Best RAG
- Related Project: Private
- Category: Paper Review
- Date: 2024-07-02
Searching for Best Practices in Retrieval-Augmented Generation
- url: https://arxiv.org/abs/2407.01219
- pdf: https://arxiv.org/pdf/2407.01219
- html: https://arxiv.org/html/2407.01219v1
- abstract: Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains. While many RAG approaches have been proposed to enhance large language models through query-dependent retrievals, these approaches still suffer from their complex implementation and prolonged response times. Typically, a RAG workflow involves multiple processing steps, each of which can be executed in various ways. Here, we investigate existing RAG approaches and their potential combinations to identify optimal RAG practices. Through extensive experiments, we suggest several strategies for deploying RAG that balance both performance and efficiency. Moreover, we demonstrate that multimodal retrieval techniques can significantly enhance question-answering capabilities about visual inputs and accelerate the generation of multimodal content using a “retrieval as generation” strategy.
추천시스템의 ReRank, Vector DB 등 다양한 방법을 식별하고 탐색
- RAG 프레임워크 최적화 연구: 효과적인 정보 검색을 위한 방법 및 조합을 탐색하여 성능 향상
- 다양한 RAG 모듈 평가: 각 모듈에 대한 최적의 방법을 식별하고, 이를 통합하여 RAG의 효율성 및 성능을 개선
- 다양한 벤치마크를 통한 RAG 방법의 효과 측정 및 전략 제안
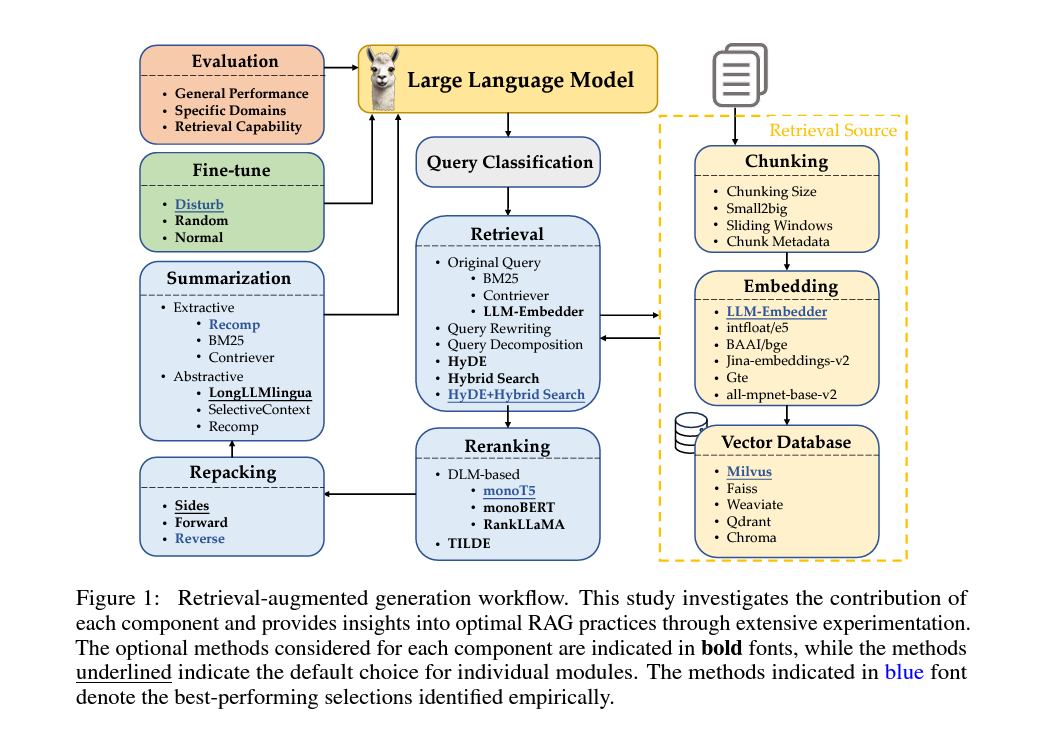
1. 서론
대규모 언어모델(Large Language Models, LLMs)은 최신 정보 부족이나 사실을 날조하는 경향이 있습니다. 이런 문제를 해결하기 위해 Retrieval-augmented Generation (RAG) 기술을 사용하여 사전 학습 및 검색 기반 모델의 장점을 결합하고 있습니다. RAG는 특정 조직과 도메인에 빠르게 적용 가능하며, 문서가 제공되는 한 모델 파라미터의 업데이트 없이도 사용할 수 있습니다.
2. 관련 연구
LLMs의 정확성 확보는 필수적이지만, 모델 크기를 확장하는 것만으로는 지식 집약적 작업에서 발생하는 환각(hallucinations) 문제를 근본적으로 해결하지 못합니다. 이에 RAG는 외부 지식베이스에서 문서를 검색하여 LLMs에 정확하고 실시간, 도메인 특화된 맥락을 제공합니다. 이전 연구들은 검색과 생성 프로세스의 상호 작용을 개선하기 위해 RAG 파이프라인을 최적화했습니다.
3. RAG 워크플로
RAG 워크플로는 다음과 같은 여러 단계로 구성됩니다.
- 1) 리퀘스트 분류: 모든 리퀘스트가 검색을 필요로 하지 않으므로, RAG 모듈을 통과할 리퀘스트를 분류합니다.
- 2) 문서 청킹: 문서를 더 작은 세그먼트로 나누어 검색 Precision를 높이고 LLMs의 길이 문제를 피합니다.
- 3) 벡터 데이터베이스: 문서의 벡터 표현을 저장하고, 쿼리와 관련된 문서를 효율적으로 검색합니다.
- 4) 검색 방법: 사용자 쿼리에 따라 가장 관련성 높은 문서를 선별하고, 이를 기반으로 적절한 응답을 생성합니다.
- 5) 재순위 결정 및 문서 재구성: 검색된 문서의 중요도에 따라 순위를 매기고, 응답 생성을 위해 문서를 재구성합니다.
- 6) 중복 재거: 검색 결과에서 중복이나 불필요한 정보를 제거하고, 요약을 통해 LLMs의 응답 생성 속도를 높입니다.
3.1 쿼리 분류
- 쿼리 필요성 판단: 모든 쿼리가 검색을 필요로 하는 것은 아니므로, 검색이 필요한 쿼리를 분류하는 과정을 설명합니다.
3.2 문서 분할(Chuncking)
문서를 더 작은 세그먼트로 청킹하는 것은 검색 정확도를 향상시키고 LLM에서 문서 길이로 인한 문제를 방지하는 데 필수적입니다. 이 과정은 토큰, 문장, 의미론적 수준에서 다양한 세밀도로 적용될 수 있습니다.
이 프로세스는 토큰, 문장 및 의미 수준과 같은 다양한 수준의 세분성에 적용될 수 있습니다.
- 토큰 수준 청킹은 간단하지만 문장을 분할하여 검색 품질에 영향을 미칠 수 있습니다.
- 의미 수준 청킹은 LLM을 사용하여 중단점을 결정하는데, 컨텍스트는 유지되지만 시간이 많이 걸립니다.
- 문장 수준 청킹은 텍스트 의미를 보존하면서 단순성과 효율성을 균형 있게 유지합니다.
이 연구에서 문장 수준 청킹, 단순성과 의미 보존의 균형을 이루며, 4차원에서 청킹을 조사합니다.
- 문서 분할(Chuncking) 기술: 문서를 효율적으로 분할하여 검색의 Precision를 높이는 다양한 기술을 소개합니다.
- 분할 크기: 다양한 크기의 덩어리가 검색 성능에 미치는 영향을 평가합니다.
3.2.1 청크(Chunk) 크기
청크 크기는 성능에 상당한 영향을 미칩니다. 큰 청크는 맥락을 제공하여 이해를 돕지만 처리 시간을 증가시킵니다. 반면, 작은 청크는 검색 Recall을 향상시키고 시간을 줄일 수 있으나 충분한 맥락을 제공하지 못할 수 있습니다.
-
Faithfulness
\[\text{Faithfulness} = \frac{\text{Matched Responses}}{\text{Total Responses}} \times 100\%\] -
Relevancy
\[\text{Relevancy} = \frac{\text{Matched Texts}}{\text{Total Retrieved Texts}} \times 100\%\]
3.2.2 청크 테크닉
청크 테크닉은 작은 청크로 쿼리를 매칭시키고, 이 작은 청크를 포함한 더 큰 청크를 맥락 정보와 함께 반환하여 검색 품질을 향상시킵니다. 이는 맥락을 유지하고 관련 정보를 검색하는 데 도움이 됩니다.
3.2.3 임베딩 모델 선택
적절한 임베딩 모델을 선택하는 것은 쿼리와 청크 블록 간의 의미론적 매칭에 중요합니다. FlagEmbedding5 평가 모듈을 사용하여 적절한 오픈 소스 임베딩 모델을 선택했습니다.
3.2.4 메타데이터 추가
메타데이터를 청크 블록에 추가하는 것은 검색을 향상시키고, 검색된 텍스트의 후처리 방법을 더욱 다양화하며, LLM이 검색된 정보를 더 잘 이해할 수 있도록 도움을 줍니다.
3.3 벡터 데이터베이스
벡터 데이터베이스는 임베딩 벡터와 메타데이터를 저장하며, 다양한 인덱싱 방식과 근접 이웃 검색(ANN)을 통해 관련 문서를 효율적으로 찾습니다. 연구에서는 인덱스 유형 다양성, 수십억 규모의 벡터 처리 능력, 하이브리드 검색 지원, 클라우드 네이티브 기능을 중점 기준으로 하여 여러 벡터 데이터베이스를 평가했습니다. 평가 결과, Milvus가 가장 포괄적인 솔루션으로 나타났으며, 모든 필수 기준을 만족시키고 다른 옵션보다 우수한 성능을 보였습니다. 이 기준은 클라우드 기반 인프라에서의 유연성, 확장성, 배포 용이성에 중점을 두고 선정되었습니다.
RAG 구현의 핵심적인 수학적 문제는 쿼리와 문서 간의 의미적 일치를 최대화하는 임베딩 벡터를 생성하는 것입니다. 이를 위해 다음과 같은 최적화 문제를 고려할 수 있습니다.
\[\text{maximize} \quad \text{similarity}(\text{embedding}(query), \text{embedding}(document))\]$\text{similarity}$는 코사인 유사도나 다른 유사도 측정 기준을 사용할 수 있습니다.
이 최적화 과정에서 임베딩 모델의 선택과 파인튜닝이 중요한 역할을 하며, 이 최적화가 검색된 문서의 품질과 생성된 응답의 정확성이 직접적인 영향을 주는 것으로 알려져있습니다.
벡터 데이터베이스는 메타데이터와 함께 임베딩 벡터를 저장하여, 다양한 인덱싱 및 근사 최근접 이웃(ANN) 방법을 통해 쿼리에 관련된 문서를 효율적으로 검색할 수 있게 합니다.
연구를 위한 적절한 벡터 데이터베이스 선택
여러 벡터 데이터베이스를 다음 네 가지 주요 기준에 따라 평가하였습니다. 다양한 인덱스 유형, 수십억 규모의 벡터 지원, 하이브리드 검색, 클라우드 네이티브. 이 기준들은 데이터베이스의 유연성, 확장성 및 클라우드 환경에서의 통합 용이성을 평가하는 데 중요합니다.
벡터 데이터베이스 비교 (표 5)
- Weaviate, Faiss, Chroma, Qdrant, Milvus 등 다섯 가지 오픈 소스 벡터 데이터베이스를 비교 분석하였습니다.
- Milvus는 모든 필수 기준을 충족하며 다른 오픈 소스 옵션들을 능가하는 가장 포괄적인 솔루션으로 평가되었습니다.
3.4 검색 방법
사용자 쿼리에 기반하여 검색 모듈은 사전 구축된 코퍼스에서 상위-k개의 관련 문서를 선택합니다. 이때, 쿼리와 문서 간의 유사성에 따라 문서를 선택합니다. 그러나 원래의 쿼리는 종종 표현의 부족이나 의미 정보의 결여로 인해 성능이 저하됩니다. 이 문제를 해결하기 위해 다음 세 가지 쿼리 변환 방법을 평가하였습니다.
- 쿼리 재작성 (Query Rewriting): 쿼리를 재작성하여 관련 문서와 더 잘 일치하도록 함.
- 쿼리 분해 (Query Decomposition): 원래 쿼리에서 파생된 하위 질문을 기반으로 문서를 검색함.
- 가상 문서 생성 (Pseudo-documents Generation): 사용자 쿼리를 바탕으로 가상 문서를 생성하고 이를 활용하여 유사한 문서를 검색함.
3.4.1 검색 방법의 결과
- TREC DL 2019 및 2020 데이터셋을 사용하여 다양한 검색 방법의 성능을 평가하였습니다. 하이브리드 검색 방법이 가장 높은 점수를 얻었으며, 특히 HyDE와 결합했을 때 더욱 향상된 성능을 보였습니다.
3.4.2 HyDE with Different Concatenation of Documents and Query
섹션 3.4.2에서는 HyDE를 이용한 다양한 문서 연결 및 쿼리 전략에 대한 연구 결과를 다룹니다. 표 7은 여러 가상 문서를 원래 쿼리에 연결했을 때 검색 성능이 향상되지만, 이로 인해 대기 시간도 증가하는 것을 보여줍니다. 이는 검색의 효과와 효율성 사이에 상충 관계가 있음을 시사합니다. 또한, 가상 문서의 수를 무차별적으로 늘릴 경우, 이점이 크지 않고 오히려 대기 시간이 길어지므로, 단일 가상 문서의 사용이 충분하다는 결론을 제시합니다. 이 연구는 가상 문서와 쿼리의 연결 전략을 최적화하는 데 중요한 통찰을 제공합니다.
3.4.3 하이브리드 검색의 가중치 조정
-
하이브리드 검색에서의 가중치 $\alpha$는 스파스 검색과 밀집 검색의 비율을 조절합니다.
\[S_h = \alpha \cdot S_s + S_d\] -
$\alpha = 0.3$에서 최적의 성능을 달성했습니다.
3.5 재순위 방법
초기 검색 이후에는 재순위 단계가 진행됩니다. 이 단계에서는 더 정밀하고 시간이 많이 소요되는 방법을 사용하여 문서를 효과적으로 재정렬합니다. DLM 재순위와 TILDE 재순위 두 가지 접근 방식을 고려하였습니다.
- DLM 재순위: 쿼리와 문서의 연결을 깊이 있는 언어 모델을 사용하여 ‘참’ 또는 ‘거짓’으로 분류합니다.
- TILDE 재순위: 쿼리 용어의 가능성을 독립적으로 계산하여 문서를 점수화하며, TILDEv2는 이 접근 방식을 향상시켜 더 빠른 재순위를 가능하게 합니다.
각 섹션은 해당 분야의 기술적 세부사항과 논리적 흐름을 유지하면서 구성되어 있습니다. 이런 구조는 각 방법이 어떻게 상호 작용하고 성능에 영향을 미치는지 명확하게 이해하는 데 도움을 줍니다.
3.6 Document Repacking
Document repacking은 재순위화 단계 후 문서의 순서를 재조정하여 LLM의 응답 생성에 미치는 영향을 최소화하는 기법입니다. 세 가지 주요 방법이 제안되었습니다.
- Forward: 문서를 재순위화 단계의 관련성 점수에 따라 내림차순으로 재배치합니다.
- Reverse: 문서를 관련성 점수에 따라 오름차순으로 재배치합니다.
- Sides: Liu et al. [48]의 연구에 따라, 중요한 정보를 입력의 시작과 끝에 배치하여 최적의 성능을 달성합니다.
3.7 Summarization
요약은 중복이나 불필요한 정보를 제거하고, 문서에서 가장 중요한 정보만을 추출하거나 재구성하여 LLM에 제공하는 과정입니다. 이 과정은 다음 두 가지 주요 방법으로 이루어집니다.
- 추출적 요약: 텍스트를 문장 단위로 세분화하고, 각 문장의 중요도에 따라 점수를 매기고 순위를 매깁니다.
- 추상적 요약: 여러 문서의 정보를 종합하여 새로운 요약문을 생성하며, 이는 주로 쿼리 기반으로 실행됩니다.
3.8 Generator Fine-tuning
생성기의 fine-tuning은 특정 쿼리에 대한 반응을 최적화하기 위해 관련 컨텍스트 또는 무관한 컨텍스트를 사용하여 이루어집니다. 이 과정은 다음과 같이 정의됩니다.
- Fine-tuning Loss: 생성된 출력 \(y\)에 대한 ground-truth 출력의 음의 로그 가능도입니다. \(\text{Loss} = -\log P(y | x, \mathcal{D})\) \(x\)는 RAG 시스템에 입력된 쿼리이며, \(\mathcal{D}\)는 입력에 대한 컨텍스트입니다.
컨텍스트 \(\mathcal{D}\)는 다음 네 가지 유형으로 구성될 수 있습니다.
- \(\mathcal{D}_g\): 쿼리와 관련된 문서만 포함.
- \(\mathcal{D}_r\): 무작위로 선택된 문서 하나만 포함.
- \(\mathcal{D}_{gr}\): 관련 문서와 무작위로 선택된 문서를 포함.
- \(\mathcal{D}_{gg}\): 관련 문서 두 개를 포함.
이런 다양한 구성을 통해 모델이 관련 및 무관한 정보에 어떻게 반응하는지 테스트하고, 결과적으로 생성기의 견고성과 관련 컨텍스트의 효율적 활용을 증진할 수 있습니다.
4 최적의 RAG 실행 방법 탐색
이 섹션에서는 RAG(검색-증강 생성) 시스템을 위한 최적의 실행 전략을 탐구합니다. 초기 설정에 따라 각 모듈을 세밀하게 조정하고 평가하면서 구조화된 반복적 접근 방식을 사용합니다. 이 과정은 모듈별로 순차적 최적화를 포함하며, 시스템 전체 성능에 미치는 영향을 평가하여 요약 모듈에 대한 가장 효과적인 설정을 확정하는 것을 목표로 합니다.
4.1 종합 평가
데이터 및 벤치마킹
다양한 자연어 처리(NLP) 작업 및 데이터셋을 통해 실험이 수행되었습니다.
- 데이터셋: 영어 위키피디아 1000만 개 텍스트와 의료 데이터 400만 개 텍스트가 포함됩니다.
실험은 일련의 NLP 작업을 대상으로 실시되며, 각 작업의 세부사항은 Appendix A.6에서 확인할 수 있습니다. 작업은 다음과 같습니다.
- 상식 인퍼런스
- 팩트 체킹
- 오픈 도메인 질의응답(QA)
- 멀티홉 QA
- 의료 QA
이 데이터셋에서 추출된 하위 집합에 대한 RAG 기능은 RAGAs [51]에서 권장하는 메트릭을 사용하여 평가되었습니다. 이 메트릭에는 충실도, 맥락 적합성, 답변 적합성, 답변 정확성이 포함됩니다. 또한, 검색된 문서와 골드 문서 사이의 코사인 유사도를 계산하여 검색 유사성을 측정했습니다.
평가 지표
- 상식 인퍼런스, 팩트 체킹, 의료 QA 작업에는 정확도가 평가 지표로 사용되었습니다.
- 오픈 도메인 QA 및 멀티홉 QA에는 토큰 수준 F1 점수와 정확한 일치(EM) 점수가 사용되었습니다.
- 최종 RAG 점수는 위에서 언급한 다섯 가지 RAG 능력의 평균으로 계산되었습니다. Trivedi 등 [52]의 방법을 따라 각 데이터셋에서 최대 500개의 예제를 추출하여 사용하였습니다.
4.2 Results and Analysis
- 문서 처리 모듈의 성능 분석: 각 모듈의 수학적 영향과 최적화 방법을 정밀 분석
- RAG 시스템 최적화 전략: 성능 극대화 및 효율성 균형 전략 제시
- 멀티모달 확장: 텍스트와 이미지 상호 작용을 위한 RAG 시스템의 적용 확장
분석 절차와 수학적 정의
이 섹션은 RAG 시스템의 각 모듈별 성능을 평가하고, 수학적 모델을 통해 성능 개선을 측정합니다.
- Query Classification Module
-
성능 개선: 전체 점수는 \(0.428\)에서 \(0.443\)으로 향상되었으며, 지연 시간은 \(16.41\)초에서 \(11.58\)초로 감소
\[\Delta \text{Score} = 0.443 - 0.428, \quad \Delta \text{Latency} = 16.41s - 11.58s\] -
효율성 증가 원인: 쿼리를 보다 효과적으로 분류하여 검색 및 재순위화 과정을 최적화함.
-
- Retrieval Module
-
Hybrid with HyDE 방법
\[\text{RAG Score} = 0.58\] - 분석: 가장 높은 점수를 기록했지만, \(11.71\)초의 계산 비용이 수반됨.
- 대안 제시: “Hybrid” 혹은 “Original” 방법을 사용하여 성능을 유지하면서 지연 시간을 줄일 것을 권장
-
- Reranking Module
-
MonoT5의 효과
\[\text{Average Score} = \text{highest among tested methods}\] -
중요성: 문서의 관련성을 강화하여 응답의 질을 향상시키는 데 필수적임을 강조.
-
- Repacking Module
-
Reverse 구성
\[\text{RAG Score} = 0.560\] -
쿼리와 관련성이 높은 문서를 가까이 배치하는 것이 최적의 결과를 가져옴을 시사
-
- Summarization Module
-
Recomp의 성능
\[\text{Comparative Performance} = \text{superior}\] -
시간 대비 성능: 시간에 민감한 상황에서 요약 모듈을 생략할 수 있으나, Recomp는 제한된 길이를 효과적으로 처리할 수 있는 능력 때문에 선호됨.
-
5 Discussion
5.1 Best Practices for Implementing RAG
- 최고 성능 전략
- 모든 모듈을 최적화된 설정으로 구성하여 최고의 성능을 달성하도록 함. 계산 비용은 높지만 결과의 질은 보장됨.
- 효율성 균형 전략
- 성능과 효율성 사이의 균형을 맞추기 위해 Hybrid 검색 방법과 TILDEv2 재순위화 방법을 사용
5.2 Multimodal Extension
- Text2Image 및 Image2Text
- 검증된 멀티모달 자료에서 정보를 검색하여 응답의 정확성을 보장
- 검색 방법은 새로운 콘텐츠를 생성하는 것보다 효율적이며, 유지 관리가 용이
6. 향후 계획
- 비디오 및 음성과 같은 다른 모달리티로 확장하고, 효율적이고 효과적인 크로스-모달 검색 기술을 개발할 계획