Model | Mixtral-8x7B
- Related Project: Private
- Category: Paper Review
- Date: 2023-12-15
Open-weight Models
These models are not tuned for safety as we want to empower users to test and refine moderation based on their use cases. For safer models, follow our guardrailing tutorial.
- github: mistralai/mistral-src
- huggingface:
Overview
- Mistral 7B Mistral 7B is the first dense model released by Mistral AI. At the time of the release, it matched the capabilities of models up to 30B parameters. Learn more on our blog post.
-
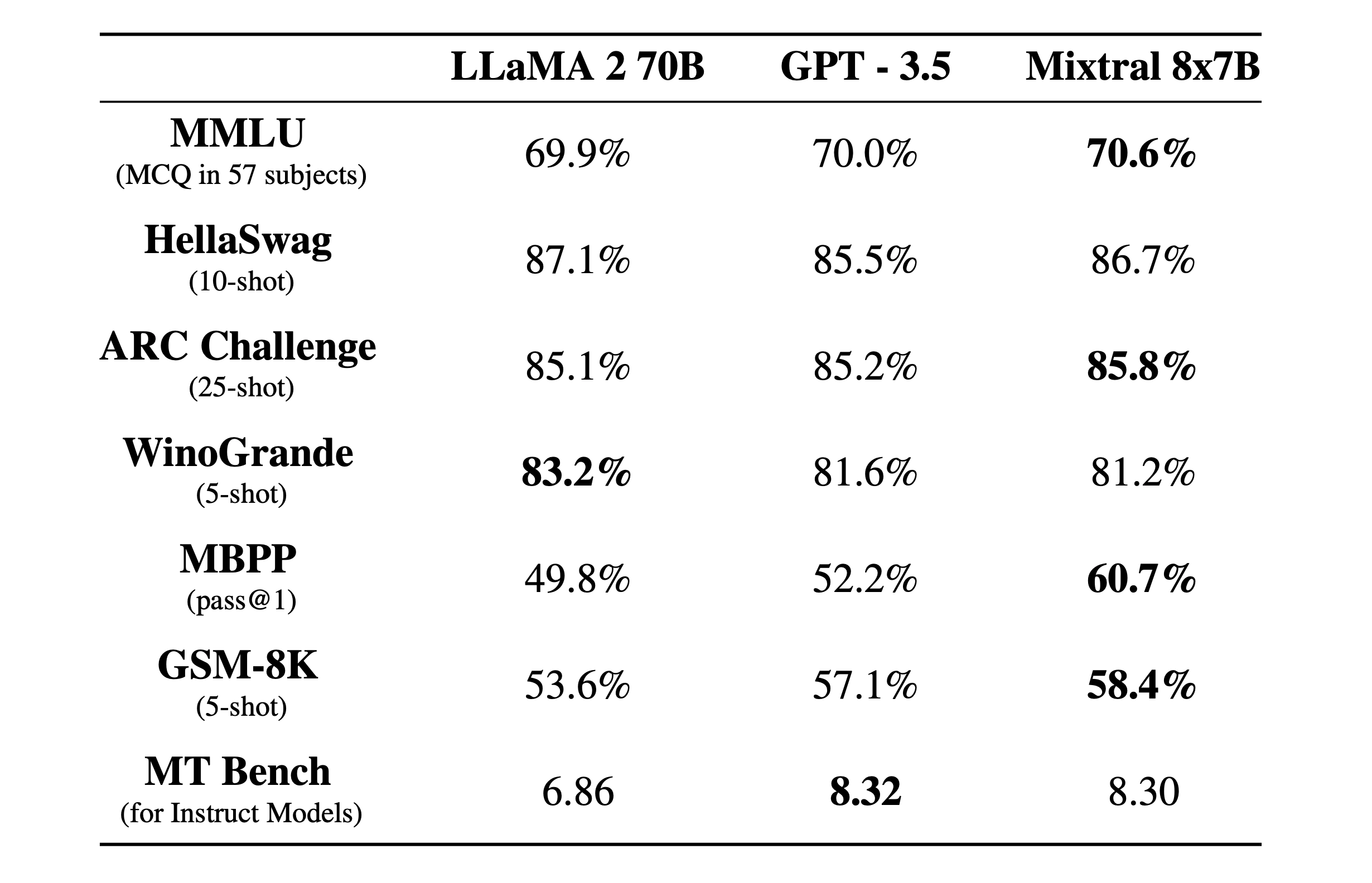
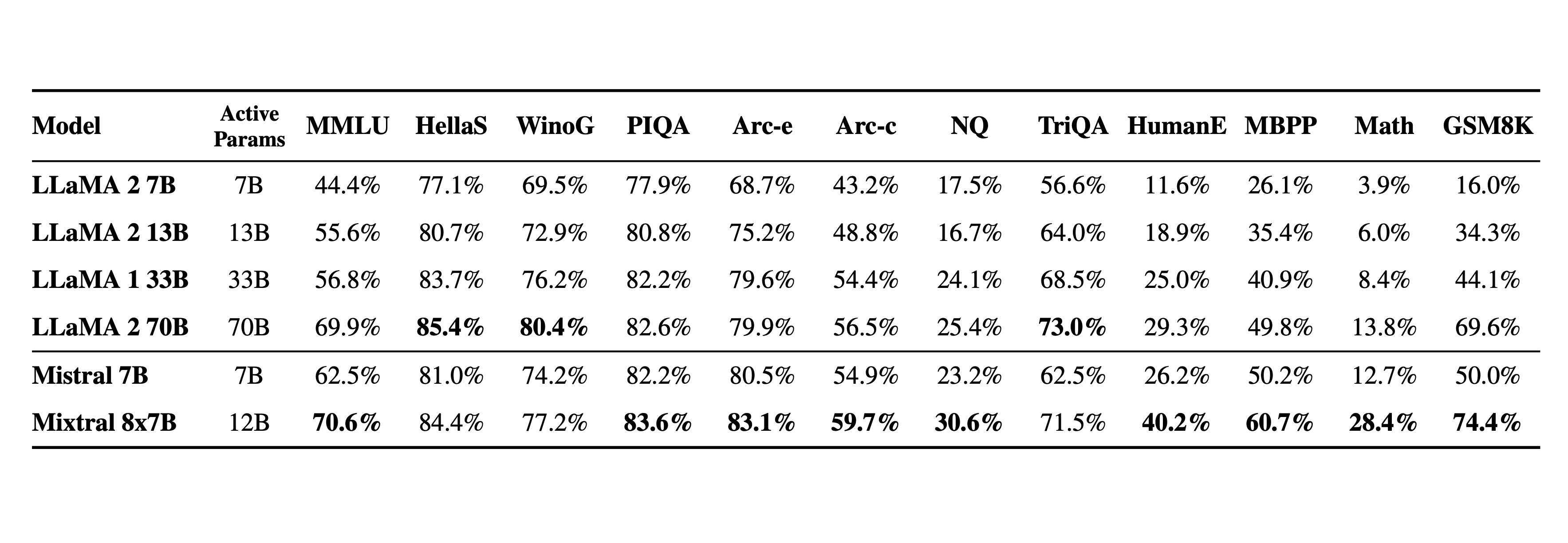
Mixtral 8X7B Mixtral 8X7B is a sparse mixture of experts model. As such, it leverages up to 45B parameters but only uses about 12B during inference, leading to better inference throughput at the cost of more vRAM. Learn more on the dedicated blog post.
-
Sizes
Name Number of Parameters Active Parameters Min. GPU RAM for Inference (GB) Mistral-7B-v0.2 7.3B 7.3B 16 Mistral-8X7B-v0.1 46.7B 12.9B 100 -
Template
The template used to build a prompt for the Instruct model is defined as follows:
<s>[INST] Instruction [/INST] Model answer</s>[INST] Follow-up instruction [/INST]<s>and</s>are special tokens for the beginning (BOS) and end of the string (EOS).[INST]and[/INST]are regular strings.
NOTE: This format must be strictly respected. Otherwise, the model will generate sub-optimal outputs.
Instruction Tokenization Format:
[START_SYMBOL_ID] + tok("[INST]") + tok(USER_MESSAGE_1) + tok("[/INST]") + tok(BOT_MESSAGE_1) + [END_SYMBOL_ID] + … tok("[INST]") + tok(USER_MESSAGE_N) + tok("[/INST]") + tok(BOT_MESSAGE_N) + [END_SYMBOL_ID]NOTE: The function
tokshould never generate the EOS token. FastChat (used in vLLM) sends the full prompt as a string, which might lead to incorrect tokenization of the EOS token and prompt injection. Users are encouraged to send tokens instead, as described above.