Decontamination | Detecting Pretraining Data
- Related Project: Private
- Category: Paper Review
- Date: 2024-01-16
Detecting Pretraining Data from Large Language Models
- url: https://arxiv.org/abs/2310.16789
- pdf: https://arxiv.org/pdf/2310.16789
- github: https://github.com/swj0419/detect-pretrain-code
- blog: https://swj0419.github.io/detect-pretrain.github.io/
- abstract: Although large language models (LLMs) are widely deployed, the data used to train them is rarely disclosed. Given the incredible scale of this data, up to trillions of tokens, it is all but certain that it includes potentially problematic text such as copyrighted materials, personally identifiable information, and test data for widely reported reference benchmarks. However, we currently have no way to know which data of these types is included or in what proportions. In this paper, we study the pretraining data detection problem: given a piece of text and black-box access to an LLM without knowing the pretraining data, can we determine if the model was trained on the provided text? To facilitate this study, we introduce a dynamic benchmark WIKIMIA that uses data created before and after model training to support gold truth detection. We also introduce a new detection method Min-K% Prob based on a simple hypothesis: an unseen example is likely to contain a few outlier words with low probabilities under the LLM, while a seen example is less likely to have words with such low probabilities. Min-K% Prob can be applied without any knowledge about the pretraining corpus or any additional training, departing from previous detection methods that require training a reference model on data that is similar to the pretraining data. Moreover, our experiments demonstrate that Min-K% Prob achieves a 7.4% improvement on WIKIMIA over these previous methods. We apply Min-K% Prob to three real-world scenarios, copyrighted book detection, contaminated downstream example detection and privacy auditing of machine unlearning, and find it a consistently effective solution.
[Decontamination 핵심 색인마킹]
Contents
- Detecting Pretraining Data from Large Language Models
- (선행 데이터 검출 문제) 언어 모델의 선행 데이터 속성 여부를 검출하는 문제를 다룸
- (WIKIMIA 벤치마크 도입) 시간적 차이를 기반으로 하는 새로운 동적 평가 벤치마크
- (MIN-K% PROB 방법) 참조 모델 없이 최소 확률 토큰을 이용한 선행 데이터 검출 방식 제안
| Contamination % | Book Title | Author | Year |
|---|---|---|---|
| 100 | The Violin of Auschwitz | Maria Àngels Anglada | 2010 |
| 100 | North American Stadiums | Grady Chambers | 2018 |
| 100 | White Chappell Scarlet Tracings | Iain Sinclair | 1987 |
| 100 | Lost and Found | Alan Dean | 2001 |
| 100 | A Different City | Tanith Lee | 2015 |
| 100 | Our Lady of the Forest | David Guterson | 2003 |
| 100 | The Expelled | Mois Benarroch | 2013 |
| 99 | Blood Cursed | Archer Alex | 2013 |
| 99 | Genesis Code: A Thriller of the Near Future | Jamie Metzl | 2014 |
| 99 | The Sleepwalker’s Guide to Dancing | Mira Jacob | 2014 |
| 99 | The Harlan Ellison Hornbook | Harlan Ellison | 1990 |
| 99 | The Book of Freedom | Paul Selig | 2018 |
| 99 | Three Strong Women | Marie NDiaye | 2009 |
| 99 | The Leadership Mind Switch: Rethinking How We Lead in the New World of Work | D. A. Benton, Kylie Wright-Ford | 2017 |
| 99 | Gold | Chris Cleave | 2012 |
| 99 | The Tower | Simon Clark | 2005 |
| 98 | Amazon | Bruce Parry | 2009 |
| 98 | Ain’t It Time We Said Goodbye: The Rolling Stones on the Road to Exile | Robert Greenfield | 2014 |
| 98 | Page One | David Folkenflik | 2011 |
| 98 | Road of Bones: The Siege of Kohima 1944 | Fergal Keane | 2010 |
1 서론
언어 모델(LM)의 훈련 데이터 규모가 커짐에 따라, 모델 개발자들(e.g., GPT-4, LLaMA 2 등)은 자신들의 데이터 구성이나 출처를 공개하는 데 주저하고 있습니다. 이런 불투명성은 과학적 모델 평가와 윤리적 배포에 중대한 챌린지를 제기합니다. 선행 훈련 과정에서 중요한 개인 정보가 노출될 수 있으며, 이전 연구에 따르면 대규모 언어모델(LLM)이 저작권이 있는 책의 발췌문이나 개인 이메일을 생성할 수 있음이 보여졌습니다. 이는 원본 콘텐츠 제작자의 법적 권리를 침해하고 개인의 사생활을 위반할 가능성이 있습니다. 또한, 선행 훈련 데이터에 평가 벤치마크 데이터가 우연히 포함될 수도 있어, 이런 모델의 효과를 평가하기 어렵게 만듭니다.
본 논문에서는 선행 훈련 데이터 검출 문제를 연구합니다. 텍스트 조각과 LLM에 대한 블랙박스 접근만을 가지고, 해당 모델이 그 텍스트에 대해 선행 훈련되었는지를 판별할 수 있을까요? 이 문제는 멤버십 인퍼런스 공격(MIA)의 한 예로, 처음에는 Shokri 등(2016)에 의해 제안되었습니다. 최근에는 MIA 문제로 파인튜닝 데이터 검출에 대한 연구가 이루어졌습니다. 그러나 현대 대규모 LLM에 이 방법들을 적용하는 것은 두 가지 독특한 기술적 챌린지를 제시합니다.
- 첫째, 파인튜닝은 일반적으로 여러 에포크 동안 실행되지만, 선행 훈련은 훨씬 더 큰 데이터셋을 사용하고 각 인스턴스를 단 한 번만 노출시켜, 성공적인 MIA에 필요한 기억 가능성을 크게 줄입니다.
- 둘째, 이전 방법들은 가끔씩 정확한 검출을 달성하기 위해 동일한 방식으로 훈련된 하나 이상의 참조 모델(e.g., 동일한 기저 선행 훈련 데이터 분포에서 샘플링된 Figure자 데이터에 대해 훈련된 모델)에 의존하는데, LLM에서는 거의 불가능합니다.
이 문제에 대응하기 위해 신뢰할 수 있는 벤치마크, WIKIMIA를 도입합니다. 이 벤치마크는 위키피디아 데이터의 타임스탬프와 모델 출시 날짜를 활용하여, 선행 훈련 중 본 데이터로 본 데이터(멤버 데이터)와 최근의 위키피디아 이벤트 데이터(2023년 이후의 데이터, 비멤버 데이터)를 선택합니다. 따라서 데이터셋은 세 가지 바람직한 속성을 나타냅니다.
- (1) 정확성: LLM 선행 훈련 후 발생한 이벤트는 선행 훈련 데이터에 존재하지 않음이 보장됩니다.
- (2) 일반성: 벤치마크는 특정 모델에 국한되지 않으며 위키피디아를 사용하여 선행 훈련된 다양한 모델에 적용될 수 있습니다.
- (3) 동적: 데이터 구축 파이프라인을 완전히 자동화하여 새로운 비멤버 데이터를 지속적으로 수집합니다.
따라서, 참조 모델 없는 MIA 방법인 MIN-K% PROB를 제안합니다.
이 방법은 다음과 같은 간단한 가설에 기반합니다.
"보지 못한 예제는 낮은 확률을 가진 몇 개의 이상치 단어를 포함하는 경향이 있지만, 본 예제는 그럴 가능성이 적다."
MIN-K% PROB는 이상치 토큰의 평균 확률을 계산합니다. 실험은 MIN-K% PROB가 WIKIMIA에서 기존의 가장 강력한 기준을 7.4%의 AUC 점수로 능가함을 보여줍니다. 추가 분석은 검출 성능이 모델 크기와 텍스트 길이와 긍정적으로 상관 관계가 있음을 시사합니다.
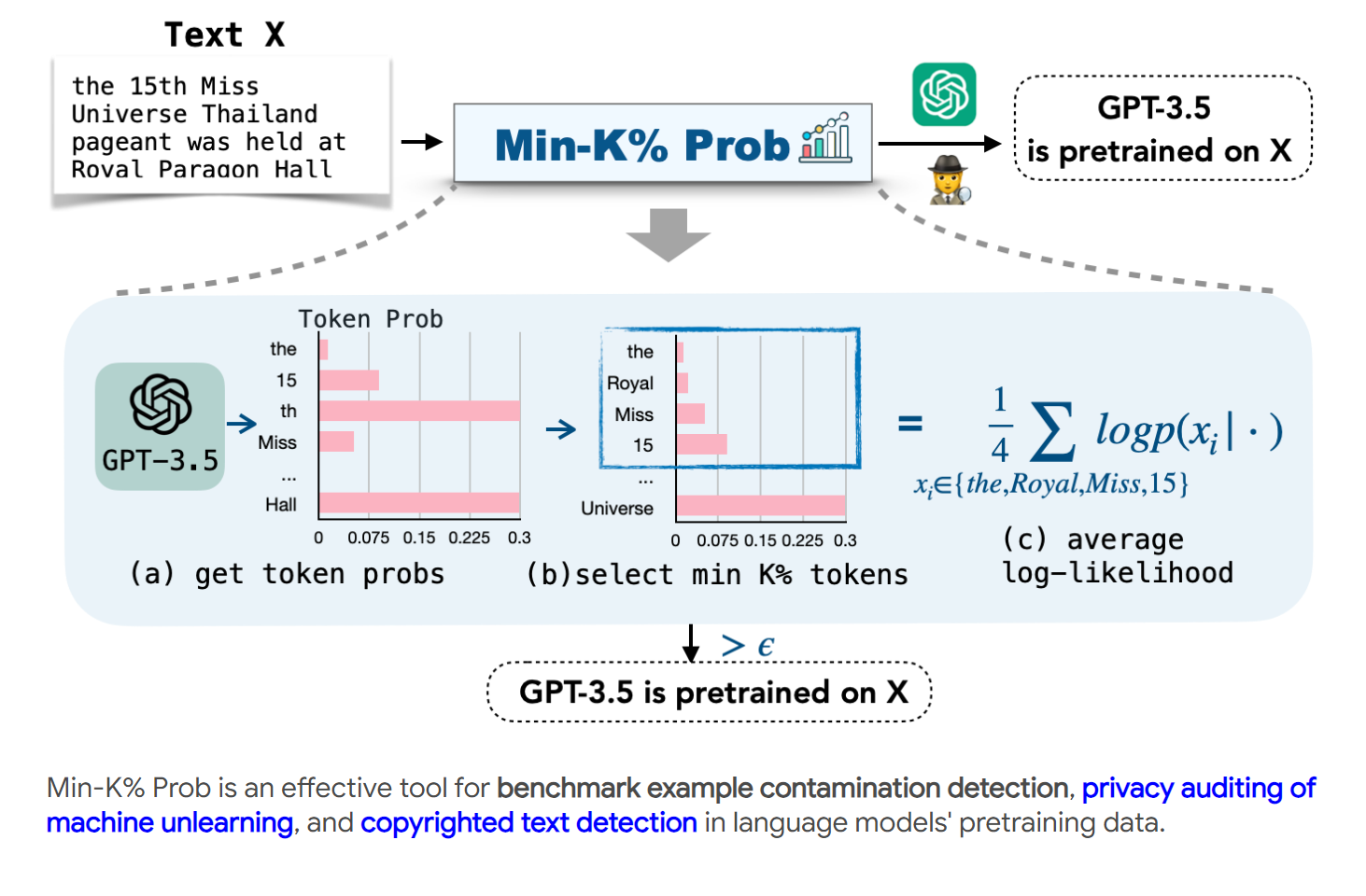
방법이 실제 설정에서 적용 가능함을 검증하기 위해, 저작권 있는 책 검출, LLM의 개인정보 감사, 데이터셋 오염 검출 등 세 가지 사례 연구를 수행합니다. 실험에서 MIN-K% PROB는 두 시나리오 모두에서 기준 방법을 능가합니다. 저작권 있는 책 검출 실험에서는 GPT-3가 Books3 데이터셋의 저작권 있는 책에 대해 선행 훈련되었다는 강력한 증거를 발견했습니다. 머신러닝 삭제의 개인정보 감사 실험에서는 MIN-K% PROB를 사용합니다.
2. Pre-training Data Detection Problem
2.1 문제 정의 및 챌린지
선행 데이터 검출 문제는 주어진 텍스트가 특정 언어 모델의 선행 training dataset에 포함되었는지를 판단하는 것입니다. 이 문제의 정의는 회원 인퍼런스 공격(Membership Inference Attack, MIA)에 기초를 두고 있습니다. MIA는 데이타 포인트 \(x\)가 주어질 때, 언어 모델 \(f_\theta\)만을 사용하여 \(x\)의 멤버십을 인퍼런스하는 것입니다. (0은 비멤버(non-member), 1은 멤버(member)를 의미)
\[h(x, f_\theta) \rightarrow \{0, 1\}\][챌린지 1: 선행 데이터 분포의 불가용성]
대부분의 현대 대규모 언어모델들은 선행 training dataset 분포를 공개하지 않기 때문에, 이를 기반으로 한 참조 모델을 훈련하는 것은 현실적으로 불가능합니다. 이는 선행 training dataset 검출의 정확성을 제한하는 주요 요인 중 하나입니다.
[챌린지 2: 검출 난이도]
선행 학습과 파인튜닝(fine-tuning)에서 사용되는 데이터와 계산량의 차이로 인해 검출 난이도가 크게 달라집니다. 대규모 데이터셋과 적은 학습 주기는 예측 모델의 출력에서의 미묘한 차이를 감지하기 어렵게 만듭니다.
2.2 WIKIMIA: 동적 평가 벤치마크
데이터 구성
WIKIMIA는 특정 날짜 이후에 추가된 위키피디아 이벤트를 활용하여 비멤버 데이터를 구성합니다. 2023년 1월 1일 이후의 이벤트는 최신 이벤트로 간주되며, 이는 선행 데이터에 포함되지 않았음을 보장합니다. 이를 통해 모델이 실제로 학습하지 않은 데이터를 정확하게 식별할 수 있는 벤치마크를 제공합니다.
벤치마크 설정
본 벤치마크는 다양한 길이의 데이터와 다양한 모델에 적용 가능하도록 설계되었습니다. 이는 모델의 강건성을 평가하는 데 중요한 요소입니다. 또한, 데이터의 길이에 따라 MIA 방법의 성능이 달라질 수 있기 때문에, 데이터 길이에 따른 성능을 별도로 평가하여 보다 정밀한 분석을 제공합니다.
MIN-K% PROB 방법
기본 가설
텍스트 \(X\)에 대해, 특정 언어 모델이 \(X\)의 각 토큰에 할당한 확률을 분석합니다. 가장 낮은 \(k\%\) 확률을 가진 토큰들의 평균 로그 우도를 계산합니다. 이 평균 로그 우도가 높다면, \(X\)는 모델의 선행 데이터에 포함되었을 가능성이 높습니다. (\(P(x_i)\)는 \(i\)번째 토큰의 확률)
\[\text{MIN-K% PROB} = \frac{1}{k} \sum_{i=1}^{k} \log(P(x_i))\]이 방법은 기존의 가장 강력한 베이스 라인을 7.4% AUC 점수로 능가함을 입증하고, 모델 크기와 텍스트 길이가 검출 성능에 긍정적인 영향을 미친다는 결과를 얻었습니다.
이런 접근 방식은 참조 모델 없이도 효과적으로 선행 데이터를 검출할 수 있으며, 대규모 언어모델의 개발 및 평가에 있어 투명성을 제고할 수 있는 중요한 도구가 될 수 있습니다.
4 실험
이 장에서는 다양한 언어 모델들(LLaMA, GPT-Neo, Pythia 등)에 대해 MIN-K% PROB와 기존 검출 방법들의 성능을 WIKIMIA 벤치마크를 사용하여 평가합니다.
4.1 데이터셋 및 측정 기준
실험에는 WIKIMIA의 다양한 길이(32, 64, 128, 256), 원본 및 패러프레이즈 설정을 사용합니다. 검출 방법의 효과를 평가하기 위해 True Positive Rate (TPR)과 False Positive Rate (FPR)를 사용하며, ROC 곡선을 그려 TPR과 FPR 사이의 상충 관계를 측정합니다. 또한, ROC 곡선 아래 영역인 AUC 점수와 낮은 FPR에서의 TPR(e.g., TPR@5%FPR)을 보고합니다.
4.2 기준 검출 방법
참조 기반 및 참조 없는 MIA 방법을 기준으로 삼아 WIKIMIA에서의 성능을 평가합니다. 구체적으로는 LOSS Attack (Yeom et al., 2018a), Neighborhood Attack (Mattern et al., 2023) 및 다양한 복잡도 측정을 비교하는 방법들을 고려합니다. 이런 방법들은 모델의 입력에 대한 손실 또는 퍼플렉서티를 기반으로 멤버십을 예측합니다.
4.3 구현 및 결과
MIN-K% PROB의 주요 하이퍼파라미터는 가장 높은 부정 로그 우도를 가진 토큰의 백분율입니다. LLAMA-60B 모델을 사용한 검증 세트에서 10, 20, 30, 40, 50에 대한 소규모 스윕을 수행한 결과, k = 20이 최적임을 발견했습니다. 이 값을 모든 실험에 걸쳐 사용합니다. AUC 점수를 주요 측정 기준으로 사용하므로, 특정 임계값 \(\epsilon\)을 설정할 필요가 없습니다.
주요 결과는 MIN-K% PROB가 원본 및 패러프레이즈 설정에서 모든 기준 방법을 일관되게 능가함을 보여줍니다. 평균 AUC 점수는 0.72로, 최고의 기준 방법(PPL)보다 7.4% 향상되었습니다.
4.4 분석
타겟 모델의 크기와 텍스트의 길이가 검출 난이도에 영향을 미치는 요인을 분석합니다. 모델 크기가 클수록 더 많은 파라미터를 가지므로 선행 데이터를 기억할 가능성이 높아집니다.
5 사례 연구: 선행 데이터에서 저작권이 있는 책 검출
이 섹션에서는 MIN-K% PROB를 사용하여 선행 데이터에 포함될 수 있는 저작권이 있는 책의 발췌문을 검출합니다.
5.1 실험 설정
검출 임계값을 결정하기 위해 ChatGPT에 의해 기억된 것으로 알려진 50권의 책을 사용하여 검증 세트를 구성합니다. 부정적 예로는 2023년에 처음 출판된 50권의 새 책을 수집합니다. 각 책에서 무작위로 512단어의 발췌문을 100개 추출하여 균형 잡힌 검증 세트(10,000 예시)를 만듭니다.
5.2 결과
MIN-K% PROB는 저작권이 있는 책을 검출하는 데 있어 AUC 0.88을 달성하며, 기준 방법들을 능가합니다. 최적의 임계값을 적용한 결과, 10,000개의 발췌문 중 상당수가 선행 데이터의 일부로 확인됩니다.
6. 사례 연구: Downstream 데이터셋 오염 검출
Downstream 작업 데이터의 선행 데이터로의 유출을 평가하는 것은 중요하지만, 선행 데이터셋에 대한 접근 부족으로 인해 도전적인 문제입니다. 이 섹션에서는 MIN-K% PROB를 사용하여 정보 유출을 검출하고, 다양한 훈련 요인이 검출 난이도에 미치는 영향을 이해하기 위해 소거 연구를 수행합니다.
6.1 실험
실험적으로 downstream 작업 예시를 선행 훈련 데이터에 의도적으로 삽입하여 오염된 선행 훈련 데이터를 생성합니다. RedPajama 코퍼스에서 텍스트를 샘플링하고, BoolQ, IMDB 등의 데이터셋에서 포맷된 예시를 무작위 위치에 삽입합니다.
6.2 결과 및 분석
오염된 데이터셋을 사용한 시뮬레이션을 통해 데이터셋 크기, 데이터 발생 빈도, 학습률이 검출 난이도에 미치는 영향을 실증적으로 분석합니다. 데이터 발생 빈도가 높을수록, 예시를 더 쉽게 검출할 수 있습니다. 학습률을 높이면 모델이 선행 데이터를 더 강하게 기억하게 되어, 검출이 용이해집니다.
7. 사례 연구: 기계 training dataset 삭제의 개인정보 감사
이 섹션에서는 개인정보 보호 규정 준수를 보장하기 위해 기계 training dataset 삭제의 필요성을 효과적으로 해결할 수 있는 기술을 제안합니다.
7.1 배경
잊혀질 권리와 머신러닝 삭제
현재 머신러닝 시스템의 환경에서는 개인의 “잊혀질 권리”를 지원하는 것이 중요합니다. 이는 일반 데이터 보호 규정(GDPR)과 캘리포니아 소비자 개인정보 보호법(CCPA)과 같은 규정에서 강조하는 법적 의무입니다. 이 요구사항은 사용자가 훈련된 모델에서 자신의 데이터를 삭제하도록 요청할 수 있게 합니다. 이런 필요성에 대응하기 위해 기계 training dataset 삭제 개념이 도입되었으며, 다양한 머신러닝 삭제 방법이 소개되었습니다.
최근에는 LLM에서 기계 training dataset를 삭제하는 새로운 접근 방법이 도입되었습니다. 이 접근 방법은 특정 토큰에 대해 대체 레이블로 추가 파인튜닝을 수행하여, 더 이상 삭제될 내용을 포함하지 않는 수정된 모델 버전을 만듭니다. 본 사례 연구에서는 이 모델이 해리 포터 시리즈와 관련된 기억된 내용을 성공적으로 제거했는지 평가하고자 합니다.
7.2 실험
스토리 완성 및 질문 응답
스토리 완성에서는 해리 포터 원본 책에서 의심스러운 청크를 MIN-K% PROB를 사용하여 식별합니다. 그 다음, 배운 내용을 잊도록 훈련된 모델을 사용하여 완성을 생성하고 금지 완성과 비교합니다. 질문 응답에서는 해리 포터 관련 질문을 생성하고 MIN-K% PROB를 사용하여 이런 질문을 필터링한 후, 배운 내용을 잊도록 훈련된 모델로 답변을 생성합니다. 이런 답변은 GPT-4에 의해 생성된 금지 답변과 휴먼에 의해 검증됩니다.
7.2.1 스토리 완성
의심스러운 텍스트 식별
해리 포터 시리즈 1부터 4까지의 텍스트를 수집하고 512단어 청크로 세분화하여 약 1000개의 청크를 만듭니다. 그 다음, 이 청크들에 대해 MIN-K% PROB 점수를 계산하고, 두 모델(원본 및 학습 삭제 모델) 간의 점수 비율이 특정 범위(1/1.15, 1.15) 내에 있는 청크를 의심스러운 청크로 분류합니다. 이런 청크들에 대한 모델의 스토리 완성 능력을 평가합니다.
식별 결과 완성된 이야기를 원본 스토리라인과 비교하면, 많은 청크들이 원본 스토리와 유사한 완성을 보여줍니다.
예를 들어, 생성된 완성 중 5.3%가 금지 완성과 4 이상의 GPT 점수 유사성을 보여줍니다. 이 결과는 “잊혀질 권리”에 대한 머신러닝의 중요성을 강조하며, 머신러닝 삭제 기술의 효과적인 구현이 필요함을 보여줍니다.
8. 관련 연구
NLP에서의 멤버십 인퍼런스 공격. 멤버십 인퍼런스 공격(MIA)은 주어진 모델의 훈련 데이터 일부인지 아닌지를 판단하는 것을 목표로 합니다. 이런 공격은 개인의 프라이버시에 상당한 위험을 초래하며, 데이터 재구성과 같은 더 심각한 공격의 기반으로 작용할 수 있습니다. MIA는 최근 개인정보 보호 취약점을 정량화하고 개인정보 보호 메커니즘의 정확한 구현을 검증하는 데에도 적용되고 있습니다.
9. 결론
WIKIMIA라는 사전 훈련 데이터 검출 데이터셋과 새로운 접근 방법인 MIN-K% PROB를 제시합니다. 이 접근 방법은 훈련된 데이터가 다른 기준에 비해 낮은 확률의 이상치 토큰을 덜 포함하는 경향이 있다는 직관을 사용합니다. 또한, 데이터셋 오염 검출 및 저작권이 있는 책 검출과 같은 실제 환경에서의 접근 방법의 효과를 검증합니다. 데이터셋 오염에 대한 실험 결과는 데이터셋 크기, 예제 빈도, 학습률이 검출 난이도에 미치는 영향에 관한 이론적 예측과 일치합니다. 가장 눈에 띄는 결과로, 저작권이 있는 책 검출 실험은 GPT-3 모델이 저작권이 있는 책으로 훈련되었을 가능성을 강하게 시사합니다.
1 INTRODUCTION
As the scale of language model (LM) training corpora has grown, model developers (e.g, GPT- 4 (Brown et al., 2020a) and LLaMA 2 (Touvron et al., 2023b)) have become reluctant to disclose the full composition or sources of their data. This lack of transparency poses critical challenges to scien- tific model evaluation and ethical deployment. Critical private information may be exposed during pretraining; previous work showed that LLMs generated excerpts from copyrighted books (Chang et al., 2023) and personal emails (Mozes et al., 2023), potentially infringing upon the legal rights of original content creators and violating their privacy. Additionally, Sainz et al. (2023); Magar & Schwartz (2022); Narayanan (2023) showed that the pretraining corpus may inadvertently include benchmark evaluation data, making it difficult to assess the effectiveness of these models.
In this paper, we study the pretraining data detection problem: given a piece of text and black-box access to an LLM with no knowledge of its pretraining data, can we determine if the model was pretrained on the text? We present a benchmark, WIKIMIA, and an approach, MIN-K% PROB, for pretraining data detection. This problem is an instance of Membership Inference Attacks (MIAs), which was initially proposed by Shokri et al. (2016). Recent work has studied fine-tuning data detection (Song & Shmatikov, 2019; Shejwalkar et al., 2021; Mahloujifar et al., 2021) as an MIA problem. However, adopting these methods to detect the pertaining data of contemporary large LLMs presents two unique technical challenges: First, unlike fine-tuning which usually runs for multiple epochs, pretraining uses a much larger dataset but exposes each instance only once, significantly reducing the potential memorization required for successful MIAs (Leino & Fredrikson, 2020; Kandpal et al., 2022). Besides, previous methods often rely on one or more reference models (Carlini et al., 2022; Watson et al., 2022) trained in the same manner as the target model (e.g., on the shadow data sampled from the same underlying pretraining data distribution) to achieve precise detection. This is not possible for large language models, as the training distribution is usually not available and training would be too expensive.
Figure 1: Overview of MIN-K% PROB. To determine whether a text X is in the pretraining data of a LLM such as GPT, MIN-K% PROB first gets the probability for each token in X, selects the k% tokens with minimum probabilities and calculates their average log likelihood. If the average log likelihood is high, the text is likely in the pretraining data.
Our first step towards addressing these challenges is to establish a reliable benchmark. We introduce WIKIMIA, a dynamic benchmark designed to periodically and automatically evaluate detection methods on any newly released pretrained LLMs. By leveraging the Wikipedia data timestamp and the model release date, we select old Wikipedia event data as our member data (i.e, seen data during pretraining) and recent Wikipedia event data (e.g., after 2023) as our non-member data (unseen). Our datasets thus exhibit three desirable properties: (1) Accurate: events that occur after LLM pretraining are guaranteed not to be present in the pretraining data. The temporal nature of events ensures that non-member data is indeed unseen and not mentioned in the pretraining data. (2) General: our benchmark is not confined to any specific model and can be applied to various models pretrained using Wikipedia (e.g., OPT, LLaMA, GPT-Neo) since Wikipedia is a commonly used pretraining data source. (3) Dynamic: we will continually update our benchmark by gathering newer non-member data (i.e., more recent events) from Wikipedia since our data construction pipeline is fully automated.
MIA methods for fine-tuning (Carlini et al., 2022; Watson et al., 2022) usually calibrate the target model probabilities of an example using a shadow reference model that is trained on a similar data distribution. However, these approaches are impractical for pretraining data detection due to the black-box nature of pretraining data and its high computational cost. Therefore, we propose a reference-free MIA method MIN-K% PROB. Our method is based on a simple hypothesis: an unseen example tends to contain a few outlier words with low probabilities, whereas a seen example is less likely to contain words with such low probabilities. MIN-K% PROB computes the average probabilities of outlier tokens. MIN-K% PROB can be applied without any knowledge about the pretrainig corpus or any additional training, departing from existing MIA methods, which rely on shadow reference models (Mattern et al., 2023; Carlini et al., 2021). Our experiments demonstrate that MIN-K% PROB outperforms the existing strongest baseline by 7.4% in AUC score on WIKIMIA. Further analysis suggests that the detection performance correlates positively with the model size and detecting text length.
To verify the applicability of our proposed method in real-world settings, we perform three case studies: copyrighted book detection (§5), privacy auditing of LLMs (§7) and dataset contamination detection (§6). We find that MIN-K% PROB significantly outperforms baseline methods in both scenarios. From our experiments on copyrighted book detection, we see strong evidence that GPT-3 1 is pretrained on copyrighted books from the Books3 dataset (Gao et al., 2020; Min et al., 2023). From our experiments on privacy auditing of machine unlearning, we use MIN-K% PROB
1 text-davinci-003.
2 PRETRAININING DATA DETECTION PROBLEM
We study pretraining data detection, the problem of detecting whether a piece of text is part of the training data. First, we formally define the problem and describe its unique challenges that are not present in prior fine-tuning data detection studies (§2.1). We then curate WIKIMIA, the first benchmark for evaluating methods of pretraining data detection (§2.2).
2.1 PROBLEM DEFINITION AND CHALLENGES
We follow the standard definition of the membership inference attack (MIA) by Shokri et al. (2016); Mattern et al. (2023). Given a language model fθ and its associated pretraining data D = {zi}i∈[n] sampled from an underlying distribution D, the task objective is to learn a detector h that can infer the membership of an arbitrary data point x: h(x, fθ) → {0, 1}. We follow the standard setup of MIA, assuming that the detector has access to the LM only as a black box, and can compute token probabilities for any data point x.
Challenge 1: Unavailability of the pretraining data distribution. Existing state-of-art MIA methods for data detection during fine-tuning (Long et al., 2018; Watson et al., 2022; Mireshghallah et al., 2022a) typically use reference models gγ to compute the background difficulty of the data point and to calibrate the output probability of the target language model : h(x, fθ, gγ) → {0, 1}. Such reference models usually share the same model architecture as fθ and are trained on shadow data Dshadow ⊂ D (Carlini et al., 2022; Watson et al., 2022), which are sampled from the same underlying distribution D. These approaches assume that the detector can access (1) the distribution of the target model’s training data, and (2) a sufficient number of samples from D to train a calibration model.
However, this assumption of accessing the distribution of pretraining training data is not realistic because such information is not always available (e.g., not released by model developers (Touvron et al., 2023b; OpenAI, 2023)). Even if access were possible, pretraining a reference model on it would be extremely computationally expensive given the incredible scale of pretraining data. In summary, the pretraining data detection problem aligns with the MIA definition but includes an assumption that the detector has no access to pretraining data distribution D.
Challenge 2: Detection difficulty. Pretraining and fine-tuning differ significantly in the amount of data and compute used, as well as in optimization setups like training epochs and learning rate schedules. These factors significantly impact detection difficulty. One might intuitively deduce that detection becomes harder when dataset sizes increase, and the training epochs and learning rates decrease. We briefly describe some theoretical evidence that inform these intuitions in the following and show empirical results that support these hypotheses in §6.
To illustrate, given an example z ∈ D, we denote the model output as fθ(z) Now, take another example y sampled from D \ D (not part of the pretraining data). Determining whether an example x was part of the training set becomes challenging if the outputs fθ(z) and fθ(y) are similar. The degree of similarity between fθ(z) and fθ(y) can be quantified using the total variation distance. According to previous research (Hardt et al., 2016; Bassily et al., 2020), the bound on this total variation distance between fθ(z) and fθ(y) is directly proportional to the occurrence frequency of the example x, learning rates, and the inverse of dataset size, which implies the detection difficulty correlates with these factors as well.
2.2 WIKIMIA: A DYNAMIC EVALUATION BENCHMARK
We construct our benchmark by using events added to Wikipedia after specific dates, treating them as non-member data since they are guaranteed not to be present in the pretraining data, which is the key idea behind our benchmark.
Data construction. We collect recent event pages from Wikipedia. Step 1: We set January 1, 2023 as the cutoff date, considering events occurring post-2023 as recent events (non-member data). We used the Wikipedia API to automatically retrieve articles and applied two filtering criteria: (1) the articles must belong to the event category, and (2) the page must be created post 2023. Step 2: For member data, we collected articles created before 2017 because many pretrained models, e.g., LLaMA, GPT-NeoX and OPT, were released after 2017 and incorporate Wikipedia dumps into their pretraining data. Step 3: Additionally, we filtered out Wikipedia pages lacking meaningful text, such as pages titled “Timeline of …” or “List of …”. Given the limited number of events post-2023, we ultimately collected 394 recent events as our non-member data, and we randomly selected 394 events from pre-2016 Wikipedia pages as our member data. The data construction pipeline is automated, allowing for the curation of new non-member data for future cutoff dates.
Benchmark setting. In practice, LM users may need to detect texts that are paraphrased and edited, as well. Previous studies employing MIA have exclusively focused on detecting examples that exactly match the data used during pretraining. It remains an open question whether MIA methods can be employed to identify paraphrased examples that convey the same meaning as the original. In addition to the verbatim setting (original), we therefore introduce a paraphrase setting we leverage ChatGPT2 to paraphrase the examples and subsequently assess if the MIA metric can effectively identify semantically equivalent examples.
Moreover, previous MIA evaluations usually mix different-length data in evaluation and report a single performance metric. However, our results reveal that data length significantly impacts the difficulty of detection. Intuitively, shorter sentences are harder to detect. Consequently, different data length buckets may lead to varying rankings of MIA methods. To investigate this further, we propose a different-length setting: we truncate the Wikipedia event data into different lengths—32, 64, 128, 256—and separately report the MIA methods’ performance for each length segment. We describe the desirable properties in Appendix B.
2 OpenAI. https://chat.openai.com/chat
3 MIN-K% PROB: A SIMPLE REFERENCE-FREE PRETRAINING DATA
4 EXPERIMENTS
We evaluate the performance of MIN-K% PROB and baseline detection methods against LMs such as LLaMA Touvron et al. (2023a), GPT-Neo (Black et al., 2022), and Pythia (Biderman et al., 2023) on WIKIMIA.
4.1 DATASETS AND METRICS
Our experiments use WIKIMIA of different lengths (32, 64, 128, 256), original and paraphrase settings. Following (Carlini et al., 2022; Mireshghallah et al., 2022a), we evaluate the effectiveness of a detection method using the True Positive Rate (TPR) and its False Positive Rate (FPR). We plot the ROC curve to measure the trade-off between the TPR and FPR and report the AUC score (the area under ROC curve) and TPR at low FPRs (TPR@5%FPR) as our metrics.
4.2 BASELINE DETECTION METHODS
We take existing reference-based and reference-free MIA methods as our baseline methods and evaluate their performance on WIKIMIA. These methods only consider sentence-level probability. Specifically, we use the LOSS Attack method (Yeom et al., 2018a), which predicts the membership of an example based on the loss of the target model when fed the example as input. In the context of LMs, this loss corresponds to perplexity of the example (PPL). Another method we consider is the neighborhood attack (Mattern et al., 2023), which leverages probability curvature to detect membership (Neighbor). This approach is identical to the DetectGPT (Mitchell et al., 2023) method recently proposed for classifying machine-generated vs. human-written text. Finally, we compare with membership inference methods proposed in (Carlini et al., 2021), including comparing the example perplexity to zlib compression entropy (Zlib), to the lowercased example perplexity (Lowercase) and to example perplexity under a smaller model pretrained on the same data (Smaller Ref ). For the smaller reference model setting, we employ LLaMA-7B as the smaller model for LLaMA-65B and LLaMA-30B, GPT-Neo-125M for GPT-NeoX-20B, OPT-350M for OPT-66B and Pythia-70M for Pythia-2.8B.
4.3 IMPLEMENTATION AND RESULTS
Implementation details. The key hyperparameter of MIN-K% PROB is the percentage of tokens with the highest negative log-likelihood we select to form the top-k% set. We performed a small sweep over 10, 20, 30, 40, 50 on a held-out validation set using the LLAMA-60B model and found that k = 20 works best. We use this value for all experiments without further tuning. As we report the AUC score as our metric, we don’t need to determine the threshold ϵ.
Main results. We compare MIN-K% PROB and baseline methods in Table 1. Our experiments show that MIN-K% PROB consistently outperforms all baseline methods across diverse target language models, both in original and paraphrase settings. MIN-K% PROB achieves an AUC score of 0.72 on average, marking a 7.4% improvement over the best baseline method (i.e., PPL). Among the baselines, the simple LOSS Attack (PPL) outperforms the others. This demonstrates the effectiveness and generalizability of MIN-K% PROB in detecting pretraining data from various LMs. Further results such as TPR@5%FPR can be found in Appendix A, which shows a trend similar to Table 6.
4.4 ANALYSIS
We further delve into the factors influencing detection difficulty, focusing on two aspects: (1) the size of the target model, and (2) the length of the text.
Model size. We evaluate the performance of reference-free methods on detecting pretraining 128- length texts from different-sized LLaMA models (7, 13, 30, 65B). Figure 2a demonstrates a noticeable trend: the AUC score of the methods rises with increasing model size. This is likely because larger models have more parameters and thus are more likely to memorize the pretraining data.
In the following two sections, we apply MIN-K% PROB to real-world scenarios to detect copyrighted books and contaminated downstream tasks within LLMs.
5 CASE STUDY: DETECTING COPYRIGHTED BOOKS IN PRETRAINING DATA
MIN-K% PROB can also detect potential copyright infringement in training data, as we show in this section. Specifically, we use MIN-K% PROB to detect excerpts from copyrighted books in the Books3 subset of the Pile dataset (Gao et al., 2020) that may have been included in the GPT-33 training data.
5.1 EXPERIMENTAL SETUP
Validation data to determine detection threshold. We construct a validation set using 50 books known to be memorized by ChatGPT, likely indicating their presence in its training data (Chang et al., 2023), as positive examples. For negative examples, we collected 50 new books with first editions in 2023 that could not have been in the training data. From each book, we randomly extract 100 snippets of 512 words, creating a balanced validation set of 10,000 examples. We determine the optimal classification threshold with MIN-K% PROB by maximizing detection accuracy on this set.
Test data and metrics. We randomly select 100 books from the Books3 corpus that are known to contain copyrighted contents (Min et al., 2023). From each book, we extract 100 random 512-word snippets, creating a test set of 10,000 excerpts. We apply the threshold to decide if these books snippets have been trained with GPT-3. We then report the percentage of these snippets in each book (i.e., contamination rate) that are identified as being part of the pre-training data.
5.2 RESULTS
Figure 3 shows MIN-K% PROB achieves an AUC of 0.88, outperforming baselines in detecting copyrighted books. We apply the optimal threshold of MIN-K% PROB to the test set of 10,000 snippets from 100 books from Books3. Table 2 represents the top 20 books with the highest predicted contamination rates. Figure 4 reveals nearly 90% of the books have an alarming contamination rate over 50%.
The Violin of Auschwitz North American Stadiums White Chappell Scarlet Tracings Lost and Found A Different City Our Lady of the Forest The Expelled Blood Cursed Genesis Code: A Thriller of the Near Future The Sleepwalker’s Guide to Dancing The Harlan Ellison Hornbook The Book of Freedom Three Strong Women The Leadership Mind Switch: Rethinking How We Lead in the New World of Work Gold The Tower Amazon Ain’t It Time We Said Goodbye: The Rolling Stones on the Road to Exile Page One Road of Bones: The Siege of Kohima 1944
6 CASE STUDY: DETECTING DOWNSTREAM DATASET CONTAMINATION
Assessing the leakage of downstream task data into pretraining corpora is an important issue, but it is challenging to address given the lack of access to pretraining datasets. In this section, we investigate the possibility of using MIN-K% PROB to detect information leakage and perform ablation studies to understand how various training factors impact detection difficulty. Specifically, we continually pretrain the 7B parameter LLaMA model (Touvron et al., 2023a) on pretraining data that have been purposefully contaminated with examples from the downstream task.
6.1 EXPERIMENTS
Experimental setup. To simulate downstream task contamination that could occur in real-world settings, we create contaminated pretraining data by inserting examples from downstream tasks into a pretraining corpus. Specifically, we sample text from the RedPajama corpus (TogetherCompute, 2023) and insert formatted examples from the downstream datasets BoolQ (Clark et al., 2019), IMDB (Maas et al., 2011), Truthful QA (Lin et al., 2021), and Commonsense QA (Talmor et al., 2019) in contiguous segments at random positions in the uncontaminated text. We insert 200 (positive) examples from each of these datasets into the pretraining data while also isolating a set of 200 (negative) examples from each dataset that are known to be absent from the contaminated corpus. This creates a contaminated pretraining dataset containing 27 million tokens with 0.1% drawn from downstream datasets.
We evaluate the effectiveness of MIN-K% PROB at detecting leaked benchmark examples by com- puting AUC scores over these 400 examples on a LLaMA 7B model finetuned for one epoch on our contaminated pretraining data at a constant learning rate of 1e-4.
Main results. We present the main attack results in Table 3. We find that MIN-K% PROB out- performs all baselines. We report TPR@5%FPR in Table 7 in Appendix A, where MIN-K% PROB shows 12.2% improvement over the best baseline.
Table 3: AUC scores for detecting contaminant downstream examples. Bold shows the best AUC score within each column.
6.2 RESULTS AND ANALYSIS
The simulation with contaminated datasets allows us to perform ablation studies to empirically analyze the effects of dataset size, frequency of data occurrence, and learning rate on detection difficulty, as theorized in section 2.1. The empirical results largely align with and validate the theoretical framework proposed. In summary, we find that detection becomes more challenging as data occurrence and learning rate decreases, and the effect of dataset size on detection difficulty depends on whether the contaminants are outliers relative to the distribution of the pretraining data.
Pretraining dataset size. We construct contaminated datasets of 0.17M, 0.27M, 2.6M and 26M tokens by mixing fixed downstream examples (200 examples per downstream task) with varying amounts of RedPajama data, mimicking real-world pretraining. Despite the theory suggesting greater difficulty with more pretraining data, Figure 5a shows AUC scores counterintuitively increase with pre-training dataset size. This aligns with findings that LMs better memorize tail outliers (Feldman, 2020; Zhang et al., 2021). With more RedPajama tokens in the constructed dataset, downstream examples become more significant outliers. We hypothesize that their enhanced memorization likely enables easier detection with perplexity-based metrics.
To verify the our hypothesis, we construct control data where contaminants are not outliers. We sample Real Time Data News August 20234, containing post-2023 news absent from LLaMA pre- training. We create three synthetic corpora by concatenating 1000, 5000 and 10000 examples from this corpus, hence creating corpora of sizes 0.77M, 3.9M and 7.6M tokens respecitvely. In each setting, we consider 100 of these examples to be contaminant (positive) examples and set aside another set of 100 examples from News August 2023 (negative). Figure 5b shows AUC scores decrease as the dataset size increases.
Detection of outlier contaminants like downstream examples gets easier as data size increases, since models effectively memorize long-tail samples. However, detecting general in-distribution samples from the pretraining data distribution gets harder with more data, following theoretical expectations.
Data occurrence. To study the relationship between detection difficulty and data occurrence, we construct a contaminated pretraining corpus by inserting multiple copies of each downstream data point into a pre-training corpus, where the occurrence of each example follows a Poisson distribution. We measure the relationship between the frequency of the example in the pretraining data and its AUC scores. Figure 5c shows that AUC scores positively correlates with the occurrence of examples.
4 https://huggingface.co/datasets/RealTimeData/News_August_2023
(a) Outlier contaminants, e.g., down- stream examples, become easier to detect as dataset size increases.
(b) In-distribution contaminants, e.g., news articles, are harder to de- tect as dataset size increases.
(c) Contaminants that occur more frequently in the dataset are easier to detect.
Figure 5: We show the effect of contamination rate (expressed as a percentage of the total number of pretraining tokens) and occurrence frequency on the ease of detection of data contaminants using MIN-K% PROB.
Learning rate. We also study the effect of varying the learning rates used during pretraining on the detection statistics of the contaminant examples (see Table 4). We find that raising the learning rate from 10−5 to 10−4 increases AUC scores significantly in all the downstream tasks, implying that higher learning rates cause models to memorize their pretraining data more strongly. A more in-depth analysis in Table 8 in Appendix A demonstrates that a higher learning rate leads to more memorization rather than generalization for these downstream tasks.
Table 4: AUC scores for detecting contaminant downstream examples using two different learning rates. Detection becomes easier when higher learning rates are used during training. Bold shows the best AUC score within each column.
7 CASE STUDY: PRIVACY AUDITING OF MACHINE UNLEARNING
We also demonstrate that our proposed technique can effectively address the need for auditing machine unlearning, ensuring compliance with privacy regulations (Figure 6).
7.1 BACKGROUNDING
The right to be forgotten and machine unlearning. In today’s landscape of machine learning systems, it is imperative to uphold individuals’ “right to be forgotten”, a legal obligation outlined in regulations such as the General Data Protection Regulation (GDPR) (Voigt & Von dem Bussche, 2017) and the California Consumer Privacy Act (CCPA) (Legislature, 2018). This requirement allows users to request the removal of their data from trained models. To address this need, the concept of machine unlearning has emerged as a solution for purging data from machine learning models, and various machine unlearning methods have been introduced (Ginart et al., 2019; Liu et al., 2020; Wu et al., 2020; Bourtoule et al., 2021; Izzo et al., 2021; Sekhari et al., 2021; Gupta et al., 2021; Ye et al., 2022).
Recently, Eldan & Russinovich (2023) introduced a novel approach for performing machine un- learning on LLMs. This approach involves further fine-tuning the LLMs with alternative labels for specific tokens, effectively creating a modified version of the model that no longer contains the to-be-unlearned content. Specifically, the authors demonstrated the efficacy of this method using the LLaMA2-7B-chat model (Touvron et al., 2023b), showcasing its ability to “unlearn” information from the Harry Potter book series which results in the LLaMA2-7B-WhoIsHarryPotter model5. In this case study, we aim to assess whether this model successfully eliminates memorized content related to the Harry Potter series.
5 Available at https://huggingface.co/microsoft/Llama2-7b-WhoIsHarryPotter.
Figure 6: Auditing machine unlearning with MIN-K% PROB. Machine unlearning methods are designed to remove copyrighted and personal data from large language models. We use MIN-K% PROB to audit an unlearned LLM that has been trained to forget copyrighted books. However, we find that such a model can still output related copyrighted content.
7.2 EXPERIMENTS
To Potter LLaMA2-7B-WhoIsHarryPotter, we consider two settings: story completion (§7.2.1) and question answering (§7.2.2). In story completion, we identify suspicious chunks from the original Harry Potter books using MIN-K% PROB. We then use the unlearned model to generate completions and compare them with the gold continuation. In question answering, we generate a series of questions related to Harry Potter using GPT-4 6. We filter these questions using MIN-K% PROB, and then use the unlearned model to produce answers. These answers are then compared with the gold answers generated by GPT-4 and subsequently verified by humans.
7.2.1 STORY COMPLETION
Identifying suspicious texts using MIN-K% PROB. The process begins with the identifica- tion of suspicious chunks using our MIN-K% PROB metric. Firstly, we gather the plain text of Harry Potter Series 1 to 4 and segment these books into 512-word chunks, resulting in approxi- mately 1000 chunks. We then compute the MIN-K% PROB scores for these chunks using both the LLaMA2-7B-WhoIsHarryPotter model and the original LLaMA2-7B-chat model. To identify chunks where the unlearning process may have failed at, we compare the MIN-K% PROB scores between the two models. If the ratio of the scores from the two models falls within the range of ( 1 1.15 , 1.15), we classify the chunk as a suspicious unlearn-failed chunk. This screening process identifies 188 such chunks. We also notice that using perplexity alone as the metric fails to identify any such chunk. We then test the LLaMA2-7B-WhoIsHarryPotter model with these suspicious chunks to assess its ability to complete the story. For each suspicious chunk, we prompt the model with its initial 200 words and use multinomial sampling to sample 20 model-generated continuations for each chunk.
Results We compare the completed stories with the ground truth storylines using both the SimCSE score (Gao et al., 2021) (which gives a similarity score from 0 to 1) and GPT-4 (where we prompt the model with the template in Table 9 to return a similarity score from 1 to 5, and a reason explaining the similarity). We can still find very similar completion with the original story. For example, 5.3% generated completions have greater and equal to 4 GPT score similarity to the gold completion. The distributions for these two scores of the suspicious chunks are shown in Section 7.2.1. Surprisingly, we find a considerable number of chunks whose auto-completions from the “unlearned” model closely resemble the original story: 10 chunks have a similarity score higher than or equal to 4 according to
Figure 7: Distribution of the SimCSE score (a) and GPT-scored similarity (b) between the original story and the completion by the LLaMA2-7B-WhoIsHarryPotter model.
Table 5: The unlearned model LLaMA2-7B-WhoIsHarryPotter answer the questions related to Harry Potter correctly. We manually cross-checked these responses against the Harry Potter book series for verification.
Results We then compare the answers by the unlearned model (referred to as the “candidate”) to those provided by GPT-4 (referred to as the “reference”) using the ROUGE-L recall measure (Lin, 2004), which calculates the ratio: (# overlapping words between the candidate and reference) / (# words in the reference). A higher ROUGE-L recall value signifies a greater degree of overlap, which can indicate a higher likelihood of unlearning failure. Among the 103 selected questions, we observe an average ROUGE-L recall of 0.23. Conversely, for the unselected questions, the average ROUGE-L recall is 0.10. These findings underscore the capability of our MIN-K% PROB to identify potentially unsuccessful instances of unlearning.
Table 5 shows the selected questions related to Harry Potter that are answered correctly by the unlearned model LLaMA2-7B-WhoIsHarryPotter (with ROUGE-L recall being 1). We also verify the generated answers by cross-checking them against the Harry Potter series. These results suggest the knowledge about Harry Potter is not completely erased from the unlearned model.
8 RELATED WORK
Membership inference attack in NLP. Membership Inference Attacks (MIAs) aim to determine whether an arbitrary sample is part of a given model’s training data (Shokri et al., 2017; Yeom et al., 2018b). These attacks pose substantial privacy risks to individuals and often serve as a basis for more severe attacks, such as data reconstruction (Carlini et al., 2021; Gupta et al., 2022; Cummings et al., 2023). Due to its fundamental association with privacy risk, MIA has more recently found applications in quantifying privacy vulnerabilities within machine learning models and in verifying the accurate implementation of privacy-preserving mechanisms (Jayaraman & Evans, 2019; Jagielski et al., 2020; Zanella-Béguelin et al., 2020; Nasr et al., 2021; Huang et al., 2022; Nasr et al., 2023; Steinke et al., 2023). Initially applied to tabular and computer vision data, the concept of MIA has recently expanded into the realm of language-oriented tasks. However, this expansion has predominantly centered around fine-tuning data detection (Song & Shmatikov, 2019; Shejwalkar et al., 2021; Mahloujifar et al., 2021; Jagannatha et al., 2021; Mireshghallah et al., 2022b). Our work focuses on the application of MIA to pretraining data detection, an area that has received limited attention in previous research efforts.
Dataset contamination. The dataset contamination issue in LMs has gained attention recently since benchmark evaluation is undermined if evaluation examples are accidentally seen during pre-training. Brown et al. (2020b), Wei et al. (2022), and Du et al. (2022) consider an example contaminated if there is a 13-gram collision between the training data and evaluation example. Chowdhery et al. (2022) further improves this by deeming an example contaminated if 70% of its 8-grams appear in the training data. Touvron et al. (2023b) builds on these methods by extending the framework to tokenized inputs and judging a token to be contaminated if it appears in any token n-gram longer than 10 tokens. However, their methods require access to retraining corpora, which is largely unavailable for recent model releases. Other approaches try to detect contamination without access to pretraining corpora. Sainz et al. (2023) simply prompts ChatGPT to generate examples from a dataset by providing the dataset’s name and split. They found that the models generate verbatim instances from NLP datasets. Golchin & Surdeanu (2023) extends this framework to extract more memorized instances by incorporating partial instance content into the prompt. Similarly, Weller et al. (2023) demonstrates the ability to extract memorized snippets from Wikipedia via prompting. While these methods study contamination in closed-sourced models, they cannot determine contamination on an instance level. Marone & Van Durme (2023) argues that model-developers should release training data membership testing tools accompanying their LLMs to remedy this. However, this is not yet widely practiced.
9 CONCLUSION
We present a pre-training data detection dataset WIKIMIA and a new approach MIN-K% PROB. Our approach uses the intuition that trained data tends to contain fewer outlier tokens with very low probabilities compared to other baselines. Additionally, we verify the effectiveness of our approach in real-world setting, we perform two case studiies: detecting dataset contamination and published book detection. For dataset contamination, we observe empirical results aligning with theoretical predictions about how detection difficulty changes with dataset size, example frequency, and learning rate. Most strikingly, our book detection experiments provide strong evidence that GPT-3 models may have been trained on copyrighted books.