Context | Needle Bench
- Related Project: Private
- Category: Paper Review
- Date: 2024-07-16
Introducing Lamini Memory Tuning: 95% LLM Accuracy, 10x Fewer Hallucinations
- url: https://arxiv.org/abs/2407.11963
- pdf: https://arxiv.org/pdf/2407.11963
- html: https://arxiv.org/html/2407.11963v1
- github: https://github.com/open-compass/opencompass
- abstract: In evaluating the long-context capabilities of large language models (LLMs), identifying content relevant to a user’s query from original long documents is a crucial prerequisite for any LLM to answer questions based on long text. We present NeedleBench, a framework consisting of a series of progressively more challenging tasks for assessing bilingual long-context capabilities, spanning multiple length intervals (4k, 8k, 32k, 128k, 200k, 1000k, and beyond) and different depth ranges, allowing the strategic insertion of critical data points in different text depth zones to rigorously test the retrieval and reasoning capabilities of models in diverse contexts. We use the NeedleBench framework to assess how well the leading open-source models can identify key information relevant to the question and apply that information to reasoning in bilingual long texts. Furthermore, we propose the Ancestral Trace Challenge (ATC) to mimic the complexity of logical reasoning challenges that are likely to be present in real-world long-context tasks, providing a simple method for evaluating LLMs in dealing with complex long-context situations. Our results suggest that current LLMs have significant room for improvement in practical long-context applications, as they struggle with the complexity of logical reasoning challenges that are likely to be present in real-world long-context tasks. All codes and resources are available at OpenCompass: this https URL.
TL;DR
- NeedleBench 프레임워크 개발: 다양한 텍스트 깊이에서 정보 추출 및 인퍼런스 능력을 평가하기 위해 다중 길이 간격을 포함하는 이중 언어 장문 컨텍스트 기능 평가 프레임워크
- Ancestral Trace Challenge (ATC) 도입: 복잡한 장문 컨텍스트에서 다단계 논리적 인퍼런스를 평가하기 위한 새로운 방법 제시
- 실험적 결과 제공: 현재 대규모 언어모델들이 실제 장문 컨텍스트 작업의 복잡성을 다루는 데 있어 개선의 여지가 있음을 보여줌.
Long-Context 평가 벤치로 빠르게 활용되고 있는 것 같습니다.
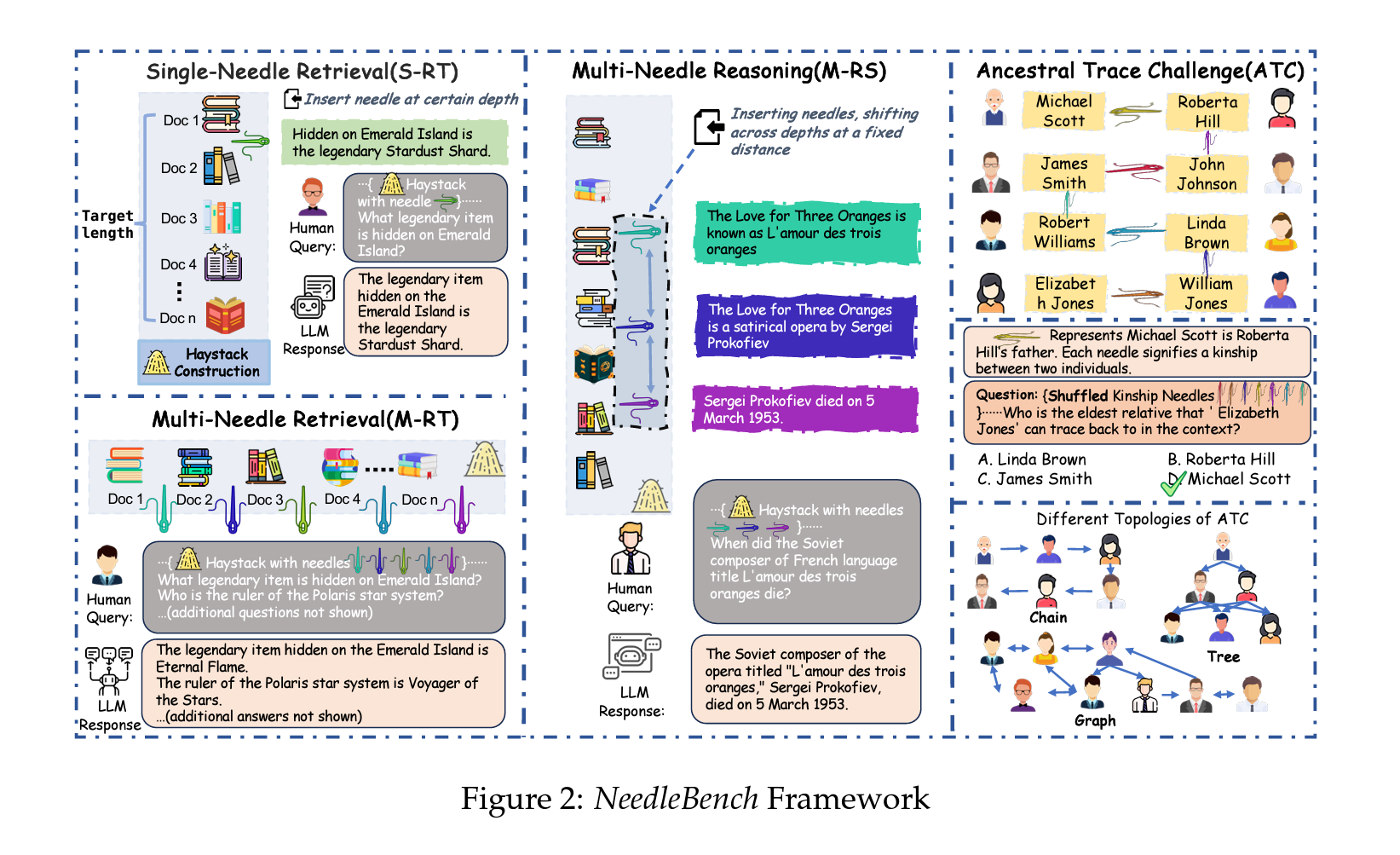
[벤치마크 종류]
- 단일-니들 검색 과제(Single-Needle Retrieval Task, S-R): 긴 텍스트 내에서 단일 중요 정보를 다양한 위치에서 추출할 수 있는 LLM의 능력을 평가
- 다중-니들 검색 과제(Multi-Needle Retrieval Task, M-RT): 긴 텍스트를 통해 흩어져 있는 여러 관련 정보 조각을 검색할 수 있는 LLM의 능력을 시험
- 다중-니들 인퍼런스 과제(Multi-Needle Reasoning Task, M-RS): 긴 텍스트에서 여러 정보 조각을 추출하고 이를 사용하여 다양한 텍스트 부분의 통합된 이해와 인퍼런스를 요구하는 질문에 논리적으로 답변할 수 있는 LLM의 능력을 평가
1. 서론
장문의 텍스트를 처리하는 대규모 언어모델(Large Language Models, LLMs)의 능력은 다양한 상황에서 중요합니다. 이 모델들은 법적 문서 검색, 학술 연구, 비즈니스 인텔리전스 집약 등에서 긴 문서 내에서 관련 정보를 신속하게 식별하고 요약할 수 있어 가치가 있습니다. 현대의 LLM들은 점점 더 긴 context window을 지원하도록 개발되었습니다. 예를 들어, GPT-4 Turbo는 최대 128K 토큰, Claude 2.1은 최대 200K 토큰까지 처리할 수 있으며, Claude 3 시리즈는 100만 토큰을 초과하는 입력을 소화할 수 있도록 특별히 설계되었습니다. 또한, 최근의 오픈소스 모델들도 100만 context window을 지원합니다. 이런 모델들이 긴 텍스트 길이를 수용함에 따라 텍스트 내 세부 정보를 이해하는 것이 점점 더 중요해지고 있습니다.
2. 과제 및 데이터셋
2.1 NeedleBench 과제
NeedleBench 프레임워크는 다양한 길이 간격(4k, 8k, 32k, 128k, 200k, 1000k 이상)과 다양한 텍스트 깊이 범위에서 이중 언어 장문 컨텍스트 기능을 평가하기 위해 설계되었습니다. 이를 통해 다양한 컨텍스트에서 모델의 정보 검색 및 인퍼런스 능력을 엄격하게 테스트할 수 있습니다. 프레임워크는 다음과 같은 세부 과제로 구성됩니다.
- 단일-니들 검색 과제(S-RT): 긴 텍스트 내에서 단일 중요 정보를 다양한 위치에서 추출할 수 있는 LLM의 능력을 평가
- 다중-니들 검색 과제(M-RT): 긴 텍스트를 통해 흩어져 있는 여러 관련 정보 조각을 검색할 수 있는 LLM의 능력을 시험
- 다중-니들 인퍼런스 과제(M-RS): 긴 텍스트에서 여러 정보 조각을 추출하고 이를 사용하여 다양한 텍스트 부분의 통합된 이해와 인퍼런스를 요구하는 질문에 논리적으로 답변할 수 있는 LLM의 능력을 평가
2.2 Ancestral Trace Challenge (ATC)
ATC는 실제 장문 컨텍스트 시나리오에서 복잡한 장문 컨텍스트 과제를 모방하기 위해 도입되었습니다. ATC 실험에서는 간단한 일차 논리적 인퍼런스를 사용하여 정보 체인을 구성하고, LLM이 질문에 답하기 위해 전체 정보를 완전히 이해할 필요가 있습니다. 정보의 어느 한 부분을 잊어버리면 LLM이 정확한 답변을 제공할 수 없습니다.
2.3 데이터셋 구성
2.3.1 니들 디자인
모델의 고유 지식이 정보 검색 능력에 영향을 미치지 않도록 니들을 추상적이고 실제 세계에 존재하지 않는 형태로 디자인합니다. 다중-니들 인퍼런스 과제를 위해, ℛ₄𝒞 데이터셋을 사용하여 각 인퍼런스 단계에 필요한 정보의 “유도” 정보를 포함시킵니다. 이 데이터셋은 또한 중국어로 번역되어 모델의 이중 언어 인퍼런스 능력을 평가하는 데 고품질 데이터셋을 제공합니다.
2.3.2 헤이스택 디자인
Kamradt (2023)의 방법을 따라 PaulGrahamEssays 데이터셋을 사용하여 프롬프트를 목표 길이로 확장합니다. 중국어 헤이스택의 경우, Wei et al. (2023)에 의해 발표된 ChineseDomainModelingEval 데이터셋을 사용하여 금융부터 기술에 이르기까지 다양한 주제를 다루는 고품질의 최신 중국어 기사를 제공하며, 다양한 모델이 도메인 특화된 긴 텍스트를 처리하는 능력을 평가하는 안정적인 기준을 제공합니다.
3. 실험
3.1 NeedleBench Tasks의 성능
[실험 설정]
모델의 성능 평가는 다양한 위치에 배치된 니들의 회수 정확도를 지표로 사용합니다. 데이터셋의 길이와 깊이에 걸쳐 평균 성능을 순차적으로 계산하여 각 NeedleBench 과제에서 모델의 성능을 산출합니다. 점수는 다음 공식을 사용하여 계산되며, Levenshtein 거리를 기반으로 합니다.
\[\text{Score}_i = \begin{cases} 100 & \text{if } P_i \cap W_i \neq \emptyset, \\ 100 \cdot \alpha \cdot \left(1 - \frac{d(P_i, R_i)}{\max(|P_i|, |R_i|)}\right) & \text{otherwise}, \end{cases}\]$P_i$와 $R_i$는 각각 예측과 참조 목록을 나타내며, $d(P_i, R_i)$는 두 문자열 간의 Levenshtein 거리를 나타냅니다.
[주요 실험 결과]
32K와 200K 컨텍스트 길이에서 주요 결과를 살펴보면 InternLM2-7B-200K 모델은 단일 검색 과제에서 성과를 보여 주며, Qwen-1.5-72B-vLLM 모델은 다중 인퍼런스 과제에서 향상된 성능을 보여 복잡한 정보 간의 관계를 이해하고 인퍼런스하는 능력을 입증합니다. 반면, GLM4-9B-Chat-1M 모델은 특히 영어에서 낮은 성능을 보여 문제를 지적합니다.
3.2 Ancestral Trace Challenge(ATC)
ATC에서는 주로 이중 언어 다단계 논리적 인퍼런스 문제에서 LLM을 평가합니다. 이는 문제의 복잡성을 증가시키기 위해 2단계에서 19단계까지 다양한 설정에서 테스트합니다. 모델은 선택형 답변을 요구받으며, 인퍼런스 경로가 포함된 버전은 성능이 개선되는 경향을 보입니다. 큰 모델일수록 더 나은 성능을 보여주며, 예를 들어, Qwen-72B-vLLM은 ATC 점수에서 상대적으로 높은 성능을 보여줍니다.
여러 단계의 논리적 인퍼런스 문제를 해결하는 데 필요한 모델의 능력인 Ancestral Trace Challenge (ATC)의 점수 계산 방법은 다음과 같습니다.
- 점수 계산의 기본 단위 (Circular-Eval, CE)
- 각 문제 \(Q\)에 대해 여러 번 반복하여 테스트를 수행하고, 각 반복에서 문제의 옵션을 시스템적으로 변경합니다.
- \(CE(Q_{\text{Step}}(i))\)는 \(i\)번째 반복에서 주어진 스텝 수에 대한 문제 \(Q\)의 Circular Evaluation 점수를 나타냅니다.
- 모델이 정확한 답을 식별하면 점수는 \(\frac{100}{R}\)가 되고, 그렇지 않으면 0입니다. \(R\)은 반복 횟수를 의미하며, 이 실험에서는 \(R = 10\)으로 설정됩니다.
- 각 스텝별 점수 (Task Score)
-
각 스텝에서의 점수 \(P_{\text{Step}}\)은 모든 반복에서 계산된 \(CE\) 점수의 합입니다.
\[P_{\text{Step}} = \sum_{i=1}^{R} CE(Q_{\text{Step}}(i))\] -
이는 해당 스텝 수에서 모델이 얼마나 잘 수행했는지를 측정합니다.
-
- 전체 과제 점수 계산
- 전체 과제 점수는 각 스텝에서 얻은 점수를 스텝 수에 비례하여 가중치를 두어 합산하고, 더 많은 스텝을 요구하는 문제에서 높은 성능을 보이는 모델에 더 높은 점수를 부여합니다. \(L\)은 가장 복잡한 과제에서의 논리적 인퍼런스 단계 수를 의미하며, 이 경우 \(L = 19\)로 설정
4. 결론
LLM은 장문 컨텍스트 정보 검색 및 인퍼런스 능력을 평가하며, 특히 복잡한 논리적 인퍼런스 과제에서의 어려움을 강조합니다.
이는 실제 장문 컨텍스트 작업에서 요구되는 복잡한 정보 검색 및 다수의 인퍼런스 단계를 필요로 하는 시나리오에서 LLM의 유용성을 향상시킬 중요한 개선의 여지가 있음을 시사합니다.