Self-Improving for NER
- Related Project: Private
- Category: Paper Review
- Date: 2023-11-17
Self-Improving for Zero-Shot Named Entity Recognition with Large Language Models
- url: https://arxiv.org/abs/2311.08921
- pdf: https://arxiv.org/pdf/2311.08921
- abstract: Exploring the application of powerful large language models (LLMs) on the fundamental named entity recognition (NER) task has drawn much attention recently. This work aims to investigate the possibilities of pushing the boundary of zero-shot NER with LLM via a training-free self-improving strategy. We propose a self-improving framework, which utilize an unlabeled corpus to stimulate the self-learning ability of LLMs on NER. First, we use LLM to make predictions on the unlabeled corpus and obtain the self-annotated data. Second, we explore various strategies to select reliable samples from the self-annotated dataset as demonstrations, considering the similarity, diversity and reliability of demonstrations. Finally, we conduct inference for the test query via in-context learning with the selected self-annotated demonstrations. Through comprehensive experimental analysis, our study yielded the following findings: (1) The self-improving framework further pushes the boundary of zero-shot NER with LLMs, and achieves an obvious performance improvement; (2) Iterative self-improving or naively increasing the size of unlabeled corpus does not guarantee improvements; (3) There might still be space for improvement via more advanced strategy for reliable entity selection.
[반복 및 투표 관련 색인마킹]
[자가평가 및 자가증강 등에 대한 수식 색인마킹]
Contents
- Self-Improving for Zero-Shot Named Entity Recognition with Large Language Models
TL;DR
- 모델 개요: LLM을 활용한 Zero-shot NER의 성능을 자가 개선(Self-Improving) 방식으로 극복하는 프레임워크 제안.
- 방법: 미표시 코퍼스를 사용한 Zero-shot 자가 주석, 신뢰성 있는 주석 선택, 자가 주석된 시연으로 인퍼런스.
- 실험: CoNLL03, ACE05, WikiGold, GENIA 데이터셋에서 프레임워크 성능 검증.
최근 대규모 언어모델(LLM) 시대에 명명된 엔티티 인식(NER) 작업의 새로운 가능성을 탐구하는 많은 연구가 있었습니다 (OpenAI, 2022; Touvron et al., 2023; Chowdhery et al., 2022). 이런 연구들은 Zero-shot 예측, Few-shot In-Context Learning(ICL) 등을 위한 프롬프트 설계, 작업별 LLM 훈련, LLM을 사용하여 데이터를 생성하는 방법을 포함합니다.
이 논문에서는 LLM을 통해 Zero-shot NER의 성능 한계를 자가 개선 방식으로 극복할 가능성을 탐구합니다. 이는 주석이 없는 데이터만 접근 가능하고 추가적인 모델 훈련이나 보조 모델이 없는 엄격한 Zero-shot 시나리오에 중점을 둡니다.
Zero-Shot NER 자가 개선
Zero-shot NER의 성능 한계를 극복하기 위해, 저자원 환경에서 자가 개선 프레임워크를 제안합니다. 이 프레임워크는 기존의 프롬프트 설계와는 독립적으로 동작하며, 어떤 프롬프트 방식도 적용할 수 있습니다.
문제 정의
주어진 입력 문장 \(x\)에서 NER 작업은 \(x\)에서 구조적 출력 \(y\)를 인식하는 것입니다. \(y\)는 \((e,t)\) 쌍의 집합으로 구성됩니다. \(e\)는 \(x\)에서의 토큰 시퀀스인 엔티티 범위이고, \(t\)는 미리 정의된 엔티티 유형 집합에 속하는 대응 엔티티 유형입니다.
Zero-Shot NER Self-Improving 상세 프로세스
Step 1: Zero-Shot 자가 주석
미표시 코퍼스 \(U = \{x_i\}_{i=1}^n\)가 주어졌다고 가정하면, 미표시 샘플 \(x_i\)에 대해 LLM을 통해 Zero-shot 프롬프팅으로 예측을 생성합니다.
\[y_i = \arg\max_y P(y|T, x_i)\]\(T\)는 NER 작업 지시 사항이고, \(y_i = \{(e^j_i, t^j_i)\}_{j=1}^m\)으로 self-consistency(SC) (Wang et al., 2022)를 적용하여 각 예측에 대한 SC 점수를 얻습니다. 각 입력 문장 \(x_i\)의 샘플 수준 SC 점수 \(c_i\)를 얻습니다.
\[c_i = \frac{1}{m} \sum_j c^j_i\]Step 2: 신뢰성 있는 주석 선택
세 가지 신뢰성 있는 주석 선택 전략을 조사합니다.
- 엔티티 수준 임계값 필터링: \(c^j_i < Th_{entity}\)인 예측 엔티티 \(e^j_i\)를 삭제.
- 샘플 수준 임계값 필터링: \(c_i < Th_{sample}\)인 샘플 \(x_i\)를 삭제.
- 2단계 다수결 투표 (Xie et al., 2023): 가장 일관된 엔티티 범위를 투표하고, 투표된 범위를 기반으로 가장 일관된 유형을 선택.
Step 3: 자가 주석된 시연으로 인퍼런스
테스트 입력 \(x_q\)에 대해 신뢰성 있는 자가 주석 데이터셋에서 \(k\)개의 시연을 검색하여 인퍼런스를 돕습니다. 네 가지 시연 검색 방법을 조사합니다.
- 무작위 검색
- 가장 가까운 검색
- 다양한 가장 가까운 검색
- SC 랭킹을 사용한 다양한 가장 가까운 검색
최종적으로, ICL을 수행하여 예측을 얻습니다.
\[y_q = \arg\max_y P(y|T, S, x_q)\]실험
CoNLL03, ACE05, WikiGold, GENIA 데이터셋에서 실험을 수행합니다. GPT-3.5를 LLM 백본으로 사용하고, text-embedding-ada-002를 텍스트 임베딩 모델로 사용합니다. 각 데이터셋에 대해 F1 점수를 보고합니다.
결과
- 주석 선택 없이도 No-demos보다 개선되었습니다.
- 각 주석 선택 전략에 따라 성능이 추가로 향상되었습니다.
- 제안된 다양한 가장 가까운 검색과 SC 랭킹을 결합한 방법이 일관된 개선을 보여주었습니다.
분석
-
미표시 데이터 증가: 미표시 코퍼스의 크기를 증가시키는 것이 자가 개선 시나리오에서 성능 향상을 보장하지 않는 것으로 관찰되었습니다.
-
반복 자가 개선: 반복 자가 개선을 통해 성능을 향상시키려 했으나 대부분의 데이터셋에서 개선을 보장하지 않았습니다.
-
신뢰성 있는 주석 선택의 상한: 신뢰성 있는 주석 선택의 상한을 평가한 결과, gold label 설정과 동등한 성능을 보였습니다.
-
SC 점수 분석: SC 점수가 주석의 신뢰성을 효과적으로 반영함을 확인했습니다.
Weaker LLM에 대한 평가 제안된 프레임워크가 강한 0-shot 능력을 가진 모델에 더 적합함을 확인했습니다.
관련 연구
LLM을 통한 정보 추출 연구는 프롬프트 설계, 작업별 LLM 지시 튜닝, 데이터 증강 등을 포함하며, 이 연구는 훈련 없는 자가 개선 프레임워크를 제안하여 기존 연구와 차별화됩니다. ICL에서의 시연에 대한 연구와도 관련이 있으며, LLM을 사용하여 미표시 코퍼스에 대해 예측을 수행하고 신뢰성 있는 자가 주석 데이터를 시연으로 선택하는 방법을 제안합니다.
[상세]
1. 서론
최근 대규모 언어모델(LLM) 시대에 명명된 엔티티 인식(NER) 작업의 새로운 가능성을 탐구하는 많은 연구가 있었습니다(OpenAI, 2022; Touvron et al., 2023; Chowdhery et al., 2022). 이런 연구에는 Zero-shot 예측 또는 Few-shot In-Context Learning(ICL)을 위한 프롬프트 설계(Wei et al., 2023b; Wang et al., 2023; Xie et al., 2023; Li et al., 2023b), NER을 위한 작업별 LLM 훈련(Zhou et al., 2023; Sainz et al., 2023), 그리고 작은 특정 모델을 훈련시키기 위해 LLM을 사용하여 데이터를 생성하는 것(Zhang et al., 2023; Ma et al., 2023; Josifoski et al., 2023)이 포함됩니다.
이 논문에서는 LLM을 통해 Zero-shot NER의 성능 한계를 자가 개선(Self-Improving) 방식으로 극복할 가능성을 탐구합니다. 이 연구는 주석이 없는 데이터만 접근 가능하고, 추가적인 모델 훈련이나 보조 모델이 없는 엄격한 Zero-shot 시나리오에 중점을 둡니다. NER을 위한 완전 훈련이 없는 자가 개선 프레임워크를 제안하며, 이는 LLM의 자가 학습 능력을 자극하기 위해 미표시 코퍼스를 활용합니다.
2. Zero-Shot NER 자가 개선
2.1 동기
Zero-shot NER의 성능 한계를 극복하기 위해, 주석이 없는 데이터만 접근 가능하고 보조 모델이나 훈련이 없는 저자원 환경에서 자가 개선 프레임워크를 제안합니다. 이는 이전 프롬프트 설계 연구와는 독립적으로 어떤 프롬프트 방식도 이 프레임워크에 적용할 수 있습니다. Figure 1은 프레임워크의 개요를 보여줍니다.
2.2 문제 정의
주어진 입력 문장 \(x\)에서, NER 작업은 \(x\)에서 구조적 출력 \(y\)를 인식하는 것입니다. \(y\)는 \((e,t)\) 쌍의 집합으로 구성됩니다. \(e\)는 \(x\)에서의 토큰 시퀀스인 엔티티 범위이고, \(t\)는 미리 정의된 엔티티 유형 집합에 속하는 대응 엔티티 유형입니다.
2.2.1 Step 1: Zero-Shot 자가 주석
미표시 코퍼스 \(U = \{x_i\}_{i=1}^n\)가 주어졌다고 가정합니다. 레이블이 없는 훈련 세트를 이 연구에서 미표시 데이터셋으로 사용합니다. 미표시 샘플 \(x_i\)에 대해, 상단의 Figure 1에 보이는 것처럼 LLM을 통해 Zero-shot 프롬프팅으로 예측을 생성합니다. 이 과정은 다음과 같이 수식화됩니다. \(y_i = \arg\max_y P(y|T, x_i)\) \(T\)는 NER 작업 지시 사항이고, \(y_i = \{(e^j_i, t^j_i)\}_{j=1}^m\)입니다. self-consistency(SC) (Wang et al., 2022)를 적용하여 각 예측에 대한 SC 점수를 얻습니다. 이는 신뢰성 있는 주석 선택을 위해 2단계에서 사용됩니다. 모델에서 여러 답변을 샘플링하고, 각 예측 엔티티 \((e^j_i, t^j_i)\)에 대한 투표는 모든 샘플된 답변에 나타난 횟수로 표시되며, 이를 엔티티 수준 SC 점수 \(c^j_i\)로 나타냅니다. 그런 다음 모든 예측 엔티티에 대한 평균 SC 점수를 취하여 각 입력 문장 \(x_i\)의 샘플 수준 SC 점수 \(c_i\)를 얻습니다. \(c_i = \frac{1}{m} \sum_j c^j_i\) 각 SC 점수가 있는 자가 주석 샘플은 다음과 같이 나타낼 수 있습니다. \((x_i, \{(e^j_i, t^j_i, c^j_i)\}_{j=1}^m, c_i)\)
2.2.2 Step 2: 신뢰성 있는 주석 선택
더 높은 SC 점수가 더 높은 신뢰성을 나타낸다고 가정합니다. 따라서 다음 세 가지 신뢰성 있는 주석 선택 전략을 조사합니다.
- 엔티티 수준 임계값 필터링: \(c^j_i < Th_{entity}\)인 예측 엔티티 \(e^j_i\)를 삭제합니다. \(Th_{entity}\)는 엔티티 수준 SC 점수의 임계값입니다.
- 샘플 수준 임계값 필터링: \(c_i < Th_{sample}\)인 샘플 \(x_i\)를 삭제합니다. \(Th_{sample}\)은 샘플 수준 SC 점수의 임계값입니다.
- 2단계 다수결 투표 (Xie et al., 2023): 이는 엔티티 수준 선택 방법으로, 먼저 가장 일관된 엔티티 범위를 투표하고, 그런 다음 투표된 범위를 기반으로 가장 일관된 유형을 선택합니다.
2.2.3 Step 3: 자가 주석된 시연으로 인퍼런스
테스트 입력 \(x_q\)가 도착하면, 신뢰성 있는 자가 주석 데이터셋에서 \(k\)개의 시연을 검색하여 인퍼런스를 돕습니다. 다음 네 가지 시연 검색 방법을 조사합니다.
- 무작위 검색: 무작위로 \(k\)개의 시연을 선택합니다.
- 가장 가까운 검색: \(x_q\)의 가장 가까운 이웃 \(k\)개를 선택합니다. 샘플의 거리는 표현 공간에서 코사인 유사도로 측정됩니다.
- 다양한 가장 가까운 검색: 먼저 \(K\)개의 가장 가까운 이웃을 검색한 후, \(K > k\)인 경우 무작위로 균등하게 \(k\)개의 샘플을 선택합니다.
- SC 랭킹을 사용한 다양한 가장 가까운 검색: 이 연구에서는 유사성, 다양성 및 신뢰성 간의 더 나은 균형을 달성하기 위해 제안합니다. \(K\)개의 가장 가까운 이웃을 검색한 후, 상위 \(k\)개의 샘플 수준 SC 점수를 가진 샘플을 선택합니다.
테스트 입력 \(x_q\)에 대해 검색된 자가 주석 시연을 \(S = \{(x_i, y_i)\}_{i=1}^k\)로 나타냅니다. 마지막으로, 프레임워크는 아래 Figure 1의 하단에 표시된 것처럼 이 \(k\)개의 샘플과 테스트 입력 문장 \(x_q\)를 연결하여 ICL을 수행합니다. 예측은 다음과 같이 얻습니다. \(y_q = \arg\max_y P(y|T, S, x_q)\)
3. 실험
3.1 설정
네 가지 널리 사용되는 NER 데이터셋, CoNLL03 (Sang and De Meulder, 2003), ACE05 (Walker et al., 2006), WikiGold (Balasuriya et al., 2009), 그리고 GENIA (Ohta et al., 2002)에서 실험을 수행합니다. GPT-3.5 (gpt-3.5-turbo)를 LLM 백본으로 사용하고, 텍스트 임베딩 모델로 text-embedding-ada-002를 사용하여 문장 표현을 얻습니다. \(k = 16\)과 \(K = 50\)로 설정합니다. SC의 경우, 온도를 0.7로 설정하고 5개의 답변을 샘플링합니다. 비용 절감을 위해, 두 번 무작위로 300개의 테스트 샘플을 샘플링하고 평균과 표준 편차를 보고합니다. 또한 레이블이 없는 훈련 샘플 500개를 무작위로 샘플링하여 미표시 코퍼스 \(U\)를 형성합니다. 초기 Zero-shot 프롬프팅은 베이스 라인이며, 이를 No-demos로 표시합니다. 이 논문에서 F1 점수를 보고합니다.
3.2 결과
주요 결과는 표 1에 나타나 있습니다. 임계값 $$ Th_{entity}
\(와\) Th_{sample} $$의 다른 값에 대한 결과는 Appendix E에서 찾을 수 있습니다.
- 주석 선택 없이 각 미표시 샘플에 대해 하나의 답변만 생성합니다. 결과는 No-demos보다 개선되었음을 보여주며, 신중하게 설계된 주석 선택 단계 없이도 프레임워크가 유용함을 드러냅니다.
- 각 주석 선택 전략에 따라 성능이 추가로 향상되었습니다.
- 제안된 다양한 가장 가까운 검색과 SC 랭킹을 결합한 방법은 다양한 설정에서 일관된 개선을 보여주었으며, 2단계 다수결 투표와 결합할 때 최고의 결과를 달성했습니다. 이는 이 전략이 시연의 유사성, 다양성 및 신뢰성 간의 더 나은 균형을 달성했음을 확인시켜줍니다.
- 무작위 검색은 자가 개선 시나리오에서 가장 가까운 검색보다 뒤처지지만, gold label 시나리오만큼 많이 뒤처지지는 않으며, 이는 자가 주석된 레이블에 포함된 노이즈 때문일 수 있습니다. 모델은 ICL의 복사 메커니즘(Lyu et al., 2023)으로 인해 가장 유사한 자가 주석 시연에서 잘못된 답변을 직접 복사할 수 있습니다.
3.3 분석
미표시 데이터 증가: \(U\)의 크기를 10배로 확장하고, 원본 훈련 세트에서 5000개의 샘플을 무작위로 샘플링했습니다. 결과는 Figure 2에 나타나 있습니다. 미표시 코퍼스의 크기를 증가시키는 것이 자가 개선 시나리오에서 성능 향상을 보장하지 않습니다. 한편, gold label 시나리오에서도 시연 풀의 크기를 증가시키는 것이 약간의 개선만을 가져옵니다. 이는 작은 데이터셋이 이미 데이터 분포를 대략적으로 포착했기 때문일 수 있습니다.
반복 자가 개선: 자가 주석 데이터를 시연으로 사용하여 다음 반복 자가 주석을 안내하는 부트스트래핑 프로세스를 형성합니다. 반복 자가 개선 프로세스의 예는 Appendix G에서 찾을 수 있습니다. 최대 8회 반복 실험을 수행합니다. 0번째 반복은 No-demos 설정을 나타냅니다. 결과는 Figure 3에 나와 있습니다. 반복 자가 개선을 증가시켜도 대부분의 데이터셋에서 개선을 보장할 수 없습니다. 이는 훈련 없는 과정에서 자가 주석의 오류 누적을 제거하기 어려운 사실 때문일 수 있습니다.
신뢰성 있는 주석 선택의 상한: 모든 샘플된 답변에서 실제 예측만 유지하고 잘못된 예측을 삭제하여 신뢰성 있는 주석 선택의 상한을 평가합니다. 결과는 표 2에 나와 있습니다. 더 자세한 결과는 Appendix F에서 찾을 수 있습니다. 상한 설정은 gold label 설정과 동등하게 수행되며, 신뢰성 있는 주석 선택을 개선할 여지가 있음을 나타냅니다.
SC 점수 분석: 엔티티 수준 SC 점수에 대한 커널 밀도 추정을 Figure 4에 나타냈습니다. 대부분의 실제 예측은 높은 SC 점수 범위에 모여 있는 반면, 대부분의 잘못된 예측은 낮은 SC 점수를 가집니다. 이는 SC 점수가 주석의 신뢰성을 효과적으로 반영함을 의미할 수 있습니다.
자가 검증: SC 외에도, LLM에게 자체 답변에 대한 신뢰도를 채점하도록 요청하여 자가 주석의 신뢰도를 측정하는 자가 검증(SV)을 탐구합니다. LLM이 인식된 엔티티를 출력한 후, 다음과 같이 요청하여 SV 점수를 얻습니다. “위의 답변을 제공하는 것에 얼마나 자신이 있습니까? 각 명명된 엔티티에 대해 0-5의 신뢰도 점수를 주세요.” SC와 SV의 비교 결과는 표 3에 나와 있습니다. 표에서 보이듯이, SV도 No-demos 베이스 라인과 비교하여 약간의 개선을 달성했습니다. 그러나 SC 측정보다 뒤처집니다. 이는 LLM이 자체 답변에 대해 지나치게 확신(confidence)을 갖는 경향이 있기 때문일 수 있습니다. CoNLL03 벤치마크에서 SV 측정 하에 3보다 낮은 신뢰도 점수를 받는 샘플이 없음을 발견했습니다. 지나친 확신 문제는 Li et al. (2023a)에서도 언급되었습니다.
Weaker LLM에 대한 평가: 제안된 자가 개선 프레임워크의 성능을 weaker LLM에서 탐구하기 위해, Llama2 chat 13B 모델(Touvron et al., 2023)에서 실험을 수행합니다. 결과는 표 4에 나와 있습니다. 이 실험에서는 2단계 다수결 투표 선택 전략과 가장 가까운 이웃 검색 방법을 사용합니다. 0-shot 시나리오에서 약한 능력을 가진 Llama2 13B 모델은 자가 개선 프레임워크 하에서 부정적인 결과를 보여줍니다. 이는 제안된 프레임워크가 강한 0-shot 능력을 가진 모델에 더 적합함을 나타냅니다. 상대적으로 약한 0-shot 능력을 가진 모델의 경우, 성능을 높이기 위해 프롬프트 설계를 개선하는 것이 더 효과적인 전략일 수 있습니다.
4. 관련 연구
LLM을 통한 정보 추출: LLM을 사용한 정보 추출(IE) 연구에는 프롬프트 설계(Wei et al., 2023b; Wang et al., 2023; Xie et al., 2023; Li et al., 2023b), 작업별 LLM 지시 튜닝(Zhou et al., 2023; Sainz et al., 2023) 및 데이터 증강(Zhang et al., 2023; Ma et al., 2023; Josifoski et al., 2023)이 포함됩니다. Zhang et al. (2023)은 LLM을 사용하여 데이터를 주석하고, 이를 특정 IE 모델을 파인튜닝하는 데 사용하며, 파인튜닝된 모델은 다음 반복에서 주석할 데이터를 선택하는 데 도움을 줍니다. 이전 연구와 달리, 이 연구는 LLM에서 Zero-shot 경계를 확장하기 위해 훈련 없는 자가 개선 프레임워크를 제안합니다. Zhang et al. (2023)과 달리, 이 프레임워크에서는 초기 레이블 데이터, 전문가 소규모 모델 또는 훈련 자원이 필요하지 않습니다. 또한, 작업은 이전 프롬프트 설계 연구와 독립적입니다. 그들은 성능을 향상시키기 위해 다양한 프롬프트 형식을 탐구했으며, 미표시 코퍼스를 사용하지 않았습니다. 그들과 달리, 이 연구는 복잡한 프롬프트 형식을 설계하지 않고 미표시 코퍼스를 사용하여 Zero-shot NER을 개선합니다.
ICL에서의 시연: 일부 연구에서는 ICL에 영향을 미치는 요인을 탐구했습니다(Lyu et al., 2023; Min et al., 2022; Wei et al., 2023a). Lyu et al. (2023)은 ICL에서 시연에 무작위로 레이블을 할당하는 것이 미치는 영향을 조사했습니다. 그러나 이 무작위 레이블링 방법은 문장 수준이 아닌 토큰 수준의 레이블 정보가 필요한 NER 작업에는 적합하지 않습니다. 그들과 달리, 먼저 LLM을 사용하여 미표시 코퍼스에 대해 예측을 하고, 그런 다음 신뢰성 있는 자가 주석 데이터를 시연으로 선택합니다.
[재고]
1 Introduction
There have been many works exploring new possibilities of the named entity recognition (NER) task in the era of large language models (LLMs) (OpenAI, 2022; Touvron et al., 2023; Chowdhery et al., 2022) recently. These studies include designing advanced prompting methods for zero-shot prediction or few-shot in-context learning (ICL) (Wei et al., 2023b; Wang et al., 2023; Xie et al., 2023; Li et al., 2023b), training task-specific LLMs for NER (Zhou et al., 2023; Sainz et al., 2023), and generating data with LLMs to train small specific models (Zhang et al., 2023; Ma et al., 2023; Josifoski et al., 2023).
*Corresponding authors. Code and data are publicly available: GitHub.
In this work, we explore the possibility of pushing the performance boundary of zero-shot NER with LLMs via self-improving. We focus on the strict zero-shot scenarios where no annotated data is available but only an unlabeled corpus is accessible, and no training resource or auxiliary models are available. We propose a totally training-free self-improving framework for NER, which utilizes an unlabeled corpus to stimulate the self-learning ability of LLMs. The framework consists of the following three steps:
- Step 1: We use LLMs to self-annotate the unlabeled corpus using self-consistency (SC, Wang et al., 2022). Each annotated entity is associated with an SC score, which is used as the measure of the reliability of this annotation.
- Step 2: We select reliable annotation to form a reliable self-annotated dataset, during which diverse annotation selection strategies are explored, including entity-level threshold filtering, sample-level threshold filtering and two-stage majority voting.
- Step 3: For each arrived test input, we perform inference via ICL with demonstrations from the reliable self-annotated dataset. Various strategies for demonstration retrieval are explored.
Our contributions include:
- We proposed a training-free self-improving framework for zero-shot NER with LLMs.
- This framework achieved significant performance improvements on four benchmarks.
- We conduct comprehensive experimental analysis, finding that increasing the size of the unlabeled corpus or iterations of self-annotating does not guarantee gains, but there might be room for improvements with more advanced strategies for reliable annotation selection.
Zero-Shot NER with Self-Improving
Motivation
To push the performance boundary of zero-shot NER with LLMs, we propose a self-improving framework under a strict zero-shot and low-resource setting: No annotated data but only an unlabeled corpus is available; No auxiliary model or training step is required. This study is orthogonal to previous prompt designing works, as any advanced prompting method can be applied to this framework. Figure 1 shows the framework overview.
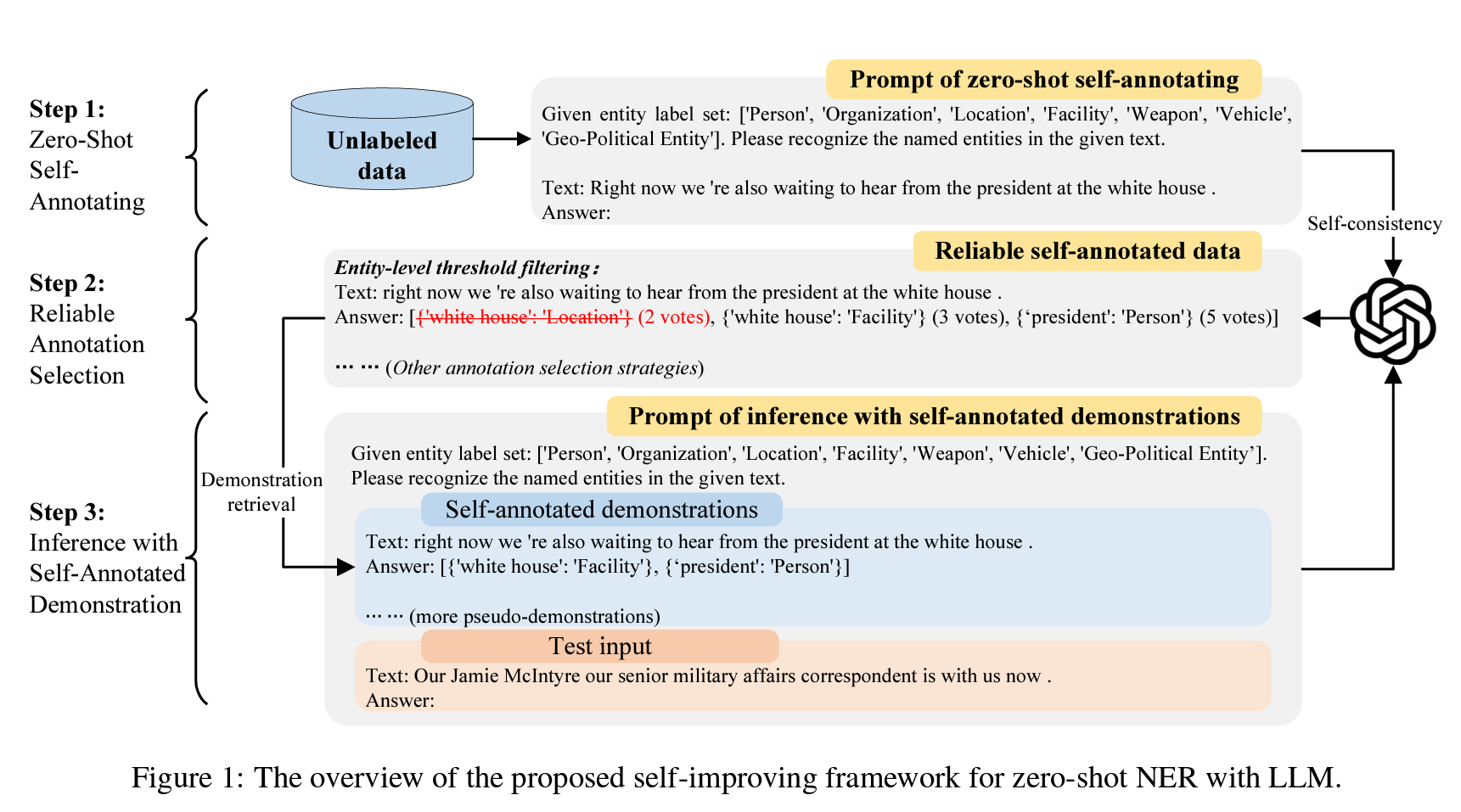
Task Formulation
Given an input sentence \(x\), the NER task is to recognize the structure output \(y\) from \(x\), which consists of a set of \((e,t)\) pairs. \(e\) is an entity span, which is a sequence of tokens from \(x\); \(t\) is the corresponding entity type, which belongs to a predefined entity type set.
Step 1: Zero-Shot Self-Annotating
| We assume an unlabeled corpus \(U = \{x_i\}_{i=1}^n\) is available. We use the training set without labels as the unlabeled dataset in this work. For unlabeled sample \(x_i\), we generate predictions with LLMs via zero-shot prompting, as shown in the upper part of Figure 1. This process is formulated as $$ y_i = \arg\max_y P(y | T, x_i) \(, where\) T \(is the task instruction of NER, and\) y_i = {(e^j_i, t^j_i)}{j=1}^m \(. We apply self-consistency (SC) (Wang et al., 2022) to obtain an SC score for each prediction, which will be used in step 2 for reliable annotation selection. We sample multiple answers from the model, and the vote for each predicted entity\)(e^j_i, t^j_i)\(is the times it appeared in all the sampled answers, which we denoted as entity-level SC score\) c^j_i \(. Then we get the sample-level SC score\) c_i \(for each input sentence\) x_i \(by taking the average SC score over all predicted entities in this sentence, i.e.,\) c_i = \frac{1}{m} \sum_j c^j_i \(. For each self-annotated sample with SC scores, we can denote it as\)(x_i, {(e^j_i, t^j_i, c^j_i)}{j=1}^m, c_i)$$. |
Step 2: Reliable Annotation Selection
We assume that a higher SC score indicates a higher reliability. Thus, we investigate the three following strategies for reliable annotation selection:
- Entity-level threshold filtering, which drops the predicted entity \(e^j_i\) if \(c^j_i < \text{Th}_{\text{entity}}\), where \(\text{Th}_{\text{entity}}\) is the threshold for entity-level SC score.
- Sample-level threshold filtering, which drops the sample \(x_i\) if \(c_i < \text{Th}_{\text{sample}}\), where \(\text{Th}_{\text{sample}}\) is the threshold for sample-level SC score.
- Two-stage majority voting (Xie et al., 2023), is an entity-level selection method, which first votes for the most consistent entity spans, then the most consistent types based on the voted spans.
Step 3: Inference with Self-Annotated Demonstration
When a test input \(x_q\) arrives, we retrieve \(k\) demonstrations from the reliable self-annotated dataset to help the inference. We investigate the following four methods for demonstration retrieval:
- Random retrieval, which randomly selects \(k\) demonstrations.
- Nearest retrieval, which selects the \(k\) nearest neighbors of \(x_q\). The distance of samples is measured by the cosine similarity in the representation space.
- Diverse nearest retrieval, which first retrieves \(K\) nearest neighbors, where \(K > k\), then uniformly samples a random set of \(k\) samples from the \(K\) neighbors.
- Diverse nearest with SC ranking, proposed by this work to achieve a better trade-off between the similarity, diversity, and reliability of self-annotated demonstrations. After retrieving \(K\) nearest neighbors, we select samples with the top- \(k\) sample-level SC scores.
| Let \(S = \{(x_i, y_i)\}_{i=1}^k\) denote the self-annotated demonstrations retrieved for the test input \(x_q\). Finally, our framework conducts ICL by concatenating these \(k\) samples as well as the test input sentence \(x_q\), as shown in the lower part of Figure 1. The prediction is obtained via $$ y_q = \arg\max_y P(y | T, S, x_q) $$. |
Experiment
Setup
We experiment on four widely-used NER datasets, CoNLL03 (Sang and De Meulder, 2003), ACE05 (Walker et al., 2006), WikiGold (Balasuriya et al., 2009), and GENIA (Ohta et al., 2002). We use GPT-3.5 (gpt-3.5-turbo) as the LLM backbone and text-embedding-ada-002 model to get sentence representations. We set \(k = 16\) and \(K = 50\). For SC, we set temperature to 0.7 and sample 5 answers. For cost saving, we randomly sample 300 test samples twice then report the means and standard deviations, and we randomly sample 500 training samples without labels to form the unlabeled corpus \(U\). The naive zero-shot prompting is our baseline, which we denote as No-demos. We report F1 scores throughout this paper.
Results
The main results are shown in Table 1. Results of other values for thresholds \(\text{Th}_{\text{entity}}\) and \(\text{Th}_{\text{sample}}\) can be found in Appendix E.
- Without annotation selection, we only generate one answer for each unlabeled sample. The results show improvements over No-demos, revealing that our framework is helpful even without any carefully designed annotation selection step.
- The performance is further improved under three annotation selection strategies respectively.
- The proposed diverse nearest with SC ranking shows consistent improvements under various settings and achieves the best results when combined with two-stage majority voting. This confirms that this strategy achieves a better trade-off between similarity, diversity, and reliability of the demonstrations.
- Random retrieval lags behind nearest retrieval in self-improving scenarios but is not as much as in the gold label scenario, likely because of the noise contained in self-annotated labels. The model may directly copy the wrong answers in the most similar self-annotated demonstrations due to the copy mechanism of ICL (Lyu et
al., 2023).
Analysis
Increasing unlabeled data. We expanded the size of \(U\) by 10 times and randomly sampled 5000 samples from the original training set. Results are shown in Figure 2. Increasing the size of the unlabeled corpus does not guarantee performance improvements under the self-improving scenario. Meanwhile, increasing the size of the demonstration pool only brings marginal improvement, even under the gold label scenario. The reason may be that the small dataset already approximately captures the data distribution.
Iterative self-improving. We use the self-annotated data as demonstrations to guide the next iteration of self-annotating, forming a bootstrapping process. The illustration of the iterative self-improving process can be found in Appendix G. We experiment up to 8 iterations. The 0-th iteration indicates the No-demos setting. Results are shown in Figure 3. Increasing iterations of self-improving cannot guarantee improvements on most datasets. This may be due to the fact that error accumulation in self-annotating is difficult to be eliminated in this training-free process.
Upper bound of reliable annotation selection. We keep only the true predictions and discard the false predictions in all the sampled answers to evaluate the upper bound of reliable annotation selection. Results are shown in Table 2. More detailed results can be found in Appendix F. Upper bound setting performs on par with the Gold label setting, indicating that there might still be space to be improved for reliable annotation selection.
SC score analysis. We plot the kernel density estimation for entity-level SC scores in Figure 4. Most true predictions gather in the interval of high SC scores, while most false predictions have low SC scores. This shows that SC scores effectively reflect the reliability of annotations.
Self-verification. Besides SC, we also explore self-verification (SV) to measure the confidence of self-annotation by asking the LLM to score its own answer about its own confidence. After the LLM outputs the recognized entities, we obtain the SV score by asking the LLM: “How confident are you in providing the above answers? Please give each named entity in your answer a confidence score of 0-5.” The comparison results between SC and SV are in Table 3. As shown in the table, SV also achieves some improvements compared with the No-demos baseline. However, it lags behind the SC measurement. This is presumably because the LLM tends to be over-confident about its own answer, since we found that no sample gets a confidence score lower than 3 under the SV measurement in the CoNLL03 benchmark. The overconfidence problem is also mentioned in Li et al. (2023a).
Evaluation on weaker LLMs. To explore the performance of the proposed self-improving framework on weaker LLMs, we conduct experiments on the Llama2 chat 13B model (Touvron et al., 2023), the results are shown in Table 4. Two-stage majority voting selection strategy and the nearest neighbor retrieval method are used in this experiment. With a much weaker ability in zero-shot scenarios, Llama2 13B model shows negative results under the self-improving framework. This indicates that the proposed framework is more suitable for models with a strong zero-shot capability. For the models with a relatively weaker zero-shot ability, improving the prompt designing might be a more effective strategy to boost performance.
Related Work
Information extraction with LLM. The research of information extraction (IE) with LLMs includes prompt designing (Wei et al., 2023b; Wang et al., 2023; Xie et al., 2023; Li et al., 2023b), task-specific LLMs instruction-tuning (Zhou et al., 2023; Sainz et al., 2023) and data augmentation (Zhang et al., 2023; Ma et al., 2023; Josifoski et al., 2023). Zhang et al. (2023) use LLM to annotate data, which is used to fine-tune a specific IE model, then the fine-tuned model is used to help select the data to be annotated in the next iteration. Unlike previous works, this work proposes a training-free self-improving framework to push the zero-shot boundary of LLM on NER. Different from Zhang et al. (2023), no seed labeled data, expert small model nor training resources are required in our framework. In addition, our work is orthogonal to previous prompt designing works. They explored various advanced prompt formats to boost performance and did not utilize an unlabeled corpus. Unlike them, this work improves zero-shot NER by using an unlabeled corpus without designing any complex prompt format.
Demonstrations in ICL. Some works explored factors that have impacts on ICL (Lyu et al., 2023; Min et al., 2022; Wei et al., 2023a). Lyu et al. (2023) investigate the impact of randomly assigning labels to demonstrations in ICL. However, this random labeling method is not suitable for tasks like NER, which requires label information on the token-level instead of sentence-level. Different from them, we first use LLM to make predictions on the unlabeled corpus, then select reliable self-annotated data as demonstrations.
1 Introduction
The remarkable zero-shot and few-shot generalization of large language models (LLMs) (OpenAI, 2022; Touvron et al., 2023; Chowdhery et al., 2022) makes the vision of one model for all possible. Named entity recognition (NER) is a fundamental task in information extraction (IE). There have been many works exploring new possibilities of the NER task in the era of LLMs. Some works study advanced prompting methods to improve zero-shot prediction or few-shot in-context learning (ICL) for NER (Wang et al., 2023; Xie et al., 2023; Wei et al., 2023b). Some works train task-specific LLMs for NER (Sainz et al., 2023; Zhou et al., 2023). Meanwhile, there are studies use LLMs as data annotator or data generator to conduct data augmentation for small language models(Ma et al., 2023; Josifoski et al., 2023).
In this work, we explore the possibility of pushing the boundary of zero-shot NER with LLMs via self-improving. We focus on the strict zero-shot scenarios where no annotated data is available but only an unlabeled corpus is accessible, and no training resource or auxiliary models are available. We propose a self-improving framework which utilize an unlabeled corpus to stimulate the self-learning ability of LLMs via a training-free paradigm. The pipeline of our framework is as follows. (1) First, we use LLMs to predict named entities for the unlabeled corpus and obtain the self-annotated data. In this process, we apply self-consistency (SC) to obtain a SC score for each prediction as the measure for the quality of self-annotation. (2) Second, we explore diverse strategy to select reliable samples from the self-annotated data and obtain a reliable sample set. Then we investigate various demonstration retrieval methods to select demonstrations for the arrived test query. To make better tradeoff between the similarity, diversity and reliability of demonstrations simultaneously, we propose the retrieval strategy of diverse nearest with SC ranking. (3) Finally, we use the selected reliable self-annotated demonstrations to assist the inference of the test query via ICL.
In summary, the main contributions are:
- We explored the possibility of boosting zero-shot NER with LLMs via self-improving. We proposed a self-improving framework which utilize an unlabeled corpus to stimulate the self-learning ability of LLMs with a training-free paradigm.
- This self-improving framework pushed the boundary of zero-shot NER with LLMs and achieved significant performance improvements.
- We conduct comprehensive analysis on this self-improving paradigm, the main findings include: (1) Iterative self-improving or simply increasing the size of unlabeled corpus does not guarantee further improvements; (2) However, the framework might still be boosted via more advanced strategies for reliable entity selection.
Figure 1: The overview of the proposed self-improving framework for zero-shot NER with LLM. The pipeline mainly consists of three steps: (1) First, we let the LLM to make predictions on the unlabeled corpus via zero-shot prompting and obtain the self-annotated data. We obtain a consistency score for each prediction via SC. (2) Second, we perform reliable sample selection on the self-annotated dataset via various strategies. (3) Finally, for the arrived test query, we use the selected reliable self-annotated data as the pseudo demonstrations in ICL and conduct inference with pseudo demonstrations
2 Related Work
IE with LLM. Some works designed different prompting methods to improve the performance of IE with LLMs. Wei et al. (2023b) propose a two-stage chatting paradigm for IE, which first recognize the types of elements then extract the mentions corresponding to each type. Wang et al. (2023) apply in-context learning (ICL) to NER by inserting special tokens into the demonstrations retrieved from the full gold training set. Xie et al. (2023) propose decomposed-QA and syntactic augmentation to boost zero-shot NER. Li et al. (2023) transfer IE into code generation task. Meanwhile, a few studies trained task-specific LLMs for IE with instruction-tuning (Zhou et al., 2023; Sainz et al., 2023). In addition, several works used LLMs to annotate data or generate synthetic data for small expert IE models (Zhang et al., 2023; Ma et al., 2023; Josifoski et al., 2023). Zhang et al. (2023) use LLM to annotate data, then fine-tune the small IE model on the data annotated by LLM, and use the fine-tuned model to help select the data to be annotated; this pipeline is conducted iteratively to form a bootstrapping process. Ma et al. (2023); Josifoski et al. (2023) generate synthetic data for IE via a structure-to-text paradigm. Different from previous work, we attempt to push the zero-shot boundary of LLM on NER through training-free self-improving. We use unlabeled corpus to stimulate the self-learning ability of LLM without any auxiliary models. Note that our work is orthogonal to the previous prompt designing works, and any advanced prompting method can be applied in the proposed framework to boost performance.
Some works explored factors that have effects on ICL (Lyu et al., 2023; Min et al., 2022; Wei et al., 2023a). Lyu et al. (2023) use random assigned labels for demonstrations in ICL. However, this random assigning is not suitable for tasks like NER, which requires label information on the fine-grained token-level instead of sentence-level. Different from them, we first use LLM to make predictions on the unlabeled corpus, then select reliable self-annotated data as pseudo
3 Zero-Shot NER with Self-Improving
We propose a self-improving framework for zero-shot NER with LLMs under the strict zero-shot setting: No annotated data but only an unlabeled corpus is available; No auxiliary models is required; The whole process is training-free, which explore the self-improving ability of the model without costly training. This study is orthogonal to the previous prompt designing works, and any advanced prompting method can be applied in the proposed framework to boost performance.
3.1 Task Formulation
Given an input sentence $x$, the NER task is to predict the structure output $y$ from $x$, which consists of a set of $(e, t)$ pairs. $e$ is an entity span, which is a sequence of tokens from $x$, and $t$ is the corresponding entity type, which belongs to a predefined entity type set.
3.2 Step 1: Self-Annotating Unlabeled Corpus
We assume an unlabeled corpus $U$ is available. In this work, we use the training set without annotation ${x_i}_{i=1}^n$ as the unlabeled corpus. In this step, we use zero-shot prompting to annotate the unlabeled corpus, as shown in the upper right of Fig. 1.
\[P(y\\|T, x_i)\]where the predicted answer is obtained via
\[y_i = \arg\max_y P(y\\|T, x_i)\]$T$ is the task instruction of NER.
Also, we apply Self-Consistency (SC) (Wang et al., 2022) to obtain the annotation confidences. For each predicted entity $(e, t)$, its vote is taken to measure its confidence, which we call entity-level SC score, $c_{e_i}$. For each input sentence, we take the average SC score over all predicted entities as the SC score of this sentence, which we call sample-level SC score, $c_i$. The self-annotated data with entity-level and sample-level SC scores are shown in the right part of Fig. 1. For each annotated sample, we denote it as a quadruple $(x_i, y_i, {c_{e_j}}, c_i)$, where ${c_{e_j}}$ is the set of entity-level SC scores corresponding to the predicted entity set.
3.3 Step 2: Reliable Sample Selection
We intend to use the self-annotated data as pseudo demonstrations to assist the inference, and provide useful guidance for test queries. This requires the pseudo demonstrations to have high quality. We use SC score to measure the quality of pseudo demonstrations and assume that a higher SC score indicates higher quality.
This step consists of two parts: we first select high-quality samples from the self-annotated dataset, then retrieve pseudo demonstrations from the high-quality sample set for inference.
Sample selection strategies:
- Entity-level SC threshold filtering, which drops the predicted entity $e$ if $c_{e_i} < Th_{entity}$, where $Th_{entity}$ is the entity-level SC threshold.
- Sample-level SC threshold filtering, which drops the sample $x_i$ if $c_i < Th_{sample}$, where $Th_{sample}$ is the sample-level SC threshold.
- Two-stage majority voting, proposed in (Xie et al., 2023), is a selection strategy on the entity-level, which first votes for the most consistent entity spans, then the most consistent types based on the voted spans.
Sample retrieval strategies: When a test query $x_q$ arrives, we retrieve $k$ samples from the reliable sample set to assist the inference of the query. We explore the following strategies for retrieval:
- Random retrieval, which randomly selects $k$ demonstrations from the sample set.
- Nearest retrieval, which selects the $k$ nearest neighbors of the input samples. We first obtain the representations of all samples, then we retrieve $k$ nearest neighbors in the representation space. We use cosine similarity to measure the distances of representations.
- Diverse nearest retrieval, which first retrieves $K$ nearest neighbors, where $K > k$, then uniformly samples a random set of $k$ samples from the $K$ nearest neighbors.
- To achieve a better trade-off between similarity, diversity, and reliability of the demonstrations, we propose diverse nearest with SC ranking. After retrieving $K$ nearest neighbors, we rank them with sample-level SC scores, and choose the top-$k$ samples as demonstrations.
3.4 Step 3: Inference
Let $S = {(x_i, y_i)}_{i=1}^k$ denote the retrieved reliable pseudo demonstrations for the test query $x_q$. Finally, our framework conducts ICL by concatenating these $k$ input-pseudo label pairs as well as the input query sentence $x_q$. Then the prediction is obtained via
\[P(y\\|T, S, x_q)\] \[y_q = \arg\max_y P(y\\|T, S, x_q)\]4 Experiments
4.1 Setup
Datasets. We evaluate the proposed framework on four commonly-used NER datasets, CoNLL03 (Sang and De Meulder, 2003), ACE05 (Walker et al., 2006), WikiGold (Balasuriya et al., 2009) and GENIA (Ohta et al., 2002).
Models. We use GPT-3.5 (gpt-3.5-turbo) as the LLM backbone for all experiments. We use text-embedding-ada-002 model to get sentence representations, which is a text embedding model from
OpenAI. We access to OpenAI models with the official API.2
Prompts. We focus on investigating the effectiveness of this training-free self-improving paradigm on NER. So we eliminate the impact of different prompting methods by using the most regular prompt format, which is as shown in Fig. 1. The complete prompts are shown in Appendix E.
Note that prompt designing is orthogonal to this work, and any advanced prompting method can be applied in our framework to boost performance.
Implementation details. For inference via ICL with pseudo demonstrations , we use k = 16 in all of our experiments. For self-consistency, we set the temperature to 0.7 and 0 for settings with and without SC, respectively. We conduct majority voting of 5 responses in our main experiments. For cost saving, we randomly sample 300 samples from the test set twice and report the means and standard deviations, except for WikiGold, of which the test set size is only 247. We randomly sample 500 samples from the original training set as the unlabeled corpus U. We explore the effect of increasing the size of U in Section 4.4, and also report the results with full gold training set for analysis.
The results of GPT-3.5 are obtained during October and November 2023 with official API.
4.2 Results
The rest of this section tries to answer the following questions:
- How does the self-improving framework perform and how do different sample selection strategies perform? (Section 4.3)
- Will increasing unlabeled data help improve the performance? (Section 4.4)
- Will increasing the iteration of self-improving help improve the performance? (Section 4.5)
- What’s the characteristics of SC in NER? (Section 4.6)
4.3 Main Results
The main results of the proposed self-improving framework are shown in Table 1, from which we obtain the following observations. (1) In the part of No sample selection, we remove SC, and use all self-annotated answers for self-improving. The results shows improvements over No-demos, revealing that our framework are helpful even without any sample selection step. (2) In the next three parts, with reliable sample selection, the performance is further improved. There is no significant performance differences between different sample selection strategies. (3) Overall, the proposed retrieval strategy of diverse nearest with SC ranking shows consistent improvements under various settings and achieve the best results when combined with two-stage majority voting. This confirms that diverse nearest with SC ranking achieves a better trade-off between similarity, diversity and reliability of demonstrations. (4) Random retrieval lags behind nearest retrieval but not as much as in the gold label setting, likely because the diversity of demonstrations is more important in pseudo label setting than in the gold label setting. The pseudo label inevitably contains noise. Although nearest retrieval obtains the most similar demonstrations, but if they contains much noise, they could harm the performance due to the copy mechanism of ICL mentioned in (Lyu et al., 2023). However, not similar but diverse demonstrations could make the model learn the fine-grained task requirement while eliminating the copy mechanism.
Figure 2: Increasing the size of unlabeled dataset does not bring obvious performance gain in self-improving paradigm.
Figure 3: The pipeline of iterative self-improving.
4.4 Increasing Unlabeled Data
We explore the effect of increasing the size of unlabeled corpus U. We expand the size of U by 10× and randomly sampled 5000 samples from the original training set. We refer to U of size 500 and 5000 as small and large unlabeled set, respectively. The results on CoNLL03 and WikiGold are shown in Fig. 2. Results on the rest of datasets are in Appendix C. Increasing the size of unlabeled corpus does not guarantee performance improvements under the self-improving paradigm. Although increasing the size of demonstration pool does improve the results under gold label setting, the performance gain is marginal, likely because that the small set already approximately cover the distribution of the dataset. This is consistent with the results on lowresource scenario in (Wang et al., 2023).
4.5 Increasing Iterations of Self-Improving
We explore the effect of iterative self-improving: we use the self-annotated data as sample pool, to guide the next iteration of self-annotating, forming a bootstrapping process. The iterative process is as shown in Fig. 3. We use two-stage majority voting and diverse nearest with SC ranking in this section for demonstration. The results on CoNLL03 and WikiGold are shown in Fig. 4. Results on the rest of datasets are in Appendix C. We experiment up to 8 iterations. The 0-th iterations indicate the No-demos setting. The impact of iterative self-improving varies on different datasets. The performance generally keeps climbing with the increase of iterations on CoNLL03. However, the performances keeps dropping or wandering around the original level on other datasets. This may due to the fact that error accumulation in the self-annotating step is difficult to be eliminated in this training-free paradigm.
Figure 4: Effect of increasing the iterations of self-improving varies on different datasets.
Figure 5: Kernal density estimation plots for SC scores. The SC scores reflect the reliability of samples to a large extent.
Table 2: The potential upper bound of SC (True-only) keeps only the true predictions in SC. TSMV refers to two-stage majority voting. We display the best results for each strategy. The setting of True-only performs on par with the Gold label setting, showing that there is still space to be improved for the reliable sample selection.
4.6 Analysis of Self-Consistency
Potential upper bound of SC. We explore the potential upper bound of SC by keeping the true predictions only (referred as true-only). The results comparison are shown in Table 2. We display the results of nearest retrieval for the true-only setting, which shows the best result among all retrieval strategies. The complete results of this setting are shown in Appendix B. True-only method performs on par with the gold label setting, showing that there is still space to be improved for the reliable sample selection. Strategies other than SC threshold filtering can be explored for selecting reliable entities.
5 Conclusions
This work explored the possibilities of pushing the boundary of zero-shot NER with LLMs via training-free self-improving. We proposed a selfimproving framework, which utilize an unlabeled corpus to stimulate the self-learning ability of LLMs. This framework mainly consists of three steps. At step one, we use LLM to make predictions on the unlabeled corpus and obtain the selfannotated data. At step two, we select reliable demonstrations from the self-annotated set via various selection strategies and retrieval approaches. Finally at step three, we conduct inference on the test query via ICL with the selected pseudo demonstrations. This framework achieves significant improvement on zero-shot NER with LLM. In addition, through comprehensive experimental analysis, we find that the proposed framework might be difficult to further improved via iterative selfannotation or simply increasing the size of unlabeled corpus, but might still be boosted via more advanced strategies for reliable entity selection.
6 Limitations
We acknowledge the following limitations of this study: (1) This work focus on exploring the zero-shot self-improving framework on NER task. The investigation of this paradigm on other IE tasks are not studied yet. (2) We applied the commonly-used self-consistency method to obtain the confidence score for measuring the quality of self-annotated data. There might be other diverse approaches to measure the quality of self-annotation. (3) The zero-shot performance still lag behind previous state-of-the-art in fully-supervised methods. We leave them to future work.