Meta - Self-Alignment with Instruction Back-translation**
- Related Project: private
- Category: Paper Review
- Date: 2023-08-15
Self-Alignment with Instruction Backtranslation
- url: https://arxiv.org/abs/2308.06259.pdf
- pdf: https://arxiv.org/pdf/2308.06259.pdf
- abstract: We present a scalable method to build a high quality instruction following language model by automatically labelling human-written text with corresponding instructions. Our approach, named instruction back-translation, starts with a language model finetuned on a small amount of seed data, and a given web corpus. The seed model is used to construct training examples by generating instruction prompts for web documents (self-augmentation), and then selecting high quality examples from among these candidates (self-curation). This data is then used to finetune a stronger model. Finetuning LLaMA on two iterations of our approach yields a model that outperforms all other LLaMA-based models on the Alpaca leaderboard not relying on distillation data, demonstrating highly effective self-alignment.
[논문 핵심 색인마킹]
Contents
- Self-Alignment with Instruction Backtranslation
TL;DR
- 대규모 언어모델의 지시 사항 따르기 능력 향상을 위한 새로운 접근 방식 제시
- 자가 증강 및 자가 선별 알고리즘을 통한 training dataset의 질 개선
- 반복적인 모델 조정을 통해 지시 사항 처리 성능을 꾸준히 향상
사람이 작성한 텍스트에 해당하는 지시문을 자동으로 레이블링하여 고품질 instruction을 따르는 언어 모델을 구축하는 확장 가능한 방법을 제시합니다. 접근 방식인 ‘instruction backt-ranslation(instruction back-translation)’은 소량의 초기 데이터와 주어진 웹 코퍼스에서 파인튜닝된 언어 초기 모델을 생성하였으며, 이 초기 모델은
- (1) 웹 문서에 대한 지시 프롬프트를 생성하여 training examples를 구성하고,
- (2) (self-curation) 이를 통해 더 우수한 모델을 파인튜닝하기 위해 사용 될 examples 후보 중에서 high quality examples를 선택합니다.
두 번의 반복을 거쳐서 LLaMA를 파인튜닝함으로써 알파카 리더보드에서 다른 모든 LLaMA 기반 모델을 능가하는 모델을 성공적으로 생성하였으며, 증류 데이터에 의존하지 않고 효과적으로 LLM을 자기 정렬(self-alignment)하였습니다.
1. 서론
최근 대규모 언어모델(LLMs)은 다양한 방식으로 지시 사항을 따르는 능력이 향상되고 있다. 특히, 휴먼이 작성한 지시 사항에 대한 주석 데이터를 사용하거나 우수한 모델에서 지식을 증류하는 방법이 주로 사용되었다. 이 연구에서는 레이블이 없는 대량의 데이터를 활용한 자가 증강과 자가 선별 알고리즘을 개발하여 지시 데이터의 품질을 향상시키고, 이를 통해 모델의 성능을 개선하는 새로운 접근 방식을 제안한다. 본 연구에서 제시된 ‘instruction back-translation’ 방법은 휴먼이 작성한 타겟 문장을 모델이 생성한 소스 문장으로 자동 주석하는 기계 번역의 고전적인 방법에서 영감을 받았다.
2. 방법
2.1 초기 데이터 준비
- Seed 데이터: 휴먼이 주석한 (지시, 출력) 페어에서 시작하여, 초기 예측을 위한 파인튜닝에 사용된다.
- Unlabeled 데이터: 웹 코퍼스를 사용하여 HTML 헤더 이후의 텍스트를 추출하고, 품질이 낮은 세그먼트를 제거하는 전처리 과정을 거친다.
2.2 자가 증강 및 선별
- 자가 증강: 기본 모델을 seed 데이터의 (출력, 지시) 페어로 파인튜닝하여, 주석이 달리지 않은 예시에 대한 후보 지시를 생성한다.
- 자가 선별: 생성된 (지시, 출력) 페어의 품질을 모델 자체가 평가하여 고품질 페어만을 선별하고, 이를 다음 단계의 파인튜닝 데이터로 사용한다.
2.3 반복적 파인튜닝
- 각 반복 단계마다 선별된 training dataset를 사용하여 모델의 instruction following 및 생성 능력을 개선한다. 최종적으로 높은 품질의 데이터만을 사용하여 최종 모델을 파인튜닝한다.
3. 실험 및 결과
3.1 실험 설정
- Seed 데이터: OpenAssistant 데이터셋에서 선택된 3200개의 예시를 사용한다.
- Base 모델 및 파인튜닝: LLaMA 모델을 사용하고, 주로 기존의 지도 학습 방법의 하이퍼파라미터를 사용하여 파인튜닝한다.
3.2 데이터 통계 및 평가
- 데이터 통계: 증강 데이터가 원래 seed 데이터보다 긴 출력을 갖는 경향이 있으며, 자가 선별된 고품질 데이터는 더 짧고 질 높은 지시 및 출력을 보여준다.
- 평가: AlpacaEval을 사용하여 자동 평가를 수행하고, 다양한 소스에서 제공하는 프롬프트를 사용하여 평가한다.
4. 논의 및 향후 연구
이 연구는 대규모 언어모델의 지시 사항 따르기 능력을 향상시키기 위한 확장 가능한 접근 방식을 제시한다. 반복적인 자가 증강 및 선별 과정을 통해 모델의 instruction following 능력이 지속적으로 개선됨을 보여준다. 향후 연구에서는 더 다양한 언어와 도메인으로 확장하여 접근 방식의 일반화 가능성을 시험할 계획이다.
Appendix
A. 생성 예시
- 수학적 인퍼런스, 일반 정보 탐색, 조언 제공, 글쓰기 등의 카테고리에서 개선된 예시 출력을 제공
B. 휴먼 평가
- MTurk 작업자를 사용하여 Mephisto 플랫폼에서 수행된 휴먼 평가. 평가 기준 및 절차에 대한 자세한 설명을 포함
1 Introduction
대규모 언어모델(Large Language Models, LLMs)이 instruction을 따르도록 파인튜닝하기 위해서는 다음 두 가지 방법이 대표적임.
- (1) 휴먼이 작성한 instruction annotation 혹은 휴먼의 선호도를 기반으로 한 대규모 데이터셋을 사용해 파인튜닝하는 것 [Ouyang et al., 2022, Touvron et al., 2023, Bai et al., 2022a]
- (2) 더 우수한 모델로부터 output을 기반으로 지식을 증류하는 것 [Wang et al., 2022a, Honovich et al., 2022, Tao et al., 2023, Chang et al., 2023, Peng et al., 2023, Xue et al., 2023].
- 최근 연구에서는 휴먼이 작성한 instruction annotation 데이터의 품질이 중요하다는 것을 강조하고 있지만(Zhou et al. [2023], Köpf et al. [2023]), 휴먼이 작성한 고품질의 instruction 주석 데이터를 사용하는 것은 확장가능하지 않은 방법임.
본 연구에서는 레이블이 없는 대량의 데이터를 활용하여 반복적인 자기 훈련 알고리즘을 개발함으로써 높은 품질의 instruction 튜닝 데이터를 생성하였고, 모델 자체를 사용하여 고품질의 training examples를 보강하고 선별하여 자체 성능을 향상시키는 데 활용하였음.
이 ‘instruction backt-ranslation(instruction backt-ranslation)’은 기계 번역에서의 휴먼이 작성한 타겟 문장이 모델이 생성 한 소스 문장의 다른 자연어로 자동적으로 annotation 하는 고전적인 backt-ranslation 방법에서 영감을 얻었다고 함.
[Sennrich et al., 2015]. Our approach, named instruction back-translation, is inspired by the classic back translation method from machine translation, in which human-written target sentences are automatically annotated with model-generated source sentences in another language.
Seed instruction following model은 먼저 자체 훈련 세트를 자가 보강하는 데 사용되고, (self-augment its training set) 이 모델이 각 웹 문서에 대해 문서의 일부로 정확하게 답변될 수 있는 프롬프트(instruction)를 예측하도록 하는 것을 목적으로 함.
그러나 instruction following training examples를 통해 instruction 프롬프트를 생성하였을 경우, (1) (휴먼이 작성한) 웹 텍스트의 품질이 고르지 못하고, (2) 생성된 지시 사항의 노이즈가 발생하므로, 위 방법으로 증강한 데이터를 직접적으로 훈련하는 것은 실험에서 부적합한 결과를 보여주였기 때문에 이를 해결하기 위해 다음과 같은 프로세스를 수행하였음.
- 1) 동일한 시드 모델이 신규 생성 보강 데이터 집합의 품질을 예측하여,
- 2) 자가 선별한 뒤
- 3) 높은 품질(instruction, output) 쌍에 대해서만 자체 훈련하는 과정을 거치도록 하였고,
- (반복) 이 과정을 통해 개선 된 모델을 사용하여 지시 데이터를 더 잘 선별할 수 있도록 하였음.
결과적으로 이렇게 생성 된 LLM ‘Humpback’은 Alpaca Leaderboard [Li et al., 2023]에서 모든 기존 비증류 모델을 능가했으며, ‘instruction backt-ranslation’은 언어 모델이 자체 지시 사항을 따르는 능력을 향상시킬 수 있는 확장 가능한 방법 중 하나라고 주장하고 있음.
2 Method
Myx는 Augmentated data 생성에 사용되고, candidate outputs for unknown instructions을 잘 예측할 수 있는 모델(“M0”,”M1”,”M2”)을 반복해서 조정함.
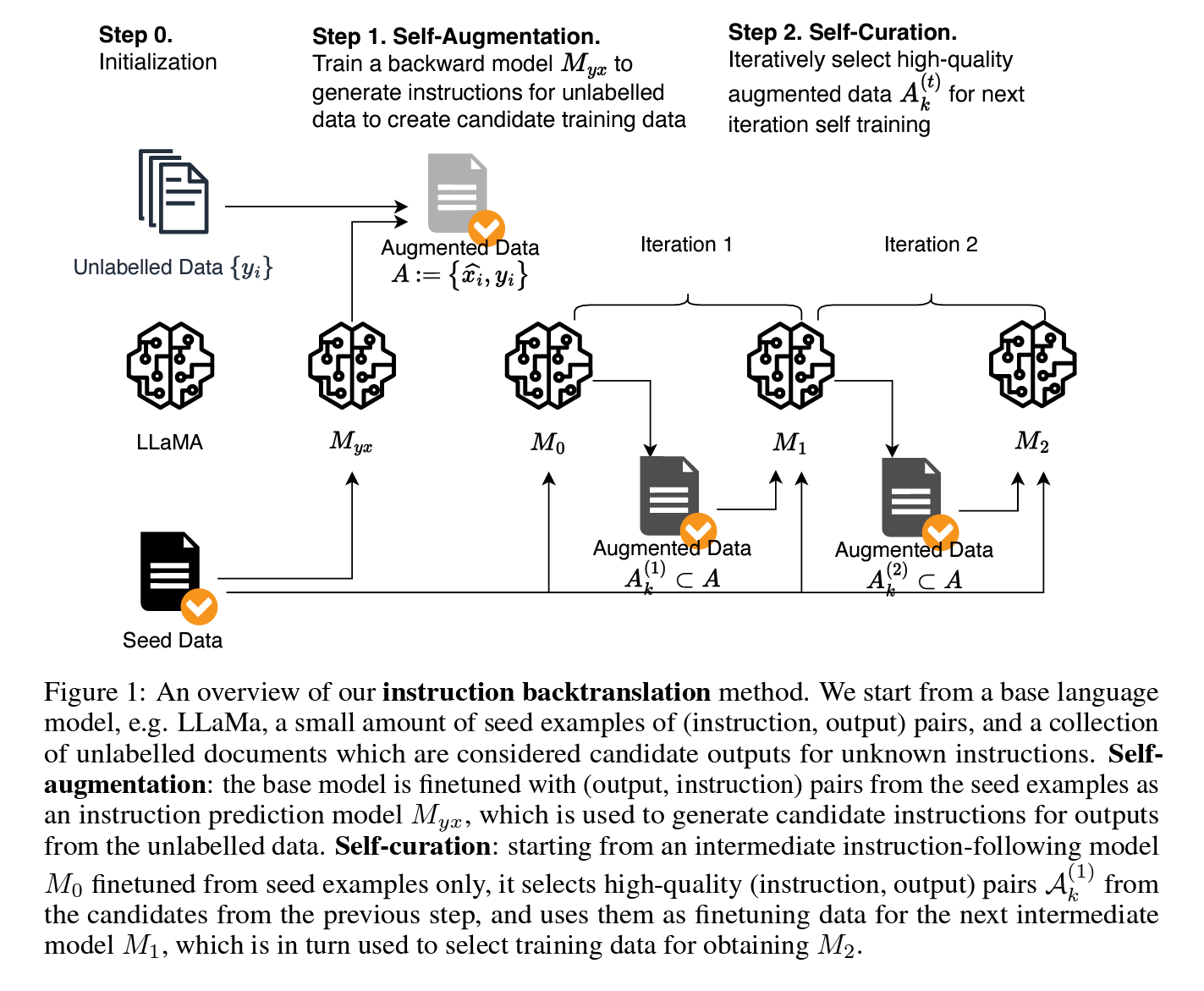 Figure 1. 개요
Figure 1. 개요
LLaMA와 같은 LMF으로부터 시작하고 a small amount of seed examples of (instruction, output) pairs 및 아직 주석이 달리지 않은 a collection of unlabeled documents를 사용하였음.
- Self augmentation(자가 증강): 기본 모델은 이런 seed data에서 (instruction, output) 쌍으로 파인튜닝되어 지시 예측 모델(“Myx”)로 사용 됨. Myx 모델은 아직 주석이 달리지 않은 데이터의 output에 대한 후보 지시(candidate outputs for unknown instructions)를 생성하는 데 사용되게 됨.
- Self-curation(자가 선별): seed data만을 사용하여 an intermediate instruction-following model “M0”부터 시작하여 이전 단계의 후보에서 고품질 (instruction, output) 쌍 “A(1)_k”를 선택하고, 이를 다음 중간 모델 “M1”의 파인튜닝 데이터로 사용한 다음, the next intermediate model “M1”은 “M2”를 얻기 위한 training dataset를 선택하는 데 사용 됨.
2.1 Initialization Seed Data
-
A seed set of human-annotated 페어(instruction, output)를 사용해 페어의 양방향을 서로를 예측하도록 학습
We start with a seed set of human-annotated (instruction, output) examples. These examples will be used to fine-tune language models to provide initial predictions in both directions: predicting an output given an instruction, and an instruction given an output.
2.2 Unlabeled Data
- Unlabeled data를 사용해서 각 문서마다 전처리를 수행하여 HTML 헤더 이후의 자체 포함 세그먼트 $y_i$를 추출함.
-
중복 제거, 길이 필터링 등등을 사용해서 휴리스틱으로 저품질 세그먼트 제거하는 전처리 거침.
We use a web corpus as a source of unlabeled data. For each document, we perform preprocessing to extract self-contained segments $y_i$, which are portions of text following an HTML header. Further steps include duplication removal, length filtering, and removal of potential low-quality segments using heuristics like the proportion of capitalized letters in the header.
2.2 Self-Augmentation (Generating Instructions)
- $(y_i, x_i)$를 사용하여 base language model을 파인튜닝하여 backward model $Myx := p(x\mid y)$를 생성함.
-
Backward model의 인퍼런스를 통해 $\hat{x}_i$의 후보를 생성하여 candidate augmented paired data $A := {(\hat{x}_i, y_i)}$를 유도한 뒤, 이 중에서 고품질 데이터를 하위 집합으로 정제하는 작업을 수행 함.
We fine-tune the base language model with (output, instruction) pairs $(y_i, x_i)$ from the seed data to obtain a backward model $Myx := p(x\mid y)$. For each unlabeled example $y_i$, we run inference on the backward model to generate a candidate instruction $\hat{x}_i$. From this, we derive the candidate augmented paired data $A := {(\hat{x}_i, y_i)}$. Not all of these candidate pairs are of high quality. Hence, using all of them for self-training might not be beneficial. This brings us to the crucial step of curating a high-quality subset.
[리커드 척도 색인마킹]
2.3 Self-Curation (Selecting High-Quality Examples)
-
2.1의 a seed set of human-annotated (instruction, output) examples으로만 파인튜닝된 M0을 시작으로, M0을 사용해 agumentated 된 $(\hat{x}_i, y_i)$에 점수를 매겨 품질 점수를 측정, 5단계 척도로 평가되는 프롬프팅을 사용했고, $a_i \geq k$인 증강된 예시의 하위 집합을 선별하여 고정립 집합 $A(1)_k$를 형성 함. We select high-quality examples using the language model itself. We start with a seed instruction model M0 fine-tuned on (instruction, output) seed examples only. Using M0, we score each augmented example $(\hat{x}_i, y_i)$ to derive a quality score $a_i$. This is done using prompting, instructing the trained model to rate the quality of a candidate pair on a 5-point scale. The precise prompt we use is given in Table 1. We then select a subset of the augmented examples with score $a_i \geq k$ to form a curated set $A(1)_k$.
-
비슷하게 위와 같은 로직으로 반복하고, 점수를 매기면서 augmentation set $A(t)_k$를 생성하고, 두 번 반복해서 최종 모델인 $M_2$를 생성. (기계 번역에서 역번역을 위해 합성 데이터를 태깅하는 데 사용되는 방법과 유사)
Iterative Self-Curation: We propose an iterative training method to produce higher quality predictions. On iteration $t$, we use the curated augmentation data $A(t-1)_k$ from the previous iteration, along with the seed data as training data to fine-tune an improved model $M_t$. This model, in turn, can be used to rescore the augmented examples for quality, resulting in an augmentation set $A(t)_k$. We perform two iterations of data selection and fine-tuning to get the final model $M_2$.
When combining both seed data and augmented data for fine-tuning, we use tagging to distinguish the two data sources. Specifically, we append an additional sentence to examples (called “system prompt”). We use $S_a:=Answer in the style of an AI Assistant$ for seed data, and $S_w:=Answer with knowledge from web search$ for augmented data. This approach is similar to methods used to tag synthetic data for back translation in machine translation (Caswell et al., 2019).
\[S_a:=Answer in the style of an AI Assistant for seed data\] \[S_w:=Answer with knowledge from web search for augmented data\]
3 Experiments
3.1 Experimental Setup
Seed Data
-
3,200여 개의 샘플 페어 중에 고품질 데이터만 선별
We utilize 3200 examples from the OpenAssistant dataset [Köpf et al., 2023] as human-annotated seed data to train our models. Each example consists of an (instruction, output) pair \({(xi, yi)}\) chosen from the first turn of the conversation tree. We selectively sample high-quality English language responses based on their human-annotated rank (rank0).
Base Model & Fine-Tuning
For fine-tuning, we employ the pretrained LLaMA model [Touvron et al., 2023] with 7B, 33B, and 65B parameters as the base models. During training, we optimize the loss on the output tokens, not the input tokens, which deviates from the standard language modeling loss. We use the same hyperparameters as existing supervised fine-tuning (SFT) methods [Zhou et al., 2023, Touvron et al., 2023] for most models: learning rate of \(1e-5\) with linear decay to \(9e-6\) at the end of training, weight decay of \(0.1\), batch size of 32 (examples), and dropout of 0.1. For fine-tuning with fewer than 3000 examples, we use a batch size of 8 (more details in Table 18). We refer to our trained Llama-based instruction backtranslation model as Humpback1. For generation, we utilize nucleus sampling [Holtzman et al., 2019] with a temperature of T=0.7 and p=0.9.*
Unlabeled Data
The English portion of the Clueweb corpus is employed as the source of unlabeled data [Overwijk et al., 2022]. Among these, we sampled 502k segments.
Baselines
We compare against several main baselines:
- text-davinci-003 [Ouyang et al., 2022]: An instruction-following model based on GPT-3 finetuned with instruction data from human-written instructions, human-written outputs, model responses, and human preferences using reinforcement learning (RLHF).
- LIMA [Zhou et al., 2023]: LLaMA models finetuned with 1000 manually selected instruction examples from a mixture of community question and answering sources (e.g., StackOverflow, WikiHow) and human expert-written instructions and responses.
- Guanaco [Dettmers et al., 2023]: LLaMA models finetuned with 9000 examples from the OpenAssistant dataset. Note the distinction from this paper’s 3200 seed examples as Guanaco includes (instruction, output) pairs from all conversation turns while only the first-turn conversations were used here.
Evaluation
We evaluate on test prompts from various sources, including Vicuna [Chiang et al., 2023] (80 prompts), Self-instruct [Zhang and Yang, 2023] (252 prompts), OpenAssistant [Köpf et al., 2023] (188 prompts), Koala [Gengetal., 2023] (156 prompts), HH_RLHF [Bai et al., 2022a] (129 prompts), LIMA [Zhou et al., 2023] (300 prompts), and crowdsourced from authors (64 prompts). In total, there are 1130 unique prompts that provide a comprehensive coverage of task categories such as writing, coding, mathematical reasoning, information seeking, advice, roleplay, safety, etc. We sample 250 prompts from these for generation quality evaluation, excluding those in the AlpacaEval test set as a development set, and another 250 prompts for generation quality evaluation. We conduct both automatic evaluation using AlpacaEval [Li et al., 2023] which calculates the win rate against baseline models based on GPT-4 judgments, as well as human preference evaluation.
| 소스에서 평가하는 프롬프트 | 프롬프트 수 |
|---|---|
| Vicuna [Chiang et al., 2023] | 80 |
| Self-instruct [Zhang and Yang, 2023] | 252 |
| OpenAssistant [Köpf et al., 2023] | 188 |
| Koala [Gengetal., 2023] | 156 |
| HH_RLHF [Bai et al., 2022a] | 129 |
| LIMA [Zhou et al., 2023] | 300 |
| 저자에 의해 크라우드소싱됨 | 64 |
3.2 Seed and Augmentation Data Statistics
Data Statistics
-
augmented data가 원래의 시드 데이터보다 longer outputs을 갖음.
In Table 2, we present the statistics of the seed data as well as various versions of augmented data. It’s evident that augmented data tends to have longer outputs compared to the seed data. Self-curated higher quality training data (A(2) 4 and A(2) 5 ) have both shorter instructions and outputs among all augmented data, closer to the length of the original seed instruction data.
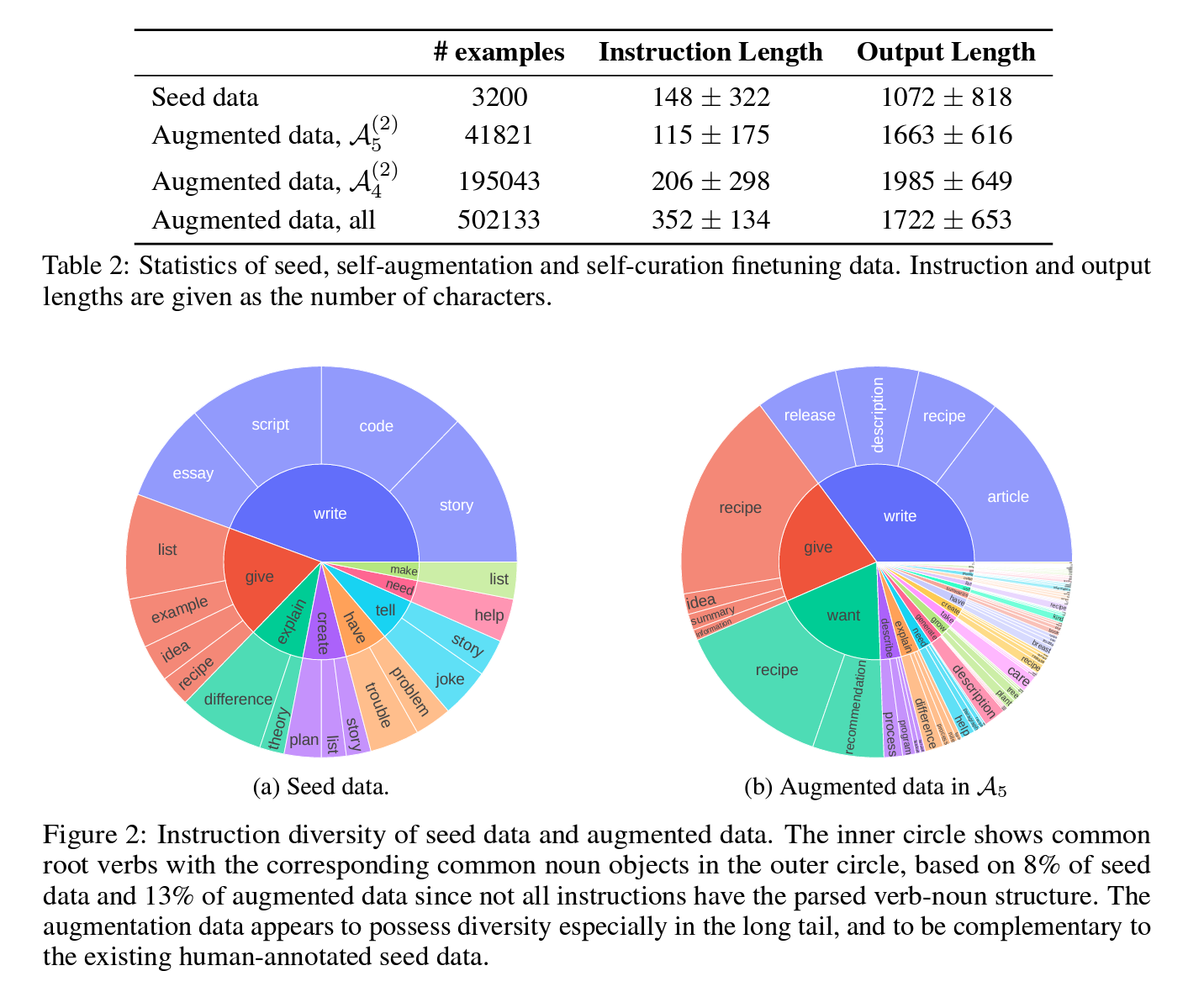
[프롬프트 분류 이미지 주요 색인마킹]
Generated Instructions
- 동사-명사 구조 분포를 시각화.
-
augmented data가 태스크의 다양성을 증가 시킴.
We analyze the task diversity of the seed data and augmented data using the approach from Wang et al. [2022a]. Figure 2 visualizes the distribution of the verb-noun structure of instructions in the seed data and augmented data (A(2) 5 category). Similar to the seed data, there are a few head tasks related to writing, information seeking, and advice. However, the content types from unlabeled data (article, recipe, description, release, etc.) complement those in the seed data (essay, script, code, story, etc.). Furthermore, the augmented data enhances task diversity, especially in the fields requiring deeper reasoning and role-play. This indicates a positive trend in diversifying the range of tasks and response styles LLMs can effectively handle.
분석 내용 요약 Data Quality vs. Data Quantity - 데이터 품질과 양의 중요성을 이해하기 위해 다양한 품질의 증강 데이터를 비교.
- A(2) 4, A(2) 5와 같은 점진적으로 작아지지만 높은 데이터 품질의 증강 데이터 비교.
- 높은 데이터 품질의 training dataset가 모델 품질을 향상시킴. (LIMA의 관찰과 일치)
- 증강 데이터의 품질이 낮을 경우 training dataset 양을 늘려도 성능 향상이 없음.Data Scaling Efficiency - 다양한 명령어 따르기 모델의 성능을 데이터 양을 변화시키면서 비교.
- 데이터 양의 로그에 대한 승률 측정을 통해 데이터 확장 효율성 계수 α 추정.
- 여러 소스에서 만든 명령어 데이터셋와 증강 데이터 방법 비교.
- 명령어 다양성과 응답 품질 향상이 더 효율적인 데이터 확장을 제공하는 것으로 보임.Joint Scaling of Data and Model - 7B 모델에서 관찰한 데이터 확장 트렌드가 더 큰 모델에서도 유지됨을 확인.
- 65B 시드 모델이 우수한 베이스라인임을 보여줌. 고품질의 증강 데이터 A5 추가로 성능이 더 향상됨.Generation Quality - AlpacaEval - AlpacaEval을 사용한 자동 평가 결과를 통해 세부적인 평가 내용과 결과 확인. Generation Quality - Human Evaluation - 모델 응답의 일반적인 품질에 대한 휴먼 평가 수행. NLP Benchmarks - Commonsense Reasoning - 다섯 가지 공통 감각 인퍼런스 벤치마크에서 평가 수행. NLP Benchmarks - MMLU - 대규모 다중 작업 언어 이해(MMLU) 벤치마크에서 평가 수행. Ablations - Data Selection Quality - 자체 증강 프로시저의 동작을 이해하기 위해 중간 모델의 성능 분석. Ablations - Joint Training - 자체 증강 데이터만을 사용하여 학습하는 경우와 시드 데이터와 자체 증강 데이터를 함께 사용하여 학습하는 경우의 비교. Further Analysis - Improvement over Seed Model -증강 데이터 추가로 시드 모델의 실패한 경우 개선되는 비율 확인. Limitations - Bias - 웹 코퍼스에서 추출한 데이터로 인해 모델이 바이어스를 증폭시킬 가능성이 있음을 확인. Limitations - Safety - 모델의 안전성에 대한 실험 결과와 개선 가능성에 대한 논의. Related Work - 지시어 따르기를 위한 LLMs의 연구와 관련된 이전 작업에 대한 개요 제시. Conclusion - 대규모 언어모델의 지시어 따르기를 위한 확장 가능한 접근 방식을 제안함.
- 자체 증강 및 정제 알고리즘을 개발하여 모델 자체를 개선함.
- Alpaca 리더보드에서 다른 지시어 따르기 모델을 능가함.
3.3 Model Training and Fine-Tuning
For model training, the process is divided into several steps, each designed to incrementally improve the model’s ability to follow and generate high-quality instructions: - Initial Training: - Model M0: We start with a seed set, using it to fine-tune the pretrained LLaMA model. This step establishes a basic level of instruction-following ability. - The model is trained to maximize the likelihood of the correct output given the corresponding instruction, using a cross-entropy loss function: \(\mathcal{L}( ext) = -\sum_{(x_i, y_i) \in \text{Seed Data}} \log p_\theta(y_i | x_i)\) - This initial model acts as a baseline for generating the first set of augmented data. - Self-Augmentation and Curation Process: - Using model M0, we generate instructions for the unlabeled data. This involves predicting potential instructions that could lead to the outputs observed in the unlabeled segments. - We then curate these generated pairs by assessing their quality through automated scoring mechanisms designed within the model, fine-tuning it to select only high-quality data:
$$
a_i = \text{score}(x_i, y_i) \quad \text{if } a_i \geq k \text{ then include } (x_i, y_i) \text{ in } A(1)_k
$$
- The curated data $A(1)_k$ from this round is used to fine-tune the next iteration of the model (M1), enhancing its instruction-generating and following capabilities.
- **Iterative Refinement:**
- The process of self-augmentation and curation is repeated, with each iteration aiming to refine the model’s ability to discern and generate even more accurate and contextually relevant instructions.
- For each iteration t, the model $M_{t-1}$ is used to generate and curate new training data, which is then used to enhance $M_t$:
$$
\text{Train } M_t \text{ on } A(t-1)_k \cup \text{Seed Data}
$$
- Each iteration ideally improves the instruction fidelity and expands the model's comprehension of diverse instruction formats and complexities.
- **Final Model Fine-Tuning (M2):**
- After sufficient iterations, the final model, M2, is fine-tuned using the highest quality curated data combined with the original seed examples. This model represents the culmination of iterative learning and is expected to have significantly enhanced instruction-following accuracy.
3.4 Experimental Validation
Setup
- The effectiveness of the instruction back-translation method is validated through rigorous testing across various benchmarks and comparing it against established models in the field.
- Performance metrics include precision, recall, and F1 score for instruction compliance, as well as user satisfaction scores from live interaction tests.
Results
- Performance Improvement: The Humpback model consistently outperforms the baselines across most evaluated aspects, particularly in scenarios involving complex instruction sets and nuanced contexts.
- Scalability and Efficiency: Despite the iterative nature of training, the method proves to be scalable due to its reliance on automated data generation and curation, significantly reducing the need for expensive human annotation.
3.5 Discussion and Future Work
In summary, this research not only advances the state of LLMs in following complex instructions but also offers a scalable method to enhance LLM capabilities without the high overhead of manual data annotation. The iterative approach ensures continuous improvement and adaptability to new types of instructions and user demands.
- Implications: The success of the Humpback model demonstrates the potential of using synthetic, model-generated instructions for training LLMs, potentially reducing the dependency on costly human-generated datasets.
- Challenges: While the model shows promising results, challenges such as handling extremely ambiguous or poorly structured instructions remain. Future work will focus on refining the model’s ability to understand and process such instructions more effectively.
- Extensions: The methodology could be extended to other languages and domains, further testing the generalizability of the instruction back-translation approach.
Appendix
A. Generation Samples
Sample outputs that show improvement over the seed model in categories such as mathematical reasoning, general information seeking, providing advice, and writing. Tables 11, 12, 13, and 14 provide examples.
[휴먼 평가 human eval 색인마킹]
B. Human Evaluation
Human evaluation conducted using the Mephisto platform with MTurk workers. Worker selection process involves filtering based on qualifications and agreement with screening tests. Criteria include Percent Assignments Approved, Number HITs Approved, Locale, and Master Qualification. Screening tests involve 200 prompts with in-house evaluation by four researchers to establish preferences. A selection of 10 examples was curated for screening based on specific criteria.
B.1 Worker Selection
Annotators are selected based on agreement rate with in-house annotators, and their rationales are analyzed. 29 annotators were selected from a pool of 1,000 applicants.
B.2 Annotation Interface
Annotation tasks were conducted with the selected annotators, maintaining communication via email. The user interface used for gathering pair-wise preferences is shown in Figures 10 and 11.
C. More Training Details
For the experiment on data scaling efficiency, models were trained with increasing numbers of examples (N) for each dataset. Fair comparison ensured by training all datasets for the same number of steps with the same batch size. Details are shown in Table 18.
| Appendix | 내용 |
|---|---|
| A. 생성 샘플 | - 생성 샘플 예시: 다양한 분야에서 시드 모델 대비 개선된 샘플 아웃풋을 제공 - 예시 카테고리: 수식적 인퍼런스, 일반적 정보 수색, 조언 제공, 글 작성 등 |
| B. 사용자 평가 | - 작업자 선별: MTurk 작업자를 이용한 Mephisto 플랫폼을 통한 사용자 평가 - 작업자 선별 기준: 자격과 스크리닝 테스트 동의도 고려 - 내부평가자의 일치율과 승인 비율을 기준으로 작업자 선택 - 스크리닝 테스트: 200개 프롬프트로 스크리닝 테스트 실시하여 작업자 선별 - 10개 예시 선별: 내부평가자와의 일치율과 내부평가 결과를 기반으로 선정 |
| - 주석 인터페이스: 이메일을 통한 작업자와의 커뮤니케이션 확립 및 보상 조정 - 플랫폼 사용: 주석 작업을 위한 인터페이스를 사용하여 선호도 조사 진행 |
|
| C. 추가 훈련 상세 정보 | - 데이터 확장 효율 실험: 데이터 예제 수(N)를 증가시키며 모델 추가 훈련 - 동일한 단계 수와 배치 크기로 공정한 비교 실시 |