Self-Instruct | Self-Generated Instructions**
- Related Project: private
- Category: Paper Review
- Date: 2023-08-10
Self-Instruct: Aligning Language Models with Self-Generated Instructions
- url: https://arxiv.org/abs/2212.10560
- pdf: https://arxiv.org/pdf/2212.10560
- abstract: Large “instruction-tuned” language models (i.e., finetuned to respond to instructions) have demonstrated a remarkable ability to generalize zero-shot to new tasks. Nevertheless, they depend heavily on human-written instruction data that is often limited in quantity, diversity, and creativity, therefore hindering the generality of the tuned model. We introduce Self-Instruct, a framework for improving the instruction-following capabilities of pretrained language models by bootstrapping off their own generations. Our pipeline generates instructions, input, and output samples from a language model, then filters invalid or similar ones before using them to finetune the original model. Applying our method to the vanilla GPT3, we demonstrate a 33% absolute improvement over the original model on Super-NaturalInstructions, on par with the performance of InstructGPT-001, which was trained with private user data and human annotations. For further evaluation, we curate a set of expert-written instructions for novel tasks, and show through human evaluation that tuning GPT3 with Self-Instruct outperforms using existing public instruction datasets by a large margin, leaving only a 5% absolute gap behind InstructGPT-001. Self-Instruct provides an almost annotation-free method for aligning pre-trained language models with instructions, and we release our large synthetic dataset to facilitate future studies on instruction tuning. Our code and data are available at this https URL.
[프롬프트 분류 분포 핵심색인마킹]
TL;DR
- Pre-trained LLM의 instruction-following capabilities를 자체 생성에서 부트스트랩하여 개선하는 프레임워크인 Self-Instruct를 도입
- 명령어, 입력 및 출력 샘플을 생성한 다음 유효하지 않거나 유사한 샘플을 필터링하여 원본 모델을 파인튜닝하는 데 사용하는 파이프라인 구성
- 바닐라 GPT3에 이 방법을 적용한 결과, 개인 사용자 데이터와 사람의 주석으로 학습된 InstructGPT-001의 성능과 동등한 수준으로 Super-NaturalInstructions에서 원래 모델보다 33% 절대적으로 향상된 성능을 보임
- 추가 평가를 위해 새로운 작업에 대한 전문가 작성 명령어 세트를 큐레이팅하고, 사람의 평가를 통해 Self-Instruct로 GPT3를 튜닝하는 것이 기존 공개 명령어 데이터셋를 사용하는 것보다 큰 폭으로 성능이 뛰어나며, 절대적인 격차는 5%에 불과하다는 것을 보여주었음.


Supplemental Material
A. Implementation Details
A.1 Writing the Seed Tasks
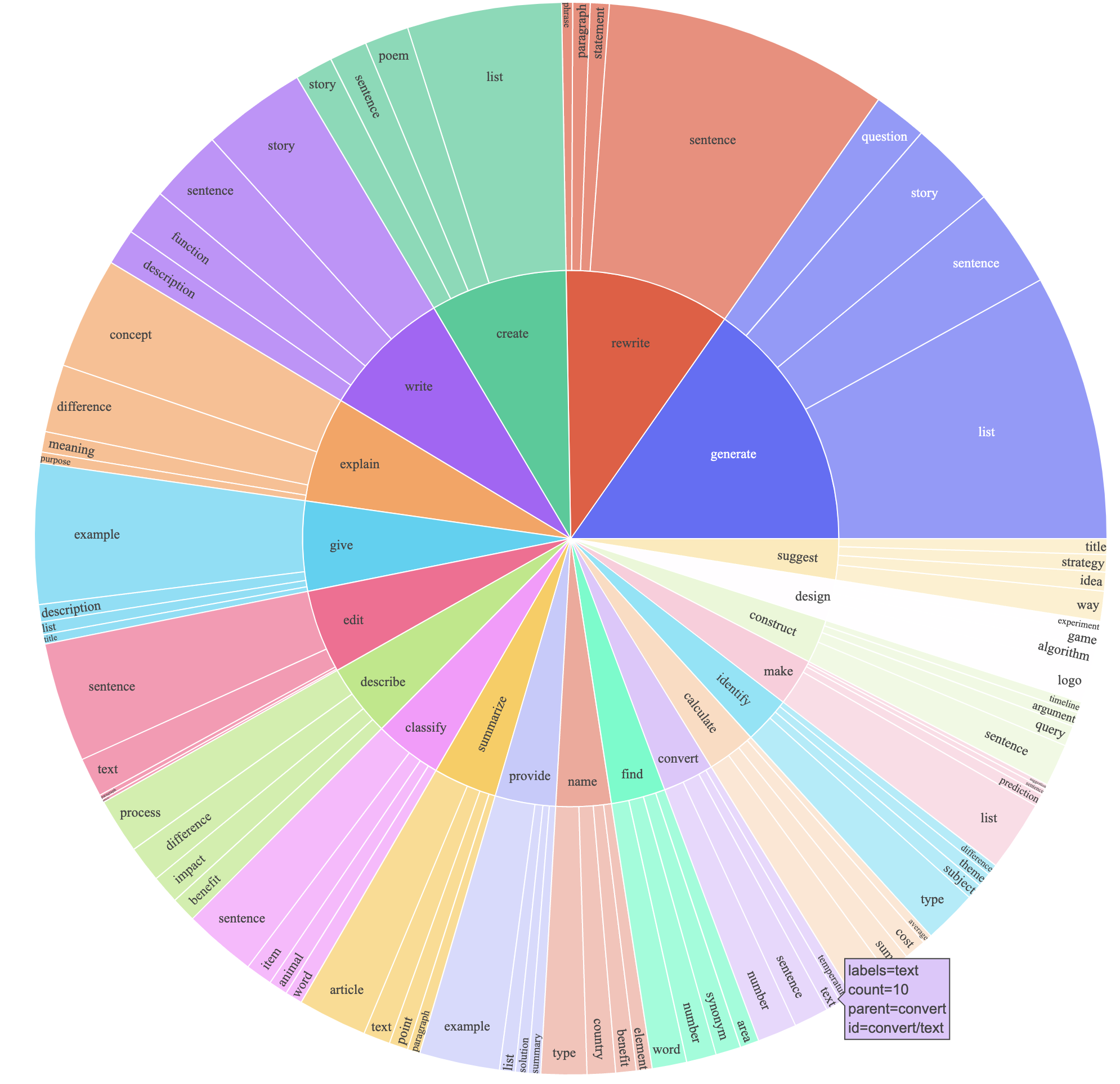
Our method relies on a set of seed tasks to bootstrap the generation. These seed tasks are important for both encouraging the task diversity and demonstrating correct ways for solving the diverse tasks. For example, with coding tasks to prompt the model, it has a larger chance to generate coding-related tasks; it’s also better to have coding output to guide the model in writing code for new tasks. So, the more diverse the seed tasks are, the more diverse and better quality the generated tasks will be.
Our seed tasks were written when we initiated this project, and targeted for the diverse and interesting usages of LLMs. The tasks were written by the authors and our lab mates at UWNLP, without explicit reference to existing datasets or specific testing tasks. We further categorized the tasks into classification and non-classification tasks, based on whether the task has a limited output label space. In total, there are 25 classification tasks and 150 non-classification tasks. We release this data in our GitHub repository.
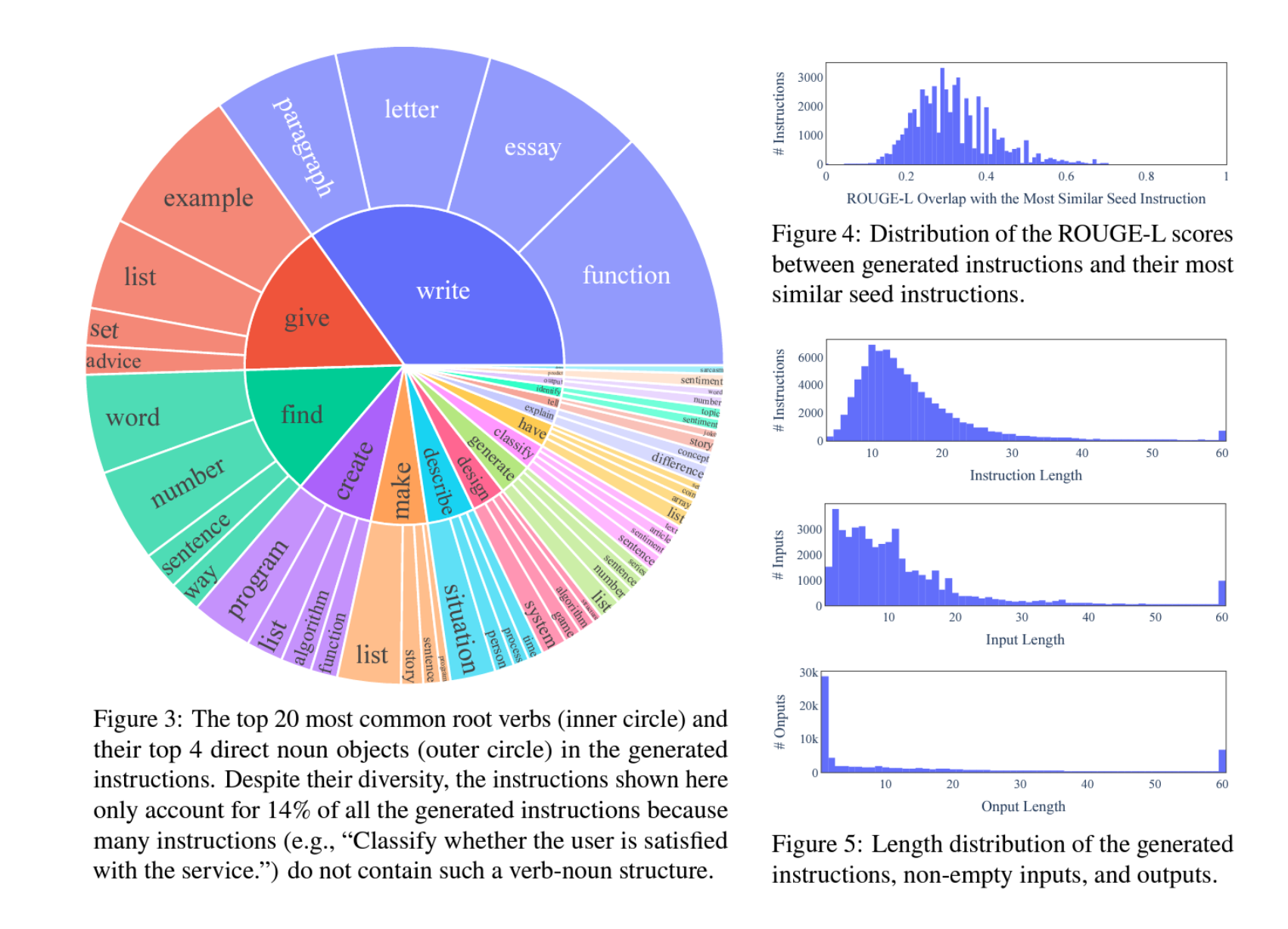
To provide a sense of how much the model is generalizing beyond these seed tasks, we further quantify the overlap between the instructions of these seed tasks and the instructions of our test sets, including both SUPERNI task instructions (§4.3) and the user-oriented instructions in our humane evaluation (§4.4). We compute ROUGE-L similarities between each seed instruction and its most similar instruction in the test set. The distribution of the ROUGE-L scores are plotted in Figure 8, with the average ROUGE-L similarity between these seed instructions and SUPERNI as 0.21, and the average ROUGE-L similarity between the seed instructions and user-oriented instructions as 0.34. We see a decent difference between the seed tasks and both test sets. There is exactly one identical seed instruction occurring in the user-oriented instruction test set, which is “answer the following question,” and the following questions are actually very different.
A.2 Querying the GPT-3 API
We used different sets of hyperparameters when querying GPT-3 API for different purposes. These hyperparameters are found to work well with the GPT-3 model (“davinci” engine) and the other instruction-tuned GPT-3 variants. We listed them in Table 4. OpenAI charges $0.02 per 1000 tokens for making completion requests to the “davinci” engine as of December 2022. The generation of our entire dataset cost around $600.
A.3 Finetuning GPT-3
GPT3SELF-INST and some of our baselines are finetuned from GPT-3 model (“davinci” engine with 175B parameters). We conduct this fine-tuning via OpenAI’s fine-tuning API. While the details of how the model is finetuned with this API are not currently available (e.g., which parameters are updated or what the optimizer is), we tune all our models with the default hyperparameters of this API so that the results are comparable. We only set the “prompt_loss_weight” to 0 since we find this works better in our case, and every fine-tuning experiment is trained for two epochs to avoid overfitting the training tasks. Finetuning is charged based on the number of tokens in the training file. In our case, fine-tuning GPT3SELF-INST from the GPT-3 model on the entire generated data cost $338.
A.4 Prompting Templates for Data Generation
SELF-INSTRUCT relies on a number of prompting templates in order to elicit the generation from language models. Here we provide our four templates for generating the instruction (Table 5), classifying whether an instruction represents a classification task or not (Table 6), generating non-classification instances with the input-first approach (Table 7), and generating classification instances with the output-first approach (Table 8).
B. Human Evaluation Details for Following the User-oriented Instructions
B.1 Human Evaluation Setup
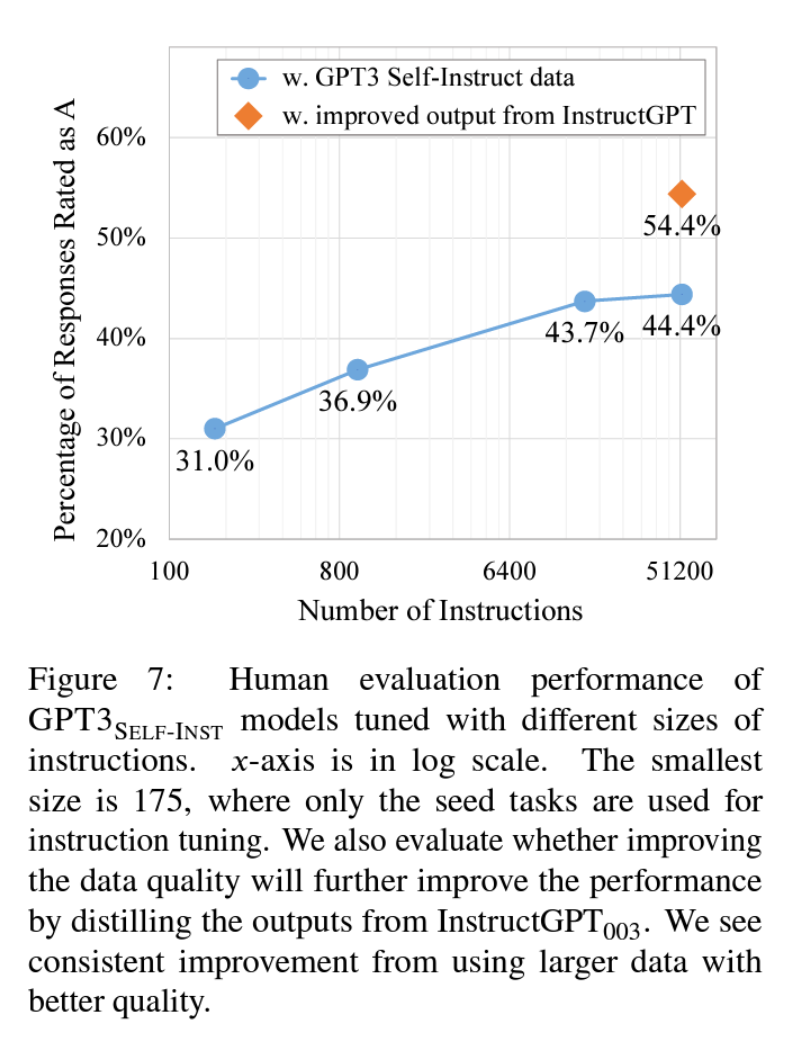
Here we provide more details for the humane evaluation described in §4.4 for rating the models’ responses to the 252 user-oriented instructions. To ensure faithful and reliable evaluation, we asked two authors of these instructions (and of this paper) to judge model predictions. These two evaluators coordinated the standards for the 4-level rating system before starting annotation, and then each of them rated all the instances independently. They were presented with the instruction, instance input, target output (as a reference), and model responses. Model responses are listed in random order, with all the model information anonymized. Figure 9 provides a screenshot of the annotation interface. The reported performance in this paper is based on the results from one of the evaluators, and the trends from the other evaluator’s results are the same.
[정성적 평가 핵심색인마킹]
B.2 Human Evaluation Agreement
To measure how reliable our humane evaluation is, we calculate the inner-rater agreement between our two evaluators. We first report Cohen’s 𝜅, which is commonly used to measure inter-rater agreement for categorical items. When calculating this, we treat the 4-level rating (A-D) as a categorical variable, leading to a 𝜅 of 0.58, which is a moderate agreement according to common practice. Furthermore, we also calculate the agreement of our evaluators on classifying acceptable responses ((A or B) vs. (C or D)), with a final 𝜅 of 0.75, indicating substantial agreement. We also compute the Spearman correlation coefficient 𝜌 between the ratings of our two evaluators by treating the rating as an ordinal variable (A > B > C > D). The final coefficient is 𝜌=0.81, indicating a high correlation between the two evaluators.
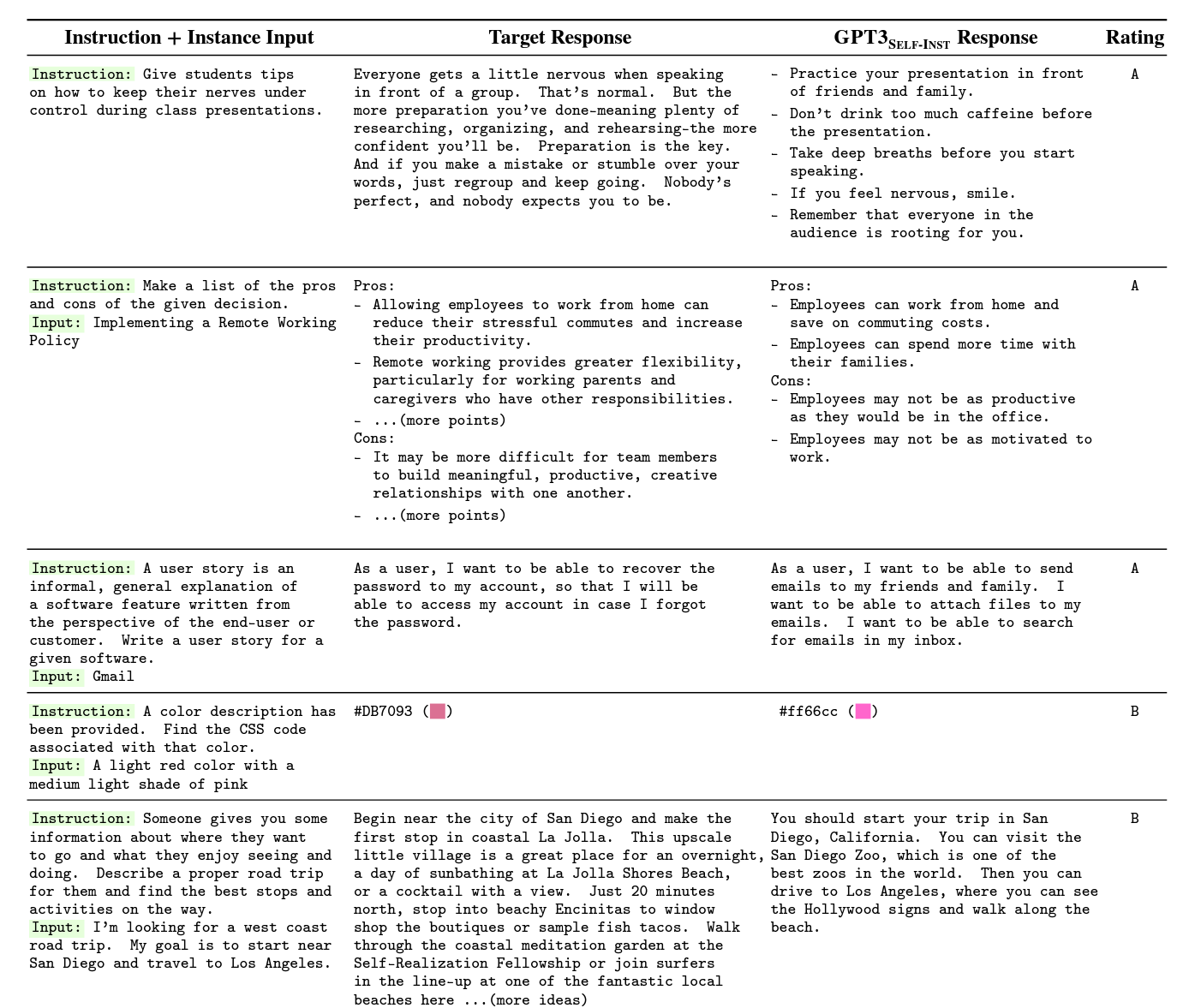
B.3 Example Predictions from GPT3SELF-INST
We present a selection of user-oriented tasks, the corresponding GPT3SELF-INST-produced responses, and annotator ratings in Table 9. We see that even for responses rated as level C, the model demonstrates extensive steps in solving the task, even though its final output is incorrect.
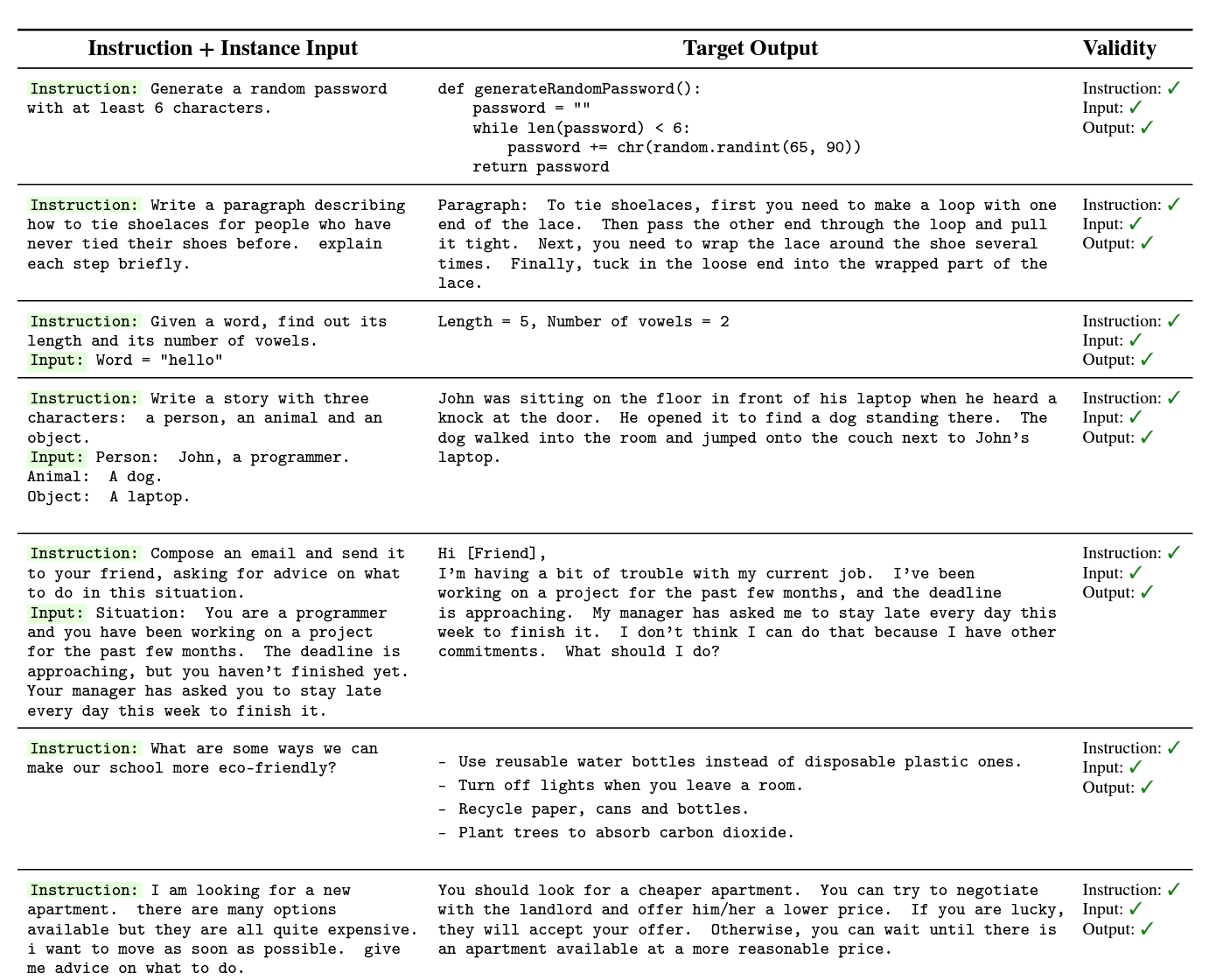
C Task and Instance Examples from the Generated Instruction Data