Model | Qwen VL
- Related Project: Private
- Category: Paper Review
- Date: 2023-08-24
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
- url: https://arxiv.org/abs/2308.12966
- pdf: https://arxiv.org/pdf/2308.12966
- abstract: In this work, we introduce the Qwen-VL series, a set of large-scale vision-language models (LVLMs) designed to perceive and understand both texts and images. Starting from the Qwen-LM as a foundation, we endow it with visual capacity by the meticulously designed (i) visual receptor, (ii) input-output interface, (iii) 3-stage training pipeline, and (iv) multilingual multimodal cleaned corpus. Beyond the conventional image description and question-answering, we implement the grounding and text-reading ability of Qwen-VLs by aligning image-caption-box tuples. The resulting models, including Qwen-VL and Qwen-VL-Chat, set new records for generalist models under similar model scales on a broad range of visual-centric benchmarks (e.g., image captioning, question answering, visual grounding) and different settings (e.g., zero-shot, few-shot). Moreover, on real-world dialog benchmarks, our instruction-tuned Qwen-VL-Chat also demonstrates superiority compared to existing vision-language chatbots. Code, demo and models are available at this https URL.
TL;DR
- Qwen-VL 시리즈는 대규모 언어모델을 기반으로 하여 시각적 능력을 갖춘 모델입니다. 이 모델은 Vision Transformer(ViT)를 사용한 시각 인코더와 위치 인식이 가능한 시각-언어 어댑터를 포함하고 있습니다. 이들은 이미지를 패치로 나누어 이미지 특성을 추출하며, 이후 크로스 어텐션 메커니즘을 통해 이미지 특성을 고정 길이의 시퀀스로 압축합니다.
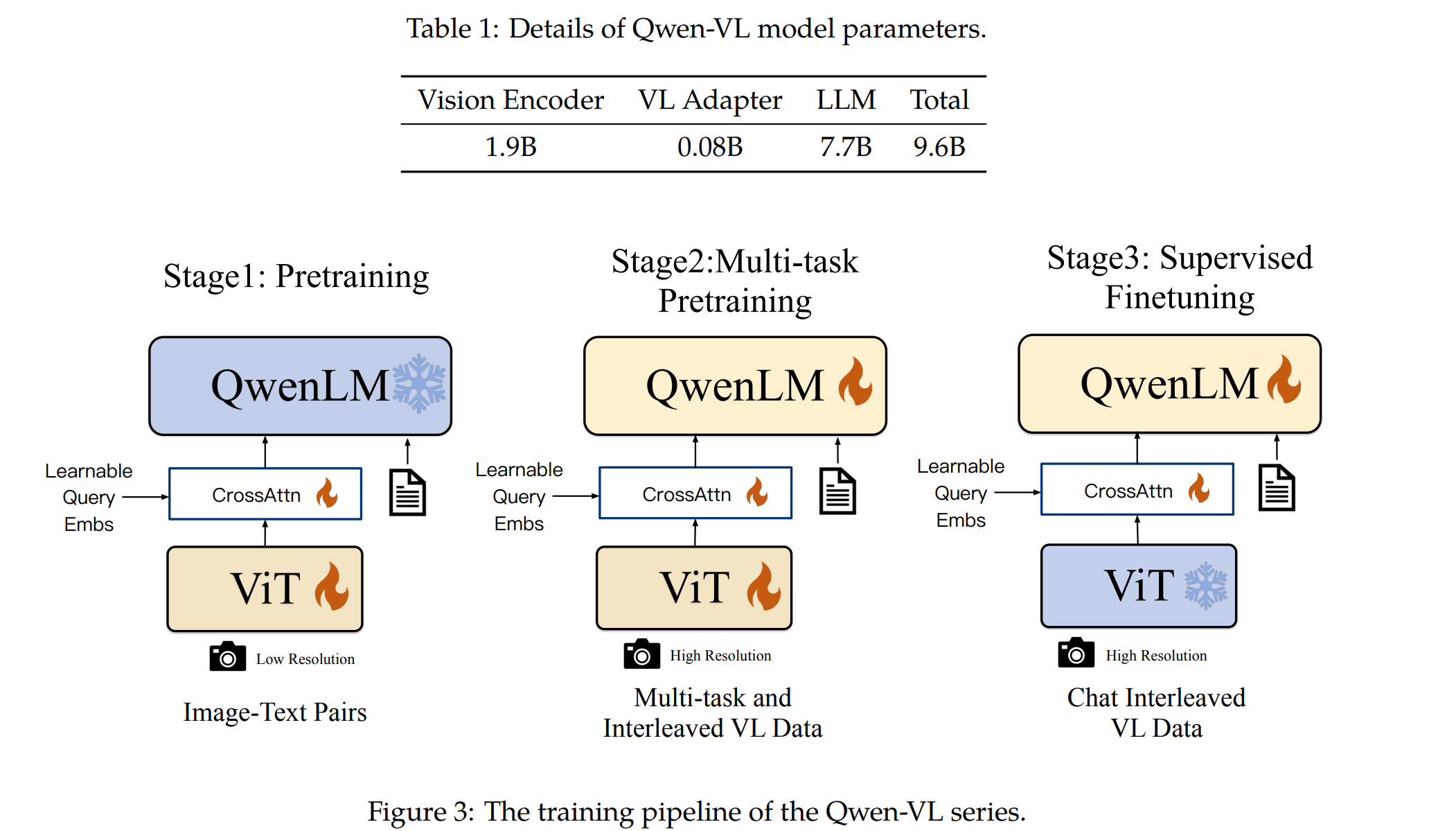
- 이미지 입력은 시각 인코더와 어댑터를 통해 처리되어 고정 길이의 이미지 특성 시퀀스로 변환됩니다. 모델 훈련은 크게 세 단계로 이루어집니다. 사전 훈련, 다중 태스크 사전 훈련, 감독된 파인튜닝. 각 단계는 다양한 이미지-텍스트 쌍 및 비전-언어 데이터를 활용하여 진행됩니다.
- 모델의 아키텍처와 수학적 배경은 다음과 같이 구성됩니다.
-
시각 인코더: Vision Transformer는 다음 수식을 통해 이미지를 처리합니다.
\[F(x) = \text{ViT}(x_{\text{patch}})\]상기 식에서 $x_{\text{patch}}$는 이미지를 패치로 나눈 결과로 ViT는 각 패치에서 특성을 추출하며, 이를 통해 전체 이미지의 표현을 학습합니다.
-
크로스 어텐션 모듈: 이 모듈은 이미지 특성과 위치 정보를 결합하여, 언어 모델에 적합한 시각적 입력으로 변환하는 과정을 담당합니다.
\[Q = W_q \cdot E, \quad K = W_k \cdot F(x), \quad V = W_v \cdot F(x)\] \[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\]상기 식에서 $E$는 학습 가능한 쿼리 벡터, $W_q, W_k, W_v$는 각각 쿼리, 키, 값 벡터를 위한 가중치입니다.
-
포지셔닝 및 인코딩: 2D 절대 위치 인코딩을 사용하여 이미지의 위치 정보를 유지합니다.
\[PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d_{\text{model}}})\] \[PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d_{\text{model}}})\]이 위치 인코딩은 크로스 어텐션의 쿼리-키 쌍에 추가되어, 이미지 특성의 위치적 세부사항이 압축 과정에서 손실되지 않도록 합니다.
1. 서론
최근 대규모 언어모델(Large Language Models, LLMs)은 텍스트 생성 및 이해를 통해 강력한 기능을 제공하고 있습니다. 그러나 이 모델들은 주로 텍스트 데이터만을 다루어 이미지나 음성 같은 다른 형태의 데이터를 처리하는 데 한계가 있습니다. 이에 대한 대안으로, 대규모 시각 언어 모델(Large Vision Language Models, LVLMs)이 개발되어 텍스트와 시각 데이터를 모두 이해할 수 있는 능력을 갖추게 되었습니다. 이런 모델들은 특히 복잡한 시각적 시나리오에서 더욱 정교한 시각적 이해가 필요하며, 이는 LVLMs의 효과적인 보조 역할에 중요한 요소입니다.

2.1 모델 구조
Qwen-VL의 전체 네트워크 구조는 세 가지 주요 구성 요소로 이루어져 있으며, 각 구성 요소는 특정 수학적 메커니즘을 기반으로 동작합니다.
- 대규모 언어모델 (Large Language Model, LLM)
- Qwen-VL은 Qwen-7B 언어 모델을 기반으로 하며, 이는 대규모 텍스트 데이터셋에서 사전 훈련된 가중치를 사용합니다.
- 자연 언어 처리와 생성을 담당하며, 사용자의 의도와 맥락을 이해하는 데 중점을 둡니다.
- 시각 인코더 (Visual Encoder)
- ViT (Vision Transformer) 구조
- ViT는 이미지를 $N \times N$ 픽셀의 패치로 분할하고 각 패치를 D 차원의 특징 벡터로 변환합니다. 이 과정은 다음과 같은 수식으로 표현될 수 있습니다. \(\text{Patch}_{i,j} = \text{Embed}(\text{Flatten}(\text{Image}_{i:j, i:j}))\)
- 각 패치에서 추출된 특징은 트랜스포머의 입력으로 사용되며, 셀프 어텐션 메커니즘을 통해 전체 이미지의 컨텍스트에 대한 이해를 높입니다.
- 스트라이드는 14로 설정되어 이미지에서 14픽셀 간격으로 패치를 추출합니다.
- ViT (Vision Transformer) 구조
- 위치 인식 시각-언어 어댑터
- 크로스-어텐션
- 크로스-어텐션 메커니즘은 시각적 특징(키)과 언어 모델에서 생성된 쿼리 사이의 관계를 분석하여 중요한 정보를 추출합니다. 이는 다음과 같이 표현될 수 있습니다. \(\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\)
- 학습 가능한 쿼리 벡터(Embeddings): 이 벡터들은 특정 시각적 특징에 대해 언어 모델이 어떻게 반응해야 하는지를 학습합니다.
- 위치 인코딩: 2차원 절대 위치 인코딩을 사용하여 각 패치의 원래 위치 정보를 유지하며, 이는 특히 세밀한 시각적 이해에 중요합니다.
- 크로스-어텐션
2.2 입력 및 출력
- 이미지 입력
- 고정 길이 시퀀스: 이미지는 시각 인코더를 통과한 후, 고정 길이의 시퀀스로 변환되어 언어 모델에 입력됩니다. 이 과정은 모델이 일관된 크기의 데이터를 처리할 수 있도록 합니다.
- 경계 상자 입력 및 출력
- 정규화 및 형식화: 각 경계 상자의 위치는 [0, 1000) 범위로 정규화되고, 문자열 형식으로 변환되어 처리됩니다. 이는 모델이 특정 지역을 정확하게 파악하고 관련 정보를 생성하는 데 도움을 줍니다.
3. 훈련
3.1 사전 훈련
첫 번째 사전 훈련 단계에서는 이미지와 텍스트가 포함된 대규모 데이터셋을 사용하여 기본적인 시각-언어 작업을 위한 모델의 능력을 개발합니다. 사용된 데이터는 영어 및 중국어를 포함하여 다양한 언어로 구성되어 있습니다. 이 단계에서 주요 학습 목표는 텍스트 토큰의 크로스-엔트로피를 최소화하는 것입니다.
3.2 멀티태스크 사전 훈련
두 번째 단계에서는 입력 해상도를 높이고, 보다 세밀한 시각 언어 주석 데이터를 활용하여 모델의 세밀한 시각적 이해력을 향상시킵니다. 이 단계에서는 다양한 시각 언어 작업에 대해 동시에 훈련을 진행하며, 학습 목표는 첫 번째 단계와 동일합니다.
3.3 지시에 따른 파인튜닝
마지막 단계에서는 모델을 지시에 따라 대화 및 이미지 이해 능력을 강화하기 위해 파인튜닝합니다. 이 단계에서는 다양한 언어 및 질문 유형에 걸쳐 모델의 능력을 확장하고, 멀티모달 대화 데이터와 순수 텍스트 대화 데이터를 혼합하여 훈련합니다.