RAT, Retrieval Augmented Thoughts
- Related Project: Private
- Category: Paper Review
- Date: 2024-03-15
RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
- url: https://arxiv.org/abs/2403.05313
- pdf: https://arxiv.org/pdf/2403.05313
- html: https://arxiv.org/html/2403.05313v1
- abstract: We explore how iterative revising a chain of thoughts with the help of information retrieval significantly improves large language models’ reasoning and generation ability in long-horizon generation tasks, while hugely mitigating hallucination. In particular, the proposed method – retrieval-augmented thoughts (RAT) – revises each thought step one by one with retrieved information relevant to the task query, the current and the past thought steps, after the initial zero-shot CoT is generated. Applying RAT to GPT-3.5, GPT-4, and CodeLLaMA-7b substantially improves their performances on various long-horizon generation tasks; on average of relatively increasing rating scores by 13.63% on code generation, 16.96% on mathematical reasoning, 19.2% on creative writing, and 42.78% on embodied task planning. The demo page can be found at this WebSite.
Contents
TL;DR
- 장기적 인퍼런스를 위한 검색 보강 생각(RAT) 전략
- 대규모 언어모델을 사용한 사실적 인퍼런스 강화
- 다양한 벤치마크에서 검증된 RAT의 효과
1. 서론
최근 대규모 언어모델(LLM)은 다양한 자연어 인퍼런스 태스크에서 높은 성능을 보여주고 있습니다. 특히, 장기적 인퍼런스를 필요로 하는 태스크에서 ‘생각의 연쇄(Chain of Thought, CoT)’ 방식을 사용할 때 이런 모델들은 향상된 결과를 보여줍니다.
하지만, 이런 방식은 가끔 사실과 다른 정보를 생성해내는 문제(Hallucination or Truthful)가 있었으며, 이를 해결하기 위해 본 논문에서는 검색 보강 생성(Retrieval-Augmented Generation, RAG)을 활용한 새로운 접근 방식인 검색 보강 생각(Retrieval-Augmented Thoughts, RAT) 전략을 제안합니다.
RAT는 외부 지식을 활용하여 모델이 생성한 중간 생각들을 사실에 기반하여 수정함으로써 보다 정확한 인퍼런스를 가능하게 합니다.
2. 방법
2.1 기존 연구
- CoT(Chain of Thoughts): 언어 모델이 복잡한 문제를 해결하기 위해 중간 단계의 인퍼런스를 출력하도록 유도하는 기법입니다.
- 검색 보강 생성(RAG): 주어진 쿼리에 대해 가장 관련성 높은 문서를 검색하여 언어 모델의 출력을 보강하는 기법입니다.
2.2 RAT의 도입
RAT는 CoT와 RAG의 결합을 통해, 각 인퍼런스 단계마다 필요한 외부 정보를 검색하고 이를 통해 중간 생각들을 개선합니다. 이 과정은 다음과 같이 구성됩니다.
- 초기 인퍼런스 생성: 언어 모델은 주어진 과제에 대해 초기 생각의 연쇄를 생성합니다.
- 동적 검색 쿼리 생성: 생성된 각 생각에 대해 관련 외부 문서를 검색할 쿼리를 동적으로 생성합니다.
- 생각 개선: 검색된 정보를 통해 각 생각을 개선하며, 이 과정을 반복하여 최종 출력을 도출합니다.
2.3 수학적 모델링
RAT의 검색 과정은 쿼리 $q$와 문서 $r_i$ 사이의 유사도를 계산하는 방식으로 이루어집니다.
\[\text{sim}(q, r_i) = \frac{q \cdot r_i}{\|q||r_i\|}\]$q$는 현재까지의 인퍼런스를 기반으로 생성된 쿼리 벡터이고, $r_i$는 검색된 각 문서의 벡터 표현입니다.
3. 실험 및 평가
RAT를 여러 벤치마크에서 평가하였으며, 특히 코드 생성, 수학적 인퍼런스, 창의적 글쓰기 등 다양한 태스크에서 기존 방법들을 뛰어넘는 성능을 보여주었습니다. RAT는 각 인퍼런스 단계에서 필요한 정보를 정확하게 검색하고 적용함으로써, 최종적으로 보다 정확하고 신뢰성 있는 출력을 생성할 수 있습니다.
4. 결론 및 향후 연구
RAT는 복잡한 장기 인퍼런스 태스크에서 언어 모델의 성능을 향상시킬 수 있는 효과적인 방법임을 입증하였습니다. 향후 연구에서는 RAT 방법을 다양한 언어 모델 및 추가 태스크에 적용하여 그 범용성과 효과를 더 깊이 탐구할 필요가 있습니다.
1 Introduction
Large Language Models (LLMs) have achieved fruitful progress on various natural language rea- soning tasks (Brown et al., 2020; Wang et al., 2023a; Wei et al., 2022; Yao et al., 2022; Zhou et al., 2023), especially when combining large- scale models (OpenAI, 2023; Team, 2022) with sophisticated prompting strategies, notably chain- of-thought (CoT) prompting (Kojima et al., 2022; Wei et al., 2022). However, there have been in- creasing concerns about the factual correctness of LLMs reasoning, citing the possible hallucinations in model responses (Rawte et al., 2023) or the intermediate reasoning paths, i.e. CoTs (Dhuli- awala et al., 2023). This issue becomes more sig- nificant when it comes to zero-shot CoT prompt- ing, aka. “let’s think step-by-step” (Kojima et al., 2022) and long-horizon generation tasks that re- quire multi-step and context-aware reasoning, in- cluding code generation, task planning, mathe- matical reasoning, etc. Factually valid interme- diate thoughts could be critical to the successful completion of these tasks.
Several prompting techniques have been proposed to mitigate this issue, one promis- ing direction, Retrieval Augmented Generation (RAG) (Lewis et al., 2020b) seeks insights from human reasoning (Holyoak and Morrison, 2012),and utilizes retrieved information to facilitate more factually grounded reasoning. In this paper, we explore how to synergize RAG with sophis- ticated long-horizon reasoning. Our intuition is that the hallucination within the intermediate reasoning process could be alleviated through the help of outside knowledge. The resulting prompting strategy, retrieval-augmented thoughts (RAT), is illustrated in Figure 1. Our strategy com- prises two key ideas. Firstly, the initial zero-shot CoT produced by LLMs along with the original task prompt will be used as queries to retrieve the information that could help revise the possi- bly flawed CoT. Secondly, instead of retrieving and revising with the full CoT and producing the final response at once, we devise a progres- sive approach, where LLMs produce the response step-by-step following the CoT (a series of sub- tasks), and only the current thought step will be revised based on the information retrieved with task prompt, the current and the past CoTs. This strategy can be an analogy to the human reasoning process: we utilize outside knowledge to adjust our step-by-step thinking during com- plex long-horizon problem-solving (Holyoak and Morrison, 2012). A comparison of RAT and coun- terparts can be found in Figure 2.
We evaluate RAT on a wide collection of chal- lenging long-horizon tasks, including code generation, mathematical reasoning, embodied task planning, and creative writing. We employ sev- eral LLMs of varied scales: GPT-3.5 (Brown et al., 2020), GPT-4 (OpenAI, 2023), CodeLLaMA- 7b (Rozière et al., 2023). The results indicate that combing RAT with these LLMs elicits strong ad- vantages over vanilla CoT prompting and RAG approaches. In particular, we observe new state- of-the-art level of performances across our selec- tion of tasks: 1) code generation: HumanEval (+20.94%), HumanEval+ (+18.89%), MBPP (+14.83%), MBPP+ (+1.86%); 2) mathemat- ical reasoning problems: GSM8K (+8.36%), and GSMHard (+31.37%); 3) Minecraft task plan- ning (2.96 times on executability and +51.94% on plausibility); 4) creative writing (+19.19% on human score). Our additional ablation studies further confirm the crucial roles played by the two key ingredients of RAT: revising CoT using RAG and progressive revision & generation. This work reveals how can LLMs revise their reasoning process in a zero-shot fashion with the help of outside knowledge, just as what humans do.
Figure 1: Pipeline of Retrieval Augmented Thoughts (RAT). Given a task prompt (denoted as \(I\)), RAT starts from initial step-by-step thoughts (\(T_1, T_2, \ldots, T_n\)) produced by an LLM in zero-shot (“let’s think step by step”). Some thought steps (such as \(T_1\)) may be flawed due to hallucination. RAT iteratively revises each thought step (\(T^*_{i-1}, T_i\)) using RAG from an external knowledge base (denoted as Library). Detailed prompting strategy can be found in subsection 2.2.
2 Retrieval Augmented Thoughts
Our goal is to support long-horizon reasoning and generation while mitigating hallucination when using LLMs. To have satisfying performance on long-horizon tasks, two ingredients are indispens- able. Firstly, access to factual information can be facilitated by retrieval. Secondly, appropriate intermediate steps that outline a scratchpad to finish complex tasks, can be facilitated by CoT. Yet, a naive combination of the two would not necessarily yield improvements. Two questions still persist: (1) what is relevant information to retrieve; (2) how to effectively correct reasoning steps with relevant factual information. To better appreciate our method and why our method can address these two questions, we first provide a brief preliminary introduction of RAG and CoT.
2.1. Preliminary
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) targets the problem of generating fictitious facts. It is primarily used in question-answering (QA) tasks. Specifically, given a set of \(n\) candidate documents \(R := \{R_i\}_n\), RAG aims to retrieve the most relevant ones with respect to a query \(Q\), which can be the question/task prompt itself or relevant information generated by LLMs. To achieve this, RAG first extracts semantic-aware embeddings of the documents \(r_i := \text{emb}(R_i) \in \mathbb{R}^K\) (where \(K\) is the size of the embedding) as well as the query \(q := \text{emb}(Q) \in \mathbb{R}^K\). The relevance between the query and a document is measured by their cosine similarity:
\[\text{sim}(Q, R_i) = \frac{q \cdot r_i}{\|q\| \|r_i\|}\]Based on their relevance, the top-ranked \(k\) documents are then fed into the prompt for LLMs to generate the final answer. With such rich and factual contexts, RAG mitigates the hallucination of LLMs. However, complex reasoning tasks can be difficult to translate into effective search queries, leading to challenges in finding relevant documents and making RAG less applicable.
Chain of Thoughts (CoT) Prompting
CoT prompting is designed to enhance the performance of LLMs under tasks that require complex reasoning steps, such as multi-step math word problems. Specifically, instead of tasking LLMs to generate the correct answer directly, CoT prompting incentivizes LLMs to first output intermediate reasoning steps, termed thoughts, that serve as a scratch space for the task, before summarizing the thoughts into a final answer. This behavior of LLMs can either be stimulated in zero-shot by prompting terms that encourage CoT reasoning or triggered by few-shot examples that perform CoT in similar tasks.
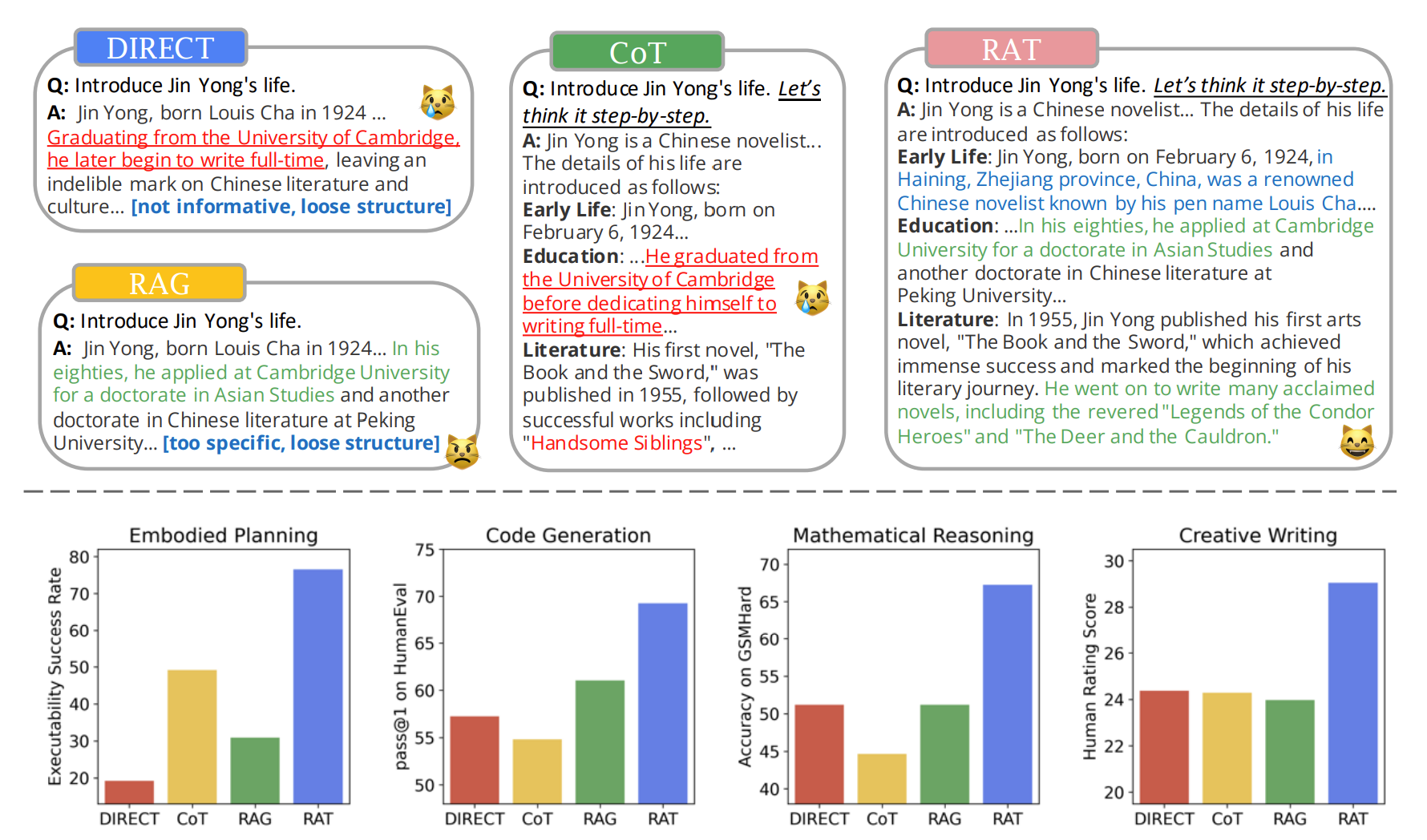
Example of LLM Reasoning Methods
Top: An example of different LLM reasoning methods on creative generation tasks. Errors or illusions in the text generated by LLMs are indicated by red text, while correct generation is represented by green text. Methods without RAG often generate incorrect information with hallucination, whereas classical RAG is highly related to retrieved content with a loose structure. RAT-generated texts perform best in terms of accuracy and completeness.
Bottom: The quantitative performance comparison for different LLM reasoning methods on complex embodied planning, mathematical reasoning, code generation, and creative generation tasks. Our RAT outperforms all the baselines on all tasks.
Algorithm: Retrieval Augmented Thoughts (RAT)
Algorithm 1: Retrieval Augmented Thoughts (RAT)
Input: Task Prompt I, Autoregressive Large Language Model pθ
1: T = {T1, T2, ..., Tn} ← pθ(·I)
2: T★ ← T1, i ← 1
3: repeat
4: Qi ← ToQuery(I, T★)
5: Ri ← RetrieveFromCorpus(Qi)
6: T★ ← pθ(·I, T★, Ri)
7: T★ ← CONCAT(T★, Ti+1)
8: i ← i + 1
9: until i > n
10: return T★
This algorithm continually refines the initial thoughts by retrieving and integrating relevant information until the final generation of thoughts is achieved.
2.2. Our Approach
-
Enhancing CoT Prompting with RAG
Our intuition to mitigate the issues of CoT prompting and RAG mentioned above is to apply RAG to revise every thought step generated by CoT prompting. This approach is illustrated in Figure 1 and described in Algorithm 1. Specifically, we begin by prompting an LLM to generate step-by-step thoughts in a zero-shot manner using the prompt “let’s think step-by-step”, denoted as \(T := \{T_i\}_n\), where \(T_i\) represents the \(i\)-th thought step. These thoughts might include intermediate reasoning steps, such as pseudo code with comments in code generation or an article outline in creative writing, or even draft responses such as a list of sub-goals in embodied task planning.
-
Revising Each Thought Step with RAG
Given that the initial thoughts \(T\) could be flawed or contain hallucinations, we use RAG to revise each generated thought step before finalizing the response. For each thought step \(T_i\):
- Convert the text {I, T1, …, Ti} into a query \(Q_i\):
Here, \(\text{ToQuery}(·)\) could be a text encoder or an LLM that transforms the task prompt \(I\) and the current and past thought steps \(T1, ..., Ti\) into a query \(Q_i\) that can be processed by the retrieval system.
- Use RAG to retrieve relevant documents \(R_i\) with \(Q_i\), which are then prepended to the prompt to generate a revised thought step \(T^*_i\):
Depending on the task, these revised thought steps \(T^*_{1:n}\) can be directly used as the final model response, for example in embodied task planning, or further prompted to produce the complete response in tasks like code generation or creative writing.
-
Causal Reasoning in Revision
When revising the \(i\)-th thought step \(T_i\), instead of using only the current step \(T_i\) or the complete chain of thoughts \(T_{1:n}\) to produce the query for RAG, we ensure that the query \(Q_i\) is produced from the current thought step \(T_i\) and previous revised thought steps \(T^*_{1:i-1}\), adopting a causal reasoning framework:
\[Q_i = \text{ToQuery}(I, T^*_{1:i-1}, T_i)\]This strategy helps correct errors in the original thoughts \(T\) by continually consulting different reference texts and ensures that each step of reasoning is informed by the most accurate and relevant information, significantly improving the quality and reliability of the generated output.
-
Addressing Complex Reasoning Challenges
Our method addresses two main problems: Firstly, the most straightforward way to understand what information will be used in complex reasoning is to “see” the reasoning steps. Our approach leverages all the generated thoughts along with the task prompt to provide more clues for more effective retrieval. Secondly, some information cannot be directly retrieved, especially in hard, complex questions. Instead, retrieving information relevant to intermediate questions, which are assumed to be easier, is more feasible. Thanks to the compositional nature of many reasoning tasks, an iterative retrieval process could also be more effective. Lastly, targeting potential hallucinations needs to be precise; revising a complete CoT with RAG could introduce errors at otherwise already-correct steps. Revising every step one by one could be more reliable. The first two points address question (1) and the last point addresses question (2). Quantitative evidence supporting these claims can be found in our ablation studies in subsection 3.4.
3. Experiments
We test our proposed method RAT on a diverse set of benchmarks that highlight long-horizon gener- ation and reasoning. Existing methods tradition- ally struggle in those benchmarks; “hallucinated” steps are obvious in LLMs’ outputs. Those steps ei- ther fail to stick to the original query or are plainly invalid. We kindly refer readers to subsection 3.3 (case analysis) for a more detailed discussion. Due to space constraints, we do not introduce each benchmark setting, nor do we discuss our results in each benchmark in full length. Rather, this section provides a comprehensive demonstra- tion of our method’s performance and provides a spotlight to provide preliminary empirical analy- sis about why and when our method works and when it fails.
3.1. Experimental Setups
We adopt four groups of benchmarks.
- Code Generation includess HumanEval (Chen et al., 2021), HumanEval+ (Liu et al., 2023b), MBPP (Austin et al., 2021), and MBPP+ (Liu et al., 2023b). These benchmarks encompass a wide range of programming problems, from sim- ple function implementations to more complex algorithmic challenges, providing a robust testbed for assessing generative capabilities.
- Mathematical Reasoning evaluation is con- ducted on GSM8K and GSM-HARD dataset, which comprises thousands of multi-step mathematical problems (Cobbe et al., 2021; Gao et al., 2022).
- Creative Writing tasks are conducted to evalu- ate the versatility of RAT, including survey, sum- marization etc., highlighting different aspects of open-ended text generation.
- Embodied Planning tasks are evaluated on open- ended environments Minecraft. A set of 100 tasks ranging from simple objectives to challenging diamond objectives are evaluated through MC- TextWorld (Lin et al., 2023).
Evaluation Metrics. For code generation, the classical pass rate pass@k is selected as the evalu- ation metrics (Chen et al., 2021; Liu et al., 2023b), 𝑘 denotes the sampling number. We compute ac- curacy to evaluate every question in mathemati- cal reasoning tasks, aligning with the established metric for the GSM8K (Cobbe et al., 2021). For embodied planning tasks, we compute the plan execution success rate in MC-TextWorld as exe- cutability (Lin et al., 2023). We also conduct hu- man elo rating evaluation to compute the trueskill rating score (Herbrich et al., 2006) for embod- ied planning (as plausibility) and creative writing tasks. These indicators are better the higher they are.
Baselines. To establish a comprehensive and eq- uitable comparison landscape, we incorporate a suite of baseline methods. Our baselines in- clude the original language models, referred to as DIRECT, and the Retrieval-Augmented Gen- eration (RAG) methodology with 𝑛 retrieved ex- amples, instantiated in both single-shot (1 shot) and multi-shot (5 shots) configurations, as documented by Lewis et al. (2020b). Additionally, we examine the zero-shot CoT (CoT) approach, as conceptualized by Kojima et al. (2022), which simulates a step-by-step reasoning process to fa- cilitate complex problem-solving tasks under zero demonstration. For different methods, the same language model is used as base models. To en- sure a fair comparison, none of the methods used examples from the benchmark as demonstrations for in-context learning.
RAT leverages the capabili- RAG Settings. ties of Retrieval-Augmented Generation meth- ods, which enhance the performance of lan- guage models by integrating external knowl- Specifically, we employed edge sources. the codeparrot/github-jupyter dataset as our primary search vector library for code gen- eration and mathematical reasoning tasks. For embodied planning tasks in Minecraft, we utilized the Minecraft Wiki1 and DigMinecraft2 websites as the information sources accessible to the LLMs.
For open-ended creative writing tasks, we use Google to search the query on the Internet. We utilized OpenAI’s text-embedding-ada-002 API service for all embedding calculations across different methods and base models.
Acknowledging the risk of benchmark contam- ination (an issue where the code library may con- tain solutions to the exact problems being eval- uated), we adopted a rigorous pre-processing methodology as described by Guo et al. (2024). The potential implications of benchmark contam- ination, along with the effectiveness of our pre- processing strategy, are discussed in detail in Ap- pendix D.
3.2. Results
The code generation results presented in Table 1 and results on other benchmarks presented in Table 2 demonstrate the comprehensive evalu- ation of the RAT across multiple benchmarks. RAT consistently outperforms the other methods across the majority of the benchmarks and metrics, showcasing its superior ability to generate long-horizon context. Notably, in the HumanEval and HumanEval+ benchmarks of code genera- tion, RAT achieves remarkable improvements in pass@1 and pass@5 rates, indicating a signifi- cant enhancement in first-attempt accuracy and within the top five attempts. For example, on the HumanEval benchmark, RAT improves pass@1 by up to 20.94% and pass@5 by up to 25.68% rela- tive to the base models’ performances. This trend is observed across different underlying base mod- els, highlighting RAT’s effectiveness regardless of the initial model’s capabilities. For mathematical reasoning tasks, RAT demonstrates a significant relative improvement, with an 8.37% increase in accuracy on GSM8K and a remarkable 31.37% increase on GSMHard, culminating in an overall average improvement of 18.44% when deployed on the GPT-3.5 model. RAT significantly outper- forms all other methods on open-ended embodied planning tasks in Minecraft, achieving the highest scores with 76.67±8.02% for executability and 29.37 human rating score for plausibility, demon- strating its superior ability to generate feasible and contextually appropriate plans in the com- plex open-world environment. RAT’s superior per- formance also keeps across a broad spectrum of creative writing tasks. Its ability to generate high- quality content in diverse scenarios was demon- strated, highlighting its potential as a powerful tool for enhancing the general creative writing capabilities of LLMs in open-ended scenarios.
The tasks are extremely diverse, while RAT can have consistent improvements over all baselines. These results underline the advantages of RAT’s approach, which leverages iterative refinement of retrieval queries based on evolving reasoning thoughts. This strategy not only enhances the relevance and quality of the information retrieved but also significantly improves the accuracy and efficiency of the generated context.
3.3. Case Analysis
Here we take the embodied planning task and creative writing task to do case analysis.
In a manner analogous to multi-document question-answering tasks (Trivedi et al., 2022a), the task of long-horizon planning in Minecraft is knowledge-dense, requiring consideration of various items for the completion of each task. However, open-world Minecraft knowledge on the internet is fragmented, making task comple- tion often dependent on information from mul- tiple sources. We observed that while language models like ChatGPT can identify necessary items through zero-shot CoT reasoning, inaccuracies in procedural steps are common. For example, ChatGPT inaccurately identified the materials for a crafting table as 4 wood blocks (the right an- swer is 4 planks), indicating lower executability reliability in CoT plans. Classical RAG algorithms, retrieving the knowledge with the question as a query and focusing on the final target item, inade- quately retrieve intermediary items, offering min- imal task improvement. Contrastingly, RAT im- proves upon CoT’s initial answers by continuously refining thoughts with targeted retrieval, align- ing closely with task progression and relevant item knowledge. This methodology significantly enhances planning effectiveness by ensuring a comprehensive understanding and retrieval of all items involved in a plan, highlighting the syn- ergy between structured reasoning and dynamic knowledge retrieval in addressing long-horizon planning challenges in Minecraft.
In addressing open-ended creative writing tasks, assessments of LM’s generations typically focus on completeness and accuracy. When tasked with “summarizing the American Civil War according to a timeline”, LMs under DIRECT and CoT prompts often produce significant halluci- nations. For example, the statement “The Civil War officially began on April 12, 1860, when Con- federate troops attacked Fort Sumter in South Carolina, a Union-held fort” contains incorrect information, where the year 1860 is erroneously mentioned instead of the correct year, 1861.
Direct queries to the internet for this task tend to retrieve limited events, frequently overlook- ing the accurate start date of the war, April 12, 1861. Moreover, the RAG approach, which tends to summarize content retrieved from searches, often misses this event in its responses, whether it’s RAG-1 or RAG-5. On the other hand, RAT bases its search on a language model’s draft answer, finding that hallucinations usually occur in details, such as specific dates, which do not hinder the search engine from identifying rele- vant information like “American Civil War starting date”. RAT utilizes the content retrieved to iden- tify and correct errors in the draft answer rather than merely summarizing the retrieved content. Therefore, RAT can achieve a complete genera- tion through reasoning and enhance the accuracy and credibility of the answer by leveraging re- trieved knowledge. Experimental results validate the effectiveness of RAT.
3.4. Ablation Study
Ablation on retrieval in RAT. In this ablation study, we investigate the influence of various re- trieval strategies on the efficacy of RAT, focusing on the optimization of content retrieval for im- proving generative outputs. The experimental results, detailed in Table 3, highlight the signif- icant advancements achieved through the itera- tive refinement of retrieval queries in RAT com- pared to baseline methods. The baseline denoted as RAG-1, employs a direct approach by using the question itself as the retrieval query. In con- trast, CoT+RAG enhances this process by utiliz- ing the entirety of the reasoning thoughts output by the language model as the query, aiming for a broader contextual understanding. However, RAT introduces a more dynamic method by em- ploying continuously modified parts of reason- ing thoughts as queries, which allows for a more focused and relevant information retrieval pro- cess. The comparative analysis shows that RAT surpasses both the baseline and the CoT+RAG method in terms of pass@1 and pass@5 metrics across the HumanEval and HumanEval+ bench- marks. Specifically, RAT demonstrates an 8.7 per- centage point increase in pass@1 and a 7.9 per- centage point increase in pass@5 over the base- line in the HumanEval benchmark, and similarly
impressive gains in the HumanEval+ benchmark. These improvements underscore the effectiveness of RAT’s retrieval strategy, which by iteratively refining next queries based on evolving reason- ing thoughts and previous queries, ensures the retrieval of highly pertinent information. This process not only enhances the relevance of the information retrieved but also significantly im- proves the quality and accuracy of the final gen- erated outputs. The results firmly establish the superiority of RAT’s dynamic retrieval method in leveraging contextual nuances to drive more precise and effective generative processes.
Ablation on causal reasoning in RAT. In this ablation study, we systematically examine the impact of causal and non-causal reasoning ap- proaches on the performance of the RAT system, with the Chain of Thought (CoT) serving as our baseline. Our findings, as summarized in Ta- ble 4, reveal significant enhancements in gen- eration capabilities when incorporating causal reasoning techniques. Specifically, the causal ap- proach, which iteratively performs reasoning and retrieval, leads to notable improvements in both pass@1 and pass@5 metrics across HumanEval and HumanEval+ benchmarks. For instance, the causal method outperforms the baseline (CoT) by 11.9 percentage points in pass@1 and by 4.6 percentage points in pass@5 on the HumanEval dataset. This approach contrasts with the non- causal method, which, although also surpass- ing the baseline, leverages the initial reasoning thought to directly retrieve all necessary steps and generate the final answer. The causal method’s superior performance underscores the value of sequential reasoning and information retrieval in enhancing the accuracy and reliability of gener- ated outputs. This iterative process likely aids in refining the search and reasoning steps based on continuously updated context, allowing for more precise and relevant information retrieval, which in turn supports more accurate final answers.
These results firmly establish the efficacy of causal reasoning in long-horizon problem-solving tasks.
3.5. Robustness of RAT
RAT was rigorously validated across a diverse set of tasks, including code generation, mathe- matical reasoning, creative writing, and embod- ied planning. This variety of tasks underscores the generalization capability of RAT, demonstrat- ing its robust performance across highly diverse challenges. Furthermore, all our experimental settings were conducted in a zero-shot manner; we did not design task-specific prompts for RAT, but rather used the simplest possible prompts (which can be found in Appendix B) to articulate questions or instructions for all methods. This approach ensures RAT’s generalization ability in open-ended scenarios.
The diversity of our evaluation was further en- hanced by testing RAT across various language models of differing capacities. This included CodeLlama-7b (Rozière et al., 2023), ChatGPT (gpt-3.5-turbo) (Ouyang et al., 2022), and the more advanced GPT-4 (gpt-4) model (OpenAI, 2023). Remarkably, RAT maintained its general- ization capability across different scales of lan- guage models, showing improvements in bench- marks such as the HumanEval for code generation tasks. Notably, the largest improvement was ob- served with GPT-4, attributed to its superior abil- ity for in-context learning from retrieved text. On MBPP+, CodeLlama-7b based RAT has demon- strated performance degradation. This decline could be due to the limited in-context learning ability of smaller language models.
For mathematical reasoning tasks, RAT demon- strated a significant relative improvement, with an overall average improvement of 18.44% when applied to the GPT-3.5 model. This trend of im- provement persisted with GPT-4, which achieved a remarkable 10.26% relative improvement from DIRECT to RAT. These findings highlight RAT’s robustness and its effective enhancement of lan- guage models’ performance across a spectrum of computational and creative tasks.
4. Related Works
Retrieval-augmented Generation (RAG). Re- cently, RAG has gained popularity for boosting the performance of LLMs by guiding their genera- tion process using the retrieved knowledge (Zhao et al., 2023). Without updating model parame- ters that may be expensive (Lewis et al., 2020a) or unstable (Ke et al., 2022a,b), RAG is a cost- effective way for LLMs to interact with the exter- nal world (Gu et al., 2018; Lewis et al., 2020a). RAG is widely applied to downstream tasks, such as code generation (Lu et al., 2022; Nashid et al., 2023; Zhou et al., 2022b), question answer- ing (Baek et al., 2023; Siriwardhana et al., 2023), and creative writing (Asai et al., 2023; Wen et al., 2023).
Reasoning-enhanced RAG. Some recent works also leverage reasoning to enhance the perfor- mance of RAG (Li et al., 2023b). For example, IRCoT (Trivedi et al., 2022b) exploits CoT to gen- erate better queries for retrieval, IRGR (Ribeiro et al., 2022) performs iteratively retrieval to search for suitable premises for multi-hop QA, GEEK (Liu et al., 2023a) can choose to query ex- ternal knowledge or perform a single logical rea- soning step in long-horizon generation tasks, and ITRG (Feng et al., 2023a) performs retrieval based on the last-step generation. However, these pre- vious RAG methods simply adopt a single query to retrieve the knowledge for question-answering tasks (Feng et al., 2023b; Gao et al., 2023), while our proposed RAT performs retrieval using reason- ing and draft answers in an autoregressive way, which significantly improves the performance of RAG in various tasks as demonstrated in Figure 2.
Language Model for Reasoning. The ad- vancement of reasoning in language models has seen notable methodologies emerge since CoT was proposed by Wei et al. (2022), which showcased LMs’ ability to generate self-derived problem-solving strategies. This foundational work spurred further innovations such as the least- to-most prompting (Zhou et al., 2022a), zero-shot CoT (Kojima et al., 2022), self-consistency (Wang et al., 2022), zero-shot CoT without prompt- ing (Wang and Zhou, 2024). Moving beyond basic prompting, Creswell et al. (2022) introduced the Selection-Inference framework, while Zelikman et al. (2022) developed STaR to refine reasoning through model finetuning. Creswell and Shanahan (2022) proposed a faithful reason- ing model, segmenting reasoning into dedicated steps, similar to Scratchpad’s approach by Nye et al. (2021) for enhancing multi-step compu- tation. Tree-of-Thought (Yao et al., 2023) and Graph-of-Thought (Besta et al., 2023) also ex- pand the reasoning paths into a complex struc- ture instead of linear CoT. These methods usually aim to improve the reasoning ability of LLM by designing prompts or providing feedback from the environment to assist in better planning and decision-making (Li et al., 2023a; Shinn et al., 2023; Wang et al., 2023c; Yao et al., 2022; Zhang et al., 2023). However, RAT takes a different approach by using RAG to access external knowl- edge that can help LLM with its reasoning pro- cess.
5. Conclusion
We have presented Retrieval Augmented Thoughts (RAT), a simple yet effective prompting strategy that synergies chain of thought (CoT) prompting and retrieval augmented generation (RAG) to address the challenging long-horizon reasoning and generation tasks. Our key ideas involve revising the zero-shot chain of thoughts produced by LLMs through RAG with the thoughts as queries, and causally revising the thoughts & generating the response progressively. RAT, a zero-shot prompting approach, has demonstrated significant advantages over vanilla CoT prompting, RAG, and other baselines on challenging code generation, mathematics reasoning, embodied task planning, and creative writing tasks.