RAG | Retrieval-Augmented Generation**
- Related Project: Private
- Category: Paper Review
- Date: 2023-09-13
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- url: https://arxiv.org/abs/2005.11401
- pdf: https://arxiv.org/pdf/2005.11401
- abstract: Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on down-stream NLP tasks. However, their ability to access and precisely manipulate knowledge is still limited, and hence on knowledge-intensive tasks, their performance lags behind task-specific architectures. Additionally, providing provenance for their decisions and updating their world knowledge remain open research problems. Pre-trained models with a differentiable access mechanism to explicit non-parametric memory can overcome this issue, but have so far been only investigated for extractive down-stream tasks. We explore a general-purpose fine-tuning recipe for retrieval-augmented generation (RAG) – models which combine pre-trained parametric and non-parametric memory for language generation. We introduce RAG models where the parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. We compare two RAG formulations, one which conditions on the same retrieved passages across the whole generated sequence, the other can use different passages per token. We fine-tune and evaluate our models on a wide range of knowledge-intensive NLP tasks and set the state-of-the-art on three open domain QA tasks, outperforming parametric seq2seq models and task-specific retrieve-and-extract architectures. For language generation tasks, we find that RAG models generate more specific, diverse and factual language than a state-of-the-art parametric-only seq2seq baseline.
- Related_articles
- Retrieval Augmented Generation with Huggingface Transformers and Ray
- Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models from Meta
- Lang Chain RAG
- ANN-Benchmarks is a benchmarking environment for approximate nearest neighbor algorithms search. This website contains the current benchmarking results. Please visit http://github.com/erikbern/ann-benchmarks/ to get an overview over evaluated data sets and algorithms. Make a pull request on Github to add your own code or improvements to the benchmarking system.
LangChain 구현자료: 모두의 AI 실전! RAG 기법
Contents
TL;DR
- 하이브리드 메모리 시스템: 파라메트릭(parametric) 및 비파라메트릭(non-parametric) 메모리를 통합하여 지식 집약적 작업을 위한 최신 성능을 달성
- RAG 모델: 입력 시퀀스를 기반으로 문서를 검색하고, 검색된 문서를 활용하여 대상 시퀀스를 생성
- RAG 모델은 수학적으로 문서를 잠재 변수로 처리하여 시퀀스 생성 확률을 근사화
1. 서론
신경 언어 모델은 외부 메모리에 접근하지 않고도 풍부한 지식을 학습할 수 있는 능력을 보여주었습니다. 최근의 언어 모델들은 다양한 NLP 작업에서 향상된 성과를 보이고 있으나, 기억 확장성 및 수정의 어려움, 예측의 통찰력 부족, 정보의 오류 생성, 메모리 확장이나 수정, 예측의 투명성 제공에 한계 등의 문제점이 존재합니다. 이런 한계를 극복하기 위해 하이브리드 모델이 제안되었으며, REALM과 ORQA와 같은 모델들이 파라메트릭 메모리와 비파라메트릭 메모리의 결합을 통해 이런 문제를 일부 해결할 수 있는 가능성을 보여줬습니다.
본 논문에서는 이런 문제를 해결하기 위해 파라메트릭 기억 시스템과 비파라메트릭 기억 시스템을 결합한 새로운 모델인 RAG(Retrieval-Augmented Generation)를 제안합니다. RAG 모델은 기존의 seq2seq 모델에 정보 검색 기능을 통합하여 지식 기반의 예측을 가능하게 합니다.
2. 방법
RAG(Retrieval-Augmented Generation) 모델은 입력 시퀀스 \(x\)를 사용하여 관련 텍스트 문서 \(z\)를 검색하고, 이 문서들을 이용해 목표 시퀀스 \(y\)를 생성하는 방식을 취합니다. 이 과정은 리트리버(retriever) \(p_{\eta}(z\\|x)\)와 제너레이터(generator) \(p_{\theta}(y\\|x, z, y_{1:i-1})\)의 두 가지 주요 구성 요소로 구성됩니다.
2.1 모델 구조
RAG-Sequence 모델
RAG-Sequence 모델은 하나의 문서를 사용하여 전체 시퀀스를 생성합니다. 이 모델에서 검색된 문서는 단일 잠재 변수로 취급되며, seq2seq 확률 \(p(y\\|x)\)을 계산하기 위해 주어진 문서에 대한 출력 시퀀스 확률을 취합합니다. 수학적으로 다음과 같이 표현됩니다.
\[p_{\text{RAG-Sequence}}(y\\|x) \approx \sum_{z \in \text{top-k}(p(\cdot\\|x))} p_{\eta}(z\\|x) \prod_{i=1}^N p_{\theta}(y_i\\|x, z, y_{1:i-1})\]\(\text{top-k}(p(\cdot\\|x))\)는 입력 \(x\)에 대해 가장 가능성 높은 상위 k개의 문서를 의미하며, 각 문서에 대해 생성된 시퀀스의 확률을 합산합니다.
RAG-Token 모델
RAG-Token 모델은 각 타겟 토큰마다 다른 문서를 사용할 수 있습니다. 이를 통해 제너레이터는 다양한 문서의 내용을 선택하여 답변을 생성할 수 있습니다. 수학적으로는 다음과 같이 정의됩니다.
\[p_{\text{RAG-Token}}(y\\|x) \approx \prod_{i=1}^N \sum_{z \in \text{top-k}(p(\cdot\\|x))} p_{\eta}(z\\|x) p_{\theta}(y_i\\|x, z, y_{1:i-1})\]이 경우 각 토큰마다 최적의 문서가 선택되어 종합적인 시퀀스 생성에 기여합니다.
2.2 리트리버: DPR(Dense Passage Retriever)
DPR은 쿼리 \(x\)에 따라 문서 \(z\)를 검색하는 데 사용되는 리트리버입니다. 이는 두 개의 BERT 모델을 기반으로 하는 양방향 인코더 구조를 따릅니다. (\(\mathbf{d}(z)\)는 문서 인코더에 의해 생성된 문서의 밀집 표현이고, \(\mathbf{q}(x)\)는 쿼리 인코더에 의해 생성된 쿼리의 표현)
\[p_{\eta}(z\\|x) \propto \exp(\mathbf{d}(z)^\top \mathbf{q}(x))\]MIPS(Maximum Inner Product Search) 문제를 통해 상위 k개 문서를 효율적으로 검색합니다.
2.3 제너레이터: BART
제너레이터는 입력 \(x\)와 검색된 문서 \(z\)를 결합하여 출력 시퀀스 \(y\)를 생성합니다. BART-large 모델을 사용하여 이런 기능을 수행하며, 다양한 노이징 함수를 사용한 사전 훈련을 통해 다양한 생성 작업에서 최고의 성능을 보여줍니다.
2.4 훈련
리트리버와 제너레이터를 동시에 훈련하여 입력/출력 쌍 \((x_j, y_j)\)에 대한 음의 마진 로그-우도를 최소화합니다.
\[\sum_j -\log p(y_j\\|x_j)\]이 과정은 Adam optimizer를 사용하여 수행됩니다. 문서 인코더는 훈련 비용이 높기 때문에 고정되며, 쿼리 인코더와 BART 제너레이터만 파인튜닝됩니다.
2.5 디코딩
테스트 시, RAG-Sequence와 RAG-Token 모델은 다른 방식으로 \(\text{arg max} \, p(y\\|x)\)를 근사합니다. RAG-Token은 각 문서에 대해 표준 빔 디코더를 사용하여 토큰을 순차적으로 생성하고, RAG-Sequence는 각 문서를 개별적으로 평가하여 가장 가능성 높은 시퀀스를 선택합니다.
이런 방법은 입력 시퀀스에 기반한 문서 검색과 해당 문서를 활용한 목표 시퀀스의 생성을 수학적으로 효과적으로 연결하며, 복잡한 자연어 처리 작업에서의 응용 가능성을 제시합니다.
3. 실험
RAG(Retrieval-Augmented Generation) 모델은 다양한 지식 집약적 작업에서 실험되었습니다. 모든 실험에서는 비파라메트릭 지식 출처로 단일 위키백과 덤프를 사용하였으며, 이는 2018년 12월의 덤프를 기반으로 합니다. 각 위키백과 기사는 100단어로 분리되어 총 2100만 문서를 형성합니다. 이 문서들은 문서 인코더를 사용하여 임베딩을 계산하고, FAISS를 사용한 MIPS 인덱스를 구축하여 빠른 검색을 가능하게 합니다. 훈련 중에는 각 쿼리에 대해 상위 k개 문서를 검색하며, k는 {5,10}로 설정하고 테스트 시에는 개발 데이터를 사용하여 k를 설정합니다.
3.1 오픈 도메인 질의응답
오픈 도메인 질의응답(QA)은 지식 집약적 작업에 중요한 실제 응용 프로그램입니다. 질문과 답변을 입력-출력 텍스트 쌍으로 처리하고 RAG를 통해 답변의 음의 로그 가능성을 직접 최소화하면서 훈련합니다. 이는 Natural Questions(NQ), TriviaQA(TQA), WebQuestions(WQ), CuratedTrec(CT)와 같은 주요 오픈 도메인 QA 데이터셋을 대상으로 합니다. 또한, 기존의 추출 QA 패러다임과 “Closed-Book QA” 접근 방식과 비교하며, 후자는 검색을 활용하지 않고 오로지 파라메트릭 지식에 의존합니다.
3.2 추상적 질의응답
RAG 모델은 간단한 추출 QA를 넘어 자유 형식의 추상적 텍스트 생성으로 질문에 답할 수 있습니다. 이를 위해 MSMARCO NLG v2.1 태스크를 사용하며, 이는 검색 엔진에서 검색된 10개의 금 문서와 함께 질문과 완전한 문장 답변이 포함됩니다. RAG는 이 문서들을 사용하지 않고 질문과 답변만을 사용하여 오픈 도메인 추상적 QA 태스크로 처리합니다.
3.3 지퍼디 질문 생성
지퍼디 형식은 주어진 사실에 대해 엔티티를 추측하는 독특한 형식을 포함합니다. RAG는 지퍼디 질문 생성이라는 새로운 태스크에 대한 생성 능력을 평가하기 위해 사용되며, 이는 기존의 오픈 도메인 QA 태스크에서 사용되는 짧고 간단한 질문들과는 다릅니다. BART 모델과 비교하며, 질문 생성에 대한 휴먼 평가를 두 차례 실시합니다.
3.4 사실 검증
FEVER 태스크는 위키백과를 기반으로 자연어 주장이 지지되거나 반박될 수 있는지를 분류합니다. 이는 검색 문제와 인퍼런스 문제를 결합한 도전적인 과제로, RAG 모델이 생성이 아닌 분류 작업을 처리할 수 있는 능력을 탐구하는 데 적합한 테스트베드를 제공합니다. RAG는 검색된 증거에 대한 감독 없이도 이 태스크를 수행할 수 있으며, 실제 세계에서 널리 적용될 수 있는 모델을 개발하는 데 중요합니다.
각 실험은 특정 수학적 프로세스를 따릅니다. 예를 들어, RAG 모델의 훈련은 다음과 같은 최적화 문제를 해결합니다.
\[\min_{\theta, \eta} \sum_{j} -\log p_{\theta, \eta}(y_j \\| x_j)\]이 최적화는 효율적인 정보 검색과 정확한 답변 생성을 보장하기 위해 고안되었습니다.
(\(p_{\theta, \eta}(y_j \\| x_j)\)는 입력 \(x_j\)에 대한 출력 \(y_j\)의 조건부 확률을 나타내며, RAG 모델의 두 주요 구성 요소인 리트리버와 제너레이터의 파라미터 \(\theta\)와 \(\eta\)에 의해 결정)
이와 같은 방법은 다양한 지식 기반 태스크에서 RAG 모델의 범용성과 효과를 입증하는 데 중요한 역할을 합니다.
4. 결과 분석
- RAG는 오픈 도메인 질문 답변에서 새로운 기준을 설정
- 서술형 및 Jeopardy 질문 생성 작업에서 BART를 상회
- 사실 검증과 생성 다양성에서 경쟁력 있는 성능을 보임.
4.1 오픈 도메인 질문 답변
RAG (Retrieval-Augmented Generation) 모델은 최신의 오픈 도메인 질문 답변(QA) 작업에서 새로운 기준을 설정하였습니다. RAG는 폐쇄형 질문 답변 방식의 유연성과 개방형 검색 기반 접근 방식의 성능을 결합하여, 고비용의 특수 전처리 기법인 ‘salient span masking’ 없이도 향상된 결과를 보여줍니다. RAG는 자연 질문(Natural Questions)과 트리비아QA(TriviaQA)에 대한 검색 지도를 통해 초기화된 DPR의 검색 엔진을 사용하며, BERT 기반 ‘crossencoder’를 사용하는 DPR QA 시스템과 비교해도 유리합니다.
4.2 서술형 질문 답변
RAG-Sequence 모델은 Open MS-MARCO NLG에서 BART 모델을 상회하는 성능을 보여줍니다. 이는 RAG 모델이 다양한 문서를 통해 정답을 생성할 수 있으며, 심지어 정답이 문서에 명시적으로 나타나지 않는 경우에도 정확한 답변을 생성할 수 있다는 것을 의미합니다.
4.3 Jeopardy 질문 생성
RAG 모델은 Jeopardy 질문 생성 작업에서 BART보다 더 구체적이고 사실적인 답변을 생성합니다. 특히 RAG-Token은 여러 문서의 내용을 통합하여 응답을 생성하는 능력에서 우수함을 보였습니다.
4.4 사실 검증
FEVER 데이터셋을 사용한 3-방향 분류 작업에서 RAG는 복잡한 파이프라인 시스템과 비교하여 경쟁력 있는 결과를 보여주었습니다. RAG는 자체적으로 증거를 검색하여 주장의 진위를 판별하는데, 이는 중요한 기능입니다.
4.5 추가 결과: 생성 다양성 및 검색 변형
RAG는 생성된 문장의 다양성에서도 BART를 능가합니다. 이는 모델이 다양한 문서에서 정보를 수집하여 더 풍부하고 다채로운 텍스트를 생성할 수 있음을 보여줍니다. 또한, 검색 엔진을 고정시키는 실험을 통해 학습된 검색이 성능 향상에 기여함을 확인하였습니다.
RAG의 성능 향상은 다음과 같은 수학적 과정으로 설명될 수 있습니다.
\(p(y \\| x) = \sum_{z} p(y \\| x, z) p(z \\| x)\) $x$는 입력 질문, $y$는 생성된 답변, $z$는 검색된 문서입니다. 이 공식은 RAG가 문서 $z$를 조건으로 하여 답변 $y$의 확률을 모델링한다는 것을 나타냅니다. 각 문서의 확률 $p(z \| x)$는 입력 질문에 기반하여 계산되며, 이를 통해 모델은 다양한 문서의 정보를 통합하여 최종 답변을 생성할 수 있습니다.
이런 성능은 RAG가 효과적으로 다양한 문서에서 정보를 수집하고 통합하여 보다 정확하고 다양한 답변을 생성할 수 있기 때문입니다.
5. 관련 연구
단일 작업 검색
이전 연구들은 다양한 자연어 처리(NLP) 작업에서 검색 기능이 성능 향상에 도움이 된다고 보고했습니다. 이런 작업들은 다음과 같습니다.
- 오픈 도메인 질문 답변 [5, 29]
- 팩트 체크 [56]
- 팩트 완성 [48]
- 장문형 질문 답변 [12]
- 위키백과 글 생성 [36]
- 대화 생성 [41, 65, 9, 13]
- 번역 [17]
- 언어 모델링 [19, 27]
이런 성공 사례들을 통합하여, 단일 검색 기반 아키텍처가 다양한 작업에서 강력한 성능을 낼 수 있음을 보여줍니다.
다목적 NLP 아키텍처
검색 기능을 사용하지 않고도 NLP 작업에 대한 일반적인 아키텍처가 큰 성공을 거두었습니다. 사전 훈련된 단일 언어 모델은 GLUE 벤치마크의 다양한 분류 작업에서 파인튜닝 후 강력한 성능을 보였습니다 [60, 61, 49, 8]. 이후 GPT-2 [50]는 사전 훈련된 좌-우 방향의 단일 언어 모델이 차별화 및 생성 작업 모두에서 우수한 성능을 달성할 수 있음을 보여주었습니다. 더 나아가 BART [32]와 T5 [51, 52]는 양방향 어텐션을 활용하여 차별화 및 생성 작업에서 더 강력한 성능을 내는 사전 훈련된 인코더-디코더 모델을 제안합니다.
검색 학습
최근 정보 검색 분야에서는 사전 훈련된 신경 언어 모델을 사용하여 문서 검색을 학습하는 데 중요한 작업이 이루어지고 있습니다 [44, 26]. 일부 연구는 질문 답변과 같은 특정 downstream 작업을 지원하기 위해 검색 모듈을 최적화하며, 검색 [46], 강화 학습 [6, 63, 62], 잠재 변수 접근 방식 [31, 20] 등 다양한 방법을 사용합니다. 이런 성공은 다양한 검색 기반 아키텍처와 최적화 기술을 활용하여 단일 작업에서 강력한 성능을 달성합니다.
메모리 기반 아키텍처
문서 색인은 신경망이 참조할 수 있는 큰 외부 메모리로 볼 수 있으며, 이는 메모리 네트워크 [64, 55]와 유사합니다. 동시에 진행된 작업 [14]은 원시 텍스트를 검색하는 대신 입력에 대한 각 엔티티의 훈련된 임베딩을 검색하도록 학습합니다. 다른 작업은 사실 임베딩에 주목하여 대화 모델이 사실적인 텍스트를 생성할 수 있도록 향상시킵니다 [15, 13].
검색 및 편집 접근 방식
방법은 검색 및 편집 스타일 접근 방식과 일부 유사점을 공유합니다. 이런 접근 방식은 기계 번역 [18, 22], 의미 파싱 [21] 등 여러 분야에서 성공적으로 증명되었습니다. 본 논문의 접근 방식은 검색된 항목을 가볍게 편집하는 데 중점을 두기보다는 여러 검색된 콘텐츠에서 콘텐츠를 집계하는 데 중점을 두고 있으며, 잠재 검색을 학습하고 관련 훈련 쌍이 아닌 증거 문서를 검색합니다. 이런 기술은 RAG 기술에서도 잘 작동할 수 있으며, 앞으로의 연구에 유망한 방향을 제시할 수 있습니다.
6. 논의 및 결론
본 연구는 검색 기능을 통합한 생성 모델이 다양한 지식 기반 NLP 작업에서 어떻게 효과적으로 작동할 수 있는지를 확인합니다.
RAG 모델은 다른 생성 모델과 비교하여 더 사실적이고 구체적인 결과를 생성하며, 지속적으로 변화하는 세계에 대응하여 모델의 지식을 업데이트할 수 있는 능력을 제공합니다.
[참고자료 1] MIPS(Maximum Inner Product Search)
거대한 데이터셋에서 가장 유사한 아이템을 빠르게 찾아내야 하는 문제가 주어질 때, 이를 해결하는 방법 중 하나가 MIPS(Maximum Inner Product Search)입니다. MIPS는 벡터 간의 내적을 최대화하는 아이템을 찾는 과정을 포함하며, 추천 시스템, 정보 검색, 데이터베이스 등 여러 분야에서 활용됩니다.
MIPS는 두 벡터의 내적 값을 최대화하는 항목을 찾는 문제입니다. 내적 값이 클수록 두 벡터는 ‘유사하다’라고 간주됩니다. 즉, 한 벡터를 고정시키고 다른 벡터들 중에서 이 고정된 벡터와 내적 값이 가장 큰 벡터를 찾아내는 것이 MIPS의 목표입니다.
내적의 수학적 정의
벡터 $\mathbf{u}$와 $\mathbf{v}$의 내적은 다음과 같이 정의되며,
\[\langle \mathbf{u}, \mathbf{v} \rangle = \sum_{i=1}^{d} u_i v_i\]상기 식에서 $d$는 벡터의 차원 수이며, $u_i$와 $v_i$는 각각 벡터 $\mathbf{u}$와 $\mathbf{v}$의 $i$번째 요소
MIPS의 응용
- 추천 시스템: 사용자의 특성 벡터(e.g., 사용자의 선호도를 나타내는 벡터)와 아이템의 특성 벡터(e.g., 영화의 특성을 나타내는 벡터) 사이의 내적을 계산하여, 사용자에게 가장 관련성 높은 아이템을 추천할 수 있습니다.
- 정보 검색: 문서의 벡터화된 표현 간의 내적을 통해 가장 관련 높은 문서를 찾을 수 있습니다.
간단한 예시
다음과 같은 두 벡터가 있다고 가정하고,
- $\mathbf{u} = [1, 2, 3]$
- $\mathbf{v} = [4, 5, 6]$
이 두 벡터의 내적을 계산하면 다음과 같이 계산할 수 있습니다. \(\langle \mathbf{u}, \mathbf{v} \rangle = 1 \times 4 + 2 \times 5 + 3 \times 6 = 4 + 10 + 18 = 32\)
벡터 정규화와 내적 최대화
벡터를 정규화한 후 내적을 수행하는 경우, 내적의 값은 두 벡터 간의 코사인 유사도와 동일해집니다. 이는 두 벡터의 방향성이 얼마나 유사한지를 나타내며, 수식은 다음과 같이 표현할 수 있습니다.
\[\cos( ext) = \frac{\langle \mathbf{u}, \mathbf{v} \rangle}{\\\|\mathbf{u}\\\| \\\|\mathbf{v}\\\|}\]$\|\mathbf{u}\|$와 $\|\mathbf{v}\|$는 각각 벡터 $\mathbf{u}$와 $\mathbf{v}$의 Euclidean Norm(distance)입니다. 두 벡터를 정규화하면 $\|\mathbf{u}\| = \|\mathbf{v}\| = 1$이 되어, 내적 값은 벡터 간 각도의 코사인 값과 동일하게 됩니다.
- $\cos( ext)$: 두 벡터 간 각도의 코사인 값을 나타내며, 이 값이 1에 가까울수록 두 벡터의 방향성이 유사함을 의미합니다.
- $\theta$: 두 벡터 사이의 각도
[참고자료 2] Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models from Meta
자연어 처리(Natural Language Processing, NLP)는 휴먼의 글과 말을 이해하도록 컴퓨터를 교육하는 과정으로, 인공지능 연구의 가장 오래된 도전 중 하나입니다. 최근 2년 동안 이 분야의 접근 방식에는 현저한 변화가 있었습니다. 특정 작업에 맞춘 특정 프레임워크를 개발하는 데 집중했던 과거와 달리, 현재는 다양한 작업에 적용할 수 있는 강력한 범용 언어 모델이 개발되어 왔습니다. 이런 모델은 사람이 추가적인 배경 지식 없이도 해결할 수 있는 작업(e.g., 감정 분석)에 적용되어 왔습니다.
1. RAG 모델의 개념과 구조
- RAG 모델은 Facebook AI의 밀집 단락 검색 시스템(Dense-Passage Retrieval System)과 양방향 자동 회귀 트랜스포머(Bidirectional and Auto-Regressive Transformers, BART) 모델을 결합한 것입니다.
- 이 모델은 엔드 투 엔드(end-to-end)로 미분 가능하며, 정보 검색 구성 요소와 seq2seq 생성기를 통합합니다.
2. 작동 원리
- RAG는 표준 seq2seq 모델처럼 입력 시퀀스를 받아 해당하는 출력 시퀀스를 생성합니다. 그러나 입력을 직접 생성기로 전달하는 대신, RAG는 입력을 사용하여 관련 문서(e.g., 위키피디아 문서)를 검색합니다.
- 검색된 문서는 원래 입력과 함께 연결되어 seq2seq 모델에 전달됩니다. 이 모델은 실제 출력을 생성합니다.
3. 지식 통합 방식
- RAG는 두 가지 유형의 지식을 활용합니다. 모델의 파라미터에 저장된 지식(파라미터 메모리)과 RAG가 검색을 통해 획득하는 문서에 저장된 지식(비파라미터 메모리).
- 이 두 지식 소스는 서로 보완적으로 작용하여, “닫힌 책” 접근 방식과 “열린 책” 접근 방식의 장점을 결합합니다.
4. 성능 향상과 유연성
- RAG는 검색된 문서에서 답을 인퍼런스하는 능력을 통해, 기존의 seq2seq 모델보다 더 정확하고 다양한 답변을 생성할 수 있습니다.
- 또한, RAG는 사용하는 문서를 교체함으로써 모델이 알고 있는 정보를 쉽게 조정하거나 보완할 수 있습니다. 이는 시간과 계산 자원을 절약하면서도 모델의 지식을 최신 상태로 유지할 수 있게 합니다.
5. 실제 적용 사례
- 자연어 질문 대답: RAG는 자연어 질문에 대한 답을 생성할 때 문서에서 직접적인 답을 찾아내지 못하는 경우에도 정확한 답을 생성할 수 있는 능력을 보여주었습니다.
- 지식 집약적 자연어 생성: 예를 들어, “Jeopardy!” 질문 생성에서 RAG는 표준 seq2seq 모델보다 더 구체적이고 다양하며 사실적인 질문을 생성할 수 있습니다.
효율적인 지식 접근으로 AI 연구의 부담 완화
인공지능 비서가 일상생활에서 더 유용한 역할을 수행하려면, 방대한 정보에 접근할 뿐만 아니라 올바른 정보에 접근하는 능력이 필수적입니다. 세계가 빠르게 변화함에 따라, 사소한 변경에도 계산 집약적인 재훈련을 요구하는 기존의 사전 훈련된 모델로는 도전적인 부분이 많습니다.
RAG는 NLP 모델이 재훈련 단계를 우회하고 최신 정보에 접근하여 사용할 수 있게 함으로써, 이런 문제를 해결합니다. 또한, 최신의 seq2seq 생성기를 사용해 결과를 출력함으로써, 미래의 NLP 모델이 더 적응력 있게 만드는 데 기여합니다. 실제로, 페이스북 AI 연구 프로젝트의 Fusion-in-Decoder에서 이미 강력한 결과를 보았습니다.
RAG의 특징 및 통합 가능성
- 접근성: RAG는 오늘날 허깅페이스의 트랜스포머 라이브러리의 일부로 공개되었습니다. 이 라이브러리는 오픈소스 NLP의 사실상의 표준이 되었으며, 접근성이 낮고 최신 모델을 다루고 있습니다. 또한 새로운 ‘Datasets’ 라이브러리와 통합되어 RAG가 의존하는 인덱싱된 지식 소스를 제공합니다.
- 코드의 간결성: 연구자와 엔지니어는 단 몇 줄의 코드로 자신의 지식 집약적 작업에 대한 솔루션을 빠르게 개발하고 배포할 수 있습니다. 이는 RAG를 사용하여 지금까지 탐색한 작업뿐만 아니라 아직 상상조차 하지 못한 작업에도 검색 기반 생성을 적용할 수 있게 합니다.
RAG의 미래 방향과 연구 전망
- RAG의 검색 구성 요소를 개선하고, 검색 코퍼스와 모델을 확장하며, KILT 벤치마크와 같은 지식 벤치마크에서 RAG의 전반적인 성능을 향상시키는 데 계속해서 집중할 계획입니다.
- 현재 감정 분석과 같은 경량 지식 작업이 접근하기 쉬운 것처럼, 지식 집약적 작업도 접근하기 쉽고 실행하기 쉬워질 것으로 예상됩니다.
결론
RAG는 AI 연구에 있어서 효율적인 지식 접근을 가능하게 하며, NLP 모델이 보다 신속하고 정확하게 정보를 처리하고 생성할 수 있도록 지원합니다. 이를 통해 AI 비서의 역할이 확장되고, 실제 사용자의 요구에 더욱 민첩하게 대응할 수 있을 것입니다. RAG 모델은 자연어 처리 분야에서의 새로운 가능성을 열어주며, 다양한 형태의 지식을 유연하게 통합할 수 있는 강력한 도구입니다. 이 모델은 특히 지식이 시간에 따라 진화하는 분야에서 유용하며, 연구 및 실제 응용 분야에서 그 가능성을 계속 확장하고 있습니다.
[참고자료 3] Picking a vector database: a comparison and guide for 2023
1. 벡터 데이터베이스란?
벡터 데이터베이스는 의미적 검색(semantic search)과 검색 강화 생성(Retrieval-Augmented Generation, RAG) 같은 기술에 근간을 두고 있습니다. 이런 데이터베이스는 대규모 언어모델, RAG, 그리고 다양한 플랫폼에서 의미적 검색을 활용할 때 필수적인 요소입니다.
2. 왜 중요한가?
일상에서 사용하는 많은 온라인 상호작용이 이런 기술에 의존하고 있으며, 이를 지원하는 벡터 데이터베이스 선택은 성능, 비용, 확장성, 그리고 규정 준수에 큰 영향을 미칩니다.
3. 2023년 벡터 데이터베이스 비교
비교 대상
- Pinecone
- Weaviate
- Milvus
- Qdrant
- Chroma
- Elasticsearch
- PGvector
이 데이터는 ANN 벤치마크, 각 데이터베이스의 문서와 내부 벤치마크, 그리고 공개된 GitHub 리포지토리를 통해 수집되었습니다.
주요 특징 비교
| 특징 | Pinecone | Weaviate | Milvus | Qdrant | Chroma | Elasticsearch | PGvector |
|---|---|---|---|---|---|---|---|
| 오픈소스 여부 | ❌ | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ |
| 자체 호스팅 | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 클라우드 관리 | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | (✔️) |
| 벡터 전용 | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ |
| 개발자 경험 | 👍👍👍 | 👍👍 | 👍👍 | 👍👍 | 👍👍 | 👍 | 👍 |
| 커뮤니티 활성도 | 페이지 & 이벤트 | 8K ☆ GitHub, 4K Slack | 23K ☆ GitHub, 4K Slack | 13K ☆ GitHub, 3K Discord | 9K ☆ GitHub, 6K Discord | 23K Slack | 6K ☆ GitHub |
| 초당 쿼리 수 | 150 | 791 | 2406 | 326 | ? | 700-1000 | 141 |
| 지연 시간(ms) | 1 | 2 | 1 | 4 | ? | ? | 8 |
| 지원 인덱스 타입 | ? | HNSW | 다양함(11개) | HNSW | HNSW | HNSW | HNSW/IVFFlat |
| 하이브리드 검색 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 디스크 인덱스 지원 | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
| 역할 기반 접근 제어 | ✅ | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ |
| 데이터 샤딩 방식 | ? | 정적 | 동적 | 정적 | 동적 | 정적 | - |
4. 벡터 데이터베이스 선택시 고려사항
오픈 소스 및 호스팅
- 오픈 소스: Weaviate, Milvus, Chroma가 강력한 오픈 소스 옵션입니다.
- 호스팅: Pinecone은 개발자 경험과 완벽한 호스팅 솔루션에서 뛰어납니다.
성능 및 커뮤니티
- 성능: 초당 쿼리 수에서는 Milvus가 가장 우수하며, 지연 시간에서는 Pinecone과 Milvus가 각각 2ms 이하의 인상적인 결과를 보여줍니다.
- 커뮤니티: Milvus는 가장 큰 커뮤니티를 자랑하며, 이는 지원과 개선에 큰 장점을 제공합니다.
확장성 및 보안 기능
- 보안: 역할 기반 접근 제어는 Pinecone, Milvus, Elasticsearch에서 제공됩니다.
- 확장성: 데이터셋이 계속해서 발전함에 따라, Milvus와 Chroma는 동적 세그먼트 배치를 제공합니다.
가격
- 저렴한 가격: Qdrant는 50k 벡터에 대해 $9로 시작하는 경쟁력 있는 가격을 제공합니다.
- 고성능 필요 시: 대규모 프로젝트를 위한 Pinecone과 Milvus의 경쟁력 있는 가격대도 주목할 만합니다.
5. 결론
벡터 데이터베이스 선택은 프로젝트의 특정 요구 사항, 예산 제약, 개인적인 선호도에 따라 달라질 수 있습니다. 이 가이드는 2023년 주요 벡터 데이터베이스를 통해 개발자들의 결정 과정을 간소화하고자 합니다.
References
Picking a vector database: a comparison and guide for 2023
- KDNuggets
- ANN Benchmarks
- Qdrant Benchmarks
- Zilliz Comparison
- GitHub 및 각 데이터베이스의 문서
1 Introduction
Pre-trained neural language models have been shown to learn a substantial amount of in-depth knowledge from data [47]. They can do so without any access to an external memory, as a parameterized implicit knowledge base [51, 52]. While this development is exciting, such models do have down-sides: They cannot easily expand or revise their memory, can’t straightforwardly provide insight into their predictions, and may produce “hallucinations” [38]. Hybrid models that combine parametric memory with non-parametric (i.e., retrieval-based) memories [20, 26, 48] can address some of these issues because knowledge can be directly revised and expanded, and accessed knowledge can be inspected and interpreted. REALM [20] and ORQA [31], two recently introduced models that combine masked language models [8] with a differentiable retriever, have shown promising results, but have only explored open-domain extractive question answering. Here, we bring hybrid parametric and non-parametric memory to the “workhorse of NLP,” i.e. sequence-to-sequence (seq2seq) models.
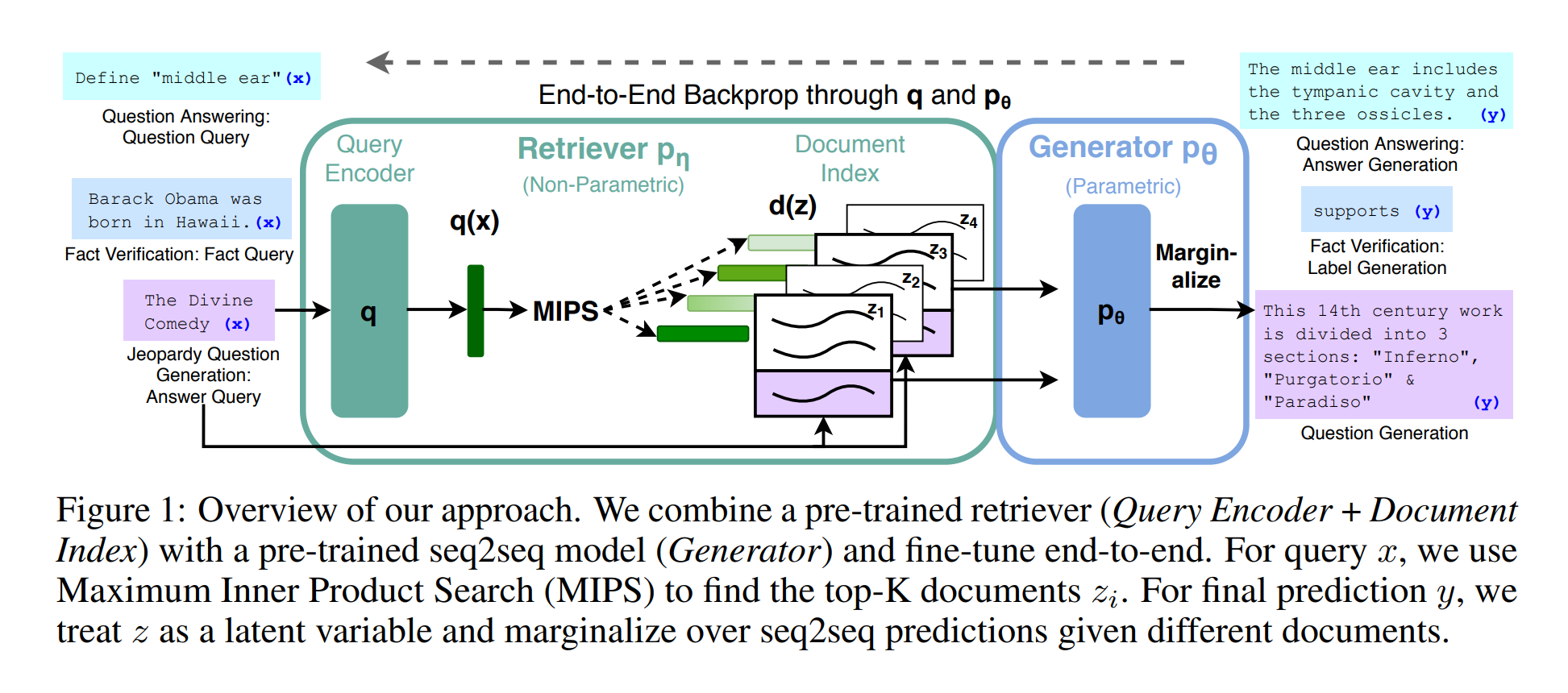
Figure 1: Overview of our approach. We combine a pre-trained retriever (Query Encoder + Document Index) with a pre-trained seq2seq model (Generator) and fine-tune end-to-end. For query x, we use Maximum Inner Product Search (MIPS) to find the top-K documents zi. For final prediction y, we treat z as a latent variable and marginalize over seq2seq predictions given different documents.
We endow pre-trained, parametric-memory generation models with a non-parametric memory through a general-purpose fine-tuning approach which we refer to as retrieval-augmented generation (RAG). We build RAG models where the parametric memory is a pre-trained seq2seq transformer, and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. We combine these components in a probabilistic model trained end-to-end (Fig. 1). The retriever (Dense Passage Retriever [26], henceforth DPR) provides latent documents conditioned on the input, and the seq2seq model (BART [32]) then conditions on these latent documents together with the input to generate the output. We marginalize the latent documents with a top-K approximation, either on a per-output basis (assuming the same document is responsible for all tokens) or a per-token basis (where different documents are responsible for different tokens). Like T5 [51] or BART, RAG can be fine-tuned on any seq2seq task, whereby both the generator and retriever are jointly learned.
There has been extensive previous work proposing architectures to enrich systems with non-parametric memory which are trained from scratch for specific tasks, e.g. memory networks [64, 55], stackaugmented networks [25] and memory layers [30]. In contrast, we explore a setting where both parametric and non-parametric memory components are pre-trained and pre-loaded with extensive knowledge. Crucially, by using pre-trained access mechanisms, the ability to access knowledge is present without additional training.
Our results highlight the benefits of combining parametric and non-parametric memory with generation for knowledge-intensive tasks—tasks that humans could not reasonably be expected to perform without access to an external knowledge source. Our RAG models achieve state-of-the-art results on open Natural Questions [29], WebQuestions [3] and CuratedTrec [2] and strongly outperform recent approaches that use specialised pre-training objectives on TriviaQA [24]. Despite these being extractive tasks, we find that unconstrained generation outperforms previous extractive approaches. For knowledge-intensive generation, we experiment with MS-MARCO [1] and Jeopardy question generation, and we find that our models generate responses that are more factual, specific, and diverse than a BART baseline. For FEVER [56] fact verification, we achieve results within 4.3% of state-of-the-art pipeline models which use strong retrieval supervision. Finally, we demonstrate that the non-parametric memory can be replaced to update the models’ knowledge as the world changes.1
2 Methods
We explore RAG models, which use the input sequence x to retrieve text documents z and use them as additional context when generating the target sequence y. As shown in Figure 1, our models leverage two components: (i) a retriever pη(z\\|x) with parameters η that returns (top-K truncated) distributions over text passages given a query x and (ii) a generator pθ(yi\\|x, z, y1:i−1) parametrized by θ that generates a current token based on a context of the previous i−1 tokens y1:i−1, the original input x and a retrieved passage z.
1 Code to run experiments with RAG has been open-sourced as part of the HuggingFace Transformers Library [66] and can be found at https://github.com/huggingface/transformers/blob/master/examples/rag/ An interactive demo of RAG models can be found at https://huggingface.co/rag/
To train the retriever and generator end-to-end, we treat the retrieved document as a latent variable. We propose two models that marginalize over the latent documents in different ways to produce a distribution over generated text. In one approach, RAG-Sequence, the model uses the same document to predict each target token. The second approach, RAG-Token, can predict each target token based on a different document. In the following, we formally introduce both models and then describe the pη and pθ components, as well as the training and decoding procedure.
2.1 Models
RAG-Sequence Model The RAG-Sequence model uses the same retrieved document to generate the complete sequence. Technically, it treats the retrieved document as a single latent variable that is marginalized to get the seq2seq probability p(y\\|x) via a top-K approximation. Concretely, the top K documents are retrieved using the retriever, and the generator produces the output sequence probability for each document, which are then marginalized,
RAG-Token Model In the RAG-Token model we can draw a different latent document for each target token and marginalize accordingly. This allows the generator to choose content from several documents when producing an answer. Concretely, the top K documents are retrieved using the retriever, and then the generator produces a distribution for the next output token for each document, before marginalizing, and repeating the process with the following output token, Formally, we define:
Finally, we note that RAG can be used for sequence classification tasks by considering the target class as a target sequence of length one, in which case RAG-Sequence and RAG-Token are equivalent.
2.2 Retriever: DPR
where d(z) is a dense representation of a document produced by a BERTBASE document encoder [8], and q(x) a query representation produced by a query encoder, also based on BERTBASE. Calculating top-k(pη(·\\|x)), the list of k documents z with highest prior probability pη(z\\|x), is a Maximum Inner Product Search (MIPS) problem, which can be approximately solved in sub-linear time [23]. We use a pre-trained bi-encoder from DPR to initialize our retriever and to build the document index. This retriever was trained to retrieve documents which contain answers to TriviaQA [24] questions and Natural Questions [29]. We refer to the document index as the non-parametric memory.
2.3 Generator: BART
The generator component pθ(yi\\|x, z, y1:i−1) could be modelled using any encoder-decoder. We use BART-large [32], a pre-trained seq2seq transformer [58] with 400M parameters. To combine the input x with the retrieved content z when generating from BART, we simply concatenate them. BART was pre-trained using a denoising objective and a variety of different noising functions. It has obtained state-of-the-art results on a diverse set of generation tasks and outperforms comparably-sized T5 models [32]. We refer to the BART generator parameters θ as the parametric memory henceforth.
2.4 Training
We jointly train the retriever and generator components without any direct supervision on what document should be retrieved. Given a fine-tuning training corpus of input/output pairs (xj, yj), we minimize the negative marginal log-likelihood of each target, Σ j − log p(yj\\|xj) using stochastic gradient descent with Adam [28]. Updating the document encoder BERTd during training is costly as it requires the document index to be periodically updated as REALM does during pre-training [20]. We do not find this step necessary for strong performance, and keep the document encoder (and index) fixed, only fine-tuning the query encoder BERTq and the BART generator.
2.5 Decoding
At test time, RAG-Sequence and RAG-Token require different ways to approximate arg maxy p(y\\|x).
RAG-Token The RAG-Token model can be seen as a standard, autoregressive seq2seq generator with transition probability: p'z∈top-k(p(·\\|x)) pη(zi\\|x)pθ(yi\\|x, zi, y1:i−1) To decode, we can plug p'θ(yi\\|x, y1:i−1) = Σθ(yi\\|x, y1:i−1) into a standard beam decoder.
RAG-Sequence For RAG-Sequence, the likelihood p(y\\|x) does not break into a conventional pertoken likelihood, hence we cannot solve it with a single beam search. Instead, we run beam search for each document z, scoring each hypothesis using pθ(yi\\|x, z, y1:i−1). This yields a set of hypotheses Y , some of which may not have appeared in the beams of all documents. To estimate the probability of an hypothesis y we run an additional forward pass for each document z for which y does not appear in the beam, multiply generator probability with pη(z\\|x) and then sum the probabilities across beams for the marginals. We refer to this decoding procedure as “Thorough Decoding.” For longer output sequences, \\|Y\\| can become large, requiring many forward passes. For more efficient decoding, we can make a further approximation that pθ(y\\|x, zi) ≈ 0 where y was not generated during beam search from x, zi. This avoids the need to run additional forward passes once the candidate set Y has been generated. We refer to this decoding procedure as “Fast Decoding.”
3 Experiments
We experiment with RAG in a wide range of knowledge-intensive tasks. For all experiments, we use a single Wikipedia dump for our non-parametric knowledge source. Following Lee et al. [31] and Karpukhin et al. [26], we use the December 2018 dump. Each Wikipedia article is split into disjoint 100-word chunks, to make a total of 21M documents. We use the document encoder to compute an embedding for each document, and build a single MIPS index using FAISS [23] with a Hierarchical Navigable Small World approximation for fast retrieval [37]. During training, we retrieve the top k documents for each query. We consider k ∈ {5, 10} for training and set k for test time using dev data. We now discuss experimental details for each task.
3.1 Open-domain Question Answering
Open-domain question answering (QA) is an important real-world application and common testbed for knowledge-intensive tasks [20]. We treat questions and answers as input-output text pairs (x, y) and train RAG by directly minimizing the negative log-likelihood of answers. We compare RAG to the popular extractive QA paradigm [5, 7, 31, 26], where answers are extracted spans from retrieved documents, relying primarily on non-parametric knowledge. We also compare to “Closed-Book QA” approaches [52], which, like RAG, generate answers, but which do not exploit retrieval, instead relying purely on parametric knowledge. We consider four popular open-domain QA datasets: Natural Questions (NQ) [29], TriviaQA (TQA) [24]. WebQuestions (WQ) [3] and CuratedTrec (CT) [2]. As CT and WQ are small, we follow DPR [26] by initializing CT and WQ models with our NQ RAG model. We use the same train/dev/test splits as prior work [31, 26] and report Exact Match (EM) scores. For TQA, to compare with T5 [52], we also evaluate on the TQA Wiki test set.
3.2 Abstractive Question Answering
RAG models can go beyond simple extractive QA and answer questions with free-form, abstractive text generation. To test RAG’s natural language generation (NLG) in a knowledge-intensive setting, we use the MSMARCO NLG task v2.1 [43]. The task consists of questions, ten gold passages retrieved from a search engine for each question, and a full sentence answer annotated from the retrieved passages. We do not use the supplied passages, only the questions and answers, to treat MSMARCO as an open-domain abstractive QA task. MSMARCO has some questions that cannot be answered in a way that matches the reference answer without access to the gold passages, such as “What is the weather in Volcano, CA?” so performance will be lower without using gold passages. We also note that some MSMARCO questions cannot be answered using Wikipedia alone. Here, RAG can rely on parametric knowledge to generate reasonable responses.
3.3 Jeopardy Question Generation
To evaluate RAG’s generation abilities in a non-QA setting, we study open-domain question generation. Rather than use questions from standard open-domain QA tasks, which typically consist of short, simple questions, we propose the more demanding task of generating Jeopardy questions. Jeopardy is an unusual format that consists of trying to guess an entity from a fact about that entity. For example, “The World Cup” is the answer to the question “In 1986 Mexico scored as the first country to host this international sports competition twice.” As Jeopardy questions are precise, factual statements, generating Jeopardy questions conditioned on their answer entities constitutes a challenging knowledge-intensive generation task.
We use the splits from SearchQA [10], with 100K train, 14K dev, and 27K test examples. As this is a new task, we train a BART model for comparison. Following [67], we evaluate using the SQuAD-tuned Q-BLEU-1 metric [42]. Q-BLEU is a variant of BLEU with a higher weight for matching entities and has higher correlation with human judgment for question generation than standard metrics. We also perform two human evaluations, one to assess generation factuality, and one for specificity. We define factuality as whether a statement can be corroborated by trusted external sources, and specificity as high mutual dependence between the input and output [33]. We follow best practice and use pairwise comparative evaluation [34]. Evaluators are shown an answer and two generated questions, one from BART and one from RAG. They are then asked to pick one of four options—quuestion A is better, question B is better, both are good, or neither is good.
3.4 Fact Verification
FEVER [56] requires classifying whether a natural language claim is supported or refuted by Wikipedia, or whether there is not enough information to decide. The task requires retrieving evidence from Wikipedia relating to the claim and then reasoning over this evidence to classify whether the claim is true, false, or unverifiable from Wikipedia alone. FEVER is a retrieval problem coupled with an challenging entailment reasoning task. It also provides an appropriate testbed for exploring the RAG models’ ability to handle classification rather than generation. We map FEVER class labels (supports, refutes, or not enough info) to single output tokens and directly train with claim-class pairs. Crucially, unlike most other approaches to FEVER, we do not use supervision on retrieved evidence. In many real-world applications, retrieval supervision signals aren’t available, and models that do not require such supervision will be applicable to a wider range of tasks. We explore two variants: the standard 3-way classification task (supports/refutes/not enough info) and the 2-way (supports/refutes) task studied in Thorne and Vlachos [57]. In both cases we report label accuracy.
4 Results
s4.1 Open-domain Question Answering
Table 1 shows results for RAG along with state-of-the-art models. On all four open-domain QA tasks, RAG sets a new state of the art (only on the T5-comparable split for TQA). RAG combines the generation flexibility of the “closed-book” (parametric only) approaches and the performance of “open-book” retrieval-based approaches. Unlike REALM and T5+SSM, RAG enjoys strong results without expensive, specialized “salient span masking” pre-training [20]. It is worth noting that RAG’s retriever is initialized using DPR’s retriever, which uses retrieval supervision on Natural Questions and TriviaQA. RAG compares favourably to the DPR QA system, which uses a BERT-based “crossencoder” to re-rank documents, along with an extractive reader. RAG demonstrates that neither a re-ranker nor extractive reader is necessary for state-of-the-art performance.
There are several advantages to generating answers even when it is possible to extract them. Documents with clues about the answer but do not contain the answer verbatim can still contribute towards a correct answer being generated, which is not possible with standard extractive approaches, leading to more effective marginalization over documents. Furthermore, RAG can generate correct answers even when the correct answer is not in any retrieved document, achieving 11.8% accuracy in such cases for NQ, where an extractive model would score 0%.
Table 1: Open-Domain QA Test Scores. For TQA, left column uses the standard test set for OpenDomain QA, right column uses the TQA-Wiki test set. See Appendix D for further details.
Table 2: Generation and classification Test Scores. MS-MARCO SotA is [4], FEVER-3 is [68] and FEVER-2 is [57] *Uses gold context/evidence. Best model without gold access underlined.
4.2 Abstractive Question Answering
As shown in Table 2, RAG-Sequence outperforms BART on Open MS-MARCO NLG by 2.6 Bleu points and 2.6 Rouge-L points. RAG approaches state-of-the-art model performance, which is impressive given that (i) those models access gold passages with specific information required to generate the reference answer , (ii) many questions are unanswerable without the gold passages, and (iii) not all questions are answerable from Wikipedia alone. Table 3 shows some generated answers from our models. Qualitatively, we find that RAG models hallucinate less and generate factually correct text more often than BART. Later, we also show that RAG generations are more diverse than BART generations (see §4.5).
4.3 Jeopardy Question Generation
Table 2 shows that RAG-Token performs better than RAG-Sequence on Jeopardy question generation, with both models outperforming BART on Q-BLEU-1. 4 shows human evaluation results, over 452 pairs of generations from BART and RAG-Token. Evaluators indicated that BART was more factual than RAG in only 7.1% of cases, while RAG was more factual in 42.7% of cases, and both RAG and BART were factual in a further 17% of cases, clearly demonstrating the effectiveness of RAG on the task over a state-of-the-art generation model. Evaluators also find RAG generations to be more specific by a large margin. Table 3 shows typical generations from each model.
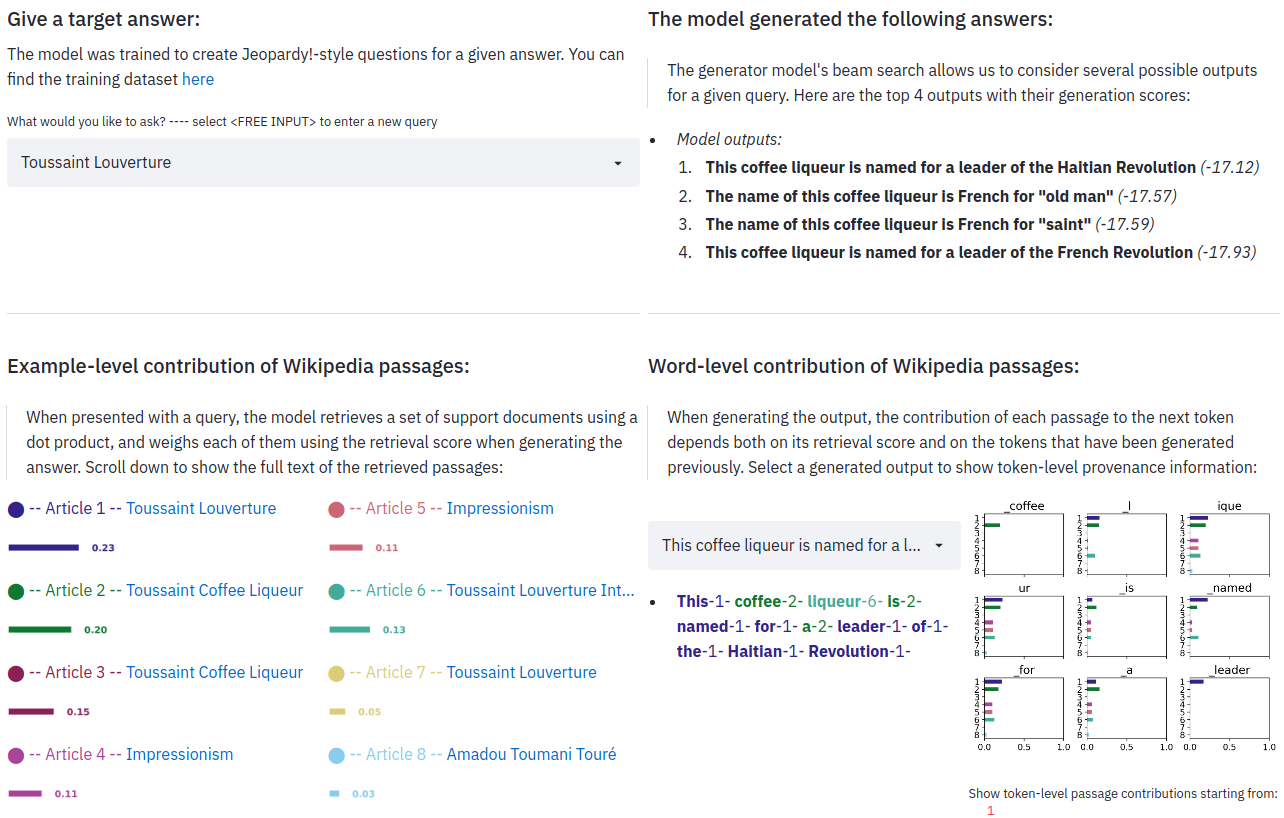
Jeopardy questions often contain two separate pieces of information, and RAG-Token may perform best because it can generate responses that combine content from several documents. Figure 2 shows an example. When generating “Sun”, the posterior is high for document 2 which mentions “The Sun Also Rises”. Similarly, document 1 dominates the posterior when “A Farewell to Arms” is generated. Intriguingly, after the first token of each book is generated, the document posterior flattens. This observation suggests that the generator can complete the titles without depending on specific documents. In other words, the model’s parametric knowledge is sufficient to complete the titles. We find evidence for this hypothesis by feeding the BART-only baseline with the partial decoding “The Sun. BART completes the generation “The Sun Also Rises” is a novel by this author of “The Sun Also Rises” indicating the title “The Sun Also Rises” is stored in BART’s parameters. Similarly, BART will complete the partial decoding “The Sun Also Rises” is a novel by this author of “A with “The Sun Also Rises” is a novel by this author of “A Farewell to Arms”. This example shows how parametric and non-parametric memories work together—the non-parametric component helps to guide the generation, drawing out specific knowledge stored in the parametric memory.
4.4 Fact Verification
Table 2 shows our results on FEVER. For 3-way classification, RAG scores are within 4.3% of state-of-the-art models, which are complex pipeline systems with domain-specific architectures and substantial engineering, trained using intermediate retrieval supervision, which RAG does not require.
Figure 2: RAG-Token document posterior p(zi\\|x, yi, y−i) for each generated token for input “Hemingway” for Jeopardy generation with 5 retrieved documents. The posterior for document 1 is high when generating “A Farewell to Arms” and for document 2 when generating “The Sun Also Rises”.
Table 3: Examples from generation tasks. RAG models generate more specific and factually accurate responses. ‘?’ indicates factually incorrect responses, * indicates partially correct responses.
For 2-way classification, we compare against Thorne and Vlachos [57], who train RoBERTa [35] to classify the claim as true or false given the gold evidence sentence. RAG achieves an accuracy within 2.7% of this model, despite being supplied with only the claim and retrieving its own evidence. We also analyze whether documents retrieved by RAG correspond to documents annotated as gold evidence in FEVER. We calculate the overlap in article titles between the top k documents retrieved by RAG and gold evidence annotations. We find that the top retrieved document is from a gold article in 71% of cases, and a gold article is present in the top 10 retrieved articles in 90% of cases.
4.5 Additional Results
Generation Diversity Section 4.3 shows that RAG models are more factual and specific than BART for Jeopardy question generation. Following recent work on diversity-promoting decoding [33, 59, 39], we also investigate generation diversity by calculating the ratio of distinct ngrams to total ngrams generated by different models. Table 5 shows that RAG-Sequence’s generations are more diverse than RAG-Token’s, and both are significantly more diverse than BART without needing any diversity-promoting decoding.
Retrieval Ablations A key feature of RAG is learning to retrieve relevant information for the task. To assess the effectiveness of the retrieval mechanism, we run ablations where we freeze the retriever during training. As shown in Table 6, learned retrieval improves results for all tasks.
We compare RAG’s dense retriever to a word overlap-based BM25 retriever [53]. Here, we replace RAG’s retriever with a fixed BM25 system, and use BM25 retrieval scores as logits when calculating p(z\\|x). Table 6 shows the results. For FEVER, BM25 performs best, perhaps since FEVER claims are heavily entity-centric and thus well-suited for word overlap-based retrieval. Differentiable retrieval improves results on all other tasks, especially for Open-Domain QA, where it is crucial.
Index hot-swapping An advantage of non-parametric memory models like RAG is that knowledge can be easily updated at test time. Parametric-only models like T5 or BART need further training to update their behavior as the world changes. To demonstrate, we build an index using the DrQA [5] Wikipedia dump from December 2016 and compare outputs from RAG using this index to the newer index from our main results (December 2018). We prepare a list of 82 world leaders who had changed between these dates and use a template “Who is {position}?” (e.g. “Who is the President of Peru?”) to query our NQ RAG model with each index. RAG answers 70% correctly using the 2016 index for 2016 world leaders and 68% using the 2018 index for 2018 world leaders. Accuracy with mismatched indices is low (12% with the 2018 index and 2016 leaders, 4% with the 2016 index and 2018 leaders). This shows we can update RAG’s world knowledge by simply replacing its non-parametric memory.
Table 4: Human assessments for the Jeopardy Question Generation Task.
Table 5: Ratio of distinct to total tri-grams for generation tasks.
Effect of Retrieving more documents Models are trained with either 5 or 10 retrieved latent documents, and we do not observe significant differences in performance between them. We have the flexibility to adjust the number of retrieved documents at test time, which can affect performance and runtime. Figure 3 (left) shows that retrieving more documents at test time monotonically improves Open-domain QA results for RAG-Sequence, but performance peaks for RAG-Token at 10 retrieved documents. Figure 3 (right) shows that retrieving more documents leads to higher Rouge-L for RAG-Token at the expense of Bleu-1, but the effect is less pronounced for RAG-Sequence.
Figure 3: Left: NQ performance as more documents are retrieved. Center: Retrieval recall performance in NQ. Right: MS-MARCO Bleu-1 and Rouge-L as more documents are retrieved.
5 Related Work
Single-Task Retrieval Prior work has shown that retrieval improves performance across a variety of NLP tasks when considered in isolation. Such tasks include open-domain question answering [5, 29], fact checking [56], fact completion [48], long-form question answering [12], Wikipedia article generation [36], dialogue [41, 65, 9, 13], translation [17], and language modeling [19, 27]. Our work unifies previous successes in incorporating retrieval into individual tasks, showing that a single retrieval-based architecture is capable of achieving strong performance across several tasks.
General-Purpose Architectures for NLP Prior work on general-purpose architectures for NLP tasks has shown great success without the use of retrieval. A single, pre-trained language model has been shown to achieve strong performance on various classification tasks in the GLUE benchmarks [60, 61] after fine-tuning [49, 8]. GPT-2 [50] later showed that a single, left-to-right, pre-trained language model could achieve strong performance across both discriminative and generative tasks. For further improvement, BART [32] and T5 [51, 52] propose a single, pre-trained encoder-decoder model that leverages bi-directional attention to achieve stronger performance on discriminative and generative tasks. Our work aims to expand the space of possible tasks with a single, unified architecture, by learning a retrieval module to augment pre-trained, generative language models.
Learned Retrieval There is significant work on learning to retrieve documents in information retrieval, more recently with pre-trained, neural language models [44, 26] similar to ours. Some work optimizes the retrieval module to aid in a specific, down-stream task such as question answering, using search [46], reinforcement learning [6, 63, 62], or a latent variable approach [31, 20] as in our work. These successes leverage different retrieval-based architectures and optimization techniques to achieve strong performance on a single task, while we show that a single retrieval-based architecture can be fine-tuned for strong performance on a variety of tasks.
Memory-based Architectures Our document index can be seen as a large external memory for neural networks to attend to, analogous to memory networks [64, 55]. Concurrent work [14] learns to retrieve a trained embedding for each entity in the input, rather than to retrieve raw text as in our work. Other work improves the ability of dialog models to generate factual text by attending over fact embeddings [15, 13]. A key feature of our memory is that it is comprised of raw text rather distributed representations, which makes the memory both (i) human-readable, lending a form of interpretability to our model, and (ii) human-writable, enabling us to dynamically update the model’s memory by editing the document index. This approach has also been used in knowledge-intensive dialog, where generators have been conditioned on retrieved text directly, albeit obtained via TF-IDF rather than end-to-end learnt retrieval [9].
Retrieve-and-Edit approaches Our method shares some similarities with retrieve-and-edit style approaches, where a similar training input-output pair is retrieved for a given input, and then edited to provide a final output. These approaches have proved successful in a number of domains including Machine Translation [18, 22] and Semantic Parsing [21]. Our approach does have several differences, including less of emphasis on lightly editing a retrieved item, but on aggregating content from several pieces of retrieved content, as well as learning latent retrieval, and retrieving evidence documents rather than related training pairs. This said, RAG techniques may work well in these settings, and could represent promising future work.
6 Discussion
In this work, we presented hybrid generation models with access to parametric and non-parametric memory. We showed that our RAG models obtain state of the art results on open-domain QA. We found that people prefer RAG’s generation over purely parametric BART, finding RAG more factual and specific. We conducted an thorough investigation of the learned retrieval component, validating its effectiveness, and we illustrated how the retrieval index can be hot-swapped to update the model without requiring any retraining. In future work, it may be fruitful to investigate if the two components can be jointly pre-trained from scratch, either with a denoising objective similar to BART or some another objective. Our work opens up new research directions on how parametric and non-parametric memories interact and how to most effectively combine them, showing promise in being applied to a wide variety of NLP tasks.
Broader Impact
This work offers several positive societal benefits over previous work: the fact that it is more strongly grounded in real factual knowledge (in this case Wikipedia) makes it “hallucinate” less with generations that are more factual, and offers more control and interpretability. RAG could be employed in a wide variety of scenarios with direct benefit to society, for example by endowing it with a medical index and asking it open-domain questions on that topic, or by helping people be more effective at their jobs.
With these advantages also come potential downsides: Wikipedia, or any potential external knowledge source, will probably never be entirely factual and completely devoid of bias. Since RAG can be employed as a language model, similar concerns as for GPT-2 [50] are valid here, although arguably to a lesser extent, including that it might be used to generate abuse, faked or misleading content in the news or on social media; to impersonate others; or to automate the production of spam/phishing content [54]. Advanced language models may also lead to the automation of various jobs in the coming decades [16]. In order to mitigate these risks, AI systems could be employed to fight against misleading content and automated spam/phishing.