Self-Tuning
- Related Project: Private
- Category: Paper Review
- Date: 2024-06-16
Self-Tuning: Instructing LLMs to Effectively Acquire New Knowledge through Self-Teaching
- url: https://arxiv.org/abs/2406.06326
- pdf: https://arxiv.org/pdf/2406.06326
- html https://arxiv.org/html/2406.06326v1
- abstract: Large language models (LLMs) often struggle to provide up-to-date information due to their one-time training and the constantly evolving nature of the world. To keep LLMs current, existing approaches typically involve continued pre-training on new documents. However, they frequently face difficulties in extracting stored knowledge. Motivated by the remarkable success of the Feynman Technique in efficient human learning, we introduce Self-Tuning, a learning framework aimed at improving an LLM’s ability to effectively acquire new knowledge from raw documents through self-teaching. Specifically, we develop a Self-Teaching strategy that augments the documents with a set of knowledge-intensive tasks created in a self-supervised manner, focusing on three crucial aspects: memorization, comprehension, and self-reflection. In addition, we introduce three Wiki-Newpages-2023-QA datasets to facilitate an in-depth analysis of an LLM’s knowledge acquisition ability concerning memorization, extraction, and reasoning. Extensive experimental results on Llama2 family models reveal that Self-Tuning consistently exhibits superior performance across all knowledge acquisition tasks and excels in preserving previous knowledge.
Contents
TL;DR
- Self-Tuning 소개: 새로운 Wiki-Newpages-2023-QA 데이터셋을 활용하여 LLM의 지식 습득 능력을 향상시키는 self-teaching 방법 제시
- 방법 개요: Self-Tuning은 QA 데이터셋에서 파생된 memorization, comprehension, self-reflection 작업을 포함하는 구조화된 3단계 접근 방식을 사용
- 성능 평가: 기존 방법보다 지식 습득 및 유지에서 향상된 성능을 보여주며, 다양한 데이터셋 시나리오에서 검증
1. 서론 및 배경
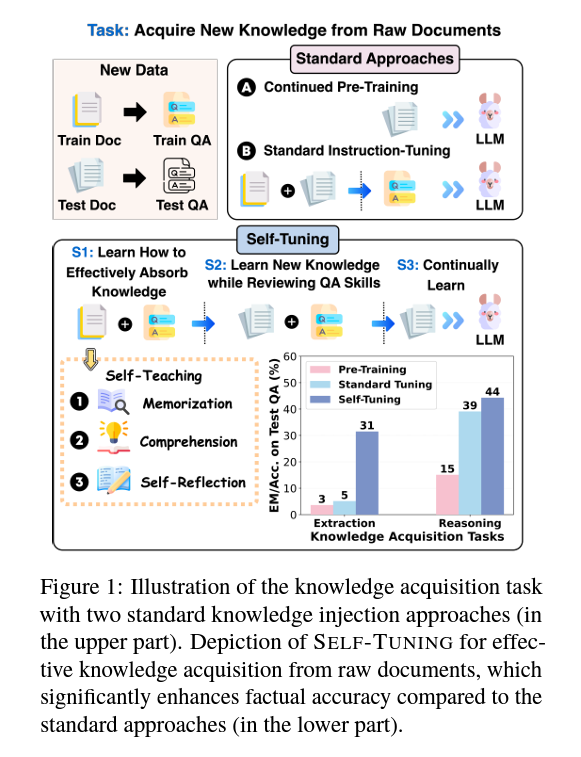
LLM은 대량의 데이터를 통한 사전 학습 중에 방대한 지식을 흡수하지만, 그 학습된 지식을 업데이트하는 데는 한계가 있습니다. 새로운 문서에서 동적으로 학습을 가능하게 하는 Self-Tuning과 같은 방법은 사실적 정확성을 향상시키고 실제 응용 프로그램에서의 신뢰성을 증진시키는 데 필수적입니다. 기존의 지속적 사전 훈련 및 지시 튜닝 접근 방식은 지식 추출 및 적용에서 한계를 보여줍니다.
2. 관련 연구
이전 연구는 지속적인 사전 훈련과 지시 튜닝을 통해 새로운 지식을 주입하는 데 중점을 두었습니다. 그러나 이런 방법은 효과적인 지식 추출과 이해를 가능하게 하는 데 종종 실패합니다. Self-Tuning은 문서 분석에서 직접 파생된 포괄적 학습 전략—기억, 이해, 자기 성찰을 통합함으로써 자신을 차별화합니다.
3. Wiki-Newpages-2023-QA 데이터셋
이 데이터셋은 LLM이 새로운 문서에서 지식을 어떻게 습득하는지 연구하기 위해 설계되었습니다. 다양한 도메인을 아우르며, 개방형 생성과 자연어 인퍼런스(NLI) 작업을 평가하는 데 필요한 견고한 플랫폼을 제공합니다.
4. Self-Tuning 프레임워크
4.1 훈련 과정
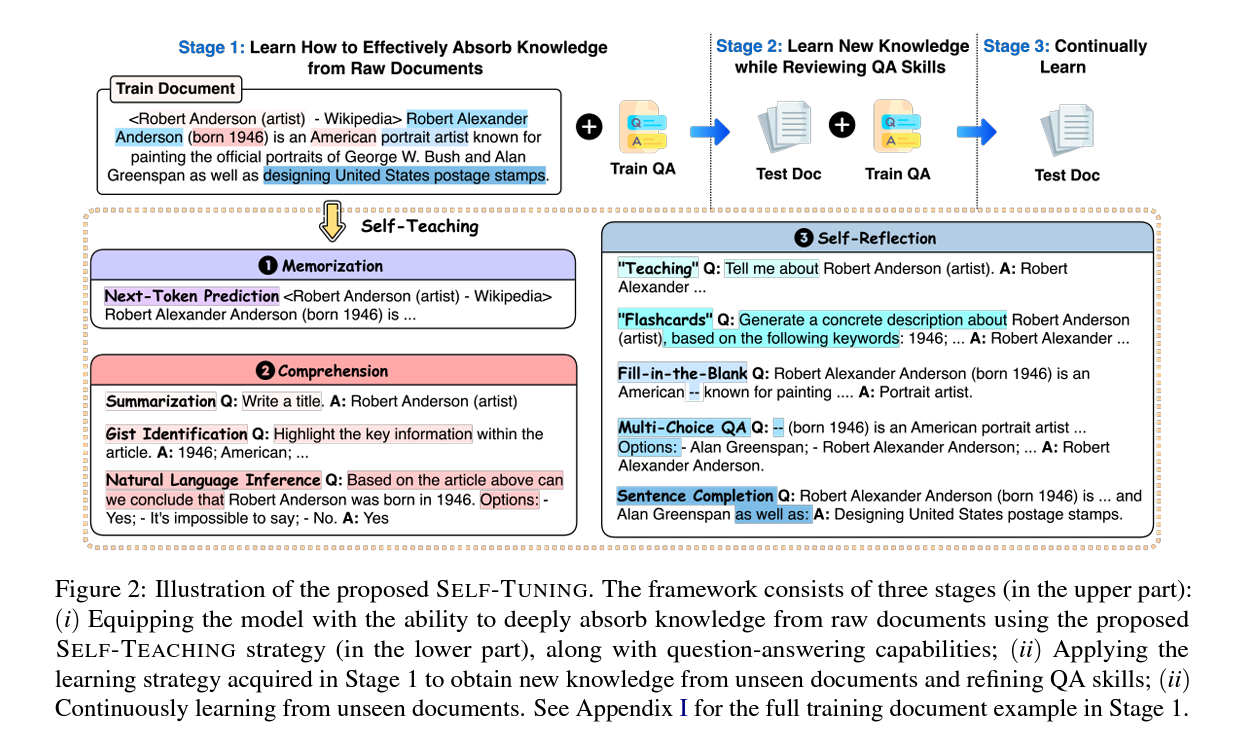
훈련은 세 단계로 이루어집니다.
- Step 1 Eq.1: LLM은 훈련 문서(\(D_{\text{trainDoc}}\))와 QA 데이터(\(D_{\text{trainQA}}\))에서 학습하며, 문서에서 파생된 self-teaching 작업(\(D_{\text{trainSelf}}\))을 통합합니다.
- Step 2 Eq.2: 학습된 전략을 새 문서(\(D_{\text{testDoc}}\))에 적용하여 QA 기술을 강화하고 지식 추출을 보강합니다.
- Step 3 Eq.3: 보이지 않는 문서에서 새로운 지식의 흡수를 계속 강화합니다.
4.2 학습 전략
- 기억(Memorization): 문서 텍스트에서 다음 토큰 예측 작업을 수행합니다.
- 이해(Comprehension): 요약, 핵심 정보 식별, 자연어 인퍼런스 작업을 포함하여 문서의 사실적 내용을 깊게 이해하고 적용하는 능력을 향상시킵니다.
- 자기 성찰(Self-Reflection): 학습된 정보의 회상 및 적용을 평가하고 강화하는 작업을 설계했습니다.
5. 실험 및 평가
Self-Tuning의 효과는 Wiki-Newpages-2023-QA 데이터셋에서 광범위한 테스팅을 통해 입증되었습니다. 기존 방법보다 모든 세 단계—기억, 추출, 인퍼런스—에서 우수한 능력을 보여줍니다. 특히, 다양한 도메인과 교차 도메인 설정에서의 강력한 성능은 그 적응성과 효과를 강조합니다.
6. 결론
Self-Tuning은 LLM의 연속 학습 및 새로운 지식의 적용 능력을 향상시키는 중요한 발전을 나타냅니다. 이 포괄적 접근 방식은 기존 방법의 중요한 격차를 해소하며, 다양한 도메인에서 LLM 응용 프로그램의 더 다이내믹하고 정확하며 신뢰할 수 있는 방법을 제공합니다.