Meta Rewarding
- Related Project: Private
- Category: Paper Review
- Date: 2024-07-28
Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge
- url: https://arxiv.org/abs/2407.19594
- pdf: https://arxiv.org/pdf/2407.19594
- abstract: Large Language Models (LLMs) are rapidly surpassing human knowledge in many domains. While improving these models traditionally relies on costly human data, recent self-rewarding mechanisms (Yuan et al., 2024) have shown that LLMs can improve by judging their own responses instead of relying on human labelers. However, existing methods have primarily focused on improving model responses rather than judgment capabilities, resulting in rapid saturation during iterative training. To address this issue, we introduce a novel Meta-Rewarding step to the self-improvement process, where the model judges its own judgements and uses that feedback to refine its judgment skills. Surprisingly, this unsupervised approach improves the model’s ability to judge {\em and} follow instructions, as demonstrated by a win rate improvement of Llama-3-8B-Instruct from 22.9% to 39.4% on AlpacaEval 2, and 20.6% to 29.1% on Arena-Hard. These results strongly suggest the potential for self-improving models without human supervision.
Contents
TL;DR
- Meta-Reward를 통한 반복 학습 및 평가 향상 (Meta Reward)
- Actor, Judge, Meta Judge 역할을 하는 모델을 통한 자가 향상 (자기 반복)
- LLM 자체로부터 훈련 데이터 생성 및 이를 통한 지속적인 모델 역량 강화 (데이터셋 생성/증강)
1. Introduction
LLM(Large Language Models)은 사용자 질문에 대한 지시 사항을 따르고 반응하는 능력이 현저하게 향상되고 있습니다. 이런 모델의 훈련 중 하나는 인스트럭션 튜닝으로, 휴먼이 만든 데이터셋에서 학습하는 것을 포함합니다. 그러나 이런 데이터의 획득은 비용과 시간이 많이 드는 작업입니다. 이에 대한 대응책으로, 자기 판단을 통한 AI의 자율적 개선이 가능한 ‘Meta-Reward’ 방법을 제안하였습니다. 이 방법은 모델이 Actor, Judge, 그리고 Meta Judge의 세 가지 역할을 수행하며, 각각의 반응, 평가, 그리고 그 평가의 평가를 자체적으로 수행합니다.
2. Meta-Reward
Meta-Reward 방법은 Actor, Judge, Meta Judge라는 세 가지 주요 역할을 하는 모델을 사용합니다. 이 방법은 주로 세 가지 단계로 구성됩니다.
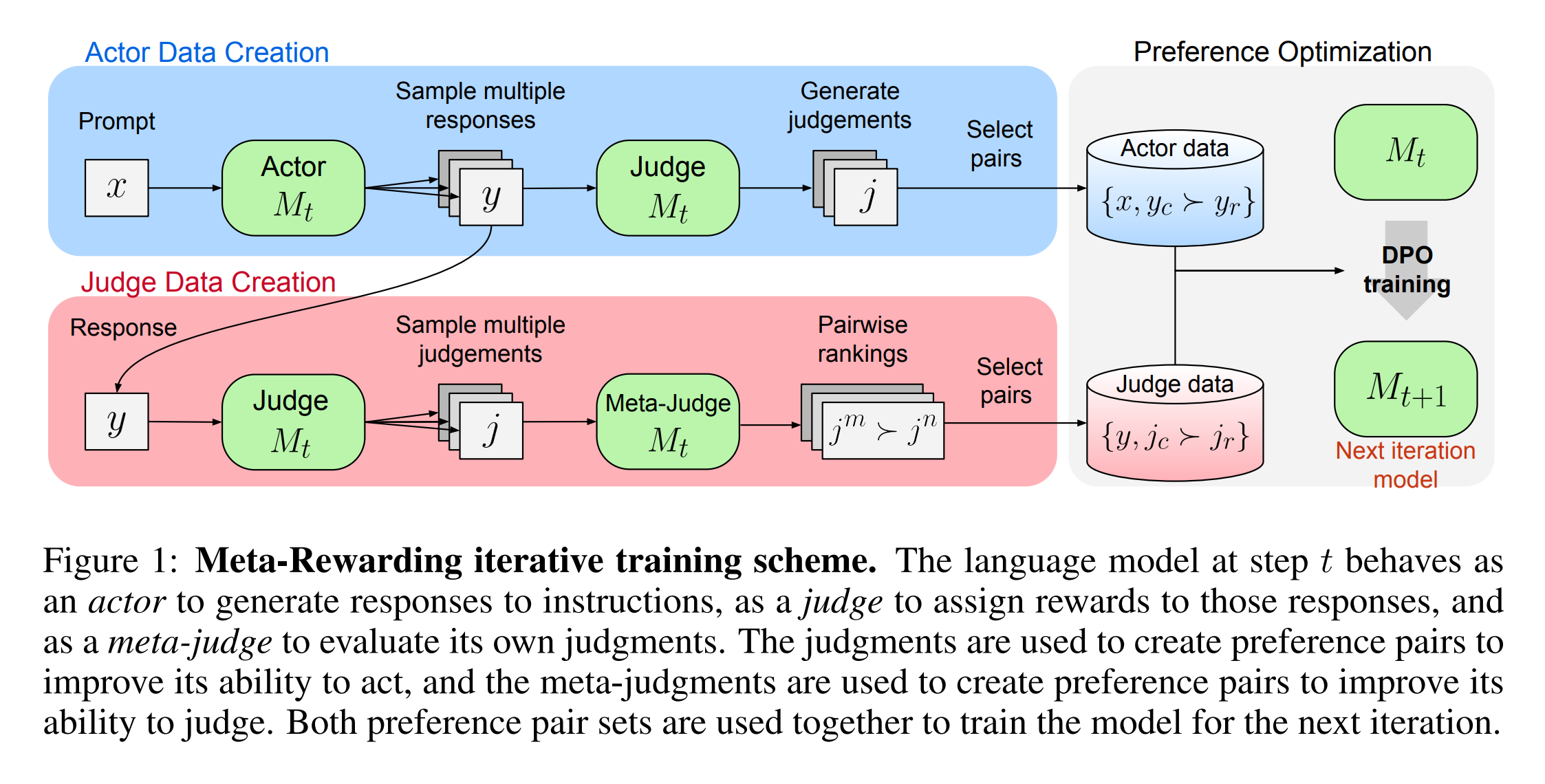
2.1 Actor 선호 데이터셋 생성
Actor 역할을 하는 모델은 다음과 같이 주어진 프롬프트에 대해 반응을 생성합니다.
\[\text{for each prompt } x, \{y_1, \dots, y_K\} \text{ are generated by sampling from } M_t \text{ at iteration } t.\]생성된 각 반응 \(y_k\)에 대해 \(N\)개의 다른 판정을 생성하고, 각 판정의 점수를 평균하여 최종 보상 점수를 계산합니다. 이 점수를 기준으로, 길이 조절 메커니즘을 통해 선호하는 반응과 기각된 반응을 선택합니다.
2.2 Judge 선호 데이터셋 생성
Meta Judge는 주어진 두 판정 \(j_m\)과 \(j_n\)을 비교하여 더 나은 판정을 선택합니다. 이 비교는 다음의 프롬프트를 사용하여 이루어집니다.
비교 결과는 위치 편향을 고려하여 가중치를 적용한 배틀 매트릭스 \(B\)에 반영되며, 이 매트릭스는 각 판정의 Elo Score를 계산하는 데 사용됩니다. 다음 Elo Score는 판정의 품질을 나타내며, 최종적으로 선호하는 판정과 기각된 판정을 선택하는 데 사용됩니다.
\[\arg \max_{\epsilon_{m,n}} \sum B_{mn} \log \frac{e^{\epsilon_m - \epsilon_n}}{1 + e^{\epsilon_m - \epsilon_n}}.\]-
로그-오즈(log-odds) 형태의 함수를 사용하고 있으며, 특히 로지스틱 회귀 모델에서 로그-오즈비를 사용하는 것과 유사한 형태를 사용합니다.
- \(e^{\epsilon_m - \epsilon_n}\): 이는 두 변수 \(\epsilon_m\)과 \(\epsilon_n\) 간의 차이를 기반으로 한 지수 함수로, 이 표현은 일종의 확률적 또는 경쟁적 상호작용을 나타낼 수 있으며, \(\epsilon_m\)이 \(\epsilon_n\)보다 클수록 그 비율이 증가합니다.
- \(\log \frac{e^{\epsilon_m - \epsilon_n}}{1 + e^{\epsilon_m - \epsilon_n}}\): 로그 함수 내부의 분수는 로지스틱 함수의 형태를 취하고 있으며, 두 변수 간의 상대적 강도를 [0, 1] 범위의 확률로 변환합니다.
- \(\epsilon_{m,n}\): 최적화 과정에서 조정되는 파라미터로, 다차원 공간에서의 위치를 결정하거나 특정 기준에 따라 최적화됩니다.
- \(B_{mn}\): \(B_{mn}\)는 \(m\)과 \(n\) 간의 상호작용 또는 연결의 강도를 나타내는 가중치로 각 로그-오즈 값에 대한 가중치로 작용하며, 전체 합을 통해 최종적인 목적함수 값을 계산합니다.
- \(\arg \max\): 주어진 함수를 최대화하는 \(\epsilon_{m,n}\)의 값을 찾는 것을 목표로 하며, 모든 가능한 \(m\), \(n\) 쌍에 대해 \(\epsilon_m\)과 \(\epsilon_n\)의 최적 차이를 찾는 것이 목적으로 합니다.
3. 실험
- 메타 보상을 통한 연속적 학습은 모델의 Actor 및 Judge 역할을 향상시킴을 확인합니다.
- 다양한 벤치마크를 사용하여 모델의 반응 및 판단 능력을 평가하고,
- 실험을 통해 모델이 복잡하고 어려운 질문에 대한 답변 능력이 개선됨을 확인합니다.
3.1 실험 설정
초기 모델인 Llama-3-8B-Instruct을 사용하여 Yuan et al. (2024c)의 실험 설정을 따르며, 이 모델을 Evaluation Fine-Tuning (EFT) 데이터셋에서 Supervised learning(Supervised Fine-Tuning, SFT)을 수행합니다. 이 데이터셋은 Open Assistant(Köpf et al., 2024)로부터 구축되어 초기 LLM as a Judge 훈련 데이터로 사용되었습니다. 메타 보상(Meta-Rewarding) 학습 전, 이미 지시 사항에 따라 튜닝된 시드 모델에서 SFT를 수행하므로, Actor 역할로의 직접 훈련은 생략합니다. 메타 보상 반복 과정은 다음과 같이 정의됩니다.
\(\text{Iter 1: } M_1 =\) DPO로 SFT 모델을 사용하여 훈련
\(\text{Iter 2: } M_2 =\) DPO로 M1을 사용하여 훈련
\(\text{Iter 3: } M_3 =\) DPO로 M2를 사용하여 Actor 선호 쌍만 훈련
\(\text{Iter 4: } M_4 =\) DPO로 M3를 사용하여 Actor 선호 쌍만 훈련
각 반복에서는 프롬프트 당 7개의 반응 변형을 생성하고, 이들 중 동일한 반응을 제거하여 총 35,000개의 반응을 생성합니다.
3.2 평가 방법
메타 보상의 목적은 모델이 Actor와 Judge 역할에서 모두 개선되도록 하는 것입니다. GPT4 as a Judge를 기반으로 하는 자동 평가 벤치마크를 사용하여 이를 평가합니다. 평가는 AlpacaEval 2, Arena-Hard, MT-Bench와 같은 벤치마크에서 이루어집니다. 특히, AlpacaEval은 일상적인 질문을 다루는 반면, Arena-Hard는 더 복잡하거나 도전적인 질문을 다룹니다.
3.3 수행 지침 평가
메타 보상을 거친 반복 학습은 모델의 승률을 향상시킵니다. 각 반복 후 AlpacaEval 벤치마크에서의 승률을 측정하며, 초기 모델 대비 39.44%의 승률을 달성하여 상당한 향상을 보여줍니다.
3.4 보상 모델 평가
메타 보상을 통해 향상된 Judge 모델의 정확도를 평가하기 위해, 시드 모델이 생성한 반응에 대한 판단력을 측정하고, 이 측정은 현재 가장 강력한 GPT-4 모델을 Judge 모델로 사용하여 진행됩니다.
Meta-Reward 방법이 Actor의 반응 생성 능력과 Judge의 평가 능력을 향상시키는 데 효과적임을 확인하기 위한 실험 결과, Llama-3-8B-Instruct 모델을 사용하여 AlpacaEval 2 벤치마크에서 길이 제어 승률이 22.9%에서 39.4%로 향상되었습니다. 이는 표준 자기보상 훈련과 비교할 때 눈에 띄는 개선을 보여줍니다.
4 Related Works
4.1 RLHF
LLM과 휴먼 가치의 정렬을 위한 노력은 크게 두 가지 방향으로 분류됩니다. 보상 모델을 사용한 정렬과 직접 선호 데이터셋을 기반으로 한 정렬입니다. Ziegler et al. (2019), Stiennon et al. (2020), Ouyang et al. (2022), Bai et al. (2022a) 등은 휴먼 선호 데이터로부터 고정된 보상 모델을 훈련시킨 후, 이를 이용해 강화학습(RL)을 통한 훈련을 진행합니다. 이런 접근에서는 주로 Proximal Policy Optimization (PPO) (Schulman et al., 2017)가 사용됩니다. 반면, P3O (Wu et al., 2023)는 대조 정책 그래디언트를 도입하여 PPO보다 우수한 성능을 보이며 가치 함수의 필요성을 제거하였습니다. Direct Preference Optimization (DPO) (Rafailov et al., 2024)과 같은 방법은 보상 모델의 훈련을 전면적으로 피하며, 직접적으로 LLM을 휴먼의 선호를 이용해 훈련시킵니다.
4.2 LLM as a Judge
LLM을 평가자로 사용하는 것은 이제 표준적인 접근 방식으로 자리 잡았습니다(Li et al., 2024; Dubois et al., 2023; 2024b; Saha et al., 2023; Bai et al., 2024). 특히, Lee et al. (2023), Zhu et al. (2023), Chen et al. (2023), Li et al. (2023) 등은 보상 모델을 훈련시키는 데 LLM을 활용합니다. 또한 Kim et al. (2023; 2024)은 LLM-as-a-Judge 훈련 데이터셋을 구축하는 방법에 대해 연구하였습니다.
4.3 Super Alignment
매우 능력이 향상된 모델을 휴먼 수준을 넘어서 정렬하는 것을 슈퍼 정렬이라고 합니다. 현재 AI 정렬 방법은 주로 휴먼이 제공하는 데모나 강화학습(RLHF)에 의존하고 있지만, 휴먼이 전문성을 넘어서는 어려운 과제에 대해 유용한 데모나 감독을 제공할 수 없는 경우가 많습니다(Sharma et al., 2023). 슈퍼 정렬을 위한 몇 가지 유망한 방향은 모델을 이용한 휴먼 감독 지원, 문제 행동이나 내부를 자동으로 탐색하는 방법 등이 있습니다.
4.4 Self-Rewarding
Yuan et al. (2024c)의 연구는 연구와 가장 밀접하게 관련되어 있으며, 모델이 자체 반응을 평가하고 그 피드백을 선호 최적화에 사용하는 반복 훈련 체계를 제안합니다. 그러나 자체 개선을 위해 Actor와 Judge를 동시에 훈련시키는 작업에 집중한 연구는 많지 않습니다.
5 Limitation
실험 설정에서 선택한 5점 평가 체계는 응답 간 최소한의 품질 차이로 인해 자주 동점이 발생하여, 여러 평가의 평균을 신중하게 계산해야 한다고 언급합니다. 훈련이 진행됨에 따라 응답이 최대 점수에 접근하면서 추가 개선을 감지하기 어려워졌습니다. 보다 미묘한 평가 체계나 비교 기반 접근 방식이 이 문제를 해결할 수 있습니다. 또한 Judge 훈련 과정에서 위치 편향을 완화하기 위한 노력에도 불구하고, 이런 문제는 지속되어 3차 반복에서의 개선을 방해하였습니다. Judge는 높은 점수를 부여하는 경향이 있어 점수 포화를 촉진하고 응답 간 구별 능력을 저하시켰습니다. Judge가 자체 생성한 응답이 아닌 응답을 평가하는 데 있어서도 개선이 제한적이었습니다. 이런 문제들이 효과적으로 해결된다면, 접근 방식의 전반적인 효과성을 크게 향상시킬 수 있을 것입니다.
[품질 평가시 이슈 5점 척도 등 색인마킹]
6 Conclusion
이 연구에서는 Meta Judge가 Meta 보상을 부여하여 선호 최적화를 위해 선택된 판단과 거부된 판단을 선택하는 새로운 메커니즘을 제안합니다. 이는 자체 보상 프레임워크(Yuan et al., 2024c)의 주요 한계, 특히 Judge의 훈련 부족을 해결합니다. Meta 보상 훈련은 인공 지능 피드백으로 훈련할 때 길이 폭발 문제를 완화하는 새로운 길이 제어 기술을 도입합니다. 방법은 AlpacaEval, Arena-Hard, MT-Bench와 같은 자동 평가 벤치마크를 통해 효과성을 입증하였습니다.
휴먼의 추가 피드백 없이도, 접근 방식은 Llama-3-8B-Instruct를 상당히 개선하고, 강력한 기준인 SPPO(Wu et al., 2024)를 능가합니다. 또한, Judge 능력 평가에서 휴먼 Judge 및 강력한 AI Judge와의 상관 관계에서 상당한 개선을 보여주었으며, 전반적으로 휴먼의 피드백 없이 모델을 자체 개선하는 것이 슈퍼 정렬을 달성하기 위한 유망한 방향임을 보입니다.