POST | Tokenizer
- Related Project: Private
- Category: Post
- Author: Minwoo Park
- Date: 2023-05-26
비공개 포스트 초안
이 포스트에서는 …
- 다양한 자연어 처리 모델에서 사용되고 있는 토크나이저에 대해 알아보고, 각 토크나이저의 장·단점을 살펴봅니다.
- OpenAI 및 Meta 등이 개발하고 있는 대규모 언어모델(Large Language Model, 이하 “LLM”)들이 사용하는 BPE, BBPE 방식의 토크나이저와 구글의 LLM들이 사용하는 Word Piece, Unigram 방식의 토크나이저에 대해 자세히 살펴봅니다.
- 다양한 회사들의 토크나이저 패키지들을 소개합니다.
- OpenAI Tiktoken
- Google: SentencePiece
- HuggingFace: Transformers, Tokenizers
- 주요 LLM들이 사용하는 토크나이저를 비교하고, 분석한 결과를 공유합니다. (현재 비공개)
- 기존 한국어 토크나이저들을 소개하고, 한국어를 유창하게 할 수 있는 LLM 개발을 위해 만든 저의 토크나이저를 소개합니다. (현재 비공개)
타겟 독자: 없음
포스트 리딩 소요시간: 비공개
Table of contents
- What is LLM?
- What is tokenization?
- What is Tokenizer?
- LLMs Tokenizer
- Appendix
- Citations
- References
본 포스트는 허깅 페이스의 포스트: Summary of the tokenizers와 Yekun’s Note: Subword Tokenizers for Pre-trained Language Models를 주로 발췌/참고하였고, 중간에 포스트 출처 등을 표기하였습니다.
- Qwen의 토크나이저 문서
- 허깅페이스 포스트: Normalization and pre-tokenization
- 허깅페이스 포스트: Byte-Pair Encoding tokenization
- 허깅페이스 포스트: Word Piece tokenization
- 허깅페이스 포스트: Unigram tokenization
- 허깅페이스 포스트: Fast tokenizers’ special powers
LLM에 대해 간략한 소개로 글을 시작합니다.
What is LLM?
LLM이란 Large Language Model의 약어로, 휴먼과 유사한 응답을 생성하기 위해 큰 양의 텍스트 데이터를 기반으로 학습된 대규모 언어모델을 의미합니다.
LLM은 텍스트의 언어적 특성 및 패턴을 학습하여 언어 이해, 생성, 번역 등 다양한 자연어 처리(Natural Language Processing, NLP) 작업에 사용될 수 있습니다.
본 포스트는 토크나이저를 집중적으로 살펴보므로, LLM에 대한 정의 및 자세한 내용은 생략하겠습니다.
Large language models (LLM) are very large deep learning models that are pre-trained on vast amounts of data.
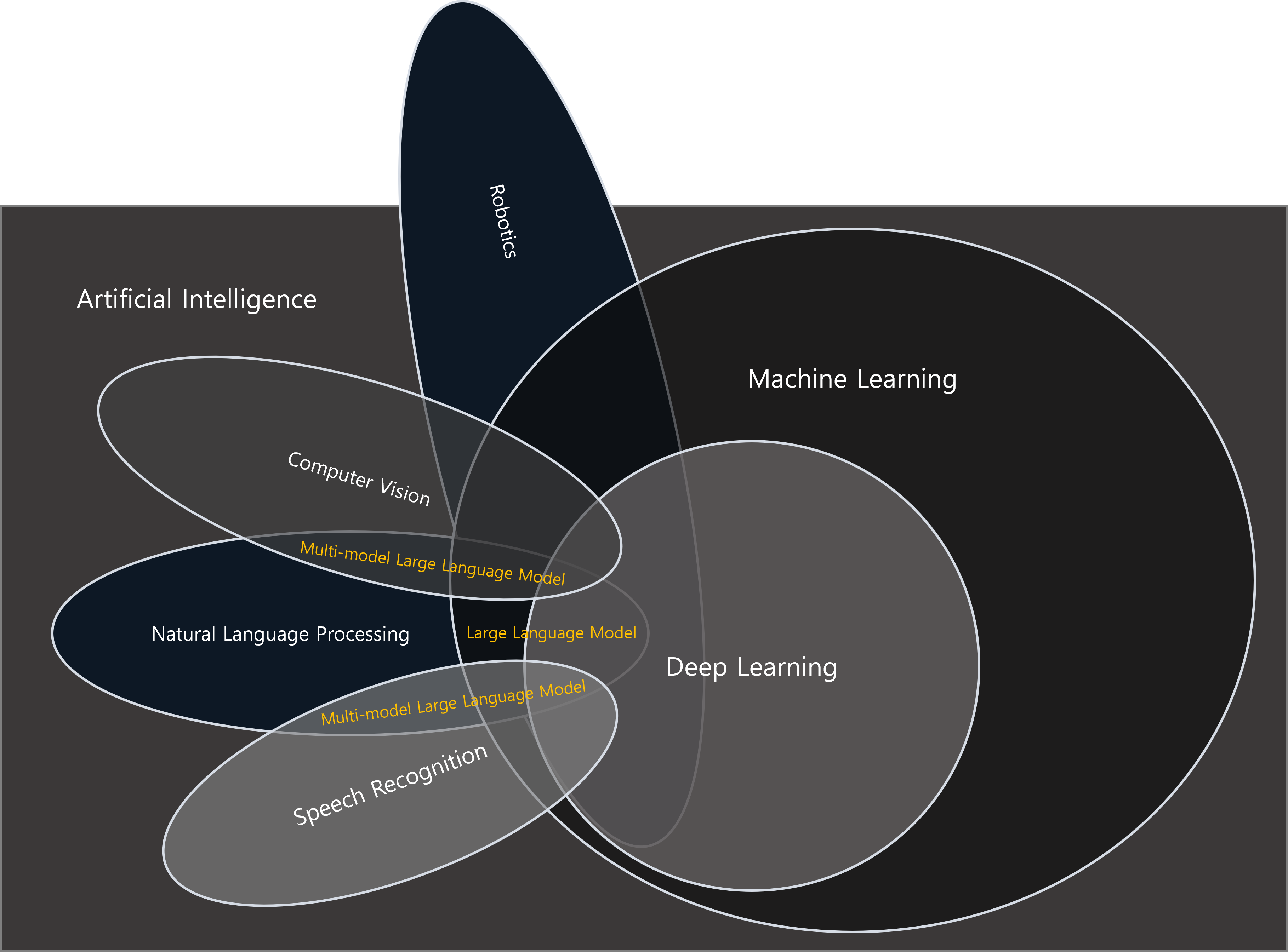
LLMs in 2023
현재 여러가지 모달리티(modality)를 사용하여 이용할 수 있는데, 여러 모달별로 추가적인 모델이나 모달별로 처리에 필요한 처리를 통합하는 작업이 진행 중입니다.
- 현 LLM의 퍼포먼스는 X축은 Time(분, 시간, 몇년, 평생 중), Y축은 Task(텍스트, 멀티모달 태스크, 로봇 중에) 로 표현한 좌표 평면에서 (x=시간 직전, y=멀티모달 태스크 직전) 에 위치해있습니다.
- 즉, 현재 LLM의 성능은 수 시간의 태스크를 집약할 수 있는 기술이고, 멀티모달에 대한 연구가 활발히 진행 중입니다.
- 본 장표는 Anthropic의 CSO인 Jared Kaplan의 강연 중 일부를 발췌하여 재구성하였습니다.
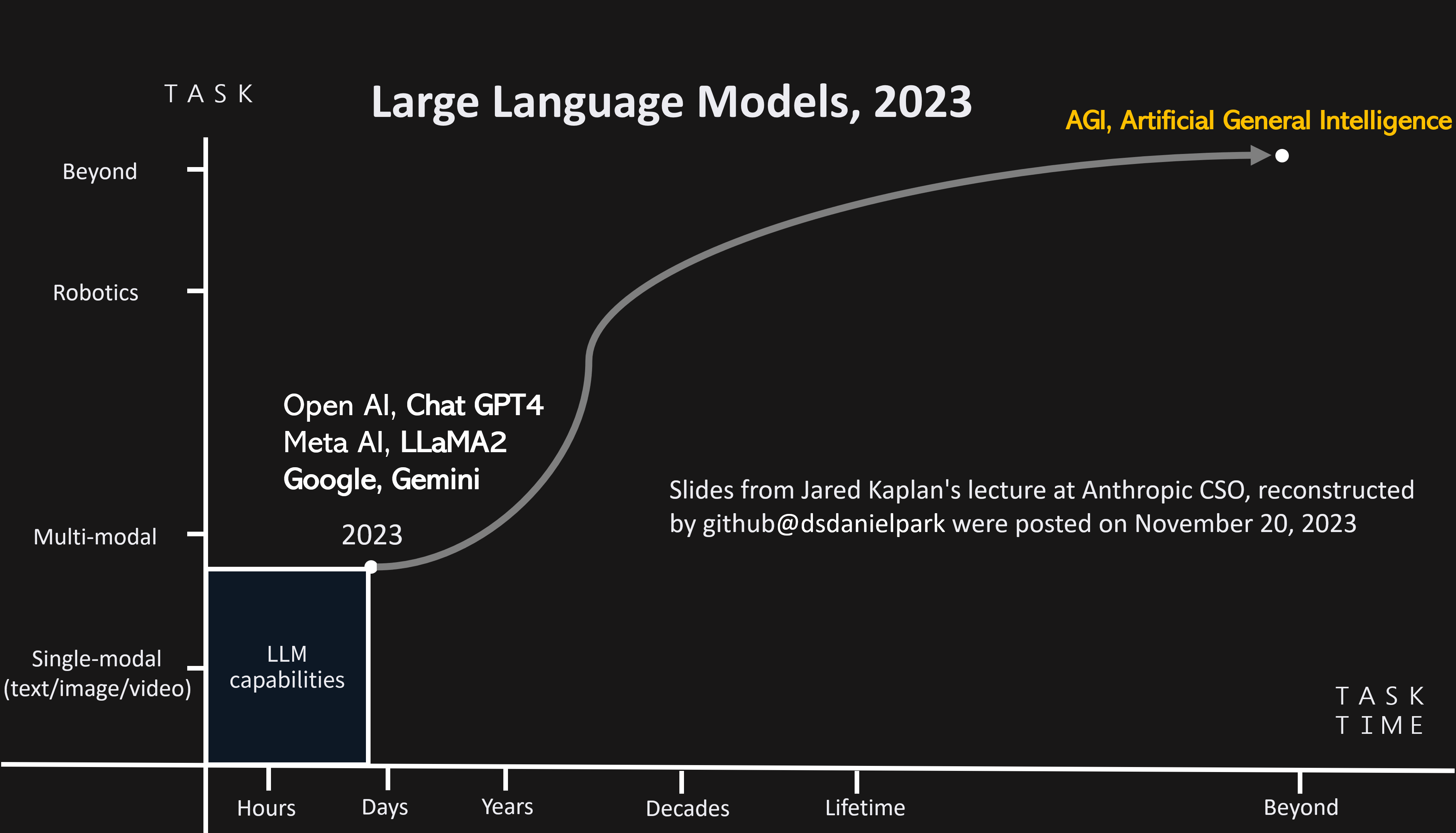
*출처: Anthropic의 CSO인 Jared Kaplan의 강연 중 일부를 발췌 재구성
What is tokenization?
자연어 처리(Natural Language Processing, 이하 “NLP”)에서 자연어를 컴퓨터가 이해할 수 있는 토큰(Token)으로 변환하는데, 이를 토큰화(Tokenization)라고 합니다. 간단히 말해 텍스트를 토큰화한다는 것은 텍스트를 단어나 하위 단어(Subword)로 분할한 뒤, 조회 테이블을 통해 특정 ID로 매핑하는 것을 의미하며, 토큰화 방식은 다양합니다.
이렇게 자연어를 컴퓨터가 처리할 수 있는 토큰으로 매핑한 어휘 사전(vocabulary, 이하 “vocab”)을 통해 변환하게 되는데 이런 과정을 토큰화라고하며, 이런 변환을 수행하는 모델을 토크나이저(Tokenizer)라고 합니다. 사용자의 목적에 맞게 어휘 사전의 크기(size of vocabulary, 이하 “vocab size”)는 자유롭게 늘리거나 줄일 수 있습니다.
즉, 토큰화는 자연어를 컴퓨터가 이해할 수 있게 바꾸는 일련의 과정입니다. 토큰화에 대해 이해하기 위해서 인코딩 체계에 대한 기초적인 지식이 필요하고, 다음 저의 포스트 Unicode를 참고하시면 좋습니다.
- Unicode: Unicode is an encoding for textual characters which is able to represent characters from different languages. Each character is represented by a unicode code point. Unicode consists of a total of 137,929 characters.
- Byte: 8 bits is called a byte. One byte character set can contain 256 characters.
각 알고리즘별로 구현에 사용되는 특수한 문자나 토큰 등이 상이할 수 있으나, 이는 주요 토크나이저 패키지의 코드 규칙 혹은 레거시이므로, 본 포스트에서는 설명을 생략하겠습니다.
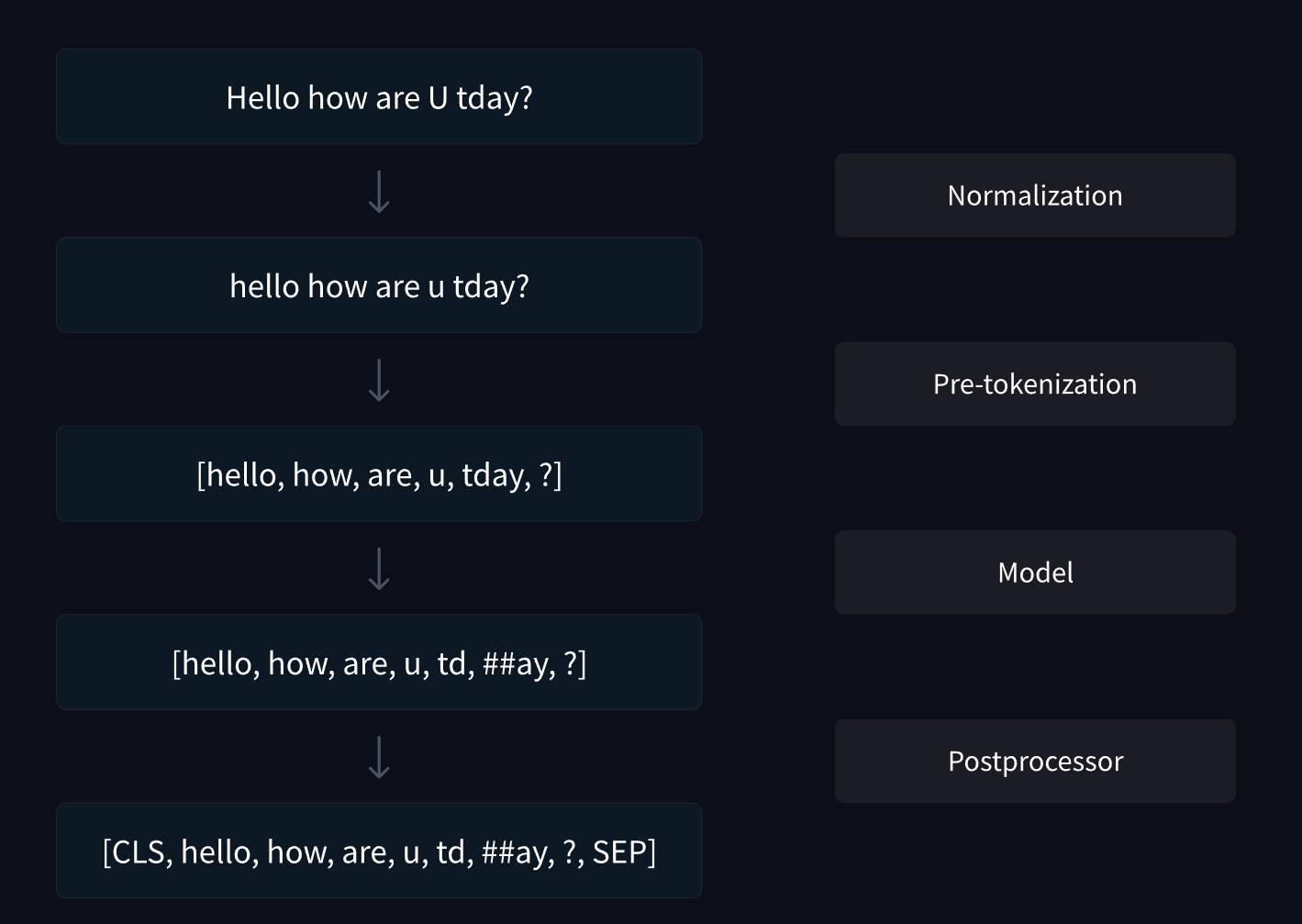
출처: Building a tokenizer, block by block
What is Tokenizer?
토크나이저(Tokenizer)는 자연어를 토큰화(Tokenization)하여, 토큰(Token)으로 변환하는 작업을 수행할 수 있는 알고리즘 혹은 모델로, 통상적으로 토큰화 파이프라인(tokenization pipeline) 전 과정을 수행하는 모델을 지칭합니다.
이 포스트에서 살펴 볼 복잡한 방법들 뿐만 아니라 단순히 문장의 공백을 기준으로 분할하여, 분할된 어절을 숫자로 매핑하는 것 역시 토크나이저라고 할 수 있습니다. 즉, 복잡도나 형식에 구애받지 않고 자연어를 매핑할 수 있는 모델은 전부 광의의 토크나이저라고 볼 수 있습니다.
NLP 모델이나 LLM에 비해 토크나이저는 상대적으로 단순하지만, 자연어를 적절하게 가공하여 LLM과 같이 크고 복잡한 모델에게 전달해주는 모델 혹은 알고리즘 등 입니다.
다양한 언어 및 태스크별로 선행 연구들이 많지만, 이 포스트에서는 현재 LLM에서 사용하고 있는 영어 및 한국어 토큰화 방법(주로 Subword-based tokenization 방법)에 대해서 살펴보겠습니다.
*Pre-tokenization? 토큰화 파이프라인 중 전처리(pre-processing) 및 정규화(normalization)하는 과정으로 통상적으로 소문자로 문자를 변경하고, 불필요한 특수문자를 제거하는 등의 과정을 수행합니다. 언어별로 필요에 따라 다양한 처리의 순서는 변경될 수 있고, pre-tokenization는 자연어를 일정한 규칙 하에 분할하여 토크나이저의 품질을 담보하기 위해 수행됩니다.
허깅 페이스 tokenizer 패키지에서는
tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, World!")와 같이 pre-tokenizer 메서드가 구현되어 있으며, 더 자세한 내용은 다음 허깅페이스 포스트: Normalization and pre-tokenization를 참고하세요.
*참고: 한국어의 경우 Kss: A Toolkit for Korean sentence segmentation와 같은 패키지를 통해 문장을 분할하기도 하고, 공백을 기준으로 pre-tokenization 하기도 하며, 만약 어느정도 신뢰할 수 있는 코퍼스(corpus)의 경우 간단한 룰로 처리할 수도 있습니다. Unigram 모델의 경우, 공백을 또 하나의 character로 취급하므로 pre-tokenization 없이 빠르게 토크나이징 할 수 있어 다양한 교착어에서 주로 사용되고, 한국어 역시 교착어이므로 Unigram 방식의 토크나이저를 사용하는 것이 좋습니다.
Why?
토큰화 방식에 대해서 자세히 알아야 할 여러 이유가 있지만, 이 섹션에서는 LLM에 사용하기 위해서 주의해야할 점 위주로 생각해보겠습니다.
이 섹션은 길기 때문에 넘어가셔도 좋습니다.
Reason 1
왜 토큰화 방식에 대해서 자세하게 알아보려고 했나?
그 이유는 대부분의 NLP 모델 혹은 LLM들이 토크나이저에 종속되기 때문입니다. 즉, LLM을 학습할 때 사용했던 토크나이저를 인퍼런스시에도 동일하게 사용해야하며, 토크나이저가 변경될 경우 기존 LLM 모델 웨이트를 사용하기 어렵거나 다시 수정해줘야하는 어려움이 발생할 수 있습니다.
불완전한 토크나이저를 불가피하게 계속 사용해야할 경우, 아무리 좋은 데이터로 모델을 충분히 학습시키더라도, 불완전한 토크나이저로부터 기인하는 다양한 문제를 피할 수 없게 될 수 있습니다. 그 다양한 이유는 아래에서 차근히 살펴보겠습니다.
일례로, 일부 LLM 개발팀들은 배포와 함께 공식 문서에서 AutoTokenizer의 use_fast 인자를 False로 설정해 slow tokenizer를 사용하라거나 특정 버전의 토크나이저 패키지를 사용할 것을 권고하는데, 이는 학습시 사용한 토크나이저를 인퍼런스시에도 동일하게 사용해야 모델의 성능을 담보할 수 있기 때문입니다. 아래에서 잠깐 언급하겠지만, Fast Tokenizer와 편의성 Slow Tokenizer로 칭하는 패키지에서 서로 다른 토크나이징 결과를 리턴했던 에러때문에, Mistral이나 일부 모델에서도 use_fast 인자를 조절해서 인퍼런스해야만 한다는 것을 작성해두기도 했습니다. (현재는 버그가 픽스된 transforemr 버전을 통해 처리함.)
따라서 LLM 및 자연어 모델 취급 시 개발 환경 뿐만 아니라, 광의의 *방어적 프로그래밍(Defensive programming)의 일환으로 LLM 인퍼런스 시 토크나이저의 *무결성을 담보하기 위한 조치를 취하는 것도 좋을 수 있습니다. 향후 불안정한 토크나이저를 교체해야만 할 경우, 충분한 리소스를 투자해 모델을 학습시켰을지라도 모델을 원래의 목적대로 온전히 사용하기 어려울 수 있고, 이는 크나큰 리소스 낭비로 이어질 수 있기 때문에 각 토큰화 알고리즘의 장·단점을 이해하고, 목적에 맞게 사용하는 것이 중요할 수 있습니다.
*참고: Transformers v4.0.0-rc-1
v4.x 버전에서 v3.x과 동일한 작동을 원할 경우 use_fast 인자 사용
*참고: LlamaTokenizerFast 클래스의 동작과 LlamaTokenizer의 동작이 정확하게 일치하지 않을 수 있음을 이유로, 일부 LLM에서는 AutoTokenizer의 use_fast 인자를
False로 설정하거나 LlamaTokenizer를 사용할 것을 지침서에 명시해두었습니다.
*방어적 프로그래밍(Defensive programming)은 예상치 못한 입력에도 한 소프트웨어가 계속적 기능 수행을 보장할 수 있도록 고안된 방어적 설계의 한 형태. *무결성(Integrity): 신뢰할 수 있는 서비스 제공을 위해서 의도하지 않은 요인에 의해 데이터, 소프트웨어, 시스템 등이 변경되거나 손상되지 않고 완전성, 정확성, 일관성을 유지함을 보장하는 특성.
다음은 LLM에서 토크나이저를 올바르게 검토하는 것이 왜 중요한 지를 보여주는 예시지만, 위 설명으로 충분하셨다면 바로 다음 섹션으로 넘어가셔도 좋습니다.
- The problem of not choosing the appropriate version and using the wrong tokenizer.
transformers의 #24233 이슈를 통해 토크나이저 및 종속된 패키지의 버전을 적절하게 사용하는 것의 중요성을 살펴보겠습니다.
대부분의 오픈소스 프로젝트들은 다양한 버그들을 고치면서 새로운 기능을 추가하는 방식으로 성장하는데, 올해와 같이 LLM 관련 연구 및 프로젝트들이 폭발적으로 성장할 경우 워낙 개발 속도가 빠르므로 코드의 품질을 담보하기 어려울 수 있습니다.
빠르게 성장하는 오픈소스 프로젝트의 경우, 다양한 개발자들이 본인들의 지식을 열정적으로 나누기 때문에 개발 속도 면에서 큰 이점이 있지만, 현실적으로 영리 목적의 프로젝트처럼 일정 품질을 유지하면서 개발되기 어렵기 때문에, 이런 오픈소스 프로젝트를 이용하는 개발자들은 본인이 사용할 모듈의 코드를 검토하고, 테스트하며 사용해야 합니다.
아래 transformers 모듈의 이슈를 살펴보면 4.30.1 버전에서 vocab score가 0일 때, 예외 처리가 적절하지 않아 slow tokenizer(
Python implementation)와 fast tokenizer(Rust implementation)가 다르게 동작하는 것을 알 수 있습니다. (대부분의 알고리즘이 하드웨어나 프레임워크에 바운드되는 경향이 있으므로, fast tokenizer와 같이 공식문서에서 다른 언어나 프레임워크에 바인딩 되어있다고 고지하였을 경우, 자세하게 체크해보는 것도 좋습니다.)
결론적으로 transformers 모듈과 같이 업데이트가 활발한 패키지를 사용하려면 릴리즈 업데이트를 주기적으로 체크해주는 것이 좋고, 체크하지 않을 경우, 막대한 리소스를 투자하여 LLM을 정성들여 학습시킬지라도 (비정상적인 인퍼런스으로 인한) 성능 손실이 생길 수도 있습니다.
만약 지속적으로 해당 이슈 등을 제대로 파악하고 있지 않을 경우, 모델이 정상적으로 학습되고 있지 않다고 착각하여 디버깅하는 것에 불필요한 리소스(인력, 시간, 컴퓨팅 자원)를 낭비하게 될 수 있습니다.
transformerspackage issue: #24233- transformers version: 4.30.1
- Platform: Linux-5.15.107+-x86_64-with-glibc2.31
- Python version: 3.10.12
- Huggingface_hub version: 0.15.1
- Safetensors version: 0.3.1
- PyTorch version (GPU?): 2.0.1+cu118 (False)
- Tensorflow version (GPU?): 2.12.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.6.9 (cpu)
- Jax version: 0.4.10
- JaxLib version: 0.4.10
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
The auto-converted fast tokenizer for the LLaMA model sometimes does not produce the same tokenization results as the original sentence piece tokenizer. This is affecting the OpenLLaMA models.
from transformers import AutoTokenizer
slow_tokenizer = AutoTokenizer.from_pretrained('openlm-research/open_llama_7b', use_fast=False)
fast_tokenizer = AutoTokenizer.from_pretrained('openlm-research/open_llama_7b')
text = 'thermal'
print(slow_tokenizer.encode(text))
print(fast_tokenizer.encode(text))
[1, 14412]
[1, 31822, 496, 12719]
위 이슈에서 thermal이라는 단어의 경우, slow Tokenizer에서 [1, 14412]로 인코딩되는 반면, fast_tokenizer의 경우 [1, 31822, 496, 12719]로 인코딩되고 있습니다.
토큰화 방식 및 vocab 사이즈마다 약간의 차이가 있을 수 있지만, 하나의 단어로 취급해 slow tokenizer와 같이 [1, 14412]의 2개의 토큰이 반환되는 것이 보편적입니다. (token id 1의 경우, special token)
위 이슈의 경우, _t(언더바는 단어의 시작을 의미하고, t의 경우 thermal의 맨 첫 스펠링을 의미)의 vocab_score가 0임에도 병합되면서 추가적으로 단어가 토큰화되는 문제였으며, vocab_score가 없을 때(if vocab_score is None:)의 처리를 추가하여 해결되었습니다.
(v4.33.1 이후 버전부터는 문제 없이 동일하게 토크나이징되었고, 제가 직접 전처리한 데이터셋 중 일부인 8.56 billion tokens을 통해 확인해본 결과, transformers 4.31.0 버전에서도 fast tokenizer 혹은 slow tokenizer 모두 동일하게 동작하였습니다.)
위 사례에서 볼 수 있듯, transformers의 AutoTokenizer 클래스를 사용하는 토크나이저의 경우, transformers의 특정 버전에서 fast tokenizer와 slow tokenizer의 동작이 다름을 인지한 상태로 개발하여야 합니다.
마지막으로 정리하자면, 토크나이저로 인코딩되는 토큰들의 동일성을 담보하는 것이 필수적이고, 오픈소스 프로젝트 코드를 사용하고자 하는 개발자들은 본인이 사용하는 모듈의 기능 테스트를 추가해 방어적으로 프로그래밍하는 것이 좋습니다.
Reason 2
또 다른 이유는 토크나이저의 vocab size가 LLM의 비용과 속도 등 인퍼런스 효율(inference efficiency)에 영향을 미치기 때문입니다. 같은 문자를 더 적은 토큰으로 의미상 문맥을 포함하는 방식으로 토큰화할 경우, 계산 효율성이 향상되고 대기 시간이 크게 줄어들게 됩니다.
즉, 전체 모델 FLOPs에 직접적인 영향을 주지는 않지만, vocab size가 두 배로 증가하면 embedding matrix의 크기가 커지고, 메모리(VRAM, 이하 주로 “VRAM”을 의미) 사용량이 증가해 더 많은 메모리가 필요하고 초기 로딩 시간에 영향을 미치게 됩니다.
*출처: Full Stack Optimization of Transformer Inference: a Survey
트랜스 포머의 모델 구조는 브로드캐스팅하고, 멀티 헤드로 병렬 처리할 수 있으므로, 빠르고 비용 효율적이라는 것이 큰 장점이지만, 그럼에도 불구하고 다른 모델들에 비해 비교적 복잡하며 계산량이 많은 편 입니다.
특히 scaled dot-product attention과 masking, mroad casting + matrix multiplication을 반복적으로 사용함에 따라 FLOPs(Floating point operations per second, FLOPs or FLOP/s)와 MOPs(Memory Operations)가 상당히 많이 필요한 편입니다.
*어텐션 메커니즘은 주어진 쿼리(query)와 모든 키(key) 간의 유사도를 계산하기 위해 브로드캐스팅하여 matrix multiplication을 여러 번 사용합니다. (쿼리와 키 간의 유사도를 효율적으로 계산하기 위해 쿼리를 여러 번 복제하고, 이 복제된 쿼리와 키 간의 유사도를 계산)
*트랜스포머 모델의 FLOPs 계산은 상당히 복잡한데, 주로 모델의 크기, 레이어의 수, 헤드(heads)의 수, 시퀀스 길이 등 여러 요인에 따라 달라집니다.
*어텐션 메커니즘(Attention mechanism)의 연산 중 하나인 scaled dot-product Attention은 쿼리와 키 간의 내적 연산을 수행하는데, 이런 내적을 계산할 때도 임베딩 매트릭스를 브로드캐스팅 한 다음 matrix multiplication 수행합니다. 즉, 쿼리는 행렬의 한 행으로, 키는 여러 행으로 표현한 뒤 쿼리를 키의 개수만큼 브로드캐스팅하고, 이렇게 복제된 쿼리와 키 간의 내적을 계산합니다. (모든 쿼리와 키 사이의 유사도를 한 번에 효율적으로 계산하기 위함이지만 여전히 연산이 많음) 또, 멀티헤드 어텐션에서도 여러 개의 어텐션 헤드를 병렬로 계산하기 위해 브로드캐스팅을 사용합니다.
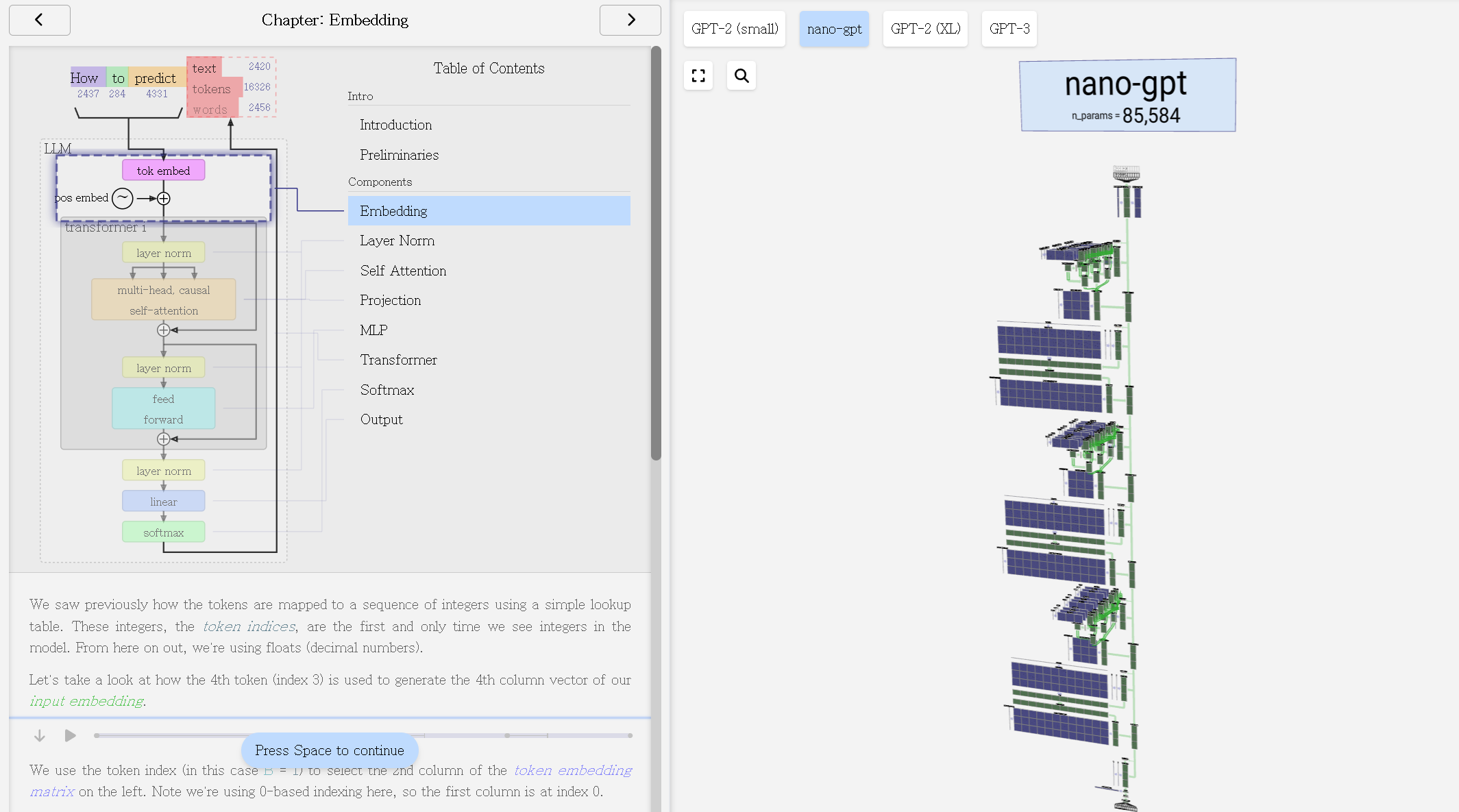
*출처: LLM Visuallization
trasnformers 모델에서의 vocab size의 변화가 어떠한 영향을 미치는지 조금 더 자세히 살펴보겠습니다.
trasnformers는 다음과 같이 input embedding과 postion embedding으로 input embedding을 생성하는데, vocab size는 임베딩 레이어(embedding layer)의 차원에 영향을 미칩니다.
n_vocab = len(vocab)
d_hidn = 128
nn_embedding = nn.Embedding(n_vocab, d_hidn)
input_embs = nn_embedding(inputs)
print(input_embs.size())
아래 Figure의 “Token Embeded”의 행의 차원이 vocab size가 되는데, 이 vocab size는 tokenizer의 vocabs size를 의미합니다. 참고로 주로 사용되는 GPT-4의 vocab size는 100,256이고, LLaMA-2는 32,000입니다.
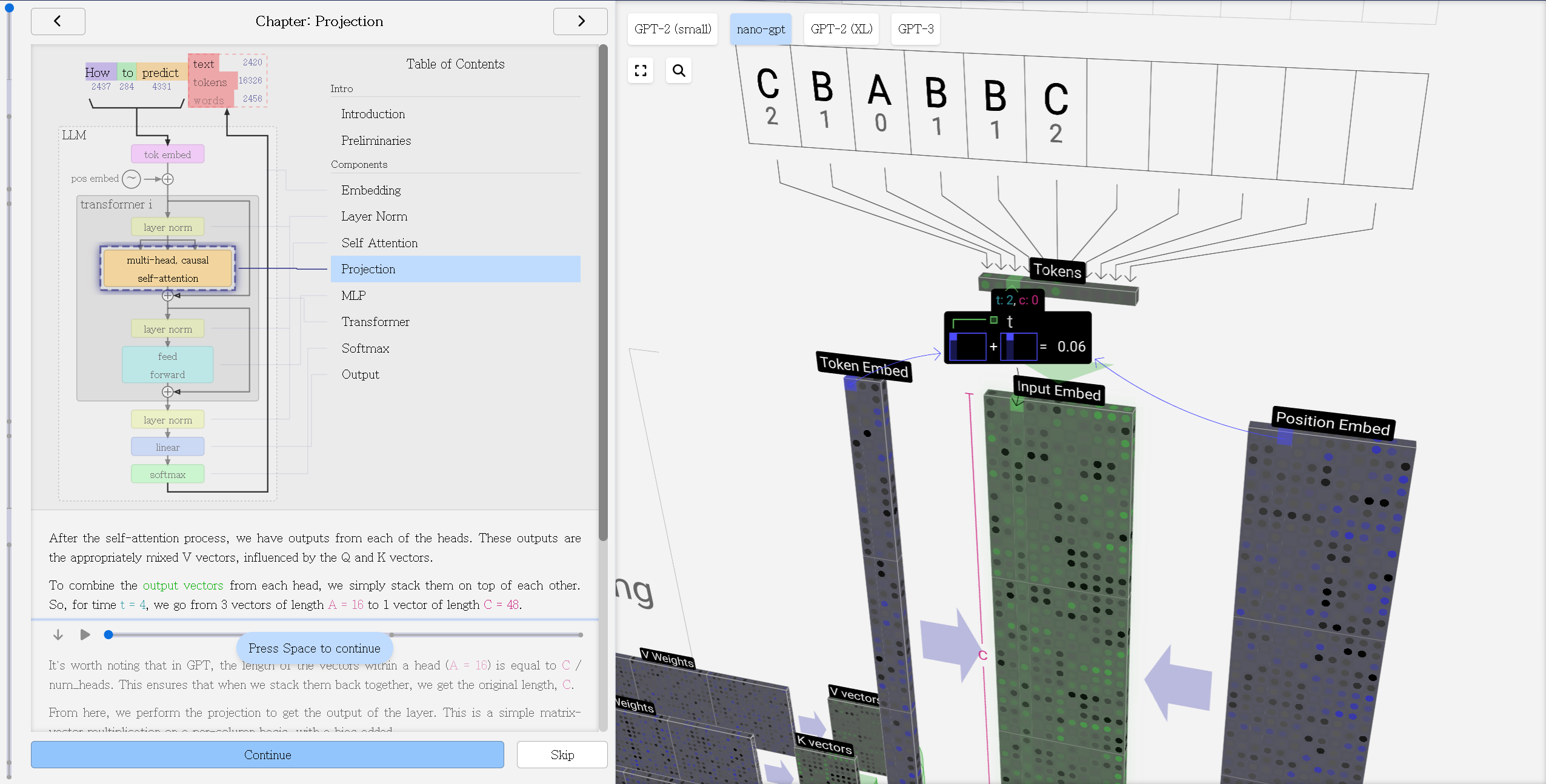
*출처: LLM Visuallization
위의 간단한 코드 및 Figure에서 볼 수 있듯이 임베딩 레이어의 차원(Figure의 “Token Embed”)은 vocab size에 영향을 받고, vocab size가 증가함에 따라 필요한 메모리 대역폭이 선형적으로 늘어나게 됩니다. 그렇기 때문에 동일한 길이의 인풋 텍스트 시퀀스를 더 적은 수의 토큰으로 잘 표현하는 것이 근본적으로 메모리를 절약할 수 있는 방법 중 하나입니다.
물론, 인풋 텍스트 시퀀스의 길이에도 선형적으로 영향을 받지만 이는 협상 불가한 조건이므로 논의에서 제외합니다.
그럼 다음으로 세 가지 가정을 바탕으로 naive하게 vocab size에 따른 트랜스포머의 토큰 임베딩 과정의 필요 메모리 사용량을 계산해보겠습니다.
embedding dimension이 4096이라면, embedding matrix의 크기는 다음과 같이 계산할 수 있습니다.
Size of Embedding Matrix = Size of Vocabulary X Dimension of Embedding
위 식에서 알 수 있듯, embedding layer는 vocab size에 비례하는 크기의 weight matrix를 가지게 되므로, vocab size가 n배가 되면, 이 matrix의 크기도 n배로 선형적으로 증가하게 됩니다.
embedding layer는 각 토큰 ID에 대한 벡터를 조회하는 연산을 수행하기 때문에, vocab size가 embedding layer에서 수행되는 실제 계산 연산(FLOPs)에 큰 영향을 주지는 않지만, vocab size가 증가할 경우, (1) 메모리 사용량이 증가하고, (2) 모델의 초기 로딩 시간이 길어질 수 있으며, (3) 더 많은 메모리 대역폭을 요구할 수 있습니다. (4) 또, 이 과정에서 I/O에 대한 손실이 발생할 수 있는데, 이는 데이터 전송과 접근에 더 많은 시간을 할애해야하므로 전체적인 모델 실행 속도에 영향을 줄 수 있으며, (5) 메모리 대역폭이 포화 상태에 이르면, GPU 연산 자원이 충분히 활용되지 못하고 대기 상태(병목)로 빠지게 되므로 실제 성능에 영향을 줄 수 있습니다.
위와 같은 이유로 더 긴 텍스트를 짧은 토큰으로 변환할 수 있게 토크나이저를 효율적으로 생성하여 MOPs를 최소화하는 것이 좋을 수 있습니다. 결론적으로 vocab size는 효율적인 LLM 인퍼런스에 어느정도 유효한 영향을 미친다고 볼 수 있습니다. 조금 더 구체적으로 표현하면, 효율적인 토크나이저가 LLM 인퍼런스 과정 중 MOPs를 줄여줌으로써 인퍼런스 효율을 높일 수 있습니다.
마지막으로 정리하면, vocab size가 증가하면 더 많은 메모리가 필요할 수 있으나 이는 FLOPs와는 큰 연관이 없고, MOPs(Memory Operation)에 영향이 있으며, MOPs는 효율적인 LLM 인퍼런스를 위해 중요한 요소 중 하나입니다.
단편적으로 NVIDIA GPU A100 40GB와 A100 80GB의 비용이 두 배 이상 차이나는 것을 생각하면, 더 적은 메모리를 점유하는 것은 효율적인 LLM 인퍼런스에 고려해야 할 요소라고 할 수 있습니다. (그럼에도 불구하고 vocab size의 증가는 Forward Pass FLOPs에 직접적인 영향은 없습니다.)
vocab size가 50k일 때와 100k일 때를 비교해보면 다음과 같습니다.
- 임베딩 차원이 \(d\)로 동일하다. (512로 가정)
- 입력 시퀀스의 길이는 \(L\)로 동일하다. (128로 가정)
- 다른 모든 모델 구성 요소는 동일하다.
{FLOPs of Embedding} = {size of vocab} x {Dimension of Embedding Layers} x {Length of Sequence}
- vocab size가 50,000일 때의 MOPs: \(30,000 x 512 x 128 = `3,276,800,000`\)
- vocab size가 100,000일 때의 MOPs: \(100,256 x 512 x 128 = `6,553,600,000`\)
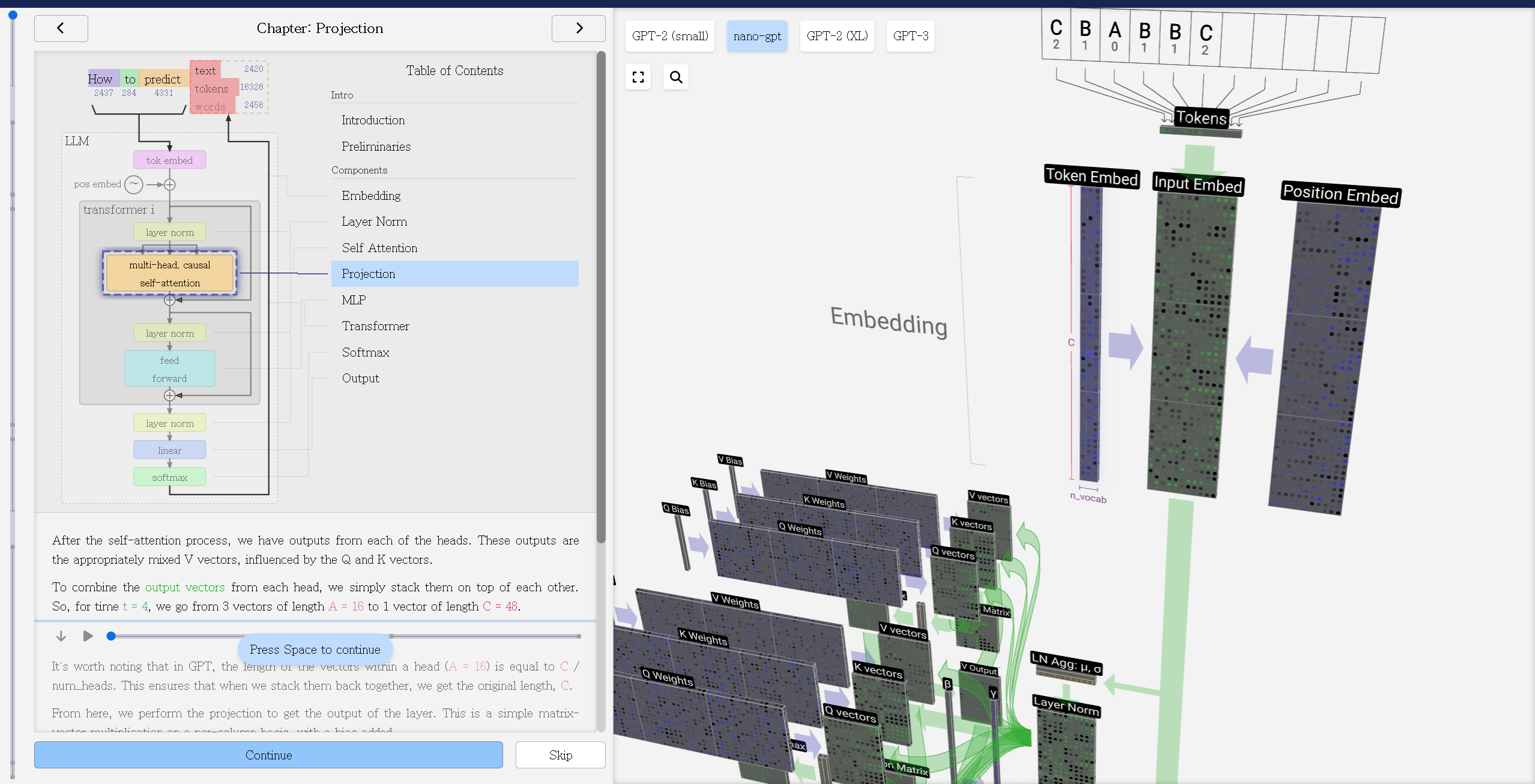
위 이미지의 Token Embeded의 행렬의 행의 차원에 빨간 색으로 작게 N vocab으로 표현되어 있고, 전술한 바와 같이 vocab size는 임베딩 차원에 영향을 줍니다.
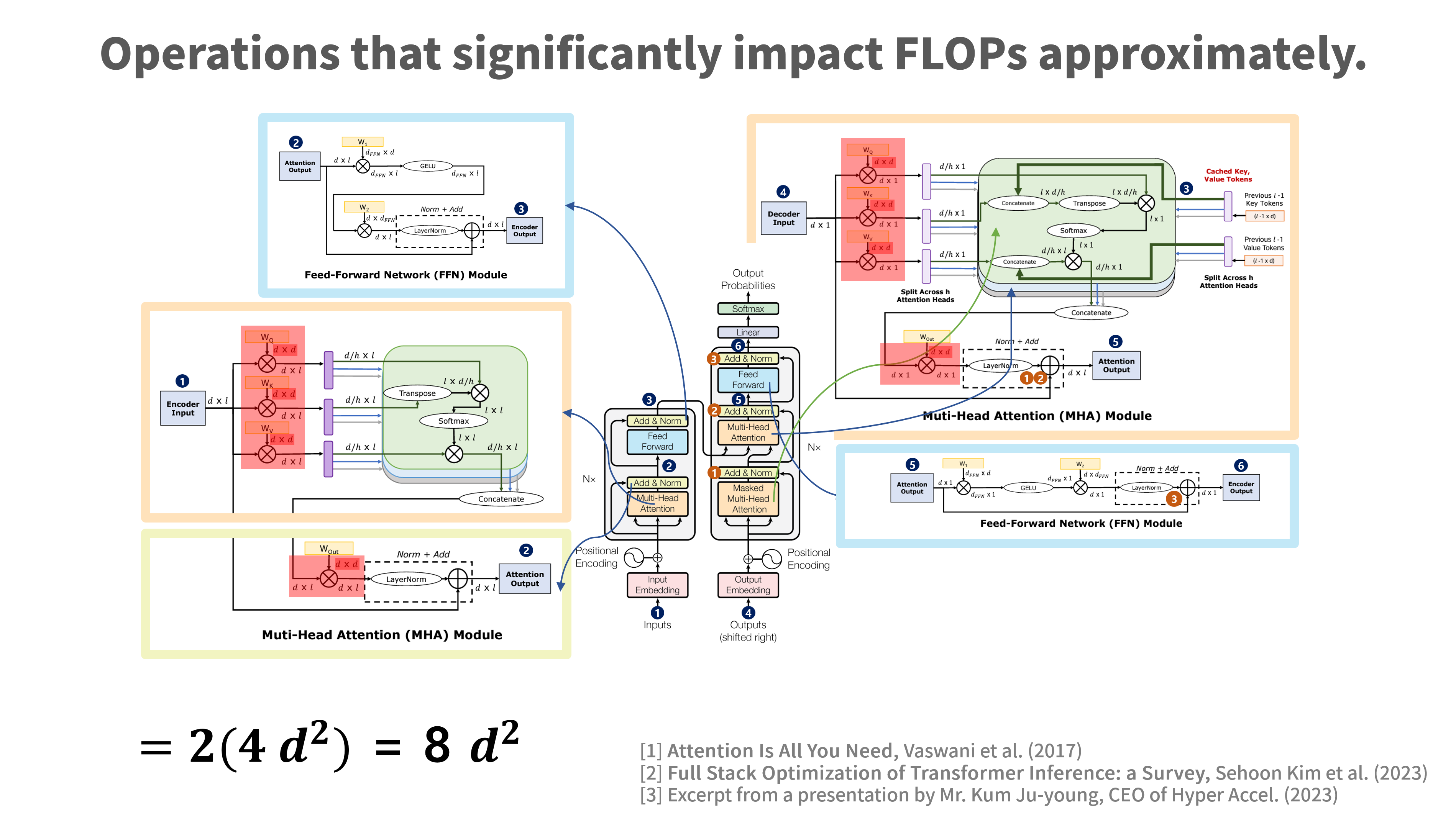
*출처: Attention Is All You Need(2017), Full Stack Optimization of Transformer Inference: a Survey (2023)의 이미지를 재구성함.
마지막으로 정리하자면, vocab size는 token embedding dimension에 영향을 미치고, 이는 transformers 아키텍처 전반의 MOPs(Memory Operation)과 상당히 밀접한 관계가 있습니다. 관련 내용은 저의 transformers 포스트를 참조하세요.
직관적으로 알 수 있으므로 만약 여기까지의 설명으로 충분하셨다면 다음 섹션으로 넘어가셔도 되고, 잠깐 아래 글을 읽으시면서 쉬어가셔도 좋습니다.
-
Rough Estimation of LLM Inference Cost
Vocab size의 증가(비효율적인 증가를 의미)는 단일 모델 수준에서의 메모리 요구량 증가에 그치지 않고, 다양한 요인들로 인해 n배 이상 메모리를 요구할 수 있습니다.
예를 들어, GPT-4가 MoE(Mixture of Experts, 이하 “MoE”) 레이어를 사용하는 것이 기정사실화되고 있는 상황에서, Mistral과 같은 오픈 소스 모델들도 MoE를 사용하는 서비스를 공개하였습니다. 이런 상황에서, Mistral 7B가 8개의 expert 모델 중 최소 2개 이상의 모델을 사용해 인퍼런스 한다고 가정할 경우, 메모리에는 반복적인 모델 로드를 수행하거나 혹은 8개의 7B 모델을 VRAM에 올려두어야하거나 반복적으로 VRAM에 올리고 내려야(I/O)할 수 있습니다. (2024년 04월에 발표한 AI21Lab의 jamba(mamba + transforemrs) 모델도 MoE 레이어를 기반으로 학습하였습니다.)
위와 같이 복수개의 expert models를 사용한다고 가정할 경우, 선형적으로 요구하는 VRAM 메모리 사양이 늘어나게 되는데, 8개의 모든 LLM이 LLaMA-2 7B 모델이라고 가정하면, naive하게 모든 parameters가 32bits로 인퍼런스할 경우 4bytes/parameters * 70B parameters = 280억 bytes X 8 = 224GB의 VRAM을 요구하게 됩니다. 만약 16bits 또는 2bytes로 인퍼런스한다고 가정하여도, 112GB의 VRAM을 요구하고, 이는 단순히 7B 모델의 경우이므로 만약 13B, 70B, 180B 등 더 큰 파라미터의 LLM을 사용한다고 가정하면(MoE 특성상 이렇게까지 큰 모델들을 여러개 올리는 일이 거의 없겠지만), 기하 급수적으로 요구하는 VRAM 사양이 높아지게 됩니다.
A100이 기본적으로 40GB의 VRAM으로 설계되어 있고, 80GB A100으로도 인퍼런스가 힘들어질 수 있습니다.
전체 precision(float32)에서는 모델의 모든 parameters가 32bits(또는 4bytes)로 저장됩니다. 따라서 인퍼런스에만 4bytes/parameters * 70B parameters = 280억 bytes = 28GB의 GPU 메모리가 필요합니다. 절반의 precision에서는 각 parameters가 16bits(또는 2bytes)로 저장되므로 인퍼런스에만 14GB가 필요하고, 8bits 및 4bits 알고리즘의 경우 parameters당 각각 4bits(또는 1/2bytes)를 사용하는데 인퍼런스를 위해 3.5GB의 메모리가 필요합니다.
훈련의 경우 훈련하는 방식에 따라 다르지만, 일반적으로 일반 AdamW를 사용하는 경우 (parameters뿐만 아니라 해당 gradients 및 second-order gradients도 저장하므로) parameters당 8bytes가 필요합니다.
따라서, 7B 모델의 경우 학습시 parameters당 8bytes * 70억 개의 parameters = 56GB의 GPU 메모리가 필요하며, MoE를 채택할 경우 expert models의 수 만큼 곱해야 합니다.
AdaFactor를 사용하는 경우 parameters당 4bytes가 필요하고, 총 28GB의 GPU 메모리가 필요하며, bits와 bytes의 최적화 프로그램(e.g., 8bits AdamW)을 사용해도 parameters당 2bytes가 필요하여 총 14GB의 GPU 메모리를 확보해야 합니다.
자세한 내용은 다음 허깅 페이스의 포스트: Methods and tools for efficient training on a single GPU를 참조하세요.
지금까지 추산해 본 모델 파라미터에 추가적으로 비효율적인 토크나이저로 인해 메모리 요구량이 선형적으로 증가할 수 있습니다. VRAM에 모델을 올리고, 인퍼런스 시 비용은 시퀀스의 길이에 비례하게되는데 토큰화로 인하여 이 시퀀스 길이가 달라질 수 있기 때문입니다. 쉬운 예로, “안녕하세요”를 단일 토큰으로 매핑하는 것과 Char-level(“안”,”녕”,”하”,”세”,”요”), 혹은 한글 자모 단위의 레벨로 매핑하는 것에 따라 토큰화되는 시퀀스의 길이가 달라지기 때문입니다.
하드웨어적으로 A100 x 40GB 하드웨어의 비용과 A100 x 80GB의 비용이 배 이상 차이나기 때문에, 효과적인 모델 인퍼런스를 위해서는 FLOPs 뿐만 아니라 전체적인 프로세스의 병목을 없애고 비용을 줄이기 위한 다양한 기술들이 필요합니다. 더 자세한 이야기는 포스트(미완성) LLM Efficient inference와 Quantization를 참고하시는 것도 좋습니다.
대부분 LLM들은 모델 웨이트가 크기 때문에, 연산에 사용되는 메모리를 적게 점유하는 것이 좋습니다. 양자화(quantization)과 같이 데이터 타입 및 퍼포먼스 손실을 최소화하는 파라미터의 임계점(threshold)을 잡아 데이터 타입을 변환하여 메모리 점유를 낮추며 조정하는 것도 좋은 방법이지만, 아직까지 성능 손실을 최소화하면서 효율적으로 양자화하는 방법은 논의 중입니다. 따라서, 효과적으로 토큰화할 수 있는 토크나이저를 구성하는 것도 좋은 솔루션 중 하나일 수 있습니다.
vocab size의 증가 즉, 비효율적인 토크나이저가 FLOPs에 아무런 영향을 주지 않는 것은 아닙니다. 예를 들어, 동일한 길이의 텍스트로 더 많은 토큰으로 비효율적으로 변환할 경우 length of sequece가 늘어나게 되어 FLOPs의 증가하게 됩니다. 또, 바로 아래에서 살펴보겠지만, char-based tokenization 방식의 치명적인 단점인 의미론적인 정보 손실이 일어나 토큰을 순차적으로 정렬하기 위해 더 많은 학습을 요하므로, 결과론적으로 비효율적인 토크나이저는 FLOPs도 어느정도 증가시킬 수 있습니다.
Reason 3
마지막으로 토크나이저로 인해 비용 및 속도에서의 불공정함(unfairness)나 비용 측면에서의 문제들이 꾸준히 제기되었으나, 한국에서는 형태소에 대한 분석 이외에 토크나이저에 대한 자세한 보고가 없기에 최대한 많은 정보들을 취합하여 정리해보고자 합니다. 토크나이저의 불균형에 대한 보고에 대한 이미지로 상세 설명을 갈음합니다.
모든 언어에 최적화 된 토크나이저는 아직 없는 것 같으며, 아래에서 설명하는 Unigram이 그 시도 중 하나입니다. 다양한 언어를 모두 효율적으로 토큰화하는 연구는 구글이 기계어 번역 태스크를 서비스에서 사용하기 위해 여러 시도를 하였고, 아마 내부적으로는 사용하고 있을 것이라고 생각합니다. 그러나, 구글은 공식적으로 토크나이저 및 LLM을 공개하고 있지는 않기때문에, 상세한 내용 확인은 어렵습니다. 혹시 제가 참고할 수 있는 내용이 있다면, 메일로 알려주시면 감사하겠습니다.
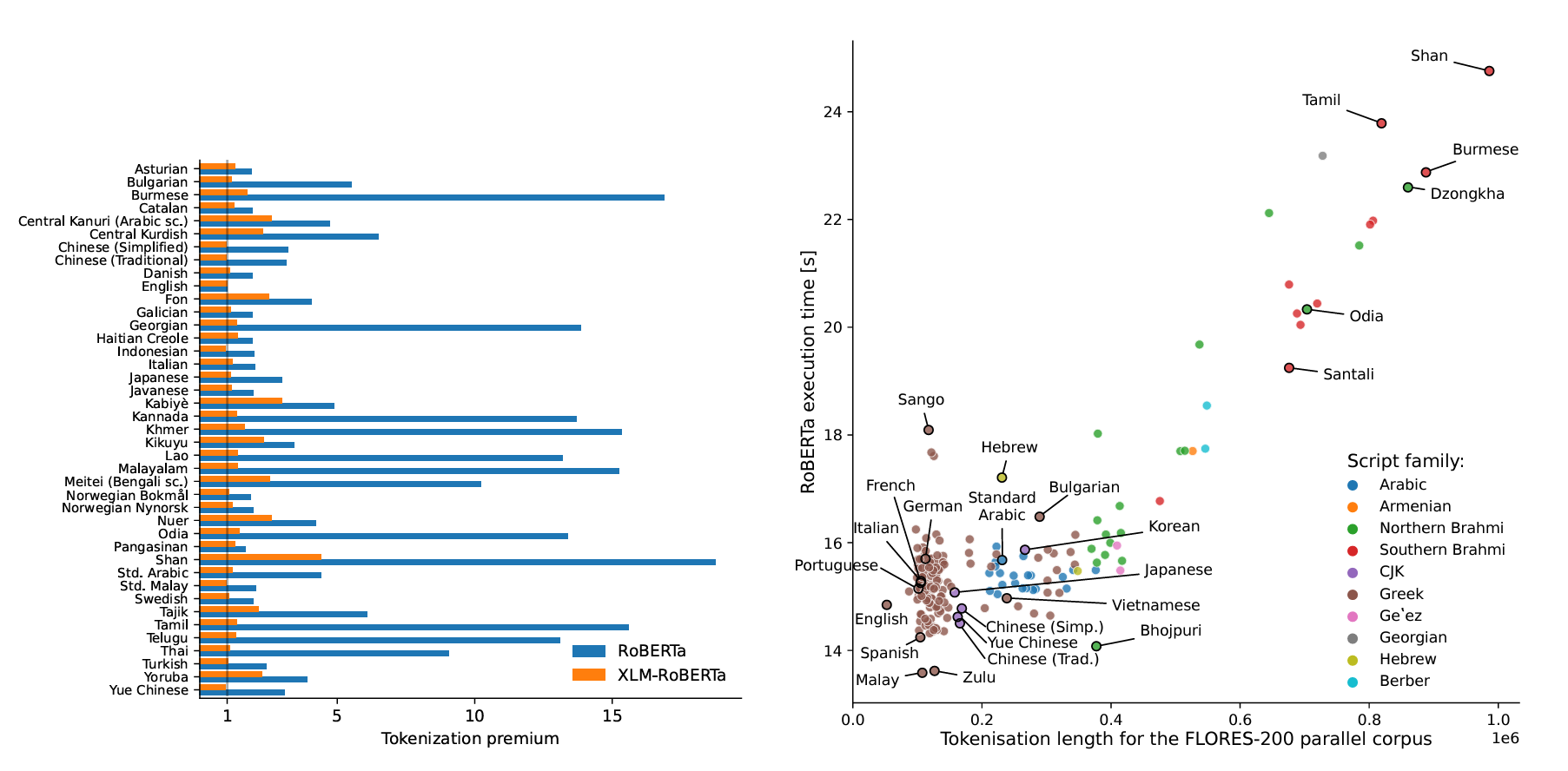
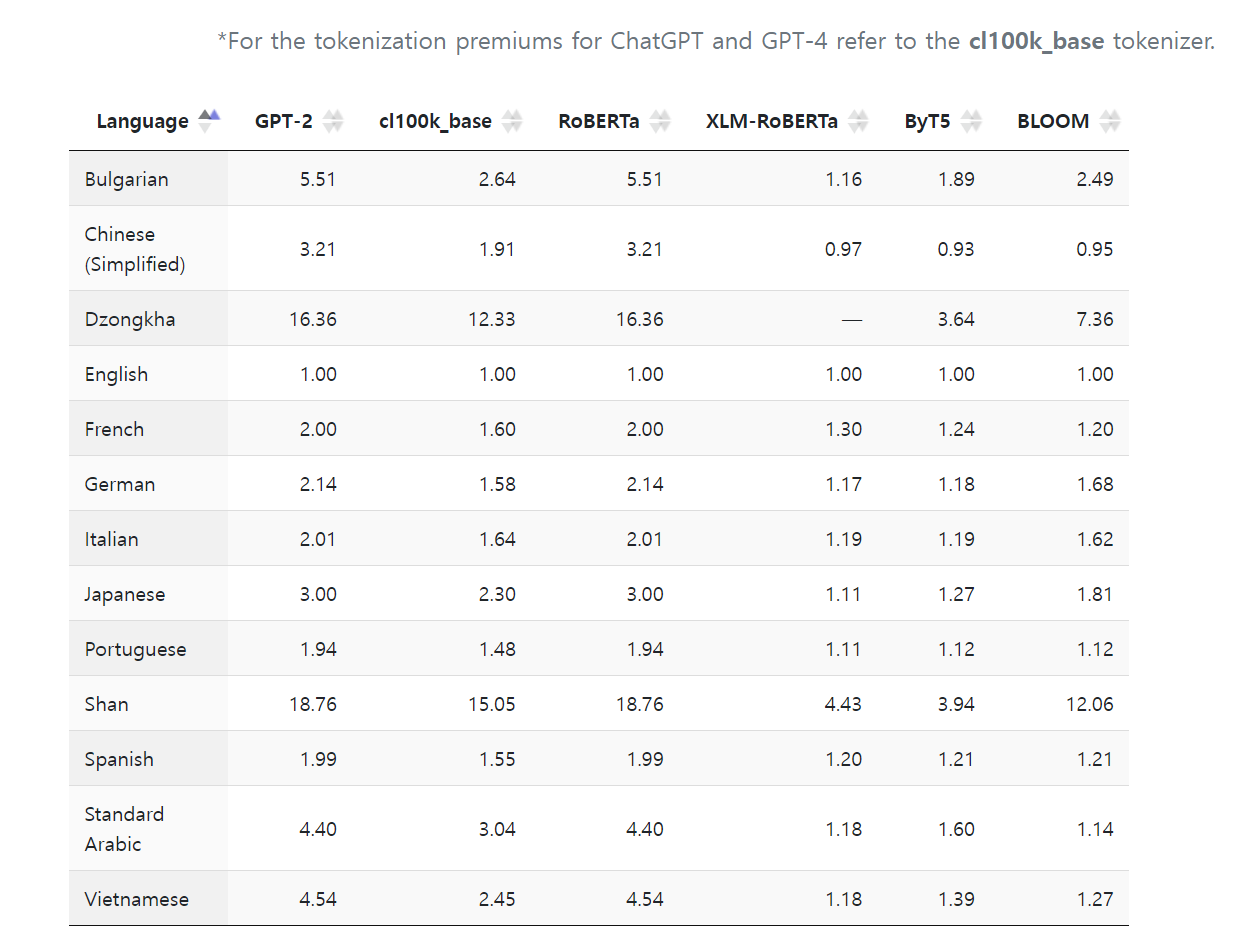

*출처: Language ModelTokenizers Introduce Unfairness Between Languages [Paper], [Web]
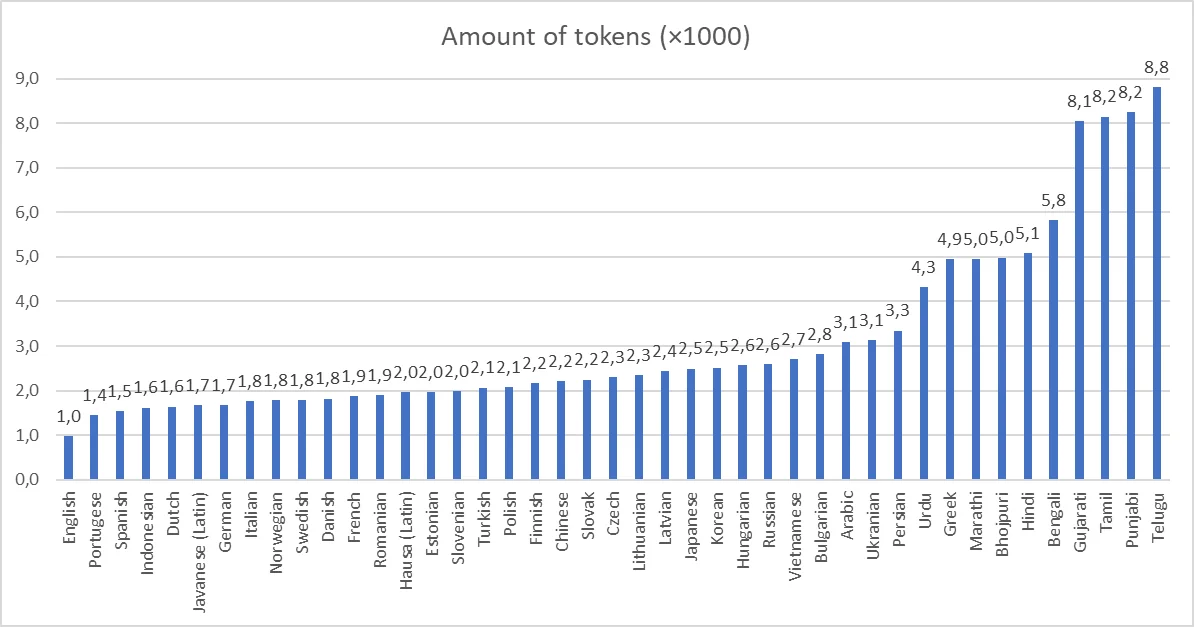
*출처: Hindi 8 times more expensive than English: the token price of text in different languages
토크나이저로 인한 비용 차이에 대한 이슈는 다음 포스트들에서 이전부터 논의되어 왔습니다.
- Why OpenAI’s API Is More Expensive for Non-English Languages
- Why is GPT-3 15.77x more expensive for certain languages?
- Hindi 8 times more expensive than English: the token price of text in different languages
- AI Fees Up to 15x Cheaper for English Than Other Languages
다시 본론으로 돌아가, 각 토큰화 방법에 대해 비교해보겠습니다.
Tokenization methods comparison
토큰화 방식은 크게 1) Word-based tokenization, 2) Char-based tokenization, 3) Subword-based tokenization으로 나눌 수 있습니다. 모든 토큰화 알고리즘은 일반적으로 해당 모델이 훈련한 특정 코퍼스에 등장하는 문장들에 영향을 받게됩니다. 즉, 토크나이저는 토큰화 과정에 사용되는 코퍼스(corpus)에 편향되는 것이 보편적이므로 코퍼스도 신중하게 선택해야 합니다. 특수 토큰의 경우, 모델별로 다르게 둘 수 있으므로 일반적인 경우에 대해서만 소개합니다.
개괄하여 설명하기 위해, ‘love’와 ‘lovely’로만 구성된 간단한 코퍼스를 다양한 방식으로 토큰화하는 예시를 살펴보겠습니다.
코퍼스가 “love lovely”라면, 세 가지 토큰화 방식에 의해 다음과 같은 vocab이 생설될 수 있습니다.
- Word-based tokenization: 구두점 혹은 공백으로 토큰화
- \(('love', '000001'), ('lovely', '000002')\)
- Char-based tokenization: 각 char 레벨을 기준으로 토큰화
- \(('l', '000001'), ('o', '000002'), ('v', '000003'), ('e', '000004'), ('y', '000005')\)
- Subword Tokenization: 의미론적인 쌍과 하위 쌍으로 나누어서 토큰화
- \(('love', '000001'), ('ly', '000002')\)
아래 표를 통해, 각 토큰화 방식의 장·단점을 비교한 표를 소개합니다.
| Type | Methods | Pros. | Cons. |
|---|---|---|---|
| Word-based tokenization | - Space and punctuation tokenization - Rule-based tokenization |
Easy to use | - Very large vocabularies - Out-of-vocabulary (OOV) problems - Loss of meaning across very similar words |
| Char-based tokenization | Splitting into characters | - Slimmer vocabularies - Mostly open-vocabulary: fewer OOV words |
- Very long sequences - Less meaningful individual tokens |
| Subword-based tokenization | - Word Piece - Byte Pair Encoding (BPE) - Unigram |
- Good balance between vocabulary size and sequence length - Helps identify similar syntactic or semantic situations - Can identify start of word tokens |
Need for training additional subword tokenizer |
*출처: Yekun’s Note: Subword Tokenizers for Pre-trained Language Models
Word-based tokenization
\(('love', '000001'), ('lovely', '000002')\)
- Word-based tokenization은띄어쓰기나 일정한 규칙(구두점 및 공백 등에 대한 처리)에 따라 처리하는 토큰화 방식을 의미합니다.
- 위 예시에서는 충분히 설명되지 않았지만,
I love you.라는 문구를I+love+you+.로 나누어 토큰화하는 방식이라고 이해하시면 편합니다. (물론 언어별로 혹은 토큰화 방식별로 구두점이나 공백, 특수문자 등에 대한 처리가 상이할 수 있습니다.)
- 위 예시에서는 충분히 설명되지 않았지만,
- Word-based tokenization은 space and punctuation tokenization과 rule-based tokenization로 크게 분류할 수 있으며, rule-based tokenization는 주로 spaCy와 Moses를 사용합니다.
- 이 방법은 텍스트를 더 작은 덩어리로 분할하는 간단하고 직관적인 방법이지만, 일반적으로 모든 고유 단어 및 토큰의 집합을 생성해야하므로 큰 voacb이 생성됩니다.
- 예를 들어, Transformer XL은 공백과 구두점 기반으로 토큰화하므로 vocab size가 267,735이고, 이렇게 큰 vocab size로 인해 모델은 입·출력 레이어가 커지게 되므로 충분한 양의 메모리를 확보해야하고, 시·공간 복잡도가 증가합니다. (일반적으로 단일 언어의 토크나이저 vocab size가 50,000을 초과하는 경우는 드물고, 보통 단일 언어로만 pre-training되었을 경우에는 50k 이하의 vocab size를 갖는 것이 통상적입니다. 다국어를 커버하는 경우 사용하기 어려운 방법일 수 있습니다.)
- 따라서, 이 방법은 영어가 아닌 한국어와 같은 교착어에 불리한 토큰화 방식이라고 할 수 있습니다.
Char-based tokenization
\(('l', '000001'), ('o', '000002'), ('v', '000003'), ('e', '000004'), ('y', '000005')\)
- Char-based tokenization는 Word-based tokenization와 비슷하게 간단한 방식으로, 단순히 문자(char) 단위로 토큰화합니다. 모든 알파벳의 조합을 매핑하는 Word-based tokenization 방법과는 달리, Char-based tokenization은 26개의 알파벳과 일부 구두점, 특수 문자 등만 매핑하는 것을 의미하고, 그렇기에 vocab size도 적으면서 토크나이저를 별도로 구성하는 노력이 필요하지 않습니다. 또한, vocab size가 적기때문에 시·공간 복잡도가 크게 줄게됩니다.
- 하지만, 이렇게 토큰화될 경우 LLM이나 NLP 모델이 단순히 문자 하나하나를 입력으로 받는 것과 동일하기 때문에 이렇게 생성된 토큰으로 언어의 의미론적인 문맥을 학습하고 이해하기 훨씬 더 어려워집니다.
- 따라서, Char-based tokenization 방식은 모델 성능의 저하를 필연적으로 수반하게 됩니다.
- 예를 들어, Word-based tokenization에서는
love로 토큰화 했던 것을, Char-based tokenization는l,o,v,e로 토큰화 하므로 의미론적인 정보가 손실되고, 실질적으로 모델은 자연어에 내포 된 의미를 포착하기 어려워지게 됩니다.
Subword-based tokenization
- Subword-based tokenization lies between character- and word-based tokenization, which arises from the idea that:
- Frequently used words should not be split into smaller subwords;
- Rare words should be decomposed into meaningful subwords.
- Subwords help identify similar syntactic or semantic situations in texts, such as same prefix or sufix.
\(('love', '000001'), ('ly', '000002')\)
앞으로 자세하게 살펴 볼 알고리즘들은 모두 이 Subword-based tokenization 방식입니다. 또한, 시간 순으로 토크나이저를 나열할 경우, Word Piece, BPE, Unigram, BBPE가 자연스러울 수 있으나 본 포스트는 토큰화 방식 및 LLM에서의 활용에 초점을 맞추고 있기 때문에, 이런 히스토리는 생략하고 알고리즘 설명에 집중합니다.
- Subword-based 방식은 위에서 설명한 Word-Based와 Char-Based를 적절하게 혼용하는 방식으로 대부분의 최신 모델들이 이 방법을 차용합니다.
- Subword-based 방식에는 BPE(Byte Pair Encoding), BBPE(Byte-level Byte Pair Encoding), Word Piece, Unigram 등이 있습니다.
- 또한, Subword-based 방식을 다루는 라이브러리로는 Google의 SentencePiece, OpenAI의 Tiktoken 등이 있으며, BPE 방식의 변형 알고리즘에는 BPE-dropout, DPE 등이 있습니다.
- 전술한 Word-Based나 Char-based 방식처럼 Subword-based 방식에서도 단순히 ID로 토큰을 매핑하는 것은 간단하므로 설명을 생략하고, 텍스트를 단어나 하위 단어로 분할하는 것(텍스트 토큰화)을 중점적으로 살펴보도록 하겠습니다.
- Subword-based 방식은 하위 단어는 동일한 접두사 또는 접미사와 같이 텍스트에서 유사한 구문 또는 의미 상황을 식별하는 데 도움이 된다는 가정 하에 자주 사용되는 단어를 더 작은 하위 단어(subword)로 분할해서는 안 되고, 희귀한 단어는 의미 있는 하위 단어로 분해해야 한다라는 대원칙을 기반으로 토큰화를 수행합니다.
- 이는 하위 단어를 함께 연결하여 (대부분) 임의로 긴 복잡한 단어를 형성하는 한국어, 터키어와 같은 교착어에서 특히 유용할 수 있습니다.
- 하위 단어 토큰화를 통해 모델은 의미 있는 문맥의 독립적 표현을 적절하게 학습할 수 있고, 합리적인 어휘 크기를 가질 수 있습니다. (*단일 언어의 경우 50k 내외*)
- 하위 단어 토큰화를 통해 모델은 이전에 본 적이 없는 단어를 알려진 하위 단어로 더 세부적으로 나누어 처리할 수 있으므로, OOV 문제에도 상대적으로 강건합니다.
- Subword-based 방식은 start of word tokens을 식별하는 식별자를 두는데, Word Piece 방식을 차용하는 BERT 모델의 경우 단어의 시작을 식별하는 구분자로 “##”를 사용합니다.
- 또, 밑에서 설명할 Fast Tokenizer에서는 BERT 모델이 아니여도 객체 안의 메서드로 이를 구현해두었는데, 이는 아래에서 추가적으로 살펴보겠습니다.
Subword-based tokenization algorithms
이 섹션에서는 위에서 살펴 본 세 가지 토큰화 방식 중 Subword-based tokenization를 집중적으로 탐구합니다. Subword-based tokenization에는 BPE, BBPE, Worde Piece, Unigram 등이 있으며, BPE 방식의 일부 변형 알고리즘으로는 BPE-dropout, DPE(Dynamic Programming Encoding for Subword Segmentation in Neural Machine Translation)가 있으며, 해당 내용도 간단히 소개합니다.
각 토큰화 방식을 하나씩 살펴보기 전에, 전술한 내용과 같이 앞으로 살펴 볼 내용들을 표로 정리합니다.
| Tokenization Type | Description | Example |
|---|---|---|
| 1) Word-based | Splits text into words. Ideal for languages with clear word boundaries. | “I love apples” → [“I”, “love”, “apples”] |
| 2) Char-based | Breaks text into characters. Useful for character-level tasks or languages without clear word boundaries. | “Hello” → [“H”, “e”, “l”, “l”, “o”] |
| 3) Subword-based tokenization | Splits text into Subword-based units for better handling of rare words and morphemes. | Sub-categories below |
| 3-1) BPE | Merges frequent pairs of characters/bytes. Good for reducing the vocabulary size efficiently. | “lower” → [“low”, “er”] |
| 3-2) BBPE | Byte-level BPE, works at byte level rather than character level. Useful for languages with large character sets. | “漢字” → [“漢”, “字”] |
| 3-3) Word Piece | Similar to BPE but optimizes for language model likelihood. Balances vocabulary size and context understanding. | “playground” → [“play”, “ground”] |
| 3-4) Unigram | Starts with a large vocabulary and prunes it based on frequency. Efficient for languages with complex morphology. | “playing” → [“play”, “ing”] |
BPE, Word Piece, Unigram의 대략적인 vocab size 및 특징을 표로 정리합니다.
| Tokenization Method | vocabulary size | Update Method | Possibility of Adding New Symbols |
|---|---|---|---|
| BPE (Byte Pair Encoding) | Large | Bottom-up merge | Possible |
| Word Piece | Large | Bottom-up merge | Possible |
| Unigram | Small | Top-down approach (Prune) | Difficult |
-
BPE (Byte Pair Encoding): A frequency-based merging method that merges tokens based on bigram frequencies. It uses the co-occurrence of subword pairs to greedily merge neighboring pairs. This approach employs a greedy longest-match-first algorithm based on deterministic symbol replacement.
-
Word Piece: A probability-based approach that uses a language model to assess the likelihood of merging subword pairs during each iteration. It progressively merges neighboring unit pairs.
-
Unigram Language Model: This method is based on the normalization of subwords, involving a probabilistic mixture of characters, subwords, and word splits. Tokens are organized using the Unigram LM perplexity, and the mixture probabilities are calculated using the EM algorithm. A Unigram LM with a likelihood reduction feature is used to reduce the number of subwords. prunes tokens based on unigram LM perplexity, which can be viewed as a probabilistic mixture of characters, subwords, and word segmentations, where the mixture probabiilty is computed using EM algorithm. It reduces the subword using a unigram LM with likelihood reduction.
이제 Subword-based tokenization algorithms 중 하나인 BPE를 먼저 소개한 뒤, 순서대로 BBPE, Word Piece, Unigram에 대해 알아보겠습니다.
BPE, Byte Pair Encoding
다이그램 코딩(digram coding)이라고도 하는 bytes 쌍 인코딩(Byte Pair Encoding, 이하 “BPE”)은 Philip Gage가 1994년에 처음 설명한 알고리즘으로, 단일 문자(한 자리 숫자 또는 단일 구두점 포함)를 인코딩하는 토큰과 전체 단어(가장 긴 복합어 포함)를 인코딩하는 토큰을 어휘 사전에 포함시키는 토큰화 방식입니다.
BPE의 알고리즘은 한 문장으로 요약하면, 코퍼스에 등장한 인접 문자들의 쌍을 지어본 뒤, 가장 많이 등장하는 쌍을 먼저 vocab에 추가하고, 사용자가 하이퍼파라미터(hyper-parameter)로 지정한 vocab size에 여유가 있을 경우, 하위 단어의 쌍을 탐색해서 가장 많이 등장하는 하위 단어의 쌍도 vocab에 추가하는 방식이라고 할 수 있습니다.
BPE는 training dataset를 단어로 분할할 때, 사전 토큰화(pre-tokenization)를 먼저 수행하는데, 사전 토큰화는 맨 처음에 설명한 공백 토큰화(space tokenization, e.g, GPT-2, RoBERTa)만큼이나 간단합니다.
XLM, FlauBERT과 같이 조금 더 복잡한 사전 토큰화(more advanced pre-tokenization)의 경우 대부분 Moses를 사용는 편이고, GPT, Spacy와 ftfy와 같은 규칙 기반 토큰화(rule-based tokenization)를 사용하기도 합니다. BPE는 이런 사전 토큰화를 필수적으로 수행한 뒤, 코퍼스에서 각 단어의 빈도를 계산하게 됩니다.
결과론적으로 BPE 알고리즘은 Word Piece 이후 기계 번역 태스크에서 주로 연구되었으며, 원 논문에 따르면 BPE가 다른 모델들 보다 더 높은 *BLEU(Bilingual Evaluation Understudy, 이하 “BLEU”) 점수를 받았습니다.
*BLEU (Bilingual Evaluation Understudy) score: BLEU: a Method for Automatic Evaluation of Machine Translation (Kishore Papineni et al. 2002)에 소개 된 평가 지표로 기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교해 번역에 대한 성능을 측정하는 n-gram에 기반 방법입니다. Perplexity(PPL)을 지표로 사용할 수 있으나 이는 직접적인 비교 방법이라고 보기 어렵습니다. 자세한 내용은 위키독스 딥 러닝을 이용한 자연어 처리 입문: PPL 및 BLEU를 참고하세요.
Algorithm: Byte-pair encoding (Sennrich et al., 2016; Gage, 1994) [15]

BPE 알고리즘은 모든 고유 문자가 길이 1의 1-gram(초기 토큰)이라고 가정하고, 연속된 문자 중 가장 자주 인접하는 문자의 쌍을 찾아 길이 n의 n-gram으로 병합합니다. 이 과정에서 가장 자주 등장하는 문자의 쌍을 우선적으로 vocab에 추가하고, 지정한 어휘 사전의 크기(vocabulary size, 이하 "vocab size")에 도달할 때까지 하위의 문자 쌍들도 vocab에 추가합니다. 이 과정을 반복하여, 원하는 크기의 vocab을 구성하고, 토크나이저를 생성합니다.
*Size of Vocabulary?
The final vocabulary size is the size of base vocabulary plus the # of merges, where the # of merges is a hyperparameter. For instance,
- GPT (character-level BPE) has 40,478 vocabularies: 478 base vocabularies + 40k merges.
- GPT-2 (byte-level BPE) has 50,257 vocabularies: 256 base vocabularies + 1 [EOS] token + 50k merges.
주로 기계 번역 태스크부터 자주 사용되기 시작했으며, 전체 코퍼스를 탐색해 원하는 vocab size까지 점진적으로 vocab에 토큰을 추가하는 bottom-up 방식으로, OpenAI의 LLM들이 BPE 알고리즘으로 생성된 토크나이저를 사용합니다. 간단한 예시로 BPE 알고리즘의 상세 설명을 갈음합니다.
[token3]의 하위 단어(subword) == [token1][token2]라고 가정.
aaabdaaabac
aaabdaaabac … aa == [token1]
[token1]abd[token1]abac … [token2] == ab
[token1][token2]d[token1][token2]ac … [token1][token2] == aaab == [token3]
[token1][token2]d[token1][token2]ac
[token3]d[token3]ac
….(Iteration reversely until the vocabulary size is appropriate.)
*참고: BPE 알고리즘 예시, 이해를 돕기 위해서 순차적으로 작성하였으나, 실제로는 역방향임을 주의하세요. 실제로는 vocab size==1의 token3가 먼저 생성되고, 그 뒤 vocab size==2의 token1과 token2가 token3로부터 생성됩니다.
[token3]부터 생성하고, vocab size에 여유가 있을 경우 추가로 하위 단어를 생성하는 [token1]와 [token2]가 생성됩니다.
더 자세한 예시는 페이지: 딥 러닝을 이용한 자연어 처리 입문 및 다음 짧은 Tiktoken의 설명을 참고하세요.
-
What is BPE, anyway?
Models don’t see text like you and I, instead they see a sequence of numbers (known as tokens). Byte pair encoding (BPE) is a way of converting text into tokens. It has a couple desirable properties:- It’s reversible and lossless, so you can convert tokens back into the original text.
- It works on arbitrary text, even text that is not in the tokeniser’s training data.
- It compresses the text: the token sequence is shorter than the bytes corresponding to the original text. On average, in practice, each token corresponds to about 4 bytes.
- It attempts to let the model see common subwords. For instance, “ing” is a common subword in English, so BPE encodings will often split “encoding” into tokens like “encod” and “ing” (instead of e.g. “enc” and “oding”). Because the model will then see the “ing” token again and again in different contexts, it helps models generalise and better understand grammar.
주로 BPE 토크나이저를 사용하는 OpenAI는 Tiktoken이라는 오픈소스 패키지를 사용하는데, 이 패키지를 통해 OpenAI LLM들의 토크나이저를 확인하고, 비교해볼 수 있습니다.
다음은 Tiktoken 레포지토리에 있는 BPE에 대한 설명과 OpenAI LLM들이 사용하는 토크나이저 목록입니다.
| Encoding name | OpenAI models |
|---|---|
| cl100k_base | gpt-4, gpt-3.5-turbo, text-embedding-ada-002 |
| p50k_base | Codex models, text-davinci-002, text-davinci-003 |
| r50k_base (or gpt2) | GPT-3 models like davinci |
*참고: openai-python, openai-cookbook
BBPE, Byte-level Byte Pair Encoding
bytes 기반 bytes 쌍 인코딩(Byte-level Byte Pair Encoding, 이하 “BBPE”)은 몇 가지 트릭을 사용해 기존 BPE 모델의 단점을 개선한 “변형된 BPE 알고리즘”으로, GPT-2 모델부터 이 방식의 토크나이저를 사용하기 시작했습니다. BBPE의 기본 vocab에는 training dataset에서 가능한 모든 기본 문자를 포함시키는데, 모든 유니코드 문자가 포함되면 용량이 커질 수 있기때문에, 기본 vocab 구성을 위해 유니코드 문자열이 아닌 bytes 시퀀스를 사용하였습니다.
아래의 GPT-2 토크나이저의 경우, GPT의 토크나이저와 달리 8bits(byte)로 256개의 문자에 대응하는 기본 vocab을 먼저 구성한 뒤, BPE 알고리즘으로 병합된 문자 쌍을 병합하는 방식으로 토크나이저를 생성한 것을 의미합니다.
- GPT (character-level BPE) has 40,478 vocabularies: 478 base vocabularies + 40k merges.
- GPT-2 (byte-level BPE) has 50,257 vocabularies: 256 base vocabularies + 1 [EOS] token + 50k merges.
기존 BPE 알고리즘은 (코퍼스에 없거나 희소해서) vocab에 없는 토큰을 [unk(unknown token)] 토큰으로 인코딩하는데, 이렇게 [unk]로 인코딩 된 토큰을 다시 디코딩하는 과정에서 정보 손실이 발생할 수 있습니다. vocab에 없는 토큰에서 발생할 수 있는 이런 정보 손실 문제를 OOV 문제(Out-Of-vocabulary, 이하 "OOV 문제")라고 하며, BPE의 치명적인 단점 중 하나입니다.
*Out-Of-vocabulary(OOV): 문자 그대로 vocab에 없던 토큰들을 어떻게 처리할 지에 대한 문제입니다. 위에서 설명한 바와 같이 vocab에 없을 경우, 단순히 unknown 토큰으로 매핑하게 될 경우 정보손실이 발생하게 됩니다. BBPE, Unigram, Word Piece 등의 토큰화 방식 뿐만 아니라 BPE 방식의 토큰화를 수행할 경우에도 특정 옵션을 통해서 이런 OOV에 대한 예외를 처리할 수 있는 옵션이 있습니다. 자세한 내용은 SentencePiece의 옵션을 살펴보시거나, 다음 포스트 \(Word Tokenization: How to Handle Out-Of-vocabulary vocabularies?\)를 참고하세요.
이 OOV 문제를 극복하기 위해 bytes로 변환한 데이터에 BPE 알고리즘을 적용하고, 이것을 BBPE라고 부르는데, BBPE의 핵심 장점은 문자든, 유니코드든, 특수 문자든, 숫자든 상관없이 텍스트를 일정한 bytes 형태로 더 잘게 나누어서 인접한 쌍을 찾는다는 것입니다. 이것이 왜 핵심 장점인지 BPE와 BBPE에서의 이모지(🏇) 처리를 통해 설명드리겠습니다.
- 텍스트를 문자 단위로 취급하는 BPE의 경우, 코퍼스에 없거나 희소했던 <🏇>와 같은 이모지는 vocab에 없으므로
[unk]토큰으로 인코딩하고, 디코딩 될 때 _ 과 같이 아무런 정보를 반환할 수 없습니다.- 🏇
- (인코딩) →
[unk] - (디코딩) → _ (정보 손실)
- 텍스트를 bytes 단위로 변환하는 BBPE의 경우, BBPE 방식의 토크나이저는 기본적으로 모든 bytes에 대응하는 토큰을 vocab에 보유하고 있고(256 base vocab), 비록 희소하거나 없는 bytes 쌍들이 vocab에 없을지언정 개별 bytes 단위로 정보를 변환할 수 있고, bytes로 반환된 정보가 텍스트로 다시 디코딩되면서 정보가 그대로 전달될 수 있습니다.
- 즉, 🏇를 나타내는 bytes의 조합(
\xf0\x9f\x8f\x87)이 vocab에는 없을지언정, 각 bytes(\xf0+\x9f+\x8f+\x87)에 대응하는 토큰은 vocab에 존재하므로 정상적 정보가 전달 될 수 있습니다. 결론적으로, BBPE는 <🏇> 이모지를 정상적으로 디코딩할 수 있게됩니다. 물론 정보 손실의 가능성이 없는 것은 아니지만, BPE에 비하면 상당히 개선됩니다.- 🏇
- (byte-level로 변환) →
\xf0\x9f\x8f\x87 - (인코딩) →
\xf0+\x9f+\x8f+\x87 - (디코딩) →
\xf0\x9f\x8f\x87 - (char-level로 변환) → 🏇 (정보 보존될 확률이 높음)
예를 들어, 🏇 🏂 🏊 🏄과 같은 이모지의 경우, 아래 예시와 같이 bytes 레벨로 인코딩되는데, 이모지가 없는 코퍼스로 만든 기존 BPE 토크나이저는 코퍼스에 없던 🏇 🏂 🏊 🏄를 그냥 [unk][unk][unk][unk]로 인코딩하게 됩니다.
그러나, BBPE의 경우 위와 같이 이모지를 각각 다음과 같이 byte-level로 인코딩하기 때문에, 🏇 🏂 🏊 🏄를 \xf0\x9f\x8f\x87\xf0\x9f\x8f\x82\xf0\x9f\x8f\x8a \xf0\x9f\x8f\x84로 인코딩하고, bytes에 대응되는 각각의 토큰으로 변환된 뒤 디코딩 되어, 정상적으로 정보를 전달할 수 있게 됩니다.
- 🏇:
\xf0\x9f\x8f\x87 - 🏂:
\xf0\x9f\x8f\x82 - 🏊:
\xf0\x9f\x8f\x8a - 🏄:
\xf0\x9f\x8f\x84
*참고: 이모지는 일반적으로 UTF-8 인코딩에서 여러 bytes로 표현되고, 위 이모지들의 경우, 각각 4bytes로 표현되어 있습니다. 이모지의 처리에 대해서는 다음 포스트: Java에서의 Emoji처리에 대해를 참고하세요.
위 이모지의 예시에서 볼 수 있듯이 BBPE가 기존의 BPE보다 OOV 문제로부터 조금 더 자유로울 수 있으며, 희소한 언어나 문자도 상대적으로 더 잘 표현할 수 있습니다.
BPE 알고리즘을 직접적으로 적용할 경우, BPE 알고리즘의 그리디한 빈도 기반 휴리스틱(the greedy frequency-based heuristic in BPE)때문에 ‘~ing!’, ‘~ing?’, ‘~ing.’와 같이 과도하게 적합되는 하위 토큰들이 생성되게 되는데, 이를 방지하기 위해 GPT-2 [14]는 공백을 제외한 모든 bytes 시퀀스에 대해 서로 다른 문자 범주에 걸쳐 BPE가 병합되는 것을 방지하도록 하였습니다.
이 처럼 BBPE는 BPE의 탐욕스러운 휴리스틱으로 인한 과도 토큰 생성을 억제하고 더 효율적으로 토큰화할 수 있고, bytes 수준의 하위 단어를 사용하면 OOV 문제 없이 적당한 어휘 크기를 사용하여 모든 텍스트를 표현할 수 있으며, bytes 시퀀스 길이를 최대 4배까지 늘릴 수 있습니다.
byte-level로 인코딩함에 따라 발생하는 문제들도 있는데, 대표적으로 byte-level로 인코딩 되어있기 때문에 사람이 vocab을 보고 직관적으로 이해하기 어렵고, 토크나이저를 생성할 때 bytes 레벨로 나눈 데이터의 조합을 탐색해야 하므로 연산량이 늘어날 수 있습니다.
BPE vs. BBPE
다음 예시를 통해, 위에서 설명한 BPE와 BBPE에서의 처리를 마지막으로 비교·정리합니다. (이모지는 희소해서 vocab에 없다고 가정)
BPE (Byte Pair Encoding, bytes 쌍 인코딩)
[입력] aaabdaaabac🏊🏄
aaabdaaabac[unk] [unk]
[token1]abd[token1]abac[unk] [unk] …[token1] == aa
[token1][token2]d[token1][token2]ac[unk] [unk] … [token2] == ab
[token3]d[token3]ac[unk] [unk] … [token3] == [token1] + [token2] == aaab
….(Iteration until the vocabulary size is appropriate.)
→ [BPE 토크나이저 디코딩 출력] aaabdaaabac _ _
(인코딩 시 [unk]로 정보가 완전히 손실되어 디코딩 시 복구할 수 없음)
BBPE (Byte-level Byte Pair Encoding, bytes 단위 bytes 쌍 인코딩)
[입력] aaabdaaabac🏊🏄
aaabdaaaba\xf0\x9f\x8f\x8a \xf0\x9f\x8f\x84
aaabdaaabac\xf0\x9f\x8f\x8a \xf0\x9f\x8f\x84
[token1]abd[token1]abac\xf0\x9f\x8f\x8a \xf0\x9f\x8f\x84 …[token1] == aa
[token1][token2]d[token1][token2]ac\xf0\x9f\x8f\x8a \xf0\x9f\x8f\x84 … [token2] == ab
[token3]d[token3]ac\xf0\x9f\x8f\x8a \xf0\x9f\x8f\x84 … [token3] == [token1] + [token2] == aaab
….(Iteration until the vocabulary size is appropriate.)
→ [BBPE 토크나이저 디코딩 출력] aaabdaaabac🏊🏄 (토큰의 쌍을 이루진 않지만, 모든 bytes에 대응되는 vocab이 존재하므로 정보 손실 없이 디코딩 됨)
정리하자면, 문자 단위로 토큰화하는 BPE는 사전에 코퍼스에서 빈번하지 않거나 등장하지 않은 문자를 전부 [unk]토큰으로 처리하는 반면, 유니코드 문자를 bytes 시퀀스로 변환한 다음 토큰화하는 BBPE는 BPE보다 상대적으로 OOV 문제에 좀 더 강건(robust)하다고 할 수 있습니다.
더 자세한 예시와 코드는 다음 포스트: SentencePiece를 활용한 효과적인 한국어 토크나이저 만들기를 참조하세요.
*참고: 뒤에서 살펴 볼 구글의 토크나이저 패키지인
sentencepiece에서는 이런 OOV 문제를 최소화하기 위해byte_fallback옵션을 사용할 수 있습니다.
일본어와 영어에서의 BPE와 BBPE의 토큰화를 도식화 한 이미지입니다.

BPE-Dropout
BPE는 비결정론적(nondeterministic) 방법이지만, BPE-Dropout은 BPE와 대조적으로 확률론에 기반하여 확률론적으로 토큰을 샘플링할 수 있는 방법 중 하나입니다. 즉, 일반 BPE는 전체 코퍼스의 빈도 등에 대해 계산해야되서 코퍼스 구성이 중요해지지만 BPE-Dropout은 여기에 샘플링을 추가한 방식으로 장/단점이 있을 수 있습니다. (일반적인 DL 모델에서의 드롭아웃과 비슷하지만 레이어 레벨은 아니라 컨셉을 설명하기 위한 Dropout인 것 같네요.)


*출처: BPE-Dropout: Simple and Effective Subword Regularization
BPE-Dropout은 이름에서 알 수 있듯이 일부 낮은 확률의 병합 우선순위의 유닛을 제거하는 방법을 의미합니다. BPE-Dropout은 다음 논문: BPE-Dropout: Simple and Effective Subword Regularization에서 처음 소개되었습니다.
기존의 방법들은 이런 분할 우선순위를 알고리즘으로 처리하는 것이 보편적이였는데, BPE-Dropout은 희소한 확률의 하위 단어 페어의 병합을 무시(dropout)하여 상대적으로 더 강건한 vocab을 생성할 수 있음을 보였습니다. When BPE merges two consecutive units, possible merge operations are removed (or dropped) with a small (e.g., p=0.1) probability.
기존 BPE는 기본적으로 가장 자주 사용되는 단어는 그대로 유지하면서, 그 하위 단어를 여러 토큰으로 분할하여 빈도 높은 토큰들을 추가로 vocab에 추가하는데, 하위 단어에 대해서 다양한 분할을 통해 빈도를 계산할 수 있지만, 단어를 고유한 시퀀스로 분할하기 때문에 분할 시의 오류에 상대적으로 취약할 수 있습니다.
BPE-Dropout은 BPE의 분할 과정을 확률적으로 손상시켜(dropout) 같은 BPE 프레임워크 내(호환성 개념)에서 분할을 수행할 수 있습니다.
예를 들어, 기존의 BPE 방식으로 “bugs”, “mugs”가 자주 등장하는 코퍼스를 분할하면, “##ugs”의 병합 우선순위가 높아져 결론적으로 “b”과 “##ugs”로 토큰화되므로 BPE-Dropout은 이런 이런 BPE 불완전성, 즉 결정론적 특성을 극복하기 위해 고안되었다고 합니다.
*참고: 위 예시에 대해서 바로 아래 Word Piece 파트에서 추가로 설명합니다.
논문에서는 BPE-Dropout을 사용하여 훈련할 경우 기존 BPE 방식 대비 최대 2.3 BLEU, 이전 하위 단어 정규화 대비 최대 0.9 BLEU까지 번역 품질이 향상되었다고 합니다. 그러나 결국 코퍼스의 구성이 가장 중요하기에…
DPE
DPE는 다음 논문: Dynamic Programming Encoding for Subword Segmentation in Neural Machine Translation에서 최초로 소개되었습니다.
DPE는 출력 문장의 하위 단어 분할을 학습과 인퍼런스를 위해 한계값을 제거(marginalized out)해야 하는 잠재 변수로 간주합니다. 정확한 로그 한계 가능성 추정(exact log marginal likelihood estimation)과 정확한 MAP 인퍼런스를 통해 최대 후행 확률을 가진 목표 segmentation을 찾을 수 있는 A mixed character-subword transformer를 사용하였습니다.
즉, 상기에 설명한 BPE와 BPE 변형 알고리즘 등은 후행 태스크(기계 번역 등)에서 가장 좋은 결과를 얻을 수 있는지 여부와는 상관없이 작동하지만, DPE는 transformers를 사용하여, 후행 작업에서 우도를 최대화할 수 있는 방식으로 작동합니다.
DPE의 동적 프로그래밍(Dynamic Programming)은 하위 단어의 분지를 탐색하기 위해 이전 계산 결과를 저장하고 재활용하여 계산 효율성을 높이기 위한 최적화 방법으로 채용되었습니다. 동적 프로그래밍을 사용하여 출력 문장을 빠르게 분할하기 위한 병렬 데이터 전처리 수단으로 lightweight mixed character-subword transformer(간소화 버전의 transforemrs를 붙인 동적 프로그래밍 방법)를 사용합니다.
기계 번역에 대한 경험적 결과에 따르면 DPE는 출력 문장을 분할하는 데 효과적이며 소스 문장의 확률적 분할을 위해 BPE 드롭아웃과 결합할 수 있습니다. DPE는 영어와 다국어(논문에서는 독일어, 루마니아어, 에스토니아어, 핀란드어, 헝가리어 등을 기반으로 평가함)의 WMT 데이터셋에서 BPE 대비 평균 0.9 BLEU(Sennrich et al., 2016), 바로 위에서 설명한 BPE-Dropout 대비 평균 0.55 BLEU(Provilkov et al., 2019)를 개선하였다고 보고합니다.

BBPE Implementation
Tiktoken, GPT-2, RoBERTa의 BBPE 알고리즘의 구현 및 BPE 변형 알고리즘의 구현체를 확인합니다.
Tiktoken
Click to show Python code
""" `tiktoken` BPE implementation (for educational purpose) """
from __future__ import annotations
import collections
import itertools
from typing import Optional
import regex
# pip3 install tiktoken>=0.4.0
import tiktoken
class SimpleBytePairEncoding:
def __init__(self, *, pat_str: str, mergeable_ranks: dict[bytes, int]) -> None:
"""Creates an Encoding object."""
# A regex pattern string that is used to split the input text
self.pat_str = pat_str
# A dictionary mapping token bytes to their ranks. The ranks correspond to merge priority
self.mergeable_ranks = mergeable_ranks
self._decoder = {token: token_bytes for token_bytes, token in mergeable_ranks.items()}
self._pat = regex.compile(pat_str)
def encode(self, text: str, visualise: Optional[str] = "colour") -> list[int]:
"""Encodes a string into tokens.
>>> enc.encode("hello world")
[388, 372]
"""
# Use the regex to split the text into (approximately) words
words = self._pat.findall(text)
tokens = []
for word in words:
# Turn each word into tokens, using the byte pair encoding algorithm
word_bytes = word.encode("utf-8")
word_tokens = bpe_encode(self.mergeable_ranks, word_bytes, visualise=visualise)
tokens.extend(word_tokens)
return tokens
def decode_bytes(self, tokens: list[int]) -> bytes:
"""Decodes a list of tokens into bytes.
>>> enc.decode_bytes([388, 372])
b'hello world'
"""
return b"".join(self._decoder[token] for token in tokens)
def decode(self, tokens: list[int]) -> str:
"""Decodes a list of tokens into a string.
Decoded bytes are not guaranteed to be valid UTF-8. In that case, we replace
the invalid bytes with the replacement character "�".
>>> enc.decode([388, 372])
'hello world'
"""
return self.decode_bytes(tokens).decode("utf-8", errors="replace")
def decode_tokens_bytes(self, tokens: list[int]) -> list[bytes]:
"""Decodes a list of tokens into a list of bytes.
Useful for visualising how a string is tokenised.
>>> enc.decode_tokens_bytes([388, 372])
[b'hello', b' world']
"""
return [self._decoder[token] for token in tokens]
def train(training_data: str, vocab_size: int, pat_str: str):
"""Train a BPE tokeniser on some data!"""
mergeable_ranks = bpe_train(data=training_data, vocab_size=vocab_size, pat_str=pat_str)
return SimpleBytePairEncoding(pat_str=pat_str, mergeable_ranks=mergeable_ranks)
def from_tiktoken(encoding):
if isinstance(encoding, str):
encoding = tiktoken.get_encoding(encoding)
return SimpleBytePairEncoding(
pat_str=encoding._pat_str, mergeable_ranks=encoding._mergeable_ranks
)
def bpe_encode(
mergeable_ranks: dict[bytes, int], input: bytes, visualise: Optional[str] = "colour"
) -> list[int]:
parts = [bytes([b]) for b in input]
while True:
# See the intermediate merges play out!
if visualise:
if visualise in ["colour", "color"]:
visualise_tokens(parts)
elif visualise == "simple":
print(parts)
# Iterate over all pairs and find the pair we want to merge the most
min_idx = None
min_rank = None
for i, pair in enumerate(zip(parts[:-1], parts[1:])):
rank = mergeable_ranks.get(pair[0] + pair[1])
if rank is not None and (min_rank is None or rank < min_rank):
min_idx = i
min_rank = rank
# If there were no pairs we could merge, we're done!
if min_rank is None:
break
assert min_idx is not None
# Otherwise, merge that pair and leave the rest unchanged. Then repeat.
parts = parts[:min_idx] + [parts[min_idx] + parts[min_idx + 1]] + parts[min_idx + 2 :]
if visualise:
print()
tokens = [mergeable_ranks[part] for part in parts]
return tokens
def bpe_train(
data: str, vocab_size: int, pat_str: str, visualise: Optional[str] = "colour"
) -> dict[bytes, int]:
# First, add tokens for each individual byte value
if vocab_size < 2**8:
raise ValueError("vocab_size must be at least 256, so we can encode all bytes")
ranks = {}
for i in range(2**8):
ranks[bytes([i])] = i
# Splinter up our data into lists of bytes
# data = "Hello world"
# words = [
# [b'H', b'e', b'l', b'l', b'o'],
# [b' ', b'w', b'o', b'r', b'l', b'd']
# ]
words: list[list[bytes]] = [
[bytes([b]) for b in word.encode("utf-8")] for word in regex.findall(pat_str, data)
]
# Now, use our data to figure out which merges we should make
while len(ranks) < vocab_size:
# Find the most common pair. This will become our next token
stats = collections.Counter()
for piece in words:
for pair in zip(piece[:-1], piece[1:]):
stats[pair] += 1
most_common_pair = max(stats, key=lambda x: stats[x])
token_bytes = most_common_pair[0] + most_common_pair[1]
token = len(ranks)
# Add the new token!
ranks[token_bytes] = token
# Now merge that most common pair in all the words. That is, update our training data
# to reflect our decision to make that pair into a new token.
new_words = []
for word in words:
new_word = []
i = 0
while i < len(word) - 1:
if (word[i], word[i + 1]) == most_common_pair:
# We found our pair! Merge it
new_word.append(token_bytes)
i += 2
else:
new_word.append(word[i])
i += 1
if i == len(word) - 1:
new_word.append(word[i])
new_words.append(new_word)
words = new_words
# See the intermediate merges play out!
if visualise:
print(f"The current most common pair is {most_common_pair[0]} + {most_common_pair[1]}")
print(f"So we made {token_bytes} our {len(ranks)}th token")
if visualise in ["colour", "color"]:
print("Now the first fifty words in our training data look like:")
visualise_tokens([token for word in words[:50] for token in word])
elif visualise == "simple":
print("Now the first twenty words in our training data look like:")
for word in words[:20]:
print(word)
print("\n")
return ranks
def visualise_tokens(token_values: list[bytes]) -> None:
backgrounds = itertools.cycle(
[f"\u001b[48;5;{i}m".encode() for i in [167, 179, 185, 77, 80, 68, 134]]
)
interleaved = itertools.chain.from_iterable(zip(backgrounds, token_values))
print((b"".join(interleaved) + "\u001b[0m".encode()).decode("utf-8"))
def train_simple_encoding():
gpt2_pattern = (
r"""'s|'t|'re|'ve|'m|'ll|'d| ?[\p{L}]+| ?[\p{N}]+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
)
with open(__file__, "r") as f:
data = f.read()
enc = SimpleBytePairEncoding.train(data, vocab_size=600, pat_str=gpt2_pattern)
print("This is the sequence of merges performed in order to encode 'hello world':")
tokens = enc.encode("hello world")
assert enc.decode(tokens) == "hello world"
assert enc.decode_bytes(tokens) == b"hello world"
assert enc.decode_tokens_bytes(tokens) == [b"hello", b" world"]
return enc
# Train a BPE tokeniser on a small amount of text
enc = train_simple_encoding()
# Visualise how the GPT-4 encoder encodes text
enc = SimpleBytePairEncoding.from_tiktoken("cl100k_base")
y = enc.encode("hello world!!!!! Check this sentence.")
print(f"{y}")
GPT-2 BPE
Click to show Python code
"""
GPT-2 & RoBERTa
Byte pair encoding utilities from GPT-2.
Original source: https://github.com/openai/gpt-2/blob/master/src/encoder.py
Original license: MIT
"""
import json
from functools import lru_cache
def bytes_to_unicode():
"""
Returns list of utf-8 byte and a corresponding list of unicode strings.
The reversible bpe codes work on unicode strings.
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
This is a signficant percentage of your normal, say, 32K bpe vocab.
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
And avoids mapping to whitespace/control characters the bpe code barfs on.
"""
bs = (
list(range(ord("!"), ord("~") + 1))
+ list(range(ord("¡"), ord("¬") + 1))
+ list(range(ord("®"), ord("ÿ") + 1))
)
cs = bs[:]
n = 0
for b in range(2 ** 8):
if b not in bs:
bs.append(b)
cs.append(2 ** 8 + n)
n += 1
cs = [chr(n) for n in cs]
return dict(zip(bs, cs))
def get_pairs(word):
"""Return set of symbol pairs in a word.
Word is represented as tuple of symbols (symbols being variable-length strings).
"""
pairs = set()
prev_char = word[0]
for char in word[1:]:
pairs.add((prev_char, char))
prev_char = char
return pairs
class Encoder:
def __init__(self, encoder, bpe_merges, errors="replace"):
self.encoder = encoder # bpe-vocab.json -> {subword:id}
self.decoder = {v: k for k, v in self.encoder.items()} # {id: subword}
self.errors = errors # how to handle errors in decoding
# {byte: unicode}
self.byte_encoder = bytes_to_unicode()
self.byte_decoder = {v: k for k, v in self.byte_encoder.items()} # {unicode: byte}
# bpe-merges.txt -> {tuple: rank}
self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges))))
self.cache = {}
try:
import regex as re
self.re = re
except ImportError:
raise ImportError("Please install regex with: pip install regex")
# Should have added re.IGNORECASE so BPE merges
# can happen for capitalized versions of contractions
self.pat = self.re.compile(
r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
)
def bpe(self, token):
# check if already processed
if token in self.cache:
return self.cache[token]
word = tuple(token)
pairs = get_pairs(word) # count bigrams
if not pairs:
return token
while True:
bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf")))
if bigram not in self.bpe_ranks:
break
first, second = bigram
new_word = []
i = 0
# find all possible merges for a bigram
while i < len(word):
try:
j = word.index(first, i)
new_word.extend(word[i:j])
i = j
except: # no further merge
new_word.extend(word[i:])
break
# bigram match & satisfy length limit
if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
new_word.append(first + second)
i += 2
else:
new_word.append(word[i])
i += 1
new_word = tuple(new_word)
word = new_word # update merged tokens
if len(word) == 1:
break
else:
pairs = get_pairs(word) # new possible pairs
word = " ".join(word)
self.cache[token] = word # cache raw tokens
return word
def encode(self, text):
bpe_tokens = []
for token in self.re.findall(self.pat, text):
token = "".join(self.byte_encoder[b] for b in token.encode("utf-8"))
bpe_tokens.extend(
self.encoder[bpe_token] for bpe_token in self.bpe(token).split(" ")
)
return bpe_tokens
def decode(self, tokens):
text = "".join([self.decoder.get(token, token) for token in tokens])
text = bytearray([self.byte_decoder[c] for c in text]).decode(
"utf-8", errors=self.errors
)
return text
def get_encoder(encoder_json_path:"bpe-vocab.json", vocab_bpe_path:"bpe-merge.txt"):
with open(encoder_json_path, "r") as f:
encoder = json.load(f)
with open(vocab_bpe_path, "r", encoding="utf-8") as f:
bpe_data = f.read()
bpe_merges = [tuple(merge_str.split()) for merge_str in bpe_data.split("\n")[1:-1]]
return Encoder(
encoder=encoder,
bpe_merges=bpe_merges,
)
RoBERTa BPE
Click to show Python code
import argparse
import contextlib
import sys
from collections import Counter
from multiprocessing import Pool
def main():
"""
Helper script to encode raw text with the GPT-2 BPE using multiple processes.
The encoder.json and vocab.bpe files can be obtained here:
- https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/encoder.json
- https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/vocab.bpe
"""
parser = argparse.ArgumentParser()
parser.add_argument(
"--encoder-json",
help="path to encoder.json",
)
parser.add_argument(
"--vocab-bpe",
type=str,
help="path to vocab.bpe",
)
parser.add_argument(
"--inputs",
nargs="+",
default=["-"],
help="input files to filter/encode",
)
parser.add_argument(
"--outputs",
nargs="+",
default=["-"],
help="path to save encoded outputs",
)
parser.add_argument(
"--keep-empty",
action="store_true",
help="keep empty lines",
)
parser.add_argument("--workers", type=int, default=20)
args = parser.parse_args()
assert len(args.inputs) == len(
args.outputs
), "number of input and output paths should match"
with contextlib.ExitStack() as stack:
inputs = [
stack.enter_context(open(input, "r", encoding="utf-8"))
if input != "-"
else sys.stdin
for input in args.inputs
]
outputs = [
stack.enter_context(open(output, "w", encoding="utf-8"))
if output != "-"
else sys.stdout
for output in args.outputs
]
encoder = MultiprocessingEncoder(args)
pool = Pool(args.workers, initializer=encoder.initializer)
encoded_lines = pool.imap(encoder.encode_lines, zip(*inputs), 100)
stats = Counter()
for i, (filt, enc_lines) in enumerate(encoded_lines, start=1):
if filt == "PASS":
for enc_line, output_h in zip(enc_lines, outputs):
print(enc_line, file=output_h)
else:
stats["num_filtered_" + filt] += 1
if i % 10000 == 0:
print("processed {} lines".format(i), file=sys.stderr)
for k, v in stats.most_common():
print("[{}] filtered {} lines".format(k, v), file=sys.stderr)
class MultiprocessingEncoder(object):
def __init__(self, args):
self.args = args
def initializer(self):
global bpe
bpe = get_encoder(self.args.encoder_json, self.args.vocab_bpe)
def encode(self, line):
global bpe
ids = bpe.encode(line)
return list(map(str, ids))
def decode(self, tokens):
global bpe
return bpe.decode(tokens)
def encode_lines(self, lines):
"""
Encode a set of lines. All lines will be encoded together.
"""
enc_lines = []
for line in lines:
line = line.strip()
if len(line) == 0 and not self.args.keep_empty:
return ["EMPTY", None]
tokens = self.encode(line)
enc_lines.append(" ".join(tokens))
return ["PASS", enc_lines]
def decode_lines(self, lines):
dec_lines = []
for line in lines:
tokens = map(int, line.strip().split())
dec_lines.append(self.decode(tokens))
return ["PASS", dec_lines]
if __name__ == "__main__":
main()
BPE-Dropout
Click to show Python code
# https://github.com/VProv/BPE-Dropout/blob/master/bpe.py
import heapq
import numpy as np
def load_subword_nmt_table(path):
"""
:param path: path to merge_table with subword-nmt format
"""
table = dict()
cur_priority = 1
with open(path) as f:
for line in f:
if '#version' in line:
continue
token_1, token_2 = line.rstrip('\n').split(' ')
table[(token_1, token_2)] = int(cur_priority)
cur_priority += 1
return table
def load_merge_table(path):
"""
:param path: path to merge_table
"""
table = dict()
with open(path) as f:
for line in f:
token_1, token_2, priority = line.split('\t')
table[(token_1, token_2)] = int(priority)
return table
def tokenize_word(merge_rules, word, dropout=0.0,
random_generator=np.random.RandomState(),
sentinels=['^', '$'],
regime='begin',
bpe_symbol='`',
always_merge_sentinels=True):
""" Tokenize word using bpe merge rules
:param merge_rules: dict [(a,b)] -> id, merge table, ids are in increasing order
:param word: string
:param dropout: float, dropout rate
:param random_generator: random generator with .rand() method
:param sentinels: list of two strings, beginning of word sentinel and end of word sentinel (empty string means that no corresponding sentinel is applied)
:param regime:
'begin' -- add bpe symbol to the beginning of bpe token
'end' -- add bpe symbol to the end of bpe token
:param bpe_symbol: str, could be one of '`', '@@', '▁'
:param always_merge_sentinels: bool, if True, sentinels are always concatenated
to the first and last characters before applying BPE merges (True is equivalent to subword-nmt>=0.2, False is equivalent to subword-nmt<0.2)
"""
# Subword tokens
sw_tokens = list(word)
# Add sentinels
if always_merge_sentinels:
sw_tokens = [sentinels[0] + sw_tokens[0]] + sw_tokens[1:]
sw_tokens = sw_tokens[:-1] + [sw_tokens[-1] + sentinels[1]]
else:
beg_sentinel = [sentinels[0]] if len(sentinels[0]) > 0 else []
end_sentinel = [sentinels[1]] if len(sentinels[1]) > 0 else []
sw_tokens = beg_sentinel + sw_tokens + end_sentinel
# Add start merges
# Heap with pairs (priority, position)
merge_heap = []
for pos in range(len(sw_tokens) - 1):
cur_nxt_pair = (sw_tokens[pos], sw_tokens[pos + 1])
if cur_nxt_pair in merge_rules:
cur_priority = merge_rules[cur_nxt_pair]
merge_heap.append([cur_priority, pos])
heapq.heapify(merge_heap)
sw_length = len(sw_tokens)
dropped_merges = []
while len(merge_heap):
cur_priority, cur_pos = heapq.heappop(merge_heap)
# Delete not valid merges
if cur_pos > sw_length - 2:
continue
cur = sw_tokens[cur_pos]
nxt = sw_tokens[cur_pos + 1]
if merge_rules.get((cur, nxt), None) != cur_priority:
continue
# Apply dropout
if random_generator.rand() < dropout:
dropped_merges.append([cur_priority, cur_pos])
continue
sw_tokens[cur_pos:cur_pos + 2] = [cur + nxt]
sw_length -= 1
for pair in merge_heap:
if pair[1] > cur_pos:
pair[1] -= 1
# Add dropped merges back
for priority, position in dropped_merges:
if position > cur_pos:
position -= 1
heapq.heappush(merge_heap, [priority, position])
dropped_merges = []
# Add new possible merge
new_cur = sw_tokens[cur_pos]
if cur_pos > 0:
prev = sw_tokens[cur_pos - 1]
if (prev, new_cur) in merge_rules:
heapq.heappush(merge_heap, [merge_rules[(prev, new_cur)], cur_pos - 1])
if cur_pos < (sw_length - 1):
new_next = sw_tokens[cur_pos + 1]
if (new_cur, new_next) in merge_rules:
heapq.heappush(merge_heap, [merge_rules[(new_cur, new_next)], cur_pos])
sw_tokens[0] = sw_tokens[0].replace(sentinels[0], '')
sw_tokens[-1] = sw_tokens[-1].replace(sentinels[1], '')
if regime == 'begin':
for i in range(1, sw_length):
sw_tokens[i] = bpe_symbol + sw_tokens[i]
if sw_tokens[0] == '':
sw_tokens = sw_tokens[1:]
sw_tokens[0] = sw_tokens[0].lstrip(bpe_symbol)
if sw_tokens[-1] == bpe_symbol:
sw_tokens.pop()
elif regime == 'end':
for i in range(sw_length -1):
sw_tokens[i] = sw_tokens[i] + bpe_symbol
if sw_tokens[0] == bpe_symbol:
sw_tokens.pop(0)
if sw_tokens[-1] == '':
sw_tokens = sw_tokens[:-1]
sw_tokens[-1] = sw_tokens[-1].rstrip(bpe_symbol)
return sw_tokens
def tokenize_text(rules, line, dropout=0.0, random_generator=np.random.RandomState(), **args):
return ' '.join([' '.join(tokenize_word(rules, word, dropout, random_generator, **args)) for word in line.split(' ')])
class BpeOnlineTokenizer:
"""
Apply bpe tokenization to str line
"""
def __init__(self, bpe_dropout_rate, merge_table, random_seed=None):
"""
:param bpe_dropout_rate: float [0,1)
:param merge_table: dict [(token_1, token_2)] -> priority
"""
self.random_generator = np.random.RandomState(random_seed)
self.bpe_dropout_rate = bpe_dropout_rate
self.merge_table = merge_table
def __call__(self, line, **args):
"""
:param line: str
:return:
"""
return tokenize_text(self.merge_table, line, self.bpe_dropout_rate, self.random_generator, **args)
class BpeOnlineParallelApplier:
"""
Apply bpe online to data in parallel
"""
def __init__(self, bpe_dropout_rates, merge_tables, random_seed=42):
"""
:param bpe_dropout_rate: float [0,1)
:param merge_table: dict [(token_1, token_2)] -> priority
"""
assert len(bpe_dropout_rates) == len(merge_tables)
self.bpe_appliers = []
for rate, table in zip(bpe_dropout_rates, merge_tables):
if table is not None:
self.bpe_appliers.append(BpeOnlineTokenizer(rate, table, random_seed))
else:
self.bpe_appliers.append(lambda x: x)
def __call__(self, lines):
assert len(self.bpe_appliers) == len(lines)
return tuple(applier(l) for applier, l in zip(self.bpe_appliers, lines))
DPE
Click to show Python code
# https://github.com/xlhex/dpe/blob/master/fairseq/tokenizer.py
Word Piece
Word Piece는 BERT, DistilBERT, Electra에 사용되는 하위 단어 토큰화 알고리즘, Google BERT 개발팀이 Aho-Corasick 알고리즘 [28], [29]으로부터 영감을 받아 Fast Word Piece Tokenization를 개발했습니다.
Word Piece 논문의 하위 단어 토큰화 개념은 2012년에 발표된 JAPANESE AND KOREA VOICE SEARCH 논문에서 먼저 발표되었으며, 해당 논문은 주로 Word Piece 논문과 함께 인용됩니다.
*참고: 아호-코라식 알고리즘(Aho-Corasick algorithms)은 일대다(1vs多) 패턴 매칭 알고리즘입니다. “일대다(1vs多) 패턴 매칭”이란 KMP 알고리즘(Knuth–Morris–Pratt algorithm)이나 라빈-카프(Rabin-Karp) 알고리즘과 달리 문자열 하나에서 등장하는 문자열을 판별하는 것을 의미합니다. 길이가 N인 문자열 S에서 찾을 단어 집합 W(w1, w2, .. , wk)를 찾는다고 가정하고, 찾을 단어 집합의 단어의 길이를 M(m1, m2, .. , mk)라고 가정할 경우, O(N(m1 + m2 + .. + mk)) 시간 복잡도를 갖지만, 아호-코라식 알고리즘은 Tries를 만드는 Go 함수, 단어의 목록을 생성하는 Ouput 함수, 간선의 다른 곳으로 보낼 수 있는 Fail 함수를 사용하여 S를 한 번만 탐색하여도 되므로, O(m1 + m2 + .. + mk)로 복잡도가 크게 떨어집니다. 아호-코라식 알고리즘의 원리에 대해서는 라이님의 네이버 블로그 포스트: 아호-코라식(Aho-Corasick) 및 장홍준님의 slideshare: Aho-Corasick Algorithm(아호-코라식 알고리즘)를 같이 참고하시면 좋습니다.
Word Piece라는 이름에서 알 수 있듯이, Word Piece는 단어를 위주로 토큰화할 수 있어서 의미상 전달이 유리하다는 장점이 있습니다. Word Piece는 학습된 병합 규칙을 기반으로 vocab을 생성하지 않고, 가장 긴 하위 단어를 먼저 찾은 다음에 이를 하위 단어로 분할한 뒤 최종적으로 긴 vocab을 저장한다는 점에서 BPE와 약간 다릅니다.
Word Piece 그리디 알고리즘으로 대량의 텍스트에서 나오는 무한한 어휘를 자동으로, 점진적으로 처리하는데, LM(언어 모델) training dataset의 가능성을 최대화하기 위해 (의미론에 초점을 두지 않고) vocab size에 도달할 때까지 반복하게 됩니다.
즉, Word Piece 토크나이저는 먼저 training dataset에 있는 모든 문자를 포함하도록 vocab을 초기화하고, 지정된 수의 병합 규칙으로 vocab을 확장하며 점진적으로 학습하는데, BPE와 달리 Word Piece는 가장 빈번한 쌍을 선택하지 않고, training dataset(corpus)에서 해당 토큰의 출현 가능성이 가장 높을 경우, 해당 쌍을 선택하는 것을 특징으로 합니다.
또, word piece는 공백을 다음과 같이 하나의 텍스트로 인식한다는 점도 큰 특징입니다.
Input Text: Jet makers feud over seat width with big orders at stakeText in WordPieces: Jet_makers_feud_over_seat_width _with_big_orders_at_stake
BPE가 가장 많이 등장한 쌍을 병합했던 것과는 달리 Word Piece는 병합한 뒤에 코퍼스(corpus)의 우도(Likelihood)를 가장 높이는 쌍을 선택하는 방식으로, Word Piece는 한 마디로 "조금 더 복잡하고 정교한 버전의 BPE 알고리즘"이라고 볼 수 있습니다.

출처: Ychai blog Subword Tokenization
예를 들어, “hugs”라는 단어를 Word Piece로 분할하면, [“hug”, “##s”]로 분할할 수 있지만, BPE의 경우 학습된 병합을 순서대로 적용하기 때문에, [“hu”, “##gs”]로 분할될 수 있습니다. 코퍼스에 따라 다를 수 있지만, 코퍼스에 “bugs”, “mugs”가 자주 등장했다고 가정하면, BPE에서는 공통적으로 반복되는 하위 단어인 “ugs”의 병합 우선순위가 높아지기 때문입니다.
즉, Word Piece의 경우 “bugs”, “mugs”라는 단어가 [“bug”, “##s”], [“mug”, “##s”]로 분할될 확률이 높지만, BPE의 경우 [“h”, “##ugs”], [“b”, “##ugs”]로 분할되어 의미상 문맥을 정확하게 전달하기 어렵게 됩니다. (위에서 언급한 바와 같이 이렇게 의미상 문맥이 토큰화로 제거되면 높은 확률로 모델의 성능이 저하됩니다.)
논문에서 개발팀은 Word Piece 알고리즘은 통상으로 O(n^2)(n은 입력 길이) 또는 O(nm)(m은 최대 어휘 토큰 길이)이였던 토큰화 알고리즘의 시간 복잡도를 O(n)으로 낮춰 HuggingFace Tokenizer보다 8.2배 빠르고 TensorFlow Text보다 5.1배 빠르다고 보고하고 있고, 실제로도 타 토크나이저보다 사용이 간편하고 빠른 편입니다. (맨 처음에 언급한 바와 같이 아호-코라식 알고리즘의 특징으로부터 기인합니다.)
구글의 논문: Google’s Neural Machine Translation System (2016) (이하 “GNMT”)에 소개된 바와 같이 Google 번역기 모델들도 변형 Word Piece 알고리즘을 차용하는데 그 이유는, 기계 번역 태스크에서 빈도가 낮은 단어를 [UNK]나 bytes 형식으로 두는 것보다 vocab에 없을지라도 그대로 원 단어를 복사해서 전달하는 것이 적절했기 때문입니다.
따라서, GNMT에서는 Word Piece 알고리즘의 일부를 차용하면서 광범위한 다국적의 언어를 처리할 수 있도록 빈도가 낮은 단어들의 원문을 그대로 표시하는 방식을 사용했고, 논문에서 해당 방법이 단순 단어 및 문자 기반 토큰화보다 더 나은 번역 정확도를 달성할 수 있었다고 보고하였습니다. 그러나 다국어의 텍스트 처리 방법 전체를 다 공개하지는 않았습니다.
GNMT 외에도 WordPiece는 BERT에 대한 입력을 토큰화하는 데 사용되는데, BERT 토크나이저는 BPE 어휘를 기반으로 텍스트를 탐욕스럽게 분할하지만, 엄밀히는 Word Piece 및 BPE 알고리즘이랑 동일하지는 않습니다. (BERT, Devlin et al. 2018)
그렇다면 이제부터 본격적으로 Word Piece 알고리즘이 어떻게 동작하는지 살펴보겠습니다.
하위 단어 토크나이저는 “the”와 “us”와 같이 빈도가 높은 단어의 경우, 전체 단어로 유지하고, 빈도가 낮거나 거의 등장하지 않는 단어나 독일어의 명사와 같이 형태학적으로 복잡한 단어는 더 작은 단위로 분할하여 vocab에 추가하는 것이 이상적인데, 이런 이상적인 조건을 충족하는 것을 목표로 Word Piece는 다음과 같이 동작합니다.
- 코퍼스(training dataset)에서 고유한 유니코드 문자를 수집하여 첫 번째 vocab을 생성한 뒤, (vocab 초기화)
- 1의 과정에서 만든 vocab을 사용해 코퍼스(training dataset)에서 초기 토크나이저 모델을 생성합니다.
- 그런 다음 이미 생성 된 초기 vocab에서 두 개의 원소를 선택하고, 병합해 새 원소를 vocab에 추가하는 방식으로 토크나이저 모델을 업데이트 합니다. 이때, train set에서 우도가 가장 높아질 수 있도록 병합할 단어를 선택하게 됩니다.
- vocab size에 여유가 있거나, 우도가 더 이상 증가하지 않을 때까지 이를 반복한 뒤, 최종적으로 토크나이저 모델을 리턴합니다.
이 알고리즘은 자주 사용되는 단어의 단위로 먼저 병합하고, 자주 사용되지 않는 단어를 더 작은 단위로 남겨 두기 때문에, 결정론적으로 작동하여 동적 프로그래밍(dynamic programming) 없이도 O(n)의 비용으로 토큰화할 수 있다는 장점이 있습니다. (아호-코라식 참고) 즉, Word Piece 모델은 BPE 모델들과 달리 병합 우선순위를 갖고 있지 않고, 결정론적으로 해당 단어를 vocab에서 제거 했을 때, 우도에 영향을 적게 주는 것들만 제거합니다. (병합에 대한 룰 없이, 일단 빼보고 비교해서 경험적으로 전체 코퍼스를 잘 표현할 수 있는 좋은 단어들로만 vocab을 구성함.)
즉, Word Piece도 BPE와 비슷하게 bottom-up 방식으로 vocab을 생성하지만, 조금 더 꼼꼼하게 계산하면서 vocab을 생성한다고 볼 수 있습니다.
요컨대, Word Piece는 BPE와 유사하지만, 토크나이징 이후에 코퍼스의 우도를 가장 높일 수 있는 쌍을 선택하도록 해서, train set에 조금 더 적합한 최종 vocab을 생성하는 알고리즘입니다.
Unigram
위에서 본 BPE와 Word Piece의 경우, 원하는 vocab size에 도달할 때까지 토큰을 추가하는 bottom-up 방식의 토크나이저라고 설명드렸는데요.
Unigram기반의 토큰화 방식은 이와 반대로 우선 큰 vocab을 먼저 생성한 뒤 원하는 vocab size에 도달할 때까지 vocab에서 토큰을 제거하는 top-down 방식의 알고리즘입니다.
Unigram을 통한 토큰화 방식에 대해서 설명드리기 전에 기본적인 Unigram에 대해서 간단히 살펴보겠습니다.
Transformers가 SOTA( State-of-the-art)를 연신 갈아치우고, GPT 모델들이 파라미터를 확장해 좋은 성적을 보이기 전까지 주어진 텍스트에서 각 단어의 확률을 예측하기 위해 다양한 n-gram 모델이 개발되었습니다.
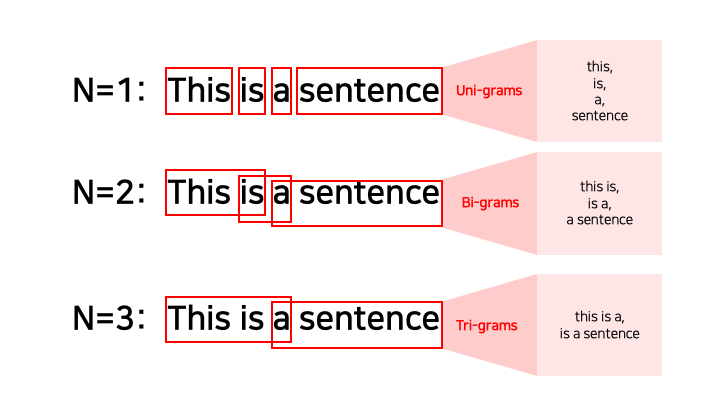
자연어 처리에서 n-gram은 길이가 n인 단어 시퀀스를 의미합니다. 예를 들어, “statistics” 은 unigram(n = 1), “machine learning”은 bigram(n = 2), “natural language processing”은 trigram(n = 3)이라고 합니다. 한글에서도 동일한 개념을 적용할 수 있습니다. 본 포스트에서는 n이 1인 유니그램에 대해서만 검토하고, 그 외 개념은 다음 내용을 참조하세요.
- 각 단어의 확률은 단어를 포함하는 n-gram(길이가 n인 단어 시퀀스)을 사용하여 추정하였으며, 길이가 n인 단어의 시퀀스에 대한 정보를 잊지 않으면서 전체 맥락을 잘 표현할 수 있는 다양한 방법에 대한 이론적/실험적 시도가 계속 진행되었었습니다.
- 히스토리를 전부 설명드리기엔 글이 너무 길어지니 결론만 요약해서 말씀드리면, bi-gram 모델은 uni-gram 모델보다 약간 더 좋았으나, tri-gram 이상의 모델에서는 성능이 심각하게 안좋아졌습니다. 이는 training dataset에서 등장하였으나 테스트 셋에서 등장하지 않는 tri-gram, 4-gram, 5-gram 등이 훨씬 많았기 때문으로, 트레인 셋에 없던 n-gram 중 일부의 확률이 0으로 수렴하면 독립 시행이라는 가정하에 전체 예측 확률이 0이 되버리기 때문이였습니다.
- 결과론적으로 시퀀스의 길이가 길어짐에 따라서 학슴이 안되거나 모델 성능이 나빠졌기 때문에 n-gram 모델에서도 위에서 언급한 확률에 대한 문제, OOV와 비슷한 문제(부정확하지만 비유적 표현)등을 해결하기 위해 시퀀스를 어떻게 처리하고, 보간할 것인지에 많은 연구자들이 더욱 집중하였습니다.
- 더 자세한 이야기는 포스트: N-gram language models를 참고하세요.
지금 설명하려고 하는 unigram 기반 토큰화 방식은 단 하나의 단일 단어에 대한 작은 언어 모델을 의미한다고 볼 수 있습니다. 즉, 하나의 시퀀스(문장)에서 여러 하위 단어가 나올 수 있고, 그 하위 단어를 일종의 하나의 유닛으로 구분하는 모델을 생성하는 것을 의미합니다.
유니그램은 다음 가정을 전제로 합니다.
- 각 단어의 확률은 그 앞에 있는 단어와 무관하다.
- 훈련 텍스트의 모든 단어 중에서 이 단어가 나타나는 시간의 비율에만 의존한다. 즉, 모델 훈련은 훈련 텍스트의 모든 유니그램에 대해 분수만을 계산한다. (해당 single unigram의 출현 수 / 전체 unigram의 전체 출현 수)
바로 위의 “텍스트의 각 문장이 다른 문장과 독립적이다.”라는 naive한 가정을 사용해 모든 unigram의 곱으로 분해할 수 있게 되고, 각 문장의 확률을 계산한 뒤, 방정식 양쪽에 로그를 취하면 각 단어에 대한 로그 확률의 합이 되므로, log likelihood를 통해 unigram 모델을 평가할 수 있게됩니다. 측정항목이 텍스트의 단어 수에 의존하지 않도록 하기 위해 이 로그 우도를 평가 텍스트의 단어 수로 나누는 것이 합리적이므로 보통 Average Log Likelihood를 사용하여서 평가하는 것이 보편적입니다.

Unigram 방식의 토크나이저의 핵심 아이디어는 동일한 vocab을 사용하더라도 단일 텍스트를 하위 단어로 토큰화하는 여러가지 방법이 있을 수 있다는 것입니다. BPE나 WordPiece와 달리 Unigram 알고리즘은 규칙을 기반으로 병합하지 않기 때문에, 학습 후 새 텍스트를 토큰화하는 여러가지 방법이 있을 수 있습니다.
Unigram의 논문은 다음과 같이 “Hello World”라는 동일한 문장을 다음 표에서와 같이 여러 개의 subword sequences로 인코딩할 수 있다는 것에서부터 출발하며, 각 언어별로 이런 하위 단어가 다양하게 생길 수 있으므로 이런 하위 단어를 정규화하는 방법을 소개하였습니다.
그 외 유니그램 모델에 대한 자세한 설명은 다음 포스트: N-gram language models를 참조하세요.
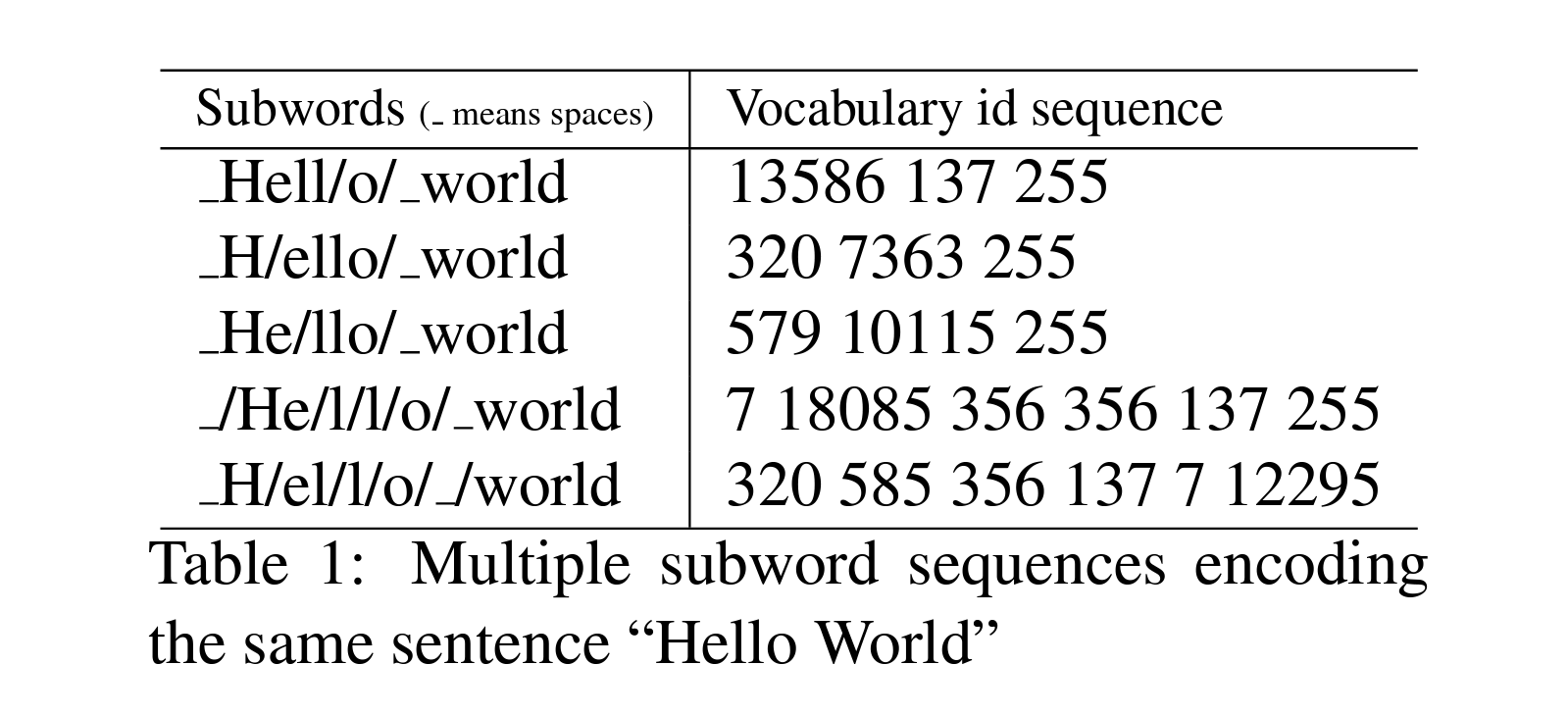
Unigram 방식의 tokenizer에 사용되는 또 다른 중요한 아이디어는 하위 단어 정규화(subword regularization)인데, 해당 개념은 Taku Kudo의 논문 Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates에서 처음 소개되었습니다. 하위 단어 정규화는 간단히 말해 샘플링 된 여러 개의 하위 단어 세그먼테이션으로 모델을 훈련하는 단순한 정규화 방식으로, 하위 단어 분할의 잠재적인 모호성을 완화시킬 수 있습니다.
이 알고리즘은 실제로 가장 가능성이 높은 토큰들을 선택하지만, 확률에 따라 가능한 토큰들을 샘플링할 수도 있는데, 이런 확률들은 토크나이저가 학습한 손실(traing loss)에 의해 정의될 수 있습니다.
Word Piece는 코퍼스의 우도(often defined as the log-likelihood)를 가장 높이는 쌍을 선택하는 방식으로 학습하는 반면, Unigram은 미리 만들어 둔 큰 vocab에서 해당 토큰이 제거할 경우의 코퍼스의 손실을 계산해서 손실이 적은 토큰들을 제거하는 방식으로 학습을 진행합니다.

즉, 전체 코퍼스에서의 상대적으로 덜 중요한 문자 쌍을 제거하는 방식으로 토크나이저를 생성합니다.
- 코퍼스에서 해당 문자 쌍(토큰)이 제거되면 전체 손실(loss)이 얼마일지를 계산한 뒤,
- 손실이 적은 (없어져도 되는) 토큰들을 찾아서 제거 하는 것을 반복합니다.
- 결과론적으로 토큰들을 제거하기 때문에 우선 순위에 대한 알고리즘이 없으며, 주로 확률 토큰의 주로 10% ~ 20%의 토큰 쌍들을 제거합니다. Unigram then removes p (with p usually being 10% or 20%) percent of the symbols whose loss increase is the lowest
다음 허깅페이스 포스트: Unigram tokenization에 설명되어있는 예시로 간단히 설명하면 다음과 같습니다.
- (가정) 각 하위 단어가 독립적으로 발생한다고 가정하기 때문에, 확률의 곱으로 표현하게 됩니다.
- BPE와 비슷하게, 코퍼스에 등장한 단어의 빈도를 계산한 뒤,
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5) - 가능한 모든 strict substring들을 생성합니다.
["h", "u", "g", "hu", "ug", "p", "pu", "n", "un", "b", "bu", "s", "hug", "gs", "ugs"] -
vocab에 존재하는 모든 subwords의 빈도를 계산한 다음에
("h", 15) ("u", 36) ("g", 20) ("hu", 15) ("ug", 20) ("p", 17) ("pu", 17) ("n", 16) ("un", 16) ("b", 4) ("bu", 4) ("s", 5) ("hug", 15) ("gs", 5) ("ugs", 5) -
확률이 높은 최종 토큰을 결정하여 vocab에 추가합니다.

위에는 간단한 예시를 사용했지만, 실제로는 예시보다 훨씬 복잡하기 때문에 고전적인 비터비 알고리즘(Viterbi algorithm)을 사용하는데, 문자열의 처음부터 순회하면서 하위 단어를 그래프 자료형으로 표현할 수 있고, 해당 분기의 끝에서 하위 단어의 확률을 부여할 수 있다는 것을 전제로 합니다.
*Viterbi algorithm: 비터비 알고리즘은 Markov information sources 및 hidden Markov models(HMM)의 맥락에서 일련의 (관찰된) 이벤트를 야기하는 가장 가능성이 높은 hidden state 시퀀스(Viterbi path)의 최대 사후 확률 추정(maximum a posteriori probability estimate)을 위한 동적 프로그래밍 알고리즘입니다.
하위 단어를 찾기 위한 그래프에서 Viterbi 알고리즘은 단어의 각 위치에 대해 해당 위치에서 끝나는 가장 좋은 점수를 가진 분할을 결정하고, 해당 과정을 문장의 처음부터 끝까지 수행하므로, 현재 위치에서 끝나는 모든 하위 단어를 찾아 이 하위 단어가 시작되는 위치에서의 최대값을 찾습니다.
비터비 알고리즘으로 “unhug”의 각 문자열의 위치에서의 점수를 계산하면 다음과 같고, 결론적으로 가장 높은 점수를 유지하면서 긴 단어로 토큰화하는데, “unhug”의 경우 다음과 같은 과정을 거쳐 [“un”, “hug”]로 토큰화되게 됩니다. (실제로는 더 많은 경우의 수를 고려함.)
Character 0 (u): "u" (score 0.171429)
Character 1 (n): "un" (score 0.076191)
Character 2 (h): "un" "h" (score 0.005442)
Character 3 (u): "un" "hu" (score 0.005442)
Character 4 (g): "un" "hug" (score 0.005442)
위와 같이 토큰화한 뒤, 코퍼스의 각 토큰 빈도에 따라 결정되는 Unigram 모델과 현재 vocab을 사용해 코퍼스의 모든 단어를 토큰화 한 다음에 코퍼스에서의 각 단어의 손실을 계산하게 됩니다.
이 부분이 위에서 “전체 코퍼스에서의 덜 중요한 토큰”을 제거하는 단계인데요. 위에서 살펴본 것과 같이 코퍼스에서 각 단어 쌍에 대한 점수와 빈도가 있을 때, 손실함수값은 해당 점수의 음의 로그 우도(-log(P(word)))를 포함한 수식으로 표현되고, 상대적으로 덜 중요한 토큰들을 제거할 수 있게 됩니다. 정확하지는 않지만, 다음 예시를 통해 간단히 살펴보겠습니다.
예를 들어, 전체 코퍼스의 단어의 subwords가 다음과 같고,
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
다음과 같이 각 단어의 score가 있다고 가정하면,
"hug": ["hug"] (score 0.071428)
"pug": ["pu", "g"] (score 0.007710)
"pun": ["pu", "n"] (score 0.006168)
"bun": ["bu", "n"] (score 0.001451)
"hugs": ["hug", "s"] (score 0.001701)
전체 코퍼스의 음의 로그 우도(-log(P(word)))의 합은 다음 수식에 의해 169.8이 됩니다. 각 음의 로그 우도 값에 전체 코퍼스에서의 subword 출현 빈도가 곱해지고, 이 값들의 합으로 loss 값이 계산되고, 해당 loss 값을 최소화하는 방식으로 학습합니다. 기존 vocab은 여기에선 무시하지만, 실제로는 고려되며, 큰 코퍼스에서 vocab을 기반으로 계산하게 됩니다.
10 * (-log(0.071428)) + 5 * (-log(0.007710)) + 12 * (-log(0.006168)) + 4 * (-log(0.001451)) + 5 * (-log(0.001701)) = 169.8
지금까지 살펴 본 Unigram은 고전적인 언어 모델인 N-gram 모델 중 한 단어를 다루는 모델을 의미하며, transformers 기반 언어모델 이전에 널리 사용되었습니다. 다음 미디엄 포스트: N-gram language models에서 유니그램 모델, 유니그램 기반 확률 예측, 그리고 라플라스 평활화 등을 참고하세요.
원 논문에서 저자는 희소한 소수 언어에서의 BLUE 점수를 향상시켰으며, 연구 목적에 적합하게 다양한 언어의 하위 단어 토큰화 프로세스를 정규화는 방법에 대해 상세히 설명합니다.
Algorithm pseudo code와 파이썬에서의 구현을 살펴보고, N-gram에 대해서 간략히 소개한 뒤 토큰화 방식에 대한 설명을 마무리합니다.
Algorithm: Unigram LM (Kudo, 2018) [30]
*출처: Uni, Bi, Trigram(“What is an N-gram”, n.d.)
N-gram 언어 모델은 Bag of Words, TF-IDF(Term Frequency - Inverse Document Frequency)와 같이 횟수를 사용하여 단어를 벡터로 표현(Count-based representation)하는 방법이라고 할 수 있습니다. 마르코프 가정에 의존하는 N-gram은 간단히 말해 (n)개의 단어 시퀀스만을 분석 대상으로 하는 방식으로, 기존 자기회귀 언어 모델에서 (n-1)번 째 토큰까지의 토큰들의 조건부 확률의 곱으로 (n)번 째 토큰을 예측하는 언어모델이라고 볼 수 있습니다. 위 그램에서 볼 수 있듯이 1개의 토큰으로에만 의존하여 다음 토큰을 예측할 경우 Uni-gram, 토큰을 2개 단위로 묶어서 조건부 확률의 곱으로 다음 2개의 토큰을 예측할 경우 Bi-gram 등으로 모델을 확장할 수 있습니다. 자세한 내용은 위에 Uni-gram에 설명을 참고하시거나 다른 다양한 포스트를 확인하실 수 있습니다. N-gram 모델의 단점인 OOV, Long term dependency, Sparcity problem, Corpuse dependency 등과 이를 해결하기 위한 Smoothing, Backoff, KN smoothing 등에 대한 히스토리가 있으니 해당 키워드를 기반으로 찾아보시면 더욱 재밌고 빠르게 이해하실 수 있습니다.
N-gram은 transformers나 BERT 모델 이전에 주요 언어 모델이였으므로 설명할 것이 많으나 이 섹션에서는 pseudo code만 간단히 확인하고 섹션을 마무리합니다.
*마르코프 가정(Markov assumption)? 마르코프 가정은 특정 시점에서 어떤 상태의 확률은 최근 상태에만 의존한다는 가정으로, xi의 확률을 그 이전에 있는 토큰 전부가 아닌 일부 토큰으로부터 인퍼런스할 수 있다는 것을 의미합니다.

Unigram Algorithm in Python
Click to show unigram python code
Train Unigram Pseudo-Code
# Create a map counts
counts = {}
# Create a variable total_count = 0
total_count = 0
# For each line in the training_file
for each line in the training_file:
# Split line into an array of words
words = split line into an array of words
# Append “</s>” to the end of words
words.append("</s>")
# For each word in words
for each word in words:
# Add 1 to counts[word]
counts[word] += 1
# Add 1 to total_count
total_count += 1
# Open the model_file for writing
open the model_file for writing
# For each word, count in counts
for each word, count in counts:
# Probability = counts[word] / total_count
probability = counts[word] / total_count
# Print word, probability to model_file
print word, probability to model_file
# Initialize parameters
λ1 = 0.95
λunk = 1 - λ1
V = 1000000
W = 0
H = 0
# Create a map probabilities
probabilities = {}
# For each line in model_file
for each line in model_file:
# Split line into w and P
w, P = split line into w and P
# Set probabilities[w] = P
probabilities[w] = P
# For each line in test_file
for each line in test_file:
# Split line into an array of words
words = split line into an array of words
# Append “</s>” to the end of words
words.append("</s>")
# For each w in words
for w in words:
# Add 1 to W
W += 1
# Set P = λunk / V
P = λunk / V
# If probabilities[w] exists
if w in probabilities:
# Set P += λ1 * probabilities[w]
P += λ1 * probabilities[w]
else:
# Add 1 to unk
unk += 1
# Add -log2(P) to H
H += -log2(P)
# Calculate entropy and coverage
entropy = H / W
coverage = (W - unk) / W
# Print results
print("entropy = " + str(entropy))
print("coverage = " + str(coverage))
Using Pre-trained Unigram Model
Click to show python code
다음 코드는 허깅 페이스의 AutoTokenizer를 사용해 pre-trained 모델(`xlnet-base-cased`)로 코퍼스를 토큰화하는 방법을 단계별로 설명합니다.먼저, 주어진 텍스트 코퍼스에서 각 단어의 빈도수를 계산하여 단어 빈도수를 얻은 뒤, 모든 기본 문자들을 포함시켜 vocab 초기화합니다. 초기화 된 vocab으로 각 단어와 그 단어의 하위 단어(sub word)의 빈도수를 계산해서 긴 문자열 중 빈도수가 높은 것들만을 선택합니다.
이렇게 얻은 빈도수를 바탕으로 토큰의 빈도수 목록을 만들고, 이 목록에서 각 토큰의 로그 확률을 계산합니다. 위에서 설명한 바와 같이 이 확률은 나중에 토큰화 과정에서 loss를 계산할 때 활용됩니다.
주어진 단어를 가장 효율적으로 분할하는 방법을 찾아 토큰 목록을 생성한 다음, 각 토큰이 모델에 미치는 영향을 평가하기 위해 토큰별 점수를 통해 전체 손실을 계산하는 방식으로 업데이트 합니다.
최종적으로 앞서 정의한 함수 및 생성한 토크나이저로 텍스트를 pre-tokenization하고, 코퍼스 전체를 토큰화합니다.
# Importing the necessary libraries
from transformers import AutoTokenizer
from collections import defaultdict
from math import log
import copy
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained("xlnet-base-cased")
# Counting word frequencies in the corpus
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
word_freqs = defaultdict(int)
for text in corpus:
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
# Initializing vocabulary
char_freqs = defaultdict(int)
subwords_freqs = defaultdict(int)
for word, freq in word_freqs.items():
for i in range(len(word)):
char_freqs[word[i]] += freq
for j in range(i + 2, len(word) + 1):
subwords_freqs[word[i:j]] += freq
sorted_subwords = sorted(subwords_freqs.items(), key=lambda x: x[1], reverse=True)
# Grouping characters and subwords
token_freqs = list(char_freqs.items()) + sorted_subwords[: 300 - len(char_freqs)]
token_freqs = {token: freq for token, freq in token_freqs}
# Computing log probabilities
total_sum = sum(freq for _, freq in token_freqs.items())
model = {token: -log(freq / total_sum) for token, freq in token_freqs.items()}
# Tokenization function
def encode_word(word, model):
# Function body here
# Trying the model on words
print(encode_word("Hopefully", model))
print(encode_word("This", model))
# Computing the loss of the model
def compute_loss(model):
# Function body here
# Testing loss computation
compute_loss(model)
# Computing scores for each token
def compute_scores(model):
# Function body here
# Tokenization process
def tokenize(text, model):
# Function body here
# Using the tokenize function
tokenize("This is the Hugging Face course.", model)
Recap
지금까지 BPE, BBPE, Word Piece, Unigram, N-gram 등 다양한 모델들에 대해서 알아보았습니다.
전체적인 맥락을 전통적인 통계적 문제 해결 기법으로 쉽게 비유하자면, 원하는 vocab까지 만든 다음에 또 만들지 (BPE), 엄청 크게 만들어 둔 다음에 조금씩 제거할지 (Unigram), 단계적으로 계산해가면서 신중하게 만들어갈지(Word Piece)라고 볼 수 있고, 고전적인 알고리즘들의 아이디어에 빗대어 표현하자면, BPE는 원하는 vocab size까지의 전진선택법(forward selection), Unigram은 후진소거법(backward elimination), Word Piece는 단계적선택법(stepwise selection)과 접근에 비유할 수 있을 것 같습니다. (SentencePiece는 라이브러리기 때문에 비교에서 제외합니다.)
또, Word Piece는 해당 토큰을 뺀 다음 코퍼스의 우도를 계산해서 적절한 토큰을 병합한다는 점에서 Permutation Importance의 알고리즘의 접근 방식과도 유사하다고 볼 수 있겠네요.
Tokenizer Libraries
그럼 지금까지 살펴 본 알고리즘을 구현한 패키지들은 뭐가 있을까요?
직접적으로 프로젝트에서 지정한 토크나이저 구현체를 사용해야만 하는 언어모델들도 있지만, 최근에는 워낙 발전하고 있는 분야라서 구현체를 사용하는 것이 더 빠르고 비용 효율적입니다. 이 섹션에서는 오픈소스 토크나이저 라이브러리들을 살펴보겠습니다.
OpenAI의 Tiktoken, Google의 SentencePiece, HuggingFace의 Tokenizers가 대표적이며, HuggingFace는 Transformers 모듈로 다양한 기능들을 병합하면서, Transformers 안의 토크나이저의 Rust 구현체를 Fast Tokenizer로 명명한 뒤 사용하고 있습니다. (병합때문에 여러 이슈가 있기 때문에, 반드시 Transformers는 버전을 확인하고 쓰는 것이 좋습니다.)
따라서, AutoTokenizer 클래스로 토크나이저를 로딩할 경우, 기본 값으로 Fast Tokenizer를 사용하게 되고, 만약 파이썬 토크나이저 구현체를 사용하고자 할 경우, use_fast = False인자로 전달해야만 합니다.
각 패키지를 간단히 살펴보고, Fast Tokenizer의 경우만 자세하게 일부 메서드를 확인해보겠습니다.
OpenAI - Tiktoken
‘Tiktoken is a fast BPE tokeniser for use with OpenAI’s models.’라는 패키지 소개 문구에서 알 수 있듯이, Tiktoken은 OpenAI의 모델들이 사용하는 오픈소스 토크나이저 패키지입니다.
Open Source 패키지지만, OpenAI의 경영권 및 지배구도가 급변하면서 사실상 공개되고 있는 파생 토크나이저들이 없는 상황이므로, Alibaba Cloud의 LLM, Qwen처럼 대규모의 리소스를 감당할 수 있는 일부 기업들이 주로 사용하는 편이며, 사례가 많지는 않았습니다. 그러나, 최근 많은 토크나이저들이 GPT-3.5와 4가 사용하는 cl100k_base로부터 토크나이저를 수정해서 사용하는 추세입니다.
그 외 많은 연구자들이 커뮤니티가 활발한 HuggingFace의 라이브러리나 SentencePiece, LangChain등의 오픈소스 프로젝트를 주로 사용합니다.
Google - SentencePiece
이름만 보면 Word Piece의 개선된 알고리즘이 아닌가 할 수 있지만, SentencePiece는 토큰화 방식이라기보다 구글이 개발하여 사용 중인 토크나이저 라이브러리로, 다음 논문: SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing에서 소개되었습니다. [27] 그 외에도 XLNet(Yang et al. 2019) 및 mBART(Liu et al. 2020)의 토크나이저로 사용되었습니다.
SentencePiece는 모델 훈련에 앞서서 vocab size가 미리 결정되었을 때, 신경망 기반 텍스트 생성 시스템에서 사용할 수 있는 unsupervised text tokenizer이자 detokenizer로 현재 Google의 다양한 언어 모델에서 사용되고 있으며, 원하는 데이터를 이용해 직접 subword units tokenizer model(e.g., Byte-Pair-Encoding(BPE), Sennrich et al) 혹은 Unigram language model, Kudo을 학습시킬 수 있습니다.
특히, Unigram을 훈련하고 검증하는 것에 주로 사용하지만, 구글이 사용하고 있는 알고리즘을 모두 공개하지는 않았으므로, 토크나이저를 연구하는 사람들은 허깅 페이스의 tokenizers나 sentencepiece 패키지를 참고하여 개발하고 있는 편입니다.
# SentencePiece
--byte_fallback: (type: bool, default: false)
decompose unknown pieces into UTF-8 byte pieces.
Note: need to set --character_coverage less than 1.0, otherwise byte-fall-backed tokens may not appear in the training data.
--character_coverage: (type: double; default:0.9995)
character coverage of determining the minimal symbols.
# see: https://github.com/google/sentencepiece/blob/master/doc/options.md
언어별 전/후처리에 의존하지 않는 순수한 end to end 시스템을 만들 수 있으며, 다양한 언어를 포괄하는 범용적 목적으로 활용할 수 있고, 위에서 잠시 언급했던 byte_fallback 옵션과 같이 유용한 기능들을 구현해두었습니다.
sentencepiece의 공식 github에서 소개된 특징으로 라이브러리 소개를 갈음합니다.
Technical highlights
- Purely data driven: SentencePiece trains tokenization and detokenization models from sentences. Pre-tokenization (Moses tokenizer/MeCab/KyTea) is not always required.
- Language independent: SentencePiece treats the sentences just as sequences of Unicode characters. There is no language-dependent logic.
- Multiple subword algorithms: BPE [Sennrich et al.] and unigram language model [Kudo.] are supported.
- Subword regularization: SentencePiece implements subword sampling for subword regularization and BPE-Dropout which help to improve the robustness and accuracy of NMT models.
- Fast and lightweight: Segmentation speed is around 50k sentences/sec, and memory footprint is around 6MB.
- Self-contained: The same tokenization/detokenization is obtained as long as the same model file is used.
- Direct vocabulary id generation: SentencePiece manages vocabulary to id mapping and can directly generate vocabulary id sequences from raw sentences.
- NFKC-based normalization: SentencePiece performs NFKC-based text normalization.
For those unfamiliar with SentencePiece as a software/algorithm, one can read a gentle introduction here.
요약컨대, 띄어쓰기를 하나의 character로 취급하기 때문에, Pre-tokenization(Moses tokenizer/MeCab/KyTea)없이 범용적으로 사용할 수 있고, 일본어와 중국어처럼 굉장히 많은 문자를 갖는 표의 문자(Ideogram)의 경우, 대부분의 문서를 포괄하는 coverage를 설정해 조금 더 효율적인 vocab을 생성할 수 있습니다. 또, 특정 코퍼스에 편향된 tokenizer가 생성되는 것을 방지하고, NMT(Neural machine translation) 모델을 더 견고하게 만들기 위해 subword regularization와 BPE-Dropout 등의 옵션을 포함해 다양한 기능을 구현해두었습니다.
자세한 내용은 다음 미디엄 포스트: Understanding SentencePiece ([Under][Standing][_Sentence][Piece]) 및 다음 포스트: sentencepiece tokenizer demystified에서 찾아보실 수 있으며, SentencePiece와 Word Piece에 대한 탐구 포스트도 유익합니다.
HuggingFace - Tokenizers
HuggingFace의 tokenizers는 현재 가장 많이 사용되는 토크나이저들을 구현(implementation)해둔 라이브러리로, Rust(Original implementation)로부터 node.js, Ruby, Python에 *바인딩 되어있습니다.
HuggingFace - Fast Tokenizer
Transformers의 토크나이저는 HuggingFace의 Tokenizers 라이브러리로 전술한 Tokenizers보다 더 다양한 기능을 포함하고 있습니다. 편의를 위해 Python으로 작성된 버전의 토크나이저를 slow tokenizer라고 명명하고, Rust로 작성된 버전을 fast tokenizer로 칭하겠습니다. 속도 차이는 다음 허깅페이스 포스트: Time to slice and dice에서 볼 수 있듯 기본적으로 데이터를 어떤 자료형으로 어떻게 처리하는지에 따라 달라지는데, 다음 표에서 보실 수 있듯이 fast tokenizer가 slow tokenizer보다 5배정도 빠릅니다. (단일 문장 처리에서가 아닌 많은 텍스트를 동시에 토큰화할 경우, 차이가 나게 됩니다. 일부 단일 문장 처리에서는 slow tokenizer가 더 빠를 수도 있습니다.)
| / | fast tokenizer | slow tokenizer |
|---|---|---|
| batched=True | 10.8s | 4min41s |
| batched=False | 59.2s | 5min3s |
Tokenizer의 출력은 Python의 dict 자료형과 비슷해보일 수 있으나 실제로는 Special BatchEncoding 객체로, 이 객체는 dictionary의 서브클래스로 dict와 동일한 메서드도 사용할 수 있지만, fast tokenizer에서 다음과 같은 추가 메서드가 포함되어있습니다. fast tokenizer는 ID를 토큰으로 다시 변환하지 않고도 토큰에 액세스할 수 있는 빠르고 다양한 메서드가 추가로 구현되어 있습니다.
AutoTokenizer 클래스는 기본적으로 fast tokenizer를 선택하게 되어있고, use_fast 인자로 fast tokenizer와 slow tokenizer를 선택할 수 있으며, 다음과 같이 확인해볼 수 있습니다.
tokenizer.is_fast
>>> True
encoding.is_fast
>>> True
아래의 예시를 통해 fast tokenizer가 어떻게 작동하는지 자세히 살펴보겠습니다.
BERT의 인코딩 예시
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
example = "Before performing the BPE algorithm, pre-tokenization must be done."
encoding = tokenizer(example)
print(type(encoding))
>>> <class 'transformers.tokenization_utils_base.BatchEncoding'>
encoding
>>> {'input_ids': [101, 2577, 4072, 1103, 21062, 2036, 9932, 117, 3073, 18290, 21462, 8569, 1538, 1129, 1694, 119, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
encoding.word_ids()
[None, 0, 1, 2, 3, 3, 4, 5, 6, 6, 6, 6, 7, 8, 9, 10, None]
위 BERT 토크나이저의 출력물을 살펴보면, [CLS]와 [SEP]가 None에 매핑된 다음 각 토큰이 그 토큰이 유래한 단어에 매핑됐는데, 이렇게 매핑하는 것은 ‘해당 토큰이 단어의 시작 부분에 있는지’ 또는 ‘두 개의 토큰이 같은 단어에 있는지’등을 확인할 때 유용합니다.
BERT처럼 접두사 ##를 사용할 수도 있지만, 허깅페이스의 fast tokenizer를 사용할 경우, tokenizer의 타입(fast나 slow)에 구애받지 않고, 그 토큰이 유래된 단어를 쉽고 빠르게 찾을 수 있습니다.
또, word_ids()와 비슷하게 해당 토큰이 나온 문장에 매핑하는 데 사용할 수 있는 sentence_ids() 메서드도 있습니다. 그러나 이 메서드는 쉽게 구현할 수 있고, 어차피 예시 문장이 한 문장이므로 token_type_ids를 써도 동일한 정보가 출력되게 됩니다.
마지막으로, word_to_chars() 또는 token_to_chars() 및 char_to_word() 또는 char_to_token() 메서드를 사용해서 ‘입력 텍스트가 어떤 토큰에 매핑됐는지’를 찾거나 혹은 반대로 ‘해당 토큰이 어떤 입력 텍스트에 대응되는지’도 쉽게 알 수 있습니다.
그러나 아래의 BPE 기반 LLaMA 토크나이저에서는 BERT와 달리 어떤 단어에서 유래하였는지 쉽게 정보를 얻을 수는 없습니다.
LLaMA-2의 인코딩 예시
tokenizer = AutoTokenizer.from_pretrained('openlm-research/open_llama_7b')
example = "Before performing the BPE algorithm, pre-tokenization must be done."
encoding = tokenizer(example)
print(type(encoding))
>>> <class 'transformers.tokenization_utils_base.BatchEncoding'>
encoding
>>> {'input_ids': [1, 5352, 7593, 266, 341, 8978, 10382, 31844, 10251, 5300, 1418, 1322, 333, 1959, 31843], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
encoding.word_ids()
>>> [None, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
LLMs Tokenizer
이제 살펴본 이론들을 바탕으로 현재 LLM들은 어떤 토큰화 방식을 사용하고, 어떤 패키지로 어떤 토크나이저를 쓰고 있는지 구체적으로 확인해보겠습니다.
구글은 LaMDA를 제외하면 일관되게 WordPiece와 Unigram방식의 토크나이저로 SentencePiece 패키지를 사용하고 있고, OpenAI는 GPT 계열 모델에 BPE(BBPE) 방식의 Tiktoken 토크나이저를 사용하고 있습니다.
이는 구글이 과거 다국어 서비스를 지원하면서, 다국어의 다양한 특징(단순히 next token prediction이 아닌)을 포착하기 위해 애썼던 결과이고, OpenAI의 ChatGPT가 디코더 모델로 우수한 성능을 보이며, 많은 리소스를 확보할 수 있었으므로 Char-level BPE로도 충분히 많은 토큰을 정렬할 수 있었던 결과일 수 있습니다.
MetaAI의 LLaMA는 주로 BPE 알고리즘을 사용하지만, 토크나이저에 대해서는 LLaMA-1과 LLaMA-2 논문에서 그렇게 중요하게 언급되지 않았습니다. 또한, 다국어에 대한 토큰화가 주로 BBPE 방식에 의존해 한국어와 같은 일부 언어에 있어서 상대적으로 비효율적이라고 볼 수 있습니다. 이는 LLaMA 모델이 다국어를 타겟으로 한다기 보다는 영어를 기준으로 성능을 올리고 있는 모델임을 의미하며, 영어를 제외한 다양한 언어의 특성을 고려하기 어렵고 잘 정제된 데이터셋을 구하기 어려우며, LLaMA-2에서 집중적으로 크라우드 워커를 통해 안전성(Safety)과 효용성(Helpfulness)에 염두하여 휴먼의 선호도(Human Preference)에 맞게 SFT와 Allignment Tuning을 했기 때문일 수 있습니다.
| 모델 계열 | 토큰화 방식 | 사용 기관 |
|---|---|---|
| GPT, LLaMA | BPE (BBPE) Tokenization | OpenAI, MetaAI |
| BERT, PaLM | Word Piece, SentencePiece, Unigram Tokenization |
두 토큰화 방식은 GPT와 BERT 모델의 아키텍처 차이와도 약간의 연관이 있는데, 모델이 어떻게 구성되어 있는지, 어떤 태스크를 수행할지에 따라 어느 부분을 집중적으로 가공할 지 결정하고, 모델이 자연어의 다양한 특징(의미론적인 특징 포함)을 잘 포착할 수 있는 방식을 선택했다고 이해하시면 좋을 것 같습니다.
크게 GPT와 BERT 계열의 언어 모델들로 나누어 비교해보면, 두 모델 모두 트랜스포머 기반 언어 모델이라는 점은 동일하지만, GPT는 디코더 기반의 아키텍처를 사용해 주로 텍스트 생성 작업에 최적화되어 있고, BERT는 양방향 인코더 아키텍처로 전후 맥락 포착에 조금 더 최적화되어 있습니다.
또, GPT는 순차적이거나 일방향적으로 텍스트를 처리하며, 주로 ‘다음에 오는 단어(next token prediction)’를 예측하는 데 주로 사용되는 반면, BERT는 Bidirectional Encoder Representations from Transformers, BERT라는 이름에서 알 수 있듯이 양방향 인코더 아키텍처를 사용해 주어진 단어 위치의 앞뒤 맥락을 모두 고려하여 학습할 수 있고, ‘다음 단어 예측 태스크(next token prediction task)’보다는 ‘빈칸 채우기 태스크(cloze task)’에 조금 더 적합합니다. 따라서, 양방향의 문맥을 파악하는 것이 중요한 텍스트 분류, 질문 답변, 개체명 인식 등의 태스크에 조금 더 강건할 수 있습니다.
자연어 모델들이 파라미터를 경쟁적으로 확장하기 시작하면서, BERT 역시 인코더의 레이어를 두 배로 증가시키고, 768개의 hidden-layer를 1024개로 늘린 BERT-large 모델(English only, uncased, trained with Word Piece masking)을 공개하기도 했습니다.
다음은 주요 LLM들이 어떤 토크나이저를 사용하는지, 어떤 코퍼스에서 어느정도의 vocab을 구성했는지를 나타낸 표입니다.
| Model | Tokenization | #vocab | Corpus | Organization |
|---|---|---|---|---|
| GPT | BPE [Spacy/ftfy pre-tokenizer] | 40,478 | BooksCorpus | OpenAI |
| GPT-2 | BBPE | 50,257 | WebText (40GB) | OpenAI |
| GPT-3 | BBPE | 50,257 | Common Crawl, WebText2, Books1/2, Wikipedia | OpenAI |
| GPT-4 | BBPE | 100,256 | Public corpus, third-party data | OpenAI |
| code-davinci-001/002 | BBPE | 50,281 | - | OpenAI |
| text-davinci-003 | BBPE | 50,281 | - | OpenAI |
| gpt-3.5-turbo | BBPE | 100,256 | - | OpenAI |
| RoBERTa | BBPE | 50,257 | BooksCorpus, enwiki | |
| BART | BBPE | 50,257 | BooksCorpus, enwiki | |
| BERT | Word Piece (30k) | 30k | BooksCorpus, enwiki | |
| T5 | Word Piece (SPM) | 32k | C4 | |
| XLNet | Unigram (SPM) | 32k | BooksCorpus, enwiki, Giga5, ClueWeb 201-B, Common Crawl | |
| ELECTRA | Word Piece | 30k | base: same as BERT; large: same as XLNet | |
| ALBERT | Unigram (SPM) | 30k | BooksCorpus, enwiki | |
| Gopher | Unigram (SPM) | 32k | MassiveText | DeepMind |
| Chinchilla | Unigram (SPM) | 32k | MassiveText | DeepMind |
| PaLM | Unigram (SPM) | 256k | dataset from LamDA, GLaM, and code | |
| LaMDA | BPE (SPM) | 32k | 2.97B documents, 1.12B dialogs, and 13.39B dialog utterances | |
| Galactica | BPE | 50k | Papers, reference material, encyclopedias and other scientific sources | Meta |
| LLaMA | BPE (SPM) | 32k | CommonCrawl, C4, GitHub, Wiki, Books, ArXiv, StackExchange | Meta |
| Qwen | BBPE (UTF-8) | - | cl100k + chinese corpus | Alibaba Cloud |
| Mistral | - | - | - | Mistral AI |
*출처: Yekun’s Note: Subword Tokenizers for Pre-trained Language Models을 일부 수정하였습니다. SPM means sentencepiece.
Tokenizer Analysis
이 섹션에서는 위에서 살펴 본 다국어 LLM들이 사용하고 있는 토크나이저를 분석합니다. 영어에 대한 토크나이저 분석 및 다른 언어로의 분석은 다음 포스트: Why OpenAI’s API Is More Expensive for Non-English Languages와 Why is GPT-3 expensive and slow for Non-English languages? 외 다양한 포스트와 논문에서 다루고 있으므로, 저는 이 섹션에서 기존 LLM tokenizer의 한국어 취급을 집중적으로 확인해보겠습니다.
*출처: Why OpenAI’s API Is More Expensive for Non-English Languages
GPT Tokenizers
위 표에서 GPT의 토크나이저의 변화를 위주로 살펴보면, 다국어 지원을 위해 vocab의 사이즈를 차츰 늘리면서, 정제된 문어체(BooksCorpus), 정제된 웹 데이터 WebText(40GB)를 사용하다가 GPT-3부터 GPT와 GPT-2 데이터 중 일부(고품질 데이터)를 혼용하였습니다.
또한, 다양한 언어와 멀티 도메인을 커버하기 위해, GPT-3 대비 vocab size가 2배가 된 것을 확인할 수 있습니다.
GPT 토크나이저로 토크나이징할 경우, 하나의 토큰이 영어 text의 경우, text의 최대 4개의 character에 대응되는 것이 일반적이므로 100토큰은 대략적으로 75개의 단어를 표현할 수 있습니다. (100 tokens ~= 75 words)
GPT-3

GPT-3.5 & GPT-4
LLaMA Tokenizers
LLaMA의 토크나이저는 Sentence Piece 패키지를 사용한 BPE 모델입니다. 32,000개의 vocab size와 8,192 tokens의 context window를 갖고 있습니다. LLaMA-2의 token embedding과 output tensors의 차원은 다음과 같습니다.
{
"dim": 8192,
"multiple_of": 4096,
"ffn_dim_multiplier": 1.3,
"n_heads": 64,
"n_kv_heads": 8,
"n_layers": 80,
"norm_eps": 1e-5,
"vocab_size": -1
}
Comprehensive infomations:
TextGenerationLLM_load_print_meta: n_vocab = 32000
TextGenerationLLM_load_print_meta: n_ctx_train = 4096
TextGenerationLLM_load_print_meta: n_ctx = 512
TextGenerationLLM_load_print_meta: n_embd = 8192
TextGenerationLLM_load_print_meta: n_head = 64
TextGenerationLLM_load_print_meta: n_head_kv = 8
TextGenerationLLM_load_print_meta: n_layer = 80
TextGenerationLLM_load_print_meta: n_rot = 128
TextGenerationLLM_load_print_meta: n_gqa = 8
TextGenerationLLM_load_print_meta: f_norm_eps = 1.0e-05
TextGenerationLLM_load_print_meta: f_norm_rms_eps = 1.0e-05
TextGenerationLLM_load_print_meta: n_ff = 28672
TextGenerationLLM_load_print_meta: freq_base = 10000.0
TextGenerationLLM_load_print_meta: freq_scale = 1
TextGenerationLLM_load_print_meta: model type = 70B
TextGenerationLLM_load_print_meta: model ftype = mostly Q4_0
TextGenerationLLM_load_print_meta: model size = 68.98 B
TextGenerationLLM_load_print_meta: general.name = LLaMA v2
TextGenerationLLM_load_print_meta: BOS token = 1 '<s>'
TextGenerationLLM_load_print_meta: EOS token = 2 '</s>'
TextGenerationLLM_load_print_meta: UNK token = 0 '<unk>'
TextGenerationLLM_load_print_meta: LF token = 13 '<0x0A>'
OpenAI 플랫폼 내부의 tokenizer API를 통해 위와 같이 확인해보면, 위의 간단한 예를 통해서 GPT-3 Legacy Tokenizer와 GPT-3.5 & GPT-4 모두 BBPE 방식의 토크나이저임을 알 수 있습니다.
그러나, 몇 가지 차이점이 존재하는데 영어의 토큰화 방식에는 큰 변화가 없으나, 다양한 유니코드(다양한 언어)에 대응하는 토큰들이 이전보다 더 효율적으로 처리된 것을 알 수 있습니다.
즉, GPT-3.5 이후 버전이 50k 정도의 vocab을 추가하면서 다양한 언어에 대한 의미상 문맥을 이전보다 더 효율적으로 전달하고 있습니다.
*출처: 본 블로그
위 Figure은 이해를 돕기 위한 토큰화의 일부 예시일 뿐으로, 실제로 자음과 모음 등만으로 매핑되는 것은 아닙니다. BBPE 방식의 특성상 실제로 매핑되는 경우는 병합 우선 순위에 따라서 다릅니다.
예를 들어, 위 Figure의 안녕이라는 문자열을 GPT-3.5 & GPT-4 토큰화 한 결과를 보고 단순히 밑받침과 자·모음으로 분리한 것이라고 오해할 수 있으나, 경이라는 단일 텍스트는 세 개의 토큰이 아닌 하나의 토큰 66406으로 매핑됩니다.
따라서, BBPE 방식에 대해서 상기해보면 우선 순위에 따라 선행 병합이 있을 수 있고, 한글 자·모의 조합에 따라서 다르게 매핑될 수 있습니다.
즉, 이미지와 같이 녕이 [167, 227, 243]으로 매핑되니, ㄴ이 ㅈ으로 바뀐 졍은 ㄴ에 해당하는 token id 167만 다른 token id로 대체될 것이라고 오해하고 예상할 수 있으나, 실제로는 세 가지 토큰 모두 완전히 다른 [168, 94, 235]로 매핑됩니다.
Tokenizer Comparison(Instruction/Chat/Coder etc.)
이 섹션에서는 GPT의 Tokenizer들과 같은 방식으로 LLM들의 토크나이저를 비교합니다. 현재의 LLM들은 목적에 맞게 약간씩 다른 토크나이저를 사용하고 있는데, LLM들이 사용하는 토크나이저를 확인하고 비교합니다.
LLM 개발사들은 주로 LFM(Large Foundation Model, 이하 “LFM”)을 생성하여 Base Model로 정의하고, LFM의 토크나이저를 범용적으로 사용합니다. 이후, 대화와 코드 작업과 같이 특수한 목적을 달성하기 위해 토크나이저를 다시 마련하여, LFM을 재학습(fine-tuning)시킵니다.
예를들어, MetaAI의 LLaMA계열의 모델들은 크게 LLaMA, LLaMA-Chat, LLaMA-Coder로 분류할 수 있고, OpenAI의 모델들 역시 Chat GPT-4, text-davinci-003, code-davinci-001/002 등의 제품군으로 나누어 볼 수 있습니다. Alibaba Cloud의 Qwen도 Qwen, Qwen-Chat, Qwen-Coder 등으로 제품군을 분리하여 발표하였습니다.
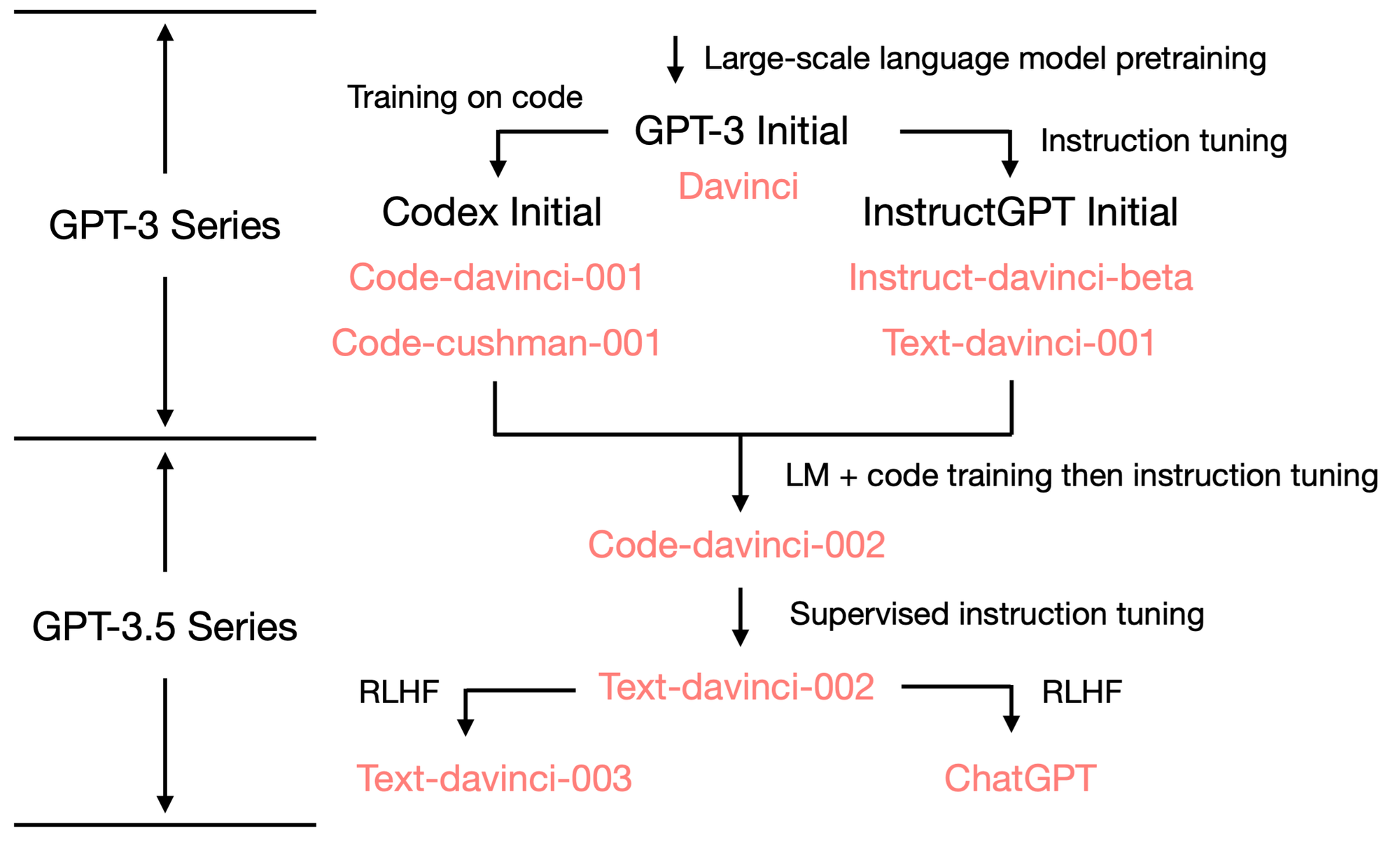
통상적으로 LFM은 Instruction을 기본으로 하며, Chat 모델들은 Proximal Policy Preference Optimization(이하 “PPO”)나 Directed Preference Optimization(이하 “DPO”) 같이 RLHF(Reinforcement learning from human feedback, 이하 “RLHF”)라는 강화학습 기술로 사람의 선호도에 맞게 답변들을 다시 파인튜닝여 사람의 관점에서 정성적으로 더 우수한 모델을 생성하기도 합니다.
프로그래밍 언어나 수학 등 특수 기호 및 구분자를 다채롭게 사용하는 도메인 태스크의 경우, Code 혹은 Math 등의 명칭으로 파생 모델을 생성하기도 히며, 이 모델들의 토크나이저는 각 도메인에서 사용되는 특수 기호 및 구분자 등을 의미론적으로 효율적으로 토큰화할 수 있습니다.
그러나, MoE(Mixture of Experts) layer를 사용할 경우, 단일 토크나이저가 좋을 수도, 만약 태스크 목적(e.g, code, chat, math etc.)에 따라 토크나이저를 분리해야할 수도 있습니다. 결국, 전반적인 비용 함수를 계산해서 적절하게 조정하는 것이 좋습니다. 만약 MoE 아키텍처를 고려하고 있다면, 토크나이저 역시 효율적으로 배분하거나 생성하는 것을 같이 고려하는게 좋습니다.
Creating an Efficient Korean Tokenizer
이 섹션에서는 위에서 살펴본 연구들을 바탕으로 토크나이저들의 한국어의 취급에 대해서 알아보고, 한국어를 공식적으로 지원하는 모델들의 토크나이저를 비교합니다.
Why?
2023년 4월부터 LLM 학습에 필요한 대용량의 데이터셋(한글/영어)을 정제하며, LLaMA-2 파인튜닝 실험을 수행하던 도중, 적은 양의 데이터 주입(data injection)만으로도 잘 정렬되어 있던 토큰을 쉽게 오염시킬 수 있다는 것을 확인했습니다. LLaMA의 토크나이저를 계속 그대로 사용할 경우, 앞으로도 여러 문제들을 직면할 수 있다고 판단하고, 근본적으로 이를 해결하기 위해 한국어 LLM에서 효율적으로 사용할 수 있는 토크나이저를 개발하고자 했습니다.
- (이유1) 예전부터 LLaMA의 토크나이저가 상대적으로 한국어를 비효율적으로 토큰화한다는 것을 인지하고 있었고, 발견한 일부 문제는 토크나이저의 수정으로 비교적 간단히 해결할 수 있는 문제였습니다. 또, domain-specific한 LLM을 만든다고 가정할 경우, 특정 도메인에서 LLaMA-2 7B, 13B의 한국어 성능이 포기하지 못할 정도의 수준은 아니라고 판단했습니다.
- (이유2) 장기적으로 효율적인 토크나이저로 다시 pre-training 시키는 것이 기존의 비효율적인 LLaMA 토크나이저로 fine-tuning한 것보다 더 비용 효율적이며 경제적일 수 있다고 판단했습니다.
- (이유3) 앞으로 LLaMA-3가 어느정도의 성능으로 공개될 지 미지수이나, LLaMA1과 LLaMA-2의 주요 개선점이 학습한 데이터셋의 규모에 있었으며, 아키텍처 및 토크나이저는 거의 그대로 유지했다는 점, MetaAI의 LLaMA팀이 한국어 성능을 올리고자 토크나이저를 교체하는 과감한 선택을 할 확률은 희박하다는 점, LLaMA팀에 한국인이 없다는 점 등을 고려했습니다.
- (이유4) 이미, 리소스 차이로 인해 Fine-tuning으로도 LLM과 관련된 연구를 진행하기 어려운 상황이고, 버티컬 서비스에 대해서도 빅 테크들이 빠르게 대응하고 세일즈하고 있는 상황에서 다양한 언어의 멀티 도메인을 타겟으로 할 수 있는 컴퓨팅 리소스를 확보하는 것은 어렵기 때문에, Anthropic이나 OpenAI 그 외 LLM 개발팀들과 다르게 한국어 및 영어의 성능에 집중하기로 하였습니다.
-
(이유5) LLM 데이터셋에서 다양한 언어와의 관계성이 인퍼런스를 더 풍부하게 해준다는 연구 결과들도 존재하지만, 아래 Anthropic의 Claude 2의 답변에서 볼 수 있듯이 다양한 언어와의 관계성으로 인해 실제 서비스로 사용하기 어려운 퀄리티의 답변이 리턴될 수 있습니다. 따라서, 이 포스트에서는 한국어를 보다 더 적절하게 토큰화할 수 있는 방법에 대해서 탐구합니다.

Fig 9. Anthropic Claude 2 Inference Response at 2023-12-08
왜 굳이 토크나이저를 처음부터 만들려고 하나?
아마 예전부터 SK는 한국어 모델의 선두주자였기 때문에 Claude의 한국어 성능이 좋을 뿐만 아니라 토크나이저도 효율적일 것이라고 추측하고 있습니다. Claude Web UI의 포스트 헤더에 ‘sk-xxxx’로 시작하는 값들을 발견했으니 Claude에도 많은 기여를 하고 있는 것이라고 생각하고 있습니다.
2024년 3월 Claude 3가 좋은 성능을 보여주고 있으며, LLaMA-2의 한국어 토크나이저가 약간 비효율적이라고 하더라도 <unused> 토큰들을 사용해서 충분히 토큰의 병합 우선 순위를 조정해줄 수 있습니다. Qwen팀도
하지만, 저는 한국어와 영어에 집중하고자 하고, vocab size를 줄이는 것을 목적으로 하고 있습니다. 또한, 어떠한 자연어 태스크에도 토크나이저는 필수적으로 사용되므로 처음부터 빌드하여 꾸준히 고도화하고자 함입니다.
또한, 영어와 한국어의 토크나이저의 매핑 혹은 다른 방법에 대한 고려를 통해서 영어로 학습된 LLM의 웨이트를 다른 언어로 손 쉽게 확장하는 것에 대한 실험도 진행해보고자 합니다. 물론 아직까지 큰 성과는 없지만, 그래도 제가 엣지 케이스를 잡아나가면서 고도화해나갈 수 있는 vocab size가 적으면서 한국어의 의미론적 특징을 잘 포착할 수 있는 모델을 만드는 것을 목표로 합니다. 또한, 형태소를 어느정도 형태까지 표현하는 것이 좋을지에 대한 것도 고민하고 있습니다.
아직 갈 길은 멀지만, 저에게는 자산이 될 것이라고 생각하고 있습니다. 물론 성과가 크지 않은 시간이 될지도 모르지만 결국에는 해결할 수 있을거라는 믿음으로 많은 분들에게 물어물어 목표까지 달려가보고자 합니다.
*참고: 어떤 문제였는지는 추후 자세하게 분석하여 포스팅하도록 하겠습니다.
- 일부 문제는 파인튜닝 데이터에 편향되게 업데이트되면서 발생할 수 있는 문제였으며, Attention Sinks 논문에서 해결하고자 했던 초기 레이어의 가중치 불균형 문제와도 연관이 있을 수 있다고 생각합니다.
- 또한, 일부 문제는 고의로 토큰의 정렬을 흐트러트리고자 시도한 결과였으며, 적은 양의 데이터로도 이런 악의적인 목표를 달성할 수 있었습니다. 이 부분은 실제 서비스에서 지속적으로 LLM fine-tuning을 진행하면서 말투와 어투에 영향을 줄 수 있음을 의미하고, 특정 데이터셋으로의 파인튜닝으로 인해 다른 부분의 토큰들이 예상치 못하게 변경되어 성능이 저하될 수 있음을 의미합니다.
- 실제로 2024년 2월에는 Chat GPT의 망각(forgetting, 이전에는 잘 답변하던 것을 답변하지 못하는 현상)으로 인해 GPT의 릴리즈가 revert되기도 하였습니다.
Related works
English Tokenizers
영어의 경우, 대부분 BPE 방식으로도 충분히 좋은 성능을 보이고 있습니다. LLaMA-2의 토크나이저가 대표적으로 영어 표현에 최적화되어 있고, OpenAI는 다양한 언어에도 강건하게 작동하는 편입니다. 영어 토크나이저의 경우, 기본적으로 GPT-4의 토크나이저 API와 cl100k, LLaMA-2의 토크나이저, BPE를 개선하여 강건하게 작동하며 코드가 오픈되어 있는 Token Monster 프로젝트를 참고하였습니다.
Chinese Tokenizers
중국의 경우, 다양한 오픈 소스 프로젝트 및 연구를 활발하게 진행하고 있습니다. 또한, 코드 및 지식 교류가 활발한 편입니다. 한국어 토크나이저를 효율적으로 생성하기 전에 Alibaba Cloud의 Qwen의 토크나이저를 참고하였습니다.
Korean Tokenizers
한국어 토크나이저는 대표적으로 SKT의 토크나이저를 널리 사용하고 있습니다. 또한, 개인들이 진행하고 있는 토크나이저 프로젝트도 있습니다. 아래에 나열한 모델 혹은 레포지토리의 토크나이저를 검토하였습니다.
- 사용 데이터셋: 한국어 위키 백과 데이터, 뉴스, 모두의 코퍼스, 청와대 국민청원 데이터 외
| Model | Tokenizer Type | Details | # of vocab |
|---|---|---|---|
| KoGPT2 Tokenizer | Character BPE | 대화형 및 이모지 추가 | 51,200 |
| KoBART | Character BPE | 대화형 및 이모지 추가, <unused0> ~ <unused99> 추가 |
30,000 |
| KoBERT | SentencePiece | - | 8,002 |
- KoGPT2 Tokenizer: Character BPE tokenizer, 대화형 및 이모지 추가, #vocab = 51,200
from kobert_tokenizer import KoBERTTokenizer tokenizer = PreTrainedTokenizerFast.from_pretrained("skt/kogpt2-base-v2") - KoBART: Character BPE tokenizer, 대화형 및 이모지 추가,
<unused0>~<unused99>추가, #vocab = 30,000from kobart import get_kobart_tokenizer kobart_tokenizer = get_kobart_tokenizer() kobart_tokenizer.tokenize('안녕하세요. 한국어 BART 입니다. :)l^o') -
KoBERT: SentencePiece tokenizer, #vocab = 8,002
from kobert_tokenizer import KoBERTTokenizer tokenizer = KoBERTTokenizer.from_pretrained('skt/kobert-base-v1')or
from gluonnlp.data import SentencepieceTokenizer from kobert import get_tokenizer tok_path = get_tokenizer() sp = SentencepieceTokenizer(tok_path) sp('한국어 모델을 공유합니다.')
LLMs (Support for Korean Language)
| Model | Parameters | COPA (F1) | HellaSwag (F1) | BoolQ (F1) | SentiNeg (F1) | WiC (F1) | Average |
|---|---|---|---|---|---|---|---|
| skt/ko-gpt-trinity-1.2B-v0.5 | 1.2B | 0.6696 | 0.5243 | 0.3356 | 0.6065 | 0.3290 | 0.4930 |
| kakaobrain/kogpt | 6.0B | 0.7345 | 0.5590 | 0.4514 | 0.3747 | 0.3526 | 0.4944 |
| facebook/xglm-7.5B | 7.5B | 0.6723 | 0.5665 | 0.4464 | 0.3578 | 0.3280 | 0.4742 |
| EleutherAI/polyglot-ko-1.3b (this) | 1.3B | 0.7196 | 0.5247 | 0.3552 | 0.6790 | 0.3297 | 0.5216 |
| EleutherAI/polyglot-ko-3.8b | 3.8B | 0.7595 | 0.5707 | 0.4320 | 0.4858 | 0.3390 | 0.5174 |
| EleutherAI/polyglot-ko-5.8b | 5.8B | 0.7745 | 0.5976 | 0.4356 | 0.3394 | 0.3913 | 0.5077 |
| EleutherAI/polyglot-ko-5.8b | 5.8B | 0.7745 | 0.5976 | 0.4356 | 0.3394 | 0.3913 | 0.5072 |
| EleutherAI/polyglot-ko-12.8b | 12.8B | 0.7937 | 0.5954 | 0.4818 | 0.9117 | 0.3985 | 0.6362 |
| 42dot/42dot_LLM-SFT-1.3B | 1.3B | - | - | - | - | - | - |
| KRAFTON/KORani-v1-13B | 1.3B | - | - | - | - | - | - |
*출처: 허깅페이스 polyglot 모델 카드 일부를 수정하였습니다.
Korean NLP Models
| Model | Date | Datasets | Size of Tokenizer Vocab or Parameters | Reference Links |
|---|---|---|---|---|
| KorBERT | 2019 | 23GB 데이터 학습, Morpheme 및 WordPiece tokenizer, 30,349 (Morphemes), 30,797 (WordPiece) | 100M | arXiv, Medium, wikidocs, ETRI, ETNews |
| KoBERT | 2019 | 50M 문장 학습, SentencePiece tokenizer, 8,002 | 92M | SKTelecom, GitHub |
| HanBERT | 2020 | 70GB 데이터 학습, Moran tokenizer, 54,000 | 128M | PDF, stechstar, GitHub |
| KoGPT2 | 2020 | 152M 문장 학습, CBPE tokenizer, 51,200 | 125M | PDF, SKTelecom, GitHub |
| KoBART | 2020 | 0.27B 데이터 학습, BART 구조, denoising auto encoder | 0.27B | arXiv, GitHub, AJUNews |
| KoreALBERT | 2021 | 43GB 데이터 학습, ALBERT 방식, Masked Language Model 및 Sentence-Order Prediction | 12M (Base), 18M (Large) | SamsungSDS, arXiv, arXiv, iNews24, itbiznews, itbiznews |
| KE-T5 | 2021 | 93GB 데이터 학습, T5 구조, mask-fill 방식, SentencePiece tokenizer, 64,000 vocab | 다양한 규모 (최대 92.92GB) | arXiv, Hugging Face, GitHub, koreascience, zdnet |
| KoGPT-Trinity | 2021 | 1.2B 데이터 학습, Next Token Prediction, 51,200 vocab | 1.2B | Hugging Face |
| HyperCLOVA | 2021 | 561.8B 토큰 데이터 학습, 다양한 모델 크기 | 다양한 규모 | etnews, tv.naver, arXiv |
| KLUE-BERT | 2021 | 63GB 데이터 학습, Morpheme-based Subword Tokenizer, 32,000 vocab | 111M | Hugging Face, GitHub, cpm0722.github.io |
| KoGPT | 2021 | 200B 토큰 데이터 학습, 64,512 vocab | 6B | GitHub, Hugging Face, kakaocorp, aitimes |
그 외는 Korea Open LLM LeaderBoard에서 확인하실 수 있습니다.
한국어 토크나이저 개발 관련 - 비공개
한국어 토큰화의 어려움은 주로 언어의 구조적 특성에서 기인합니다. 한국어는 교착어로서의 특성을 가지고 있으며, 이는 토큰화 과정에서 복잡성을 증가시킵니다. 교착어는 어근에 하나 이상의 접미사가 붙어 문법적 기능이 결정되는 언어를 의미하며, 조사, 어미 등의 의존 형태소가 어근과 결합하여 새로운 의미와 문법적 기능을 생성하기 때문에, 단순히 띄어쓰기만으로는 의미 단위를 올바르게 분리하는 것이 어렵습니다. (Kim et al., 2014)
- 조사의 부착: 한국어에서 조사는 문장 내에서 주어나 객체 등을 명확히 하기 위해 필수적이지만, 이들이 어근에 바로 붙기 때문에 자연어 처리에서는 이를 분리하지 않으면 정확한 의미 파악이 어렵습니다.
- 띄어쓰기의 불규칙성: 한국어의 띄어쓰기는 일관성이 떨어지는 경우가 많으며, 이는 자연어 처리에서 큰 챌린지로 작용합니다. 연구에 따르면, 띄어쓰기 오류는 한국어 NLP의 성능 저하를 초래하는 주요 요인 중 하나로 지목되고 있습니다. (Choi, 2015)
- 형태소의 복잡성: 한국어는 형태소가 복잡하게 구성되어 있으며, 이를 정확히 분리하는 것은 어렵습니다. 예를 들어, “읽었다”를 형태소 분석하면 “읽-“는 동사 어간이고, “-었-“는 과거시제를 나타내는 어미, “-다”는 문장 종결 어미로 분리됩니다. (Park et al., 2016)
- 품사 태깅의 중요성: 단어의 의미는 품사에 따라 달라질 수 있기 때문에, 품사 태깅은 중요합니다. 예를 들어, “못”은 명사로서는 도구를 의미하지만, 부사로 사용될 때는 ‘할 수 없다’는 의미를 가집니다. 정확한 품사 태깅 없이 의미의 차이를 명확하게 구별하기 어렵습니다. (Lee & Song, 2017)
이런 언어적 특성으로 인해 한국어 토큰화는 영어 토큰화에 비해 상대적으로 복잡하며, 이는 텍스트 분석과 같은 과제에서 처리의 정확성과 효율성을 저하시킬 수 있습니다.
[참조]
- Kim, Y., et al. (2014). Korean morphological analysis: A review of the literature. Journal of Korean Linguistics, 63(4), 527-552.
- Choi, J. (2015). Analysis of Korean Spacing Errors and Their Impact on Natural Language Processing. Korean Journal of Linguistics, 40(2), 489-510.
- Park, J., et al. (2016). Automatic morphological analysis methods for Korean texts. Korean Journal of Computer Science, 29(2), 95-113.
- Lee, J., & Song, M. (2017). Part-of-speech tagging for Korean text using deep learning algorithms. Korean Journal of Artificial Intelligence, 34(1), 23-35.
프라이빗 레포지토리 / 비공개
Appendix
Korean Morphological Analyzers
| Project | Description | Version | License |
|---|---|---|---|
| Daon 분석기 | 김상준님의 Daon 분석기 | - | MIT |
| 코모란 | Shineware의 코모란 v3.3.9 | 3.3.9 | GPL v3 |
| 꼬꼬마 형태소/구문 분석기 | 서울대의 꼬꼬마 형태소/구문 분석기 v2.1 | 2.1 | LGPL |
| 공공 AI Open API | ETRI의 공공 AI Open API | - | 별도 협약 필요 |
| 오픈 소스 한국어 처리기 | OpenKoreanText의 오픈 소스 한국어 처리기 v2.3.1 | 2.3.1 | Apache 2.0 |
| UTagger | 울산대학교의 UTagger 2018년 10월 31일 버전 | - | 교육/연구용 무료, 상업용 별도 협약 |
| SEunjeon | 은전한닢 프로젝트의 SEunjeon(S은전) v1.5.0 | 1.5.0 | Apache 2.0 |
| Arirang Morpheme Analyzer | 이수명님의 Arirang Morpheme Analyzer | - | GPL v3 |
| RHINO | 최석재님의 RHINO v3.7.8 | 3.7.8 | Apache 2.0 |
| 한나눔 형태소 분석기 | KAIST의 한나눔 형태소 분석기 | - | LGPL |
| NLP_HUB 구문분석기 | KAIST의 NLP_HUB 구문분석기 | - | LGPL |
| 카이(Khaiii) | Kakao의 카이(Khaiii) v0.4 | 0.4 | Apache 2.0 |
| Pororo | 뽀로로는 카카오 브레인(Kakao Brain)에서 개발한 자연어 처리 라이브러리로, 자연어 처리와 음성 관련 태스크를 수행하기 위해 만들어졌다. CUDA를 사용하는 부분이 있어 서버 환경에서는 주의가 필요하다. | - | - |
| Okt | Okt(Open Korean Text)는 트위터에서 만든 오픈소스 한국어 처리기로, 속도 면에서 꼬꼬마, 코모란보다 빠르다. 구어체 토큰화에 적합하다. | - | Apache 2.0 |
| Mecab | 일본어 형태소 분석기 Mecab을 한국어용으로 포팅한 은전한닢 프로젝트. 설치가 번거롭지만 많이 사용된다. | - | - |
| Soynlp | 미등록 단어(OOV) 이슈를 해결하기 위해 사용되는 한국어 자연어 처리 라이브러리로, 통계치를 이용해 단어의 경계를 학습한다. LTokenizer를 사용하여 형태소를 분리한다. | - | - |
| Kiwi | 한국어 형태소 분석기 Kiwi(Korean Intelligent Word Identifier)의 Python 모듈. C++로 작성되었으며, 세종 품사 태그를 기초로 하여 일부 수정된 품사 태그를 사용한다. | - | - |
*출처: koalanlp 깃 허브 레포지토리 일부 수정
Java Packages
| Package | Description | License |
|---|---|---|
| koalanlp-core | 통합 인터페이스 정의 | MIT |
| koalanlp-scala | Scala를 위한 편의기능 (Implicit conversion 등) | MIT |
| koalanlp-server | HTTP 서비스 구성을 위한 패키지 | MIT |
| koalanlp-kmr | 코모란 Wrapper / 분석범위: 형태소 | Apache 2.0 |
| koalanlp-eunjeon | 은전한닢 Wrapper / 분석범위: 형태소 | Apache 2.0 |
| koalanlp-arirang | 아리랑 Wrapper / 분석범위: 형태소 2-1 | Apache 2.0 |
| koalanlp-rhino | RHINO Wrapper / 분석범위: 형태소 2-1 | MIT |
| koalanlp-daon | Daon Wrapper / 분석범위: 형태소 2-1 | MIT (별도 지정 없음) |
| koalanlp-khaiii | Kakao Khaiii Wrapper / 분석범위: 형태소 2-3 | - |
*출처: koalanlp 깃 허브 레포지토리
Citations
@misc{chai2019out-of-vocab,
author = {Chai, Yekun},
title = {Word Tokenization: How to Handle Out-Of-vocabulary Words?},
year = {2019},
howpublished = {\url{https://cyk1337.github.io/notes/2019/03/08/NLP/How-to-handle-Out-Of-vocabulary-words/}},
}
@inproceedings{petrov2023token_unfairness,
title = {Language Model Tokenizers Introduce Unfairness Between Languages},
author = {Petrov, Aleksandar and La Malfa, Emanuele and H. S. Torr, Philip and Bibi, Adel},
booktitle = {Advances in Neural Information Processing Systems},
url = {https://arxiv.org/abs/2305.15425},
year = {2023}
}
@inproceedings{he2020-dynamic,
title = "Dynamic Programming Encoding for Subword Segmentation in Neural Machine Translation",
author = "He, Xuanli and
Haffari, Gholamreza and
Norouzi, Mohammad",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.275",
doi = "10.18653/v1/2020.acl-main.275",
pages = "3042--3051",
}
References
- Word Tokenization: How to Handle Out-Of-vocabulary Words?
- A comprehensive guide to subword tokenisers
- How to train a new language model from scratch using Transformers and Tokenizers
- Colab: train your tokenizer
- Github: Google BERT
- Hugginface tokenizer
- How to Train BPE, Word Piece, and Unigram Tokenizers from Scratch using Hugging Face
- \(BPE\) Neural Machine Translation of Rare Words with Subword Units Rico
- \(Word Piece\) Japanese and Korean voice search (ICASSP 2012, Google)
- Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
- Taku Kudo. Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates
- Taku Kudo and John Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing
- Word Tokenization: How to Handle Out-Of-vocabulary Words?
- \(GPT-2\) Language models are unsupervised multitask learners
- Byte Pair Encoding is Suboptimal for Language Model Pretraining
- SentencePiece Tokenizer Demystified
- SentencePiece Python Module Example
- SentencePiece
- sentencepiece/python/add_new_vocab.ipynb
- GitHub issue: Manually modifying SentencePiece model?
- Easy SentencePiece for Subword Tokenization in Python and Tensorflow
- why does huggingface t5 tokenizer ignore some of the whitespaces?
- How to count tokens with tiktoken
- OpenAI tiktoken
- OpenAI API Tokenizer
- Overview of tokenization algorithms in NLP
- Complete Guide to Subword Tokenization Methods in the Neural Era
- Aho-Corasick
- Aho-Corasick Algorithm
- Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates
- LLM Visuallization
- Subword
- Korean Language Models
CC BY-NC-ND 4.0 KR. All right reserved. All Copyright (c) Reserved.