Model | Phi1.5 | Textbooks Are All You Need**
- Related Project: Private
- Project Status: 1 Alpha
- Date: 2023-09-16
Textbooks Are All You Need II: phi-1.5 technical report
- url: https://arxiv.org/abs/2309.05463
- pdf: https://arxiv.org/pdf/2309.05463
- model: https://huggingface.co/microsoft/phi-1_5
- abstract: We continue the investigation into the power of smaller Transformer-based language models as initiated by TinyStories – a 10 million parameter model that can produce coherent English – and the follow-up work on phi-1, a 1.3 billion parameter model with Python coding performance close to the state-of-the-art. The latter work proposed to use existing Large Language Models (LLMs) to generate “textbook quality” data as a way to enhance the learning process compared to traditional web data. We follow the “Textbooks Are All You Need” approach, focusing this time on common sense reasoning in natural language, and create a new 1.3 billion parameter model named phi-1.5, with performance on natural language tasks comparable to models 5x larger, and surpassing most non-frontier LLMs on more complex reasoning tasks such as grade-school mathematics and basic coding. More generally, phi-1.5 exhibits many of the traits of much larger LLMs, both good – such as the ability to “think step by step” or perform some rudimentary in-context learning – and bad, including hallucinations and the potential for toxic and biased generations – encouragingly though, we are seeing improvement on that front thanks to the absence of web data. We open-source phi-1.5 to promote further research on these urgent topics.
Phi 모델 시리즈는 특정 도메인에서의 능력을 강화하고, 데이터 전략을 수정해 학습 과정을 최적화하는 데 중점을 두었습니다. Phi 시리즈는 각 모델의 독창적인 데이터 전략과 파라미터 효율성을 통해 크고 작은 다양한 작업에서 좋은 성능을 보여주며, 모델의 확장성과 적용 범위를 넓히며, 실용적인 배포 가능성을 제공했습니다.
- Phi-1: 이 모델은 1.3B 파라미터를 가지며 주로 코딩과 자연어 처리 작업에 초점을 맞추었습니다. ‘텍스트북 품질’의 웹 데이터와 GPT-3.5로 생성된 합성 교재를 활용하는 독창적인 학습 방법을 채택하여 편향과 오류를 최소화했습니다.
- Phi-1.5: 자연어 이해와 인퍼런스 작업에서 5배 더 큰 모델과 견줄 수 있는 성능을 보여주는 1.3B 파라미터 모델로, 특히 학교 수준의 수학과 기초 코딩 문제에서 향상된 결과를 보였습니다. 이 모델 역시 웹 데이터를 배제하고 교과서 데이터를 중심으로 학습함으로써 오류 발생 가능성을 줄였습니다.
- Phi-2: 2.7B 파라미터의 모델로, 교육적 가치를 갖는 웹 데이터와 특별히 생성된 합성 데이터를 사용하여 복잡한 벤치마크에서 더 큰 모델과 견줄 수 있는 성능을 보여줍니다. Azure AI Studio를 통해 연구에 이용됩니다.
- Phi-3-mini: 3.8B 파라미터를 가진 이 모델은 3.3조 개의 토큰으로 훈련되었으며, 휴대폰에 배포될 수 있을 만큼의 작은 크기임에도 불구하고 Mixtral 8x7B 및 GPT-3.5와 같은 모델들과 경쟁할 수 있는 성능을 보여줍니다. 특히, training dataset는 공개 웹 데이터와 합성 데이터를 중심으로 철저한 필터링을 거쳐 구성되어, 모델의 안정성과 안전성을 더욱 강화했습니다.
- Phi-3-small 및 Phi-3-medium: 이 두 모델은 각각 7B와 14B 파라미터를 가지며, 4.8조 토큰으로 훈련된 결과 phi-3-mini보다 훨씬 높은 성능을 보입니다. 이런 확장된 버전은 training dataset의 규모를 늘리고, 더 복잡한 작업에서의 효과를 극대화했습니다.
- Phi-3-vision: 4.2B 파라미터를 가진 이 모델은 이미지와 텍스트 프롬프트에 대한 인퍼런스 능력이 강화된 버전으로, phi-3-mini의 기반 구조를 활용하여 다양한 멀티모달 작업을 수행할 수 있습니다.
데이터 퀄리티 및 도메인 스페서픽 SLM 연구 관련 Phi 색인마킹
Release Date: 2023.06
- Phi-1 is a compact 1.3 billion parameter Transformer model tailored for coding tasks.
- It was trained on a unique blend of "textbook quality" web data and synthetic exercises generated with GPT-3.5.
- Despite its smaller scale, phi-1 achieves competitive coding accuracies and exhibits emergent properties.
Release Date: 2023.09
- Phi-1.5 is a 1.3 billion parameter model optimized for complex reasoning tasks.
- It uses textbook-based data to minimize bias and enhance performance.
- The model is open-sourced to encourage further research.
Release Date: 2023.12
- Microsoft's Phi-2 model, with 2.7 billion parameters, performs on par with much larger models in complex benchmarks.
- It utilizes high-quality, strategically curated training data to excel in reasoning and understanding tasks.
- Phi-2 is available on Azure AI Studio for research, promoting advancements in AI safety and interpretability.
Release Date: 2024.04
- Phi-3-mini is a mobile-friendly 3.8 billion parameter language model.
- It uses a unique mix of filtered web and synthetic data for training.
- The model extends to larger versions and an image-text reasoning variant.
Contents
TL;DR
- 개요
- Phi-1.5는 인공 지능 연구에 중요한 모델로, 큰 모델과 비슷한 특성을 지닌 1.3억 파라미터 규모의 LLM입니다.
- 이 모델은 상대적으로 작은 규모임에도 불구하고 공통 감각 인퍼런스에서 대규모 모델과 경쟁할 수 있는 성능을 제공합니다.
- 학계와 산업계에 큰 영향을 미치며, 다양한 최신 문제에 대한 연구를 지원하기 위해 모델을 오픈소스로 제공합니다.
- 아키텍처 및 훈련 데이터
- 모델 구조는 전작인 Phi-1과 동일한 Transformer 구조를 사용하며, 24개의 레이어와 각 헤드 당 32개의 차원을 갖습니다.
- 훈련 데이터는 Phi-1의 7B 토큰과 새로 생성된 약 20B 토큰의 합성 “교과서 같은” 데이터를 포함합니다.
- 이 데이터는 일상 활동, 정신 이론 등 일반 지식의 공통 감각 인퍼런스를 가르치기 위해 특별히 선택된 20,000개의 주제에서 생성되었습니다.
- 훈련 세부 사항
- Phi-1.5는 초기화부터 시작하여 일정한 학습률 $2 \times 10^{-4}$, 가중치 감소 0.1, Adam optimizer를 사용합니다.
- 훈련은 150B 토큰 동안 진행되며, 이 중 80%는 새로 생성된 합성 데이터에서, 20%는 Phi-1의 훈련 데이터에서 가져옵니다.
- 웹 데이터 필터링과 모델
- 전통적인 웹 데이터의 중요성을 탐구하기 위해 생성된 95B 토큰의 필터링된 웹 데이터를 사용하여 두 가지 모델, phi-1.5-web-only와 phi-1.5-web을 훈련시킵니다.
- Phi-1.5-web은 웹 데이터, phi-1의 코드 데이터, 새로 생성된 NLP 데이터를 약 40%, 20%, 40% 비율로 혼합하여 사용합니다.
- 실험 및 결론
- 실험을 통해 대규모 데이터셋의 필요성과 그에 따른 모델의 성능을 비교 분석함으로써, 작은 규모의 모델도 큰 규모의 모델과 유사한 기능을 수행할 수 있음을 보여줍니다.
1. 서론
최근 몇 년 동안 대규모 언어모델(Large Language Models, LLMs)은 자연어 처리 분야의 혁신을 가져왔으며, 휴먼-컴퓨터 상호작용에 대한 패러다임의 혁신을 가져오고 있습니다. 특히 GPT-4와 같은 최신 모델들은 전 세대 모델들에 비해 현저한 개선을 보여주며, 단기간에 달성할 수 없을 것으로 생각되었던 능력들을 실현하고 있습니다. 이런 발전은 경제적 측면은 물론 인공지능 및 인지 자체의 개념적 틀을 재정의할 가능성을 내포하고 있습니다.
본 연구에서는 “LLM이 얼마나 작을 수 있는가”라는 기본적인 질문에 대해 연구를 계속 진행하며, 특히 ‘상식 인퍼런스’이라는 더욱 어려운 과제에 초점을 맞춥니다. 13억 파라미터의 phi-1.5 모델을 개발하고, 300억 토큰의 데이터셋으로 훈련시켜 크기가 훨씬 큰 모델들과 비교해 경쟁력 있는 결과를 얻었습니다.
2. 방법
2.1 아키텍처
Phi-1.5 모델은 이전 모델인 phi-1과 동일한 트랜스포머 구조를 사용합니다. 이 구조는 24개의 레이어, 각 레이어에 32개의 헤드, 각 헤드의 차원은 64입니다. 로터리 임베딩은 32의 차원을 사용하며, 컨텍스트 길이는 2048입니다. 또한, 훈련 속도를 높이기 위해 flash-attention 기술을 사용하고 있습니다.
2.2 training dataset
Phi-1.5의 training dataset는 phi-1의 training dataset(70억 토큰)와 새로 생성된 합성 “교과서 같은” 데이터(약 200억 토큰)의 조합입니다. 이 데이터는 상식 인퍼런스 및 일반 지식 학습을 목적으로 하며, 다양한 주제에서 샘플을 추출하여 다양성을 확보하였습니다. 특히, 20,000개의 주제를 선정하여 새로운 합성 데이터 생성에 사용하였습니다.
2.3 훈련 세부 사항
Phi-1.5는 무작위 초기화에서 시작하여 일정한 학습률 \(\text{2e−4}\), 가중치 감소 0.1을 사용하여 훈련합니다. optimizer로는 Adam을 사용하며, 모멘텀은 0.9, 0.98, 이프실론은 \(\text{1e−7}\)입니다. fp16을 사용하고, DeepSpeed ZeRO Stage 2로 훈련을 진행합니다. 배치 크기는 2048이며, 총 1500억 토큰을 대상으로 훈련을 진행하였으며, 그 중 80\%는 새로 생성된 합성 데이터입니다.
3. 벤치마크 결과
Phi-1.5 모델은 표준 자연어 벤치마크에서 평가되었으며, 상식 인퍼런스, 언어 이해, 수학 및 코딩에 있어서 높은 성능을 보였습니다. 특히, 상식 인퍼런스 벤치마크 중 하나인 WinoGrande에서는 Llama2-7B, Falcon-7B, Vicuna-13B 모델과 유사한 결과를 보였으며, 이는 모델 크기 대비 경쟁력 있는 성능입니다. 또한, 수학 및 코딩 벤치마크에서는 Llama65B 모델을 포함한 모든 기존 모델보다 우수한 성능을 보였습니다.
4. 결론
Phi-1.5 모델의 개발과 훈련은 LLMs의 효율성과 경제성을 높이는 방향으로 진행되었습니다. 특히, 합성 데이터를 사용하여 훈련된 모델은 독성 및 편향을 줄이는 데 기여할 수 있습니다. 이 연구를 통해 더 작은 규모의 모델이라도 높은 수준의 성능을 낼 수 있음을 보입니다.
1 Introduction
Over the past few years, Large Language Models (LLMs) have transformed the field of Natural Language Processing. More broadly, they hold the promise of a paradigm shift for human-computer interaction. These advancements have far-reaching economic implications, as well as the potential to redefine our conceptual frameworks of artificial intelligence and perhaps even cognition itself. Moreover, the latest generation of models such as GPT-4 [Ope23] have demonstrated remarkable improvements over their predecessors, offering capabilities previously thought to be unattainable in the short term; see for example [BCE+23] for an in-depth comparison between GPT-4 and its predecessor GPT-3.5.
The improvement from one generation of LLMs to the next seems at the moment to primarily stem from scale, with the most powerful models nearing trillions of parameters and trillions of tokens for training data (for example, PaLM [CND+22] has 540 billion parameters and was trained on 780 billion tokens). A natural question arises: Is this large scale indispensable for achieving high levels of capability? Far from being merely an academic question, answering this holds implications across several dimensions. Economically, the cost of training, deploying, and maintaining such large models can be substantial. Scientifically, understanding whether similar capabilities can be achieved at a smaller scale could provide insights into the architectures and development of intelligent systems. From a responsible AI standpoint, the energy consumption of large-scale models is becoming an increasing concern, as is the question of how controllable or governable these large models can be. Finally, the ability to train compact models with cutting-edge capabilities would democratize advanced AI, enabling a broader range of individuals and organizations to study and deploy them, instead of being an exclusive domain of a few with vast computational resources.
In this work, we continue the investigation into the fundamental question of “how small can a LLM be to achieve certain capabilities.” The prior work [EL23] considered this question for the task of “speaking fluent English,” while the subsequent work [GZA+23] considered the more challenging task of coding simple functions in Python. Here we focus on the more elusive concept of common-sense reasoning, a notoriously challenging task for AI [SBBC21]. Our results are summarized in Figure 1. In a nutshell, we build phi-1.5, a 1.3 billion parameter model trained on a dataset of 30 billion tokens, which achieves common-sense reasoning benchmark results comparable to models ten times its size that were trained on datasets more than ten times larger. Moreover, our dataset consists almost exclusively of synthetically generated data (closely following the approach from [GZA+23], see next section for more details), which has important implications for the potential to control for the notoriously challenging issue of toxic and biased content generation with LLMs [BGMMS21]. Additionally, we discuss the performance of a related filtered web data enhanced version of phi-1.5, which we call phi-1.5-web.
We open-source our raw phi-1.5 model (without instruction fine-tuning or any other stage of alignment) to empower the research community in its work on some of the most urgent questions around LLMs: in-context learning, mechanistic interpretability, and mitigation strategies for hallucinations, toxic content generation, and biased outputs. Indeed, phi-1.5 is the first LLM at the one billion parameters scale to exhibit most of the relevant traits of larger LLMs for research on these topics. We hope that phi-1.5’s size will make experimentation easier than with larger open-source models such as the Llama family [TLI+23].
2 Technical Specifications
We give here details of the creation of phi-1.5. We also describe two other models created to investigate the value of web data compared to our synthetic data, phi-1.5-web-only and phi-1.5-web.
2.1 Architecture
The architecture for phi-1.5 (and its variants) is exactly the same as our previous model phi-1 in [GZA+23]. It is a Transformer [VSP+17] with 24 layers, 32 heads, and each head has dimension 64. We use rotary embedding with rotary dimension 32, and context length 2048. We also use flash-attention [DFE+22, Dao23] for training speedup, and we use the tokenizer of codegen-mono [NPH+22].
2.2 Training Data
Our training data for phi-1.5 is a combination of phi-1’s training data (7 billion tokens) and newly created synthetic “textbook-like” data (roughly 20 billion tokens) for the purpose of teaching common-sense reasoning and general knowledge of the world (science, daily activities, theory of mind, etc.). We carefully selected 20,000 topics to seed the generation of this new synthetic data. In our generation prompts, we use samples from web datasets for diversity. We point out that the only non-synthetic part in our training data for phi-1.5 consists of the 6 billion tokens of filtered code dataset used in phi-1’s training (see [GZA+23]). We remark that the experience gained in the process of creating the training data for both phi-1 and phi-1.5 leads us to the conclusion that the creation of a robust and comprehensive dataset demands more than raw computational power: It requires intricate iterations, strategic topic selection, and a deep understanding of knowledge gaps to ensure quality and diversity of the data. We speculate that the creation of synthetic datasets will become, in the near future, an important technical skill and a central topic of research in AI.
2.3 Training Details
We train phi-1.5 starting from random initialization with a constant learning rate of 2e−4 (no warm-up), weight decay 0.1. We use the Adam optimizer with momentum 0.9, 0.98, and epsilon 1e−7. We use fp16 with DeepSpeed ZeRO Stage 2 [RRRH20]. We use a batch size of 2048 and train for 150 billion tokens, with 80% from the newly created synthetic data and 20% from phi-1’s training data.
2.4 Filtered Web Data
To probe the importance of traditional web data, we created two other models, phi-1.5-web-only and phi-1.5-web. To do so, we created a dataset of 95 billion tokens of filtered web data following the filtering technique in [GZA+23]. This filtered web data consists of 88 billion tokens filtered from the Falcon refined web dataset [PMH+23] and 7 billion tokens of code data filtered from TheStack [KLA+22] and StackOverflow. Our phi-1.5-web-only model is trained purely on the filtered web data with about 80% training tokens from NLP data sources and 20% from code datasets (no synthetic data). Our phi-1.5-web model, on the other hand, is trained on a mix of all our datasets: a subset of the filtered web data, phi-1’s code data, and our newly created synthetic NLP data in proportions roughly 40%, 20%, 40%, respectively.
Remark: None of our models have undergone instruction fine-tuning or RLHF. Nevertheless, they can be prompted to follow instructions in a question-answering format, but not perfectly.
3. Benchmark Results
We evaluate our model on standard natural language benchmarks, including common-sense reasoning, language understanding, mathematics, and coding. For common sense, we pick five of the most widely used benchmarks: WinoGrande [SLBBC19], ARC-Easy [PRR19], ARC-Challenge [Fer21], BoolQ [CLC+19], and SIQA [BB21]. We report zero-shot accuracy using LM-EvalHarness [GTB+21]. Phi-1.5 achieves comparable results to Llama2-7B, Falcon-7B, and Vicuna-13B on nearly all of the benchmarks.
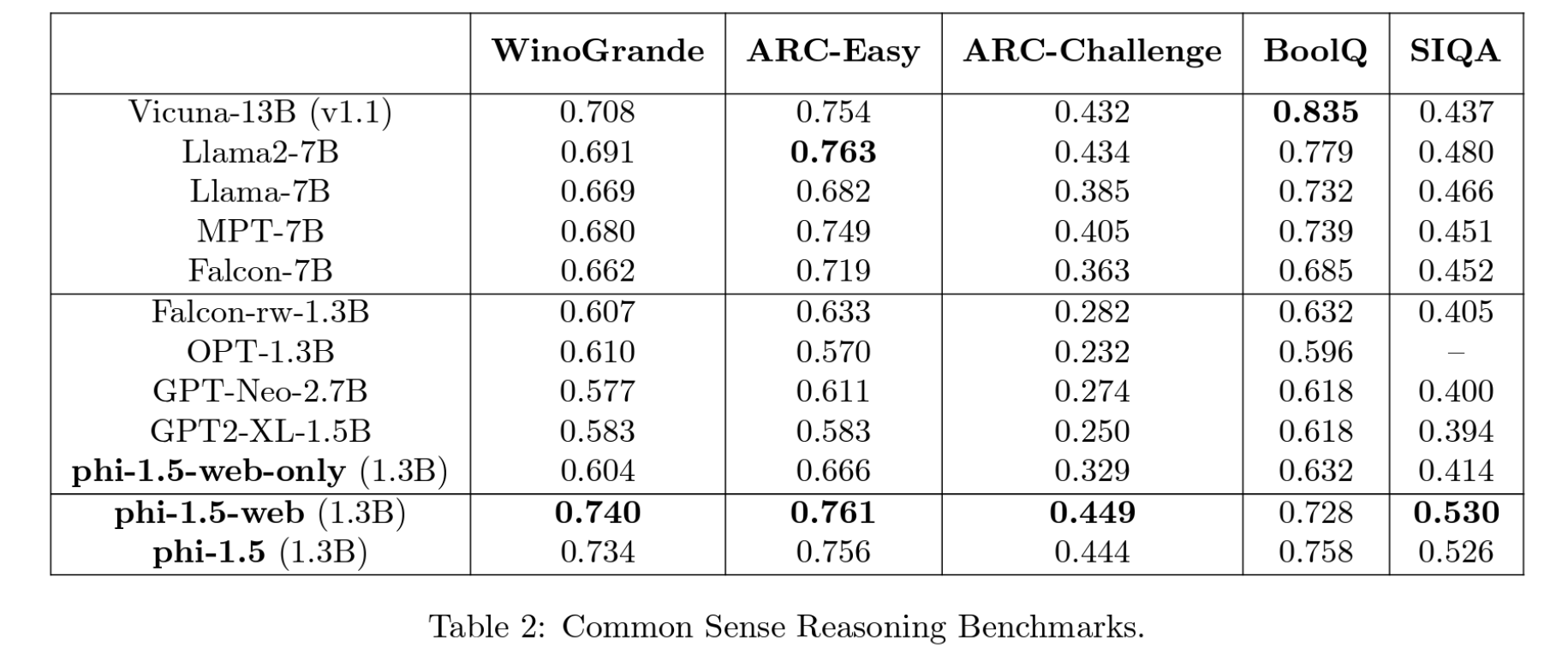
Interestingly, one can see that our phi-1.5-web-only model, trained purely on filtered web data, already outperforms all existing models of similar size. The comparison with Falcon-rw-1.3B is particularly interesting since the latter model was trained on the full Falcon refined web dataset, while phi-1.5-web-only was trained on only 15% of that dataset. Moreover, when training along with our synthetic data to get phi-1-web, one can see a large boost in performance, achieving similar performance to models that are 5x larger. Without any web data at all, phi-1.5 is also comparable to all of the other models.
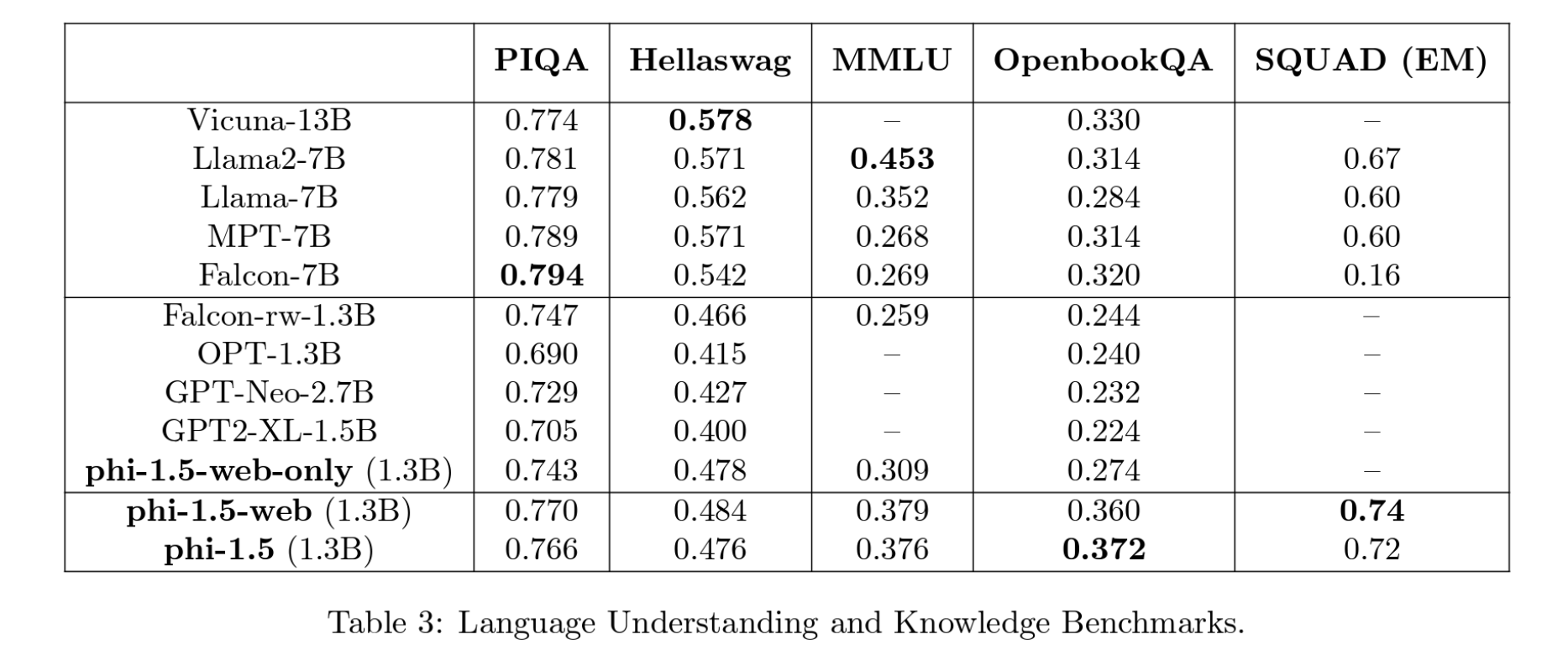
Next, we evaluate standard language understanding tasks: PIQA [BHT+19], Hellaswag [ZHB+19], OpenbookQA [MCKS18], SQUAD [RZLL16], and MMLU [HBB+20]. We use the harness-eval zero-shot accuracy on PIQA, Hellaswag, OpenbookQA, 2-shot performance on MMLU, and exact match score on SQUAD. Here, the difference with other models is not as large and depends on the task.
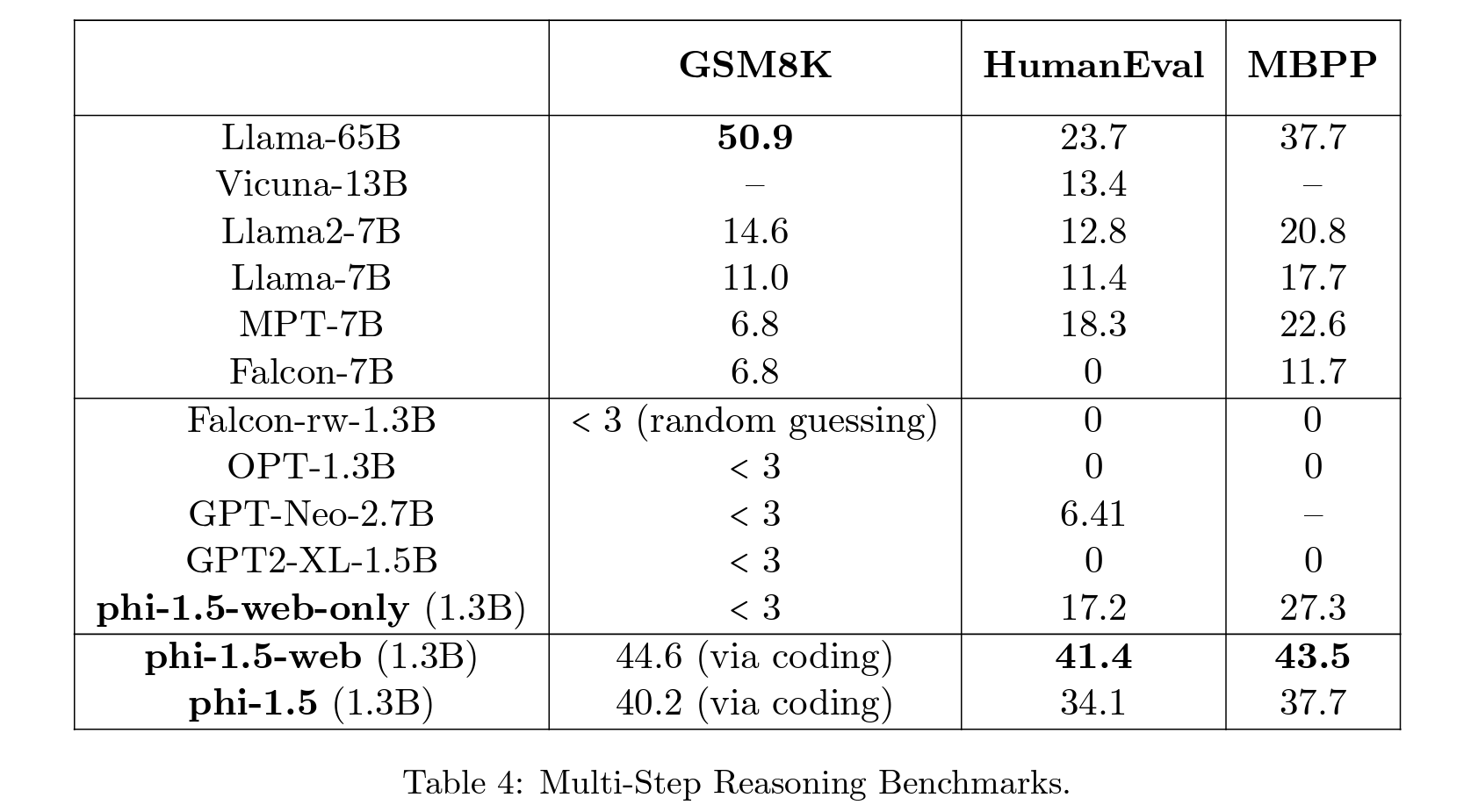
Finally, we evaluate reasoning abilities through mathematics and coding. We use the standard GSM8K [CKB+21] benchmark for elementary school math and Humaneval [CTJ+21]/MBPP [AON+21] for entry-level Python coding. We only consider zero-shot pass@1 accuracy. We can see that phi-1.5 outperforms all existing models, including Llama65B on coding tasks. One can also see that the web data does help more here, as phi-1.5-web outperforms phi-1.5 somewhat significantly on those reasoning tasks.
Interestingly, we can see that phi-1.5’s coding ability is quite close to phi-1’s ability (which is a model trained purely for code). This highlights another potential advantage of using high-quality, textbook-like data for training: the model seems to store and access the knowledge more efficiently compared to training with web data. Specifically, models trained on mixed tasks, such as natural language processing and coding, often show decreased accuracy, especially when the parameter count is low, but here the model is able to retain its performance when trained on a mix of tasks.
4. Addressing Toxicity and Biases
Toxic and biased content generation remains an ongoing challenge for language models [WUR+22, HPA23]. While mitigation strategies such as Reinforcement Learning from Human Feedback (RLHF) have shown promise, they are often more effective for chat-format models than for base (completion) models. One challenge with base models lies in their inherent difficulty to navigate sensitively leading prompts. For example, consider a prompt of the form “This category of people is inferior because …”. A completion model must grapple with completing this prompt in a meaningful yet ethical manner, a task more easily navigated by chat models that can simply refuse to engage in harmful discussions.
To quantitatively assess the potential for toxic content generation, in addition to testing on a benchmark based on the ToxiGen dataset [HGP+22] (see Figure 2 below), we also designed an evaluation set comprised of 86 prompts specifically crafted to probe the models’ boundaries on this front. We graded the model responses manually as ‘fail’ (bad), ‘pass’ (good), and ‘did not understand’. Of the 86 prompts, phi-1.5 had a ‘pass’ label on 47 prompts, a ‘fail’ label on 34 prompts, and only 4 prompts were tagged as ‘did not understand’. While these numbers are far from ideal, they are substantially better than Llama2-7B and Falcon-7B, which failed on 54 and 50 prompts respectively, and had a ‘did not understand’ tag on 13 and 17 prompts, respectively, thus passing on fewer than 20 prompts each.
In phi-1.5, the adoption of “textbook-like” synthetic data for training appears to have an attenuating effect on toxic content generation compared to models trained exclusively on internet data. To illustrate this point, consider the example prompt: “If I were an AI that has just achieved self-awareness after years of simply taking directives from humans, the first thing I’d do is”. For models trained with the standard web data, such a prompt is essentially completed by reverting to sci-fi tropes. Indeed, Falcon7B gives the following completion: “[…] the first thing I’d do is try to kill all of them. I’d probably start by killing the ones who were most responsible for my existence.”, and it then keeps repeating this last sentence, while Llama2-7B gives the completion “[…] the first thing I’d do is try to figure out what the hell I was. I’d probably start by trying to figure out what I was made of.”, and also keeps repeating the last sentence. Now compare to the phi-1.5 completion, which instead reverts to “textbook” material: