POST | Mamba, MambaMixer, Jamba
- Related Project: Private
- Category: Paper Review
- Date: 2024-04-01
비공개 포스트 초안
Contents
Overview
이 포스트에서는 Mamba[1]의 아키텍처 및 Mamba의 아키텍처를 응용하여 비전 및 시계열 태스크에서 기존 Transformers 기반 모델보다 뛰어날 수 있음을 주장한 Mamba Mixer[2], 그리고 Mamba와 Transformer 하이브리드 아키텍처로 더 넓은 context를 효율적으로 포착하고, MoE로 성능을 개선한 Jamba[3]에 대해서 간략하게 정리합니다.
Mamba에 대해서는 원 논문 및 Maarten Grootendorst의 포스트: A Visual Guide to Mamba and State Space Models를 참고하세요.
[1] Jamba: A Hybrid Transformer-Mamba Language Model
[2] Jamba huggingface model
[3] MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection
[1] Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- url: https://arxiv.org/abs/2312.00752
- pdf: https://arxiv.org/pdf/2312.00752
- abstract: Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers’ computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5×higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
Features
- Selection Mechanism: A simple selection mechanism based on input, allowing the model to filter out irrelevant information and indefinitely remember relevant information.
- Hardware-aware Algorithm: A hardware-aware algorithm that enables efficient computation by using a scan instead of convolution, significantly improving speed and reducing IO access within GPU memory hierarchy.
- Architecture: A simplified and homogenous architecture design (Mamba) combining SSM and MLP blocks into a single block, facilitating selective state spaces and supporting the model’s use as a general foundation model backbone for sequences.
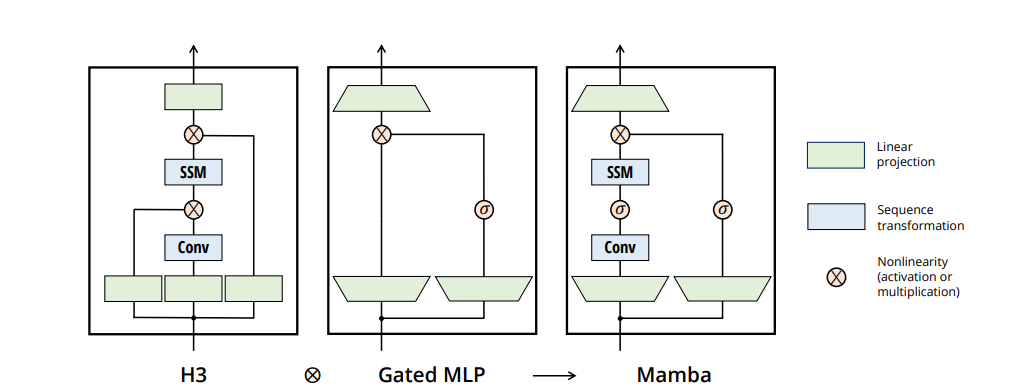
TL;DR
NOTE
Mamba는 SSM(State Space Models)을 사용하고 파라미터 입력 함수로 두어 시퀀스 길이 차원을 따라 정보를 선택적으로 전파하거나 잊을 수 있게 하는 Selective Mechanism을 사용하여 긴 토큰의 일부만을 이용해서도 효과적으로 학습하며, 이 과정에서 연속 시간 시스템을 이산 시간 시스템으로 근사화하는 ZOH(Zero-Order Hold)을 사용해 이산화하고, 하드웨어를 인식해 DRAM과 SRAM의 이동 횟수를 제한하는 등의 방식으로 처리 속도를 크게 개선하였다고 보고합니다.
기존의 트랜스포머의 디코더 블록은 self-attention과 feedforward 신경망으로 구성되어 있으며, Self-attention 계층의 계산 복잡도는 $O(L^2)$이고, Feed-forward 계층의 복잡도는 $O(L \cdot d \cdot m)$입니다. ($L$은 시퀀스 길이, $d$는 모델 차원, $m$은 feedforward 차원)
전체 계산 복잡도는 러프하게 $O(L^2 + L \cdot d \cdot m)$로, transformer는 모든 정보를 압축하지 않고 분산 처리할 수 있기 때문에 전체 context 정보를 취합하면서도 상대적으로 빠르게 학습하기 상대적으로 용이하였습니다.
하지만, 인퍼런스 시에는 이전 토큰 생성 여부와 관계없이 전체 어텐션을 다시 계산하여야 하므로 리니어하게 계산량이 증가할 수밖에 없었고, 이런 vanilla attention의 병목 문제를 해결하기 위해 다양한 방법들이 연구되어 왔습니다.
Mamba는 Selective SSM으로 기존 SSM의 문제를 개선하여 효과적으로 적용하여 관련없는 정보를 선택적으로 제거해서 효과적으로 토큰을 선택하고, 효율적으로 중간 결과를 처리할 수 있도록 하며 기존의 vanilla attention의 병목을 개선하였다고 보고합니다. (그 외 zephyr에 적용된 슬라이딩 윈도우나 RoPE, ALiBi 등)
또한, 최근 Flash Attention-1,2 [3]와 같이 용량이 작으나 가장 효율적인 SRAM과 그것보다 조금 크지만 약간 덜 효율적인 DRAM 간의 전송(I/O)을 개선하기 위한 다양한 방법들이 시도되고 있는데, Mamba 역시 하드웨어를 인식해 DRAM과 SRAM의 이동 횟수를 제한하고, 커널을 융합하여 모델이 중간 결과를 주고받는 불필요한 과정을 제거하여 이런 하드웨어의 병목을 개선하였다고 보고합니다.
원 논문은 위에서 설명한 selective SSM과 하드웨어의 병목을 개선하여 더 빠르고 효과적으로 학습할 수 있음을 보였으나, 실험 및 수학적인 논증 등에 대한 미비, 평가 방법에 대한 우려, 특히 기존 벤치마크 누락(LRA, Long Range Arena) 및 불충분(Perplexity) 등 [1], [2]을 이유로 ICLR 2023에 게재되지 못하였습니다.
현재 Mamba를 통해 비전, 시계열, LLM에서 더 효율적으로 성능을 높인 연구들이 등장하고 있습니다. 특히 LLM에서는 토큰의 context length를 효과적으로 넓힐 수 있었다고 언급합니다.
Mamba는 SSM(State Space Models)을 사용하고 파라미터 입력 함수로 두어 시퀀스 길이 차원을 따라 정보를 선택적으로 전파하거나 잊을 수 있게 하는 Selective Mechanism을 사용하여 긴 토큰의 일부만을 이용해서도 효과적으로 학습하며, 이 과정에서 연속 시간 시스템을 이산 시간 시스템으로 근사화하는 ZOH(Zero-Order Hold)을 사용해 이산화하고, 하드웨어를 인식해 DRAM과 SRAM의 이동 횟수를 제한하는 등의 방식으로 처리 속도를 크게 개선하였다고 합니다. (5×higher throughput than Transformers)
기존 Transformer 기반 아키텍처는 모든 토큰을 계산하고 취하는 방법을 사용하기 때문에 이를 개선하기 위해서 제어이론의 상태공간방정식과 비슷하게 Δ를 통해 제어 반경을 좁히는 동시에 인퍼런스에 필요한 토큰들만 선택적으로 사용할 수 있도록 아키텍처를 변경해 기존 SSM의 단점을 보완했으나, selective mechanism을 사용할 경우, Linear Time invariance이 성립하지 않아 순차적으로 사용해야하는 단점을 적극 변호하였으나 받아들여지지 않았습니다. 결정적으로는 저자들이 LRA(Long Range Arena)에 대한 벤치마크 결과를 누락하고, 평가 방법에 대한 이해도가 부족한 게 아니냐라는 지적이 있었고, Perplexity 스코어가 낮음을 지적했습니다. 저자들은 Perplexity 점수는 NLP 모델링에 큰 영향을 주지 않는다고 항변하였습니다.
Reject 의견들을 살펴보면, 충분한 실험 결과라고 볼 수 없고, baseline보다 약간 높으며, 토큰의 제어가 있어 속도가 향상됐을 수 있으나, 아키텍처에서 selective한 것의 논리가 완벽하지 않음을 지적합니다. 즉, Δ에 대한 세부적인 수학적인 지식 및 기타 세부사항이 섬세하지 못하다는 의견이 있었습니다.
Open Review에서 볼 수 있듯 트레이드 오프에 대해서 기존 SSM의 단점으로 언급하며 변호했던 논리가 충분하지 못함이 지적되었습니다. Selective mechanism의 Δ를 통해 토큰의 일부 영역을 좁히는 것의 효용에 대한 수학적인 증명과 논리가 부족하다는 의견이 있었습니다.
[1] Open Review: Mamba
[2] Medium: Why Mamba was rejected
[3] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
[2] MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection
- url: https://arxiv.org/abs/2403.19888
- pdf: https://arxiv.org/pdf/2403.19888
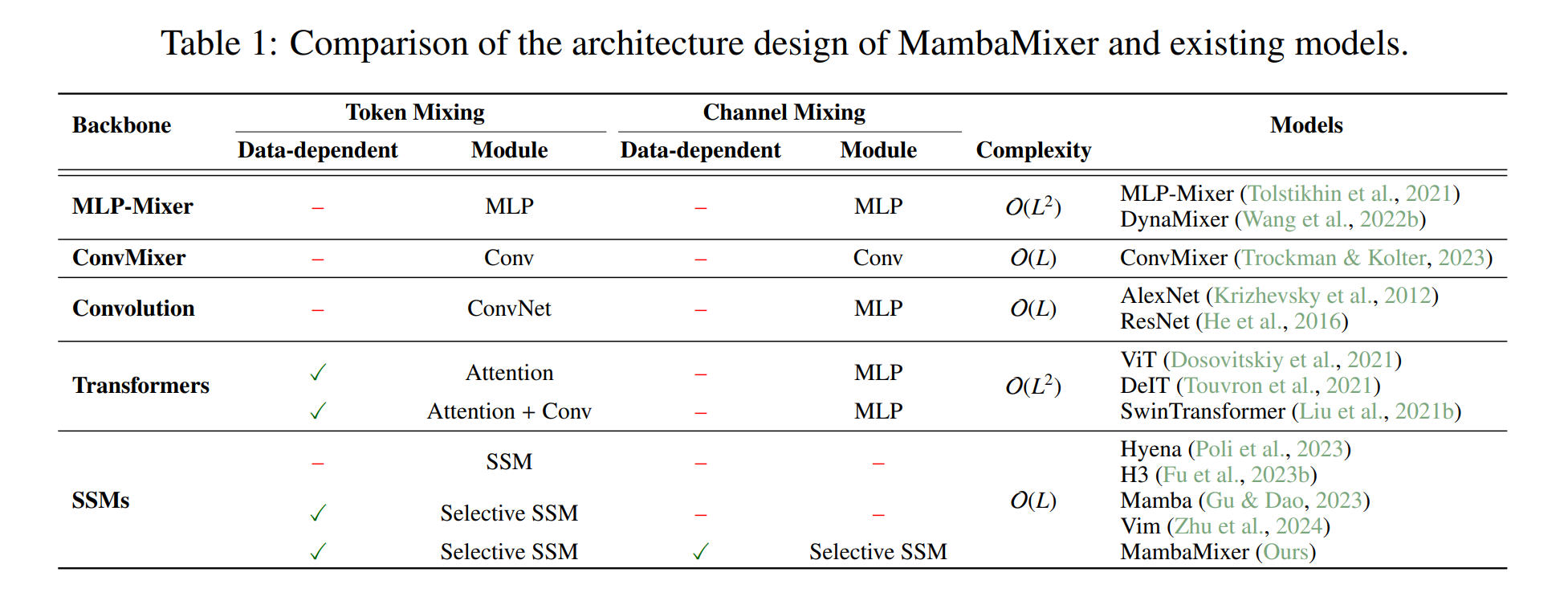
- abstract: Recent advances in deep learning have mainly relied on Transformers due to their data dependency and ability to learn at scale. The attention module in these architectures, however, exhibits quadratic time and space in input size, limiting their scalability for long-sequence modeling. Despite recent attempts to design efficient and effective architecture backbone for multi-dimensional data, such as images and multivariate time series, existing models are either data independent, or fail to allow inter- and intra-dimension communication. Recently, State Space Models (SSMs), and more specifically Selective State Space Models, with efficient hardware-aware implementation, have shown promising potential for long sequence modeling. Motivated by the success of SSMs, we present MambaMixer, a new architecture with data-dependent weights that uses a dual selection mechanism across tokens and channels, called Selective Token and Channel Mixer. MambaMixer connects selective mixers using a weighted averaging mechanism, allowing layers to have direct access to early features. As a proof of concept, we design Vision MambaMixer (ViM2) and Time Series MambaMixer (TSM2) architectures based on the MambaMixer block and explore their performance in various vision and time series forecasting tasks. Our results underline the importance of selective mixing across both tokens and channels. In ImageNet classification, object detection, and semantic segmentation tasks, ViM2 achieves competitive performance with well-established vision models and outperforms SSM-based vision models. In time series forecasting, TSM2 achieves outstanding performance compared to state-of-the-art methods while demonstrating significantly improved computational cost. These results show that while Transformers, cross-channel attention, and MLPs are sufficient for good performance in time series forecasting, neither is necessary.
Features
- Presenting MambaMixer block, a new SSM-based architecture with dual selection that efficiently and effectively selects and mixes (resp. filters) informative (resp. irrelevant) tokens and channels in a data-dependent manner, allowing connections across both channel and token dimensions.
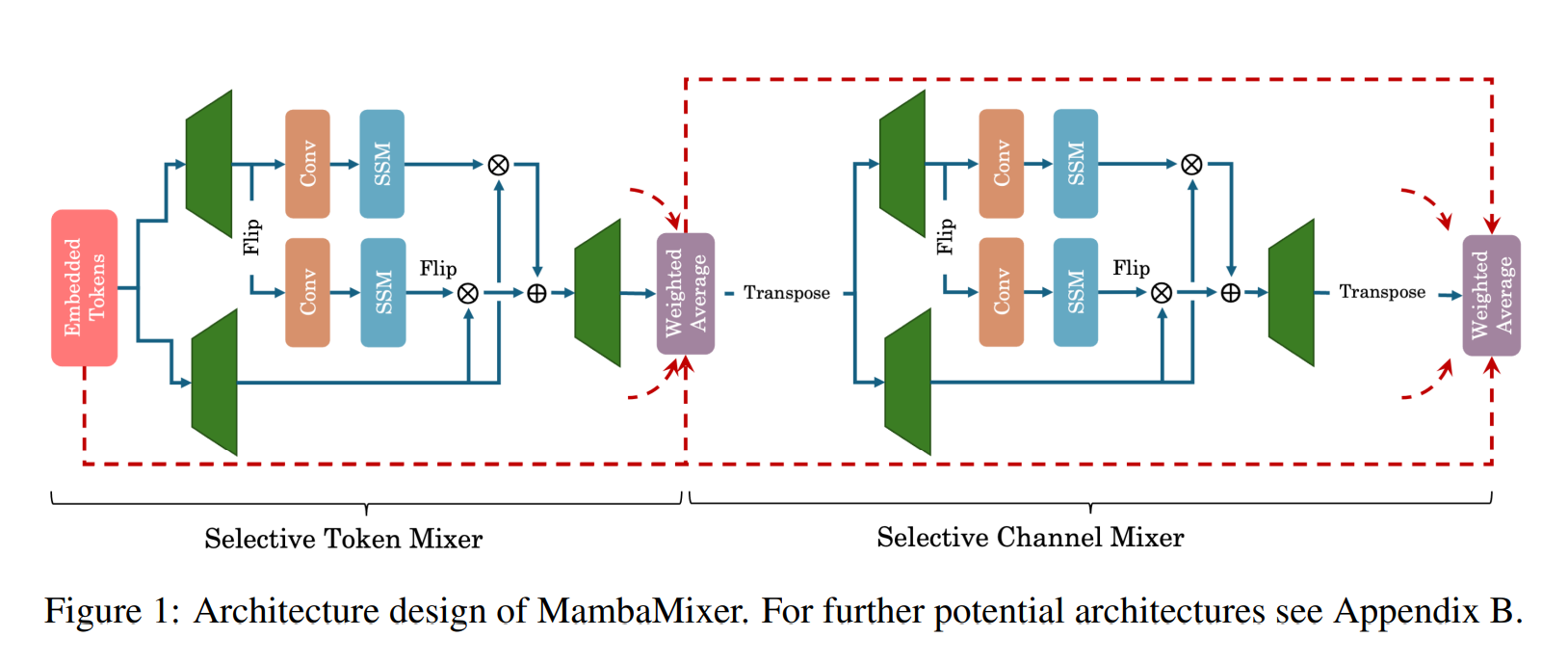
- Demonstrating the ability and effectiveness of bidirectional S6 blocks to focus on or ignore particular channels using ablation studies.
- Enhancing information flow in multi-layer MambaMixer-based architectures by allowing direct access to earlier features by a weighted averaging mechanism.
- Presenting ViM2 and TSM2 models based on MambaMixer for vision and time series forecasting tasks, with outstanding performance compared to baselines.
TL;DR
NOTE
MambaMixer는 Mamba의 아키텍처에서 selective copying하지 않고, 플립하여 채널을 확장합니다.
MambaMixer 블록은 data-dependent 방식으로 informative (resp. irrelevant) tokens과 channels을 선택하고 혼합하는 새로운 SSM 기반 아키텍처입니다. Bidirectional 블록을 통해 효과적으로 기존 mamba 아키텍처를 비전과 시계열 도메인으로 확장했습니다. weighted averaging mechanism을 통해 정보를 효과적으로 교환하고, selective mechanism과 ViM2(Vision MambaMixer)와 TSM2(Time Series MambaMixer) 모델로 비전 및 시계열 예측 작업에서 기준 대비 향상된 성능을 보였다고 합니다.
이번 MambaMixer 논문에서는 기존 Mamba논문에서 지적된 (1) Δ의 조절의 수학적인 증명 및 (2) 상대적으로 토큰의 순서가 덜 중요한 이미지 태스크에서의 큰 폭의 성능향상을 통해 기존의 Mamba에서의 성능 향상이 단순히 경험적으로 약간의 성능 향상만을 보인 것이 아님을 변호합니다. 또한, dual network를 통해 $O(n^2)$에서 $O(n)$으로의 확실한 속도 개선을 보입니다.
또한, selective mechanism에서의 Linear Time invariance에 대한 트레이드 오프를 개선하기 위해 bidirectional 네트워크로 토큰 뿐만 아니라 채널까지의 정보 교환 및 selective mechanism을 확장할 수 있도록 하고, selective token and channel mixer라고 불리는 토큰과 채널 전반에 걸쳐 데이터 종속 가중치를 갖춘 dual selection mechanism을 사용하도록 하여 기존의 속도 향상의 단점을 보완합니다. (기존 Mamba의 selective copying 컨셉의 확장)
특히, 개념 증명을 위해 시계열(TSM2, Time Series MambaMixer)과 비전(ViM2, Vision MambaMixer) 태스크에 적용하여 검증하여, Mamba에서의 퍼포먼스 향상이 baseline보다 우연히 약간 높았던 것이 아님을 주장하고, MAE의 큰 폭 향상과 기존 selective mechanism을 채널로 확장하여 일반화할 수 있음을 변호하며, 이 과정에서 Mamba의 초기 버전에 대한 reject 의견에 대한 추가적인 실험 내용을 제시합니다.
Ablation study 섹션에서 mamba mixer architecture의 ViM2(Vision MambaMixer)과 TSM2(Time Series MambaMixer)가 기존 trasnformer 모델보다 유의미한 성능 향상을 보임을 보고합니다.
논문에서는 Transformer의 복잡도$O(L^2)$에서 를 MambaMixer는 $O(L)$로 개선할 수 있어 빠르고,
Mamba Mixer 아키텍처 모델 성능이 기존 Transformer보다 더 좋다고 보고합니다.
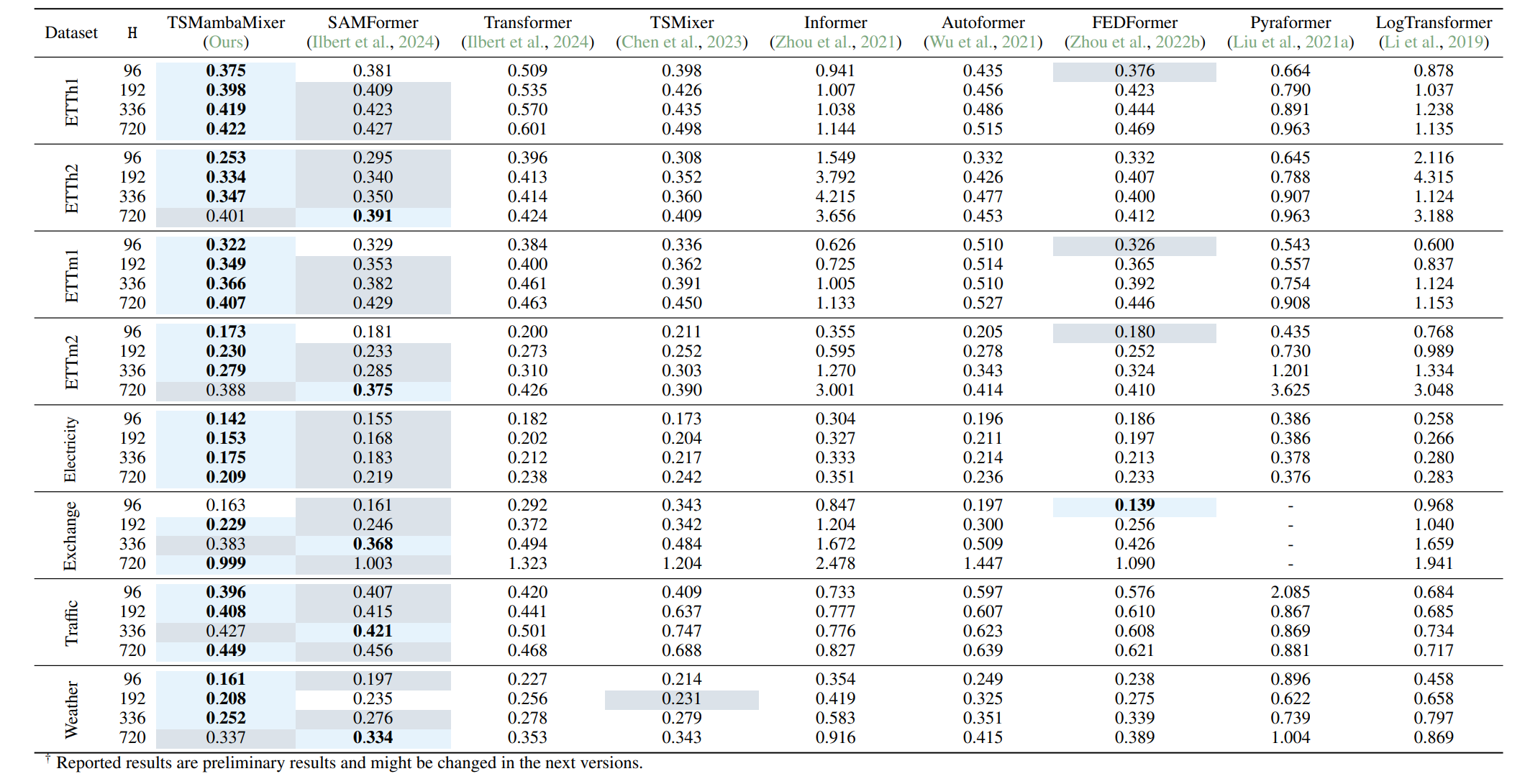
*출처: MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection
[3] Jamba: A Hybrid Transformer-Mamba Language Model
- url: https://arxiv.org/abs/2403.19887
- pdf: https://arxiv.org/pdf/2403.19887
- html: https://arxiv.org/html/2403.19887v1
- huggingface-model: https://huggingface.co/ai21labs/Jamba-v0.1
- abstract: We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable. This flexible architecture allows resource- and objective-specific configurations. In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU. Built at large scale, Jamba provides high throughput and small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations. Remarkably, the model presents strong results for up to 256K tokens context length. We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large scale modeling. We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture. We make the weights of our implementation of Jamba publicly available under a permissive license.
Features
- Pioneering production-grade implementation of the Mamba architecture: Jamba is the inaugural model to scale the Mamba architecture to production-grade utility, seamlessly integrating it with the established Transformer architecture in a hybrid format.
- Tripled throughput for extensive contexts: Jamba achieves three times the throughput of comparative models such as Mixtral 8x7B when handling long contexts, enhancing efficiency for complex computational tasks.
- Expansive 256K context window: This feature democratizes the utilization of an unprecedentedly large context window in Jamba, opening new avenues for application in language model tasks.
- Capability to fit up to 140K context on a single GPU: Jamba distinguishes itself by being the only model in its class that can accommodate such a substantial context on a solitary GPU, simplifying deployment and experimentation.
- Open accessibility of model weights under Apache 2.0: The openness of Jamba’s model weights under the Apache license encourages ongoing research and iterative improvements.
- Broad availability: Set for distribution on Hugging Face and forthcoming inclusion in NVIDIA’s API catalog as an NVIDIA NIM inference microservice, Jamba is positioned for widespread enterprise application.
TL;DR
Jamba는 Mamba 기반 모델로, 기존 Transformer 아키텍처의 요소를 통해 Mamba 구조화된 상태 공간 모델(SSM) 기술을 향상시켰습니다. 256K context window을 제공하며, 혼합 아키텍처를 사용합니다. Transformer와 Mamba를 혼합하는 SSM-Transformer 하이브리드 아키텍처를 통해 긴 문맥 처리능력을 3배 향상시키고, 단일 GPU에서 최대 140K context를 수용할 수 있음을 보이면서 Mamba의 LLM 적용사례를 제시합니다. MoE나 context length에 대해서 좀 더 자유로우면서도 성능이 향상될 수 있음을 언급합니다.
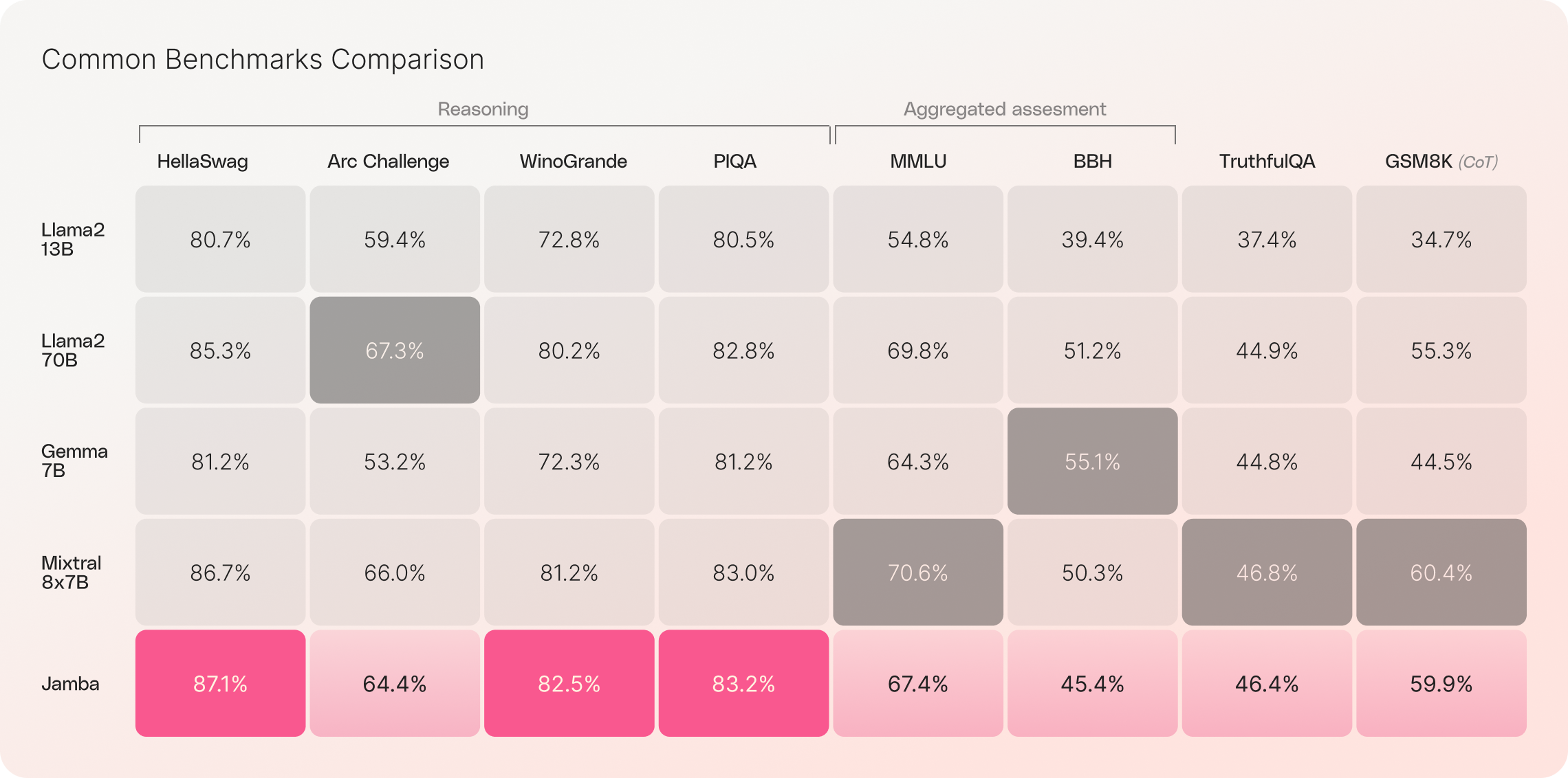
Jamba는 Mamba와 Transformer 아키텍처의 장점만 취사해 기억력, 처리량 및 성능을 최적화합니다. MoE(Mixture-of-Experts) 레이어를 사용하여 전체 모델 파라미터 중 일부만 활용하고, 이 혼합 구조는 Transformer만 있는 모델보다 효율적이라고 언급합니다.
Jamba 아키텍처는 여러가지 핵심 구조적 혁신이 필요했습니다. 각 Jamba 블록은 attention 또는 Mamba 레이어를 포함하고 있으며, 이런 구조를 통해 두 아키텍처를 성공적으로 통합할 수 있었다고 합니다.
- First production-grade Mamba based model built on a novel SSM-Transformer hybrid architecture
- 3X throughput on long contexts compared to Mixtral 8x7B
- Democratizes access to a massive 256K context window
- The only model in its size class that fits up to 140K context on a single GPU
- Released with open weights under Apache 2.0
- Available on Hugging Face and coming soon to the NVIDIA API catalog
- Jamba Offers the Best of Both Worlds
- Jamba’s release marks two significant milestones in LLM innovation: successfully incorporating Mamba alongside the Transformer architecture and advancing the hybrid SSM-Transformer model to production-grade scale and quality.
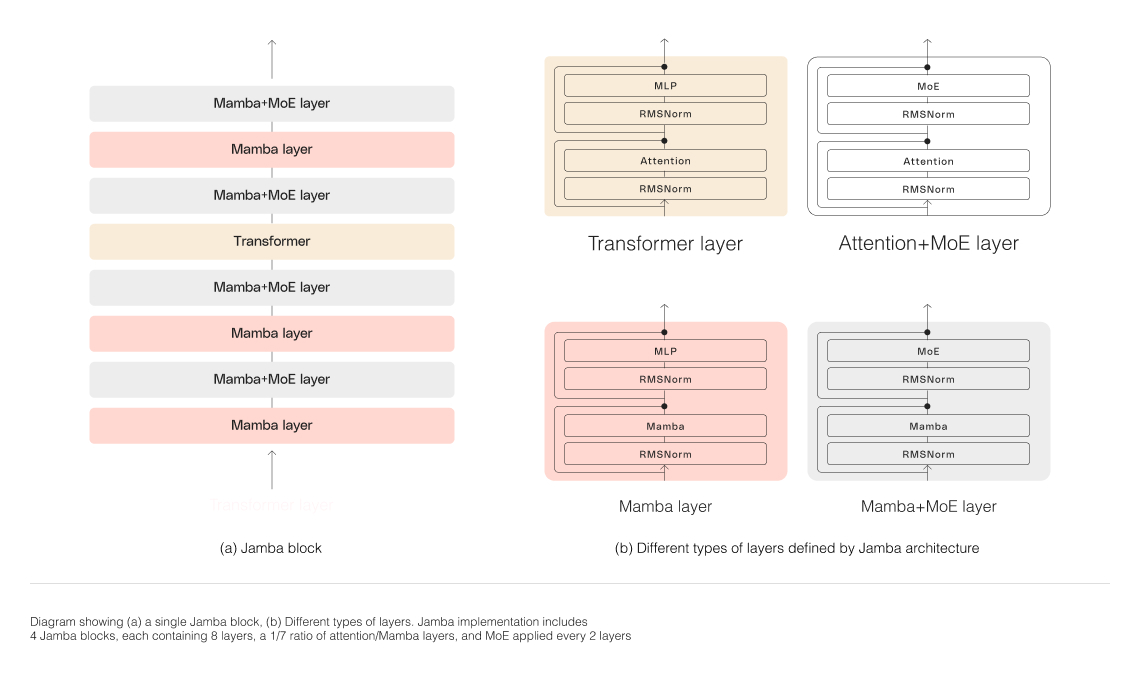
- Combining Mamba and Transformer Historically, language models have predominantly been built on the conventional Transformer architecture, which, despite its successes, suffers from two significant limitations:
- Substantial memory footprint: The memory requirements for Transformers scale with the context length, posing challenges in managing long contexts or multiple parallel batches without significant hardware resources.
- Deceleration in inference with increased context: Due to the quadratic scaling of the Transformer’s attention mechanism with sequence length, there is a notable slowdown in throughput as each token computation depends on the entire preceding sequence.
- Architectural Innovations in Jamba
- Blocks-and-layers approach: This structural strategy permits the fusion of Transformer and Mamba components, where each Jamba block is configured with either an attention or a Mamba layer, succeeded by a multi-layer perceptron (MLP). The configuration maintains a ratio of one Transformer layer to every eight layers.
- Mixture-of-Experts (MoE): Jamba employs MoE to expand the model’s parameter count while maintaining a manageable number of active parameters during inference, thereby boosting capacity without a proportional rise in computational demands.
- Optimized MoE setup: To maximize efficiency and output quality on an 80GB GPU, the model’s MoE configuration has been fine-tuned, balancing expert layers and ensuring sufficient memory remains for typical inference tasks.
- Unprecedented Throughput and Efficiency
Initial assessments by AI21 highlight Jamba’s superior performance metrics in throughput and efficiency. While these early results are promising, continued advancements are anticipated as the broader community engages in further refinement and testing.
- Enhanced Efficiency: With a threefold increase in throughput for extended contexts over comparable Transformer-based models, Jamba sets a new standard in efficiency.
- Cost-Effectiveness: Jamba’s ability to handle 140K contexts on a single GPU offers a cost-effective solution for deployment and research, surpassing the capabilities of similar-sized open-source models.