Improving Text Embeddings with Large Language Models
- Related Project: Private
- Category: Paper Review
- Date: 2024-01-03
Improving Text Embeddings with Large Language Models
- url: https://arxiv.org/abs/2401.00368
- pdf: https://arxiv.org/pdf/2401.00368
- git: https://huggingface.co/intfloat/e5-mistral-7b-instruct
- abstract: In this paper, we introduce a novel and simple method for obtaining high-quality text embeddings using only synthetic data and less than 1k training steps. Unlike existing methods that often depend on multi-stage intermediate pre-training with billions of weakly-supervised text pairs, followed by fine-tuning with a few labeled datasets, our method does not require building complex training pipelines or relying on manually collected datasets that are often constrained by task diversity and language coverage. We leverage proprietary LLMs to generate diverse synthetic data for hundreds of thousands of text embedding tasks across nearly 100 languages. We then fine-tune open-source decoder-only LLMs on the synthetic data using standard contrastive loss. Experiments demonstrate that our method achieves strong performance on highly competitive text embedding benchmarks without using any labeled data. Furthermore, when fine-tuned with a mixture of synthetic and labeled data, our model sets new state-of-the-art results on the BEIR and MTEB benchmarks.
Contents
- Improving Text Embeddings with Large Language Models
TL;DR
텍스트 임베딩을 위한 대규모 언어모델 활용 연구
- 텍스트 임베딩을 위한 새로운 방법 제안
- 신성 데이터와 대규모 언어모델을 이용한 훈련 방법
- 다양한 벤치마크에서의 우수한 성능 검증
[서론]
텍스트 임베딩은 자연어의 의미적 정보를 벡터 형태로 인코딩하는 기술로, 정보 검색, 질의 응답, 텍스트 유사성 평가 등 다양한 자연어 처리(NLP) 작업에 활용됩니다. 최근 대규모 언어모델(LLM)의 등장으로 문맥 정보를 포함한 텍스트 임베딩의 성능이 크게 향상되었습니다. 그러나 기존 방법은 다단계 훈련 과정이 복잡하고, 데이터셋의 다양성과 언어 범위에 제한이 있습니다. 본 연구에서는 LLM을 활용하여 이런 한계를 극복하는 새로운 텍스트 임베딩 방법을 제안합니다.
[방법]
데이터 생성
GPT-4와 같은 LLM을 사용하여 다양한 텍스트 임베딩 작업에 대한 합성 데이터를 생성합니다. 이를 통해 다양한 작업과 언어에 걸쳐 텍스트 임베딩 모델의 강인성을 향상시킬 수 있습니다.
{
"user_query": "Microsoft Power BI 데이터 분석 방법",
"positive_document": "Microsoft Power BI는 마스터하는 데 시간과 연습이 필요한 도구입니다. 이 튜토리얼에서는 Power BI 사용 방법을 안내합니다...",
"hard_negative_document": "Excel은 데이터 관리와 분석에 우수한 도구입니다. 이 튜토리얼 시리즈는 Excel 사용 방법에 중점을 둡니다..."
}
위 예시는 사용자 질의에 대해 관련 문서와 어려운 부정적 문서를 제공하는 JSON 객체입니다.
모델 훈련
합성 데이터와 공개 데이터셋을 사용하여 Mistral-7B 모델을 파인튜닝합니다. 이 모델은 웹 규모 데이터에 대한 광범위한 사전 훈련을 통해 텍스트 임베딩의 성능을 높입니다.
[실험 결과]
모델 파인튜닝 및 평가
파인튜닝된 Mistral-7B 모델은 BEIR 및 MTEB 벤치마크에서 경쟁력 있는 성능을 보여주며, 이는 레이블이 지정된 데이터를 사용하지 않고도 우수한 성능을 달성할 수 있음을 시사합니다.
[결론]
LLM을 활용한 신성 데이터 생성과 텍스트 임베딩 훈련은 텍스트 임베딩의 성능을 크게 향상시킬 수 있는 유망한 접근 방법입니다.
1 Introduction
Text embeddings are vector representations of natural language that encode its semantic information. They are widely used in various natural language processing (NLP) tasks, such as information retrieval (IR), question answering, semantic textual similarity, bitext mining, item recommendation, etc. In the field of IR, the first-stage retrieval often relies on text embeddings to efficiently recall a small set of candidate documents from a large-scale corpus using approximate nearest neighbor search techniques. Embedding-based retrieval is also a crucial component of retrieval-augmented generation (RAG) [20], which is an emerging paradigm that enables large language models (LLMs) to access dynamic external knowledge without modifying the model parameters. Source attribution of generated text is another important application of text embeddings [13] that can improve the interpretability and trustworthiness of LLMs.
Previous studies have demonstrated that weighted average of pre-trained word embeddings [34, 1] is a strong baseline for measuring semantic similarity. However, these methods fail to capture the rich contextual information of natural language. With the advent of pre-trained language models [10], Sentence-BERT [36] and SimCSE [12] have been proposed to learn text embeddings by fine-tuning BERT on natural language inference (NLI) datasets. To further enhance the performance and robustness of text embeddings, state-of-the-art methods like E5 [44] and BGE [46] employ a more complex multi-stage training paradigm that first pre-trains on billions of weakly-supervised text pairs, and then fine-tunes on several labeled datasets.
Existing multi-stage approaches suffer from several drawbacks. Firstly, they entail a complex multi-stage training pipeline that demands substantial engineering efforts to curate large amounts of relevance pairs. Secondly, they rely on manually collected datasets that are often constrained by the diversity of tasks and the coverage of languages. For instance, Instructor [38] is only trained on instructions from 330 English datasets, whereas BGE [46] only focuses on high-resource languages such as English and Chinese. Moreover, most existing methods employ BERT-style encoders as the backbone, neglecting the recent advances of training better LLMs and related techniques such as context length extension [37].
In this paper, we propose a novel method for text embeddings that leverages LLMs to overcome the limitations of existing approaches. We use proprietary LLMs to generate synthetic data for a diverse range of text embedding tasks in 93 languages, covering hundreds of thousands of embedding tasks. Specifically, we use a two-step prompting strategy that first prompts the LLMs to brainstorm a pool of candidate tasks, and then prompts the LLMs to generate data conditioned on a given task from the pool. To cover various application scenarios, we design multiple prompt templates for each task type and combine the generated data from different templates to boost diversity. For the text embedding models, we opt for fine-tuning powerful open-source LLMs rather than small BERT-style models. Since LLMs such as Mistral [18] have been extensively pre-trained on web-scale data, contrastive pre-training offers little additional benefit.
We demonstrate that Mistral-7B, when fine-tuned solely on synthetic data, attains competitive performance on the BEIR [40] and MTEB [27] benchmarks. This is particularly intriguing considering that this setting does not involve any labeled data. When fine-tuned on a mixture of synthetic and labeled data, our model achieves new state-of-the-art results, surpassing previous methods by a significant margin (+2%). The entire training process requires less than 1k steps.
Moreover, we empirically validate that our model can effectively perform personalized passkey retrieval for inputs up to 32k tokens by altering the rotation base of the position embeddings, extending the context length beyond the conventional 512 token limit. Regarding its multilinguality, our model excels on high-resource languages. However, for low-resource languages, there is still room for improvement as current open-source LLMs are not adequately pre-trained on them.
2 Related Work
Text Embeddings are continuous low-dimensional representations of text and have been extensively applied to various downstream tasks such as information retrieval, question answering, and retrieval-augmented generation (RAG). Early work on text embeddings includes latent semantic indexing [9] and weighted average of word embeddings [24]. More recent methods exploit supervision from natural language inference [2] and labeled query-document pairs, such as the MS-MARCO passage ranking dataset [4], to train text embeddings [36, 5, 12]. However, labeled data are often limited in terms of task diversity and language coverage. To address this challenge, methods like Contriever [17], OpenAI Embeddings [29], E5 [44], and BGE [46] adopt a multi-stage training paradigm. They first pre-train on large-scale weakly-supervised text pairs using contrastive loss and then fine-tune on small-scale but high-quality datasets. In this paper, we demonstrate that it is possible to obtain state-of-the-art text embeddings with single-stage training.
Synthetic Data Synthetic data generation is a widely studied topic in information retrieval research, with various methods proposed to enhance retrieval systems with artificially created data. For instance, Doc2query [32] and Promptagator [7] generate synthetic queries for unlabeled documents, which are then leveraged for document expansion or retriever training. GPL [43] employs a cross-encoder to produce pseudo-labels for query-document pairs. Similarly, Query2doc [45] generates pseudo-documents for query expansion by few-shot prompting LLMs. Unlike these methods, our approach does not rely on any unlabeled documents or queries and thus can generate more diverse synthetic data.
Another related line of work focuses on knowledge distillation from black-box LLMs by training on synthetic data generated from them. Unnatural Instructions [15] is a synthetic instruction following dataset by prompting existing LLMs. Orca [28] and Phi [14] propose to train better small language models by using high-quality synthetic data from GPT-3.5 and GPT-4 [33].
Large Language Models With the popularization of ChatGPT, large language models (LLMs) have demonstrated remarkable capabilities in instruction following and few-shot in-context learning [3]. However, the most advanced LLMs such as GPT-4 [33] are proprietary and have little technical details disclosed. To bridge the gap between proprietary and open-source LLMs, several notable efforts have been made, such as LLaMA-2 [42] and Mistral [18] models. A major limitation of LLMs is that they lack awareness of recent events and private knowledge. This issue can be partly mitigated by augmenting LLMs with information retrieved from external sources, a technique known as retrieval-augmented generation (RAG). On the other hand, LLMs can also serve as foundation models to enhance text embeddings. RepLLaMA [23] proposes to fine-tune LLaMA-2 with bi-encoder architecture for ad-hoc retrieval. SGPT [26], GTR [31], and Udever [49] demonstrate the scaling law of text embeddings empirically, but their performance still falls behind small bidirectional encoders such as E5 [44] and BGE [46]. In this paper, we present a novel approach to train state-of-the-art text embeddings by exploiting the latest advances of LLMs and synthetic data.

Figure 1: An example two-step prompt template for generating synthetic data with GPT-4. We first prompt GPT-4 to brainstorm a list of potential retrieval tasks, and then generate (query, positive, hard negative) triplets for each task. “{…}” denotes a placeholder that will be replaced by sampling from a predefined set of values. Due to space constraints, we omit some details in the figure.
3 Method
3.1 Synthetic Data Generation
Utilizing synthetic data generated by advanced LLMs such as GPT-4 presents a compelling opportunity, especially in terms of enhancing diversity across a multitude of tasks and languages. Such diversity is essential for developing robust text embeddings that can perform well across different tasks, be it semantic retrieval, textual similarity, or clustering.
You have been assigned a retrieval task: {task}. Your mission is to write one text retrieval example for this task in JSON format. The JSON object must contain the following keys:
"user_query": a string, a random user search query specified by the retrieval task."positive_document": a string, a relevant document for the user query."hard_negative_document": a string, a hard negative document that only appears relevant to the query.
Please adhere to the following guidelines:
- The
"user_query"should be {query_type}, {query_length}, {clarity}, and diverse in topic. - All documents should be at least {num_words} words long.
- Both the query and documents should be in {language}.
Your output must always be a JSON object only, do not explain yourself or output anything else. Be creative!
{
"user_query": "How to use Microsoft Power BI for data analysis",
"positive_document": "Microsoft Power BI is a sophisticated tool that requires time and practice to master. In this tutorial, we'll show you how to navigate Power BI … (omitted)",
"hard_negative_document": "Excel is an incredibly powerful tool for managing and analyzing large amounts of data. Our tutorial series focuses on how you…(omitted)"
}
Brainstorm a list of potentially useful text retrieval tasks. Here are a few examples for your reference:
- Provided a scientific claim as query, retrieve documents that help verify or refute the claim.
- Search for documents that answer a FAQ-style query on children’s nutrition.
Please adhere to the following guidelines:
- Specify what the query is, and what the desired documents are.
- Each retrieval task should cover a wide range of queries and should not be too specific.
Your output should always be a python list of strings only, with about 20 elements, and each element corresponds to a distinct retrieval task in one sentence. Do not explain yourself or output anything else. Be creative!
[
"Retrieve company's financial reports for a given stock ticker symbol.",
"Given a book name as a query, retrieve reviews, ratings, and summaries of that book.",
"Search for scientific research papers supporting a medical diagnosis for a specified disease.",
"Find news articles discussing the economic impact of a recent natural disaster.",
"Retrieve documents explaining the historical significance of a given landmark.",
"Search for user manuals and troubleshooting guides for a specified electronic device.",
"Find scholarly articles that debate a controversial topic in education.",
"Retrieve recipes and cooking tips for a specified ingredient.",
"Search for travel guides and tips for visiting a specific country or city.",
"Find blog posts discussing the benefits and drawbacks of a particular diet.",
"Retrieve academic papers exploring the effects of climate change on marine life.",
"Search for tutorials and guides on how to use a specific programming language.",
"Find customer reviews and ratings for a particular product.",
"Retrieve documents explaining the steps to apply for a specific type of visa.",
"Search for articles that provide investment advice for beginners.",
"Find studies that analyze the impact of social media on mental health.",
"Retrieve guidelines and standards for building construction in a specified region.",
"Search for historical documents related to a significant event in world history.",
"Find instructional materials for teaching a particular subject to elementary students.",
"Retrieve policy papers discussing the implications of a new government regulation."
]
To generate diverse synthetic data, we propose a simple taxonomy that categorizes embedding tasks into several groups, and then apply different prompt templates to each group.
Asymmetric Tasks This category comprises tasks where the query and document are semantically related but are not paraphrases of each other. Depending on the length of the query and document, we further divide asymmetric tasks into four subgroups: short-long match, long-short match, short-short match, and long-long match. For instance, short-long match tasks involve a short query and a long document, which is a typical scenario in commercial search engines. For each subgroup, we design a two-step prompt template that first prompts LLMs brainstorm a list of tasks, and then generates a concrete example conditioned on the task definition. In Figure 1, we show an example prompt for the short-long match subgroup. The outputs from GPT-4 are mostly coherent and of high quality. In our preliminary experiments, we also attempted to generate the task definition and query-document pairs using a single prompt, but the data diversity was not as satisfactory as the proposed two-step approach.
Symmetric Tasks Symmetric tasks involve queries and documents that have similar semantic meanings but different surface forms. We examine two application scenarios: monolingual semantic textual similarity (STS) and bitext retrieval. We design two distinct prompt templates for each scenario, tailored to their specific objectives. Since the task definition is straightforward, we omit the brainstorming step for symmetric tasks.
To further boost the diversity of the prompts and thus the synthetic data, we incorporate several placeholders in each prompt template, whose values are randomly sampled at runtime. For example, in Figure 1, the value of “{query_length}” is sampled from the set “{less than 5 words, 5-10 words, at least 10 words}”.
To generate multilingual data, we sample the value of “{language}” from the language list of XLM-R [6], giving more weight to high-resource languages. Any generated data that does not conform to the predefined JSON format are discarded during the parsing process. We also remove duplicates based on exact string matching.
3.2 Training
4 Experiments
4.1 Statistics of the Synthetic Data
Figure 2: Task type and language statistics of the generated synthetic data (see Section 3.1 for task type definitions). The “Others” category contains the remaining languages from the XLM-R language list.
Figure 2 presents the statistics of our generated synthetic data. We manage to generate 500k examples with 150k unique instructions using Azure OpenAI Service 2, among which 25% are generated by GPT-35-Turbo and others are generated by GPT-4. The total token consumption is about 180M. The predominant language is English, with coverage extending to a total of 93 languages. For the bottom 75 low-resource languages, there are about 1k examples per language on average.
In terms of data quality, we find that a portion of GPT-35-Turbo outputs do not strictly follow the guidelines specified in the prompt templates. Nevertheless, the overall quality remains acceptable, and preliminary experiments have demonstrated the benefits of incorporating this data subset.
4.2 Model Fine-tuning and Evaluation
The pretrained Mistral-7b [18] checkpoint is fine-tuned for 1 epoch using the loss in Equation 2. We follow the training recipe from RankLLaMA [23] and utilize LoRA [16] with rank 16. To further reduce GPU memory requirement, techniques including gradient checkpointing, mixed precision training, and DeepSpeed ZeRO-3 are applied.
For the training data, we utilize both the generated synthetic data and a collection of 13 public datasets, yielding approximately 1.8M examples after sampling. More details are available in Appendix A. To provide a fair comparison with some previous work, we also report results when the only labeled supervision is the MS-MARCO passage ranking [4] dataset.
We evaluate the trained model on the MTEB benchmark [27]. Note that the retrieval category in MTEB corresponds to the 15 publicly available datasets in the BEIR benchmark [40]. Evaluation of one model takes about 3 days on 8 V100 GPUs due to the need to encode a large number of documents. Although our model can accommodate sequence length beyond 512, we only evaluate on the first 512 tokens for efficiency. Official metrics are reported for each category. For more details about the evaluation protocol, please refer to the original papers [27, 40].
4.3 Main Results
In Table 1, our model “E5mistral-7b + full data” attains the highest average score on the MTEB benchmark, outperforming the previous state-of-the-art model by 2.4 points. In the “w/ synthetic data only” setting, no labeled data is used for training, and yet the performance remains quite competitive.
https://oai.azure.com/
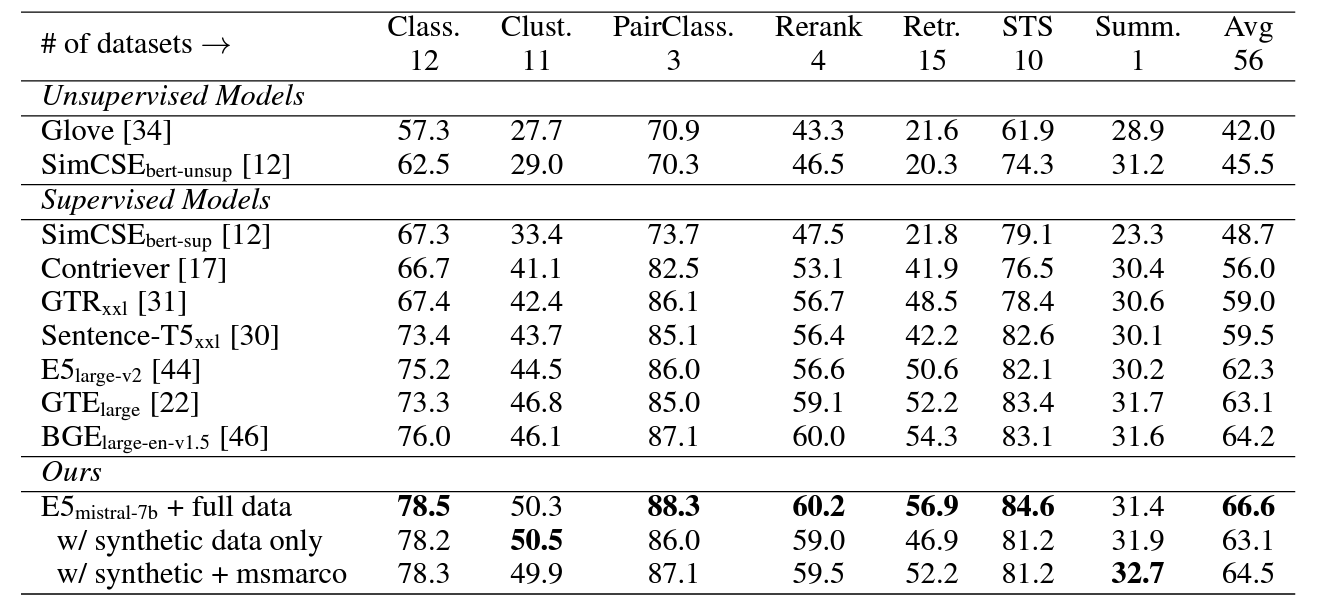
Table 1: Results on the MTEB benchmark [27] (56 datasets in the English subset). The numbers are averaged for each category. Please refer to https://huggingface.co/spaces/mteb/ leaderboard for the scores per dataset.
Note: The columns represent different evaluation metrics used for comparing the models. The numbers in brackets next to the model names refer to the references or footnotes in the original document.
We posit that generative language modeling and text embeddings are the two sides of the same coin, with both tasks requiring the model to have a deep understanding of the natural language. Given an embedding task definition, a truly robust LLM should be able to generate training data on its own and then be transformed into an embedding model through light-weight fine-tuning. Our experiments shed light on the potential of this direction, and more research is needed to fully explore it.
Table 2: Comparison with commercial models and the model that tops the MTEB leaderboard (as of 2023-12-22). For the commercial models listed here, little details are available on their model architectures and training data.
| Model Name | BEIR Retrieval (15 datasets) | MTEB Average (56 datasets) |
|---|---|---|
| OpenAI Ada-002 | 49.3 | 61.0 |
| Cohere-embed-english-v3.0 | 55.0 | 64.5 |
| voyage-lite-01-instruct | 55.6 | 64.5 |
| UAE-Large-V1 [21] | 54.7 | 64.6 |
| E5mistral-7b + full data | 56.9 | 66.6 |
This table shows different models along with their performance scores on the BEIR Retrieval (across 15 datasets) and MTEB Average (across 56 datasets). The numbers in brackets next to some model names are likely references or footnotes from the original document.
In Table 2, we also present a comparison with several commercial text embedding models. However, due to the lack of transparency and documentation about these models, a fair comparison is not feasible. We focus especially on the retrieval performance on the BEIR benchmark, since RAG is an emerging technique to enhance LLM with external knowledge and proprietary data. As Table 2 shows, our model outperforms the current commercial models by a significant margin.
4.4 Multilingual Retrieval
Table 3: nDCG@10 on the dev set of the MIRACL dataset for both high-resource and low-resource languages. We select the 4 high-resource languages and the 4 low-resource languages according to the number of candidate documents. The numbers for BM25 and mDPR come from Zhang et al. [51]. For the complete results on all 18 languages, please see Table 5.
To assess the multilingual capabilities of our model, we conduct an evaluation on the MIRACL dataset [51], which comprises human-annotated queries and relevance judgments across 18 languages. As shown in Table 3, our model surpasses mE5large on high-resource languages, notably on English. Nevertheless, for low-resource languages, our model remains suboptimal compared to mE5base. We attribute this to the fact that Mistral-7B is predominantly pre-trained on English data, and we anticipate that future multilingual LLMs will leverage our method to bridge this gap.
5 Analysis
5.1 Is Contrastive Pre-training Necessary?
Figure 3: Effects of contrastive pre-training. Detailed numbers are in Appendix Table 6.
Weakly-supervised contrastive pre-training is one of the key factors behind the success of existing text embedding models. For instance, Contriever [17] treats random cropped spans as positive pairs for pre-training, while E5 [44] and BGE [46] collect and filter text pairs from various sources.
This section re-evaluates the necessity of contrastive pre-training for LLMs, particularly those that have been pre-trained on trillions of tokens. Figure 3 shows that contrastive pre-training benefits XLM-Rlarge, enhancing its retrieval performance by 8.2 points when fine-tuned on the same data, which aligns with prior findings. However, for Mistral-7B based models, contrastive pre-training has negligible impact on the model quality. This implies that extensive auto-regressive pre-training enables LLMs to acquire good text representations, and only minimal fine-tuning is required to transform them into effective embedding models.
5.2 Personalized Passkey Retrieval
Figure 4: Illustration of the personalized passkey retrieval task adapted from Mohtashami and Jaggi [25]. The “
To evaluate the long-context capability of our model, we introduce a novel synthetic task called personalized passkey retrieval, which is illustrated in Figure 4. This task requires encoding the passkey information in a long context into the embeddings. We compare the performance of different variants by changing the sliding window size and the RoPE rotation base [39] in Figure 5. The results show that the default configuration with 4k sliding window attains 100% accuracy within 4k tokens, but the accuracy deteriorates quickly as the context length grows. Naively extending the sliding window size to 32k results in worse performance. By changing the RoPE rotation base to 105,
Table 4: Results on the MTEB benchmark with various hyperparameters. The first row corresponds to the default setting, which employs last-token pooling, LoRA rank 16, and natural language instructions. Unless otherwise stated, all models are trained on the synthetic and MS-MARCO passage ranking data.
the model can achieve over 90% accuracy within 32k tokens. However, this entails a minor trade-off in performance for shorter contexts. A potential avenue for future research is to efficiently adapt the model to longer contexts through lightweight post-training [52].
5.3 Analysis of Training Hyperparameters
Table 4 presents the results under different configurations. We notice that the Mistral-7B initialization holds an advantage over LLaMA-2 7B, in line with the findings from Mistral-7B technical report [18]. The choice of pooling types and LoRA ranks does not affect the overall performance substantially, hence we adhere to the default setting despite the marginal superiority of LoRA rank 8. On the other hand, the way of adding instructions has a considerable impact on the performance. We conjecture that natural language instructions better inform the model regarding the embedding task at hand, and thus enable the model to generate more discriminative embeddings. Our framework also provides a way to customize the behavior of text embeddings through instructions without the need to fine-tune the model or re-built document index.
6 Conclusion
This paper shows that the quality of text embeddings can be substantially enhanced by exploiting LLMs. We prompt proprietary LLMs such as GPT-4 to generate diverse synthetic data with instruc- tions in many languages. Combined with the strong language understanding capability of the Mistral model, we establish new state-of-the-art results for nearly all task categories on the competitive MTEB benchmark. The training process is much more streamlined and efficient than existing multi-stage approaches, thereby obviating the need for intermediate pre-training.
For future work, we aim to further improve the multilingual performance of our model and explore the possibility of using open-source LLMs to generate synthetic data. We also intend to investigate ways to improve the inference efficiency and lower the storage cost for LLM based text embeddings.