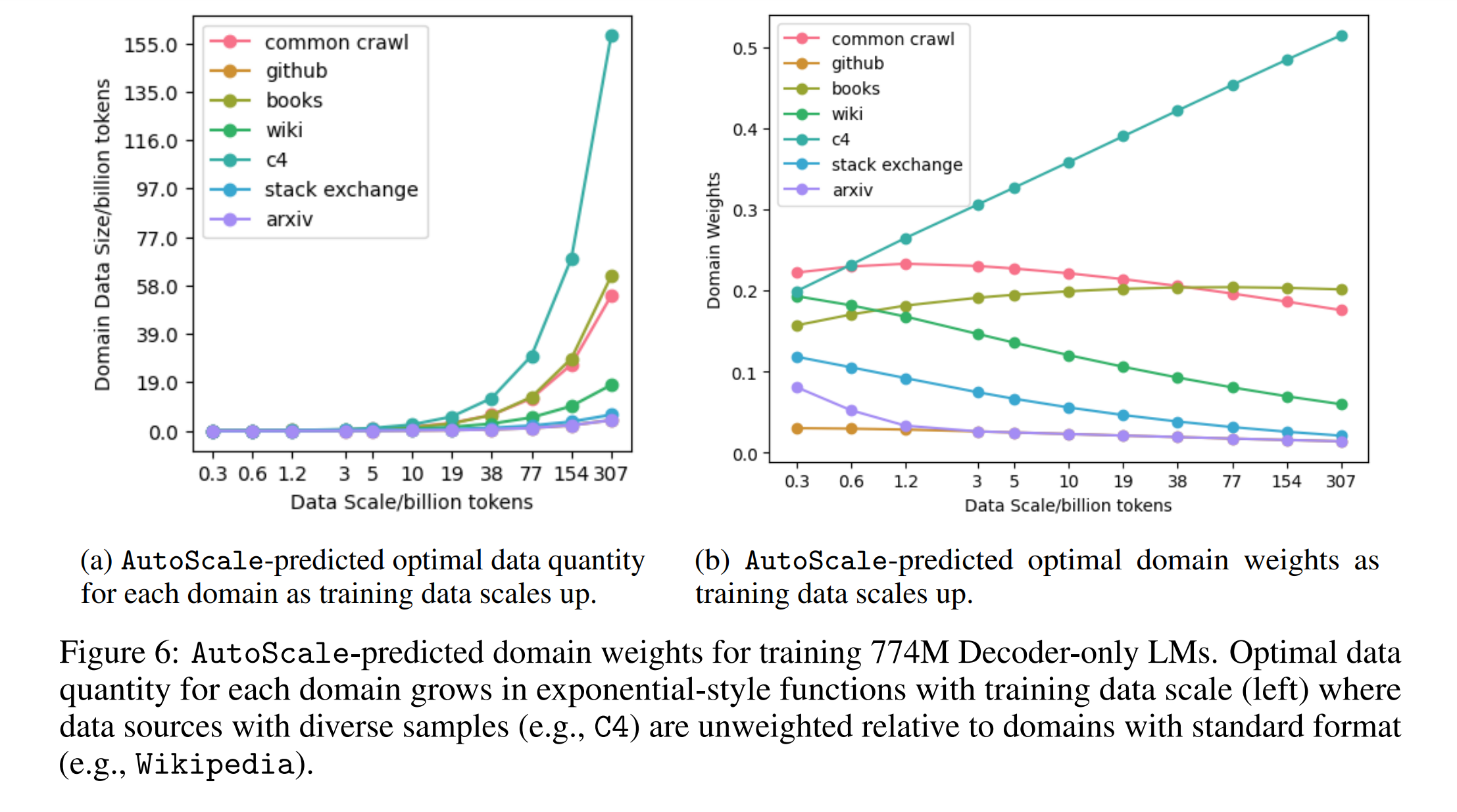
이 관계를 기반으로, 훈련 데이터 양이 증가함에 따라 최적 데이터 구성이 지수적인 형태로 스케일링됩니다는 이론을 제시합니다. 이 이론은 합리적인 가정과 경험적 관찰을 통해 뒷받침됩니다. 구체적으로, 작은 스케일에서 최적화된 데이터 구성을 바탕으로 더 큰 스케일에서의 최적 구성을 예측할 수 있습니다.
3.2 AutoScale: 큰 스케일에서의 최적 훈련 데이터 자동 예측
AutoScale 도구는 작은 스케일에서의 최적 도메인 가중치를 기반으로 하여 큰 스케일에서의 최적 훈련 데이터 구성을 자동으로 예측합니다. 이 도구는 초기 두 가중치 \(w(1)^*\)와 \(w(2)^*\)에서 시작하여, \(N(x)^* = N(2)^* (N(1)^*)^{-1} N(2)^*\)를 반복적으로 계산하여 목표 데이터 스케일 \(N(t)\)에 도달할 때까지 최적의 도메인 데이터를 예측합니다.
스케일링 법칙의 적용
이 이론은 각 도메인의 최적 데이터 양이 훈련 데이터의 크기에 따라 지수적으로 변화합니다는 것을 나타냅니다. 이를 수학적으로 표현하면, 각 도메인에 대한 최적의 데이터 양 \(N^*_i\)는 다른 스케일의 최적 구성을 통해 예측할 수 있는 지수 함수 형태로 표현됩니다. 이는 복잡한 최적화 문제를 풀지 않고도 더 큰 스케일에서의 최적 구성을 빠르게 추정할 수 있게 합니다.
AutoScale 알고리즘의 작동 원리
\[\textbf{Algorithm 2: AutoScale}\] \[\textbf{Require:} \\ \text{Optimal domain weights (obtained from DDO)} \\ w^{(1)*} \text{ at data scale } N^{(1)} \text{ and } w^{(2)*} \text{ at data scale } N^{(2)}, \\ \text{target data scale } N^{(t)}, \\ \text{where } N^{(1)} < N^{(2)} < N^{(t)}.\] \[\begin{align*} \text{Optimal domain data } N^{(1)*} & \leftarrow w^{(1)*} \cdot N^{(1)}; \\ \text{Optimal domain data } N^{(2)*} & \leftarrow w^{(2)*} \cdot N^{(2)}; \\ \text{Next optimal domain data } N^{(x)*} & \leftarrow \frac{N^{(2)*}}{(N^{(1)*})^{-1} \cdot N^{(2)*}}; \\ \text{Next data scale } N^{(x)} & \leftarrow \left\lfloor N^{(x)*} \right\rfloor; \\ \text{while } N^{(x)} & < N^{(t)} \text{ do} \\ \text{Next optimal domain data } N^{(x)*} & \leftarrow N^{(x)*} \cdot (N^{(1)*})^{-1} \cdot N^{(2)*}; \\ \text{Next data scale } N^{(x)} & \leftarrow \left\lfloor N^{(x)*} \right\rfloor; \\ \text{end while} \\ \text{Output predicted optimal domain weights } w^{(t)*} & \leftarrow \frac{N^{(x)*}}{N^{(x)}}. \end{align*}\]AutoScale은 두 가지 작은 스케일 \(N(1)\)과 \(N(2)\)에서 얻은 최적의 도메인 데이터 \(N(1)^*\)과 \(N(2)^*\)를 사용하여, \(N(3)^* = N(2)^* (N(1)^*)^{-1} N(2)^*\) 공식을 적용합니다. 이 과정은 각 도메인에 대해 필요한 데이터 양이 어떻게 변화해야 하는지를 보여주며, 이를 반복하여 원하는 크기 \(N(t)\)에 이를 때까지 계속됩니다.
이 접근 방식은 큰 스케일의 데이터 구성을 빠르고 정확하게 예측할 수 있다고 주장하며, 특히 대규모 데이터셋와 고성능 컴퓨팅 환경에서 유용하고, 큰 스케일에서의 데이터 구성 최적화 문제를 효율적으로 해결할 수 있게 해준다고 언급합니다.
4. Empirical Results
4.1 Experimental setup
본 연구에서는 GPT-2 Large 아키텍처를 사용하여 774M 디코더 전용 언어 모델을 RedPajama 데이터셋에서 처음부터 사전 훈련하였습니다. 이 데이터셋은 다양한 도메인에서 총 1.2T 토큰을 포함하고 있으며, Common Crawl, C4, GitHub, Wikipedia, ArXiv, 그리고 StackExchange 등으로 구성됩니다.
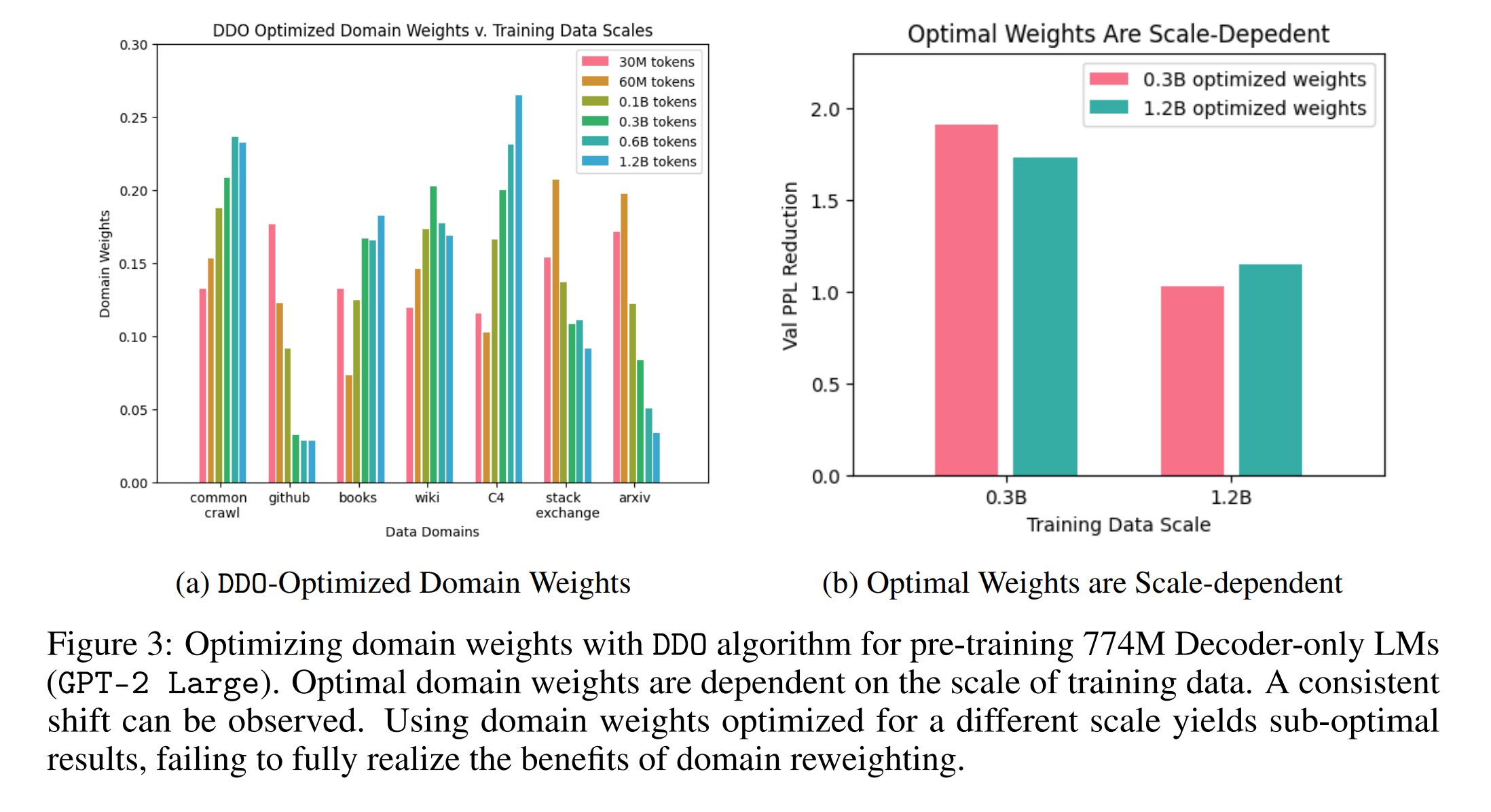
4.2 Causal Language Modeling with Decoder-only LMs (GPT)
본 섹션에서는 다양한 도메인 가중치를 통한 훈련의 효율성을 비교 분석합니다. 기본적으로 Uniform 가중치는 모든 도메인에서 동일하게 데이터를 샘플링하지만, LLaMA 가중치는 특정 도메인의 데이터를 우선적으로 사용하는 전략을 따르며, DoReMi 방법은 두 가지의 보조 모델을 사용하여 최적의 도메인 가중치를 결정합니다. 수학적으로 이는 아래와 같은 최적화 문제로 표현될 수 있습니다.
\[\min_{w} \max_{d \in \text{Domains}} \text{Loss}_d(w)\]\(w\)는 도메인별 가중치이며, \(\text{Loss}_d(w)\)는 도메인 \(d\)에서의 손실을 의미하며, DoReMi는 이 최적화 문제를 해결하기 위해 참조 모델과 최적화 모델을 교대로 훈련시키면서 가중치를 조정합니다.
훈련된 모델은 여러 downstream 태스크에서의 성능을 평가하며, 다양한 도메인 가중치를 사용한 경우와 비교하여 상대적인 성능 개선을 보고합니다. AutoScale 방법은 예측 모델을 사용하여 훈련 데이터 규모가 증가함에 따라 최적의 도메인 가중치가 어떻게 변화할지 예측하고, 이를 통해 더 큰 규모의 데이터에서도 효과적인 도메인 가중치를 제시합니다.
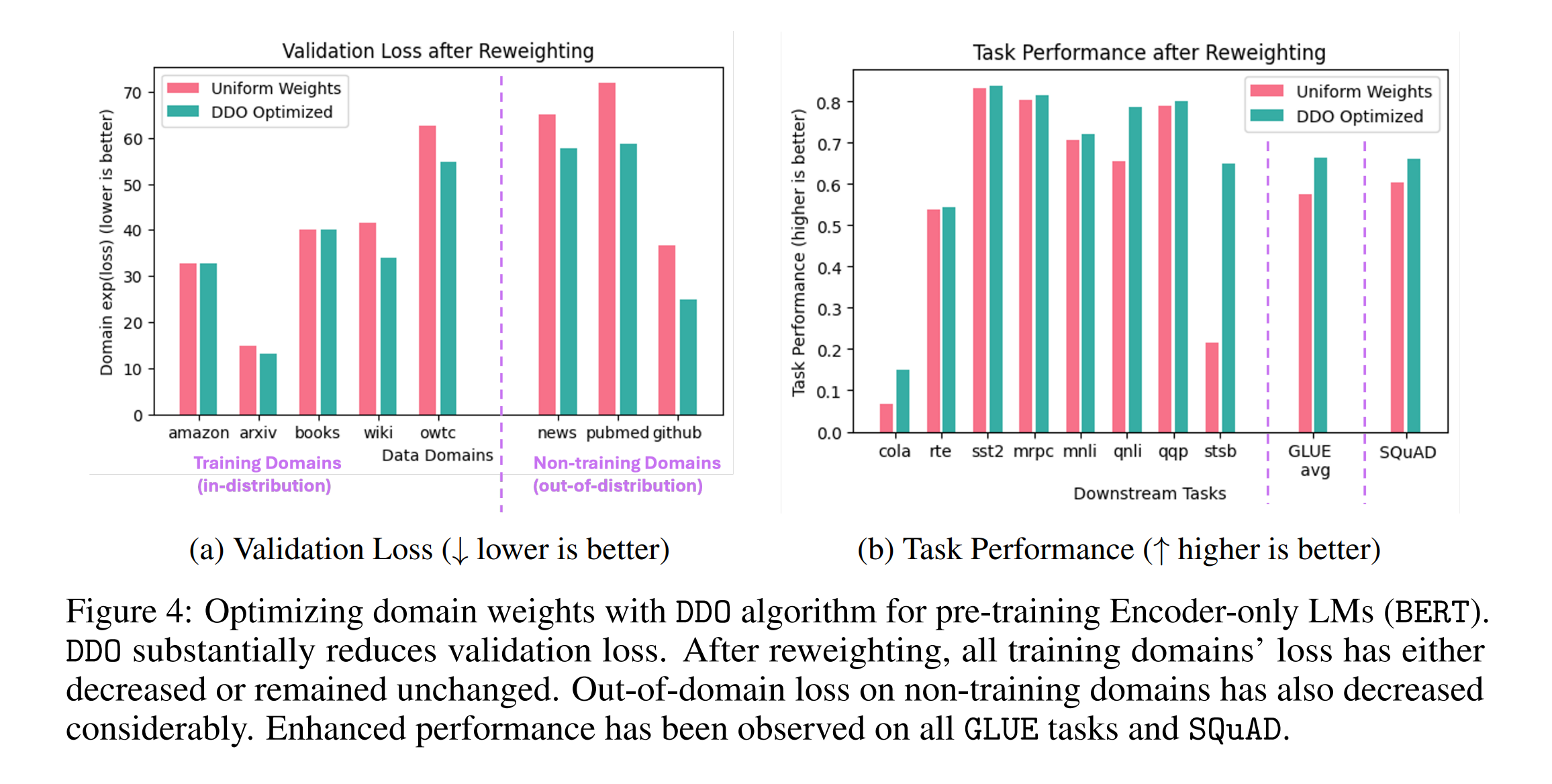
4.3 Masked Language Modeling with Encoder-only LMs (BERT)
MLM에서는 각 훈련 도메인의 손실을 최소화하는 도메인 가중치를 찾는 것을 목표로 합하며, 이는 CLM과 유사한 최적화 문제로 접근해 다음과 같이 표현할 수 있습니다.
\[\min_{w} \sum_{d \in \text{Domains}} w_d \times \text{Loss}_d(w)\]AutoScale을 통해 예측된 가중치는 일관된 훈련 속도 향상을 보여주며, 이는 다양한 데이터 스케일에서 검증되며 특히, 대규모 데이터에서의 손실 감소와 downstream 태스크 성능 향상은 AutoScale이 가중치를 동적으로 조정함으로써 얻은 이점을 강조합니다.
5. Conclusion
5.1 주요 결론
이 연구에서는 고정된 컴퓨팅 자원에서 최적의 데이터 구성이 훈련 데이터의 규모에 따라 다르게 나타나며, 소규모 실험에서 경험적으로 최적의 구성을 결정하는 일반적인 방식이 최종 모델을 확장할 때 최적의 데이터 혼합을 제공하지 않음을 보여줍니다. 이런 챌린지를 해결하기 위해, 모든 원하는 대상 규모에서 훈련을 위한 컴퓨트-최적 데이터 구성을 찾는 자동화된 도구인 AutoScale을 제안합니다.
5.2 AutoScale의 성과
실증적 연구에서 774M 디코더 전용 LMs와 인코더 전용 LMs의 사전 훈련을 통해, AutoScale은 재가중치 없이 기본선 대비 최소 25% 빠르게 검증 손실을 줄이며 최대 38%의 속도 향상을 달성하여 downstream 태스크에서 전반적으로 좋은 성능을 보여줍니다.
5.3 연구의 한계
AutoScale이 대규모 언어모델 사전 훈련을 위한 데이터 구성 최적화에서 유망한 결과를 달성했지만, 이 연구의 일반화 가능성, downstream 성능의 직접 최적화, 더 세밀한 데이터 큐레이션과 같은 여러가지 방면에서 추가적인 탐구가 필요합니다.
5.4 향후 연구
- 일반화 가능성: 이 연구를 더 큰 규모의 설정, 다른 데이터 형태, 보다 포괄적인 평가 기준으로 확장하고, 작업하는 규모에서 제공된 통찰의 타당성을 재검토하는 것이 흥미로울 것입니다.
- Downstream 성능의 직접 최적화: LLM의 성능은 다양한 downstream 태스크에서의 성능으로 특징지어지며, 이 연구에서 중점을 둔 손실은 downstream 성능의 거친, 부정확한 대리 변수에 불과합니다. AutoScale을 확장하여 downstream 성능을 직접 최적화하는 것이 흥미로울 것입니다.
- 더 세밀한 데이터 큐레이션: AutoScale은 고정된 데이터 도메인을 다루고 도메인이 혼합되는 방식만 최적화합니다. 각 도메인 내의 코퍼스를 전략적으로 선택하고 데이터 선택 전략을 훈련의 다른 단계에 맞게 조정할 수 있습니다면 추가적인 개선이 이루어질 수 있습니다.
AutoScale은 LLM의 사전 훈련과 관련된 복잡성과 자원 요구를 줄이는 데 기여함으로써 AI의 민주화에 기여합니다. 이를 통해 소규모 조직, 학술 기관, 개인 연구자들이 첨단 AI 연구 및 개발에 더 쉽게 참여할 수 있게 되어 AI 커뮤니티 전반에 걸쳐 혁신과 협력을 촉진합니다. 또한, 대량의 데이터 학습은 대규모 컴퓨팅 자원을 요구하는데, 이는 상당한 에너지를 소비할 뿐만 아니라 상당한 탄소 발자국을 남기고, 기술의 빠른 발전으로 인해 전자 폐기물도 발생시킵니다.
[일반적으로 인용하기 좋은 문구 색인마킹]