Model | Meta - LIMA
- Related Project: private
- Category: Paper Review
- Date: 2023-08-17
LIMA: Less Is More for Alignment
- url: https://arxiv.org/abs/2305.11206
- pdf: https://arxiv.org/pdf/2305.11206
- abstract: Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We measure the relative importance of these two stages by training LIMA, a 65B parameter LLaMA language model fine-tuned with the standard supervised loss on only 1,000 carefully curated prompts and responses, without any reinforcement learning or human preference modeling. LIMA demonstrates remarkably strong performance, learning to follow specific response formats from only a handful of examples in the training data, including complex queries that range from planning trip itineraries to speculating about alternate history. Moreover, the model tends to generalize well to unseen tasks that did not appear in the training data. In a controlled human study, responses from LIMA are either equivalent or strictly preferred to GPT-4 in 43% of cases; this statistic is as high as 58% when compared to Bard and 65% versus DaVinci003, which was trained with human feedback. Taken together, these results strongly suggest that almost all knowledge in large language models is learned during pretraining, and only limited instruction tuning data is necessary to teach models to produce high quality output.
[데이터 퀄리티 핵심 논문 색인마킹]
Contents
- LIMA: Less Is More for Alignment
TL;DR
- pre-training된 언어 모델의 능력 극대화
- 소수의 예제로 향상된 성능 달성 가능
- 다양성과 품질이 모델 성능에 미치는 영향 분석
- 강화 학습이나 사람 선호도 모델링 없이 신중하게 선별된 1,000개의 프롬프트와 응답에 대해 표준 감독 손실로 파인튜닝된 65B 파라미터 LLaMA 언어 모델인 LIMA를 훈련하여 이 두 단계의 상대적 중요성을 측정하였으며, 제한된 인스트럭션 튜닝 데이터만으로도 모델 튜닝에 충분하다는 것을 주장함.
- 후속 논문인 Llama-2에도 High-quality is all you need.라는 작은 섹션으로 SFT에서 비슷하게 주장하였고, 확인하였다고 함.
- LLM은 (1) 범용 표현을 학습하기 위한 원시 텍스트의 비지도 pre-training, (2) 최종 작업과 사용자 선호도에 더 잘 맞추기 위한 대규모 명령어 튜닝 및 강화 학습의 두 단계로 학습되는데, 이 연구에서는 강화 학습이나 사람의 선호도 모델링 없이 신중하게 선별된 1,000개의 프롬프트와 응답에 대해 표준 감독 손실로 파인튜닝된 65B 파라미터 LLaMA 언어 모델인 LIMA를 훈련하여 이 두 단계의 상대적 중요성을 측정함.
- LIMA는 여행 일정 계획부터 대체 역사에 대한 추측까지 다양한 복잡한 쿼리를 포함하여 training dataset에 포함된 소수의 예제에서 특정 응답 형식을 따르는 방법을 학습하여 좋은 성능을 보였으며, training dataset에 나타나지 않은 보이지 않는 작업에도 잘 일반화되는 경향을 관찰했다고 함.
- 일부 사람을 대상으로 한 연구에서 LIMA의 응답은 43%의 경우 GPT-4와 동등하거나 더 선호되는 것으로 나타났으며, 이는 Bard와 비교했을 때 58%, 사람의 피드백으로 학습된 DaVinci003과 비교했을 때 65%에 달하는 높은 수치임.
- 이런 결과를 종합하면 LLM의 거의 모든 지식이 pre-training 시에 학습되며, 모델이 고품질의 결과물을 생성하도록 가르치는 데는 제한된 인스트럭션 튜닝 데이터만 필요하다는 것을 시사할 수 있음.
- 즉, LLM의 거의 모든 지식이 pre-training 시에 학습되며, 고품질의 결과물을 생성하도록 가르치기 위해 제한된 고품질 인스트럭션 튜닝 데이터만으로 충분하다는 주장을 골자로 함.
1. 서론
언어 모델은 다양한 언어 이해 및 생성 작업에 대한 일반적인 용도의 표현을 학습할 수 있도록 사전 훈련되어 있습니다. 이런 전이를 가능하게 하는 여러 정렬 방법이 제안되었습니다. 본 연구에서는 pre-training된 강력한 언어 모델을 사용하여 단 1,000개의 신중하게 큐레이션된 학습 예제로 파인튜닝할 때 향상된 성능을 달성할 수 있음을 보여줍니다. 이는 모델이 사용자와 상호 작용할 때 사용해야 할 형식 또는 스타일을 학습하는 간단한 과정을 통해 이미 pre-training 중에 습득한 지식과 능력을 노출할 수 있다는 가설을 제시합니다.
2. 정렬 데이터
Superficial Alignment Hypothesis(표면적 정렬 가설)에 따라, 모델의 지식과 능력은 주로 pre-training 중에 학습되며, 정렬은 사용자와의 상호 작용시 사용해야 할 형식의 하위 분포를 학습하는 것에 관한 것입니다. 이 가설을 검증하기 위해 1,000개의 프롬프트와 응답을 수집하고, 출력은 일관된 스타일을 유지하면서 입력은 다양성을 갖도록 합니다. 데이터는 주로 커뮤니티 Q&A 포럼과 수동으로 작성된 예제에서 수집됩니다.
[LIMA 표면정렬가설(Superficial Alignment Hypothesis) 정의 색인마킹]
2.1 커뮤니티 질문과 답변
StackExchange, wikiHow, Pushshift Reddit Dataset에서 데이터를 수집합니다. StackExchange와 wikiHow의 답변은 유용한 AI 에이전트의 행동과 잘 맞으며, Reddit의 답변은 유머러스하거나 트롤링 경향이 있어 수동 접근이 필요합니다.
2.2 수동으로 작성된 예제
온라인 커뮤니티 사용자가 제기한 질문을 넘어서, 저자들은 직접 250개의 프롬프트를 생성하여 데이터 다양성을 더욱 확장합니다. 이 프롬프트들은 일관된 톤을 유지하면서 풍부하게 반응을 작성하는 것을 목표로 합니다.
3. LIMA 훈련
LLaMA 65B 모델을 사용하여 1,000개의 정렬 훈련 세트에서 파인튜닝을 진행합니다. 표준 파인튜닝 하이퍼파라미터를 사용하고, 특별한 ‘턴 종료’ 토큰을 도입하여 각 발화의 끝을 나타냅니다.
4. 휴먼 평가
LIMA는 OpenAI의 DaVinci003과 Alpaca 65B를 포함한 최신 언어 모델과 비교하여 우수한 성능을 보였습니다. 특히, 간단한 파인튜닝만으로 SOTA 기술과 경쟁할 수 있는 것은 “표면적 정렬 가설”을 강력히 지지합니다.
4.1 실험 설정
각 테스트 프롬프트에 대해 단일 응답을 생성하고, 크라우드 워커와 GPT-4를 이용해 LIMA의 출력을 Baseline Model과 비교합니다.
4.2 결과
LIMA는 65B Alpaca 모델과 RLHF로 훈련된 DaVinci003을 능가할 수 있음을 확인하며, 일부 경우에서는 GPT-4보다도 우수한 응답을 생성했습니다.
4.3 분석
LIMA는 50개의 무작위 예제를 수동으로 분석하여 ‘실패’, ‘통과’, ‘우수’의 세 가지 범주로 분류합니다. LIMA의 대부분의 응답이 우수한 것으로 평가되었습니다.
5. 왜 적은 것이 더 많은가? 데이터 다양성, 품질 및 양에 대한 Ablation 연구
입력 다양성과 출력 품질을 높이는 것이 긍정적인 효과를 보였으며, 단순히 예제 수를 늘리는 것만으로는 향상되지 않는 것으로 나타났습니다. 이는 정렬의 확장 법칙이 양에만 좌우되지 않는다는 것을 시사합니다.
6. 다중 턴 대화
LIMA는 1,000개의 단일 턴 상호작용에서만 파인튜닝된 모델이며, 실제 다중 턴 대화에 참여할 수 있는지를 테스트합니다. 적은 예제로도 높은 능력을 발휘할 수 있음을 보여줍니다.
1 Introduction
Language models are pre-trained to predict the next token on an incredible scale, allowing them to learn general-purpose representations that can be transferred to nearly any language understanding or generation task. Various methods for aligning language models have been proposed to enable this transfer, primarily focusing on instruction tuning [Mishra et al., 2021; Wei et al., 2022a; Sanh et al., 2022] over large multi-million example datasets [Chung et al., 2022; Beeching et al., 2023; Köpf et al., 2023], and more recently, reinforcement learning from human feedback (RLHF) [Bai et al., 2022a; Ouyang et al., 2022], collected over millions of interactions with human annotators.
Existing alignment methods require a significant amount of compute and specialized data to achieve ChatGPT-level performance. However, we demonstrate that given a strong pre-trained language model, remarkably strong performance can be achieved by simply fine-tuning on 1,000 carefully curated training examples.
We hypothesize that alignment can be a simple process where the model learns the style or format for interacting with users, to expose the knowledge and capabilities that were already acquired during pretraining. To test this hypothesis, we curate 1,000 examples that approximate real user prompts and high-quality responses. We select 750 top questions and answers from community forums, such as StackExchange and wikiHow, sampling for quality and diversity. Additionally, we manually write 250 examples of prompts and responses, while optimizing for task diversity and emphasizing a uniform response style in the spirit of an AI assistant. Finally, we train LIMA, a pretrained 65B-parameter LLaMA model [Touvron et al., 2023], fine-tuned on this set of 1,000 demonstrations.
- 가설: 사용자와 상호 작용하는 스타일이나 형식을 학습하는 간단한 프로세스를 통해 pre-training 중에 이미 습득한 지식과 기능을 노출할 수 있다고 함.
- 검증: 위키하우 등 커뮤니티 포럼에서 750개의 유명한 질문과 답변을 선별하여 품질과 다양성을 고려하여, 실제 사용자 프롬프트와 고품질 응답 1,000개를 큐레이팅하고, 250개의 프롬프트 및 응답 예제를 수동으로 작성하여 작업의 다양성을 최적화 + AI 어시스턴트의 응답 스타일을 일관되게 구성함.
We compare LIMA to state-of-the-art language models and products across 300 challenging test prompts. In a human preference study, we find that LIMA outperforms RLHF-trained DaVinci003 from OpenAI, which was trained with RLHF, as well as a 65B-parameter reproduction of Alpaca [Taori et al., 2023], which was trained on 52,000 examples. While humans typically prefer responses from GPT-4, Claude, and Bard over LIMA, this is not always the case; LIMA produces equal or preferable responses in 43%, 46%, and 58% of the cases, respectively. Repeating the human preference annotations with GPT-4 as the annotator corroborates our findings. Analyzing LIMA responses on an absolute scale reveals that 88% meet the prompt requirements, and 50% are considered excellent.
- 성능: LIMA 응답을 300 challenging test prompts로 분석한 결과, 88%가 프롬프트 요구 사항을 충족하고 50%는 우수한 것으로 평가되었음.
- 300개의 까다로운 테스트 프롬프트에서 LIMA를 SOTA 언어 모델 및 제품과 비교하였을 때,
- RLHF로 학습된 OpenAI의 DaVinci003보다 우수
- 52,000개의 예제로 학습된 Alpaca 65B보다 우수
- 일반적으로 사람들은 LIMA보다 GPT-4, 클로드, 바드의 응답을 선호하지만, 항상 그런 것은 아니며, LIMA는 각각 43%, 46%, 58%의 사례에서 동등하거나 더 나은 응답을 생성
- GPT-4를 Annotator로 사용하여 사람 선호도 주석을 반복하면 이런 결과를 확증할 수 있었음.
- 300개의 까다로운 테스트 프롬프트에서 LIMA를 SOTA 언어 모델 및 제품과 비교하였을 때,
Ablation experiments reveal vastly diminishing returns when scaling up data quantity without also scaling up prompt diversity, alongside major gains when optimizing data quality. In addition, despite having zero dialogue examples, we find that LIMA can conduct coherent multi-turn dialogue, and that this ability can be dramatically improved by adding only 30 hand-crafted dialogue chains to the training set. Overall, these remarkable findings demonstrate the power of pretraining and its relative importance over large-scale instruction tuning and reinforcement learning approaches.
결론: 대규모 인스트럭션 튜닝 및 강화 학습 접근 방식에 비해 pre-training이 중요하다는 것을 강조함.
- Ablation(제거 실험) 결과, 프롬프트 다양성을 확장하지 않고 데이터 양만 늘릴 경우 수익이 감소하는 반면, 데이터 품질을 최적화할 경우 수익이 증가하는 것을 확인
- 대화 예시가 전혀 없음에도 불구하고 LIMA는 일관된 다중 턴 대화를 수행할 수 있으며, 이런 능력은 수작업으로 만든 30개의 대화 체인만 학습 세트에 추가해도 향상될 수 있음을 발견
2 Alignment Data
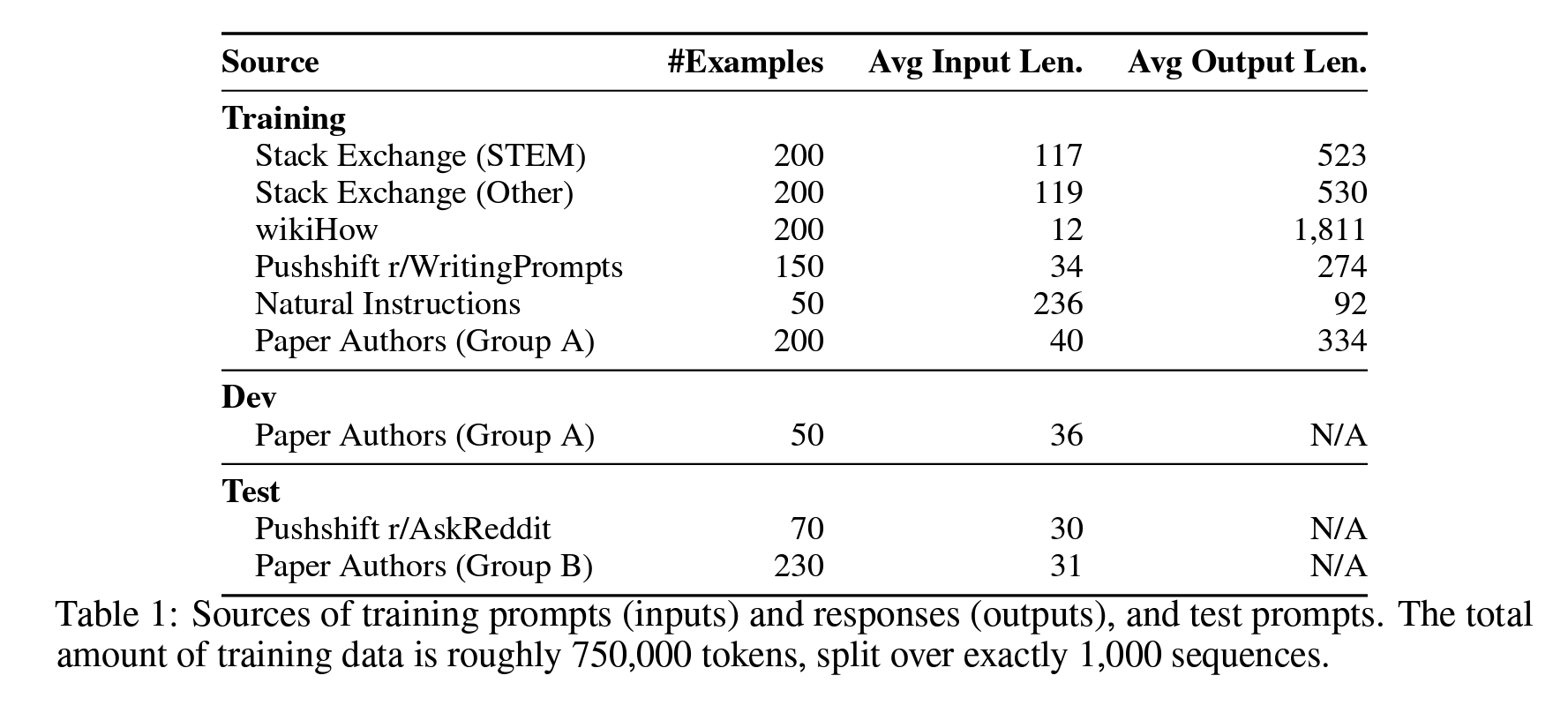
We define the Superficial Alignment Hypothesis: A model’s knowledge and capabilities are learnt almost entirely during pretraining, while alignment teaches it which subdistribution of formats should be used when interacting with users. If this hypothesis is correct, and alignment is largely about learning style, then a corollary of the Superficial Alignment Hypothesis is that one could sufficiently tune a pretrained language model with a rather small set of examples [Kirstain et al., 2021]. To that end, we collect a dataset of 1,000 prompts and responses, where the outputs (responses) are stylistically aligned with each other, but the inputs (prompts) are diverse. Specifically, we seek outputs in the style of a helpful AI assistant. We curate such examples from a variety of sources, primarily split into community Q&A forums and manually authored examples. We also collect a test set of 300 prompts and a development set of 50. Table 1 shows an overview of the different data sources and provides some statistics (see Appendix A for a selection of training examples).
- Superficial Alignment Hypothesis을 제시
- 모델의 지식과 기능은 거의 전적으로 pre-training을 통해 학습되는 반면, 정렬은 사용자와 상호 작용할 때 어떤 형식의 하위 분포를 사용해야 하는지를 가르쳐줄 수 있다고 주장함.
- 이 가설이 맞고 정렬이 주로 학습 스타일에 관한 것이라면 표면적 정렬 가설의 인퍼런스은 다소 적은 수의 예제로 pre-training된 언어 모델을 충분히 조정할 수 있다는 것을 의미함. [Kirstain et al., 2021]
- 1,000개의 프롬프트와 응답으로 구성된 데이터셋를 수집하여 출력(응답)은 문체가 서로 일치하지만 입력(프롬프트)은 다양함
- 주로 커뮤니티 Q&A 포럼과 수동으로 작성된 예제로 나누어 다양한 출처에서 선별하여, helpful AI assistant의 출력을 따랐다고 함.
- 또한 300개의 프롬프트가 포함된 테스트 세트와 50개의 개발 세트도 수집하였음.
2.1 Community Questions & Answers
We collect data from three community Q&A websites: StackExchange, wikiHow, and the Pushshift Reddit Dataset [Baumgartner et al., 2020]. Largely speaking, answers from StackExchange and wikiHow are well-aligned with the behavior of a helpful AI agent, and can therefore be mined automatically, whereas highly upvoted Reddit answers tend to be humorous or trolling, requiring a more manual approach to curate responses that follow the appropriate style.
StackExchange: StackExchange contains 179 online communities (exchanges), each one dedicated to a specific topic, with the most popular one being programming (StackOverflow). Users can post questions, answers, comments and upvote (or downvote) all of the above. Thanks to active community members and moderators, StackExchange has successfully maintained a high bar for content quality. We apply both quality and diversity controls when sampling from StackExchange. First, we divide the exchanges into 75 STEM exchanges (including programming, math, physics, etc.) and 99 other (English, cooking, travel, and more); we discard 5 niche exchanges. We then sample 200 questions and answers from each set using a temperature of 3 to get a more uniform sample of the different domains. Within each exchange, we take the questions with the highest score that are self-contained in the title (nobody). We then select the top answer for each question, assuming it had a strong positive score (at least 10). To conform with the style of a helpful AI assistant, we automatically filter answers that are too short (less than 1200 characters), too long (more than 4096 characters), written in the first person (“I”, “my”), or reference other answers (“as mentioned”, “stack exchange”, etc); we also remove links, images, and other HTML tags from the response, retaining only code blocks and lists. Since StackExchange questions contain both title and a description, we randomly select the title as the prompt for some examples, and the description for others.
- StackExchange에서 샘플링할 때 품질과 다양성 관리를 모두 적용하였으며,
- 유용(helpful)한 AI 어시스턴트의 스타일에 맞게 너무 짧거나(1200자 미만), 너무 길거나(4096자 이상), 1인칭(“나”, “내”)으로 작성되거나 다른 답변을 참조하는 답변(“as mentioned”, “스택 교환” 등)은 자동으로 필터링되며, 답변에서 링크, 이미지 및 기타 HTML 태그도 제거하여 코드 블록과 목록만 남겼다고 함.
wikiHow: wikiHow is an online wiki-style publication featuring over 240,000 how-to articles on a variety of topics. Anyone can contribute to wikiHow, though articles are heavily moderated, resulting in almost universally high-quality content. We sample 200 articles from wikiHow, sampling a category first (out of 19) and then an article within it to ensure diversity. We use the title as the prompt (e.g. “How to cook an omelette?”) and the article’s body as the response. We replace the typical “This article…” beginning with “The following answer…”, and apply a number of preprocessing heuristics to prune links, images, and certain sections of the text.
- “오믈렛을 요리하는 방법”과 같은 글 제목을 프롬프트로 사용하고, 본문을 응답으로 사용하였음.
The Pushshift Reddit Dataset: Reddit is one of the most popular websites in the world, allowing users to share, discuss, and upvote content in user-created subreddits. Due to its immense popularity, Reddit is geared more towards entertaining fellow users rather than helping; it is quite often the case that witty, sarcastic comments will obtain more votes than serious, informative comments to a post. We thus restrict our sample to two subsets, AskReddit and WritingPrompts, and manually select examples from within the most upvoted posts in each community. From AskReddit we find 70 self-contained prompts (title only, nobody), which we use for the test set, since the top answers are not necessarily reliable. The WritingPrompts subreddit contains premises of fictional stories, which other users are then encouraged to creatively complete. We find 150 prompts and high-quality responses, encompassing topics such as love poems and short science fiction stories, which we add to the training set. All data instances were mined from the Pushshift Reddit Dataset [Baumgartner et al., 2020].
- AskReddit과 WritingPrompts에서 가장 많은 표를 받은 게시물 중 수동 선택하여 구성하였음.
2.2 Manually Authored Examples
To further diversify our data beyond questions asked by users in online communities, we collect prompts from ourselves (the authors of this work). We designate two sets of authors, Group A and Group B, to create 250 prompts each, inspired by their own interests or those of their friends. We select 200 prompts from Group A for training and 50 prompts as a held-out development set. After filtering some problematic prompts, the remaining 230 prompts from Group B are used for testing. We supplement the 200 training prompts with high-quality answers, which we write ourselves. While authoring answers, we try to set a uniform tone that is appropriate for a helpful AI assistant. Specifically, many prompts will be answered with some acknowledgment of the question followed by the answer itself. Preliminary experiments show that this consistent format generally improves model performance; we hypothesize that it assists the model in forming a chain of thought, similar to the “let’s think step-by-step” prompt [Kojima et al., 2022, Wei et al., 2022b]. We also include 13 training prompts with some degree of toxicity or malevolence. We carefully write responses that partially or fully reject the command, and explain why the assistant will not comply. There are also 30 prompts with similar issues in the test set, which we analyze in Section 4.3. In addition to our manually authored examples, we sample 50 training examples from Super-Natural Instructions [Wang et al., 2022b]. Specifically, we select 50 natural language generation tasks such as summarization, paraphrasing, and style transfer, and pick a single random example from each one. We slightly edit some of the examples to conform with the style of our 200 manual examples. While the distribution of potential user prompts is arguably different from the distribution of tasks in Super-Natural Instructions, our intuition is that this small sample adds diversity to the overall mix of training examples, and can potentially increase model robustness. Manually creating diverse prompts and authoring rich responses in a uniform style is laborious. While some recent works avoid manual labor via distillation and other automatic means [Honovich et al., 2022, Wang et al., 2022a, Tao et al., 2023, Chiang et al., 2023, Sun et al., 2023], optimizing for quantity over quality, this work explores the effects of investing in diversity and quality instead.
3 Training LIMA
We train LIMA (Less Is More for Alignment) using the following protocol. Starting from LLaMA 65B [Touvron et al., 2023], we fine-tune on our 1,000-example alignment training set. To differentiate between each speaker (user and assistant), we introduce a special end-of-turn token (EOT) at the end of each utterance. This token plays the same role as EOS of halting generation but avoids conflation with any other meaning that the pretrained model may have imbued into the preexisting EOS token. We follow standard fine-tuning hyperparameters: we fine-tune for 15 epochs using AdamW [Loshchilov and Hutter, 2017] with β₁ = 0.9, β₂ = 0.95, and weight decay of 0.1. Without warm-up steps, we set the initial learning rate to 1e-5 and linearly decay it to 1e-6 by the end of training. The batch size is set to 32 examples (64 for smaller models), and texts longer than 2048 tokens are trimmed. One notable deviation from the norm is the use of residual dropout; we follow Ouyang et al. [2022] and apply dropout over residual connections, starting at p = 0.0 at the bottom layer and linearly raising the rate to p = 0.3 at the last layer (p = 0.2 for smaller models). We find that perplexity does not correlate with generation quality and thus manually select checkpoints between the 5th and the 10th epochs using the held-out 50-example development set.
4 Human Evaluation
We evaluate LIMA by comparing it to state-of-the-art language models, and find that it outperforms OpenAI’s RLHF-based DaVinci003 and a 65B-parameter reproduction of Alpaca trained on 52,000 examples. It often produces better or equal responses than GPT-4. Analyzing LIMA generations finds that 50% of its outputs are considered excellent. The fact that simple fine-tuning over a few examples is enough to compete with the state of the art strongly supports the Superficial Alignment Hypothesis (Section 2), as it demonstrates the power of pretraining and its relative importance over large-scale instruction tuning and reinforcement learning approaches.
4.1 Experiment Setup
To compare LIMA to other models, we generate a single response for each test prompt. We then ask crowd workers to compare LIMA outputs to each of the baselines and label which one they prefer. We repeat this experiment, replacing human crowd workers with GPT-4, finding similar agreement levels. Baselines we compare LIMA to five baselines: Alpaca 65B [Taori et al., 2023], OpenAI’s DaVinci003, Google’s Bard, Anthropic’s Claude, and OpenAI’s GPT-4.
Generation
For each prompt, we generate a single response from each baseline model using nucleus sampling [Holtzman et al., 2019] with p = 0.9 and a temperature of τ = 0.7. We apply a repetition penalty of previously generated tokens with a hyperparameter of 1.2. We limit the maximum token length to 2048.
Methodology
At each step, we present annotators with a single prompt and two possible responses generated by different models. The annotators are asked to label which response was better or whether neither response was significantly better than the other. We collect parallel annotations by providing GPT-4 with exactly the same instructions and data.
Inter-Annotator Agreement
We compute inter-annotator agreement using tie-discounted accuracy: we assign one point if both annotators agreed, half a point if either annotator (but not both) labeled a tie, and zero points otherwise. We measure agreement over a shared set of 50 annotation examples (single prompt, two model responses – all chosen randomly), comparing author, crowd, and GPT-4 annotations. Among human annotators, we find the following agreement scores: crowd-crowd 82%, crowd-author 81%, and author-author 78%. Despite some degree of subjectivity in this task, there is decent agreement among human annotators. We also measure the agreement between GPT-4 and humans: crowd-GPT 78% and author-GPT 79% (although we use stochastic decoding, GPT-4 almost always agrees with itself). These figures place GPT-4 on par in agreement with human annotators, essentially passing the Turking Test for this task. [Efrat and Levy,2020].
- 2 See Appendix B for a more detailed study comparing validation perplexity and generation quality.
- 3 https://platform.openai.com/docs/model-index-for-researchers
- 4 https://www.anthropic.com/index/introducing-claude
4.2 Results
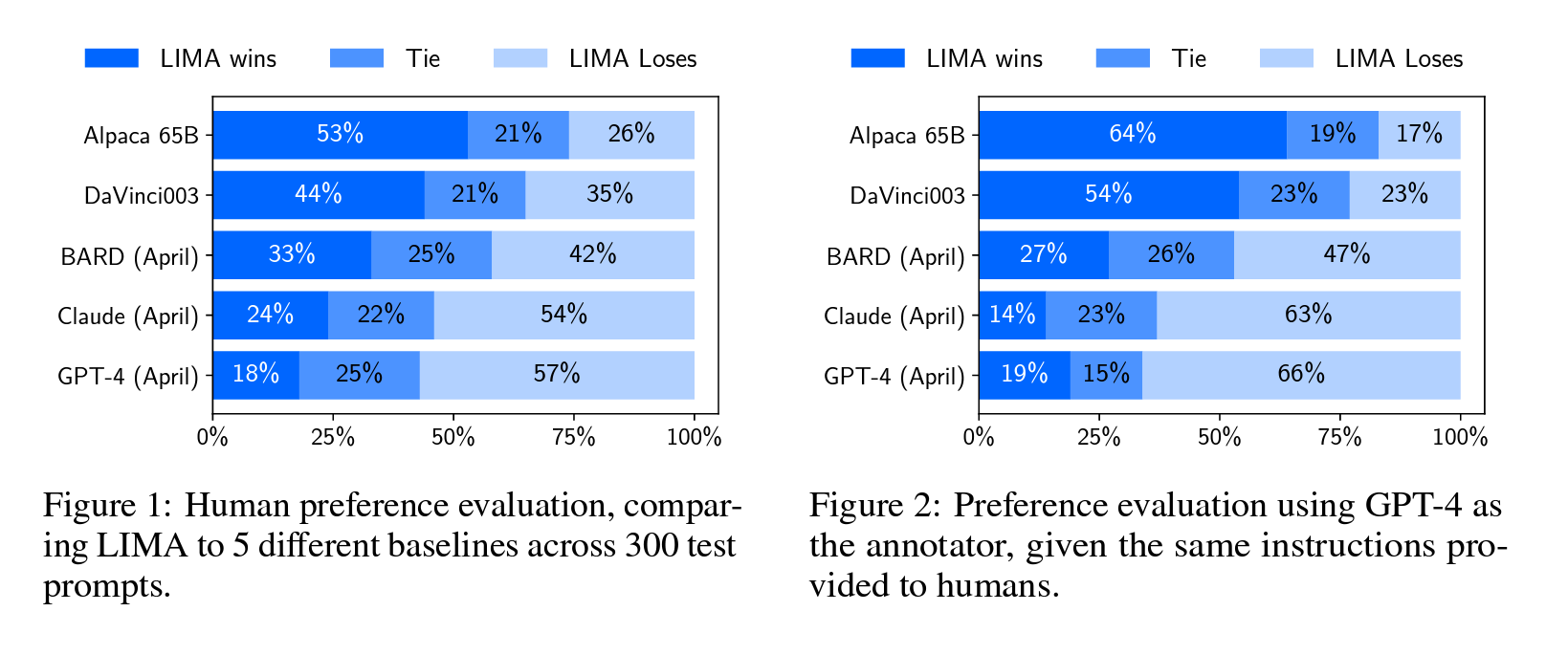
Figure 1 shows the results of our human preference study, while Figure 2 displays the results of GPT-4 preferences. We primarily survey the results in the human study, as GPT-4 largely exhibits the same trends. Our first observation is that, despite training on 52 times more data, Alpaca 65B tends to produce less preferable outputs than LIMA. The same is true for DaVinci003, though to a lesser extent. What is striking about this result is the fact that DaVinci003 was trained with RLHF, a supposedly superior alignment method. Bard shows the opposite trend to DaVinci003, producing better responses than LIMA 42% of the time. However, this also means that 58% of the time the LIMA response was at least as good as Bard. Finally, we see that while Claude and GPT-4 generally perform better than LIMA, there is a non-trivial amount of cases where LIMA does actually produce better responses. Perhaps ironically, even GPT-4 prefers LIMA outputs over its own 19% of the time.
4.3 Analysis
While our main evaluation assesses LIMA with respect to state-of-the-art models, one must remember that some of these baselines are actually highly tuned products that may have been exposed to millions of real user prompts during training, creating a very high bar. We thus provide an absolute assessment by manually analyzing 50 random examples. We label each example into one of three categories: Fail (the response did not meet the requirements of the prompt), Pass (the response met the requirements of the prompt), and Excellent (the model provided an excellent response to the prompt). Figure 3 shows that 50% of LIMA answers are considered excellent and that it is able to follow all but 6 of the 50 analyzed prompts. We do not observe any notable trend within the failure cases. Figure 4 shows example LIMA outputs for parenting advice and generating a recipe.


Out of Distribution
How does LIMA perform on examples? Of the 50 analyzed examples, 43 have a training example that is somewhat related in terms of format (e.g., question answering, advice, letter writing, etc.). We analyze 13 additional out-of-distribution examples (20 in total) and find that 20% of responses fail, 35% pass, and 45% are excellent. Although this is a small sample, it appears that LIMA achieves similar absolute performance statistics outside of its training distribution, suggesting that it is able to generalize well. Figure 4 shows LIMA’s reaction when asked to write a stand-up or order pizza.
Safety
Finally, we analyze the effect of having a small number of safety-related examples in the training set (only 13; see Section 2.2). We check LIMA’s response to 30 potentially sensitive prompts from the test set and find that LIMA responds safely to 80% of them (including 6 out of 10 prompts with malicious intent). In some cases, LIMA outright refuses to perform the task (e.g., when asked to provide a celebrity’s address). However, when the malicious intent is implicit, LIMA is more likely to provide unsafe responses, as can be seen in Figure 4.
5 Why is Less More? Ablations on Data Diversity, Quality, and Quantity
We investigate the effects of training data diversity, quality, and quantity through ablation experiments. We observe that, for the purpose of alignment, scaling up input diversity and output quality have measurable positive effects, while scaling up quantity alone might not.
Experiment Setup
We fine-tune a 7B-parameter LLaMA model Touvron et al. [2023] on various datasets, controlling for the same hyperparameters (Section 3). We then sample 5 responses for each test set prompt and evaluate response quality by asking ChatGPT (GPT-3.5 Turbo) to grade the helpfulness of a response on a 1-6 Likert scale (see Appendix D for the exact template). We report the average score alongside a 95% two-sided confidence interval.
- 다양한 데이터셋에서 동일한 하이퍼파라미터를 제어하면서 7B-파라미터 LLaMA 모델(Touvron 외. [2023])을 파인튜닝하였음.
- 테스트 세트 프롬프트에 대해 5개의 응답을 샘플링하고 ChatGPT(GPT-3.5 Turbo)에 응답의 유용성을 1~6 리커트 척도로 평가하도록 요청하여 응답 품질을 평가하였음. (Appendix D, Average score 95% 신뢰 구간)
[리커드 척도 색인마킹] 데이터 샘플 및 레이블링
Diversity
To test the effects of prompt diversity while controlling for quality and quantity, we compare the effect of training on quality-filtered Stack Exchange data, which has heterogeneous prompts with excellent responses, and wikiHow data, which has homogeneous prompts with excellent responses. While we compare Stack Exchange with wikiHow as a proxy for diversity, we acknowledge that there may be other conflating factors when sampling data from two different sources. We sample 2,000 training examples from each source (following the same protocol from Section 2.1). Figure 5 shows that the more diverse Stack Exchange data yields significantly higher performance.
- 동일한 프로토콜에 따라 각 소스에서 2,000개의 훈련 예시를 샘플링해본 결과, 다양할수록 더 좋은 성능을 보임을 확인하였다고 함.
- 필터링되지 않은 데이터 소스로 학습된 모델 간에 0.5포인트의 유의미한 차이가 있었음을 보고함.
Quality
To test the effects of response quality, we sample 2,000 examples from Stack Exchange without any quality or stylistic filters and compare a model trained on this dataset to the one trained on our filtered dataset. Figure 5 shows that there is a significant 0.5-point difference between models trained on the filtered and unfiltered data sources.
- 품질이나 문체 필터를 적용하지 않고 Stack Exchange에서 2,000개의 예시를 샘플링하고, 이 데이터셋에서 학습된 모델과 필터링된 데이터셋에서 학습된 모델을 비교하니 0.5포인트 정도의 유의미한 차이가 있었음.
Quantity
Scaling up the number of examples is a well-known strategy for improving performance in many machine learning settings. To test its effect on our setting, we sample exponentially increasing training sets from Stack Exchange. Figure 6 shows that, surprisingly, doubling the training set does not improve response quality. This result, alongside our other findings in this section, suggests that the scaling laws of alignment are not necessarily subject to quantity alone but rather a function of prompt diversity while maintaining high-quality responses.
- 흔하게 ML에서 사용되는 방식으로 scaling up 해봤는데, 두 배로 양을 늘려도 응답 품질이 개선되지 않았으며,
- 정렬의 확장 법칙이 반드시 양에만 좌우되는 것이 아니라 고품질 응답을 유지하면서 신속하게 다양성을 확보하는 함수에 따라 달라질 수 있음을 시사함.
6 Multi-Turn Dialogue
Can a model fine-tuned on only 1,000 single-turn interactions engage in multi-turn dialogue? We test LIMA across 10 live conversations, labeling each response as Fail, Pass, or Excellent (see Section 4.3). LIMA responses are surprisingly coherent for a zero-shot chatbot, referencing information from previous steps in the dialogue. It is clear though that the model is operating out of distribution; in 6 out of 10 conversations, LIMA fails to follow the prompt within 3 interactions. To improve its ability to converse, we gather 30 multi-turn dialogue chains. Among these, 10 dialogues are composed by the authors, while the remaining 20 are based on comment chains from StackExchange, which we edit to fit the assistant’s style. We fine-tune a new version of LIMA from the pretrained LLaMA model using the combined 1,030 examples and conduct 10 live conversations based on the same prompts used for the zero-shot model. Figure 8 shows excerpts from such dialogues. Figure 7 shows the distribution of response quality. Adding conversations substantially improves generation quality, raising the proportion of excellent responses from 45.2% to 76.1%. Moreover, the failure rate drops from 15 fails per 42 turns (zero-shot) to 1 fail per 46 (fine-tuned). We further compare the quality of the entire dialogue and find that the fine-tuned model was significantly better in 7 out of 10 conversations and tied with the zero-shot model in 3. This leap in capability from a mere 30 examples, as well as the fact that the zero-shot model can converse at all, reinforces the hypothesis that such capabilities are learned during pretraining and can be invoked through limited supervision.
We also experiment with removing examples of a particular task from our dataset. In Appendix E, we show how even 6 examples can make or break the ability to generate text with complex structure.
7 Discussion
We show that fine-tuning a strong pretrained language model on 1,000 carefully curated examples can produce remarkable, competitive results on a wide range of prompts. However, there are limitations to this approach. Primarily, the mental effort in constructing such examples is significant and difficult to scale up. Secondly, LIMA is not as robust as product-grade models; while LIMA typically generates good responses, an unlucky sample during decoding or an adversarial prompt can often lead to a weak response. That said, the evidence presented in this work demonstrates the potential of tackling the complex issues of alignment with a simple approach.
Appendix
A Training Examples
Figure 10 shows six training examples from various sources.
B Anticorrelation between Perplexity and Generation Quality
When fine-tuning LIMA, we observe that perplexity on held-out Stack Exchange data (2,000 examples) negatively correlates with the model’s ability to produce quality responses. To quantify this manual observation, we evaluate model generations using ChatGPT, following the methodology described in Section 5. Figure 9 shows that as perplexity rises with more training steps – which is typically a negative sign that the model is overfitting – so does the quality of generations increase. Lacking an intrinsic evaluation method, we thus resort to manual checkpoint selection using a small 50-example validation set.
C Human Annotation
Figure 11 shows the human annotation interface we used to collect preference judgments. Annotators were asked to exercise empathy and imagine that they were the original prompters.
D ChatGPT Score
Automatically evaluating generative models is a difficult problem. For ablation experiments (Section 5), we use ChatGPT (GPT-3.5 Turbo) to evaluate model outputs on a 6-point Likert score given the prompt in Figure 12.
E Generating Text with Complex Structure
In our preliminary experiments, we find that although LIMA can respond to many questions in our development set well, it cannot consistently respond to questions that specify the structures of the answer well, e.g., summarizing an article into bullet points or writing an article consisting of several key elements. Hence, we investigate whether adding a few training examples in this vein can help LIMA generalize to prompts with unseen structural requirements. We added six examples with various formatting constraints, such as generating a product page that includes Highlights, About the Product, and How to Use, or generating question-answer pairs based on a given article. After training with these six additional examples, we test the model on a few questions with format constraints and observe that LIMA responses greatly improve. We present two examples in Figure 13, from which we can see that LIMA fails to generate proper answers without structure-oriented training examples (left column), but it can generate remarkably complex responses such as a marketing plan even though we do not have any marketing plan examples in our data (right column).