Vector Search | Lucene
- Related Project: Private
- Category: Paper Review
- Date: 2023-08-29
Vector Search with OpenAI Embeddings: Lucene Is All You Need
- url: https://arxiv.org/abs/2308.14963
- pdf: https://arxiv.org/pdf/2308.14963
- abstract: We provide a reproducible, end-to-end demonstration of vector search with OpenAI embeddings using Lucene on the popular MS MARCO passage ranking test collection. The main goal of our work is to challenge the prevailing narrative that a dedicated vector store is necessary to take advantage of recent advances in deep neural networks as applied to search. Quite the contrary, we show that hierarchical navigable small-world network (HNSW) indexes in Lucene are adequate to provide vector search capabilities in a standard bi-encoder architecture. This suggests that, from a simple cost-benefit analysis, there does not appear to be a compelling reason to introduce a dedicated vector store into a modern “AI stack” for search, since such applications have already received substantial investments in existing, widely deployed infrastructure.
Contents
TL;DR
- 백터 저장소의 필요성 재고: Lucene 사용으로 동일 성능 달성 가능
- OpenAI 임베딩과 Lucene을 활용한 MS MARCO 데이터셋 실험
- 비용 대비 효과 및 기존 시스템과의 통합 고려하여 백터 저장소 추가 의문 제기
1 서론
검색 분야에서는 ‘바이인코더(bi-encoder) 아키텍처’를 중심으로 한 표현 학습이 주목받고 있습니다. 이 아키텍처는 쿼리, 패시지 및 기타 다양한 멀티미디어 콘텐츠를 밀집 벡터(임베딩)로 표현합니다. 대규모 언어모델(LLM)의 검색 기능 강화에 밀집 검색 모델이 기반이 되며, 이는 생성 AI의 넓은 맥락에서 LLM 기능 향상에 도움을 줍니다.
현재의 주된 이야기는 밀집 벡터를 관리하기 위해 기업이 “벡터 저장소”나 “벡터 데이터베이스”를 필요로 한다는 것입니다. 이는 현대 기업 아키텍처의 필수 구성 요소로 제시되고 있지만, 본 논문은 이런 주장에 대한 반론을 제시합니다. 많은 기관들이 이미 이런 기능에 상당한 투자를 해 왔기 때문에, 별도의 벡터 저장소가 필요하지 않다는 것이 논문의 주장입니다. 최근 Lucene 라이브러리의 주요 릴리스에서는 HNSW 인덱싱 및 벡터 검색 기능이 포함되어 있어, 이 기능들이 시간이 지남에 따라 지속적으로 향상되고 있습니다.
2 아키텍처에서 구현까지
바이인코더 아키텍처의 핵심 아이디어는 쿼리와 패시지를 밀집 벡터로 인코딩하는 것입니다. 이 벡터들은 관련 쿼리-패시지 쌍이 높은 점수를 받도록 설계되었으며, 이 점수는 임베딩의 내적으로 계산됩니다. 검색은 벡터 공간에서 최근접 이웃 검색 문제로 재구성될 수 있습니다. 이 구성은 전통적인 ‘단어 봉투’ 희소 표현과는 다르게, 벡터 공간에서의 최근접 이웃 검색은 완전히 다른 기술을 필요로 합니다. 이는 인덱스 기반 HNSW(Hierarchical Navigable Small-World Network)가 대표적입니다.
\[\text{Score} = \mathbf{query\_emb} \cdot \mathbf{passage\_emb}\]위와 같이 쿼리 벡터와 패시지 벡터 사이의 내적을 계산하여 점수를 도출하며, $\mathbf{query_emb}$와 $\mathbf{passage_emb}$는 각각 쿼리와 패시지의 벡터 표현입니다.
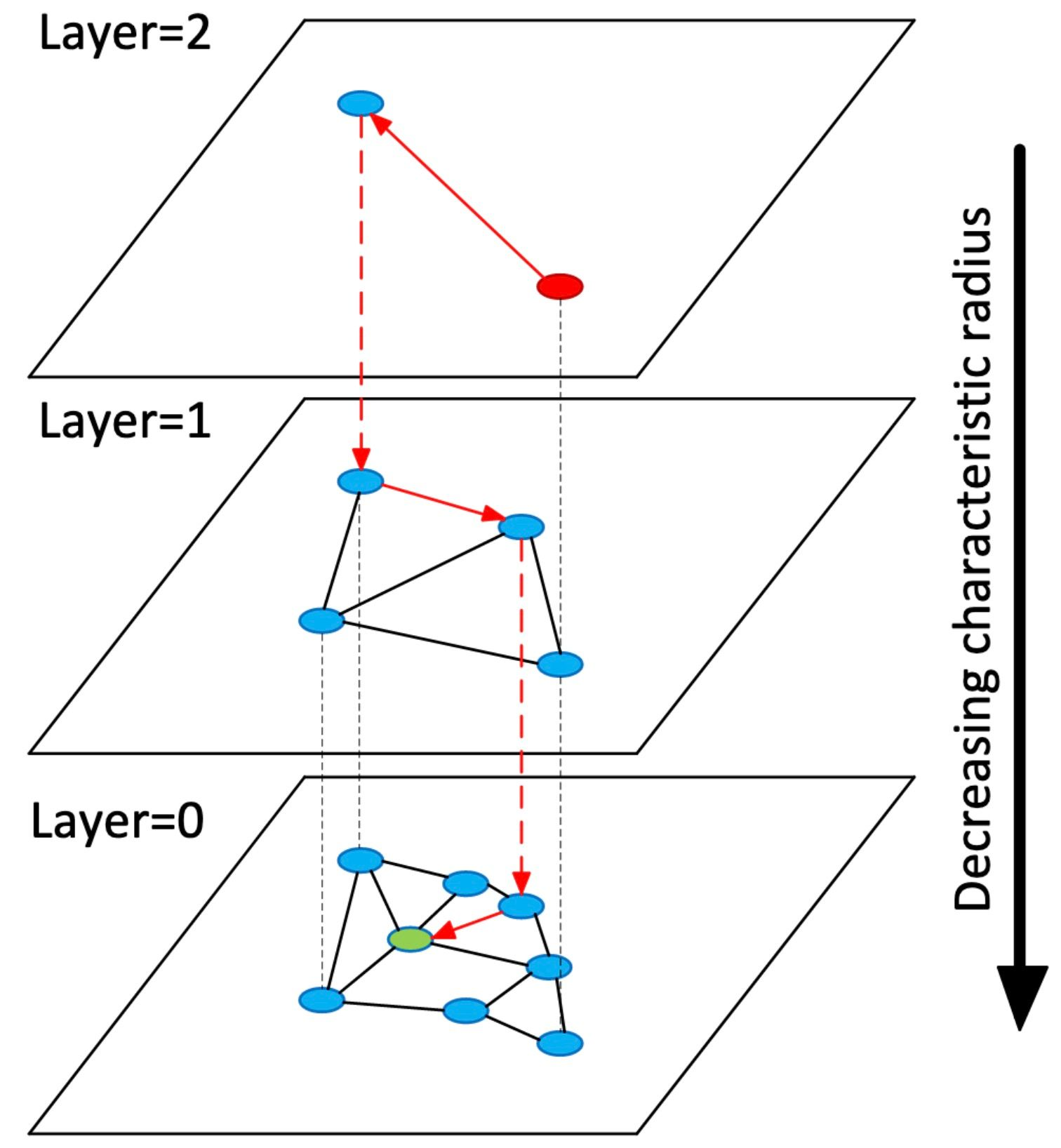
*출처: HNSW, Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs
3 실험
실험은 MS MARCO 패시지 랭킹 테스트 컬렉션을 사용하여 수행되었습니다. OpenAI의 ada2 모델을 사용하여 쿼리와 패시지 임베딩을 생성하고, 이를 Lucene으로 인덱싱했습니다.
- RR@10: 재현율 상위 10개 문서
- AP: 평균 Precision
- nDCG@10: 정규화 누적 이득
- R@1k: 1000 등급 내 재현율
실험 설정에서는 벡터 차원이 1536으로 설정되었으며, Lucene의 HNSW 구현은 벡터 차원을 1024로 제한합니다. 이 제한을 해결하기 위해 벡터 차원을 구성 가능하게 만드는 수정이 Lucene 소스에 병합되었습니다. 실험 결과 ada2 임베딩은 상태 기술과 비교하여 효과적인 성능을 보였습니다.
이 연구는 Lucene과 같은 기존의 검색 플랫폼만으로도 최신 AI 기술을 활용할 수 있음을 보여 줍니다. 추가적인 벡터 저장소의 필요성에 의문을 제기하며, 기존 시스템과의 통합을 강조합니다.
1 Introduction
Recent advances in the application of deep neural networks to search have focused on representation learning in the context of the so-called bi-encoder architecture, where content (queries, passages, and even images and other multimedia content) is represented by dense vectors (so-called “embeddings”). Dense retrieval models using this architecture form the foundation of retrieval augmentation in large language models (LLMs), a popular and productive approach to improving LLM capabilities in the broader context of generative AI (Mialon et al., 2023; Asai et al., 2023).
The dominant narrative today is that since dense retrieval requires the management of a potentially large number of dense vectors, enterprises require a dedicated “vector store” or “vector database” as part of their “AI stack”. There is a cottage industry of startups that are pitching vector stores as novel, must-have components in a modern enterprise architecture; examples include Pinecone, Weaviate, Chroma, Milvus, Qdrant, just to name a few. Some have even argued that these vector databases will replace the venerable relational database.1
The goal of this paper is to provide a counterpoint to this narrative. Our arguments center around a simple cost–benefit analysis: since search is a brownfield application, many organizations have already made substantial investments in these capabilities. Today, production infrastructure is dominated by the broad ecosystem centered around the open-source Lucene search library, most notably driven by platforms such as Elasticsearch, OpenSearch, and Solr. While the Lucene ecosystem has admittedly been slow to adapt to recent trends in representation learning, there are strong signals that serious investments are being made in this space. Thus, we see no compelling reason why separate, dedicated vector stores are necessary in a modern enterprise. In short, the benefits do not appear to justify the cost of additional architectural complexity.
It is important to separate the need for capabilities from the need for distinct software components. While hierarchical navigable small-world network (HNSW) indexes (Malkov and Yashunin, 2020) represent the state of the art today in approximate nearest neighbor search—the most important operation for vector search using embeddings—it is not clear that providing operations around HNSW indexes requires a separate and distinct vector store. Indeed, the most recent major release of Lucene (version 9, from December 2021) includes HNSW indexing and vector search, and these capabilities have steadily improved over time. The open-source nature of the Lucene ecosystem means that advances in the core library itself will be rapidly adopted and integrated into other software platforms within the broader ecosystem.
The growing popularity of so-called embedding APIs (Kamalloo et al., 2023) further strengthens our arguments. These APIs encapsulate perhaps the most complex and resource-intensive aspect of vector search—the generation of dense vectors from pieces of content. Embedding APIs hide model training, deployment, and inference behind the well-known benefits of service-based computing, much to the delight of practitioners. To support our arguments, we demonstrate vector search with OpenAI embeddings (Neelakantan et al., 2022) using the popular MS MARCO passage ranking test collection (Bajaj et al., 2018). Specifically, we have encoded the entire corpus and indexed the embedding vectors using Lucene. Evaluation on the MS MARCO development set queries and queries from the TREC Deep Learning Tracks (Craswell et al., 2019, 2020) show that OpenAI embeddings are able to achieve a respectable level of effectiveness. And as Devins et al. (2022) have shown, anything doable in Lucene is relatively straightforward to replicate in Elasticsearch (and any other platform built on Lucene). Thus, we expect the ideas behind our demonstration to become pervasive in the near future.
We make available everything needed to reproduce the experiments described in this paper, starting with the actual OpenAI embeddings, which we make freely downloadable.2 At a high-level, our demonstration shows how easy it is to take advantage of state-of-the-art AI techniques today without any AI-specific implementations per se: embeddings can be computed with simple API calls, and indexing and searching dense vectors is conceptually identical to indexing and searching text with bag-of-words models that have been available for decades.
2 From Architecture to Implementation
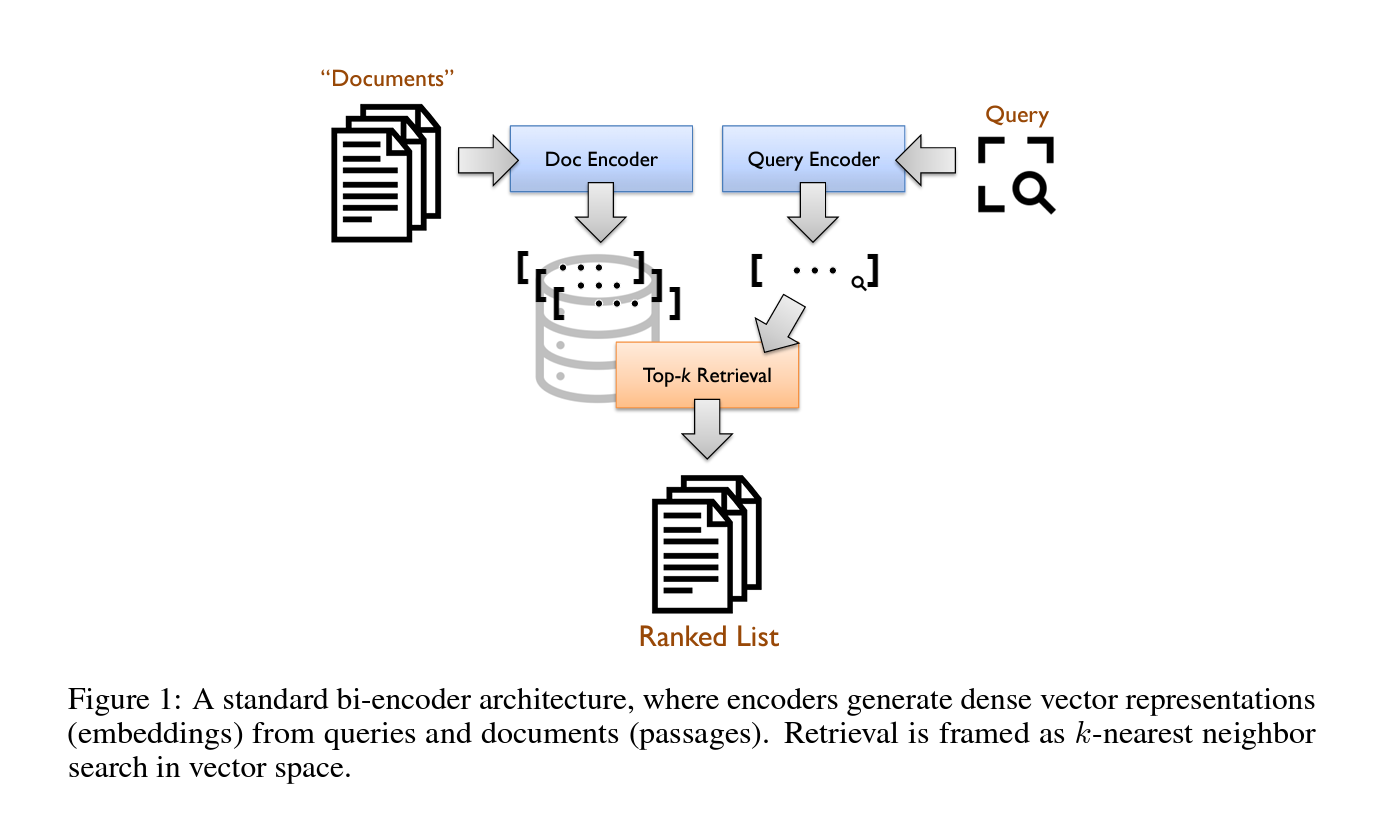
The central idea behind the bi-encoder architecture (see Figure 1) is to encode queries and passages into dense vectors—commonly referred to as “embeddings”—such that relevant query–passage pairs receive high scores, computed as the dot product of their embeddings. In this manner, search can be reformulated as a nearest neighbor search problem in vector space: given the query embedding, the system’s task is to rapidly retrieve the top-k passage embeddings with the largest dot products (Lin, 2021). Typically, “encoders” for generating the vector representations are implemented using transformers, which are usually fine-tuned in a supervised manner using a large dataset of relevant query–passage pairs (Karpukhin et al., 2020; Xiong et al., 2021).
This formulation of search, in terms of comparisons between dense vectors, differs from “traditional” bag-of-words sparse representations that rely on inverted indexes for low-latency query evaluation. Instead, nearest neighbor search in vector space requires entirely different techniques: indexes based on hierarchical navigable small-world networks (HNSW) (Malkov and Yashunin, 2020) are commonly acknowledged as representing the state of the art. The Faiss library (Johnson et al., 2019) provides a popular implementation of HNSW indexes that is broadly adopted today and serves as a standard baseline. Despite conceptual similarities (Lin, 2021), it is clear that top-k retrieval on sparse vectors and dense vectors require quite different and distinct “software stacks”. Since hybrid approaches that combine both dense and sparse representations have been shown to be more effective than either alone (Ma et al., 2022b; Lin and Lin, 2023), many modern systems combine separate retrieval components to achieve hybrid retrieval. For example, the Pyserini IR toolkit (Lin et al., 2021a) integrates Lucene and Faiss for sparse and dense retrieval, respectively.
Recognizing the need for managing both sparse and dense retrieval models, the dominant narrative today is that the modern enterprise “AI stack” requires a dedicated vector store or vector database, alongside existing fixtures such as relational databases, NoSQL stores, event stores, etc. A vector store would handle, for example, standard CRUD (create, read, update, delete) operations as well as nearest neighbor search. Many startups today are built on this premise; examples include Pinecone, Weaviate, Chroma, Milvus, Qdrant, just to name a few. This is the narrative that our work challenges.
2 https://github.com/castorini/anserini/blob/master/docs/experiments-msmarco-passage-openai-ada2.md
Figure 1: A standard bi-encoder architecture, where encoders generate dense vector representations (embeddings) from queries and documents (passages). Retrieval is framed as k-nearest neighbor search in vector space.
Modern enterprise architectures are already exceedingly complex, and the addition of another software component (i.e., a distinct vector store) requires carefully weighing costs as well as benefits. The cost is obvious: increased complexity, not only from the introduction of a new component, but also from interactions with existing components. What about the benefits? While vector stores no doubt introduce new capabilities, the critical question is whether these capabilities can be provided via alternative means.
Search is a brownfield application. Wikipedia defines this as “a term commonly used in the informa- tion technology industry to describe problem spaces needing the development and deployment of new software systems in the immediate presence of existing (legacy) software applications/systems.” Additionally, “this implies that any new software architecture must take into account and coexist with live software already in situ.” Specifically, many organizations have already made substantial investments in search within the Lucene ecosystem. While most organizations do not directly use the open-source Lucene search library in production, the search application landscape is dominated by platforms that are built on top of Lucene such as Elasticsearch, OpenSearch, and Solr. For example, Elastic, the publicly traded company behind Elasticsearch, reports approximately 20,000 subscrip- tions to its cloud service as of Q4 FY2023.3 Similarly, in the category of search engines, Lucene dominates DB-Engines Ranking, a site that tracks the popularity of various database management systems.4 There’s a paucity of concrete usage data, but it would not be an exaggeration to say that Lucene has an immense install base.
The most recent major release of Lucene (version 9), dating back to December 2021, includes HNSW indexing and search capabilities, which have steadily improved over the past couple of years. This means that differences in capabilities between Lucene and dedicated vector stores are primarily in terms of performance, not the availability of must-have features. Thus, from a simple cost–benefit calculus, it is not clear that vector search requires introducing a dedicated vector store into an already complex enterprise “AI stack”. Our thesis: Lucene is all you need.
We empirically demonstrate our claims on the MS MARCO passage ranking test collection, a standard benchmark dataset used by researchers today. We have encoded the entire corpus using OpenAI’s ada2 embedding endpoint, and then indexed the dense vectors with Lucene. Experimental results show that this combination achieves effectiveness comparable to the state of the art on the development queries as well as queries from the TREC 2019 and 2020 Deep Learning Tracks.
3 https://ir.elastic.co/news-events/press-releases/press-releases-details/2023
4 Elastic-Reports-Fourth-Quarter-and-Fiscal-2023-Financial-Results/default.aspx https://db-engines.com/en/ranking/search+engine
Our experiments are conducted with Anserini (Yang et al., 2018), a Lucene-based IR toolkit that aims to support reproducible information retrieval research. By building on Lucene, Anserini aims to bridge the gap between academic information retrieval research and the practice of building real-world search applications. Devins et al. (2022) showed that capabilities implemented by researchers in Anserini using Lucene can be straightforwardly translated into Elasticsearch (or any other platform in the Lucene ecosystem), thus simplifying the path from prototypes to production deployments.
Our demonstration further shows the ease with which state-of-the-art vector search can be imple- mented by simply “plugging together” readily available components. In the context of the bi-encoder architecture, Lin (2021) identified the logical scoring model and the physical retrieval model as distinct conceptual components. In our experiments, the logical scoring model maps to the OpenAI embedding API—whose operations are no different from any other API endpoint. What Lin calls the physical retrieval model focuses on the top-k retrieval capability, which is handled by Lucene. In Anserini, vector indexing and search is exposed in a manner that is analogous to indexing and retrieval using bag-of-words models such as BM25. Thus, the implementation of the state of the art in vector search using generative AI does not require any AI-specific implementations, which increases the accessibility of these technologies to a wider audience.
3 Experiments
Experiments in this paper are relatively straightforward. We focused on the MS MARCO passage ranking test collection (Bajaj et al., 2018), which is built on a corpus comprising approximately 8.8 million passages extracted from the web. Note that since the embedding vectors are generated by OpenAI’s API endpoint, no model training was performed. For evaluation, we used the standard development queries as well as queries from the TREC 2019 and TREC 2020 Deep Learning Tracks.
In our experimental setup, we utilized the OpenAI ada2 model (Neelakantan et al., 2022) for generating both query and passage embeddings. This model is characterized by an input limit of 8191 tokens and an output embedding size of 1536 dimensions. However, to maintain consistency with the existing literature (Pradeep et al., 2021; Ma et al., 2022a), we truncated all passages in the corpus to 512 tokens. It is unknown whether OpenAI leveraged the MS MARCO passage corpus during model development, but in general, accounting for data leakage is extremely challenging for large models, especially those from OpenAI that lack transparency.
Using tiktoken, OpenAI’s official tokenizer, we computed the average token count per passage in our corpus to be 75.2, resulting in a total of approximately 660 million tokens. In order to generate the embeddings efficiently, we queried the API in parallel while respecting the rate limit of 3500 calls per minute. We had to incorporate logic for error handling in our code, given the high-volume nature of our API calls. Ultimately, we were able to encode both the corpus and the queries, the latter of which are negligible in comparison, in a span of two days.
As previously mentioned, all our retrieval experiments were conducted with the Anserini IR toolkit (Yang et al., 2018). The primary advantage of Anserini is that it provides direct access to underlying Lucene features in a “researcher-friendly” manner that better comports with modern evaluation workflows. Our experiments were based on Lucene 9.5.0, but indexing was a bit tricky because the HNSW implementation in Lucene restricts vectors to 1024 dimensions, which was not sufficient for OpenAI’s 1536-dimensional embeddings.5 Although the resolution of this issue, which is to make vector dimensions configurable on a per codec basis, has been merged to the Lucene source trunk,6 this feature has not been folded into a Lucene release (yet) as of early August 2023. Thus, there is no public release of Lucene that can directly index OpenAI’s ada2 embedding vectors. Fortunately, we were able to hack around this limitation in an incredibly janky way.7
Experimental results are shown in Table 1, where we report effectiveness in terms of standard metrics: reciprocal rank at 10 (RR@10), average precision (AP), nDCG at a rank cutoff of 10 (nDCG@10), and recall at a rank cutoff of 1000 (R@1k). The effectiveness of the ada2 embeddings is shown in the Unsupervised Sparse Representations BM25 (Ma et al., 2022a)∗ BM25+RM3 (Ma et al., 2022a)∗ Learned Sparse Representations uniCOIL (Ma et al., 2022a)∗ SPLADE++ ED (Formal et al., 2022)∗ Learned Dense Representations TAS-B (Hofstätter et al., 2021) TCT-ColBERTv2 (Lin et al., 2021b)∗ ColBERT-v2 (Santhanam et al., 2022) Aggretriever (Lin et al., 2023)∗ last row of the table. Note that due to the non-deterministic nature of HNSW indexing, effectiveness figures may vary slightly from run to run.
7 The sketch of the solution is as follows: We copy relevant source files from the Lucene source trunk directly into our source tree and patch the vector size settings directly. When we build our fatjar, the class files of our “local versions” take precedence, and hence override the vector size limitations.
Table 1: Effectiveness of OpenAI ada2 embeddings on the MS MARCO development set queries (dev) and queries from the TREC 2019/2020 Deep Learning Tracks (DL19/DL20), compared to a selection of other models. ∗ indicates results from Pyserini’s two-click reproductions (Lin, 2022) available at https://castorini.github.io/pyserini/2cr/msmarco-v1-passage.html, which may differ slightly from the original papers. All other results are copied from their original papers.
For comparison, we present results from a few select points of reference, classified according to the taxonomy proposed by Lin (2021); OpenAI’s embedding models belong in the class of learned dense representations. Notable omissions in the results table include the following: the original OpenAI paper that describes the embedding model (Neelakantan et al., 2022) does not report comparable results; neither does Izacard et al. (2021) for Contriever, another popular learned dense representation model. Recently, Kamalloo et al. (2023) also evaluated OpenAI’s ada2 embeddings, but they did not examine any of the test collections we do here. Looking at the results table, our main point is that we can achieve effectiveness comparable to the state of the art using a production-grade, completely off-the-shelf embedding API coupled with Lucene for indexing and retrieval.
To complete our experimental results, we provide performance figures on a server with two Intel Xeon Platinum 8160 processors (33M Cache, 2.10 GHz, 24 cores each) with 1 TB RAM, running Ubuntu 18.04 with ZFS. This particular processor was launched in Q3 of 2017 and is no longer commercially available; we can characterize this server as “high end”, but dated. Indexing took around three hours with 16 threads, with the parameters M set to 16 and efC set to 100, without final segment optimization. Using 32-bit floats, the raw 1536-dimensional vectors should consume 54 GB on disk, but for convenience we used an inefficient JSON text-based representation. Therefore, our collection of vectors takes up 109 GB as compressed text files (using gzip). For vector search, using 16 threads, we were able to achieve 9.8 queries per second (QPS), fetching 1000 hits per query with the efSearch parameter set to 1000. These results were obtained on the MS MARCO development queries, averaged over four separate trials after a warmup run.
4 Discussion
Our demonstration shows that it is possible today to build a vector search prototype using OpenAI embeddings directly with Lucene. Nevertheless, there are a number of issues worth discussing, which we cover below.
Jank. We concede that getting our demonstration to work required a bit of janky implementation tricks. Even though all the required features have been merged to Lucene’s source trunk, no official release has been cut that incorporates all the patches (at least at the time we performed our experiments in early August, 2023). Quite simply, the complete feature set necessary for production deployment is not, as they say, ready for prime time. However, to use another cliché, this is a small matter of programming (SMOP). We see no major roadblocks in the near future: the next official release of Lucene will incorporate the necessary features, and after that, all downstream consumers will begin to incorporate the capabilities that we demonstrate here.
Nevertheless, Lucene has been a relative laggard in dense retrieval. Despite this, we believe that recent developments point to substantial and sustained investments in the Lucene ecosystem moving forward. For example, in its Q4 FY 2023 report, Elastic announced the Elasticsearch Relevance Engine, “powered by built-in vector search and transformer models, designed specifically to bring the power of AI innovation to proprietary enterprise data.” A recent blog post8 from Amazon Web Services explained vector database capabilities in OpenSearch, providing many details and reference architectures. These are just two examples of commitments that help bolster the case for Lucene that we have articulated here. Overall, we are optimistic about the future of the ecosystem.
Performance. Lucene still lags alternatives in terms of indexing speed, query latency and through- put, and related metrics. For example, Ma et al. (2023) recently benchmarked Lucene 9.5.0 against Faiss (Johnson et al., 2019). Experiments suggest that Lucene achieves only around half the query throughput of Faiss under comparable settings, but appears to scale better when using multiple threads. Although these results only capture a snapshot in time, it would be fair to characterize Lucene as unequivocally slower. However, Faiss is relatively mature and hence its headroom for performance improvements is rather limited. In contrast, we see many more opportunities for gains in Lucene. Coupled with signs of strong commitment (discussed above), we believe that the performance gap between Lucene and dedicated vector stores will decrease over time.
Alternatives. We acknowledge a number of competing alternatives that deserve consideration. Note that the core argument we forward is about cost–benefit tradeoffs: In our view, it is not clear that the benefits offered by a dedicated vector store outweigh the increased architectural complexity of introducing a new software component within an enterprise. From this perspective, we can identify two potentially appealing alternatives:
- Fully managed services. One simple way to reduce architectural complexity is to make it someone else’s problem. Vespa9 is perhaps the best example of this solution, providing both dense retrieval and sparse retrieval capabilities in a fully managed environment, eliminating the need for users to explicitly worry about implementation details involving inverted indexes, HNSW indexes, etc. Vepsa provides a query language that supports a combination of vector search, full-text search, as well as search over structured data. Our main question here concerns traction and adoption: as a brownfield application, we’re not convinced that enterprises will make the (single, large) leap from an existing solution to a fully managed service.
- Vector search capabilities in relational databases. In the same way that vector search grows naturally out of an already deployed and mature text search platform (e.g., Elasticsearch), we can see similar arguments being made from the perspective of relational databases. Despite numerous attempts (spanning decades) at toppling its lofty perch (Stonebraker and Hellerstein, 2005; Pavlo et al., 2009), relational databases remain a permanent fixture in enterprise “data stacks”. This means that by building vector search capabilities into relational databases, enterprises gain entrée into the world of dense retrieval (essentially) for free. A great example of this approach is pgvector,10 which provides open-source vector similarity search for Postgres. We find the case compelling: if your enterprise is already running Postgres, pgvector adds vector search capabilities with minimal additional complexity. It’s basically a free lunch.
5 Conclusions
There is no doubt that manipulation of dense vectors forms an important component of search today. The central debate we tackle is how these capabilities should be implemented and deployed in production systems. The dominant narrative is that you need a new, distinct addition to your enterprise “AI stack”—a vector store. The alternative we propose is to say: If you’ve built search applications already, chances are you’re already invested in the Lucene ecosystem. In this case, Lucene is all you need. Of course, time will tell who’s right.