Flash Attention
- Related Project: private
- Category: Paper Review
- Date: 2023-07-06
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- url: https://arxiv.org/abs/2205.14135
- pdf: https://arxiv.org/pdf/2205.14135
- abstract: Transformers are slow and memory-hungry on long sequences, since the time and memory complexity of self-attention are quadratic in sequence length. Approximate attention methods have attempted to address this problem by trading off model quality to reduce the compute complexity, but often do not achieve wall-clock speedup. We argue that a missing principle is making attention algorithms IO-aware – accounting for reads and writes between levels of GPU memory. We propose FlashAttention, an IO-aware exact attention algorithm that uses tiling to reduce the number of memory reads/writes between GPU high bandwidth memory (HBM) and GPU on-chip SRAM. We analyze the IO complexity of FlashAttention, showing that it requires fewer HBM accesses than standard attention, and is optimal for a range of SRAM sizes. We also extend FlashAttention to block-sparse attention, yielding an approximate attention algorithm that is faster than any existing approximate attention method. FlashAttention trains Transformers faster than existing baselines: 15% end-to-end wall-clock speedup on BERT-large (seq. length 512) compared to the MLPerf 1.1 training speed record, 3× speedup on GPT-2 (seq. length 1K), and 2.4× speedup on long-range arena (seq. length 1K-4K). FlashAttention and block-sparse FlashAttention enable longer context in Transformers, yielding higher quality models (0.7 better perplexity on GPT-2 and 6.4 points of lift on long-document classification) and entirely new capabilities: the first Transformers to achieve better-than-chance performance on the Path-X challenge (seq. length 16K, 61.4% accuracy) and Path-256 (seq. length 64K, 63.1% accuracy).
TL;DR
- 자연어 처리 및 이미지 분류에서 사용되는 대형 트랜스포머 아키텍처의 효율성 향상
- 메모리 접근 최적화를 통한 속도 및 메모리 사용 효율 개선
- FlashAttention 알고리즘으로 긴 시퀀스 처리의 문제 해결
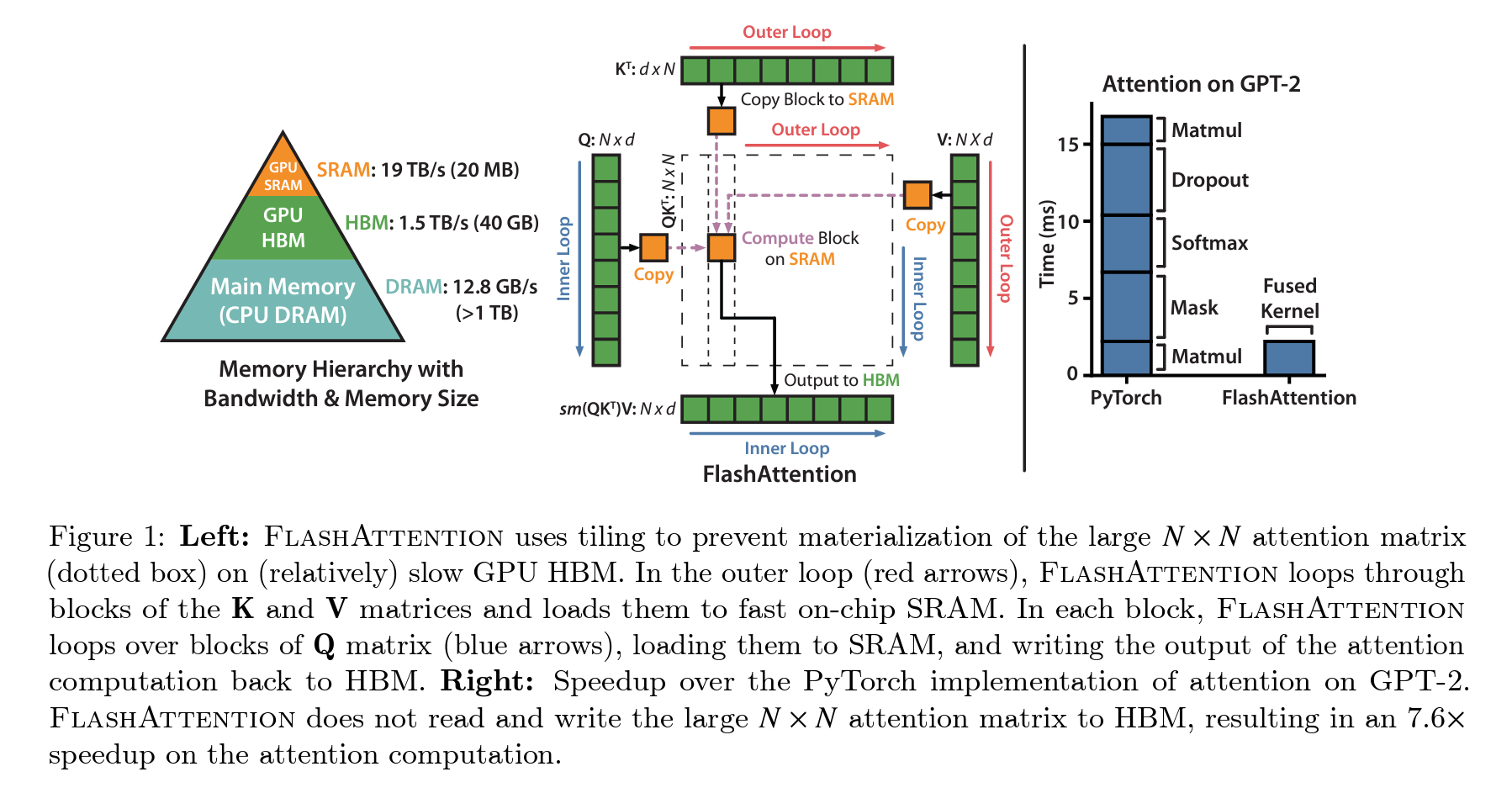
1. 서론 및 배경 지식
트랜스포머 모델은 자연어 처리와 이미지 분류에서 널리 쓰이며, 그 크기와 깊이가 증가함에 따라 긴 컨텍스트를 효과적으로 다루는 것이 중요한 과제로 부상했습니다. 기존 연구에서는 계산 및 메모리 요구 사항을 줄이기 위해 여러 근사 attention 방법들이 제시되었으나, 벽시계 속도 향상을 달성하지 못했습니다. 본 연구에서는 IO-aware, 즉 메모리 접근을 고려하여 효율성을 극대화하는 새로운 접근 방식을 제안합니다.
트랜스포머 모델은 자연어 처리와 이미지 분류에 널리 사용되지만, 시퀀스 길이가 길어질수록 계산 및 메모리 요구가 급격히 증가합니다. 이는 트랜스포머 내부의self-attention 메커니즘이 시퀀스 길이에 따라 제곱적으로 증가하기 때문입니다. 이를 수식으로 표현하면, 입력 시퀀스의 길이를 \(N\), 헤드의 차원을 \(d\)라 할 때, 표준self-attention 메커니즘은 \(O(N^2)\)의 메모리를 요구합니다.
2. 문제 정의 및 접근 방식
기존 트랜스포머 모델의 attention 메커니즘은 시퀀스 길이에 대해 제곱적인 시간 및 메모리 복잡성을 가지며, 이로 인해 긴 시퀀스를 효율적으로 처리하는 것이 어렵습니다. 메모리 접근을 최적화하여 이런 문제를 해결하고자 하며, 특히 GPU의 고속 SRAM과 상대적으로 느린 HBM 사이의 데이터 이동을 최소화합니다.
3. FlashAttention 알고리즘
3.1 기본 개념
FlashAttention은 기존 attention 메커니즘을 수정하여 메모리 접근을 최소화합니다. 이를 위해 입력을 블록으로 나누고, 각 블록에 대해 독립적으로 소프트맥스 감소를 수행하는 tiling 기법과, backward pass에서 중간 attention 행렬을 저장하지 않고 다시 계산하는 recomputation 기법을 사용합니다.
3.2 수학적 분석
FlashAttention의 IO 복잡도는 표준 attention 메커니즘에 비해 줄어듭니다. 표준 구현은 \(\Theta(N d + N^2)\)의 HBM 접근이 필요하지만, FlashAttention은 \(\Theta\left( \frac{N^2 d^2}{M} \right)\)로 줄어들며, 상기 수식에서 \(M\)은 SRAM의 크기입니다.
4. FlashAttention 알고리즘의 핵심 원리
4.1 Tiling (타일링)
타일링은 입력 데이터를 작은 블록으로 나누고, 각 블록에 대해 attention 계산을 별도로 수행하는 기법입니다. 이는 큰 메모리 접근을 여러 작은 접근으로 분할하여 전체적인 메모리 트래픽을 감소시키는 효과가 있습니다. 타일링을 통해 계산을 분할하면 다음과 같은 수식으로 표현할 수 있습니다.
\(\text{softmax}(QK^T) \approx \text{Tile}( \text{softmax}(Q_1K_1^T), \ldots, \text{softmax}(Q_nK_n^T))\) 상기 수식에서 \(Q_i, K_i\)는 각각의 타일을 나타냅니다.
4.2 Recomputation (재계산)
재계산은 필요한 계산 결과를 중간에 저장하지 않고, 필요할 때마다 다시 계산하여 메모리 사용을 줄이는 방법입니다. Attention 메커니즘에서는 소프트맥스 결과를 저장하는 대신, 필요할 때 입력 \(Q, K\)로부터 다시 계산합니다. 이 접근 방식은 메모리 접근을 줄이면서도 계산 효율을 유지할 수 있게 합니다.
5. 수학적 분석 및 이론적 근거
FlashAttention은 표준 self-attention과 비교하여 \(O(N^2 d^2 M)\)의 메모리 접근을 요구합니다. 수식에서 \(M\)은 SRAM의 크기를 나타냅니다.
이는 표준self-attention가 요구하는 \(O(N^2)\)보다 훨씬 적은 접근이 필요하다는 것을 의미합니다. 이런 절감 효과는 특히 메모리 접근이 병목이 되는 경우 더욱 두드러집니다.
하한 분석 어떤 attention 알고리즘도 SRAM 크기에 대해 \(O(N^2 d^2 M)\) 보다 적은 메모리 접근으로는 정확한 attention 계산을 할 수 없다는 하한선을 제안해, 계산에 필요한 최소한의 메모리 접근량을 정의하고, 최적화의 한계를 명확히 할 수 있습니다.
6. 실험 및 결과
FlashAttention을 사용한 모델 훈련은 벽시계 시간을 기준으로 기존 방법보다 최대 7.6배 빠르며, 메모리 사용량도 선형적으로 감소합니다. 긴 문서 분류와 같은 실제 태스크에서도 모델의 성능이 향상되었으며, 특히 긴 시퀀스에서 더 높은 품질의 결과를 확인합니다.
7. 한계점 및 향후 연구 방향
FlashAttention의 현재 구현은 CUDA 커널 작성을 필요로 하며, 이는 다소 낮은 수준의 프로그래밍을 요구합니다. 그러나, 다중 GPU 환경에서의 IO-옵티마이징과 관련된 추가 연구가 필요한 상황이라고 합니다.
본 논문은 트랜스포머 모델의 계산 및 메모리 요구를 줄이는 새로운 방법을 제시하고, 긴 시퀀스를 처리하는 능력을 향상시킬 수 있음을 시사하며, FlashAttention은 계산과 메모리 효율성을 향상시키는 동시에 트랜스포머 모델의 가능성을 확장합니다.