Hallucination | Lamini Memory Tuning
- Related Project: Private
- Category: Paper Review
- Date: 2024-07-16
Introducing Lamini Memory Tuning: 95% LLM Accuracy, 10x Fewer Hallucinations
- url: https://www.lamini.ai/blog/lamini-memory-tuning
- abstract: In the burgeoning field of artificial intelligence, Lamini Memory Tuning emerges as a groundbreaking approach that enhances the factual accuracy of large language models (LLMs) while significantly minimizing hallucinations. This method marks a pivotal advancement by resolving the apparent contradiction between achieving high factual precision and maintaining the generalization abilities inherent to LLMs. By integrating millions of expert adapters, such as LoRAs, Lamini Memory Tuning meticulously embeds precise facts into open-source LLMs like Llama 3 or Mistral 3. It is uniquely designed to generate expert-level accuracy on specific subjects—such as detailed knowledge about the Roman Empire—by creating specialized experts on various topics provided. Furthermore, it employs an innovative retrieval mechanism that only activates the most pertinent experts during inference, ensuring both high-speed performance and cost-effectiveness. A notable implementation of this method with a Fortune 500 company demonstrated a dramatic improvement, achieving 95% factual accuracy and reducing hallucinations from 50% to a mere 5%. This method provides a compelling solution that does not compromise on speed, cost, or accuracy, setting a new standard for LLM applications.
TL;DR
- 라미니 메모리 튜닝: 대규모 언어모델의 정확성 향상 및 환각 감소
- 모델 최적화: 특정 사실에 대해 제로 오류를 목표로 하는 믹스처 오브 메모리 전문가 채택
- 효과 증명: 포춘 500 기업 사례를 통해 데이터 정확성 및 처리 속도에서 현저한 개선
Lamini Memory Tuning은 대규모 언어모델(LLM)에 사실정보를 정교하게 통합하는 새로운 방식입니다. 이 방법은 LoRA 어댑터와 같은 수백만 개의 전문가 어댑터를 조정하여 특정 사실에 대한 거의 완벽한 기억을 가능하게 합니다. 모델은 특정 문제에 대한 가장 관련성 높은 전문가만을 검색하여 반응하는 방식으로 동작합니다. 이 접근 방식은 정보 검색에서 영감을 받아, 검색 시 모든 모델 가중치가 아닌 필요한 부분만을 동적으로 활성화합니다.
참신! 응용!
-
높은 정확성: Lamini Memory Tuning은 사용자가 지정한 사실에 대해 거의 오차 없는 성능을 보장합니다. 예를 들어, 로마 제국에 대한 사실을 정확하게 기억하도록 설정할 경우, 모델은 카이사르, 수로, 군단 등에 대한 전문 지식을 정확하게 제공합니다.
-
비용 및 지연 시간 감소: 이 방법은 가장 관련성 높은 전문가만을 동적으로 검색하므로, 전체 모델을 항상 로드하고 실행하는 것보다 비용 및 처리 시간을 줄이며, 특히 대규모 모델을 사용할 때 경제적 이점을 제공합니다.
-
환각 감소: 기존 LLM들은 평균 오류를 최소화하기 위해 훈련되므로 때때로 정확하지 않은 ‘환각’을 생성할 수 있습니다. Lamini Memory Tuning은 특정 사실에 대해 정확도를 최적화하므로, 환각을 크게 줄이고 사용자가 중요하게 생각하는 사실에 대해 정확한 정보만을 제공합니다.
-
일반화 능력 유지: 이 방법은 특정 사실에 대한 정확성을 높이면서도, 모델이 다른 모든 데이터에 대해 일반화하는 능력을 유지합니다. 이는 모델이 특정 사실 주변에서도 유창한 프로즈를 생성할 수 있게 해, 모델의 유용성을 크게 향상시킵니다.
Lamini Memory Tuning은 특정 사실에 대한 거의 완벽한 정확도와 함께, 향상된 일반화 능력을 제공합니다. 이는 고비용, 높은 지연시간, 그리고 환각이라는 기존 LLM 사용의 주요 문제들을 효과적으로 해결했다고 보고합니다.
1. 문제 정의
대규모 언어모델(LLM)은 평균적인 오류를 최소화하도록 훈련되어 있으나, 이는 모델이 특정 사실에 대해 정확히 기억하는 능력은 떨어지게 만듭니다. 이런 모델은 매끄러운 문장 생성은 가능하지만, 정확한 사실 기반의 응답 생성에서는 오류가 발생하기 쉽습니다.
2. 선행 연구와 비교
기존의 방법들, 예를 들어 프롬프팅과 검색 강화 생성(RAG)은 모델이 관련 정보를 표면화하고 그 정보에 따라 확률을 조정하도록 합니다. 이는 모델이 관련 정보를 기반으로 응답을 생성하도록 도움을 할 수 있지만, 이 방법들만으로는 완전히 정확한 답변을 보장하기 어렵습니다.
3. 라미니 메모리 튜닝 방법
라미니 메모리 튜닝은 모델이 특정 사실을 거의 완벽하게 기억하도록 최적화하는 새로운 방법입니다. 이 방법은 각각의 메모리 전문가(e.g., LoRA)를 이용하여 모델에 튜닝을 가하고, 인퍼런스 시점에서 가장 관련성 높은 전문가를 선택하여 응답을 생성하도록 합니다.
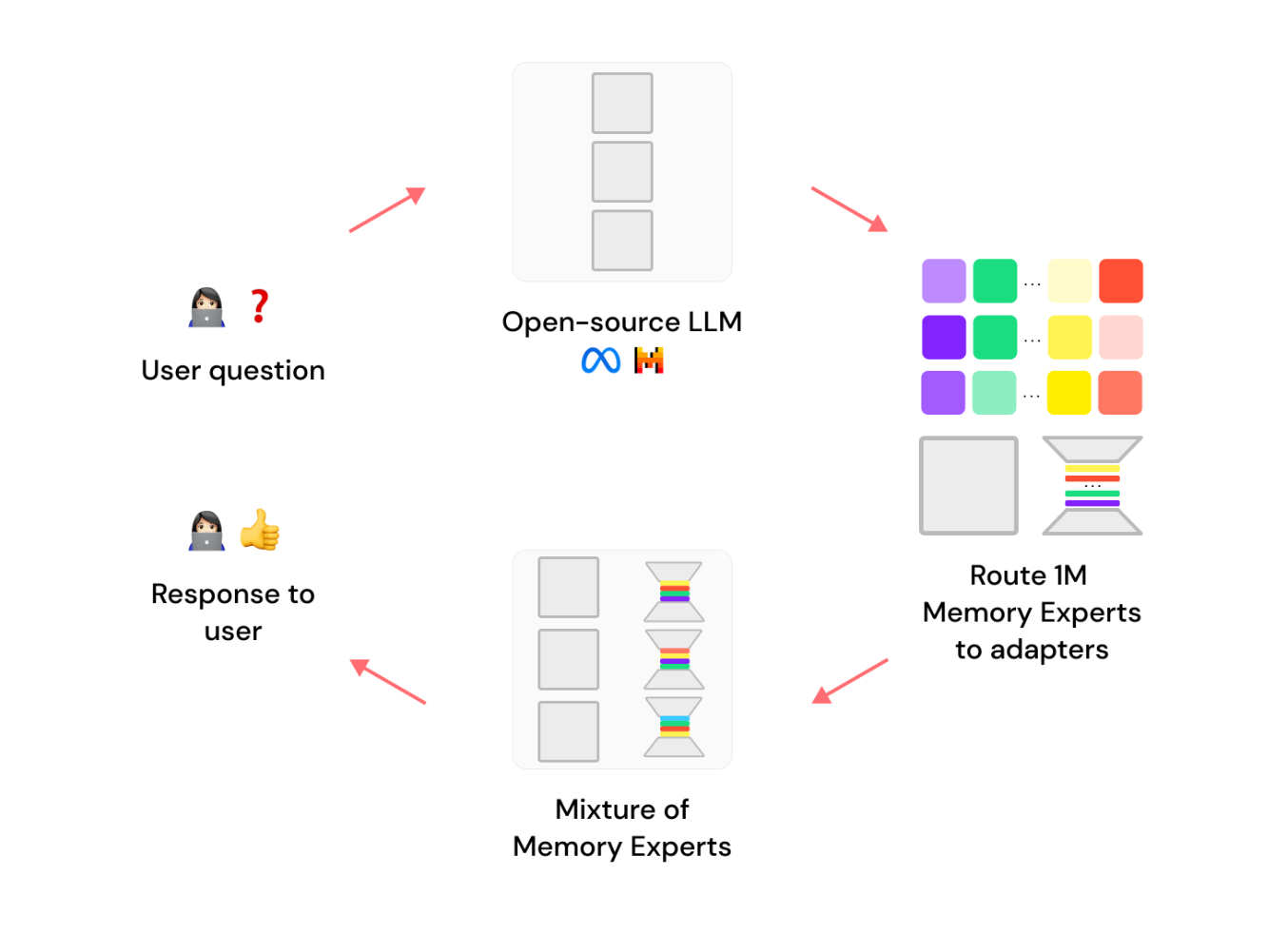
라미니 메모리 튜닝은 수백만의 메모리 전문가를 활용하여 특정 사실에 대한 모델의 출력 확률을 조정합니다. 각 전문가는 특정 데이터 포인트에 대해 튜닝되어 모델이 그 사실을 정확하게 기억하도록 합니다. 이는 다음과 같은 수식으로 표현될 수 있습니다.
\[P(\text{fact} \mid \text{input}) = 1\]$P$는 주어진 입력에 대한 사실의 조건부 확률을 나타냅니다. 이는 모델이 해당 사실을 출력할 확률을 최대화하며, 다른 모든 가능성은 배제됩니다.
4. 실험과 결과
포춘 500 기업을 대상으로 한 실험에서, 라미니 메모리 튜닝은 기존 방법 대비 95%의 높은 정확도를 달성했습니다. 이는 특정 사실에 대한 집중적인 튜닝과 메모리 전문가의 효과적인 활용을 통해 가능했습니다.
5. 결론
라미니 메모리 튜닝은 대규모 언어모델의 활용 가능성을 확장시키는 방법입니다.