Rank RAG
- Related Project: Private
- Category: Paper Review
- Date: 2024-07-02
RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs
- url: https://arxiv.org/abs/2407.02485v1
- pdf: https://arxiv.org/pdf/2407.02485v1
- html: https://arxiv.org/html/2407.02485v1
- abstract: Large language models (LLMs) typically utilize the top-k contexts from a retriever in retrieval-augmented generation (RAG). In this work, we propose a novel instruction fine-tuning framework RankRAG, which instruction-tunes a single LLM for the dual purpose of context ranking and answer generation in RAG. In particular, the instruction-tuned LLMs work surprisingly well by adding a small fraction of ranking data into the training blend, and outperform existing expert ranking models, including the same LLM exclusively fine-tuned on a large amount of ranking data. For generation, we compare our model with many strong baselines, including GPT-4-0613, GPT-4-turbo-2024-0409, and ChatQA-1.5, an open-sourced model with the state-of-the-art performance on RAG benchmarks. Specifically, our Llama3-RankRAG significantly outperforms Llama3-ChatQA-1.5 and GPT-4 models on nine knowledge-intensive benchmarks. In addition, it also performs comparably to GPT-4 on five RAG benchmarks in the biomedical domain without instruction fine-tuning on biomedical data, demonstrating its superb capability for generalization to new domains.
Contents
강화된 검색-증강 생성(RankRAG) 모델의 수학적 접근 및 응용
- RankRAG는 지능형 언어 모델(LLM)을 이용하여 정보 검색과 문답 생성을 동시에 지휘하는 새로운 프레임워크를 제안합니다.
- 기존 검색 후 생성(RAG) 접근 방식의 한계를 극복하고, 상위 𝑘개의 컨텍스트를 재순위하여 보다 정확한 답변 생성을 목표로 합니다.
- RankRAG는 다양한 지식 집약적 NLP 작업에 대해 상당한 성능 향상을 보여주며, 특히 소량의 랭킹 데이터를 통합한 지시 조정 학습이 효과적임을 입증합니다.
1. 서론
최근 검색-증강 생성(Retrieval-augmented generation, RAG) 기법이 긴 꼬리 지식, 최신 정보 제공, 특정 도메인 및 작업에 대한 언어 모델의 적응력 향상에 널리 사용되고 있습니다. 이 기법은 대규모 문서 집합에서 관련 컨텍스트을 검색하여 해당 컨텍스트을 바탕으로 답변을 생성합니다. 그러나 기존 RAG 접근 방식은 상위 $𝑘$개 컨텍스트만을 읽는 과정에서 정확성과 효율성 사이의 균형을 맞추는 데 한계가 있습니다.
2. 관련 연구
이전 연구에서는 독립적인 검색 및 생성 단계를 사용하여 지능형 언어 모델을 통한 정보 검색의 정확성을 높이고자 하였습니다. 그러나, 종종 추가적인 랭킹 모델이 필요하며, 이는 0-shot 일반화 능력이 제한적일 수 있으며, 검색 후 단계에서의 일반화 능력이 부족한 점이 발견하였습니다. 최근 연구는 랭킹 작업에 있어서 언어 모델의 강력한 능력을 활용하는 방법을 탐구하고 있습니다.
RankRAG는 이런 문제를 해결하기 위해 독특한 지시 조정(instruction tuning) 접근 방식을 사용합니다.
3. 방법
3.1 문제 설정
검색-증강 생성에서는 다음과 같은 문제 설정을 갖고 있습니다. 주어진 질문 \(q\)에 대해, 검색기 \(\mathcal{R}\)은 가장 관련성 높은 상위 \(k\)개의 컨텍스트 \(\mathcal{C} = \{c_1, \dots, c_k\}\)을 검색합니다. 그 후 언어 모델은 이 컨텍스트들을 사용하여 최종 답변을 생성합니다.
이 과정에서 사용되는 언어 모델은 주로 자기 회귀적 언어 모델(auto-regressive language models)입니다.
3.2 현재 RAG 파이프라인의 한계
현재 RAG 시스템들은 대부분 BM25나 BERT 기반의 모델을 사용하여 문서를 검색합니다. 이런 모델들은 질문과 문서 사이의 텍스트적 유사성을 독립적으로 평가합니다. 하지만 이런 접근 방식은 새로운 작업이나 도메인에서의 효과성이 제한적입니다. 예를 들어, Xu et al. (2024b)의 연구에 따르면, 상위 \(k\)개의 컨텍스트 수를 늘릴수록 성능은 포화 상태에 이르며, \(k = 10\)에서 최적의 성능을 보입니다. 이는 상위 \(k\)개의 선택에 있어서 정보의 포괄성과 관련 없는 내용의 도입 사이의 트레이드오프를 시사합니다.
4. RankRAG 방법 상세
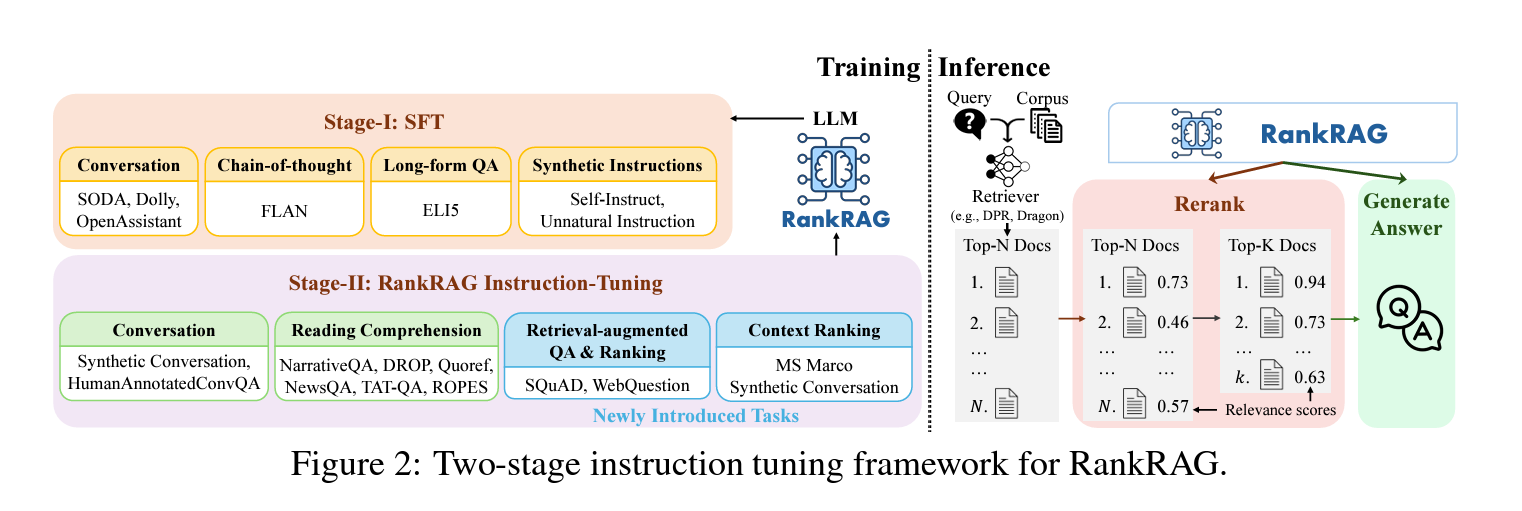
RankRAG는 기존의 ‘검색 후 생성’의 접근 방식을 개선하기 위해 언어 모델을 지시 조정하여 질문과 컨텍스트 사이의 관련성을 동시에 포착하고, 검색된 컨텍스트을 이용하여 답변을 생성하도록 합니다. 이는 두 단계로 진행됩니다.
- Step 1: 감독된 파인튜닝(SFT)(4.1): 다양한 고품질 지시 데이터셋를 사용하여 언어 모델의 instruction following 능력을 향상시킵니다. 이 데이터는 ELI5, OpenAssistant 등에서 수집됩니다.
- Step 2: 통합 지시 조정(4.2): 이 단계에서는 언어 모델을 컨텍스트 랭킹과 검색-증강 생성 두 가지 역할에 맞추어 조정합니다. 특히, MS MARCO와 같은 랭킹 데이터를 사용하여 질문에 대한 컨텍스트의 관련성 평가 능력을 개발합니다.
4.1 Step 1: 감독된 파인튜닝(SFT)
감독된 파인튜닝을 통해 LLM이 지시를 따르는 능력이 향상됩니다. 이 단계에서는 고품질 지시 데이터셋를 사용하여 LLM의 기본 지시-따르기 능력을 강화합니다.
4.2 Step 2: 검색 및 생성을 위한 통합 지시 조정
이 단계에서는 LLM을 검색-증강 생성과 컨텍스트 랭킹 모두에 대해 조정하여 초기 검색 결과의 정확성을 향상시킵니다. 이는 다음 데이터를 포함합니다.
- 컨텍스트 풍부 QA 데이터: 다양한 QA 데이터셋를 활용하여 컨텍스트을 이용한 답변 생성 능력을 강화합니다.
- 검색-증강 QA 데이터: 추가로 검색된 컨텍스트을 포함하는 QA 작업을 통해 LLM의 견고성을 높입니다.
- 컨텍스트 랭킹 데이터: MS MARCO 등의 랭킹 데이터셋를 사용하여 질문-컨텍스트 쌍의 관련성을 평가하는 능력을 키웁니다.
5. 실험 설정 및 평가
RankRAG 모델은 다양한 벤치마크에서 기존 모델들과 비교하여 평가되었으며, RankRAG는 지식 집약적 NLP 작업에서 향상된 성능을 보였습니다.
6. 결론 및 효율성 논의
RankRAG는 추가된 재순위 단계로 인해 처리 시간이 증가하나, 이는 검색 및 생성 단계와 비교하여 상대적으로 짧은 입력을 필요로 하는 관계 평가 단계에서 상쇄됩니다.