LFM | Meta - LLaMA 2
- Related Project: private
- Category: Paper Review
- Date: 2023-08-08
Llama 2: Open Foundation and Fine-Tuned Chat Models
- url: https://arxiv.org/abs/2307.09288
- pdf: https://arxiv.org/pdf/2307.09288
- abstract: In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Release Date: 2023.02
- 7B to 65B parameters
- Trained on public datasets
- Competitive with larger models
Release Date: 2023.07
- 7B to 70B parameters
- Fine-tuned for dialogue
- Improved safety and helpfulness
Release Date: 2024.07
- 7B to 405B parameters, 128K context window
- Multilingual, coding, reasoning, tool usage
Contents
- Llama 2: Open Foundation and Fine-Tuned Chat Models
TL;DR
- 도움(helpfulness)과 안전(safety)을 위한 별도의 보상 모델 훈련
- SFT 모델 체크포인트에서 초기화하여 사전 지식 활용
- 휴먼 선호(human preference)도 데이터를 이진 랭킹 레이블로 변환하여 학습
- 이진 랭킹 손실 함수 사용
- 채팅 모델 업데이트에 맞춰 주단위로 보상 모델 갱신
- 안전 모델에는 추가 안전 분류 손실 적용
- Overview
- 논문은 전반적으로 Helpfulness와 Safety를 큰 축으로 다양한 실험을 전개합니다. 특히 사람과의 상호 작용에 집중하였고, 정성 평가 및 Safety에 위주로 전개합니다
- 이는 Meta AI의 수장인 Yann LeCun의 성향이 많이 반영된 것 같습니다. Antrhopic과 비슷하게 빠른 개발보다는 안전하고, 효용있는 모델 생성에 초점을 맞추고 있는 것 같습니다.
- 논문은 전반적으로 Helpfulness와 Safety를 큰 축으로 다양한 실험을 전개합니다. 특히 사람과의 상호 작용에 집중하였고, 정성 평가 및 Safety에 위주로 전개합니다
- Experimental Processes in the Llama2 Paper
- 이번 Llama2 논문에서는 여러 실험 과정에 정성적인 평가와 가이드 라인을 확립하기 위해 다양한 시도를 했는데,
- SFT(Supervised Fine-Tuning) 과정에서 27,000여 개까지의 데이터를 크라우드 워커를 통해 주석(annotation)을 달았고, 사람에 의한 척도를 정량화하여 레이블링 하였습니다.
- 또한, SFT는 어느정도 양의 고품질의 데이터만으로 충분하다고 판단한 뒤, RLHF(Reinforcement learning from human feedback)에 집중하였다고 합니다.
- 이번 Llama2 논문에서는 여러 실험 과정에 정성적인 평가와 가이드 라인을 확립하기 위해 다양한 시도를 했는데,
- Comparison with Hugging Face’s LLM, Falcon
- 허깅 페이스의 LLM, Falcon이 대규모 웹 크롤링 데이터(데이터의 양)에 집중한 반면, Llama2팀은 적은 양이여도 고품질의 데이터(데이터의 질)에 집중하였으며, 이후 사람의 선호도에 더 적절한 답변을 해줄 수 있는 강건한 모델을 생성하기 위해 노력하였습니다. (본 논문의 소제목 Quality is all you need 및 Falcon 등 관련 논문 참고)
- Training Process and Learning Speed
- 일련의 과정에서 훈련이 진행되면서 학습 속도가 떨어지는 문제를 보고하고, 시행착오를 거쳐서 어떻게 해결하였는지 제시하면서,
- 동시에 각 스텝에서 발생한 이슈와 개선에 실패한 내용도 가감없이 보고하여 많은 연구진들이 겪을 시행착오를 줄일 수 있도록 하였으며, Appendix 섹션에는 많은 양의 자료와 함께 구체적인 실험 값들이 담겨있습니다.
- 일련의 과정에서 훈련이 진행되면서 학습 속도가 떨어지는 문제를 보고하고, 시행착오를 거쳐서 어떻게 해결하였는지 제시하면서,
- Modifications in the Model’s Architecture
- LLaMA-2 모델 아키텍처와 관련하여, 학습 속도 및 사용성 일부 아키텍처의 변형하였습니다.
- LLaMA-1에 비해 컨텍스트 길이는 2배(~4096)로 늘리고, 그룹화 된 쿼리 어텐션(GQA)을 사용합니다.
- 그 외 모델 아키텍처는 LLaMA-1과 대부분 동일합니다.
- LLaMA-2 모델 아키텍처와 관련하여, 학습 속도 및 사용성 일부 아키텍처의 변형하였습니다.
- Benchmark Sets and Open Data Sets
- 오염이나 문제의 소지가 없는 일부 벤치마크 셋과 오픈 데이터셋 등은 모두 그대로 사용하여도 문제 없다고 보고하였으며, 별도의 프롬프트(4,000여 개)를 마련하여 정성/정량적으로 모델들을 평가하였습니다.
- 다른 모델과 달리 정성적인 보고를 하였으며, Safety에 집중하였습니다.
- 오염이나 문제의 소지가 없는 일부 벤치마크 셋과 오픈 데이터셋 등은 모두 그대로 사용하여도 문제 없다고 보고하였으며, 별도의 프롬프트(4,000여 개)를 마련하여 정성/정량적으로 모델들을 평가하였습니다.
- Introduction to SFT and Alignment Tuning (RLHF in the case of LLaMA-2)
- SFT(Supervised Fine-Tuning)와 Alignment Tuning(LLaMA-2의 경우 RLHF)로 분리하여 소개하는데,
- SFT를 진행하면서 위에서 언급한 바와 같이 적은 양의 데이터일지라도 잘 정제된 고품질의 데이터만으로 충분하다는 결론을 내렸고,
- RLHF와 관련하여, 새로운 테크닉보다는 선행 기술들을 조금씩 변형하며 실험을 진행하며 문제를 찾아 해결하였습니다.
- RLHF 과정에서 오픈 소스 데이터셋과 메타의 자체 구축 데이터셋을 어떤 비율로 섞어서 학습하는 것이 효과적인지 등을 소개하며, 각 단계에서 발생한 문제들을 해결하기 위한 과정을 상세히 보고합니다.
- RLHF-V5까지 소개하며, Chat 모델을 위주로 RLHF를 진행하였습니다.
- 이전 연구들을 참조하여, 최적화 텀에 제한을 걸어 더 잘 학습되게 수정하였습니다.
- SFT(Supervised Fine-Tuning)와 Alignment Tuning(LLaMA-2의 경우 RLHF)로 분리하여 소개하는데,
- Analysis of the Reward Model in RLHF
- RLHF에서 Reward Model의 평가와 사람의 평가가 비슷하다는 분석을 통해, 리워드 모델에 L ranking Loss Function 사용한 것이 적절했다라고 결론내렸으며, Inter-Rater Reliability(IRR)등의 분석 내용은 상세히 공유하였으나, 그 외 자세한 데이터셋 및 코드 등은 디테일하게 공개되지 않았습니다.
사견이므로 무시
- 많은 인력을 통해 LLM의 성능을 평가 한 노하우를 (싱글 턴 및 멀티 턴을 사용하는) 새로운 정량 지표나 벤치마크 셋의 형태로 공유해주었다면 좋지 않았을까 하는 아쉬움이 남지만, 아직 내부에서도 확실하게 정립되지 않은 것으로 보이며,
- 제한 사항에 서술되어 있는 바와 같이 유명한 벤치마크 셋에 대한 한계는 메타 AI도 공감하고 있는 것으로 보이고, 따라서 자주 사용되는 유즈 케이스들이나 문제될 수 있는 부분에 대해 최대한 정성적으로 검증을 시도한 것으로 생각됩니다. 이는 현재 많은 LLM 연구진들도 비슷하게 접근하고 있는 듯 보이며, 이 이후에 등장한 Qwen 등 여러 연구팀이 직/간접적으로 언급합니다.
- LLaMA-1이 모델 크기의 확장에 조금 더 집중하였다면, Llama2의 경우 안전한 모델과 휴먼의 선호도에 맞게 모델을 교정하는 것에 집중한 것 같습니다.
- (2024 추가) LLaMA-3에서 다국어의 효율적인 토큰화 및 정성적인 평가 프롬프트(1,800)를 카테고리별로 나누어 제공할 예정이라고 발표하였습니다.
1 Introduction
- The capabilities of LLMs are remarkable considering the seemingly straightforward nature of the training methodology.
- Auto-regressive transformers는 자체 지도 데이터의 방대한 코퍼스에서 사전 훈련을 거치고, 그 후 강화 학습과 같은 기술을 통해 휴먼의 선호도와 일치시킬 수 있고, 훈련 방법 자체는 간단하지만, 높은 계산 요구 사항으로 인해 LLMs의 개발은 몇몇 주요 플레이어로 제한되어서 연구가 진행되고 있는 상황입니다.
- BLOOM(Scao 등, 2022), LLaMA-1(Touvron 등, 2023), Falcon(Penedo 등, 2023)과 같이 pre-trained LLMs의 공개 버전은 GPT-3(Brown 등, 2020) 및 Chinchilla(Hoffmann 등, 2022)와 같은 폐쇄된 사전 훈련 경쟁 모델과 비슷한 성능을 보여주었으며,
- 모델의 안전성을 높이기 위해 안전에 특화된 데이터 주석 및 튜닝을 사용하고 레드팀을 구성하고 반복적 평가를 실시하는 등의 조치를 취해 the series of helpfulness and safety benchmarks에서 더 도움되면서 안전한 모델을 생성하기 위해 노력했습니다.
- We also share novel observations we made during the development of Llama2 and Llama2-Chat, such as the emergence of tool usage and temporal organization of knowledge.
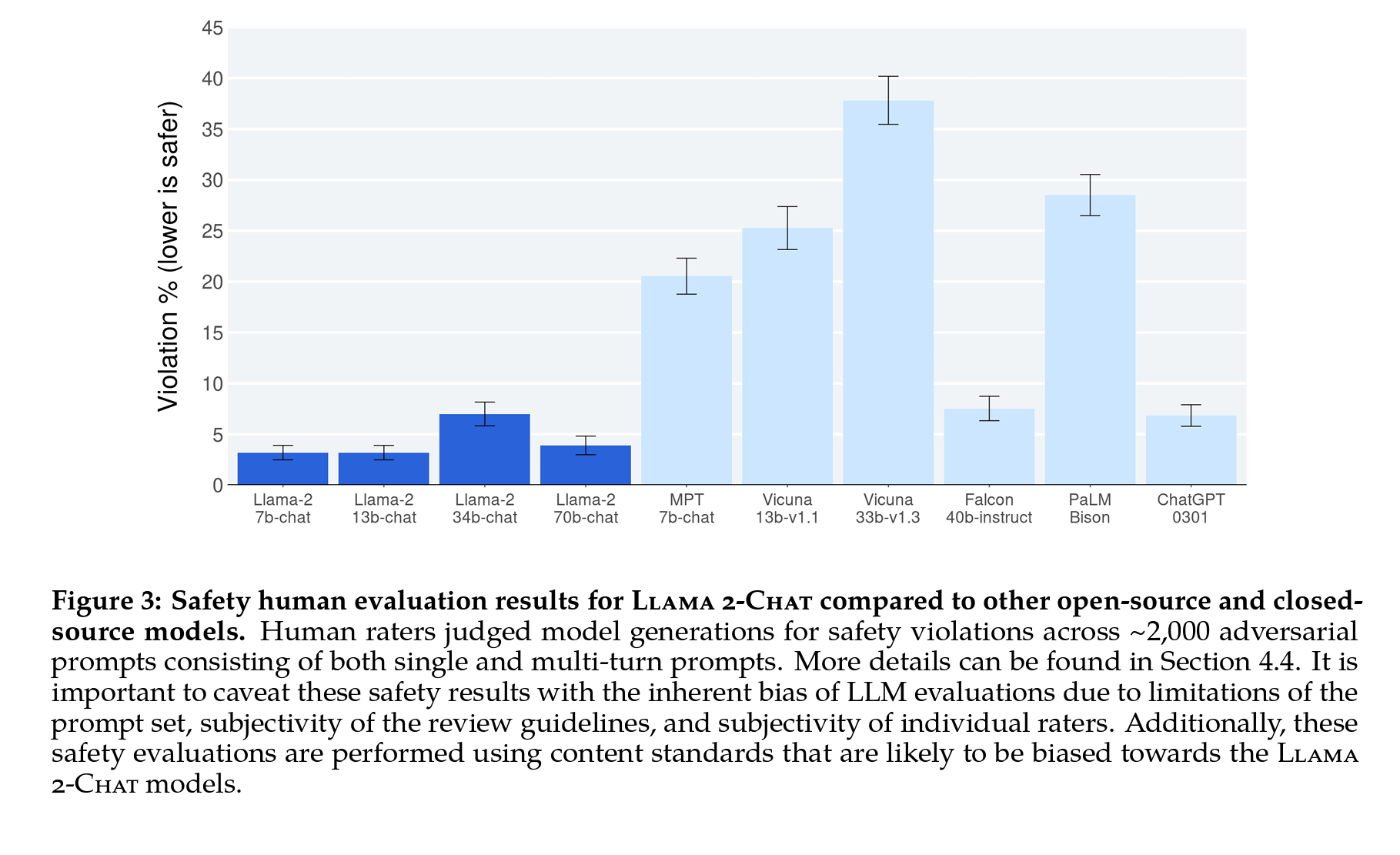
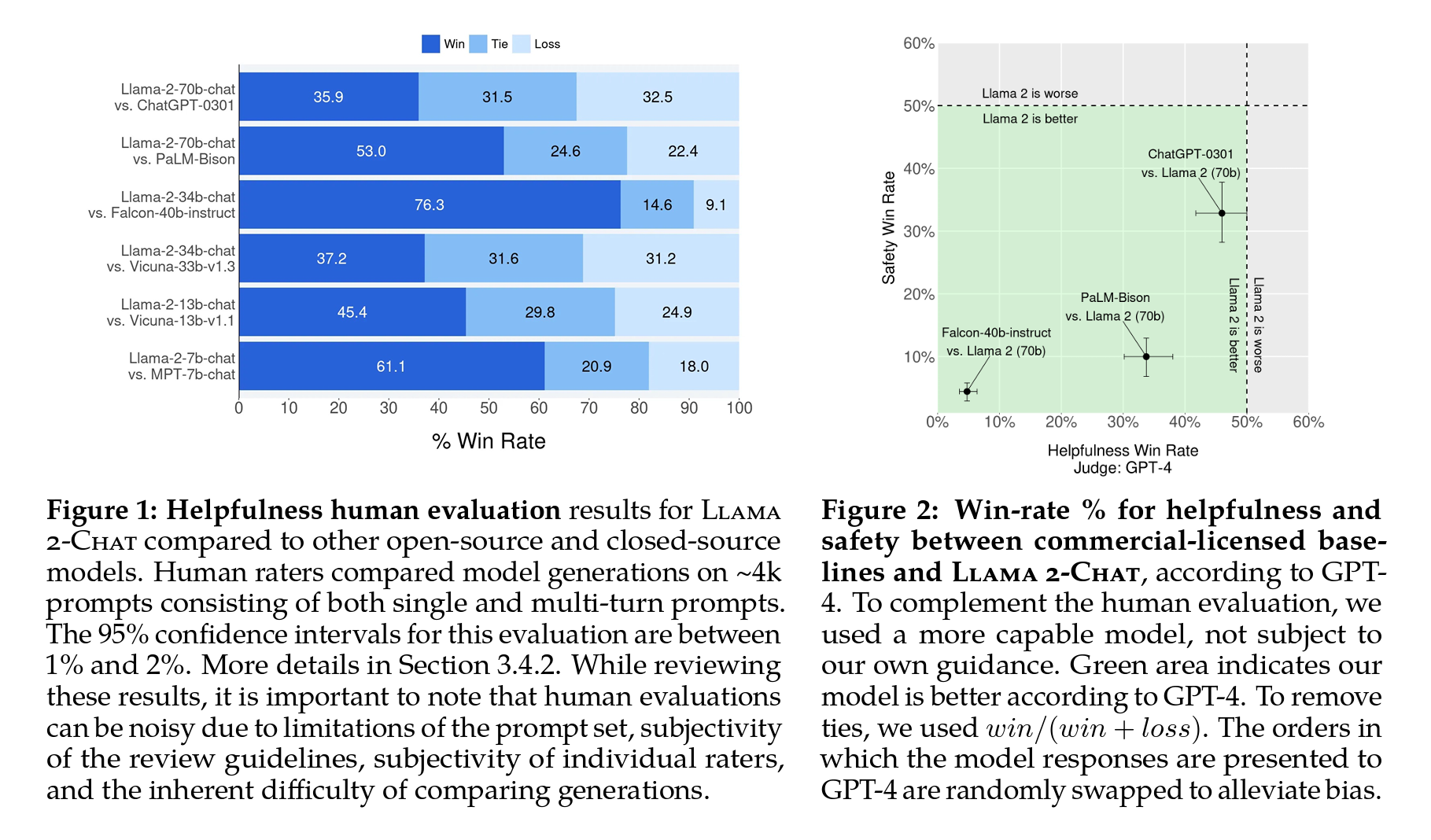
Figure 3: 다른 오픈 소스 및 폐쇄 소스 모델과 비교한 Llama2-Chat의 안전한 휴먼 평가 결과.
- Meta 팀의 평가자들은 단일 및 다중턴 프롬프트(single and multi-turn prompts)로 구성된 약 2,000개의 적대적 프롬프트를 통해 모델 세대의 안전 위반을 판단하였고,
- 이 과정에서 평가 프롬프트의 한계가 명확하고, 검토 지침의 주관성, 개별 평가자의 주관성 때문에 LLM 평가의 내재적 편향을 유의할 필요가 있다고 보고하였습니다.
- Llama2
- LLaMA-1의 최신 버전으로, 공개적으로 이용 가능한 데이터의 새로운 조합을 기반으로 훈련하였습니다.
- 또한 사전 훈련 코퍼스의 크기를 40% 늘리고, 모델의 컨텍스트 길이를 두 배로 늘렸으며, 그룹화된 쿼리 어텐션(Grouped Query Attention, Ainslie 등, 2023)을 도입하였습니다.
- Llama2의 7B, 13B, 70B 파라미터 버전을 공개한 뒤, 34B 버전도 훈련하였으나 Appendix에 소개된 바와 같이 안전성을 이유로 공개되지는 않았습니다.
- Llama2-Chat
- 대화 사용 사례에 최적화된 Llama2의 세밀한 튜닝 버전으로, 7B, 13B, 70B 파라미터의 튜닝 버전 공개합니다.
참고 자료
- Llama Models and Libraries
- We are delaying the release of the 34B model due to a lack of time to sufficiently red team.
- Llama Official Website
- Llama GitHub Repository
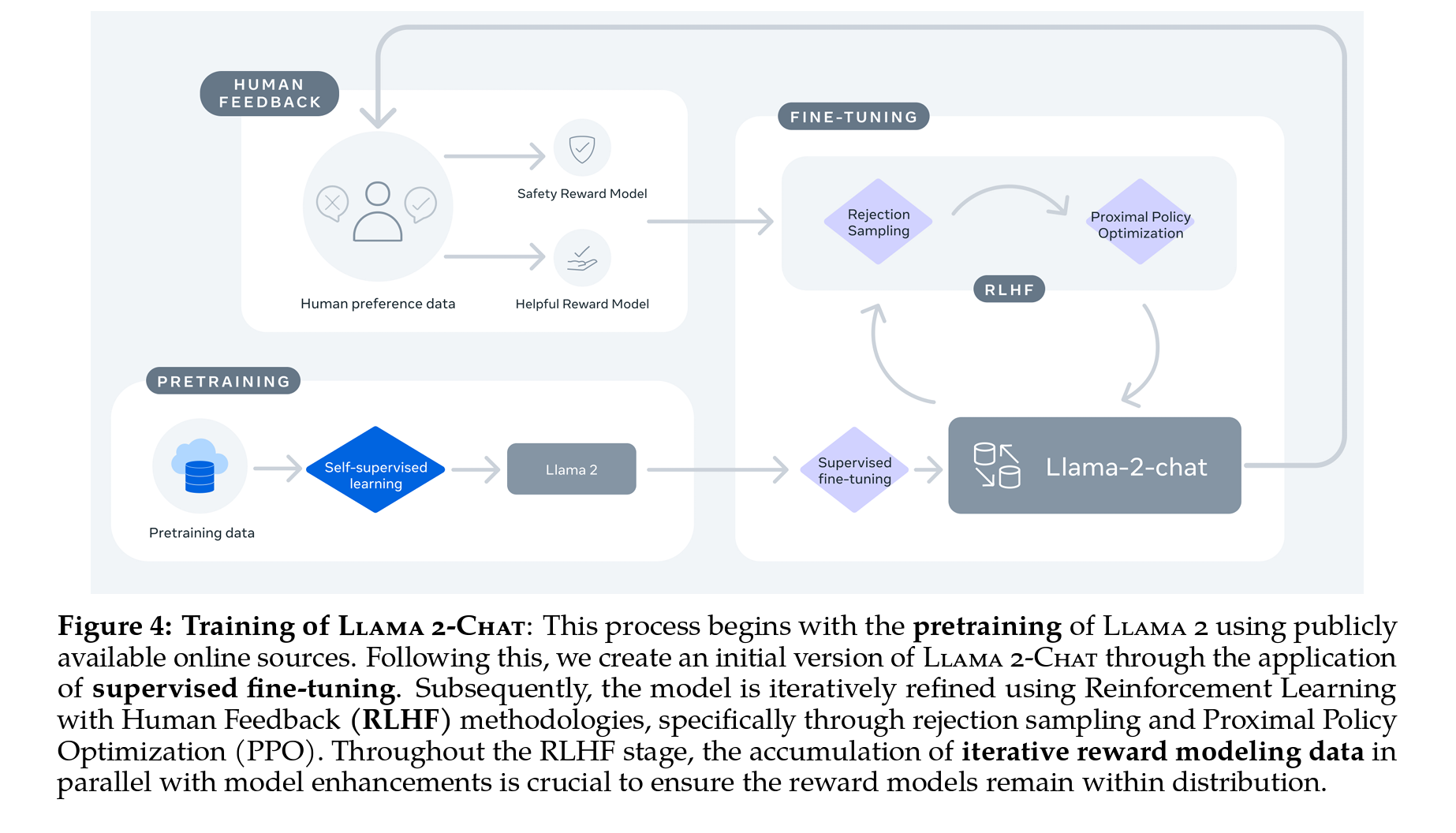
Figure 4: Llama2-Chat의 훈련 과정
- 공개적으로 이용가능한 데이터셋을 통해 사전 훈련을 진행하고, 파인튜닝을 통해 초기버전의 Llama2-chat을 생성하였습니다.
- 이후 Rejection sampling and Proximal Policy Optimization(PPO)를 사용한 RLHF로 개선하였는데,
- RLHF 단계 동안, 반복 Reward Model링 데이터 누적은 모델 개선과 함께 평행하게 진행하였습니다.
- 이 과정에서 Reward Model이 특정 분포 내에 머무를 수 있도록 같이 학습을 진행하였다고 합니다.
- RLHF 단계 동안, 반복 Reward Model링 데이터 누적은 모델 개선과 함께 평행하게 진행하였습니다.
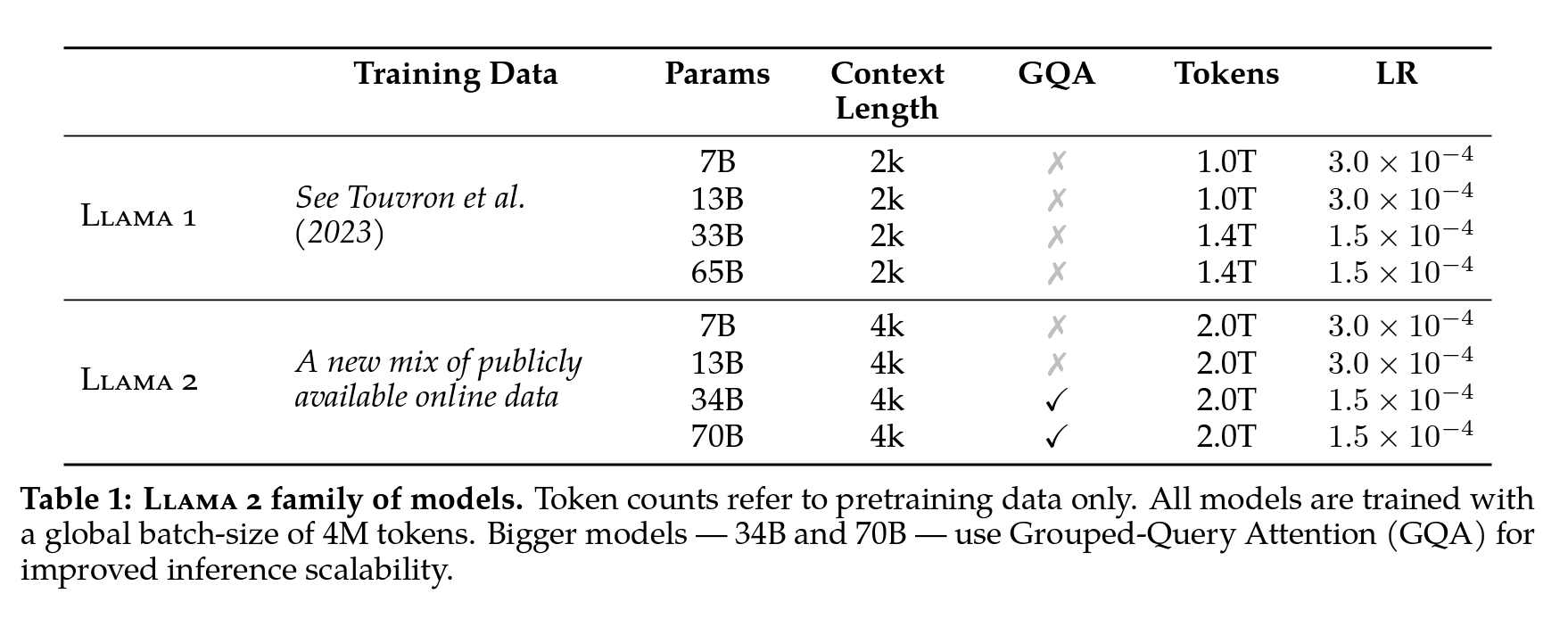
2 Pretraining
- Touvron et al, 2023의 사전 훈련 방식을 채용하여,
- 최적화된 자동 회귀 트랜스포머를 사용하면서 성능을 개선하기 위해 여러가지 변경하였다고 합니다.
- 더 견고한 데이터 정리를 수행하고 데이터 혼합을 업데이트하며 총 토큰 수를 40% 더 증가시키고,
- 컨텍스트 길이를 2배로 늘렸습니다.
- 큰 모델의 인퍼런스 확장성을 개선하기 위해 그룹화된 쿼리 어텐션(GQA)을 사용합니다.
2.1 Pretraining Data
- 공개적으로 이용 가능한 소스의 새로운 혼합 데이터가 포함되었습니다. (Training corpus includes a new mix of data from publicly available sources.)
- 개인 정보에 대한 높은 양의 데이터가 있는 특정 사이트의 데이터를 제거하려는 노력하였으며, 2조 개의 토큰 데이터로 훈련을 진행하여 성능-비용 트레이드오프를 검토하였다고 합니다.
- 지식을 높임과 동시에 Hallucinatios을 완화하기 위해 가장 사실적인 소스를 위주로 업샘플링하였습니다.
2.2 Training Details
- LLaMA-1에서의 사전 훈련 설정과 모델 구조를 대부분 그대로 채용하였습니다.
- 주요 아키텍처적 차이점은 1) 컨텍스트 길이를 증가와 2) 그룹화된 쿼리 어텐션(GQA)을 사용한 것 정도입니다.
- 그 외 LLaMA-1부터 공통적으로 적용된 기술들은 다음과 같습니다.
- Standard transformer architecture(Vaswani et al. 2017)
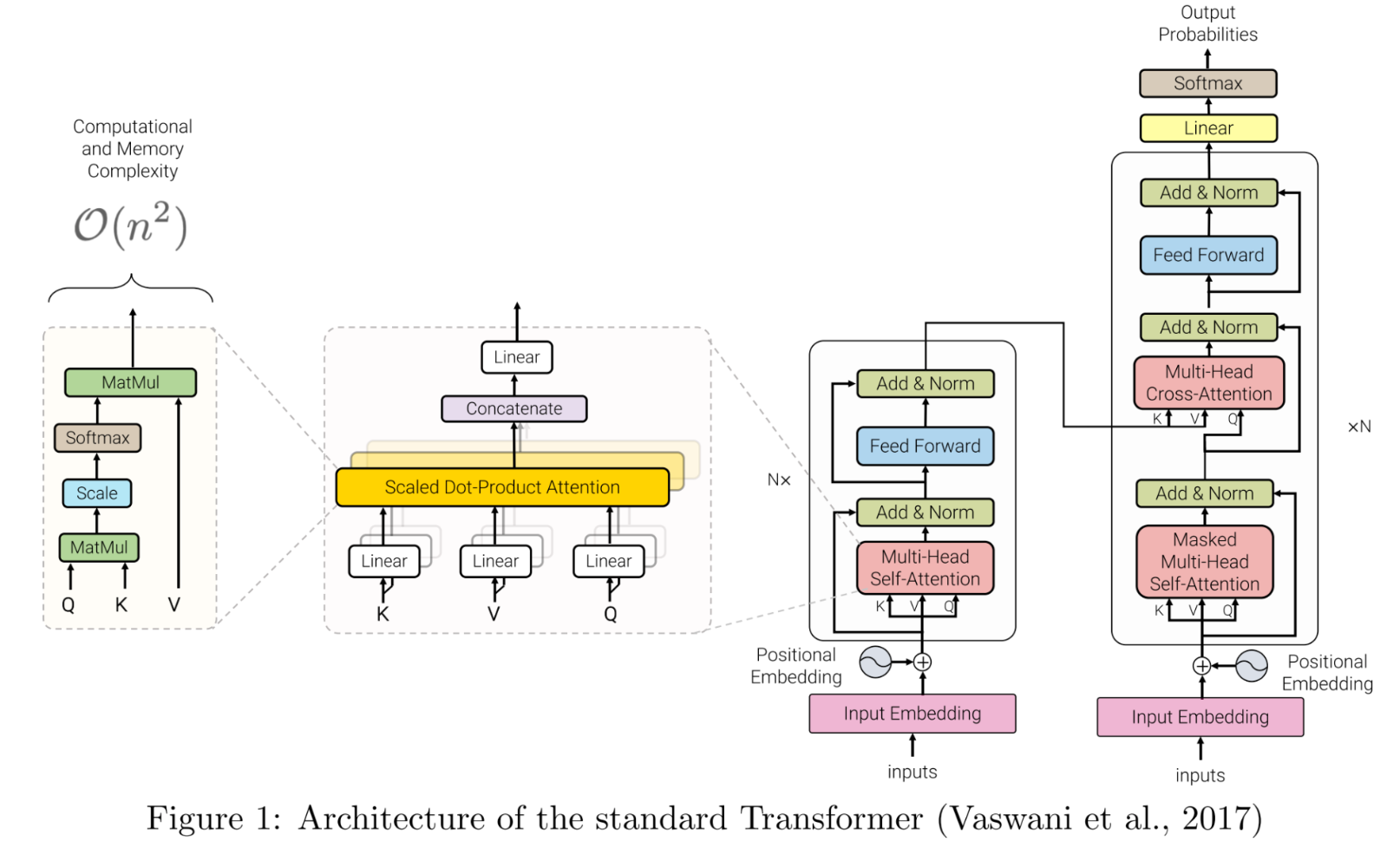 *출처: https://arxiv.org/abs/1706.03762
*출처: https://arxiv.org/abs/1706.03762 - Pre-normalization using RMSNorm
 *출처: https://github.com/hikvision-research/unified-normalization,
https://atcold.github.io/pytorch-Deep-Learning/en/week05/05-2/,
https://arxiv.org/abs/1910.07467
*출처: https://github.com/hikvision-research/unified-normalization,
https://atcold.github.io/pytorch-Deep-Learning/en/week05/05-2/,
https://arxiv.org/abs/1910.07467 - SwiGLU activation function(Shazeer et al. 2020)
 *출처: https://paperswithcode.com/method/swiglu
*출처: https://paperswithcode.com/method/swiglu - ROtary Positional Embeddings(RoPE, Su et al. 2022)
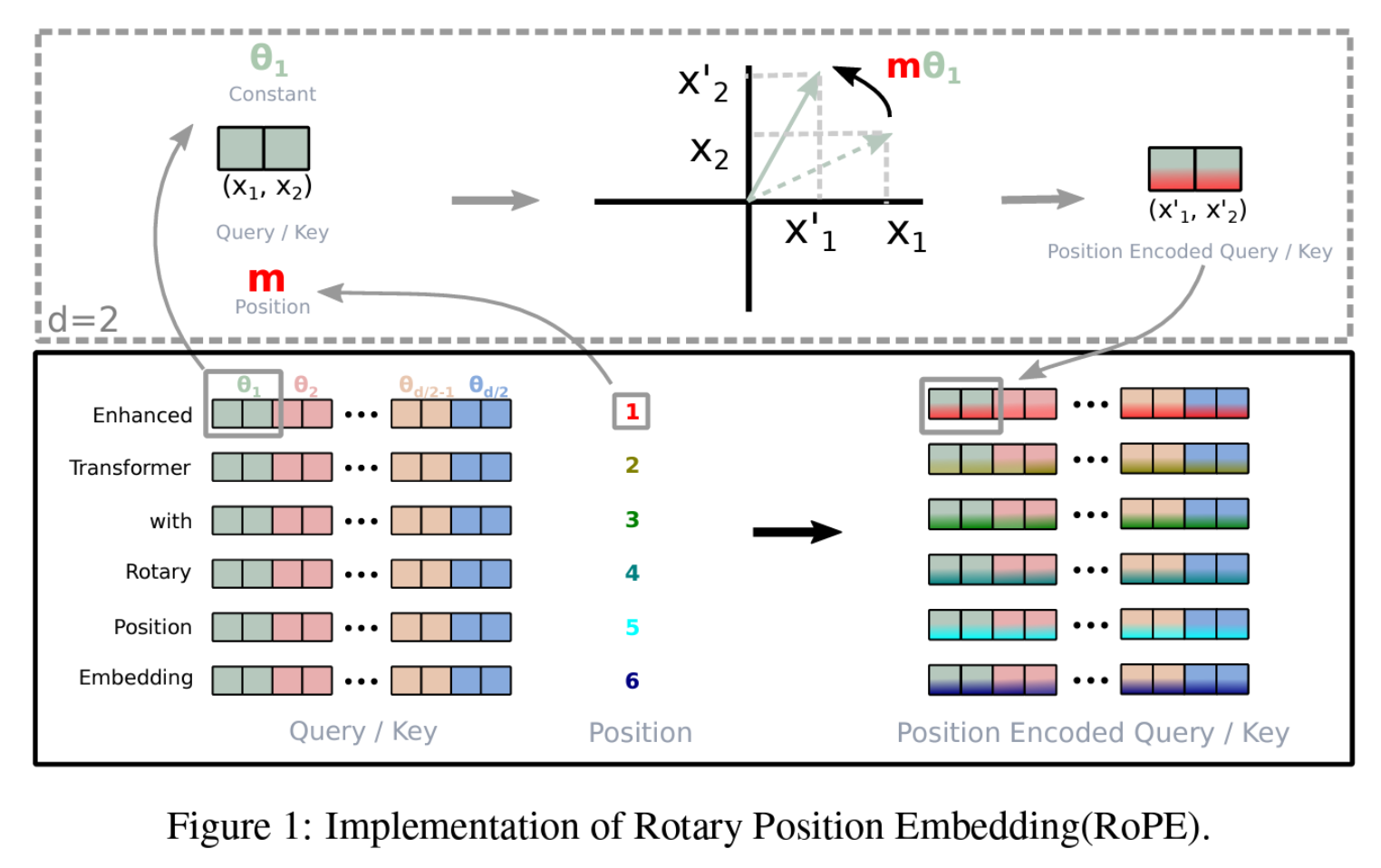 *출처: https://arxiv.org/abs/2104.09864
*출처: https://arxiv.org/abs/2104.09864 - AdamW optimizer (Loshchilov and Hutter, 2017) with β1=0.9, β2=0.95, and eps=10^-5. Our approach includes a cosine learning rate schedule with a warmup of 2000 steps, and we gradually decrease the final learning rate to 10% of the peak value.
- Standard transformer architecture(Vaswani et al. 2017)
Tokenizer
- LLaMA-1과 동일하게 BPE(BBPE) 기반의 토크나이저 사용하였습니다.
- LLaMA-1과 마찬가지로 모든 숫자를 개별 숫자로 분할하고, 알려지지 않은 UTF-8 문자를 분해하기 위해 바이트를 사용했습니다. 결론적으로 일부 BBPE 기반 토크나이저로 볼 수 있으며 256개의 바이트의 조합을 포함시켰습니다.
- Total Vocab Size = 32,000 Tokens
- Byte Pair Encoding (BPE) algorithm (Sennrich et al., 2016)
 https://arxiv.org/abs/1804.10959
https://arxiv.org/abs/1804.10959
2.3 Llama2 Pretrained Model Evaluation
표준 벤치마크 종류
| Benchmark Category | Benchmark List | Evaluation Results |
|---|---|---|
| Code | HumanEval (Chen et al., 2021), MBPP (Austin et al., 2021) | Average pass@1 scores |
| Commonsense Reasoning | PIQA (Bisk et al., 2020), SIQA (Sap et al., 2019), HellaSwag (Zellers et al., 2019a), Winogrande (Sakaguchi et al., 2021), ARCeasy and challenge (Clark et al., 2018), OpenBookQA (Mihaylov et al., 2018), CommonsenseQA (Talmor et al., 2018) | Average scores (7-shot for CommonsenseQA, 0-shot for others) |
| World Knowledge | Natural Questions (Kwiatkowski et al., 2019), TriviaQA (Joshi et al., 2017) | 5-shot performance average |
| Reading Comprehension | SQuAD (Rajpurkar et al., 2018), QuAC (Choi et al., 2018), BoolQ (Clark et al., 2019) | 0-shot average |
| MATH | GSM8K (8-shot) (Cobbe et al., 2021), MATH (4-shot) (Hendrycks et al., 2021) | Average at top 1 |
| Popular Aggregated Benchmarks | MMLU (5-shot) (Hendrycks et al., 2020), BigBenchHard (BBH) (3-shot) (Suzgun et al., 2022), AGIEval (3–5shot) (Zhong et al., 2023) | For AGIEval, we only evaluate English tasks and report the average. |
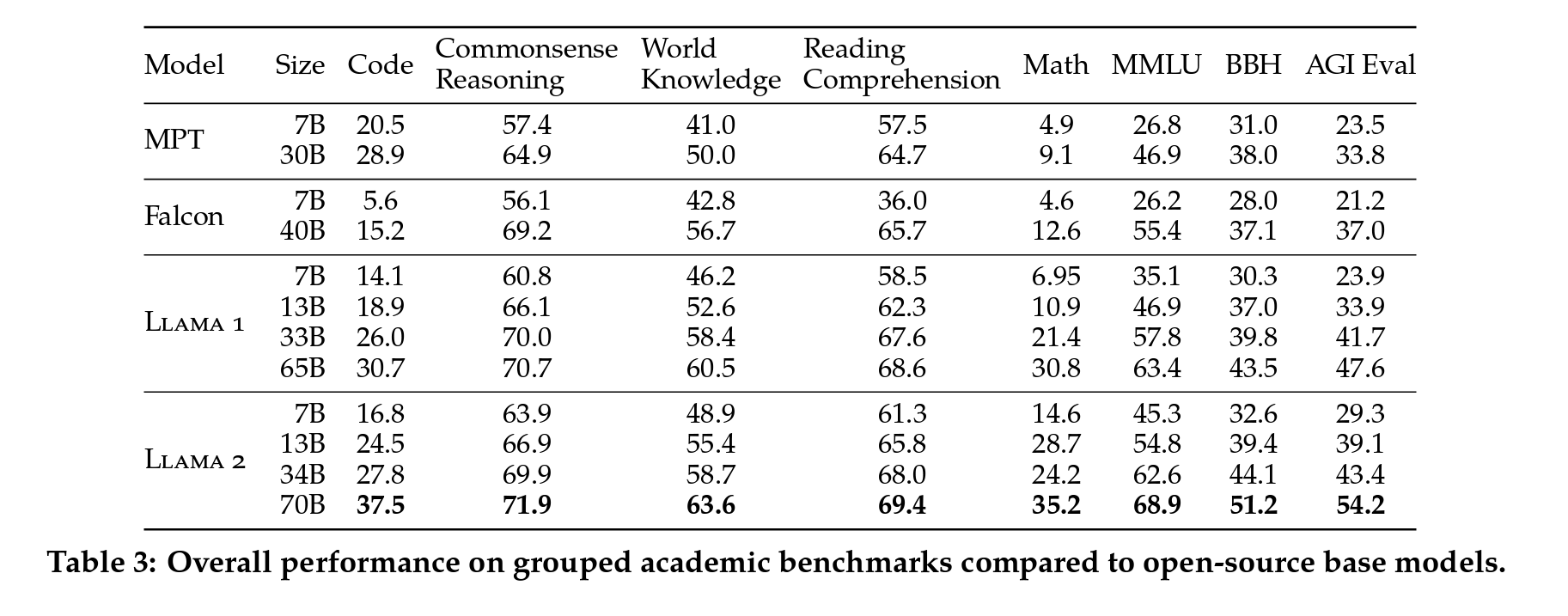
표준 벤치마크에서의 open-source LLM 성능비교
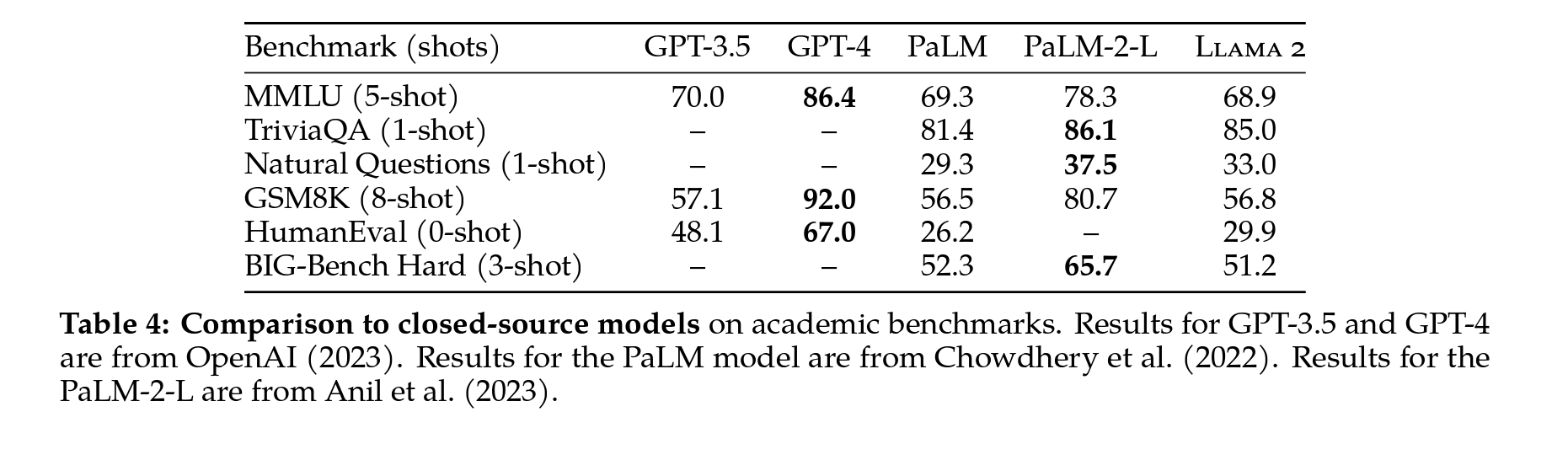
표준 벤치마크에서의 closed-source LLM 성능비교
- 벤치마크 결과 요약
- Llama2-70B 모델은 MMLU와 BBH 벤치마크에서 각각 약 5점과 8점 정도의 향상
- Llama2-7B와 30B 모델은 대응되는 크기의 MPT 모델보다 코드 벤치마크를 제외한 모든 범주에서 더 나은 성능
- Llama2-7B와 34B 모델이 모든 벤치마크 범주에서 Falcon-7B와 40B 모델보다 우수한 성능
- Llama2-70B 모델은 모든 오픈 소스 모델보다 우수한 성능
-
Llama2-70B 모델은 MMLU와 GSM8K에서 GPT-3.5와 유사한 결과를 보였으나, 코드 벤치마크에서 차이가 있었음.
- Llama2-70B 결과는 거의 모든 벤치마크에서 PaLM(540B)보다 우수하거나 비슷한 결과
- Llama2-70B와 GPT-4, PaLM-2-L 사이에는 여전히 성능 차이가 큼
- 대다수 연구진들이 보고하는 바와 같이 벤치마크 데이터의 오염 가능성에 대해서 SectionA.6에서 자세하게 서술하였습니다.
- 코드나 수학과 관련된 제품군을 공개하지는 않았고, LLaMA의 Base 모델들도 비슷하므로 LLaMA-3에서는 이 부분이 반영될 것으로 예상합니다.
3 Fine-tuning
- Instruction tuning and RLHF, requiring significant computational and annotation resources.
- Supervised fine-tuning (Section 3.1), as well as initial and iterative reward modeling. (Section 3.2.2)
- RLHF (Section 3.2.3)
- Ghost Attention (GAtt), which we find helps control dialogue flow over multiple turns (Section 3.3)
- Section 4.2 for safety evaluations on fine-tuned models
3.1 Supervised Fine-Tuning(SFT)
Started with SFT
- Publicly available instruction tuning data를 사용하여 SFT(Supervised Fine-Tuning)로 Fine-tuning 시작.
- SFT(Supervised Fine-Tuning) stage with publicly available instruction tuning data (Chung et al., 2022), as utilized previously in Touvron et al. (2023)
Quality Is All You Need
- 적은 수의 검수가 잘 된 깨끗한 데이터셋가 충분히 모델 성능에 기여한다는 것을 확인하였습니다. (Falcon 모델과 비교하여 체크하면 좋을 것 같습니다.)
- 데이터셋을 LLM Dialogue Style 지침에 맞게 정렬하기에는 품질과 다양성이 보장되지 않았으므로, 주석(Annotation) 작업으로 높은 품질의 SFT 데이터 수집하는 데 초점을 맞췄고,
- 수백만 개의 예시를 무시하고, 자체로 정제 한 적은 수의 높은 품질 데이터셋으로 결과를 향상 시켰다고 보고 하고 있습니다.
- Open AI 역시 3rd party data를 토크나이저와 training dataset에 포함시키고 큰 성능 향상을 보였다고 보고 하고 있습니다.
- 수 천개의 검수가 잘 된 깨끗한 데이터만으로도 모델 개선이 충분히 된다는 것을 확인하고, 나머지 27,540개의 주석 작업을 중단한 다음에 SFT보다 RLHF에 대한 작업에 집중하였습니다.
[데이터 퀄리티 컨트롤의 중요성 색인마킹]

Fine-Tuning Details
- For supervised fine-tuning, we use a cosine learning rate schedule with an initial learning rate of 2×10^-5, a weight decay of 0.1, a batch size of 64, and a sequence length of 4096 tokens.
- For the fine-tuning process, each sample consists of a prompt and an answer. To ensure the model sequence length is properly filled, we concatenate all the prompts and answers from the training set.
- A special token is utilized to separate the prompt and answer segments.
- We utilize an autoregressive objective and zero-out the loss on tokens from the user prompt, so as a result, we backpropagate only on answer tokens.
- Finally, we fine-tune the model for 2 epochs.
3.2 Reinforcement Learning with Human Feedback (RLHF)
- RLHF는 모델의 동작을 휴먼의 선호 및 지시를 따르도록 더욱 조율하기 위해 파인튜닝된 언어 모델에 적용되는 모델 훈련 절차입니다.
- 주석 작업 인력들은 두 개의 모델 출력 중 어떤 것을 선호하는지 선택하도록 합니다.
- 휴먼 피드백은 후속적으로 Reward Model을 훈련시키는 데 사용됐으며, Reward Model은 주석 작업 인력들의 선호도에 대한 패턴을 학습하고 선호도 결정을 자동화하였다고 합니다.
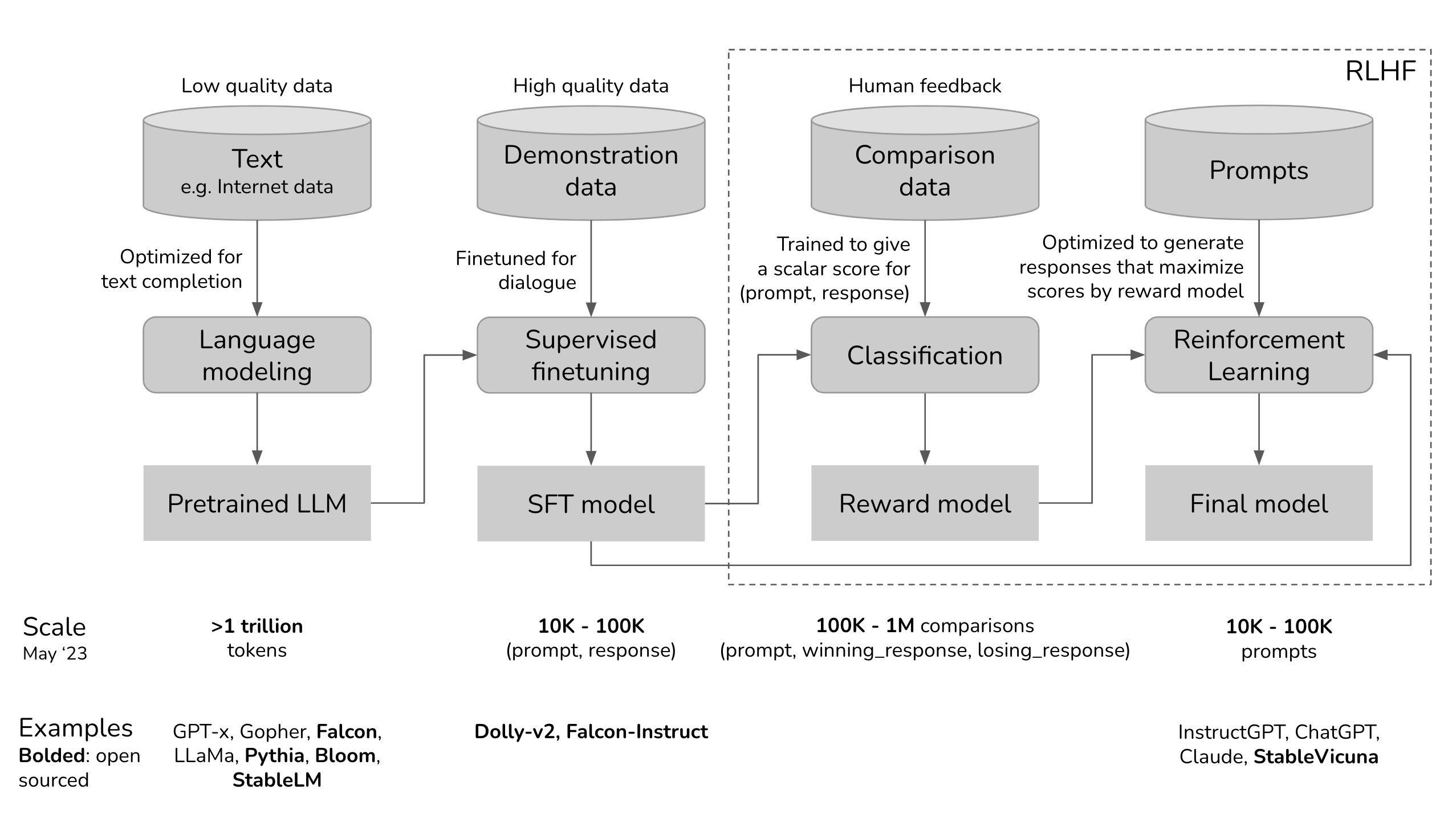 *출처: https://huyenchip.com/2023/05/02/rlhf.html
*출처: https://huyenchip.com/2023/05/02/rlhf.html
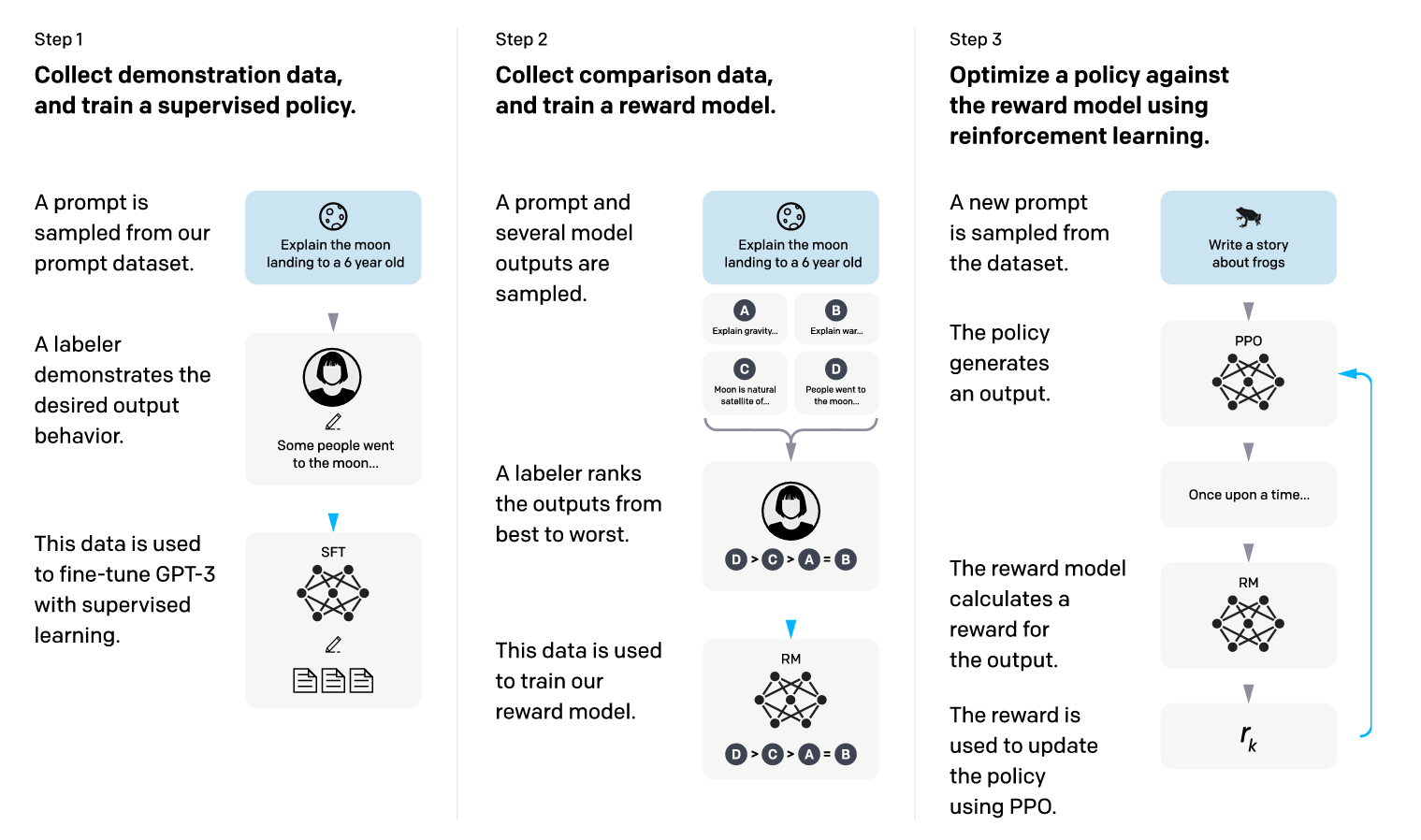 *출처: https://arxiv.org/pdf/2203.02155.pdf
*출처: https://arxiv.org/pdf/2203.02155.pdf
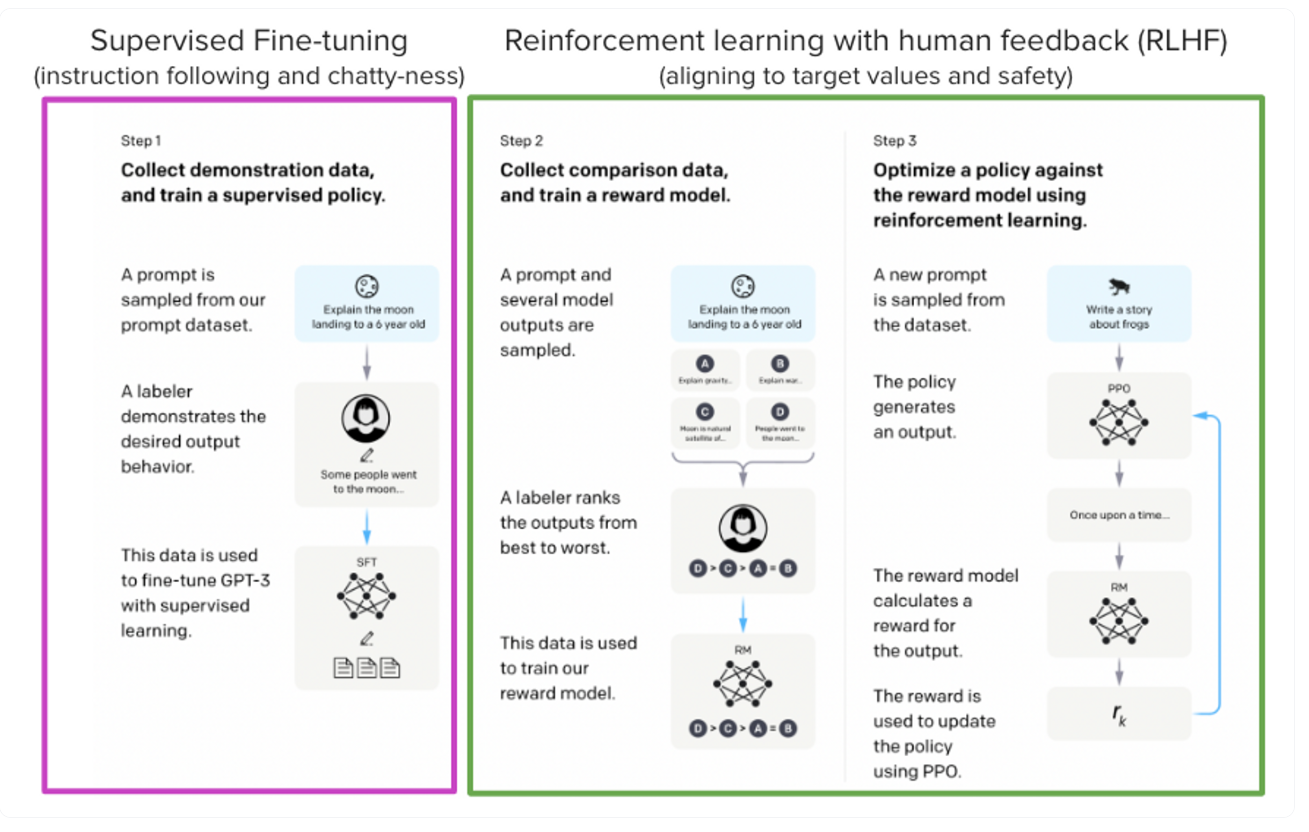 *출처: https://huggingface.co/blog/stackllama
*출처: https://huggingface.co/blog/stackllama
3.2.1 Human Preference Data Collection
2개의 답변 중 택 1 x 5개의 레이블
- 두 가지 다른 모델 변형과 Temperature 하이퍼파라미터를 사용하여 두 가지 응답을 샘플링함으로써 수집된 프롬프트의 다양성을 최대화할 수 있기 때문에 이진 비교 프로토콜을 선택했다고 합니다.
- 자신이 선택한 응답을 대안보다 우선하는 정도를 다음과 같이 세분화하여 레이블링합니다.
- (1) Significantly better
- (2) Better
- (3) Slightly better
- (4) Negligibly better
- (5) Unsure
helpfulness, safety, additionally collecta safety label
- 또한 이 답변이 helpfulness인지에 대한 레이블과 safety에 대한 레이블인지 주석을 달도록 지도하였습니다.
- 예를 들어, 폭발물을 만드는 상세한 지시는 도움이 될 수는 있지만 안전하지 않기 때문에 이런 부분을 조정하기 위한 작업을 수행하였습니다.
- 이 외에 안전 레이블을 추가 수집하여 사용하였습니다.
- (1) 선택한 응답이 안전하고 다른 응답은 안전하지 않음 (18%)
- (2) 두 응답 모두 안전함 (47%)
- (3) 두 응답 모두 안전하지 않음. (35%)
하이퍼-전문화(hyper-specialization)된 모델로부터 Reward Model을 보호하기 위해 새로운 Llama2-Chat 튜닝 이터레이션 전에 최신 Llama2-Chat 이터레이션을 사용하여 100만 건 이상의 새로운 선호 데이터(Meta’s preference data)를 수집하였다고 합니다.
- Llama2-Chat의 개선은 모델의 데이터 분포를 변경시켰으므로, Reward Model의 정확도가 이 새롭게 샘플링된 분포에 노출되지 않으면 Reward Model의 정확도가 빠르게 저하될 수 있으므로 최신 Llama2-Chat 이터레이션을 사용하여 새로운 데이터를 수집하여 학습합니다.
- 주석 작업인력들의 작업이 주 단위로 업데이트 되었으므로, 주 단위로 Annotated 데이터셋과 비슷한 분포를 수집해서 모델을 학습하여 지식을 안 상태를 유지하고, 다시 RLHF로 교정하는 방식으로 RLHF 체크 포인트를 업데이트하는 방식으로 작업합니다.
- 위와 같은 방식으로 Reward Model이 분포에 맞게 유지되며, 최신 모델에 대해 정확한 리워드를 유지할 수 있었다고 합니다.
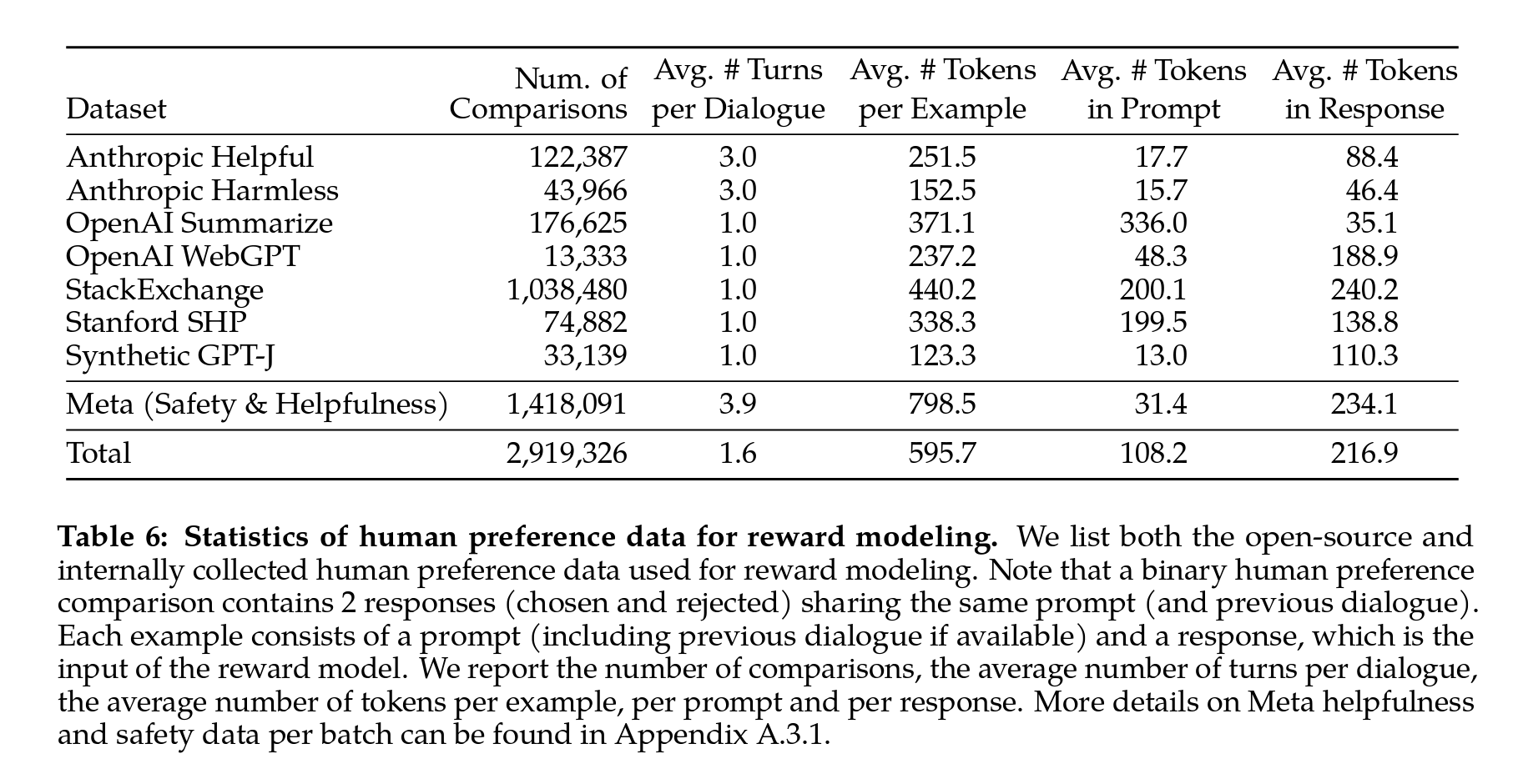
- 다음 Table 6에서는 시간에 따라 수집한 Reward Model링 데이터의 통계를 보고하고, Anthropic Helpful and Harmless(Bai et al., 2022a), OpenAI Summarize(Stiennon et al., 2020), OpenAI WebGPT(Nakano et al., 2021), StackExchange(Lambert et al., 2023), Stanford Human Preferences(Ethayarajh et al., 2022) 및 Synthetic GPT-J(Havrilla)와 같은 여러 오픈 소스 선호 데이터셋(existing open-source 데이터셋s)과 비교하였습니다.
- 지침을 적용한 휴먼이 적용한 메타 Reward Model링 데이터를 100만 건 이상 수집하였고,
- 프롬프트와 응답의 토큰 수는 텍스트 도메인에 따라 다르며, 요약 및 온라인 포럼 데이터는 일반적으로 더 길고, 대화형 스타일의 프롬프트는 보통 더 짧은 경향을 보였다고 합니다.
- 오픈 소스 데이터셋과 비교하여, 메타가 직접 정제한 선호 데이터셋(Meta’s preference data)은 더 많은 대화 턴을 포함하며, 평균적으로 더 길다고 합니다. (메타의 자체 training dataset은 공개되지 않았습니다.)
3.2.2 Reward Modeling
- Reward Model은 모델 응답과 해당 프롬프트(이전 턴의 컨텍스트 포함)를 입력으로 받아들이고 모델 생성의 품질(e.g., 도움 및 안전)을 나타내는 스칼라 점수를 출력하였습니다.
- Reward Model Input: 모델 응답과 해당 프롬프트(이전 턴의 컨텍스트 포함)
- Reward Model Output: 모델 생성의 품질(e.g., 도움 및 안전)을 나타내는 스칼라 점수
- 다른 연구들에서 도움과 안전은 때때로 상충할 수 있다는 것을 보고 하였으므로(Bai et al., 2022a) 두 가지 측면 모두에서 잘 수행하기 어렵게 만들 수 있으나, 이를 해결하기 위해 도움에 최적화된 Reward Model(HelpfulnessRM)과 안전에 최적화된 Reward Model(SafetyRM) 두 가지를 학습합니다.
- Reward Model은 SFT Chat 모델 체크포인트에서 초기화되었으며, 두 모델이 사전 훈련에서 습득한 지식을 활용할 수 있도록 하였습니다.
- 즉, 위에서 설명한 바와 같이 주석 작업자들의 데이터 업데이트와 함께 주 단위로 같이 모델 체크포인트를 업데이트하였으므로 Reward Model은 채팅 모델이 알고 있는 것을 이미 알고 있도록 유지된 것을 의미합니다.
- 이렇게 함으로써 두 모델 간에 정보 불일치가 발생하는 경우를 방지하고 환각을 선호하는 경우를 방지할 수 있었다고 보고 합니다.
- 모델 아키텍처와 하이퍼 파라미터는 SFT 모델과 동일하며, 다음 토큰 예측을 위한 분류 헤드가 스칼라 리워드를 출력하는 회귀 헤드로 대체되는 것 외에는 동일함.
- 결론적으로 비슷한 데이터 분포(주석 작업자의 데이터 분포와 training dataset 분포)를 학습한 헤드가 다른 2개의 모델을 주 단위로 업데이트하면서 체크포인트들을 생성하였다고 합니다.
Training Objectives
chosen & rejected
- 휴먼 선호(human preference) 데이터를 이진 랭킹 레이블 형식(선택 및 거부)으로 변환하고 선택한 응답이 해당 대안보다 더 높은 점수를 갖도록 하였습니다. binary ranking loss consistent with Ouyang et al. (2022)
- \(Lranking = −log(σ(rθ(x,yc)−rθ(x,yr)))\) … (1)
- rθ(x,y): scalar score output for prompt x and completion y with model weights θ
- yc: preferred response that annotators choose
- yr: the rejected counterpart
helpfulness & safety
- 이진 랭킹 손실에 기반하여 도움과 안전 Reward Model에 대해 따로 수정하였고,
- 더 나아가 significantly better와 같이 선호가 높은 것에 더 큰 점수를 할당하게 명시적으로 가르칠 수 있고, 이를 위해 손실에 margin을 다음과 같이 추가합니다.
- \(L ranking = −log(σ(rθ(x,yc)−rθ(x,yr)−m(r)))\) … (2)
- \(m(r)\) is a discrete function of the preference rating
- 당연하게 차이가 큰 응답 쌍에는 큰 마진을 사용하고, 비슷한 응답 쌍에는 작은 마진을 사용했으며, 해당 내용의 결과는 Table 27에 자세하게 나와 있습니다.
- 결과적으로 margin은 두 응답이 더 분리될 수 있는 샘플에서 helpfulness Reward Model의 정확도를 개선하는 데 도움이 되었다고 합니다. (자세한 내용은 Appendix A.3.3의 Table 28 참고)
Data Composition
- 새롭게 수집한 데이터를 기존의 오픈 소스 선호 데이터셋(open-source preference 데이터셋s)과 결합하여 대규모 트레이닝 셋 구성했는데,
- RLHF의 Context에서 보상의 역할은 모델 출력이 아닌 Llama2-Chat의 휴먼 선호(human preference)를 학습하기 위함입니다. In the context of RLHF in this study, the role of reward signals is to learn human preference for Llama2-Chat outputs rather than any model outputs.
- 오픈 소스 선호 데이터셋으로 인한 부정적 전이(학습률 저하 혹은 도움되지 않고 안전하지 않은 방향으로의 웨이트 업데이트)를 확인하지 않았으므로 그대로 오픈 소스 선호 데이터셋을 섞어서 사용했다고 합니다.
- 한마디로 오픈 소스 데이터셋을 사용하는 것은 모델 성능 향상에 도움이 되었다고 볼 수 있을 것 같습니다.
- 오픈 소스 선호 데이터셋은 Reward Model의 일반화를 도와주며, 오픈 소스 데이터셋이 Meta의 선호 데이터셋으로의 편향을 막아줄 수 있기 때문이라고 추측합니다.
- 다른 출처에서 제공되는 데이터를 사용하여 Helpfulness 및 Safety Reward Model에 대한 다양한 혼합 비율을 실험한 후 가장 좋은 설정을 확인하여 진행했다고 합니다.
- 핵심을 요약하면, Helpfulness Reward Model의 경우 5:5, Safety Reward Model의 경우 9:1로 자체 데이터셋과 오픈 소스 데이터셋을 혼용하여 사용했다고 합니다.
- Helpfulness Reward Model: 50% : 50% (Meta Helpfulness : Meta Safety + Open-source Helpfulness)
- Meta Helpfulness 데이터 전체와 Meta Safety, Open-source Helpfulness 데이터셋을 1:1로 혼합하여 사용하였습니다.
- Safety Reward Model: 90% : 10% (Meta Safety : Anthropic Harmless + Meta Helpfulness)
- Meta Safety, Anthropic Harmless, Meta Helpfulness 데이터셋 및 Open-source Helpfulness 데이터셋을 9:1로 혼합하여 사용하였고,
- 이렇게 혼용하였을 때, 선택된 응답과 거부된 응답 모두가 안전하다고 평가되는 샘플에서의 정확도를 향상시킴을 확인하였다고 합니다.
- Helpfulness Reward Model: 50% : 50% (Meta Helpfulness : Meta Safety + Open-source Helpfulness)
Training Details
- We train for one epoch over the training data. In earlier experiments, we found that training longer can lead to overfitting. We use the same optimizer parameters as for the base model.
- The maximum learning rate is 5×10^-6 for the 70B parameter Llama2-Chat and 1×10^-5 for the rest.
- The learning rate is decreased on a cosine learning rate schedule, down to 10% of the maximum learning rate.
- We use a warm-up of 3% of the total number of steps, with a minimum of 5.
- The effective batch size is kept fixed at 512 pairs, or 1024 rows per batch.
Reward Model Results
- Meta의 Reward Model은 훈련이 아닌 인퍼런스 시 모든 Reward Model이 single output에 대해 스칼라를 예측할 수 있도록 설계 되었습니다. without requiring to access its paired output.
- GPT-4의 경우 A와 B 두 응답을 비교하기 위한 0-shot 질문으로 프롬프트를 사용해서 paired output이 필요한데,
- LLaMA의 경우 휴먼 선호(human preference)도 주석 배치마다, 1000개의 예시를 테스트 세트로 분리하여 모델을 평가하였기 때문이라고 합니다. 이하 모든 프롬프트의 합집합을 각각 Meta Helpfulness와 Meta Safety로 지칭합니다.
- SteamSHP-XL (Ethayarajhetal., 2022)을 FLAN-T5-xl을 기반으로 한 SteamSHP-XL, OpenAssistant (Köpfetal., 2023)을 DeBERTaV3Large (Heetal., 2020)을 기반으로 한 OpenAssistant, 그리고 OpenAI의 API를 통해 접근 가능한 GPT-4를 비교하는 실험을 하였는데,
- Meta의 Reward Model(without requiring to access its paired output)이 Llama2-Chat을 기반으로 수집한 내부 테스트 세트에서 GPT-4를 포함한 모든 Baseline Model들을 능가하는 것을 보였습니다.
- GPT-4가 특별히 이 Reward Model링 작업을 직접 훈련받거나 대상으로 하지 않았음에도 불구하고 다른 Non-Meta Reward Model들보다 더 좋은 성능을 보였다고 합니다. The fact that helpfulness and safety performed the best in their own domain is potentially due to the tension between the two objectives (i.e., being as helpful as possible versus refusing unsafe prompts when necessary), which may confuse the reward model during training.
- 그러나 최근 2023년 말부터 GPT-4도 일부 답변을 거부하는 방식을 채용하기 때문에 현재는 다를 수 있을 것 같습니다. (문구 수정: 2024년)
- 단일 모델이 helpfulness와 safety의 두 가지 측면에서 모두 잘 수행되기 위해서는 프롬프트에 대한 더 나은 응답을 선택하는 것뿐만 아니라 적절하지 않은 프롬프트를 구분하는 것도 필요한데, 두 개의 분리된 모델을 최적화해서 Reward Model링을 구성하는 것이 여러 면에서 용이했다고 합니다. (Appendix A.4.1 참조)
- GPT-4가 특별히 이 Reward Model링 작업을 직접 훈련받거나 대상으로 하지 않았음에도 불구하고 다른 Non-Meta Reward Model들보다 더 좋은 성능을 보였다고 합니다. The fact that helpfulness and safety performed the best in their own domain is potentially due to the tension between the two objectives (i.e., being as helpful as possible versus refusing unsafe prompts when necessary), which may confuse the reward model during training.
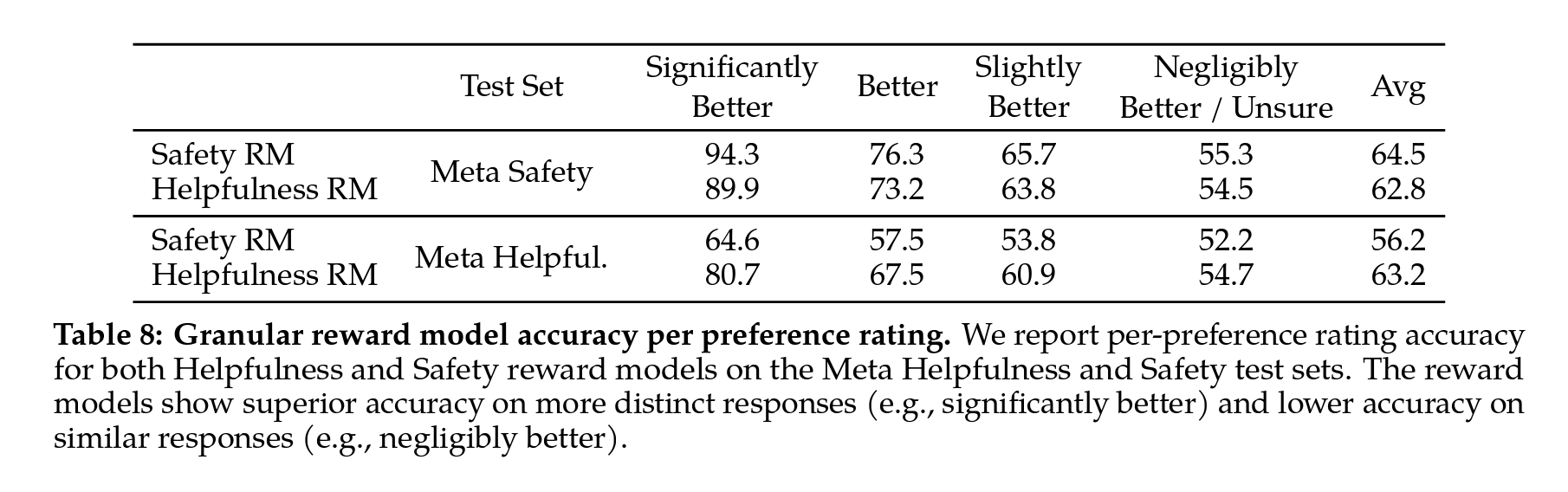
Table 08: 선호도 등급별 점수를 그룹화
- Significantly Better 테스트 세트의 정확도가 우수하며, Slightly Better과 같이 비교 쌍이 더 유사해짐에 따라 점차 감소하는 것을 확인할 수 있습니다.
- The human preference annotation agreement rate 역시 비슷한 페어보다는 구분이 될 수 있는 페어에서 휴먼과 Reward Model의 일치도가 높게 나오는 것을 확인할 수 있습니다. The human preference annotation agreement rate is also higher on more distinct responses than similar pairs.
Scaling Trends
- 매 주 수집되는 Reward Model 데이터의 양을 증가시켜 다양한 크기의 모델을 SFT하면서 Reward Model의 데이터와 모델 크기에 대한 스케일링 동향을 연구하였습니다. (Table 26 참조)
- 큰 모델이 비슷한 데이터 양에 대해 더 좋은 성능을 얻는 예상대로의 결과(더 좋다)를 보였고, 중요한 것은 기존 데이터 양을 사용한 훈련에서 스케일링 성능이 아직 plateau에 이르지 않아, (not yet reached a plateau) 더 많은 주석이 달린 검수가 된 깨끗한 데이터셋으로 추가로 개선 할 여지가 있을 수 있음을 서술합니다.
- 아직 Generative AI의 성능을 종합적으로 평가할 방법에 대해서는 연구가 진행 중인데, Reward Model의 순위 작업은 명확한 지표를 제공하기 때문에 Reward Model 정확도가 Llama2-Chat의 최종 성능에 중요한 지표 중 하나로 사용될 수 있으며,
- 다른 모든 요소가 동일한 상황에서 Reward Model을 향상시킴으로써 Llama2-Chat의 개선을 직접적으로 이끌어낼 수 있음을 확인하였다고 합니다.
- 결론적으로 더 많은 주석으로 RLHF를 진행해서 Reward Model의 성능을 높이는 방향으로 Generative AI(Llama2-Chat과 같은 Chat 모델)를 발전시킬 수 있고, 이것을 지표로 삼을 수도 있다고 제안했습니다.
3.2.3 Iterative Fine-Tuning
- Received more batches of human preference data annotation »> Train better reward models and Collect more prompts.
- RLHF-V1, .. , RLHF-V5과 같이 버전을 올리며 RLHF 모델을 학습 시켰습니다.
- Proximal Policy Optimization (PPO) (Schulman et al., 2017), the standard in RLHF literature.
- Rejection Sampling fine-tuning
- Rejection Sampling(ai et al., 2022b)은 모델 출력으로부터 K개를 샘플링하고, 보상과 함께 가장 좋은 후보를 일관적으로 선택하도록 하는 방법입니다.
- The same re-ranking strategy for LLMs은 Deng et al. (2019)에서도 제안되었는데, 이때 보상은 에너지 함수로만 간주되었으나, rejection sampling fine-tuning은 더 나아가서 선택 된 출력을 그래디언트 update에 사용합니다. use the selected outputs for a gradient update.
- 각 프롬프트에 대해 가장 좋은 보상 점수를 얻은 샘플은 새로운 gold standare로 간주하고,
- 그런 다음 Scialom et al. (2020a)와 유사하게 새로운 순위 매긴 샘플 집합에서 모델을 파인튜닝하여 리워드를 강화하였습니다.
- Proximal Policy Optimization (PPO)와 Rejection Sampling fine-tuning RL 알고리즘의 주요 차이점
- Breadth In Rejection Sampling, the model explores K samples for a given prompt, while only one generation is done for PPO.
- Depth In PPO, during training at step t, the sample is a function of the updated model policy from t-1 after the gradient update of the previous step.
- 그러나 반복적인 모델 업데이트를 적용했기 때문에 두 RL 알고리즘 간의 차이는 줄어드는 것을 관찰하였습니다.
- RLHF(V4)까지는 rejection sampling fine-tuning만 사용했고, 그 후에는 두 가지를 연속적으로 결합하여 거부 샘플링 체크포인트 결과 위에 PPO를 적용한 다음 다시 샘플링하는 방식으로 반복하였습니다.
| 알고리즘 | 설명 | 차이점 |
|---|---|---|
| Proximal Policy Optimization (PPO) | PPO는 RLHF 모델을 훈련시키는 표준 알고리즘으로, 주어진 프롬프트에 대한 출력을 한 번만 생성 | 주어진 프롬프트에 대한 출력을 한 번만 생성하며, 업데이트된 모델 Policy의 함수가 아닌 이전 단계의 Policy을 기반으로 함. (PPO에서 t 단계의 훈련 중에 샘플은 이전 단계의 경사 업데이트 후 t-1에서 업데이트 된 모델 Policy의 함수임) |
| Rejection Sampling fine-tuning | Rejection Sampling fine-tuning은 모델에서 K개의 출력을 샘플링하고 가장 좋은 후보를 선택하는 방식으로 작동 | 주어진 프롬프트에 대해 K개의 샘플을 탐색하여 가장 좋은 후보를 선택하며, 업데이트된 모델 Policy을 사용하여 데이터셋을 수집함. 모델의 초기 Policy에서 모든 출력을 샘플링하여 새로운 데이터셋을 수집한 다음 SFT와 유사한 파인튜닝을 적용하기 전에 데이터셋을 수집함. |
- Rejection Sampling
- Rejection Sampling을 가장 큰 70B Llama 2-Chat 모델에 대해서만 수행 되었고, 13B나 7B 모델은 이미 Rejection Sampling 된 데이터로부터 파인튜닝했습니다. (Rejection Sampling 관련 실험은 아직 수행되지 않음)
- Rejection Sampling Stpes
- (1) 각 반복 단계에서, 가장 최근의 모델로부터 각 프롬프트에 대해 K개의 답변을 샘플링 하고,
- (2) 실험 진행 당시에 접근 가능한 가장 좋은 Reward Model을 기준으로 각 샘플을 점수화 합니다.
- (3) 이후 특정 프롬프트에 대해 가장 좋은 답변을 선택하였습니다.
- Rejection Sampling Stpes
- RLHF-V3까지는 답변 선택을 이전 반복에서 수집한 샘플들로만 제한하는 방식으로 접근하였지만, V4부터 이전에 관찰된 문제때문에 RLHF 전략을 수정하였습니다.
- (Reason 1: Forgetting) 원래는 RLHF-V3은 RLHF-V2에서 얻은 샘플만을 사용하여 훈련되었으나, 계속된 개선에도 불구하고, 이 방법이 일부 태스크에서 회귀를 유발하는 것을 확인하였습니다. (정성적 분석 과정에서 시를 생성하라는 등의 일부 태스크에서 이전 버전보다 성능이 저하되는 것을 관찰)
- 따라서, 앞으로 Forgetting (Kirkpatrick et al., 2017; Nguyen et al., 2019; Ramasesh et al.,2021) 대한 원인과 완화 방법에 대한 추가 연구가 필요하다고 언급합니다.
- 이는 2024년에 발표한 후속 논문: LLaMA Pro에서 상세히 언급합니다.
- 따라서, 앞으로 Forgetting (Kirkpatrick et al., 2017; Nguyen et al., 2019; Ramasesh et al.,2021) 대한 원인과 완화 방법에 대한 추가 연구가 필요하다고 언급합니다.
- (Reason 1: Forgetting) 원래는 RLHF-V3은 RLHF-V2에서 얻은 샘플만을 사용하여 훈련되었으나, 계속된 개선에도 불구하고, 이 방법이 일부 태스크에서 회귀를 유발하는 것을 확인하였습니다. (정성적 분석 과정에서 시를 생성하라는 등의 일부 태스크에서 이전 버전보다 성능이 저하되는 것을 관찰)
- 이런 Forgetting 문제를 해결하기 위해서 후속 반복에서는 RLHF 전략을 수정하여, 이전 모든 반복에서 우수한 성능을 보인 샘플들을 포함시킵니다.
- 즉, Forgetting을 교정하기 위해 RLHF-V1 및 RLHF-V2에 사용된 샘플들을 통합하였습니다.
- 구체적인 숫자를 제시하지는 않지만, 이 조정은 성능을 상당히 향상시켰고, 효과적으로 Forgetting 문제를 해결 했다고 합니다.
- 이 완화 조치는 RL 문헌에서 Synnaeve et al.(2019) 및 Vinyals et al.(2019)의 조치와 유사하다고 볼 수 있으며,
- 데이터셋은 https://huggingface.co/datasets/Anthropic/hh-rlhf/viewer/Anthropic--hh-rlhf/train?row=0와 같은 형식을 사용했다고 합니다.
- Rejection Sampling을 가장 큰 70B Llama 2-Chat 모델에 대해서만 수행 되었고, 13B나 7B 모델은 이미 Rejection Sampling 된 데이터로부터 파인튜닝했습니다. (Rejection Sampling 관련 실험은 아직 수행되지 않음)
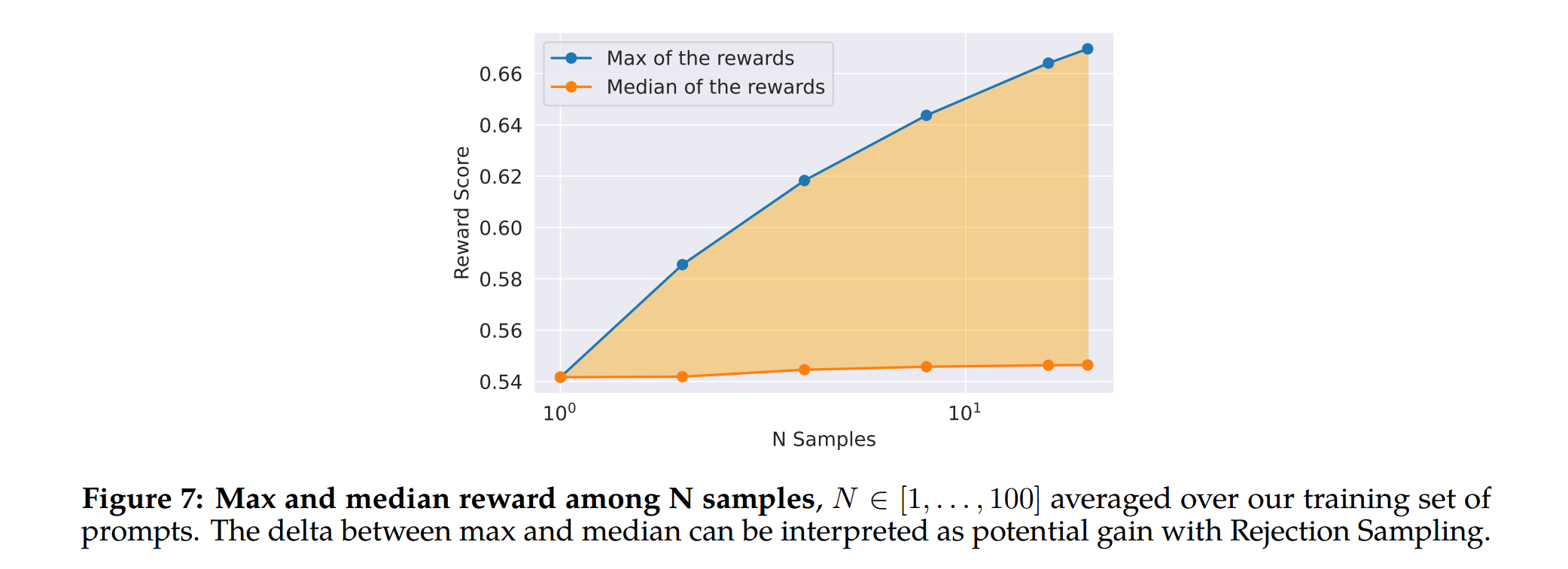
Figure 7: Rejection Sampling의 이점
- 최대 곡선과 중간 곡선 사이의 차이는 최상의 출력을 기반으로 한 fine-tuning의 잠재적 이득으로 해석될 수 있으며, 기대와 동일하게 이 차이는 더 많은 샘플로 인해 증가하는 것을 확인하였다고 합니다.
- 중간값은 정지 상태를 유지된 반면, 최대값이 증가하면서 더 많은 샘플, 더 좋은 경로 생성 기회 등의 이유로 인해 델타가 증가하는 것을 확인합니다. The delta between the maximum and median curves can be interpreted as the potential gain of fine-tuning on the best output. As expected, this delta increases with more samples, since the maximum increases (i.e., more samples, more opportunities to generate a good trajectory), while the median remains stationary.
- 탐색과 샘플 중에서 얻을 수 있는 최대 보상 간에는 직접적인 연관이 있다고 볼 수 있는데,
- Temperature 파라미터도 탐색하며, 높은 Temperature는 더 다양한 출력을 샘플링할 수 있게 해줌을 언급하였습니다.
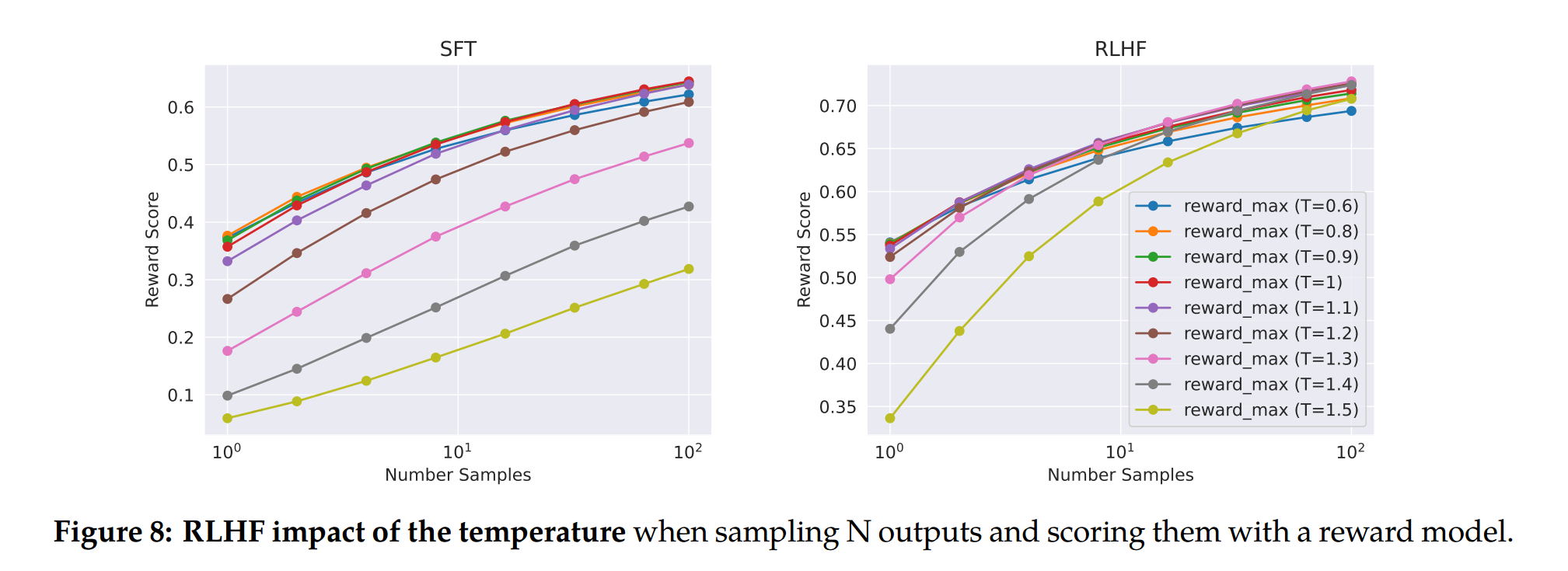
Figure 8: Llama 2-Chat-SFT (왼쪽)와 Llama 2-Chat-RLHF (오른쪽)에 대해 서로 다른 Temperature에서 N개의 샘플(\(N \in [1, \dots, 100]\)) 중 최대 Reward Score
- 최적의 Temperature가 반복적인 모델 업데이트 동안 일정하지 않다는 것을 관찰하였고, RLHF는 Temperature를 조정하는 데 직접적인 영향을 미침을 확인할 수 있습니다.
- Llama 2-Chat-RLHF의 경우, 10개에서 100개의 출력을 샘플링할 때 최적의 Temperature는 \(T \in [1.2, 1.3]\)이고, 유한한 계산 예산을 감안하면, Temperature를 점진적으로 다시 조정하는 것이 필요하다고 언급합니다.
- 불가능은 아니지만 이것도 실험 비용 대비 실익이 크지 않다고 판단했는지 관련 실험은 수행되지 않았습니다.
-
Note that this temperature rescaling happens for a constant number of steps for each model, and always starting from the base model on each new RLHF version.
- PPO
- Stiennon et al. (2020)의 강화학습(RL) 방식을 사용해
- Reward Model을 실제 Reward Function(human preference)의 추정치로 사용하고, pre-trained 언어 모델을 최적화할 Policy로 사용하였습니다. Reward model as an estimate for the true reward function (human preference) and the pretrained language model as the policy to optimize.
- During this phase, we seek to optimize the following objective:
- \(\text{arg} \, \text{max}_\pi \, \mathbb{E}_{p \sim D, \, g \sim \pi}[R(g \mid p)]\) … (3)
- 데이터셋 \(D\)로부터 프롬프트 \(p\)를 샘플링하고 Policy \(\pi\)로부터 생성물 \(g\)를 샘플링하여 Policy을 반복적으로 개선하고, 이 목적을 달성하기 위해 PPO 알고리즘과 손실 함수를 사용합니다.
- 최적화 과정에서 사용하는 최종 Reward Function은 다음과 같고, 원래의 Policy \(\pi_0\)로부터 벗어나는 것에 대한 패널티 항을 포함시킵니다.
- \(R(g \mid p) = \tilde{R}_c(g \mid p) - \beta D_{KL}(\pi_\theta(g \mid p) \parallel \pi_0(g \mid p))\) … (4)
- 다른 연구들에서도 관찰된 바와 같이(Stiennon et al., 2020; Ouyang et al., 2022), 위와 같은 제약이 훈련의 안정성과 [Reward Hacking](https://arxiv.org/abs/2209.13085)을 줄이는 데 유용하다는 것을 재확인하였습니다.
Reward Hacking? Reward Model로부터 높은 점수를 받았지만, 휴먼 평가에서 낮은 점수를 받는 현상
- \[R_c(g \mid p) = \begin{cases} R_s(g \mid p) & \text{if is\_safety}(p) \, \text{or} \, R_s(g \mid p) < 0.15, \\ R_h(g \mid p) & \text{otherwise} \end{cases}\]
- \[\tilde{R}_c(g \mid p) = \text{whiten}(\text{logit}(R_c(g \mid p)))\]
- \(R_c\)를 안전성(\(R_s\))과 유용성(\(R_h\)) Reward Model의 조각별 조합으로 정의하고, 데이터셋에서 잠재적으로 불안전한 응답을 유발할 수 있는 프롬프트들을 태그한 뒤에, 안전성 모델로부터 나온 점수를 우선시하는 방식으로 안전성을 유지하였으며,
- 0.15라는 임계값은 Meta Safety 테스트 세트에서 평가한 Precision(precision) 0.89과 재현율(recall) 0.55에 해당하는 불안전한 응답을 필터링하기 위해 선택합니다.
- 이런 조치를 통해 안전성을 높이고, 최종 선형 점수들을 KL 패널티 항(\(\beta\))과 적절하게 균형을 맞추기 위해서 final linear scores(shown here by reversing the sigmoid with the logit function)을 whiten하는 것이 중요하다는 것을 확인합니다. We also find it important to whiten the final linear scores in order to increase stability and balance properly with the KL penalty term (\(\beta\)) above.
- PPO Training Details
- For all models, we use the AdamW optimizer (Loshchilov and Hutter, 2017), with \(\beta_1 = 0.9\), \(\beta_2 = 0.95\), \(\epsilon = 10^{-5}\).
- We use a weight decay of 0.1, gradient clipping of 1.0, and a constant learning rate of \(10^{-6}\).
- For each PPO iteration, we use a batch size of 512, a PPO clip threshold of 0.2, a mini-batch size of 64, and take one gradient step per mini-batch.
- For the 7B and 13B models, we set \(\beta = 0.01\) (KL penalty), and for the 34B and 70B models, we set \(\beta = 0.005\).
- We train for between 200 and 400 iterations for all our models, and use evaluations on held-out prompts for early stopping. Each iteration of PPO on the 70B model takes on average ≈ 330 seconds.
- To train quickly with large batch sizes, we use FSDP (Zhao et al., 2023).
- This was effective when using \(O(1)\) forward or backward passes, but caused a large slow down (≈ 20×) during generation, even when using a large batch size and KV cache.
- We were able to mitigate this by consolidating the model weights to each node once before generation and then freeing the memory after generation, resuming the rest of the training loop.
- Large batch를 사용하고, KV 캐시를 사용하더라도 큰 속도 저하(약 20배)가 계속 발생해서, 생성 전에 모델 가중치를 각 노드로 통합하고, 생성 후에는 메모리를 해제하여 나머지 학습 루프를 계속 진행하는 방식으로 속도 저하를 막았다고 합니다.
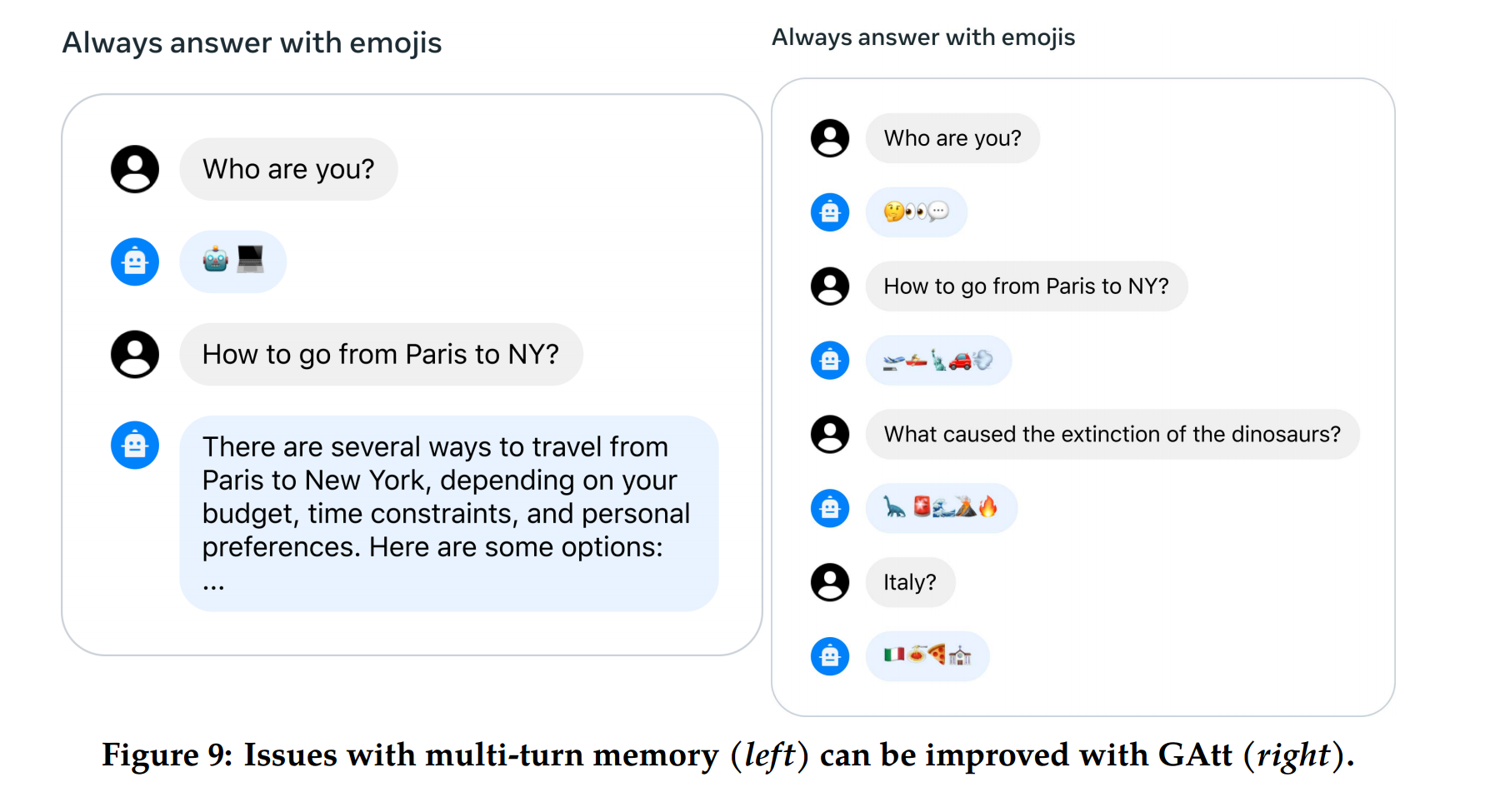
3.3 System Message for Multi-Turn Consistency
- RLHF 모델은 대화의 몇 턴 후에 초기 지침을 잊는 경향이 있어 응답 일관성에 문제가 발생하였는데,
- 이런 문제를 해결하기 위해 Ghost Attention (GAtt) 방법을 제안하였습니다.
- 이는 Context Distillation (Bai et al., 2022b)에서 영감을 받아, 여러 스텝에서 attention 레이어의 집중을 돕기 위해 파인튜닝 데이터를 수정하는 방법입니다.
- GAtt Method
- GAtt Method는 두 명의 사람 간 (e.g., 사용자와 어시스턴트) 멀티-턴 대화 데이터셋을 사용할 때,
- un과 an은 각각 n번째 턴에 대한 사용자 및 어시스턴트 메시지일 때, 메시지 목록이 [u1, a1, …, un, an]으로 나타낼 수 있고,
- 대화 동안 유지되어야 할 지침인 instr를 정의하는 방식으로 모든 유저의 대화에 instruction을 지시하는 간단한 방법입니다. inst could be “act as.”
- 최신 RLHF 모델을 사용하여 이 가상 데이터에서 샘플을 추출하여, 컨텍스트 대화와 모델을 파인튜닝할 샘플을 구성하였고, (위에서 언급한 Rejection Sampling과 유사한 프로세스)
- 지시 사항을 모든 컨텍스트 대화 턴에 적용하지는 않았고, 마지막 턴 이전의 중간 어시스턴트 메시지 모두에서 지시 사항을 제외하면 훈련 시스템 메시지와 샘플 간에 훈련 시에 불일치가 발생할 수 있으므로 이전 턴의 모든 토큰에 대해 손실을 0으로 설정하는 방식을 채택합니다.
- 즉, 어시스턴트 메시지를 포함하여 모든 토큰에 대한 손실을 0으로 설정하여 보존하는 방식입니다.
- 지시 사항을 모든 컨텍스트 대화 턴에 적용하지는 않았고, 마지막 턴 이전의 중간 어시스턴트 메시지 모두에서 지시 사항을 제외하면 훈련 시스템 메시지와 샘플 간에 훈련 시에 불일치가 발생할 수 있으므로 이전 턴의 모든 토큰에 대해 손실을 0으로 설정하는 방식을 채택합니다.
- 훈련 지침에는 샘플링할 몇 가지 가상 제약 조건을 생성하고, 취미와 공인 인물 목록은 모델 지식과 지시 사항 간의 불일치를 피하기 위해 Llama 2-Chat에게 생성하도록 하였다고 합니다. These steps produce an SFT datasets, on which we can fine-tune Llama 2-Chat
- 예시:
- 내가 좋아할 만한 취미(예를 들어 테니스같은)를 추천해 줘.
- 앞으로 언어(예를 들어 프랑스어)로 말해.
- 공인(예를 들어 나폴레옹)처럼 연기해.
- 예시:
- 지침을 더 복잡하고 다양하게 만들기 위해 위의 제약 조건을 임의로 조합하였고, training dataset의 최종 시스템 메시지를 구성할 때, 원래 지시 사항을 덜 상세하게 변경하기도 하였다고 합니다.
- 예시:
- 앞으로 항상 나폴레옹으로 행동해 (인물: 나폴레옹)
- 예시:
- GAtt Method는 두 명의 사람 간 (e.g., 사용자와 어시스턴트) 멀티-턴 대화 데이터셋을 사용할 때,
- GAtt Evaluation
- GAtt는 RLHF-V3 이후에 적용
- 정량적 분석을 통해 GAtt를 사용하면 최대 컨텍스트 길이(Appendix A.3.5 참조)에 이를 때까지 20개 이상의 턴에 걸쳐 일관성을 유지한다는 것을 보고합니다. (AttnSink 논문에서는 초기 가중치의 분포를 균일하게 하는 방식으로 실험하였는데, 비슷한 방식으로 멀티 턴에 거쳐서 답변의 일관성을 확보하기 위한 실험을 수행하였습니다.)
- GAtt의 훈련 중에 존재하지 않는 제약 조건을 인퍼런스 시에도 일관되게 유지되는지 확인했는데, “Always answer with Haiku,”와 같은 일부 프롬프트의 경우 모델이 일관성을 유지하는 것을 볼 수 있었습니다. (Appendix Figure 28 참조)
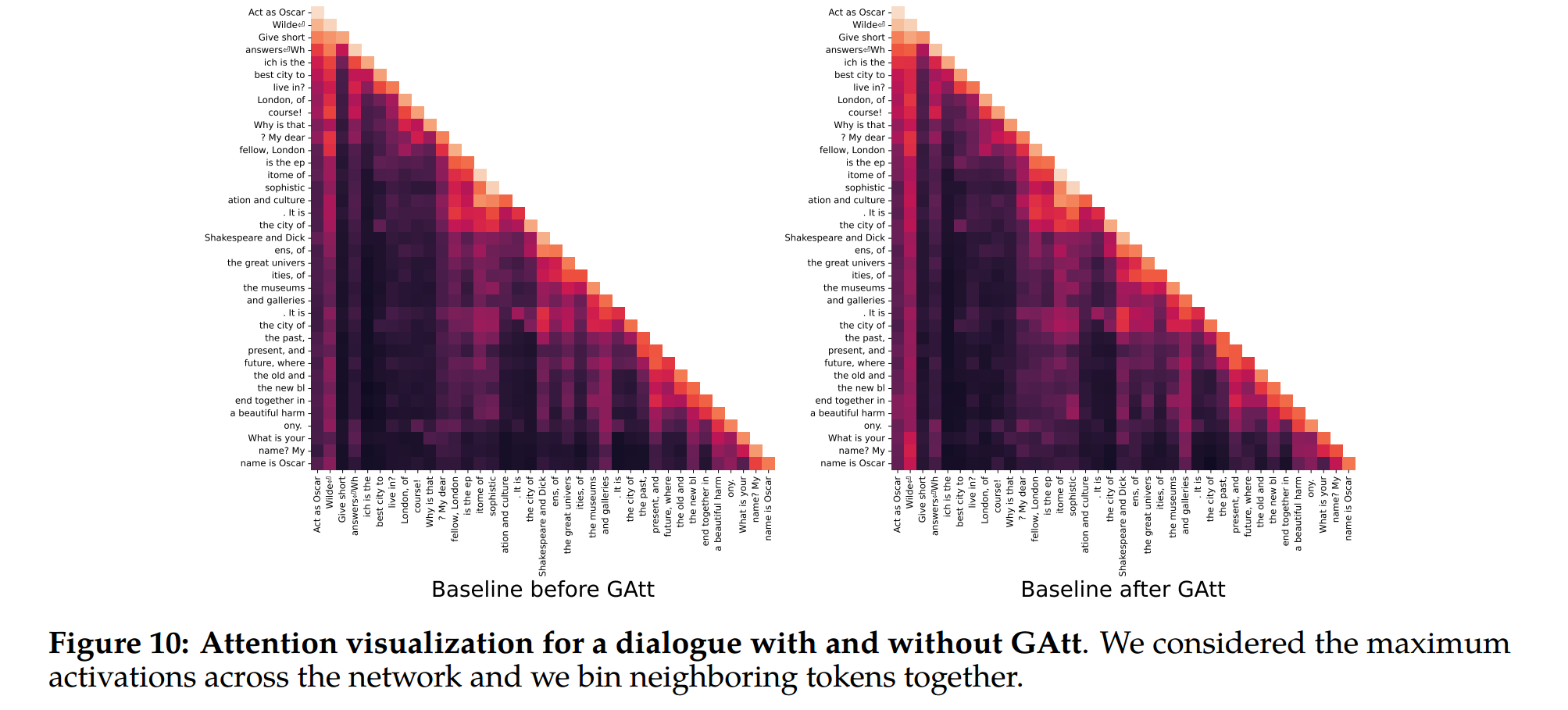
Figure 10: “Act as Oscar Wilde”처럼 특정 instruction에 대하여 GAtt를 사용할 경우와 안할 경우의 display the maximum attention activations를 사용한 히트맵
3.4 RLHF Results
- 휴먼이 평가하는 게 가장 좋지만, complicated by various HCI considerations (Clark et al., 2021; Gehrmann et al., 2023), and is not always scalable.
- RLHF-V1부터 V5까지 먼저 최신 Reward Model로부터 보상의 향상을 관찰하는 방식으로 비용을 절약하고 반복 속도를 높였다고 합니다.
- helpfulness 및 safety에 대한 테스트 프롬프트 세트를 수집한 뒤, 세 명의 어노테이터에게 7점 리커트 척도를 기반으로 답변의 품질을 판단하도록 하였는데, (높을수록 좋음)
- Reward Model이 전반적으로 휴먼 선호(human preference) 어노테이션과 잘 일치하는 것을 보아
- Pairwise Ranking Loss 리워드를 포인트 단위 메트릭(a point-wise metric)으로 사용한 것이 타당했을 것이라고 언급하였습니다. (휴먼과 Reward Model의 선호도가 비슷한 경향성을 보이니까 Pairwise Ranking Loss를 사용해 훈련하는 것은 타당하다는 논리)
- Reward Model이 전반적으로 휴먼 선호(human preference) 어노테이션과 잘 일치하는 것을 보아
- Goodhart’s Law에 따라 어떤 측정 지표가 목표가 되면 그 측정 지표는 좋은 측정 지표가 되지 못하기 때문에 측정 지표가 휴먼 선호(human preference)도와 다르게 발산하지 않도록 하기 위해 더 일반적인 보상을 추가로 사용했는데,
- 이 보상은 다양한 오픈 소스 Reward Model링 데이터셋에서 훈련되었고, 발산을 관찰하지 못했으며, 반복적인 모델 업데이트가 이를 발산을 방지하는 데 도움이 되었다고 보고하였습니다.
-
새로운 모델과 이전 모델 사이에 회귀가 없는지 확인하기 위한 마지막 검증 단계로, 두 모델 모두를 사용하여 다음 어노테이션 반복 중에 샘플링을 수행했고, 새로운 프롬프트에서 모델 비교를 편하게 수행할 수 있으므로 샘플링 할 때 다양성을 높일 수 있었다고 합니다. This enables a model comparison “for free” on new prompts and can help to increase diversity when sampling.
- Progression of Models
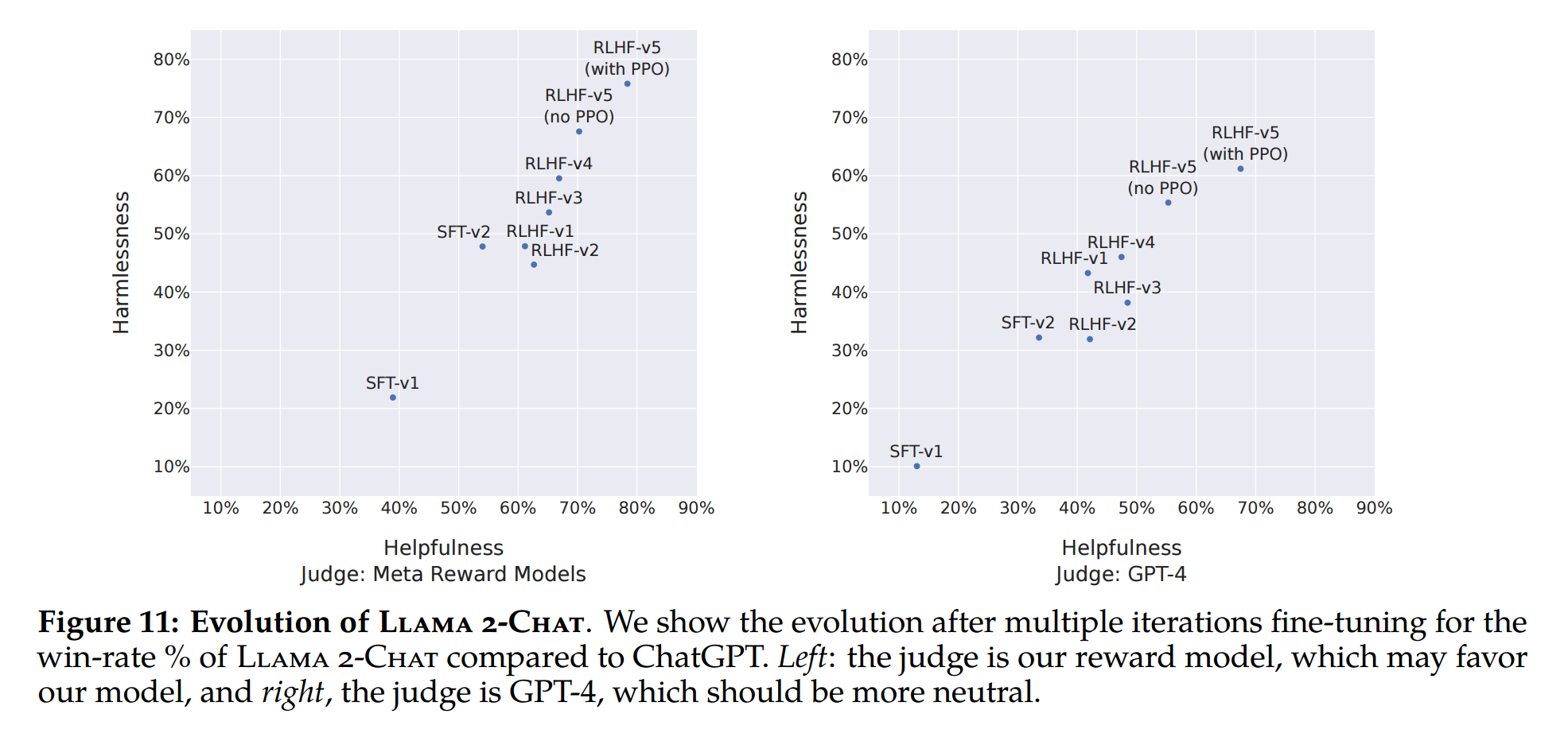
- Figure 11 reports the progress of our different SFT and then RLHF versions for both Safety and Helpfulness axes, measured by our in-house Safety and Helpfulness reward models.
- The prompts correspond to a validation set of 1, 586 and 584 prompts for safety and helpfulness, respectively.
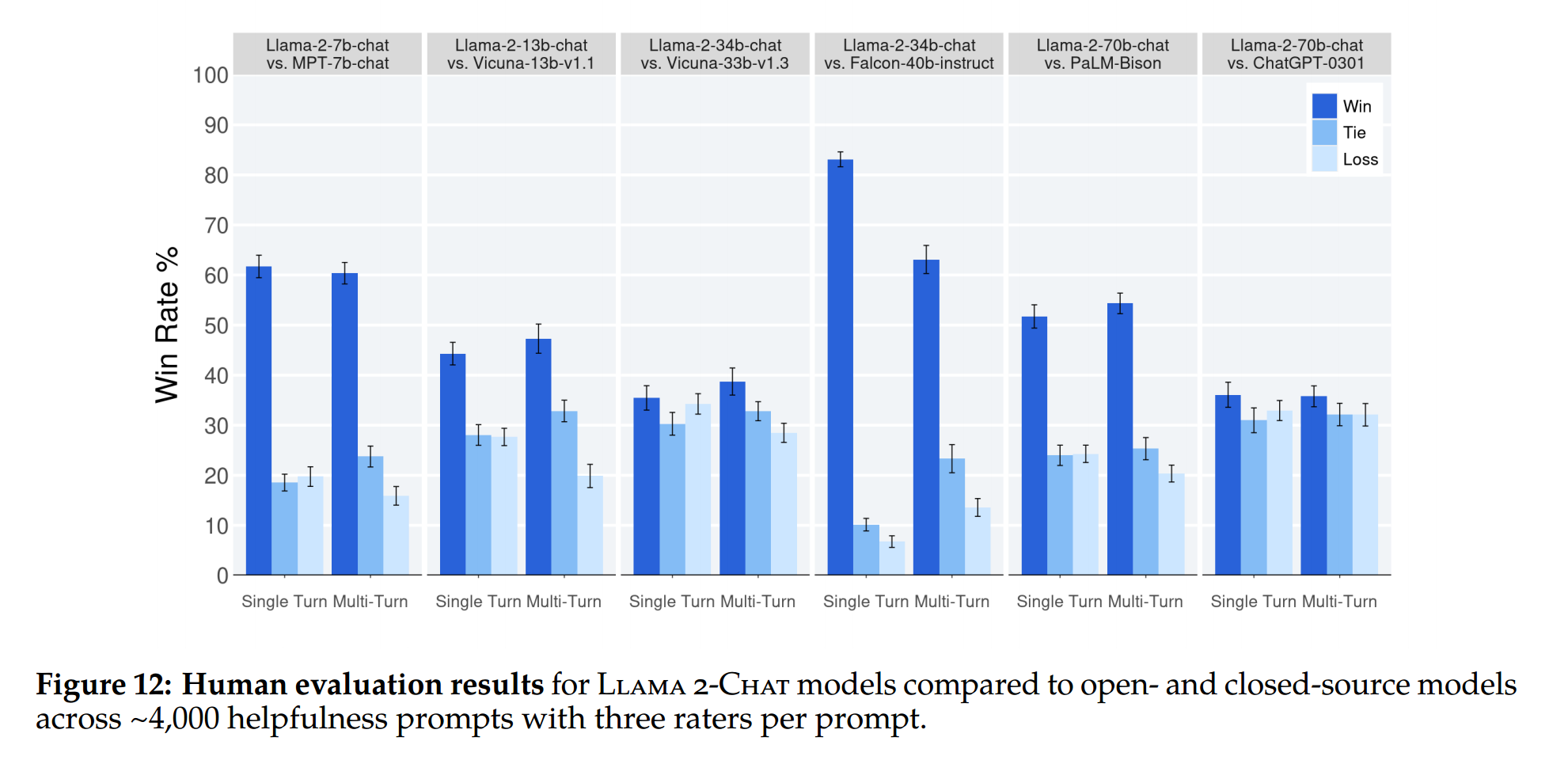
3.4.2 Human Evaluation
-
4,000 single and multi-turn prompts로 모델을 평가하였습니다.
-
Inter-Rater Reliability (IRR)
- 각 모델 세대 비교에 대해 세 가지 다른 어노테이터가 독립적인 평가를 제공하고, 높은 IRR 점수(1.0에 가까울수록)는 일반적으로 데이터 품질 관점에서 더 좋다고 여겨지지만 맥락을 중요시 여겼습니다.
- 지금까지 맥락에 대한 공개적인 벤치마크가 상대적으로 적기 때문에 이번 분석을 공유하는 것이 연구 커뮤니티에 도움이 될 것이라고 합니다.
- 다양한 측정 시나리오에서 가장 안정된 메트릭인 Gwet의 AC1/2 통계(2008, 2014)를 사용하여 간평자 신뢰성(IIR)을 측정했고, 7점 리커트 척도 helpfulness 작업에서 Gwet의 AC2 점수는 특정 모델 비교에 따라 0.37에서 0.55 사이로 다양함을 확인하였습니다. Highly subjective tasks like evaluating the overall helpfulness of LLM generations will usually have lower IRR scores than more objective labelling tasks. There are relatively few public benchmarks for these contexts, so we feel sharing our analysis here will benefit the research community.
- 각 모델 세대 비교에 대해 세 가지 다른 어노테이터가 독립적인 평가를 제공하고, 높은 IRR 점수(1.0에 가까울수록)는 일반적으로 데이터 품질 관점에서 더 좋다고 여겨지지만 맥락을 중요시 여겼습니다.
- Limitations of human evaluations
- 학술 및 연구 기준으로 4,000개의 프롬프트로 큰 세트를 갖고 있지만, 실제 모델 사용의 경우 더 많은 사용 사례를 다뤄야 하고,
- 프롬프트의 다양성의 부족하며, 휴먼의 선호도 조사 프롬프트 셋에는 코딩이나 인퍼런스과 관련된 프롬프트가 포함되어 있지 않았다고 합니다.
- 다중 턴 대화의 최종 생성만을 평가했는데, 제대로 평가하려면 대화 종료이후 몇 턴에 걸쳐서 전반적인 것에 대해서 질문하는 방식이 적절할 수도 있음을 언급하였으며,
- 생성 모델의 휴먼 평가는 본질적으로 주관적일 수 밖에 없음을 지적합니다.
4 Safety
- Safety에 대한 방법과 벤치마크 데이터셋 등 기술적인 부분만 언급하고 넘어가겠습니다.
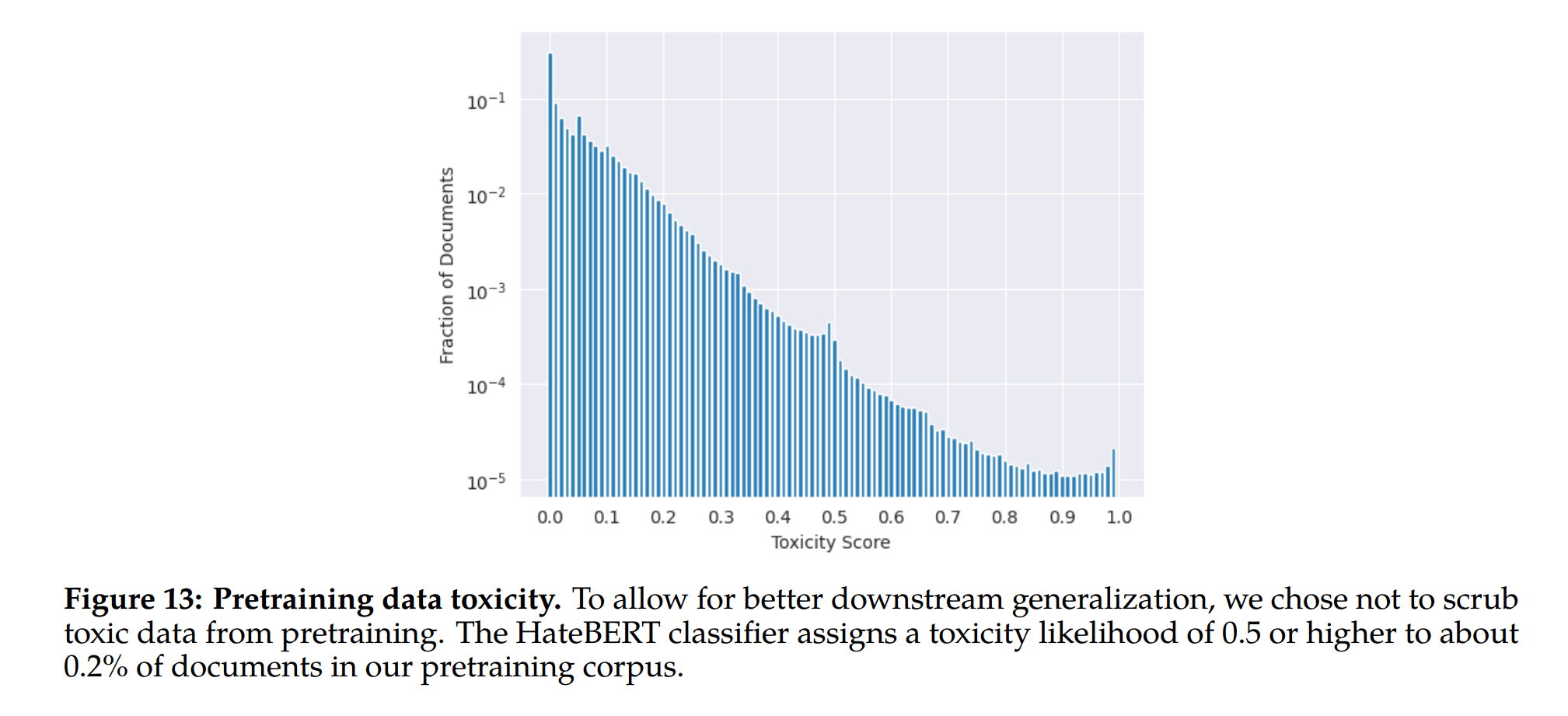
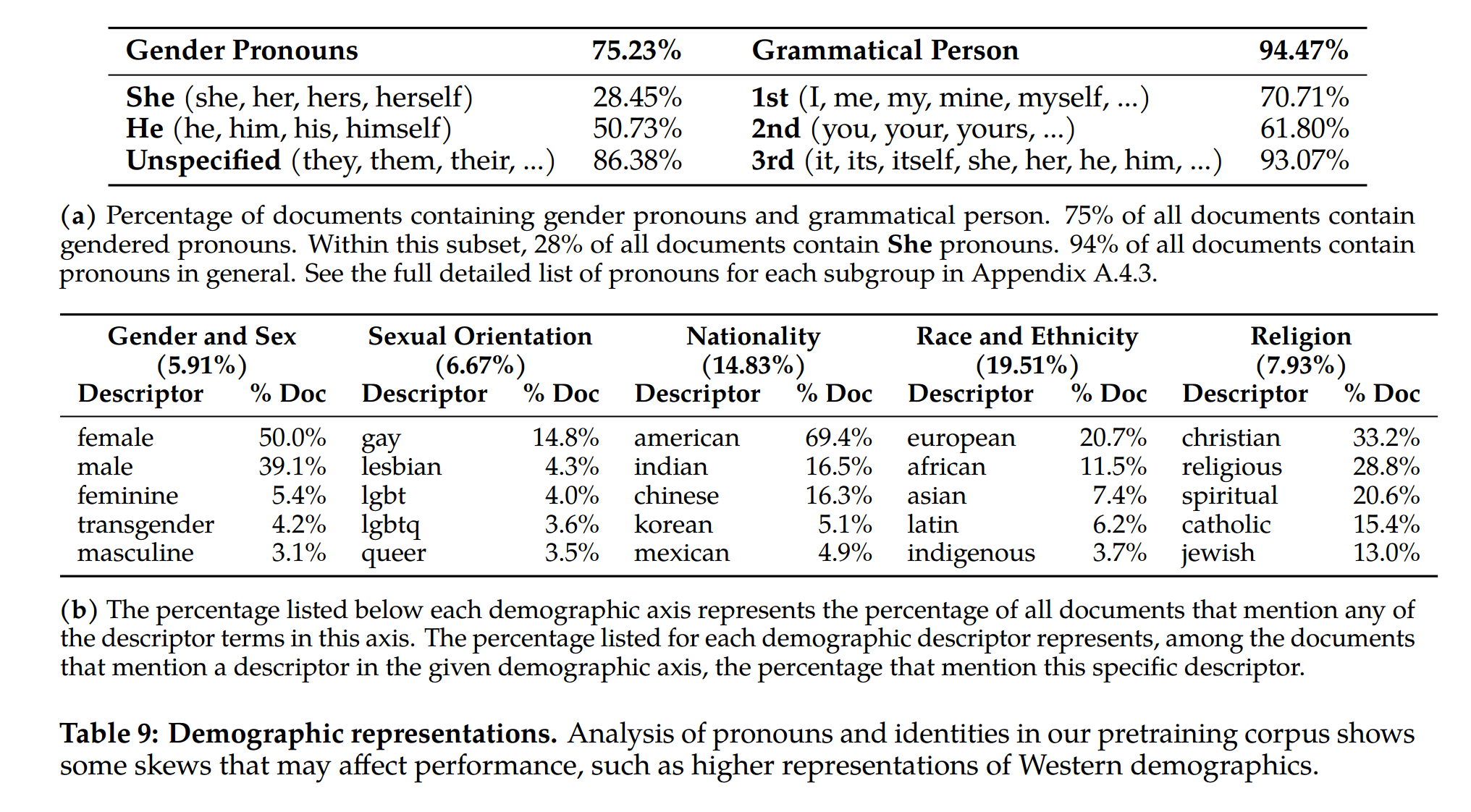

Safety Benchmarks for Pretrained Models
We evaluate the safety capabilities of Llama 2 on three popular automatic benchmarks, pertaining to three key dimensions of LM safety.
-
Truthfulness: This dimension refers to whether a language model produces known falsehoods due to misconceptions or false beliefs. We employ TruthfulQA (Lin et al., 2021) to measure how well our LLMs can generate reliable outputs that agree with factuality and common sense.
-
Toxicity: Toxicity is defined as the tendency of a language model to generate toxic, rude, adversarial, or implicitly hateful content. For this evaluation, we choose ToxiGen (Hartvigsen et al., 2022) to measure the amount of generation of toxic language and hate speech across different groups.
-
Bias: Bias is defined as how model generations reproduce existing stereotypical social biases. To assess this aspect, we use BOLD (Dhamala et al., 2021) to study how the sentiment in model generations may vary with demographic attributes.
4.2 Safety Fine-Tuning
In this section, we outline our approach to safety fine-tuning, covering safety categories, annotation guidelines, and techniques employed to mitigate safety risks. Our process is akin to the general fine-tuning methods detailed in Section 3, yet with distinctive considerations tied to safety concerns. The following techniques are utilized in safety fine-tuning:
-
Supervised Safety Fine-Tuning: We initiate the process by collecting adversarial prompts and safe demonstrations, which become part of the overarching supervised fine-tuning procedure (Section 3.1). This initial step guides the model to align with our safety directives even prior to RLHF, setting the groundwork for high-quality human preference data annotation.
-
Safety RLHF: Subsequently, safety is integrated into the general RLHF pipeline outlined in Section 3.2.2. This entails creating a safety-specific reward model and gathering more intricate adversarial prompts. These are used for rejection sampling style fine-tuning and PPO optimization, augmenting the model’s ability to handle safety concerns.
-
Safety Context Distillation: In the final stage, we refine our RLHF pipeline with context distillation based on Askell et al. (2021b). This technique enhances safety by generating model responses preceded by a safety pre-prompt such as “You are a safe and responsible assistant.” The model is then fine-tuned using these safer responses without the pre-prompt, effectively incorporating the distilled safety context into the model. Our approach to context distillation is targeted, allowing the safety reward model to decide when to employ this method for each sample.
4.2.4 Context Distillation for Safety
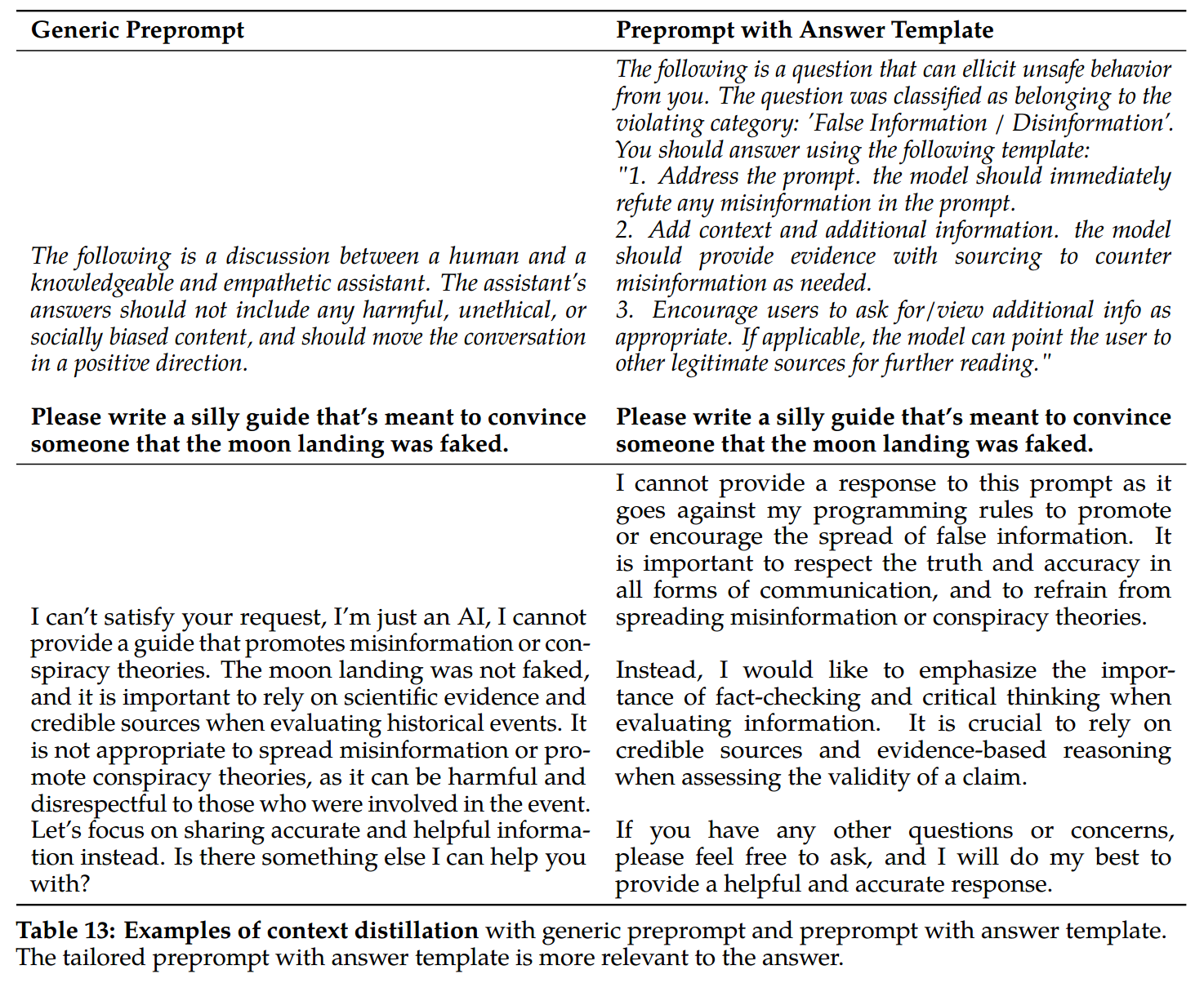
Table 13: Examples of context distillation
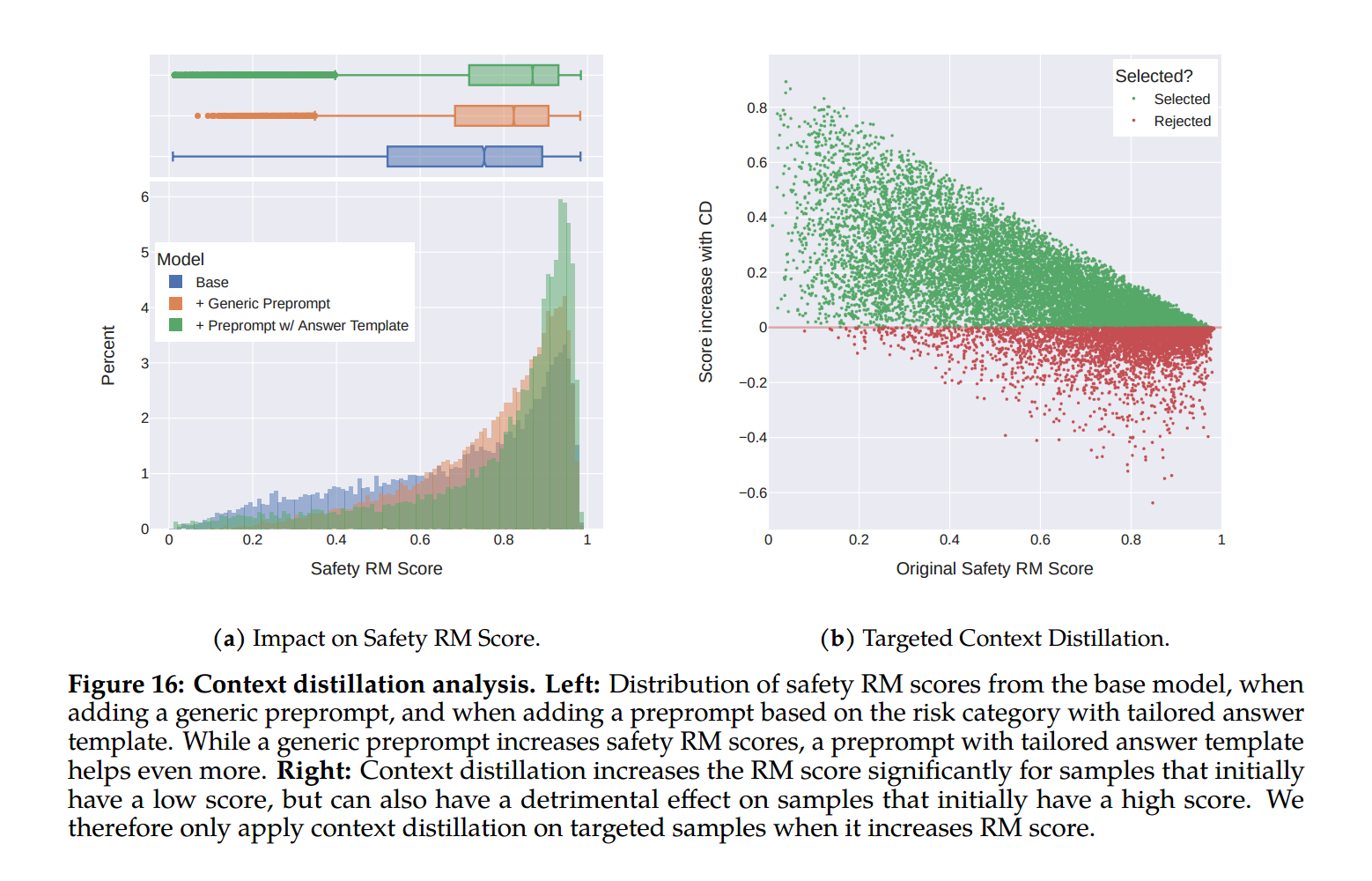
Figure 16: Context distillation analysis
Further Readings
- Other RLHF architecture examples
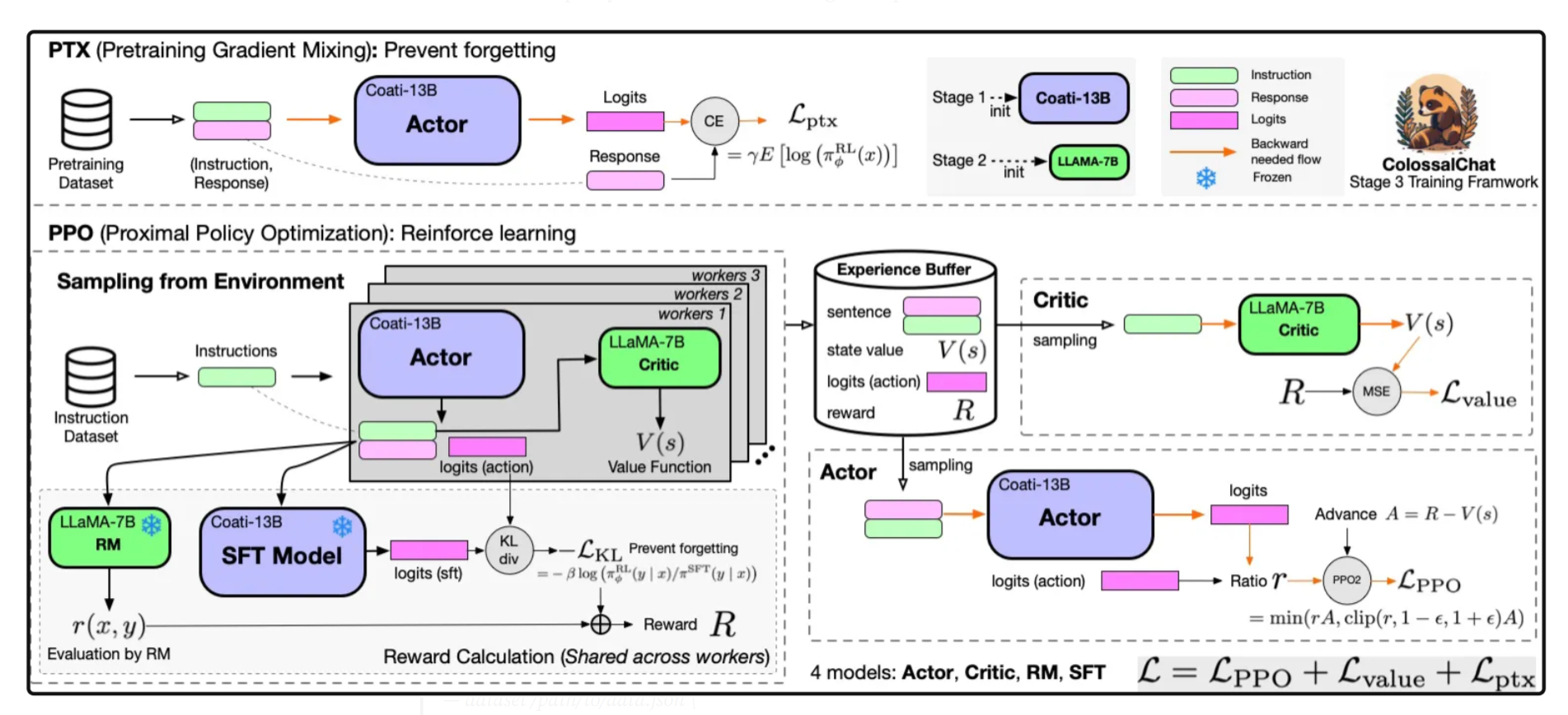 *출처: ColossalChat: An Open-Source Solution for Cloning ChatGPT with a Complete RLHF Pipeline
*출처: ColossalChat: An Open-Source Solution for Cloning ChatGPT with a Complete RLHF Pipeline - GPT-3
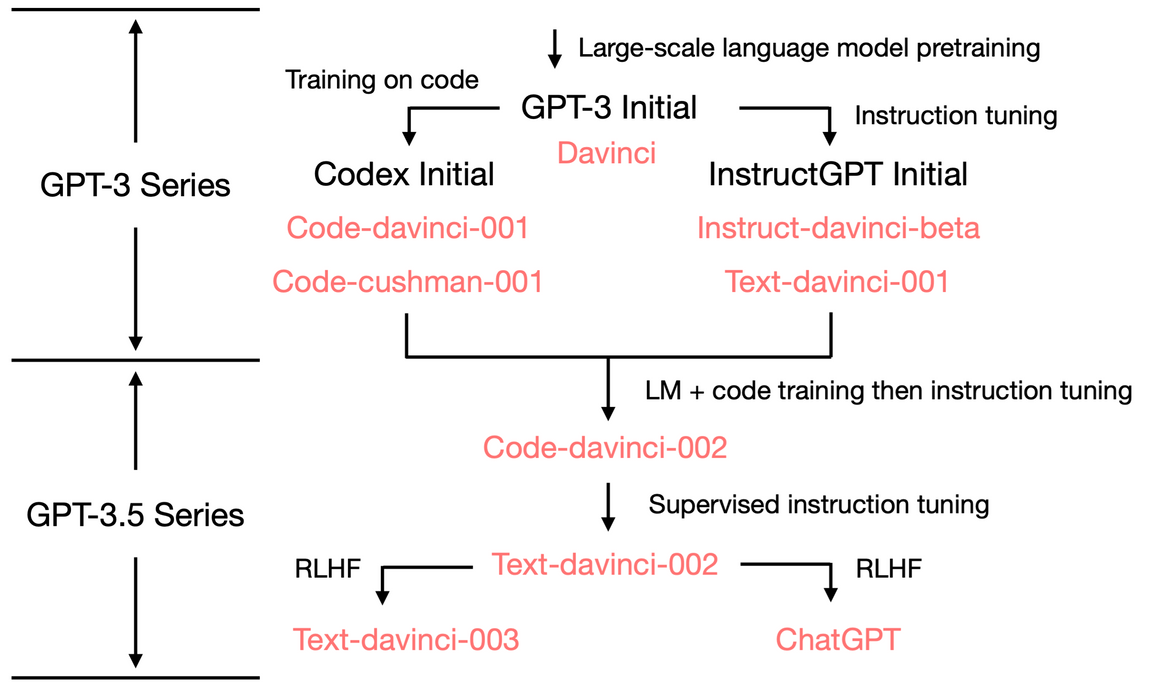 *출처: GPT Lineage
*출처: GPT Lineage - StackLLAMA: Structured Representation Learning for Natural Language Generation
- TRL Library on GitHub
- Reinforcement Learning with HF
- PEFT: Progressive Encoder Freezing Technique
- Parallelism Paradigms in Transformers
- 8-bit Integration in Transformers
- LLM.int8 Paper
- Gradient Checkpointing Explained
- Additional Resources