RAG | Speculative RAG
- Related Project: Private
- Category: Paper Review
- Date: 2024-07-09
Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting
- url: https://arxiv.org/abs/2407.08223v1
- pdf: https://arxiv.org/pdf/2407.08223v1
- html: https://arxiv.org/html/2407.08223v1
- related model: Wizard
- abstract: Retrieval augmented generation (RAG) combines the generative abilities of large language models (LLMs) with external knowledge sources to provide more accurate and up-to-date responses. Recent RAG advancements focus on improving retrieval outcomes through iterative LLM refinement or self-critique capabilities acquired through additional instruction tuning of LLMs. In this work, we introduce Speculative RAG - a framework that leverages a larger generalist LM to efficiently verify multiple RAG drafts produced in parallel by a smaller, distilled specialist LM. Each draft is generated from a distinct subset of retrieved documents, offering diverse perspectives on the evidence while reducing input token counts per draft. This approach enhances comprehension of each subset and mitigates potential position bias over long context. Our method accelerates RAG by delegating drafting to the smaller specialist LM, with the larger generalist LM performing a single verification pass over the drafts. Extensive experiments demonstrate that Speculative RAG achieves state-of-the-art performance with reduced latency on TriviaQA, MuSiQue, PubHealth, and ARC-Challenge benchmarks. It notably enhances accuracy by up to 12.97% while reducing latency by 51% compared to conventional RAG systems on PubHealth.
TL;DR
- 대규모 언어모델의 한계 극복을 위한 방법 제시: 검색 기능을 향상시킨 언어 모델을 통해 정보 수집 및 답변 생성의 정확성을 높임.
- Speculative RAG 프레임워크 도입: 다양한 문서로부터 추출된 정보를 이용하여 고품질의 답변 초안을 생성, 검증 및 통합
- 실험적 검증 및 효율성 개선: 다양한 벤치마크 데이터셋에서 Speculative RAG의 우수성과 효율성을 입증
- TriviaQA, MuSiQue, PubHealth, ARC-Challenge를 사용하여 성능을 측정하고 이전 방법들과 비교하여 개선된 결과를 보여주며,
- 드래프팅과 검증의 분리로 효율성 증대: 작은 RAG 드래프터와 대형 일반 언어 모델을 사용하여 답안 생성의 효율성과 정확성을 극대화함.
2-stage로 나누어서 성능을 높임
1. 서론
대규모 언어모델(LLM)은 질의응답 작업에서 향상된 성과를 보이고 있습니다. 이런 모델들은 방대한 데이터셋으로 훈련되어 사용자의 질문에 대해 타당해 보이는 답변을 생성할 수 있는 방대한 파라미터 메모리를 활용합니다. 그러나 최신 정보나 생소한 사실을 요구하는 지식 집약적 질문에 직면했을 때는 사실 오류가 발생하거나 허구적 내용을 생성하는 문제가 있습니다.
이를 해결하기 위해 등장한 Retrieval Augmented Generation(RAG) 기술은 외부 데이터베이스에서 정보를 검색하여 모델의 맥락에 통합함으로써 지식 집약적 작업에서의 오류를 줄입니다. 그러나 검색된 문서를 인코딩하는 과정은 추가적인 시간 지연을 유발하고 복잡한 인퍼런스를 필요로 하며, 이로 인해 효율성과 효과성 사이의 균형을 맞추는 것이 중요한 연구 주제로 자리잡았습니다.
1.1 기존 연구
초기 RAG 시스템은 검색된 문맥의 질을 향상시키는 데 주력했지만, 이런 시스템들은 종종 처리 시간과 관련된 문제를 간과했습니다. 기존 방법들은 여러 번의 정제 반복이나 맞춤형 지시 학습을 필요로 하여, 일반 언어 모델에 추가적인 훈련이나 더 큰 지연을 초래했습니다.
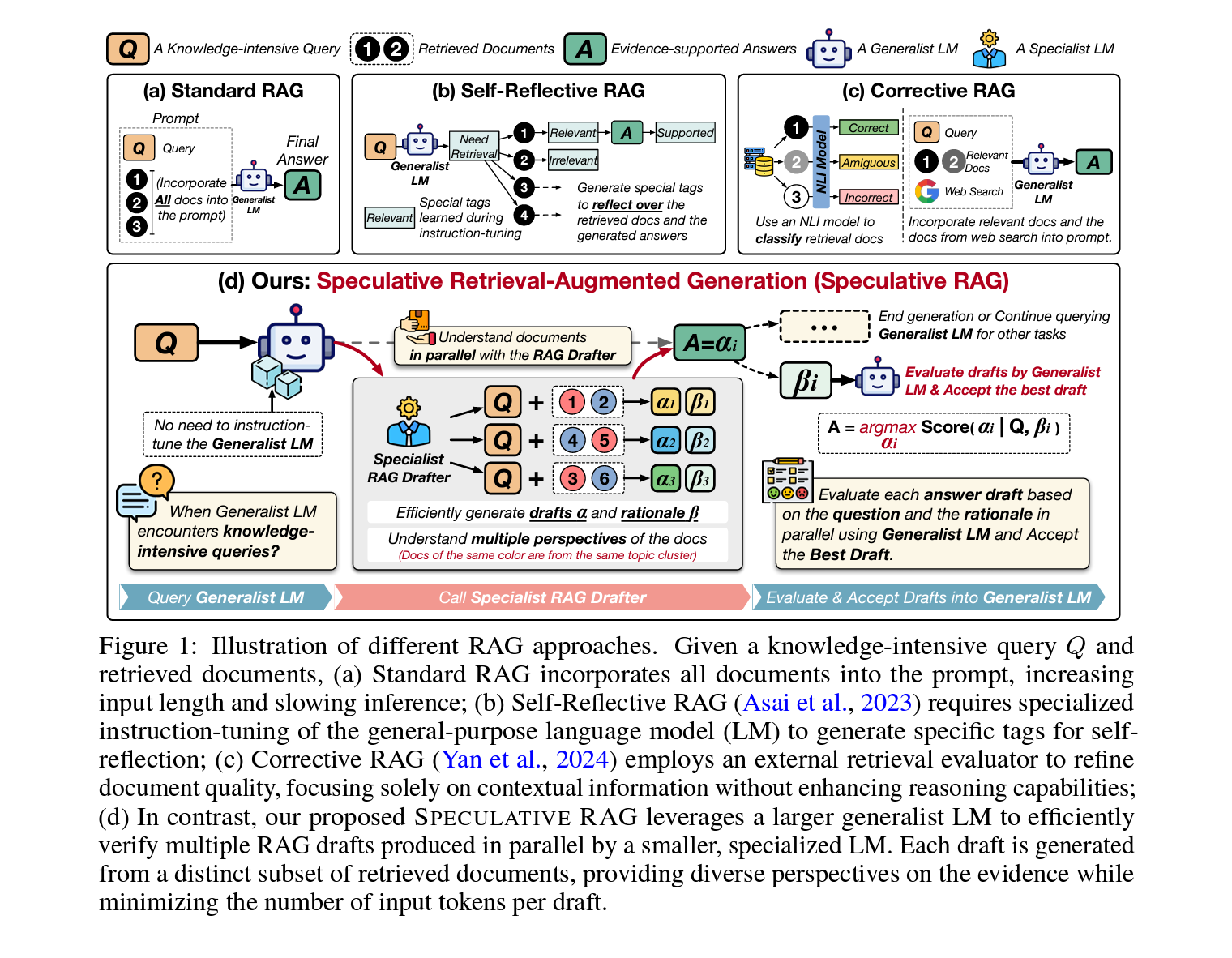
1.2 Speculative RAG의 제안
본 논문에서는 이런 문제를 해결하기 위해 Speculative RAG라는 새로운 프레임워크를 제안합니다. 이는 Speculative Decoding 개념을 RAG에 적용하여, 작은 특화된 모델이 검색된 문서의 하위 집합으로부터 고품질의 답변 초안을 병렬로 생성하고, 큰 일반적인 모델이 이 초안들을 검증하여 가장 정확한 답변을 결정합니다. 이 접근 방식은 문서 집합 각각의 이해도를 높이고, 중간에 잃어버리는 현상을 완화합니다.
2. 관련 연구
- 2.1 기존 RAG 시스템: 기존 시스템은 외부 데이터베이스에서 문서를 검색하여 언어 모델의 생성 과정에 통합합니다. 최근 연구는 언제 어떤 문서를 검색해야 하는지를 통해 LLM이 이해할 수 있도록 돕거나, 검색된 문맥을 더 잘 활용하는 방법을 설계하는 데 초점을 맞췄습니다.
- 2.2 Speculative Decoding: 이는 작은 모델로 여러 토큰을 동시에 생성하고, 대상 모델로 이를 병렬로 검증하는 방식으로 자동 회귀 디코딩의 지연을 줄이는 전략입니다. 본 논문은 이 개념을 답변 수준의 초안 작성으로까지 확장합니다.
- 2.3 연구의 차별성: 전통적인 RAG 모델과 달리, Speculative RAG는 검색된 문서를 효율적으로 이해하고 다양한 관점에서 초안을 생성하여 일반 LLM이 검증하고 통합할 수 있게 함으로써, 고차원적 인퍼런스를 가능하게 합니다. 이 접근 방식은 연산 효율성을 크게 향상시키며, 여러 벤치마크 데이터셋에서 그 효과를 입증합니다.
3. Speculative Retrieval Augmented Generation through Drafting
문제 정의
지식 집약적 작업에서 각 항목은 \((Q, D, A)\) 로 표현될 수 있습니다. \(Q\)는 추가 지식이 필요한 질문 또는 명제이며, \(D = \{d_1, \dots, d_n\}\)는 데이터베이스에서 검색된 \(n\)개의 문서 집합이고, \(A\)는 예상되는 답변입니다. 특히 질의응답 작업에서는 \(Q\)와 \(A\)가 자연어 형태의 질문과 기대되는 답변이며, 명제 검증 작업에서는 \(Q\)가 명제이고 \(A \in \{True, False\}\)는 명제의 정확성을 나타내는 boolean이고, 다중 선택 작업에서는 \(Q\)가 몇 가지 옵션을 포함한 질문이며 \(A \in \{A, B, C, \dots\}\)는 정답의 인덱스입니다. RAG 시스템의 목표는 검색된 지원 문서에 의해 제공된 맥락을 기반으로 기대되는 답변을 포함하는 유창한 응답을 생성하거나 제공된 옵션에서 기대되는 답변을 선택하는 것입니다.
3.1 Speculative RAG 개요
Speculative RAG는 검색된 문서에 대한 언어 모델(LM)의 인퍼런스 능력을 효율적으로 향상시키는 것을 목표로 합니다. 전통적인 방법들이 전체 LM의 파라미터를 확장하거나 지식 집약적 작업을 처리하기 위해 프롬프트 튜닝에 의존하는 것과 달리, Speculative RAG는 분할 정복 전략을 채택합니다.
- 문서 클러스터링 및 샘플링
- 클러스터링: 초기 단계에서, 관련 문서들을 클러스터로 그룹화하여, 검색 결과에서 각기 다른 관점을 대표하게 합니다. 이 단계는 검색된 문서들의 다양성을 효과적으로 포착하는 것을 보장합니다.
- 샘플링: 각 클러스터에서 단일 문서를 샘플링합니다. 이 샘플링된 부분집합은 \(\delta \subset D\)로 표시되며, 문서들은 질문의 맥락을 포괄적으로 대표하는 다양한 관점을 포함합니다.
- 초안 생성
- 배치: 부분집합 \(\delta\)는 질문 \(Q\)와 함께 RAG Drafter 엔드포인트 \(M_{\text{Drafter}}\)로 전달됩니다.
- 초안 작성: RAG Drafter는 작고 전문가로 튜닝된 LM으로, 여러 개의 초안 \(\alpha\)와 그에 해당하는 근거 \(\beta\)를 병렬로 빠르게 생성합니다. 이 LM은 검색된 문서를 이해하고 입력 문서에 충실한 근거를 생산하는 데 특화되어 있습니다.
- 검증 및 최종 답변 선택
- 검증: 각 초안-근거 쌍 \((\alpha, \beta)\)에 대해, 일반 LM \(M_{\text{Verifier}}\)를 사용하여 질문 \(Q\)와 그 근거 \(\beta\)를 기반으로 신뢰 점수를 계산합니다. 특이점으로, \(M_{\text{Verifier}}\)는 사전 훈련 중 이미 배운 언어 모델링 능력을 활용하기 때문에 프롬프트 튜닝이 필요 없습니다.
- 최종 답변 선택: 가장 높은 신뢰 점수를 가진 초안을 최종 답변으로 선택하고 일반 LM의 생성 결과에 통합합니다.
이런 과정을 통해 Speculative RAG는 빠르고 효율적으로 문서의 인퍼런스과 답변 생성을 개선하여 더 나은 사용자 경험을 제공할 수 있습니다.
이 코드는 클러스터링, 서브셋 구성, 초안 생성 및 평가를 통해 최적의 답변을 선택하는 과정을 단계적으로 설명하며, 질문 \(Q\), 검색된 문서 집합 \(D\), 클러스터 수 \(k\), 그리고 샘플링할 서브셋 수 \(m\)을 입력으로 받아 최종 답변 \(\hat{A}\)를 예측하는 것을 표현합니다.
Process Pseudo Code
\[\begin{align*} \textbf{Data}: & \quad (Q, D = \{d_i\}_{i=1}^n) \text{ is the question and } n \text{ retrieved documents;} \\ & \quad m \text{ subsets, each containing } k \text{ documents, are sampled from } D; \\ & \quad k \text{ also corresponds to the number of clusters during clustering.} \\ \textbf{Result}: & \quad \hat{A} \text{ is the predicted answer to the question.} \\ 1 & \quad \text{Function Speculative RAG}(Q, D, m, k): \\ 2 & \quad \quad \{c_1, c_2, \dots, c_k\} \leftarrow \text{K-Means} \mathcal{C}(d_1, \dots, d_n \mid Q) \\ & \quad \quad \text{\# Cluster the documents into } k \text{ groups using an embedding model } \mathcal{C}. \\ 3 & \quad \quad \Delta \leftarrow \{\} \\ 4 & \quad \quad \text{repeat} \\ 5 & \quad \quad \quad \delta_j \leftarrow \{\} \\ & \quad \quad \quad \text{\# Construct a subset of the retrieved documents } \delta_j \\ 6 & \quad \quad \quad \text{for } c_i \in \{c_1, \dots, c_k\} \text{ do} \\ 7 & \quad \quad \quad \quad \delta_j = \delta_j \cup \{\text{random.sample}(c_i)\} \\ & \quad \quad \quad \quad \text{\# Sample one document from each cluster } c_i \text{ into subset } \delta_j. \\ 8 & \quad \quad \quad \text{end for} \\ 9 & \quad \quad \quad \Delta = \Delta \cup \{\delta_j\} \\ 10 & \quad \quad \text{until } |\Delta| = m \\ & \quad \quad \text{\# Repeat the sampling until there are } m \text{ unique subsets in total.} \\ 11 & \quad \quad \text{for } \delta_j \in \Delta \text{ do in parallel} \\ & \quad \quad \quad \text{\# Process } m \text{ subsets in parallel.} \\ 12 & \quad \quad \quad \alpha_j, \beta_j \leftarrow M_{\text{Drafter}}.\text{generate}(Q, \delta_j) \\ & \quad \quad \quad \text{\# Generate the draft } \alpha \text{ and rationale } \beta \text{ with } M_{\text{Drafter}}. \\ 13 & \quad \quad \quad \rho_j \leftarrow M_{\text{Verifier}}.\text{score}(\alpha_j \mid Q, \beta_j) \\ & \quad \quad \quad \text{\# Compute the confidence score } \rho \text{ with } M_{\text{Verifier}}. \\ 14 & \quad \quad \text{end} \\ 15 & \quad \quad \hat{A} \leftarrow \arg\max_{\alpha_j} \rho_j \\ & \quad \quad \text{\# Select the one with the highest score as the final answer.} \\ 16 & \quad \quad \text{return } \hat{A} \\ \end{align*}\]3.2 전문가 RAG 작성자
전문가 RAG 작성자, \(\mathcal{M}_{\text{Drafter}}\)로 표시,는 일반적인 문제를 다루기보다 주어진 질문에 대한 지원 문서를 바탕으로 전문적인 답변을 제공하는 데 중점을 둡니다. 이 접근 방식은 \(\mathcal{M}_{\text{Drafter}}\)를 훈련하여 지원 문서의 맥락을 이해하고 그에 기반한 답변 초안과 근거를 생성하도록 합니다.
지시 튜닝
질문 \(Q\), 응답 \(A\), 그리고 검색된 지원 문서 \(D\)로 구성된 삼중항 \((Q, A, D)\)에 대해, 응답 \(A\)의 근거 \(E\)를 문서 \(D\)에 기반하여 추가합니다. \(E\)는 문서에서 필수 정보를 추출하고 응답이 질문에 합리적인 이유를 간결하게 설명합니다(Hsieh et al., 2023). 강력한 언어 모델을 활용하여 각 삼중항에 대한 근거 \(E\)를 자동으로 합성합니다. 구체적으로, 강력한 LM을 직접 쿼리하여 문서의 지식을 이해하고 지시와 응답 사이의 중간 근거를 제공합니다. 근거를 생성한 후에는 표준 언어 모델링 목표를 사용하여 사전 훈련된 LM을 파인튜닝합니다. 이는 증가된 데이터 항목 \((Q, A, D, E)\)에 대한 확률 \(\log P_{\mathcal{M}_{\text{Drafter}}}(A, E \\| Q, D)\)을 최대화하는 것을 목표로 합니다.
다각도 샘플링
지식 집약적 질문에 대해, 검색 쿼리로 사용된 질문 \(Q\)를 바탕으로 데이터베이스에서 문서 세트를 검색합니다. 이 문서들은 질문의 모호성 때문에 다양한 내용을 포함할 수 있습니다. 답변 초안을 생성하기 위해 사용된 문서 부분집합의 중복을 최소화하고 다양성을 증가시키기 위해 다각도 샘플링 전략을 사용합니다. 먼저 지시 인식 임베딩 모델(Peng et al., 2024)과 K-Means 클러스터링 알고리즘(Jin & Han, 2011)을 사용하여 문서를 몇 가지 주제로 클러스터링합니다.
-
임베딩 계산
\[\text{emb}(d_1, \ldots, d_n) = \mathcal{E}(d_1, \ldots, d_n \mid Q)\] -
K-평균 클러스터링
\[\{c_1, \ldots, c_k\} = \text{K-Means}(\text{emb}(d_1), \ldots, \text{emb}(d_n))\]-
\(\text{emb}(d_1, \ldots, d_n)\): 이 표현은 문서 \(d_1, \ldots, d_n\)의 임베딩을 나타냅니다. 이 함수는 주어진 문서들에 대한 벡터 표현을 생성합니다. 이 벡터들은 각 문서의 내용을 요약하며, 다음 단계에서 클러스터링과 같은 작업에 사용됩니다.
-
\(\mathcal{E}(d_1, \ldots, d_n \mid Q)\): 이 함수는 문서 \(d_1, \ldots, d_n\)을 조건부로 임베딩합니다, 조건 \(Q\)는 질문이나 쿼리를 의미할 수 있습니다. 이 조건부 접근은 문서들을 질문 \(Q\)의 맥락에서 해석하고 임베딩하는 데 도움을 주며, 문서의 임베딩이 질문에 더 관련 있게 만들어, 결과적인 임베딩이 질문에 대한 문서의 적합성을 더 잘 반영하도록 합니다.
-
\(\text{K-Means}(\text{emb}(d_1), \ldots, \text{emb}(d_n))\): 이 표현은 \(\text{K-Means}\) 클러스터링 알고리즘을 사용하여 문서의 임베딩들을 \(k\) 개의 클러스터로 그룹화합니다. 클러스터링은 각각의 임베딩 \(\text{emb}(d_i)\)를 분석하여 유사한 특성을 가진 임베딩들을 같은 클러스터로 할당합니다. \(c_1, \ldots, c_k\)는 이 클러스터링 과정에서 생성된 각 클러스터의 중심을 나타내며, 각 중심은 해당 클러스터에 속한 임베딩들의 평균 위치를 대표합니다.
-
이런 방식으로, 임베딩과 클러스터링을 통해 문서들을 구조화하고, 특정 쿼리나 질문에 대한 문서들의 관련성을 평가하는 데 도움을 줍니다.
\[\delta = \{\text{random.sample}(c) \text{ for } c \in \{c_i\}_{i=1}^k\}\]\(\mathcal{E}\)는 제공된 지시(질문 \(Q\))에 대한 문자열을 임베딩하는 지시 인식 임베딩 모델이고, \(\text{emb}(d_i)\)는 검색된 문서 \(d_i\)의 임베딩, \(c_j\)는 유사한 주제와 내용을 가진 검색된 문서의 클러스터이며, \(k\)는 클러스터 수를 제어하는 하이퍼파라미터입니다. 각 클러스터에서 하나의 문서를 샘플링하여 문서 부분집합 \(\delta\)를 구성하고, 각 부분집합은 \(k\)개의 다양한 내용의 문서를 포함합니다.
결론적으로, \(m\)개의 부분집합을 병렬 인퍼런스에 사용합니다.
RAG 초안 작성
\(m\)개의 문서 부분집합에 대해 \(\mathcal{M}_{\text{Drafter}}\)를 실행하고 해당 답변 초안을 생성합니다. 각 문서 부분집합을 프롬프트에 포함시키고 \(\mathcal{M}_{\text{Drafter}}\)에 응답을 쿼리합니다. \(m\)개의 초안이 답변 후보로서 생성되며, 각 초안은 검색 결과의 다양한 관점에 근거를 두고 있습니다. 구체적으로, 문서 부분집합 \(\delta_j = \{d_{j1}, \ldots, d_{jk}\}\)가 주어지면, 다음 프롬프트와 함께 \(\mathcal{M}_{\text{Drafter}}\)를 병렬로 쿼리합니다.
\[Q, d_{j1}, \ldots, d_{jk} \rightarrow \alpha_j, \beta_j\]프롬프트는 제기된 질문 \(Q\)와 문서 부분집합을 포함하며, 생성 결과에는 답변 초안 \(\alpha_j\)와 근거 \(\beta_j\)가 포함됩니다. 조건부 생성 확률은 다음과 같이 정의됩니다.
\[\rho_{\text{Draft}, j} = P(\beta_j \mid Q, d_{j1}, \ldots, d_{jk}) + P(\alpha_j \mid Q, d_{j1}, \ldots, d_{jk}, \beta_j)\]- \(\rho_{\text{Draft}, j}\): 초안 \(j\)에 대한 총 신뢰 점수를 나타냅니다. 이 값은 두 확률의 합으로 계산됩니다.
- \(P(\beta_j \mid Q, d_{j1}, \ldots, d_{jk})\): 질문 \(Q\)와 문서 \(d_{j1}, \ldots, d_{jk}\)을 기반으로 한 근거 \(\beta_j\)의 확률을 나타냅니다. 이는 주어진 문서 집합과 질문을 바탕으로 생성된 근거의 신뢰도를 평가합니다.
- \(P(\alpha_j \mid Q, d_{j1}, \ldots, d_{jk}, \beta_j)\): 질문 \(Q\), 문서 \(d_{j1}, \ldots, d_{jk}\) 및 근거 \(\beta_j\)를 기반으로 한 초안 \(\alpha_j\)의 확률을 나타냅니다. 이는 주어진 문서 집합과 근거를 바탕으로 생성된 초안의 신뢰도를 평가합니다.
이 수식은 주어진 질문과 문서들, 그리고 생성된 근거를 바탕으로 초안의 신뢰 점수를 계산하는 방법을 보여주며, 두 확률의 합을 통해 최종적으로 가장 신뢰할 수 있는 초안을 선택할 수 있습니다. 이 확률은 근거를 생성하는 신뢰성과 답변 초안을 생성하는 신뢰도를 측정합니다.
4. 실험
4.1 Baseline Model
기존 RAG 방식은 문서를 검색하여 그 문서를 활용해 답을 생성합니다. 비교적 간단한 구조에서 벗어나 본 연구에서는 Speculative RAG 모델을 제안하여 문서 검색 결과의 질을 향상시키고, 여러 문서를 동적으로 검토하며 필요한 정보만을 추려내어 답안을 생성합니다.
4.2 실험 설정
Mistral 7B와 Mixtral 8x7B 모델을 기반으로 하여 다양한 RAG 작업을 수행합니다. 특히, 문서의 임베딩을 사전에 계산하여 검색 과정에서 이를 활용하며, 복수의 문서에서 정보를 추출하여 복잡한 인퍼런스이 요구되는 질문에 답합니다. 예를 들어, MuSiQue 데이터셋에서는 상위 15개 문서를 검색하여 각 질문에 대해 10개의 드래프트를 생성하며, 각 드래프트는 6개 문서를 사용합니다.
4.3 주요 결과
Speculative RAG는 기존 RAG, Self-Reflective RAG, 및 Corrective RAG와 비교하여 모든 벤치마크에서 우수한 성능을 보여주며, 특히 RAG 드래프터의 지능적인 튜닝과, 검증 과정에서의 일관된 논리적 근거 평가가 기여합니다. 예를 들어, ℳ Verifier-8x7B + ℳ Drafter-7B 구성은 트리비아QA에서 74.24%, MuSiQue에서 31.57%, PubHealth에서 76.60%, ARC-Challenge에서 80.55%의 정확도를 기록합니다.
4.4 지연 시간 분석
실험 결과, Speculative RAG는 기존의 RAG 모델에 비해 처리 속도가 빠르며, 특히 병렬 드래프트 생성을 통해 지연 시간을 최소화합니다. 이는 RAG 드래프터의 작은 크기와 효율적인 문서 처리 능력 덕분입니다.
4.5 복제 연구
다양한 드래프팅과 검증 전략을 실험한 결과, 문서의 다양성을 활용하고 중복을 최소화하는 방식이 성능을 크게 향상시킵니다. 반면, 일관된 논리적 근거 없이 무작위 선택을 할 경우 성능이 크게 저하됩니다.
5. 결론
Speculative RAG는 RAG 작업을 드래프팅과 검증 두 단계로 분리함으로써 효율성과 정확성을 크게 향상시키는 새로운 접근 방식을 제시합니다. 이는 각 단계를 전문화하여 수행함으로써 문서의 다양한 관점을 더 잘 활용하고, 긴 문맥에 대한 위치 편향의 위험을 줄이면서도 높은 품질의 답안을 생성할 수 있습니다.