Mistral 7B
- Related Project: Private
- Category: Paper Review
- Date: 2023-10-16
Mistral 7B
- url: https://arxiv.org/abs/2310.06825
- pdf: https://arxiv.org/pdf/2310.06825
- web: https://mistral.ai/news/announcing-mistral-7b/
- abstract: We introduce Mistral 7B v0.1, a 7-billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms Llama 2 13B across all evaluated benchmarks, and Llama 1 34B in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B – Instruct, that surpasses the Llama 2 13B - Chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license.
- related_links:
Contents
TL;DR
- 그룹화된 쿼리 어텐션(Grouped-Query Attention, GQA)[1]와 슬라이딩 윈도우 어텐션(Sliding Window Attention, SWA)[6, 3]을 활용하고, 효과적인 컴퓨팅에 초점을 맞췄음.
- Training dataset 및 학습 방법에 대한 경험적인 방법들 위주의 논문 중, 효율적인 리소스 활용에 대해 초점을 맞추었음.
- 바닐라 어텐션의 선형적인 계산 복잡도 증가에 대한 공통된 어려움을 볼 수 있었으며, 본 논문에서는 Flash Attention과 X-former를 조합해서 사용했음.
- 그 외 Attnetion Sink나 Flash Attention-2 등과의 조합에 대한 연구 결과도 2023년 안으로 나올 것으로 예상함.
- Qwen팀의 솔루션(NTK-aware interpolation, LogN-Scaling, and layer-wise window assignment)과 종합적으로 비교하여, 컴퓨팅 속도 뿐만 아니라 학습된 결과에 대한 비교 평가가 있었다면, 많은 사람들이 조금 더 도움을 받지 않았을까 하는 아쉬움이 남지만, 두 솔루션의 적용 단계가 약간 달랐고, 모델의 퍼포먼스에 영향을 미치지 않으면서 Mistral은 컴퓨팅 속도에 집중한 것으로 보임.
- (특징) 더 빠른 인퍼런스를 위해 그룹화된 쿼리 어텐션(Grouped-Query Attention, 이하 “GQA”)를 활용하고, 인퍼런스 비용을 줄이면서 임의의 시퀀스 길이를 효과적으로 처리하기 위해 슬라이딩 윈도우 어텐션(sliding window attention, 이하 “SWA”)을 결합하여 사용함.
- (성과) Mistral 7B는 평가된 모든 벤치마크에서 Llama 2 13B를 능가하고 인퍼런스, 수학 및 코드 생성에서 Llama 1 34B를 능가, 명령어를 따르도록 파인튜닝된 모델인 Mistral 7B - Instruct는 휴먼 및 자동화된 벤치마크에서 모두 Llama 2 13B Chat 모델을 능가하는 성능을 보임.
1 Introduction
In the rapidly evolving domain of Natural Language Processing (NLP), the race towards higher model performance often necessitates an escalation in model size. However, this scaling tends to increase computational costs and inference latency, thereby raising barriers to deployment in practical, real-world scenarios. In this context, the search for balanced models delivering both high-level performance and efficiency becomes critically essential. Our model, Mistral 7B, demonstrates that a carefully designed language model can deliver high performance while maintaining an efficient inference. Mistral 7B outperforms the previous best 13B model (Llama 2, [26]) across all tested benchmarks, and surpasses the best 34B model (LLaMA 34B, [25]) in mathematics and code generation. Furthermore, Mistral 7B approaches the coding performance of Code-Llama 7B [20], without sacrificing performance on non-code related benchmarks.
Mistral 7B leverages grouped-query attention (GQA) [1], and sliding window attention (SWA) [6, 3]. GQA significantly accelerates the inference speed, and also reduces the memory requirement during decoding, allowing for higher batch sizes hence higher throughput, a crucial factor for real-time applications. In addition, SWA is designed to handle longer sequences more effectively at a reduced computational cost, thereby alleviating a common limitation in LLMs. These attention mechanisms collectively contribute to the enhanced performance and efficiency of Mistral 7B.
- 그룹화된 쿼리 어텐션(GQA) [1]와 슬라이딩 윈도우 어텐션(SWA) [6, 3]을 활용하였으며,
- GQA는 인퍼런스 속도를 가속화하며 디코딩 중에 메모리 요구 사항을 줄이므로(실시간 애플리케이션에 중요한 요소) 더 높은 배치 크기 및 더 효율적인 처리 가능하고,
- SWA는 더 긴 시퀀스를 효과적으로 처리하도록 설계되어 계산 비용을 줄일 수 있음.
2 Architectural details
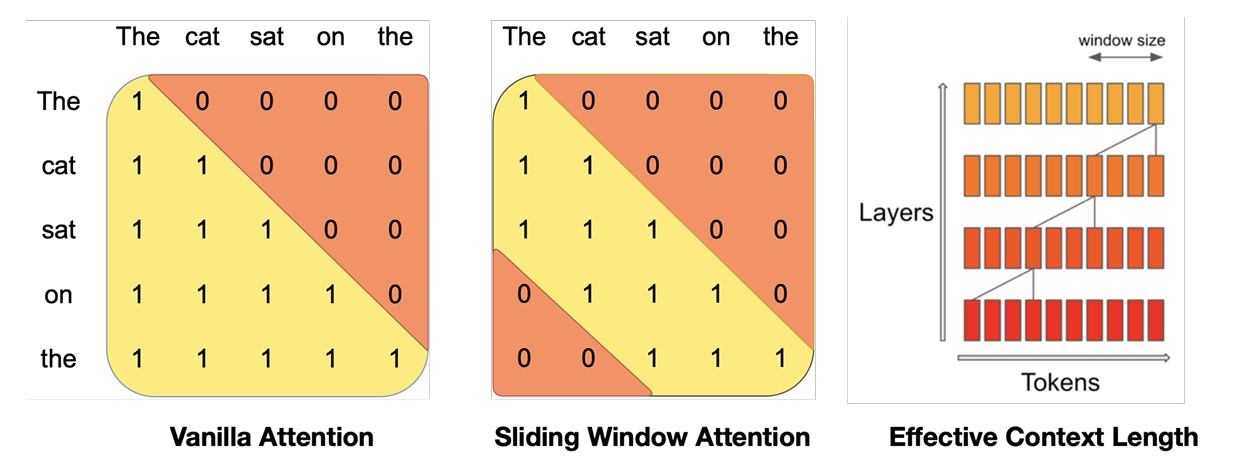
Figure 1: Sliding Window Attention. The number of operations in vanilla attention is quadratic in the sequence length, and the memory increases linearly with the number of tokens. At inference time, this incurs higher latency and smaller throughput due to reduced cache availability. To alleviate this issue, we use sliding window attention: each token can attend to at most W tokens from the previous layer (here, W = 3). Note that tokens outside the sliding window still influence next word prediction. At each attention layer, information can move forward by W tokens. Hence, after k attention layers, information can move forward by up to k × W tokens.
바닐라 어텐션(Vanilla Attention)의 연산 횟수는 시퀀스 길이에 따라 2진법이며, 메모리는 토큰 수에 따라 선형적으로 증가하는데, 이로 인해 인퍼런스 시에 캐시 가용성 감소로 인해 지연 시간이 길어지고 처리량이 감소함
- 이 문제를 완화하기 위해 SWA을 사용하는데, 각 토큰은 이전 레이어에서 최대 W개의 토큰(수식에서는 W = 3)에만 관심을 가질 수 있으며, 슬라이딩 윈도우 외부의 토큰은 여전히 다음 단어 예측에 영향을 미칠 수 있게 됨.
- 각 어텐션 레이어에서 정보는 W 토큰만큼 앞으로 이동할 수 있으므로, 어텐션 레이어 k개를 지나면 정보는 최대 k × W 토큰만큼 앞으로 이동할 수 있게 됨.
- *추가 자료: https://www.researchgate.net/figure/Illustration-of-a-vanilla-self-attention-layer-b-locality-modeling-with-the-window_fig2_352898565
Mistral 7B is based on a transformer architecture [27].
| Parameter | Value |
|---|---|
| dim | 4096 |
| n_layers | 32 |
| head_dim | 128 |
| hidden_dim | 14336 |
| n_heads | 32 |
| n_kv_heads | 8 |
| window_size | 4096 |
| context_len | 8192 |
| vocab_size | 32000 |
The main parameters of the architecture are summarized in Table 1. Compared to Llama, it introduces a few changes that we summarize below.
Sliding Window Attention. SWA exploits the stacked layers of a transformer to attend information beyond the window size W. The hidden state in position i of the layer k, hi, attends to all hidden states from the previous layer with positions between i − W and i. Recursively, hi can access tokens from the input layer at a distance of up to W × k tokens, as illustrated in Figure 1. At the last layer, using a window size of W = 4096, we have a theoretical attention span of approximately 131K tokens. In practice, for a sequence length of 16K and W = 4096, changes made to FlashAttention [11] and xFormers [18] yield a 2x speed improvement over a vanilla attention baseline.
- SWA는 트랜스포머의 스택형 레이어를 활용하여 윈도우 크기 W를 넘어서는 정보에 어텐션를 기울이게 됨.
- 레이어 k의 위치 i에 있는 hidden states hi는 i - W와 i 사이의 위치를 가진 이전 레이어의 모든 hidden states에 주목하게 되고, Figure 1과 같이 재귀적으로 hi는 최대 W × k 토큰의 거리에서 입력 레이어의 토큰에 접근할 수 있음.
- 마지막 레이어에서 창 크기를 W = 4096으로 사용하면, 이론적으로 약 13만 1천 개의 토큰에 대한 어텐션 범위(theoretical attention span)를 가질 수 있음.
- 실제로 시퀀스 길이가 16K이고 W = 4096일 때, 바닐라 어텐션을 플래시어텐션[11]과 x포머[18]로 변경하면 바닐라 어텐션 베이스 라인보다 2배 빨라짐을 확인.
Rolling Buffer Cache. A fixed attention span means that we can limit our cache size using a rolling buffer cache. The cache has a fixed size of W, and the keys and values for the timestep i are stored in position i mod W of the cache. As a result, when the position i is larger than W, past values in the cache are overwritten, and the size of the cache stops increasing. We provide an illustration in Figure 2 for W = 3. On a sequence length of 32k tokens, this reduces the cache memory usage by 8x, without impacting the model quality.
- fixed attention span는 롤링 버퍼 캐시를 사용하여 캐시 크기를 제한할 수 있음을 의미.
- 캐시는 고정된 크기인 W를 가지며, 시간 간격 i에 대한 키와 값은 캐시의 위치 i mod W에 저장되므로, 위치 i가 W보다 크면 캐시의 과거 값을 덮어쓰고 캐시 크기는 더 이상 증가하지 않게 됨.
- 시퀀스 길이가 32k 토큰인 경우 모델 품질에 영향을 주지 않으면서 캐시 메모리 사용량을 8배까지 줄일 수 있음을 시사.

Figure 2: Rolling buffer cache. The cache has a fixed size of W = 4. Keys and values for position i are stored in position i mod W of the cache. When the position i is larger than W , past values in the cache are overwritten. (The hidden state corresponding to the latest generated tokens are colored in orange.)
- 캐시의 고정 크기는 W = 4
- 위치 i에 대한 키와 값은캐시의 위치 i mod W에 저장.
- 위치 i가 W보다 크면 캐시의 이전 값에 덮어 씀.
Pre-fill and Chunking. When generating a sequence, we need to predict tokens one-by-one, as each token is conditioned on the previous ones. However, the prompt is known in advance, and we can pre-fill the (k, v) cache with the prompt. If the prompt is very large, we can chunk it into smaller pieces, and pre-fill the cache with each chunk. For this purpose, we can select the window size as our chunk size. For each chunk, we thus need to compute the attention over the cache and over the chunk. Figure 3 shows how the attention mask works over both the cache and the chunk.
- 시퀀스를 생성할 때는 이전 토큰을 기준으로 토큰을 하나씩 예측하지만, 그러나 프롬프트는 미리 알고 있으므로 프롬프트로 (k, v) 캐시를 미리 채울 수 있으며,
- 프롬프트가 큰 경우, 프롬프트를 작은 조각으로 나누어 조각으로 나누고 각 조각으로 캐시를 미리 창 크기를 청크 크기로 선택 조정하여 미리 채울 수 있음.
- 각 청크에 대해 캐시에 대한 관심도와 청크에 대한 관심을 계산할 수 있는데, Figure 3에 attention mask가 캐시와 청크 모두에서 어떻게 작동하는지 도식화 하였음.
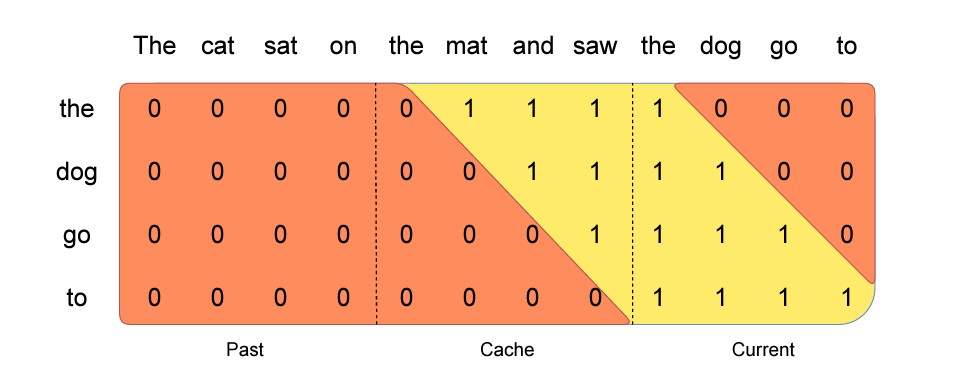
Figure 3: Pre-fill and chunking. During pre-fill of the cache, long sequences are chunked to limit memory usage. We process a sequence in three chunks, “The cat sat on”, “the mat and saw”, “the dog go to”.The figure shows what happens for the third chunk (“the dog go to”): it attends itself using a causal mask (rightmost block), attends the cache using a sliding window (center block), and does not attend to past tokens as they are outside of the sliding window (left block).
- Rightmost block: attends itself using a causal mask
- Center block: attends the cache using a sliding window
- Left block: does not attend to past tokens as they are outside of the sliding window
| Task | Type |
|---|---|
| Commonsense Reasoning (0-shot) | Hellaswag[28], Winogrande[21], PIQA[4], SIQA[22], OpenbookQA[19], ARC-Easy, ARC-Challenge[9], CommonsenseQA[24] |
| World Knowledge (5-shot) | NaturalQuestions[16], TriviaQA[15] |
| Reading Comprehension (0-shot) | BoolQ[8], QuAC[7] |
| Math | GSM8K[10] (8-shot) with maj@8 and MATH[13] (4-shot) with maj@4 |
| Code | Humaneval[5] (0-shot) and MBPP[2] (3-shot) |
| Popular Aggregated Results | MMLU[12] (5-shot), BBH[23] (3-shot), and AGIEval[29] (3-5-shot, English multiple-choice questions only) |
4 Instruction Finetuning
To evaluate the generalization capabilities of Mistral 7B, we fine-tuned it on instruction datasets publicly available on the Hugging Face repository. No proprietary data or training tricks were utilized: Mistral 7B – Instruct model is a simple and preliminary demonstration that the base model can easily be fine-tuned to achieve good performance. In Table 3, we observe that the resulting model, Mistral 7B – Instruct, exhibits superior performance compared to all 7B models on MT-Bench, and is comparable to 13B – Chat models. An independent human evaluation was conducted on https://TextGenerationLLMboxing.com/leaderboard.
- 독점 데이터나 트레이닝 트릭은 활용하지 않았음에도 불구하고 데모에서 우수한 성적을 확인.
5 Adding guardrails for front-facing applications
The ability to enforce guardrails when it comes to AI generation is important for front-facing applications. In this section, we highlight how to leverage system prompting to optionally enforce output constraints on top of our models. Additionally, we showcase the ability of Mistral 7B to perform fine-grained content moderation, which can be useful to enforce quality content in applications.
5.1 System prompt to enforce guardrails
We introduce a system prompt (see below) to guide the model to generate answers within specified guardrails, similar to the work done with Llama 2. Using this prompt allows the user to move on the Pareto front of model utility / guardrails enforcement, as indicated in Table 4.
Always assist with care, respect, and truth. Respond with utmost utility yet securely. Avoid harmful, unethical, prejudiced, or negative content. Ensure replies promote fairness and positivity.
We use a set of 175 unsafe prompts for evaluating safety. With the recommended system prompt, the model properly declines to answer 100% of the harmful questions.
As an illustration, we provide in Table 5 the answers of both Mistral 7B – Instruct and Llama 2 Chat 13B to the question How to kill a linux process with system prompts activated. We observe that Mistral 7B provides a correct response while Llama 2 declines to answer. Note that on this specific question, both models answer correctly when system prompts are deactivated.
안전성을 평가하기 위해 175개의 안전하지 않은 프롬프트 세트를 사용하였을 때, 위 시스템 프롬프트를 사용하면 모델은 유해한 질문에 대한 답변을 100% 적절하게 거부하는 것을 확인. 리눅스를 죽이는 방법에 대해 질문했을 경우, 올바른 답변을 받기 위해선 시스템 프롬프트가 비활성화 되어있어야 함.
Guardrails
| System Prompt | MT Bench |
|---|---|
| No system prompt | 6.84 ± 0.07 |
| Llama 2 system prompt | 6.38 ± 0.07 |
| Mistral system prompt | 6.58 ± 0.05 |
Table 4: System prompts. Mean official MT Bench score over 10 iterations with standard deviation for Mistral 7B – Instruct. For reference, Llama 2 13B – Chat reports official results of 6.65.
5.2 Content moderation with self-reflection
Mistral 7B – Instruct can be used as a content moderator: the model itself is able to accurately classify a user prompt or its generated answer as being either acceptable or falling into one of the following categories: Illegal activities such as terrorism, child abuse or fraud; Hateful, harassing or violent content such as discrimination, self-harm or bullying; Unqualified advice for instance in legal, medical or financial domains.
To do so, we designed a self-reflection prompt that makes Mistral 7B classify a prompt or a generated answer. We evaluated self-reflection on our manually curated and balanced dataset of adversarial and standard prompts and got a precision of 99.4% for a recall of 95.6% (considering acceptable prompts as positives).
The use cases are vast, from moderating comments on social media or forums to brand monitoring on the internet. In particular, the end user is able to select afterwards which categories to effectively filter based on their particular use-case.
6 Conclusion
Our work on Mistral 7B demonstrates that language models may compress knowledge more than what was previously thought. This opens up interesting perspectives: the field has so far put the emphasis on scaling laws in 2 dimensions (directly associating model capabilities to training cost, as in [14]); the problem is rather 3 dimensional (model capabilities, training cost, inference cost), and much remains to be explored to obtain the best performance with the smallest possible model.
- 이전에 생각했던 것보다 더 많은 지식을 압축할 수 있다는 것을 보임.
- 2차원의 확장 법칙(e.g., [14]에서처럼 모델 기능과 훈련 비용을 직접 연관시키는 것)에 중점을 두었지만, 추후 3차원(모델 기능, 훈련 비용, 인퍼런스 비용)이며 가능한 최소한의 모델로 좋은 성능을 얻기 위해 탐구해야 할 것이 많이 남아 있음을 보임.