DPO | stepwise-DPO
- Related Project: Private
- Category: Paper Review
- Date: 2024-04-06
sDPO: Don’t Use Your Data All at Once
- url: https://arxiv.org/abs/2403.19270
- pdf: https://arxiv.org/pdf/2403.19270
- html: https://arxiv.org/html/2403.19270v1
- abstract: As development of large language models (LLM) progresses, aligning them with human preferences has become increasingly important. We propose stepwise DPO (sDPO), an extension of the recently popularized direct preference optimization (DPO) for alignment tuning. This approach involves dividing the available preference datasets and utilizing them in a stepwise manner, rather than employing it all at once. We demonstrate that this method facilitates the use of more precisely aligned reference models within the DPO training framework. Furthermore, sDPO trains the final model to be more performant, even outperforming other popular LLMs with more parameters.s
TL;DR
- 대규모 언어모델(LLM)은 사전 훈련, 지도 학습, 정렬 조정을 통해 발전하지만, 정렬 조정 단계의 복잡성을 줄이기 위한 효과적인 방법이 필요하며,
- 직접 선호 최적화(Direct Preference Optimization, DPO)를 이용하여 사용자 또는 우수한 AI의 판단에 기초한 선호 데이터셋을 통해 LLM을 훈련시키는 방법을 제안
- 차별화된 참조 모델을 사용하여 DPO를 단계적으로 적용(sDPO), 결과적으로 더 정렬된 모델을 효과적으로 생성
[선수 지식]
DPO (Direct Preference Optimization)
사용자 또는 AI의 판단을 반영한 선호 데이터셋을 이용하여 LLM을 학습시키는 방법으로, 구체적으로는 선택된 답변과 거부된 답변의 로그 확률을 비교함으로써 모델을 최적화 함.
DPO의 핵심은 Preference Loss의 최소화로, 이는 다음과 같이 수식으로 표현
\[L_{\text{DPO}}(\pi_{\theta}, \pi_{\text{ref}}) = \mathbb{E}_{(x, y_{\text{w}}, y_{\text{l}}) \sim D} \left[ -\log \sigma \left( \beta \left( \gamma_{\pi_{\theta}}(x, y_{\text{w}}, y_{\text{l}}) - \gamma_{\pi_{\text{ref}}}(x, y_{\text{w}}, y_{\text{l}}) \right) \right) \right]\]- \(\sigma\)는 시그모이드 함수
- \(\beta\)는 스케일링 팩터
- \(\gamma_{\pi}(x, y_{\text{w}}, y_{\text{l}}) = \log \frac{\pi(y_{\text{w}}\\|x)}{\pi(y_{\text{l}}\\|x)}\)임
- \(\pi_{\theta}\)는 학습되는 모델
- \(\pi_{\text{ref}}\)는 참조 모델
- \(D\)는 선호 데이터셋
[방법]
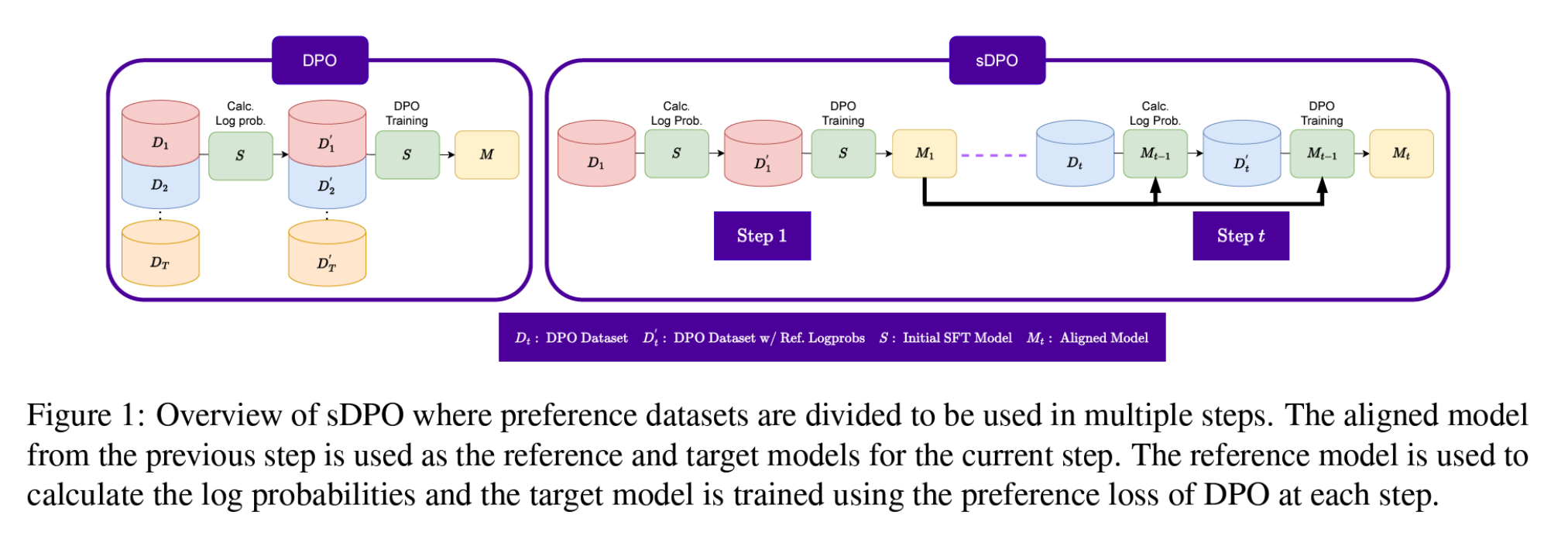
sDPO (Stepwise Direct Preference Optimization)
- sDPO의 도입: 참조 모델을 단계별로 업데이트하여 점진적으로 더 정렬된 모델을 사용함으로써 더 높은 정렬을 달성했다고 주장. 각 단계에서는 이전 단계의 출력 모델을 새로운 참조 모델로 사용. (\(T\)는 총 단계 수, \(\pi_{\theta_t}\)는 \(t\) 단계의 타깃 모델, \(\pi_{\theta_{t-1}}\)는 \(t-1\) 단계의 참조 모델)
[실험]
- 데이터셋: ‘Ultrafeedback’ 및 기타 선호 데이터셋을 사용하여 sDPO의 효과를 검증
- 벤치마크: 각 모델의 H4 점수를 사용하여 SOLAR-10.7B + SFT + sDPO 모델의 성능을 다른 최고 성능 모델과 비교
[결론]
- sDPO는 기존 DPO에 비해 더 높은 정렬 성능을 제공
- 참조 모델의 선택이 결과 모델의 성능에 큰 영향을 미침을 확인
- sDPO는 향후 선호 데이터를 활용한 모델 최적화에 중요한 방법이 될 가능성이 있음.