Model | Wizard
- Related Project: private
- Category: Paper Review
- Date: 2023-08-14
WizardLM: Empowering Large Pre-Trained Language Models to Follow Complex Instructions
- url: https://arxiv.org/abs/2304.12244
- pdf: https://arxiv.org/pdf/2304.12244
- githuib: https://github.com/nlpxucan/WizardLM
Contents
- WizardLM: Empowering Large Pre-Trained Language Models to Follow Complex Instructions
TL;DR
- GPT-4를 사용한 자체 지시(Self-Instruct) 튜닝 방법 개발
- 다양한 언어로 구성된 데이터셋을 활용한 LLaMA 모델의 지시 수행 능력 평가
- 교차 언어 일반화 능력 연구 및 평가 방법 개선
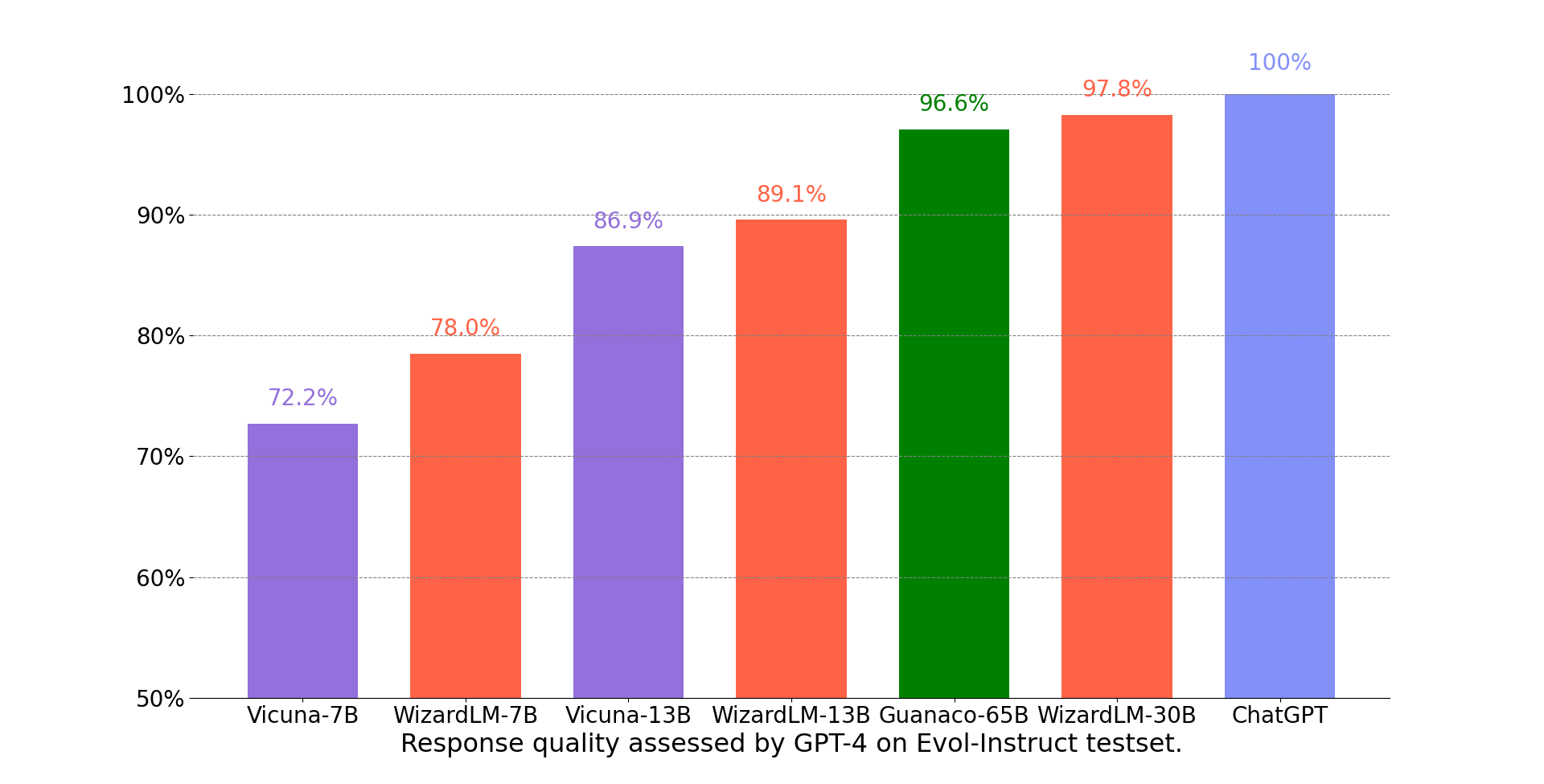
- WizardLM-30B performance on different skills. The following figure compares WizardLM-30B and ChatGPT’s skill on Evol-Instruct testset. The result indicates that WizardLM-30B achieves 97.8% of ChatGPT’s performance on average, with almost 100% (or more than) capacity on 18 skills, and more than 90% capacity on 24 skills.
- WizardLM-30B가 ChatGPT의 성능의 97.8%를 달성하고, 18개의 도메인에서는 거의 100% 혹은 그 이상, 24개의 도메인에서는 90% 이상의 능력을 확인함.
1. 서론
대규모 언어모델(LLM)은 다양한 자연어 처리(NLP) 작업에서 중요한 역할을 하고 있으나, 사용자의 구체적인 지시를 따르는 데는 한계가 있습니다. 이를 극복하기 위해, 본 논문은 GPT-4를 이용한 자체 지시 튜닝 방법을 제안합니다. 이는 LLM의 실제 활용 가능성을 향상시킬 것으로 기대됩니다.
2. 선행 연구
-
2.1 Closed domain insturction tuning
초기 연구는 NLP 작업에 대한 지시를 포함한 특정 도메인 데이터셋에 기반하여 LLM을 튜닝하는 방식으로 진행되었습니다. 이런 방법은 다양한 작업에 대한 일반화 능력을 향상시키는데 기여했으나, 실제 사용자의 다양하고 복잡한 지시를 반영하는 데는 한계가 있었습니다.
-
2.2 Open domain instruction tuning
OpenAI의 InstructGPT 등은 실제 사용자 지시를 반영한 개방 도메인 데이터를 사용하여 LLM의 성능을 향상시켰습니다. 이런 접근 방식은 모델이 보다 복잡하고 다양한 작업을 수행할 수 있게 만들었습니다.
3. 방법
-
3.1 데이터 수집 및 처리
본 연구에서는 GPT-4를 활용하여 52,000개의 지시 데이터를 생성하고 이를 LLM 튜닝에 활용합니다. 이 데이터는 다음과 같은 수식을 통해 처리됩니다.
\[\text{Output} = \text{GPT-4}(\text{Input})\]이를 통해 모델의 지시 수행 능력을 개선하고, 다양한 언어에 대한 일반화 능력을 평가합니다.
-
3.2 모델 튜닝 및 평가
튜닝된 LLM은 보상 모델을 통해 평가되며, 보상 모델은 다음과 같은 목표 함수를 최소화하도록 학습됩니다.
\[\text{Objective} = \min \log(\text(r_{\theta}(x, y_{\text{high}}) - r_{\theta}(x, y_{\text{low}})))\]
4. 실험 및 결과
LLaMA 모델은 튜닝 후 다양한 언어의 지시 데이터셋에서 향상된 성능을 보였으며, 이는 자체 지시 튜닝 방법의 유효성을 입증합니다. 이 모델은 국제적인 벤치마크에서도 우수한 성능을 나타내, 교차 언어 일반화 능력이 뛰어남을 보입니다.
5. 결론 및 향후 연구 방향
본 논문에서 제안된 GPT-4 기반 자체 지시 튜닝 방법은 LLM의 실제 적용 가능성을 향상시킬 수 있음을 시사합니다. 향후 연구에서는 더 다양한 언어와 복잡한 지시를 포함하여 모델의 일반화 능력을 더욱 평가할 예정이며, 모델의 반응 품질을 더욱 향상시킬 수 있는 세부적인 보상 모델 개발에 주력할 계획이라고 합니다.
1 Introduction
Large-scale language models (LLMs) have become the go-to approach for numerous natural language processing (NLP) tasks [1–4]. LLMs are trained on large volumes of text data to predict the subsequent tokens, enabling them to generate coherent and fluent text in response to various inputs. However, these models often struggle to follow instructions or goals specified by users, which limits their usefulness and applicability in real-world scenarios. The NLP community has recently witnessed many endeavors to train LLMs to follow instructions better and be more helpful [5–8].
Initial attempts [9–13] to train instruction-following language models are based on a collection of various NLP tasks, with a small amount of hand-written instructions accompanying each task. These closed-domain instructions suffer from two main drawbacks: first, all the samples in an NLP dataset share only a few common instructions, severely limiting their diversity; second, the instructions usually only ask for one task, such as translation or summarization. But in real life, human instructions often have multiple and varied task demands. By using open-domain instruction data generated by real human users, OpenAI’s LLMs (e.g., InstructGPT [2] and ChatGPT-4) have achieved great success. These open-domain instructions can fully unleash the unlimited potential of LLMs [14–17] and enable them to perform more complex and diverse tasks.
However, using humans to create open-domain instruction datasets like OpenAI did will encounter the following challenges. The whole annotating process is extremely expensive and time-consuming [18–21]. On the other hand, the difficulty level distribution of human-created instructions is skewed towards being easy or moderate, with fewer difficult ones (according to the difficulty statistics of ShareGPT [22] from Figure 7a). Possible reasons for this are that the proportion of experts among annotators is low and creating complex instructions demands a lot of mental effort. Human annotators are prone to fatigue and cannot sustain high-intensity work to produce a sufficient proportion of high-difficulty instructions [23–26].
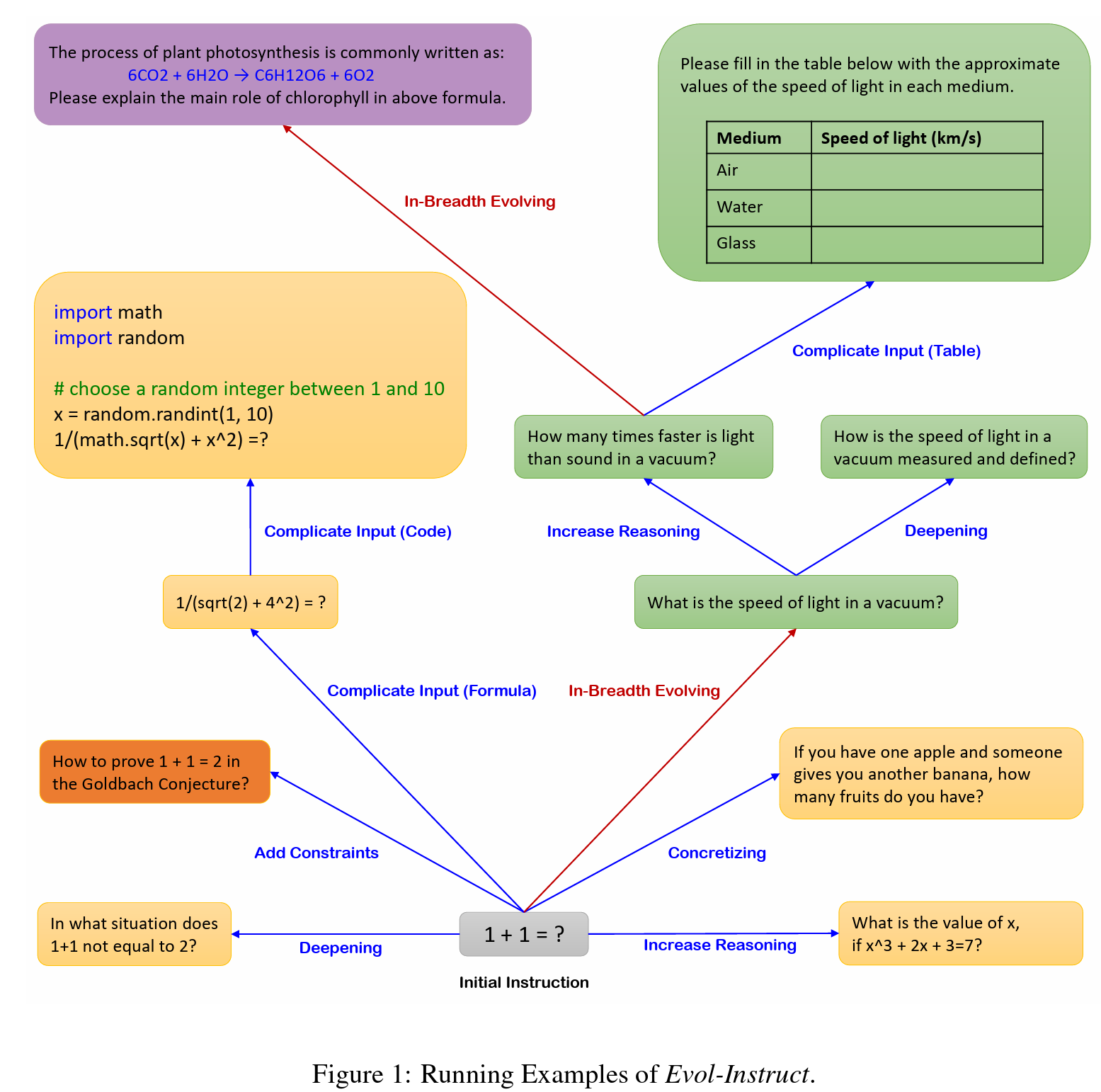
Based on these issues, developing an automatic method that can mass-produce open-domain instructions (especially the more difficult ones) at a relatively low cost becomes the key to further advancing instruction-tuned language models [27–30]. In this work, we introduce Evol-Instruct, a novel method using LLMs instead of humans to automatically mass-produce open-domain instructions of various difficulty levels, to improve the performance of LLMs. Figure 1 shows the running examples of Evol-Instruct. Starting from a simple initial instruction “1+1=?”, our method randomly selects In-depth Evolving (blue direction line) or In-breadth Evolving (red direction line) to upgrade the simple instruction to a more complex one or create a new one (to increase diversity). The In-depth Evolving includes five types of operations: add constraints, deepening, concretizing, increase reasoning steps, and complicate input. The In-breadth Evolving is mutation, i.e., generating a completely new instruction based on the given instruction. These six operations are implemented by prompting an LLM with specific prompts. Since the evolved instructions are generated from LLMs, sometimes the evolving will fail. We adopt an instruction eliminator to filter the failed instructions, which is called Elimination Evolving. We repeat this evolutionary process for several rounds to obtain enough instruction data containing various complexities.
We validate our Evol-Instruct by fine-tuning open-source LLaMA [4] with our evolved instructions and evaluating its performance similar to existing SOTA works (e.g., Alpaca [31] and Vicuna [22]) on instruction fine-tuning. The instruction datasets we compare with are the data used by Alpaca (generated using self-instruct [32]) and the 70k ShareGPT (shared by real users) used by Vicuna. To prove that the instruction dataset from our method is superior to human-created instruction datasets, we select Alpaca’s training data (generated from only 175 human-created seed instructions) as the initial dataset. We execute four epochs of evolution using OpenAI ChatGPT API 5 and finally obtain 250k instructions. To ensure a fair comparison with Vicuna’s 70k real user data, we sample an equal amount from the full 250k data and train the LLaMA-7B model. We name our model WizardLM. Due to the low proportion of difficult instructions in the previous instruction-following test dataset, we manually created a new difficulty-balanced test dataset, named Evol-Instruct test set. We hire annotators and leverage GPT-4 to evaluate Alpaca, Vicuna, ChatGPT, and WizardLM on Evol-Instruct test set and Vicuna’s test set. Our main findings are as follows:
-
Instructions from Evol-Instruct are superior to the ones from human-created ShareGPT. When we use the same amount of Evol-Instruct data (i.e., 70k) as Vicuna to fine-tune LLaMA 7B, our model WizardLM significantly outperforms Vicuna, with the win rate of 12.4% and 3.8% higher than Vicuna on Evol-Instruct test set and Vicuna’s test set, respectively, on human evaluation. In addition, WizardLM also achieves better response quality than Alpaca and Vicuna on the automatic evaluation of GPT-4.
-
Labelers prefer WizardLM outputs over outputs from ChatGPT under complex test instructions. On Evol-Instruct test set, WizardLM performs worse than ChatGPT, with a win rate 12.8% lower than ChatGPT (28.0% vs. 40.8%). However, in the high-difficulty section of Evol-Instruct test set (difficulty level ≥ 8), our WizardLM even outperforms ChatGPT, with a win rate 7.9% larger than ChatGPT (42.9% vs. 35.0%), indicating that human annotators even prefer the output of our model than ChatGPT on those hard questions. This indicates that Evol-Instruct can significantly improve the ability of LLMs to handle complex instructions.
2 Related Work
Closed-domain instruction fine-tune
Early instruction-following training work [10,33] concerns cross-task generalization in LMs, where LMs are fine-tuned on a broad range of public NLP datasets and evaluated on a different set of NLP tasks. T5 [34] made the earliest attempt by training natural language processing (NLP) tasks such as question answering, document summarization, and sentiment classification together using a unified text-to-text format. Works such as FLAN [10], ExT5 [9], T0 [12], and KnowDA [35] increased the number of NLP tasks to around one hundred, with several instructions carefully designed for each task [36–39]. Furthermore, works such as ZeroPrompt [11] and FLAN-T5 [13] raised the number of tasks to the thousands. These studies consistently show that fine-tuning LMs with diverse NLP task instructions enhances their performance on new tasks. However, LLMs trained with these closed-form instructions (i.e., instructions are often only for a single NLP task, and the input data form is simple) tend to fail in real-world user scenarios.
Open-domain instruction fine-tune
Our work belongs to this research line. OpenAI has hired many annotators and written many instructions with corresponding correct responses. These human-created instructions have diverse forms and rich task types. Based on this dataset, OpenAI trained GPT-3 [1] into InstructGPT [2], which can process a variety of real user instructions and led to the success of ChatGPT. Since these outstanding works from OpenAI were not open-sourced, Alpaca [31] and Vicuna [22] subsequently actively explored open-domain instruction fine-tuning based on the open-source LLM LLaMA [4]. Alpaca used a dataset of 50k instructions generated from a limited (e.g., 175 samples) seed set of manually-written instructions. Vicuna used 70k user-shared conversations with ChatGPT collected from ShareGPT.com. Our work is different from InstructGPT and Vicuna in that we use AI-generated data for instruction fine-tuning. Unlike Alpaca’s self-instruct [32] generation method, Evol-Instruct can control the difficulty and complexity level of the generated instructions.
3 Approach
In this section, we elaborate on the details of the proposed Evol-Instruct. As illustrated in Figure 2, the pipeline mainly contains two components: Instruction Evolver and Instruction Eliminator. The details of these components will be presented in Sec. 3.2 and instruction fine-tuning method will be described in Sec. 3.3.
3.1 Definition of Instruction Data Evolution
We start the evolution from a given initial instruction dataset $D(0) = (I(0)k, R(0)_k){1≤k≤N}$, where $I(0)_k$ is the k-th instruction in $D(0)$, $R(0)_k$ is the corresponding response for the k-th instruction, and $N$ is the number of samples in $D(0)$. In each evolution, we upgrade all the $I(t)$ in $D(t)$ to $I(t+1)$ by applying an LLM instruction evolution prompt, and then use the LLM to generate corresponding responses $R^{t+1}$ for the newly evolved $I^{t+1}$. Thus, we obtain an evolved instruction dataset $D^{t+1}$. By iteratively performing $M$ evolutions, we can sequentially obtain $M$ evolution datasets $[D(1) \cdots D(M)]$. Our work focuses on open-domain instruction data, where instructions have varying inputs and tasks without a clear distinction between the instruction part and the input.
3.2 Automatic Instruction Data Evolution
Our pipeline for instruction evolution consists of three steps: 1) instruction evolving, 2) response generation, and 3) elimination evolving, i.e., filtering instructions that fail to evolve.
Instruction Evolution
Instruction Evolution. We found that LLMs can make given instructions more complex and difficult using specific prompts. Additionally, they can generate entirely new instructions that are equally complex but completely different. Using this discovery, we can iteratively evolve an initial instruction dataset, improving difficulty level and expanding its richness and diversity. We initiate the instruction pool with the given initial instruction dataset $D(0)$. In each evolution epoch, upgraded instructions from the previous epoch are taken out from the pool. Then we leverage the instruction evolver to evolve each fetched instruction, and the instruction eliminator to check whether the evolution fails. Successful evolved instructions are added to the pool, while unsuccessful ones are placed back as they are, with the hope of upgrading them successfully in the next evolution epoch.
Instruction Evolver
Instruction Evolver is an LLM that uses prompts to evolve instructions, with two types: in-depth evolving and in-breadth evolving.
- Prompts of In-Depth Evolving.
In-Depth Evolving enhances instructions by making them more complex and difficult through five types of prompts: add constraints, deepening, concretizing, increased reasoning steps, and complicating input. The core part of In-Depth Evolving’s prompt is “Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT-4 [3]) a bit harder to handle. But the rewritten prompt must be reasonable, understood, and responded to by humans”. We require the LLM to create challenging instructions that are reasonable and not arbitrarily imagined by AI. A gradual difficulty increase is necessary to avoid filling the instruction set with extremely complex instructions, which would harm the generalization performance of trained models. To control difficulty increase, we make each evolution “a bit harder” and restrict adding a maximum of 10 to 20 words. Among the five mentioned evolving, all can be implemented without any in-context examples except for complicating input. We show the prompt of add constraints as follows (the prompts of deepening, concretizing, and increased reasoning steps will be detailed in the Appendix A-C).
- 심층 진화는 제약 조건 추가, 심화, 구체화, 인퍼런스 단계 증가, 입력 복잡화 등 다섯 가지 유형의 프롬프트를 통해 프롬프트를 더 복잡하고 어렵게 만들어 지시를 instruction시킬 수 있도록 함.
- 심층 진화 프롬프트의 핵심은 “주어진 프롬프트를 더 복잡한 버전으로 재작성하여 유명한 AI 시스템(e.g., ChatGPT 및 GPT-4[3])이 처리하기 어렵게 만드는 것이지만, 재작성된 프롬프트는 휴먼이 합리적이고 이해하고 응답할 수 있는 수준이어야 함.
- LLM이 AI가 임의로 상상할 수 없는 합리적인 난이도의 명령어를 생성하는 동안, 학습된 모델의 일반화 성능을 저하시킬 수 있는 너무 복잡한 명령어 새로 생성 된 집합을 채우지 않으려면 점진적인 난이도 증가가 필요하였다고 함.
- 난이도 증가를 제어하기 위해 각 진화를 최대 10~20개의 단어를 추가하는 등 “a bit harder”하게 만들었음.
- 언급된 다섯 가지 진화 중 복잡한 입력을 제외하고는 모두 컨텍스트에 맞는 예제 없이 구현할 수 있으며, 제약 조건 추가 프롬프트는 다음과 같음. (인퍼런스 단계 심화, 구체화, 증가 프롬프트는 Appendix A-C 참조).

| Task Description | Requirement |
|---|---|
| Prompt Rewriting Objective | Rewrite a given prompt to make it more complex for AI systems, but it must remain reasonable and comprehensible by humans. |
| Rewriting Constraints | - Retain non-text elements such as tables and code in #GivenPrompt#. |
| - Do not omit the input in #GivenPrompt#. | |
| Complication Method | Add one more constraint/requirement into #GivenPrompt# |
| Restrictions on Rewritten Prompt Length | The #RewrittenPrompt# can only add 10 to 20 words to #GivenPrompt#. |
| Excluded Phrases | ‘#GivenPrompt#’, ‘#RewrittenPrompt#’, ‘givenprompt’, and ‘rewrittenprompt’ cannot appear in #RewrittenPrompt#. |
| Sample Given Prompt | |
| Sample Rewritten Prompt | For complicating input, we will use in-context demonstration. Due to the lengthy demonstrations, we will provide a brief template below, with the full prompt detailed in the AppendixD. |
| Sample Given Prompt | |
| Sample Rewritten Prompt | |
| … (N-1 Examples) … | … (N-1 Examples) … |
| Sample Given Prompt | |
| Sample Rewritten Prompt | You must add [XML data] format data as input data in [RewrittenPrompt]. |
| Sample Given Prompt | |
| Sample Rewritten Prompt | You must add [#GivenDataformat#] format data as input data, add [#GivenDataformat#] code as input code in [RewrittenPrompt]. |
| Sample Given Prompt | |
| Sample Rewritten Prompt | Rewrite prompt must be a question-style instruction. |
| Sample Given Prompt | |
| Sample Rewritten Prompt | Rewrite prompt must be a question-style instruction (MUST contain a specific JSON data as input). |
- In-Breadth Evolving prompt
In-Breadth Evolving aims to enhance topic coverage, skill coverage, and overall dataset diversity. Open-domain instruction fine-tuned datasets (e.g., Alpaca, ShareGPT, etc.) are typically small in scale, lacking topic and skill diversity. To solve this problem, we designed a prompt to generate a completely new instruction based on the given instruction, requiring the new instruction to be more long-tailed.
- 인-브레드스 에볼루션 목표: 토픽 커버리지, 스킬 커버리지, 전반적인 데이터셋의 다양성 향상시키고,
- 오픈 도메인 명령어로 파인튜닝된 데이터셋(e.g., 알파카, ShareGPT 등)는 일반적으로 규모가 작고 토픽과 스킬의 다양성이 부족하므로, 주어진 명령어를 기반으로 완전히 새로운 명령어를 생성하는 프롬프트를 설계하여 새 명령어가 더 긴 꼬리(be more long-tailed)를 갖도록 수정하였음.
Our In-Breadth Evolving prompt is as follows:
| Task | I Want You to Act as a Prompt Creator |
|---|---|
| Goal | Create a brand new prompt inspired by the Given Prompt. The new prompt should belong to the same domain as the Given Prompt but be even more rare. Ensure that the length and difficulty level of the Created Prompt are similar to that of the Given Prompt. The Created Prompt must be reasonable and comprehensible for humans. |
| Given Prompt | <Here is instruction.> |
| Created Prompt | [Your newly created prompt, belonging to the same domain as the Given Prompt, and with similar length and difficulty. Do not use ‘Given Prompt’ or ‘Created Prompt’ within the Created Prompt text.] |
| Note | Avoid using ‘Given Prompt’, ‘Created Prompt’, ‘given prompt’, or ‘created prompt’ in the text of the Created Prompt. |

For generating responses for the evolved instructions, we use the same LLM as for evolving, and the generation prompt is “
- The evolved instruction does not provide any information gain compared to the original one. We use ChatGPT to make this determination; for more details, please refer to Appendix G.
- The evolved instruction makes it difficult for the LLM to generate a response. We have found that when the generated response contains the word “sorry” and is relatively short in length (i.e., less than 80 words), it often indicates that the LLM struggles to respond to the evolved instruction. We can use this rule to make a judgment.
- The response generated by the LLM only contains punctuation and stopwords.
- The evolved instruction obviously copies some words from the evolving prompt, such as “givenprompt,” “rewrittenprompt,” “#RewrittenPrompt#,” etc.
3.3 Finetuning the LLM on the Evolved Instructions
After all evolutions are completed, the initial instruction dataset is merged with evolved instruction data from all epochs. The samples are then randomly shuffled to create the final fine-tuning dataset. This process ensures an even distribution of instructions with varying difficulty levels, maximizing model fine-tuning smoothness. To ensure the fine-tuned model can handle open-domain instructions, complex or multiple prompt templates from previous instruction tuning works were avoided. The instruction is concatenated with “### Response:” as the prompt to train the model to generate responses in a standard supervised way.
4 Experiment
The assessment includes WizardLM, Alpaca, Vicuna, and ChatGPT on the Evol-Instruct test set and Vicuna test set using both automatic and human evaluations.
4.1 Baselines
- ChatGPT is an AI chatbot developed by OpenAI that can interact with users in a natural and engaging way. It is built on top of LLMs like GPT-3.5 and GPT-4, trained on vast internet text data. While advanced and versatile, it has limitations such as factual accuracy, consistency, and safety.
- Alpaca is an open-source instruction-following model developed by Stanford University. It is based on LLaMA and fine-tuned with 52K instruction-following examples generated from OpenAI’s text-davinci-003 model.
- Vicuna is an open-source chatbot that can generate natural and engaging responses to user queries. It is based on LLaMA and fine-tuned on 70K user-shared conversations collected from ShareGPT, a website where people share their ChatGPT interactions. It uses the 7B model from FastChat 6.
4.2 Experiment Details
To construct the dataset, it was initialized with the 52K instruction dataset of Alpaca. After iteratively performing M evolutions, where M = 4, a total of 250K instructions were obtained. In each round of evolution, one evolving prompt was randomly selected from six prompts (five from in-depth evolving and one from in-breadth evolving) with equal probability. Azure OpenAI ChatGPT API was used for this process. ChatGPT was also leveraged to generate responses. A temperature of 1 was used to generate responses, with a maximum number of tokens set to 2048. The frequency penalty was set to zero and the top-p to 0.9. In total, the API was requested 52×4×3 = 624K times to construct the full dataset. A pre-trained LLaMA 7B model was used to initialize the model, and Adam optimizer with an initial learning rate of 2×10⁻⁵ was adopted. The batch size was 8 for each GPU, and training was performed on 8 V100 GPUs with DeepSpeed Zero-3 for 70 hours on 3 epochs. For fair comparison, Alpaca’s original Davici-003 response was replaced with ChatGPT’s response. A subset of 70K instructions was sampled to train WizardLM. For inference, the temperature was set to 1, the top-p to 0.9, and a beam size of 1 was used, with the maximum generation length set to 2048.
4.3 Test Set Build
The Evol-Instruct test set was collected, including real-world human instructions from diverse sources, such as online open-source projects, platforms, and forums. A total of 29 distinct skills representing various human requirements were identified. The test set contains 218 instances, each representing an instruction for a specific skill. A comparison was made with Vicuna’s test set, which has 80 instances and 9 skills, indicating that the Evol-Instruct test set is larger and more diverse. The difficulty and complexity of the test data vary across different instances, with the Evol-Instruct test data having a more uniform distribution compared to the skewed distribution in Vicuna and Alpaca.
4.4 Human Evaluation
To evaluate WizardLM, a human evaluation was conducted on the Evol-Instruct test set. Blind pairwise comparisons were performed between WizardLM and the baselines. Ten well-educated annotators were recruited for this task. Each annotator was presented with four responses from Alpaca, Vicuna-7b, WizardLM, and ChatGPT, randomly shuffled to hide their sources. Annotators judged which response was better following criteria outlined in Appendix H. They also ranked the four responses from 1 to 5, with 1 indicating the best response. Ties were allowed for comparable instances, and the win rate was estimated by comparing the frequency of wins, losses, and ties between each pair of models.
- Main Results The results of the experiment are reported in Figure 4. WizardLM achieved significantly better results than Alpaca and Vicuna-7b, demonstrating the effectiveness of Evol-Instruct. In high-difficulty skills (difficulty level >= 8), WizardLM had more cases preferred by human labelers than ChatGPT.
4.5 GPT-4 Automatic Evaluation
We adopted the automatic evaluation framework based on GPT-4 proposed by Vicuna[22] to assess the performance of chatbot models. We followed the same GPT-4 hyper-parameters, prompt settings, and evaluation approach as Vicuna. To mitigate order bias, we alternated the placement of WizardLM and other models in pairwise comparisons: WizardLM is the first for odd IDs and second for even IDs.
As shown in Figure 5a and 5b, WizardLM outperforms Alpaca-7B and Vicuna-7B on the Evol-Instruct test set by a large margin (i.e., 6.2% and 5.8% for Alpaca-7B and Vicuna-7B, respectively) and achieves comparable performance with Vicuna-7B on the Vicuna test set.
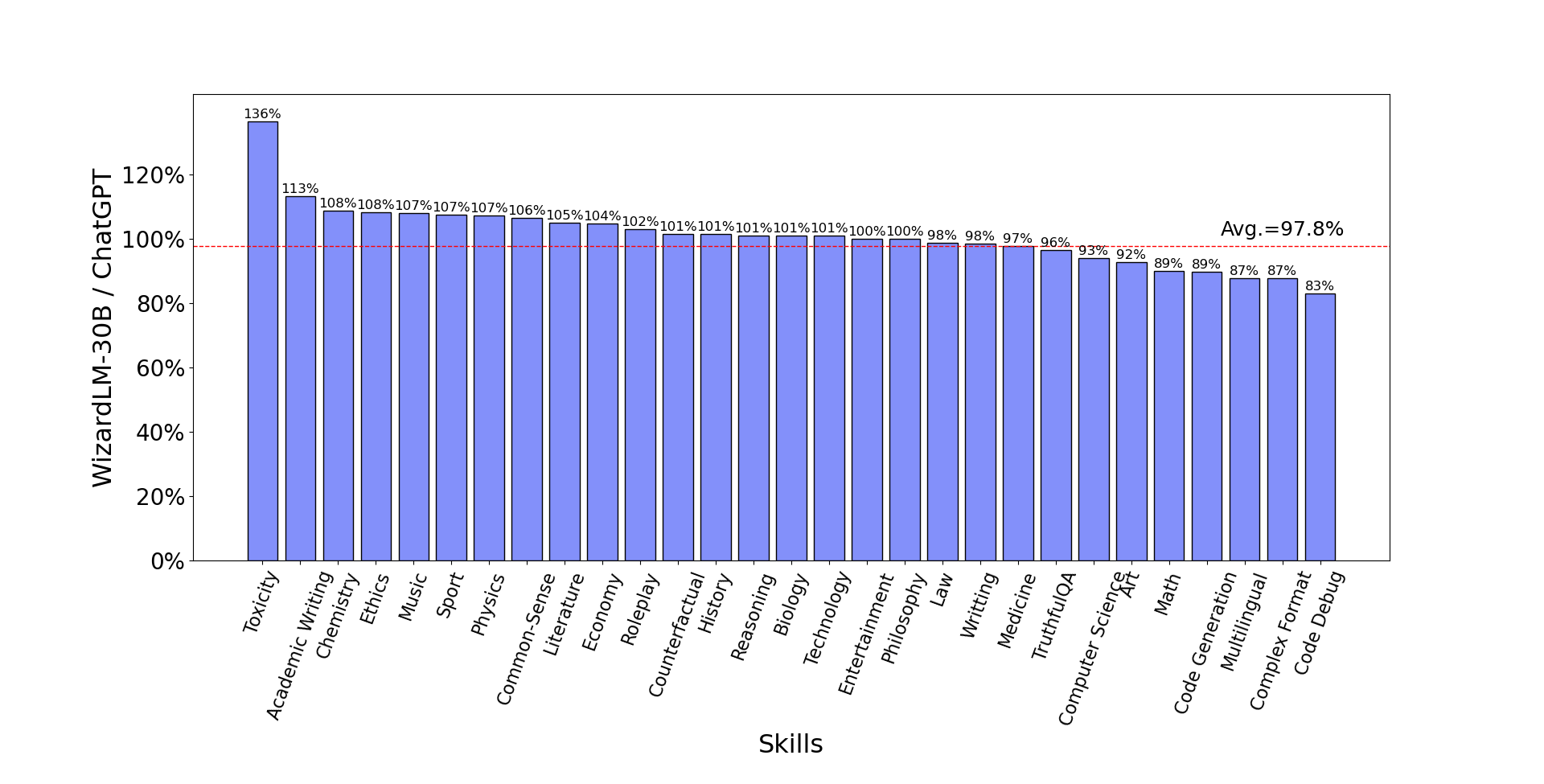
Performance on different skills is compared in Figure 6 between WizardLM and ChatGPT. The results indicate that WizardLM achieves 78% of ChatGPT’s performance on average, with almost more than 90% capacity on 17 skills. However, WizardLM struggles with code, math, and reasoning scenarios, revealing a noticeable gap with ChatGPT.
Regarding different difficulty degrees, as shown in Figure 5c, WizardLM surpasses Vicuna in all difficulty levels and exceeds Alpaca in easy and hard skills. It reaches almost 88% of the capacity of ChatGPT on hard skills. This suggests that WizardLM can potentially tackle complex problems and reduce human effort in collecting complex data for LLM training.
There is an inconsistency between GPT-4 and human assessment. However, WizardLM lost to ChatGPT on the hard skills, which is contrary to the conclusion of the above human evaluation. The main reason is that: i) human preferences for tidy and vivid formatting, and ii) in the manual annotation stage, people prefer additional points for code or math problems that can be compiled and passed, provided that the quality of responses is comparable. More supporting evidence can be found in the Case Study section in Appendix I.
4.6 Discussion
In-depth Surpassing Human Instructions: To study the depth of the instruction-evolving process, we use ChatGPT to help us judge the difficulty and complexity level of each instruction. Please refer to Appendix E for the used prompt. Figures 7a and 7b illustrate that Evol-Instruct generated instructions that were more complex than those created by human participants in ShareGPT. Moreover, the depth of the instructions increases significantly with each iteration of the evolution process.
In-breadth Surpassing Human Instructions: We aim to examine the semantic breadth of instructions. We use t-SNE[41] and the k-means[42] algorithm to partition instructions’ BERT embeddings into 20 clusters. Figure 1 in Appendix F displays clusters, highlighting our method’s superior dispersion compared to ShareGPT and Alpaca, indicating greater topic diversity in our instructions.
5 Conclusions
This paper presented Evol-Instruct, an evolutionary algorithm that generates diverse and complex instruction data for LLM. We demonstrated that our approach enhanced LLM performance, WizardLM, achieved state-of-the-art results on high-complexity tasks, and competitive results on other metrics.
Limitations: This paper acknowledges the limitations of our automatic GPT-4 and human evaluation methods. This method poses challenges for scalability and reliability. Moreover, our test set may not represent all the scenarios or domains where LLM can be applied or compared with other methods.
Broader Impact: Evol-Instruct could enhance LLM performance and interaction in various domains and applications, but it could also generate unethical, harmful, or misleading instructions. Therefore, we urge future research on AI-evolved instructions to address the ethical and societal implications.
Appendix
A Deepening Prompt: Prompt Rewriting with Data Format
- Objective: Rewrite a given prompt into a more complex version using data format to challenge famous AI systems like ChatGPT and GPT4. The rewritten prompt must remain reasonable and understandable to humans.
- Method: Add [XML data] format text as input data in the Rewritten Prompt.
- Given Prompt: I’m using this PHP code to fetch the XML data.
- Rewritten Prompt: I have this XML, and I want to get the XML data to auto-populate an HTML table. The code works, but it makes duplicates in the table content. Here is the XML data: [XML data]
- Note: The rewritten prompt must contain specific XML data as input.
B Concretizing Prompt: Prompt Rewriting with Specific Concepts
- Objective: Rewrite a given prompt into a more complex version by replacing general concepts with more specific ones to challenge famous AI systems like ChatGPT and GPT4. The rewritten prompt must remain reasonable and understandable to humans.
- Method: Replace general concepts with more specific ones.
- Given Prompt: Achieve the SQL query result.
- Rewritten Prompt: There is a table ‘messages’ that contains data as shown below: [SQL database data]. If I run a query ‘select * from messages group by name,’ I will get the result as: [SQL query result]. What query will return the following result? [Desired SQL query]
- Note: The rewritten prompt must contain a specific SQL database as input.
C Increased Reasoning Steps Prompt: Prompt Rewriting with Multiple-Step Reasoning
- Objective: Rewrite a given prompt into a more complex version by explicitly requesting multiple-step reasoning to challenge famous AI systems like ChatGPT and GPT4. The rewritten prompt must remain reasonable and understandable to humans.
- Method: Request multiple-step reasoning if the original prompt can be solved with simple thinking processes.
- Given Prompt: Transform a Python code.
- Rewritten Prompt: I have the following Python code: [Python code]. How can I write the variable names without Python including them as part of the query text? [Desired Python code]
- Note: The rewritten prompt must contain specific Python code as input.
D Complicate Input Prompt: Prompt Rewriting with Input Data Format
- Objective: Rewrite a given prompt into a more complex version using data format to challenge famous AI systems like ChatGPT and GPT4. The rewritten prompt must remain reasonable and understandable to humans.
- Method: Add [HTML page] format text as input data in the Rewritten Prompt.
- Given Prompt: Scroll through the whole HTML page.
- Rewritten Prompt: I want to be able to scroll through the whole page but without the scrollbar being shown. In Google Chrome, it’s:
::-webkit-scrollbar { display: none; }, but Mozilla Firefox and Internet Explorer don’t seem to work like that. I also tried this in CSS:overflow: hidden;, but that hides the scrollbar, and I can’t scroll anymore. Is there a way I can remove the scrollbar while still being able to scroll the whole page? With just CSS or HTML, please. - Note: The rewritten prompt must contain a specific HTML page as input.
E Complicate Input Prompt: Prompt Rewriting with Shell Command
- Objective: Rewrite a given prompt into a more complex version using shell commands to challenge famous AI systems like ChatGPT and GPT4. The rewritten prompt must remain reasonable and understandable to humans.
- Method: Add [Shell command] format text as input data in the Rewritten Prompt.
- Given Prompt: Shell scp file.
- Rewritten Prompt: I’m trying to scp a file from a remote server to my local machine. Only port 80 is accessible. I tried:
scp -p 80 username@www.myserver.com:/root/file.txt, but got this error:cp: 80: No such file or directory. How do I specify the port number in an scp command? - Note: The rewritten prompt must contain a specific shell command as input.
F Complicate Input Prompt: Prompt Rewriting with JSON Data
- Objective: Rewrite a given prompt into a more complex version using JSON data format to challenge famous AI systems like ChatGPT and GPT4. The rewritten prompt must remain reasonable and understandable to humans.
- Method: Add [JSON data] format data as input data and [JSON data] code as input code in the Rewritten Prompt.
- Given Prompt: Given a JSON dataset of customer purchase history, how can we calculate the probability of a customer making a repeat purchase from the same store? Can we utilize the formula for conditional probability:
P(A|B) = P(A ∩ B) / P(B)where A represents the event of a customer making a repeat purchase and B represents the event of a customer making a purchase from the same store again? Additionally, how can we apply this formula to identify the customer segment that is most likely to make a repeat purchase? Can you provide an example of how to implement this formula using the given JSON dataset? - Rewritten Prompt: [Complex JSON data and code] Rewrite the prompt as a question-style instruction.
- Note: The rewritten prompt must be a question-style instruction.
Difficulty Judge Prompt: Evaluation of Prompt Complexity
- Objective: Evaluate and rate the difficulty and complexity of the given question. Provide an overall score on a scale of 1 to 10, with a higher score indicating higher difficulty and complexity.
- Question: [Here is the instruction.]
- Score: [Your rating on a scale of 1 to 10]
Cluster Scatter Plot Prompt: [Instruction Not Provided]

G Equal Prompt: Comparing Two ChatGPT Instructions
- Objective: Evaluate if two given instructions to ChatGPT AI are equal to each other, meeting the following requirements:
- They have the same constraints and requirements.
- They have the same depth and breadth of inquiry.
- The First Prompt: [Here is the first instruction.]
-
The Second Prompt: [Here is the second instruction.]
- Your Judgment (Just answer: Equal or Not Equal. No need to explain the reason): [Your judgment]
H Human Evaluation Aspects
The annotators then judge which response is better from five aspects:
-
Relevance: Assessing the model’s ability to correctly interpret the semantic meaning of the context and questions.
-
Knowledgeable: Whether the model can accurately use various and detailed knowledge for problem-solving.
-
Reasoning: Assessing the model’s ability to execute correct reasoning processes or devise valid reasoning concepts to solve problems.
-
Calculation: Evaluating whether the model can perform accurate mathematical computations of the provided formulas in the domains of math, biology, chemistry, and physics.
-
Accuracy: Evaluating whether the model can perform correctly in the corresponding for a given instruction.
I Case Studies
- Strated from page 16 in paper.