Data Composition | CMR Scaling Law
- Related Project: Private
- Category: Paper Review
- Date: 2024-07-26
CMR Scaling Law: Predicting Critical Mixture Ratios for Continual Pre-training of Language Models
- url: https://arxiv.org/abs/2407.17467
- pdf: https://arxiv.org/pdf/2407.17467
- abstract: Large Language Models (LLMs) excel in diverse tasks but often underperform in specialized fields due to limited domain-specific or proprietary corpus. Continual pre-training (CPT) enhances LLM capabilities by imbuing new domain-specific or proprietary knowledge while replaying general corpus to prevent catastrophic forgetting. The data mixture ratio of general corpus and domain-specific corpus, however, has been chosen heuristically, leading to sub-optimal training efficiency in practice. In this context, we attempt to re-visit the scaling behavior of LLMs under the hood of CPT, and discover a power-law relationship between loss, mixture ratio, and training tokens scale. We formalize the trade-off between general and domain-specific capabilities, leading to a well-defined Critical Mixture Ratio (CMR) of general and domain data. By striking the balance, CMR maintains the model’s general ability and achieves the desired domain transfer, ensuring the highest utilization of available resources. Therefore, if we value the balance between efficiency and effectiveness, CMR can be consider as the optimal mixture ratio.Through extensive experiments, we ascertain the predictability of CMR, and propose CMR scaling law and have substantiated its generalization. These findings offer practical guidelines for optimizing LLM training in specialized domains, ensuring both general and domain-specific performance while efficiently managing training resources.
TL;DR
- 대규모 언어모델(LLM)은 특정 도메인에 맞춰 계속적인 전이 학습을 통해 성능을 개선
- 도메인 손실과 일반 손실 간의 균형을 최적화하는 Critical Mixture Ratio (CMR) 제시
- 데이터 혼합 비율과 규모의 법칙을 이용한 효율적인 연속적 사전학습(CPT)을 통한 대규모 언어모델의 도메인별 성능 최적화할 수 있으며, 최적의 데이터 혼합 비율(CMR)은 모델 규모와 훈련 토큰의 양에 따라 변화하며, 이는 손실 예측을 통해 결정된다고 주장
- CMR을 예측하기 위해 실험을 한 결과 멱법칙(Power Law) 관계가 성립됨을 확인하였고, 이는 효율적인 도메인 전환을 가능하게 할 수 있다고 주장
[주요 인사이트 Section 5]
CMR의 존재와 예측 가능성은 도메인 특화 데이터와 일반 데이터 사이의 트레이드오프에서 비롯되며, 도메인 데이터 비율이 높을수록 도메인에 대한 지식이 증가하지만, 너무 높은 비율은 일반적 능력의 감소로 이어질 수 있다고 언급합니다. 이런 상황에서 최적의 혼합 비율을 찾기 위해 손실 함수와 관련 변수들의 멱법칙을 통한 정량적 분석을 수행합니다.
1. Introduction
(대규모 언어모델의 성능 문제) 대규모 언어모델(LLM)은 질문 응답, 번역, 요약, 역할 수행 등 다양한 능력을 보여주지만, 특정 도메인에서의 성능 저하가 문제로 지적되어 왔는데, 이는 도메인에 특화된 사전 훈련 데이터의 부족이 큰 영향을 미치는 것으로 알려져있습니다.
(연속 전이 학습(CPT)의 도입) 이런 문제를 해결하기 위해, 연속 전이 학습(Continual Pre-Training, CPT) 방법을 제안합니다. CPT는 기존의 일반적 성능 저하 없이 새로운 도메인 관련 능력을 LLM에 부여할 가능성을 제공하며, 여러 도메인(코드, 법률, 의학 등)에서 CPT의 효과가 입증되었지만, 손실 예측과 모델 크기, 훈련 토큰 수와의 상호작용은 아직 완전히 탐구되지는 않았습니다.
(데이터 혼합 비율의 중요성) 비효율적인 훈련 또는 부족한 훈련을 초래할 수 있는 부적절한 데이터 혼합 비율은 CPT의 큰 챌린지 중 하나로 최적의 데이터 혼합 비율이 존재하는지, 그리고 그 비율이 모델 규모나 훈련 토큰 양에 따라 어떻게 변화하는지가 중요한 연구 주제입니다. (예전부터 배치 사이즈나 적절한 데이터의 양에 대한 것은 모든 AI 도메인에서 연구 주제였습니다.)
2. Main Results
(CPT의 목표 간 균형) 모델의 특정 크기를 고려할 때, 특정 훈련 데이터 제약 조건 하에서 목표를 달성할 수 있는 가능한 혼합 비율 집합이 존재한다고 언급합니다.
(손실 예측) 일반 손실은 처음에 증가한 후 감소하는 반면, 도메인 손실은 감소하는 경향이 있으므로 손실과 혼합 비율, 훈련 양 사이의 관계는 멱법칙(Power Law) 형태로 잘 맞아떨어지며, 이를 통해 다양한 혼합 비율과 훈련 토큰 하에서 손실을 예측할 수 있다고 언급합니다.
(CMR의 예측) 손실 예측을 통해 CMR을 예측할 수 있으며, 최대 훈련 토큰 양을 고려할 때, CMR은 모델 규모가 증가함에 따라 상승하는 것을 관찰합니다. 예를 들어, 460M 모델의 경우 29.76%, 940M 모델의 경우 34.89%로 측정되었다고 합니다.
손실 \(L\)과 데이터 혼합 비율 \(r\) 및 훈련 토큰 \(t\) 간의 멱법칙(Power Law) 관계를 정의하면 다음과 같습니다.
\[L(r, t) = k \cdot r^a \cdot t^b\]\(k, a,\) 및 \(b\)는 상수로, 이 식을 통해 특정 \(r\)과 \(t\)에서의 손실을 예측할 수 있으며, 이는 CMR을 찾는데 중요하게 사용됩니다.
3 Background and Methods
- 계속된 사전 훈련(CPT)의 목표 정의 - 일반 및 도메인 특화 데이터셋을 혼합하여 언어 모델을 훈련시키고, 일반 및 도메인 손실 최소화를 추구
- 가능 혼합 비율 및 중요 혼합 비율(CMR) 설정 - 특정 혼합 비율에서 최적의 학습 효과를 달성하기 위해 설정된 비율
- 데이터 준비 및 실험 설정 - 다양한 언어 및 도메인 데이터셋을 사용하여 모델의 성능을 평가
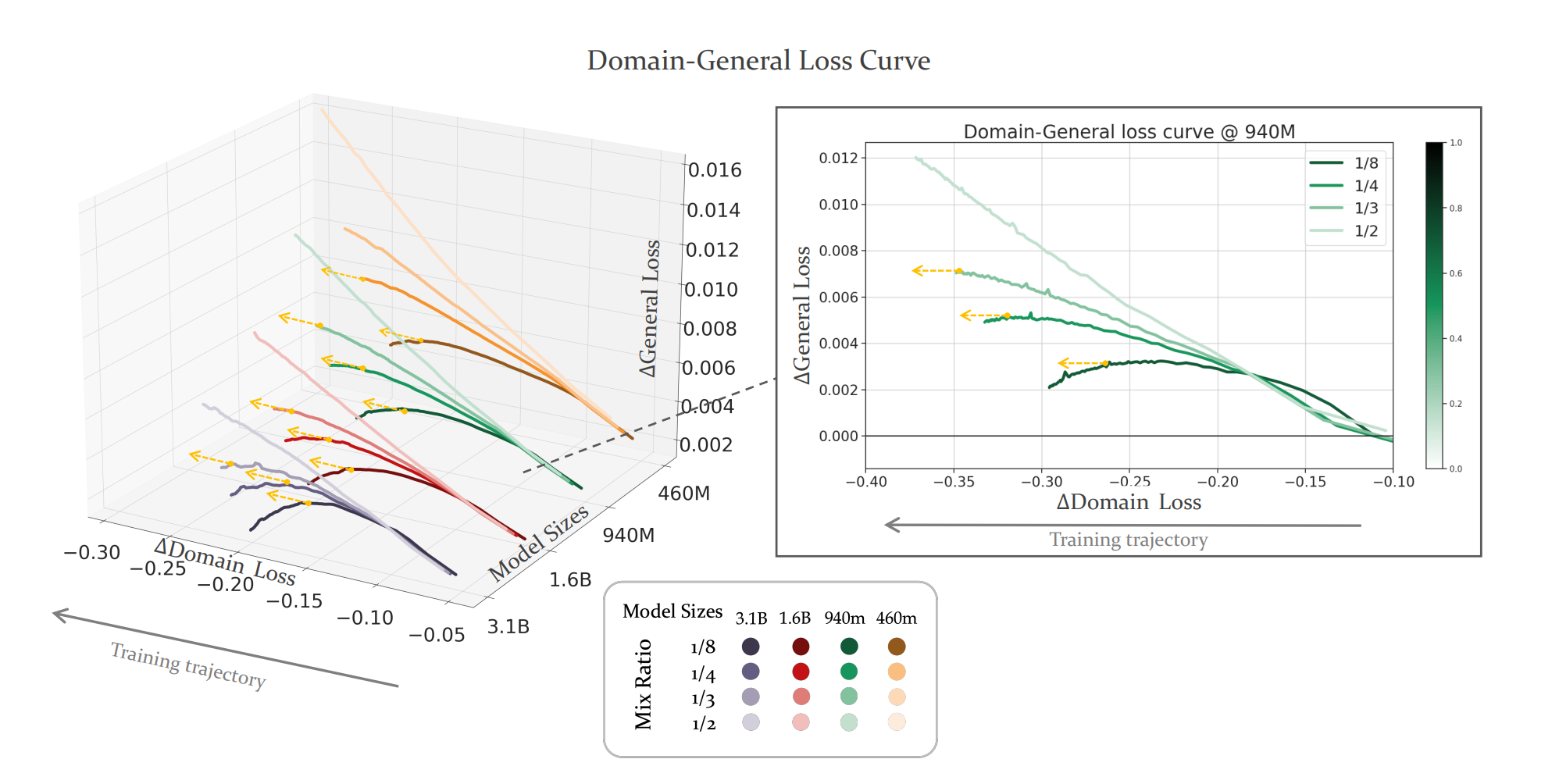
Figure 1: Follow the direction of the training trajectory to track the trend of the curve. Each bunch of lines represents a model size scale: {3.1B, 1.6B, 940M, 460M} and each group of line colors represents the mixture ratios {1/8, 1/4, 1/3, 1/2} from dark to light. In order to better display the trend, we have omitted proportions greater than 1/2. The yellow dashed lines(<–) point horizontally, indicating the corresponding ratios where \(\frac{dL\Delta_{\text{gen}}}{dL\Delta_{\text{dom}}}\) closed to 0. The third set of lines of model size 940M, which has been zoomed in and depicted on the right side, showing the trend of the training curve more apparently. All horizontal and vertical cross-sections of the 3D diagram on the left side are detailed in the Appendix D.
- \(L\Delta_{\text{gen}}\) 일반적인 손실의 변화량으로 모델의 전반적인 성능을 평가하는 데 사용되는 메트릭
- \(L\Delta_{\text{dom}}\) 특정 도메인에 관련된 손실의 변화량을 나타내며 모델이 특정 작업이나 데이터셋에 적용될 때의 성능 변화를 반영
3.1 연속 사전 훈련(CPT)의 목표 설정
연속 사전 훈련(CPT)의 목표는 다음 수식을 사용하여 정의됩니다. 주어진 사전 훈련된 대규모 언어모델 \(MS\)에 대해, 일반 데이터셋 \(D_{gen}\)과 도메인 특화 데이터셋 \(D_{dom}\)을 혼합한 데이터셋 \(D_R\)에서 모델을 추가적으로 훈련합니다. 혼합 비율 \(R\)은 다음과 같이 정의됩니다.
\[R = \frac{|D_{dom}|}{|D_{gen}| + |D_{dom}|}\]이를 통해 얻은 목표는 다음과 같습니다.
- 일반 손실 최소화: 훈련 종료 시, 일반 손실은 특정 기준 \(\epsilon\) 이내로 감소하거나 유지되어야 합니다. \(L_{CPT_{gen}}(MS, D_R, T_{max}) \leq L_{gen}(MS) + \epsilon \quad \text{(Eq. 1)}\)
- 도메인 손실 감소: 도메인 손실은 더 크게 감소해야 합니다. \(L_{CPT_{dom}}(MS, D_R, T_{max}) < L_{dom}(MS) \quad \text{(Eq. 2)}\)
3.2 가능 혼합 비율 및 중요 혼합 비율(CMR) 정의
가능 혼합 비율은 특정 \(\epsilon\)을 만족하는 비율 집합 \(A\)로부터 선택됩니다. 이는 다음 조건을 만족하는 \(R\)의 집합 \(F\)입니다.
\[F = \{R | \exists T_0 \in [0, T_{max}] : \frac{\partial L_{\Delta gen}(R, T)}{\partial L_{\Delta dom}(R, T)} = -\frac{1}{\lambda} < 0, R \in A\} \quad \text{(Eq. 5)}\]CMR은 이 \(F\) 집합에서 가장 큰 값을 갖는 \(R\)로 정의되며, 일반적인 손실 증가 없이 도메인 데이터를 최대한 활용할 수 있는 비율을 의미합니다.
[데이터 준비]
데이터 준비 단계에서는 중국어, 영어, 그리고 코드로 구성된 2200억 토큰의 일반 사전 훈련 데이터셋을 준비했습니다. 특화 도메인 데이터셋으로는 금융 및 학술 논문을 포함하였으며, 각각 최소 200억 토큰을 포함합니다.
- 일반 사전 훈련 데이터 구성: 2200억 토큰의 대규모 데이터셋으로, 중국어(44%), 영어(36%), 코드(20%)로 구성됨. 각 언어 데이터는 백과사전, 책, 뉴스, 논문, 소셜 미디어 등 다양한 출처에서 수집됨.
- 도메인 특화 데이터셋: 금융(금융 뉴스, 정책, 규제, 회사 발표, 증권 및 펀드 회사 보고서) 및 학술 논문(오직 Arxiv에서 수집) 데이터셋을 각각 최소 200억 토큰 규모로 구성하여 CPT에 사용
[LLM 아키텍처]
- 모델 구조: 연구에서 사용된 LLM은 Llama 시리즈 아키텍처를 따름, 표준 멀티헤드 어텐션을 사용하고, 모델 파라미터는 460M에서 3.1B 범위
[실험 설정]
실험 설정에서는 2000억 토큰의 일반 데이터셋으로 기본 사전 훈련을 진행하고, 이후 200억 토큰을 사용하여 혼합 데이터셋에서 CPT를 진행합니다. 학습 속도, 배치 크기, 시퀀스 길이 등의 파라미터는 실험에 따라 조정되었습니다.
- 데이터셋 분할: 일반 사전 훈련을 위해 2000억 토큰, CPT를 위해 200억 토큰으로 분할.
- 사전 훈련 단계: 2000억 토큰으로 사전 훈련을 실시하며 최대 학습률 3e-4, 배치 크기 512, 시퀀스 길이 4096 설정
- CPT 단계: 다른 혼합 비율의 도메인 데이터셋과 함께 200억 토큰을 사용하여 추가 10,000 스텝 동안 훈련
[평가 방법]
모델의 성능 평가는 사전 훈련 손실을 통해 진행되며, 이는 downstream 작업 성능과 높은 상관관계를 가집니다. MSE 및 R²를 사용하여 핏팅의 품질을 측정하며, 이는 실험 결과의 해석을 명확하게 제공합니다.
- 성능 지표: 사전 훈련 손실을 사용하여 모델의 일반 및 도메인 특화 태스크 수행 능력 평가. 이는 downstream 작업 성능과 높은 상관관계를 가짐.
- 품질 측정: 평균 제곱 오차(MSE) 및 결정 계수(R²)를 사용하여 피팅의 품질을 분석하고, 오류를 명확하고 해석 가능한 방식으로 제공
4. 중요 혼합 비율의 존재 여부
중요 혼합 비율(Critical Mixture Ratio, CMR)은 도메인 특화 데이터 비율을 조정함으로써 도메인 손실을 최소화하고 기존 기능을 유지하는 최적의 비율을 말합니다. 이 섹션에서는 다양한 모델 크기에 대해 특정 비율에서 하락 추세를 보이는 곡선이 존재함을 보여주며, 이는 CMR의 존재를 시사합니다.
각 모델의 CMR은 그 모델의 크기와 한정된 훈련 토큰 양에 따라 다르게 정의됩니다. 예를 들어, M940M 모델의 CMR은 훈련 토큰 볼륨 범위 내에서 약 1/4로 예측됩니다.
\[\Delta \text{General Loss} = \Delta \text{Domain Loss}\]5. CMR 예측 가능성
CMR의 예측 가능성은 리소스 제약과 도메인 데이터 한계 하에서 최적의 혼합 비율을 찾기 위해 CMR 스케일링 법칙을 탐구함으로써 검증됩니다. 이 과정은 다음과 같은 두 가지 기본 요소에 의존합니다.
- 다양한 혼합 비율에 대한 손실 예측
- 다양한 훈련 토큰 볼륨에 대한 손실 예측
손실 예측은 다음과 같은 형식의 멱법칙으로 모델링됩니다.
\[L(R) = \alpha \cdot R^s + \beta\]\(\alpha\)는 계수, \(s\)는 지수, \(\beta\)는 편향으로 이를 통해 CMR은 다음과 같이 예측될 수 있습니다.
\[R_{CMR} = \alpha_4 \cdot T^{s_4} + \beta_3\]이런 예측은 훈련 토큰 볼륨을 고려할 때 각 모델의 최적 혼합 비율을 찾는 데 중요하며, 다양한 도메인과 데이터 비율에서 이 법칙이 일관되게 적용되는지 실험을 통해 검증합니다.
CMR의 존재와 예측 가능성은 도메인 특화 데이터와 일반 데이터 사이의 트레이드오프에서 비롯되며, 도메인 데이터 비율이 높을수록 도메인에 대한 지식이 증가하지만, 너무 높은 비율은 일반적 능력의 감소로 이어질 수 있습니다. 이런 상황에서 최적의 혼합 비율을 찾기 위해 손실 함수와 관련 변수들의 멱법칙을 통한 정량적 분석이 이루어집니다. 이는 CMR을 구체적으로 정의하고 예측하는 데 기초가 되며, 각 모델의 크기와 훈련 데이터의 양에 따라 이상적인 비율이 어떻게 달라지는지 설명합니다.
6. 관련 연구
6.1 연속적 사전학습(Continual Pre-Training, CPT)
연속적 사전학습은 대규모 언어모델(LLMs)이 새로운 도메인에 적응하고 특수 작업을 위해 모델을 처음부터 훈련하는 데 따르는 높은 비용을 감소시키는 목적으로 사용됩니다. 예를 들어, 코드, 의학, 법률 및 과학 분야에서 모델을 맞춤화하는 데 CPT가 활용됩니다. 이런 접근 방식은 다양한 도메인의 데이터 혼합을 사용하여 모델의 downstream 작업 성능을 향상시키고, 모든 형태의 사후 학습에서 흔히 발생하는 재앙적 망각을 완화합니다.
6.2 규모의 법칙
모델의 성능과 파라미터의 수 및 훈련 데이터의 크기 증가 사이의 멱함수 관계를 설명하는 연구가 많습니다. 이 관계는 사전 훈련, 감독된 파인튜닝 등 다양한 단계에서 중요합니다. Hoffmann 등의 연구에 따르면, 규모의 법칙은 \(L = E + \frac{A}{S^\alpha} + \frac{B}{T^\beta}\) 형식으로 표현될 수 있으며, \(E, A, B, \alpha, \beta\)는 적합 파라미터입니다.
6.3 데이터 혼합 규모의 법칙
사전학습 단계에서 다양한 데이터 혼합 비율이 규모의 법칙에 미치는 영향을 조사한 연구가 있습니다. 그러나 이런 법칙은 CPT에 적용되지 않습니다. Que 등의 연구는 모델 크기와 훈련 토큰 볼륨을 고정하여 도메인 손실을 최소화하는 데만 초점을 맞추었습니다.
7 결론
이 연구에서는 CPT하에 LLMs의 규모 행동을 조사하여 도메인별 성능의 한계를 해결하고자 했습니다. 일반 및 도메인별 데이터의 혼합 비율을 최적화하기 위한 Critical Mixture Ratio (CMR)를 명확히 정의하였습니다. 실험 결과는 손실, 혼합 비율, 훈련 데이터 크기 간의 멱법칙 관계를 밝혀내어 CMR을 효과적으로 예측할 수 있게 하였습니다. 이런 발견은 LLM 훈련을 최적화하는 실용적인 지침을 제공하며, 특수 분야에서 LLM의 능력을 향상시키기 위한 향후 연구의 길을 열어줍니다.
8 제한 사항
연구에서 사용된 모델 크기는 400M에서 3.1B 범위이지만, 현대 LLMs 중에서는 상대적으로 작은 편에 속합니다. 이는 모델 크기 측정의 정확성에 영향을 줄 수 있습니다. 또한 이 연구는 금융 및 학술 논문 도메인에서만 연속적 사전학습을 수행했으며, 더 많은 도메인에서의 실험은 보다 세밀한 결과를 제공하고 새로운 통찰력을 가져올 수 있습니다. 큰 모델에 대한 CMR을 예측하기 위해 여러 규모의 법칙을 활용하는 것은 향후 연구 과제로 남겨두었습니다.