Attention | Cross Attn
- Related Project: Private
- Category: Paper Review
- Date:2023-05-26
Cross-Attention is All You Need: Adapting Pretrained Transformers for Machine Translation
- arxiv: https://arxiv.org/abs/2104.08771
- github: https://arxiv.org/pdf/2104.08771
- abstract: We study the power of cross-attention in the Transformer architecture within the context of transfer learning for machine translation, and extend the findings of studies into cross-attention when training from scratch. We conduct a series of experiments through fine-tuning a translation model on data where either the source or target language has changed. These experiments reveal that fine-tuning only the cross-attention parameters is nearly as effective as fine-tuning all parameters (i.e., the entire translation model). We provide insights into why this is the case and observe that limiting fine-tuning in this manner yields cross-lingually aligned embeddings. The implications of this finding for researchers and practitioners include a mitigation of catastrophic forgetting, the potential for zero-shot translation, and the ability to extend machine translation models to several new language pairs with reduced parameter storage overhead.
주로 인코더와 디코더에 의존하는 Vision 혹은 Time serise 태스크에 사용되고 있으며, Text Generation Large Langauge Model에도 시도되었던 아키텍처
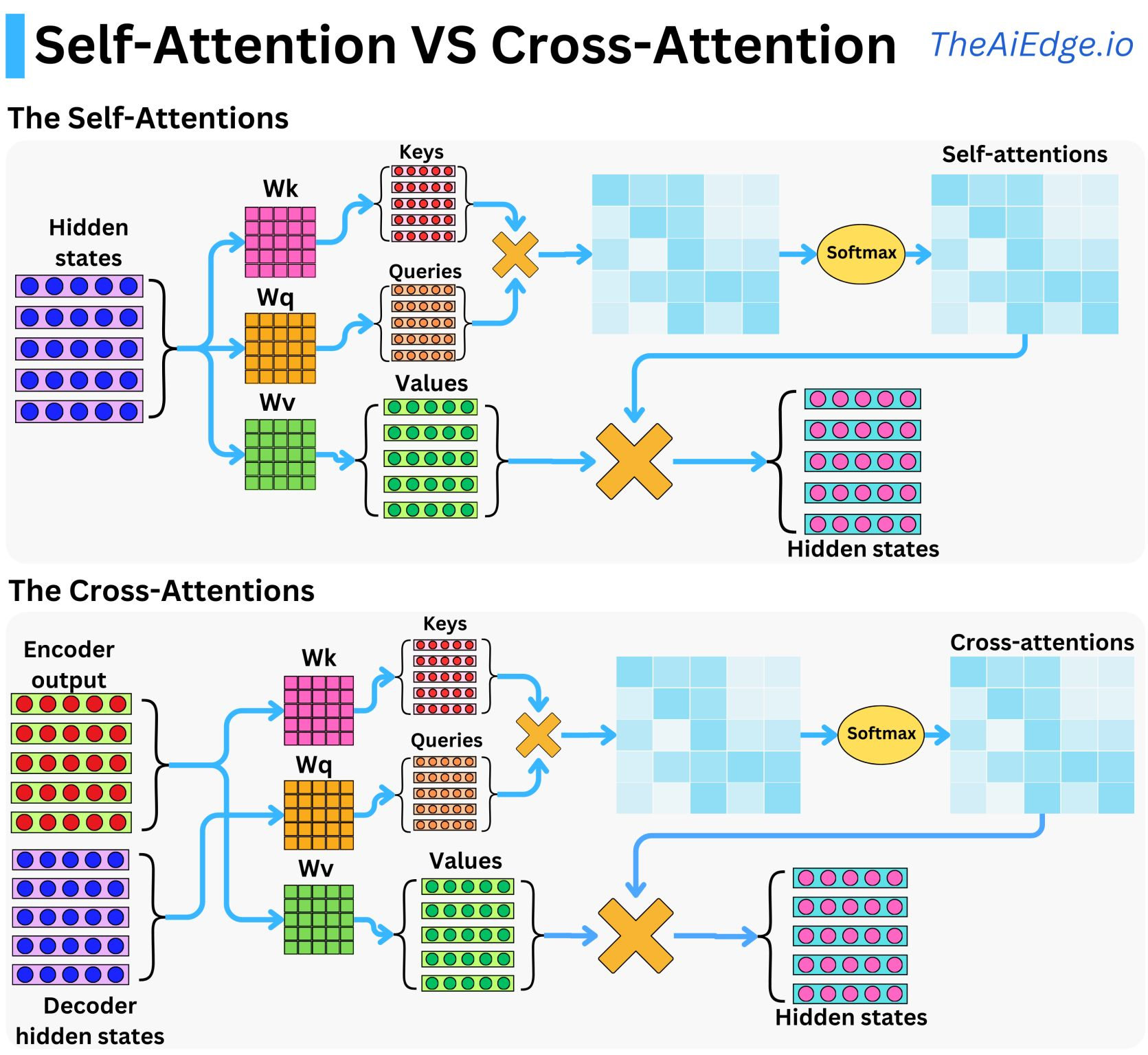
*출처: theaiedge.io