Model | Code Llama
- Related Project: Private
- Category: Paper Review
- Date: 2023-08-26
Code Llama: Open Foundation Models for Code
- url: https://arxiv.org/abs/2308.12950
- pdf: https://arxiv.org/pdf/2308.12950
- html: https://arxiv.org/html/2308.12950v3
- paper: https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
- github: https://github.com/facebookresearch/codellama
- post: https://ai.meta.com/blog/code-llama-large-language-model-coding/
- abstract: We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.
Contents
TL;DR
CodeLlama: 코드 생성을 위한 Llama2 기반 모델
- 다단계 훈련 및 파인튜닝을 통한 성능 최적화
- 다양한 프로그래밍 벤치마크에서 상위 성능 달성
- License: research and commercial use
- Performance: HumanEval 53%, MBPP 55%
- Model Variations: 7B, 13B, 34B
- Code Llama: foundation model
- Code Llama - Python: Python specializations
- Code Llama - Instruct: Instruction-following models
1 서론
대규모 언어모델(LLM)은 자연어 처리 능력의 향상으로 다양한 응용 프로그램에 활용되고 있습니다. 특히 도메인 특화 데이터셋을 활용한 훈련을 통해 자연어와 도메인 특화 언어 이해를 결합한 응용 프로그램의 효과를 크게 향상시킬 수 있습니다. 이런 모델은 프로그램 합성, 코드 완성, 디버깅, 문서 생성 등 컴퓨터 시스템과의 공식적인 상호작용에서 특히 효과적입니다. (Xu & Zhu, 2022)
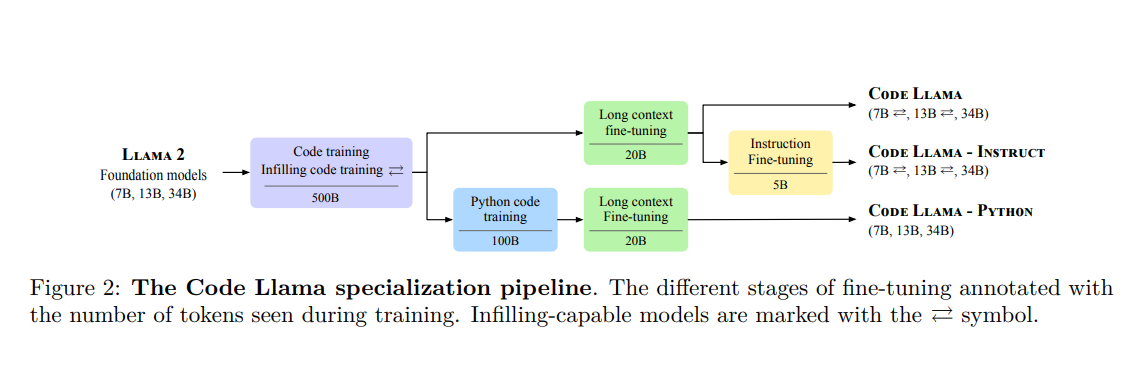
본 연구에서는 Llama2에서 파생된 코드 생성 및 입력을 위한 LLM 패밀리인 CodeLlama를 소개합니다. CodeLlama는 완성 및 입력 모델에 대한 인퍼런스 코드를 제공하며, 동일한 사용자 정의 허가 하에 배포됩니다. 접근 방식은 Llama2 모델의 능력을 점진적으로 전문화하고 향상시키기 위해 다양한 훈련 및 파인튜닝 단계를 적용하는 것에 기반합니다.
주요 개발 단계
-
기초 모델에서의 코드 훈련: 대부분의 코드 생성 LLM은 코드만을 대상으로 훈련되지만, Codex는 일반 언어 모델에서 파인튜닝되었습니다. 범용 텍스트와 코드 데이터에 대해 pre-trained Llama2 모델에서 시작합니다. 이런 접근 방식이 동일한 예산으로 코드만을 대상으로 훈련된 동일한 아키텍처보다 더 나은 성능을 보이는 것으로 나타났습니다. (3.4.1절 참조)
-
입력: LLM의 자동 회귀 훈련과 파인튜닝은 프롬프트 완성에 적합하지만, 전체 주변 맥락을 고려하여 텍스트의 누락된 부분을 채우는 능력은 제공하지 않습니다. 7B 및 13B CodeLlama 모델의 코드 훈련에 자동 회귀 및 인과 입력 예측을 포함하는 다중 작업 목표를 특징으로 합니다. (3.2절 참조)
-
긴 input context: 함수 레벨이나 파일 레벨이 아닌 저장소 레벨 인퍼런스를 위해서는 Llama2에서 지원하는 4,096 토큰을 초과하는 훨씬 long context을 모델에 제공해야 합니다. RoPE 위치 임베딩의 파라미터를 수정하여 최대 context length를 100,000 토큰까지 확장하는 추가 파인튜닝 단계를 제안합니다. (3.3절 참조)
-
지시 파인튜닝: 최종 사용자를 위해, LLM의 유용성은 지시 파인튜닝을 통해 크게 향상됩니다. CodeLlama-Instruct 변형은 안전성과 유용성을 향상시키기 위해 독점 지시 데이터와 새로 생성된 자체 지시 데이터셋에서 추가로 파인튜닝됩니다. (4절 참조)
이 모델은 자연어를 해석하여 명령줄 프로그램에 적합한 옵션을 결정하고 해결책을 설명합니다. HumanEval, MBPP, APPS 및 MultiPL-E와 같은 주요 코드 생성 벤치마크에서 모델을 폭넓게 평가하였고, 상위 모델들은 오픈 소스 LLM 중 새로운 최고 기준을 설정하였습니다.
2 Code Llama: Llama2를 활용한 코드 전문화
2.1 CodeLlama 모델 개요
CodeLlama 모델은 코드 생성을 목적으로 하는 기반 모델입니다. 이 모델은 7B, 13B, 34B의 세 가지 크기로 구성되며, 7B와 13B 모델은 섹션 2.3에서 설명할 입력 목표를 활용하여 훈련되고, IDE에서 파일 중간의 코드를 완성하는 데 적합합니다. 34B 모델은 입력 목표 없이 훈련되었습니다. 모든 CodeLlama 모델은 Llama2 모델의 가중치로 초기화되고 코드 중심 데이터셋에서 500B 토큰으로 훈련된 후 긴 컨텍스트를 처리하도록 섹션 2.4에서 설명한 대로 파인튜닝됩니다.
2.2 데이터셋 구성 및 사용
CodeLlama는 500B 토큰의 초기 단계에서 7B, 13B, 34B 버전의 Llama2로 시작하여 훈련됩니다. 주로 공개적으로 이용 가능한 코드에서 중복을 제거한 데이터셋에서 훈련되며, 8%의 샘플 데이터는 코드와 관련된 자연 언어 데이터셋에서 가져옵니다. 이는 코드 토론 및 자연 언어 질문이나 답변에 포함된 코드 스니펫을 포함합니다. 모델이 자연 언어 이해 능력을 유지할 수 있도록 일부 배치는 자연 언어 데이터셋에서 샘플링됩니다.
2.3 입력 목표의 수학적 구성
입력 목표는 주변 컨텍스트가 주어진 프로그램의 누락된 부분을 예측하는 작업입니다. 이는 코드 IDE에서 커서의 위치에서 코드 완성, 타입 인퍼런스, 코드 내 문서화 등의 응용 프로그램을 포함합니다. 인과 마스킹 개념을 따라 입력 모델을 훈련합니다.
\[\text{Objective} = \sum_{t=1}^{T} \log P(x_t | x_1, \dots, x_{t-1}; \theta)\]위 수식에서 \(x_t\)는 토큰, \(T\)는 시퀀스 길이, 그리고 \(\theta\)는 모델 파라미터
2.4 긴 컨텍스트 파인튜닝
긴 시퀀스를 효과적으로 처리하는 것은 중요한 연구 주제입니다. CodeLlama는 모델이 16,384 토큰의 시퀀스를 처리하도록 설정하는 전용 긴 컨텍스트 파인튜닝(LCFT) 단계를 제안합니다. 이는 4,096 토큰에서 사용된 Llama2 및 초기 코드 훈련 단계와 비교됩니다. 긴 시퀀스 처리 기능을 향상시키기 위해 긴 시퀀스에서 훈련 시간을 파인튜닝 단계로 제한함으로써 비용을 크게 증가시키지 않고 긴 시퀀스 처리 기능을 획득합니다.
2.5 지시 파인튜닝
CodeLlama-Instruct 모델은 CodeLlama를 기반으로 하며 추가적으로 약 5B 토큰으로 휴먼 지시를 더 잘 따르도록 파인튜닝됩니다. 이런 파인튜닝은 다음과 같은 세 가지 데이터 유형에서 수행됩니다.
- 독점 데이터셋: Llama2를 위해 수집된 지시 튜닝 데이터셋을 사용합니다.
- 자체 지시: 전문 개발자의 비용이 많이 드는 입력 대신, 실행 피드백을 사용하여 선택된 데이터로 모델을 훈련했습니다.
- 리허설: 일반 코딩 및 언어 이해 능력에 대한 회귀를 방지하기 위해, CodeLlama-Instruct는 코드 데이터셋(6%)과 자연 언어 데이터셋(2%)의 작은 비율로도 훈련했습니다.
[데이터셋 변화로 인한 회귀 방지 리허설 색인마킹]
1 Introduction
Large language models (LLMs) power a rapidly increasing number of applications, having reached a proficiency in natural language that allows them to be commanded and prompted to perform a variety of tasks (OpenAI, 2023; Touvron et al., 2023b) By utilizing large, in-domain datasets, their efficacy can be greatly improved for applications that require a combination of both natural and domain-specific language and understanding of specialized terminology. By training on domain-specific datasets, they have proved effective more broadly on applications that require advanced natural language understanding. A prominent use-case is the formal interaction with computer systems, such as program synthesis from natural language specifications, code completion, debugging, and generating documentation (for a survey, see Xu & Zhu, 2022, also see Section 5)
In this work, we present CodeLlama, a family of LLMs for code generation and infilling derived from Llama2 (Touvron et al., 2023b) and released under the same custom permissive license. We provide inference code for both completion and infilling models in the accompanying repository.
Our approach is based on gradually specializing and increasing the capabilities of Llama2 models by applying a cascade of training and fine-tuning steps (Figure 2):
-
Code-training from foundation models. While most LLMs for code generation such as AlphaCode (Li et al., 2022), InCoder (Fried et al., 2023), or StarCoder (Li et al., 2023) are trained on code only, Codex (Chen et al., 2021) was fine-tuned from a general language model. We also start from a foundation model (Llama2, Touvron et al., 2023b) pretrained on general-purpose text and code data. Our comparison (Section 3.4.1) shows that initializing our model with Llama2 outperforms the same architecture trained on code only for a given budget.
-
Infilling. Autoregressive training and fine-tuning of LLMs is suitable for prompt completion but does not provide the capability to fill a missing portion of text while taking the full surrounding context into account. Our code-training for 7B and 13B CodeLlama models features a multitask objective (Fried et al., 2023) consisting of both autoregressive and causal infilling prediction, enabling applications such as real-time completion in source code editors or docstring generation. Similarly to Bavarian et al. (2022); Li et al. (2023), our ablation study shows that infilling capabilities come at low cost in code generation performance for a given training compute budget (Section 3.2)
-
Long input contexts. Unlocking repository-level reasoning for completion or synthesis – as opposed to function-level or file-level – requires prompting the model with much longer context than the 4,096 tokens supported by Llama2. We propose an additional fine-tuning stage that extends the maximum context length from 4,096 tokens to 100,000 tokens by modifying the parameters of the RoPE positional embeddings (Su et al., 2021) used in Llama2. Our experiments show CodeLlama operating on very large contexts with a moderate impact on performances on standard coding benchmarks (Section 3.3)
-
Instruction fine-tuning. For end-users, the utility of LLMs is significantly improved by instruction fine-tuning (Ouyang et al., 2022; Wei et al., 2022; OpenAI, 2023; Touvron et al., 2023b), which also helps preventing unsafe, toxic, or biased generations. CodeLlama-Instruct variants are further fine-tuned on a mix of proprietary instruction data for improved safety and helpfulness, and a new machine-generated self-instruct dataset created by prompting Llama2 for coding problems and CodeLlama to generate associated unit tests and solutions. Our results show that CodeLlama-Instruct significantly improves performance on various truthfulness, toxicity, and bias benchmarks at moderate cost in terms of code generation performance (Section 4)
Different combinations of these approaches lead to a family of code-specialized Llama2 models with three main variants that were released in three sizes (7B, 13B, and 34B parameters):
- CodeLlama: a foundational model for code generation tasks.
- CodeLlama-Python: a version specialized for Python.
- CodeLlama-Instruct: a version fine-tuned with human instructions and self-instruct code synthesis data.
An example of using CodeLlama-Instruct is given in Figure 1. It showcases that the model interprets natural language to determine suitable options for a command-line program and provides an explanation of the solution. We provide further qualitative examples in Appendix K. We perform exhaustive evaluations of our models on major code generation benchmarks: HumanEval (Chen et al., 2021), MBPP (Austin et al., 2021), and APPS (Hendrycks et al., 2021), as well as a multilingual version of HumanEval (MultiPL-E, Cassano et al., 2023), where our best models establish a new state of the art amongst open-source LLMs. The technical details of our training and fine-tuning procedures are provided in Section 2, followed by in-depth experiments and ablation studies, details of the safety/helpfulness evaluations, and a discussion of related work.
2 Code Llama: Specializing Llama 2 for code
2.1 The CodeLlama models family
-
CodeLlama. The CodeLlama models constitute foundation models for code generation. They come in three model sizes: 7B, 13B, and 34B parameters. The 7B and 13B models are trained using an infilling objective (Section 2.3) and are appropriate to be used in an IDE to complete code in the middle of a file, for example. The 34B model was trained without the infilling objective. All CodeLlama models are initialized with Llama2 model weights and trained on 500B tokens from a code-heavy dataset (see Section 2.2 for more details) They are all fine-tuned to handle long contexts as detailed in Section 2.4.
-
CodeLlama-Python. The CodeLlama-Python models are specialized for Python code generation and also come in sizes of 7B, 13B, and 34B parameters. They are designed to study the performance of models tailored to a single programming language, compared to general-purpose code generation models. Initialized from Llama2 models and trained on 500B tokens from the CodeLlama dataset, CodeLlama-Python models are further specialized on 100B tokens using a Python-heavy dataset (Section 2.2) All CodeLlama-Python models are trained without infilling and subsequently fine-tuned to handle long contexts (Section 2.4)
-
CodeLlama-Instruct. The CodeLlama-Instruct models are based on CodeLlama and fine-tuned with an additional approx. 5B tokens to better follow human instructions. More details on CodeLlama-Instruct can be found in Section 2.5.
2.2 Dataset
We train CodeLlama on 500B tokens during the initial phase, starting from the 7B, 13B, and 34B versions of Llama2. As shown in Table 1, CodeLlama is trained predominantly on a near-deduplicated dataset of publicly available code. We also source 8% of our samples’ data from natural language datasets related to code. This dataset contains many discussions about code and code snippets included in natural language questions or answers. To help the model retain natural language understanding skills, we also sample a small proportion of our batches from a natural language dataset. Data is tokenized via byte pair encoding (BPE, Sennrich et al. (2016)), employing the same tokenizer as Llama and Llama2. Preliminary experiments suggested that adding batches sampled from our natural language dataset improves the performance of our models on MBPP.
2.3 Infilling
Code infilling is the task of predicting the missing part of a program given a surrounding context. Applications include code completion at the cursor’s position in code IDEs, type inference, and generation of in-code documentation (e.g., docstrings) We train infilling models following the concept of causal masking (Aghajanyan et al., 2022; Fried et al., 2023), where parts of a training sequence are removed to the end, and the reordered sequence is predicted autoregressively. We train the general-purpose 7B and 13B models with an infilling objective, following the recommendations of Bavarian et al. (2022) More precisely, we split training documents at the character level into a prefix, a middle part, and a suffix with the splitting locations sampled independently from a uniform distribution over the document length. We apply this transformation with a probability of 0.9 and to documents that are not cut across multiple model contexts only. We randomly format half of the splits in the prefix-suffix-middle (PSM) format and the other half in the compatible suffix-prefix-middle (SPM) format described in Bavarian et al. (2022, App. D) We extend Llama2’s tokenizer with four special tokens that mark the beginning of the prefix, the middle part or the suffix, and the end of the infilling span. To limit the distribution shift between autoregressive and infilling training, we suppress the implicit leading space that SentencePiece tokenizers add upon encoding the middle part and the suffix (Kudo & Richardson, 2018) In SPM format, we concatenate the prefix and the middle part before encoding to tokens. Note that our model doesn’t encounter subtokens splits in the SPM format while it does in the PSM format. Results on the effect of infilling training on downstream generation tasks and the performance of our infilling models on infilling benchmarks are reported in Section 3.2.
2.4 Long context fine-tuning
Effective handling of long sequences is a major topic of research in transformer-based language modeling (Vaswani et al., 2017) The fundamental modeling challenges are extrapolation, i.e., operating on sequence lengths beyond those seen at training time, and the quadratic complexity of attention passes which favors training on short-to-medium length inputs.
For CodeLlama, we propose a dedicated long context fine-tuning (LCFT) stage in which models are presented with sequences of 16,384 tokens, up from the 4,096 tokens used for Llama2 and our initial code training stages. By limiting the training time spent on processing long sequences to a fine-tuning stage, we gain long-range capabilities without significantly increasing the cost of training our models. Our strategy is similar to the recently proposed fine-tuning by position interpolation (Chen et al., 2023b), and we confirm the importance of modifying the rotation frequencies of the rotary position embedding used in the Llama2 foundation models (Su et al., 2021)
2.5 Instruction fine-tuning
Our instruction fine-tuned models CodeLlama-Instruct are based on CodeLlama and trained to answer questions appropriately. They are trained on three different types of data.
-
Proprietary dataset: We use the instruction tuning dataset collected for Llama2 and described in detail by Touvron et al. (2023b) Specifically, we use the version referred to in their paper as “RLHF V5,” collected through several stages of reinforcement learning from human feedback and human feedback annotation (see their Section 3 for more details) It combines thousands of Supervised Fine-Tuning and millions of Rejection Sampling examples. Each example consists of a multi-turn dialogue between a user and an assistant. For Rejection Sampling, the output was selected among several generations using a reward model. The final dataset contains both Helpfulness and Safety data. This enables CodeLlama to inherit Llama2’s instruction following and safety properties.
-
Self-instruct: Our proprietary dataset contains a few examples of code-related tasks. Collecting supervised data from human annotators or training from human feedback (Ouyang et al., 2022) is expensive for coding tasks as it requires input from professional developers. Instead of human feedback, we use execution feedback to select data to train our instruct model. We construct the self-instruction dataset following the recipe below, resulting in ∼14,000 question-tests-solution triplets:
- Generate 62,000 interview-style programming questions by prompting (Figure 9) Llama 270B.
- De-duplicate the set of questions by removing exact duplicates, resulting in ∼52,000 questions.
- For each of these questions: (a) Generate unittests by prompting CodeLlama 7B (Figure 10) (b) Generate ten Python solutions by prompting CodeLlama 7B (Figure 11) (c) Run the unittests on the ten solutions. Add the first solution that passes the tests (along with its corresponding question and tests) to the self-instruct dataset.
We use CodeLlama 7B to generate the tests and Python solutions, as we found it more efficient than generating fewer solutions per question with the 34B model for the same compute budget.
-
Rehearsal: In order to prevent the model from regressing on general coding and language understanding capabilities, CodeLlama-Instruct is also trained with a small proportion of data from the code dataset (6%) and our natural language dataset (2%)
2.6 Training details
Optimization: Our optimizer is AdamW (Loshchilov & Hutter, 2019) with β1 and β2 values of 0.9 and 0.95. We use a cosine schedule with 1000 warm-up steps, and set the final learning rate to be 1/30th of the peak learning rate. We use a batch size of 4M tokens which are presented as sequences of 4,096 tokens each. Despite the standard practice of using lower learning rates in fine-tuning stages than in pre-training stages, we obtained the best results when retaining the original learning rate of the Llama2 base model. We carry these findings to the 13B and 34B models, and set their learning rate to 3e−4 and 1.5e−4, respectively. For python fine-tuning, we set the initial learning rate to 1e−4 instead. For CodeLlama-Instruct, we train with a batch size of 524,288 tokens and on approximately 5B tokens in total.
Long context fine-tuning: For long context fine-tuning (LCFT), we use a learning rate of 2e−5, a sequence length of 16,384, and reset RoPE frequencies with a base value of θ=106. The batch size is set to 2M tokens for model sizes 7B and 13B and to 1M tokens for model size 34B, respectively. Training lasts for 10,000 gradient steps by default. We observed instabilities in downstream performance for certain configurations, and hence set the number of gradient steps to 11,000 for the 34B models and to 3,000 for CodeLlama 7B.